This project titled "Prediction Model for a Student to Find Best Department of Bachelor Admission", submitted by Md. Abu Taleb, ID of the Department of Computer Science and Engineering, Daffodil International University, has been accepted as satisfactory towards the partial fulfillment of requirements for the degree of B.Sc. Department of Computer Science and Engineering Faculty of Natural Sciences and Information Technology Påskelilje International University.
We hereby declare that this project was carried out by us under the supervision of Mrs. We also declare that neither this project nor any part of this project has been submitted elsewhere for the award of any degree or diploma. In-depth knowledge and great interest of our supervisor in the field of “Machine Learning” to carry out this project.
We would like to express our heartfelt gratitude to Almighty Allah and the Head of CSE Department, for his kind help in completing our project, and also to other faculty members and staff of CSE Department of Daffodil International University. We would like to thank our entire coursemate at Daffodil International University who participated in this discussion while completing the courses. Our research title is “Prediction Model for a Student to Find the Best Department for Undergraduate Admission”.
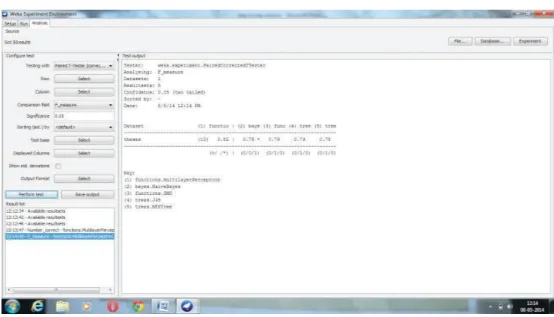
Fig.4.2: Comparison of classifiers using WEKA Experimenter Fig. 4.3: Validation and testing of SSC & HSC result with the entire data set.
Expected Output
Report Layout
BACKGROUND
- Introduction
- Related Works
- Comparative Analysis and Summary
- Scope of the Problem
- Data Collection
- Model selection
- Data labeling
The algorithms they used for implementations were Naïve Bayes, Multi-Layer Perception, KNN, Random forest and Logistic. After researching some research articles and projects, we decided to go with KNN (K- Nearest Neighbor) because,. KNN has the best accuracy among other same classification algorithm with the accuracy of 90% or more with proper training and labeling.
Since we decided to use KNN (K-Nearest Neighbor) as the main classification model, we will work with KNN layers and deep learning algorithms. But due to the wide use of Colab and the easy and fast way of implementation, we decided to go with Google Colab. At runtime, we used Colab and Google GPUs to achieve the best result.
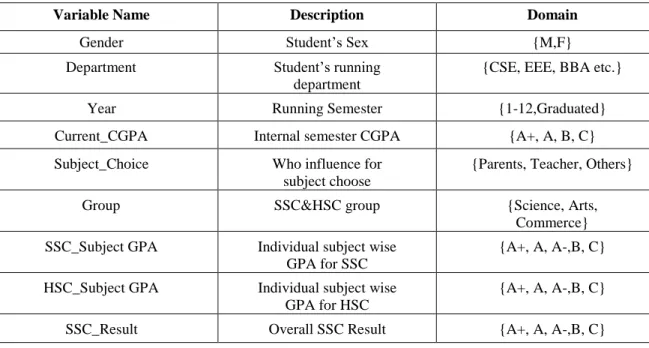
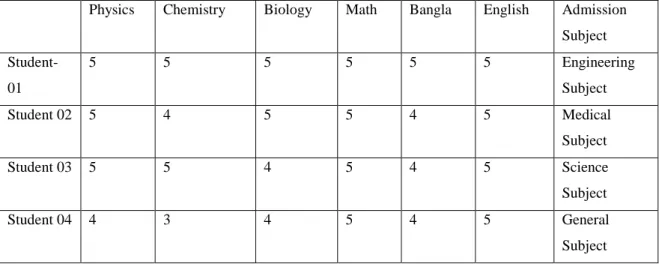
Our main aim is to make a classifier of SSC & HSC result with the subject and further compare them to get the result. Using SSC & HSC result wise; we will be able to get a good range of accuracy in order to find the best possible comparison between their good results. If we have a good range between good and bad, then we will be able to tell how bad or good in that subject is the best solution and whether it is edible or not.
The main goal of this research work is to create a system that can predict the best subject for graduate students and prove that KNN is the best algorithm model for data classifier. But when we started collecting data at the local level, it becomes very difficult because most of the students didn't like that we know about their result without any reason. We test different types of models with the test data and try to find the best one.
