ĐẠI HỌC QUỐC GIA HÀ NỘI TRƯỜNG ĐẠI HỌC CÔNG NGHỆ
NGUYỄN THỊ LIÊN
PHÂN TÍCH QUAN ĐIỂM TRONG LĨNH VỰC THỨC ĂN TRẺ EM SỬ DỤNG KỸ THUẬT HỌC MÁY
LUẬN VĂN THẠC SĨ CÔNG NGHỆ THÔNG TIN
NGƯỜI HƯỚNG DẪN KHOA HỌC: TS. NGUYỄN VĂN VINH
Hà Nội 2021
ĐẠI HỌC QUỐC GIA HÀ NỘI TRƯỜNG ĐẠI HỌC CÔNG NGHỆ
NGUYỄN THỊ LIÊN
PHÂN TÍCH QUAN ĐIỂM TRONG LĨNH VỰC THỨC ĂN TRẺ EM SỬ DỤNG KỸ THUẬT HỌC MÁY
NGÀNH: CÔNG NGHỆ THÔNG TIN CHUYÊN NGÀNH: HỆ THỐNG THÔNG TIN
MÃ SỐ: 60480104
LUẬN VĂN THẠC SĨ CÔNG NGHỆ THÔNG TIN
NGƯỜI HƯỚNG DẪN KHOA HỌC: TS. NGUYỄN VĂN VINH
Hà Nội 2021
MỤC LỤC
DANH MỤC CÁC KÝ HIỆU VÀ CHỮ VIẾT TẮT ... v
DANH MỤC CÁC BẢNG BIỂU ... vi
DANH MỤC CÁC HÌNH VẼ, ĐỒ THỊ ... vii
LỜI CAM ĐOAN……... viii
LỜI CẢM ƠN………. ... ix
MỞ ĐẦU………. ... 1
1.Lý do chọn đề tài ... 1
2.Mục tiêu và nhiệm vụ của luận văn ... 2
3.Bố cục luận văn ... 2
CHƯƠNG 1:TỔNG QUAN VỀ BÀI TOÁN PHÂN TÍCH QUAN ĐIỂM ... 3
1.1.Giới thiệu ... 3
1.2.Định nghĩa và khái niệm trong phân tích quan điểm ... 4
1.2.1.Các thành phần của một quan điểm ... 4
1.2.2.Các nhiệm vụ của phân tích quan điểm ... 7
1.3.Những thách thức trong lĩnh vực phân tích quan điểm... 10
1.4.Các ứng dụng của phân tích quan điểm ... 12
1.5.Phân lớp quan điểm ... 13
Kết luận chương ... 14
CHƯƠNG 2:CÁC KỸ THUẬT HỌC MÁY TRONG BÀI TOÁN PHÂN TÍCH QUAN ĐIỂM ... 15
2.1.Các phương pháp tiếp cận của phân tích quan điểm... 15
2.1.1.Phương pháp tiếp cận dựa trên luật ... 15
2.1.2.Phương pháp tiếp cận dựa vào học máy ... 16
2.2.Phương pháp Naïve Bayes ... 16
2.3.Phương pháp Support Vector Machine (SVM) ... 18
2.4. Phương pháp Hồi quy Logistic (Logistic regression) ... 21
2.4.1.Giới thiệu ... 21
2.4.2.Mô hình Logistic ... 21
2.4.3.Hàm Logistic và các tỉ lệ ... 23
2.5.Phương pháp tiếp cận học sâu (Deep Learning) ... 25
2.5.1.Mạng Neural hồi quy RNN ... 26
2.5.2.Mạng Long Short-Term Memory ... 28
Kết luận chương ... 32
CHƯƠNG 3:ỨNG DỤNG PHÂN TÍCH QUAN ĐIỂM VỚI DỮ LIỆU THỨC ĂN TRẺ EM ... 33
3.1.Hệ thống phân tích quan điểm ... 33
3.2.Đặc điểm của dữ liệu thức ăn trẻ em... 34
3.3.Tiền xử lý dữ liệu và gán nhãn ... 35
3.3.1.Tiền xử lý dữ liệu ... 35
3.3.2.Gán nhãn dữ liệu ... 36
3.4.Trích chọn đặc trưng ... 39
3.5.Xây dựng và lựa chọn mô hình ... 41
3.6.Phương pháp đánh giá mô hình ... 42
CHƯƠNG 4:THỰC NGHIỆM VÀ ĐÁNH GIÁ ... 45
4.1.Môi trường thực nghiệm: ... 45
4.2.Xây dựng và lựa chọn mô hình ... 45
4.3.Huấn luyện mô hình ... 48
4.4.Kết quả thực nghiệm ... 48
4.5.Đánh giá thực nghiệm ... 51
Kết luận chương……….52
KẾT LUẬN………. ... 53
Tài liệu tham khảo….. ... 54
DANH MỤC CÁC KÝ HIỆU VÀ CHỮ VIẾT TẮT
Viết tắt Đầy đủ tiếng anh Ý nghĩa tiếng việt
ACC Accuracy Độ chính xác trung bình các
thuật toán
BOW Bag of word Túi từ
LSTM Long Short Term Memory Mạng bộ nhớ thuật ngữ ngắn dài
NLP Natural Language Processing Xử lý ngôn ngữ tự nhiên
OA Opinion analysis Phân tích quan điểm
SA Sentiment Analysis Phân tích cảm xúc
SVM Support Vector Machine Máy véc-tơ hỗ trợ TF-IDF Term Frequency – Inverse
Document Frequency
Tần suất tài liệu nghịch đảo thuật ngữ
DANH MỤC CÁC BẢNG BIỂU
Bảng 3. 1: Một số từ dừng trong tiếng Việt ... 36
Bảng 4. 1: Kết quả huấn luyện mô hình với độ đo ACC ... 48
Bảng 4. 2: Kết quả độ chính xác theo cỡ của dữ liệu huấn luyện ... 49
Bảng 4. 3: Thời gian huấn luyện của các tập dữ liệu ... 50
DANH MỤC CÁC HÌNH VẼ, ĐỒ THỊ
Hình 2. 1: SVM tìm dòng tốt nhất phân tách hai lớp ... 19
Hình 2. 2: Ví dụ về siêu phẳng trong SVM ... 19
