REGRESI KEKAR PENDUGA M, PENDUGA S, DAN
PENDUGA MM PADA ANALISIS REGRESI BERGANDA
NILA FAULINA
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASINYA
Dengan ini saya menyatakan bahwa tesis dengan judul Regresi Kekar Penduga M, Penduga S, dan Penduga MM pada Analisis Regresi Berganda adalah karya saya sendiri dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apapun kepada perguruan tinggi manapun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam daftar pustaka dibagian akhir tesis ini.
Bogor, Januari 2012
ABSTRACT
NILA FAULINA. Robust Regression M-Estimation, S-Estimation, and MM-Estimation in Multiple Regression. Under direction of AUNUDDIN and ITASIA DINA S.
In classical multiple regression, the ordinary least squares estimation is the best method if assumptions are met to obtain regression weights when analyzing data. However, if the data does not satisfy some of these assumptions, then sample estimates and results can be misleading. Therefore, statistical techniques that are able to cope with or to detect outlying observations have been developed. Robust regression is an important method for analyzing data that are contaminated with outliers. It can be used to detect outliers and to provide resistant results in the presence of outliers. The purpose of this study is compare robust regression M-estimation, S-M-estimation, and MM-estimation with ordinary least square methods via simulation study. The simulation study is used in determine which methods best in all of the linear regression scenarios.
RINGKASAN
NILA FAULINA. Regresi Kekar Penduga M, Penduga S, dan Penduga MM pada Analisis Regresi Berganda. Dibawah bimbingan AUNUDDIN dan ITASIA DINA S.
Metode kuadrat terkecil (MKT) atau ordinary least square (OLS) merupakan salah satu metode yang sering digunakan untuk mendapatkan nilai-nilai penduga parameter dalam pemodelan regresi. Penggunaan MKT memerlukan beberapa asumsi klasik yang harus dipenuhi oleh komponen sisaan atau galat (εi)
dalam model yang dihasilkan. Beberapa asumsi itu antara lain adalah bahwa komponen sisaan memenuhi asumsi kenormalan, kehomogenan ragam, dan tidak ada autokorelasi. Myers (1990) menyatakan bahwa apabila asumsi klasik itu terpenuhi, maka penduga parameter yang diperoleh bersifat best linear unbiased estimator (BLUE).
Dalam berbagai kasus ditemui berbagai hal yang menyebabkan tidak terpenuhinya asumsi klasik tersebut. Saat asumsi ada yang tidak terpenuhi, maka penggunaan MKT akan memberikan kesimpulan yang bersifat kurang baik atau nilai penduga parameternya bersifat bias, interpretasi hasil yang diberikan juga menjadi tidak valid.
Salah satu penyebab tidak terpenuhinya asumsi klasik adalah adanya pencilan (outliers) pada data amatan. Pencilan ini dapat diketahui secara visual atau secara eksak dengan melakukan diagnosis sisaan dari model regresi yang terbentuk. Suatu data dinyatakan sebagai pencilan berdasarkan kriteria tertentu dalam metode diagnosis sisaan yang digunakan.
Selanjutnya, diperlukan alternatif metode penduga parameter lain yang dapat mengatasi adanya pencilan dalam data amatan. Metode itu adalah metode regresi kekar (robust), beberapa penduga yang sering digunakan adalah penduga M, penduga S, dan penduga MM. Diharapkan, melalui metode regresi kekar dapat diperoleh penduga parameter yang lebih baik yang bersifat bias dan mempunyai ragam minimum sehingga menghasilkan model yang lebih baik dari model hasil MKT.
Penelitian ini menggunakan data simulasi yang dibangkitkan sebanyak 100 data dan diulang sebanyak 20 kali. Plot pencaran titik data antara peubah respon dengan peubah penjelas mengungkapkan bahwa secara keseluruhan pola pencaran titik tersebut bisa didekati oleh garis lurus (model regresi linier). Titik-titik yang terlihat terlalu jauh dari kumpulan data disebut sebagai pencilan.
Hasil pendugaan parameter β0 pada kelompok data tanpa pencilan (0%
regresi. Dari hasil pendugaan dapat dilihat bahwa penduga MKT merupakan penduga yang sangat peka terhadap pencilan. Nilai dugaan yang diperoleh dari MKT menyimpang jauh dari nilai yang diharapkan.
Hasil pendugaan parameter β1 pada kelompok data tanpa pencilan (0%
pencilan) dugaan yang diperoleh hampir sama untuk setiap metode. Namun dapat dikatakan yang paling baik dari keempat metode adalah metode penduga S karena lebih mendekati nilai parameter. Pada kelompok data dengan pencilan 5% penduga S dan penduga MM memberikan hasil yang hampir sama dan merupakan penduga terbaik. Untuk hasil dugaan MKT masih jauh dari yang diharapkan. Pada kelompok data dengan pencilan 10% metode regresi kekar memberikan hasil yang hampir sama. Pada kelompok data dengan pencilan 15% juga memberikan hasil yang tidak berbeda jauh, namun dapat dikatakan metode yang paling baik adalah metode penduga S. Dari hasil pendugaan dapat dilihat bahwa penduga MKT merupakan penduga yang sangat peka terhadap pencilan karena hasil yang diberikan masih menyimpang dari nilai yang diharapkan.
Hasil pendugaan parameter β2 pada kelompok data tanpa pencilan (0%
pencilan) dugaan yang diperoleh hampir sama untuk setiap metode. Namun dapat dikatakan yang paling baik dari keempat metode adalah metode penduga MM. Pada kelompok data dengan pencilan 5% penduga yang paling baik diantara keempat metode adalah metode penduga S. Sedangkan hasil dugaan MKT hampir mendekati nilai yang diharapkan. Pada kelompok data dengan pencilan 10% penduga yang paling baik diantara keempat metode adalah metode penduga S. Pada kelompok data dengan pencilan 15% penduga M merupakan penduga yang paling baik.
Dari penelitian ini disimpulkan bahwa metode regresi kekar penduga M, penduga S, dan penduga MM lebih kekar terhadap pencilan dibandingkan MKT. Dengan membandingkan dugaan koefisien regresi dan efisiensi dari penduga diketahui bahwa penduga M lebih efisien dalam mengatasi pencilan dibandingkan penduga S dan penduga MM. Sedangkan antara penduga S dan penduga MM, penduga MM mempunyai efisiensi lebih baik daripada penduga S. Namun secara keseluruhan semakin besar persentase pencilan efisiensi masing-masing penduga semakin menurun.
© Hak Cipta milik IPB, tahun 2012
Hak Cipta dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan yang wajar IPB.
REGRESI KEKAR PENDUGA M, PENDUGA S, DAN
PENDUGA MM PADA ANALISIS REGRESI BERGANDA
NILA FAULINA
Tesis
Sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada
Program Studi Statistika
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
Judul Tesis : Regresi Kekar Penduga M, Penduga S, dan Penduga MM pada Analisis Regresi Berganda
Nama : Nila Faulina NIM : G151070081
Disetujui Komisi Pembimbing
Prof. Dr. Ir. Aunuddin, M.Sc
Ketua Program Studi Statistika
Dra. Itasia Dina Sulvianti, M.Si Ketua Anggota
Diketahui
Dekan Sekolah Pascasarjana
Dr. Ir. Erfiani, M.Si Dr. Ir. Dahrul Syah, M.Sc.Agr
Tanggal Ujian : 26 Januari 2012
Kupersembahkan karya ini untuk
Orang tuaku yang menyayangiku
Suamiku tercinta dan Anakku Amira Zahira
PRAKATA
Syukur nikmat penulis panjatkan kepada Allah SWT atas berkah, rahmat, dan karunia-Nya sehingga penulis dapat menyelesaikan penulisan tesis ini.
Dalam penyelesaian tesis ini, penulis banyak mendapat masukan dari Dosen Pembimbing, keluarga dan teman-teman. Dengan segala keterbatasan dan kekurangan akhirnya tesis yang berjudul Regresi Kekar Penduga M, Penduga S, dan Penduga MM pada Analisis Regresi Berganda dapat diselesaikan dengan baik.
Penulis mengucapkan terima kasih kepada:
1. Bapak Prof. Dr. Ir. Aunuddin, M.Sc dan Ibu Dra. Itasia Dina Sulvianti, M.Si selaku pembimbing yang telah banyak memberikan arahan, saran, dan bimbingan.
2. Seluruh anggota keluarga penulis, terutama suami dan anakku yang senantiasa memberikan dorongan dan doa yang tulus.
3. Seluruh Dosen dan karyawan Departemen Statistika FMIPA IPB yang telah memberikan layanan pengajaran dan administrasi dengan baik.
4. Teman-teman statistika sebagai teman diskusi, dan khususnya teman kost Ciwaluya 24, terima kasih kerjasamanya.
Penulis menyadari bahwa masih banyak kekurangan dalam penyusunan tesis ini, oleh karena itu kritik, saran, dan masukan sangat penulis harapkan demi penyempurnaan dan perbaikan tulisan ini. Semoga karya ilmiah ini bermanfaat untuk semua pembaca. Amin.
Bogor, Januari 2012
RIWAYAT HIDUP
Penulis dilahirkan di Lubuk Sikaping (Sumatera Barat) pada tanggal 20 Desember 1982 dari pasangan Marjohan dan Nursis. Penulis merupakan anak ke dua dari 3 bersaudara. Menyelesaikan SMA pada tahun 2000, dan pada tahun yang sama penulis melanjutkan program Sarjana di Fakultas MIPA, Jurusan Matematika, Universitas Andalas (UNAND) Padang.
Pada tahun 2005 s/d 2010 penulis bekerja di STKIP PGRI Sumatera Barat sebagai Dosen Tetap Yayasan. Pada tahun 2007 penulis mendapat kesempatan untuk melanjutkan program Magister Sains pada Program Studi Statistika, Sekolah Pascasarjana, Institut Pertanian Bogor (IPB).
