STUDI KOMPARASI
METODE ARITHMETIC CODING DAN HUFFMAN CODING DALAM ALGORITMA ENTROPY UNTUK KOMPRESI CITRA DIGITAL
Hari Antoni Musril1
ABSTRACT
Nowadays, there are many methods of data compression available.Most of them can be classified into one of the two big categories, i.e., statistical based and dictionary based. An Example of dictionary based coding is Lempel Zip Welch. The example of statistical based coding are Huffman coding and Arithmetic coding, as the newest algorithm. This paper describes the principles of Arithmetic coding along with its advantages compared to Huffman coding method. In this final paper conducted compression of digital image by use of Arithmetic Coding and Huffman Coding. The test image which have been selected compressed use Minerva software, first image compressed by Arithmetic Coding, then same image compressed by Huffman Coding. Afterwards by using facility exist in Minerva software will getting time use for compression, compression ratio, and image size measure result of compression. As the final conclusion, the algorithm is outstanding for the use of data compression matters. The number of bit coding of arithmetic is less than that of Huffman coding. The modification with the numerical integer is capable of dealing with the limitations of the encoder and decoder equipments over to long floating point processing. Due to the less number of the bit codings, and can be implemented. At Arithmetic Coding getting big compression ratio and image size measure result of compression which is smaller to be compared to Huffman Coding, but time required by Huffman Coding quicker compared to Arithmetic Coding.
Keywords : Arithmetic Coding, Huffman Coding, data compression, algorithm
INTISARI
Ada banyak sekali metode kompresi data yang ada saat ini. Sebagian besar metode tersebut bisa dikelompokkan ke dalam salah satu dari dua kelompok besar, statistical based dan dictionary based. Contoh dari dictionary based coding adalah Lempel Ziv Welch dan contoh dari statistical based coding adalah
Huffman Coding dan Arithmetic Coding yang merupakan algoritma terbaru. Tulisan ini mengulas prinsip-prinsip dari Arithmetic Coding serta keuntungan – keuntungannya dibandingkan dengan metode Huffman Coding. Dalam tulisan ini dilakukan pengkompresian citra digital menggunakan Arithmetic Coding dan
Huffman Coding. Citra uji yang telah dipilih dikompresi menggunakan software
Minerva, pertama citra dikompresi menggunakan Arithmetic Coding, kemudian citra yang sama dikompresi dengan Huffman Coding. Setelah itu dengan menggunakan fasilitas yang ada pada software Minerva akan didapatkan waktu
yang digunakan untuk kompresi, rasio kompresi, dan ukuran citra hasil kompresi. Pada akhirnya ditarik kesimpulan, bahwa algoritma ini cukup baik untuk dipakai dalam keperluan kompresi data. Alasan pertama karena jumlah coding bit pada
arithmetic coding lebih sedikit dibandingkan dengan huffman coding. Modifikasi dengan menggunakan bilangan integer juga mampu mengatasi keterbatasan peralatan – peralatan encoder dan decoder dari pengolahan floating point yang terlalu panjang. Kedua karena jumlah bit kodenya lebih sedikit dan dapat diimplementasikan. Pada Arithmetic Coding didapatkan rasio kompresi yang besar dan ukuran citra hasil kompresi yang lebih kecil dibandingkan Huffman Coding, namun waktu yang dibutuhkan oleh Huffman Coding lebih cepat dibandingkan Arithmetic Coding.
PENDAHULUAN
Perkembangan teknologi digital memperlihatkan kemajuan yang sangat pesat. Data digital selain mudah dalam penyebarannya melalui jaringan internet, juga mudah dan murah dalam penggandaan
serta penyimpanannya.
Perkembangan ini juga berhubungan erat dengan ketersediaan media penyimpanan yang dibutuhkan untuk penyimpanan data tersebut. Kebutuhan ini disebabkan karena data yang disimpan semakin lama semakin banyak, dan ukuran data yang besar.
Teknologi kompresi data merupakan suatu teknologi yang bertujuan untuk memaksimalkan keterbatasan ruang penyimpanan. Tujuan utama dari diciptakannya teknologi ini adalah untuk efisiensi ruang dan waktu, dimana kedua elemen inilah yang menjadi titik fokus para pengguna komputer untuk dimaksimalkan.
Kompresi citra bertujuan untuk meminimalkan jumlah bit yang diperlukan dalam merepresentasikan citra. Kompresi citra dikembangkan untuk memudahkan penyimpanan dan pengiriman citra. Teknik kompresi yang ada sekarang memungkinkan citra dikompresi sehingga ukurannya menjadi jauh lebih kecil daripada ukuran citra asli.
Berdasarkan output, kompresi data dikelompokkan menjadi teknik kompresi data secara lossless dan
lossy. Kompresi tipe lossy adalah kompresi dimana terdapat data yang hilang selama proses kompresi, akibatnya kualitas data yang dihasilkan jauh lebih rendah daripada kualitas data asli. Sementara itu, kompresi tipe
lossless tidak menghilangkan informasi setelah proses kompresi terjadi, akibatnya kualitas citra hasil kompresi tidak menurun. Pada tulisan ini akan memfokuskan proses kompresi dengan tipe lossless.
Tipe kompresi secara lossless
terdiri dari beberapa algoritma diantaranya run length encoding, entropy encoding, dan adaptive dictionary based. Tulisan ini akan menggunakan algoritma entropy
sebagai teknik kompresi citra. Algoritma entropy terdiri dari
arithmetic coding dan huffman coding, akan dilakukan pembandingan antara kedua metode tersebut.
PENDEKATAN PEMECAHAN MASALAH
Pengantar Citra dan Citra Digital Pengolahan citra secara digital mulai diminati pada awal tahun 1921, pada saat pertama kalinya sebuah foto berhasil ditransmisikan secara digital melalui kabel laut dari kota New York ke kota London (Bartlane Cable Picture Transmission System). Keuntungan utama yang dirasakan pada saat itu
adalah pengurangan waktu
pengiriman foto dari sekitar 1 minggu menjadi kurang dari 3 jam. Foto tersebut dikirim dalam bentuk kode digital dan kemudian diubah kembali oleh pointer telegraph.
Sekitar tahun 1960 seiring dengan pertumbuhan komputer, kebutuhan akan pengolahan citra yang sanggup memenuhi suatu kecepatan proses dan kapasitas memori yang dibutuhkan oleh berbagai algoritma pengolahan citra juga semakin pesat.
Citra
Citra merupakan istilah lain untuk gambar, sebagai salah satu
komponen multimedia yang
memegang peranan sangat penting sebagai bentuk informasi visual [1].
Proses pengolahan data dapat dilakukan oleh komputer, baik berupa mikrokomputer sederhana atau komputer biasa, tergantung jumlah data dan jenis pengolahan. Proses penampilan data merupakan salah satu yang penting karena
bagaimanapun juga citra digital hasil olahan harus dapat dinilai oleh mata
manusia melalui sebuah
penampilan.
Citra dapat didefinisikan sebagai fungsi intensitas cahaya dua dimensi f(x,y), dimana x dan y
merupakan koordinat spasial, nilai f
pada suatu titik (x,y) sebanding dengan kecerahan (brigthness) yang biasanya dinyatakan dalam tingkatan abu - abu (gray-level) dari citra di titik tersebut.
Nilai intensitas cahaya akan bernilai antara 0 sampai tidak berhingga karena cahaya ini merupakan bentuk energi, atau secara matematis :
0 ≤ f(x,y) < ∞ ...(1)
Nilai f(x,y) sebenarnya adalah hasil kali dari :
1. i(x,y) = jumlah cahaya yang berasal dari sumbernya (illumination), intensitasnya antara 0 sampai tidak berhingga.
2. r(x,y) = derajat kemampuan obyek memantulkan cahaya (reflection), nilainya antara 0 dan 1.
