2.1. Pengertian Data mining
Data mining adalah salah satu solusi untuk menjelaskan proses penambangan
informasi dalam suatu basis data yang berskala besar. Saat suatu organisasi baik itu perusahaan maupun suatu institusi yang mempunyai data yang kompleks, tidak menutup kemungkinan banyak sekali informasi yang dapat diperoleh, serta bagaimana solusi data mining bisa diterapkan dengan berbagai teknik diantaranya yaitu classification, association dan clustering. Dengan data mining dimana melalui serangkaian prosesnya akan menghasilkan suatu nilai tambah berupa pengetahuan baru yang selama ini tidak diketahui secara manual dari sekumpulan data
Data mining merupakan teknologi yang sangat berguna untuk membantu
perusahaan-perusahaan menemukan informasi yang sangat penting dari gudang data (Data warehouse) mereka. Data mining juga dapat meramalkan tren dan sifat-sifat perilaku bisnis yang sangat berguna untuk mendukung pengambilan keputusan penting. Analisis otomasi yang dilakukan oleh data mining melebihi yang dilakukan oleh sistem pendukung keputusan tradisional yang sudah banyak digunakan. Data
mining dapat menjawab pertanyaan-pertanyaan bisnis yang jika dibandingkan dengan
cara tradisional memerlukan banyak waktu dan biaya tinggi. Data mining mengeksplorasi basis data untuk menemukan pola-pola yang tersembunyi, mencari informasi untuk memprediksi yang mungkin saja terlupakan oleh para pelaku bisnis karena terletak di luar ekspektasi mereka.
Kemajuan dalam pengumpulan data dan teknologi penyimpanan yang cepat memungkinkan organisasi menghimpun jumlah data yang sangat luas. Alat dan teknik analisis data yang tradisional tidak dapat digunakan untuk mengektrak
informasi dari data yang sangat besar. Untuk itu diperlukan suatu metoda baru yang dapat menjawab kebutuhan tersebut. Data mining merupakan teknologi yang menggabungkan metoda analisis tradisional dengan algoritma yang canggih untuk memproses data dengan volume besar. Ada beberapa definisi dari data mining yang dikenal diantaranya adalah :
a. Data mining adalah serangkaian proses untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara manual (Maimon O dan Rokahi L, 2010).
b. Data mining adalah analisis otomatis dari data yang berjumlah besar atau kompleks dengan tujuan untuk menemukan pola atau kecenderungan yang penting yang biasanya tidak disadari keberadaannya (Witten et all, 2011).
c. Data mining atau Knowledge Discovery in Database (KDD) adalah pengambilan informasi yang tersembunyi, dimana informasi tersebut sebelumnya tidak dikenal dan berpotensi bermanfaat. Proses ini meliputi sejumlah pendekatan teknis yang berbeda, seperti clustering, data summarization, learning classification rules (Chakrabarti S. et all, 2009).
Selain definisi di atas beberapa definisi juga diberikan seperti tertera di bawah
ini. “Data mining merupakan bidang dari beberapa keilmuan yang menyatukan teknik
dari pembelajaran mesin, pengenalan pola, statistik, basis data, dan visualisasi untuk penanganan permasalahan pengambilan informasi dari basis data yang besar.” (Larose, 2005). Kemajuan luar biasa yang terus berlanjut dalam bidang data mining didorong oleh beberapa faktor, antara lain (Larose, 2005);
1. Pertumbuhan yang cepat dalam kumpulan data.
2. Penyimpanan data dalam data warehouse, sehingga seluruh perusahaan memiliki akses kedalam basis data yang handal.
3. Adanya peningkatan akses data melalui navigasi web dan intranet.
4. Tekanan kompetisi bisnis untuk meningkatkan penguasaan pasar dalam globalisasi ekonomi.
5. Perkembangan teknologi perangkat lunak untuk data mining (ketersediaan teknologi).
6. Perkembangan yang hebat dalam kemampuan komputasi dan pengembangan kapasitas media penyimpanan.
Secara umum, data mining dapat melakukan dua hal yaitu memberikan kesempatan untuk menemukan informasi menarik yang tidak terduga, dan juga bisa menangani data berskala besar. Dalam menemukan informasi yang menarik ini, ciri khas data
mining adalah kemampuan pencarian secara hampir otomatis, karena dalam banyak
teknik data mining ada beberapa parameter yang masih harus ditentukan secara manual atau semi manual. Data mining juga dapat memanfaatkan pengalaman atau bahkan kesalahan di masa lalu untuk meningkatkan kualitas dari model maupun hasil analisisnya, salah satunya dengan kemampuan pembelajaran yang dimiliki beberapa teknik data mining seperti klasifikasi.
2.2.Tahapan Data mining
Salah satu tuntutan dari data mining ketika diterapkan pada data berskala besar adalah diperlukan metodologi sistematis tidak hanya ketika melakukan analisis saja tetapi juga ketika mempersiapkan data dan juga melakukan interpretasi dari hasilnya sehingga dapat menjadi aksi ataupun keputusan yang bermanfaat.
