PEMBANGUNAN
SPAM E-MAIL FILTERING SYSTEM
DENGAN METODE
NAIVE BAYESIAN
Indrastanti R. Widiasari.1, Teguh Indra Bayu2
1, 2
Fakultas Teknologi Informasi, Universitas Kristen Satya Wacana
1
[email protected], [email protected]
1. Pendahuluan populer yaitu Naive Bayesian filtering. Metode ini
memanfaatkan teorema probabilitas yaitu teorema Bayes dan fungsionalitas data mining yaitu klasifikasi Naive Bayesian. Kelebihan Naive Bayesian filtering adalah tingkat akurasi yang tinggi dan error rate yang minimum.
Electronic mail (e-mail) merupakan media komunikasi dalam jaringan intranet maupun internet untuk berdiskusi (maillist), transfer informasi berupa file (mail attachment) bahkan dapat digunakan untuk media iklan suatu perusahaan atau produk tertentu [1]. Mengingat fasilitas e-mail yang murah dan kemudahan untuk mengirimkan ke berapapun jumlah penerimanya, maka beberapa pihak tertentu memanfaatkannya dengan mengirimkan e-mail berisi promosi produk atau jasa, pornografi, virus, dan hal-hal yang tidak penting ke ribuan pengguna e-mail. E-mail inilah yang biasanya disebut dengan spam mail. Dampak buruk yang paling utama dari adanya spam mail adalah terbuangnya waktu dengan percuma untuk menghapus spam mail dari inbox satu persatu. Meskipun berbagai perangkat lunak e-mail filtering banyak tersedia, namun masalah spam mail juga semakin berkemba
2. Spam
Spam muncul pertama kali pada bulan Mei tahun 1978. Spam tersebut bersifat iklan yang dikirimkan oleh Digital Equipment Corporation (DEC) tentang product DecSystem-20, kemudian pada April 1994, spam menyebar melalui USENET news merupakan forum diskusi yang paling populer pada masa itu dengan jumlah group mencapai ribuan dan semua group menerima iklan dari forum diskusi tersebut. Spam merupakan unsolicited e-mail (e-mail yang tidak diminta) yang dikirim ke banyak orang [2]. Spam juga dapat diartikan sebagai e-mail yang berisi promosi produk atau jasa, pornografi, virus, dan hal-hal yang tidak penting yang dikirim ke ribuan pengguna e-mail.
ng.
Berdasarkan permasalahan yang ada, maka hal yang harus dilakukan untuk mem-filter spam sehingga penggunaan spam dapat dicegah secara optimal oleh e-mail filtering. Metode yang digunakan merupakan
285
berdasarkan kata-kata (token) yang terkandung pada sebuah e-mail [3]. Metode filter pada saat pertama kali dijalankan harus dilakukan proses training
menggunakan dua koleksi e-mail, satu koleksi merupakan spam mail dan koleksi yang lain merupakan good mail. Proses training ini digunakan sebagai data pembanding terhadap e-mail yang masuk. Dengan cara seperti ini, pada setiap e-mail
baru yang diterima, Bayesian filter dapat memperkirakan probabilitas (prediksi) spam
berdasarkan kata-kata yang sering muncul di koleksi
spam mail atau di koleksi good mail.
3. Email
E-mail (Electronic Mail) atau surat elektronik sudah mulai dipakai pada tahun 1960-an. Pada saat itu internet belum terbentuk, yang ada hanyalah kumpulan mainframe yang terbentuk sebagai jaringan. Mulai tahun 1980-an, surat elektronik sudah bisa dinikmati oleh banyak orang. E-mail
merupakan media komunikasi dalam jaringan intranetmaupun internetuntuk berdiskusi (maillist), transfer informasi berupa file (mail attachment) bahkan dapat digunakan untuk media iklan suatu perusahaan atau produk tertentu [1]. E-mail terdiri dari 3 komponen [4] yaitu :
• Envelope
Proses ini digunakan oleh Mail Transport Agent
(MTA)untuk melihat rute atau jalur pesan. Biasanya
user tidak melihat bagian ini karena prosesnya terjadi pada bagian MTAuntuk pengiriman.
