23
BAB III
METODE PENELITIAN
Pada bab ini akan membahas metode penelitian yang akan digunakan dalam melakukan pengujian sistem meliputi: penjelasan dan gambaran penelitian, desain arsitektur dari sistem yang berisi implementas algoritma Jaringan Saraf Tiruan yang akan diujikan, arsitektur basis data penyimpanan data history, proses kerja sistem, serta skenario pengujian sistem yang nantinya akan direalisasikan.
Jaringan Saraf Tiruan (JST) memiliki keunggulan dalam hal pelatihan dan pembelajaran suatu pola data sehingga JST dapat berfungsi sebagai alat peramalan di masa depan. Analisis Teknikal pada saham adalah suatu metode analisis yang menitikberatkan kepada pergerakan nilai saham di masa lalu untuk memprediksi pergerakan saham di masa depan. Pada skripsi ini, dilakukan penelitian untuk meramal nilai saham di masa depan dengan terlebih dahulu melakukan pembelajaran jaringan dari saham di masa lalu. Berikut adalah tahapan kerja yang dilakukan dalam penelitian.
1. Pembuatan Basis Data
24
3.1. Pembuatan Basis Data
Pada penelitian ini, terdapat basis data history untuk menunjang penelitian. Basis data tersebut berisi data historical saham, nilai-nilai variabel JST yang diperlukan dalam penelitian serta data history dari hasil penelitian. Database Management yang digunakan adalah
Microsoft Structured Query Language (SQL) Server Express Edition 2005. Gambar 3.1 adalah gambar Entity Relational Diagram (ERD) dari basis data sistem.
tabel_data_prediksi
25
3.2. Pengambilan dan Pemodelan Data
Data adalah bagian yang penting dalam penelitian ini. Tanpa data, maka penelitian tidak dapat dilakukan.
3.2.1. Pengambilan Data
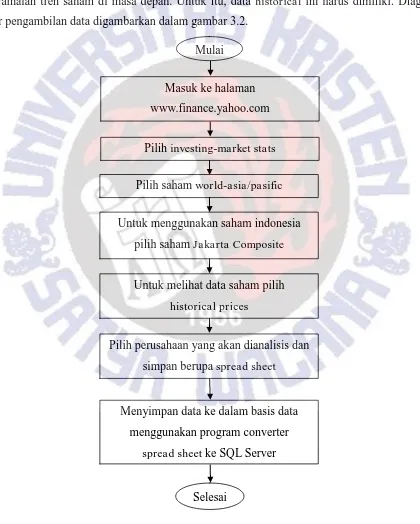
Dalam analisis Teknikal saham, data historical adalah data yang akan menentukan peramalan tren saham di masa depan. Untuk itu, data historical ini harus dimiliki. Diagram alir pengambilan data digambarkan dalam gambar 3.2.
Gambar 3.2 Diagram Alir Pengambilan Data
Masuk ke halaman www.finance.yahoo.com
Mulai
Selesai
Menyimpan data ke dalam basis data menggunakan program converter
spread sheet ke SQL Server Pilih investing-market stats
Pilih saham world-asia/pasific
Untuk menggunakan saham indonesia pilih saham Jakarta Composite
Untuk melihat data saham pilih
historical prices
26
Data historical akan diproses dalam sistem peramalan JST dan menghasilkan data hasil peramalan. Data historical saham tersebut diambil dari 20 Perusahaan Perseroan Terbatas Terbuka di Bursa Efek Indonesia, yang akan diambil dari www.finance.yahoo.com dari tahun 2003-2011. Berikut adalah daftar perusahaan tersebut.
- Bank Danamon Indonesia - Bank Mandiri
- Indofood Sukses Makmur - Siantar Top
- Gudang Garam
- Bentoel Internasional Investama - Sentul City
- Lippo Cikarang - Astra International - Gajah Tunggal
- Mustika Ratu - Mandom Indonesia - Kimia Farma (Persero) - Darya-Varia Laboratoria - Indocement Tunggal Prakarsa - Holcim Indonesia
- Aneka Tambang (Persero) - Resource Alam Indonesia - Astra Agro Lestari
- Tunas Baru Lampung
Perusahaan-perusahaan di atas diambil dari beberapa sektor saham sehingga memungkinkan variasi penelitian yang dipengaruhi dari faktor-faktor khas di tiap perusahaan. Data tiap perusahaan akan dibagi menjadi data pembelajaran dari JST dan data uji. www.finance.yahoo.com menyediakan data berupa file spread sheet, sehingga bisa dikonversi ke dalam bentuk basis data SQL.