Data mining seharusnya dipahami sebagai suatu proses, yang memiliki
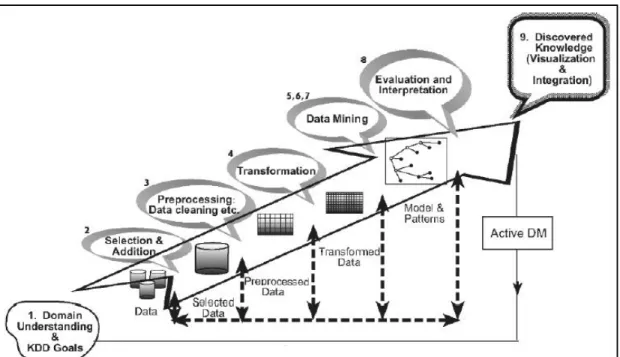
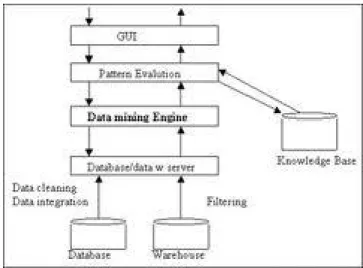
tahapan-tahapan tertentu dan juga ada umpan balik dari setiap tahapan-tahapan ke tahapan-tahapan sebelumnya. Pada umumnya proses data mining berjalan interaktif karena tidak jarang hasil data mining pada awalnya tidak sesuai dengan harapan analisnya sehingga perlu dilakukan desain ulang prosesnya. Proses data mining sesuai pada gambar 2.1
Gambar 2.1. Proses data mining (Maimon O dan Rokahi L, 2010)
Sebagai suatu rangkaian proses, data mining dapat dibagi menjadi beberapa tahap. Tahap-tahap tersebut bersifat interaktif di mana pemakai terlibat langsung atau dengan perantaraan knowledge base.
a. Pembersihan data
Digunakan untuk membuang data yang tidak konsisten dan terdapat noise b. Intergrasi Data
Data yang diperlukan untuk data mining tidak hanya berasal dari satu basis data tetapi juga berasal dari beberapa basis data atau file teks. Hasil integrasi data sering diwujudkan dalam sebuah data warehouse karena dengan data warehouse, data dikonsolidasikan dengan struktur khusus yang efisien. Selain itu data
warehouse juga memungkinkan tipe analisis seperti Online Analytical Processing
c. Transformasi data
Transformasi dan pemilihan data ini untuk menentukan kualitas dari hasil data
mining, sehingga data diubah menjadi bentuk sesuai untuk di-Mining.
d. Aplikasi Teknik Data mining
Aplikasi teknik data mining sendiri hanya merupakan salah satu bagian dari proses data mining. Ada beberapa teknik data mining yang sudah umum dipakai. e. Evaluasi pola yang ditemukan
Dalam tahap ini hasil dari teknik data mining berupa pola-pola yang khas maupun model prediksi dievaluasi untuk menilai apakah hipotesa yang ada memang tercapai.
f. Presentasi Pengetahuan
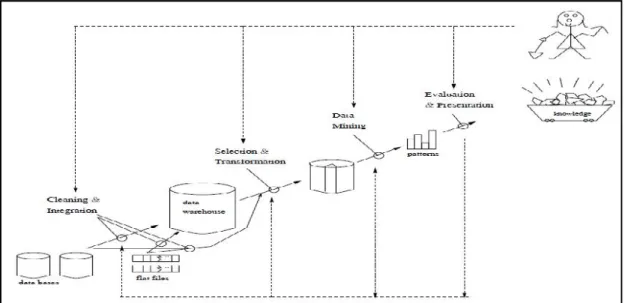
Presentasi pola yang ditemukan untuk menghasilkan aksi tahap terakhir dari proses data mining adalah bagaimana memformulasikan keputusan atau aksi dari hasil analisis yang didapat. Proses akur produksi data mining terlampir pada gambar 2.2
2.3.Teknik Data mining
Data mining adalah serangkaian proses untuk menggali nilai tambah dari suatu
kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara manual. Perlu diingat bahwa kata mining sendiri berarti usaha untuk mendapatkan sedikit data berharga dari sejumlah besar data dasar. Karena itu data mining sebenarnya memiliki akar yang panjang dari bidang ilmu seperti kecerdasan buatan (artificial intelligent),
machine learning, statistik dan basisdata. Beberapa teknik yang sering disebut-sebut
dalam literatur data mining antara lain yaitu association rule mining, clustering,
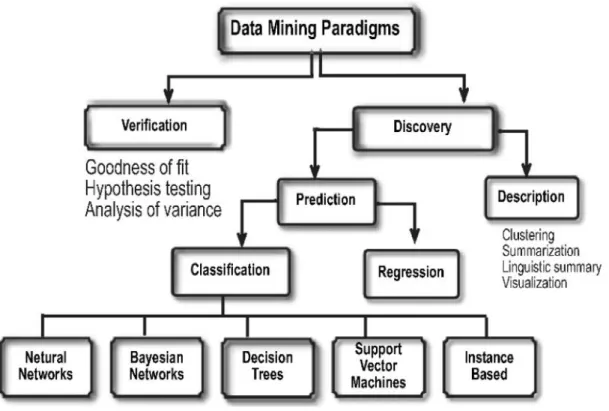
klasifikasi, neural network, genetic algorithm dan lain-lain. Penggolongan teknik data mining terdapat pada gambar 2.3
a. Classification
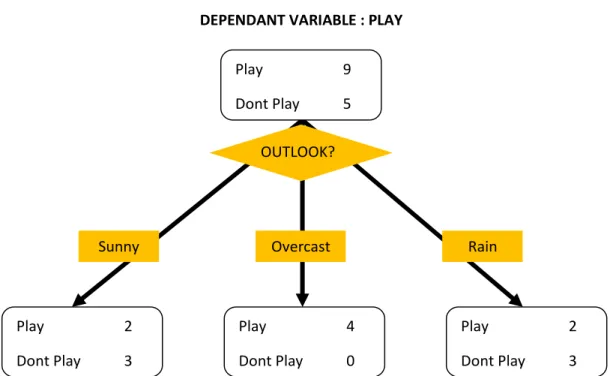
Gambar 2.4. Tahapan Teknik Klasifikasi (Witten et all. 2011)
Suatu teknik dengan melihat pada prilaku dan atribut dari kelompok yang telah didefinisikan.Contoh klasifikasi sesuai pada gambar 2.4. Teknik ini dapat memberikan klasifikasi pada data baru dengan memanipulasi data yang ada yang telah diklasifikasi dan dengan menggunakan hasilnya untuk memberikan sejumlah aturan. Aturan-aturan tersebut digunakan pada data baru untuk diklasifikasi. Teknik ini menggunakan supervised induction, yang memanfaatkan kumpulan pengujian dari record yang terklasifikasi untuk menentukan kelas-kelas tambahan. Salah satu contoh yang mudah dan popular adalah dengan Decision tree yaitu salah satu metode klasifikasi yang paling populer karena mudah untuk diinterpretasi. Decision tree adalah model prediksi menggunakan struktur pohon atau struktur berhirarki.