Hình 2. 3: Siêu phẳng phân chia lề xa nhất ... 21
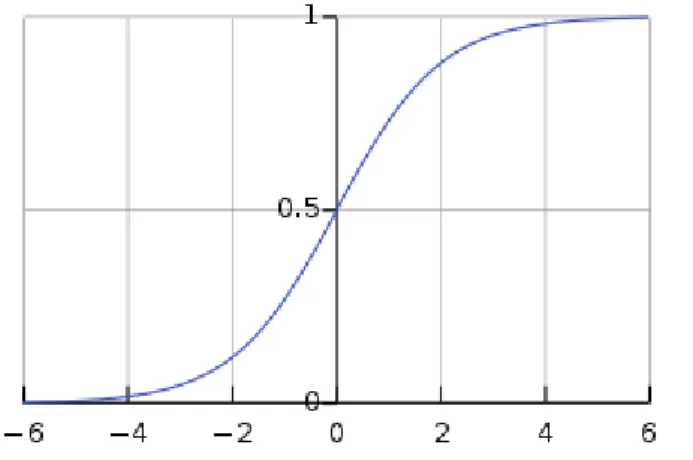
Hình 2. 4: Đồ thị của hàm Logistic khi t thuộc (-6,6) ... 23
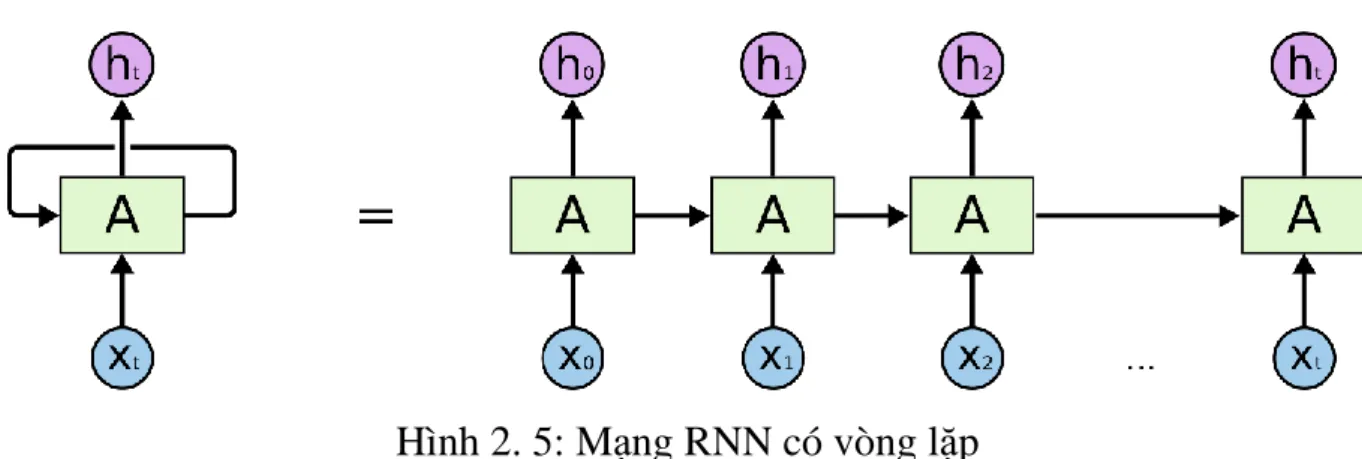
Hình 2. 5: Mạng RNN có vòng lặp ... 27
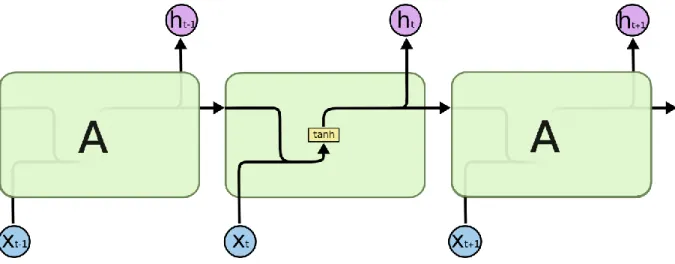
Hình 2. 6: Mô đun lặp lại trong RNN ... 28
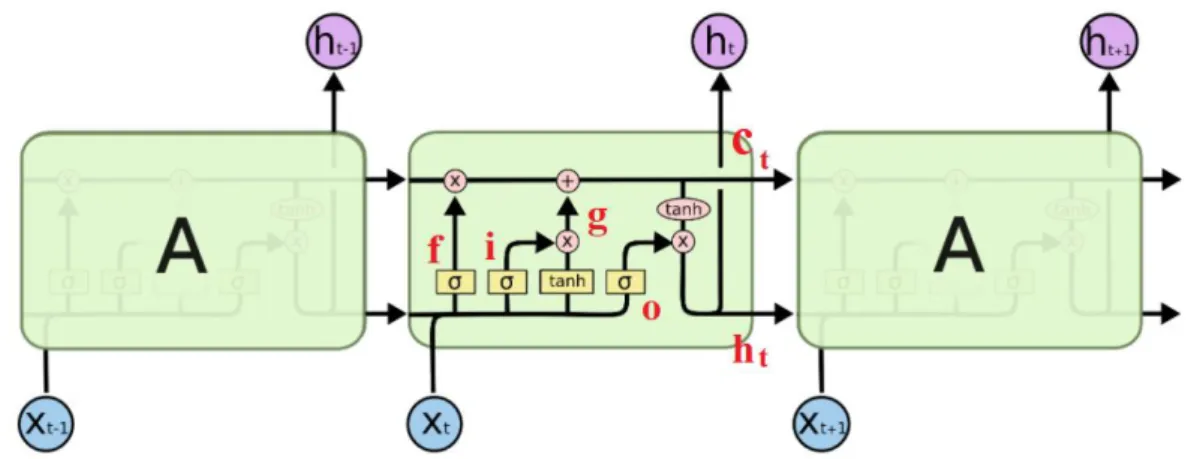
Hình 2. 7: Mô đun lặp lại trong một LSTM ... 28
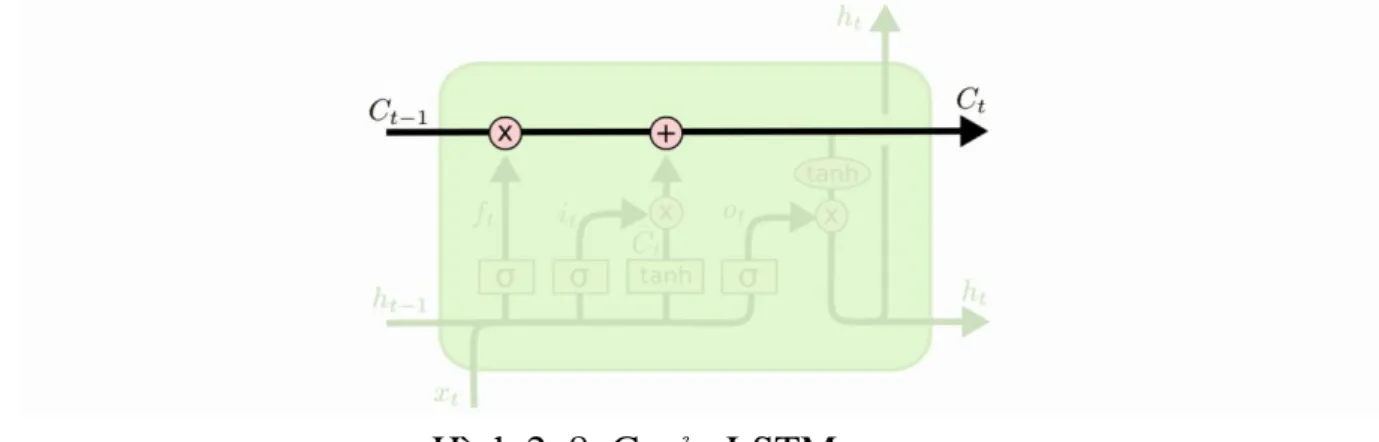
Hình 2. 8: Ct của LSTM ... 29
Hình 2. 9: Cổng trạng thái LSTM ... 30
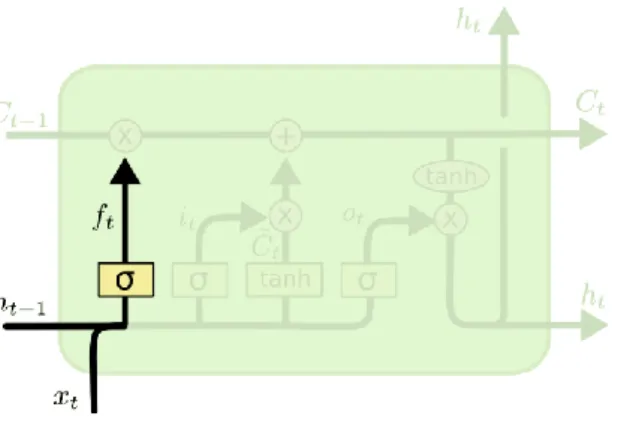
Hình 2. 10: Cổng quên LSTM ... 30
Hình 2. 11: Cổng vào it của tanh 𝐶𝑡 ̃ ... 31
Hình 2. 12: Giá trị state Ct ... 31
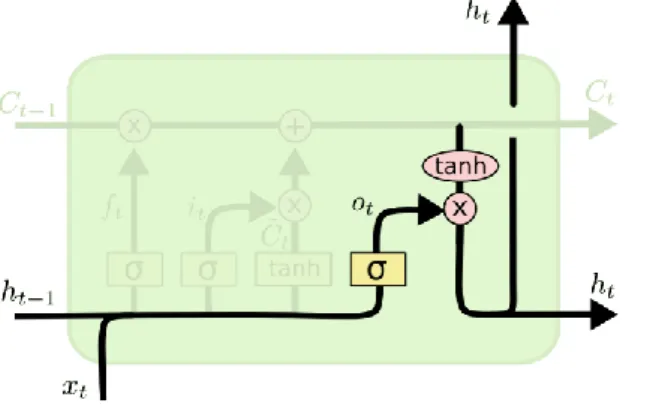
Hình 2. 13: Kết quả trả về ht ... 31
Hình 3. 1: Kiến trúc hệ thống phân tích quan điểm ... 34
Hình 3. 2: Tập dữ liệu thức ăn trẻ em ... 35
Hình 3. 3: Nhập dữ liệu cần gán nhãn ... 37
Hình 3. 4: Thực hiện gán nhãn dữ liệu ... 38
Hình 3. 5: Tập dữ liệu thức ăn trẻ em sau khi được gán nhãn ... 38
Hình 3. 6: Tỉ lệ tập dữ liệu đã được gán nhãn ... 39
Hình 3. 7: Mô hình phân lớp học máy truyền thống ... 42
Hình 4. 1: Tệp dữ liệu sau khi được tải ... 46
Hình 4. 2: Chương trình loại bỏ những nhãn lớn hơn 1 và nhỏ hơn 5 ... 47
Hình 4. 3: Kết quả đánh giá các mô hình sử dụng độ đo ACC ... 48
Hình 4. 4: Kết quả đánh giá độ lớn của dữ liệu với độ đo ACC ... 49
Hình 4. 5: Một số bình luận dự đoán sai nhãn khi dùng LTSM………51
LỜI CAM ĐOAN
Em xin cam đoan nội dung trình bày trong luận văn này là do em tự nghiên cứu tìm hiểu dưới sự hướng dẫn của giảng viên TS.Nguyễn Văn Vinh. Mọi tham khảo các tài liệu, công trình nghiên cứu của một số tác giả, em đã ghi rõ tên tài liệu, nguồn gốc tài liệu, tên tác giả trong “TÀI LIỆU THAM KHẢO” ở cuối luận văn.
Mọi sao chép không hợp lệ hay gian lận em xin hoàn toàn chịu trách nhiệm.
Hà Nội, Ngày 26 tháng 11 năm 2021 Người cam đoan
Nguyễn Thị Liên
LỜI CẢM ƠN
Trước hết em xin gửi lời cảm ơn và bày tỏ lòng biết ơn sâu sắc đến thầy Nguyễn Văn Vinh, người đã định hướng đề tài, cung cấp cho em những kiến thức, những tài liệu và tận tình hướng dẫn chỉ bảo em trong suốt quá trình thực hiện đề tài luận văn.
Em cũng xin chân thành cảm ơn các thầy, cô giáo của khoa Công nghệ thông tin – Trường Đại học Công nghệ - Đại học Quốc gia Hà Nội đã dạy bảo, truyền thụ kiến thức, tạo điều kiện tốt nhất trong suốt quá trình em học tập tại trường.
Em cũng xin chân thành cảm ơn bạn bè đồng nghiệp, các bạn học viên K24 đã ủng hộ và khuyến khích tôi trong suốt quá trình học tập tại trường.
Cuối cùng, Em xin gửi lời cảm ơn sâu sắc nhất đến gia đình, người thân luôn kịp thời động viên và giúp đỡ tôi vượt qua những khó khăn trong học tập cũng như trong cuộc sống.
Hà Nội, Ngày 26 tháng 11 năm 2021 Học viên
Nguyễn Thị Liên
MỞ ĐẦU 1. Lý do chọn đề tài
Hiện nay sự phát triển nhanh chóng của khoa học, công nghệ đã có những đóng góp quan trọng, làm thay đổi cơ bản mọi mặt của đời sống kinh tế - xã hội. Sự ra đời, phát triển của mạng Internet đã tạo nên những đột phá trong kết nối, chia sẻ thông tin, thúc đẩy phát triển kinh tế, giao lưu văn hóa. Bên cạnh đó, sự phát triển bùng nổ của các trang diễn đàn, mạng xã hội, các trang web lấy ý kiến người dùng chính là cầu nối để mọi người dễ dàng thể hiện quan điểm cá nhân về những sự kiện nổi bật đáng quan tâm, những thông tin kinh tế, những trao đổi về các lĩnh vực của đời sống xã hội, thị trường, sản phẩm và dịch vụ.