Secara harfiah, citra (image) adalah gambar pada bidang dwimatra (dua dimensi). Citra juga didefinisikan sebagai kumpulan dari elemen gambar yang secara keseluruhan merekam suatu adegan/scene melalui media indra visual. Suatu citra didapatkan dari penangkapan kekuatan sinar yang dipantulkan oleh objek. Citra dapat dibedakan atas citra analog dan citra digital. Citra analog adalah citra yang masih dalam bentuk sinyal analog, seperti pengambilan gambar oleh kamera atau citra tampilan di layar ataupun monitor (sinyal video).
Ditinjau dari sudut pandang matematis, citra merupakan fungsi menerus (continue) dari intensitas cahaya pada bidang dwimatra. Sumber cahaya menerangi objek, objek memantulkan kembali
sebagian dari berkas cahaya tersebut. Pantulan cahaya ini ditangkap oleh alat-alat optik, misalnya mata pada manusia, kamera, pemindai (scanner), dan sebagainya, sehingga bayangan objek yang disebut citra tersebut terekam.
Citra sebagai keluaran dari suatu sistem perekaman dapat bersifat :
1. Optik berupa foto,
2. Analog berupa sinyal video seperti gambar pada monitor televisi,
3. Digital yang dapat langsung disimpan pada pita magnetik. Citra Digital
Citra digital adalah citra dengan f(x,y) yang nilainya didigitalisasikan (dibuat diskrit) baik dalam koordinat spasialnya maupun dalam gray level-nya [2]. Sebuah citra diubah ke bentuk digital agar mudah diolah atau disimpan dalam memori komputer atau media lain.
Secara teoritis citra dapat dikelompokkan menjadi empat kelas citra, yaitu : kontinu – kontinu, kontinu – diskrit, diskrit – kontinu, diskrit – diskrit. Penlabelan kontinu berarti nilai yang digunakan adalah tidak terbatas dan tidak terhingga, sedangkan label diskrit menyatakan terbatas dan berhingga. Suatu citra digital merupakan representasi dua dimensi array sampel diskrit suatu citra kontinu f(x,y). Amplitudo setiap sampel dikuantisasi untuk menyatakan bilangan hingga bit. Setiap elemen array dua dimensi disebut suatu pixel (picture element). Ranah nilai intensitas dalam suatu citra ditentukan oleh alat digitalisasi yang digunakan untuk menangkap dan menkonversi citra analog ke citra digital (A/D Converter). Perolehan citra digital ini dapat dilakukan secara langsung oleh kamera digital maupun dengan menggunakan A/D Converter. Untuk mengubah citra kontinu menjadi citra digital diperlukan proses pembuatan
kisi–kisi arah horizontal dan arah vertikal, sehingga diperoleh gambar dalam bentuk array dua dimensi. Proses ini disebut sebagai proses digitalisasi/sampling.
Citra monokrom atau citra hitam putih merupakan citra satu kanal, dimana citra f(x,y) merupakan fungsi tingkat keabuan dari hitam ke putih, x menyatakan variabel baris (garis jelajah) dan y menyatakan variabel kolom atau posisi di garis jelajah. Sebaliknya citra berwarna dikenal juga dengan citra
multispectral.
Citra diskrit dihasilkan dari melalui proses digitalisasi terhadap citra kontinu. Sedangkan citra kontinu dihasilkan dari sistem optik yang menerima sinyal analog. Beberapa sistem optik dilengkapi dengan fungsi digitalisasi sehingga ia mampu menghasilkan citra diskrit, misalnya kamera digital dan
scanner. Citra diskrit disebut juga sebagai citra digital, seperti gambar 1.
Gambar 1. Citra Digital
Digitalisasi dari koordinat spasial citra disebut dengan image sampling, sedangkan digitalisasi dari
gray-level citra disebut dengan gray-level quantization. Citra digital secara matematis dapat dituliskan sebagai suatu matriks dimana baris
dan kolomnya menunjukkan gray level di titik tersebut.
Pengolahan citra merupakan pemrosesan citra, sehingga didapatkan hasil berupa citra dalam bentuk lain seperti resampling, pengeditan, kompresi dan lain-lain. Pengolahan citra bertujuan untuk memperbaiki kualitas citra agar mudah diinterpretasi oleh mata manusia dan mesin (komputer). Untuk melakukan pengolahan terhadap citra gambar digital, maka pengolahan dilakukan terhadap
pixel-pixel dari citra tersebut.
Citra digital secara matematis dapat dituliskan sebagai suatu matriks dimana baris dan kolomnya menunjukkan gray level di titik tersebut. Pada umumnya citra digital berbentuk empat persegi panjang, dan dimensi ukurannya dinyatakan sebagai tinggi x lebar (atau lebar x panjang). Citra digital yang tingginya
N, lebarnya M, dan memiliki L
derajat keabuan dapat dianggap sebagai fungsi :
Citra digital yang berukuran N x M lazim dinyatakan dengan matriks yang berukuran N baris dan M kolom
sebagai berikut :
Indeks baris (i) dan indeks kolom (j) menyatakan suatu koordinat titik pada citra, sedangkan
f(i,j) merupakan intensitas (derajat keabuan) pada titik (i,j). Nilai derajat
keabuan memiliki rentang nilai dari l
min sampai l max, atau
Lmin < f < lmax ...(2) Selang (lmin, lmax) disebut skala keabuan. Biasanya selang (lmin, lmax) sering digeser untuk alasan – alaasan praktis menjadi selang [0, L], yang dalam hal ini nilai intensitas 0 menyatakan hitam, nilai intensitas L menyatakan putih, sedangkan nilai intensitas antara 0 sampai L bergeser dari hitam ke putih. Sebagai contoh, citra hitam putih dengan 256 level artinya mempunyai skala abu dari 0 sampai 255 atau [0, 255], yang dalam hal ini nilai intensitas 0 menyatakan hitam, nilai intensitas 255 menyatakan putih, dan nilai antara 0 sampai 255 menyatakan warna keabuan yang terletak antara hitam dan putih. Intensitas suatu titik pada citra berwarna merupakan kombinasi dari tiga intensitas : derajat keabuan merah (fmerah(x,y)), hijau (fhijau(x,y)), dan biru (fbiru(x,y)).
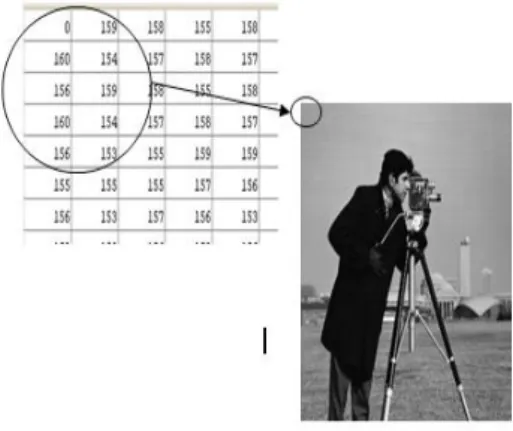
Masing-masing elemen pada citra digital (berarti elemen matriks) disebut image elemen, picture element atau pixel. Jadi, citra yang berukuran N x M mempunyai NM
buah pixel. Sebagai contoh, misalkan sebuah citra digital berukuran 256 x 256 pixel dan direpresentasikan secara numerik dengan matriks yang terdiri dari 256 buah baris (di-indeks dari 0 sampai 255) dan 256 buah kolom (diindeks dari 0 sampai 255) seperti contoh berikut :
Pixel pertama pada koordinat (0,0) mempunyai nilai intensitas 0 yang berarti warna pixel tersebut hitam, pixel kedua pada koordinat (0,1) mempunyai intensitas 134 yang berarti warnanya antara hitam dan putih, dan seterusnya.
