II-1
BAB II
DASAR TEORI
2.1
Pengolahan Sinyal Digital Pada Sistem Pengenalan Ucapan
Sistem produksi suara manusia menghasilkan sinyal akustik analog yang bersifat kontinyu terhadap waktu, yaitu sinyal yang ditimbulkan oleh getaran pita suara (akustik). Sinyal akustik analog ini kemudian diubah menjadi sinyal listrik analog oleh mikrofon. Bentuk sinyal yang dipakai oleh sistem pengenalan ucapan adalah sinyal digital, oleh karena itu harus dilakukan proses digitalisasi dengan melakukan sampling dan kuantisasi terhadap sinyal analog akustik masukan. Sinyal masukan diubah menjadi sinyal listrik analog melalui microphone kemudian dikonversi menjadi sinyal listrik digital oleh soundcard.
Setelah dilakukan digitalisasi sinyal kemudian dilakukan analisis spektral terhadap sinyal tersebut. Proses ini digunakan untuk menghasilkan spectral envelope (ciri sinyal) dari sinyal. Ciri sinyal tersebut dapat berupa angka-angka yang menunjukkan amplitudo, pitch atau frekuensi. Dalam kerangka sistem ciri tersebut disebut dengan feature. Proses pengambilan ciri tersebut biasa disebut feature extraction. Feature akan dipakai sebagai acuan model ucapan dan sebagai data masukan untuk proses pencocokan atau pengenalan pola.
2.1.1 Sampling dan Kuantisasi
Gambar II-1 Proses Digitasi
Gambar II-1 menunjukkan sinyal analog akustik yang kontinyu, x
( )
t , yang dikenai lowpass filtering pada frekuensi sampling tertentu untuk mengurangi distorsi frekuensi tinggi kemudian oleh A/D converter dikonversi menjadi sinyal listrik digital yang diskrit{
xi = x( )
i.T}
. Tiap sample hasil sampling akan dikuantisasi secara uniformmenjadi n bit. Nilai n bergantung pada teknik decoding yang digunakan untuk membentuk suatu format file tertentu.
Filtering terhadap sinyal harus dilakukan pada frekuensi sampling yang tepat. Secara teori frekuensi maksimum dapat direpresentasikan oleh setengah frekuensi sampling, tetapi pada prakteknya digunakan sampling rate yang lebih tinggi. Hal ini disebut dengan filter non-ideal. Pada umumnya frekuensi sampling untuk sinyal ucapan melalui telepon adalah frekuensi 8 kHz. Pada sistem pengenalan dan sintesis ucapan digunakan frekuensi sampling sebesar 16 kHz. Sinyal audio standart menggunakan sample rate 44.1 kHz (Compact Disc) atau 48 kHz (Digital Audio Tape) untuk merepresentasikan frekuensi hingga 20 kHz [ROB98].
Jika periode sampling terlalu besar, maka sinyal asli tidak dapat direproduksi dari sinyal sampling, dan jika digunakan periode sampling yang terlalu kecil maka sinyal sampling yang tidak berguna akan terambil. Teorema sampling Shanon-Someya dapat dipakai untuk menentukan periode sampling yang sesuai.
Teorema dari Shanon-Someya mengatakan bahwa jika sampling sinyal analog x(t) dengan kandungan frekuensi antara 0 – W Hz dilakukan dengan periode sampling
W i
T = 2 [detik], W adalah nilai frekuensi tertinggi dari gelombang analog, maka sinyal asli dapat direproduksi dengan persamaan:
( )
{
(
(
)
)
}
W i t W W i t W W i x t x 2 2 2 2 sin 2 − − =∑
∞ ∞ −π
π
(II-1)dimana x
(
i 2W)
adalah sinyal sampling dari x( )
t pada waktu ti =i 2W ( i adalah bilangan integer). Selanjutnya, 1T =2W[ ]
Hz disebut frekuensi Nyquist.Frekuensi pada saat sampling minimal dua kali dari kandungan frekuensi analog. Jika frekuensi sampling kurang dari frekuensi Nyquist atau kurang dari dua kali frekuensi analog, maka terjadi distorsi yang disebut aliasing [IZZ02].
Pengambilan sinyal digital hasil sampling dan kuantisasi dari soundcard dapat dilakukan dengan 2 cara, yaitu secara real time dan non-real time. Pada pengambilan sinyal secara real time, sinyal yang diambil dari soundcard akan langsung diproses oleh sistem. Pengambilan sinyal secara non-real time dilakukan dengan menyimpan sinyal dalam file sementara sebelum diproses sehingga ukuran sinyal yang diambil juga terbatas.
