ANALISIS DAN IMPLEMENTASI MODEL PARALEL HYBRID
DENGAN MPI DAN OPENMP
PADA METODE CONJUGATE GRADIENT
ANGGI HARYO SAKSONO
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2010
ANALISIS DAN IMPLEMENTASI MODEL PARALEL HYBRID
DENGAN MPI DAN OPENMP
PADA METODE CONJUGATE GRADIENT
ANGGI HARYO SAKSONO
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2010
ABSTRACT
ANGGI HARYO SAKSONO. The Analysis and Implementation of Parallel Hybrid Model with MPI and OpenMP on Conjugate Gradient Method. Supervised by HENDRA RAHMAWAN.
Conjugate Gradient method is one of the iterative methods to solve linear equation system. The method consumes much time to get the solution. Therefore to reduce its execution time, parallel processing is implemented on this method. There was a research related to this topic by Hoefler et al (2007). On their research, they were optimizing a pure MPI implementation by modifying collective functions into a non-blocking collective communication. This research used parallel hybrid model by combining MPI and OpenMP.
The aim of this research is to analyze and implement the complexity and the performance of sequential, MPI and hybrid conjugate gradient algorithm. The analysis performed in this research includes the analysis of performance metrics and the experimental results of every implementation. This research uses 8 computers for running MPI processes and for hybrid experiment added 4 threads for running OpenMP on every computer. There are five matrices uses in this research obtained from matrices collection of University of Florida.
The results of this research show that the execution time of all implementation for matrices with greater sizes give longer time. For example, on sequential implementation a matrice size of 2548 x 2548 takes 28.94 seconds and a matrice size of 4884 x 4884 takes 48.24 seconds. The execution time of MPI conjugate gradient is less than its sequential implementation, and the execution time of hybrid conjugate gradient is less than its MPI conjugate gradient. The speedup of MPI and hybrid conjugate gradient grows but not proportionally with the increasing size of matrices used. The overall result of hybrid implementation is quite good when the number of thread used is the same as the number of processor available on the computer.
Keywords : parallel processing, parallel hybrid model, mixed mode MPI/OpenMP programming, conjugate gradient, parallel conjugate gradient.
Penguji:
1. Endang Purnama Giri. S.Kom., M.Kom 2. Dr. Ir. Sri Nurdiati., M.Sc
Judul Skripsi : Analisis dan Implementasi Model Paralel Hybrid dengan MPI dan OpenMP pada Metode Conjugate Gradient
Nama : Anggi Haryo Saksono
NIM : G64076008
Menyetujui:
Pembimbing
Hendra Rahmawan, S.Kom, M.T
Mengetahui :
Ketua Departemen Ilmu Komputer,
Dr. Ir. Sri Nurdiati, M.Sc
NIP. 19601126 198601 2 001
PRAKATA
Alhamdulillahi Rabbil 'alamin, puji dan syukur penulis panjatkan kepada Allah SWT atas segala
limpahan rahmat, hidayah, serta karunia-Nya sehingga skripsi ini berhasil diselesaikan. Shalawat dan salam tidak lupa saya tujukan kepada baginda Nabi Muhammad SAW, sebab karena beliaulah penulis bisa merasakan nikmat iman dan islam. Tema yang dipilih pada penelitian yang dilaksanakan sejak bulan September 2009 ini adalah pemrosesan paralel, dengan judul Analisis dan Implementasi Model Paralel Hybrid dengan MPI dan OpenMP Pada Metode Conjugate Gradient.
Terima kasih penulis ucapkan kepada pihak-pihak yang telah membantu penyelesaian tugas akhir ini, diantaranya:
1. Kedua orang tua dan seluruh keluarga yang selalu memberi dukungan dan doa kepada penulis. 2. Bapak Hendra Rahmawan selaku dosen pembimbing yang telah banyak membantu, memberi
saran dan membimbing penulisi selama melakukan penelitian.
3. Bapak Endang Purnama Giri dan Ibu Sri Nurdiati yang telah menguji penulis dengan materi-materi yang masih dapat ditangani oleh penulis.
4. Teman sejawat Purwa Purdiawan, R. A Fakih Basyarudin, Iqbal Nurdiansyah, Dimas Cahyo P, dan Indra Rusdiansyah atas segala kerja sama dan bantuan selama penelitian maupun saat seminar dan ujian sidang.
5. Seluruh teman-teman penghuni kos Pak Timo yang memberikan dukungan moril dan materi serta canda-tawa penghilang penat selama penelitian ini.
6. Kepada para “penunggu” laboratorium komputer yaitu pak Edi, Aput, Dayat, Toni, dan Yudha yang telah membantu dan menemani penulis selama percobaan.
7. Semua teman-teman Ilmu Komputer Ekstensi Angkatan Dua atas persahabatan, kebersamaan, semangat dan segala bantuannya.
Kritik dan saran yang membangun sangat penulisi harapkan untuk kemajuan di masa depan. Semoga tulisan ini dapat bermanfaat bagi akademisi Ilmu Komputer.
Bogor, April 2010
RIWAYAT HIDUP
Penulis dilahirkan di Jakarta pada tanggal 28 Januari 1987 sebagai anak keempat dari lima bersaudara dari pasangan Suwardoyo dan Sumeni. Tahun 2004 penulis berhasil menamatkan pendidikan di SMA Negeri 91, Pondok Kelapa, Jakarta dan pada tahun yang sama penulis lulus seleksi masuk Program Diploma IPB melalui jalur reguler. Penulis memilih Program Studi Teknik Informatika, Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam.
Pada tahun 2007 penulis berhasil lulus dari Program Diploma IPB dan langsung diterima bekerja sebagai staf di KPSI IPB. Pada tahun yang sama pula penulis melanjutkan pendidikan ke jenjang Strata 1 di IPB pada Jurusan Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam.
DAFTAR ISI Halaman DAFTAR GAMBAR...viii DAFTAR LAMPIRAN...ix PENDAHULUAN...1 Latar Belakang...1 Tujuan...1 Ruang Lingkup...1 Manfaat...2 TINJAUAN PUSTAKA...2
Disain Algoritme Paralel...2
Model Pemrograman Paralel...2
Speedup...3
Efisiensi...4
Cost...4
Total Parallel Overhead...4
Isoefisiensi...4
Matriks Simetri...4
Matriks Definit Positif...4
Conjugate...4 Conjugate Gradient (CG)...4 METODE PENELITIAN...4 Tahapan Penelitian...4 Studi Pustaka...5 Analisis Algoritme CG...5 Implementasi CG Sekuensial...5
Penerapan Metode Foster...5
Analisis dan Implementasi MPI Algoritme CG...5
Identifikasi, Analisis dan Implementasi Hybrid...6
Perancangan Percobaan...6
Percobaan...6
Analisis Hasil Percobaan...7
HASIL DAN PEMBAHASAN...7
Analisis dan Implementasi Algoritme CG Sekuensial...7
Penerapan Metode Foster...7
Analisis dan Implementasi Algoritme CG MPI...9
Penerapan Model Hybrid...11
Analisis dan Implementasi Algoritme CG Hybrid...12
Analisis Hasil Waktu Eksekusi...14
Analisis Hasil Speedup...16
Analisis Hasil Efisiensi...17
Analisis Cost...18
Analisis Total Parallel Overhead...18
KESIMPULAN DAN SARAN...19
Kesimpulan...19
Saran...20
DAFTAR PUSTAKA...20
DAFTAR GAMBAR
Halaman
1 Metode Conjugate Gradient...4
2 Skema tahapan penelitian...5
3 Skema jaringan yang digunakan pada percobaan...6
4 Kompleksitas tahapan pada fungsi CG sekuensial...7
5 Grafik perhitungan kompleksitas CG sekuensial...7
6 Skema keterkaitan fungsi pada iterasi CG...8
7 Struktur algoritme CG MPI pada bagian iterasi...9
8 Struktur algoritme dan kompleksitas fungsi CG MPI...10
9 Grafik perhitungan kompleksitas CG MPI...10
10 Grafik perhitungan speedup CG MPI...10
11 Grafik perhitungan efisiensi CG MPI...11
12 Struktur algoritme CG hybrid pada bagian iterasi...12
13 Struktur algoritme dan kompleksitas fungsi CG hybrid...12
14 Grafik perhitungan kompleksitas untuk tiap jumlah thread dengan ukuran matriks 2548 x 2548. 13 15 Grafik perhitungan kompleksitas untuk tiap ukuran matriks dengan 2 thread...13
16 Grafik perhitungan speedup untuk tiap jumlah thread dengan ukuran matriks 2548 x 2548...13
17 Grafik perhitungan speedup untuk tiap ukuran matriks dengan 2 thread...13
18 Grafik perhitungan efisiensi untuk tiap jumlah thread dengan ukuran matriks 2548 x 2548...14
19 Grafik perhitungan efisiensi untuk tiap ukuran matriks dengan 2 thread...14
20 Grafik waktu eksekusi implementasi CG sekuensial...14