3.2.2. Pemodelan Data
27
Tabel 3.1 Gambaran Pola Pelatihan JST
Indeks Nilai Data Masukan saham penutupan yang akan di prediksi adalah pada tanggal 7 Nopember 2011 (tanggal 5 dan 6 Nopember adalah hari libur). JST akan melakukan pelatihan hingga target terpenuhi dan mendapatkan bobot yang terakhir. Dengan bobot yang terakhir tersebut, dapat diprediksi nilai harga saham penutupan pada tanggal 7 Nopember 2011. Data masukan untuk mendapatkan hasil prediksi tersebut merupakan data uji pada tanggal 04 Nopember 2011.
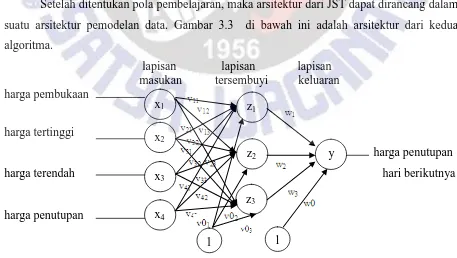
Setelah ditentukan pola pembelajaran, maka arsitektur dari JST dapat dirancang dalam suatu arsitektur pemodelan data. Gambar 3.3 di bawah ini adalah arsitektur dari kedua
Gambar 3.3 Arsitektur Pemodelan Jaringan Propagasi Mundur
28
Keterangan gambar 3.3 adalah sebagai berikut : - xi menjelaskan neuron pada lapisan masukan
- zj menjelaskan neuron pada lapisan tersembunyi
- y menjelaskan neuron pada lapisan keluaran
- vij menjelaskan bobot antara lapisan masukan dan tersembunyi
- v0j menjelaskan bobot bias pada lapisan tersembunyi
- wj menjelaskan bobot antara lapisan tersembunyi dan keluaran
- w0menjelaskan bobot bias pada lapisan keluaran
- nilai 1 berarti bobot bias dikalikan dengan nilai awal 1 (bobot lain dikalikan nilai dari neuron masukannya)
Gambar 3.3 menjelaskan bahwa pola sebanyak n data akan dipakai sebagai data pelatihan. 1 iterasi berarti pelatihan sudah dilakukan pada n data. Pelatihan pola tersebut akan terus berulang sampai iterasi mencapai iterasi maksimum yang ditentukan. Pelatihan juga akan berhenti saat MSE mencapai target error yang ditentukan.
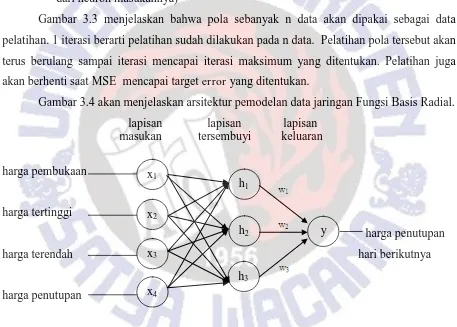
Gambar 3.4 akan menjelaskan arsitektur pemodelan data jaringan Fungsi Basis Radial. lapisan lapisan lapisan
masukan tersembuyi keluaran harga pembukaan
harga tertinggi
harga penutupan harga terendah hari berikutnya
harga penutupan
Gambar 3.4 Pemodelan Data Fungsi Basis Radial
Keterangan gambar 3.4 adalah sebagai berikut : - xi menjelaskan neuron pada lapisan masukan
- hj menjelaskan neuron pada lapisan tersembunyi
- y menjelaskan neuron pada lapisan keluaran
- wj menjelaskan bobot antara lapisan tersembunyi dan keluaran
Pemodelan data pada algoritma Fungsi Basis Radial memiliki perbedaan dengan x1
x2
x3
x4
h1
h2
h3
29
Sistem Peramalan Tren
Investasi Saham
dipanggil
simpan query
pemodelan data algoritma Propagasi Mundur. Perbedaan itu terletak pada bagian antara lapisan masukan dan lapisan tersembunyi, di mana pemodelan pada algoritma Fungsi Basis Radial tidak memiliki bobot antara lapisan masukan dan tersembunyi. Hal ini dikarenakan algoritma ini melakukan pengelompokan (clustering) data terlebih dahulu. Fungsi pengelompokan tersebut adalah untuk membagi data berdasarkan kedekatan data ke cluster-cluster tertentu yang direpresentasikan ke dalam neuron pada lapisan tersembunyi. Setelah data dikelompokan, pelatihan jaringan dilakukan sampai iterasi mencapai target yang ditentukan. Selain perbedaan di atas, jaringan Fungsi Basis Radial juga tidak menggunakan bobot bias dalam pelatihan jaringan.