Sebagai contoh intensitas f
dari gambar hitam putih pada titik
(x,y) disebut derajat keabuan, yang dalam hal ini derajat keabuannya bergerak dari hitam ke putih sedangkan citranya disebut citra hitam-putih atau citra monokrom. Citra hitam-putih dengan 256 level artinya mempunyai skala abu dari 0 sampai 255 atau [0,255], dimana nilai intensitas 0 menyatakan hitam, sedangkan nilai intensitas 255 menyatakan putih, dan nilai antara 0 sampai 255 menyatakan warna keabuan yang terletak antara hitam dan putih. Citra hitam-putih disebut juga citra satu kanal, karena warnanya hanya ditentukan oleh satu fungsi intensitas saja. Untuk lebih jelasnya, perhatikan Gambar 2 berikut :
Gambar 2. Nilai Intensitas Citra Digital
Citra sering diasosiasikan dengan kedalaman pixel-nya. Jadi, citra dengan kedalaman 8 bit disebut juga citra 8-bit (atau citra 256 warna). Pada kebanyakan aplikasi, citra hitam – putih dikuantisasi pada 256 level dan membutuhkan 1 byte
(8 bit) untuk representasi setiap
pixel-nya (G = 256 = 28). Citra biner (binary image) hanya dikuantisasi pada dua level : 0 dan 1. Tiap pixel
pada citra biner cukup
direpresentasikan dengan 1 bit, yang mana bit 0 berarti hitam dan bit 1 berarti putih. Besarnya daerah derajat keabuan yang yang digunakan menentukan resolusi kecerahan dari citra yang diperoleh. Sebagai contoh, jika digunakan 3 bit untuk menyimpan harga bilangan bulat, maka jumlah derajat keabuan yang diperoleh hanya 8, jika digunakan 4 bit, maka derajat keabuan yang diperoleh adalah 16 buah. Semakin banyak jumlah derajat keabuan (berarti jumlah bit kuantisasinya makin banyak), semakin bagus gambar yang diperoleh karena kemenerusan derajat keabuan akan semakin tinggi sehingga mendekati citra aslinya.
Penyimpanan citra digital yang menjadi N x M buah pixel dan dikuantisasi menjadi G = 2m Dimana : G = derajat keabuan m = bilangan bulat positif
Level derajat keabuan
membutuhkan memori
sebanyak :
b = N x M x m bit ... (3)
Secara keseluruhan, resolusi gambar ditentukan oleh N dan m.
Makin tinggi nilai N (atau M) dan m, maka citra yang dihasilkan semakin bagus kualitasnya (mendekati citra menerus). Unjuk citra dengan jumlah objek yang sedikt, kualitas citra ditentukan oleh nilai m. Sedangkan untuk citra dengan jumlah objek yang banyak, kualitasnya ditentukan oleh N (atau M). Seluruh tahapan proses digitalisasi (penerokan dan kuantisasi) di atas dikenal sebagai konversi analaog ke digital, yang biasanya menyimpan hasil proses di dalam media penyimpanan.
Pengolahan Citra
Pengolahan citra adalah pemrosesan citra, khususnya dengan menggunakan komputer, menjadi citra yang kualitasnya lebih baik [3]. Pengolahan citra bertujuan memperbaiki kualitas citra agar mudah diinterpretasi oleh manusia atau mesin (dalam hal ini komputer). Teknik–teknik pengolahan citra mentransformasikan citra menjadi citra lain. Jadi, masukannya adalah citra dan keluarannya juga citra, namun citra keluaran mempunyai kualitas lebih baik daripada citra masukan. Termasuk ke dalam bidang ini juga adalah pemampatan citra (image compression).
Gambar 3. Operasi Pengolahan Citra
Pengolahan citra digital dapat dilakukan dengan cara – cara sebagai berikut :
1. Representasi dan pemodelan citra
2. Peningkatan kualitas citra 3. Restorasi citra
4. Analisis citra 5. Rekonstruksi citra 6. Kompresi citra
Dalam tulisan ini, pengolahan citra digital difokuskan pada teknik kompresi citra. Umumnya, operasi – operasi pada pengolahan citra diterapkan pada citra bila :
1. Perbaikan atau modifikasi citra perlu dilakukan untuk meningkatkan kualitas penampakan atau untuk menonjolkan beberapa aspek informasi yang terkandung di dalam citra,
2. Elemen di dalam citra perlu dikelompokkan, dicocokkan, atau diukur,
3. Sebagian citra perlu digabung dengan bagian citra yang lain.
Kompresi Citra Digital
Kompresi citra adalah aplikasi kompresi data yang dilakukan terhadap citra digital dengan tujuan untuk mengurangi redundansi dari data – data yang terdapat dalam citra sehingga dapat disimpan atau ditransmisikan secara efisien [4]. Kompresi citra bertujuan untuk meminimalkan jumlah bit yang diperlukan untuk merepresentasikan
citra. Kompresi berarti
memampatkan/mengecilkan ukuran. Prinsip umum yang digunakan pada proses pemampatan citra adalah mengurangi duplikasi data di dalam citra sehingga memori yang dibutuhkan untuk merepresentasikan citra menjadi lebih sedikit daripada representasi citra semula.
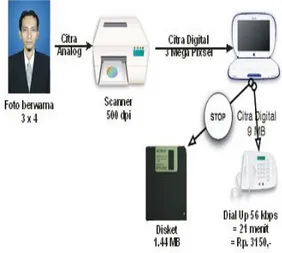
Apabila sebuah foto berwarna berukuran 3 inci x 4 inci diubah ke bentuk digital dengan tingkat resolusi
sebesar 500 dot per inch (dpi), maka diperlukan 3 x 4 x 500 x 500 = 3.000.000 dot (pixel). Setiap pixel terdiri dari 3 byte dimana masing-masing byte merepresentasikan warna merah, hijau, dan biru. Sehingga citra digital tersebut memerlukan volume penyimpanan sebesar 3.000.000 x 3 byte + 1080 = 9.001.080 byte setelah ditambahkan jumlah byte yang diperlukan untuk menyimpan format (header) citra.
Citra tersebut tidak bisa disimpan ke dalam disket yang berukuran 1.4 MB. Selain itu, pengiriman citra berukuran 9 MB memerlukan waktu lebih lama. Untuk koneksi internet dial-up (56 kbps), pengiriman citra berukuran 9 MB memerlukan waktu 21 menit. Untuk itulah diperlukan kompresi citra sehingga ukuran citra tersebut menjadi lebih kecil dan waktu pengiriman citra menjadi lebih cepat. Citra yang belum dikompres disebut citra mentah (raw image). Sementara citra hasil kompresi disebut citra terkompresi (compressed image). Proses pengiriman dan penyimpanan citra tersebut diilustrasikan pada gambar 4.
Gambar 4. Proses Konversi Citra Analog Ke Citra Digital Beserta
Kompresi citra dikembangkan untuk memudahkan penyimpanan dan pengiriman citra. Teknik kompresi yang ada sekarang memungkinkan citra dikompresi sehingga ukurannya jauh lebih kecil daripada ukuran asli.
Jenis Kompresi Citra
Ada empat pendekatan yang digunakan dalam kompresi citra, yaitu [5]:
1. Pendekatan statistik
Kompresi citra didasarkan pada frekuensi kemunculan derajat keabuan pixel di dalam seluruh bagian citra.
2. Pendekatan ruang
Kompresi citra didasarkan pada hubungan spasial antara
pixel – pixel didalam suatu kelompok yang memiliki derajat keabuan yang sama di dalam suatu daerah di dalam citra.
3. Pendekatan kuantisasi
Kompresi citra dilakukan dengan mengurangi jumlah derajat keabuan yang tersedia. 4. Pendekatan fraktal
Kompresi citra didasarkan pada kenyataan bahwa kemiripan bagian – bagian di dalam citra dapat dieksploitasi dengan suatu matriks transformasi.
Proses Pada Pemampatan Citra Dalam pemampatan citra terdapat dua proses utama, yaitu: 1. Pemampatan citra (image
compression).