Play 9
Dont Play 5
OUTLOOK?
Sunny Overcast Rain
Play 2 Dont Play 3 Play 4 Dont Play 0 Play 2 Dont Play 3
Decision tree adalah struktur flowchart yang menyerupai tree (pohon),
dimana setiap simpul internal menandakan suatu tes pada atribut, setiap cabang merepresentasikan hasil tes, dan simpul daun merepresentasikan kelas atau distribusi kelas. Alur pada decision tree ditelusuri dari simpul akar ke simpul daun yang memegang prediksi kelas untuk contoh tersebut. Decision
tree mudah untuk dikonversi ke aturan klasifikasi (classification rules). b. Association
Gambar 2.5. Tahapan Teknik Asosiasi (Witten et all. 2011)
Pada gambar 2.5 digambarkan tahapan teknik asosiasi. Teknik asosiasi digunakan untuk mengenali kelakuan dari kejadian-kejadian khusus atau proses dimana link asosiasi muncul pada setiap kejadian. Contoh dari aturan assosiatif dari analisis pembelian di suatu pasar swalayan adalah bisa diketahui berapa besar kemungkinan seorang pelanggan membeli roti bersamaan dengan susu. Dengan pengetahuan tersebut pemilik pasar swalayan dapat mengatur penempatan barangnya atau merancang program promosi pemasaran dengan memakai kupon diskon untuk kombinasi barang tertentu.
Penting tidaknya suatu aturan asosiatif dapat diketahui dengan dua parameter, support yaitu prosentase kombinasi atribut tersebut dalam basis data dan confidence yaitu kuatnya hubungan antar atribut dalam aturan asosiatif. Motivasi awal pencarian association rule berasal dari keinginan untuk menganalisis data transaksi supermarket, ditinjau dari perilaku
customer dalam membeli produk. Association rule ini menjelaskan seberapa
sering suatu produk dibeli secara bersamaan.
c. Clustering
Gambar 2.6. Proses clustering (Witten et all. 2011)
Clustering sesuai pada gambar 2.6. digunakan untuk menganalisis
pengelompokkan belum didefinisikan sebelum dijalankannya tool data
mining. Biasanya menggunkan metode neural network atau statistik. Clustering membagi item menjadi kelompok-kelompok berdasarkan yang
ditemukan tool data mining. Prinsip dari clustering adalah memaksimalkan kesamaan antar anggota satu kelas dan meminimumkan kesamaan antar
cluster. Clustering dapat dilakukan pada data yang memiliki beberapa atribut
yang dipetakan sebagai ruang multidimensi. Ilustrasi dari clustering dapat dilihat di Gambar dimana lokasi, dinyatakan dengan bidang dua dimensi, dari pelanggan suatu took dapat dikelompokkan menjadi beberapa cluster dengan pusat cluster ditunjukkan oleh tanda positif (+). Banyak algoritma clustering memerlukan fungsi jarak untuk mengukur kemiripan antar data, diperlukan juga metoda untuk normalisasi bermacam atribut yang dimiliki data.
2.4.Kernel K-Mean
K-Means adalah suatu metode penganalisisan data atau metode Data mining yang melakukan proses pemodelan tanpa supervisi (unsupervised) dan merupakan salah satu metode yang melakukan pengelompokan data dengan sistem partisi. Metode k-means berusaha mengelompokkan data yang ada ke dalam beberapa kelompok, dimana data dalam satu kelompok mempunyai karakteristik yang sama satu sama lainnya dan mempunyai karakteristik yang berbeda dengan data yang ada di dalam kelompok yang lain. Dengan kata lain, metode ini berusaha untuk meminimalkan variasi antar data yang ada di dalam suatu cluster dan memaksimalkan variasi dengan data yang ada di cluster lainnya.