3.3. Perancangan Perangkat Lunak Peramalan JST
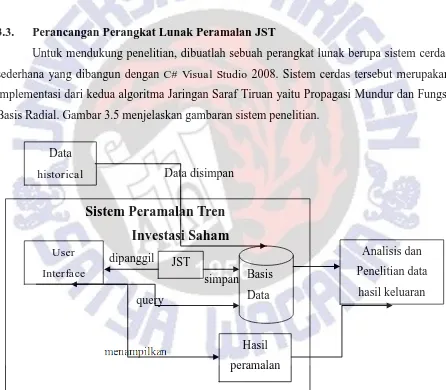
Untuk mendukung penelitian, dibuatlah sebuah perangkat lunak berupa sistem cerdas sederhana yang dibangun dengan C# Visual Studio 2008. Sistem cerdas tersebut merupakan implementasi dari kedua algoritma Jaringan Saraf Tiruan yaitu Propagasi Mundur dan Fungsi Basis Radial. Gambar 3.5 menjelaskan gambaran sistem penelitian.
Data disimpan
Gambar 3.5 Blok Diagram Sistem Penelitian
3.3.1. Arsitektur Perangkat Lunak JST
Perangkat lunak peramalan JST, berfungsi sebagai antar muka sehingga penelitian Data
historical
User
Interface JST
Hasil peramalan
Analisis dan Penelitian data
hasil keluaran Basis
Data
30
dapat dilakukan dengan baik. Di dalam perangkat lunak ini terdapat implementasi dari kedua algoritma yang diujikan yaitu Propagasi Mundur dan Fungsi Basis Radial.
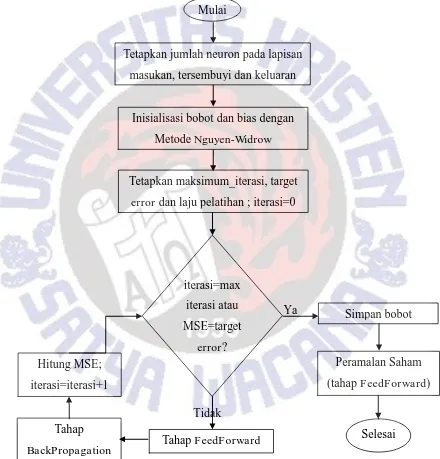
3.3.1.1Arsitektur Jaringan Propagasi Mundur
Gambar 3.6 akan menjelaskan diagram alir arsitektur Propagasi Mundur.
Ya
Tidak
Gambar 3.6 Diagram Alir Arsitektur Propagasi Mundur
Hitung MSE; iterasi=iterasi+1
Tahap FeedForward
Tetapkan maksimum_iterasi, target
error dan laju pelatihan ; iterasi=0 Mulai
Tahap
BackPropagation
iterasi=max iterasi atau MSE=target
error?
Inisialisasi bobot dan bias dengan Metode Nguyen-Widrow
Tetapkan jumlah neuron pada lapisan masukan, tersembuyi dan keluaran
Selesai Simpan bobot
31
Pada langkah pertama, perlu ditentukan jumlah neuron pada tiap lapisan. Pada lapisan masukan sudah ditentukan bahwa neuron masukan adalah 4 buah yang menggambarkan harga saham pembukaan, tertinggi, terendah dan penutupan. Neuron pada lapisan tersembunyi ditentukan sesuai dengan variasi penelitian. Sedangkan neuron pada lapisan output hanya ada 1 buah yang menggambarkan harga saham penutupan keesokan harinya.
Selanjutnya inisialisasi bobot dan bias awal menggunakan metode Nguyen-Widrow.
Metode ini digunakan untuk mendapatkan bobot dan bias awal yang lebih baik daripada dibangkitkan dengan fungsi acak biasa. Pemilihan bobot dan bias awal yang baik akan mempengaruhi jaringan Saraf dalam mencapai nilai minimum terhadap kesalahan/error, serta mempengaruhi kecepatan pelatihan sampai mencapai konvergen[1, h.94].
