59
Daftar Pustaka:
Chistie, E. S. 2012. Aplikasi Portal Akademik Mobile Berbasis Android. Skripsi. Medan. Universitas Sumatera Utara.
Januardi, Andri. 2013. Analisa Perbandingan Algoritma Brute Force Dan Boyer
Moore Dalam Pencarian Word Suggestion Menggunakan Metode Perbandingan Eksponensial. Pelita Informatika Budi Darma IV(4).
Juanita, M. & Xiaohua, Mei. 2014. Kamus Lengkap Mandarin – Indonesia & Indonesia – Mandarin. Diva Press: Yogyakarta
Lukito, Lanvin. 2012. Studi Perbandingan Algoritma Brute Force, Boyer Moore dan
Deterministic Finite Automata dalam Pencarian String pada Dokumen.
Undergraduate thesis, Universitas Kristen Maranatha.
M. Echols, John dan Shadily, Hassan, Kamus Inggris - Indonesia, An English-
Indonesian Dictionary, di edit dan di revisi oleh John U. Wolff dan James T.
Collins bekerjasama dengan Hassan Shadily, Jakarta: PT. Gramedia, 1992, Cetakan XX.
Ramadhansyah. 2013. Perancangan Aplikasi Kamus Bahasa Gayo dengan Menggunakan Metode Boyer-Moore. Jurnal Pelita Informatika Budi
Darma IV(3).
Rifki. 2013. Penerapan Pattern Matching untuk Deteksi Plagiarisme Tugas. Jurnal Institut Teknologi Bandung.
Safaat, N. 2012. Pemrograman Aplikasi Mobile Smartphone dan Tablet PC
Berbasis Android. Informatika: Bandung.
Sagita. V., dkk. 2013. Studi Perbandingan Implementasi Algoritma Boyer-
Moore, Turbo Boyer-Moore, dan Tuned Boyer-Moore dalam Pencarian
String. Jurnal Ultimatics IV.
Silitonga, Y.A. 2014. Implementasi Pembuatan Kamus Bahasa Batak Toba- Indonesia
Utomo, Darmawan., dkk. 2008. Perbandingan Algoritma String Searching Brute
Force, Knuth Morris Pratt, Boyer Moore dan Karp Rabin Pada Teks Alkitab
Bahasa Indonesia. Jurnal Ilmiah Elektronika, Vol 7
Utomo, E. P. 2012. From Newbie to Advanced – Mudahnya Membuat Aplikasi
Android. Andi : Yogyakarta.
23
3.1 Analisis Sistem
Tahapan yang dilakukan untuk menghasilkan pemahaman yang menyeluruh terhadap kebutuhan sistem sehingga diperoleh tugas-tugas yang akan dikerjakan sistem disebut analisis sistem. Tahapan ini dilakukan agar pada saat proses perancangan aplikasi tidak terjadi kesalahan yang berarti. Ada dua tahapan analisis dalam tugas akhir ini yaitu: analisis masalah dan analisis persyaratan.
Memahami kelayakan masalah akan dibahas dianalisis masalah juga untuk menjelaskan fungsi-fungsi yang ditawarkan dan mampu dikerjakan sistem akan dibahas dianalisis persyaratan.
3.1.1 Analisis Masalah
Diagram Ishikawa (fishbone diagram) biasanya disebut juga diagram sebab akibat yang biasanya digunakan untuk mengidentifikasi masalah yang ada pada sistem yang akan dirancang. Dengan diagram ini dapat mengidentifikasi, mengeksplorasi dan menggambarkan suatu masalah dengan mengikutsertakan sebab dan akibat dari permasalahan. Dengan demikian proses pencapaian sistem akan sangat dibantu dengan adanya Diagram Ishikawa ini.
Pengguna Sistem
Kamus android bahasa Mandarin Algorima
Boyer Moore dan Algoritma Brute Force
Metode Kamus Mesin Kamus masih berbentuk buku Kesulitan dalam mendapatkan aplikasi elektronik Sulit mendapatkan
informasi yang cepat Mempunyai mobilitas tinggi Pencarian kata belum bisa dilakukan Belum adanya aplikasi Tidak dapat di update setiap saat Proses data sangat banyak Metode dilakukan manual
Gambar 3.1 Diagram Ishikawa untuk Analisis Permasalahan Sistem
Berdasarkan gambar 3.1 diketahui bahwa masalah utama permasalahan sistem ialah terhadap pengguna sistem dikarenakan pengguna sulit mendapatkan informasi yang cepat kemudian masalah selanjutnya adalah mesin, yaitu belum adanya aplikasi kamus berbasis android yang dapat melakukan pencarian arti kata yang dapat update tiap saat, kemudian masalah selanjutnya kamus masih berbentuk umum dan sulit dalam mendapatkan aplikasi elektronik dan permasalahan yang terakhir adalah metode, yaitu proses data yang sangat banyak dan metode dilakukan secara manual.
3.1.2 Analisis Persyaratan (Requirement Analysis)
Analisis persyaratan terbagi dua bagian, yaitu persyaratan fungsional dan persyaratan nonfungsional. Persyaratan fungsional mendeskripsikan aktivitas yang disediakan suatu sistem. Sedangkan Persyaratan nonfungsional mendeskripsikan fitur, karakteristik dan batasan lainnya.
3.1.2.1 Analisis Persyaratan Fungsional
Tedapat beberapa hal yang menjadi persyaratan fungsional dalam pembuatan kamus yang akan dibangun, antara lain :
1. Sistem dapat membaca pattern yang ingin dicari pada teks yang telah di input. 2. Sistem harus dapat menghasilkan arti kata dari pattern yang dicari dengan
menggunakan algoritma Boyer-Moore dan algoritma Brute Force.
25
3. Sistem ini menggunakan parameter running time.
3.1.2.2 Analisis Persyaratan Non-Fungsional
Beberapa persyaratan non-fungsional yang harus dipenuhi didalam sistem yang akan dirancang bangun ini antara lain : (Silitonga,2014)
a. Performa
Sistem harus mampu melaksanakan setiap tugas secara utuh dalam selang waktu yang tidak terlalu lama sesuai dengan ukuran data input yang diberikan.
b. Informasi
Sistem harus mampu menyediakan informasi tentang data-data yang akan digunakan pada sistem.
c. Ekonomi
Sistem harus dapat bekerja dengan baik tanpa harus mengeluarkan biaya tambahan dalam penggunaan perangkat keras maupun perangkat lunak.
d. Kontrol
Sistem yang telah dibangun harus tetap dikontrol setelah selesai dirancang agar fungsi dan kinerja sistem tetap terjaga dan dapat memberikan hasil yang sesuai dengan keinginan pengguna.
e. Efisiensi
Sistem harus dirancang sesederhana mungkin agar memudahkan pengguna dalam menggunakan atau menjalankan aplikasi tersebut.
f. Pelayanan
Sistem yang telah dirancang bisa dikembangkan ke tingkat yang lebih kompleks lagi bagi pihak-pihak yang ingin mengembangkan sistem tersebut.
3.2 Pemodelan
Pada penelitian ini digunakan UML (Unified Modeling Language) sebagai bahasa pemodelan untuk mendesain dan merancang Implementasi Algoritma Brute Force dan
Boyer Moore dalam pembuatan kamus Bahasa Mandarin – Indonesia – Inggris
platform android. Model UML yang digunakan antara lain use case diagram, activity
diagram, dan sequence diagram.