After trying everything we chose a KNN algorithm because Google has already done something great to make our job easy. When we have seen that python has built a library like pandas, numpy, sea born etc for this kind of data classifier work and we can work with Google CoLab when we work with this kind of data need some kind of expensive GPU, but Google offers free virtual ones. GPU for my work we decided to work on this model. At this stage, we have renamed all the data as their name and also numbered them sequentially.
RESEARCH METHODOLOGY 3.1 Introduction
- Research Subject and Instrumentation
- Data Collection Procedure
- Statistical Analysis
- Implementation Requirements
- Experimental Setup
- Model Summary
- Experimental Results & Analysis
- Discussion
We have collected data from students studying in different universities and from job holders working in different companies. Moreover, we thought that this kind of data would provide a more accurate result and that this data could also be easily labeled. In this stage we filtered some noisy and incomplete data and tried to remove it.
In this phase, we divided the data and stored it in two data folders for. In this step, we saved all the data in Google Drive because we used an online emulator that makes our task easier. We used the software to find the appropriate algorithm in different perspectives according to our data to find the best result.
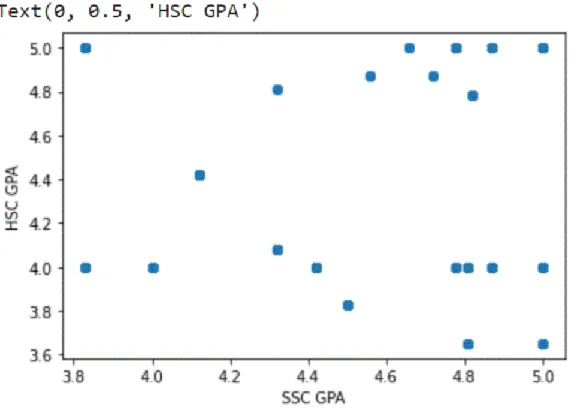
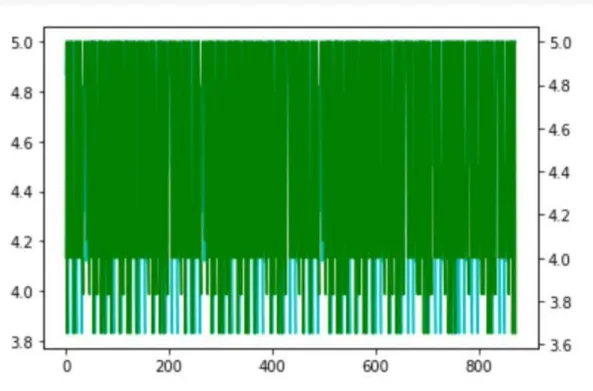
As we have worked on predicting subjects for students which are best for them, that's why we have collected SSC and HSC results with subject wise results. Here we have shown the relationship between SSC and HSC GPA using the model. We implemented KNN (K nearest neighbor) model on our data, it provides satisfactory accurate data graph suggested by WEKA.
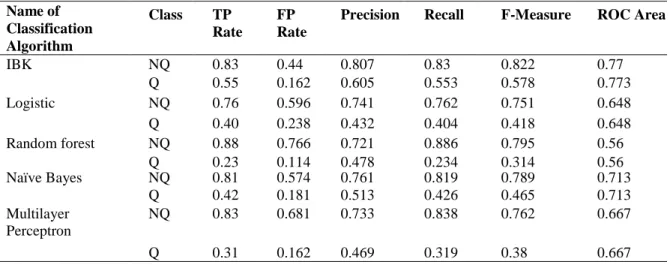
In principle, the K Nearest Neighbor (KNN) model is much simpler and easier to implement and we do not need to build a new model. During this project in development, we tested and analyzed our dataset with five popular classification algorithms. We also demonstrated that the comparison accuracy of all classifiers was completed and finally decided that the IBK algorithm model (KNN-K Nearest Neighbor) performs the best with an accuracy of about 75%.
Here we have shown comparison results of all classifiers using WEKA. Experimenter is shown in Figure 4.2. In this case, we also showed that IBK also performs the best among all other classifiers with an F-measure of 82%. In Figure 4.3, we have presented all data in the form of students' secondary and higher secondary school grades regarding the entire data set.
In this report, we used classification techniques for predictions in our dataset of 887 students. We used that dataset to analyze students' previous result sheet and also to predict future career background.

IMPACT ON SOCIETY, ENVIRONMENT AND SUSTAINABILITY
Impact on Society
Impact on Environment
Ethical Aspects
Project will prove a result or outcome, which profession or department will be best for the student. Since we developed the project with incremental model, it will be updated easily.
CONCLUSION AND FUTURE WORK
Summary of the Study
Conclusions
Recommendations
In the future we will develop a complete open source platform with a huge amount of student data.
APENDIX RESEARCH REFLECTION