v i
:
o
t
d
e
t
a
c
i
d
e
d
s
i
s
i
s
e
h
T
s
i
h
T
t
s
i
r
h
C
s
u
s
e
J
y
l
i
m
a
F
'
R
A
E
B
'
y
M
D
e
h
t
d
n
i x .s
u s s e l b d o G y a M . e n o y b
r K a il ir p
ii i x .
A Reviewo fRelatedStudy…... 1 1 .
B Theoreitca lDesc irpiton…... 41 .
1 EngilshPhonology…... 1 4 .
a Placeo faritculaiton…... 1 4 .
b Manne ro faritculaiton…... 1 5 .
c Energyo faritculaiton…... 1 7 .
d Labiodentalf ircaitve s…... 1 9 .
2 KoreanLanguage…... 2 0 .
3 Phonologica lSrtategie s…... 2 4 .
a SoundSubsttiuiton…... 2 4 .
b SoundDeleiton…... 52 .
c SoundSimpil ifcaiton…... 52 .
d SoundAssimliaiton…... 2 6 .
e Inseriton…... 2 7 .f SyllabicSrtucture…... 2 8 .
C Theoreitca lFramework…... 3 1
Y G O L O D O H T E M . I I I R E T P A H
C 3 3
.
A ResearchMethod…... 3 3 .
B ResearchSubjec t…... 3 5 .
C ResearchI nsrtument s…... 3 7 .
ii i v x
e s e R f o h c r a e s e R l a n o it a R e h T : 1 . 3 t r a h c w o l
F archProcedure……… 34
x i x
1
x i d n e p p
A Dataof/ /fi nSingleWord s……… 1 09 2
x i d n e p p
A Dataof/ /fi nWordGroup s……… 1 15 3
x i d n e p p
A Dataof/ v/i nSingleWord s……… 1 18 4
x i d n e p p
A Dataof/ v/i nWordGroups……… 1 23 5
x i d n e p p
A Datao ff/ /and/ v /Combinaitoni nSingleWord sand … … . … … … … … … … … … … … … … … … s p u o r G d r o
CHAPTER I INTRODUCTION
This study deals with phonological analysis towards labiodental fricatives produced by South Korean singers in the live performance video. This chapter consists of six sections. The first section is background of study which discusses the reason of conducting this study. The second is problem formulation. This part states the questions that will be answered in this study. The third section is problem limitation which constricts the scope of the study. The fourth is objective of study. The last two sections are benefits of study and definition of terms.
A. Research Background
number of second language speakers will reach around 335 million. This fact shows that English is utilized more often than the first language and an apt symbol of globalization, diversification, and modernization.
The non-native speakers try to produce approximate sound as closely as possible to the native standard or Received Pronunciation (RP). However, the production of English by non-native speakers brings out the labeling English as ‘foreign’ and ‘second’ language. EFL or English as Foreign Language is taught to speakers whom English has no internal function in their first language country, whereas ESL or English as Second Language is taught to speakers whom English has an internal function in their first language country or speakers who emigrate to country which has English as the L1. It drives a new tension which has begun to emerge in the context of EFL. Lately, in the past half century, English has rapidly transformed from foreign language into international language or EIL. The transformation of English affects the transformation of English as Second Language. Some countries which use English as target language are undergoing process of switching from intra-national use of English to an inter-national one.
has two writing system, Hangul and Hanja. This study has been narrowed into Hangul sound production as comparison because it is used mostly by Korean speakers. People nowadays do not use Hanja in daily activities.
Hangul is sound-based letter. One letter represents one sound. Hangul consists of 19 consonants, 10 vowels, and 2 semivowel pronouns (USMI, 2008). It is different from English that consists of 24 consonant sounds including round sound, 12 vowels, and 8 diphthongs. Considering the number of standard sounds which belong to each language, some sounds of another language seem hard to reproduce in the other one. Two of them are labiodental fricatives, the consonants /f/ and /v/. Labiodental fricatives are sounds produced by unremitting airflow through the mouth which is involving the lower lip and the upper teeth (O’Grady, Dobrovolsky, and Katamba, 1997.).
Besides the reason mentioned above, there is one more reason why this study explores the Korean language, especially Hangul. Hangul has unique writing system related to English. Roman alphabets do not commonly utilize to represent Korean language. Vertical line, horizontal line, and dot are the main elements of Hangul features of letter. However, these features surprisingly can be applied in English. The followings are some example of Hangul- English writing features.
There are two of many English words which become vocabulary in Korean language, namely 패스트푸드 for fast food and 러브 라인for love line.
actually read /pæsətə pʊdə/ using English accent. While, the second one is (reo-beu ra-in) or in phonological transcription is /lɒbə laɪn/. That words demonstrate the writing system of Hangul representing English. The first example shows English word containing voiceless labiodental fricatives or /f/ and another example is voiced sound /v/. Hangul which does not have those sound label them with the closest quality sounds, /p/ in English accent for /f/ and /b/ for /v/.
The differences between Korean language and English, and the unique character of Hangul writing features drive the study into error analysis. The study deals with error analysis and accuracy where the writer tries to examine whether the Korean Language speakers can produce the sound correctly or with some inaccuracy. The Korean Language speakers are represented by Korean singers. They are the members of four famous groups which sing English songs, Super Junior, SHINee, CN Blue, and 2 AM. The video themselves are visual recording of live performance in television or visual radio streaming. Though there is accuracy analysis applied, it does not intend to correct the error. The analysis is just employed as the comparison and the base of the language strategic study towards English as Foreign language.
B. Problem Formulation
1. How accurate do the South Korean singers produce labiodental fricatives in English?
2. What are the linguistic strategies used by South Korean singers when they face labiodental fricatives in English?
C. Problem Limitation
The aim of this study is to answer two questions that have been mentioned in the Problem Formulation. The answers of the problems will produce profound discussion on the linguistic especially in branch phonology. The study focuses on sound production of English by second language speakers who are represented by South Korean singers. South Korean singers are chosen because they represent the Korean speaker who use English mostly because they do their debut internationally. When they sing in live performance they try to produce sound as similar as the native does. The live performance also has an important role here because from the live performance performed by the South Korean singers this study will be able to conduct real-situation sounds that are produced without any correction and manipulation. The study is conducted towards 20 live-performance music videos of English songs performed by four famous Korean groups; they are
videos with various number of songs within. The videos are chosen based on year. The videos are performed within year 2009-2011. The English songs are chosen randomly. The native singers are also various. Some singers are American English, some are British English, and some singers are Canadian or Black English. However, there are four songs sung by more than one group, they are Neyo’s So Sick, Gleen Hansard’s Falling Slowly, and Jason Mraz’ Lucky. From these songs, the writer wants to see the treatment toward same words done by different speakers.
In major, this study will phonologically analyze the labiodental fricatives which are produced by the South Korean speakers represented by South Korean singers when they sing English songs. The writer is also eager to discover the linguistic strategy to solve the differences sound instead of creating judgment whether their production of sounds is wrong or right.
D. Objective of Study
The objectives of the study are set as follows.
