1
Industry 4.0
Dunia industri saat ini sedang memasuki Era Industri 4.0, yaitu era dimana hampir seluruh aktivitas manusia, baik bisnis maupun lainnya, dipengaruhi dan bergantung pada teknologi digital. Fashion Industry 4.0 sendiri baru dihadirkan pada tahun 2012 di Hannover Fair di Jerman, cukup terlambat karena awal tahun 2000-an merupakan awal dimulainya era Internet dan konektivitas antarpribadi yang ditandai dengan munculnya era Internet 3.0. Dalam dunia pendidikan, banyak kampus yang berlomba-lomba memasukkan materi adopsi teknologi Industri 4.0 ke dalam kurikulumnya.
Data Science
Materi Data Science, Big Data, Internet of Things telah diadopsi pada beberapa mata kuliah khusus bahkan pada program studi di beberapa universitas.
Big Data Analitics
Data yang diimpor ke Apache Solr dapat dilihat pada query di kernel yang dihasilkan. Klik sumber file data yang diinginkan (aplikasi ini menggunakan database MySQL), lalu klik connect. Data yang diimpor ke Apache Solr dapat dilihat pada query di kernel yang dihasilkan.
5
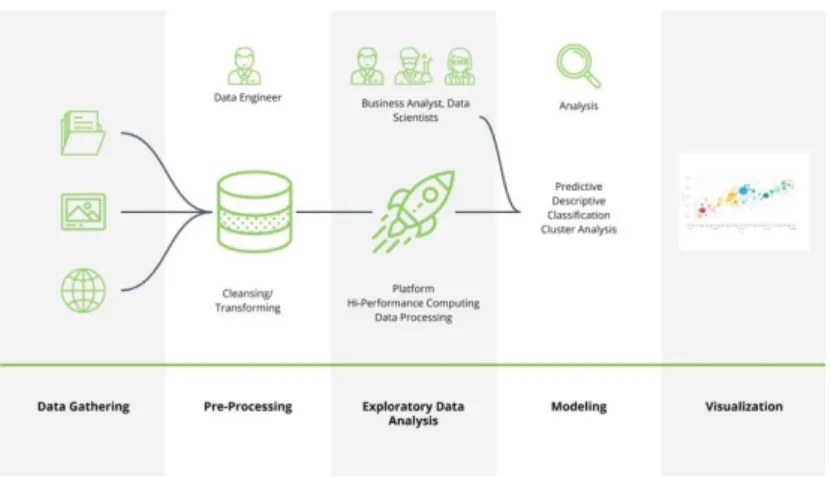
Siklus Hidup Analisis Data
Pengolahan data akan selalu diawali dengan perolehan data, dimana sumber perolehan data ini bisa berasal dari berbagai tempat, seperti database, file mentah, dan konten dari Internet. Pembersihan data adalah proses mengoreksi, atau membiaskan, atau bahkan menghapus data yang dianggap tidak lengkap dan kurang mewakili bisnis dan proses yang dianalisis. Proses pembersihan dan transformasi data ini idealnya dilakukan oleh seorang data scientist, namun tidak jarang seorang data engineer juga melakukan pembersihan dan transformasi, seperti menjalankan query untuk memfilter data dan transformasi sederhana seperti mengubah format tanggal.
Analisa Deskriptif vs Analisa Prediktif vs Analisa
Analisis Deskriptif vs Analisis Prediktif vs Analisis Peskriptif Analisis deskriptif adalah metode analisis yang umum.
Kualitas Data
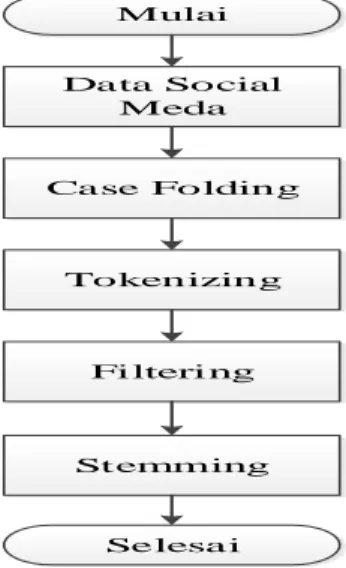
Berikut ini flowchart analisa data berita menggunakan LDA pada Jupyter Notebook dapat dilihat pada gambar 4. Berikut kode pembuatan model bigram dan trigram pada Jupyter Notebook dapat dilihat dibawah ini. Berikut ini kode untuk membangun topik mining menggunakan metode LDA pada notebook Jupyter, dapat dilihat di bawah ini.