Gần đây, bài toán phân tích quan điểm đã được ứng dụng rộng rãi trong các lĩnh vực: du lịch, khách sạn, các dịch vụ tài chính cho đến tiêu dùng, chăm sóc sức khỏe. Khi xã hội ngày càng phát triển thì các bậc phụ huynh ngày càng quan tâm nhiều đến tương lai con em mình, trong đó mục tiêu hàng đầu chính là bổ sung thêm các chất dinh dưỡng nhằm phát triển chiều cao, trí thông minh cho các bé.
Ngày nay, thay vì sử dụng cách thu thập đánh giá, phát phiếu thăm dò cũng như hỏi trực tiếp, trưng cầu ý kiến qua các trang web, các cá nhân hay tổ chức đã phân tích tự động lượng dữ liệu đánh giá lớn từ các trang mạng xã hội, các diễn đàn, các trang đánh giá sản phẩm nhằm tận dụng nguồn thông tin hữu ích giúp tiết kiệm phần nào chi phí.
Các tổ chức doanh nghiệp, các công ty có thể lấy ý kiến đánh giá về sản phẩm và dịch vụ của họ qua các bình luận trên các trang mạng. Việc thu thập các ý kiến đánh giá rất quan trọng cho các doanh nghiệp và tổ chức vì họ luôn mong muốn tìm kiếm xem người tiêu dùng có nhận xét gì về sản phẩm và dịch vụ của họ, nhờ đó họ có thể xây dựng các chiến lược bán hàng và phát triển sản phẩm. Ngoài ra người tiêu dùng cũng mong muốn tham khảo các ý kiến đánh giá về sản phẩm hay dịch vụ mà họ quan tâm trước khi họ đưa ra quyết định trong việc mua, bán hay sử dụng các sản phẩm hoặc dịch vụ đó.
Vấn đề đặt ra là làm thế nào biết được một chủ đề hoặc một sự kiện có bao nhiêu đánh giá tiêu cực hay tích cực, trong khi số lượng đánh giá rất lớn, vượt qua khả năng của con người. Chính vì vậy bài toán phân tích quan điểm được đặt ra để giải quyết vấn đề trên. Hiện nay, có nhiều kỹ thuật cho bài toán nhưng hiệu quả nhất là sử dụng kỹ thuật học máy.
Chính vì lý do đó học viên đã lựa chọn đề tài: “Phân tích quan điểm trong lĩnh vực thức ăn trẻ em sử dụng kỹ thuật học máy”.
2. Mục tiêu và nhiệm vụ của luận văn
Luận văn định hướng tìm hiểu các phương pháp phân tích quan điểm, trên cơ sở đó đề xuất phương pháp và thử nghiệm các kỹ thuật học máy trong bài toán phân tích quan điểm, cụ thể là dữ liệu thức ăn trẻ em, từ những dữ liệu thu thập được trên website, các diễn đàn đánh giá sản phẩm, các mạng xã hội, học viên xin được đề xuất nghiên cứu và đưa ra mô hình ứng dụng. Mô hình bao gồm các bước từ thu thập dữ liệu, tiền xử lý dữ liệu, vectơ hóa dữ liệu đến lựa chọn mô hình học máy và huấn luyện. Cuối cùng là đưa ra những đánh giá hiệu quả của thuật toán, bộ dữ liệu, kết quả đạt được và đánh giá về tính khả thi ứng dụng mô hình.
3. Bố cục luận văn
Luận văn được bố trí thành bốn chương có nội dung như sau:
Chương 1: Giới thiệu tổng quan về bài toán phân tích quan điểm trong lĩnh vực thức ăn trẻ em. Chương này tìm hiểu tổng quan: định nghĩa, khái niệm, các nhiệm vụ, thách thức trong phân tích quan điểm, tiếp đó bài toán chuẩn hóa trên tập dữ liệu thức ăn trẻ em được giới thiệu.
Chương 2: Các kỹ thuật học máy trong bài toán phân tích quan điểm. Ở chương này nghiên cứu, tìm hiểu các phương pháp học máy cho bài toán phân tích quan điểm.
Chương 3: Ứng dụng kỹ thuật học máy để phân tích quan điểm trong lĩnh vực thức ăn trẻ em.
Chương 4: Thực nghiệm và đánh giá. Xây dựng cài đặt mô hình, huấn luyện mô hình tiến hành thử nghiệm, đánh giá mô hình.
Kết luận tổng kết quá trình thực hiện luận văn, những kết quả đạt được và định hướng phát triển bài toán trong tương lai.
CHƯƠNG 1: TỔNG QUAN VỀ BÀI TOÁN PHÂN TÍCH QUAN ĐIỂM Phân tích quan điểm là một lĩnh vực được các nhà nghiên cứu và các nhà phát triển trong lĩnh vực Internet dành nhiều sự quan tâm trong thập niên vừa qua.
Mục tiêu hướng đến của phân tích quan điểm là xây dựng các hệ thống tự động xác định các quan điểm, tình cảm, đánh giá, thái độ và cảm xúc của con người cho các thực thể hoặc các thuộc tính của chúng được thể hiện trong các văn bản bằng ngôn ngữ tự nhiên.
1.1. Giới thiệu
Các thực thể mà phân tích quan điểm quan tâm rất rộng. Nó có thể là các thông tin về thị trường, các sản phẩm hoặc dịch vụ, các sự kiện nổi bật, những thông tin về kinh tế - chính trị. Các thực thể này thường được thể hiện qua các cuộc thảo luận, tin tức, bình luận, phản hồi đánh giá. Để hệ thống có thể tự động thực hiện các nhiệm vụ đề ra, phân tích quan điểm dựa trên ngôn ngữ tính toán, khai thác văn bản, truy vấn thông tin, xử lý ngôn ngữ tự nhiên, thống kê, phân tích dự đoán và học máy.
Phân tích quan điểm thường sử dụng kết hợp giữa các giải pháp xử lý ngôn ngữ tự nhiên và phương pháp trong học máy để phân lớp, trích xuất và xác định quan điểm được thể hiện trong văn bản hoặc tài liệu.
Những dữ liệu đánh giá này thực sự hữu ích cho cả các nhà sản xuất, nhà hoạch định chiến lược cũng như người tiêu dùng. Đối với nhà sản xuất và nhà hoạch định chiến lược, các thông tin hữu ích giúp họ có thể nắm bắt thông tin, ý kiến của khách hàng hài lòng hay thất vọng về sản phẩm, dịch vụ của họ, qua đó kịp thời điều chỉnh, cải tiến sản phẩm, nâng cấp dịch vụ để đáp ứng nhu cầu của khách hàng cũng như có các đối sách và quyết định phù hợp nhằm xử lý các vấn đề liên quan. Ngoài ra, đối với người sử dụng, họ có thêm thông tin hữu ích giúp đánh giá về các sản phẩm và dịch vụ được quan tâm để có thể đưa ra các quyết định đúng đắn cho mình.
Dữ liệu phân lớp quan điểm có thể được thu thập từ nhiều nguồn như:
website, các trang mạng xã hội, blog, các cộng đồng. Đặc điểm của dữ liệu dạng này thường là các đánh giá theo thang điểm, cấp độ hoặc là một cụm câu ngắn tổng kết tính năng của sản phẩm hoặc dịch vụ cụ thể được thể hiện bằng ngôn ngữ tự nhiên. Từ đó, có thể thấy dữ liệu được thu thập đều có kiểu không tập trung, vụn vặt, đa dạng và đặc biệt là thuần văn bản.
Vấn đề là tập dữ liệu được thu thập là khổng lồ, rất đa dạng về các khía cạnh quan tâm của người sử dụng, hơn nữa các ý kiến được viết theo ngôn ngữ
tự nhiên thường không có cấu trúc hay đúng ngữ pháp, các bài spam khiến việc trích lọc thông tin hữu ích khó khăn, tốn thời gian và chi phí.
Như vậy, nhiệm vụ quan trọng là phân lớp quan điểm của người sử dụng từ tập dữ liệu đầu vào nhằm đưa ra kết quả mong muốn. Đây chính là nội dung trọng tâm mà luận văn sẽ nghiên cứu tìm hiểu và giải quyết.
1.2. Định nghĩa và khái niệm trong phân tích quan điểm
Phân tích quan điểm (Opinion Analysis – OA) hay phân tích biểu cảm (Sentiment Analysis –SA) là lĩnh vực nghiên cứu phân tích các quan điểm, thái độ, biểu cảm, tình cả và cảm xúc của con người về thực thể và các thuộc tính thể hiện trong văn bản nhằm mục đích phát hiện quan điểm tiêu cực hoặc tích cực.
Các thực thể có thể là các sản phẩm, dịch vụ, sự kiện nổi bật, sự vật, sự việc [4,8]
1.2.1. Các thành phần của một quan điểm
Trong nghiên cứu, nhiều nhà khoa học đã đưa ra cấu trúc tổng quan của một quan điểm [3,4,9,11]. Luận văn sử dụng bài đánh giá về sữa bột Dialac để giới thiệu vấn đề. (Các câu trong bài đánh giá được đánh số cho tiện cho việc tham khảo)
Người bình luận: Nguyễn Thị A Ngày:11/05/2020
“Tôi có mua một hộp sữa Dialac 123 cho con mình 3 tháng trước (1). Con tôi thích sữa này do vị ngon tự nhiên của nó (2). Tôi cũng thích sữa Dialac vì nó giúp con tôi cải thiện được vấn đề dinh dưỡng (3). Tôi thấy chuyên gia khuyên dùng sữa này do chứa nhiều vi chất tốt cho trẻ nhỏ (4). Tuy nhiên, giá của sữa khá cao so với thu nhập của tôi (5).”
Từ ví dụ trên ta thấy:
1. Bài đánh giá có một số ý kiến cả tích cực và tiêu cực về sữa bột Dialac 123. Câu (2) bày tỏ ý kiến tích cực về vị ngon của sữa. Câu (3) bày tỏ ý kiến tích cực về sữa Dialac 123. Câu (4) bày tỏ ý kiến tích cực về thành phần của sữa theo tìm hiểu của chuyên gia. Câu (5) bày tỏ ý kiến trái chiều về giá của sản phẩm. Từ những ý kiến này, ta có thể đưa ra nhận xét quan trọng sau:
Theo quan sát: Một quan điểm bao gồm hai thành phần chính: Mục tiêu g và cảm nhận về mục tiêu s tức cặp <g, s>. Trong đó,
g có thể là bất kỳ thực thể hay khía cạnh của thực thể mà quan điểm
đã được thể hiện
s là cảm nhận về mục tiêu g. s có thể là đánh giá theo kiểu phân cực như: tiêu cực, tích cực hoặc trung tính; hay đánh giá theo thang điểm từ 1 đến 5 sao.