21 Grafik waktu eksekusi implementasi MPI...15
22 Grafik waktu eksekusi untuk setiap implementasi dengan ukuran matriks 2548 x 2548...15
23 Grafik waktu eksekusi untuk setiap implementasi dengan ukuran matriks 4884 x 4884...15
24 Grafik waktu eksekusi implementasi hybrid untuk tiap ukuran matriks dengan 2 thread...15
25 Grafik waktu eksekusi dan waktu iterasi implementasi MPI dan hybrid 2 thread untuk ukuran matriks 2548 x 2548...16
26 Grafik speedup hasil percobaan implementasi MPI...16
27 Grafik speedup hasil percobaan hybrid untuk setiap ukuran matriks dengan 2 thread...17
28 Grafik speedup hasil percobaan untuk setiap implementasi dengan ukuran matriks 2548 x 2548.17 29 Grafik efisiensi hasil percobaan implementasi MPI...17
30 Grafik efisiensi hasil percobaan hybrid untuk setiap ukuran matriks dengan 2 thread...17
31 Grafik efisiensi hasil percobaan untuk setiap implementasi dengan ukuran matriks 2548 x 2548.17 32 Grafik cost hasil percobaan implementasi MPI...18
33 Grafik cost hasil percobaan untuk setiap implementasi dengan ukuran matriks 2548 x 2548...18
34 Grafik overhead hasil percobaan implementasi MPI...18
35 Grafik overhead hasil percobaan untuk setiap implementasi dengan ukuran matriks 2548 x 2548...18
DAFTAR LAMPIRAN
Halaman
1 Grafik waktu eksekusi implementasi MPI dan hybrid pada untuk setiap kombinasi...22
2 Grafik speedup implementasi MPI dan hybrid pada untuk setiap kombinasi...23
3 Grafik efisiensi implementasi MPI dan hybrid pada untuk setiap kombinasi...24
4 Grafik cost implementasi MPI dan hybrid pada untuk setiap kombinasi...25
PENDAHULUAN Latar Belakang
Model pemrograman paralel dibutuhkan dalam implementasi pemrograman paralel pada suatu sistem paralel. Sistem distributed memory dapat menggunakan model pemrograman
message-passing. Implementasi dari model message-passing yang banyak digunakan adalah Message Passing Interface (MPI). Pada sistem shared memory dapat menggunakan model
pemrograman shared-memory dan implementasi yang biasa digunakan adalah Open
Multi-Processing (OpenMP). Sistem distributed-shared memory merupakan hasil kombinasi dua
sistem paralel. Model pemrograman sistem ini harus mampu memanfaatkan kemampuan kedua sistem penyusunnya, sehingga model ini haruslah model kombinasi juga, yaitu model
hybrid. Model hybrid adalah hasil kombinasi
dua atau lebih model pemrograman paralel (Smith, 2000; Dongara et al. 2003).
Pada penelitian ini, model hybrid akan diimplementasikan pada metode Conjugate
Gradient (CG). CG adalah metode yang paling
terkenal yang digunakan dalam penyelesaian sistem persamaan linear (SPL) yang besar dengan matriks simetris dan definit positif (Schewchuk, 1994). Metode ini bersifat iteratif, sehingga dapat diaplikasikan pada SPL yang mana akan sulit jika diselesaikan dengan metode secara langsung. Dipilihnya metode CG dalam penelitian ini karena metode ini membutuhkan waktu komputasi yang lama dalam penyelesaiannya, sehingga baik jika dioptimasi secara paralel.
Penelitian yang terkait dengan hal ini telah dilakukan oleh Hoefler et al. (2007), dengan judul Optimizing a Conjugate Gradient Solver
with Non-Blocking Collective Operations.
Penelitian tersebut menggunakan library MPI yang sudah dimodifikasi pada bagian fungsi kolektif, yakni dimodikasi secara non-blocking. Pada penelitian tersebut diperoleh kesimpulan bahwa peningkatan waktu eksekusi sampai dengan 34% dari pada sekedar fungsi kolektif yang standar. Berdasarkan hasil penelitian tersebut, maka pada penelitian ini digunakan cara lain untuk mengoptimasi paralel CG MPI, yaitu dengan mengimplementasikan model
hybrid.
Pada penelitian ini untuk model
message-passing digunakan library MPI, sedangkan
untuk model shared-memory digunakan library
OpenMP. Penggunaan kedua library ini karena berdasarkan fakta bahwa keduanya paling banyak digunakan secara luas pada model
hybrid, dikarenakan keunggulan keduanya
berdasarkan tingkat portability. Kedua library ini juga dianggap mewakili standar industri untuk sistem distributed memory dan shared
memory (Smith, 2000).
Tujuan
Tujuan dari penelitian ini adalah:
1. Mengimplementasikan konsep pemrosesan paralel dengan model pemrograman paralel
hybrid secara bertahap pada metode CG.
2. Menganalisis kinerja algoritme CG sekuensial, CG MPI, dan CG hybrid dari
performance metric.
3. Menganalisis kinerja algoritme CG sekuensial, CG MPI, dan CG hybrid dari hasil percobaan yang diperoleh.
Ruang Lingkup
Ruang lingkup dan batasan yang digunakan pada penelitian ini yaitu:
1. Seluruh tahapan penelitian dilakukan pada sistem operasi Linux.
2. Implementasi model hybrid menggunakan
library MPI untuk mewakili model message-passing dan library OpenMP untuk
mewakili model shared-memory. Bahasa pemrograman yang digunakan adalah C dengan kompilator GNU C.
3. Penelitian ini menggunakan delapan buah komputer untuk eksekusi implementasi MPI dan untuk implementasi hybrid menggunakan maksimal 4 thread.
4. Matriks koefisien SPL yang digunakan adalah model dense. Ada 5 buah matriks yang digunakan dan diperoleh dari koleksi matriks University of Florida.
5. Percobaan yang dilakukan hanya mengukur tingkat performance berdasarkan waktu eksekusi, speedup, efisiensi, cost, total
parallel overhead, dan isoefisiensi.
6. Pada percobaan yang dilakukan, eksekusi program dari metode CG tidak sampai terpenuhinya toleransi residu yang diinginkan. Banyaknya iterasi dibatasi hanya sampai 1000 iterasi, karena pada penelitian ini ingin melihat pengaruh ukuran data, bukan dari banyaknya iterasi. Selain itu
dengan 1000 iterasi sudah cukup untuk melihat performance dari hasil implementasi.
Manfaat
Dengan dilakukannya implementasi permrosesan paralel pada metode CG, kecepatannya dalam menyelesaikan sistem persamaan linear akan meningkat, sehingga akan mengurangi waktu komputasi. Lebih jauh lagi implementasi model hybrid pada penelitian ini dapat lebih meningkatkan performance komputasi paralel dibandingkan dengan implementasi MPI murni, dan akan menghasilkan strategi paralel yang lebih efisien.
TINJAUAN PUSTAKA Disain Algoritme Paralel
Dalam mendisain suatu algoritme paralel, menurut Foster (1995), ada beberapa langkah yang harus dilakukan, yaitu partitioning,
communication, agglomeration, dan mapping.
1. Partitioning
Ada dua pendekatan pada tahap partitioning, yaitu domain decomposition dan functional
decomposition. Pada pendekatan domain decomposition, hal yang pertama dilakukan
adalah memisahkan data dan jika mungkin membaginya menjadi bagian-bagian yang sama besar, kemudian mengasosiasikan komputasi pada data tersebut. Pendekatan yang kedua adalah functional decomposition, yaitu membagi komputasi terlebih dahulu, kemudian menentukan data yang dibutuhkan oleh komputasi tersebut.
2. Communication
Pada tahap ini diatur bagaimana bentuk komunikasi yang digunakan untuk mengirim data antar task. Ada dua pola komunikasi yang digunakan, yaitu local communication dan
global communication. Pada local
communication tiap task berkomunikasi dengan
sekumpulan kecil task-task tetangga, sedangkan pada global communication tiap task berkomunikasi dengan banyak task.
3. Agglomeration
Pada tahap agglomeration beberapa task dikombinasi menjadi task-task yang lebih besar untuk meningkatkan performance dan meminimumkan global communication.
4. Mapping
Pada tahap ini diatur bagaimana tiap task dipetakan ke suatu processor. Mapping digunakan untuk memaksimalkan penggunaan
processor dan meminimalkan biaya komunikasi.
Model Pemrograman Paralel
Model pemrograman paralel hadir sebagai abstraksi di atas arsitektur hardware dan
memory, jadi seorang programmer harus
berhadapan dengan model pemrograman ini untuk membuat suatu program paralel. Ada tiga model pemrograman yang banyak digunakan, yaitu message-passing, shared-memory, dan
hybrid.