Objective function yang berusaha diminimalkan oleh k-means adalah:
J (U, V) = SUM (k=1 to N) SUM (i=1 to c) (a_ik * (x_k, v_i)^2) dimana:
U : Matriks keanggotaan data ke masing-masing cluster yang berisikan nilai 0 dan 1 V : Matriks centroid/rata-rata masing-masing cluster
c : Jumlah cluster
a_ik : Keanggotaan data ke-k ke cluster ke-i x_k : data ke-k
v_i : Nilai centroid cluster ke-i
Prosedur yang digunakan dalam melakukan optimasi menggunakan k-means adalah sebagai berikut:
Step 1. Tentukan jumlah cluster
Step 2. Alokasikan data ke dalam cluster secara random
Step 3. Hitung centroid/rata-rata dari data yang ada di masing-masing cluster. Step 4. Alokasikan masing-masing data ke centroid/rata-rata terdekat
Step 5. Kembali ke Step 3, apabila masih ada data yang berpindah cluster atau apabila perubahan nilai centroid, ada yang di atas nilai threshold yang ditentukan atau apabila perubahan nilai pada objective function yang digunakan, di atas nilai threshold yang ditentukan Centroid/rata-rata dari data yang ada di masing-masing
cluster yang dihitung pada Step 3. didapatkan menggunakan rumus sebagai
berikut:
v_ij = SUM (k=0 to N_i) (x_kj) / N_i dimana:
i,k : indeks dari cluster j : indeks dari variabel
v_ij : centroid/rata-rata cluster ke-i untuk variabel ke-j
x_kj : nilai data ke-k yang ada di dalam cluster tersebut untuk variabel ke-j N_i : Jumlah data yang menjadi anggota cluster ke-i
Sedangkan pengalokasian data ke masing-masing cluster yang dilakukan pada Step 4. dilakukan secara penuh, dimana nilai yang memungkinkan untuk a_ik adalah 0 atau 1. Nilai 1 untuk data yang dialokasikan ke cluster dan nilai 0 untuk data yang dialokasikan ke cluster yang lain. Dalam menentukan apakah suatu data teralokasikan ke suatu cluster atau tidak, dapat dilakukan dengan menghitung jarak data tersebut ke masing-masing centroid/rata-rata masing-masing cluster. Dalam hal
ini, a_ik akan bernilai 1 untuk cluster yang centroidnya terdekat dengan data tersebut, dan bernilai 0 untuk yang lainnya.
2.4.1. Cluster Validity Criterion
Untuk menentukan jumlah cluster yang paling tepat, saat menggunakan metode k-means dapat dilakukan dengan beberapa cara. Salah satunya adalah dengan cara manual yang saya jelaskan dalam posting saya tentang Akurasi Hasil Pemodelan K-Means yang sering juga direfer sebagai Bootstrapped Method. Selain itu ada beberapa cara yang lain yang juga bisa digunakan seperti di bawah ini.
2.4.2. Elbow Criterion (RMSSDT dan RS)
Elbow criterion adalah salah satu cara untuk menentukan jumlah cluster yang paling tepat untuk pemodelan k-means. Elbow criterion untuk k-means ini mengkombinasikan antara nilai RMSSTD dan RS statistics, dimana cluster yang paling tepat untuk suatu dataset ditentukan apabila perbedaan nilai antara RMSSTD dan RS menjadi berbanding terbalik dengan keadaan sebelumnya.
RMSSTD (Root Means Square Standard Deviation) merupakan alat ukur tingkat kemiripan (homogeneity) data yang terdapat di dalam cluster yang ditemukan (within
clusters). Makin rendah nilai RMSSTD makin mirip data di dalam cluster yang
ditemukan. RMSSDT dihitung menggunakan rumus sebagai berikut:
RMSSTD = SQRT (SUM(i=1 to k) SUM(j=1 to d) (SUM(k=1 to N_i) ((x_kj – mu_j)^2)) / SUM(i=1 to k) SUM(j=1 to d) (N_i – 1))
RS (R Squared) digunakan untuk mengukur tingkat kesamaan atau ketidaksamaan antara cluster (between clusters). RS mempunyai nilai antara 0 dan 1. Nilai 0 untuk cluster yang sama dan 1 untuk cluster yang benar-benar berbeda. RS dihitung dengan rumus:
RS = (SS_t – SS_w) / SS_t
SS_t = SUM(j=1 to d) (SUM(k=1 to N) ((x_kj – mu_j)^2) dan
SS_w = SUM(i=1 to k) SUM(j=1 to d) (SUM(k=1 to N_i) ((x_kj – mu_j)^2)) Notasi:
mu_j : means/rata-rata nilai dari variabel dimensi ke-j N_i : jumlah data di dalam cluster ke-i
N : jumlah data keseluruhan d : jumlah dimensi dari data k : jumlah cluster
Elbow criterion adalah suatu modelling criterion yang bisa digunakan untuk
menentukan jumlah cluster dengan melihat perubahan perbandingan antara nilai RMSSTD dan RS. Hal ini dilihat dengan membandingkan persentase tingkat perubahan kedua nilai (RMSSTD dan RS). Apabila muncul suatu keadaan yang berbanding terbalik dengan keadaan sebelumnya, maka titik sebelum terjadinya perubahan tersebut dianggap sebagai jumlah cluster yang paling tepat.