DAFTAR ISI
Halaman
DAFTAR TABEL ... xiv
DAFTAR GAMBAR ... xv
DAFTAR LAMPIRAN ... xvi
PENDAHULUAN Latar belakang ... 1
Tujuan penelitian ... 2
TINJAUAN PUSTAKA Pencilan ... 3
Metode Kuadrat Terkecil (MKT) ... 4
Penduga M ... 5 Deskripsi Data Simulasi ... 14
Diagnosis Sisaan ... 15
Pendugaan Parameter Regresi Menggunakan MKT dan Metode regresi Kekar ... 16
Efisiensi ... 18
SIMPULAN DAN SARAN Simpulan ... 23
Saran ... 23
DAFTAR PUSTAKA ... 24
DAFTAR TABEL
Halaman
1 Ringkasan Jenis Pengamatan Pencilan... 4
2 Penduga Koefisien Regresi dengan MKT dan Metode Regresi Kekar ... 16
3 Rataan Nilai Efisiensi untuk Data Tanpa Pencilan ... 18
4 Rataan Nilai Efisiensi untuk Data dengan 5% Pencilan ... 19
5 Rataan Nilai Efisiensi untuk Data dengan 10% Pencilan ... 20
DAFTAR GAMBAR
Halaman
1 Plot jenis pengamatan pencilan ... 3
2 Ilustrasi titik leverage ... 4
3 Fungsi objektif untuk fungsi penimbang Huber ... 7
4 Fungsi objektif untuk fungsi penimbang Tukey (bisquare) ... 8
5 Plot pencaran titik data antara peubah respon dan peubah penjelas yang mempunyai (a) pencilan 0%, (b) pencilan5%, (c) pencilan10%, dan (d) pencilan15% ... 14
DAFTAR LAMPIRAN
Halaman
1 Rataan Bias Dugaan Parameter MKT, Penduga M, Penduga S dan
Penduga MM ... 26 2 Ragam Dugaan Parameter MKT, Penduga M, Penduga S dan Penduga
PENDAHULUAN
Latar Belakang
Analisis regresi merupakan suatu metode statistika yang digunakan untuk menelaah hubungan antara sepasang peubah atau lebih. Peubah-peubah tersebut dibedakan menjadi dua bagian yakni peubah respon dan peubah penjelas. Peubah respon disebut juga dengan peubah tak bebas dan biasanya disimbolkan dengan huruf Y. Sedangkan peubah penjelas disebut juga dengan peubah bebas dan pada umumnya disimbolkan dengan huruf X.
Tujuan dari analisis regresi adalah untuk menduga parameter model yang menyatakan pengaruh hubungan antara peubah respon dan peubah penjelas. Metode yang banyak digunakan untuk menduga parameter model regresi adalah metode kuadrat terkecil (Ordinary Least Squares, OLS). Hal ini disebabkan oleh mudahnya penghitungan metode ini dan merupakan penduga tak bias terbaik untuk parameter model regresi jika data yang digunakan memenuhi asumsi klasik (Draper & Smith 1998). Asumsi yang harus dipenuhi dalam metode kuadrat terkecil, yaitu: (1) data merupakan sampel yang diambil secara acak dari suatu populasi dan sisaan yang dihasilkan bersifat saling bebas, (2) nilai harapan dari sisaan sama dengan nol, (3) tidak terdapat korelasi yang kuat antar peubah bebas, (4) sisaan memiliki ragam yang sama (homoskedastisitas).
Myers (1990) menyatakan bahwa apabila asumsi klasik itu terpenuhi, maka penduga parameter yang diperoleh bersifat best linear unbiased estimator (BLUE), yaitu memiliki nilai harapan sama dengan nol dan mempunyai ragam minimum. Dalam berbagai kasus ditemui beberapa hal yang menyebabkan tidak terpenuhinya asumsi tersebut. Salah satunya adalah ditemuinya pencilan (outliers) pada data. Pencilan ini dapat diketahui secara visual atau secara eksak dengan melakukan diagnosis sisaan dari model regresi yang terbentuk.
pencilan sekaligus menyesuaikan dugaan parameter regresi sehingga memberikan hasil yang stabil atau resistant ketika ada pencilan dalam data.
Beberapa metode penduga kekar yang telah dikembangkan diantaranya adalah metode penduga parameter regresi berdasarkan pada penduga M (maximum likelihood estimator), penduga S (scale), dan penduga MM (lebih dari satu prosedur penduga M). Penduga M merupakan penduga kekar yang memiliki efisiensi yang tinggi, sedangkan penduga S memiliki efisiensi yang rendah. Sementara penduga MM adalah penduga prosedur dua tahap yang merupakan kombinasi dua penduga dari kelompok yang berbeda. Penduga MM dibangun dari kombinasi penduga S dan penduga M.
Efisiensi suatu penduga merupakan ukuran sampel yang diperlukan untuk mendapatkan keakuratan yang sama dengan penduga lainnya. Efisiensi suatu penduga terhadap penduga lainnya diperlukan untuk mengetahui bahwa penduga tersebut merupakan penduga terbaik yaitu penduga dengan ragam terkecil. Berdasarkan hal ini akan dibandingkan antara metode regresi kekar penduga M yang memiliki efisiensi tinggi dengan penduga S yang memiliki efisiensi yang rendah serta penduga MM yang merupakan kombinasi antara penduga S dan penduga M.
Tujuan Penelitian
TINJAUAN PUSTAKA
Pencilan
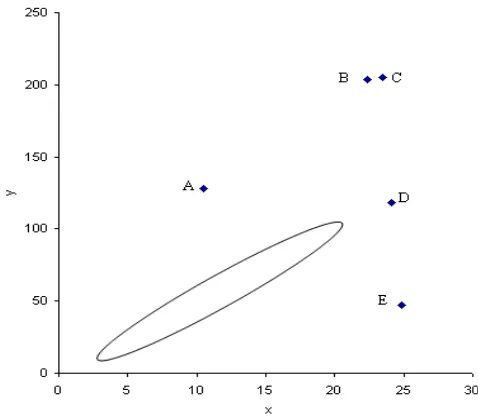
Aunuddin (1989) mendefinisikan pencilan sebagai nilai ektstrim yang menyimpang agak jauh dari kumpulan pengamatan lainnya, yang secara kasar berada pada jarak sejauh tiga atau empat kali simpangan baku dari nilai tengahnya. Ryan (1997) mengelompokkan pencilan dalam berbagai tipe:
1. Pencilan-x, yakni pengamatan yang hanya menyimpang pada sumbu x saja. Pengamatan ini disebut juga sebagai titik leverage.
2. Pencilan-y, yakni pengamatan yang menyimpang hanya karena arah peubah tak bebasnya.
3. Pencilan-x,y, yaitu pengamatan yang menyimpang pada keduanya yakni pada peubah x dan peubah y.
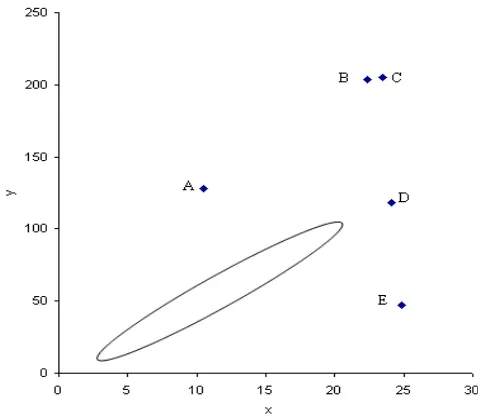
Gambar 1 mengilustrasikan berbagai jenis pencilan. Elips menggambarkan mayoritas data. Titik A, B, dan C adalah pencilan dalam ruang Y karena nilai-nilai y atau nilai respon secara signifikan berbeda dari keseluruhan data dan merupakan pencilan sisaan. Titik B, C dan D adalah pencilan dalam ruang X, karena nilai-nilai x pada titik tersebut berbeda dan ini juga disebut sebagai titik leverage. Titik D walaupun terpencil di ruang X, namun bukanlah pencilan sisaan. Titik B dan C adalah titik leverage dan merupakan pencilan sisaan. Titik E merupakan pencilan sisaan.
Semua tipe pencilan yang digambarkan di atas dapat diringkas dalam Tabel 1 berikut.
Tabel 1 Ringkasan Jenis Pengamatan Pencilan Titik Pencilan-Y Pencilan-X Pencilan Sisaan
A √ - √
B √ √ √
C √ √ √
D √ √ -
E - √ √
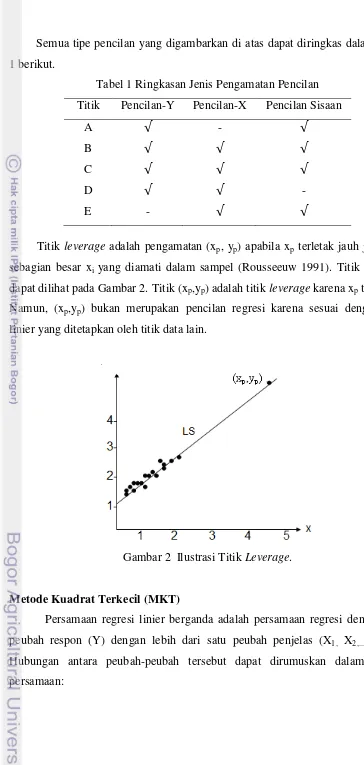
Titik leverage adalah pengamatan (xp, yp) apabila xp terletak jauh jauh dari
sebagian besar xi yang diamati dalam sampel (Rousseeuw 1991). Titik leverage
dapat dilihat pada Gambar 2. Titik (xp,yp) adalah titik leverage karena xp terpencil.
Namun, (xp,yp) bukan merupakan pencilan regresi karena sesuai dengan pola
linier yang ditetapkan oleh titik data lain.
Gambar 2 Ilustrasi Titik Leverage.
Metode Kuadrat Terkecil (MKT)
Persamaan regresi linier berganda adalah persamaan regresi dengan satu peubah respon (Y) dengan lebih dari satu peubah penjelas (X1, X2,...,Xp).
Yi = β0 + β1X1i + β2X2i + … + βpXpi + εi untuk i = 1, 2, …, n
dengan Yi merupakan pengamatan ke-i (dari n pengamatan) untuk peubah respon
dan Xpi merupakan peubah penjelas ke-p dari pengamatan ke-i. Komponen βp
merupakan parameter yang belum diketahui dan akan diduga, sedangkan εi
merupakan komponen galat yang diasumsikan menyebar normal, bebas dan identik, yang mempunyai nilai tengah 0 dan ragam homogen.