1. Message-passing
Message-passing telah digunakan secara
luas sebagai pendekatan untuk mencapai komputasi paralel. Pada model ini suatu komputasi terdiri dari satu atau lebih proses yang saling berkomunikasi dengan mengirim dan menerima messages. Komunikasi dilakukan dengan memanggil fungsi-fungsi yang telah didefinisikan pada library yang digunakan (Dongara et al. 2003).
Menurut Dongara et al (2003) salah satu implementasi message-passing yang banyak digunakan adalah Message Passing Interface (MPI). MPI bukanlah suatu bahasa pemrograman, melainkan suatu library yang menyediakan banyak fungsi yang dapat dipanggil oleh program. MPI dapat digunakan pada beberapa bahasa pemrograman, di antaranya C/C++ dan Fortran.
Menurut Barney (2009) ada dua tipe komunikasi yang digunakan pada MPI, yaitu
point-to-point dan kolektif.
• Point-to-point
Tipe komunikasi point-to-point merupakan komunikasi yang melibatkan hanya dua proses pada grup yang sama. Salah satu proses melakukan operasi send, dan proses lainnya melakukan operasi receive pasangannya.
• Kolektif
Komunikasi kolektif harus melibatkan keseluruhan proses yang ada pada suatu grup. Ada tiga tipe operasi dari komunikasi ini, pertama sinkronisasi, semua proses pada operasi ini akan menunggu sampai keseluruhan proses pada grup yang sama mencapai titik sinkronisasi yang sudah
ditentukan. Tipe kedua adalah perpindahan data, tipe operasi ini digunakan untuk mengirim atau menerima data dari dan ke semua proses pada grup yang sama. Ketiga adalah komputasi kolektif, salah satu proses akan mengumpulkan data dari seluruh proses pada grup yang sama, selanjutnya dilakukan suatu operasi pada data tersebut, seperti penjumlahan atau pengurangan. 2. Shared-memory
Menurut El-Rewini et al (2005) model pemrograman shared-memory barangkali menjadi model yang paling mudah untuk dimengerti karena memiliki kesamaan dengan pemrograman pada sistem operasi. Pada model ini semua proses berbagi alamat memory yang sama, dan melakukan operasi baca dan tulis secara asynchronous, sehingga mekanisme seperti semaphores dapat digunakan untuk mengontrol akses ke memory tersebut.
Pada model pemrograman shared-memory harus ada tiga konstruksi utama pada program, yaitu task creation, komunikasi, dan sinkronisasi.
• Task creation
Sekumpulan proses dibentuk melalui perintah fork, exec, dan perintah lainnya yang terkait. Secara keseluruhan suatu aplikasi merupakan kumpulan konstruksi
fork-join.
• Komunikasi
Komunikasi di antara proses paralel dapat dilakukan dengan menulis dan membaca
shared variable pada segmen data shared
yang ada pada proses paralel. • Sinkronisasi
Sinkronisasi dibutuhkan untuk melindungi
shared variable dengan meyakinkan bahwa
variabel tersebut hanya diakses oleh satu proses pada waktu yang sama.
Implementasi model shared-memory salah satunya adalah Open Multi-Processing (OpenMP). OpenMP diimplementasikan sebagai suatu kombinasi dari penggunaan
library, sekumpulan compiler directive atau pragma dan environment variable. OpenMP
menggunakan model fork-join dalam eksekusi secara paralel. Program OpenMP dimulai dengan sebuah proses, yaitu master thread.
Master thread melakukan eksekusi secara
sekuensial sampai daerah paralel pertama yang dijumpai. Master thread kemudian memulai
operasi Fork, yaitu membuat sekumpulan
thread paralel. Perintah-perintah yang ada pada
daerah yang diparalelkan dieksekusi secara paralel oleh thread-thread tersebut. Setelah semua thread selesai melakukan eksekusi dan mencapai akhir bagian paralel, kemudian dilakukan operasi Join, yaitu semua thread melakukan sinkronisasi dan mengakhiri thread masing-masing, dan hanya menyisakan master
thread (Barney 2009).
3. Hybrid
Menurut Smith (2000) model pemrograman
hybrid adalah model pemrograman yang
mengombinasikan dua atau lebih model pemrograman paralel. Dengan digunakannya model pemrograman ini, maka seharusnya keunggulan-keunggulan dari model pemrograman penyusunnya dapat diperoleh. Sistem ini akan menggunakan model pemrograman message-passing untuk mengakomodir komunikasi antar komputer, dan model shared-shared memory untuk mengakomodir komunikasi antar processor pada komputer yang sama.
Kombinasi MPI dengan OpenMP biasanya banyak digunakan pada sistem hybrid
distributed-memory. Secara teori, kombinasi
tersebut akan menghasilkan strategi paralel yang lebih efisien dan optimal dibandingkan dengan penggunaan murni MPI. Ada beberapa keuntungan dari penggunaan model pemrograman hybrid, di antaranya:
• Program yang memiliki skalabilitas proses MPI yang buruk, dapat dioptimasi dengan model ini.
• Program yang memiliki skalabilitas OpenMP yang buruk, dapat dioptimasi dengan model ini.
• Program yang memiliki masalah kekurangan
memory lokal dapat teratasi karena
penggunaan MPI.
• Lebih mudah dalam implementasi dibandingkan dengan MPI.
Speedup
Speedup S didefinisikan sebagai rasio
dari waktu yang digunakan untuk menyelesaikan masalah dalam sekuensial Ts
terhadap waktu yang diperlukan untuk menyelesaikan masalah yang sama dalam paralel Tp, dirumuskan pada Persamaan 1
S=Ts
Tp . [1]
Efisiensi
Efisiensi E adalah rasio antara speedup dengan banyaknya processor p. Efisiensi didefinisikan sebagai berikut berikut (Grama et
al. 2003) yang dirumuskan pada Persamaan 2.
E=Sp= Ts
p Tp
. [2]
Cost
Cost C untuk menyelesaikan masalah
dalam sistem paralel didefinisikan sebagai hasil perkalian waktu pelaksanaan dengan jumlah
processor yang digunakan. Fungsi biaya paralel
dirumuskan pada Persamaan 3 (Grama et al. 2003).
C= pTp. [3]
Total Parallel Overhead
Overhead biasanya disebabkan oleh faktor idle, waktu komunikasi dan komputasi. Fungsi
overhead dinotasikan dengan simbol To.
Fungsi overhead dirumuskan pada Persamaan 4 (Grama et al. 2003).
To= pTp−Ts. [4]
Isoefisiensi
Menurut Grama et al. (2003) efisiensi akan menurun jika jumlah processor meningkat dan efisiensi akan meningkat jika ukuran data juga ditingkatkan. Jadi efisiensi dapat dibuat konstan jika jumlah processor dan ukuran data sama-sama ditingkatkan. Efisiensi yang konstan ini disebut sebagai isoefisiensi. Fungsi Isoefisiensi dirumuskan pada Persamaan 5, dimana K=E / E−1.
W=K ToW , p. [5]
Matriks Simetri
Menurut Schewchuk (1994) sebuah matriks A disebut simetri jika
AT=A. [6]
Matriks Definit Positif
Menurut Schewchuk (1994) sebuah matriks
A disebut definit positif jika untuk semua
vektor x≠0,
xTAx0. [7]
Conjugate
Menurut Schewchuk (1994), jika ada sebuath matriks A, dua vektor x dan y disebut conjugate jika
xT Ay
=0, x≠ y . [8]
Conjugate Gradient (CG)
Metode Conjugate Gradient (CG) adalah sebuah algoritme untuk mencari solusi numerik dari suatu sistem persamaan linear tertentu, yaitu yang dengan matriks simetri dan definit positif. Metode ini bersifat iteratif, sehingga dapat diaplikasikan pada SPL yang berukuran besar dan akan sangat sulit jikalau diselesaikan dengan metode langsung, seperti eliminasi Gauss. Disamping itu, metode CG juga dapat diterapkan untuk menyelesaikan masalah optimasi tak berkendala. Secara umum, metode ini membangkitkan vektor-vektor yang saling berkonjugasi dan juga merupakan gradient dari fungsi kuadrat. Metode ini menyelesaikan sistem persamaan linear dengan cara menemukan titik minimum dari fungsi kuadrat (Schewchuk, 1994). Secara lengkapnya metode CG disajikan pada Gambar 1.