1. It aims to observe the performance of South Korean singers to pronounce English words containing labiodental fricatives or consonant /f/ and /v/. 2. It wants to see what linguistic strategies can be used to solve the occurring
of the non-existent sounds, labiodental fricatives, in South Korean language when Korean speaker speak English.
E. Benefits of the Study
possibly make will not be seen as the obstacle of English proficiency but as the variety of English. This study also wants to show the cases of English proficiency especially in pronunciation. So, by using the information, Korean learners can solve the problems that may come when they learn English.
This study is expected to be a source of reference for students because in Indonesia sources for Korean Language are still limit. So, it will help the future research related to Korean Language or English variation. Besides, now some students in English Education Study Program have taken Korean Language class. The writer hopes that this study can help the EESP students who are interested to Korean Language for their future study.
F. Definition of Terms
To avoid misunderstanding during doing this study, it is better for the writer to define some terms frequently used in this study.
1. Phonological Analysis
insertion, consonant omitting in consonant sequence, onset maximalism, and gemination.
2. Labiodental Fricatives
Labiodental fricative sounds are consonant sounds, /f/ and /v/, which are produced with a continuous airflow through the mouth with involving the lower
lip and the upper teeth. For examples, everything, for, and above, /evriθɪŋ, fɔ:r , əbʌv/ (O’Grady, Dobrovolsky, and Katamba, 1997). In this study, the labiodental
fricatives become the object of discussion. The writer wants to see how accurate Korean singer to produce these sounds.
3. South Korean Singers
South Korean singers are idols who speak South Korean Language in their daily conversation. However, they sing not only Korean songs but also foreign songs such as Japanese songs and English songs. The chosen singers come from various background of social. In this study, the South Korean singers are samples who produce the sound. The way they produce the sound will be the main discussion.
4. Live-performance Music Videos
CHAPTER II
REVIEW OF RELATED LITERATURE
This chapter covers three major parts. The first part is a review of former research which discusses about the role of the first language of Korean speaker in the development of English in Korea. The second part exposes theoretical review related to English. This part discusses about labiodental fricatives and the nature of English phonology . The following part within same part present the theoretical review related to Korean language or Hangul. This part presents the discussion about the characteristics of Korean language based on its original sounds. Then, still in the same section, there is a part which discusses the phonological strategies usually used in interlingual language. The last, the third part, is the theoretical framework which discusses the application of the theory within the study.
A. Review of Related Study
The previous research which was conducted by Anna Marie Schmidt from Kent State University, Ohio, discussed about the consonant labeling between Korean Language and English. This research talked about consonants identification happened within cross-language. This research focused on Korean perception towards English.
identification occurred. It was an action where the L2 speakers tried to substitute the L1 phonemes they perceive to be most familiar to L2 phonemes.
This research had three goals. Firstly, this study wanted to examine the perceptual relationship between consonants in Korean and English. This part did not only see the differences but also the possible similarities. Here the writer wanted to see which specific L2 sound were perceived as most similar to which specific L1 sound when L2 speakers substitute sound using their L1. Then, the second goal was to examine the labeling and assessment of the differences towards vowel context because the phonetic detail between Korean and English is different. The last one, this study had a goal to assess token-to-token variability.
The next one was method. Due to discussing the cross-language perception towards English by Koreans, the stimuli which was used must be English. The recordings of this research were made of 3 monological female native speakers' sound production. They actually spoke standart American English. Besides, the selected stimuli was 594 syllable which was goten from the accumulation of 3 repetition x 22 consonants x 3 vowels x 3 talkers. The vowels used were /i ɑ u/.
After discussing about the goals and the method, now is the time for exposing the result. Though English consonants were labeled as a greater variety of Korean consonants, those results agreed with the finding of Kim (1972) that /d g dʒ/ were covered in Korean, whereas /b v/ were consistently labeled as the lax
Korean /p/. Besides, English /ð/ was labeled as /t p tʃ/ in Korean. English /f θ/ were
also labeled as various Korean consonants including Koran /ph p* h s* t*/.
In this research voiced English consonants were labeled as both tense and lax Korean consonants. Due to focusing on labiodental fricatives, the current study only focused on the result of sound /f/ and /v/ labeling in the former research. In the former research, the English /f/ stimuli were in major labeled as Korean labial stop, even the rating was low. While, English /v/ was labeled mostly as Korean lax /p/.
B. Theoretical Description
This part deals with three parts where each part deals with different languages or both. In the first part the writer presents theories related to English phonology, whereas the next part is about Korean language. Then, in the last part, the theory of possible phonology strategies are discussed.
1. English Phonology
Collins and Mees (2003) states that phonology is a study of the selection patterns of sounds in a single language. Therefore, when it deals with English it becomes English phonology. Phonology brings three issues that can be examined; one of them that also will be used in this research is articulation. Articulation deals with the changing place of tongue, lips, teeth, and other speech organs to produce certain sounds.
Generally in articulation there are three important aspects, they are place of articulation,manner of articulation, and energy of articulation.
a. Place of Articulation
Place of articulation enlightens where the sound is produced, where the air stream can be modified to produce a different sound.
1) Labial
producing the both lips, whether the upper or the lower one, involved, the sound is named as bilabial, for examples are /b/, /p/, or /m/. While, if the sound is produced with the involving of upper teeth and lower lip, it is called labio-dental sound, they are /f/ and /v/.
2) Dental
Sound that is produced with involving the tongue placed againts or near the teeth is called as dentals. If the tongue place between the teeth, the sound is named as interdentals. Here are the sound that related to dental, thing /θɪŋ/ and
this /ðɪs/.
3) Alveolar
Alveolar ridge is a small ridge stick out from behind the upper front teeth within the oral cavity. Alveolar sound itself is produced when the tongue touch near the ridge.
4) Palato-alveolar and Palatal
Behind the alveolar ridge, there is an area called as palate-alveolar, the roof of the mouth which rises sharply. There is the highest part of the roof of the mouth named palate. Therefore, the sound produced there is called as palatals. 5) Velar
6) Uvulars
Uvular is the sound produced with the tongue near or touching the uvula area, the small fleshy flap of tissue hanging down from the velum.
7) Pharyngeals
The area of the throat between the uvula and the larynx is known as the pharynx. Sound made through the modification of airflow in this region by retracting the tongue or constricting the pharynx are called pharyngeals.
8) Glotal
Sound produced by using the vocal folds as the primary articulators at the glottis are glottal.
b. Manner of Articulation
1) Stop
Stops are made with complete and temporary closure of airflow through the vocal tract, preventing the air to escape.
2) Fricative
3) Africates
When a stop articulation is released, the tongue moves rapidly away from the place of articulation. Some non-continuant consonants show a slow release of the closure; these sounds are called affricates.
4) Liquids
Liquids is the form of a special class of consonant. 5) Laterals
Lateral sounds are produced when the air escapes through the mouth along the lowered sides of the tongue.
