Dengan ini saya menyatakan bahwa skripsi yang berjudul Pengembangan Sistem Komunikasi Publik di Twitter dengan Metode Naive Bayes Classification adalah karya saya di bawah arahan komisi pembimbing dan belum pernah diajukan ke universitas manapun dalam bentuk apapun. Kehadiran teknologi informasi dan komunikasi mendorong perubahan pengelolaan organisasi secara menyeluruh, termasuk komunikasi publik. Bentuk komunikasi publik tidak hanya dilakukan secara tatap muka, namun juga sering dilakukan melalui media sosial seperti Twitter.
Pada penelitian yang telah dilakukan sejak bulan Mei 2015 ini, tema yang dipilih adalah klasifikasi Twitter yang bertajuk Pengembangan Sistem Komunikasi Publik di Twitter Menggunakan Metode Klasifikasi Naive Bayes. 1 Supardi sebagai ayah, Puji Astuti sebagai ibu, Adit dan Wahyu sebagai saudara kandung, serta seluruh anggota keluarga yang selalu memberikan doa, dukungan dan semangat untuk menyelesaikan penelitian ini. 2 Ny.Dr. Yani Nurhadryani, SSi MT selaku dosen pembimbing yang selalu ikhlas dan sabar dalam memberikan arahan dan bimbingan hingga akhir penelitian ini.
4 Nabila Aditiarini yang selalu memberikan motivasi, sumbangan, dukungan, dorongan dan doa untuk menyelesaikan penelitian ini. 6 Ega Adityawan dan M Zahid Rausyanfikri yang telah membantu penulis dalam memahami metode klasifikasi Naïve Bayes.

PENDAHULUAN
Berdasarkan latar belakang di atas, maka rumusan masalah dalam penelitian ini adalah bagaimana membuat sistem berdasarkan klasifikasi tweet pada akun @BimaAryaS. Tujuan dari penelitian ini adalah untuk membangun sistem yang dapat mengklasifikasikan tweet @BimaAryaS berdasarkan kategori yang telah ditentukan. Manfaat yang diperoleh dari penelitian ini adalah membantu pengguna Twitter khususnya para pengikut Bima Arya (@BimaAryaS) dalam mencari informasi tertentu tentang Kota Bogor berdasarkan kategori yang telah ditentukan.
1 Penelitian ini menggunakan data tweet dari akun resmi Bima Arya Sugiarto (@BimaAryaS) dengan sampel yang diambil sebanyak 3 orang sehingga diperoleh tweet dari tanggal 5 November 2014 hingga 16 Januari 2016. Pembuatan kategori dilakukan dari data latih sebanyak 316 tweet sehingga sedapat mungkin diklasifikasikan ke dalam 4 kategori umum yaitu peristiwa, infrastruktur, pendidikan dan berita dan 1 kelompok tweet yang tidak termasuk dalam 4 kategori tersebut diklasifikasikan ke dalam tidak berkategori.
TINJAUAN PUSTAKA
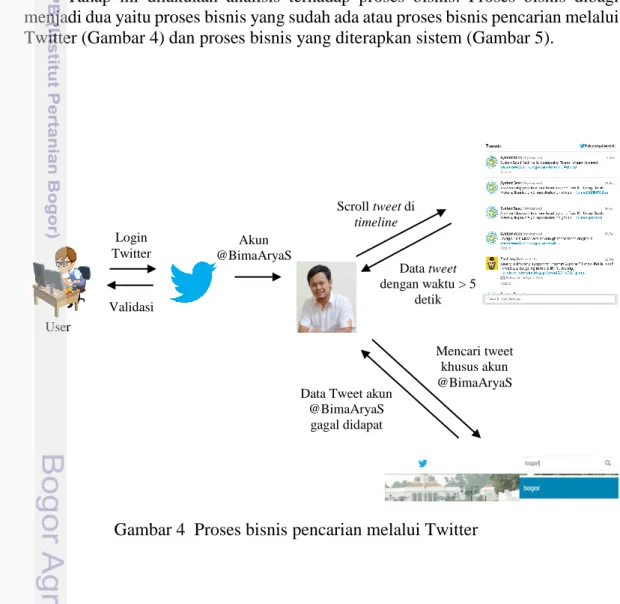
Pengumpulan data otomatis pada penelitian ini menggunakan application programming interface (API) milik Twitter. Pengumpulan data tidak terjadi secara otomatis, karena data yang diperlukan tidak dapat diambil melalui pemrograman, seperti ada tidaknya informasi visi misi di website. Begitu pula di media sosial, tidak semua data media sosial bisa diambil melalui API, karena media sosial tidak selalu menyediakan API untuk setiap konten yang dimilikinya.