1 Diberikan SPL Ax=b 2 Pilih x0 awal, x0=0 3 r0=b – Ax0 4 d0=r0 5 i=0 6 rr=r i T r i
7 While imax and ∥r i∥≥tol 8 q= A d i 9 dq=d iT q 10 i=rr / dq 11 x i1=x i i d i 12 r i 1=r i − i q i 13 rr2=r i1 T r i1 14 i =rr2 / rr
15 d i1=r i1 i d i
16 i=i1
Gambar 1 Metode Conjugate Gradient. METODE PENELITIAN Tahapan Penelitian
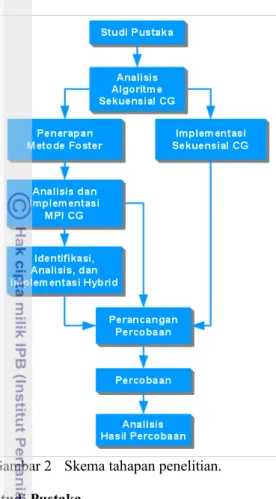
Untuk menunjang keberhasilan suatu penelitian, maka dibuatlah tahapan-tahapan penelitian yang terstruktur. Pada penelitian ini ada beberapa tahapan yang dilakukan. Adapun tahapan tersebut disajikan pada Gambar 2.
Gambar 2 Skema tahapan penelitian. Studi Pustaka
Pada tahap ini dikumpulkan informasi mengenai algoritme CG dan metode yang biasanya digunakan dalam pengembangan aplikasi paralel hybrid. Pustaka-pustaka yang digunakan diperoleh dari beberapa buku cetak dan elektronik, dan juga dari beberapa halaman internet.
Analisis Algoritme CG
Hal yang pertama dilakukan pada penelitian ini yaitu mempelajari dan memahami langkah-langkah yang ada pada algoritme CG. Dengan memahaminya, maka dapat dengan mudah dibuat implementasi programnya. Pada tahap ini dilakukan analisis dari algoritme CG sekuensial yaitu meliputi cara kerja dan perhitungan tingkat kompleksitas dari algoritme.
Implementasi CG Sekuensial
Pada tahap ini dibuat implementasi sekuensial dari algoritme CG berdasarkan cara kerja yang telah dipelajari ditahap sebelumnya. Kode program sekuensial yang dibuat terdiri dari fungsi-fungsi yang mewakili proses-proses pada algoritme CG. Penggunaan fungsi ini dilakukan agar mempermudah dalam tahap-tahap pengembangan selanjutnya. Program
yang dibuat membutuhkan argumen input yang harus dimasukkan pada saat program dijalankan, yaitu berupa ukuran matriks, nama
file matriks, nama file vektor, dan banyaknya
iterasi CG.
Pada kode program juga ditambahkan fungsi pencatat waktu yang digunakan untuk menghitung waktu eksekusi. Fungsi pencatat waktu yang digunakan harus mampu mencatat waktu sampai dengan tingkat akurasi mili detik, agar memiliki tingkat presisi yang tinggi. Waktu eksekusi kemudian dicetak pada bagian akhir program sebagai log dari program.
Penerapan Metode Foster
Setelah implementasi sekuensial dibuat, langkah selanjutnya algoritme sekuensial diubah agar dapat dieksekusi secara paralel, yaitu dengan menerapkan metode Foster. Berdasarkan algoritme dan kode program CG sekuensial yang telah dibuat, kemudian dipelajari bagian atau fungsi mana saja yang dapat diparalelkan. Output dari tahap ini adalah seperti apa algoritme dan strategi paralel yang akan digunakan, meliputi konsep dekomposisi komputasi dan data, konsep komunikasi yang digunakan, dan bagaimana komputasi yang ada dijalankan secara paralel.
Analisis dan Implementasi MPI Algoritme CG Selanjutnya pada tahap ini dilakukan analisis dan implementasi terhadap algoritme dan strategi yang telah dibuat pada tahap sebelumnya. Analisis yang dilakukan meliputi perhitungan kompleksitas komputasi dan komunikasi dari algoritme paralel, serta perhitungan tingkat performance paralelnya.
Menurut Smith (2000) tahapan pertama dalam mengembangkan program paralel model
hybrid adalah melakukan implementasi paralel
secara message-passing terlebih dulu. Implementasi message-passing dibuat dengan bahasa pemrograman C dan menggunakan
library MPI.
Penggunaan fungsi-fungsi MPI baik dalam dekomposisi data maupun dalam komunikasi antar proses dipilih yang paling sesuai dengan strategi paralel yang telah ditentukan. Argumen program MPI juga tidak berbeda dengan argumen program sekuensial. Begitupun dengan perhitungan waktu eksekusi program, cara yang digunakan juga sama dengan program sekuensial.
Identifikasi, Analisis dan Implementasi Hybrid
Tahap selanjutnya dalam pengembangan model hybrid adalah identifikasi algoritme MPI. Identifikasi dilakukan untuk mencari tahu fungsi-fungsi mana saja pada program yang dapat diparalelkan secara shared-memory yaitu dengan OpenMP.
Menurut Chapman et al. (2008) paralel OpenMP dapat dilakukan salah satunya dengan cara membagi beban komputasi. Beban komputasi pada suatu algoritme biasanya terdapat pada pada konstruksi loop, atau dapat juga diketahui dengan membuat skema keterkaitan input dan output pada fungsi-fungsi yang digunakan, kemudian dicari tahu fungsi-fungsi yang tidak saling terkait. Kedua hal inilah yang kemudian diparalelkan secara OpenMP, sehingga algoritme CG MPI bisa menjadi algoritme CG hybrid.
Setelah melakukan identifikasi, selanjutnya dilakukan analisis terhadap algoritme CG
hybrid yang telah dibuat. Analisis yang
dilakukan yaitu hasil analisis pada algoritme CG MPI ditambah dengan pengubahan hybrid.
Implementasi pada kode program dilakukan sebagai tahap akhir dalam pengembangan model hybrid. Implementasi ini diterapkan pada fungsi-fungsi yang telah teridentifikasi dapat diparalelkan secara shared-memory. Pada kode program, ditambahkan baris-baris perintah dan
directive OpenMP. Argumen input dari program
juga ditambah satu lagi, yaitu argumen jumlah
thread, sehingga jumlah thread yang diciptakan
saat eksekusi program bisa dikontrol. Perancangan Percobaan
Pada tahap ini ditentukan rancangan dari percobaan yang akan dilakukan, termasuk di dalamnya metode percobaan dan data matriks yang digunakan. Ada lima buah matriks yang digunakan pada percobaan, matriks-matriks tersebut dapat dilihat pada Tabel 1.
Percobaan implementasi MPI dan hybrid dilakukan dengan mengombinasikan argumen-argumen input program. Untuk implementasi MPI, skema percobaan yang dilakukan yaitu mengombinasikan argumen matriks dan jumlah komputer, sedangkan untuk implementasi
hybrid, skema percobaan yang dilakukan yaitu
mengombinasikan argumen matriks, jumlah komputer dan jumlah thread.
Tabel 1 Matriks yang digunakan pada percobaan
Nama Matriks Dimensi
662_bus 662 x 662 sherman1 1000 x 1000 ex10hs 2548 x 2548 bcsstk16 4884 x 4884 bloweybq 10001 x 10001 Percobaan
Semua percobaan yang dilakukan pada tiap implementasi dilakukan dengan tiga kali perulangan atau iterasi, kemudian diambil rata-rata waktu komputasinya. Percobaan implementasi MPI dan hybrid dilakukan dengan 1-8 buah komputer untuk komputasi, tetapi pada implementasi hybrid ditambahkan kombinasi jumlah 1-4 thread pada tiap penggunaan kombinasi komputer, sehingga ada 32 kombinasi untuk implementasi hybrid.
Semua tahapan percobaan tersebut dilakukan pada lingkungan sistem operasi Linux. Pada saat percobaan dilakukan, komputer-komputer yang digunakan sudah dalam keadaan dikondisikan, maksudnya yaitu kondisi processor dalam keadaan idle. Output waktu yang keluar pada setiap eksekusi program dicatat dalam bentuk tabel yang selanjutnya akan digunakan dalam tahap analisis.
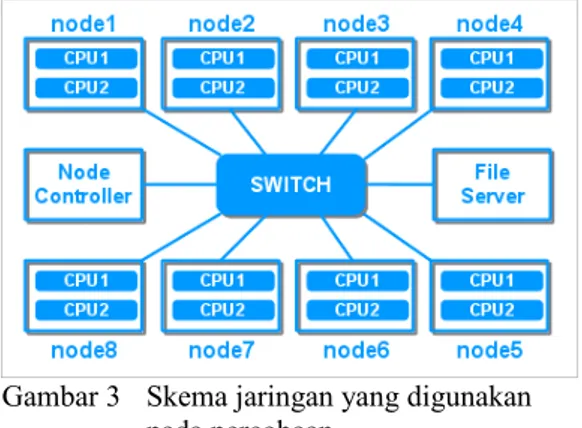
Gambar 3 Skema jaringan yang digunakan pada percobaan.
