2020
MODUL MATA KULIAH
Manajemen dan Analisis Data Kesehatan Menggunakan SPSS
Disusun oleh
Desi Rusmiati, S.SiT, M.KM
Desi Rusmiati, S.SiT, M.KM
1 Penelitian memiliki tujuan untuk mengumpulkan data, baik melalui wawancara, pengukuran, atau pemeriksaan. Manajemen data merupakan kegiatan pengelolaan data sebagai salah satu tahapan kegiatan penelitian, yang dimulai dari tahap persiapan penerimaan data sampai persiapan analisis data. Tahapan dalam manajemen data meliputi proses penerimaan data - pengelompokan data, pemeriksaan-pengkodean data, perekaman data dan pembersihan data. Kemudian data yang sudah bersih disimpan menggunakan sistem penyimpanan yang baik dan aman, sehingga jika dibutuhkan data dapat diakses dengan cepat.Manajemen data memiliki peranan yang sangat penting dalam suatu penelitian sebab jika terjadi kesalahan dalam pengelolaan data akan berpengaruh terhadap hasil penelitian secara keseluruhan. Karena banyaknya tahap yang harus dilalui dalam proses manajemen data termasuk analisis statistiknya maka dalam selanjutnya akan dibahas mengenai konsep manajemen data lebih lanjut berikut dengan pemanfaatan program SPSS for Windows untuk membantu menganalisa data.
A. Pengertian Manajemen Data
Manajemen data adalah salah satu tahapan kegiatan dalam suatu penelitian, dimana prosesnya dimulai dari penerimaan kuesioner hingga menjadi data yang siap untuk dianalisis. Adapun tujuan dari manajemen data adalah untuk menghasilkan informasi yang benar.
B. Hal-hal yang Diperlukan dalam Manajemen Data
Dalam buku Manajemen Data yang ditulis oleh Sri Poedji H, dkk (2014) dikemukakan beberapa hal yang perlu diperhatikan dalam melakukan manajemen data terhadap substansi penelitian adalah:
1. Kepentingan atau minat penelitian yang tercantum dalam perumusan tujuan dan permasalahan yang menjadi ruang lingkup penelitian.
2. Kemampuan peneliti, termasuk di dalamnya keterbatasan waktu, tenaga, dan biaya penelitian
3. Menjaga kualitas dan kesahihan data dengan melakukan prosedur manajemen data 4. Bentuk dan jenis variabel yang akan dianalisis
5. Skala pengukuran (skala nominal, skala ordinal, skala interval, dan skala rasio) 6. Tipe skala (Likert Scale, Guttman Scale, Semantic Differensial, Rating Scale) 7. Kemudahan dan kesulitan instrumen penelitian
8. Validitas dan realibitas intrumen.
PENGANTAR MANAJEMEN DATA
Desi Rusmiati, S.SiT, M.KM
2 Kemudian juga dikemukakan beberapa hal yang secara khusus perlu diperhatikan dalam melakukan langkah-langkah manajemen data adalah sebagai berikut :1. Perangkat lunak
Perangkat lunak hendaknya mampu merekam data, mengolah data, dan menganalisis data dengan baik. Hal yang perlu diperhatikan dalam pemilihan perangkat lunak adalah kemampuan dari perangkat lunak tersebut untuk memuat jumlah variabel dan jumlah record, sehingga tidak terjadi masalah ketika sudah dilakukan proses data.
2. Prosedur Manajemen Data
Prosedur manajemen data tetap mengikuti tahapan yang seharusnya tetapi mudah dilaksanakan oleh petugas. Hal ini terkait dengan kerumitan dan besar kecilnya suatu penelitian.
3. Validasi dalam Manajemen Data
Prosedur validasi data dapat dilakukan dengan cara melakukan dua kali perekaman dengan orang yang berbeda, atau cek antara data perekaman yang dihasilkan dengan isian pada kuesioner.
4. Petugas Manajemen Data
Petugas manajemen data sebaiknya memiliki sifat teliti dan tekun serta mampu mengoperasikan komputer, analisis statistik, dan menggunakan perangkat lunak terkait statistik.
5. Penyimpanan Data
Perlu dipahami pentingnya penyimpanan data sehingga perlu dilakukan penyimpanan hasil perekaman data dalam suatu media elektromagnetik yang sangat peka terhadap suatu perlakukan misalnya compact disk atau hardisk.
Desi Rusmiati, S.SiT, M.KM
3 C. Tahapan Kegiatan Manajemen DataGambar 1. Tahapan Kegiatan Manajemen Data
Pengumpulan data
Penerimaan – pengelompokan data
Pemeriksaan
Pengkodean
Perekaman data
Pengumpulan data
Inventarisir
• Sampel/spesimen
• Jumlah
• Lokasi/perlakuan
• Pengelompokan
• Penomoran
• Peletakan berkas
• Periksa kelengkapan data
• Periksa konsistensi data
• Periksa kelogisan data
• Mengenal struktur data
• Penyusunan buku kode
• Pembuatan program entri
• Enti data
• Deteksi kode tidak sesuai
• Cek konsistensi data
• Deteksi data outlier
• Deteksi duplikasi sampel
Desi Rusmiati, S.SiT, M.KM
4 A. Mengenal SPSS for WindowsSPSS for Windows merupakan salah satu program olah data statistik yang paling banyak diminati oleh para peneliti. Sebab SPSS for Windows relatif fleksibel dan dapat digunakan untuk hampir semua bentuk dan tingkatan penelitian. Hampir semua model aplikasi statistik, mulai dari yang sederhana yakni Statistik Deskriptif (Mean, Median, Modus, Sum, Prosentase, Minimum, Maksumum; Kuartil, Desil, Persentil, Range, Varians, Standard Deviasi, dan lain-lain) hingga Statistik Inferensial dengan model Non-Parametrik (Chi Square, Wilcoxon, Kendall Tau, dan lain-lain). Selain itu, dalam SPSS for Windows ini dilengkapi pula dengan menu pengelolaan berbagai jenis Grafik dengan tingkat resolusi yang tinggi.
B. Memulai SPSS
Untuk dapat menggunakan program SPSS for Windows maka terlebih dahulu memastikan program tersebut sudah terinstal di komputer. Jika sudah terinstal maka untuk mengaktifkan SPSS dimulai dengan langkah-langkah sebagai berikut :
1. Klik Start 2. Klik Program
3. Klik SPSS for Windows 4. Klik SPSS 1.0 for Windows.
Maka akan muncul tampilan sebagai berikut :
Gambar 2. Memulai SPSS
PENGANTAR SPSS
Desi Rusmiati, S.SiT, M.KM
5 Setelah Program SPSS for windows di klik kemudian dilayar monitor akan muncul kotak dialog awal SPSS sebagai berikut :Gambar 3. Kotak Dialog Awal SPSS
Tampilan diatas merupakan pilihan dari fasilitas yang ada di SPSS, dengan pilihan sebagai berikut :
a. Run the tutorial ; digunakan saat memerlukan tutorial dalam menggunakan SPSS b. Type in data ; tipe data yang digunakan
c. Run an existing query ; digunakan jika ingin membuka dan melanjutkan dengan menggunakan data base yang bukan berasal dari sistem SPSS. Seperti exel, lotus atau dbase
d. Create new query using data base urizard ; digunakan jika ingin membuat data base baru yang bersumber pada program lain yang masih satu sistem.
e. Open en existing data source ; digunakan jika ingin membuka file data penelitian pada data editor yang aktif sebagai file *.tmp.
f. Open another type of file ; digunakan untuk membuka type file yaitu file dari out put viewer yang masih aktif dalam sistem SPSS.
Jika dalam keadaan default, pilihannya adalah open an existing data source. Jika ingin membuka file yang sudah ada klik OK. Namun jika akan membuat file data baru klik CANCEL maka akan muncul layar kosong SPSS yang bisa diisi dengan data baru.
Desi Rusmiati, S.SiT, M.KM
6 C. Mengenal Jendela SPSSSetelah membuka program SPSS, dan pada layar monitor muncul kotak dialog seperti Gambar 2 di atas, abaikan pilihan-pilihan pada kotak dialog tersebut lalu tekan CANCEL. Kemudian layar kerja SPSS akan terbuka (Untitled - SPSS Data Editor) seperti pada gambar berikut:
Gambar 4. Layar Kerja SPSS
Perhatikan di kiri bawah ada dua Jendela yaitu (1) Data View dan (2) Variabel View yang merupakan dua model layar kerja pada program SPSS for windows. Layar kerja yang pertama (Data View) adalah layar kerja yang digunakan untuk memasukan data, sedangkan layar kerja yang kedua (Variabel View) adalah layar kerja yang digunakan untuk memasukan nama variabel dan karakteristiknya. Untuk dapat menggunakannya klik saja pada kotak yang tersedia. Berikut penjelasan lebih lanjut mengenai Data view dan Variabel view.