3.2.1 Use Case Diagram
Use Case Diagram merupakan bentuk pemodelan dari sistem yang menggambarkan
functional requirements dari sebuah sistem. Functional requirements dibuat
berdasarkan informasi dari kebutuhan sistem dan aktor yang berperan di dalamnya.
Use Case Diagram untuk sistem dalam penelitian ini dapat dilihat pada Gambar 3.2.
Gambar 3.2 Use Case Diagram pada sistem
Sistem <<includes>> <<includes>> <<includes>> <<includes>> <<includes>> <<includes>> <<includes>> <<includes>> Pencarian algoritma Boyer Moore Pilih bahasa Input kata Proses identifikasi pattern Pencarian string dari kanan ke kiri
Hasil pencarian dan running time Pencarian algoritma Boyer Moore Pilih bahasa Input kata Proses identifikasi pattern Pencarian string dari kiri ke kanan
Hasil pencarian dan running
time
27
Use Case pada Gambar 3.2 menjelaskan bahwa user dapat melakukan proses
pencarian menggunakan algoritma Boyer Moore dan pencarian Algoritma Brute
Force. Pada pencarian algoritma Boyer Moore user menentukan bahasa yang akan
digunakan, kemudian melakukan input data, setelah input data, ada proses identifikasi
pattern yang dilakukan oleh algoritma Boyer Moore yaitu pencarian string dari kanan
ke kiri, setelah itu didapatkan hasil pencarian dan juga di tampilkan running time dari pencarian tersebut, sebaliknya pada pencarian Brute Force sama seperti pencarian
Boyer Moore namun bedanya pada proses pencarian string, algoritma Brute Force
akan melakukan pencarian string dari kanan ke kiri dan menampilkan hasil running
time yang berbeda karena perbedaan proses pencarian.
3.2.2 Activity Diagram
Activity diagram adalah bentuk pemodelan dari sistem yang menggambarkan alur dari
proses yang terjadi pada sebuah use case dan untuk menggambarkan logika dari suatu sistem. Activity diagram dibuat berdasarkan use case yang telah ditentukan sebelumnya pada proses requirement analysis. Activity diagram yang terdapat pada sistem ini adalah sebagai berikut.
3.2.2.1Activity diagram pada pencarian Boyer Moore
Gambar 3.3 Activity Diagram Algoritma Boyer Moore
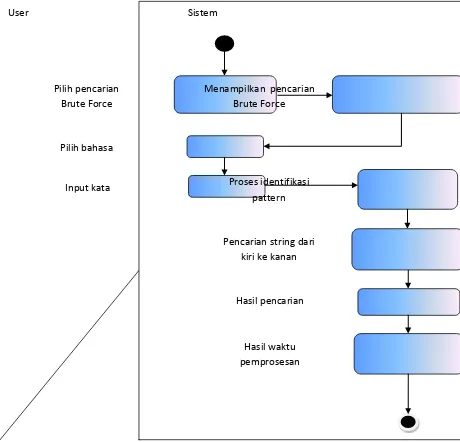
3.2.2.2Activity diagram pada pencarian Brute Force
Pada Proses pencarian algoritma Brute Force, aktivitas yang berlangsung dapat dilihat pada Activity diagram di Gambar 3.4
User Sistem
Pilih pencarian Boyer Moore
Menampilkan pencarian Boyer Moore
Input kata Pilih bahasa
Proses identifikasi pattern
Hasil pencarian Pencarian string dari
kanan ke kiri
Hasil waktu pemprosesan
29
Gambar 3.4 Activity Diagram Algoritma Brute Force
3.2.3 Sequence Diagram
Berikut ini dijelaskan proses tampil Kamus Mandarin dan pencarian string yang terjadi pada sistem dengan menggunakan sequence diagram.
User Sistem
Hasil pencarian Pilih pencarian
Brute Force
Menampilkan pencarian Brute Force
Input kata Pilih bahasa
Proses identifikasi pattern
Pencarian string dari kiri ke kanan
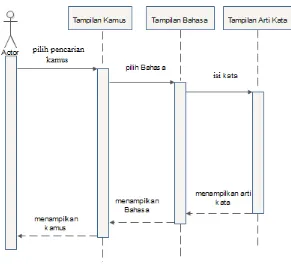
3.2.3.1 Sequence Diagram Tampil Kamus Mandarin
Pada proses tampil kamus Mandarin, sistem akan menampilkan Kamus Bahasa Mandarin beserta arti katanya. Sequence diagram untuk proses tampil Kamus Mandarin diperlihatkan pada Gambar 3.5
Gambar 3.5 Sequence Diagram Tampil Kamus Mandarin
Pada gambar 3.5 sequence diagram terlihat proses menampilkan kamus yang dimulai dengan memilih tampil kamus pada tampilan awal. Kemudian pengguna akan dihadapkan pada beberapa pilihan pada Menu Pilihan. Kemudian pengguna akan memilih bahasa yang diinginkan, lalu sistem akan mengelompokan database sesuai dengan pemilihan bahasa yang dilakukan oleh pengguna. Dan secara otomatis sistem akan menampilkan arti kata yang telah sesuai dengan pattern yang diinputkan oleh si pengguna. Kamus pun dapat dioptimalkan dengan baik.
31
3.2.4 Flowchart Sistem
3.2.4.1Flowchart Gambaran Umum Sistem
Gambaran umum sistem ini dapat dilihat pada flowchart di bawah ini :
mulai
Input kata
Cari kata
cocok
Mendapatkan arti
Menampilkan running time
selesai ya tidak
Gambar 3.6 Flowchart Sistem Kamus Mandarin
pencocokan algoritma Boyer-Moore dan Brute Force untuk memperoleh arti kata. Tahap selanjutnya adalah teks telah tampil sesuai dengan pattern yang diinputkan. Kemudian pengguna melakukan pemilihan teks dalam bentuk kata untuk mendapatkan arti kata bahasanya. Lalu tahap yang terakhir adalah menghasilkan hasil arti kata dan menampilkan running time proses pencarian .