Pada saat percobaan digunakan tambahan dua komputer lagi yang salah satu digunakan sebagai file server untuk menyimpan kode program dan programnya, file matriks, dan file vektor, serta satu buah komputer lagi untuk
running MPI. Skema jaringan yang digunakan
Spesifikasi dari masing-masing komputer yang digunakan adalah:
1. Intel Pentium® Core 2 Duo ( 2,20 GHz). 2. DDR2 RAM 1024 MB.
3. Hard disk 80 GB. 4. Mouse dan Keyboard. 5. LAN 100 Mbps.
6. Sistem operasi Linux (openSUSE 11.2). 7. Library MPI ( OpenMPI 1.4.7). 8. OpenMP runtime library (libgomp44). Analisis Hasil Percobaan
Pada tahap ini akan dianalisis dengan menghitung performance metric berdasarkan waktu eksekusi dari hasil percobaan yang diperoleh. Analisis dilakukan terhadap hasil percobaan implementasi sekuensial, MPI, dan
hybrid.
HASIL DAN PEMBAHASAN Analisis dan Implementasi Algoritme CG Sekuensial
Analisis algoritme CG sekuensial hanya diukur berdasarkan persamaan kompleksitas, namun karena pembahasan meliputi keseluruhan waktu eksekusi, maka tiap-tiap tahap akan dihitung, termasuk dalam pembacaan file matriks berukuran n x n
maupun file vektor berukuran n. Adapun keseluruhan tahap dalam algoritme sekuensial adalah:
1. Membaca file matriks (n x n blok) sebagai koefisien SPL.
2. Membaca file vektor (n blok) sebagai nilai target dari SPL.
3. Fungsi CG sekuensial untuk menghasilkan solusi SPL.
Kompleksitas fungsi CG sekuensial berdasarkan Gambar 1 untuk tiap tahap disajikan pada Gambar 4. Untuk N kali iterasi pada CG, maka total kompleksitas pada keseluruhan tahap yaitu:
tsekuensial=N n 2
5n. [9]
Dari Persamaan 10 dapat diketahui bahwa kompleksitas sangat tergantung dari ukuran matriks/vektor n dan banyaknya iterasi CG
N . Waktu eksekusi dari implementasi
sekuensial dapat direpresentasikan oleh Persamaan 9. Grafik hasil perhitungan Persamaan 9 disajikan pada Gambar 5.
Implementasi atau kode program yang dibuat terdiri atas fungsi-fungsi yang mewakili
proses-proses yang ada pada algoritme CG sekuensial, seperti fungsi untuk membaca file matriks, membaca file vektor, dan fungsi CG. Di dalam fungsi CG terdapat beberapa fungsi lagi, seperti fungsi perkalian matriks vektor, fungsi perkalian dua vektor, dan fungsi saxpy. Fungsi pencatat waktu diletakkan di bagian awal sebelum proses membaca file matriks dan sesudah fungsi CG. 1 Diberikan SPL Ax=b 2 Pilih x0 awal, x0=0 3 r0=b – Ax0 4 d0=r0 5 i=0 6 rr=r i T r i
7 While imax and ∥r i∥≥tol
8 q=A d i n2 9 dq=d iT q n 10 i=rr / dq 11 x i1=x i i d i n 12 r i 1=r i − i q i n 13 rr2=r i1 T r i1 n 14 i =rr2 / rr
15 d i1=r i1 i d i n
16 i=i1
Gambar 4 Kompleksitas tahapan pada fungsi CG sekuensial.
Gambar 5 Grafik perhitungan kompleksitas CG sekuensial.
Penerapan Metode Foster
Algoritme CG paralel didisain berdasarkan metode Foster, namun penggunaan metode Foster ini hanya digunakan untuk membuat algoritme CG MPI. Berikut ini adalah penjelasan dari tahapan-tahapannya.
1. Partitioning
Dalam menentukan strategi dekomposisi yang digunakan, pertama-tama harus diketahui
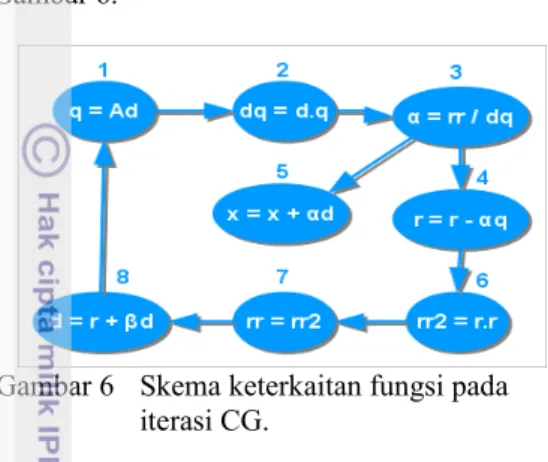
dulu komputasi yang ada. Komputasi yang ada dapat terlihat dari stuktur atau alur algoritme dan dari skema keterkaitan antar fungsi yang ada pada algoritme yang akan diparalelkan. Berdasarkan Gambar 1, skema keterkaitan antar fungsi di dalam iterasi CG disajikan pada Gambar 6.
Gambar 6 Skema keterkaitan fungsi pada iterasi CG.
Dari gambar tersebut dapat dilihat bahwa tiap tahap pada algoritme CG saling memiliki keterkaitan, sehingga sulit jika diterapkan teknik pipeline. Untuk penerapan functional
decomposition sebenarnya dapat dilakukan pada
bagian komputasi saxpy (no 4, dan 5), hanya saja kurang tepat untuk diterapkan pada paralel MPI, karena biaya komunikasi yang dibutuhkan lebih besar dari pada beban komputasi yang ada. Oleh karena itu dekomposisi yang paling mungkin dan mudah dilakukan adalah domain
decomposition.
Domain decomposition yang dilakukan tidak
pada semua tahapan algoritme CG, hanya pada perkalian matriks vektor saja. Pada perkalian dua vektor dan saxpy sebenarnya dapat diterapkan domain decomposition, hanya saja kurang tepat untuk paralel MPI, karena beban komputasinya terlalu kecil, sehingga jika dipaksakan untuk diparalelkan hanya akan menambah besar biaya komunikasi.
Dalam melakukan domain decomposition,
file matriks dengan ukuran n2 akan dibaca oleh
node root, kemudian didistribusikan kepada
seluruh node p. Tiap node akan mendapatkan matriks sebesar n2/ p. Matriks akan didekomposisi secara row-wised bukan secara column-wised, karena kompleksitas komunikasi secara row-wised lebih kecil.
Pada distribusi vektor, file vektor dengan ukuran n akan dibaca oleh node root, kemudian didistribusikan kepada seluruh node. Tiap node akan mendapatkan vektor yang sama dengan ukuran n pula.
Di dalam fungsi CG, komputasi perkalian matriks vektor dilakukan oleh tiap node. Komputasi ini dilakukan sesuai dengan matriks yang didapatkan masing-masing node. Hasil yang diperoleh masing-masing node n / p
didistribusikan kepada keseluruhan node untuk digunakan pada tahapan komputasi berikutnya.
Jadi seluruh tahapan yang ada pada Gambar 6 akan dikerjakan oleh seluruh node yang terlibat saat eksekusi. Untuk perkalian matriks vektor (no 1), masing-masing node akan melakukan komputasi dengan data matriks yang berbeda, sedangkan untuk komputasi no 2-8 masing-masing node akan mengerjakannya dengan data vektor yang sama.
2. Communication
Berdasarkan tahap partitioning, proses komunikasi yang diterapkan yaitu secara global
communication. Proses komunikasi ini
dibutuhkan pada setiap tahap. Komunikasi pertama terjadi pada saat pendistribusian matriks oleh node root yang dilakukan dengan fungsi MPI_Scatterv. Proses komunikasi yang kedua pada saat pendistribusian vektor oleh
node root dengan menggunakan fungsi
MPI_Bcast. Komunikasi ketiga yaitu di dalam fungsi CG, pada saat tiap-tiap node mendistribusikan hasil perkalian matriks vektor ke seluruh node dan ini dilakukan pada setiap iterasi. Fungsi yang digunakan pada komunikasi ini adalah MPI_Allgatherv.
3. Agglomeration
Berdasarkan pengertian dari agglomeration, maka tidak terdapat proses agglomeration secara eksplisit pada disain algoritme CG paralel. Hal ini dikarenakan memang tidak ada pengombinasian task-task yang saling terkait, namun secara implisit terdapat pada fungsi-fungsi MPI yang digunakan, seperti MPI_Gatherv, MPI_Bcast, dan MPI_Allgatherv. 4. Mapping
Komputasi yang diparalelkan secara MPI hanyalah pada bagian perkalian matriks vektor, jadi mapping yang dilakukan yaitu menugaskan seluruh node yang tersedia untuk melakukan komputasi tersebut sesuai komputasi yang didapat masing-masing node.