9
Pengenalan Python Programming
Kelebihan Anaconda Data Platform adalah kita dapat dengan mudah mengkonfigurasi semua perpustakaan yang terkait dengan pemodelan yang sedang kita kerjakan, semuanya di satu tempat. Lalu kemudahan lainnya adalah kita bisa mendapatkan lingkungan sesuai dengan kebutuhan kita, misalnya kita mempunyai proyek lain yang menggunakan Python 2.x, kita bisa menggunakan perpustakaan khusus untuk Python 2.x tanpa mengubah proyek yang mengganggu kebiasaan. . Versi Python 3.x. Python juga cukup mudah dalam hal instalasinya, tidak perlu dijelaskan lebih lanjut, kemudahannya sudah bisa anda rasakan ketika anda menginstall Anaconda Data Platform.
Tipe Data
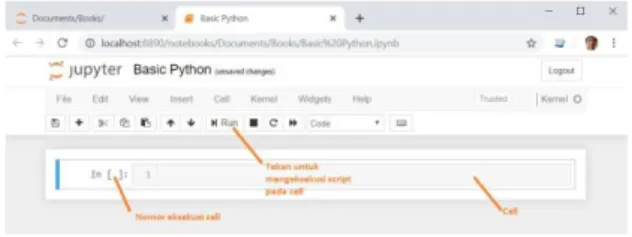
Ekspresi Lambda yang merupakan implementasi dari Pemrograman Fungsional juga sepenuhnya mendukung pemrograman Python. Python juga mendukung pengembangan perangkat lunak dengan desktop (dengan antarmuka QT) dan antarmuka pengguna berbasis web. Untuk membuat file buku catatan baru, klik menu Baru di kanan atas, lalu pilih Python 3, segera buku catatan baru bernama Untitled akan terbuka di tab baru di browser Anda.

Sintaks Data, Variable
Looping
Operator Logika
Untuk memeriksa tipe suatu variabel, Anda dapat menggunakan fungsi tipe seperti gambar di bawah ini. Berikut ini adalah blok program yang ditulis dengan menggunakan operator logika 'if' dan operator logika 'dan'.
Struktur Data
Menurut Tan et al (2006), data mining adalah proses memperoleh informasi berguna dari gudang database besar. Alasan menggunakan Support Vector Machines adalah SVM cocok untuk menangani data dengan banyak dimensi. Data yang telah lolos tahap pra-pemrosesan disimpan kembali dalam bentuk file .xlsx bernama clean-data.xlsx.
19
Teks Mining
Text Mining merupakan penerapan konsep teknik data mining untuk mencari pola dalam teks dengan tujuan menemukan informasi yang berguna untuk tujuan tertentu. Proses text mining dibagi menjadi 3 tahapan utama yaitu proses awal teks (text pre-processing), transformasi teks dan penemuan pola (Even, Yahir Zohar, 2002).
Teks Processing
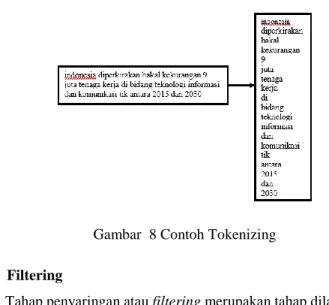
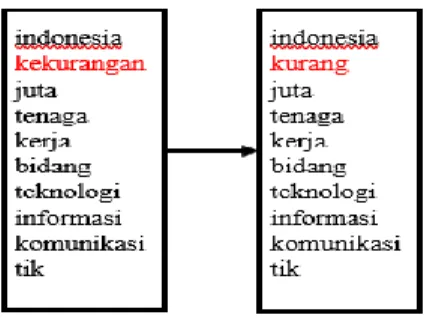
Tokenisasi atau tokenisasi adalah proses pemisahan kata-kata dalam suatu dokumen menjadi kata-kata yang saling independen. Tokenisasi dilakukan untuk memperoleh token atau potongan kata yang akan menjadi entitas yang mempunyai nilai dalam penyusunan matriks dokumen pada proses selanjutnya. Stop word merupakan tahapan untuk menghilangkan kata-kata yang tidak berpengaruh/tidak informatif namun sering muncul dalam dokumen.