Jika data yang dibutuhkan di media sosial tidak dapat diperoleh secara otomatis, maka pendataan dilakukan secara manual. Data yang digunakan dalam penelitian ini adalah data tweet dari Bima Arya (@BimaAryaS) yang diambil menggunakan Twitter REST API, sehingga datanya tidak dapat diambil secara real time. Algoritma Nazief dan Adriani merupakan algoritma asli teks bahasa Indonesia yang dibuat oleh Nazief dan Adriani (1996).
Cara kerja algoritma ini adalah dengan menggabungkan metode attachment trimming dan kamus tambahan kata dasar, yang digunakan untuk memeriksa kesesuaian kata dengan kata dasar pada kamus sebelum melakukan trimming pada lampiran (Husnayain 2015). 5 Apabila seluruh langkah telah selesai namun belum berhasil, maka kata awal dianggap sebagai kata dasar dan proses dianggap selesai.
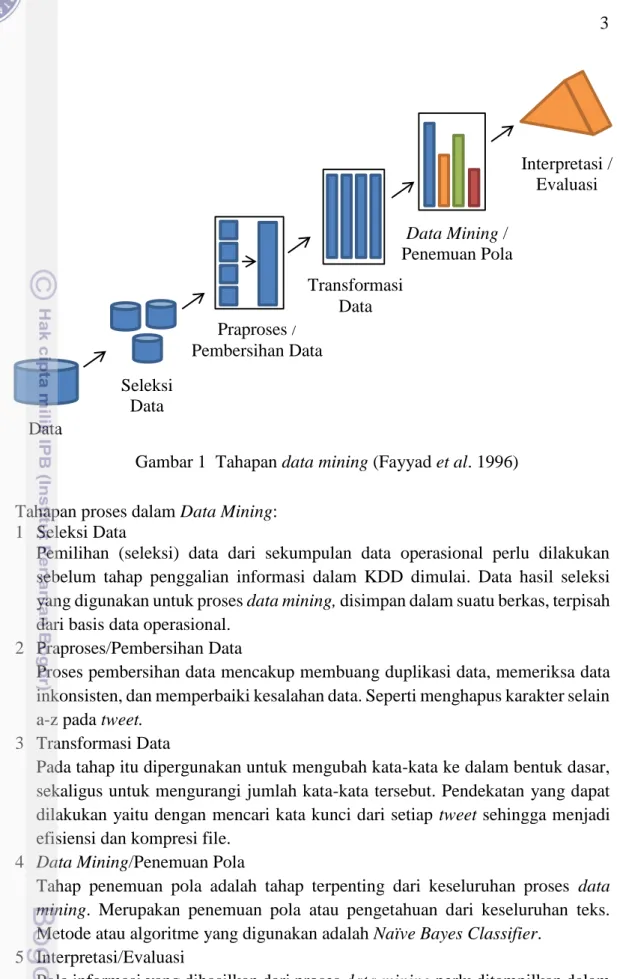
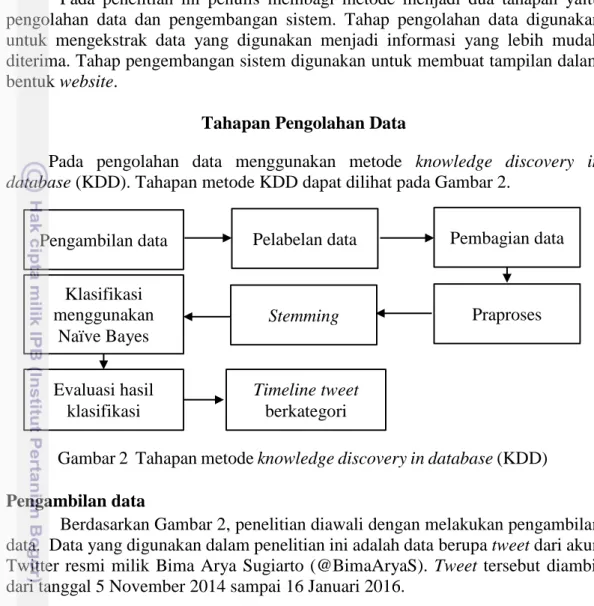
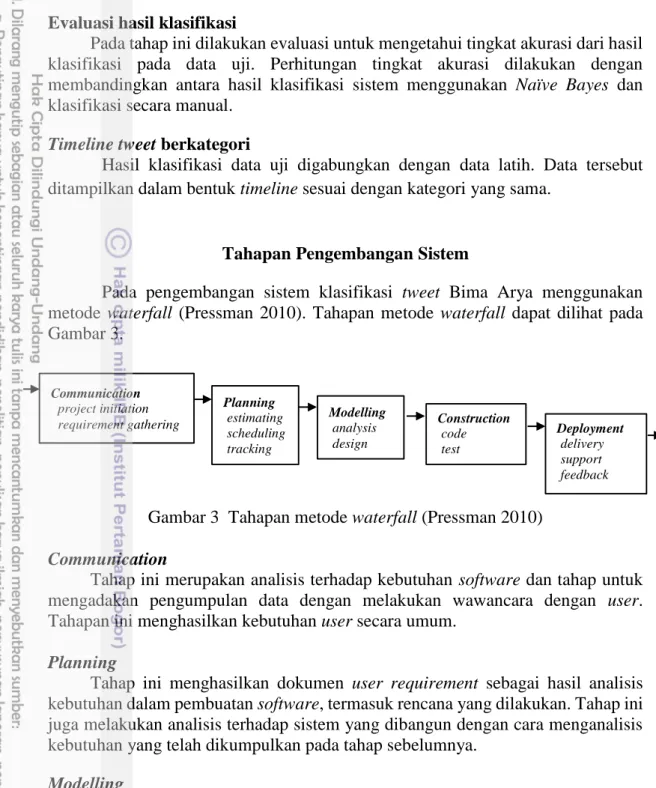
METODE
Pada dokumen tweet dilakukan pembersihan data seperti menghapus URL, menghapus nama pengguna, mengubah titik dan koma menjadi spasi, menghapus simbol dan angka, mengubah menjadi huruf kecil, dan menghilangkan stop word. Algoritma ini digunakan karena memiliki akurasi yang lebih baik dibandingkan dengan algoritma tribal Indonesia lainnya. Bayes Optimal Classifier menghitung probabilitas satu kelas untuk setiap atribut yang ada dan menentukan kelas mana yang paling optimal.