Berdasarkan strategi paralel yang telah dirancang dengan metode Foster, maka struktur algoritme CG pada bagian iterasinya disajikan pada Gambar 7.
Komputasi Keterangan
qlocal= Alocaldi
Perkalian MatVec, tiap node memiliki matriks berbeda Alocal, dan memiliki vektor di yang sama, dihasilkan vektor qlocal berukuran
n/ p yang berbeda pada tiap node.
q=Allgatherqlocal
Semua node melakukan allgather, sehingga tiap node memiliki vektor q
yang berukuran n
secara utuh.
dq=d i T q
Semua node akan melakukan komputasi pada bagian ini dan akan menghasilkan data vektor yang sama.
i=rr / dq x i1= x i i d i r i 1=r i − i q i rr2=r i1 T r i1 i=rr2 / rr
d i1=r i1 i d i
i=i1
Gambar 7 Struktur algoritme CG MPI pada bagian iterasi.
Analisis dan Implementasi Algoritme CG MPI
Algoritme paralel MPI yang dibuat terdiri dari tiga bagian, pertama bagian distribusi matriks, kedua distribusi vektor dan ketiga bagian iterasi fungsi CG. Dalam menganalisis kompleksitas algoritme MPI yang telah dibuat, ketiga bagian tersebut diikutsertakan seluruhnya dalam perhitungan. Berikut ini adalah kompleksitas dari masing-masing bagian tersebut:
1. Distribusi matriks
Dalam mendistribusikan file matriks berukuran n2 , masing-masing node mendapatkan bagian matriks sebesar n2
/ p. Dalam mendistribusikan file matriks tersebut, implementasi MPI yang dibuat yaitu menggunakan fungsi MPI_Scatterv.
Menurut Grama et al (2003), kompleksitas MPI_Scatter / MPI_Scatterv dan MPI_Gather dengan mengabaikan startup time ts yaitu:
twm p – 1. [10]
tw : waktu dibutuhkan untuk mentransfer
message per word.
m : ukuran message yang akan dikirim. p : banyaknya node yang menerima message. Ukuran message yang akan dikirim m
adalah n2/ p, sehingga berdasarkan
kompleksitas MPI_Scatterv, maka kompleksitas dalam mendistribusikan file matriks tmatriks yaitu: tmatriks= twn 2 p p – 1. [11] 2. Distribusi vektor
Dalam mendistribusikan vektor, ukuran vektor yang didapatkan oleh seluruh node adalah sama besar, yaitu n. Fungsi MPI_Bcast digunakan dalam pendistribusian vektor ke seluruh node. Menurut Grama et al (2003), kompleksitas MPI_Bcast dengan mengabaikan startup time ts yaitu:
twm log p. [12]
sehingga kompleksitas mendistribusikan file vektor tvektor adalah:
tvektor=twn log p. [13]
3. Iterasi fungsi CG
Berdasarkan partitioning yang telah ditentukan, maka pada bagian iterasi fungsi CG bagian yang diparalelkan secara MPI adalah pada perkalian matriks vektor. Hasil perkalian ini kemudian didistribusikan ke seluruh node.
Pada implementasinya, fungsi-fungsi sekuensial yang digunakan tidak mengalami perubahan, namun hanya dilakukan penambahan fungsi dalam pendistribusian hasil perkalian matriks vektor saja. Fungsi yang digunakan dalam hal ini adalah MPI_Allgatherv.
Pada dasarnya fungsi MPI_Allgatherv hampir sama dengan MPI_Gatherv, hanya saja pada MPI_Allgatherv seluruh node melakukan pengiriman data, sehingga kompleksitasnya pun sama. Dengan demikian kompleksitas pada bagian iterasi ini titerasi adalah:
titerasi= N n
nptwp p – 15
. [14] Struktur algoritme MPI dan kompleksitasnya tiap tahap pada bagian iterasi CG disajikan pada Gambar 8. Berdasarkan Gambar 8, maka total kompleksitas algoritme CG MPI tmpi pada tiga bagian yang telahtmpi=tmatrikstvektortiterasi. [15] tmpi=n
tw p−1 p N ntwlog p N
n p5
. [16] 1 Diberikan SPL Ax=b 2 Pilih x0 awal, x0=0 3 r0=b – Ax0 4 d0=r0 5 i=0 6 rr=r i T r i 7 While imax and ∥r i∥≥tol
8 qlocal= Alocaldi n2/ p 9 q=Allgather qlocal twn/ p p – 1 10 dq=d i
T q n
11 i=rr / dq
12 x i1=x i i d i n 13 r i1=r i− i q i n 14 rr2=r i1
T r
i1 n
15 i=rr2 / rr
16 d i1=r i1 i d i n
17 i=i1
Gambar 8 Struktur algoritme dan kompleksitas fungsi CG MPI. Dalam perhitungan kompleksitas pada penelitian ini, kecepatan jaringan (LAN) yang digunakan adalah 100 Mbps dan tipe data yang digunakan adalah double. Karena tipe data
double, maka ukuran message per word adalah
8 byte, sehingga nilai tw adalah 0.64 x 106.
Gambar 9 Grafik perhitungan kompleksitas CG MPI.
Grafik hasil perhitungan kompleksitas berdasarkan Persamaan 16 terhadap lima ukuran matriks yang digunakan disajikan pada Gambar 9.
Setelah diketahui kompleksitas total dari implementasi yang telah dibuat, selanjutnya dilakukan analisis performance-nya.
1. Speedup
Berdasarkan Persamaan 1, 9, dan 16 maka
speedup dapat dihitung menggunakan
Persamaan 17. S=t Nn5 w p−1 p N ntwlog pN
n p5
. [17] Pada Gambar 10 disajikan grafik hasil perhitungan speedup berdasarkan Persamaan 17 terhadap lima ukuran matriks yang digunakan.Gambar 10 Grafik perhitungan speedup CG MPI.
Dari Gambar 10, dapat diketahui bahwa: • Nilai speedup yang diperoleh hampir
mendekati dengan nilai ideal dari speedup untuk setiap jumlah node yang digunakan, yaitu mendekati linear.
• Untuk setiap ukuran matriks yang diinputkan, semakin tinggi jumlah node yang digunakan, semakin tinggi speedup yang diperoleh.
• Semakin tinggi jumlah node yang digunakan, untuk ukuran matriks yang semakin kecil, maka nilai speedup yang diperoleh semakin menurun dan menjauhi nilai ideal.
2. Efisiensi
Nilai efisiensi didapatkan dengan menggunakan Persamaan 18.
E=t Nn5
w p−1N ntwp log pN n5 p . [18] Pada Gambar 11, disajikan grafik hasil perhitungan efisiensi berdasarkan Persamaan 18 terhadap lima ukuran matriks yang digunakan.
Gambar 11 Grafik perhitungan efisiensi CG MPI.
Dari Gambar 11, dapat diketahui bahwa: • Efisiensi yang diperoleh hampir mendekati
nilai ideal dari efisiensi, yaitu 1.
• Semakin tinggi jumlah node yang digunakan, nilai efisiensinya mengalami penurunan, namun tingkat penurunannya kecil.
• Semakin tinggi jumlah node yang digunakan, untuk ukuran matriks yang semakin kecil, maka nilai efisiensi yang diperoleh semakin menurun dan menjauhi nilai ideal.
3. Cost
Untuk nilai cost didapatkan dengan Persamaan 19.
C=ntw p−1 N ntwp log p N n5 p.
[19] 4. Total Parallel Overhead
Untuk nilai overhead didapatkan dengan Persamaan 20.
To=ntw p−1N ntwplog p5 N p−1. [20] 5. Isoefisiensi
Dari Persamaan overhead yang diperoleh, maka dapat diketahui isoefisiensi dari algoritme yang dibuat. Untuk setiap peningkatan jumlah
node, seberapa besar problem size W yang
harus menjadi input untuk mempertahankan nilai efisiensi yang ingin diperoleh.
W =E n tw p−1 N ntwp log p5 N p−1
E−1 .
[21] Jadi jika ingin diperoleh nilai efisiensi sebesar E untuk setiap peningkatan jumlah
node, maka ukuran problem size yang harus
digunakan dapat diketahui dengan persamaan 21. Penerapan Model Hybrid
Dalam penerapan model paralel hybrid dari model paralel message-passing atau MPI, hal pertama yang dilakukan adalah identifikasi bagian-bagian yang dapat diparalelkan secara
shared-memory atau OpenMP. Berdasarkan
struktur algoritme CG MPI yang telah dibuat, terdapat tiga bagian utama, yaitu distribusi matriks, distribusi vektor, dan iterasi fungsi CG.