Bila ditulis dalam bentuk matriks model umum regresi linier dinyatakan dengan
Y = Xβ + ε
dengan Y merupakan vektor pengamatan pada peubah respon berukuran (n x 1) dan X adalah matriks berukuran (n x p) dengan p peubah penjelas dan n pengamatan, β adalah vektor koefisien regresi (parameter) berukuran (p x 1) dan ε adalah vektor sisaan berukuran (n x 1). Metode yang sering digunakan oleh para peneliti adalah metode kuadrat terkecil yang dirancang untuk menghasilkan penduga b untuk menduga β, dan nilai dugaan
sehingga
yang meminimumkan jumlah kuadrat sisaan
Penduga M
Penduga M pertama kali dikenalkan oleh Huber pada tahun 1964 sebagai alternatif penduga regresi kekar untuk MKT. Metode ini mengganti pada persamaan (1) menjadi .
Secara umum penduga M meminimumkan fungsi objektif :
1. (e) ≥ 0 2. (0) = 0 3. (e) = (-e)
4. ≥ untuk >
Misalkan = adalah turunan dari , maka untuk meminimumkan persamaan (2) :
Ditentukan fungsi pembobot , dan misalkan maka persamaan dapat ditulis sebagai berikut
Pembobot dalam penduga M bergantung pada sisaan dan koefisien. Prosedur untuk mendapatkan parameter penduga yaitu iterasi yang disebut dengan kuadrat terkecil tertimbang iteratif (iteratively reweighted least squares/IRLS), tahapanya :
1) Duga parameter regresi b(0) dengan MKT.
2) Pada setiap iterasi t, hitung sisaan dan gabungkan pembobot dari iterasi sebelumnya.
3) Penduga parameter kuadrat terkecil terboboti yang baru adalah
dengan X adalah matriks model dengan adalah baris ke-i, dan
4) Ulangi langkah 2 dan 3 hingga didapatkan penaksiran parameter yang konvergen.
1. Fungsi penimbang yang disarankan oleh Huber memakai fungsi objektif
dengan
dan fungsi penimbang
Gambar 3 Fungsi objektif untuk fungsi penimbang Huber.
2. Fungsi penimbang yang disarankan oleh Tukey memakai fungsi objektif
dengan
Gambar 4 Fungsi objektif untuk fungsi penimbang Tukey (bisquare).
Pengaruh besarnya simpangan e terhadap nilai dugaan dapat dilihat dari perilaku p(e) atau w(e) (Gambar 3 dan 4). Berdasarkan kurva p(e) terlihat bahwa kedua fungsi penimbang tersebut berprilaku mirip rataan dalam selang tertentu di bagian tengah data, di luar batas tersebut pengaruhnya menjadi konstan pada fungsi Huber dan mengecil menuju nol pada penimbang ganda Tukey Aunuddin 1989). Sedangkan dari kurva w(e) terlihat bahwa fungsi Huber memberikan penimbang sebesar satu untuk dan mengecil pada . Pada fungsi Tukey, penimbangnya mengecil setelah e beranjak dari nol dan ketika
penimbangnya nol (Fox 2002). Dengan kata lain semakin besar simpangann mutlak ei akan semakin kecil penimbangnya begitu pula sebaliknya dengan
harapan memperkecil dampak dari pencilan.
Pemilihan konstanta k pada regresi kekar bertujuan menentukan penduga kekar untuk pencilan dan penduga efisien. Bila nilai konstantanya kecil maka model regresi akan lebih kekar tetapi kurang efisien. Sedangkan bila nilai konstantanya besar maka model regresi akan kurang kekar tetapi lebih efisien. Lu (2004) menyatakan bahwa konstanta yang menghasilkan efisiensi 95% dimana galatnya normal serta selalu memberikan perlindungan terhadap pencilan yaitu konstanta sebesar k = 1.345 untuk fungsi penimbang Huber dan sebesar k = 4.685 untuk fungsi penimbang ganda Tukey.
yang sama dengan nilai sebenarnya sedangkan ukuran penyebarannya dilihat dari nilai ragam dugaannya. Besar kecilnya nilai ragam ini menjadi petunjuk mengenai tingkat ketelitian dari dugaan yang diperoleh.
Beberapa peneliti menyarankan untuk mendekati sebaran koefisien regresi
b dengan sebaran asimptotiknya. Hal ini dikarenakan adanya proses iterasi dengan penimbang yang nilainya tergantung pada sisaan yang menjadi sumber kesulitan.
Dengan menggunakan untuk menduga , dan
untuk menduga maka menghasilkan matrik ragam peragam asimptotik untuk b adalah
Penduga S
Penduga S adalah salah satu penduga yang memiliki efisiensi yang rendah. Penduga ini diperoleh dari minimasi dugaan M skala sisaan.
Definisi 1. Misalkan penduga dan vektor sisaan. Penduga S didefinisikan sebagai dengan diperoleh dari dugaan M skala sisaan yang merupakan solusi
(Rousseeuw & Yohai 1984).
Penduga S dapat dinyatakan dalam bentuk lain, yaitu . Bentuk yang terakhir ini bisa representasikan dengan sistem persamaan yang merupakan formula penghitungan simultan pendugaan kekar parameter regresi dan pendugaan kekar skala (Maronna et al. 2006), yaitu:
dan jika dan maka . Sementara fungsi adalah turunan fungsi yang memenuhi beberapa asumsi, yakni:
untuk dan fungsi terbatas, fungsi tidak turun dan , fungsi kontinu, dan untuk .
Penduga MM
Penduga MM pertama kali dikenalkan oleh Yohai (1987). Penduga MM merupakan kombinasi antara penduga yang mempunyai nilai breakdown tinggi (50%) dengan efisiensi yang tinggi (kurang lebih 95% hampir sama dengan metode kuadrat terkecil). Dalam penelitian ini penduga MM berasal dari gabungan antara penduga S yang mempunyai nilai breakdown tinggi dengan penduga M yang mempunyai efisiensi yang tinggi sehingga penduga ini memenuhi kriteria yang diharapkan untuk suatu penduga kekar.
Penduga MM mengacu pada fakta bahwa lebih dari satu prosedur penduga M digunakan untuk menghitung penduga akhir. Mengikuti kasus penduga M, IRLS digunakan untuk mendapatkan penduga. Prosedurnya sebagai berikut:
1. Penduga awal dari koefisien b(1) dan sisaan diambil dari regresi dengan resistant tinggi yaitu penduga S. Meskipun penduga harus konsisten, ini tidak perlu efisien.
2. Sisaan dari penduga awal pada Tahap 1 digunakan untuk menghitung sisaan penduga M skala, .
3. Penduga awal sisaan dari Tahap1 dan sisaan skala dari Tahap 2 digunakan dalam iterasi pertama kuadrat terkecil terboboti untuk menentukan koefisien regresi penduga M.
dimana wi penimbang Huber.
4. Penimbang baru dihitung , menggunakan sisaan dari WLS awal (Langkah 3).
Efisiensi
METODOLOGI PENELITIAN
Data
Data yang digunakan dalam penelitian ini adalah data simulasi. Banyak data (n) yang dibangkitkan adalah 100 dan diulang 20 kali. Prosedur pembangkitan data simulasi adalah sebagai berikut:
1. Tentukan parameter bagi populasi yaitu β0, β1, dan β2. Dalam kasus ini β0,
β1, dan β2 yang digunakan adalah 5, 5, dan 5.
2. Bangkitkan nilai X1 acak normal dengan nilai tengah 15 dan ragam 1.
3. Bangkitkan nilai X2 acak normal dengan nilai tengah 25 dan ragam 1.
4. Tentukan nilai Y = 5 + 5X1 + 5X2.
5. Bangkitkan sisaan (ε) acak normal dengan nilai tengah 0 dan ragam 1.
6. Tentukan nilai Y = 5 + 5X1 + 5X2 + ε. Hasil ini digunakan sebagai data
dengan 0% pencilan (tanpa pencilan).
7. Bangkitkan sisaan (ε) acak normal dengan nilai tengah 50 dan ragam 1.
Hasil ini akan digunakan sebagai pencilan.
8. Ambil secara acak sisaan yang diperoleh dari langkah 5 sebanyak 95% dan dari langkah 7 sebanyak 5% sebagai pencilan lalu gabungkan.
9. Tentukan nilai Y dengan menjumlahkan hasil dari langkah 4 dan langkah 8. 10. Ulangi langkah 8 – 9 untuk pencilan 10% dan 15%.
11. Ulangi langkah 2 – 10 sebanyak 20 kali.
Metode Analisis
Metode simulasi data digunakan untuk membandingkan metode regresi kekar penduga M, penduga S, dan penduga MM dengan MKT dalam menduga parameter regresi dari gugus data yang memiliki pencilan. Analisis yang dilakukan melalui tahapan sebagai berikut:
1. Lakukan plot pada masing-masing gugus data untuk melihat pencilan.
3. Lakukan diagnosis sisaan dari model hasil pendugaan MKT pada masing-masing gugus data, untuk menunjukkan secara visual adanya pencilan dalam data.
4. Lakukan pendugaan parameter regresi terhadap masing-masing gugus data menggunakan metode regresi kekar penduga M, penduga S, dan penduga MM. 5. HItung ragam .
6. Hitung efisiensi penduga parameter β.
HASIL DAN PEMBAHASAN
Deskripsi Data Simulasi
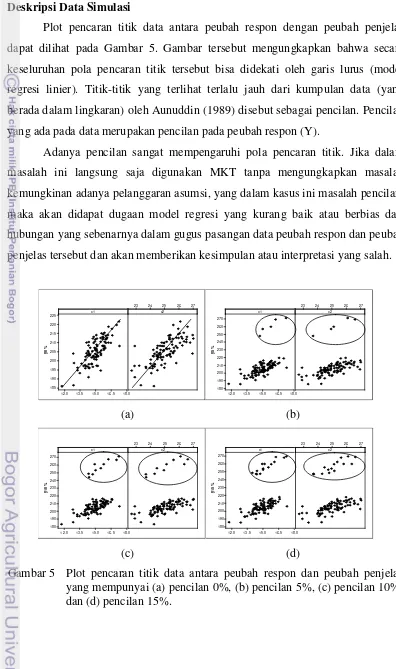
Plot pencaran titik data antara peubah respon dengan peubah penjelas dapat dilihat pada Gambar 5. Gambar tersebut mengungkapkan bahwa secara keseluruhan pola pencaran titik tersebut bisa didekati oleh garis lurus (model regresi linier). Titik-titik yang terlihat terlalu jauh dari kumpulan data (yang berada dalam lingkaran) oleh Aunuddin (1989) disebut sebagai pencilan. Pencilan yang ada pada data merupakan pencilan pada peubah respon (Y).