Pada proses digitalisasi, Gambar II-2, sinyal ucapan akustik analog (ucapan manusia) diubah menjadi sinyal listrik analog oleh mikrofon. Sinyal listrik analog diubah
menjadi sinyal digital oleh A/D converter (soundcard) dan dilakukan teknik decoding tertentu oleh software recorder untuk membentuk file WAVE.
Gambar II-2 Pengambilan sinyal secara non-real time
Pengambilan sinyal secara real time membutuhkan double buffering yaitu buffer pemrosesan untuk menyimpan sinyal yang diproses dan buffer pengisian untuk menyimpan sinyal berikutnya. Selain itu diperlukan juga pemroses yang cepat serta algoritma yang mangkus agar pemrosesan dalam buffer dapat diselesaikan sebelum buffer pengisian penuh.
2.1.2 Analisis Spektral
Analisis spektral merupakan bagian utama dalam feature extraction yang digunakan untuk mendapatkan informasi spektral ucapan. Sinyal ucapan merupakan sinyal yang berubah lambat terhadap waktu pada selang waktu yang singkat. Perubahan ini kira-kira 20-50 ms untuk mencapai keadaan tetap (stationer). Pada periode yang cukup lama (lebih dari 50 ms) karakteristik sinyal silih berganti merefleksikan bunyi ucapan yang berbeda. Jadi pengolahan sinyal harus dilakukan pada selang waktu singkat tersebut untuk memperoleh informasi spektral dari sinyal ucapan.
Spektrum selang waktu singkat dapat dianggap sebagai hasil kali dua elemen yaitu spectral envelope yang berubah lambat terhadap frekuensi dan spectral fine structure yang berubah cepat terhadap frekuensi [FUR98]. Spectral fine structure menghasilkan pola periodik untuk suara voiced dan akan menghasilkan pola tidak periodik (aperiodic) untuk suara unvoiced, atau dengan kata lain spectral fine structure berhubungan dengan periodisitas sinyal yang dihasilkan oleh sumber suara. Spectral envelope atau feature spectral secara keseluruhan tidak hanya memperlihatkan karakteristik resonan dan antiresonan organ-organ tetapi juga keseluruhan bentuk spectrum sumber glottal dan karakteristik radiasi pada bibir (lips) dan lubang hidung artikulasi (nostril) [FUR98].
Metode ekstraksi spectral envelope dibagi dalam dua metode yaitu metode Analisis Parametrik (PA) dan metode Analisis Non Parametrik (NPA). Pada metode PA, model yang memenuhi persyaratan obyektif sinyal dipilih dan parameter model
ditentukan sehingga model memberikan informasi mengenai sinyal, sedang metode NPA dapat diaplikasikan pada berbagai jenis sinyal karena tidak dilakukan pemilihan model. Metode yang termasuk dalam metode Analisis Parametrik adalah analysis-by-synthesis, linear predictive coding, dan maximum likelihood. Sedangkan yang termasuk dalam metode Analisis Non Parametrik yaitu short-time autocorrelation, short-time spectrum dengan menggunakan algoritma Fast Fourier Transform (FFT), cepstrum, bank of band pass filter, dan zero-crossing analysis [FUR89].
2.1.2.1 Filter Bank Analisis
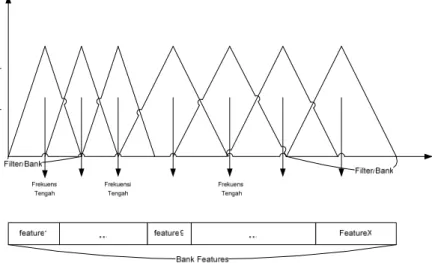
Gambar II-3 menunjukkan bahwa metode ini menganalisis sinyal ucapan melalui sederetan filter dengan frekuensi tengah yang berbeda-beda. Masing-masing filter dapat memiliki bandwidth yang sama atau berbeda. Bandwidth adalah rentang frekuensi untuk setiap filter. Tiap filter akan beririsan dengan filter sebelum dan sesudahnya.
A m p lit u d o R e s p o n s e
Gambar II-3 Filter Bank
Ciri khas sinyal hasil filtering dapat diambil berbagai cara, misalnya dari frekuensi maksimum atau frekuensi rata-rata dari tiap-tiap sinyal terfilter. Ciri tersebut dapat dianggap sebagai feature dari satu bank. Metode filter bank akan memberikan hasil yang optimal jika jumlah bank banyak [IZZ02].