6) Glides
Glide is a very rapidly articulated non-syllabic segment.
c. Energy of Articulation
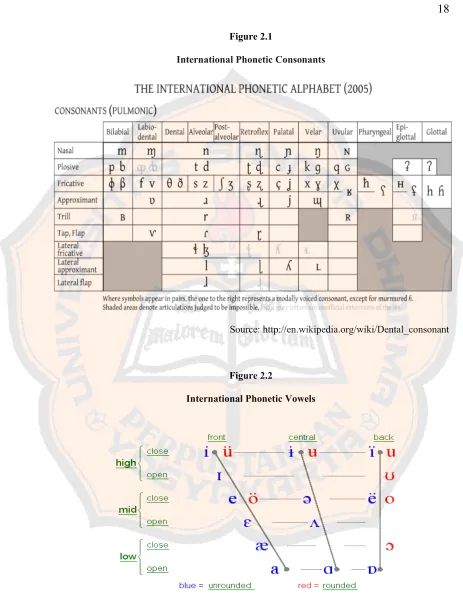
Figure 2.1
International Phonetic Consonants
Source: http://en.wikipedia.org/wiki/Dental_consonant
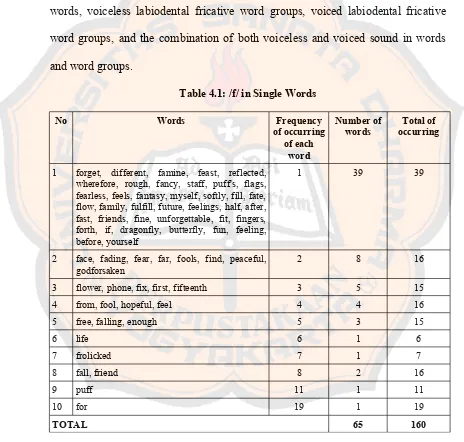
Figure 2.2
International Phonetic Vowels
The next theory will focus on the sound intended to research, the labiodental fricatives.
d. Labiodental Fricatives
After having further understanding about articulation, the writer wants to narrow the scope into labiodental fricatives or /f/ and /v/. Labiodental fricatives are sounds which are produced by involving the near contact of the lower lip to the upper front teeth. This sound is produced when the soft palate being raised and the nasal resonator being shut off. While, the inner surface of the lower lip makes contact with the edge of the upper teeth so that the air which is escaping produces friction (Indriani, 2005).
Fricatives are sound produced when the airflow is forced through a narrow opening in the vocal tract so that noise produced by friction is created. Related to the place, labiodental, there are two sounds of labiodental fricatives: voiceless labiodental fricative or /f/ and voiced labiodental fricative or /v/. The difference between the two sounds is the way of air stream flow (Akmajian, et.al., 2001).
2. Korean Language
South Korea people have their own national writing system named Hangul. Hangul is original language from South Korea. Seeing from historical viewpoint, this language has a story. In the beginning, Korean people do not have letters, so that they apply Chinese letters in their writing. However, there are many people that do not understand the meaning of Chinese letters because they are too complicated. Knowing that, King Kim Sejong (1397-1450) tried to create simple letter (Lee and Ramsey, 2011). Inspiring from the nature, Hangul has unique philosophy in each form of letter. The circle (o) is a depiction of heaven. Then, the diagonal line ( _ ) is a depiction of Earth. The last, the longitudinal line ( l ) is depiction of man.
Korean language has nineteen consonants, ten vowels, and two semi-vowels phonemes (Ho-min Sohn, 2000). Focusing on the consonant, there are three types of sound productions towards the nineteen sounds: the three way contrasts (lax-aspirated-tense) in stop consonant, two way contrasts (lax-tense) in the alveo-dental fricative, and no contrast (only aspirated) in the glottal fricative. First is lax or plain [p, t, k, c, k, s]. Then, aspirated [ph, th, ch, kh, h]. The last is
tense [p’, t’, c’, k’, s’]. The rest consonant sounds are [l, m, n, ŋ].
Influencing dialectical variations, vowels system consists of five front vowels (three unround: [i e ɛ]; two round: [ö ü]) and five back vowels (three
Figure 2.3
Korean Letters and Sounds
Source: http://thinkzone.wlonk.com/Language/Korean.htm
The Korean phonetic syllable structure is ( C) (G) V (C). Therefore, only one optional consonant (C) and one optional glide of semivowel (G) in the onset position, and one optional consonant in the coda position are allowed in Korean speech. The only obligatory element is the nucleus vowel (V) (Young-key Kim, 2001).
voicing delay of about 30 to 50 msec, whereas the aspirated one are produced with strong aspiration lasting about 100 msec. If there is any comparison with English, voiceless sound in English are produced in range about 70 to 85 msec. As the result, English speaker are often unable to hear the distinction between two ways of Koreans' sound production. English speakers often label Korean reinforced consonants as voiced sounds though in reality reinforced sounds are voiceless sounds.
In the medial position, between voiced sound, preceded and followed by vowel, the lax consonants are phonetically voiced. Therefore, the word 바 보 (papo) is pronounced as [pʌbo] and the word 고기 (koki) is pronounced as [kogi],
etc. In Korean, the changing between voiceless and voiced sound does not affect the meaning. For Koreans /b d j g/ are same to /p t c k/. Then, the consonants in final position are only pronounced as lax consonants or voiceless and unreleased ones. Reinforced consonants and aspirated consonants do not occur in final position.
sound in the beginning of syllable only if the syllable is noninitial. On the other hand, the aspirated and reinforced sound, as well as the fricatives and affricates, can not appear in the end of syllable.
Related to the length of the sound produced, there are two types in Korean, double consonants and simplified consonants. Double consonants or geminates are reinforced consonants because the consonants are produced longer. The example is the word 아빠. This word has /pp/ like in (appa). However, Koreans still has simplified sound or homorganic lax consonants. For example the word 앞
(aph). The plosive will be sounded if the sound is followed by vowel. However, if both of the sounds are consonants the word will be pronounced as [ʌp]. Similar to
Lee and Ramsey's theory, Rogers (2005) stated that Korean, especially Hangul, has three classes of obstruents: plain, aspirated, and tense.
and //h/, Korean only has three, namely /s/, /ss/, and /h/. Thus, for English /f/ and /v/, Koreans replace them with the variations of bilabial plosives.
3. Phonological Strategies
Phonological strategies are strategies which are used to solve the problem of sound production. When we talk about cross-language, language strategies will occurred mostly (Schmidt, 1994). This matter is related to accuracy. Sound differences among languages were always occurred. The speakers of certain language will use 'interlingual identification' where they try to identify the way to solve the in-existing sound by replacing with similar sound, omitted, or other strategies.
a. Sound Substitution
want a copy?'. She waved the hand out while she was speaking. However, the friend answered, 'I think milk is better.' Both former examples shows that the sound /f/ is substituted with /p/. Theoretically, Korean writing system has the rule that the sound /f/ will be substituted with /p/, whereas /v/ with /b/.
b. Sound Deletion
Sound deletion is the phonological process where one sound with a syllable is omitted (Jenkins, 2009).There are some types of deletion (Nathan, 2008). The first one is aphesis or apheresis. This is the type of deletion in the initial position of word. [weɪ] can refer to two words, way and away. However, if
we talk about sound deletion the former phonetic transcription must be a part of away /əweɪ/. In this case the schwa sound is omitted.