Trong ví dụ trên, mục tiêu của quan điểm trong câu (2) là vị sữa Dialac 123 và mục tiêu của quan điểm câu (3) là sữa Dialac 123. Mục tiêu cũng được gọi là chủ đề trong bài đánh giá hoặc tài liệu chứa đánh giá.
2. Trong ví dụ trên, có hai người đưa ra đánh giá là người con và Nguyễn Thị A. Hai đối tượng này được gọi là nguồn quan điểm hoặc người đưa ra đánh giá [3,5]. Người đưa ra đánh giá trong câu (2) là con của tác giả còn các câu (3), (4), (5) là chính tác giả.
3. Thời gian đưa ra đánh giá là ngày 11/05/2020. Thông tin này rất quan trọng trong thực tế vì thông thường nhà sản xuất rất muốn biết các đánh giá sẽ thay đổi ra sao theo thời gian và xu hướng của các quan điểm.
Vậy, từ ví dụ trên ta có thể định nghĩa quan điểm trong các mô hình mức tài liệu hay mức câu gồm 4 thành phần như sau:
Định nghĩa 1.1: Quan điểm (Opinion)
Là một bộ gồm 4 thành phần: <gi, sj, hk, tl> trong đó:
gi là mục tiêu i của biểu cảm hay quan điểm
sj là biểu cảm của các ý kiến về mục tiêu gi. sj có thể là một đánh giá từ 1 đến 5 sao hoặc chia thành các cực của vấn đề như tiêu cực, tích cực và trung tính
hk là người hoặc tổ chức giữ quan điểm
tl là thời gian khi các quan điểm được thể hiện
Trong cấu trúc trên, cả 4 thành phần đều rất cần thiết. Ví dụ, thành phần người giữ quan điểm rất quan trọng. Ý kiến của chuyên gia dinh dưỡng sẽ được đánh giá cao hơn ý kiến của một người bình thường về lĩnh vực dinh dưỡng. Hay, nhân tố thời gian thường rất quan trọng trong thực tế vì ý kiến của ngày hôm nay có thể khác so với các năm trước đây.
Mỗi một quan điểm phải có mục tiêu đánh giá cần xác định vì trong một câu hoặc một tài liệu có thể có nhiều mục tiêu đánh giá. Chúng thường được xác định bởi danh từ hoặc cụm danh từ. Vì vậy, điều chúng ta cần thực hiện là xác định từng mục tiêu cụ thể và từng đánh giá cho mục tiêu này. Ví dụ, “Cháo dinh dưỡng tốt cho trẻ em nhưng cửa hàng này nấu chưa được chuẩn” ta có thể thấy
có 2 mục tiêu được xác định “cháo dinh dưỡng” và “cửa hàng”. Trong đó, mục tiêu “cháo dinh dưỡng” được đánh giá tích cực còn mục tiêu “cửa hàng” bị đánh giá tiêu cực. Các từ hoặc cụm từ chẳng hạn: “tốt”, “xấu”, “đẹp”, “ngon”, “dở”,
“hư hỏng”,… thể quan điểm hoặc đánh giá của chủ thể về mục tiêu. Nó thường hay có cú pháp xác định và vì thế có thể cho phép trích xuất cả mục tiêu lẫn đánh giá của chúng. [4,6,13]
Tuy nhiên, có một số trường hợp có thể một trong 4 thành phần bị khuyến thiếu. Ví dụ, trong câu “Sữa bột Dialac rất tốt cho trẻ sơ sinh” thì thành phần bị khuyết thiếu là thời gian tl. Vì vậy, trong quá trình phân tích quan điểm cần lưu ý các cú pháp câu nhằm phục vụ mục đích tách và trích rút dữ liệu được chính xác.
Định nghĩa 1.1 tuy khá ngắn gọn tuy nhiên không dễ sử dụng trong thực tế, đặc biệt là trong lĩnh vực đánh giá trực tuyến về sản phẩm, dịch vụ và thương hiệu vì mô tả đầy đủ về mục tiêu có thể phức tạp và thậm chí thể không xuất hiện trong cùng một câu. Ví dụ, trong câu (2) mục tiêu đánh giá thực sự là “vị của sữa Dialac”
hay trong câu (4) mục tiêu đánh giá là “hàm lượng vi chất trong sữa”. Hai câu này chỉ đề cập đến một khía cạnh của sữa Dialac chứ không phải bản thân thực thể là sữa Dialac. Trong thực tế, mục tiêu thường có thể được phân tích và mô tả theo cách có cấu trúc với nhiều cấp độ. Điều này tạo điều kiện thuận lợi cho cả việc phân tích ý kiến và sau đó sử dụng kết quả ý kiến đã được phân tích. Ví dụ, “vị của sữa Dialac” có thể được phân tách thành một thực thể và một thuộc tính của thực thể và có thể được biểu diễn dưới dạng một cặp,
<Sữa Dialac 123, vị sữa>
Chúng ta hãy sử dụng thuật ngữ thực thể để biểu thị đối tượng mục tiêu đã được đánh giá. Thực thể có thể được định nghĩa như [4,6].
Định nghĩa 1.2: Thực thể (entity)
Một thực thể e là một sản phẩm, dịch vụ, chủ đề, vấn đề, con người, tổ chức hoặc sự kiện. Nó được mô tả với một cặp, e: (T, W), trong đó T là hệ thống phân cấp của các bộ phận, bộ phận con và W là tập hợp các thuộc tính của e. Mỗi bộ phận hoặc bộ phận con cũng có tập hợp các thuộc tính riêng.
Ví dụ 1: Một loại sữa cụ thể là một thực thể, ví dụ Dialac 123. Nó có một tập hợp các thuộc tính, ví dụ: Màu sắc, trọng lượng, công thức và một tập các bộ phận ví dụ: tem mác, vỏ hộp, bột sữa. Kiểu dáng cũng có tập hợp các thuộc tính riêng, ví dụ: kiểu hộp giấy, hộp sắt, màu sắc…
Định nghĩa này về cơ bản mô tả một thành phần phân cấp của thực thể dựa
trên quan hệ bộ phận. Nút gốc là tên của thực thể, ví dụ: Dialac 123 trong bài đánh giá ở trên. Tất cả các nút khác là các bộ phận và các bộ phận con, v.v ... Mỗi ý kiến được thể hiện trên bất kỳ nút nào và bất kỳ thuộc tính nào.
Ví dụ 2: Trong bài đánh giá ví dụ của chúng tôi ở trên, câu (3) bày tỏ ý kiến tích cực về toàn thể sữa bột Dialac 123. Câu (2) bày tỏ ý kiến tích cực về thuộc tính vị của bột sữa. Rõ ràng, người ta cũng có thể bày tỏ ý kiến về các bộ phận hoặc thành phần của sữa bột Dialac 123.
Thực thể này với tư cách là một hệ thống phân cấp của bất kỳ số cấp nào cần có một mối quan hệ lồng nhau để biểu diễn nó, điều này thường quá phức tạp đối với các ứng dụng. Lý do chính là vì xử lý ngôn ngữ tự nhiên (Natural Language Processing - NLP) không hề đơn giản. Việc nhận biết các bộ phận và thuộc tính của một thực thể ở các mức độ chi tiết khác nhau gặp nhiều khó khăn.
Tuy nhiên, hầu hết các ứng dụng cũng không cần phân tích phức tạp như vậy. Do đó, ta có thể đơn giản hoá hệ thống phân cấp thành hai cấp và sử dụng các thuật ngữ để biểu thị hai thành phần khía cạnh và thuộc tính Trong cây đơn giản hóa, nút gốc vẫn là chính thực thể, nhưng các nút cấp hai (cũng là cấp lá) là các khía cạnh khác nhau của thực thể. Khung đơn giản hóa này thường được sử dụng trong các hệ thống phân tích biểu cảm thực tế.
Lưu ý rằng trong các tài liệu nghiên cứu, các thực thể còn được gọi là đối tượng, và các khía cạnh cũng được gọi là đặc điểm (như trong tính năng sản phẩm). Tuy nhiên, các tính năng ở đây có thể gây nhầm lẫn với các tính năng được sử dụng trong học máy, trong đó một tính năng có nghĩa là một thuộc tính dữ liệu.
Để tránh nhầm lẫn, các khía cạnh đã trở nên phổ biến hơn trong những năm gần đây. Lưu ý rằng một số nhà nghiên cứu cũng sử dụng các khía cạnh thuật ngữ, thuộc tính và chủ đề, và trong các ứng dụng cụ thể, các thực thể và khía cạnh cũng có thể được gọi bằng các tên khác dựa trên quy ước miền ứng dụng.
Sau khi phân tích mục tiêu ý kiến, chúng ta có thể xác định lại một ý kiến [4-6]. Từ đó, có một định nghĩa quan điểm dùng trong mức khía cạnh:
1.2.2. Các nhiệm vụ của phân tích quan điểm
Với các định nghĩa mục 1.2.1, ta có thể đi vào các mục tiêu và nhiệm vụ chính của phân tích quan điểm [4,6].
Mục tiêu của phân tích quan điểm: Đưa ra một văn bản đánh giá d, phân tích tất cả các bộ đánh giá (ei, aij, sijkl, hk, tl) trong d.
Nhiệm vụ chính được bắt nguồn từ bộ 5 thành phần. Đầu tiên là thực thể.
Mục tiêu của ta cần thực hiện là trích xuất các thực thể. Nhiệm vụ này tương tự như nhận dạng thực thể được đặt tên (NER) trong khai thác thông tin [4-6]. Vì vậy, bản thân việc phân tích là một vấn đề. Sau khi trích xuất, chúng ta cũng cần phải phân lớp các thực thể được trích xuất. Trong văn bản ngôn ngữ tự nhiên, người ta thường viết cùng một thực thể theo những cách khác nhau. Ví dụ, Dialac 123 có thể được viết là Dia 123 và Dialac 123. Chúng ta cần nhận ra rằng tất cả chúng đều đề cập đến cùng một thực thể.