Pada proses ini, citra dalam representasi tidak mampat
dikodekan dengan
representasi yang
meminimumkan kebutuhan memori. Citra dengan format
bitmap pada umumnya tidak dalam bentuk mampat. Citra yang sudah dimampatkan disimpan ke dalam arsip dengan format tertentu. Kita mengenal format JPG dan GIF
sebagai format citra yang sudah dimampatkan.
2. Penirmampatkan citra (image decompression).
Pada proses ini, citra yang sudah dimampatkan harus dapat dikembalikan lagi (decoding) menjadi representasi yang tidak mampat. Proses ini diperlukan jika citra tersebut ditampilkan ke layar atau disimpan ke dalam arsip dengan format tidak mampat. Dengan kata lain, penirmampatan citra mengembalikan citra yang termampatkan menjadi data
bitmap.
Kriteria Pemampatan Citra
Kriteria yang digunakan dalam mengukur metode pemampatan citra adalah:
1. Waktu pemampatan dan
penirmampatan (decompression).
Waktu pemampatan citra dan penirmampatannya sebaiknya
cepat. Ada metode
pemampatan yang waktu pem ampatannya lama, namun wak tu penirmampatannya cepat. Ada pula metode yang waktu pemampatannya cepat tetapi waktu penirmampatannya lambat. Tetapi ada pula
metode yang waktu
pemampatan dan
penirmampatannya cepat atau keduanya lambat.
2. Kebutuhan memori.
Memori yang dibutuhkan untuk merepresentasikan citra seharusnya berkurang secara berarti. Ada metode yang
berhasil memampatkan
dengan persentase yang besar, ada pula yang kecil. Pada beberapa metode,
ukuran memori hasil
pemampatan bergantung pada citra itu sendiri. Citra yang mengandung banyak elemen
duplikasi (misalnya citra langit cerah tanpa awan, citra lantai keramik) umumnya berhasil dimampatkan dengan memori
yang lebih sedikit
dibandingkan dengan
memampatkan citra yang mengandung banyak objek (misalnya citra pemandangan alam).
3. Kualitas pemampatan (fidelity) Informasi yang hilang akibat pemampatan seharusnya seminimal mungkin sehingga kualitas hasil pemampatan tetap dipertahankan. Kualitas
pemampatan dengan
kebutuhan memori biasanya berbanding terbalik. Kualitas pemampatan yang bagus umumnya dicapai pada proses pemampatan yang menghasilkan pengurangan memori yang tidak begitu besar, demikian pula sebaiknya. Dengan kata lain, ada timbal balik (trade off) antara kualitas citra dengan ukuran hasil pemampatan. 4. Format keluaran
Format citra hasil pemampatan sebaiknya cocok untuk pengiriman dan penyimpanan data. Pembacaan citra bergantung pada bagaimana
citra tersebut
direpresentasikan (atau disimpan). Pemilihan kriteria yang tepat bergantung pada pengguna dan aplikasi.
Kompresi citra dikembangkan untuk memudahkan penyimpanan dan pengiriman citra. Teknik kompresi yang ada sekarang memungkinkan citra dikompresi sehingga ukurannya menjadi jauh lebih kecil daripada ukuran asli. Teknik Pemampatan
Teknik pemampatan citra dapat diklasifikasikan ke dalam dua kelompok besar [6], yaitu :
1. Lossless
, yaitupemampatan yang
dilakukan tidak
menghilangkan kandungan asal data, seperti membuang atau merubah kandungan asal selama terjadinya pemampatan. Kategori ini banyak
digunakan dalam
pemampatan data teks. Metode lossless cocok untuk kompresi citra yang mengandung informasi penting yang tidak boleh rusak akibat kompresi. Misalnya kompresi citra hasil diagnosa medis. Contoh teknik dengan
menggunakan metode
pemampatan lossless
adalah : Run Length Encoding, Entropy Encoding (Huffman, Arithmetic), dan Adaptive Dictionary Based (LZW).
2. Lossy
, yaitu pemampatanyang dilakukan dengan
membuang sedikit
kandungan asal dari data, dimana data tersebut banyak terjadi penumpukan nilai atau adanya nilai yang
tidak dibutuhkan
(mengandung nilai yang tidak mempunyai makna), seperti bingkai gambar, ruang kosong dan lain-lain. Contoh pemampatan ini digunakan pada data gambar (image) atau suara.Teknik – teknik yang digunakan dalam metode pemampatan dengan lossy
adalah :Color reduction, teknik ini digunakan untuk warna – warna tertentu yang mayoritas maka informasi dari warna tersebut disimpan dalam
color pallet.Chroma subsampling, yaitu teknik yang memanfaatkan fakta bahwa mata manusia merasa bahwa brightness
(luminance) lebih berpengaruh daripada warna (chrominance) itu sendiri, maka dilakukan pengurangan resolusi warna dengan disampling ulang.
Nisbah Pemampatan Citra
Nisbah (ratio) hasil
pemampatan (compress)
merupakan indikator untuk mengetahui performance dari
hasil sebuah metoda
pemampatan. Untuk
mendapatkan nisbah dengan menggunakan rumus sebagai berikut :
Besarnya nilai nisbah (ratio) yang didapatkan dari metoda pemampatan, maka performance
manipulasi data dari User Interface ke Repository akan meningkat.
Algoritma Entropy Coding
Entropy coding adalah sebuah skema lossless kompresi berbasis pada properti statistik dari citra atau aliran informasi yang dikompres.
Meskipun entropy coding
diimplementasikan secara berbeda untuk tiap - tiap standar, dasar dari skema entropy coding adalah dengan menyandikan pola yang paling sering muncul dengan jumlah bit yang paling kecil. Dengan cara ini, data dapat dimampatkan dengan faktor tambahan dari 3 atau 4.
Entropi secara umum dapat diinterpretasikan jumlah rata-rata minimum dari jumlah pertanyaan ya/tidak untuk menentukan harga spesifik dari variable x. Dalam
konteks bahasan, entropi
merepresentasikan batas bawah (lower bound) dari jumlah rata-rata bit per satu nilai input yaitu rata-rata panjang code word digunakan untuk mengkode input.
Metode dari entropy encoding
adalah pengkodean data dengan BPS (bits per symbol) untuk tiap alphabet yang mendekati nilai
entropi, karena semakin dekat BPS dari alphabet tersebut dengan nilai
entropi, semakin efisien pula kode kompresi tersebut. Metode entropy coding dalam pemampatan citra terdiri dari arithmetic coding dan
huffman coding.
Entropy merupakan sebuah nilai/besaran yang merupakan alat yang digunakan untuk menyatakan jumlah dari distorsi probabilitas yang tidak kontinu. Dengan menggunakan sebuah pendekatan statistik yang acak untuk mencirikan tekstur dari input citra.
Entropy dirumuskan dengan :
Entropy coding merupakan cara yang tepat untuk menghindari sinyal yang tidak kontinu dan untuk mengefisienkan dari representasi sinyal yang kecil. Tetapi dengan adanya penghindaran sinyal yang tidak kontinu ini mengakibatkan adanya pemblokingan pada proses rekonstruksi citranya.
Metode Arithmetic Coding
Arithmetic coding merupakan metode untuk kompresi data lossless
yang menggunakan variabel jumlah bit [7]. Jumlah bit yang digunakan untuk menyandikan setiap simbol
bervariasi sesuai dengan
kemungkinan kemunculan simbol tersebut.
Arithmetic Coding
menggantikan satu deretan simbol input dengan sebuah bilangan
panjang dan semakin kompleks pesan yang dikodekan, maka akan semakin banyak bit yang diperlukan untuk keperluan tersebut.
Output dari arithmetic coding
adalah sebuah angka yang lebih kecil dari 1 dan lebih besar atau sama dengan 0. Angka tersebut secara unik dapat di- decode sehingga menghasilkan deretan simbol yang dipakai untuk menghasilkan angka tersebut.
Untuk menghasilkan angka output tersebut, tiap simbol yang akan di- encode diberi satu set nilai probabilitas. Contoh untuk penggunaan metode arithmetic coding ini adalah sebagai berikut, misalnya kata TELEMATIKA akan
di-encode. Maka didapatkan probabilitas seperti tabel 1 berikut.