Clustering
SVM (SUPPORT VECTOR MECHINE)
Syarat suatu fungsi menjadi fungsi kernel adalah memenuhi teorema Mercer yang menyatakan bahwa matriks kernel yang dihasilkan harus semi-pasti positif. Kernel ini digunakan karena merupakan kernel yang paling sederhana dan membutuhkan waktu pemrosesan yang lebih sedikit. Namun algoritma ini membutuhkan waktu yang lama, apalagi jika digunakan untuk data yang besar, karena algoritma ini menggunakan program numerik kuadratik sebagai inner loop.
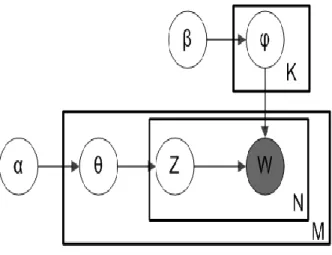
LDA (Laten Direchlet Allocation
K-MEANS
Pusat cluster adalah rata-rata seluruh data/objek dalam suatu cluster tertentu atau median dari cluster tersebut. Perhitungan yang cepat dan mudah menjadi kelebihan dari algoritma ini, namun algoritma K-Means tidak dapat memberikan akurasi yang tepat. Rupanya David dan Sergei berhasil menunjukkan dalam jurnal tersebut bahwa algoritma K-Means yang ditambah dengan teknik penempatan acak memberikan hasil yang lebih baik dibandingkan algoritma K-Means biasa dalam hal kecepatan dan akurasi.
Bagging Dan Adaftive
Aplikasi Jupyter Notebook akan otomatis terbuka di Google Chrome untuk digunakan seperti terlihat pada gambar di bawah ini. Kemudian data yang telah diolah sebelumnya akan dianalisis dan dimasukkan ke dalam notebook Jupyter seperti di bawah ini. Impor data berita ke dalam notebook Jupyter merupakan tahap awal untuk melakukan proses analisis dalam format file .xlsx.
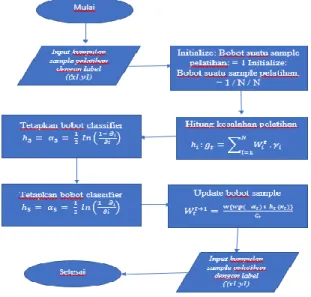
TF-IDF (Term Frekuency Invers Document Frequency)
39
Implementasi Algoritma Support Vector Mechine
Support Vector Machine (SVM) merupakan metode klasifikasi yang menggunakan pembelajaran mesin (supervised learning) untuk memprediksi kelas dari model atau pola berdasarkan hasil proses pelatihan. Mengklasifikasikan sentimen pada data tweet dan komentar ketenagakerjaan telematika di Twitter menggunakan metode klasifikasi Support Vector Machine (SVM). Berikut proses data Support Vector Machine menggunakan 10 data tweet yang dibobotkan dengan TF-IDF.

Tahapan Pembuatan Aplikasi Analisis Sentimen
Algoritma Latent Dirichlet Allocation merupakan algoritma yang banyak digunakan dalam penambangan topik dan digunakan dalam proses analisis data berita serta diterapkan pada machine learning dengan bahasa pemrograman Python pada aplikasi Jupyter Notebook. Aplikasi Jupyter Notebook akan otomatis terbuka di Mozilla Firefox untuk digunakan seperti terlihat pada gambar di bawah ini. Di bawah ini adalah contoh kode untuk menginstal salah satu modul di Python yang dapat dilihat di bawah ini.
Tahap selanjutnya adalah tahap preprocessing pada Jupyter Notebook untuk membersihkan kata-kata yang tidak diperlukan atau kata-kata yang tidak masuk akal dan menghilangkan semua tanda baca pada data berita dan mengubahnya menjadi huruf kecil. Setelah menginstal Jupyter Dashboard, otomatis akan ada tool Jupyter Dashboard di notebook Jupyter yang bisa dijalankan, jadi klik dashboard preview di view menu bar. Proses ini menggunakan metode algoritma K-Means++ untuk clustering yang akan mengelompokkan data menjadi beberapa cluster.