The second type is syncope. Syncope is a very common deletion where the vowel in the middle of the word is deleted, for example the word family [fæmli]. Lastly, there is apocope. Apocope is usually consonant deletion. The final sound of a word is omitted which is usually placed within consonant cluster.
c. Sound Simplification
versus lit. It is possible to hear the contrast in the first pair of word because they are initial consonants. However, the second word pair sometimes is impossible to get the contrast because they are final sound. It also happens in Korean language which does not have minimal pair. Between b/p, d/t, and g/k there is no contrast. In Korean language voiced and voiceless sound do not exist. Amazingly, if the speaker from other language produce the sound randomly, may be they use /p/ or /b/, the Korean addressee still understand.
This strategy is also similar to the rule of one of Korean phonological process, neutralization. One condition which differs the simplification and neutralization is in Korean this process happened only in the last syllable. In Korean final syllable, the slight puff of air sometimes heard in English is impossible. The final sound is never released. Consonants which form the final sound are called pachim (Chang, 1995). However, in Korean not all consonants can be placed in final syllable: /k n t l m p ŋ/. Other sounds which cannot occur in the final syllable will be neutralized as following.
ᄃᄉᄌᄎᄐᄒᄊ
as pronounced as /t/ᄇᄑ
as pronounced as /p/ᄀᄁᄏ
as pronounced as /k/Based on the preceding theory, all the final sounds become voiceless sound. d. Sound Assimilation
sound. When the sound in the preceding syllable is assimilated to the next sound it is called anticipatory assimilation or regressive assimilation, or simply leftforward assimilation. When the direction goes forward from the causing sound to the affected sound it is said as perseveratory assimilation, or progressive assimilation, or rightforward assimilation.
Assimilation also has relationship with geminates. Geminates is double consonants sound in sequence (Harris, 1996). Therefore, when assimilation happens and changes one sound to be same to neighbor sound, so that there are two identical sounds, it is named gemination.
e. Insertion
The opposite way of sound deletion is sound insertion. This strategy adds a sound into a word. Nathan (2008) explained two reasons of applying insertion. Firstly, the insertion is done to prevent consonant cluster that violate syllable structure. Secondly, it is applied to ease transition between segments that have multiple incompatible.
it sounds, they add vowel in the end of the word, or example, ice [aısә]. It happens because the letter 's' is pronounced as /t/ instead of /s/ in the final. Thus, the speaker add the short vowel, schwa sound, to make it sound.
f. Syllabic Structure
Figure 2.4 Hierarchical structure
McMahon (2002) stated that there were two types of syllable, open and closed one. In open syllable, there are only two possible phoneme classes, onset and nucleus. Coda does not appear in this type of syllable. While, closed syllable has code to be the border of syllable.
Within closed syllable there are two phenomena where the coda modification is allowed. They are onset maximalism and gemination.
1) Onset Maximalism
Within a syllable, there is a sequence. The ordinary one is onset, nucleus and coda sequence or C-V-C. However, consonant has a better sound if it is placed in the initial syllable. Therefore, the strategy onset maximalism occurs. Onset maximalism is the strategy which rearrange a syllable syllable. When in the initial syllable there is a coda, using onset maximalism strategy the coda will be
consonant consonant vowel consonant
O O N C R
moved into initial of the followed syllable. This strategy has a nature to move code into onset as many as possible (Mcmahon, 2002). For example, the word leader is chosen. Naturally, this word is segmented as lead.er or /liːd.ər/. However, when this strategy applied, the word will be pronounced as /liː/ and /dər/. The /d/ is
not be pronounced in the first syllable but the second one.
This strategy is also used for ambisyllabic sound. Ambisyllabic sound is the sound which belongs to the previous syllable as the coda but it sounds as if it is the part of the next syllable as the initial sound. Therefore, within word contains ambisyllabic sound, onset maximalism is applied. The word which has ambisylabic sound is cover. Phonologically, this word is produced as /kʌv.ər/ but usually it sounds as /kʌ.vər/.
However, there are some rules within this strategy. Not all codas can be changed into onset. When the syllable contains consonant cluster in the end syllable, it does not mean that all consonants should be moved into the next syllable because the rules of consonants combination between initial consonant cluster and ending consonant cluster are different, for example falter. This word has consonant cluster in the ending of the syllable but not all consonants can be moved into onset position. The cluster /lt/ does not exist in the initial syllable, so that only /t/ is moved into the next syllable, from /fɒlt.ər/ to be /fɒl.tər/.
word is pronounced as (geol-da) /gɒldʌ/. While, when it is followed by vowel,
onset maximalism will be directly applied as '걸어' (geol-eo) which is pronounced as (geo-reo) /gɒrɒ/ (Lee and Ramsey, 2000).
2) Gemination
Geminates are double or long consonants (Harris, 1996). Katamba (1996) also stated that sounds were geminated if the same consonantal articulation is held for the duration of two consonantal beats. The former explanation also can be named 'true gemination'. There is also the fake one. Fake geminates are pairs of identical consonants which accidentally occur together as a result of juxtaposition of two morphemes.
C. Theoretical Framework
As the framework, some points can be summed up. Between English and Korean language there are some sounds which are absent. Thus, the Koreans use the sounds which are present in their language to label the absent language. In this case is labiodental fricatives. Koreans use the variation of /p/ and /b/ which have the highest quality of similarity as the labeling to /f/ and /v/. The variation of bilabial plosives are used because Korean speakers have no minimal pairs, the lax-aspirated-tense sounds occur depends on the position or the neighbor.
inaccuracy will be explained deeper using phonological strategies so that what kind of phonological process happening will be revealed.
CHAPTER III
RESEARCH METHODOLOGY
The current chapter elaborates the methodology of the study. It begins
with the method which is applied in the study. Then, the next section deals with
the object of the study. In the third section the instruments of the research is
discussed. The next section talks about the data collection. The fifth section
focuses on analyzing the data. The last one exposes the chronological steps of the
study.
A. Research Method
Since this study dealt with sound production analysis, which focuses on
the accuracy when Koreans produce labiodental fricatives, this research employed
qualitative research. This study tries to see how accurate the sound to be
produced.
If we see the sources of data collecting, this study can be narrowed into
document analysis. Document analysis is described as a method of research
utilized to written or visual materials for the aim of identifying specified
characteristics of the material or a project that focuses on analyzing and
interpreting recorded materials within its own context (Ary & Razavieh, 2002).
The videos were utilized as the main object to analyze types of errors in sound
The forms of material that can be used in document analysis are various. It
can be textbooks, newspapers, speeches, television programs, etc. In this case, this
study employed video as the research subject. The videos were employed because
the writer also wanted to see the lip movement and mouth to get clearer sound
transcription. The videos were the form of music videos where the singers sang
English songs in live performance. The subject within the videos is South Korean
singer. The reason to employ live-performance music video is due to the absence
of editing in their performance. So, the writer will obtain the real-condition data.