Adanya pencilan sangat mempengaruhi pola pencaran titik. Jika dalam masalah ini langsung saja digunakan MKT tanpa mengungkapkan masalah kemungkinan adanya pelanggaran asumsi, yang dalam kasus ini masalah pencilan, maka akan didapat dugaan model regresi yang kurang baik atau berbias dari hubungan yang sebenarnya dalam gugus pasangan data peubah respon dan peubah penjelas tersebut dan akan memberikan kesimpulan atau interpretasi yang salah.
y
Plot Pe ncaran Titik dari y0% vs x1, x2
y
Plot Pe ncaran Titik dari y5% vs x1, x2
(a) (b)
Plot Pe ncaran Titik dari y10% vs x1, x2
y
Plot Pe ncaran Titik dari y15% vs x1, x2
(c) (d)
Alternatif langkah yang biasa dilakukan adalah menghilangkan atau membuang data pencilan secara langsung terlebih dahulu sebelum dilakukan analisis lanjutan. Data pencilan dapat dibuang jika data itu diperoleh dari kesalahan teknis peneliti seperti kesalahan mencatat amatan atau kesalahan ketika menyiapkan peralatan (Draper & Smith 1998).
Apabila pencilan timbul dari kombinasi keadaan yang tidak biasa yang sangat penting dan tidak bias diberikan oleh data lainnya, maka pencilan itu tidak dapat dibuang begitu saja, melainkan perlu digunakan suatu metode analisis kusus yang dapat mengatasi masalah pencilan dalam melakukan analisis lanjutan seperti pembentukan model regresi.
Diagnosis Sisaan
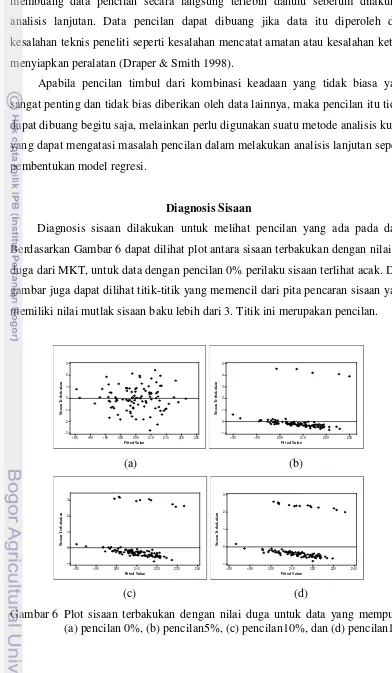
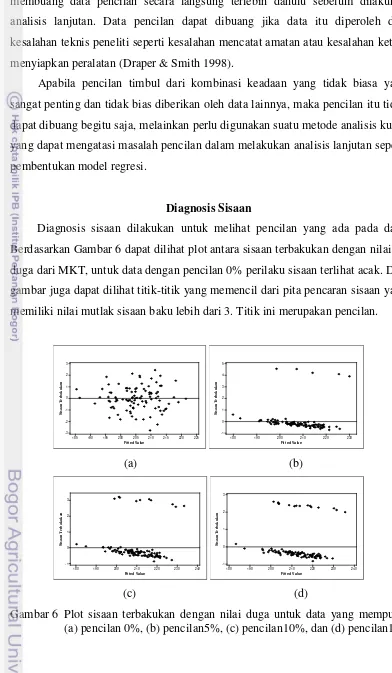
Diagnosis sisaan dilakukan untuk melihat pencilan yang ada pada data. Berdasarkan Gambar 6 dapat dilihat plot antara sisaan terbakukan dengan nilai Y-duga dari MKT, untuk data dengan pencilan 0% perilaku sisaan terlihat acak. Dari gambar juga dapat dilihat titik-titik yang memencil dari pita pencaran sisaan yang memiliki nilai mutlak sisaan baku lebih dari 3. Titik ini merupakan pencilan.
Fit t ed Value
Untuk menangani masalah pencilan tersebut digunakan metode regresi kekar yang dikenal tidak peka terhadap adanya pencilan sehingga menghasilkan perilaku sisaan yang lebih baik. Metode egresi kekar yang digunakan adalah metode penduga M, penduga S, dan penduga MM.
Pendugaan Parameter Regresi Menggunakan MKT dan Metode Regresi Kekar
Pendugaan Parameter β0
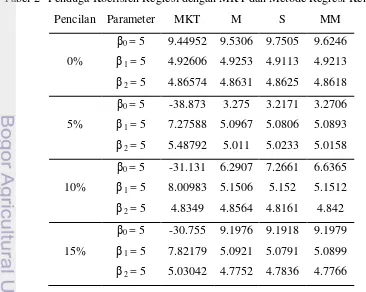
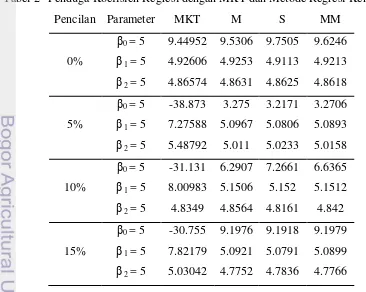
Hasil pendugaan parameter β0 dapat dilihat pada Tabel 2. Pada kelompok
data tanpa pencilan (0% pencilan) dugaan yang diperoleh hampir sama untuk setiap metode. Namun dapat dikatakan MKT yang paling baik dari keempat metode dalam menduga parameter β0. Pada kelompok data dengan pencilan 5%
penduga yang paling baik diantara keempat metode adalah metode penduga S. Sedangkan hasil dugaan MKT sangat jauh dari yang diharapkan. Pada kelompok data dengan pencilan 10% penduga yang paling baik diantara keempat metode adalah metode penduga M. Pada kelompok data dengan pencilan 15% secara keseluruhan metode regresi kekar memberikan hasil yang hampir sama dalam menduga koefisien regresi.
Tabel 2 Penduga Koefisien Regresi dengan MKT dan Metode Regresi Kekar
Dari hasil pendugaan dapat dilihat bahwa penduga MKT merupakan penduga yang sangat peka terhadap pencilan. Nilai dugaan yang diperoleh dari MKT menyimpang jauh dari nilai yang diharapkan ketika ada pencilan pada data. Secara umum, dapat dilihat pada Lampiran 1 dan 2, ragam dan rataan bias untuk masing-masing metode.
Pendugaan Parameter β1
Hasil pendugaan parameter β1 dapat dilihat pada Tabel 2. Pada kelompok
data tanpa pencilan (0% pencilan) dugaan yang diperoleh hampir sama untuk setiap metode. Namun dapat dikatakan yang paling baik dari keempat metode adalah metode penduga S karena lebih mendekati nilai parameter. Pada kelompok data dengan pencilan 5% penduga S dan penduga MM memberikan hasil yang hampir sama dan merupakan penduga terbaik. Untuk hasil dugaan MKT masih jauh dari yang diharapkan. Pada kelompok data dengan pencilan 10% metode regresi kekar memberikan hasil yang hampir sama. Pada kelompok data dengan pencilan 15% juga memberikan hasil yang tidak berbeda jauh, namun dapat dikatakan metode yang paling baik adalah metode penduga S. Dari hasil pendugaan dapat dilihat bahwa penduga MKT merupakan penduga yang sangat peka terhadap pencilan karena hasil yang diberikan masih menyimpang dari nilai yang diharapkan. Secara umum, dapat dilihat pada Lampiran 1 dan 2, ragam dan rataan bias untuk masing-masing metode.
Pendugaan Parameter β2
Hasil pendugaan parameter β2 dapat dilihat pada Tabel 2. Pada kelompok
merupakan penduga yang paling baik. Secara umum, dapat dilihat pada Lampiran 1 dan 2, ragam dan rataan bias untuk masing-masing metode.
Dari hasil yang diperoleh dapat diketahui bahwa nilai dugaan yang diperoleh dengan menggunakan metode regresi kekar lebih baik daripada MKT. Hasil dugaan yang diperoleh dari metode regresi kekar hampir mendekati parameter. Dapat dilihat bahwa penduga MKT merupakan penduga yang sangat peka terhadap pencilan karena hasil yang diberikan masih menyimpang dari nilai yang diharapkan.
Efisiensi
Efisiensi suatu penduga kekar terhadap penduga lainnya diperlukan untuk mengetahui bahwa penduga tersebut merupakan penduga terbaik, yaitu penduga dengan ragam terkecil. Pada Tabel 3 dapat dilihat bahwa pada data yang tidak mengandung pencilan (0% pencilan), penduga M cukup efisien dibandingkan penduga S dan penduga MM. Hal ini dapat dilihat dari besarnya nilai eff ( ) > 1 yakni untuk penduga M dengan penduga S diperoleh eff ( ) = 1.14, eff ( ) = 1.17, dan eff ( ) = 1.19. Nilai-nilai tersebut mempunyai arti bahwa untuk mendapatkan ragam yang sama tentang penduga parameter , metode penduga S memerlukan 114% data dibanding metode penduga M, begitu juga tentang penduga parameter , metode penduga S memerlukan data sebesar 117% dibanding metode penduga M, serta memerlukan 119% untuk parameter .
Tabel 3 Rataan Nilai Efisiensi untuk Data Tanpa Pencilan
Parameter Eff ( )
M vs S M vs MM S vs MM
β0 1.14 1.05 0.92
β1 1.17 1.07 0.92
β2 1.19 1.08 0.91
bahwa untuk mendapatkan ragam yang sama tentang penduga parameter , metode penduga MM memerlukan 105% data dibanding metode penduga M, begitu juga tentang penduga parameter , metode penduga MM memerlukan data sebesar 107% dibanding metode penduga M, serta memerlukan 108% untuk parameter .
Sedangkan untuk penduga S dengan penduga MM dapat dilihat bahwa penduga MM cukup efisien dibanding penduga S. Hal ini dilihat dari eff ( ) = 0.92, eff ( ) = 0.92, dan eff ( ) = 0.91. Nilai-nilai tersebut mempunyai arti bahwa untuk mendapatkan ragam yang sama tentang penduga parameter , metode MM hanya memerlukan 92% data dibanding metode S, begitu juga tentang penduga parameter , metode MM memerlukan data sebesar 92% disbanding metode S, serta memerlukan 91% untuk parameter .