1. Variabel View
Jendela variabel view merupakan layar kerja untuk pengisian variabel. Untuk dapat menggunakannya terlebih dahulu klik variabel view pada menu, sehingga akan muncul tampilan sebagai berikut :
Desi Rusmiati, S.SiT, M.KM
7Gambar 5. Jendela Variabel View
Aturan penulisan variabel view (kolom-kolom yang harus diisi) adalah sebagai berikut :
a. Name atau nama variabel:
Aturan pemberian nama variabel adalah 1) Wajib diawali dengan Huruf, dan 2) tidak boleh lebih dari 8 karakter, 3) tidak boleh ada spasi (spacebar). Misalnya, anda tidak bisa mengetik “Jenis Kelamin” atau “Je-kel” sebagai variabel, tetapi hanya bisa “Kelamin” saja serta 4) tidak boleh ada yang sama.
b. Type atau jenis data:
Untuk menentukan type data, klik pada kolom type, kemudian akan muncul kotak dialog pilihan type datanya
Gambar 6. Kotak Dialog Variabel Type
Desi Rusmiati, S.SiT, M.KM
8 Terdapat 8 pilihan type data yang dapat digunakan, yaitu :• Numeric : data berupa angka
• Comma : data berupa angka dengan tanda koma sebagai pemisah bilangan
• Dot : data berupa angka dengan tanda titik sebagai pemisah bilangan ribuan
• Sciectific notation : sama seperti numerik tetapi menggunakan simbol E untuk kelipatan 10 (misal 120000 = 1,20E+5)
• Date : menampilkan data berupa tanggal atau waktu
• Dollar : data dengan tanda dolar
• Custom currency : data berupa huruf dan karakter lainnya c. Widith
Kolom ini untuk penentuan lebar kolom. Caranya dengan diklik maka akan muncul tanda panah, kemudian klik tanda panah ke bawah untuk mengurangi lebar kolom dan tanda panah ke atas untuk menambah lebar kolom. Atau dapat langsung mengetik langsung pada lebar kolom yang sudah tersedia.
d. Decimals
Untuk menentukan bilangan desimal yang diperlukan. Cara menggunakannya sama dengan widith.
e. Label atau keterangan variabel:
Karena nama variabel tidak boleh lebih dari 8 karakter, biasanya pemberian nama variabel menggunakan singkatan, supaya singkatan tersebut dapat dimengerti maka anda bisa memberi keterangan atau penjelasan terhadap variabel tersebut di kolom label. Misalnya pada variabel “pendidikan” anda bisa memberi label
“pendidikan kepala keluarga”, variabel “umur_ibu” bisa diberi label dengan “umur ibu berdasarkan ulang tahun terakhir”.
f. Values atau kode variabel:
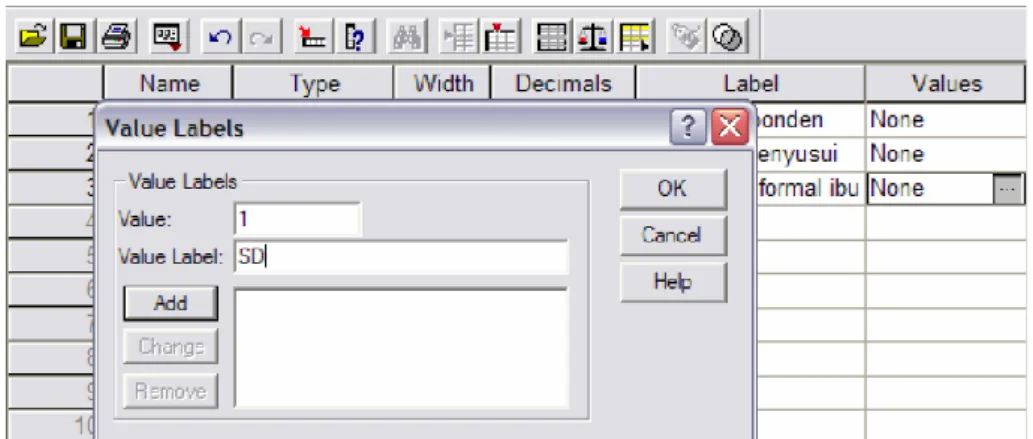
Disebut juga pengelompokan atau klasifikasi. Value ini digunakan untuk variabel dummy atau berdasarkan kelompok. Misalnya Jenis kelamin dapat anda masukkan dengan mengetik “Laki-laki” atau “Perempuan”, tetapi hal ini tidak efisien (waktu dan tenaga hilang percuma). Sebaiknya anda beri kode 1=”Laki-laki” dan 2=“Perempuan”, sehingga anda cukup memasukkan angka 1 atau 2. Supaya nantinya output SPSS yang muncul untuk Kelamin bukan angka 1 dan 2 tetapi yang muncul adalah Laki dan Perempuan, maka anda perlu mengisi Values. Cara menggunakan sebagai berikut :
• Klik kolom Value (pada bagian kanan bertanda....) kemudian muncul kotak dialog value
Desi Rusmiati, S.SiT, M.KM
9• pada kotak kolom value ketikan angka 1 jika sudah tekan tabs untuk pindah ke kotak Value Label dan ketik Laki-laki. Kemudian klik Add. Sehingga pada kolom paling bawah muncul tulis 1 = Laki=laki. Lakukan hal yang sama untuk koding berikutnya. Berikut hasilnya :
Gambar 7. Kotak Dialog Value
g. Missing
Digunakan untuk menjelaskan data yang hilang/rusak. Dalam kolom ini ada tiga pilihan yaitu no missing value (tidak ada data yang akan dihilangkan), discrite missing value (data mana saja yang akan dihilangkan) dan range plus (data yang berupa interval yaitu nilai tertinggi dan nilai terendah yang akan dihilangkan). Kolom ini cenderung untuk diabaikan atau tidak digunakan/lewat saja.
h. Colomms
Digunakan untuk menentukan lebar kolom caranya sama seperti mengatur widith. Secara default lebar kolom adalah 8 karakter
i. Align
Untuk meletakan data pada posisi yang tersedia yaitu rata kiri, rata kanan atau ditengah-tengah. Caranya klik kolom align (pada tanda panah) kemudian klik pilihan yang ada.
j. Measure
Untuk menentukan jenis data yang akan kita masukan. Caranya klik pada kolom measure (klik pada tanda panah) maka akan muncul pilihan Scale, Nominal, Ordinal pilih salah satu dengan mengkliknya.
Desi Rusmiati, S.SiT, M.KM
10 2. Data ViewSetelah mengisi variabel view, selanjutnya memasukan data pada jendela Data View. Untuk mengaktifkannya, klik data view pada bagian bawah spreedsheet dan akan muncul tampilan sebagai berikut :
Gambar 8. Jendela Data View
Entry data dapat langsung dilakukan pada data editor. Data editor memiliki bentuk tampilan sejenis spreadsheet (seperti Excel) yang digunakan sebagai fasilitas untuk memasukkan/mengisikan data. Ada tiga hal yang harus diperhatikan :
• Baris menunjukkan kasus/responden
• Kolom menunjukkan variabel
• Sel merupakan perpotongan antara kolom dan baris menunjukkan nilai/data
D. Mengenal Jendela Output SPSS
Jendela Output SPSS tidak langsung muncul pada saat pertama kali menjalankan program SPSS, namun sebenarnya sudah terbuka hanya saja belum aktif. Biasanya akan muncul setelah file data di save atau setelah melakukan analisis data. Jendela ini akan menampilkan hasil-hasil analysin statistik dan grafik yang telah dibuat. Berikut adalah tampilan jendela Output :
Desi Rusmiati, S.SiT, M.KM
11Gambar 9. Jendela Output SPSS
E. Mengenal Menu Bar
Sistem kerja SPSS for Windows dikendalikan oleh menu (bar menu)/Bar menu terletak di sebelah atas dengan urutan dari kiri ke kanan sbb: File, Edit, View, Data, Transform, Analyze, Graphs, Utilities, Window, Help.
• File : digunakan untuk membuat file data baru, membuka file data yang telah tersimpan (ekstensi SAV), atau membaca file data dari program lain, seperti
• dbase, excell dll.
• Edit : digunakan untuk memodifikasi, mengcopy, menghapus, mencari, dan mengganti data.
• View : digunakan untuk mengatur tampilan font, tampilan kode/label
• Data : digunakan untuk membuat/mendefinisikan nama variabel, mengambil/menganalisis sebagian data, menggabungkan data.
• Transform : digunakan untuk transformasi/modifikasi data seperti pengelompokan variabel, pembuatan variabel baru dari perkalian/penjumlahan variabel yang ada dll.
• Analyze : digunakan untuk memilih berbagai prosedur statistik, dari statistik sederhana (deskriptif) sampai dengan analisis statistik komplek (multivariat).
• Graphs : digunakan untuk membuat grafik meliputi grafik Bar, Pie, garis, Histogram, scatter plot dsb.
• Utilities : digunakan untuk menampilkan berbagai informasi tentang isi file.
Desi Rusmiati, S.SiT, M.KM
12• Window : digunakan untuk berpindah-pindah antar jendela, misalnya dari jendela data ke jendela output.
• Help : memuat informasi bantuan bagaimana menggunakan berbagai fasilitas pada SPSS.
Desi Rusmiati, S.SiT, M.KM
13 A. PendahuluanApabila anda belum punya data SPSS (masih mulai dari awal untuk memasukkan data), maka jendela data yang muncul masih kosong. Untuk memulainya, anda dapat membuka jendela Variabel Vew terlebih dahulu dengan cara meng-klik-nya, selanjutnya mulailah membuat variabel yang dibutuhkan dengan cara mengetik nama variabel yang diinginkan.