2.5.CART (Classification and Regression Trees)
CART (Classification and Regression Trees) adalah salah satu metode atau algoritma dari salah satu teknik eksplorasi data yaitu teknik pohon keputusan. Metode ini dikembangkan oleh Leo Breiman, Jerome H. Friedman, Richard A. Olshen dan Charles J. Stone sekitar tahun 1980-an. CART merupakan metodologi statistik nonparametrik yang dikembangkan untuk topik analisis klasifikasi, baik untuk peubah respon kategorik maupun kontinu (Breiman et al. 1993). CART menghasilkan suatu pohon klasifikasi jika peubah responnya kategorik, dan
menghasilkan pohon regresi jika peubah responnya kontinu. Tujuan utama CART adalah untuk mendapatkan suatu kelompok data yang akurat sebagai penciri dari suatu pengklasifikasian. Bentuk dari CHART adalah seperti berikut ini :
Gambar 2.7. Diagram CART
Pada Gambar 2.7 di atas A, B dan C merupakan peubah penjelas yang terpilih untuk menjadi simpul. A merupakan simpul induk, sementara B dan C merupakan simpul anak dimana C juga merupakan simpul akhir yang tidak bercabang lagi.
Sementara α dan β merupakan suatu nilai yang merupakan nilai tengah antara dua
nilai amatan peubah xj secara berurutan. Diagram yang dihasilkan oleh CART ini merupakan suatu model, biasanya diinterpretasikan ke dalam suatu tabel untuk penjelasannya. Hal ini berbeda dengan regresi konvensional dimana model regresi dapat dituliskan menjadi model matematik atau persamaan regresinya.
Pembangunan pohon dilakukan melalui penyekatan gugus data dengan sederetan penyekat biner sampai dihasilkan simpul akhir. Tahapannya adalah sebagai berikut:
1. Tentukan semua kemungkinan penyekatan pada tiap peubah penjelas. Tiap penyekatan ini bergantung pada nilai yang berasal dari satu peubah penjelas. Untuk peubah kontinu xj, penyekatan yang diperbolehkan adalah xj ≤ c dan xj ≥ c, dimana c adalah nilai tengah antara dua nilai amatan peubah xj secara berurutan.
Jadi jika xj mempunyai sebanyak n nilai yang berbeda maka akan ada n-1 penyekatan.
2. Untuk peubah kategorik, penyekatan yang terjadi berasal dari semua kemungkinan penyekatan berdasarkan terbentuknya dua anak gugus yang saling lepas (disjoint). Jika xj peubah kategorik nominal dengan L kategori, maka akan ada 2L-1 – 1 penyekatan, sedangkan jika xj adalah peubah kategorik ordinal maka akan ada L – 1 penyekatan.
3. Hitung kehomogenan simpul berdasarkan jumlah kuadrat dalam simpul, JKS(t), dimana jumlah kuadrat sisaan pada simpul t dinyatakan sebagai:
dimana yi(t) = nilai individu peubah respon pada simpul ke-t dan (t ) y = nilai tengah peubah respon pada simpul ke-t. Nt adalah jumlah data yang ada pada simpul ke-t.
4. Lakukan untuk semua peubah penjelas sehingga didapat peubah sebagai penyekat terbaik dimana kehomogenannya maksimum. Misalkan ada penyekatan s yang menyekat t menjadi simpul anak kiri tL dan simpul anak kanan tR, fungsi penyekatan yang digunakan adalah:
dan penyekat terbaik
dengan Ω adalah gugus yang berisi semua
kemungkinan penyekatan.
5. Jika simpul induk telah didapat, maka simpul anak kiri dan kanan dibuat dengan cara yang sama untuk semua peubah penjelas berdasarkan data yang sudah dikelompokkan oleh simpul induk.
6. Pembentukan pohon dilakukan sampai dipenuhi suatu aturan penghentian tertentu. Dalam kasus ini aturan yang digunakan adalah jika jumlah amatan dalam simpul
7. Pemangkasan pohon dilakukan untuk mendapatkan pohon akhir yang lebih sederhana. Pemangkasan pohon dilakukan dengan cross-validation atau sampel tes terpisah untuk mengukur keterandalan pohon. Metode pemangkasan pohon dengan training sample 50% dipilih sebagai metode pemangkasan karena ukuran sampel yang besar, sehingga memungkinkan untuk membagi sampel tadi menjadi subsampel training sample dan testing sample masingmasing 50% dari seluruh data yang ada. Proses pemangkasan pohon yang terjadi adalah dengan membangun pohon menggunakan training sample kemudian menggunakan pohon yang terbentuk tadi untuk subsampel testing sample. Dalam hal ini metode kuadrat terkecil menggunakan kuadrat tengah galat (KTG) untuk mengukur ketelitian dugaan. Pohon optimal adalah pohon dengan nilai KTG terkecil.
8. Dari pohon optimal yang terpilih, untuk setiap subpohon, CART menghitung ringkasan statistiknya dari simpul-simpul terakhir. Pada metode kuadrat terkecil untuk aturan penyekatan, maka hitung rataan dan standar deviasi dari pubah respon. Nilai rataan dari simpul akhir merupakan nilai dugaan dari peubah respon pada kasus simpul akhir tersebut.
Metode CART menghasilkan model yang sederhana dan mudah untuk diinterpretasikan. Model yang dihasilkan berupa pohon regresi dengan peubah-peubah yang berpengaruh sebagai penciri menjadi simpul-simpulnya. Peubah yang paling berpengaruh akan menjadi simpul pertama yang dihasilkan. Masalah pencilan data dapat diselesaikan dengan cara yang sederhana oleh metode CART. Pencilan akan diisolasi ke dalam simpul tertentu sehingga tidak mempengaruhi penyekatan.