Định nghĩa 2.4: Danh mục thực thể và biểu thức thực thể
Một danh mục thực thể đại diện cho một thực thể duy nhất, trong khi một biểu thức thực thể là một từ thực tế hoặc cụm từ thực tế xuất hiện trong văn bản chỉ ra một danh mục thực thể.
Mỗi danh mục thực thể (hoặc đơn giản là thực thể) phải có một tên duy nhất trong một ứng dụng cụ thể. Quá trình nhóm các biểu thức thực thể thành các loại thực thể được gọi là phân lớp thực thể.
Định nghĩa 2.5: Danh mục khía cạnh và biểu thức khía cạnh
Một danh mục khía cạnh của một thực thể đại diện cho một khía cạnh duy nhất của thực thể, trong khi một biểu thức khía cạnh là một từ hoặc cụm từ thực tế xuất hiện trong văn bản chỉ ra một loại khía cạnh.
Mỗi danh mục khía cạnh (hoặc đơn giản là khía cạnh) cũng nên có một tên duy nhất trong một ứng dụng cụ thể. Quá trình nhóm các biểu thức khía cạnh thành các loại khía cạnh (khía cạnh) được gọi là phân lớp khía cạnh.
Biểu thức khía cạnh thường là danh từ và cụm danh từ nhưng cũng có thể là động từ, cụm động từ, tính từ và trạng từ.
Định nghĩa 2.6: Biểu thức khía cạnh tường minh
Biểu thức khía cạnh là danh từ và cụm danh từ được gọi là biểu thức khía cạnh tường minh.
Ví dụ: “mùi vị” trong “ Mùi vị của sữa Dialac 123 rất tuyệt vời” là một biểu thức khía cạnh tường minh
Định nghĩa 2.7: Biểu thức khía cạnh không tường minh
Các biểu thức khía cạnh không phải là danh từ hoặc cụm danh từ được gọi là biểu thức khía cạnh ngầm định.
Ví dụ, khía cạch “kích thước” trong câu “hộp sữa này hơi nhỏ” là một khía
cạnh không tường minh. Vì đánh giá này không rõ người sử dụng đưa ra ý kiến là phù hợp hay không phù hợp.
Thành phần thứ ba trong định nghĩa 2.3 là quan điểm. Nhiệm vụ này phân lớp quan điểm trên khía cạnh nào đó là tích cực, tiêu cực hay trung tính. Thành phần thứ tư và thành phần thứ năm lần lượt là người giữ ý kiến và thời gian. Chúng cũng cần được trích xuất và phân lớp đối với các thực thể và khía cạnh. Lưu ý rằng người có ý kiến (còn được gọi là nguồn quan điểm [16]) có thể là một cá nhân hoặc tổ chức đã bày tỏ một ý kiến. Đối với đánh giá sản phẩm và blog, người có ý kiến thường là tác giả của bài đăng. Người nắm giữ ý kiến quan trọng hơn đối với các bài báo vì họ thường nêu rõ cá nhân hoặc tổ chức đưa ra ý kiến. Tuy nhiên, trong một số trường hợp, việc xác định những người có quan điểm cũng có thể quan trọng trong phương tiện truyền thông xã hội, ví dụ: xác định ý kiến từ các nhà quảng cáo hoặc những người trích dẫn quảng cáo của các công ty.
Dựa trên các thảo luận trên, chúng ta có thể xác định mô hình thực thể và mô hình tài liệu quan điểm [4,6].
Định nghĩa 2.8: Mô hình của thực thể
Một thực thể ei được đại diện bởi chính nó như một tổng thể và một tập hợp hữu hạn các khía cạnh Ai = {ai1, ai2,…, ain}.; ei có thể được biểu diễn với bất kỳ một trong số hữu hạn các biểu thức thực thể của nó {eei1, eei2,…, eeis}. Mỗi khía cạnh aij ∈ Ai của thực thể ei có thể được thể hiện bằng bất kỳ một trong số các biểu thức khía cạnh hữu hạn của nó {aeij1, aeij2,…, aeijm}.
Định nghĩa 2.9: Mô hình tài liệu quan điểm
Một tài liệu quan điểm d chứa các quan điểm trên một tập hợp các thực thể {e1, e2,…, er} và một tập hợp con các khía cạnh của chúng từ một tập hợp những người có ý kiến {h1, h2,…, hp} tại một thời điểm cụ thể.
Cuối cùng, để đưa ra được một bộ tài liệu quan điểm D, phân tích quan điểm bao gồm 6 nhiệm vụ [4] chính sau:
Nhiệm vụ 1 (trích xuất và phân lớp thực thể): Trích xuất tất cả các biểu thức thực thể trong D và phân lớp hoặc nhóm các biểu thức thực thể đồng nghĩa thành các cụm thực thể (hoặc danh mục). Mỗi cụm biểu thức thực thể chỉ ra một ei thực thể duy nhất.
Nhiệm vụ 2 (trích xuất và phân lớp khía cạnh): Trích xuất tất cả các biểu thức khía cạnh của các thực thể và phân lớp các biểu thức khía cạnh này thành các
cụm. Mỗi cụm biểu thức khía cạnh của thực thể ei đại diện cho một khía cạnh duy nhất aij.
Nhiệm vụ 3 (trích xuất và phân lớp ý kiến): Trích xuất ý kiến cũ để lấy ý kiến từ văn bản hoặc dữ liệu có cấu trúc và phân lớp chúng. Nhiệm vụ tương tự với hai nhiệm vụ trên.
Nhiệm vụ 4 (trích xuất và chuẩn hóa thời gian): Trích xuất các thời điểm mà các ý kiến được đưa ra và chuẩn hóa các định dạng thời gian khác nhau.
Nhiệm vụ 5 (phân lớp quan điểm theo khía cạnh): Xác định xem một quan điểm trên một khía cạnh aij là tích cực, tiêu cực hay trung tính hoặc chỉ định xếp hạng quan điểm bằng số cho khía cạnh đó.
Nhiệm vụ 6 (tạo nhóm ý kiến): Đưa ra tất cả các nhóm ý kiến (ei, aij, sijkl, hk, tl) được thể hiện trong tài liệu d dựa trên kết quả của các nhiệm vụ trên.
1.3. Những thách thức trong lĩnh vực phân tích quan điểm
Bài toán về lĩnh vực phân tích quan điểm là một lĩnh vực thu hút nhiều sự quan tâm của các nhà nghiên cứu. Những kết quả nghiên cứu trong lĩnh vực này đã và đang áp dụng trong lĩnh vực công nghiệp nhằm mục đích phát triển các dịch vụ của mình. Tuy nhiên, bên đó, có một số thách thức phải đối mặt. Theo Tài liệu tham khảo [4,5,11,13,16], các kỹ thuật hiện tại chỉ là sơ khai để xác định và trích xuất các ý kiến và so sánh. Chủ yếu những thách thức này liên quan đến tính xác thực của dữ liệu được trích xuất và các phương pháp được sử dụng trong đó.
Trong thực tế, các bình luận đánh giá hay quan điểm được đưa ra bởi những người khác nhau nên sẽ có phong cách viết khác nhau từ cách thức sử dụng ngôn ngữ, chữ viết tắt đến cách biểu đạt quan điểm. Mọi người đều không bày tỏ ý kiến theo cùng một cách.
Một thách thức quan trọng trong bài toán phân tích quan điểm là quan điểm sẽ thay đổi theo thời gian. Tại thời điểm này một quan điểm về sản phẩm có thể là tốt nhất nhưng theo một thời gian sau nó không phải là tốt nhất nữa, người ta sẽ có nhiều sự lựa chọn hơn khi các sản phẩm mới tốt hơn về giá cả và chất lượng.
Tuy nhiên, cũng có những sản phẩm ban đầu đưa ra ngoài thị trường chưa được tốt và đánh giá cao nhưng qua thời gian, quá trình cải thiện chất lượng của sản phẩm hoặc dịch vụ được người tiêu dùng đánh giá cao hơn.
Ví dụ: Năm 2012 Iphone 5 được người tiêu dùng đánh giá là tích cực nhưng tại thời điểm này có những đánh giá tiêu cực vì có nhiều những dòng sản phẩm mới
đã ra đời.
Độ mạnh của quan điểm là một trong những thách thức trong phân tích quan điểm để xác định các yếu tố quyết định sức mạnh của một ý kiến trong một bối cảnh nào đó. Bổ sung thêm việc phân lớp các từ thành các mức độ xu hướng quan điểm khác nhau, một số từ bổ nghĩa có thể được dùng để xác định độ mạnh của quan điểm (“rất”, “một chút”, “hết sức”, “hơi”,...). Cụm từ “rất hài lòng” và
“hơi hài lòng” sẽ được phân lớp thành rất tích cực và kém tích cực nếu “rất” và
“hơi” được phân tích và sử dụng để xác định mức độ đối lập.
Một thách thức lớn trong phân tích quan điểm là các câu đánh giá có sự pha trộn đã xuất hiện khi mọi người thể hiện đánh giá hai quan điểm (tích cực và tiêu cực) trong cùng một câu. Mọi người có nhiều ý kiến khác nhau trong cùng một câu hay những bình luận mang quan điểm trung tính cũng có thể gây khó khăn để phân tích cú pháp hoặc phân tích quan điểm. Các câu mang quan điểm tích cực, tiêu cực hay trung tính đều quan trọng khi huấn luyện các mô hình phân tích quan điểm. Vì dữ liệu gắn thẻ yêu cầu các tiêu chí phải nhất quán, nên cần phải có một định nghĩa tốt về vấn đề xác định các văn bản trung tính như những văn bản khách quan không chứa tình cảm rõ ràng hay những lời chúc, những mong muốn (“tôi ước sản phẩm tốt hơn; “ tôi ước sữa này có nhiều chất dinh dưỡng”) là những câu khó phân loại.