Tabel 1. Probabilitas Kata “TELEMATIKA” Karakter Probabilitas A 2/10 E 2/10 I 1/10 K 1/10 L 1/10 M 1/10 T 2/10
Setelah probabilitas tiap
karakter diketahui. Tiap
simbol/karakter akan diberikan range tertentu yang nilainya berkisar di antara 0 dan 1, sesuai dengan probabilitas yang ada. Dalam hal ini tidak ada ketentuan urutan-urutan penentuan segmen, asalkan antara
encoder dan decoder melakukan hal yang sama. Maka didapatkan range untuk kata TELEMATIKA seperti pada tabel 2 berikut.
Tabel 2. Range Kata “TELEMATIKA”
Karakter Probabilitas Range
A 2/10 0.00 – 0.20 E 2/10 0.20 – 0.40 I 1/10 0.40 – 0.50 K 1/10 0.50 – 0.60 L 1/10 0.60 – 0.70 M 1/10 0.70 – 0.80 T 2/10 0.80 – 1.00
Dari tabel ini, satu hal yang perlu dicatat adalah tiap karakter melingkupi range yang disebutkan kecuali bilangan yang tinggi.
Jadi huruf/simbol „T‟ sesungguhnya mempunyai range mulai dari 0.80 sampai dengan 0.9999…..
Selanjutnya untuk melakukan proses encoding dipakai algoritma berikut :
-Set low = 0.0
-Set high = 1.0
-- While (simbol input masih ada) do
- Ambil simbol input
- CR = high – low
-High = low + CR*high_range (simbol)
-Low = low + CR*low_range (simbol)
- End While
-Cetak Low
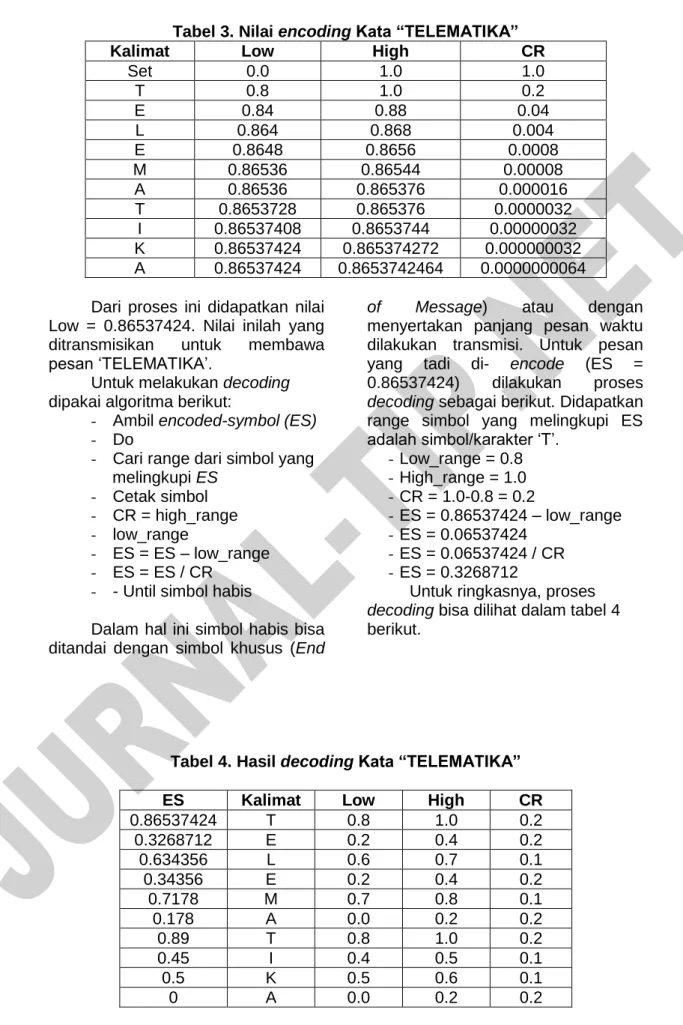
Di sini „Low‟ adalah output dari proses arithmetic coding. Untuk kata „TELEMATIKA‟ di atas, pertama kita ambil karakter „T‟. Nilai CR adalah 1-0 =1. High_range (T) = 1.1-01-0, Low_range(T) = 0.80. Kemudian didapatkan nilai high = 0.00 + CR*1.00 =1.00, low = 0.00 + CR*0.80 = 0.80.
Kemudian diambil karakter „E‟. Nilai CR adalah 1.0–0.8 = 0.2. High_range(E) = 0.40, Low_range (E) = 0.20. Kemudian didapatkan nilai high = 0.80 + CR*0.4 = 0.88, low = 0.80 + CR*0.2 = 0.84. sehingga didapatkan nilai-nilai berikut ini untuk
encoding kata „TELEMATIKA‟ seperti
Tabel 3. Nilai encoding Kata “TELEMATIKA”
Kalimat Low High CR
Set 0.0 1.0 1.0 T 0.8 1.0 0.2 E 0.84 0.88 0.04 L 0.864 0.868 0.004 E 0.8648 0.8656 0.0008 M 0.86536 0.86544 0.00008 A 0.86536 0.865376 0.000016 T 0.8653728 0.865376 0.0000032 I 0.86537408 0.8653744 0.00000032 K 0.86537424 0.865374272 0.000000032 A 0.86537424 0.8653742464 0.0000000064
Dari proses ini didapatkan nilai Low = 0.86537424. Nilai inilah yang ditransmisikan untuk membawa pesan „TELEMATIKA‟.
Untuk melakukan decoding
dipakai algoritma berikut:
- Ambil encoded-symbol (ES)
- Do
- Cari range dari simbol yang melingkupi ES - Cetak simbol - CR = high_range - low_range - ES = ES – low_range - ES = ES / CR
- - Until simbol habis
Dalam hal ini simbol habis bisa ditandai dengan simbol khusus (End
of Message) atau dengan menyertakan panjang pesan waktu dilakukan transmisi. Untuk pesan yang tadi di- encode (ES = 0.86537424) dilakukan proses
decoding sebagai berikut. Didapatkan range simbol yang melingkupi ES adalah simbol/karakter „T‟. - Low_range = 0.8 - High_range = 1.0 - CR = 1.0-0.8 = 0.2 - ES = 0.86537424 – low_range - ES = 0.06537424 - ES = 0.06537424 / CR - ES = 0.3268712
Untuk ringkasnya, proses
decoding bisa dilihat dalam tabel 4 berikut.
Tabel 4. Hasil decoding Kata “TELEMATIKA”
ES Kalimat Low High CR
0.86537424 T 0.8 1.0 0.2 0.3268712 E 0.2 0.4 0.2 0.634356 L 0.6 0.7 0.1 0.34356 E 0.2 0.4 0.2 0.7178 M 0.7 0.8 0.1 0.178 A 0.0 0.2 0.2 0.89 T 0.8 1.0 0.2 0.45 I 0.4 0.5 0.1 0.5 K 0.5 0.6 0.1 0 A 0.0 0.2 0.2
Implementasi Arithmetic Coding harus memperhatikan kemampuan encorder dan decoder, yang pada umumnya mempunyai keterbatasan jumlah mantissa (angka dibelakang koma). Hal ini dapat menyebabkan “error”/ kesalahan apabila suatu arithmetic coding
mempunyai kode dengan floating point yang sangat panjang.