• Header
E-mail mengandung header yang digunakan sebagai informasi mengenai e-mail tersebut, mulai dari alamat pengirim, penerima, subjek dan lain-lain.
Header originating date field dan original address fields sifatnya mandatory (diperintah), artinya user
tidak dapat menggganti secara manual mengenai informasi tanggal pengiriman maupun alamat pengirim.
• Body
Merupakan isi pesan dari pengirim ke penerima. Dalam mail body juga terdapat file attachment yang digunakan untuk mengirimkan e-mail berupa file
(mail attachment).
4. Metode Naive Bayesian
Metode Naïve Bayesian merupakan metode yang digunakan untuk memprediksi suatu kejadian pada masa yang akan datang, dengan cara membandingkannya dengan data atau evidence
(bukti) yang ada pada masa lampau. Penggunaan probabilitas kata atau token dijadikan sebagai inputan probabilitas dari kejadian. Klasifikasi Naive Bayesian akan melihat data lama (previous data)
dalam menentukan nilai kemiripan data yang baru. Jadi harus terdapat data lama yang digunakan sebagai data pembanding dalam proses Bayes.
5. Perhitungan Probabilitas Berdasarkan
Algoritma Bayesian.
Bayesian filter pada saat pertama kali dijalankan harus melakukan proses training terlebih dahulu. Proses training menggunakan sejumlah spam mail
dan sejumlah goodmail yang ditambahkan ke dalam suatu tabel atau data pembanding. Bayesian filter
akan menghitung probabilitas lokal dari suatu kata, misalnya kata sex, untuk muncul di kelompok spam mail. Probabilitas lokal ini dapat dilihat seperti pada Persamaan 1 [3].
dimana
PLocal-spam : probabilitas suatu kata
sex terdapat pada spam mail.
Nspam : jumlah spam mail dengan kata sex di dalamnya.
Nnonspam : jumlah nonspam mail dengan kata sex di dalamnya.
Persamaan 2 digunakan untuk menghitung probabilitas lokal dari suatu kata, terutama jika nilai
Nspam dan Nnonspam kecil adalah bahwa probabilitas akan terletak di sekitar probabilitas ketidakpastian (P = 0.5). Berbeda dengan Persamaan 1, pada Persamaan 2 tidak akan memberikan nilai mutlak, jika terdapat frekuensi suatu kata dalam
spam mail dan tidak terdapat dalam frekuensi good mail.
(1)
286
dimana :
C1 dan C2 : konstanta yang dipilih melalui
eksperimen.
Nilai dari C1 = dua dan C2 = satu, dan jika suatu kata
“x” hanya ditemukan pada dua spam mail dan tidak ditemukan sama sekali pada good mail, maka probabilitas lokal suatu pesan baru yang mengandung kata tersebut dikategorikan sebagai
spam adalah 0.83. Probabilitas ini tidak terlalu tinggi untuk dikategorikan sebagai spam. Sementara jika kata tersebut ditemukan pada sepuluh spam mail dan tidak ditemukan sama sekali pada good mail, maka probabilitas lokalnya akan sama dengan 0.95, yang cukup tinggi untuk dikategorikan sebagai spam. Perhitungan probabilitas ini jika dilakukan dengan Persamaan 1, akan memberikan hasil yang terlalu kasar, yaitu probabilitas mutlak sama dengan satu.
Probabilitas lokal dari masing-masing kata tersebut kemudian menggunakan aturan rantai (chain rule) Bayesian untuk menentukan probabilitas total dari suatu pesan adalah spam.
Chain ruleBayesian dapat dilihat pada Persamaan 1. Untuk menentukan probabilitas total, perhitungan tersebut dilakukan terus menerus secara iterative
(tindakan mengulangi proses biasanya dengan tujuan mendekati tujuan yang diinginkan atau hasil) dari probabilitas lokal masing-masing kata pada pesan tersebut.