The study focuses on their pronunciation when they meet labiodental fricatives.
The result of the live-performance music video observation which is in the form
of phonetic transcription becomes the data for the study.
This study wants to see the accuracy of the subjects when produce the
certain sounds, in this case are labiodental fricatives, by analyzing the sound
production. Skehan argued that accuracy is a matter of how well the second
language speaker produces the target language in relation to the rule system of the
target language (Ellis and Barkhizen, 2009).
To see the accuracy, error analysis is employed. Ellis and Barkhizen
(2009) stated “error analysis (EA) consists of a set of procedures for identifying,
describing, and explaining learner errors.” It means that error analysis tries to
discover the errors that occur in the live-performance video when the South
Corder (1974) distinguished error analysis into five steps, they are sample
collecting, error identification, error description, error explanation, and the last is
error evaluation. However, this study, which does not deal with the correction,
limits the research until the fourth step.
B. Research Subjects
For conducting the study, the writer needed subject to be investigated. In
this study the writer employed 20 videos to be examined. In this video, South
Korean singers sang English song. The songs are originally sung by western
singers, such as Jason Mraz, Ne-Yo, Erick Clapton, etc. There were 19 songs. 2
songs were sung by 3 different groups, 1 by 2 groups. They were Glen Hasard's
Falling Slowly which was sung by Super Junior, 2AM and CN Blue, Neyo's So
Sick was sung by 2AM, CN Blue and SHINee, and Jason Mraz's Lucky was sung
by CN Blue and SHINee. The videos are in type of live-performance videos,
where the singers do live performance without any manipulation or lip-sync
because the videos are parts of television or radio program. The live performance
videos was chosen because the writer wanted to see the singers’ pronunciation in
the real condition where nobody created the condition. The videos were chosen by
year of performance randomly. The videos were from 2009 until 2011.
In addition, the singers in the videos were chosen with some purposes
based on the background of the singers. They are singers from the most famous
Blue, and 2 AM. They are chosen because they are in international market.
Besides, each group has their own background. The first group, Super Junior is a
male group consists of 13 members. They could be said as senior group because
the group had done debut in 2005. The range age of this group is between 24 to
30. On the other side, SHINee debuted in 2008. This male group consists of 5
members ranging in age between 19 and 23. Both groups first debuted in South
Korea then go internationally, such as Japan, Taiwan, Paris, and many more. The
third group, CN Blue which consists of 4 members in range of age from 19 to 23
years old do their debut for the first time in the Japan in 2009. Because their debut
in Japan, they usually sang song in Japanese or English instead of Korean
language. The last group is 2 AM, a male group consists of 4 members which are
in age range between 20 until 29 years old which has debut in South Korea firstly
and now in Asia.
The reason of choosing only boy group was the nature of Korean language
speaking. In Korean there are some differences in manner of speaking between
male and female speakers. Female speakers usually use intimate language and
agyeo, the cute way to express what they want to say. They also use so many
accenting in their sentences. While male speaker prefer to use formal language
and reduce accenting. So, it can be said that male speakers use language which is
C. Research Instruments
There were some instruments used in this document analysis.
Those instruments are:
1. Human Instrument
For gathering the data, the writer employs human as the instrument. Ary
and Razavieh (2002) stated that one major character which shows the difference
between qualitative and quantitative research is the condition where human can be
used as primary instrument for gathering data, or human as instrument.
Qualitative research such document analysis study which dealt with human
experiences and situation needed a flexible instrument to ensnare the complexity
of both subject. Therefore, this study that deals with the situation where South
Korean people speak English as international language employs the writer herself
as the instrument to examine the phenomena happened in the subject.
2. The Videos of Korean Singers who Perform English Songs
Dealing with document analysis, the document that is obtained during the
observation is also called research instrument. The document is in form of video,
live-performance video of Korean singers. In the video, the Korean singers do live
performance. Editing was absent in their performances. The songs that the Korean
speakers sing are English songs. The videos come from 2009 until 2011, time
D. Data Gathering Technique
Since this study uses document analysis as the research technique, the
main source of this study is the document in the form of video. Using the video,
this study deals with document observation where the writer gather the data by
observing the sound produced in the video.
The documents are in the form of live-performance music videos which
are collected by downloading from youtube.com. The writer at the first time tried
to find the link to some television and radio live-performance show. This part was
the hardest part of the process gathering document due to deletions of the link to
some variety shows or reporting as spam by the copyright owner - the station
television and radio. After searching out the link, the next step which should do
was downloading the video using keepvid.com. Using keepvid.com, the video
could be downloaded in the form of MP4 which had higher quality of picture and
sound than flash video (.flv) form.
After downloading the video, the first thing to do was lyrics matching.
Here, the writer tried to match the lyrics to the video, which part should be
omitted, which part is repeated. The purpose was to make the lyrics have exactly
same part and sequence to the video. Then, the writer finds the words containing
labiodental fricatives sound. After that, the writer transcribed the words based on
the sound produced in the video.
Though dealing with qualitative research, the study also used some table
The following is the basic table used to collect the data. In more detail, the table
was a table showing the word containing labiodental fricatives sound, the standard
phonetic transcription, the number of appearance, the number of accurate
appearance and also the inaccurate one, the variation phonetic transcription based
the sound production in the video, and the last is the number of the same variation
occur.
Table 3.1: Basic Table
No
Word/ Word Group
Standard Phonetic Transcription
Frequency of Pronunciation Variation
Appearance Accuracy Inaccuracy Phonetic Transcription
Frequency of Appearance
1
2
3
...
The findings were also classified into groups. There are 5 types, single
word contains voiceless sound group, single word contains voiced sound group,
word group contains voiceless sound group, word group contains voiced sound
group, and the combination sound group. The findings were divided into main 2
type, single word and word group in order to observe the possible strategy
whether is affected by neighbor or not. Word group itself is a kind of group which
has random combination. It does not create fixed phrase, such as adjective phrase,
noun phrase, etc. it contains various type of words. For example, it can be a
combination of noun verb, verb article, and many more. This word groups are
E. Data Analysis Technique
There are two questions in this study related to English performance done
by Korean speakers. The first to second questions were done with document
analysis. Focusing on the sound, the first thing to do after collecting the word was
changing the sound into phonetic transcription. Then, the writer did type
classification. Firstly, the findings were classified into 5 major types, /f/ in single
word, /f/ in word group, /v/ in single word, /v/ in word group, and combination.
This step means the writer had moved the phonetic transcription into table.
After to be classified into five major types, the findings, once more, were
classified into six types. This types was made based on the sound position. The
first type is labiodental fricatives in the initial syllable. Then, the second one is
labiodental fricatives within consonant cluster in the initial syllable. Then, the
sound is placed into the end of syllable of syllable-final. The fourth one is still in
the same position but within consonant cluster. Number five is ambisyllabic sound
and the last is modification when the sound appears more than once within one
word or word group.