Masalah ini bisa diatasi dengan mengimplementasikan
arithmetic coding menggunakan bilangan integer (16 atau 32 bit integer). Hal ini juga amat mempercepat proses, karena perhitungan integer jauh lebih cepat dari perhitungan floating point. Metode Huffman Coding
Metode huffman coding
merupakan salah satu metode yang terdapat pada teknik entropy coding. Dalam huffman coding, panjang blok dari keluaran sumber dipetakan dalam blok berdasarkan panjang variabel. Cara seperti ini disebut sebagai fixed to variable-length coding. Ide dasar dari cara huffman
ini adalah memetakan mulai simbol yang paling banyak terdapat pada sebuah urutan sumber sampai dengan yang jarang muncul menjadi urutan biner. Dalam variable-length coding, sinkronisasi merupakan suatu masalah. Ini berarti harus terdapat satu cara untuk memecahkan urutan biner yang diterima ke dalam suatu
codeword.
Seperti yang disebutkan di atas, bahwa ide dari huffman coding
adalah memilih panjang codeword
dari yang paling besar
probabilitasnya sampai dengan urutan codeword yang paling kecil probabilitasnya. Apabila kita dapat memetakan setiap keluaran sumber dari probabilitas pi ke sebuah
codeword dengan panjang 1/pi dan pada saat yang bersamaan dapat
memastikan bahwa dapat
didekodekan secara unik, kita dapat mencari rata – rata panjang kode
H(x). Huffman coding dapat mendekodekan secara unik dengan
H(x) minimum, dan optimum pada keunikan dari kode – kode tersebut. Algoritma dari huffman encoding
adalah :
1. Pengurutan keluaran sumber dimulai dari probabilitas paling tinggi.
2. Menggabungkan dua
keluaran yang sama dekat ke dalam satu keluaran yang probabilitasnya merupakan jumlah dari probabilitas sebelumnya.
3. Apabila setelah dibagi masih terdapat dua keluaran, maka lanjut kelangkah berikutnya, namun apabila masih terdapat lebih dari dua, kembali ke langkah satu.
4. Memberikan nilai 0 dan 1 untuk keluaran.
Apabila sebuah keluaran merupakan hasil dari penggabungan dua keluaran dari langkah sebelumnya, maka berikan 0 dan 1 untuk codeword-nya, ulangi sampai keluaran merupakan satu keluaran yang berdiri sendiri.
Untuk menetukan kode-kode dengan kriteria bahwa kode harus unik dan karakter yang sering muncul dibuat kecil jumlah bitnya, kita dapat menggunakan algoritma Huffman. Sebagai contoh, sebuah file yang akan dimampatkan berisi karakter-karakter “PERKARA”. Dalam kode ASCII masing-masing karakter dikodekan sebagai : P = 50H = 01010000B E = 45H = 01000101B R = 52H = 01010010B K = 4BH = 01001011B A = 41H = 01000001B Maka jika diubah dalam rangkaian bit, “PERKARA” menjadi :
010100000100010101010010010010 11010000010101001001000001 P E R K A R A
Tugas kita yang pertama adalah menghitung frekuensi kemunculan masing-masing karakter, jika kita hitung ternyata P muncul sebanyak 1 kali, E sebanyak 1 kali, R sebanyak 2 kali, K sebanyak 1 kali dan A sebanyak 2 kali. Jika disusun dari yang kecil :
E = 1 A = 2 K = 1 R = 2 P = 1
Untuk karakter yang memiliki frekuensi kemunculan sama seperti E, K dan P disusun menurut kode ASCII-nya, begitu pula untuk A dan R.
Selanjutnya buatlah node masing-masing karakter beserta frekuensinya seperti terlihat pada gambar 5.
P,1
E,1
K,1
A,2
R,2
Gambar 5. Langkah 1 algoritma Huffman
Ambil 2 node yang paling kiri (P dan E), lalu buat node baru yang merupakan gabungan dua node tersebut, node gabungan ini akan memiliki cabang masing-masing 2 node yang digabungkan tersebut. Frekuensi dari node gabungan ini adalah jumlah frekuensi cabang-cabangnya. Jika kita gambarkan akan menjadi seperti gambar 6.
E,1
K,1
P,1
A,2
R,2
EK,2
Gambar 6. Langkah 2 algoritma Huffman.
Jika kita lihat frekuensi tiap node pada level paling atas, EK=2, P=1, A=2, dan R=2. Node-node tersebut harus diurutkan lagi dari yang paling kecil, jadi node EK harus digeser ke sebelah kanan node P
dan ingat jika menggeser suatu node yang memiliki cabang, maka seluruh cabangnya harus diikutkan juga. Setelah diurutkan hasilnya akan menjadi sebagai seperti gambar 7
E,1
K,1
P,1
EK,2
A,2
R,2
Gambar 7 Langkah 3 algoritma Huffman.
Setelah node pada level paling atas diurutkan (level berikutnya tidak perlu diurutkan), berikutnya kita gabungkan kembali 2 node paling kiri seperti yang pernah dikerjakan sebelumnya. Node P digabung dengan node EK menjadi node PEK dengan frekuensi 3 dan gambarnya akan menjadi seperti gambar 8.
E,1
K,1
P,1
R,2
A,2
EK,2
PEK,3
Gambar 8. Langkah 4 algoritma Huffman
Kemudian diurutkan lagi menjadi seperti gambar 9
Gambar 9. Langkah 5 algoritma Huffman
Demikian seterusnya sampai diperoleh pohon Huffman seperti gambar 10 berikut :
E,1
K,1
P,1
EK,2
A,2
R,2
PEK,3
AR,4
PEKAR,7
Gambar 10. Langkah 6 algoritma Huffman.Setelah pohon Huffman terbentuk, berikan tanda bit 0 untuk setiap cabang ke kiri dan bit 1 untuk setiap cabang ke kanan seperti gambar 11 berikut :
E,1
K,1
P,1
EK,2
A,2
R,2
PEK,3
AR,4
PEKAR,7
1
1
1
1
0
0
0
Gambar 11. Langkah 7 algoritma Huffman.Untuk mendapatkan kode Huffman masing-masing karakter, telusuri karakter tersebut dari node yang paling atas (PEKAR) sampai ke node karakter tersebut dan susunlah bit-bit yang dilaluinya. Untuk mendapatkan kode Karakter E, dari node PEKAR kita harus menuju ke node PEK melalui bit 0 dan selanjutnya menuju ke node EK melalui bit 1, dilanjutkan ke node E melalui bit 0, jadi kode dari karakter E adalah 010. Untuk mendapatkan kode Karakter K, dari node PEKAR kita harus menuju ke node PEK melalui bit 0 dan selanjutnya menuju ke node EK melalui bit 1, dilanjutkan ke node K melalui bit 1, jadi kode dari karakter K adalah 011. Untuk mendapatkan kode Karakter P, dari node PEKAR kita harus menuju ke node PEK melalui bit 0 dan selanjutnya menuju ke node P melalui bit 0, jadi kode dari karakter P adalah 00. Untuk mendapatkan kode Karakter A, dari node PEKAR kita harus menuju ke node AR melalui bit 1 dan selanjutnya menuju ke node A melalui bit 0, jadi kode dari karakter A adalah 10. Terakhir, untuk mendapatkan kode Karakter R, dari node PEKAR kita harus menuju ke
E,1
K,1
P,1
R,2
A,2
EK,2
PEK,3
node AR melalui bit 1 dan selanjutnya menuju ke node R melalui bit 1, jadi kode dari karakter R adalah 11. Hasil akhir kode Huffman dari file di atas adalah :
E = 010 K = 011 P = 00 A = 10 R = 11
Dengan kode ini, file yang berisi karakter-karakter “PERKARA” akan menjadi lebih kecil, yaitu :
00 010 11 011 10 11 10 = 16 bit P E R K A R A
Dengan Algoritma Huffman berarti file ini dapat kita hemat sebanyak 56-16 = 40 bit. Nisbah = 100% -
%
100
56
16
x
= 71,43%Untuk proses pengembalian ke file aslinya, kita harus mengacu kembali kepada kode Huffman yang telah dihasilkan, seperti contoh di atas hasil pemampatan adalah : 000101101100 1110
Ambillah satu-persatu bit hasil pemampatan mulai dari kiri, jika bit tersebut termasuk dalam daftar kode, lakukan pengembalian, jika tidak ambil kembali bit selanjutnya dan jumlahkan bit tersebut. Bit pertama dari hasil pemampatan di atas adalah 0, karena 0 tidak termasuk dalam daftar kode kita ambil lagi bit kedua yaitu 0, lalu digabungkan menjadi 00,
jika kita lihat daftar kode 00 adalah kode dari karakter P.