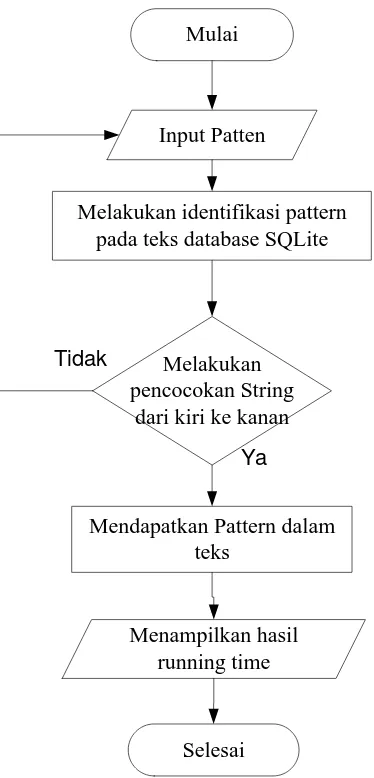
3.2.4.2 Flowchart Proses Boyer-Moore
Mulai
Input Patten
Menampilkan hasil running time
Mendapatkan Pattern dalam teks
Selesai
Melakukan identifikasi pattern pada teks database SQLite
Melakukan pencocokan String
dari kanan ke kiri Tidak
Ya
Gambar 3.7 Flowchart Proses Boyer-Moore
Dari Gambar 3.7 dapat dilihat proses Boyer-Moore yang terdapat pada sistem yang akan dibangun ini. Pertama masukkan pattern berupa karakter untuk dapat melakukan
33
pencarian string. Kemudian melakukan pembacaan pattern pada teks pada SQLite, apakah string dicari merupakan cocok yang terdapat pada teks. Melakukan pencocokan string dari kana ke kiri sesuai dengan inputan pattern yang diinginkan oleh sipengguna. Dan dilakukan sampai pattern yang dicari dilakukan pencocokan. Setelah melakukan pencocokan, maka pattern akan mendapatkan kecocokan pada teks yang telah tersedia. Dimana sudah terjadi pengkelompokan data untuk langsung dapat mengetahui artinya. Akhirnya sistem mengeluarkan output, dimana sistem ini secara otomatis mengeluarkan semua pilihan berdasarkan pattern yang diinputkan.
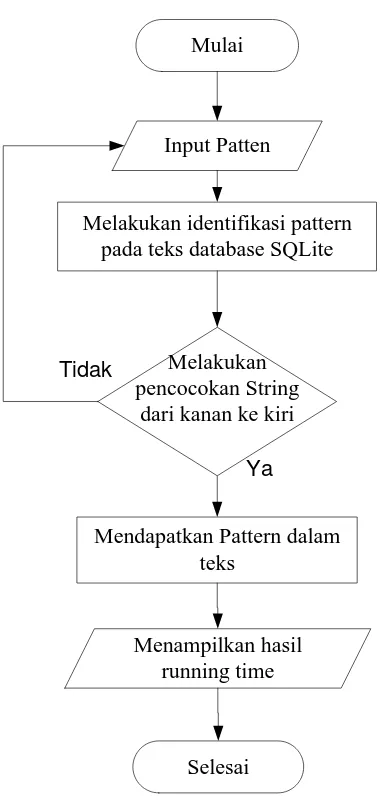
3.2.4.3 Flowchart Proses Brute Force
Mulai
Input Patten
Menampilkan hasil running time
Mendapatkan Pattern dalam teks
Selesai
Melakukan identifikasi pattern pada teks database SQLite
Melakukan pencocokan String
dari kiri ke kanan Tidak
Ya
Gambar 3.8. Flowchart proses Brute Force
pencarian string. Kemudian melakukan pembacaan pattern pada teks pada SQLite, apakah string dicari merupakan cocok yang terdapat pada teks. Melakukan pencocokan string dari kiri ke kanan sesuai dengan inputan pattern yang diinginkan oleh sipengguna. Dan dilakukan sampai pattern yang dicari dilakukan pencocokan. Setelah melakukan pencocokan, maka pattern akan mendapatkan kecocokan pada teks yang telah tersedia. Dimana sudah terjadi pengkelompokan data untuk langsung dapat mengetahui artinya. Akhirnya sistem mengeluarkan output, dimana sistem ini secara otomatis mengeluarkan semua pilihan berdasarkan pattern yang diinputkan dan menampilkan running time proses pencarian menggunakan algoritma Brute Force
3.3 Pseudocode
3.3.1 Pseudocode Algoritma Boyer Moore
procedure BoyerMooreSearch(
input m, n : integer,
input P : array[0..n-1] of char,
input T : array[0..m-1] of char,
output ketemu : array[0..m-1] of boolean
)
Deklarasi:
i, j, shift, bmBcShift, bmGsShift: integer
BmBc : array[0..255] of interger
BmGs : array[0..n-1] of interger
Algoritma:
preBmBc(n, P, BmBc)
preBmGs(n, P, BmGs)
i:=0
while (i<= m-n) do
j:=n-1
while (j >=0 n and T[i+j] = P[j]) do
j:=j-1
endwhile
if(j < 0) then
ketemu[i]:=true;
endif
bmBcShift:= BmBc[chartoint(T[i+j])]-n+j+1
35
bmGsShift:= BmGs[j]
shift:= max(bmBcShift, bmGsShift)
i:= i+shift
3.3.2 Pseudocode Algoritma Brute Force
procedure BruteForceSearch(
input m, n : integer,
input P : array[0..n-1] of char,
input T : array[0..m-1] of char,
output ketemu : array[0..m-1] of boolean
)
Deklarasi:
i, j: integer
Algoritma:
for (i:=0 to m-n) do
j:=0
while (j < n and T[i+j] = P[j]) do
j:=j+1
endwhile
if(j >= n) then
ketemu[i]:=true;
endif
endfor
3.4ERD (Entity Relationship Diagram)
Pada Gambar 3.9 terlihat bahwa pada sistem ini terdapat relasi antara words dan extraword, dimana setelah kata di tambahkan pada table extraword, maka kata yang ditambahkan tadi langsung tersimpan pada database words.
Words Indonesia
Mandarin Inggris
ExtraWord ID From
To Extra
Submits
Gambar 3.9. ERD (Entity Relationship Diagram)
a. Tabel Words
Tabel ini berupa semua kata yang disimpan pada database. Table ini terdiri dari 3 field yaitu Indonesia, Mandarin, Inggris yang dapat dilihat pada table 3.1
Table 3.1 Tabel Words
Field Type Ukuran Keterangan
Indonesia Varchar 50 Kata dalam bahasa indonesia
Mandarin Varchar 50 Kata dalam bahasa mandarin
Inggirs Varchar 50 Kata dalam bahasa inggris
b. Tabel Extraword
Tabel ini digunakan untuk menambahkan kata baru pada database. Table ini terdiri dari beberapa field yang dapat dilihat pada table 3.2
37
Tabel 3.2 Tabel Extraword
Field Type Ukuran Keterangan
ID Integer (PK) - Bahasa awal yang dipakai
From Varchar 3 Pilihan bahasa yang digunakan
To Varchar 3 Pilihan bahasa yang digunakan
Extra Varchar 80 Menambahkan kata ke dalam database
3.5 Perancangan Sistem
Antarmuka merupakan perantara antara pengguna dengan sistem. Tampilan antarmuka sangat mempengaruhi penggunaan suatu sistem, oleh karena itu antarmuka harus dirancang sedemikian rupa sehingga memudahkan pengguna dalam menggunakan sistem tersebut. Pada tahap ini akan dilakukan perancangan antarmuka sistem yang akan digunakan dan dalam perancangannya sebagai aplikasi Android maka tampilan antarmuka ini dirancang pada masing – masing layout yang saling berintegrasi satu sama lain. Rancangan antarmuka sistem ini terdiri dari beberapa layout yang memiliki tujuan dan kegunaan yang berbeda – beda, seperti layout Tampilan Awal, layout Info Aplikasi, layout Pilihan, layout Tampil Kamus Mandarin, dan layout Hasil. Namun dari sejumlah layout tersebut, layout Tampil Kamus Mandarin, dan layout Hasil merupakan tampilan utama yang dinamis dan akan dirancang secara khusus.