6. Metode Tokenizing, Scoring dan Combining
Metode tokenizing akan membaca mail dan memecahnya menjadi beberapa kata (token). Proses
tokenizing dapat dilakukan pada body message,
header message, kode-kode HTML, dan gambar.
Tokenizing pada body message dilakukan dengan mendeteksi spasi kata dan kemunculan suatu kata yang sering digunakan dan terdapat dalam mail. Proses tokenizing adalah proses membuat daftar karakteristik kata-kata spam dan non-spam mail.
Tokenizing pada header message dapat dilakukan dengan menghitung jumlah penerima message pada
recipient (to/Cc) header. Sedangkan tokenizing pada kode HTML dapat dilakukan pada kode font, tabel, atau background.
Setelah mail yang diterima dipisahkan menjadi beberapa token, maka setiap token akan diberi nilai atau disebut juga dengan metode scoring. Metode ini memberikan nilai (score) pada setiap token yang telah diproses dengan metode tokenizing dengan menggunakan Persamaan 2. Kemudian dilakukan proses training secara manual oleh user yang akan menentukan mail tersebut adalah spam mail atau
good mail. Score yang diberikan yaitu 0.99 untuk
spammail murni dan 0.01 untuk goodmail murni.
Setelah proses tokenizing dan scoring dilakukan, kemudian dengan menggunakan algoritma Naive Bayesian dilakukan metode combining. Metode
combining adalah suatu rumus probabilitas yang digunakan untuk menghitung probabilitas token
yang terdapat di dalam suatu mail. Setiap score yang terdapat pada token akan dihitung (combine) dan dirumuskan untuk menghasilkan suatu nilai antara 0% sampai dengan 100%. Nilai hasil tersebut dikenal dengan istilah threshold value. Nilai yang dihasilkan adalah nilai yang menentukan e-mail
tersebut dinyatakan sebagai good mail atau spam mail. Setelah proses combining, dapat ditentukan e-mail tersebut adalah spam mail atau good mail
berdasarkan hasil perhitungan yang diperoleh.
7. Aplikasi Spam E-mailFilteringSystem
Perancangan perangkat lunak program terdiri dari empat bagian yang utama, yaitu proses training, proses tokenizing, proses scoring, dan proses
combining. Proses ini harus berurutan untuk mendapatkan hasil yang optimal dalam pengklasifikasian mail. Sebelum user dapat menggunakan program untuk pengklasifikasian mail
secara otomatis dan memiliki false positive maupun
false negative yang optimal, user harus terlebih dahulu melakukan proses training. Apabila user
sudah mempunyai referensi dari e-mail yang dikategorikan sebagai spam maupun good mail. Proses training ini terjadi saat pertama kali program dibuat dan belum adanya data yang terdapat dalam tabel token. Proses tokenizing merupakan proses memilah kata atau token dalam mail body
berdasarkan spasi kata dan kata yang sering muncul.
Proses scoring merupakan proses pemberian score
terhadap kemunculan kata dalam good mail maupun
spam mail. Data dalam tabel token berisi kumpulan
token, frekuensi kemunculan token dalam Inbox
maupun Junk E-mail, dan score yang diperoleh dari frekuensi kemunculan token. Sedangkan combining
ini digunakan untuk mendapatkan 15 token yang mempunyai nilai terjauh dari 0.5, kemudian dilakukan perhitungan dengan menggunakan metode
287
Gambar 4 Use Case Diagram User
Gambar 4 menjelaskan bagian yang dapat dilakukan oleh seorang user. Add to Spam digunakan untuk memindahkan e-mail ke dalam folder spam. Add to Good digunakan untuk memindahkan e-mail
ke dalam folder good. Analysis digunakan untuk melihat dasar suatu e-mail dapat dikategorikan sebagai spam atau good mail. Rebuild digunakan untuk menghapus data dalam tabel token, kemudian menggantinya dengan data yang baru. Update
digunakan untuk meng-update frekuensi kemunculan suatu token. Lihat Token digunakan untuk melihat isi dari tabel token (data pembanding). Pilih Letak Folder Good digunakan untuk merubah letak inbox. Pilih Letak Folder Junk digunakan untuk merubah letak junk. Ubah letak spam level
digunakan untuk merubah level dari spam yang biasa diset pada nilai 50%. Lihat Pembuat digunakan untuk melihat identitas pembuat program.