Metode Naïve Bayes atau Naïve Bayes Classifier (NBC) merupakan salah satu metode yang digunakan untuk klasifikasi teks. Pengklasifikasi Naïve Bayes menyederhanakan hal ini dengan mengasumsikan bahwa dalam setiap kategori, setiap atribut bergantung satu sama lain (Tan et al. 2006). Nilai ni adalah kemunculan kata ai pada kategori vj, n adalah banyaknya kosakata yang muncul pada kategori vj dan |kosakata| adalah jumlah anggota kumpulan kata unik di semua data pelatihan.
Pada tahap ini dilakukan evaluasi untuk mengetahui tingkat keakuratan hasil klasifikasi pada data uji. Tingkat akurasi dihitung dengan membandingkan hasil klasifikasi sistem menggunakan Naïve Bayes dan klasifikasi manual. Tahap ini merupakan tahap analisis kebutuhan perangkat lunak dan tahap pengumpulan data melalui wawancara pengguna.
Tahap ini menghasilkan dokumen kebutuhan pengguna sebagai hasil analisis kebutuhan pengembangan perangkat lunak, termasuk rencana yang diimplementasikan. Tahap ini juga menganalisis sistem yang sedang dibangun dengan menganalisis kebutuhan yang telah dikumpulkan pada tahap sebelumnya. Setelah proses coding dilakukan proses pengujian untuk mendeteksi kesalahan pada sistem agar selanjutnya dapat diperbaiki.
HASIL DAN PEMBAHASAN
Kategori 'Infrastruktur' ditujukan untuk tweet yang menginformasikan tentang perbaikan di bidang infrastruktur, termasuk pemeliharaan taman, pembersihan spanduk ilegal, dan perbaikan saluran air. Kategori 'Edukasi' diperuntukkan bagi tweet yang menginformasikan tentang sekolah, kompetisi di bidang pendidikan, prestasi siswa Bogor secara nasional dan internasional. Kategori 'Berita' ditujukan untuk tweet yang memberitakan kejahatan seperti pembunuhan, perampokan, serta tweet yang berisi tindakan aparat keamanan dalam menangkap penjahat.