3.5.1 Antarmuka Menu Halaman Utama
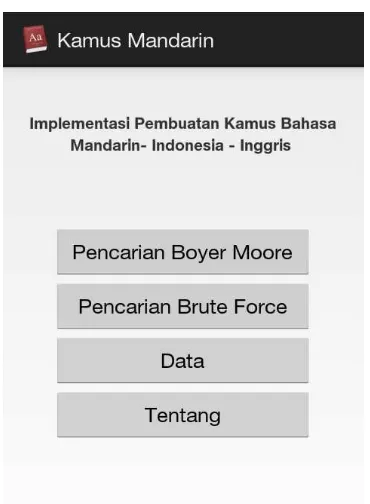
Gambar 3.10 Rancangan Antarmuka Halaman Utama
Keterangan :
1. Listview Pencarian Boyer Moore
Digunakan untuk melakukan pencarian arti menggunakan Algoritma Boyer Moore 2. Listview pencarian Brute Force
Digunakan untuk melakukan pencarian arti kata menggunakan algoritma Brute
Force
3. Data
Menampilkan berupa bentuk kata, dimana menampilkan semua bahasa yang diinputkan dan dapat menambahkan kata.
4. Tentang
Digunakan untuk mengetahui latar belakang adanya kamus bahasa Mandarin secara umum.
39
3.5.2 Antarmuka Pilih Pencarian
Antarmuka Pilih Pencarian juga merupakan layout pada android. Layout ini memiliki tampilan didalamnya, Layout Pilih pencarian string dan input pada pattern. Layout tersebut melakukan pencarian hasil dari pencocokan pattern pada teks pada SQLite (database untuk aplikasi android) oleh algoritma Boyer-Moore yang sebelumnya telah diberikan inputan.
Gambar 3.11 Rancangan Antarmuka Pilih Pencarian
Keterangan :
2. Terdapat bahasa Mandarin – Indonesia – Inggris tergantung user sama halnya dengan posisi (1). Namun pada posisi (2) sistem berfokus pada arti bahasa yang pilihan terdapat 3 bahasa, yaitu : Mandarin – Indonesia - Inggris.
3. Untuk melakukan cari kata, untuk mendapatkan hasil dari terjemahan dari kata yang dicari. User harus melakukan inputan data pada posisi (3) agar sistem dapat melakukan pencarian string dengan metode pencocokan algoritma.
4. Hasil running time dari kedua pencarian algoritma.
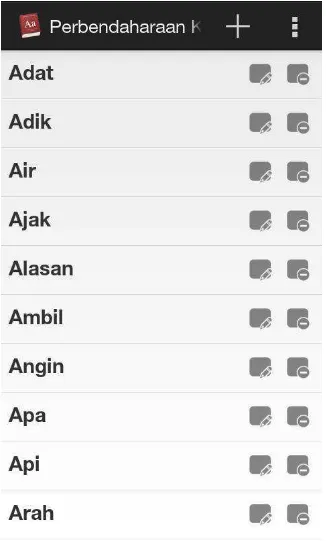
3.5.3 Antarmuka Pilih Data
Antarmuka Pilih Data merupakan layout yang dihadapkan kepada pengguna sebagai referensi untuk melihat bahasa dalam bentuk kata dan dapat menambahkan data serta mengurangi data sesuai yang diinginkan.
Gambar 3.12 Rancangan Antarmuka Pilih Data
41
Keterangan :
1. Pada listview (1) untuk menambahkan pembendaharaan kata Bahasa Mandarin – Indonesia- Inggris.
2. Pada listview (2) untuk mengurangi pembendaharaan kata Bahasa Mandarin – Indonesia – Inggris.
3. Pada listview (3) menampilkan kata – kata Bahasa Mandarin – Indonesia – Inggris yang diinput.
3.5.4 Antarmuka Pilih Tentang
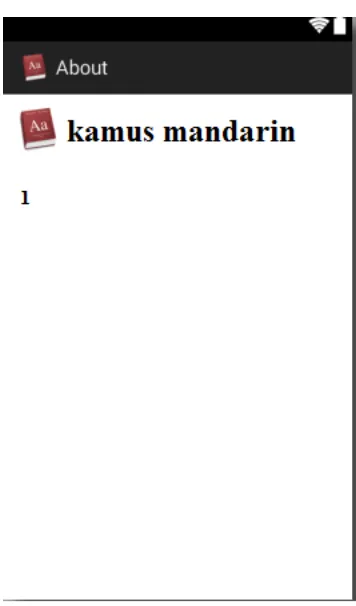
Antarmuka Pilih Tentang merupakan layout pada android. Layout ini menampilkan latar belakang terbentuknya kamus Mandarin pada platform android.
Gambar 3.13 Rancangan Antarmuka Pilih Tentang
Keterangan :
BAB 4
IMPLEMENTASI DAN PENGUJIAN SISTEM
Pada bab 4 ini penulis memaparkan bagaimana implementasi dan perbandingan dari sistem serta hasil pengujian aplikasi menggunakan algoritma Boyer-Moore dan Brute
Force yang sudah dibangun menggunakan java.
4.1. Implementasi Sistem
Sistem ini dibangun dengan aplikasi android, sehingga membutuhkan conection android untuk menjalankannya. Implementasi sistem ini hanya untuk mengetahui kerja sistem dan hasil running time algoritma Boyer-Moore dan Brute Force pada platform android. Aplikasi ini bertujuan untuk menunjukkan pencarian string pada kamus Bahasa Mandarin – Indonesia - Inggris menggunakan pattern sebagai pencari didalam teksnya yang sudah diinputkan terlebih dahulu sesuai dengan batasan masalah yang tercantum sebelumnya. Aplikasi ini merupakan pengembangan lebih lanjut dari penelitian – penelitian sebelumnya mengenai algoritma Boyer-Moore dan Brute Force pada kasus yang berbeda dan implementasi yang berbeda, seperti diaplikasi Android.
Proses implementasi yang dirancang pada sistem ini dibagi menjadi form dalam bahasa java, di antaranya yaitu untuk halaman utama, Pencarian, Data dan Tentang aplikasi.
4.1.1 Halaman utama
Halaman utama merupakan form yang pertama muncul pada saat aplikasi dijalankan.
Form ini terdiri 4 Menu pada aplikasi android, yaitu Pencarian Boyer-Moore,
Pencarian Brute Force, Data, dan Tentang. .
Gambar 4.1 Halaman Utama
Pada Gambar 4.1 halaman utama dari android terdiri dari , menu pencarian, menu data dan menu tentang.
4.1.2 Pilihan Pencarian
Pilihan Pencarian merupakan form yang digunakan untuk melakukan proses pencarian string dengan pencocokan pattern menggunakan algoritma Boyer Moore yaitu dari kiri ke kanan dan algoritma Brute Force yaitu dari kanan ke kiri. Pada menu ini disediakan interface untuk input pattern, textbox berupa pemilihan bahasa untuk menampilkan teks dan menentukan terjemahan hasil kata dalam pencarian string. Sistem akan secara langsung menampilkan informasi hasil pencarian string dan
running time pada proses pencarian. Tampilan untuk pilihan pencarian dapat dilihat
Gambar 4.2 Form Pencarian
4.1.3 Pilihan Data
Menu Data merupakan Form yang digunakan untuk menampilkan kata – kata yang telah diinput pada android tersebut . Dapat menginput data dan delete data untuk melakukan pembaharuan pembendaharan kata. Tampilan untuk Menu Data dapat dilihat pada Gambar 4.3.