Tabel 4 Rataan Nilai Efisiensi untuk Data dengan 5% Pencilan
Parameter Eff ( )
M vs S M vs MM S vs MM
β0 1.21 1.12 0.93
β1 1.15 1.07 0.93
β2 1.15 1.07 0.93
Pada Tabel 4 dapat dilihat bahwa pada data yang mengandung 5% pencilan, penduga M cukup efisien dibandingkan penduga S dan penduga MM. Hal ini dapat dilihat dari besarnya nilai eff ( ) > 1 yakni untuk penduga M dengan penduga S diperoleh eff ( ) = 1.21, eff ( ) = 1.15, dan eff ( ) = 1.15. Nilai-nilai tersebut mempunyai arti bahwa untuk mendapatkan ragam yang sama tentang penduga parameter , metode S memerlukan 121% data dibanding metode M, begitu juga tentang penduga parameter , metode S memerlukan data sebesar 115% dibanding metode M, serta memerlukan 115% untuk parameter .
untuk mendapatkan ragam yang sama tentang penduga parameter , metode MM memerlukan 112% data dibanding metode M, begitu juga tentang penduga parameter , metode MM memerlukan data sebesar 107% dibanding metode M, serta memerlukan 107% untuk parameter .
Sedangkan untuk penduga S dengan penduga MM dapat dilihat bahwa penduga MM cukup efisien dibanding penduga S. Hal ini dapat dilihat dari eff ( ) = 0.93, eff ( ) = 0.93, dan eff ( ) = 0.93. Nilai-nilai tersebut mempunyai arti bahwa untuk mendapatkan ragam yang sama tentang penduga parameter , metode MM hanya memerlukan 93% data dibanding metode S, begitu juga tentang penduga parameter , metode MM memerlukan data sebesar 93% dibanding metode S, serta memerlukan 93% untuk parameter .
Tabel 5 Rataan Nilai Efisiensi untuk Data dengan 10% Pencilan
Parameter Eff ( )
M vs S M vs MM S vs MM
β0 1.11 1.09 0.98
β1 1.03 1.02 0.99
β2 1.03 1.02 0.98
Pada Tabel 5 dapat dilihat bahwa pada data yang mengandung 10% pencilan, penduga M cukup efisien dibandingkan penduga S dan penduga MM. Hal ini dapat dilihat dari besarnya nilai eff ( ) > 1 yakni untuk penduga M dengan penduga S diperoleh eff ( ) = 1.11, eff ( ) = 1.03, dan eff (
) = 1.03. Nilai-nilai tersebut mempunyai arti bahwa untuk mendapatkan ragam yang sama tentang penduga parameter , metode S memerlukan 111% data dibanding metode M, begitu juga tentang penduga parameter , metode S memerlukan data sebesar 103% dibanding metode M, serta memerlukan 103% untuk parameter .
untuk mendapatkan ragam yang sama tentang penduga parameter , metode MM memerlukan 109% data dibanding metode M, begitu juga tentang penduga parameter , metode MM memerlukan data sebesar 102% dibanding metode M, serta memerlukan 102% untuk parameter .
Sedangkan untuk penduga S dengan penduga MM dapat dilihat bahwa penduga MM cukup efisien dibanding penduga S. Hal ini dilihat dari eff ( ) = 0.98, eff ( ) = 0.99, dan eff ( ) = 0.98. Nilai-nilai tersebut mempunyai arti bahwa untuk mendapatkan ragam yang sama tentang penduga parameter , metode MM hanya memerlukan 98% data dibanding metode S, begitu juga tentang penduga parameter , metode MM memerlukan data sebesar 99% dibanding metode S, serta memerlukan 98% untuk parameter .
Tabel 6 Rataan Nilai Efisiensi untuk Data dengan 15% Pencilan
Parameter Eff ( )
M vs S M vs MM S vs MM
β0 1.06 1.04 0.98
β1 1.04 1.02 0.98
β2 0.98 0.96 0.98
Untuk penduga M dengan penduga MM, penduga M cukup efisien dibandingkan penduga MM untuk parameter dan . Hal ini dapat dilihat dari besarnya nilai eff ( ) > 1 yakni untuk penduga M dengan penduga S diperoleh eff ( ) = 1.04, eff ( ) = 1.02. Untuk parameter , penduga S lebih efisien disbanding penduga M karena eff ( ) = 0.96. Nilai-nilai tersebut mempunyai arti bahwa untuk mendapatkan ragam yang sama tentang penduga parameter , metode S memerlukan 104% data dibanding metode M, begitu juga tentang penduga parameter , metode S memerlukan data sebesar 102% dibanding metode M. Untuk pendugaan parameter penduga S hanya memerlukan 96% data dibandingkan metode penduga M.
SIMPULAN DAN SARAN
Simpulan
Dari hasil pembahasan di atas metode regresi kekar penduga M, penduga S, dan penduga MM lebih kekar terhadap pencilan dibandingkan MKT. Dengan membandingkan dugaan koefisien regresi dan efisiensi dari penduga diperoleh diketahui bahwa penduga M lebih efisien dalam mengatasi pencilan dibandingkan penduga S dan penduga MM. Sedangkan antara penduga S dan penduga MM, penduga MM mempunyai efisiensi lebih baik daripada penduga S. Namun secara keseluruhan semakin besar persentase pencilan efisiensi masing-masing penduga semakin menurun.
Saran
DAFTAR PUSTAKA
Aunuddin. 1989. Analisis Data. Bahan Pengajaran. PAU Ilmu Hayat. IPB, Bogor. Draper NR, Smith H. 1998. Applied regression analysis. New York: J Wiley. Fox, John. 2002. Robust Regression. Appendix to An R and S-PLUS Companion
to Applied Regressi
Lu, Shuang. 2004. An Experiment with Experimental Proc RobustReg.
Juli
2009]
Maronna RA, Martin D, Yohai VJ. 2006. Robust statistics: theory and methods. West Sussex: J Wiley.
Myers RH. 1990. Classical and modern regression with applications (2nd ed). Boston: PWS- Kent.
Rousseeuw PJ, Yohai VJ. 1984. Robust regression by means of S-estimators. Di dalam Franke J, Hardle W, dan Martin D, editor. Robust and nonlinear time series; Lecture notes in statistics, 26. Berlin: Springer-Verlag. hlm 256-272.
Rousseeuw PJ, Leroy, A.M. 1987. Robust Regression and Outlier Detection, Canada: John Wiley & Sons, Inc.
Rousseeuw PJ. 1991. A Diagnostic plot for regression outlier and leverage points, Computational Statistics and DatabAnalysis, 11:127-129.
Ryan TP. 1997. Modern regression methods. New York: J Wiley.
Wackerly DD, Mendenhall W, Scheaffe, RL. 2008. Mathematical Statistics with Applications (7thed) . Duxbury: Thomson.
Lampiran 1 Rataan Bias Dugaan Parameter MKT, Penduga M, Penduga S dan Penduga MM
Persentase
Pencilan Parameter MKT M S MM
β0
4.4495 4.5306 4.7505 4.6246
0% β 1 0.0739 0.0747 0.0887 0.0787
β 2 0.1343 0.1369 0.1375 0.1382
β0
43.8730 1.7250 1.7829 1.7294 5% β 1
2.2759 0.0967 0.0806 0.0893
β 2
0.4879 0.0110 0.0233 0.0158
β0
36.1310 1.2907 2.2661 1.6365 10% β 1
3.0098 0.1506 0.1520 0.1512
β 2
0.1651 0.1436 0.1839 0.1580
β0
35.7550 4.1976 4.1918 4.1979 15% β 1
2.8218 0.0921 0.0791 0.0899
β 2
Lampiran 2 Ragam Dugaan Parameter MKT, Penduga M, Penduga S dan Penduga MM
Persentase
Pencilan Parameter MKT M S MM
β0
7.30902 8.434958 13.82575 10.61261 0% β 1 0.007399 0.008538 0.013853 0.010671
β 2 0.009734 0.011236 0.018225 0.014042 β0
24.02019 9.166967 12.79994 10.69028 5% β 1
0.024314 0.009274 0.012299 0.010323
β 2
0.031987 0.01221 0.017266 0.014496
β0
42.09946 9.586454 11.52874 10.31502 10% β 1
0.042617 0.009702 0.011794 0.010588
β 2
0.056065 0.012769 0.016231 0.014568
β0
67.22819 9.538215 10.40514 9.820076 15% β 1
0.068053 0.009663 0.011794 0.01113
β 2
ABSTRACT
NILA FAULINA. Robust Regression M-Estimation, S-Estimation, and MM-Estimation in Multiple Regression. Under direction of AUNUDDIN and ITASIA DINA S.
In classical multiple regression, the ordinary least squares estimation is the best method if assumptions are met to obtain regression weights when analyzing data. However, if the data does not satisfy some of these assumptions, then sample estimates and results can be misleading. Therefore, statistical techniques that are able to cope with or to detect outlying observations have been developed. Robust regression is an important method for analyzing data that are contaminated with outliers. It can be used to detect outliers and to provide resistant results in the presence of outliers. The purpose of this study is compare robust regression M-estimation, S-M-estimation, and MM-estimation with ordinary least square methods via simulation study. The simulation study is used in determine which methods best in all of the linear regression scenarios.
RINGKASAN
NILA FAULINA. Regresi Kekar Penduga M, Penduga S, dan Penduga MM pada Analisis Regresi Berganda. Dibawah bimbingan AUNUDDIN dan ITASIA DINA S.
Metode kuadrat terkecil (MKT) atau ordinary least square (OLS) merupakan salah satu metode yang sering digunakan untuk mendapatkan nilai-nilai penduga parameter dalam pemodelan regresi. Penggunaan MKT memerlukan beberapa asumsi klasik yang harus dipenuhi oleh komponen sisaan atau galat (εi)
dalam model yang dihasilkan. Beberapa asumsi itu antara lain adalah bahwa komponen sisaan memenuhi asumsi kenormalan, kehomogenan ragam, dan tidak ada autokorelasi. Myers (1990) menyatakan bahwa apabila asumsi klasik itu terpenuhi, maka penduga parameter yang diperoleh bersifat best linear unbiased estimator (BLUE).