CART dapat melakukan eksplorasi data untuk penyusunan model regresi yang melibatkan banyak peubah dengan ukuran besar dan kompleks. Eksplorasi data ini dapat dilakukan dengan lebih mudah untuk melihat hubungan antara peubah respon kontinu dengan peubah-peubah penjelasnya. Kekomplekan tersebut dapat berupa dimensinya yang besar atau jenis peubahnya campuran, misalnya kontinu dan kategorik, baik nominal maupun ordinal. Metode CART ini dapat menjadi satu alternatif jika beberapa asumsi seperti kenormalan, multikolinieritas dan
heterokedastisitas untuk model regresi tidak dipenuhi oleh beberapa peubah-peubanhnya.
2.6.Paket Statistik untuk Ilmu Sosial
SPSS adalah program komputer yang dipakai untuk analisis statistika (Wikipedia, 2012), SPSS banyak digunakan dalam berbagai riset pemasaran, pengendalian dan perbaikan mutu (quality improvement), serta riset-riset sains. SPSS pertama kali muncul dengan versi PC (bisa dipakai untuk komputer desktop) dengan nama SPSS/PC+ (versi DOS). Tetapi, dengan mulai populernya system operasi windows. SPSS mulai mengeluarkan versi windows (mulai dari versi 6.0 sampai versi terbaru sekarang). SPSS (Statistical Package for the Social Sciences) dianggap timer (alat pengukur waktu) tertua di bidang data mining (Programming and Data Management
for IBM SPSS Statistics 20: A Guide for IBM SPSS Statistics and SAS Users,2011).
Ini awalnya dirancang untuk digunakan oleh ilmuwan sosial untuk menganalisis data dari survei. SPPS mengizinkan pengguna untuk menarik data dan menampilkan operasi analisis statistik yang rumit, seperti komputasi regresi dan menampilkan presentasi data grafis. Ini juga menggunakan inferensial yang rumit dan prosedur statistik yang multi variasi, seperti analisis varians (ANOVA), analisis faktor, analisis kluster,dan analisis data katerogikal. SPSS terutama sekali sangat cocok digunakan untuk survei penelitian.
SPPS 18.0 digunakan pada studi ini untuk menampilkan analisis regresi pada data set kedua yang dijelaskan pada Tabel 3.2 Keduanya merupakan langkah yang bijak dan penuh model regresi yang dijalankan untuk menentukan model yang terbaik yang sesuai dengan data.
2.7.Komunitas Rapidminer
Rapidminer dahulu YALE ini adalah permulaan yang bebas dan terbuka untuk KDD dan ML, yang menyediakan beraneka ragam metode yang mengizinkan bentuk dasar
dari aplikasi baru (Mierswa et all., 2006 ). Rapidminer (dahulunya YALE ) dan propagandanya membuktikan lebih dari 400 operator dari segala aspek data mining. Operator meta secara otomatis mengoptimalkan desain eksperimen dan pengguna tidak memerlukan waktu yang panjang untuk menentukan langkah dan parameter yang lebih panjang. Sejumlah besar teknik visualisasi dan kemungkinan untuk meletakkan breakpoints setelah masing masing operator memberikan pandangan tentang keberhasilan desain anda- bahkan untuk menjalankan percobaan (http://www.rapidminer.com )
Rapidminer 5.0 digunakan pada studi ini untuk menampilkan kelompok siswa pada kumpulan data dan memperlihatkan matriks presentasi yang tersebar dari kelompok data.
2.8.Malcolm Baldrige National Quality Award (MBNQA)
Malcolm Baldrige National Quality Award (MBNQA) atau yang biasa disebut
Baldrige Award atau Baldrige Criteria adalah suatu sistem manajemen kualitas yang
pada awalnya berlaku di Amerika Serikat yang bertujuan untuk mengukur komitmen terhadap kinerja suatu organisasi, dan memberikan kerangka kerja untuk memperbaiki dan menyempurnakan kinerja tersebut (Criteria for Performance
Excellence). Penghargaan ini disahkan dengan ditandatanganinya Malcolm Baldrige National Quality Imporvement Act oleh Presiden Ronald Reagen pada tanggal 20
Agustus 1987.
Pada mulanya penghargaan ini muncul karena pemerintah Amerika Serikat pada saat itu menggalakkan kebutuhan akan perbaikan atau penyempurnaan kualitas dalam kaitannya dengan persaingan bisnis di Amerika dan pasar luar negeri terutama Jepang.
Nama Malcolm Baldrige berasal dari nama Menteri Perdagangan Amerika yang menjabat dari tahun 1981 sampai meninggalnya beliau pada tahun 1987 karena kecelakaan. Dedikasinya yang tinggi terhadap perbaikan untuk dunia perdagangan di
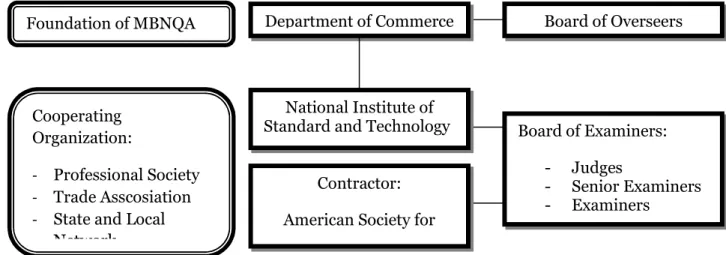
Board of Overseers Board of Examiners: - Judges - Senior Examiners - Examiners Foundation of MBNQA Cooperating Organization: - Professional Society - Trade Asscosiation - State and Local
Network
Department of Commerce
National Institute of Standard and Technology
Contractor: American Society for
Quality Control
Amerika membuat nama beliau dijadikan symbol untuk penghargaan ini. Sampai saat ini Departemen Perdagangan Amerika Serikat bertanggung jawab atas pemberian penghargaan ini, dan memberikan tugas kepada National Institute of Standard and
Technology (NIST) untuk mengelola program dan administrasi pemberian penghargaan ini berdasarkan Public Law 100-107 serta dibantu oleh American
Society for Quality Control (ASQC).