.
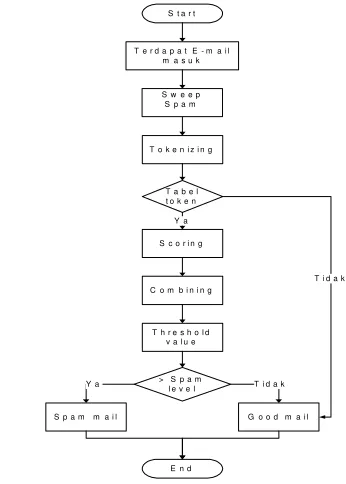
Gambar 5 Flowchart ProgramUtama
Flowchart sistem secara keseluruhan setelah adanya data dalam tabel token atau setelah terjadi
proses training dapat dilihat pada Gambar 5. Mail
diterima oleh Microsoft Office Outlook 2007, kemudian jika terdapat e-mail yang masuk akan secara otomatis dilakukan sweep spam
(membersihkan spam mail yang ada pada Inbox
secara otomatis), lalu terjadi proses tokenizing atau
mail yang masuk dilakukan pemisahan berdasarkan spasi kata dan kata yang sering muncul dalam mail body dan terdapat dalam tabel token. Apabila kata dalam mail body tidak terdapat pada tabel token, maka e-mail langsung dikategorikan sebagai good mail, akan tetapi jika mail yang masuk dan kata dalam token terdapat dalam tabel token, maka dilakukan proses scoring terhadap kata dalam token
tersebut, kemudian menuju ke proses combining
yaitu setiap kata dalam token yang terdeteksi tersebut diambil 15 kata yang mempunyai score
tertinggi dari 0.5, kemudian dilakukan perhitungan
Naive Bayesian. Apabila hasil perhitungan Naive Bayesian menghasilkan nilai kurang dari spam threshold, maka mail dikategorikan sebagai good mail. Apabila hasil perhitungan Naive Bayesian
menghasilkan nilai lebih dari spam threshold, maka
mail akan dikategorikan sebagai spam mail. Kemudian muncul pesan bahwa mail akan dipindah ke folder spam atau dibiarkan berada di folder inbox, jika user menekan button “Yes” maka mail akan berpindah ke folder spam, jika tidak maka mail akan tetap berada di folder Inbox
Gambar 6 Flowchart Sistem Training
Add to Spam Add to Good Analysis
288
Perancangan pada sistem training dilakukan pada saat program diinstalasi. Proses training
dilakukan karena belum adanya token yang tersimpan pada program yang dibuat. Proses training
dilakukan saat program tersebut baru pertama kali digunakan oleh user adalah untuk penyimpanan
token baru yang digunakan untuk pengkategorian
mail. Proses ini dilakukan pada saat user menekan
button “Add to Spam” atau saat user menekan
button “Add to Good”. Sistem training dapat dilihat pada Gambar 6.
Cara memasukkan data ke dalam tabel token
dilakukan dengan cara menekan button “Add to Spam” atau “Add to Good”. Pada saat user menekan
button “Add to Spam” dilakukan proses tokenizing
dan scoring, bahwa mail yang ditambahkan ke folder spam tersebut dikategorikan sebagai e-mail spam,
terjadi penambahan token dan score di dalam tabel
token. Sedangkan pada saat user menekan button “Add to Good” dilakukan proses tokenizing dan
scoring, bahwa mail yang ditambahkan ke folder good tersebut dikategorikan sebagai good mail, terjadi penambahan token dan score di dalam tabel
token.