Setelah proses pembuatan varaibel selesai, selanjutnya buka jendela Data Vew dan masukkan datanya. Berikut adalah data mengenai perilaku menyusui ibu dalam buku Analisa Data Kesehatan (Sutanto, 2001) yang dapat kita jadikan sebagai bahan latihan melakukan entry data:
Penelitian “Faktor-faktor yang berhubungan dengan perilaku menyusui eksklusif di Daerah X tahun 2001”. Berikut ini instrumen yang digunakan dalam penelitian :
MEMASUKAN DATA
Desi Rusmiati, S.SiT, M.KM
14 Survei dilakukan pada 30 responden, dengan hasil seperti pada tabel 1 berikut :Tabel 1. Data Latihan 1
Penelitian “Faktor-faktor yang berhubungan dengan perilaku menyusui eksklusif di Daerah X tahun 2001
Desi Rusmiati, S.SiT, M.KM
15 B. Langkah-langkah memasukan (Entry) Data1. Langkah pertama : membuat nama variabel a. Buka jendela variabel view
Gambar 10. Jendela Variabel view
b. Membuat nama variabelnya :
• Membuat variabel No
o pada kolom name ketik nama variabel “No”
o pada kolom Type, untuk varibel No karena datanya yang akan masuk berbentuk angka berarti anda pilih numeric (secara otomatis SPSS memberikan default Numeric)
o pada kolom Width, Secara standar lebar kolom sudah diatur SPSS lebar kolom (Width) 8 karakter, jadi abaikan saja untuk width nya
o pada kolom Decimal, SPSS secara otomatis memberi ruang untuk 2 desimal, untuk variabel No tentunya berbentuk bilangan bulat (tidak ada desimal) jadi kolom Decimal diberi angka 0 atau dikosongkan.
Desi Rusmiati, S.SiT, M.KM
16 o pada kolom Label, ketik/isikan keterangan untuk memperjelas variabel No,misalnya diketik “Nomor Responden”
o pada kolom Values, variabel No bukan merupakan variabel koding, maka kolom Value tidak diisi/diabaikan saja, sehingga proses pembuatan variabel No sudah selesai, dan tampilan lengkapnya menjadi sebagai berikut :
Gambar 11. Variabel No
• Membuat Variabel Umur
o pada kolom name ketik nama variabel “Umur”
o pada kolom Type, untuk varibel umur karena datanya yang akan masuk berbentuk angka berarti anda pilih numeric (secara otomatis SPSS memberikan default Numeric, jadi abaikan saja untuk isi kolom type jangan diubah)
o pada kolom Width, Secara standar lebar kolom sudah diatur SPSS lebar kolom (Width) 8 karakter, jadi abaikan saja untuk width nya
o pada kolom Decimal, SPSS secara otomatis memberi ruang untuk 2 desimal, untuk variabel umur tentunya berbentuk bilangan bulat (tidak ada desimal) jadi kolom Decimal diberi angka 0 atau dikosongkan.
o pada kolom Label, ketik/isikan keterangan untuk memperjelas variabel umur, misalnya diketik “Umur ibu menyusui”
o pada kolom Values, variabel No bukan merupakan variabel koding, maka kolom Value tidak diisi/diabaikan saja, sehingga proses pembuatan variabel umur sudah selesai.
• Membuat Variabel Pendidikan
o pada kolom name ketik nama variabel “Didik”
o pada kolom Type, untuk varibel didik karena datanya yang akan masuk berbentuk angka berarti anda pilih numeric (secara otomatis SPSS memberikan default Numeric, jadi abaikan saja untuk isi kolom type jangan diubah)
o pada kolom Width, Secara standar lebar kolom sudah diatur SPSS lebar kolom (Width) 8 karakter, jadi abaikan saja untuk width nya
Desi Rusmiati, S.SiT, M.KM
17 o pada kolom Decimal, SPSS secara otomatis memberi ruang untuk 2desimal, untuk variabel didik tentunya berbentuk bilangan bulat (tidak ada desimal) jadi kolom Decimal diberi angka 0 atau dikosongkan.
o pada kolom Label, ketik/isikan keterangan untuk memperjelas variabel didik, misalnya diketik “Pendidikan formal ibu menyusui”
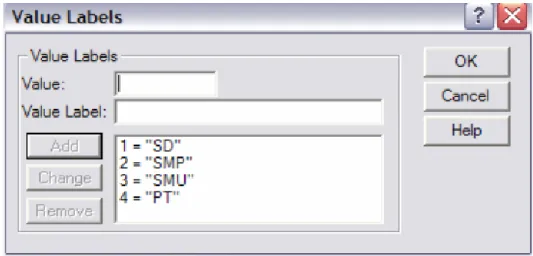
o pada kolom Values, oleh karena variabel Didik merupakan variabel yang berbentuk koding, yaitu kode 1 = SD, 2=SMP, 3=SMU, 4=PT maka kolom Value harus diisi dengan cara meng Klik kolom Value akan muncul menu :
Gambar 12. Kotak Dialog Menu Value
Pada kotak Value isikan angka 1, lalu klik kotak Value Label isikan SD, hasilnya nampak sbb :
Gambar 13. Kotak Dialog Menu Value
Kemudian klik tombol Add sehinga di kotak bagian bawah akan muncul :
Desi Rusmiati, S.SiT, M.KM
18Gambar 14. Kotak Dialog Menu Value
Lakukan hal yang sama untuk mengisi koding SMP, SMA, dan PT, sehingga hasilnya sebagai berikut :
Gambar 15. Kotak Dialog Menu Value
Kemudian, klik tombol OK sehingga selesailah pembuatan variabel Didik.
• Membuat Variabel Kerja
o pada kolom name ketik nama variabel “Kerja”
o pada kolom Type, untuk varibel kerja karena datanya yang akan masuk berbentuk angka berarti anda pilih numeric (secara otomatis SPSS memberikan default Numeric, jadi abaikan saja untuk isi kolom type jangan diubah)
o pada kolom Width, Secara standar lebar kolom sudah diatur SPSS lebar kolom (Width) 8 karakter, jadi abaikan saja untuk width nya
Desi Rusmiati, S.SiT, M.KM
19 o pada kolom Decimal, SPSS secara otomatis memberi ruang untuk 2desimal, untuk variabel kerja tentunya berbentuk bilangan bulat (tidak ada desimal) jadi kolom Decimal diberi angka 0 atau dikosongkan.
o pada kolom Label, ketik/isikan keterangan untuk memperjelas variabel Kerja, misalnya diketik “Status Pekerjaan ibu menyusui”
o pada kolom Values, oleh karena variabel Kerja merupakan variabel yang berbentuk koding, yaitu kode 0 = bekerja, 1 = tidak bekerja
• Membuat Variabel BB ibu
o pada kolom name ketik nama variabel “BBibu”
o pada kolom Type, untuk varibel BB ibu karena datanya yang akan masuk berbentuk angka berarti anda pilih numeric (secara otomatis SPSS memberikan default Numeric, jadi abaikan saja untuk isi kolom type jangan diubah)
o pada kolom Width, Secara standar lebar kolom sudah diatur SPSS lebar kolom (Width) 8 karakter, jadi abaikan saja untuk width nya
o pada kolom Decimal, SPSS secara otomatis memberi ruang untuk 2 desimal, untuk variabel BB ibu datanya berbentuk bilangan bulat (tidak ada desimal) jadi kolom Decimal diberi angka 0 atau dikosongkan.
o pada kolom Label, ketik/isikan keterangan untuk memperjelas variabel BB ibu, misalnya diketik “Berat badan ibu menyusui”
o pada kolom Values, abaikan/biarkan aja karena variabel BB ibu berbentuk numerik. Proses pembuatan variabel BB ibu selesai
• Membuat Variabel Eksklusif
o pada kolom name ketik nama variabel “Eksklu”
o pada kolom Type, untuk varibel eksklusif karena datanya yang akan masuk berbentuk angka berarti anda pilih numeric (secara otomatis SPSS memberikan default Numeric, jadi abaikan saja untuk isi kolom type jangan diubah)
o pada kolom Width, Secara standar lebar kolom sudah diatur SPSS lebar kolom (Width) 8 karakter, jadi abaikan saja untuk width nya
o pada kolom Decimal, SPSS secara otomatis memberi ruang untuk 2 desimal, untuk variabel eksklusif tentunya berbentuk bilangan bulat (tidak ada desimal) jadi kolom Decimal diberi angka 0 atau dikosongkan.
o pada kolom Label, ketik/isikan keterangan untuk memperjelas variabel eksklusif, misalnya diketik “Status menyusui eksklusif”
Desi Rusmiati, S.SiT, M.KM
20 o pada kolom Values, oleh karena variabel eksklusif merupakan variabelyang berbentuk koding, yaitu kode 0 = Tidak eksklusif, 1 = eksklusif
• Membuat Variabel HB 1
o pada kolom name ketik nama variabel “Hb1”
o pada kolom Type, untuk varibel Hb1 karena datanya yang akan masuk berbentuk angka berarti anda pilih numeric (secara otomatis SPSS memberikan default Numeric, jadi abaikan saja untuk isi kolom type jangan diubah)
o pada kolom Width, Secara standar lebar kolom sudah diatur SPSS lebar kolom (Width) 8 karakter, jadi abaikan saja untuk width nya
o pada kolom Decimal, SPSS secara otomatis memberi ruang untuk 2 desimal, untuk variabel Hb1 merupakan data kontinyu (ada desimal) jadi kolom Decimal diberi angka 1 sesuai dengan datanya.
o pada kolom Label, ketik/isikan keterangan untuk memperjelas variabel Hb1, misalnya diketik “Kadar HB ibu menyusui pada pengukuran pertama”
o pada kolom Values, abaikan/biarkan aja karena variabel Hb1 berbentuk numerik. Proses pembuatan variabel Hb1 selesai.