Dari kompleksitas tiga bagian tersebut, kompleksitas tertinggi ada pada bagian iterasi dikarenakan pada bagian ini terjadi komputasi, sehingga pada bagian inilah yang lebih tepat diparalelkan secara OpenMP. Sebenarnya pada bagian distribusi matriks dan distribusi vektor dapat diparalelkan secara OpenMP, namun pada kedua bagian ini komputasi yang terjadi hanyalah baca file dan distribusi data lewat jaringan. Oleh karena itu lamanya waktu komputasi pada bagian ini lebih ditentukan oleh kecepatan hardware, sehingga tidak tepat diparalelkan secara OpenMP.
Pada bagian Penerapan Metode Foster pada tahap partitioning, disebutkan bahwa ada beberapa komputasi yang tidak tepat bila dipararelkan secara MPI. Bagian-bagian inilah yang akan dipararelkan secara OpenMP. Berdasarkan Gambar 8, komputasi-komputasi yang ada adalah perkalian matriks vektor, perkalian dua vektor, dan saxpy. Pada ketiga komputasi ini terdapat konstruksi-konstruksi
loop yang dapat diparalelkan, jadi pada
komputasi-komputasi inilah dilakukan pararel OpenMP. Cara seperti ini sama saja dengan melakukan domain decomposition, karena pada hakikatnya yang dipararelkan adalah data.
Selain dengan melakukan pararel pada kontruksi loop, bila dilihat Gambar 6 pada no 4 dan 5, bagian ini dapat dilakukan partitioning secara functional decomposition. Bagian ini tidak tepat jika dipararelkan secara MPI, namun lebih tepat dipararelkan secara OpenMP. Dengan dilakukannya functional decomposition, maka pada bagian ini terjadi dua pararelisasi, yaitu pararelisasi fungsi secara struktural dan paralelisasi data didalamnya.
Berdasarkan strategi paralel hybrid yang telah dirancang, maka struktur algoritme CG
hybrid pada bagian iterasinya disajikan pada
Komputasi Keterangan
qlocal=Alocaldi
Perkalian MatVec akan dilakukan oleh semua node secara MPI, dan dilakukan oleh semua thread secara OpenMP pada tiap node.
q=Allgather qlocal
Semua node melakukan allgather, sehingga tiap node memiliki vektor q
yang berukuran n secara utuh.
dq=d iT q
Semua node akan melakukan komputasi secara paralel OpenMP.
i=rr / dq x i1= x i i d i
Semua node akan melakukan komputasi secara paralel OpenMP dan kedua operasi saxpy ini diparalel secara data dan fungsi
r i 1=r i − i q i
rr2=r i1 T r
i1
Semua node akan melakukan komputasi secara paralel OpenMP.
i=rr2 / rr d i1=r i 1 i d i
Semua node akan melakukan komputasi secara paralel OpenMP.
i=i1
Gambar 12 Struktur algoritme CG hybrid pada bagian iterasi.
Analisis dan Implementasi Algoritme CG Hybrid
Dalam eksekusi bagian loop yang diparalelkan secara OpenMP, sejumlah thread akan dibangkitkan untuk mengeksekusi bagian
loop tersebut secara bersamaan. Jika suatu
konstruksi loop memiliki kompleksitas n
dieksekusi oleh t thread, maka
kompleksitasnya menjadi n/t. Dengan demikian kompleksitas algoritme CG hybrid akan ditentukan oleh banyaknya node p , banyaknya thread t, ukuran matriks dan vektor n, serta banyaknya iterasi CG N .
Agar suatu loop dieksekusi secara paralel OpenMP, maka digunakanlah compiler
directive atau pragma. Berikut ini adalah kode
program pada bagian perkalian matriks vektor yang sudah ditambahkan pragma.
#pragma omp parallel for default(none) shared(rowSize, colSize, q, A, x) private(i, j)
for(i=0;i<rowSize;i++) //outer loop
{
q[i] = 0;
for(j=0;j<colSize;j++) //inner loop
q[i]+= A[i*colSize+j]*x[j]; }
Pada kode program tersebut, matriks A akan dipartisi secara row-wised, karena yang diparalelkan adalah outer loop. Jika dieksekusi oleh t thread, maka masing-masing thread akan melakukan outer loop sebanyak
rowSize/t dan melakukan inner loop sebanyak colSize.
Berdasarkan strategi paralel hybrid yang telah ditentukan, maka struktur dan kompleksitas dari algoritme CG hybrid disajikan pada Gambar 13.
1 Diberikan SPL Ax=b 2 Pilih x0 awal, x0=0 3 r0=b – Ax0 4 d0=r0 5 i=0 6 rr=r i T r i
7 While imax and ∥r i∥≥tol 8 qlocal=Alocaldi n2/ pt 9 q= Allgather qlocal twn/ p p – 1 10 dq=d i
T q n/ t
11 i=rr / dq
12 x i1= x i i d i n/ t 13 r i1=r i− i q i
14 rr2=r i1 T r
i1 n/ t 15 i=rr2 / rr
16 d i1=r i1 i d i n/ t 17 i=i1
Gambar 13 Struktur algoritme dan kompleksitas fungsi CG hybrid.
Berdasarkan Gambar 13, maka kompleksitas pada bagian fungsi CG hybrid adalah:
titerasi= N n
n pt tw p p – 1 4 t
. [22]Dengan demikian kompleksitas total algoritme CG thybrid hybrid menjadi:
thybrid=n
tw p−1 p N ntwlogp N t
n p4
. [23] Pada Gambar 14 disajikan hasil perhitungan kompleksitas berdasarkan Persamaan 23 untuksetiap jumlah thread dengan ukuran matriks tetap. Sedangkan pada Gambar 15 ditampilkan hasil perhitungan terhadap lima ukuran matriks yang digunakan dengan jumlah thread tetap.
Gambar 14 Grafik perhitungan kompleksitas untuk tiap jumlah thread dengan ukuran matriks 2548 x 2548.
Gambar 15 Grafik perhitungan kompleksitas untuk tiap ukuran matriks dengan 2 thread.
Setelah diketahui kompleksitas total dari implementasi hybrid yang telah dibuat, selanjutnya dilakukan analisis performance-nya. 1. Speedup
Berdasarkan Persamaan 23, maka speedup dari implementasi hybrid dihitung dengan Persamaan 24. S=t Nn5 w p−1 p N ntwlog p N t
n p4
. [24] Berdasarkan Persamaan 24, pada Gambar 16 disajikan grafik hasil perhitungan speeduphybrid dengan jumlah thread 1, 2, 3, dan 4 pada
salah satu ukuran matriks yang digunakan. Kemudian pada Gambar 17 disajikan grafik
speedup hybrid untuk setiap ukuran matriks
yang digunakan dengan dua thread.
Dari Gambar 16 dan Gambar 17 dapat diketahui bahwa:
• Speedup yang diperoleh hampir mendekati nilai ideal pada tiap-tiap kombinasi node dan
thread.
• Untuk setiap ukuran matriks yang diinputkan, semakin tinggi jumlah node dan
thread yang digunakan, semakin tinggi speedup yang diperoleh.
• Semakin tinggi jumlah node yang digunakan dengan jumlah thread tetap, untuk ukuran matriks yang semakin kecil, maka nilai
speedup yang diperoleh semakin menurun
dan menjauhi nilai ideal.
Gambar 16 Grafik perhitungan speedup untuk tiap jumlah thread dengan ukuran matriks 2548 x 2548.
Gambar 17 Grafik perhitungan speedup untuk tiap ukuran matriks dengan 2 thread. 2. Efisiensi
Untuk nilai efisiensi, maka dapat dihitung dengan persamaan 25. E= N n5 tw p−1 N ntwplog p N t n4 p . [25] Grafik hasil perhitungan dari Persamaan 25, disajikan pada Gambar 18 dan Gambar 19. Grafik untuk salah satu matriks yang digunakan disajikan pada Gambar 18, sedangkan pada Gambar 19 disajikan grafik untuk setiap ukuran
matriks yang digunakan dengan dua thread. Dari kedua Gambar 18 dan Gambar 19 dapat diketahui bahwa:
• Efisiensi yang diperoleh hampir mendekati nilai ideal dari efisiensi, yaitu 1 pada tiap-tiap kombinasi node dan thread.
• Semakin tinggi jumlah node yang digunakan dengan jumlah thread tetap, semakin kecil ukuran matriks, maka nilai efisiensinya semakin menurun.
• Semakin tinggi jumlah node dan jumlah
thread yang digunakan, untuk ukuran
matriks yang semakin kecil, nilai efisiensi yang diperoleh mengalami penurunan dan menjauhi nilai ideal, namun tingkat penurunannya kecil.
Gambar 18 Grafik perhitungan efisiensi untuk tiap jumlah thread dengan ukuran matriks 2548 x 2548.
Gambar 19 Grafik perhitungan efisiensi untuk tiap ukuran matriks dengan 2 thread. 3. Cost
Untuk nilai cost didapatkan dengan Persamaan 26.