Dalam berbagai kasus ditemui berbagai hal yang menyebabkan tidak terpenuhinya asumsi klasik tersebut. Saat asumsi ada yang tidak terpenuhi, maka penggunaan MKT akan memberikan kesimpulan yang bersifat kurang baik atau nilai penduga parameternya bersifat bias, interpretasi hasil yang diberikan juga menjadi tidak valid.
Salah satu penyebab tidak terpenuhinya asumsi klasik adalah adanya pencilan (outliers) pada data amatan. Pencilan ini dapat diketahui secara visual atau secara eksak dengan melakukan diagnosis sisaan dari model regresi yang terbentuk. Suatu data dinyatakan sebagai pencilan berdasarkan kriteria tertentu dalam metode diagnosis sisaan yang digunakan.
Selanjutnya, diperlukan alternatif metode penduga parameter lain yang dapat mengatasi adanya pencilan dalam data amatan. Metode itu adalah metode regresi kekar (robust), beberapa penduga yang sering digunakan adalah penduga M, penduga S, dan penduga MM. Diharapkan, melalui metode regresi kekar dapat diperoleh penduga parameter yang lebih baik yang bersifat bias dan mempunyai ragam minimum sehingga menghasilkan model yang lebih baik dari model hasil MKT.
Penelitian ini menggunakan data simulasi yang dibangkitkan sebanyak 100 data dan diulang sebanyak 20 kali. Plot pencaran titik data antara peubah respon dengan peubah penjelas mengungkapkan bahwa secara keseluruhan pola pencaran titik tersebut bisa didekati oleh garis lurus (model regresi linier). Titik-titik yang terlihat terlalu jauh dari kumpulan data disebut sebagai pencilan.
Hasil pendugaan parameter β0 pada kelompok data tanpa pencilan (0%
regresi. Dari hasil pendugaan dapat dilihat bahwa penduga MKT merupakan penduga yang sangat peka terhadap pencilan. Nilai dugaan yang diperoleh dari MKT menyimpang jauh dari nilai yang diharapkan.
Hasil pendugaan parameter β1 pada kelompok data tanpa pencilan (0%
pencilan) dugaan yang diperoleh hampir sama untuk setiap metode. Namun dapat dikatakan yang paling baik dari keempat metode adalah metode penduga S karena lebih mendekati nilai parameter. Pada kelompok data dengan pencilan 5% penduga S dan penduga MM memberikan hasil yang hampir sama dan merupakan penduga terbaik. Untuk hasil dugaan MKT masih jauh dari yang diharapkan. Pada kelompok data dengan pencilan 10% metode regresi kekar memberikan hasil yang hampir sama. Pada kelompok data dengan pencilan 15% juga memberikan hasil yang tidak berbeda jauh, namun dapat dikatakan metode yang paling baik adalah metode penduga S. Dari hasil pendugaan dapat dilihat bahwa penduga MKT merupakan penduga yang sangat peka terhadap pencilan karena hasil yang diberikan masih menyimpang dari nilai yang diharapkan.
Hasil pendugaan parameter β2 pada kelompok data tanpa pencilan (0%
pencilan) dugaan yang diperoleh hampir sama untuk setiap metode. Namun dapat dikatakan yang paling baik dari keempat metode adalah metode penduga MM. Pada kelompok data dengan pencilan 5% penduga yang paling baik diantara keempat metode adalah metode penduga S. Sedangkan hasil dugaan MKT hampir mendekati nilai yang diharapkan. Pada kelompok data dengan pencilan 10% penduga yang paling baik diantara keempat metode adalah metode penduga S. Pada kelompok data dengan pencilan 15% penduga M merupakan penduga yang paling baik.
Dari penelitian ini disimpulkan bahwa metode regresi kekar penduga M, penduga S, dan penduga MM lebih kekar terhadap pencilan dibandingkan MKT. Dengan membandingkan dugaan koefisien regresi dan efisiensi dari penduga diketahui bahwa penduga M lebih efisien dalam mengatasi pencilan dibandingkan penduga S dan penduga MM. Sedangkan antara penduga S dan penduga MM, penduga MM mempunyai efisiensi lebih baik daripada penduga S. Namun secara keseluruhan semakin besar persentase pencilan efisiensi masing-masing penduga semakin menurun.
PENDAHULUAN
Latar Belakang
Analisis regresi merupakan suatu metode statistika yang digunakan untuk menelaah hubungan antara sepasang peubah atau lebih. Peubah-peubah tersebut dibedakan menjadi dua bagian yakni peubah respon dan peubah penjelas. Peubah respon disebut juga dengan peubah tak bebas dan biasanya disimbolkan dengan huruf Y. Sedangkan peubah penjelas disebut juga dengan peubah bebas dan pada umumnya disimbolkan dengan huruf X.
Tujuan dari analisis regresi adalah untuk menduga parameter model yang menyatakan pengaruh hubungan antara peubah respon dan peubah penjelas. Metode yang banyak digunakan untuk menduga parameter model regresi adalah metode kuadrat terkecil (Ordinary Least Squares, OLS). Hal ini disebabkan oleh mudahnya penghitungan metode ini dan merupakan penduga tak bias terbaik untuk parameter model regresi jika data yang digunakan memenuhi asumsi klasik (Draper & Smith 1998). Asumsi yang harus dipenuhi dalam metode kuadrat terkecil, yaitu: (1) data merupakan sampel yang diambil secara acak dari suatu populasi dan sisaan yang dihasilkan bersifat saling bebas, (2) nilai harapan dari sisaan sama dengan nol, (3) tidak terdapat korelasi yang kuat antar peubah bebas, (4) sisaan memiliki ragam yang sama (homoskedastisitas).
Myers (1990) menyatakan bahwa apabila asumsi klasik itu terpenuhi, maka penduga parameter yang diperoleh bersifat best linear unbiased estimator (BLUE), yaitu memiliki nilai harapan sama dengan nol dan mempunyai ragam minimum. Dalam berbagai kasus ditemui beberapa hal yang menyebabkan tidak terpenuhinya asumsi tersebut. Salah satunya adalah ditemuinya pencilan (outliers) pada data. Pencilan ini dapat diketahui secara visual atau secara eksak dengan melakukan diagnosis sisaan dari model regresi yang terbentuk.
pencilan sekaligus menyesuaikan dugaan parameter regresi sehingga memberikan hasil yang stabil atau resistant ketika ada pencilan dalam data.
Beberapa metode penduga kekar yang telah dikembangkan diantaranya adalah metode penduga parameter regresi berdasarkan pada penduga M (maximum likelihood estimator), penduga S (scale), dan penduga MM (lebih dari satu prosedur penduga M). Penduga M merupakan penduga kekar yang memiliki efisiensi yang tinggi, sedangkan penduga S memiliki efisiensi yang rendah. Sementara penduga MM adalah penduga prosedur dua tahap yang merupakan kombinasi dua penduga dari kelompok yang berbeda. Penduga MM dibangun dari kombinasi penduga S dan penduga M.
Efisiensi suatu penduga merupakan ukuran sampel yang diperlukan untuk mendapatkan keakuratan yang sama dengan penduga lainnya. Efisiensi suatu penduga terhadap penduga lainnya diperlukan untuk mengetahui bahwa penduga tersebut merupakan penduga terbaik yaitu penduga dengan ragam terkecil. Berdasarkan hal ini akan dibandingkan antara metode regresi kekar penduga M yang memiliki efisiensi tinggi dengan penduga S yang memiliki efisiensi yang rendah serta penduga MM yang merupakan kombinasi antara penduga S dan penduga M.
Tujuan Penelitian
TINJAUAN PUSTAKA
Pencilan
Aunuddin (1989) mendefinisikan pencilan sebagai nilai ektstrim yang menyimpang agak jauh dari kumpulan pengamatan lainnya, yang secara kasar berada pada jarak sejauh tiga atau empat kali simpangan baku dari nilai tengahnya. Ryan (1997) mengelompokkan pencilan dalam berbagai tipe:
1. Pencilan-x, yakni pengamatan yang hanya menyimpang pada sumbu x saja. Pengamatan ini disebut juga sebagai titik leverage.
2. Pencilan-y, yakni pengamatan yang menyimpang hanya karena arah peubah tak bebasnya.
3. Pencilan-x,y, yaitu pengamatan yang menyimpang pada keduanya yakni pada peubah x dan peubah y.
Gambar 1 mengilustrasikan berbagai jenis pencilan. Elips menggambarkan mayoritas data. Titik A, B, dan C adalah pencilan dalam ruang Y karena nilai-nilai y atau nilai respon secara signifikan berbeda dari keseluruhan data dan merupakan pencilan sisaan. Titik B, C dan D adalah pencilan dalam ruang X, karena nilai-nilai x pada titik tersebut berbeda dan ini juga disebut sebagai titik leverage. Titik D walaupun terpencil di ruang X, namun bukanlah pencilan sisaan. Titik B dan C adalah titik leverage dan merupakan pencilan sisaan. Titik E merupakan pencilan sisaan.
Semua tipe pencilan yang digambarkan di atas dapat diringkas dalam Tabel 1 berikut.
Tabel 1 Ringkasan Jenis Pengamatan Pencilan Titik Pencilan-Y Pencilan-X Pencilan Sisaan
A √ - √
B √ √ √
C √ √ √
D √ √ -
E - √ √
Titik leverage adalah pengamatan (xp, yp) apabila xp terletak jauh jauh dari
sebagian besar xi yang diamati dalam sampel (Rousseeuw 1991). Titik leverage
dapat dilihat pada Gambar 2. Titik (xp,yp) adalah titik leverage karena xp terpencil.
Namun, (xp,yp) bukan merupakan pencilan regresi karena sesuai dengan pola
linier yang ditetapkan oleh titik data lain.
Gambar 2 Ilustrasi Titik Leverage.
Metode Kuadrat Terkecil (MKT)
Persamaan regresi linier berganda adalah persamaan regresi dengan satu peubah respon (Y) dengan lebih dari satu peubah penjelas (X1, X2,...,Xp).