Terdapat dua alternatif yang dapat digunakan dalam penentuan jarak antar frekuensi tengah, yaitu seragam, selisih frekuensi antar frekuensi tengah tiap filter sama, atau tidak seragam, selisih frekuensi antar frekuensi tengah tiap filter tidak sama, misal naik teratur dengan kenaikan 2 kali lipat tiap filter [SOE01].
2.1.2.2 Linear Prediction Analysis (Linear Predictive Coding)
Metode LPC diturunkan dari ide dasar bahwa sample sinyal ucapan pada saat ke-n, s
( )
n , dapat didekati sebagai kombinasi linier dari sejumlah p sample ucapan sebelumnya. Hal tersebut dapat dinotasikan sebagai berikut:(
n)
a s(
n)
a s(
n i)
s a s)n ≈ 1 −1 + 2 −2 +...+ i − (II-2)∑
= − = p i i n i n as s 1 ) (II-3)Sinyal ucapan pada sample ke-n, s
( )
n dapat didekati oleh beberapa buah sample sebelumnya dengan bantuan koefisien prediksi ai, keofisien a1, a2, .., ai diasumsikan sebagai konstanta dalam blok analisis sinyal ucapan. Nilai estimasi ai merupakan hasil terbaik jika jumlah kuadrat error antara sinyal sebenarnya sn dan sinyal perkiraan s)n minimum.2.1.2.3 Formant Analysis
Formant adalah frekuensi resonansi dari lintasan suara (vocal tract). Formant Analysis dapat digunakan untuk menganalisis sinyal ucapan, karena posisi dua atau tiga frekuensi formant pertama menggambarkan dengan baik suatu ucapan [NIK96]. Jadi feature yang akan digunakan untuk proses pengenalan adalah frekuensi formant ini. Transformasi Fourier ataupun linear prediction dapat digunakan untuk mendapatkan nilai-nilai formant tersebut yaitu dengan mendapatkan spectral envelope dan mengambil N frekuensi yang terbesar amplitudonya (maksimum lokal) atau semua frekuensi yang merupakan maksimum lokal.
2.1.2.4 Fast Fourier Analysis
Fast Fourier Analysis menggunakan transformasi Fourier cepat dan transformasi balikannya untuk menghasilkan feature yang akan digunakan untuk proses pengenalan. 2.1.2.4.1 Fast Fourier Transform
Fast Fourier Transform merupakan algoritma yang digunakan untuk mengambil feature dari suatu sinyal pada ranah waktu tertentu. Fast Fourier Transform merupakan perkembangan dari Discrete Fourier Transform yang memiliki persamaan:
( )
,0(
1)
1 0 / 2 1 =∑
≤ ≤ − − = − k N e x k X N n N nk i n π (II-4)Yaitu X adalah feature sinyal ke-k, k x adalah sinyal ke-n, N adalah banyak sinyal pada n waktu tertentu dan i adalah −1.
2.1.2.4.2 Windowing
Pada proses pengolahan sinyal, diasumsikan bahwa sinyal bersifat stasioner untuk waktu yang singkat dan dilakukan transformasi Fourier terhadap blok sinyal yang sempit tersebut untuk mengembalikan sinyal pada frekuensi domain. Transformasi Fourier dilakukan dengan mengalikan sinyal dengan sebuah fungsi window yang bernilai nol di luar batas tertentu.
Terdapat dua fungsi window yang biasa digunakan, yaitu Rectangular Window dan Hamming Window. Rectangular Window yang didefinisikan sebagai:
≤ < = lainnya N n wn 0 0 1 (II-5)
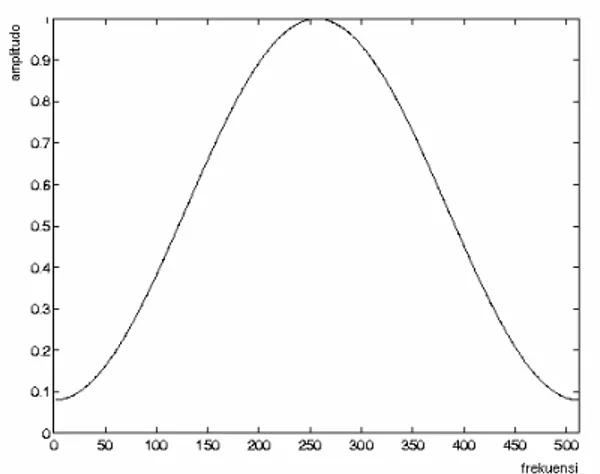
Fungsi window ini akan dihasilkan sinyal yang diskontinyu seperti yang ditunjukkan pada Gambar II-4.