Tujuan dari pemberian penghargaan ini adalah untuk mempromosikan :
- Kesadaran akan pentingnya kualitas manajemen dan dampaknya terhadap persaingan.
- Pemahaman akan persayaratan-persayaratan untuk kesempurnaan dalam kualitas (Excellence in Quality)
Gambar 2.8. Struktur Administrasi MBNQA
Saling berbagi informasi mengenai berbagai strategi sukses dan keuntungan-keuntungan yang didapatkan. Malcolm Baldrige memberikan suatu perspektif sistem untuk pengelolaan organisasi dan proses-proses kunci menuju keunggulan kinerja. Tujuh kategori dan sebelas inti Malcolm Baldrige merupakan mekanisme untuk membangun dan mengintegrasikan kriteria-kriteria dalam mengembangkan sistem
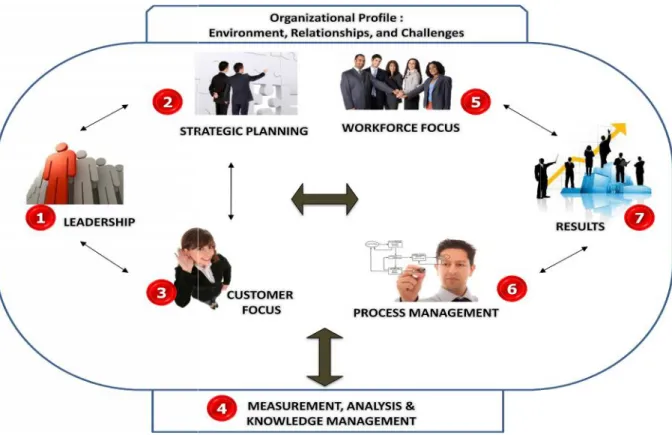
organisasi bisnis yang unggul. Perspektif sistem berarti memandang dan mengelola organisasi secara keseluruhan, dengan mengintegrasikan komponen-komponennya, menuju keunggulan kinerja. Sistem kinerja MBCfPE ini ditunjukkan pada gambar berikut:
Gambar 2.9. Kerangka Kerja MBCfPE
Gambar 2.9 menunjukkan bahwa sistem Malcolm Baldrige disusun oleh tujuh kategori dalam bagan inti yang mendefinisikan organisasi, proses-proses dan hasil-hasil.
- Kepemimpinan (Kategori 1), Perencanaan Strategis (Kategori 2) dan Fokus Pasar
dan Pelanggan (Kategori 3) merepresentasikan atau mewakili tritunggal kepemimpinan. Kategori ini ditempatkan bersama untuk menekankan dan organisasi bisnis yang unggul. Perspektif sistem berarti memandang dan mengelola organisasi secara keseluruhan, dengan mengintegrasikan komponen-komponennya, menuju keunggulan kinerja. Sistem kinerja MBCfPE ini ditunjukkan pada gambar berikut:
Gambar 2.9. Kerangka Kerja MBCfPE
Gambar 2.9 menunjukkan bahwa sistem Malcolm Baldrige disusun oleh tujuh kategori dalam bagan inti yang mendefinisikan organisasi, proses-proses dan hasil-hasil.
- Kepemimpinan (Kategori 1), Perencanaan Strategis (Kategori 2) dan Fokus Pasar
dan Pelanggan (Kategori 3) merepresentasikan atau mewakili tritunggal kepemimpinan. Kategori ini ditempatkan bersama untuk menekankan dan organisasi bisnis yang unggul. Perspektif sistem berarti memandang dan mengelola organisasi secara keseluruhan, dengan mengintegrasikan komponen-komponennya, menuju keunggulan kinerja. Sistem kinerja MBCfPE ini ditunjukkan pada gambar berikut:
Gambar 2.9. Kerangka Kerja MBCfPE
Gambar 2.9 menunjukkan bahwa sistem Malcolm Baldrige disusun oleh tujuh kategori dalam bagan inti yang mendefinisikan organisasi, proses-proses dan hasil-hasil.
- Kepemimpinan (Kategori 1), Perencanaan Strategis (Kategori 2) dan Fokus Pasar
dan Pelanggan (Kategori 3) merepresentasikan atau mewakili tritunggal kepemimpinan. Kategori ini ditempatkan bersama untuk menekankan dan
menjadi landasan tentang pentingnya suatu kepemimpinan berfokus pada strategi dan pelanggan.
- Fokus Sumber Daya Manusia (Kategori 5), Manajemen Proses (Kategori 6) dan
Hasil-hasil (Kategori 7) mewakili tritunggal Hasil. Karyawan perusahaan dan proses-proses kunci menyelesaikan pekerjaan dari organisasi yang menghasilkan keunggulan kinerja hasil-hasil.