Yi = β0 + β1X1i + β2X2i + … + βpXpi + εi untuk i = 1, 2, …, n
dengan Yi merupakan pengamatan ke-i (dari n pengamatan) untuk peubah respon
dan Xpi merupakan peubah penjelas ke-p dari pengamatan ke-i. Komponen βp
merupakan parameter yang belum diketahui dan akan diduga, sedangkan εi
merupakan komponen galat yang diasumsikan menyebar normal, bebas dan identik, yang mempunyai nilai tengah 0 dan ragam homogen.
Bila ditulis dalam bentuk matriks model umum regresi linier dinyatakan dengan
Y = Xβ + ε
dengan Y merupakan vektor pengamatan pada peubah respon berukuran (n x 1) dan X adalah matriks berukuran (n x p) dengan p peubah penjelas dan n pengamatan, β adalah vektor koefisien regresi (parameter) berukuran (p x 1) dan ε adalah vektor sisaan berukuran (n x 1). Metode yang sering digunakan oleh para peneliti adalah metode kuadrat terkecil yang dirancang untuk menghasilkan penduga b untuk menduga β, dan nilai dugaan
sehingga
yang meminimumkan jumlah kuadrat sisaan
Penduga M
Penduga M pertama kali dikenalkan oleh Huber pada tahun 1964 sebagai alternatif penduga regresi kekar untuk MKT. Metode ini mengganti pada persamaan (1) menjadi .
Secara umum penduga M meminimumkan fungsi objektif :
1. (e) ≥ 0 2. (0) = 0 3. (e) = (-e)
4. ≥ untuk >
Misalkan = adalah turunan dari , maka untuk meminimumkan persamaan (2) :
Ditentukan fungsi pembobot , dan misalkan maka persamaan dapat ditulis sebagai berikut
Pembobot dalam penduga M bergantung pada sisaan dan koefisien. Prosedur untuk mendapatkan parameter penduga yaitu iterasi yang disebut dengan kuadrat terkecil tertimbang iteratif (iteratively reweighted least squares/IRLS), tahapanya :
1) Duga parameter regresi b(0) dengan MKT.
2) Pada setiap iterasi t, hitung sisaan dan gabungkan pembobot dari iterasi sebelumnya.
3) Penduga parameter kuadrat terkecil terboboti yang baru adalah
dengan X adalah matriks model dengan adalah baris ke-i, dan
4) Ulangi langkah 2 dan 3 hingga didapatkan penaksiran parameter yang konvergen.
1. Fungsi penimbang yang disarankan oleh Huber memakai fungsi objektif
dengan
dan fungsi penimbang
Gambar 3 Fungsi objektif untuk fungsi penimbang Huber.
2. Fungsi penimbang yang disarankan oleh Tukey memakai fungsi objektif
dengan
Gambar 4 Fungsi objektif untuk fungsi penimbang Tukey (bisquare).
Pengaruh besarnya simpangan e terhadap nilai dugaan dapat dilihat dari perilaku p(e) atau w(e) (Gambar 3 dan 4). Berdasarkan kurva p(e) terlihat bahwa kedua fungsi penimbang tersebut berprilaku mirip rataan dalam selang tertentu di bagian tengah data, di luar batas tersebut pengaruhnya menjadi konstan pada fungsi Huber dan mengecil menuju nol pada penimbang ganda Tukey Aunuddin 1989). Sedangkan dari kurva w(e) terlihat bahwa fungsi Huber memberikan penimbang sebesar satu untuk dan mengecil pada . Pada fungsi Tukey, penimbangnya mengecil setelah e beranjak dari nol dan ketika
penimbangnya nol (Fox 2002). Dengan kata lain semakin besar simpangann mutlak ei akan semakin kecil penimbangnya begitu pula sebaliknya dengan
harapan memperkecil dampak dari pencilan.
Pemilihan konstanta k pada regresi kekar bertujuan menentukan penduga kekar untuk pencilan dan penduga efisien. Bila nilai konstantanya kecil maka model regresi akan lebih kekar tetapi kurang efisien. Sedangkan bila nilai konstantanya besar maka model regresi akan kurang kekar tetapi lebih efisien. Lu (2004) menyatakan bahwa konstanta yang menghasilkan efisiensi 95% dimana galatnya normal serta selalu memberikan perlindungan terhadap pencilan yaitu konstanta sebesar k = 1.345 untuk fungsi penimbang Huber dan sebesar k = 4.685 untuk fungsi penimbang ganda Tukey.
yang sama dengan nilai sebenarnya sedangkan ukuran penyebarannya dilihat dari nilai ragam dugaannya. Besar kecilnya nilai ragam ini menjadi petunjuk mengenai tingkat ketelitian dari dugaan yang diperoleh.
Beberapa peneliti menyarankan untuk mendekati sebaran koefisien regresi
b dengan sebaran asimptotiknya. Hal ini dikarenakan adanya proses iterasi dengan penimbang yang nilainya tergantung pada sisaan yang menjadi sumber kesulitan.
Dengan menggunakan untuk menduga , dan
untuk menduga maka menghasilkan matrik ragam peragam asimptotik untuk b adalah
Penduga S
Penduga S adalah salah satu penduga yang memiliki efisiensi yang rendah. Penduga ini diperoleh dari minimasi dugaan M skala sisaan.
Definisi 1. Misalkan penduga dan vektor sisaan. Penduga S didefinisikan sebagai dengan diperoleh dari dugaan M skala sisaan yang merupakan solusi
(Rousseeuw & Yohai 1984).
Penduga S dapat dinyatakan dalam bentuk lain, yaitu . Bentuk yang terakhir ini bisa representasikan dengan sistem persamaan yang merupakan formula penghitungan simultan pendugaan kekar parameter regresi dan pendugaan kekar skala (Maronna et al. 2006), yaitu:
dan jika dan maka . Sementara fungsi adalah turunan fungsi yang memenuhi beberapa asumsi, yakni:
untuk dan fungsi terbatas, fungsi tidak turun dan , fungsi kontinu, dan untuk .
Penduga MM
Penduga MM pertama kali dikenalkan oleh Yohai (1987). Penduga MM merupakan kombinasi antara penduga yang mempunyai nilai breakdown tinggi (50%) dengan efisiensi yang tinggi (kurang lebih 95% hampir sama dengan metode kuadrat terkecil). Dalam penelitian ini penduga MM berasal dari gabungan antara penduga S yang mempunyai nilai breakdown tinggi dengan penduga M yang mempunyai efisiensi yang tinggi sehingga penduga ini memenuhi kriteria yang diharapkan untuk suatu penduga kekar.
Penduga MM mengacu pada fakta bahwa lebih dari satu prosedur penduga M digunakan untuk menghitung penduga akhir. Mengikuti kasus penduga M, IRLS digunakan untuk mendapatkan penduga. Prosedurnya sebagai berikut:
1. Penduga awal dari koefisien b(1) dan sisaan diambil dari regresi dengan resistant tinggi yaitu penduga S. Meskipun penduga harus konsisten, ini tidak perlu efisien.
2. Sisaan dari penduga awal pada Tahap 1 digunakan untuk menghitung sisaan penduga M skala, .
3. Penduga awal sisaan dari Tahap1 dan sisaan skala dari Tahap 2 digunakan dalam iterasi pertama kuadrat terkecil terboboti untuk menentukan koefisien regresi penduga M.
dimana wi penimbang Huber.
4. Penimbang baru dihitung , menggunakan sisaan dari WLS awal (Langkah 3).
Efisiensi
METODOLOGI PENELITIAN
Data
Data yang digunakan dalam penelitian ini adalah data simulasi. Banyak data (n) yang dibangkitkan adalah 100 dan diulang 20 kali. Prosedur pembangkitan data simulasi adalah sebagai berikut:
1. Tentukan parameter bagi populasi yaitu β0, β1, dan β2. Dalam kasus ini β0,
β1, dan β2 yang digunakan adalah 5, 5, dan 5.
2. Bangkitkan nilai X1 acak normal dengan nilai tengah 15 dan ragam 1.
3. Bangkitkan nilai X2 acak normal dengan nilai tengah 25 dan ragam 1.
4. Tentukan nilai Y = 5 + 5X1 + 5X2.
5. Bangkitkan sisaan (ε) acak normal dengan nilai tengah 0 dan ragam 1.
6. Tentukan nilai Y = 5 + 5X1 + 5X2 + ε. Hasil ini digunakan sebagai data
dengan 0% pencilan (tanpa pencilan).
7. Bangkitkan sisaan (ε) acak normal dengan nilai tengah 50 dan ragam 1.
Hasil ini akan digunakan sebagai pencilan.
8. Ambil secara acak sisaan yang diperoleh dari langkah 5 sebanyak 95% dan dari langkah 7 sebanyak 5% sebagai pencilan lalu gabungkan.
9. Tentukan nilai Y dengan menjumlahkan hasil dari langkah 4 dan langkah 8. 10. Ulangi langkah 8 – 9 untuk pencilan 10% dan 15%.
11. Ulangi langkah 2 – 10 sebanyak 20 kali.
Metode Analisis
Metode simulasi data digunakan untuk membandingkan metode regresi kekar penduga M, penduga S, dan penduga MM dengan MKT dalam menduga parameter regresi dari gugus data yang memiliki pencilan. Analisis yang dilakukan melalui tahapan sebagai berikut:
1. Lakukan plot pada masing-masing gugus data untuk melihat pencilan.
3. Lakukan diagnosis sisaan dari model hasil pendugaan MKT pada masing-masing gugus data, untuk menunjukkan secara visual adanya pencilan dalam data.
4. Lakukan pendugaan parameter regresi terhadap masing-masing gugus data menggunakan metode regresi kekar penduga M, penduga S, dan penduga MM. 5. HItung ragam .
6. Hitung efisiensi penduga parameter β.
HASIL DAN PEMBAHASAN
Deskripsi Data Simulasi
Plot pencaran titik data antara peubah respon dengan peubah penjelas dapat dilihat pada Gambar 5. Gambar tersebut mengungkapkan bahwa secara keseluruhan pola pencaran titik tersebut bisa didekati oleh garis lurus (model regresi linier). Titik-titik yang terlihat terlalu jauh dari kumpulan data (yang berada dalam lingkaran) oleh Aunuddin (1989) disebut sebagai pencilan. Pencilan yang ada pada data merupakan pencilan pada peubah respon (Y).