9.1 Perancangan Sistem Tokenizing
Perancangan pada sistem tokenizing
dilakukan pada mail body. Tokenizing pada mail body dilakukan dengan mendeteksi spasi kata dan karakter suatu kata yang sering muncul dalam mail body. Untuk mengawali dan mengakhiri suatu karakter dengan menggunakan operasi “^ dan $”. Sebagai operasi penambahan suatu huruf atau kata dengan menggunakan “+, *, ?”. Operasi penggabungan menggunakan “|”. Mengelompokkan huruf, kata, atau angka, dengan menggunakan “{},(),[]”..
9.2 Perancangan Sistem Scoring
Proses scoring merupakan kelanjutan dari proses
tokenizing. Setelah mail yang diterima dipisahkan menjadi beberapa token, maka setiap token akan diberi nilai atau disebut juga dengan metode scoring. Proses ini memberikan nilai (score) pada setiap
token yang telah diproses dengan proses tokenizing. Selanjutnya dilakukan proses training secara manual oleh user yang akan menentukan mail tersebut
PGood didapat dari proses perhitungan berapa banyak token tersebut yang terdapat di dalam good mail. Kemudian ditambahkan dan dibagi dengan berapa banyak good mail yang ada.
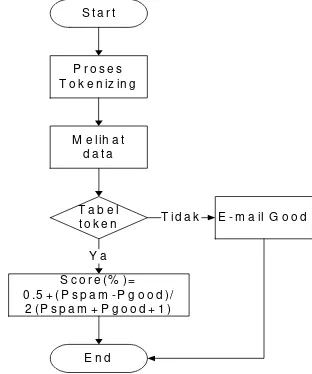
Gambar 7 Flowchart Sistem Scoring
Sistem scoring dapat dilihat pada Gambar 7. Proses
scoring yang didapatkan dari jumlah token yang ada di frekuensi spam maupun jumlah token yang ada di frekuensi good. Kemudian dengan menggunakan Persamaan (2), dilakukan perhitungan untuk menentukan score pada setiap token yang terdapat dalam tabel token yang nantinya akan digunakan dalam proses combining.
9.3 Perancangan Sistem Combining
Setelah melakukan proses tokenizing dan
scoring, kemudian dengan menggunakan metode
Naive Bayesian, dilakukan proses combining. Proses ini mengambil 15 token yang memiliki nilai terjauh dari nilai netral (0.5) di dalam satu mail. Setelah mendapatkan 15 token tersebut, maka dijalankan proses perhitungan dengan algoritma Naive Bayesian dan akan mendapatkan suatu nilai (threshold value). Hasil threshold value kemudian dibandingkan dengan nilai dari spam threshold, yang nilainya dapat disesuaikan antara 0% sampai 100%. Spam threshold biasanya diset pada nilai minimal 50% agar keakuratan dalam filtrasi mail
mendapatkan hasil yang optimal. Nilai dari 50% diperoleh dari data pada penelitian sebelumnya, karena 50% merupakan nilai netral [6]. Jika suatu
289
S t a r t
P r o s e s S c o r i n g
M e n g a m b i l 1 5 t o k e n y a n g m e m p u n y a i n i l a i
t e r j a u h d a r i 0 . 5
> S p a m l e v e l
G o o d m a i l S p a m m a i l
E n d
Y a T i d a k
M e l i h a t D a t a
T h r e s h o l d v a l u e ( % ) = P s p a m / ( P s p a m + P g o o d )
T h r e s h o l d v a l u e
dibandingkan dengan nilai dari spam threshold yang terdapat di dalam program. Nilai dari spam threshold
ini dapat ditentukan sendiri oleh user.