Gambar 4.3 Form Data
45
4.1.4 Pilihan Tentang
Menu Tentang merupakan form yang digunakan hanya untuk menampilkan informasi
tentang sistem aplikasi kamus Mandarin yang dibuat. Pada pilihan tentang berisi informasi tentang latar belakang pembuatan aplikasi kamus. Tampilan untuk Menu Tentang dapat dilihat pada Gambar 4.4.
Gambar 4.4 Form Tentang
4.2. Pengujian Sistem
Pengujian sistem dilakukan untuk mengetahui kinerja setiap algoritma yang telah diimplentasikan kedalam program. Fokus utama pada pengujian penelitian ini untuk mengetahui seberapa efektif dan efisien penerapan algoritma dalam pemampatan berkas. Pengujian sistem ini dilakukan untuk melihat bagaimana algoritma
Boyer-Moore dan algoritma Brute Force melakukan pencarian string dengan pencocokan
karakter. Pengujian ini dilakukan pada masing masing algoritma dengan 2 kasus uji coba, antara lain :
4.2.1. Pengujian pada 1 karakter
4.2.1.1 Pengujian Boyer Moore pada 1 karakter
Gambar 4.5 Pengujian Boyer Moore 1 Karakter
Pada gambar 4.5 terlihat bahwa pengujian Boyer Moore menggunakan karakter “m”
dimana ketika di input karakter “m” langsung di cocokkan pada sistem. Dapat dilihat
pada gambar 4.5 dimana terdapat output yang sudah didapatkan dari menginput
karakter “m”, seperti : mau “yao” , meja “biao”, memancing “yu”, memasak
“chushi” dan terlihat running time sistem ketika mencari kata b adalah 38ms.
Dapat dilihat pada SQLitenya, dimana sistem langsung mengkelompokkan data/teks sesusai dengan karakter yang diminta/pattern. Sistem hanya melakukan pencarian pada column indo, bukan terjemahannya.
Sistem sudah dipaketkan, jadi bilamana terpilih salah satu diantara column, Misalkan; pada pencarian string menemukan teks mau, maka sepaket dengan mau adalah yao dan want, maka sistem akan mengeluarkan kata – kata tersebut . Namun dikarnakan pemilihannya hanya terdapat dua, jadi sistem hanya mengeluarkan bahasa
47
Indonesia dan Mandarin sesuai dengan pemilihan pada button bahasa. Berikut merupakan table data pada proses pencarian kata “b” yang dapat dilihat pada table 4.1
Tabel 4.1 Database Proses pencarian 1 karakter ID Column_Indo Column_Mandarin Column_English
1 Mau Yao want
2 Meja Biao Table
3 Memancing Yu Fishing
4 Memasak chushi Cooking
4.2.1.2 Pengujian Brute Force pada 1 karakter
Gambar 4.6 Pengujian Brute Force 1 Karakter
4.2.2. Pengujian pada 2 karakter
4.2.2.1 Pengujian Boyer Moore pada 2 karakter
Gambar 4.7 Pengujian Boyer Moore pada 2 karakter
Pada gambar 4.7 terlihat bahwa pada pengujian Boyer Moore karakter “ma” menghasilkan output mati “si”, mau “yao”, memancing “yu” dan memasak “chushi”,
dan running time 23ms
Tabel 4.2 Database Proses pencarian 2 karakter ID Column_Indo Column_Mandarin Column_English
1 Mau Yao Want
2 Mati Si Dead
3 Memancing Yu Fishing
4 Memasak chushi Cooking
49
Pada table 4.2 terlihat bahwa pada sistem mengeluarkan output dari karakter
“ma”, namun ada juga kata memancing dan memasak dikarenakan pemapingan
sudah cocok dan kata tersebut terkandung karakter “ma”.
Prinsip kerja algoritma Boyer Moore membandingkan karakter dari kanan ke kiri dan memiliki loncatan karakter yang besarsehingga mempercepat pencarian
string karena dengan hanya memeriksa sedikit karakter, dapat langsung diketahui
bahwa string yang dicari tidak ditemukan dan dapat digeser ke posisi berikutnya, proses ini dapat dilihat pada table 4.3
Tabel 4.3 Proses algoritma Boyer-Moore
Teks M E M A S A K
Pattern M A
1. Proses algoritma pada karakter “MA”
Pattern adalah “MA” dan teksnya adalah “MEMASAK” bisa dilihat dimana prinsip dari Boyer-Moore adalah pencocokan dari kanan ke kiri.
2. Proses algoritma pada karakter “MA”
Pattern “MA“ melakukan pencocokan , pertama jelas yang dilakukan dimulai dari
karakter “A”. Maka sistem melakukan pencocokan, ternyata pola dari “A” tersebut
tidak ada pada teks, maka sistem mengecek kembali untuk tidak langsung
membuang waktu lama pada proses pencocokan. Apakah karakter “E” ada pola
pada pattern yang ingin dicari. Jika tidak ada maka bergeser sebanyak jumlah karakter yang ada pada pola yang ingin dicari.
3. Proses algoritma pada karakter “MA”
Jika karakter “E” tidak terdapat pada pattern yang ingin dicari, maka bergeser
sebanyak selisih dari jumlah karakter yang ada.
4. Proses algoritma pada karakter „MA” Setelah tidak ada mengalami kecocokan
maka pattern akan melakukan pergeseran dari kiri ke kanan sebesar jumlah karakter dan setelah bergesar dilanjutkan kembali pencocokan/pemapping kembali untuk mendapatkan pencocokan string , dan telah terjadi kecocokan karakter
Tabel 4.4 proses Match algoritma Boyer-Moore
[image:30.595.210.425.87.534.2]4.2.2.2 Pengujian Brute Force Pada 2 karakter
Gambar 4.8 Pengujian Brute Force pada 2 karakter
Pada gambar 4.8 terlihat bahwa pengujian Brute Force karakter “be” menghasilkan
output yang sama dengan Boyer Moore namun pada pengujian Brute Force
menghasilkan running time 29ms
Prinsip kerja Algoritma Brute Force adalah melakukan pencocokan dari kiri ke kanan, algoritma ini akan mencocokkan karakter per karakter pattern dengan karakter pada teks yang bersesuaian, proses pencarian Brute Force dapat dilihat pada table 4.5
Teks M E M A S A K
Pattern M A
51
Tabel 4.5 Proses awal algoritma Brute Force
Teks M E M A S A K
Pattern M A
indeks 0 1 2 3 4 5 6
1. Pattern adalah “MA” dan teksnya adalah “MEMASAK” bisa dilihat dimana prinsip dari Brute Force adalah pencocokan dari kiri ke kanan
2. Pattern “MA“ melakukan pencocokan , pertama jelas yang dilakukan dimulai
dari karakter “M”. Maka sistem melakukan pencocokan, ternyata pola dari
“M” tersebut cocok pada teks, maka sistem mengecek kembali untuk tidak
langsung membuang waktu lama pada proses pencocokan. Apakah karakter
“E” ada pola pada pattern yang ingin dicari. Jika tidak ada maka bergeser
sebanyak jumlah karakter yang ada pada pola yang ingin dicari.