The next steps was analyzing of the error done by the singer using the
phonetic transcription and what sounds they used to replace the absent sounds. In
this part, the writer made comparison between the standard sound which could be
found in dictionary and the sound performed by the Korean singers. Then, the
writer bserved the variation to decide what phonological strategies used to solve
F. Research Procedures
After gathering the data, based on the finding, the writer starts to analyze
the linguistic strategy used on the substitute. The error analysis steps are applied
here.
1. Sample collecting
This step is to provide the data for EA. The sample is collected randomly,
but there are some details used to limit the choice. The video comes from 4 groups
which have been mentioned before and to be on aired within 2009 until 2011. In
the video the Korean singers sing English songs. The song English should be sung
in live performance so that the data can be conducted without any manipulation.
2. Error identification
The error can be identified by comparing the phonetic transcription of the
subject sound produce towards the standard pronunciation based on dictionary.
The writer does not compare the sound with the native sound because some of the
native singers also produce non-standard sound.
3. Description of errors
In this part the errors are classified, whether this happen in the beginning
only, in the end, both, or in the middle of a word, or maybe the error happens
because of the other words within word groups. Here, the writer also classify the
sound based on the voiceless and voiced sound so that the study can reveal which
4. Error explanation
Error explanation tries to give clear sight towards the errors done and what
the substitutes employ in the error. This explanation will drive to the strategic
explanation. The strategies applied to solve the problem drive to the deep research
towards what phonological strategies used.
Then, the following is the procedures of finishing the research.
1. The first thing do was collecting the video from YouTube.com.
2. Secondly, the writer found the lyrics. The important thing do was
matching the lyrics with the live-performance videos.
3. Thirdly, the writer should find the words contained labiodental fricatives.
4. Next, the words found had to be transcribed into phonetic symbols.
5. After having the phonetic transcription, the writer moves those into the
table so that the number of accurate or inaccurate production occurred.
6. Then, the next step is categorizing the findings into three major group,
/f/, /v/, and combination of both sounds. After that, each group was still
divided into two group, single word and word group.
7. Due to the grouping, the analysis of accuracy became easier. Within the
each group, the writer tried to see the number of accuracy and made
percentage.
8. By putting aside the accuracy, using the findings of inaccuracy, the writer
tried to classify the strategies used to solve the problem of sound absence.
The following is the chart used to explicate the chronology of the research
procedures.
Flow Chart 3.1: The rationale of research procedures
Phonological strategy classification
Writing the report
Collecting the videos from YouTube.com
Matching the lyrics to the video
Finding the words
Transcribing the sound heard from the video into phonetic symbols
Moving the finding into the table
Categorizing the finding into group
Error analyzing /v/
/f/ /f/ and /v/
Single word Word group Single word Word group Single word Word group
CHAPTER IV
RESULTS AND DISCUSSION
This chapter presents the results of the document analysis to answer the
three problems formulated in the study. This chapter discusses the findings of the
accuracy of Korean speakers, in this case singers, pronounce words or word
groups containing voiceless /f/ and voiced /v/ labiodental fricatives when they
sing English songs in live performance, the findings of speakers' linguistic
strategy to solve the non-exist sounds which is labiodental fricatives, the findings
of syllable structure of word and word group contain labiodental fricatives and the
additional findings of the research which can be topic for future research.
A. Accuracy of Voiceless and Voiced Labiodental Fricative Sound
Articulation within Words and Word Groups by Korean Speakers
This part will discuss how accurate the Korean speakers which are
represented by Korean singers pronounce the absent sounds, in this case
labiodental fricatives.
1. Total Number of Words and Word Groups
From 20 videos analyzed, the writer found 561 single words and word
groups using labiodental fricatives. After collecting the words, the writer tried to
word class and word groups class. Each class was also divided using manner of
articulation, or in other words it was divided into voiceless and voiced sounds.
From that classification, it was discovered five types of labiodental fricatives.
They were voiceless labiodental fricative words, voiced labiodental fricative
words, voiceless labiodental fricative word groups, voiced labiodental fricative
word groups, and the combination of both voiceless and voiced sound in words
and word groups.
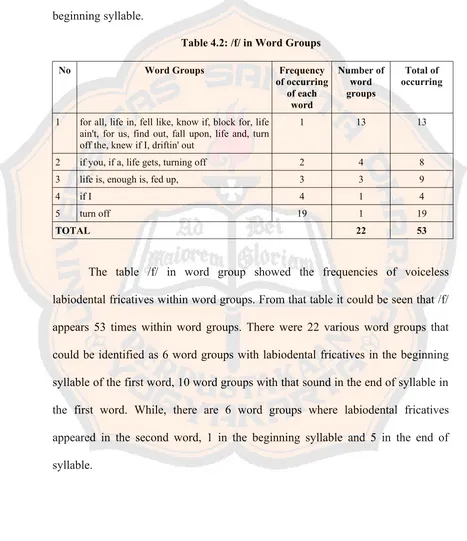
Table 4.1: /f/ in Single Words
No Words Frequency
of occurring of each
word
Number of words
Total of occurring
1 forget, different, famine, feast, reflected, wherefore, rough, fancy, staff, puff's, flags, fearless, feels, fantasy, myself, softly, fill, fate, flow, family, fulfill, future, feelings, half, after, fast, friends, fine, unforgettable, fit, fingers, forth, if, dragonfly, butterfly, fun, feeling, before, yourself
1 39 39
2 face, fading, fear, far, fools, find, peaceful, godforsaken
2 8 16
3 flower, phone, fix, first, fifteenth 3 5 15
4 from, fool, hopeful, feel 4 4 16
5 free, falling, enough 5 3 15
6 life 6 1 6
7 frolicked 7 1 7
8 fall, friend 8 2 16
9 puff 11 1 11
10 for 19 1 19
TOTAL 65 160
Starting from the table /f/ in single words which contains voiceless
which contained 53 words had /f/ in the beginning of syllable and 12 words in the
other place. It could be in the end of syllable or before other letter in the
beginning syllable.