Ngày nay, xu hướng người tiêu dùng sử dụng dịch vụ hoặc mua sắm đã thay đổi so với các phương thức truyền thống. Việc tham khảo ý kiến, các đánh giá hay nhận xét ngày càng được nhận được sự quan tâm từ người tiêu dùng cũng như nhà sản xuất và các chuyên gia. Vì vậy, Nhiều người đã lợi dụng các yếu tố này nhằm trục lợi bằng cách đưa ra các nhận xét tốt cho sản phẩm của họ hoặc đưa ra các đánh giá xấu cho các sản phẩm của đối thủ. Những hoạt động này được gọi là giả mạo quan điểm hoặc lừa đảo [6] . Với sự phát triển mạnh mẽ của mạng xã hội, việc lan truyền thông tin ngày càng dễ dàng. Các bình luận có thể được chia sẻ một cách nhanh chóng và hầu như thiếu sự kiểm soát từ các cơ quan chức năng và các nhà quản lý mạng. Từ đó, các thông tin giả mạo các ý kiến đánh giá ngày càng trở nên tinh vi và khó kiểm soát, đây là một thách thức lớn đối với việc phát hiện chúng.
Xử lý ngôn ngữ tự nhiên trong câu quan điểm: Các ý kiến mà mọi người bày tỏ trên các trang mạng xã hội thường viết theo ngôn ngữ tự nhiên, các đánh giá của người tiêu dùng cũng thường dùng các ngôn ngữ văn bản không chính thức và không theo quy tắc ngữ pháp, có thể họ viết tắt hoặc dùng các biểu tượng cảm
xúc. Mỗi người khác nhau sẽ có cách viết khác nhau. Vì vậy, vấn đề xử lý ngôn ngữ tự nhiên trong việc xử lý các ý kiến đánh giá là một thách thức lớn.
1.4. Các ứng dụng của phân tích quan điểm
Quan điểm về sản phẩm đã luôn là một phần quan trọng trong việc cung cấp thông tin cho quá trình ra quyết định. Trước khi Internet trở nên phổ biến nếu chúng ta muốn mua một sản phẩm nào chúng ta thường hỏi ý kiến bạn bè, người thân về vấn đề chúng ta đang quan tâm nhưng như thế tham khảo được rất ít thông tin, thường không hiệu quả nhiều. Ngày nay việc tiếp cận với các đánh giá của khách hàng về các sản phẩm, dịch vụ mà chúng ta quan tâm đã dễ dàng. Và khách hàng thường tìm kiếm sự tin cậy trong những lời khuyên, tư vấn trực tuyến là rất nhiều nên nhu cầu có một hệ thống ứng dụng để hỗ trợ người tiêu dùng tìm kiếm thông tin là cần thiết cho cả khách hàng và doanh nghiệp.
Nghiên cứu thị trường dành cho người mua và bán. Thông tin quan điểm đối với một sản phẩm cụ thể có vai trò rất quan trọng. Khi chúng ta muốn mua một sản phẩm nào đó, chúng ta không biết được loại sản phẩm đó có phù hợp hay không, cửa hàng nào dịch vụ khách hàng tốt, giá bán ở đâu rẻ hơn, chất lượng ở đâu tốt hơn để đưa ra các quyết định chính xác vì vậy các quan điểm về sản phẩm của những người dùng trước là một kênh thông tin quan trọng chúng ta thường quan tâm tới ý kiến của người khác đối với sản phẩm đó, theo dạng như “Những người khác đã nghĩ và đánh giá về sản phẩm đó như thế nào ?”. Ví dụ khi chúng ta muốn mua một hộp sữa cho bé chúng ta sẽ hỏi bạn bè người thân hoặc tìm hiểu trên các diễn đàn mạng xã hội những bình luận, đánh giá của người dùng trước về các dòng sản phẩm của các hãng sữa phù hợp với thể trạng trẻ em Việt Nam...v.v”.
Như vậy quan điểm của người khác giúp các cá nhân có thêm thông tin trước khi quyết định một vấn đề. Ngoài ra khi biết được thông tin quan điểm đối với một sản phẩm, dịch vụ từ các khách hàng thì rõ ràng nó giúp mang lại các thông tin hữu ích cho các công ty, tổ chức thay đổi hoặc cải tiến dòng sản phẩm, dịch vụ của mình.
Cải thiện chất lượng của sản phẩm, dịch vụ: Dựa vào quan điểm của người dùng, các nhà sản xuất có thể thay đổi một số tính năng của sản phẩm, dịch vụ theo hướng tích cực nhằm phục vụ nhu cầu của khách hàng.
Phân tích quan điểm cũng có vai trò quan trọng như một công nghệ hỗ trợ cho các hệ thống khác. Một ứng dụng tiềm năng đó là hệ thống gợi ý giúp ta có thể áp dụng phân tích quan điểm trong các hệ thống khuyến cáo, giúp cho hệ thống đưa ra các gợi ý về các sản phẩm cho người dùng có khả năng quan tâm cao nhất
nhằm mục đích tăng lợi nhuận cho doanh nghiệp. Ngoài ra hệ thống còn có thể xác định sở thích của khách hàng về sản phẩm để đưa ra các chiến lược kinh doanh tốt hơn nhằm phục vụ khách hàng, tăng doanh thu cho các doanh nghiệp.
Một dạng ứng dụng vô cùng hữu ích đối với các chính trị gia đó là hệ thống hỗ trợ thông minh cho chính phủ. Chẳng hạn như khi một luật chuẩn bị được ban hành, Quốc Hội rất muốn lắng nghe, lấy ý kiến của nhân dân về dự thảo luật để xem nó có hợp lý hay không, nhân dân có những phản ứng như thế nào . Hay đối với các cuộc bầu tổng thống, chủ tịch nước, thủ tướng thì những ý kiến đánh giá của người dân giữ một vai trò cực kỳ quan trọng đối với kết quả của cuộc bầu cử.
1.5. Phân lớp quan điểm
Phân tích quan điểm cho toàn bộ văn bản là bài toán cơ bản nhất trong phân tích quan điểm giống với bài toán phân lớp văn bản thông thường. Cho trước một tập các văn bản đánh giá sản phẩm, đối với từng văn bản đầu vào, bài toán yêu cầu tính điểm (phân lớp) quan điểm chung cho nó. Dựa trên điểm quan điểm đã đạt được, từng văn bản sau đó được gán các nhãn quan điểm hoặc các hạng tương ứng. Các nhãn có thể được gán như nhãn tích cực (Positive), tiêu cực (Negative) hoặc trung tính. Trong trường hợp cần xếp hạng quan điểm chi tiết cho văn bản thì hạng được gán cho văn bản là “1 sao” (có nghĩa là rất tiêu cực) hoặc “2 sao”
(tiêu cực mức trung bình) hoặc “3 sao” (trung tính) hoặc “4 sao” (tích cực) hoặc
“5 sao” (rất tích cực). Việc phân tích quan điểm theo loại bài toán này thường ở mức tài liệu và không quan tâm tới vấn đề chi tiết hơn như người đánh giá sản phẩm thích hay không thích khía cạnh nào của sản phẩm.
Phân tích quan điểm ở mức câu gần giống với mức tài liệu. Tuy nhiên, do câu thường chứa lượng thông tin ít hơn rất nhiều ở mức tài liệu. Trong một số trường hợp, mỗi câu chỉ chứa một ý kiến hay quan điểm về một thực thể. Các trường hợp phức tạp hơn, một câu có thể có nhiều quan điểm hay đánh giá về các khía cạnh khác nhau của một đối tượng hoặc thậm chí có thể có sự thay đổi về quan điểm trong cùng một câu [5,6,13]. Phân tích quan điểm mức độ câu rất gần với bài toán phân lớp chủ quan và khách quan, trong đó chúng ta cần phân lớp xem một câu đã cho là chủ quan (có quan điểm, ý kiến riêng) hay khách quan (câu chỉ đưa ra thông tin). Tuy nhiên, các câu khách quan cũng có thể từ đó suy ra quan điểm. Trong mức này, các câu thể hiện quan điểm đến thực thể sẽ dễ dàng gán nhãn hơn. Phân loại quan điểm theo khía cạnh
Phân lớp quan điểm ở mức tài liệu hay mức câu theo các định hướng phân cực là tích cực, tiêu cực hay trung tính không thể hiện hết ý nghĩa trong hầu hết
các ứng dụng bởi vì các phân lớp này không xác định được đánh giá hoặc mục tiêu đánh giá hoặc gán với các đánh giá với các mục tiêu. Trong trường hợp khi một tài liệu đánh giá cho một thực thể duy nhất là tích cực thì không có nghĩa là mọi ý kiến đánh giá cho mọi khía cạnh của nó đều là tích cực. Trên thực tế, chúng ta thấy một thực thể có thể được đánh giá ở nhiều khía cạnh khác nhau, và mỗi khía cạnh có thể được đánh giá với nhiều mức độ khác nhau. Do đó, để có thể phân tích chi tiết đánh giá về một thực thể, chúng ta cần xác định với mỗi khía cạnh của nó được đánh giá là tích cực, tiêu cực hay trung tính. Đây chính là mục tiêu của bài toán phân tích quan điểm theo khía cạnh, có hai nhiệm vụ chính: Trích các khía cạnh trong các thực thể được đánh giá và phân lớp quan điểm theo khía cạnh là nhiệm vụ xác định các quan điểm về một khía cạnh đã được trích theo các cực: tiêu cực, trung tính hay tích cực hoặc đánh giá theo mức 1 đến 5 sao.
Phân tích quan điểm trong lĩnh vực thức ăn trẻ em đang trở nên rất quan trọng nhằm mục đích phát hiện những quan điểm, tình cảm tích cực hoặc tiêu cực trong các câu bình luận của khách hàng. Qua đó, doanh nghiệp sẽ có những chính sách cải tiếp tiến sản phẩm, nâng cấp dịch vụ để đáp ứng nhu cầu của khách hành, Không những thể khách hàng có thể tham khảo những bình luận để có thể đưa ra những quyết định đúng đắn khi lựa chọn sản phẩm.
Đầu vào: Cho một câu (đoạn văn bản) thuộc miền dữ liệu thức ăn trẻ em.