Selanjutnya bit ketiga diambil yaitu 0, karena 0 tidak terdapat dalam daftar kode, kita ambil lagi bit keempat yaitu 1 dan kita gabungkan menjadi 01. 01 juga tidak terdapat dalam daftar, jadi kita ambil kembali bit selanjutnya yaitu 0 dan digabungkan menjadi 010. 010 terdapat dalam daftar kode yaitu karakter E. Demikian selanjutnya dikerjakan sampai bit terakhir sehingga akan didapatkan hasil pengembalian yaitu PERKARA.
Pemrograman dengan
menggunakan algoritma Huffman, menyertakan daftar kode dalam file pemampatan, selain itu jumlah byte disertakan sebagai acuan file untuk pengembalian kebentuk file aslinya. HASIL DAN PEMBAHASAN Citra Uji
Dalam tulisan ini dilakukan pengujian kompresi terhadap citra uji. Agar hasil pengujian dapat dibandingkan hasilnya, maka citra yang diuji tidak dapat satu buah citra saja. Berikut ini dilampirkan sepuluh citra yang akan diuji. Citra uji tersebut berformat BMP dengan kapasitas (ukuran) citra yang berbeda – beda antara satu dengan yang lainnya, dapat dilihat pada gambar 12 berikut ini :
Gambar 12 : Citra Uji
Proses Kompresi
Proses Kompresi Arithmetic Coding
Pada proses kompresi
arithmetic coding menggunakan software Minerva, kita harus memilih tipe algoritma kompresi, seperti yang ada pada gambar 13 berikut ini :
Gambar 13. Pemilihan Kompresi Arithmetic Coding
Untuk melakukan kompresi citra dengan metode arithmetic coding kita memilih pilihan tipe
kompresi arithmetic entropy coding. Setelah melakukan pemilihan dan pengaturan pada menu – menu yang ada pada program seperti gambar 3.2 di atas, selanjutnya klik tombol “OK“. Pada proses kompresi ini akan diperlihatkan rasio kompresi, waktu yang dibutuhkan untuk melakukan kompresi, dan ukuran citra hasil kompresi.
Proses Kompresi Huffman Coding
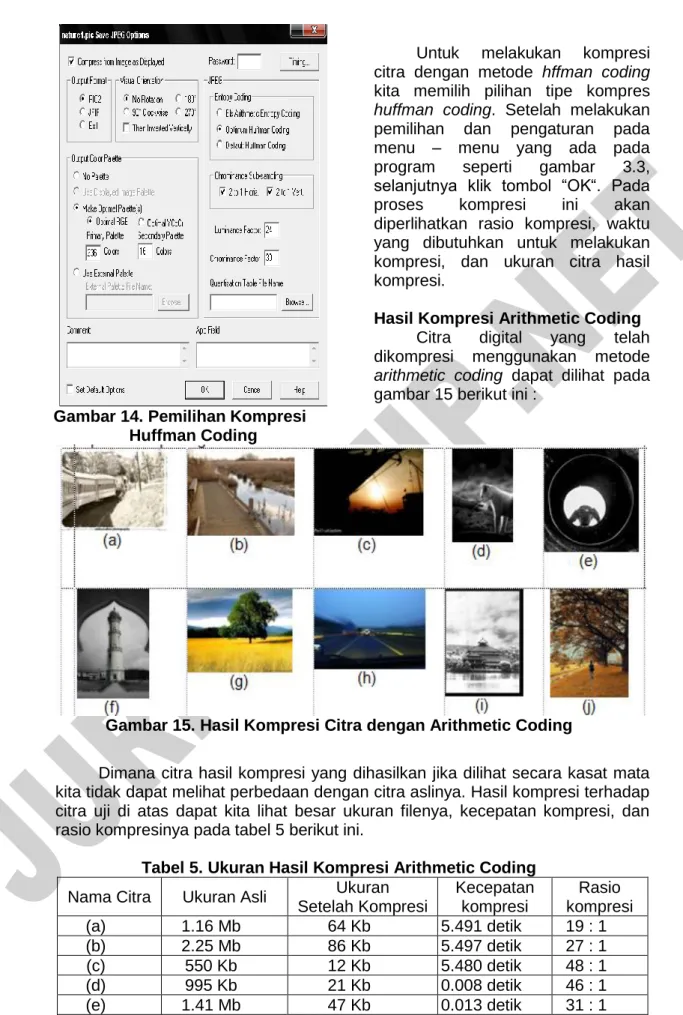
Pada proses kompresi huffman coding menggunakan software Minerva, kita harus memilih tipe algoritma kompresi, seperti yang ada pada gambar 14 berikut ini :
Gambar 14. Pemilihan Kompresi Huffman Coding
Untuk melakukan kompresi citra dengan metode hffman coding
kita memilih pilihan tipe kompres
huffman coding. Setelah melakukan pemilihan dan pengaturan pada menu – menu yang ada pada program seperti gambar 3.3, selanjutnya klik tombol “OK“. Pada proses kompresi ini akan diperlihatkan rasio kompresi, waktu yang dibutuhkan untuk melakukan kompresi, dan ukuran citra hasil kompresi.
Hasil Kompresi Arithmetic Coding Citra digital yang telah dikompresi menggunakan metode
arithmetic coding dapat dilihat pada gambar 15 berikut ini :
Gambar 15. Hasil Kompresi Citra dengan Arithmetic Coding
Dimana citra hasil kompresi yang dihasilkan jika dilihat secara kasat mata kita tidak dapat melihat perbedaan dengan citra aslinya. Hasil kompresi terhadap citra uji di atas dapat kita lihat besar ukuran filenya, kecepatan kompresi, dan rasio kompresinya pada tabel 5 berikut ini.
Tabel 5. Ukuran Hasil Kompresi Arithmetic Coding
Nama Citra Ukuran Asli Ukuran
Setelah Kompresi Kecepatan kompresi Rasio kompresi (a) 1.16 Mb 64 Kb 5.491 detik 19 : 1 (b) 2.25 Mb 86 Kb 5.497 detik 27 : 1 (c) 550 Kb 12 Kb 5.480 detik 48 : 1 (d) 995 Kb 21 Kb 0.008 detik 46 : 1 (e) 1.41 Mb 47 Kb 0.013 detik 31 : 1
(f) 0.97 Mb 25 Kb 0.008 detik 41 : 1
(g) 2.25 Mb 112 Kb 0.026 detik 21 : 1
(h) 956 Kb 13 Kb 0.008 detik 77 : 1
(i) 1.25 Mb 39 Kb 0.011 detik 34 : 1
(j) 1.05 Mb 68 Kb 0.014 detik 16 : 1
Data pada tabel 5 di atas diperoleh dari perhitungan yang dilakukan oleh software “Minerva“.
Dari data tersebut dapat kita lihat bahwa metode arithmetic coding
mampu melakukan kompresi citra digital dengan tingkat rasio yang tinggi, sehingga menghasilkan citra terkompresi dengan ukuran yang kecil.
Dari sini dapat dilihat citra yang terkompresi kalau dilihat dengan mata kita sendiri tidak terlihat adanya perbedaan dari citra aslinya, walaupun ukuran file dan data awal dari citra tersebut sudah jauh berkurang dibandingkan citra aslinya.
Keterangan yang didapatkan pada tabel 5 di atas diperoleh berdasarkan informasi yang direkam oleh software Minerva yang digunakan. Gambar 16 dan gambar 17 berikut ini secara berurutan memperlihatkan waktu kompresi, rasio kompresi, dan ukuran file hasil kompresi terhadap citra a.