- Garis anak panah horizontal dalam bagan inti Malcolm Baldrige (lihat gambar)
mengaitkan tritunggal Kepemimpinan ke Tritunggal Hasil, yang merupakan suatu keterkaitan untuk keunggulan organisasi bisnis.
- Lebih lanjut, anak panah menunjukkan hubungan utama diantara Kepemimpinan
(Kategori 1) dan Hasil-hasil (Kategori 7). Anak panah dua arah menunjukkan pentingnya umpan balik dalam suatu sistem manajemen kinerja yang efektif,
- Pengukuran, Analisis dan Manajemen Pengetahuan (Kategori 4) adalah penting
terhadap efektifitas manajemen dari organisasi dan terhadap sistem (manajemen pengetahuan) berdasarkan fakta (pengukuran dan analisis) untuk peningkatan kinerja dan daya saing. Pengukuran dan analisis berguna sebagai suatu landasan untuk sistem manajemen kinerja dari organisasi bisnis itu (manajemen pengetahuan).
2.9.Penelitian yang Relevan
Analisis performansi merupakan salah satu hal yang penting dalam mengukur hasil kerja suatu organisasi atau perusahaan. Pembahasan ini terus berkembang dan data
mining merupakan salah satu metode yang paling populer dan handal. Penelitian
tentang analisis performansi telah banyak dilakukan di berbagai bidang dan berbagai metode. Ada banyak hal yang dapat diteliti pada bidang ini, karena terdapat banyak data yang berpotensial untuk ditambang. Data mining dapat diterapkan dalam
menganalisis performansi akademis mahasiswa dengan menghubungkan beberapa faktor menggunakan metode Decision tree (Adeye dan Kuya, 2006). Bahkan ada penelitian yang membahas prediksi beberapa faktor yang menyebabkan mahasiswa melakukan Drop Out dengan metode yang sama (Quadri & Kalyankar, 2010). Selain di bidang pendidikan, analisis performansi juga dapat diimplementasikan pada suatu organisasi atau perusahaan seperti analisis performansi pada perusahaan komputer terkemuka di Jepang yakni Fujitsu (Yaginuma, 2000). Analisis yang dilakukannya dengan kombinasi algoritma neural network dan decision tree. Adapun manfaat dari penelitian diatas diharapkan dapat membantu para peneliti dalam melakukan analisis performansi dengan algoritma dcision tree
Penelitian analisis performansi dengan algortima decision tree khususnya algoritma pohon klasifikasi dan regresi (CART) telah banyak dilakukan. Penelitian terhadap penerapan data mining dengan menggunakan metode CART untuk menjelaskan prinsip-prinsip dasar pohon konstruksi (Timofeev dan Roman, 2004). Ada juga yang menggunakan metode yang sama sebagai metode alternatif dalam regresi yang melibatkan peubah yang banyak dan kompleks, yang lebih efektif jika dibandingkan dengan regresi konvensional (Komalasari dan Wieta B, 2007). Adapun manfaat dari penelitian diatas diharapkan dapat membantu para peneliti bagaimana mengeksplorasi data yang kompleks berdasarkan hasil metode pohon regresi.
Selain penelitian diatas, ada banyak penelitian lain yang menggunakan teknik
data mining dalam menganalisis performansi suatu organisasi/ perusahaan.
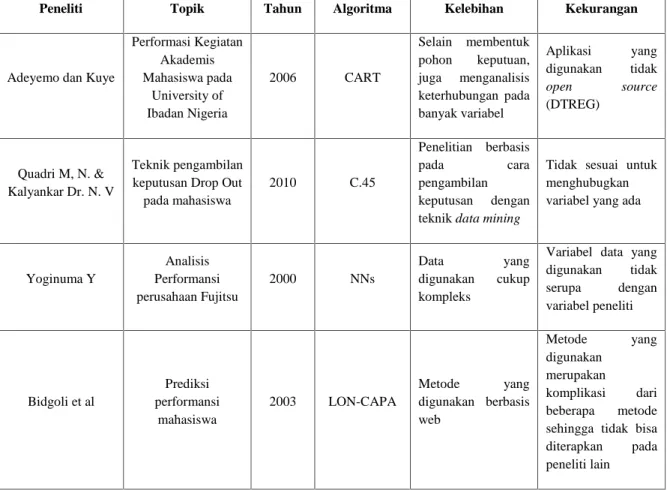
Tabel 2.1. Tabel Perbandingan Penelitian yang Relevan
Peneliti Topik Tahun Algoritma Kelebihan Kekurangan
Adeyemo dan Kuye
Performasi Kegiatan Akademis Mahasiswa pada University of Ibadan Nigeria 2006 CART Selain membentuk pohon keputuan, juga menganalisis keterhubungan pada banyak variabel Aplikasi yang digunakan tidak open source (DTREG) Quadri M, N. & Kalyankar Dr. N. V Teknik pengambilan keputusan Drop Out pada mahasiswa 2010 C.45 Penelitian berbasis pada cara pengambilan keputusan dengan teknik data mining
Tidak sesuai untuk menghubugkan variabel yang ada
Yoginuma Y Analisis Performansi perusahaan Fujitsu 2000 NNs Data yang digunakan cukup kompleks
Variabel data yang digunakan tidak serupa dengan variabel peneliti Bidgoli et al Prediksi performansi mahasiswa 2003 LON-CAPA Metode yang digunakan berbasis web Metode yang digunakan merupakan komplikasi dari beberapa metode sehingga tidak bisa diterapkan pada peneliti lain