• Membuat Variabel HB 2
o pada kolom name ketik nama variabel “Hb2”
o pada kolom Type, untuk varibel Hb2 karena datanya yang akan masuk berbentuk angka berarti anda pilih numeric (secara otomatis SPSS memberikan default Numeric, jadi abaikan saja untuk isi kolom type jangan diubah)
o pada kolom Width, Secara standar lebar kolom sudah diatur SPSS lebar kolom (Width) 8 karakter, jadi abaikan saja untuk width nya
o pada kolom Decimal, SPSS secara otomatis memberi ruang untuk 2 desimal, untuk variabel Hb2 merupakan data kontinyu (ada desimal) jadi kolom Decimal diberi angka 1 sesuai dengan datanya.
o pada kolom Label, ketik/isikan keterangan untuk memperjelas variabel Hb1, misalnya diketik “Kadar HB ibu menyusui pada pengukuran kedua”
o pada kolom Values, abaikan/biarkan aja karena variabel Hb2 berbentuk numerik. Proses pembuatan variabel Hb2 selesai.
• Membuat Variabel BB Bayi
o pada kolom name ketik nama variabel “BBbayi”
Desi Rusmiati, S.SiT, M.KM
21 o pada kolom Type, untuk varibel BBbayi karena datanya yang akan masukberbentuk angka berarti anda pilih numeric (secara otomatis SPSS memberikan default Numeric, jadi abaikan saja untuk isi kolom type jangan diubah)
o pada kolom Width, Secara standar lebar kolom sudah diatur SPSS lebar kolom (Width) 8 karakter, jadi abaikan saja untuk width nya
o pada kolom Decimal, SPSS secara otomatis memberi ruang untuk 2 desimal, untuk variabel BBbayi datanya berbentuk bilangan bulat (tidak ada desimal) jadi kolom Decimal diberi angka 0 atau dikosongkan.
o pada kolom Label, ketik/isikan keterangan untuk memperjelas variabel BBbayi, misalnya diketik “Berat badan bayi”
o pada kolom Values, abaikan/biarkan aja karena variabel BBbayi berbentuk numerik. Proses pembuatan variabel BBbayi selesai.
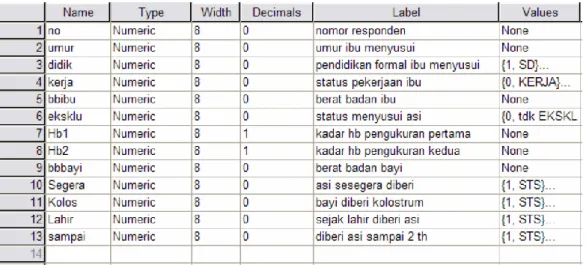
Lakukan hal yang sama untuk membuat variabel Segera, Kolos, Lahir, Sampai.
Sehingga semua variabel selesai dibuat dan akan muncul tampilan variabel view sebagai berikut :
Gambar 16. Jendela Variabel View
2. Langkah kedua : memasukan data
Setelah semua variabel dibuat, maka selanjutnya adalah memasukan data hasil survei kedalam format yang telah dibuat diatas. Untuk memasukkan data anda harus berpindah ke layar/jendela Data View, yaitu dengan Klik tombol Data View, nampak tampilannya berikut ini :
Gambar 17. Jendela Data View
Desi Rusmiati, S.SiT, M.KM
22 Memasukkan data bisa menyamping satu persatu responden di entry datanya, atau bisa juga perkolom kearah bawah. Berikut tampilan setelah 10 data dientry :Gambar 18. Jendela Data View Setelah Data Dientry
C. Mengedit Data 1. Menghapus isi sel
• Klik sel yang akan dihapus isinya
• Tekan tombol ‘Delete’ (pada Keyboard)/clear pada edit
• Jika tidak jadi menghapus, klik Undo
• Untuk menghapus isi sejumlah sel sekaligus, pilihlah sejumlah sel tersebut dengan drag (menyorot/memblok) dengan mouse.
Desi Rusmiati, S.SiT, M.KM
23Gambar 19. Menghapus Isi Sel
Dari tampilan di atas berarti kita membuat blok untuk variabel Kerja pada responden no 3 s/d 5, tekan ‘delete’ untuk menghapusnya.
2. Menghapus isi sel satu kolom (menghapus variabel)
• Klik heading kolom (nama variabel) yang akan dihapus isi-isi selnya, misalkan akan dihapus variabel BBibu: klik heading BBibu seperti berikut :
Gambar 20. Menghapus Isi Sel Satu Kolom
• Tekan tombol delete
• Untuk menghapus isi sel sejumlah kolom sekaligus, pilihlah sejumlah kolom tersebut dengan memblok pada bagian heading.
3. Menghapus baris (menghapus case/responden)
• Klik baris yang akan dihapus, contoh nomer responden 5 akan dihapus
Gambar 21. Menghapus Baris
Desi Rusmiati, S.SiT, M.KM
24• Tekan tombol delete
• Untuk menghapus beberapa case sekaligus, pilihlah sejumlah case tersebut dengan drag (menyorot dan memblok) pada bagian nomor case.
4. Mengcopy isi sel
• Pilih sel (sejumlah sel dengan menyorot) yang akan dicopy isinya.
• Tekan ‘Ctrl+C’
• Pindahkan penunjuk sel ke sel yang akan dituju
• Tekan ‘Ctrl+V’
5. Mengcopy isi satu kolom (mengcopy variabel)
• Klik heading kolom (nama variabel) yang akan dicopy isinya
• Tekan ‘Ctrl+C’
• Klik Heading kolom yang dituju
• Tekan ‘Ctrl+V’
Hasil dari instruksi tersebut adalah mengcopy kolom sekaligus format variabelnya (type variabel, lebar kolom, value label dsb), dan sudah pasti tetap tidak merubah nama variabel. Bila dikehendaki tidak ada perubahan format variabel kolom yang dituju, yang dilakukan adalah:
• Klik heading kolom (nama variabel) yang akan dicopy isinya
• Tekan ‘Ctrl+C’
• Pindahkan penunjuk sel ke baris pertama kolom yang dituju
• Tekan ‘Ctrl+V’
• Untuk mengcopy isi sel sejumlah kolom sekaligus, pilihlah sejumlah kolom tsb dengan drag pada bagian heading
Desi Rusmiati, S.SiT, M.KM
25 6. Mengcopy isi satu baris (case/responden)• Tekan ‘Ctrl+C’
• Klik nomor case yang akan dituju atau pindahkan penunjuk sel ke kolom Klik nomer Case yang akan dicopy
• pertama baris yang dituju
• Tekan ‘Ctrl+V’
7. Menyisipkan Kolom
• Pindahkan penunujuk sel pada kolom yang disisipi
• Klik ‘Data’, pilih ‘Insert Variable’, terlihat kolom baru muncul.
8. Menyisipkan Baris
• Pindahkan penunjuk sel pada baris yang akan disisipi
• Klik ’Data’, pilih ‘Insert Case’, terlihat kasus/ responden baru muncul
D. Menyimpan File Data
Setelah data dimasukan, maka data tersebut perlu disimpan untuk keperluan analisis selanjutnya. Cara penyimpanan yang pertama adalah sebagai berikut :
• Klik pada menu File kemudian Klik Save As (pilih folder tempat menyimpan data), kemudian pada layar monitor akan muncul kotak dialog Save Data As
• Ketikan nama file (misalnya file kita beri nama “latihan”) pada kolom File name kemudian klik save lagi atau enter. Tampilan pada layar monitor sebagi berikut :
Gambar 22. Menyimpan Data
Desi Rusmiati, S.SiT, M.KM
26 Cara menyimpan data kedua adalah :• Dari layar SPSS, langsung saja tekan Ctrl + S
E. Menutup SPSS
• Untuk keluar dari program SPSS dengan cara :
• Klik menu File
• Klik Exit, atau
• Klik tombol Close (x) yang ada di pojok kanan atas jendela propram aplikasi.
F. Mengaktifkan/memanggil file data
Jika sudah mempunyai data dalam format SPSS yang disimpan, silakan buka dengan SPSS, sebagai berikut:
1. Klik “File”, pilih “Open”, geser ke “Data” akan tampil kotak dialog sebagai berikut :
Gambar 23. Membuka File Data
Terlihat ada beberapa kotak isian
• Look in : Anda dapat memilih/mengganti direktori tempat file disimpan. Secara otomatis tampilan pertama akan muncul direktori SPSS.
Desi Rusmiati, S.SiT, M.KM
27• File Name : tempat untuk mengetikkan nama file, atau dapat juga dilakukan dengan meng-klik nama file yang tertampil pada kotak bagian atas file name.
• File of type : data dapat disimpan dalam berbagai format yang dapat dipilih dalam kotak ini. Secara otomatis akan muncul file format SPSS (.sav)
2. Misalkan sekarang akan diaktifkan file data: “Latihan” dari drive c direktori MyDocumen, maka caranya klik kotak File name: ketik “latihan”, atau klik “latihan yang terlihat/tertampil pada kotak di atasnya.