Gambar 16. Waktu Proses
Kompresi Arithmetic Coding citra Uji a
Gambar 17. Ukuran Hasil kompresi,
Rasio kompresi Arithmetic Coding Citra Uji a
Hasil Kompresi Huffman Coding Citra digital yang telah dikompresi menggunakan metode
huffman coding dapat dilihat pada gambar 18 berikut ini :
(a) (b) (c) (d) (e) (f) (g) (h) (i) (j)
Gambar 18 : Hasil Kompresi Citra dengan Huffman Coding
Dimana citra hasil kompresi yang dihasilkan jika dilihat secara kasat mata kita tidak dapat melihat perbedaan dengan citra aslinya. Hasil kompresi terhadap citra uji di
atas dapat kita lihat besar ukuran filenya, kecepatan kompresi, dan rasio kompresinya pada tabel 6 berikut ini.
Tabel 6. Ukuran Hasil Kompresi Huffman Coding
Nama citra Ukuran asli
Ukuran Setelah kompresi Kecepatan kompresi Rasio Kompresi (a) 1.16 Mb 70 Kb 0.011 detik 17 : 1 (b) 2.25 Mb 95 Kb 0.017 detik 25 : 1 (c) 550 Kb 14 Kb 0.004 detik 42 : 1 (d) 995 Kb 24 Kb 0.006 detik 41 : 1 (e) 1.41 Mb 52 Kb 0.010 detik 28 : 1 (f) 0.97 Mb 27 Kb 0.005 detik 38 : 1 (g) 2.25 Mb 128 Kb 0.021 detik 18 : 1 (h) 956 Kb 15 Kb 0.006 detik 66 : 1 (i) 1.25 Mb 44 Kb 0.008 detik 29 : 1 (j) 1.05 Mb 76 Kb 0.010 detik 14 : 1
Data pada tabel 6 di atas diperoleh dari perhitungan yang dilakukan oleh software “Minerva“.
Dari data tersebut dapat kita lihat bahwa metode huffman coding
mampu melakukan kompresi citra digital dengan waktu yang relatif singkat, sehingga waktu yang dibutuhkan untuk menghasilkan citra terkompresi lebih singkat.
Dari sini dapat dilihat citra yang terkompresi kalau dilihat dengan mata kita sendiri tidak terlihat adanya perbedaan dari citra aslinya, walaupun ukuran file dan data awal dari citra tersebut sudah jauh berkurang dibandingkan citra aslinya.
Keterangan yang didapatkan pada tabel 6 di atas diperoleh berdasarkan informasi yang direkam
oleh software Minerva yang digunakan. Gambar 19 dan gambar 20 berikut ini secara berurutan memperlihatkan waktu kompresi, rasio kompresi, dan ukuran file hasil kompresi terhadap citra a.
Gambar 19. Waktu Proses Kompresi Huffman Coding citra Uji
a
Gambar 20. Ukuran Hasil kompresi,
Rasio kompresi Huffman Coding Citra Uji a
Perbandingan Hasil Kompresi Setelah dilakukan kompresi terhadap masing – masing citra uji dengan menggunakan teknik kompresi arithmetic coding dan
huffman coding dapat kita teliti hasilnya pada gambar 21 berikut ini : Citra Hasil Kompresi dengan Arithmetic Coding :
(a) (b) (c) (d) (e) (f) (g) (h) (i) (j)
Citra Hasil Kompresi dengan Huffman Coding :
(a) (b) (c)
(e)
(f)
(g) (h)
(i) (j)
Gambar 21. Perbandinga Hasil Kompresi Citra Arithmetic Coding dengan Huffman Coding
Secara kasat mata kita tidak dapat memperhatikan letak perbedaan antara citra digital hasil kompresi dengan arithmeti coding
dan huffman coding. Namun melalui analisa menggunakan software Minerva kita dapat mengetahui perbandingan hasil kompresi antara kedua citra digital tersebut. Karena pada prinsipnya susunan dari simbol – simbol yang merepresentasikan
citra uji tersebut telah mengalami perubahan. Pada tabel 7 berikut ini
akan diperlihatkan hasil
perbandingan antar arithmetic coding
dengan huffman coding terhadap citra uji yang telah ditentukan sebelumnya.
Tabel 7. Perbandingan Ukuran
Arithmetic Coding dengan Huffman Coding
Nama citra
Ukuran asli
Arithmetic Coding Huffman Coding
Ukuran Kecepatan Rasio Ukuran Kecepatan Rasio (a) 1.16 Mb 64 Kb 5.491 detik 19 : 1 70 Kb 0.011 detik 17 : 1 (b) 2.25 Mb 86 Kb 5.497 detik 27 : 1 95 Kb 0.017 detik 25 : 1 (c) 550 Kb 12 Kb 5.480 detik 48 : 1 14 Kb 0.004 detik 42 : 1 (d) 995 Kb 21 Kb 0.008 detik 46 : 1 24 Kb 0.006 detik 41 : 1 (e) 1.41 Mb 47 Kb 0.013 detik 31 : 1 52 Kb 0.010 detik 28 : 1 (f) 0.97 Mb 25 Kb 0.008 detik 41 : 1 27 Kb 0.005 detik 38 : 1 (g) 2.25 Mb 112 Kb 0.026 detik 21 : 1 128 Kb 0.021 detik 18 : 1 (h) 956 Kb 13 Kb 0.008 detik 77 : 1 15 Kb 0.006 detik 66 : 1 (i) 1.25 Mb 39 Kb 0.011 detik 34 : 1 44 Kb 0.008 detik 29 : 1 (j) 1.05 Mb 68 Kb 0.014 detik 16 : 1 76 Kb 0.010 detik 14 : 1
Dari tabel 7 di atas dapat kita ketahui bahwa hasil kompresi terhadap citra uji dengan menggunakan metode arithmetic coding memiliki ukuran citra terkompresinya lebih kecil
dibandingkan metode huffman coding, sedangkan dari segi waktu pelaksanaan proses kompresinya metode huffman coding lebih cepat dari pada metode arithmetic coding. Untuk rasio kompresi, metode
arithmetic coding lebih besar dibandingkan metode huffman coding.
KESIMPULAN
Berdasarkan hasil penelitian yang dilakukan untuk kompresi citra digital dengan menggunakan metoda
arithmetic coding dan huffman coding
dapat ditarik kesimpulan sebagai berikut :
1. Algoritma arithmetic coding ini cukup baik dipakai untuk kompresi data,
2. Algoritma ini akan lebih optimal dibandingkan dengan huffman coding apabila ada data atau
simbol yang memiliki
probabilitas besar,
3. Banyaknya simbol dan
frekuensi masing – masing simbol menentukan nilai entropi suatu data,
4. Berdasarkan hasil penelitian, waktu kompresi huffman coding
lebih cepat dibandingkan dengan arithmetic coding,
5. Pada kompresi dengan
arithmetic coding, data hasil kompresi lebih kecil (lebih efisien) dibandingkan huffman coding.
DAFTAR PUSTAKA
[1] Munir, Rinaldi. 2003.
Pengolahan Citra Digital dengan Pendekatan Algoritmik. Informatika. Bandung.
[2] Gonzales, Rafael C. Woods, Richard E. 2002. Digital Image Processing Second Edition. Prentice Hall. New Jersey. [3] Marvin, CH Wijaya dan Priyono,
Agus. 2007. Pengolahan Citra Digital Menggunakan Matlab, Informatika Bandung.
[4] Gonzales, Rafael C. Woods, Richard E. Image Processing Using Matlab
.
[5] Erhardt, A. Ferron, Theory and Applications of Digital Image Processing. http://www.dip-seminaronline.com/english/ [6] Kumar, Satish. 2001. Introduction To Image Compression. http://www.lee.et.todressen.de/ 2001
[7] Santoso, Petrus. 2001. Studi Kompresi Data dengan Metode Arithmetic Coding,
http://puslit.petra.ac.id/journals/ electrical/ 14. 2001