Gambar 8 Flowchart Sistem Combining
Proses combining didapatkan dari proses tokenizing
dan scoring seperti terlihat pada Gambar 8. Jadi setiap token terdeteksi dalam mail body danterdapat dalam tabel token diurutkan score-nya, kemudian diambil 15 token yang mempunyai nilai terjauh dari 0.5 yang dipakai dalam proses persentase untuk menghasilkan threshold value, kemudian nilai dari
threshold value dibandingkan dengan level spam
atau spam threshold yang digunakan untuk mengkategorikan mail sebagai good mail maupun
spam mail.
9.4 Perancangan Tabel Token
Perancangan pembuatan tabel token berupa suatu
textfile dengan ekstensi *.bsw. Dalam file tersebut akan berisi data-data dari beberapa jumlah mail yang dikategorikan ke dalam good mail dan juga dari beberapa jumlah kata yang dikategorikan sebagai
spam mail. Dalam tabel yang disimpan tersebut terdapat kata-kata token. dan setiap token memiliki tiga field yaitu field dari good frekuensi, field dari
spam frekuensi, dan score setiap kata token.
Gambar 9 Tabel Token
Proses penyimpanan ke dalam tabel dilakukan dengan pencarian token terlebih dahulu, kemudian jika belum terdapat token, maka token baru ditambahkan. Jika sudah terdapat token, maka ditambahkan sesuai kemunculan token, di folder inbox atau folder spam. Proses yang dilakukan kemudian dengan mengurutkan token terlebih dahulu, baru disimpan ke dalam tabel.
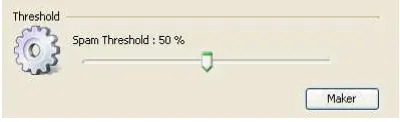
9.5 Perancangan Spam Threshold
Pada aplikasi ini user dapat menentukan seberapa besar nilai spam threshold dari e-mail yang akan diterima. Gambar 11 merupakan tampilan dari spam threshold, spam threshold dibuat menggunakan
trackbar, yang digunakan sebagai pembanding dengan nilai yang diperoleh dari persamaan Naive Bayesian, nilainya dapat diubah-ubah dari angka satu sampai 100%, akan tetapi spam threshold ini
di-set pada nilai 50%. Agar program berjalan dengan baik dalam pengkategorian mail.
Gambar 10 Spam Threshold
10. Kesimpulan
Berdasarkan hasil pembuatan programanti
290
sebagai spam adalah dengan melihat threshold value
setiap e-mail yang masuk, kemudian dibandingkan dengan spam level yang biasa di-set pada nilai 50%. Jika threshold value nilainya lebih besar dari spam level, maka e-mail dikategorikan sebagai e-mail spam. Sebaliknya, jika threshold value nilainya kurang dari spam level, maka e-mail dikategorikan sebagai e-mail good. Berdasarkan pengujian yang dilakukan dari 150 e-mail yang masuk. Anti spam
mempunyai persentase keberhasilan sebesar 96.67%.
Daftar Pustaka:
[1]. Rachli, 2009, TARacli,
http://www.cert.or.id/~budi/courses/security/20 06-2007/Report-Muhamad-Rachli.doc, Diakses pada tanggal 28 Juli 2010.
[2]. Raharjo, 2006, Spam,
http://www.cert.or.id/~budi/presentation/SPAM -present.ppt, Diakses pada tanggal 26 Juli 2010.
[3]. Pratiwi, 2009, Laporan Proyek Akhir, http://www.cert.or.id/~budi/courses/ec5010/pr ojects/yani-report.doc, Diakses pada tanggal 28 Juli 2010.
[4]. Purbo, Onno W, 2001, TCP/IP Standar, Desain, dan Implementasi, Jakarta: Elex Media Komputindo.
[5]. Jsmith, 2003, The Real E-mail System,
http://forum.persiannetworks.com/f100/t30928. html, Diakses pada tanggal 27 Juli 2010. [6]. Graham, Paul, 2003, Stopping Spam,