Adanya pencilan sangat mempengaruhi pola pencaran titik. Jika dalam masalah ini langsung saja digunakan MKT tanpa mengungkapkan masalah kemungkinan adanya pelanggaran asumsi, yang dalam kasus ini masalah pencilan, maka akan didapat dugaan model regresi yang kurang baik atau berbias dari hubungan yang sebenarnya dalam gugus pasangan data peubah respon dan peubah penjelas tersebut dan akan memberikan kesimpulan atau interpretasi yang salah.
y
Plot Pe ncaran Titik dari y0% vs x1, x2
y
Plot Pe ncaran Titik dari y5% vs x1, x2
(a) (b)
Plot Pe ncaran Titik dari y10% vs x1, x2
y
Plot Pe ncaran Titik dari y15% vs x1, x2
(c) (d)
Alternatif langkah yang biasa dilakukan adalah menghilangkan atau membuang data pencilan secara langsung terlebih dahulu sebelum dilakukan analisis lanjutan. Data pencilan dapat dibuang jika data itu diperoleh dari kesalahan teknis peneliti seperti kesalahan mencatat amatan atau kesalahan ketika menyiapkan peralatan (Draper & Smith 1998).
Apabila pencilan timbul dari kombinasi keadaan yang tidak biasa yang sangat penting dan tidak bias diberikan oleh data lainnya, maka pencilan itu tidak dapat dibuang begitu saja, melainkan perlu digunakan suatu metode analisis kusus yang dapat mengatasi masalah pencilan dalam melakukan analisis lanjutan seperti pembentukan model regresi.
Diagnosis Sisaan
Diagnosis sisaan dilakukan untuk melihat pencilan yang ada pada data. Berdasarkan Gambar 6 dapat dilihat plot antara sisaan terbakukan dengan nilai Y-duga dari MKT, untuk data dengan pencilan 0% perilaku sisaan terlihat acak. Dari gambar juga dapat dilihat titik-titik yang memencil dari pita pencaran sisaan yang memiliki nilai mutlak sisaan baku lebih dari 3. Titik ini merupakan pencilan.
Fit t ed Value
Untuk menangani masalah pencilan tersebut digunakan metode regresi kekar yang dikenal tidak peka terhadap adanya pencilan sehingga menghasilkan perilaku sisaan yang lebih baik. Metode egresi kekar yang digunakan adalah metode penduga M, penduga S, dan penduga MM.
Pendugaan Parameter Regresi Menggunakan MKT dan Metode Regresi Kekar
Pendugaan Parameter β0
Hasil pendugaan parameter β0 dapat dilihat pada Tabel 2. Pada kelompok
data tanpa pencilan (0% pencilan) dugaan yang diperoleh hampir sama untuk setiap metode. Namun dapat dikatakan MKT yang paling baik dari keempat metode dalam menduga parameter β0. Pada kelompok data dengan pencilan 5%
penduga yang paling baik diantara keempat metode adalah metode penduga S. Sedangkan hasil dugaan MKT sangat jauh dari yang diharapkan. Pada kelompok data dengan pencilan 10% penduga yang paling baik diantara keempat metode adalah metode penduga M. Pada kelompok data dengan pencilan 15% secara keseluruhan metode regresi kekar memberikan hasil yang hampir sama dalam menduga koefisien regresi.
Tabel 2 Penduga Koefisien Regresi dengan MKT dan Metode Regresi Kekar
Dari hasil pendugaan dapat dilihat bahwa penduga MKT merupakan penduga yang sangat peka terhadap pencilan. Nilai dugaan yang diperoleh dari MKT menyimpang jauh dari nilai yang diharapkan ketika ada pencilan pada data. Secara umum, dapat dilihat pada Lampiran 1 dan 2, ragam dan rataan bias untuk masing-masing metode.
Pendugaan Parameter β1
Hasil pendugaan parameter β1 dapat dilihat pada Tabel 2. Pada kelompok
data tanpa pencilan (0% pencilan) dugaan yang diperoleh hampir sama untuk setiap metode. Namun dapat dikatakan yang paling baik dari keempat metode adalah metode penduga S karena lebih mendekati nilai parameter. Pada kelompok data dengan pencilan 5% penduga S dan penduga MM memberikan hasil yang hampir sama dan merupakan penduga terbaik. Untuk hasil dugaan MKT masih jauh dari yang diharapkan. Pada kelompok data dengan pencilan 10% metode regresi kekar memberikan hasil yang hampir sama. Pada kelompok data dengan pencilan 15% juga memberikan hasil yang tidak berbeda jauh, namun dapat dikatakan metode yang paling baik adalah metode penduga S. Dari hasil pendugaan dapat dilihat bahwa penduga MKT merupakan penduga yang sangat peka terhadap pencilan karena hasil yang diberikan masih menyimpang dari nilai yang diharapkan. Secara umum, dapat dilihat pada Lampiran 1 dan 2, ragam dan rataan bias untuk masing-masing metode.
Pendugaan Parameter β2
Hasil pendugaan parameter β2 dapat dilihat pada Tabel 2. Pada kelompok
merupakan penduga yang paling baik. Secara umum, dapat dilihat pada Lampiran 1 dan 2, ragam dan rataan bias untuk masing-masing metode.
Dari hasil yang diperoleh dapat diketahui bahwa nilai dugaan yang diperoleh dengan menggunakan metode regresi kekar lebih baik daripada MKT. Hasil dugaan yang diperoleh dari metode regresi kekar hampir mendekati parameter. Dapat dilihat bahwa penduga MKT merupakan penduga yang sangat peka terhadap pencilan karena hasil yang diberikan masih menyimpang dari nilai yang diharapkan.
Efisiensi
Efisiensi suatu penduga kekar terhadap penduga lainnya diperlukan untuk mengetahui bahwa penduga tersebut merupakan penduga terbaik, yaitu penduga dengan ragam terkecil. Pada Tabel 3 dapat dilihat bahwa pada data yang tidak mengandung pencilan (0% pencilan), penduga M cukup efisien dibandingkan penduga S dan penduga MM. Hal ini dapat dilihat dari besarnya nilai eff ( ) > 1 yakni untuk penduga M dengan penduga S diperoleh eff ( ) = 1.14, eff ( ) = 1.17, dan eff ( ) = 1.19. Nilai-nilai tersebut mempunyai arti bahwa untuk mendapatkan ragam yang sama tentang penduga parameter , metode penduga S memerlukan 114% data dibanding metode penduga M, begitu juga tentang penduga parameter , metode penduga S memerlukan data sebesar 117% dibanding metode penduga M, serta memerlukan 119% untuk parameter .
Tabel 3 Rataan Nilai Efisiensi untuk Data Tanpa Pencilan
Parameter Eff ( )
M vs S M vs MM S vs MM
β0 1.14 1.05 0.92
β1 1.17 1.07 0.92
β2 1.19 1.08 0.91
bahwa untuk mendapatkan ragam yang sama tentang penduga parameter , metode penduga MM memerlukan 105% data dibanding metode penduga M, begitu juga tentang penduga parameter , metode penduga MM memerlukan data sebesar 107% dibanding metode penduga M, serta memerlukan 108% untuk parameter .
Sedangkan untuk penduga S dengan penduga MM dapat dilihat bahwa penduga MM cukup efisien dibanding penduga S. Hal ini dilihat dari eff ( ) = 0.92, eff ( ) = 0.92, dan eff ( ) = 0.91. Nilai-nilai tersebut mempunyai arti bahwa untuk mendapatkan ragam yang sama tentang penduga parameter , metode MM hanya memerlukan 92% data dibanding metode S, begitu juga tentang penduga parameter , metode MM memerlukan data sebesar 92% disbanding metode S, serta memerlukan 91% untuk parameter .
Tabel 4 Rataan Nilai Efisiensi untuk Data dengan 5% Pencilan
Parameter Eff ( )
M vs S M vs MM S vs MM
β0 1.21 1.12 0.93
β1 1.15 1.07 0.93
β2 1.15 1.07 0.93
Pada Tabel 4 dapat dilihat bahwa pada data yang mengandung 5% pencilan, penduga M cukup efisien dibandingkan penduga S dan penduga MM. Hal ini dapat dilihat dari besarnya nilai eff ( ) > 1 yakni untuk penduga M dengan penduga S diperoleh eff ( ) = 1.21, eff ( ) = 1.15, dan eff ( ) = 1.15. Nilai-nilai tersebut mempunyai arti bahwa untuk mendapatkan ragam yang sama tentang penduga parameter , metode S memerlukan 121% data dibanding metode M, begitu juga tentang penduga parameter , metode S memerlukan data sebesar 115% dibanding metode M, serta memerlukan 115% untuk parameter .
untuk mendapatkan ragam yang sama tentang penduga parameter , metode MM memerlukan 112% data dibanding metode M, begitu juga tentang penduga parameter , metode MM memerlukan data sebesar 107% dibanding metode M, serta memerlukan 107% untuk parameter .
Sedangkan untuk penduga S dengan penduga MM dapat dilihat bahwa penduga MM cukup efisien dibanding penduga S. Hal ini dapat dilihat dari eff ( ) = 0.93, eff ( ) = 0.93, dan eff ( ) = 0.93. Nilai-nilai tersebut mempunyai arti bahwa untuk mendapatkan ragam yang sama tentang penduga parameter , metode MM hanya memerlukan 93% data dibanding metode S, begitu juga tentang penduga parameter , metode MM memerlukan data sebesar 93% dibanding metode S, serta memerlukan 93% untuk parameter .
Tabel 5 Rataan Nilai Efisiensi untuk Data dengan 10% Pencilan
Parameter Eff ( )
M vs S M vs MM S vs MM
β0 1.11 1.09 0.98
β1 1.03 1.02 0.99
β2 1.03 1.02 0.98
Pada Tabel 5 dapat dilihat bahwa pada data yang mengandung 10% pencilan, penduga M cukup efisien dibandingkan penduga S dan penduga MM. Hal ini dapat dilihat dari besarnya nilai eff ( ) > 1 yakni untuk penduga M dengan penduga S diperoleh eff ( ) = 1.11, eff ( ) = 1.03, dan eff (
) = 1.03. Nilai-nilai tersebut mempunyai arti bahwa untuk mendapatkan ragam yang sama tentang penduga parameter , metode S memerlukan 111% data dibanding metode M, begitu juga tentang penduga parameter , metode S memerlukan data sebesar 103% dibanding metode M, serta memerlukan 103% untuk parameter .