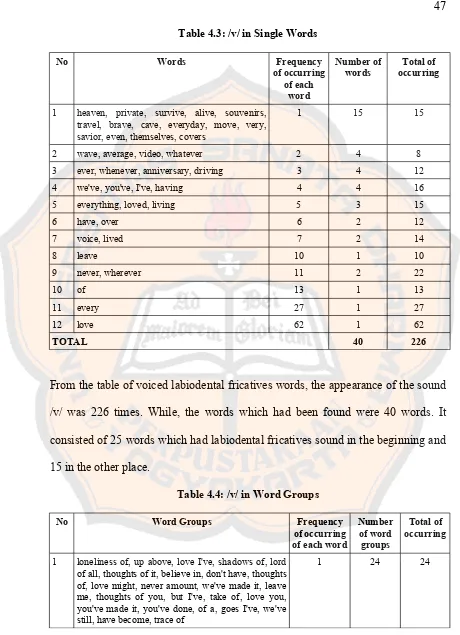
Table 4.2: /f/ in Word Groups
No Word Groups Frequency
of occurring of each
word
Number of word groups
Total of occurring
1 for all, life in, fell like, know if, block for, life ain't, for us, find out, fall upon, life and, turn off the, knew if I, driftin' out
1 13 13
2 if you, if a, life gets, turning off 2 4 8 3 life is, enough is, fed up, 3 3 9
4 if I 4 1 4
5 turn off 19 1 19
TOTAL 22 53
The table /f/ in word group showed the frequencies of voiceless
labiodental fricatives within word groups. From that table it could be seen that /f/
appears 53 times within word groups. There were 22 various word groups that
could be identified as 6 word groups with labiodental fricatives in the beginning
syllable of the first word, 10 word groups with that sound in the end of syllable in
the first word. While, there are 6 word groups where labiodental fricatives
appeared in the second word, 1 in the beginning syllable and 5 in the end of
Table 4.3: /v/ in Single Words
No Words Frequency
of occurring of each
word
Number of words
Total of occurring
1 heaven, private, survive, alive, souvenirs, travel, brave, cave, everyday, move, very, savior, even, themselves, covers
1 15 15
2 wave, average, video, whatever 2 4 8 3 ever, whenever, anniversary, driving 3 4 12 4 we've, you've, I've, having 4 4 16
5 everything, loved, living 5 3 15
6 have, over 6 2 12
7 voice, lived 7 2 14
8 leave 10 1 10
9 never, wherever 11 2 22
10 of 13 1 13
11 every 27 1 27
12 love 62 1 62
TOTAL 40 226
From the table of voiced labiodental fricatives words, the appearance of the sound
/v/ was 226 times. While, the words which had been found were 40 words. It
consisted of 25 words which had labiodental fricatives sound in the beginning and
15 in the other place.
Table 4.4: /v/ in Word Groups
No Word Groups Frequency
of occurring of each word
Number of word groups
Total of occurring
1 loneliness of, up above, love I've, shadows of, lord of all, thoughts of it, believe in, don't have, thoughts of, love might, never amount, we've made it, leave me, thoughts of you, but I've, take of, love you, you've made it, you've done, of a, goes I've, we've still, have become, trace of
No Word Groups Frequency of occurring of each word
Number of word groups
Total of occurring
2 vapor in, world of, wave should 2 3 6 3 themselves out, over you, move I, over us 3 4 12
4 have a 4 1 4
5 have stayed, love songs 6 2 12
6 because of you, tired of, because of 8 3 24
7 have been 10 1 10
8 sick of 25 1 25
TOTAL 39 117
Next, table /v/ in word group, showed the finding of labiodental fricatives
within word groups. From the finding, there were 39 different word groups which
were performed 117 times. From that 39 word groups, 4 word groups had
labiodental fricatives sound in the beginning which was placed in first word. With
the highest number, 17 word groups, there were two different types of word
groups. Both of them had that sound in the end of the syllable but the first 17
word group group had that sound in the end of syllable of the first word, whereas
the another 17 word group group had labiodental fricatives sound in the end of
syllable of the second word in sequence. Besides, there was one word group who
has labiodental fricatives in both first and second word in sequence. This word
group had that sound in the beginning of syllable of the first word and in the end
Table 4.5: /f/ and /v/ in Single Words and Word Groups
No Single Words and Word Group Frequency
of occurring of each
word
Number of words
Total of occurring
1 even if I, for all of time, lives forever 1 3 3
2 forever 2 1 2
TOTAL 4 5
The last table, which contained the findings of combination both voiceless
and voiced sound, showed four different types, 1 single word and 3 word groups.
Total appearances of those types are 5 times. Within the single word, the voiceless
sound appeared in the beginning of second syllable in sequence and the voiced
sound appeared in the beginning of the third syllable. The other hand, the three
word groups also had their own combination. One had voiced sound in the
beginning of syllable of the first word and the end of the syllable of the second
word. The next word group had voiceless sound in the beginning of the first word
and voiced sound in the end of the third word. The last word group had voiced
sound in the end of first word and the exactly same combination as the previous
word in the second word. While, the voiceless sound appeared in the beginning of
the second syllable and the voiced sound appeared in the beginning of the third
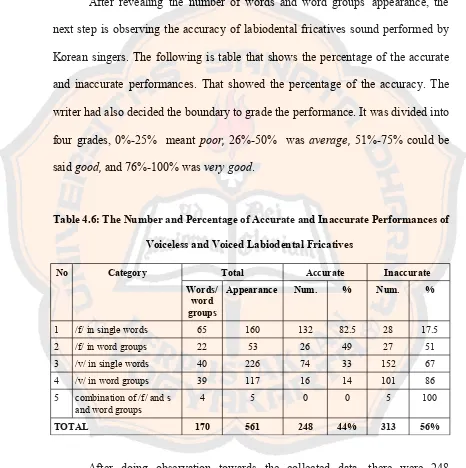
2. The Percentage of Accurate and Inaccurate Performances towards
Labiodental Fricative Sound
After revealing the number of words and word groups' appearance, the
next step is observing the accuracy of labiodental fricatives sound performed by
Korean singers. The following is table that shows the percentage of the accurate
and inaccurate performances. That showed the percentage of the accuracy. The
writer had also decided the boundary to grade the performance. It was divided into
four grades, 0%-25% meant poor, 26%-50% was average, 51%-75% could be said good, and 76%-100% was very good.
Table 4.6: The Number and Percentage of Accurate and Inaccurate Performances of
Voiceless and Voiced Labiodental Fricatives
No Category Total Accurate Inaccurate
Words/ word groups
Appearance Num. % Num. %
1 /f/ in single words 65 160 132 82.5 28 17.5 2 /f/ in word groups 22 53 26 49 27 51 3 /v/ in single words 40 226 74 33 152 67 4 /v/ in word groups 39 117 16 14 101 86 5 combination of /f/ and s
and word groups
4 5 0 0 5 100
TOTAL 170 561 248 44% 313 56%
After doing observation towards the collected data, there were 248
appearances which were produced accurately and 313 inaccurately. If it was seen
inaccurate. Therefore, relying on the result, the ability of Korean speakers
producing English was in the level average.
Each type showed different results. There was one type which has bigger
number in accurate performance and four categories in inaccurate one. Starting
from /f/ in single word, there were 160 times of appearance, where 132
performances were accurate and the rest were inaccurate. Here, 82.5% showed
that voiceless labiodental fricatives can be pronounced accurately, whereas 17.5%
is pronounced inaccurately. From the percentage, it could simply said that
voiceless labiodental fricatives within single word could be performed accurately
by Korean speaker or it could be placed in very good grade.
On the other hand, there were 22 word groups containing /f/ sound found
within 20 videos chosen. From total appearance, 53 times, there were 26 times
performed accurately and 27 times inaccurately. In percentage, 49% was accurate
and 51% was inaccurate. This final number could be categorized in average. Thirdly, showed that /v/ appeared 226 times within 40 single words. 74
times were performed accurately and 152 inaccurately. In percentage, it could be
see that the accuracy of voiced labiodental fricatives pronunciation was less than a
half, only 33%, whereas the inaccuracy reached 67%. Based on that percentage,
the ability of Korean speaker to perform voiced sound of labiodental fricatives
was average.