3. Jika karakter “M” tidak terdapat pada pattern yang ingin dicari, maka bergeser
sebanyak satu langkah ke kanan yang dapat dilihat pada table 4.6 Tabel 4.6 proses kedua algoritma Brute Force
4. Jika karakter “MA” tidak mengalami kecocokan, maka bergeser satu langkah
ke kanan sampai menemukan kecocokan. dan telah terjadi kecocokan karakter
“MA” pada indeks ke 3 pada proses pergeseran pattern sebanyak 3 seperti
yang terlihat pada tabel 4.7.
Teks M E M A S A K
Pattern M A
Tabel 4.7 proses akhir algoritma Brute Force
4.3. Hasil Pengujian
Pengujian sistem ini dilakukan untuk melihat hasil akhir pencarian dan perbedaan
running time dari Algoritma Boyer Moore dan Algoritma Brute Force. Pengujian ini
dilakukan pada 4 kasus uji coba, antara lain: 1. Pengujian terhadap 3 karakter 2. Pengujian terhadap 4 karakter 3. Pengujian terhadap 5 karakter 4. Pengujian terhadap 6 karakter
Hasil pengujian akan ditampilkan dalam bentuk grafik pada akhir pengujian.
[image:32.595.131.511.531.726.2]4.3.1 pengujian 3 karakter
Gambar 4.9 Pengujian 3 karakter pada kata “air”
Teks M E M A S A K
Pattern M A
Indeks 0 1 2 3 4 5 6
53
Pada gambar 4.9 terlihat bahwa pada proses pengujian algoritma Boyer Moore (kiri) dan pengujian Brute Force (kanan) pada 3 karakter yaitu “air” dengan
arti kata “shui”, menampilkan masing masing running time sebesar 2ms
[image:33.595.143.519.182.411.2]4.3.2 pengujian 4 karakter
Gambar 4.10 Pengujian 4 karakter pada kata “mata”
Pada gambar 4.10 terlihat bahwa pada proses pengujian algoritma Boyer
Moore (kiri) dan pengujian Brute Force (kanan) pada 3 karakter yaitu “mata”
dengan arti kata “yan”, menampilkan masing masing running time sebesar
3ms dan 4ms
4.3.3 pengujian 5 karakter
[image:33.595.132.501.558.740.2]Pada gambar 4.11 terlihat bahwa pada proses pengujian algoritma Boyer
Moore (kiri) dan pengujian Brute Force (kanan) pada 3 karakter yaitu
“makan” dengan arti kata “chi”, menampilkan masing masing running time
sebesar 3ms dan 4ms
[image:34.595.164.515.247.436.2]4.3.4 pengujian 6 karakter
Gambar 4.12 Pengujian 6 karakter pada kata “bahaya”
Pada gambar 4.12 terlihat bahwa pada proses pengujian algoritma Boyer
Moore (kiri) dan pengujian Brute Force (kanan) pada 3 karakter yaitu
“bahaya” dengan arti kata “weixian”, menampilkan masing masing running
time sebesar 4ms dan 5ms
4.3.5 Hasil perbandingan Running Time pencocokan string
Hasil perbandingan Running Time pencarian menggunakan algoritma Boyer
Moore dan algoritma Brute Force ditampilkan pada table 4.8
55
Tabel 4.8 Hasil perbandingan dari segi running time Kata
Rata – Rata
Air Mata Makan Bahaya
Algoritma Boyer Moore
2ms 3ms 3ms 4ms 3ms
Algoritma Brute Force
2ms 4ms 4ms 5ms 3.75ms
Dari table 4.8 dapat dilihat bahwa algoritma Boyer Moore memiliki running time yang lebih cepat dari Brute Force yaitu dengan perbedaan 0.75ms.
Running Time (ms)
0 1 2 3 4 5 6
0.. 1 2 3 karakter 4 karakter 5 karakter 6 karakter Panjang Karakter
Boyer Moore Brute Force
Gambar 4.13. Grafik perbedaan Running Time Algoritma Boyer Moore dan Algoritma Brute Force
[image:35.595.141.465.368.638.2]dari grafik tersebut adalah 0.75ms dimana Algoritma Boyer Moore memiliki rata – rata sebesar 3ms dan Algoritma Brute Force memiliki rata – rata 3.7ms.
Berdasarkan kompleksitas waktu pencarian Algoritma Boyer Moore dan Algoritma Brute Force sama – sama memiliki kompleksitas waktu pencarian Big Ө (
m × n ), sehingga dapat kita lihat pada gambar grafik memiliki lengkungan garis nilai
yang sama, namun Algoritma Boyer Moore lebih cepat karena memiliki perbandingan karakter teks 3n sedangkan Algoritma Brute Force memiliki perbandingan karakter teks 2n.
57
BAB 5
KESIMPULAN DAN SARAN
5.1Kesimpulan
Setelah melakukan studi literatur, analisis dan perancangan dan pengujian terhadap perbandingan Algoritma Boyer-Moore dan Algoritma Brute Force dalam Pencarian String Pada Platform Android, maka dapat disimpulkan sebagai berikut:
1. Sistem hanya dapat melakukan pencarian string dengan pengujian karakter dan mendapatkan arti kata.
2. Hasil pengujian menunjukkan bahwa implementasi Algoritma Boyer-Moore dan Algoritma Brute Force pada sistem dapat melakukan pencarian dengan 1 karakter dan 2 karakter dan berjalan sesuai dengan benar.
3. Proses pencocokan string pada Algoritma Boyer-Moore dan Algoritma Brute
Force harus memiliki panjang karakter lebih banyak untuk dapat
mengoptimalkannya. Pada aplikasi kamus kata berimbuhan memiliki panjang karakter lebih banyak. Hasil pencarian string menjadi optimal.
4. Algoritma Boyer Moore memiliki running time yang lebih cepat dari Algoritma Brute Force yaitu dengan perbedaan 0.75ms.
5. Algoritma Boyer Moore dan Algoritma Brute Force sama – sama memiliki fase pencarian kompleksitas waktu Big Ө ( m × n ), namun Algoritma Boyer
5.2Saran
Adapun saran yang dapat penulis berikan untuk mengembangkan penelitian ini adalah sebagai berikut:
1. Pada aplikasi Kamus Bahasa Mandarin – Indonesia – Inggris untuk dikembangkan dalam hal penambahan keterangan atau informasi pada kata yang dicari. Untuk dapat mengunakan bahasa yang lebih efektif pada kosa kata.
2. Pada pencarian setidaknya berupa bentuk kalimat sehingga algoritma
Boyer-Moore dan Algoritma Brute Force dapat digunakan secara optimal.
3. Pada algoritma Boyer-Moore dan Algoritma Brute Force untuk dapat dikembangkan lagi, agar dapat melakukan pencarian lebih efektif dan cepat.
4. Pada penelitian selanjutnya dapat dilakukan pencarian terhadap kompleksitas
waktu Big Ө pada Algoritma Boyer Moore dan Algoritma Brute Force.