Maksimum iterasi dan target error adalah variabel yang ditentukan untuk membatasi lama dari pelatihan jaringan. Kedua variabel ini akan mempengaruhi lama dari pelatihan. Semakin besar maksimum iterasi yang ditentukan, semakin lama pelatihan. Demikian juga dengan target error. Semakin kecil target error yang diinginkan, semakin lama pelatihan jaringan. Penentuan laju pelatihan akan mempengaruhi kecepatan perubahan bobot.
Tahap selanjutnya adalah pembelajaran jaringan. Untuk memulai pelatihan jaringan, inisialisasi iterasi menjadi 0. Tahap pembelajaran pada algoritma Propagasi Mundur dibagi menjadi 2 tahap yaitu, Tahap FeedForward dan tahap Backward. Tahap FeedForward dan tahap Backward pada algoritma Propagasi Mundur akan terus dilakukan sampai MSE mencapai target error atau jika iterasi sudah mencapai maksimum iterasi yang ditetapkan.
Setelah target error dan maksimum iterasi tercapai, bobot dan bias terakhir disimpan untuk digunakan sebagai pembobot peramalan. Pada tahap peramalan hanya digunakan tahap
32
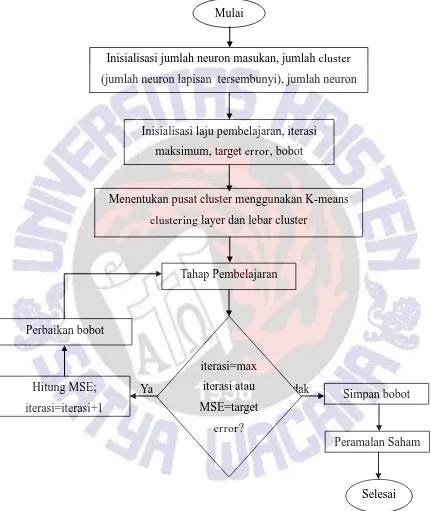
3.3.1.2Arsitektur Jaringan Fungsi Basis Radial
Gambar 3.7 akan menjelaskan diagram alir arsitektur Fungsi Basis Radial.
Ya Tidak
Gambar 3.7 Diagram Alir Arsitektur Fungsi Basis Radial
Arsitektur algoritma Fungsi Basis Radial sedikit agak berbeda dengan Propagasi Mundur. Pada langkah awal tentukan jumlah neuron pada lapisan masukan, tersembunyi dan keluaran. Jumlah neuron lapisan masukan adalah 4 buah yang merupakan gambaran dari
Inisialisasi laju pembelajaran, iterasi maksimum, target error, bobot
Mulai
Selesai Menentukanpusat cluster menggunakan K-means
clustering layer dan lebar cluster
Tahap Pembelajaran
Peramalan Saham iterasi=max
iterasi atau MSE=target
error? Perbaikan bobot
Hitung MSE; iterasi=iterasi+1
Simpan bobot Inisialisasi jumlah neuron masukan, jumlah cluster
33
harga pembukaan, tertinggi, terendah dan keluaran. Jumlah neuron pada lapisan tersembunyi dipilih sesuai inputan. Sedangkan jumlah neuron pada lapisan keluaran adalah 1 yang menggambarkan harga saham hari berikutnya.
Inisialisasi jumlah cluster, laju pembelajaran, iterasi maksimum, target error dan bobot awal. Penentuan jumlah cluster akan menentukan juga jumlah neuron pada lapisan tersembunyi. Artinya, jumlah cluster dan neuron lapisan tersembunyi adalah sama. Target
error dan iterasi pada algoritma ini memiliki fungsi yang sama dengan algoritma Propagasi Mundur. Keduanya berfungsi untuk membatasi pelatihan jaringan. Sedangkan bobot awal pada algoritma Fungsi Basis Radial hanya berada pada lapisan tersembunyi ke lapisan keluaran. Biasanya, bobot awal ini diinisialisasi bernilai 0.