.C=n
tw p−1Nntwplog pNt n4 p
.[26]
4. Total Parallel Overhead
Untuk nilai overhead didapatkan dengan Persamaan 27. To=n
tw p−1 Nntwplogp N t n4 p−n t−5 t
. [27] 5. IsoefisiensiKemudian untuk memperoleh efisiensi yang tetap E, maka untuk setiap peningkatan jumlah node dan jumlah thread, problem size
W yang harus digunakan dihitung dengan Persamaan 28.
W= E
E−1To. [28]
Analisis Hasil Waktu Eksekusi
Untuk menganalisis hasil waktu eksekusi, dilakukan perbandingan hasil perhitungan kompleksitas dengan hasil waktu percobaan yang diperoleh. Waktu eksekusi hasil percobaan implementasi CG sekuensial dibandingkan dengan hasil kompleksitas yang telah dihitung pada Persamaan 9. Grafik waktu eksekusi implementasi CG sekuensial disajikan pada Gambar 20.
Setelah dibandingkan dengan seksama antara Gambar 5 dan Gambar 20, terlihat bahwa keduanya memiliki kesamaan bentuk, berarti hal ini menunjukkan hasil perhitungan kompleksitas dan hasil percobaan memiliki kesesuaian. Semakin besar ukuran matriks semakin tinggi waktu eksekusinya, jadi waktu eksekusi sekuensial benar dipengaruhi oleh ukuran matriks/vektor.
Gambar 20 Grafik waktu eksekusi implementasi CG sekuensial. Pada implementasi MPI, grafik waktu eksekusi percobaan pada tiap ukuran matriks disajikan pada Gambar 21. Jika Gambar 9 dibandingkan dengan Gambar 21, maka akan
terlihat memiliki kesesuaian bentuk walaupun tidak terlalu sama persis. Hal ini menunjukkan bahwa hasil perhitungan kompleksitas CG MPI bersesuaian dengan hasil percobaan implementasi MPI.
Gambar 21 Grafik waktu eksekusi implementasi MPI.
Dari Gambar 21 juga dapat diketahui bahwa waktu eksekusi dipengaruhi oleh jumlah node yang digunakan, namun bukan berarti semakin banyak node yang digunakan waktu eksekusi akan menurun signifikan. Grafik tersebut menunjukkan untuk jumlah node mendekati 8, maka semakin landai bentuk garisnya. Hal ini berarti menunjukkan pengaruh jumlah node semakin berkurang terhadap menurunnya waktu eksekusi.
Selanjutnya disajikan grafik perbandingan waktu eksekusi untuk implementasi MPI dan
hybrid untuk ukuran matriks 2548 x 2548 dan
4884 x 4884 pada Gambar 22 dan Gambar 23.
Sedangkan pada Gambar 24, disajikan grafik waktu eksekusi pada tiap matriks dengan menggunakan 2 thread.
Jika dibandingkan Gambar 22 dan Gambar 23 dengan Gambar 14, maka ada kesesuaian bentuk yakni menurun pada setiap thread yang digunakan, namun tingkat penurunannya lebih rendah dibandingkan Gambar 14. Selain itu pada Gambar 22 dan Gambar 23, urutan waktu eksekusi hybrid pada penggunaan 1 thread sampai 4 thread tidak sesuai dengan hasil perhitungan kompleksitas seperti pada Gambar 8. Seharusnya semakin tinggi jumlah thread yang digunakan, semakin rendah waktu eksekusi, namun tidak demikian adanya. Waktu eksekusi dengan 3 thread lebih rendah dari pada waktu eksekusi 2 thread, dan waktu eksekusi 4
thread hampir menyamai waktu eksekusi 2 thread walaupun masih lebih rendah sedikit
pada 2 thread. Anomali ini terjadi karena
processor pada komputer yang digunakan hanya
memiliki 2 core. Sehingga penggunaan jumlah
thread lebih dari jumlah core processor menjadi
penyebab waktu eksekusi lebih lambat atau paling tidak hampir menyamai waktu eksekusi 2 thread.
Gambar 22 Grafik waktu eksekusi untuk setiap implementasi dengan ukuran matriks 2548 x 2548.
Gambar 23 Grafik waktu eksekusi untuk setiap implementasi dengan ukuran matriks 4884 x 4884.
Gambar 24 Grafik waktu eksekusi
implementasi hybrid untuk tiap ukuran matriks dengan 2 thread. Berdasarkan hasil perhitungan kompleksitas, untuk perbandingan waktu eksekusi hybrid 1
thread dengan MPI, seharusnya nilai
kompleksitas implementasi MPI lebih tinggi sedikit dari hybrid 1, akan tetapi pada hasil waktu eksekusi memperlihatkan sebaliknya.
Kemudian dilakukan pengamatan processor
usage pada saat eksekusi program berlangsung.
Saat eksekusi hybrid 1 thread, pada masing-masing komputer hanya 1 core processor yang melakukan komputasi dengan nilai usage hampir 100%. Sedangkan pada saat eksekusi MPI, 2 core processor yang tersedia pada masing-masing komputer melakukan eksekusi dengan nilai usage sekitar 50%. Jadi pada eksekusi MPI, komputasi didistribusikan pada seluruh core processor yang tersedia. Hal inilah yang menyebabkan waktu eksekusi implementasi MPI lebih rendah dibandingkan dengan hybrid 1 thread.
Pada Gambar 24, grafik yang dihasilkan sedikit berbeda dengan hasil perhitungan kompleksitas pada Gambar 15. Garis-garis pada Gambar 24 terlihat lebih landai, namun secara keseluruhan masih menurun seiring semakin tinggi jumlah node yang digunakan. Grafik untuk setiap kombinasi matriks, jumlah node, dan jumlah thread yang digunakan lebih lengkapnya disajikan pada Lampiran 1.
Dari Gambar 22, Gambar 23, dan Gambar 24, dapat diketahui bahwa waktu eksekusi implementasi hybrid memang sangat dipengaruhi oleh ukuran matriks/vektor, jumlah
node, dan jumlah thread yang digunakan.
Waktu eksekusi tercepat diperoleh oleh hybrid 2
thread dengan 8 node.
Secara umum pada grafik-grafik waktu eksekusi hasil percobaan MPI dan hybrid, seharusnya waktu eksekusi semakin menurun drastis untuk setiap peningkatan jumlah node pada ukuran matriks 10001. Akan tetapi tidak demikian adanya, penurunan waktu eksekusi tidak terlampau tinggi sebagaimana mestinya. Kemudian dilakukan analisis lebih lanjut, yaitu dengan dilakukan pemisahan waktu komputasi yang ada, seperti waktu distribusi matriks/vektor dan waktu iterasi CG. Grafik hasil pemisahan disajikan pada Gambar 25.
Dari pemisahan tersebut dapat diketahui bahwa waktu iterasi CG pada kedua implementasi jauh lebih kecil dari pada total waktu eksekusi. Berarti lamanya waktu eksekusi pada ukuran matriks 10001 disebabkan oleh lamanya waktu distribusi matriks/vektor. Lebih tepatnya waktu distribusi matriks yang menjadi penyebab lamanya waktu eksekusi. Lamanya waktu ini lebih disebabkan oleh proses I/O. Pada masing-masing komputer, hanya terdapat main memory (RAM) sebesar 1 GB, sehingga swap memory yang terdapat di
hard disk dilibatkan dalam proses pembacaan
matriks yang berukuran besar. Jadi lamanya waktu distribusi matriks dikarenakan saat eksekusi berlangsung terdapat proses baca tulis ke hard disk.
Gambar 25 Grafik waktu eksekusi dan waktu iterasi implementasi MPI dan
hybrid 2 thread untuk ukuran
matriks 10001 x10001. Analisis Hasil Speedup
Berdasarkan hasil waktu eksekusi, kemudian dihitung nilai speedup dari tiap-tiap implementasi dan tiap-tiap kombinasi. Grafik
speedup untuk implementasi MPI disajikan
pada Gambar 26.
Gambar 26 Grafik speedup hasil percobaan implementasi MPI.
Jika dilakukan perbandingan antara Gambar 26 dengan Gambar 16, maka akan tampak sangat berbeda. Pada Gambar 16 nilai speedup hampir mendekati nilai idealnya pada tiap jumlah node, namun pada Gambar 26 nilai
speedup tertinggi tidak sampai 4. Hal ini
diakibatkan dari waktu eksekusi yang dihasilkan implementasi MPI tidak sesuai dengan hasil perhitungan kompleksitas. Pada Gambar 21 semakin tinggi jumlah node, maka semakin landai grafiknya, sehingga pada Gambar 26 semakin tinggi jumlah node, maka speedup yang diperoleh semakin menjauhi nilai ideal.