Berikut penjelasan flowchart pengolahan data menggunakan metode K-Means++ untuk clustering tenaga kerja pada industri telematika. Berikut penjelasan flowchart pengolahan data menggunakan metode TF-IDF untuk analisis tenaga kerja pada bidang telematika. Implementasi Sistem Hybrid Pada Perusahaan Jasa Telematika Indonesia Menggunakan Metode K-Means Clustering dan Klasifikasi ID3.

72
Implementasi Algoritma Lda (Laten Direchlet
Tahapan Pembuatan Aplikasi Topic Mining
Setelah itu dilanjutkan dengan proses clustering menggunakan metode K-Means++ pada baris 16 dan 17 untuk menghasilkan data keanggotaan cluster. Ekstrak dan copy folder banana dashboard yang sudah diunduh ke Solr_Home/solr-7.3.0/server/solr-webapp/webapp. Masukkan nama koleksi dengan nama inti yang dibuat dan kolom waktu dengan atribut waktu sebagai tergores.
Seleksi fitur pada dataset faktor kesiapsiagaan bencana di provinsi-provinsi di Indonesia menggunakan metode PCA (Principal Component Analysis). Fatimah, Moch.abdul mukid, Agus Rusgiyono (2017) analisis skor kredit menggunakan metode bagging dan k-nearest neighbour ISSN GAUSSIAN JOURNAL Volume 6 EDISI 1 Tahun 2017 Halaman 161-170 Ganda.M 2015 Penerapan sistem hybrid pada usaha industri jasa.
91
Implementasi K -Means Pada Clustering
Hasil klaster selanjutnya akan dianalisis untuk mengetahui hubungannya dengan variabel kendala dan prospek usaha (rencana pengembangan). Jika CG berubah atau tidak sama dengan sebelumnya, hitung ulang langkah 3 dengan nilai CG baru hingga nilai CG tidak berubah lagi. Atribut pada baris 10 tidak dimasukkan dalam proses clustering karena merupakan informasi administrasi dari SMK yang tidak mempengaruhi pengelompokan data.
Hasil cluster ini akan dianalisis lebih lanjut untuk menguji keragamannya dan menganalisis karakteristik masing-masing cluster data.
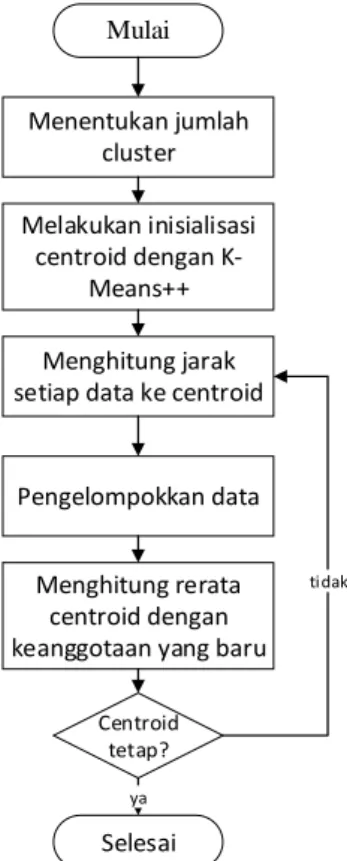
Tahapan Pembuatan Aplikasi Clustering Metode K-
Buat folder “statis” untuk menyimpan CSS atau bootstrap situs, dan folder “template” untuk menyimpan file html yang akan dibuat. Setelah tampilan laporan dibuat, untuk mempublikasikan hasil laporan ke layanan Power BI, klik ikon "Terbitkan" di menu mulai. Laporan telah diterbitkan dan Power BI menyediakan kode semat untuk laporan yang dapat dibagikan.
Jika ingin menambahkan lebih dari 1 diagram, Anda dapat mengklik tanda “+” untuk menambahkan panel atau ulangi dari langkah 3 hingga langkah 6. Irfan Wahyudin lahir di Surabaya, menempuh studi S1 Matematika di ITS Surabaya, pada tahun 2002 - 2007. Ia kemudian melanjutkan studi Magister Ilmu Komputer di IPB University, Bogor pada tahun 2018, di mana ia mengambil konsentrasi penelitian pada text mining dan machine learning.