Besides, the writer invents the result of /v/ within word groups was 117
performances were inaccurate. That result shows that 86% of total number of the
appearance frequency was pronounced inaccurately, whereas 14% could be
pronounced accurately. From the percentage, it could simply said that voiceless
labiodental fricatives within word group could not be performed accurately by
Korean speaker or it could be placed in poor grade.
The last category is the combination of /f/ and /v/ within single words and
word groups. There are four combinations, 3 word groups and 1 word. The first
word group, a three-word word group, had the voiced sound in the beginning of
the second syllable in the first word, whereas the voiceless sound was place in the
end of single syllable in second word of sequences which was followed by vowel
in the next word. From the total appearances there was none which was accurate.
So, this type could be categorized as poor grade.
After being categorized into five major types, they were classified, again,
into six smaller and more specific types based on the position of the sound. The
first type is the sound in the initial of syllable. The next type is the sound within
consonant cluster in the initial of syllable. The following type has the sound in the
final position. The fourth type has the sound within final consonant cluster. The
next one, type number five, is the group of single words or word groups which has
ambisyllabic sound. The last one is the variation, where the sound has double or
more position within. Based on the five specific sound, the accuracy analysis
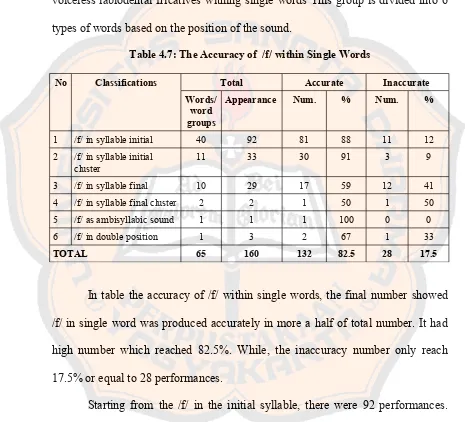
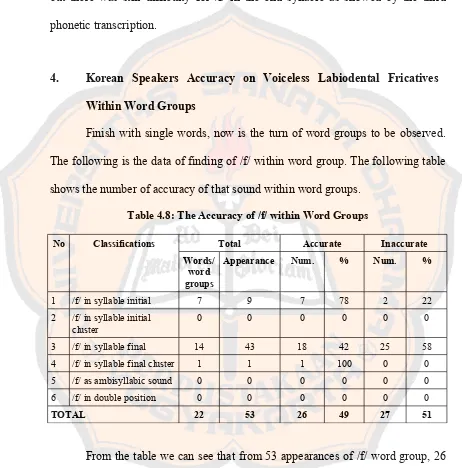
3. Korean Speakers Accuracy on Voiceless Labiodental Fricatives
Within Single Words
The following table shows the accuracy of Korean singer pronouncing
voiceless labiodental fricatives withing single words This group is divided into 6
types of words based on the position of the sound.
Table 4.7: The Accuracy of /f/ within Single Words
No Classifications Total Accurate Inaccurate
Words/ word groups
Appearance Num. % Num. %
1 /f/ in syllable initial 40 92 81 88 11 12 2 /f/ in syllable initial
cluster
11 33 30 91 3 9
3 /f/ in syllable final 10 29 17 59 12 41 4 /f/ in syllable final cluster 2 2 1 50 1 50 5 /f/ as ambisyllabic sound 1 1 1 100 0 0 6 /f/ in double position 1 3 2 67 1 33
TOTAL 65 160 132 82.5 28 17.5
In table the accuracy of /f/ within single words, the final number showed
/f/ in single word was produced accurately in more a half of total number. It had
high number which reached 82.5%. While, the inaccuracy number only reach
17.5% or equal to 28 performances.
Starting from the /f/ in the initial syllable, there were 92 performances.
From the total number, 81 performances were produced accurately, whereas 11
performances were inaccurate. If the number was served in percentage, the
Some example of /f/ in the initial of the first syllable or in word initial,
such as famine /fæmin/, feel /fiːl/, fall /fɔːl /, and for /fɔːʳ/. Sound within the two
earlier appeared words were pronounced accurately as /femen/ and /fɪl/. While, the
next words, fall and for, were produced both accurately /fɒl/ and /fɒ/, and /fɒr/
and /fɒ/, and inaccurately as /pɒl/ and /pɒ/. Then, the second position is second
syllable initial, such as godforsaken /gɒdfəseɪkən/and unforgettable /ʌnfəgetəbl/. The first word was produced accurately as /gʌdfɒsekən/, whereas the second one
was inaccurately as /ɒmpogerəbə/. The next positions are both in the beginning of
the first or second syllable within one word, fulfill /fʊlfɪl/ which is pronounced as same as the standard pronunciation.
The next sub-type is /f/ within consonant cluster in the initial of the
syllable. From the total appearances, 33 performances, 30 were accurate and 3
were inaccurate. In percentage, the accurate number impressively reached 91%,
whereas the inaccurate number reached 9%. Those numbers showed that Korean
speakers attained high grade, very good, in this type.
Consonant cluster in the syllable initial has three position, in the first
syllable, second syllable, and third syllable. For giving the clear explanation,
example will be given for each position. Starting from the initial word, there were
free /friː/ and friend /frend/ which were pronounced as /frɪ/ and /pren/. Then, the
butterfly /bʌtəflaɪ/ with accurate /f/ sound production, /drʌgofrʌ/ and /bʌtəfraɪ/. Though the sound can be pronounced, the combination of consonant or consonant
cluster still find difficulty to be produced. For example, the word free will be /fɪ/
or the word from will be /fɒm/.
Then, the third one is /f/ in syllable final. From total 29 performances,
there were 17 performances or 59% were accurate and 12 or 41% were inaccurate.
Here, some example of this type, staff /stɑːf/ was pronounced as /stʌf/, life /laɪf/ as /laɪp/, /laɪ/ and /laɪf/, after /ɑːftəʳ/ as /æftər/, and enough /ɪnʌf/ as /ɪnaʊ/, /ɪnʌ/,
and /ɪnʌf/.
In the next sub-type, /f/ in syllable final cluster, there were 2 performance
that could be seen. The example of this sub-type were puff's /pʌfs/ which was
pronounced as /pərəf/ and myself /maɪself/ as /maɪsep/. We could see that /f/ in
the first could be pronounced accurately by omitting another sound within cluster,
whereas the next word omitted all the sound in cluster and replaced them with /p/.
Besides, the next sub type, /f/ which was sounded in the end of syllable but to be
geminated into the following syllable, or ambisyllabic sound was produced
accurately. This sound moved into the next syllable as in the word different /dɪfərənt/ which was pronounced as /dɪfən/.
The in the next sub-type, /f/ in both initial and final position, the sound
could be produced accurately. This sub-type had /f/ in initial and final of the first