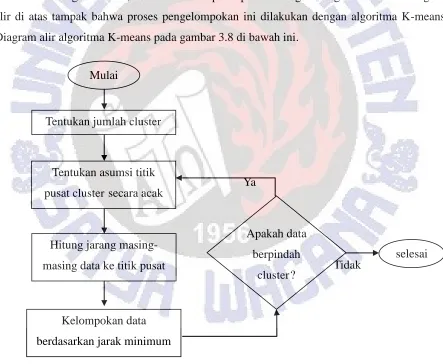
Pada langkah kedua, ditentukan nilai pusat pada masing-masing cluster. Pada diagram alir di atas tampak bahwa proses pengelompokan ini dilakukan dengan algoritma K-means. Diagram alir algoritma K-means pada gambar 3.8 di bawah ini.
Ya
Tidak
Gambar 3.8 Diagram Alir K-means
Gambar 3.8 di atas menjelaskan bagaimana algoritma means bekerja. Algoritma K-means mengelompokkan data berdasarkan jarak minimum data terhadap nilai pusat yang telah dipilih. Pada awal algoritma, nilai pusat dipilih dengan acak berdasar data yang ada.
Tentukan jumlah cluster
Mulai
Tentukan asumsi titik pusat cluster secara acak
Hitung jarang masing-masing data ke titik pusat
Kelompokan data berdasarkan jarak minimum
Apakah data berpindah
cluster?
34
Selanjutnya data tersebut dicari jaraknya terhadap titik pusat. Jarak tersebut menjadi acuan pengelompokan data sesuai jarak minimum terhadap titik pusat. Kemudian jumlah dari tiap kelompok cluster dibagi jumlah anggota clusternya. Hasil pembagian tersebut adalah nilai pusat yang baru. Langkah ini diulang sampai tidak ada perpindahan kelompok cluster lagi.
Setelah nilai-nilai pusat cluster sudah ditentukan, maka lebar cluster dapat dihitung. Pada algoritma Fungsi Basis Radial, nilai lebar adalah jarak maksimum antara 2 cluster yang dipilih.
Tahap selanjutnya adalah tahap pembelajaran. Tahap pembelajaran akan terus diulang sampai target error dan iteraksi maksimum dicapai. Jika sudah dicapai, maka tahap peramalan dapat dilakukan dengan menggunakan bobot terakhir dari hasil pembelajaran sebelumnya yang sudah disimpan.
3.3.2. Normalisasi Data
Sebelum data historical diproses oleh perangkat lunak peramalan JST, perlu dilakukan normalisasi data. Normalisasi data tersebut dilakukan supaya JST dapat mengenali data yang akan menjadi masukkan bobot-bobotnya dalam proses pelatihan. Normalisasi data memanipulasi data yang ada sedemikian rupa sehingga nilai-nilai dalam data historical
adalah antara 0 dan 1. Normalisasi ini dilakukan dengan cara memadukan nilai minimum
Xnorm = adalah nilai ternormalisasi
X = data sebenarnya
Xmin = adalah nilai minimum dalam data
Xmax = adalah nilai miksimum dalam data
Fungsi dari normalisasi ini adalah memodifikasi level variabel ke nilai yang wajar. Jika tidak dinormalisasi, nilai variabel bisa terlalu besar pada proses pelatihan. Normalisasi juga berfungsi untuk mengurangi fluktuasi dan noise di dalam data.
35
3.3.3. Mean Square Error (MSE)
MSE digunakan untuk menganalisis hasil peramalan adalah dengan membandingkan nilai hasil dari peramalan dan data sebenarnya yang sudah dinormalisasi. Rumus ini berfungsi untuk menghitung rata-rata error jaringan pada saat pembelajaran. MSE juga berfungsi untuk melihat perubahan tingkat kesalahan dari jaringan pada setiap iterasi. MSE dapat digunakan sebagai batasan untuk menghentikan pelatihan sesuai target kesalahan yang sudah ditetapkan sebelumnya. Rumus 13 adalah cara menghitung MSE [4, h.8]:
n
3.4. Pelatihan, Percobaan dan Pengujian JST
Tahap dimana data saham diproses dalam perangkat lunak peramalan JST. Melalui data saham yang sudah tersimpan di basis data, perangkat lunak peramalan JST akan memproses data dengan algoritma yang ada di dalamnya.
3.4.1. Pelatihan JST
Tahap ini adalah tahap pembelajaran jaringan untuk mendapatkan bobot teroptimal yang mempengaruhi presepsi jaringan atas informasi yang dibawa (data masukan dan keluaran). Sebelum melakukan peramalan, jaringan perlu dilatih terlebih dahulu hingga batasan tertentu. Setelah batasan tersebut dicapai, maka peramalan dapat dilakukan dengan berdasarkan bobot terakhir yang sudah disimpan.