Gambar 24. Membuka File Data Latihan
3. Kemudian klik Open, data akan muncul di layar.
Desi Rusmiati, S.SiT, M.KM
27 Statistik dekriptif digunakan untuk menyusun data yang jumlah reltif banyak ke dalam suatu tabel frekuensi.Dengan membuat tabel frekuensi dari banyak data-data penelitian akan dapat membantu memudahkan membaca data tersebut. Bahkan dapat digunakan untuk mengambil suatu kesimpulan secara deskripsi terhadap berbagai data penelitian.
Teknik ini merupakan teknik yang paling mudah dan paling banyak digunakan untuk mendeskripsikan data.
Untuk data numerik statistik deskriptif berupa nilai pusat dan nilai sebaran (mean, median, modus, standar deviasi, standar error, dll) sedangkan untuk data kategorik berupa distribusi frekuensi dimana frekuensi yang dimunculkan dalam bentuk proporsi atau persentase. Sedangkan nilai pusat berupa nilai tengah dan nilai sebaran (mean, median, SD, SE, dll) untuk data atau variabel numerik.
A. BUKU KODE
kita akan membicarakan prosedur statistik deskriptif yang sering digunakan dalam melakukan analisis data.
Untuk latihan melakukan uji deskriptif, kita akan menggunakan data hasil penelitian “Faktor-faktor yang berhubungan dengan perilaku menyusui eksklusif di Daerah X tahun 2001” (Tabel 1. Data Latihan 1) yang sudah di entry dan di simpan dengan nama file “latihan”. Data tersebut berisi variabel yang mempengaruhi perilaku menyusui eksklusif.
Agar kita bisa mengolah data tersebut, maka kita harus mengetahui keterangan dari variabel dan value-nya yang biasanya dimuat dalam buku kode. Buku kode untuk file tersebut adalah sbb :
Variabel Keterangan
No Umur Didik
Kerja
BBibu Eksklu
HB1 HB2 BBbayi
Nomor responden Umur ibu menyusui (tahun) Pendidikan formal ibu menyusui 1 = SD
2 = SMP 3 = SMA 4 = PT
Status pekerjaan ibu menyusui 0 = bekerja
1 = tidak bekerja
Berat badan ibu menyusui (Kg) Status menyusui eksklusif 0 = tidak eksklusif 1 = eksklusif
Kadar HB ibu menyusui pada pengukuran pertama (gr%) Kadar HB ibu menyusui pada pengukuran kedua (gr%)
Berat badan bayi (Kg)
Kita harus memahami konsep jenis data statistik sebelum menganalisanya baik data Numerik maupun data Kategorik. Sebab analisis data numerik akan berbeda dengan analisis data kategorik, termasuk cara penyajian dan
UJI UNIVARIAT (DESKRIPTIF)
Desi Rusmiati, S.SiT, M.KM
28 cara interpretasinya. Data numerik biasanya ditampilkan dalam bentuk nilai tengah dan nilai sebaran (misalnya nilai rata-rata dan standar deviasi). Sedangkan data kategorik ditampilkan dalam bentuk persentase atau proporsi.B. ANALISIS DESKRIPTIF DATA KATEGORIK
Cara yang paling sering digunakan untuk menampilkan data katagorikal adalah dengan menggunakan tabel distribusi frekuensi. Berikut langkah-langkah melakukan analisis deskriptif :
1. Bukalah file latihan.SAV, sehingga data tampak di jendela Data Editor 2. Dari menu utama pilih Analyze
3. Pilih Descriptive Statistic 4. Pilih Frequencie
Gambar 25. Membuka Menu Analyze Frequencies
Pada layar tampak kotak dialog seperti gambar berikut:
Gambar 26. Kotak Dialog Frequencies1
Desi Rusmiati, S.SiT, M.KM
29 5. Pada kotak dialog tersebut, klik pada variabel DIDIK yang terdapat pada kotak sebelah kiri. Kemudian klik tanda>, sehingga kotak dialog menjadi seperti gambar berikut:
Gambar 27. Kotak Dialog Frequencies 2
4. Klik OK untuk menjalankan prosedur. Pada jendela output tampak hasil seperti berikut :
Pada kolom Frequency menunjukkan jumlah kasus dengan nilai yang sesuai. Jadi pada contoh di atas, ada 8 ibu yang berpendidikan SD dari 40 ibu yang ada. Proporsi dapat dilihat pada kolom Percent, pada contoh di atas, ada 20% ibu yang berpendidikan SD.
Kolom Valid Percent menampilkan proporsi jika missing cases tidak diikutsertakan sebagai penyebut.
Pada contoh di atas, kolom Percent dan Valid Percent memberikan hasil yang sama karena pada data ini tidak ada missing cases. Cumulative Percent menjelaskan tentang persen kumulatif, jadi pada contoh di atas, ada 40%
ibu yang berpendidikan SD dan SMP (20% + 20%).
Desi Rusmiati, S.SiT, M.KM
30 C. PENYAJIAN DATA KATEGORIKPenyajian data mempunyai prinsip efisiensi, artinya sajikan hanya informasi penting saja, jangan semua output komputer disajikan dalam laporan. Contoh penyajian data kategorik sbb:
Tabel 1
Distribusi Frekuensi Pendidikan Ibu
Pendidikan Ibu Jumah (n) Persentase (%)
SD 8 20
SMP 8 20
SMA 12 30
PT 12 30
Total 40 100
Contoh Interpretasi:
Distribusi frekuensi tingkat pendidikan ibu menyusui dapat dilihat pada Tabel-1 dimana sebagian besar ibu menyusui pendidikannya adalah SMA dan Perguruan Tinggi yaitu masing-masing sebanyak 30%.
D. ANALYSIS DESKRIPTIF DATA NUMERIK
Pada data numerik atau kontinyu, peringkasan data dapat dilakukan dengan melaporkan ukuran tengah dan sebarannya. Ukuran tengah yang dapat digunakan adalah rata-rata, median dan modus. Sedangkan ukuran sebaran yang dapat digunakan adalah nilai minimum, maksimum, range, standar deviasi dan persentil. Dari ukuran-ukuran tersebut, yang paling sering digunakan adalah rata-rata dan standar deviasi. Sebagai contoh, kita akan coba mencari ukuran tengah dan sebaran dari UMUR, Bbibu.
Berikut langkah-langkah melakukan analisis deskriptif :
1. Bukalah file latihan.SAV, sehingga data tampak di jendela Data Editor 2. Dari menu utama pilih Analyze
3. Pilih Descriptive Statistic 4. Pilih Descriptive
Desi Rusmiati, S.SiT, M.KM
31Gambar 28. Menu Anayze Descriptive
Pada layar tampak kotak dialog seperti gambar berikut:
Gambar 29. Kotak Anayze Descriptive 1
5. Pada kotak dialog tersebut, klik pada variabel UMUR yang terdapat pada kotak sebelah kiri. Tekan Ctrl (jangan dilepas), Klik variabel BBibu, lepaskan Ctrl. Dengan cara ini kita memilih 2 variabel sekaligus. Kemudian klik tanda panah, sehingga kotak dialog menjadi seperti gambar berikut:
Desi Rusmiati, S.SiT, M.KM
32Gambar 30. Kotak Anayze Descriptive 2
6. Klik OK untuk menjalankan prosedur. Pada layar output tampak hasil seperti berikut :
Nilai rata-rata dapat dilihat pada kolom Mean, sedangkan nilai standar deviasi dapat dilihat pada Std Devation. Pada contoh di atas, rata-rata umur ibu adalah 25,10 tahun dengan standar deviasi 4,929 tahun dan umur minimun 19 tahun serta umur maksimum 35 tahun. Sedangkan untuk berat badan ibu rata-rata berat badan ibu menyusui adalah 53,50 kg, berat badan minimum 45 kg, berat maksimum 70 kg, dan standar deviasi 8,137 kg.
7. Dengan cara di atas, kita dapat memperoleh nilai rata-rata, minimum, maksimum serta standar deviasi. Tetapi kita tidak memperoleh nilai standar error, padahal nilai ini diperlukan untuk melakukan estimasi inteval pada parameter populasi. Untuk mendapatkan nilai-nilai tersebut lakukan perintah option
Desi Rusmiati, S.SiT, M.KM
33 Perintah Option..1. Jika Anda juga ingin agar SPSS menampilkan standar error, anda dapat memilih menu
Gambar 31. Menu Option dalam Anayze Descriptive 1
Misalnya anda menginginkan stander error maka klik SE Mean, kemudian klik Continue dan OK hasilnya pada Jendela Output adalah sebagai berikut:
Gambar 32. Tampilan Menu Option dalam Anayze Descriptive 2
Desi Rusmiati, S.SiT, M.KM
34 Setelah Klik OK pada layar output tampak hasil seperti berikut :Dari hasil tersebut kita dapat melakukan estimasi interval dari umur ibu maupun berat badan ibu. Kita dapat menghitung 95% confidence interval umur ibu, yaitu 25,10 + 1,96 x 0,779 (mean + SE mean). Jadi kita 95% yakin bahwa rata-rata umur ibu di populasi berada pada selang 23,6 tahun sampai 26,6 tahun. Hal serupa dapat kita lakukan pada variabel berat badan ibu.