Gambar II-4 Sinyal Hasil Pemotongan dengan Rectangular Window
Salah satu cara untuk menghindari diskontinyu pada ujung window adalah dengan meruncingkan sinyal menjadi nol atau dekat dengan nol sehingga dapat mengurangi kesalahan.
Teknik Windowing yang sering digunakan dalam analisis sinyal ucapan adalah Hamming Window. Fungsi Hamming Window didefinisikan sebagai:
(
)
(
)
− − ≤ < = lainnya N n N n wn 0 0 1 / 2 cos 46 . 0 54 . 0π
(II-6)Fungsi di atas hanyalah fungsi cosinus naik sederhana yang dapat ditunjukkan pada Gambar II-5 [TON98].
2.1.2.4.3 Analisis Cepstral
Sinyal ucapan s didekomposisi dari sebuah eksitasi n e dan linear filter n H
( )
eiθ dan pada frekuensi domain didapatkan persamaan:( ) ( ) ( )
eiθ H eiθ E eiθS = (II-7)
( )
iθe
H dapat merepresentasikan envelope dari speech power spectra dan E
( )
eiθ merepresentasikan eksitasi dari sinyal.Dengan menggunakan analogi terhadap fungsi logaritma logz=logz +iarg
{ }
z dari persamaan di atas didapatkan persamaan:( )
(
iθ)
(
( )
iθ)
(
( )
iθ)
e E e H e S log log log = + (II-8)Pada kebanyakan aplikasi pemrosesan sinyal ucapan, komponen yang dibutuhkan adalah spectral amplitudo saja sehingga dari persamaan di atas didapatkan persamaan:
( )
(
iθ)
(
( )
iθ)
(
( )
iθ)
e E e H e S log log log = + (II-9)Variasi komponen log
(
S( )
eiθ)
direpresentasikan oleh frekuensinya. Frekuensi yang tinggi merepresentasikan variasi yang banyak sedangkan frekuensi rendah merepresentasikan variasi yang sedikit. Oleh karena itu ada fourier transform memisahkan antara H( )
eiθ dan E( )
eiθ sehingga didapatkan analisis cepstral yang ditunjukkan oleh Gambar II-6.Gambar II-6 Analisis Cepstral
2.1.2.5 Mel Frequency Cepstral Coefficient (MFCC)
Mel Frequency Cepstral Coefficients (MFCCs) merupakan koefisien yang merepresentasikan audio. Kebanyakan sistem pengenal ucapan saat ini menggunakan
MFCC sebagai feature karena sistem pengenal ucapan menjadi lebih robust dalam berbagai kondisi [MOL01].
Pre-Emphasis Windowing | FFT |
Mel Filter Bank Logarithm
DCT
MFCC vector Speech Waveform
Gambar II-7 Langkah-langkah MFCC
Gambar II-7 di atas menunjukkan langkah-langkah analisis sinyal sehingga didapatkan koefisien MFCC. Langkah-langkah tersebut dijelaskan sebagai berikut:
1. Preemphasis
Pada langkah ini dilakukan filtering terhadap sinyal menggunakan FIR filter orde satu untuk meratakan spektral sinyal tersebut.
2. Frame Blocking (Tracking)
Pada langkah ini sinyal ucapan yang telah teremphasi dibagi menjadi beberapa frame dengan masing-masing frame memuat N sampel sinyal dan frame yang saling yang berdekatan dipisahkan sejauh M sample.
3. Windowing
Merupakan proses weigthing terhadap setiap frame yang telah dibentuk pada langkah sebelumnya menggunakan fungsi Window. Fungsi window telah dijelaskan pada bab 2.1.2.4.2 di atas.
4. FFT (Fast Fourier Transform)
Pada langkah ini setiap frame hasil dari fungsi window dikenai proses FFT. Fungsi FFT digunakan untuk mengubah sinyal yang semula merupakan time domain menjadi frequency domain. Persamaan FFT dapat dilihat pada bab 2.1.2.4.1 di atas.