Đầu ra: Dự đoán câu bình luận rất tích cực (5), tích cực (4), trung tính (3), tiêu cực (2) hay rất tiêu cực (1).
Ví dụ ta có bình luận: “Sữa Pediasure này rất tốt cho trẻ em”. Câu bình luận này rất tích cực, dự đoán trả về giá trị 5.
Kết luận chương
Chương 1 luận văn đã trình bày những vấn đề cơ bản nhất về phân tích quan điểm cũng như các thành phần, nhiệm vụ, thách thức, xu hướng và ứng dụng của phân tích quan điểm. Từ đó, đặt ra bài toán phân tích quan điểm trong lĩnh vực thức ăn trẻ em, ứng dụng các mô hình học máy để xây dựng mô hình phân lớp quan điểm nhằm mục tiêu tạo ra các lớp quan điểm theo các tiêu chí sắp xếp và phân lớp mà người sử dụng đã đề cập trong văn bản. Từ đó, đánh giá được ý kiến của người sử dụng qua các lớp đã phân.
CHƯƠNG 2: CÁC KỸ THUẬT HỌC MÁY TRONG BÀI TOÁN PHÂN TÍCH QUAN ĐIỂM
Phân tích quan điểm sử dụng các kỹ thuật xử lý ngôn ngữ tự nhiên (Natural Language Processing – NLP) để xác định xem văn bản có ý nghĩa là tích cực, tiêu cực hay trung tính. Phân tích quan điểm thường được thực hiện trên văn bản đánh giá, nhận xét, bình luận, … nhằm giúp doanh nghiệp tự động phân tích phản hồi của khách hàng để thu thập được thông tin nhận xét đánh giá sản phẩm, dịch vụ.
2.1. Các phương pháp tiếp cận của phân tích quan điểm
Các kỹ thuật phân tích quan điểm có thể chủ yếu được chia thành cách tiếp cận dựa trên từ vựng (Lexicon Based Approach) và cách tiếp cận học máy (Machine Learning Approach). Các kỹ thuật học máy được áp dụng trong lĩnh vực phân tích quan điểm có thể được chia thành phương pháp học có giám sát, học không giám sát và gần đây là tiếp cận dựa trên học sâu (Deep Learning Approach) là cách tiếp cận hiện đại hơn, có thể tự động trích xuất đặc trưng và biểu diễn dữ liệu ở mức nhiều thông tin, giàu ngữ nghĩa. Tuy nhiên chi phí thời gian huấn luyện cho các mô hình này là rất lớn.
Học không giám sát không có đầu ra mục tiêu rõ ràng liên quan đến đầu vào và nó là học thông qua quan sát. Mục đích là để máy học mà không đưa ra bất kỳ hướng dẫn rõ ràng nào. Cách tiếp cận nổi tiếng trong học tập không giám sát là phân cụm, trong đó tìm ra điểm tương đồng của các yếu tố trong dữ liệu huấn luyện. Tham số độ tương tự cụm được xác định dựa trên các chỉ số như khoảng cách Euclide. K-means, Hierarchical, mô hình hỗn hợp Gaussian, Bản đồ tự tổ chức, và mô hình Markov ẩn là một số thuật toán phân cụm [10,14]
Học có giám sát là phương pháp sử dụng tập dữ liệu đã biết để đưa ra dự đoán kết quả đầu ra. Việc học có giám sát yêu cầu hai bộ tài liệu: bộ huấn luyện và bộ kiểm thử. Để học các thuộc tính khác nhau của tài liệu, tập huấn luyện được sử dụng và để đánh giá tập kiểm tra trình phân lớp hiệu suất được sử dụng.
2.1.1. Phương pháp tiếp cận dựa trên luật
Các hệ thống này tự động thực hiện phân tích quan điểm dựa trên một tập hợp các luật được tạo thủ công do con người tạo ra giúp xác định tính chủ quan, quan điểm tích cực, quan điểm tiêu cực, trung tính hoặc chủ đề của một ý kiến.
Các luật này có thể bao gồm các kỹ thuật NLP khác nhau được phát triển trong ngôn ngữ học tính toán như tạo mã nguồn, mã hóa, phân tích cú pháp và dựa vào danh sách từ điển và từ vựng (Lexicons). Cơ chế hoạt động cơ bản của hệ thống
dựa trên luật:
1. Xác định hai danh sách các từ phân cực, các từ tiêu cực như quá xấu, quá tệ, chất lượng quá kém, tồi quá… và các từ tích cực như rất tốt, rất đẹp, thật tuyệt …
2. Đếm số từ tích cực và tiêu cực xuất hiện trong một văn bản nhất định.
3. Nếu số lần xuất hiện từ tích cực nhiều hơn số lần xuất hiện từ tiêu cực, hệ thống sẽ trả về cảm xúc tích cực và ngược lại. Nếu các con số là chẵn, hệ thống sẽ trả về một cảm giác trung tính.
Các hệ thống dựa trên luật rất đơn giản vì chúng không tính đến cách các từ được kết hợp theo một trình tự. Tất nhiên, các kỹ thuật xử lý nâng cao hơn có thể được sử dụng và các luật mới được thêm vào để hỗ trợ các cách diễn đạt và từ vựng mới. Tuy nhiên, việc thêm các luật mới có thể ảnh hưởng đến các kết quả trước đó và toàn bộ hệ thống có thể trở nên rất phức tạp. Vì các hệ thống dựa trên luật thường yêu cầu tinh chỉnh và bảo trì, chúng cũng sẽ cần đầu tư thường xuyên.
2.1.2. Phương pháp tiếp cận dựa vào học máy
Các phương pháp tiếp cận dựa vào học máy không dựa trên các luật được tạo thủ công, mà dựa trên các kỹ thuật máy học. Một nhiệm vụ phân tích quan điểm thường được mô hình hóa như một bài toán phân lớp, theo đó một bộ phân lớp được cung cấp đầu vào là một văn bản và trả về đầu ra là một danh mục, ví dụ: tích cực, tiêu cực hoặc trung tính.
Một bộ phân lớp học máy có thể được phát triển nếu nó được xây dựng dựa trên kho ngữ liệu huấn luyện có chứa nhãn chính xác cho mỗi đầu vào.
Một số phương pháp tiếp cận học máy là sử dụng tập dữ liệu đã biết để đưa ra dự đoán kết quả đầu ra. Các kỹ thuật truyền thống yêu cầu hai bộ tài liệu: bộ huấn luyện và bộ kiểm thử. Để học các thuộc tính khác nhau của tài liệu, tập huấn luyện được sử dụng và để đánh giá tập kiểm tra trình phân lớp hiệu suất được sử dụng. Các thuật toán học máy được sử dụng phổ biến trong bài toán phân tích quan điểm: Naïve Bayes, Maximum Entropy, Support Vector Machine (SVM), Logistic Regression, Deep Learning. Các thuật toán này có hiệu quả trong bài toán phân tích quan điểm.
2.2. Phương pháp Naïve Bayes
Bộ phân lớp quan điểm Naïve Bayes [7] được xây dựng dựa trên lý thuyết Bayes về xác suất có điều kiện để phân lớp quan điểm:
(2.1) Mục tiêu là tìm được phân lớp c sao cho P(c|d) là lớn nhất hay xác suất của tài liệu d thuộc lớp c là lớn nhất.
Ta có thể nhận thấy từ công thức trên P(d) không đóng vai trò gì trong việc quyết định phân lớp c P(c|d) lớn nhất ⟺ P(c).P(d|c) lớn nhất.
Để có thể xấp xỉ giá trị của P(d|c), thuật toán Naïve Bayes giả sử rằng: các vector đặc trưng fi của một tài liệu khi đã biết phân lớp là độc lập với nhau. Từ đó ta có công thức:
(2.2) Trong đó f là các vector đặc trưng cho tài liệu d.
Khi tiến hành huấn luyện, thuật toán sử dụng phương pháp xấp xỉ hợp lý cực đại MLE (Maximum Likelihood Estimation) để xấp xỉ P(c) và P(fi|c) cùng thuật toán làm mịn add-one (add-one smoothing). Ta có:
(2.3) Trong đó Nc là số văn bản được phân loại vào lớp c; N là tổng số văn bản trong tập huấn luyện.
(2.4) Trong đó Ncfi là số lần xuất hiện của vector đặc trưng i trong tài liệu thuộc phân lớp c.
Đánh giá bộ phân lớp sử dụng thuật toán Naive Bayes, ta nhận thấy:
Ưu điểm: Đơn giản, dễ cài đặt, bộ phân lớp chạy nhanh và cần ít bộ nhớ lưu trữ. Không cần nhiều dữ liệu huấn luyện để xấp xỉ được bộ tham số.
Nhược điểm: Các đặc trưng đầu vào phải độc lập, điều này khó xảy ra trong thực tế làm giảm chất lượng của mô hình.
Trong nhiều bài toán còn phụ thuộc vào dữ liệu để lựa chọn các mô hình Naive Bayes. Bao gồm 3 mô hình được đưa ra dưới đây:
o Gaussian : Mô hình Gaussian giả định rằng các đối tượng địa lý tuân theo phân phối chuẩn. Điều này có nghĩa là nếu các bộ dự đoán nhận các giá trị liên tục thay vì rời rạc, thì mô hình giả định rằng các giá trị này được lấy mẫu từ phân phối Gaussian.
o Multiomial : Bộ phân lớp Naïve Bayes đa lớp được sử dụng khi dữ liệu được phân phối đa lớp. Nó chủ yếu được sử dụng cho các vấn đề phân lớp tài liệu, nó có nghĩa là một tài liệu cụ thể thuộc về danh mục nào như tích cực, tiêu cực, rất tích cực, tiêu cực hoặc trung tính. Trình phân lớp sử dụng tần suất từ cho các yếu tố dự đoán.
o Bernoulli : Bộ phân lớp Bernoulli hoạt động tương tự như bộ phân lớp Đa thức, nhưng các biến dự báo là các biến Booleans độc lập. Chẳng hạn như nếu một từ cụ thể có trong tài liệu hay không. Mô hình này cũng nổi tiếng với các nhiệm vụ phân lớp tài liệu.