Perintah Explore
Cara yang lain untuk mengeluarkan nilai statistik deskriptif dari data numerik (nilai rata-rata/mean std. Dev) beserta 95% confidence interval adalah sebagai berikut: Dari menu utama, pilihlah:
1. Klik Analyze
2. Pilih Descriptive Statistik 3. Pilih Explore
2. Setelah kotak dialog muncul, klik pada variabel umur ibu yang terdapat pada kotak sebelah kiri. Tekan Ctrl (jangan dilepas), Klik variabel berat badan ibu lalu lepaskan Ctrl. Dengan cara ini kita memilih 2 variabel sekaligus. Kemudian klik tanda <, sehingga kedua variabel tersebut masuk ke kota Dependent List seperti gambar berikut:
Desi Rusmiati, S.SiT, M.KM
35Gambar 33. Kotak Dialog Explore
3. Klik OK untuk menjalankan prosedur, sehingga hasilnya seperti berikut:
Desi Rusmiati, S.SiT, M.KM
36 Dari hasil tersebut kita mendapatkan estimasi titik dan estimasi interval dari variabel numerik yang diukur.Kita dapat melihat nilai rata-rata dan 95% confidence interval dari umur ibu yaitu 25,10 tahun (23,52—26,68), artinya kita 95% yakin bahwa rata-rata umur ibu di populasi berada pada selang 23,52 sampai 26,68 tahun. Hal serupa dapat kita lakukan pada variabel berat badan ibu.
E. GRAFIK HISTOGRAM PADA DATA NUMERIK
Analisis data Numerik akan lebih lengkap apabila dilengkapi dengan grafik. Salah satu Grafik yang cocok untuk data numerik adalah HISTOGRAM.
1. Dari menu utama, pilihlah:
Graphs Histogram…
Maka akan muncul kotak dialog berikut :
Gambar 34. Kotak Dialog Menu Grafik 1
Desi Rusmiati, S.SiT, M.KM
37 2. Pada kotak dialog tersebut, klik pada variabel UMUR yang terdapat pada kotak sebelah kiri. Kemudian klik tanda<, sehingga kotak dialog seperti berikut:
Gambar 35. Kotak Dialog Menu Grafik 2
3. Klik Display normal curve (untuk menampilkan garis distribusi normal), Kemudian klik OK untuk menjalankan prosedur. Hasilnya sbb: (Lakukan prosedur yang sama untuk menampilkan grafik HISTOGRAM berat badan ibu)
Desi Rusmiati, S.SiT, M.KM
38 F. UJI NORMALITAS DISTRIBUSI DATA NUMERIKAnalisis data Numerik akan lebih lengkap apabila dilengkapi UJI NORMALITAS. Terutama jika akan dilakukan uji statistik parametrik terhadap variabel tersebut maka distribusi normal merupakan salah prasyarat yang harus dipenuhi. Uji normalitas dapat dilakukan melalui perintah Explore..
1. Dari menu utama, pilihlah:
Analyze
Descriptive Statistic <
Explore…
2. Pada kotak dialog tersebut, pilih variabel umur dan berat badan ibu, Kemudian klik tanda panah ke kanan >, untuk memasukkannya ke kotak Dependent list
3. Klik Plots.., kemudian aktifkan Histogram dan Normality plot with test.
Perhatikan hasil seperti gambar berikut :
Gambar 36. Kotak Dialog Uji Normalitas
4. Klik Continue dan OK, hasilnya sebagai berikut :
Desi Rusmiati, S.SiT, M.KM
39 Hasil uji test normalitasDengan uji Kolmogorov-Smirnov, disimpulkan bahwa pada alpha 0.05 distribusi data umur ibu adalah tidak normal (nilai-p = 0.052) begitupun dengan distribusi data berat badan ibu (nilai-p = 0.000). Kesimpulan normal atau tidaknya suatu data didasarkan pada prinsip uji hipotesis yang berpatokan pada Ho dan Ha. Dalam hal ini, Ho berbunyi “Distribusi data sama dengan distribusi normal”, Ha berbunyi “Distribusi data tidak sama dengan distribusi normal”. Apabila nilai-p kurang dari alpha 0.05 (mis 0.000), maka Ho ditolak dan disimpulkan “Distribusi data adalah tidak normal”. Sedangkan apabila nilai-p lebih dari alpha 0.05 (mis. 0.222), maka Ho gagal ditolak dan disimpulkan “Distribusi data adalah normal”.
G. PENYAJIAN DATA NUMERIK
Penyajian data mempunyai prinsip efisiensi, artinya sajikan hanya informasi penting saja, jangan semua output komputer disajikan dalam laporan. Contoh penyajian data numerik sbb:
Tabel 2. Distribusi umur dan Berat Badan Ibu Menyusui Di Kab. X tahun X
Variabel Mean SD Minimal-Maksimal 95% CI
Umur ibu 25,10 4,929 19-35 23,52-26,68
Berat badan ibu 53,50 8,137 45-70 50,90-56,10
Contoh interpretasi:
Berdasarkan Tabel 1 di atas diketahui rata-rata umur ibu adalah 25,10 tahun (95% CI : 23,52-26,68), dengan standar deviasi 4,929 tahun. Umur termuda 19 tahun dan umur tertua 35 tahun. Dari hasil estimasi interval dapat disimpulkan bahwa 95% diyakini bahwa rata-rata umur ibu adalah diantara 23,52 sampai dengan 26,68 tahun. Kemudian diketahu juga rata-rata berat badan ibu adalah 53,50 kg (95% CI : 50,90-56,10) dengan standar deviasi 8,137 kg dan berat minimal adalah 45 kg serta dengan 95% CI diketahui bahwa rata-rata berat badan ibu adalah diantara 50,90 sampai dengan 56,10 kg.
Desi Rusmiati, S.SiT, M.KM
40 Dalam suatu penelitian kualitas dari instrumen perlu diperhatikan mengingat data yang akan dikumpulkan haruslah akurat dan objektif, sebab suatu penelitian akan dapat dipercaya (akurat) jika data yang diperoleh pun akurat. Maka data yang terkumpul tidak akan berguna jika alat pengukur (instrumen penelitian) tidak mempunyai validitas dan realibitas yang tinggi. Dalam pengujian validitas dan reliabilitas instrumen, tentunya harus disesuaikan dengan bentuk instrumen yang akan digunakan dalam penelitian.Salah satu instrumen yang dapat digunakan dalam mengumpulkan data adalah kuesioner. Perlu diingat bahwa pertanyaan-pertanyaan yang sudah dibuat dalam kuesioner tidak dapat langsung digunakan untuk mengumpulkan data, namun harus terlebih dahulu dilakukan ujicoba kepada sekelompo orang, kecuali jika pertanyaan- pertanyaan yang akan digunakan tersebut berasal dari penelitianyang telah dilakukan oeh suatu institusi dan sudah dianggap valid.
A. VALIDITAS
Validitas berasal dari kata Validity yang mempunyai arti sejauhmana ketepatan suatu alat ukur dalam mengukur suatu data. Validitas suatu instrumen menunjukkan tingkat ketepatan suatu instrumen untuk mengukur apa yang harus diukur. Jadi validitas suatu instrumen berhubungan dengan tingkat akurasi dari suatu alat ukur mengukur apa yang akan diukur. Misalnya bila seseorang akan mengukur cincin, maka dia harus menggunakan timbangan emas. Dilain pihak bila seseorang ingin menimbang berat badan, maka dia harus menggunakan timbangan berat badan. Jadi dapat disimpulkan bahwa timbangan emas valid untuk mengukur berat cincin, tapi timbangan emas tidak valid untuk menimbang berat badan.
B. RELIABILITAS
Reliabilaitas adalah tingkat ketetapan suatu instrumen mengukur apa yang harus diukur. Merupakan suatu ukuran yang menunjukkan sejauhmana hasil pengukuran tetap konsisten bila dilakukan pengukuran dua kali atau lebih terhadap gejala yang sama dan dengan alat ukur yang sama. Misalkan seseorang ingin mengukur jarak dari satu tempat ke tempat lain dengan menggunakan dua jenis alat ukur. Alat ukur pertama denganmeteran yang dibuatdari logam, sedangkan alat ukur kedua dengan menghitung langkah kaki. Pengukuran dengan meteran logam akan mendapatkan hasil yang sama kalau pengukurannya diulang dua kali atau lebih. Sebaliknya pengukuran yang dilakukan dengan kaki, besar kemungkinan akan didapatkan hasil yang berbeda kalau
UJI INSTRUMEN
Desi Rusmiati, S.SiT, M.KM
41 pengukurannya diulang dua kali atau lebih. Dari ilustrasi ini berarti meteran logam lebih reliable dibandingkan langkah kaki untuk mengukur jarak.C. CARA MENGUKUR VALIDITAS
Untuk mengetahui validitas suatu instrumen (dalam hal ini kuesioner) dilakukan dengan cara melakukan korelasi antar skor masing-masing variabel dengan skor totalnya.
Suatu variabel (pertanyaan) dikatakan valid bila skor variabel tersebut berkorelasi secara signifikan dengan skor totalnya. Teknik korelasi yang digunakan korelasi Pearson Product Moment :
Keputusan uji:
Bila r hitung lebih besar dari r tabel →Ho ditolak, artinya variabel valid
Bila r hitung lebih kecil dari r tabel →Ho gagal ditolak, artinya variabel tidak valid
D. CARA MENGUKUR REALIBILITAS
Realibilitas merupakan keadaan yang mengukur bahwa instrumen yang digunakan menghasilkan hasil pengukuran yang tidak berubah-ubah dan konsisten (Wibowo, 2014).