5. Mel-scale dan Filter Bank
Pada tahap ini dilakukan wrapping terhadap spektrum yang dihasilkan dari FFT sehingga dihasilkan Mel-scale untuk menyesuaikan resolusi frekuensi terhadap
properti pendengaran manusia. Kemudian Mel-scale dikelompokkan menjadi sejumlah critical bank menggunakan filter bank. Seperti yang dijelaskan pada bab 2.1.2.1 bahwa filter bank terdiri dari sekumpulan filter segitiga yang saling beririsan. 6. Logarithm dan DCT (Discrete Cosine Transform)
Langkah terakhir adalah dilakukan DCT terhadap nilai logaritmik dari hasil keluaran filter bank sehingga dihasilkan vektor MFCC. DCT digunakan untuk mereduksi dimensi vektor Mel-scale hasil dari langkah ke-5 menjadi 13 koefisien saja.
( ) ( ) ( )
(
)(
)
k N N k n n x k w k y N n ,..., 1 , 2 1 1 2 cos 1 = − − =∑
= π (II-10) dimana,( )
= = ≤ ≤ 1 , 1 2 , 2 k N N k N k w (II-11) N adalah panjang x. x dan y mempunyai ukuran yang sama. Jika x adalah sebuah matriks maka fungsi dct akan melakukan transformasi untuk setiap kolom. Indeks dimulai dari n = 1 dan k = 1 karena indeks vektor pada MATLAB dimulai 1 hingga N.Mel-Cepstrum merupakan koefisien yang dihasilkan dari proses Fourier transform terhadap log-spectrum. Mel-Cepstrum disebut sebagai Mel-frequency scale karena non-linear frekuensi pada Mel-Cepstrum dibungkus menjadi sebuah skala frekuensi perseptual. Koefisien hasil dari Fourier transform kemudian disebut sebagai Mel frequency cepstrum coefficients (MFCC). Dalam merepresentasikan sebuah frame dari suatu sinyal hanya beberapa koefisien saja yang digunakan. Jumlah koefisien merupakan parameter yang sangat menentukan dalam merepresentasikan sebuah frame [AUC04]. Pada umumnya nilai tertinggi pada koefisien cepstral dibuang untuk memperhalus cepstra dan mengurangi pitch yang tidak relevan sehingga didapatkan koefisien yang compact merepresentasikan suatu ciri sinyal tertentu.
2.2
Clustering
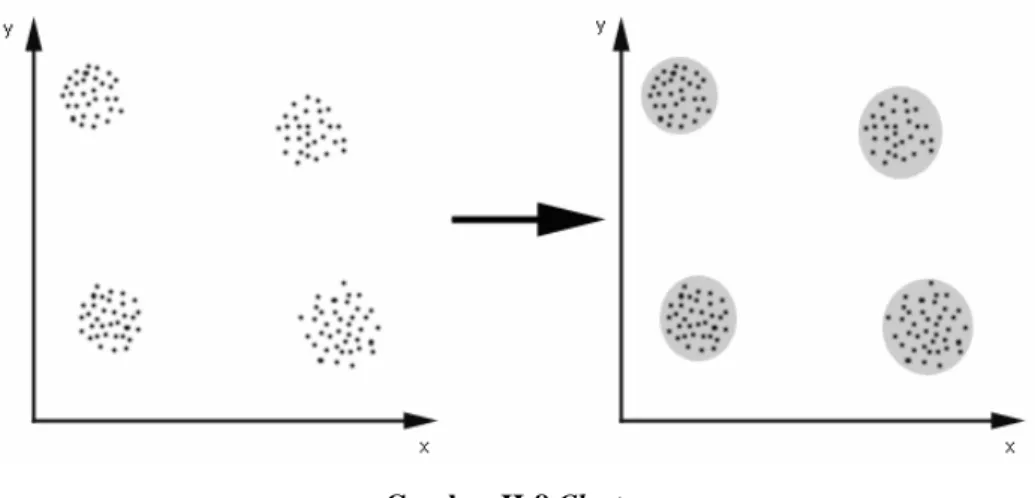
Clustering merupakan suatu teknik penyelesaian masalah yang bersifat unsupervised learning yaitu menemukan pola dari data yang labelnya tidak diketahui sebelumnya. Clustering adalah proses untuk mengelompokkan obyek dalam suatu kelompok/cluster tertentu berdasarkan persamaan yang dimiliki oleh setiap obyek tersebut. Obyek mempunyai kesamaan dengan obyek lainnya dalam satu cluster tetapi berbeda secara signifikan dengan obyek yang berada pada cluster lain [ELE07].