2.3. Phương pháp Support Vector Machine (SVM)
Support Vector Machines (SVM) là phương pháp học có giám sát bao gồm phân tích dữ liệu và phát hiện mẫu, được sử dụng cho phân lớp và phân tích hồi quy. Thuật toán SVM được Vladimir Vapnik đề xuất vào năm 1995[10].
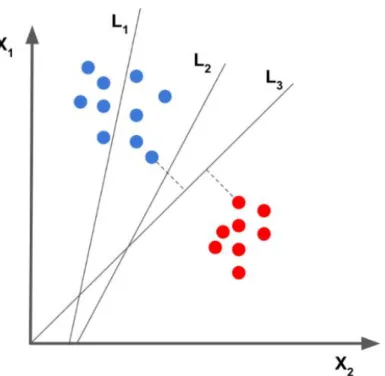
Cách dễ nhất để hiểu SVM là sử dụng một bài toán phân lớp nhị phân. Hai lớp được hiển thị bằng hai màu khác nhau. SVM tìm dòng tốt nhất phân tách hai lớp. Ta thấy dữ liệu được biểu diễn dưới dạng các chấm trên mặt phẳng 2D. Dữ liệu thuộc hai lớp khác nhau được biểu thị bằng màu sắc của các dấu chấm xanh và chấm đỏ.Đối với phân tích quan điểm, điều này sẽ là tích cực và tiêu cực. Một cách để học cách phân biệt giữa hai lớp là vẽ một đường phân chia không gian 2D thành hai phần. Huấn luyện hệ thống chỉ đơn giản là tìm dòng. Khi đã huấn luyện hệ thống (tức là đã tìm thấy đường thẳng), có thể biết liệu một điểm dữ liệu mới thuộc lớp màu xanh hay màu đỏ bằng cách chỉ cần kiểm tra xem nó nằm ở phía nào của đường thẳng.
Hình 2. 1: SVM tìm dòng tốt nhất phân tách hai lớp
Trong ví dụ hình 2.2 trên, rõ ràng là dong L1 không phải là một lựa chọn tốt vì nó không tách biệt hai lớp. L2 và L3 đều tách biệt hai lớp, nhưng trực quan chúng ta biết L3 là lựa chọn tốt hơn L2 vì nó phân tách rõ ràng hơn hai lớp.
Ý tưởng chính của thuật toán này là cho trước một tập huấn luyện được biểu diễn trong không gian vector, trong đó mỗi tài liệu là một điểm trong không gian n chiều và từ các dữ liệu huấn luyện ban đầu được gán nhãn sẽ tìm ra một siêu phẳng phân lớp chính xác các dữ liệu
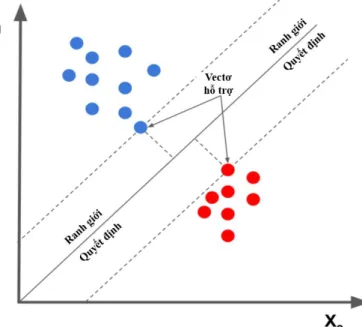
Hình 2. 2: Ví dụ về siêu phẳng trong SVM
Chất lượng của siêu phẳng được quyết định bởi khoảng cách của điểm dữ liệu gần nhất của mỗi lớp đến mặt phẳng. Khoảng cách biên càng lớn thì mặt phẳng quyết định càng tốt, đồng thời việc phân lớp càng chính xác. Mục đích của thuật toán là tìm được khoảng cách biên lớn nhất để tạo ra kết quả phân lớp tốt
Trong ví dụ trên siêu phẳng tối ưu phân chia dữ liệu thành hai lớp màu xanh và màu đỏ. Các điểm gần nhất là các vector hỗ trợ được tô đậm. Hai bên của siêu phẳng là hai lề chứa các vector hỗ trợ – tức là các điểm dữ liệu gần siêu phẳng nhất. SVM thực chất là bài toán tối ưu, mục tiêu của thuật toán này là tìm được một không gian siêu phẳng khi Vectơ hỗ trợ có khoảng cách lớn nhất có thể từ ranh giới quyết định (tức là tách siêu phẳng) và hai lớp nằm trên các mặt khác nhau của siêu phẳng.
Xét một tập dữ liệu mẫu:
𝒟= ( x1, y1),...,( xl,yl)}, x ∈ ℝn , y ∈{-1,1} (2.5) Trong đó xi là một véc tơ đặc trưng hay một điểm (trong không gian n chiều i x ∈ ℝn) biễu diễn tập mẫu di cặp (xi, yi) biểu diễn rằng với một vector đặc trưng xi thì được gán nhãn là yi tương ứng trong đó y ∈{-1,1} hay nói cách khác với tập mẫu di sẽ được gán nhãn cho trước là yi. Ta có phương trình một siêu phẳng
(2.6)
Trong đó wx là tích vô hướng giữa véc tơ x và véc tơ pháp tuyến w∈ℝn được biểu diễn trong không gian n chiều, và b ∈ ℝ là hệ số tự do.
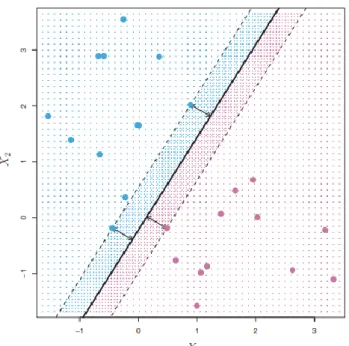
Thực tế, các dữ liệu ban đầu có thể sinh ra vô số các siêu phẳng khác nhau để phân lớp dữ liệu tuy nhiên bài toán đặt ra là trong một không gian n chiều với các tập dữ liệu mẫu như vậy làm thế nào để tìm được một siêu phẳng luôn đảm bảo sự phân chia dữ liệu một cách tốt nhất, ta có thể hiểu một siêu phẳng tốt là một siêu phẳng mà khoảng cách từ các điểm dữ liệu được phân lớp gần nhất với siêu phẳng đó là lớn nhất. Phương trình chứa các điểm dữ liệu này được gọi là các lề, như vậy siêu phẳng tốt là siêu phẳng mà khoảng cách giữa nó và lề càng xa càng tốt.
Hình 2. 3: Siêu phẳng phân chia lề xa nhất
Ưu điểm của phương pháp SVM: Thích hợp với bài toán phân tích quan điểm, các đặc trưng lớn, có thể giao nhau hoặc phụ thuộc nhau. Nhiều đặc trưng nhưng chạy khá nhannh vì học trên Vectơ hỗ trợ.
2.4. Phương pháp Hồi quy Logistic (Logistic regression) 2.4.1. Giới thiệu
Một thuật toán rất nổi tiếng trong thống kê được sử dụng để dự đoán một số giá trị (Y) cho một tập hợp các tính năng (X).
Thuật toán Hồi quy Logistic thuộc học máy có giám sát để phân loại dữ liệu. Mô hình hồi quy Logistic áp dụng cho biến phụ thuộc là biến định tính hoặc định lượng chỉ có hai giá trị (có hoặc không) hay nhị phân là 0 hoặc 1. Điều này phù hợp với bài toán phân loại bình luận người dùng cụ thể là phân tích quan điểm. Đầu ra của bài toán đó là xác định bình luận đó là tích cực hay tiêu cực.
2.4.2. Mô hình Logistic
Đầu tiên, ta sẽ xem xét mô hình logistic như sau: Hãy xem xét một mô hình có hai yếu tố dự đoán, x1 và x2, và một biến phản hồi nhị phân Y, mà chúng tôi biểu thị p = P (Y = 1). Giả định mối quan hệ tuyến tính giữa các biến dự đoán và tỷ lệ cược log của sự kiện Y = 1. Mối quan hệ tuyến tính này có thể được viết dưới dạng toán học sau (trong đó ℓ là tỷ lệ cược log, b là cơ số của logarit và là các thông số của mô hình):
0 1 1 2 2
logb 1
p x x
p
(2.7) Có thể sử dụng lũy thừa để phục hồi tỉ lệ cược ta có:
0 1 1 2 2
1
x x
p b
p
(2.8)
Bằng thao tác đại số (chia cả tử và mẫu số cho b 01 1x2 2x ) ta thu được xác suất Y = 1 là:
0 1 1 2 2
0 1 1 2 2 ( 0 1 1 2 2) 0 1 1 2 2
1 ( )
1 1
x x
x x x x b
p b S x x
b b
(2.9)
Trong đó Sb là hàm sigmoid với cơ sở b. Công thức trên cho thấy rằng sau khi i được sửa, chúng ta có thể dễ dàng tính toán tỷ lệ cược Y = 1 cho một quan sát nhất định, hoặc xác suất Y = 1 cho một quan sát nhất định. Trường hợp sử dụng chính của mô hình logistic là đưa ra một quan sát (x1,x2) và ước tính xác suất p mà Y = 1. Trong hầu hết các ứng dụng, cơ số b của lôgarit thường được coi là e. Tuy nhiên, trong một số trường hợp, việc truyền đạt kết quả có thể dễ dàng hơn bằng cách làm việc trong cơ sở 2 hoặc cơ sở 10.
Chúng tôi xem xét một ví dụ với b = 10 và các hệ số 0 3,1 1,và2 2 Cụ thể, mô hình là:
10 1 2
log 3 2
1
p x x
p
(2.10)
Trong đó, p là xác suất của sự kiện khi Y=1.
Có thể hiểu như sau:
0 3 là chặn y. Đó là tỷ lệ cược của sự kiện Y = 1, khi các yếu tố dự đoán x1 x2 0. Bằng cách tính lũy thừa, chúng ta có thể thấy rằng khi x1 x2 0 tỷ lệ cược của trường hợp Y = 1 là 1/ (1000 1) 1/ 1001. Tương tự, xác suất của sự kiện Y = 1 khi
1 2 0
x x có thể được tính là 1/ (1000 1) 1/ 1001
11có nghĩa là tăng x1 lên 1 sẽ làm tăng tỷ lệ lên 1. Vì vậy, nếu x1 tăng 1, tỷ lệ cược rằng Y = 1 tăng theo hệ số của 101. Lưu ý rằng xác suất của Y = 1 cũng đã tăng lên, nhưng nó không tăng nhiều vì tỷ lệ