Maka dalam hal ini suatu pertanyaan dikatakan reliabel jika jawaban seseorang terhadap pertanyaan adalah konsisten atau stabil dari waktu ke waktu. Jadi jika misalnya responden menjawab “setuju” terhadap perilaku mencuci tangan dapat mengurangi kejadian diare, maka jika beberapa waktu kemudian ia ditanya lagi untuk hal yang sama, maka seharusnya tetap konsisten pada jawaban semula yaitu setuju. Pengukuran reliabilitas pada dasarnya dapat dilakukan dengan dua cara :
1) Repeated Measure atau ukur ulang. Pertanyaan ditanyakan pada reponden berulang pada waktu yang berbeda (misal sebulan kemudian), dan kemudian dilihat apakah ia tetap konsistendengan jawabannya.
2) One Shot atau diukur sekali saja. Disini pengukurannya hanya sekali dan kemudian hasilnya dibandingkan dengan pertanyaan lain. Pada umumnya pengukuran dilakukan dengan One Shot dengan beberapa pertanyaan Pengujian reliabilitas dimulai dengan menguji validitas terlebih dahulu.
Jadi jika pertanyaan tidak valid, maka pertanyaan tersebut dibuang. Pertanyaan- pertanyaan yang sudah valid kemudian baru secara bersama-sama diukur reliabilitasnya
Desi Rusmiati, S.SiT, M.KM
42 E. LATIHANDalam Buku Analisis Data Kesehatan (Sutanto, 2006) diuraikan langkah-langkah dalam melakukan uji validitas dan realibilitas terhadap kuesioner yang bertujuan untuk mengetahui tingkat stress pekerja industri berikut:
1. Apakah anda sering terpaksa bekerja lembur?
1.tidak pernah 2.jarang 3.kadang-kadang 4.sering 5.selalu 2. Menurut anda, apakah dalam hidup ini perlu bersaing?
1.tidak pernah 2.jarang 3.kadang-kadang 4.perlu 5.sangat perlu 3. Apakah anda mudah marah?
1.tidak 2.jarang 3.kadang-kadang 4.sering 5.Ya 4. Apakah anda sering terjadi konflik dengan keluarga?
1.tidak 2.jarang 3.kadang-kadang 4.sering 5.Ya 5. Apakah anda sering terjadi konflik dengan teman kerja?
1.tidak 2.jarang 3.kadang-kadang 4.sering 5.Ya
Kuesioner tersebut diujikan kepada 15 responden dengan hasil berikut:
Ujilah kelima pertanyaan diatas apakah sudah valid dan reliabel
Desi Rusmiati, S.SiT, M.KM
43 Penyelesaian:Langkahnya:
1. Masukkan data tersebut ke SPSS 2. Klik ‘Analyze’
3. Pilih ‘Scale’
4. Pilih ‘Reliability Analysis’
Gambar 37. Kotak Dialog Uji Validitas Realibilitas 1
5. Masukkan semua variabel ke dalam kotak ‘Items’ (ingat variabel yang masuk hanya variabel yang akan diuji saja, yaitu P1, P2, P3, P4 dan P5) bentuknya sbb:
Gambar 38. Kotak Dialog Uji Validitas Realibilitas 2
6. Pada ‘Model’, biarkan pilihan pada ‘Alpha’
7. Klik Option ‘Statistics’
Desi Rusmiati, S.SiT, M.KM
44Gambar 39. Kotak Dialog Uji Validitas Realibilitas 3
8. Pada bagian ‘Descriptives for’ klik pilihan ‘ítem’, Scale if Item deleted.
9. Klik ‘Continue’
10. Klik ‘OK’., terlihat hasil outputnya sbb :
Gambar 40. Output Uji Validitas Realibilitas 1
Gambar 41. Output Uji Validitas Realibilitas 2
Interpretasi:
Hasil analisis reliability memperlihatkan dua bagian. Bagian utama menunjukkan hasil statistik deskriptif masing-masing variabel dalam bentuk mean, varian dll. Pada bagian kedua memperlihatkan hasil dari proses validitas dan reliabilitas. Kaidah yang berlaku bahwa pengujian dimulai dengan menguji validitas kuesioner baru dilanjutkan uji reliabilitas.
Desi Rusmiati, S.SiT, M.KM
45 1. UJI VALIDITASUji validitas suatu kuesioner dilakukan dengan cara membandingkan nilai r tabel dengan nilai r hitung.
a. Menentukan nilai r tabel
Untuk menentukan besar nilai r tabel, maka digunakan tabel r berikut:
Tabel 3. “r” Tabel
DF Alpha = 0,005 DF Alpha = 0,005
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
0,997 0,950 0,878 0,811 0,754 0,707 0,666 0,632 0,602 0,572 0,553 0,532 0,514 0,497 0,482
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
0,468 0,456 0,444 0,433 0,423 0,413 0,404 0,398 0,388 0,381 0,374 0,367 0,361 0,355 0,349
Dengan rumus: 𝒅𝒇 = 𝒏 − 𝟐
Maka dari data pada latihan di atas didapatkan nilai df = 15-2=13, sehingga pada tingkat kemaknaan 5%, didapat nilai r tabel = 0,514
b. Menentukan nilai r hasil perhitungan
Nilai r hitung dapat dilihat pada output SPSS pada kolom “Corrected item-Total Correlation”
c. Menetukan hasil uji validitas
Hasil uji validitas terhadap masing-masing pertanyaan dilakukan dengan cara membandingkan nilai r hitung masing-masing pertanyaan dengan nilai r tabel yang sudah didapatkan (0,514)
Maka berdasarkan data latihan di atas disimpulkan dari 5 pertanyaan, ada satu pertanyaan yang tidak valid (P2) sebab nilai r hitungnya (0,3275) lebih rendah dari nilai r tabelnya (0,514). Kemudian untuk pertanyaan P1, P3,P4 dan P5 dinyatakan valid.
Desi Rusmiati, S.SiT, M.KM
46 Langkah selanjutnya melakukan analisis lagi dengan mengeluarkan pertanyaan yang tidak valid. Lakukan prosedur/langkah seperti di atas yaitu :1. Klik ‘Analyze’
2. Pilih ‘Scale’
3. Pilih ‘Reliability Analysis’
4. Masukkan keempat variabel ke dalam kotak ‘Items’ (variabel P2 tidak ikut dianalisis)
5. Klik “OK” Kemudian muncul tampilan Output sbb:
Gambar 42. Output Uji Validitas Realibilitas 3
Interpretasi:
Sekarang terlihat bahwa dari keempat pertanyaan, semua mempunyai nilai r hasil (Corrected item-Total Correlation) berada di atas dari niali r tabel (r=0,514), sehingga dapat disimpulkan keempat pertanyaan tersebut valid.
2. Uji Realibilitas
Setelah semua pertanyaan valid semua, analisis dilanjutkan dengan uji reliabilitas dengan cara membandingkan nilai r hasil dengan r tabel.dalam uji reliabilitas sebagai nilai r hasil adalah nilai “Alpha” (terletak di akhir output). Ketentuannya: bila r Alpha > r tabel, maka pertanyaan tersebut reliabel
Dari hasil uji di atas ternyata, nilai r Alpha (0,993) lebih besar dibandingkan dengan nilai r table (0,514), maka keempat pertanyaan di atas dinyatakan reliabel.
Desi Rusmiati, S.SiT, M.KM
47 A. PENGERTIANTidak jarang suatu penelitian memiliki data yang berupa kategorik, bahkan dalam beberapa keadaan data numerik diubah menjadi data kategorik melalui suatu pengklasifikasian atau pengelompokan. Untuk menguji apakah ada hubungan antara dua variabel kategorik atau untuk menguji apakah ada perbedaan proporsi dua atau lebih kelompok maka statistik uji yang tepat adalah Uji Chi Square (Kai Kuadrat)
Misalnya ingin mengetahui hubungan antara pendidikan ibu dengan kejadian menyusui eksklusif. Dimana pengamatan dilakukan terhadap ibu yang memiliki tingkat pendidikan tinggi dan pendidikan rendah kemudian mengamati bagaimana perilaku menyusuinya apakah menyusui secara eksklusif atau tidak. Apabila pengamatan diatas disusun didalam suatu tabel, maka tabel tersebut dinamakan tabel kontingensi (tabel silang). Dari data tersebut dapat dilakukan uji statistik dengan uji kai kuadrat untuk melihat ada tidaknya asosiasi/hubungan antara dua sifat/variabel tersebut (pendidikan dan menyusui eksklusif).
Secara spesifik uji chi square dapat digunakan untuk menentukan/menguji:
1. Ada tidaknya hubungan/asosiasi antara 2 variabel (test of independency)
2. Apakah suatu kelompok homogen dengan sub kelompok lain (test of homogenity) 3. Apakah ada kesesuaian antara pengamatan dengan parameter tertentu yang
dispesifikasikan (Goodness of fit).
Secara umum tidak ada asumsi yang harus dipenuhi untuk uji χ2, karena distribusi χ2 ini termasuk free-distribution. Secara lebih jelas berikut ketentuan-ketentuan penting dalam menggunakan uji Chi Square (Machfoedz, 2010):
1. Jumlah sampelcukup besar
2. Pengamatan bersifat independen (uppaired)
3. Perhitungan untuk menguji hipotesis menggunakan kai kuadrat datanya harus diskrit baik berupa data frekuensi atau data kategori, jadi skala nominal atau ordinal, atau data kontinyu yang telah dikelompokan menjadi data kategori.