Gambar II-8 Cluster
Gambar II-8 menunjukkan mengenai pengelompokan data menjadi 4 buah cluster didasarkan pada persamaan kriteria jarak antara dua atau lebih obyek. Dua atau lebih obyek akan masuk dalam satu kelompok/cluster yang sama jika jarak setiap obyek tersebut mempunyai jarak terdekat terhadap kriteria jarak yang telah ditentukan. Hal ini disebut dengan distance-based clustering. Jenis teknik clustering yang lain adalah conceptual clustering yaitu dua atau lebih obyek masuk dalam satu kelompok/cluster tertentu jika cluster tersebut dapat mendefinisikan konsep umum obyek-obyek tersebut. Dengan kata lain, obyek tersebut dikelompokkan berdasarkan konsep yang dideskripsikan tidak berdasarkan pengukuran tertentu.
Algoritma clustering dapat dibagi menjadi beberapa kelompok berdasarkan cara pengelompokan data, yaitu [ELE07]:
1. Exclusive Clustering
Gambar II-9 Exclusive Clustering
Pada exclusive clustering data yang sudah masuk dalam suatu kelompok/cluster tertentu maka tidak akan masuk dalam kelompok/cluster lain. Hal ini dapat dilihat
pada Gambar II-9, yaitu garis lurus pada bidang dua dimensi tersebut merupakan pemisah antar setiap point. Algoritma K-Means merupakan jenis algoritma exclusive clustering.
2. Overlapping Clustering
Overlapping Clustering menggunakan fuzzy set dalam pengelompokkan data sehingga setiap titik mungkin masuk dalam dua atau lebih cluster dengan derajat keanggotaan yang berbeda. Pada algoritma ini data akan diasosiasikan terhadap nilai keanggotaan yang sesuai. Algoritma fuzzy C-means merupakan jenis algoritma overlapping clustering.
3. Hierarchical Clustering
Algoritma hierarchical clustering merupakan penggabungan antara dua cluster yang saling berdekatan. Kondisi awal pada clustering ini direalisasikan dengan membentuk setiap datum sebagai sebuah cluster. Algoritma yang masuk dalam hierarchical clustering adalah algoritma hierarchical clustering.
4. Probabilistic Clustering
Clustering ini menggunakan pendekatan probabilistik. Algoritma yang merupakan probabilistic clustering adalah algoritma gaussians mixture.
Komponen yang paling penting dalam teknik clustering adalah pengukuran jarak titik-titik data. Jika vektor setiap instan data merupakan unit fisik yang sama maka jarak Euclidean dapat digunakan sebagai ukuran jarak untuk mengelompokkan instans data yang sama dalam satu kelompok.
Gambar II-10 Perbedaan Skala Pengukuran Jarak [ELE07]
Gambar II-10 menunjukkan permasalahan dalam penggunaan skala pendefinisian jarak dilihat secara grafis untuk menentukan cluster yang akan dibentuk. Pada gambar tersebut ukuran jarak antar obyek berdasarkan dua skala yaitu lebar dan tinggi. Kedua
pengukuran tersebut menggunakan unit fisik yang sama (dalam meter) tetapi dengan penggunaan skala pengukuran yang berbeda maka akan menghasilkan cluster yang berbeda juga. Hal tersebut dapat dilihat pada gambar (a) instan di-cluster berdasarkan skala lebar dan tinggi yang sama sedangkan pada gambar (b) instan di-cluster berdasarkan skala lebar dan tinggi yang berbeda. Hal ini tidak terjadi pada pengelompokan secara grafis saja, penggunaan formula matematis yang berbeda juga dapat menghasilkan cluster yang berbeda. Oleh karena itu penentuan formula matematis yang tepat dalam satu kasus tertentu sangat diperlukan dalam clustering.
Pada data dengan dimensi besar, ukuran yang sering dipakai adalah Minkowski metric, yaitu:
(
)
d p K p k j k i j i p x x x x d 1 1 , , , − =∑
= (II-12)dimana d menujukkan dimensi dari data. Jarak Euclidean merupakan kasus khusus pada Minkowski metric yaitu pada saat p=2, sedangkan jarak manhattan pada saat p=1. Akan tetapi tidak ada teori yang dapat dijadikan sebagai pedoman dalam memilih ukuran yang tepat untuk setiap aplikasi tertentu. Beberapa kasus umum menunjukkan bahwa data feature vector tidak dapat dibandingkan secara langsung. Hal ini terjadi karena komponen tersebut bukan merupakan variabel kontinyu, seperti besaran panjang, tetapi merupakan variabel dengan kategori nominal seperti hari dalam minggu misal senin, selasa, rabu, kamis, jumat, sabtu, dan minggu. Dalam kasus ini pengetahuan domain harus digunakan untuk menentukan formula ukuran yang tepat [ELE07].