Kategori 'Uncategorized' ditujukan untuk tweet yang tidak termasuk dalam 4 kelas di atas dan tweet yang kosong karena pra-pemrosesan. Dari tweet terbaru, 81 tweet (20%) digunakan untuk data pengujian dan sisanya 316 tweet (80%) digunakan untuk data pelatihan. Tidak meratanya sebaran data latih dan data uji disebabkan karena lebih banyak tweet pada akun @BimaAryaS yang mempunyai ciri-ciri kategori Event dibandingkan dengan tweet yang mempunyai ciri-ciri kategori lain.
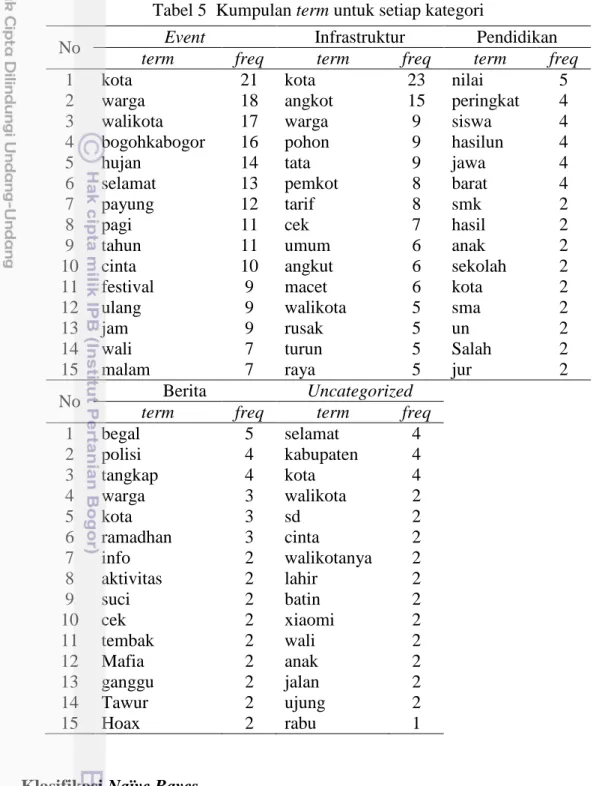
Misal kemunculan kata hujan pada kelas event adalah 2, maka jumlah kata pada tag event adalah 15, dan jumlah kata unik pada seluruh data latih adalah 22. Dari tabel di atas dapat disimpulkan terlihat tweet yang benar pada tag Event adalah 37 dari 49 tweet. Tweet berlabel Infrastruktur terklasifikasi dengan benar oleh sistem sebanyak 6 dari 12 tweet, tweet berlabel Pendidikan sebanyak 1 dari 2 tweet, dan tweet berlabel Berita tidak ada yang terklasifikasi dengan benar dari total 2 tweet yang dihasilkan sistem. dan tweet berlabel Tak Berkategori, 8 dari 16 tweet diklasifikasikan dengan benar.
UR01 Mencari tweet tertentu Sistem dapat menampilkan tweet tertentu dengan memasukkan kata kunci yang diinginkan. Update Tweet UR07 Sistem dapat menambahkan tweet terbaru sesuai dengan tweet dari timeline akun Bima Arya. Antarmuka digunakan untuk mencari tweet yang diinginkan pada halaman responsif dan bagi administrator untuk memperbarui database secara langsung dalam formulir yang disediakan.
Untuk mendapatkan tweet yang diinginkan, pengguna memasukkan satu kata pada kolom pencarian pada bagian pencarian tweet (Gambar 11). Tweet dengan label acara dapat dilihat di bagian acara (Gambar 12) dengan memilih bilah menu acara di bagian atas sistem. Tweet yang ditampilkan merupakan gabungan tweet berlabel Event pada data latih dan data uji.
Tweet dengan tag Infrastruktur, tag Pendidikan, tag Berita dan tag Uncategorized juga dapat dilihat pada Lampiran 6.
SIMPULAN DAN SARAN
Tiga pengguna menyatakan sistem yang dibuat sudah baik karena dapat menampilkan sesuai kebutuhan pengguna.
DAFTAR PUSTAKA
19 Hatur nuhun kang @ridwankamil tos sumping & ngadukung Dies Natalis PAN di Tugu Juang Bdg. 27 Prof. Sachs: Jepang mangrupikeun panaratas dina téknologi pro-lingkungan & nagara dimana téknologi luhur saluyu sareng umur panjang. 28 Global warming kudu disanghareupan ku aksi koléktif global Revolusi dina paripolah manusa jeung lingkungan.
RIWAYAT HIDUP