Pada tahun 2016, Irfan dipromosikan menjadi AVP Software Development dan Data Warehouse di PT Bank Bukopin, Tbk hingga tahun 2017. Fredi menempuh pendidikan di Program Studi Teknologi Industri Pertanian, Fakultas Teknologi Pertanian, Institut Pertanian Bogor (IPB) (1999) dan melanjutkan gelar masternya di bidang agribisnis. Manajemen, Institut Pertanian Bogor (IPB) pada tahun 2001.
112
Implementasi Pipeline Dan Datalake
Metode Inverse Document Frekuensi Term Frekuensi (TF-IDF) adalah metode yang digunakan untuk menentukan seberapa dekat keterkaitan kata (istilah) pada suatu dokumen dengan memberikan bobot pada setiap kata. Metode TF-IDF ini menggabungkan dua konsep yaitu frekuensi kemunculan suatu kata dalam suatu dokumen dan frekuensi kebalikan dari dokumen yang mengandung kata tersebut (Fitri, 2013). Dalam perhitungan bobot menggunakan TF-IDF, terlebih dahulu dihitung nilai TF per kata dengan bobot tiap kata 1.
WordIDF adalah nilai IDF setiap kata yang akan dicari, td adalah jumlah total dokumen yang ada, df adalah jumlah kata yang muncul di seluruh dokumen. Setelah diperoleh nilai TF dan IDF, maka bobot akhir TF-IDF dirumuskan pada Persamaan 1, dimana w (wordi) adalah nilai bobot setiap kata, dan TF (wordi) merupakan hasil perhitungan TF.
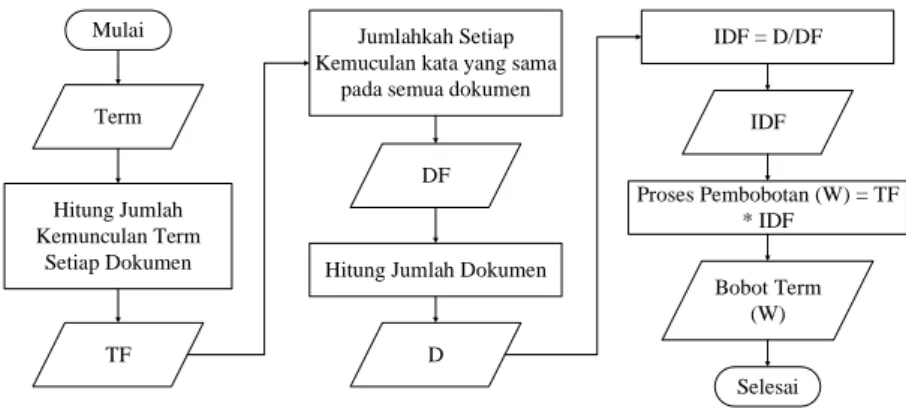
Tahapan Pembuatan Aplikasi Pipeline Dan Datalake
Pengguna bebas menginstal Apache Solr di sistem apa pun dengan persyaratan sistem minimum dan Java yang sesuai. Kajian eksplorasi profesi pemasaran dan kaitannya dengan lowongan, jabatan, deskripsi dan persyaratan pekerjaan bagi pemasar (Penelitian pada situs pencarian kerja kari.com dan loker.id). Pengalaman karirnya antara lain bekerja sebagai API developer untuk perangkat meteran listrik digital pada tahun 2006 hingga 2008.
Kemudian beliau bekerja sebagai Senior Software Developer dan Datawarehouse Analyst pada tahun 2008 hingga 2011 hingga 2016 di PT Bank Bukopin, Tbk. Beberapa prestasi yang diraihnya antara lain pada tahun 2013 terpilih sebagai dosen berprestasi di lingkungan Kopertis IV Jawa Barat Banten, tahun 2017 menjadi presenter terbaik pada Seminar Nasional Hibah Penelitian Kompetitif Kemenristekdikti. Perguruan Tinggi, pada tahun 2017 meraih Best Paper Award pada International Conference on Global Optimization and Its Application (The 6th ICoGOIA) Malacca, Malaysia, dan pada tahun 2018 meraih Best Presenter Seminar Nasional Mono Year Community Service Awards yang diraih dari Kementerian Riset, Teknologi, dan Pendidikan Tinggi.