2.2.1 Algoritma K-Means
K-means (MacQueen, 1967) merupakan algoritma clustering yang sederhana. Algoritma ini termasuk dalam kelompok exclusive clustering yaitu satu data hanya masuk dalam satu cluster tertentu. Ide utama dari algoritma ini adalah menentukan jumlah cluster di awal dan mendefinisikan sejumlah k centroid yaitu satu centroid untuk setiap kelompok/cluster.
Pemilihan data sebagai centroid harus diperhatikan dengan baik karena perbedaan posisi centroid akan memberikan hasil yang berbeda. Salah satu cara yang dapat dilakukan adalah dengan memilih centroid yang posisinya sejauh mungkin dengan centroid lain. Setelah centroid ditentukan langkah selanjutnya adalah mengelompokkan data sesuai dengan jarak terdekat dengan centroid. Jika sudah tidak ada lagi data yang
harus dikelompokan maka tahap pertama telah selesai. Pada tahap berikutnya dilakukan perhitungan ulang untuk menentukan centroid yang baru dari setiap cluster yang terbentuk. Kedua langkah tersebut dilakukan berulang kali hingga tidak ada lagi perubahan centroid (centroid tidak bergerak) [ELE07]. Algoritma K-Means bertujuan untuk meminimalkan fungsi obyektif dalam hal ini fungsi tersebut adalah fungsi kuadrat error. ( ) 2 1 1
∑∑
= = − = k j n i j j i c x J (II-13) dimana ( )j j 2 i cx − merupakan jarak antara titik ( )j i
x dan centroid cj sebagai indikator jarak dari sejumlah n titik data dari centroid masing-masing [ELE07].
Seperti yang dijelaskan di atas langkah-langkah penyelesaian algoritma K-Means adalah sebagai berikut:
1. Menentukan K buah titik yang merepresentasikan obyek pada setiap cluster (centroid awal).
2. Menetapkan setiap obyek pada kelompok/cluster dengan posisi centroid terdekat. 3. Jika semua obyek sudah dikelompokkan maka dilakukan perhitungan ulang dalam
menentukan centroid yang baru.
4. Ulangi langkah ke-2 dan ke-3 sampai centroid tidak berubah.
Prosedur pada algoritma K-Means di atas terbukti pasti akan terminate tetapi tidak selalu menghasilkan konfigurasi yang paling optimal. Hal ini berkaitan dengan global minimal. Keakuratan algoritma K-Means sangat dipengaruhi oleh penentuan secara random centroid awal. Masalah-masalah tersebut dapat diatasi dengan menjalankan algoritma K-Means berulang kali. Algoritma K-means merupakan algoritma yang sederhana yang dapat diadaptasikan pada banyak domain permasalahan. Algoritma ini dapat digunakan pada data yang menggunakan representasi fuzzy feature vector.
2.2.2 Kuantisasi Vektor
Hasil dari Cepstral Analysis adalah sekumpulan feature vector dari beberapa ciri spektral dari sinyal ucapan. Misalkan feature vector dinotasikan sebagai vektor Vl, l =1, 2, ..., L dan setiap vektor mempunyai p dimensi, hal ini dapat berarti bahwa analisis spektral dapat mengurangi information rate yang dibutuhkan dalam penyimpanan sinyal pada media fisik karena hanya beberapa informasi yang signifikan (spectral envelope) saja yang disimpan. Misalkan 10 kHz sample suara dengan 16-bit amplitudo, maka untuk
menyimpan sample sinyal asli tanpa kompresi adalah 160.000 bps (bit per second). Dengan dilakukan analisis spektral, misalkan feature vector mempunyai 10 dimensi dan information rate-nya adalah 100 feature per second maka untuk menyimpan feature sample tersebut hanya dibutuhkan 16x10x100. Dari sini dapat dilihat bahwa dengan melakukan analisis spektral dapat menghemat 10 kali lipat space yang dibutuhkan.
Pada kebanyakan aplikasi pengenalan ucapan hanya satu bentuk ciri spektral yang dibutuhkan, misal amplitudo. Berdasarkan hal tersebut kemudian muncul suatu ide untuk membangun sebuah codebook untuk setiap vektor yang berbeda. VQ codebook merupakan vektor pusat yang merepresentasikan sekumpulan vector feature yang berada dalam satu area/kelompok. Ide ini kemudian dikenal dengan metode vector quantization (VQ). VQ sangat efisien untuk merepresentasikan informasi spektral suatu sinyal [RAB93].