6
BAB 2
TINJAUAN PUSTAKA 2.1Algoritma Boyer-Moore
Algoritma Boyer-Moore adalah salah satu algoritma pencarian string, dipublikasikan oleh Robert S. Boyer, dan J. Strother Moore pada tahun 1977. Algoritma ini dianggap sebagai algoritma yang paling efisien pada aplikasi umum.Tidak seperti algoritma pencarian string yang ditemukan sebelumnya, algoritma Boyer-Moore mulai mencocokkan karakter dari sebelah kanan pattern (pola yang di cari). Ide dibalik algoritma ini adalah bahwa dengan memulai pencocokkan karakter dari kanan, dan bukan dari kiri, maka akan lebih banyak informasi yang didapat. (Helmi, 2013)
2.1.1 Kelebihan Algoritma Boyer-Moore :
Tidak seperti pencarian string lainnya Brute Force, Knuth-Morris-Pratt yang mempunyai cara kerja membandingkan satu – persatu karakter dari kiri ke kanan.
Boyer-Moore membandingkan karakter dari kanan ke kiri dan memiliki loncatan
karakter yang besarsehingga mempercepat pencarian string karena dengan hanya memeriksa sedikit karakter, dapat langsung diketahui bahwa string yang dicari tidak ditemukan dan dapat digeser ke posisi berikutnya.
2.1.2 Kelemahan Algoritma Boyer-Moore :
Algoritma Boyer-Moore mencocokan Pattern dari kanan ke kiri oleh sebab itu kelemahan dari algoritma ini adalah ketika semua karakter memiliki kesamaan atau cocok dan hanya karakter terakhir atau karakter paling kiri yang berbeda maka pencarian ini akan memerlukan waktu yang sedikit lama (Utomo, 2008).
Teks G R A C E Pattern H A L I M
[image:40.595.164.426.84.149.2]Pada tabel 2.1, dengan melakukan pencocokan dari posisi paling akhir/kanan pattern dapat dilihat bahwa karakter “M” pada pattern “HALIM” tidak cocok dengan karakter “E” pada teks “GRACE” , dan karakter “E” tidak pernah ada dalam pattern “HALIM” yang dicari sehingga pattern “HALIM” dapat digeser melewati teks “GRACE” sehingga posisinya menjadi:
Tabel 2.2.Contoh pergeseran algoritma Boyer-Moore Teks G R A C E
Pattern H A L I M
Tabel 2.2 menunjukkan bahwa algoritma Boyer-Moore memiliki pergeseran karakter yang besar sehingga mempercepat pencarian pattern karena dengan hanya memeriksa sedikit karakter, dapat langsung diketahui bahwa pattern yang dicari tidak ditemukan dan dapat digeser ke posisi berikutnya (Ginting, 2014)
Algoritma Boyer-Moore menggunakan dua buah tabel untuk mengolah informasi saat terjadi kegagalan pencocokan pattern.Tabel pertama disebut bad character shitf juga sering disebut occurrence heuristic (OH). Tabel kedua disebut dengan istilah good
suffix shift juga disebut match heuristic (MH) (Charras, 2014)
Secara sistematis, langkah-langkah yang dilakukan algoritma Boyer-Moore pada saat mencocokkan pattern adalah:
Algoritma boyer-moore mulai mencocokkan pattern pada karakter paling akhir/kanan.
[image:40.595.147.498.352.419.2]8
Dari kanan ke kiri, algoritma ini akan mencocokkan karakter per karakter
pattern dengan karakter di teks yang bersesuaian, sampai salah satu kondisi
berikut dipenuhi:
a. Karakter di pattern dan di teks yang dibandingkan tidak cocok (mismatch).
b. Semua karakter di pattern cocok, kemudian algoritma akan memberitahukan penemuan di posisi ini.
Algoritma kemudian menggeser pattern dengan mengambil nilai terbesar dari penggeseran good-suffix dan penggeseran bad-character, lalu mengulangi langkah 2 sampai pattern berada di ujung teks. (Ramadhansyah,2013)
2.1.3 Pencarian Dengan Algoritma Boyer-Moore
Buat tabel pergeseran pattern yang dicari (P) dengan pendekatan Match
Heuristic (MH) dan Occurence Heuristic (OH), untuk menentukan jumlah
pergeseran yang akan dilakukan jika mendapat karakter tidak cocok pada proses pencocokan dengan teks (T).
Jika dalam proses pembandingan terjadi ketidakcocokan antara pasangan karakter pada pattern dan karakter teks, pergeseran dilakukan dengan memilih salah satu nilai pergeseran dari dua tabel, dan memiliki nilai pergeseran paling besar dari tabel Match Heuristic dan Occurence Heuristic .
Dua kemungkinan penyelesaian dalam melakukan pergeseran pattern, Jika karakter yang tidak cocok, tidak ada pada pattern maka pegeseran adalah sebanyak jumlah karakter pada pattern. dan jika karakter yang tidak cocok, ada pada pattern, maka banyaknya pergeseran bergantung dari nilai pada tabel
Match Heuristic dan Occurence Heuristic.
Jika semua karakter telah cocok, artinya pattern telah ditemukan di dalam teks. (Ramadhansyah,2013)
Cara menghitung tabel occurence heuristic : Contoh pattern : MOORE
[image:42.595.123.461.345.411.2]Panjang karakter : 5
Tabel 2.3.occurence heuristic
Index 0 1 2 3 4
Pattern M O O R E
Occurence Heuristic
Langkah-langkah pemberian nilainya adalah sebagai berikut : 1. Lakukan perhitungan, OH = ( length -1 –index)
length = panjang karakter= 5
2. Karakter pertama adalah “M” dengan Index = 0 OH = (5 - 1 - 0 = 4)maka nilai karakter “M” = 4 3. Karakter kedua adalah “O” dengan index = 1
OH = (5 - 1 - 1 = 3)maka nilai karakter “O” = 3 4. Karakter ketiga adalah “O” dengan index = 2
OH = (5 - 1 - 2 = 2)maka nilai karakter “O” = 2 5. Karakter keempat adalah “R” dengan index = 3
OH = (5 - 1 - 3 = 1)maka nilai karakter “R” = 1 6. Karakter kelima adalah “E” dengan index = 4
OH = (5 - 1 - 4 = 0)maka nilai karakter “E” = 0
10
Tabel 2.4.Hasil pencarian Occurence Heuristic
Index 0 1 2 3 4
Pattern M O O R E
Occurence Heuristic 4 3 2 1 0
7. Jika ada karakter yang berulang ambil nilai OH terkecil, dalam kasus ini ada karakter “O” yang bernilai 3 dan 2, maka jadikan karakter “O” bernilai 2. Dapat dilihat pada tabel 2.5.