Terdapat banyak data saham yang disimpan di dalam basis data sekitar dari data dari tahun 2003 sampai 2011. Setiap data historical masing-masing perusahaan disimpan berdasarkan tanggal hari kerja. Artinya dari rentang waktu tersebut, dapat dipilih dan dibagi perusahaan apa serta kapan waktu yang akan digunakan sebagai data pelatihan dan data pengujian.
36
3.4.2. Percobaan dan Pengujian Data
Bagian ini dibagi menjadi tahap percobaan dan pengujian data. Namun pada dasarnya kedua tahap ini memiliki skenario yang hampir sama. Berikut adalah skenario percobaan dan pengujian saham.
- Menvariasikan banyaknya data pelatihan JST
- Menvariasikan banyak neuron tersembunyi pada kedua algoritma. Dimana algoritma Propagasi Mundur dipilih 5 buah jumlah neuron yaitu 5, 10, 20, 30 dan 50 buah neuron. Pada Algorima Fungsi Basis Radial dipilih 3 buah jumlah neuron tersembunyi/cluster yaitu 2, 3 dan 4.
Pada tahap pelatihan, kedua algoritma memiliki beberapa variabel yang sama dalam melakukan pembelajaran. Variabel tersebut adalah banyak neuron tersembunyi, laju pelatihan, iterasi maksimum dan target error. Pada tahap percobaan ini, dilakukan beberapa variasi percobaan untuk mendapatkan laju pelatihan terbaik dan iterasi maksimum yang tidak terlalu lama. Berdasarkan hasil yang ada (hasil peramalan dan dan tingkat kesalahan peramalan(MSE), serta waktu pelatihan) akan ditentukan laju pelatihan dan iterasi maksimum yang akan digunakan sebagai variabel pengujian terhadap 20 data saham perusahaan.
Pada tahap percobaan ini, dipilih 3 perusahaan dengan fluktuasisaham yang berbeda dibagi berdasar kestabilan perusahaan. Pembagian perusahaan tersebut adalah :
- Perusahaan yang Relatif Stabil
Perusahaan ini memiliki pergerakan saham yang stabil. Ini didukung oleh faktor fundamental perusahaan yang kuat. Untuk mewakili perusahaan ini dipilihlah data Bank Mandiri sebagai data uji coba.
- Perusahaan yang Biasa
Persuhaan ini memiliki pergerakan saham yang biasa dalam arti tidak terlalu signifikan. Data perusahaan yang dipilih adalah data Bank Danamon Indonesia.
- Perusahaan yang Relatif Tidak Stabil
Perusahaan ini memilik pergerakan data saham yang pergerakannya signifikan. Data yang digunakan adalah data perusahaan Sentul City.
37
Setelah didapatkan nilai laju kecepatan dan nilai iteraksi maksimum yang tepat, maka pengujian terhadap 20 perusahaan dapat dilakukan. Dari pengujian ini akan dapat disimpulkan pengaruh neuron tersembunyi dan banyaknya data pelatihan terhadap hasil peramalan dan tingkat kesalahan peramalan (MSE) serta lamanya waktu pelatihan.
3.5. Analisa Hasil Percobaan dan Pengujian
Bagian ini adalah tahap mempelajari dan menganalisa hasil dari percobaan dan pengujian yang sudah dilakukan. Parameter yang dianalisa untuk membandingkan kedua algoritma adalah sebagai berikut :
1. Kecepatan Pelatihan
Dengan variasi nilai variabel yang sudah dijelaskan di atas, maka akan dianalisa pengaruh variabel-variabel tersebut terhadap kecepatan pelatihan dari masing-masing algoritma.
2. Hasil Peramalan
Nilai hasil peramalan yang sudah didenormalisasi akan dibandingkan dengan nilai aktual. Pada parameter ini, akan disimpulkan algoritma apa yang lebih baik untuk kasus peramalan saham. Selain itu, akan dianalisa pengaruh variabel-variabel jaringan terhadap hasil peramalan.
3. Tingkat Kesalahan pada Pelatihan (MSE)
Pada setiap skenario percobaan dan pengujian, sudah disimpan setiap perubahan nilai MSE sampai batasan tertentu yang sudah ditetapkan. Pada parameter ini, akan dianalisa pengaruh variasi tiap variabel terhadap MSE.
4. Pengaruh Faktor-Faktor Lain terhadap Hasil Peramalan JST