Ada beberapa keuntungan dari pengunaan representasi VQ, yaitu: 1. Mengurangi besarnya storage untuk informasi analisis spektral
Seperti yang dijelaskan pada paragraf pertama bab ini bahwa representasi VQ sangat efisien untuk menyimpan informasi spektral oleh karena itu beberapa VQ-based-speech-recognition-system dalam prakteknya menggunakan representasi ini [RAB93]. 2. Mengurangi kompleksitas komputasi.
Pada sistem pengenalan ucapan komponen komputasi yang paling utama adalah dalam menentukan persamaan ciri spektral antara dua buah feature vector. Dengan representasi VQ, komplektibilitas komputasi dapat dikurangi dengan table looked up [RAB93].
3. Merepresentasikan sinyal ucapan secara diskrit.
Dengan mengasosiasikan sebuah label phonetic pada setiap vektor codebook, pemilihan vektor codebook yang paling mencirikan sebuah sinyal ekuivalen dengan pelabelan setiap feature vector[RAB93].
Pembangunan VQ codebook dan prosedur dalam analisis VQ dilakukan dengan clustering. Beberapa elemen yang dibutuhkan dalam proses clustering tersebut adalah sekumpulan feature vector (spectral analysis vector) v1,v2,...vL sebagai data pelatihan, perbedaan nilai spectral envelope dua buah vektor untuk mengukur tingkat persamaan kedua vektor tersebut, prosedur untuk menghitung codebook sebagai centroid dan prosedur untuk mengklasifikasikan vektor masukan ke vektor codebook (centroid)
terdekat serta menggunakan indeks codebook untuk mengacu codebook tertentu. Prosedur klasifikasi yang sering digunakan adalah nearest neighbour labeling [RAB93].
Clustering terhadap sinyal ucapan dilakukan terhadap L buah training vector yang akan dikelompokan dalam M buah vektor codebook (algoritma Lloyd/K-Means). Langkah-langkah yang dilakukan adalah sebagai berikut:
1. Inisialisasi
Memilih M buah vektor di luar data pelatihan sebagai initial set codeword (prototype vector/centroid awal).
2. Nearest Neighbour Search
Dilakukan pada setiap vektor pelatihan yaitu mencari codeword yang paling dekat dengan vektor pelatihan kemudian me-assign vektor tersebut pada area/cell (cluster) letak codeword yang terdekat tersebut.
3. Meng-update centroid
Meng-update codeword setiap cell dengan me-assign codebook dari data pelatihan. 4. Iterasi
Mengulangi langkah 2 dan 3 hingga rata-rata perbedaan nilai spectral envelope telah mencapai nilai threshold tertentu. (codebook/centroid secara signifikan tidak berubah) Prosedur iteratif di atas telah terbukti bekerja dengan baik tetapi lebih baik lagi jika mendesain M buah vektor codebook melalui beberapa tahap, mulai dari 2 M buah vektor codebook hingga mencapai M buah vektor. Prosedur ini disebut dengan binary split algorithm [Gambar II-11]. Secara umum langkah-langkah dalam prosedur tersebut adalah sebagai berikut:
1. Desain sebuah vektor codebook yang merupakan centroid dari seluruh data vektor pelatihan.
2. Split setiap codebook ynmenjadi 2 buah codebook sesuai dengan rumus
(
)
(
ε
)
ε
− = + = − + 1 1 n n n n y y y y (II-14)Rentang n dari 1 sampai dengan jumlah codebook saat ini dan
ε
merupakan parameter untuk splitting (0.01≤ε ≤0.05).3. Memilih centroid/codebook yang terbaik (vektor rata-rata setiap cluster) dengan menggunakan algoritma K-Means.
Find Centroid Split each centroid D’=0 Classify vectors Find Centroids Compute D (Distortion) D-D’ < δ D=D’ m<M Stop yes No yes m = 1 no m = 2*m



![Gambar II-10 Perbedaan Skala Pengukuran Jarak [ELE07]](https://thumb-ap.123doks.com/thumbv2/123dok/2338470.2738862/11.892.208.712.757.1005/gambar-ii-perbedaan-skala-pengukuran-jarak-ele.webp)
![Gambar II-11 Diagram Alir Binary split Codebook Generation Algorithm[RAB93]](https://thumb-ap.123doks.com/thumbv2/123dok/2338470.2738862/16.892.214.710.103.613/gambar-diagram-alir-binary-split-codebook-generation-algorithm.webp)