4. Jumlah frekuensi yang diharapkan (Expected = E) harus sama dengan jumlah frekuensi yang diamati atau diobservasi (O)
5. Bila derajat kebebasan = 1 (tabel 2x2) maka tidak boleh ada nilai ekspektasi (E) yang sangat kecil. Bila nilai yang diharapkan terletak dalam satu sel terlalu kecil (<5) dan digunakan uji chi square maka akan dapat menimbulkan taksiran yang berlebih (over estimate), hindari penggunaan chi square.
UJI BEDA PROPORSI (X2 : CHI SQUARE)
Desi Rusmiati, S.SiT, M.KM
48 B. KONSEP UJI CHI SQUAREDasar dari uji kai kuadrat adalah membandingkan frekuensi yang diamati (observasi) dengan frekuensi yang diharapkan (ekspektasi). Bila nilai frekuensi observasi dengan nilai frekuensi harapan sama, maka dikatakan tidak ada perbedaan yang bermakna (signifikan). Sebaliknya, bila nilai frekuensi observasi dengan nilai frekuensi berbeda, maka dikatakan ada perbedaan yang bermakna (signifikan).
Pembuktian dengan uji chi square dengan rumus-rumus berikut:
𝑿
𝟐= ∑ (𝑶 − 𝑬)
𝟐𝑬
𝒅𝒇 = (𝒌 − 𝟏)(𝒃 − 𝟏)
𝑬 = 𝒏𝒃 × 𝒏𝒌 𝑵
Keterangan : O = nilai observasi E = nilai ekspektasi k = jumlah kolom b = jumlah baris
nb = jumlah nilai marginal baris nk =jumlah nilai marginal kolom df = derajat kebebasan (dk)
Dalam buku Statistik Inferensial (Mahfoedz, 2010) untuk mempermudah analisis chi square digunakan contoh tabel silang 3x4 berikut:
Variabel 1 Variabe 2 (misal jenis KB)
Jumlah
Pil IUD Susuk Tubektomi
Puskesmas A b b b tb N (nilai marginal)
Puskesmas B b b b tb N (nilai marginal)
Puskesmas C tb tb tb tb N (nilai marginal)
Jumlah N (nilai marginal)
N (nilai marginal)
N (nilai marginal)
N (nilai marginal)
N (grand total)
Keterangan:
b = dapat ditentukan dengan bebas tb = tidak bisa ditentukan
n = nilai kolom dan baris diketahui
Desi Rusmiati, S.SiT, M.KM
49 jumlah nilai setiap kolom dan baris disebut nilai marginal, dan jumlah seluruhnya disebut n = grand total.N (grand total) dari jumlah nilai kolom dan baris sudah diketahui dari survei awal.
Dalam matematika, bila sel-sel yang bertuliskan b tersebut kita isi dengan bebas nilainya, maka sel-sel pada tb berisi nilai yang tidak bebas lagi untuk ditentukan nilainya, karena jumlah kolom dan baris bahkan grand total, sudah diketahui nilainya. Jumlah b inilah yang disebut dengan derajat kebebasan (dk). Contoh tabel di atas, dk 2x3 yang diperoleh dari rumus
𝒅𝒇 = (𝒌 − 𝟏)(𝒃 − 𝟏)
Maka,
𝒅𝒇 = (𝟒 − 𝟏)(𝟑 − 𝟏)
Nilai ekspektasi adalah nilai yang diharapkan terjadi sesuai dengan hipotesis penelitian. Nilai ekspektasi dihitung dengan menggunakan perkalian antara nilai marginal kolom dengan nilai marinal baris di bagi dengan grand total (n).
𝑬 = 𝒏𝒃 × 𝒏𝒌 𝑵
Contoh :
Variabel Diabetes Tidak Diabetes Jumlah
Puskesmas A 3 27 30
Puskesmas B 7 13 20
Puskesmas C 5 20 25
Jumlah 15 60 75
Perhitungan nilai ekpektasi (E) adalah dengan memberi penomoran pada setiap sel.
Maka, 𝑬𝟏= 𝟑𝟎 ×𝟏𝟓
𝟕𝟓 = 𝟔 𝑬𝟐=𝟑𝟎 ×𝟔𝟎𝟕𝟓 = 𝟐𝟒 𝑬𝟑=𝟐𝟎 ×𝟏𝟓𝟕𝟓 = 𝟒 𝑬𝟒 𝟐𝟎 ×𝟔𝟎
𝟕𝟓 = 𝟏𝟔
𝑬𝟓=𝟐𝟓 ×𝟏𝟓
𝟕𝟓 = 𝟓 𝑬𝟔=𝟐𝟓 ×𝟔𝟎
𝟕𝟓 = 𝟐𝟎
Desi Rusmiati, S.SiT, M.KM
50 Kemudian selanjutnya menguji hipotesis x2, berdasarka contoh tabel di atas kita akan menguji apakah ada perbedaan bermakna antara ketiga puskesmas tersebut :Ho = f1 = f2 = f3 Ha = fi ≠ f2 ≠ f3
*f adalah frekuensi
Rumus yang akan kita gunakan selanjutnya adalah :
𝑿
𝟐= ∑ (𝑶 − 𝑬)
𝟐𝑬
Kita akan melakukan perhitungan untuk contoh kasus di atas, dan untuk memudahkan akan digunakan tabel sebagai berikut :
O E (O – E) (O – E)2 (𝑂 − 𝐸)2
𝐸
3 6 -3 9 1,50
27 24 3 9 0,38
7 4 3 9 2,25
13 16 -3 9 0,56
5 5 0 0 0
20 20 0 0 0
4,69
𝒅𝒇 = (𝟐 − 𝟏)(𝟑 − 𝟏) = 𝟐
Maka,
X2 dk 2 α 0,05 = 5,991 (dari tabel chi squrare) X2 hasil perhitungan = 4,69
4,69 < 5,991
Kesimpulan :
Ho diterima pada derajat kemaknaan 5% atau nilai p>0,05. Jadi tidak ada perbedaan yang bermakna frekuensi penderita diabetes pada ketiga puskesmas tersebut.
Desi Rusmiati, S.SiT, M.KM
51 C. LATIHANSebagai latihan melakukan uji Chi Square kita akan menggunakan data pada tabel.1 Penelitian “Faktor-faktor yang berhubungan dengan perilaku menyusui eksklusif di Daerah X tahun 2001 (latihan entry data hal. 14) yang sebelumnya telah disimpan dengan nama file latihan. Berikut langkah-langkah melakukan uj statistik Chi Square :
1. Bukalah file latihan.SAV, sehingga data tampak di Data editor window.
2. Dari menu utama, pilihlah:
a. Analyze
b. Descriptif statistic c. Crosstabs
Berikut tampilannya :
d. Setelah mengklik crosstabs maka akan muncul kotak dialog dan masukan variabel dependen (eksklusif) ke kotak column dan pindahkan variabel independen (kerja) ke kotak rows, seperti tampak pada gambar berikut :
Desi Rusmiati, S.SiT, M.KM
52 3. Pada menu “Statistics” pilih Chi-Square dan Risk dengan mengklik kotak disampingnyahingga muncul tanda “√”. Jika anda klik sekali lagi, maka tanda “√” akan hilang.
Kemudian Klik Continue.
4. Pada menu “Cells”, kemudian aktifkan Observed pada menu Count dan aktifkan Rows pada menu Percentages hingga muncul tanda “√” (persentase yang dipilih adalah persen baris/percentages Row sebab data yang digunakan dari penelitian cross sectional, tapi jika penelitian case control maka yang digunakan adalah pecentages column) . Kemudian Klik Continue.
Desi Rusmiati, S.SiT, M.KM
53 5. Klik OK untuk menjalankan prosedur. Pada jendela output tampak hasil seperti berikut:Output SPSS di atas menampilkan tabel silang antara pemeberian ASI ekslusif dan status pekerjaan ibu, kemudian tabel Chi Square test yang menunjukan hasil uji Chi Square dari berbagai macam uji, seperti Pearson Chi-square, Continuity Correction, atau Fisher’s Exact Test. Masing-masing uji tersebut dilengkapi dengan p- value untuk test 2-sisi. Untuk memilih nilai χ2 atau p-value yang paling sesuai, kita harus berpedoman pada asumsi-asumsi yang terkait dengan uji χ2. Selain itu, output juga menampilkan tabel Risk Estimates yang menunjukan nilai Odd Ratio.
Dalam buku Analisa Data Kesehatan (Sutanto, 2011) disebutkan ketentuan hasil uji Chi Square sebagai berikut:
Desi Rusmiati, S.SiT, M.KM
54• Bila pada 2 x 2 dijumpai nilai Expected (harapan) kurang dari 5, maka yang digunakan adalah “Fisher’s Exact Test”
• Bila tabel 2 x 2, dan tidak ada nilai E < 5, maka uji yang dipakai sebaiknya
“Continuity Correction (a)”
• Bila tabelnya lebih dari 2 x 2, misalnya 3 x 2, 3 x 3 dsb, maka digunakan uji
“Pearson Chi Square”
• Uji “Likelihood Ratio” dan “Linear-by-Linear Assciation”, biasanya digunakan untuk keperluan lebih spesifik, misalnya analisis stratifikasi pada bidang epidemiologi dan juga untuk mengetahui hubungan linier dua variabel katagorik, sehingga kedua jenis ini jarang di