Tabel 2.5. Hasil akhir pencarian Occurence Heuristic
Index 0 1 2 3 4
Pattern M O O R E
Occurence Heuristic 4 2 2 1 0
2.2Algoritma Brute Force
Algoritma Brute Force adalah algoritma untuk mencocokkan pattern dengan semua teks antara 0 dan n-m untuk menemukan keberadaan pattern dalam teks (Riyanarto Sarno, Yeni Anistyasari, dan Rahimi Fitri, 2012). Di dalam pencocokkan string, terdapat istilah teks dan pattern. Teks merupakan kata yang dicari dan dicocokkan dengan pattern. Sedangkan pattern merupakan kata yang diinputkan untuk dicocokkan. Secara rinci, langkah – langkah yang dilakukan algoritma ini saat mencocokkan string adalah:
1. Algoritma Brute Force mulai mencocokkan pattern dari awal teks.
2. Dari kiri ke kanan, algoritma ini akan mencocokkan karakter per karakter pattern dengan karakter pada teks yang bersesuaian, sampai salah satu kondisi berikut terpenuhi :
a. Karakter di pattern dan di teks yang dibandingkan tidak cocok.
[image:43.595.121.461.344.410.2]3. Algoritma kemudian terus menggeser pattern sebesar satu ke kanan, dan mengulangi langkah ke -2 sampai pattern berada di ujung teks.
2.2.1 Kelemahan dan Kelebihan Algoritma Brute Force
Algoritma Brute Force juga memiliki kelebihan dan kelemahan. Adapun kelebihan dari algoritma Brute Force yaitu:
1. Algoritma Brute Force dapat digunakan untuk memecahkan hampir sebagian besar masalah
2. Algoritma Brute Force sederhana dan mudah dimengerti
3. Algoritma Brute Force menghasilkan algoritma yang layak untuk beberapa masalah penting seperti pencarian, pengurutan, pencocokkan string , atau perkalian matriks
4. Algoritma Brute Force menghasilkan algoritma baku (standard) untuk tugas- tugas komputasi penjumlahan / perkalian n buah bilangan, menentukan elemen minimum atau maksimum di dalam tabel (list).
Sedangkan kelemahan dari algoritma Brute Force yaitu sebagai berikut: 1. Algoritma Brute Force jarang menghasilkan algoritma yang manjur 2. Beberapa algoritma Brute Force lambat, sehingga tidak dapat diterima 3. Tidak sekonstuktif/sekreatif teknik pemecahan masalah lainnya
Contoh penggunakan algoritma Brute Force untuk pencarian pattern dalam teks: Teks = GRACE HALIM
Pattern = HALIM
Contoh implementasi pencarian pattern pada teks proses ke 1
Teks G R A C E H A L I M
Pattern H A L I M
Index 0 1 2 3 4 5 6 7 8 9 10
12
Tidak cocok, geser pattern sebanyak satu langkah ke kanan menuju indeks berikutnya.
Contoh implementasi pencarian pattern pada teks proses ke 2
Teks G R A C E H A L I M
Pattern H A L I M
Index 0 1 2 3 4 5 6 7 8 9 10
Tidak cocok, geser pattern sebanyak satu langkah ke kanan menuju indeks berikutnya. Contoh implementasi pencarian pattern pada teks proses ke 3
Teks G R A C E H A L I M
Pattern H A L I M
Index 0 1 2 3 4 5 6 7 8 9 10
Tidak cocok, geser pattern sebanyak satu langkah ke kanan menuju indeks berikutnya.
Contoh implementasi pencarian pattern pada teks proses ke 4
Teks G R A C E H A L I M
Pattern H A L I M
Index 0 1 2 3 4 5 6 7 8 9 10
Tidak cocok, geser pattern sebanyak satu langkah ke kanan menuju indeks berikutnya.
Contoh implementasi pencarian pattern pada teks proses ke 5
Teks G R A C E H A L I M
Pattern H A L I M
Index 0 1 2 3 4 5 6 7 8 9 10
Tidak cocok, geser pattern sebanyak satu langkah ke kanan menuju indeks berikutnya.
Teks G R A C E H A L I M
Pattern H A L I M
Index 0 1 2 3 4 5 6 7 8 9 10
Tidak cocok, geser pattern sebanyak satu langkah ke kanan menuju indeks berikutnya.
Contoh implementasi pencarian pattern pada teks proses ke 7
Teks G R A C E H A L I M
Pattern H A L I M
Index 0 1 2 3 4 5 6 7 8 9 10
Pattern cocok, pencarian berhenti pada indeks ke 6.
2.3Bahasa Mandarin
Penelitian tentang Analisis Homograf aksara Cina dan Analisis bahasa berdasarkan unsur semantik sudah pernah diteliti sebelumnya oleh peneliti lain, seperti : Tesis Ridwan Azhar (1998) yang berjudul “Analisis Semantik Bahasa Melayu Dialek Bandar Khalipah” dilakukan untuk memperoleh gambaran deskriptif analisis semantik Bahasa Melayu Dialek Bandar Khalipah. Penelitian dilakukan berdasarkan semantik leksikal dan sematik kalimat menurut teori dan konsep semantik. Hasil penelitian yang disajikan menggunakan pendekatan semantik struktural yang mendeskripsikan bahasa dengan kerangka teori analisis makna. Pembahasaan semantik bahasa Melayu dialek Bandar Khalipah, mencakup : kata, kata turunan, ciri-ciri makna leksikal, hubungan makna leksikal, makna kalimat, dan hubungan makna kalimat.
Disertasi SunQiang 孙强dari Universitas Sichuan (2007) berjudul “Penelitian Homograf Aksara Cina Modern” yang membandingkan kosa kata homograf pada masa lalu dengan masa sekarang. Penelitian ini dilakukan dengan metode library
research (penelitian perpustakaan) yaitu dengan mengumpulkan kosakata homograf
yang terdapat didalam kamus “现代汉语词典 (第五版)” xiàn dài hàn yŭ cí diăn (dì
14
wŭ băn).
Skripsi Wedhawati dari Balai Bahasa Yogyakarta (2005) berjudul“Konfigurasi
Medan Leksikal Verbal Indonesia yang berkomponen Makna(+suara+makna)”. Dalam penelitian medan leksikal ini yang ditelaah sejumlah medanleksikal verbal yang berkomponen makna dalam Bahasa Indonesia. Medan leksikalitu terbentuk dari butir-butir leksikal verbal simpelks yang bersifat internal danintralingual. Butir-butir leksikalverbal adalah butir-butir leksikal yang relasasinya
dalam ujaran atau kalimat termasuk kelas kata verba.
Skripsi Risatyah dari Universitas Negri Malang (2010) berjudul “Pengajaran
Bahasa Inggris Berbasis Leksikon untuk Meningkatkan kemampuan Pembelajaran
Usia Muda dalam Memproduksi Classroom Lekxico-grammatical Units di 3 to 6
2.4Sejarah Android
Android merupakan sebuah sistem operasi, middleware dan aplikasi utama untuk perangkat mobile device yang direlease oleh Google. Android SDK (Software
Development Kit) menyediakan Tools dan API yang diperlukan untuk
mengembangkan aplikasi pada platform Android dengan menggunakan bahasa pemrograman Java dengan tujuan membuat sebuah standar terbuka untuk perangkat telepon selular (mobile device). Android bukan linux, akan tetapi Android dibangun diatas Linux Kernel yaitu versi 2.6.Android menyertakan libraries C/C++ yang digunakan oleh berbagai komponen dari sistem operasi Android.
Android Inc. didirikan oleh Andy Rubin, Rich Milner, Nick Sears dan Chris
Whitepada tahun 2003 di Palo Alto, California, USA. Pada Agustus 2005 Google
membeliAndroid Inc. Kemudian untuk mengembangkanAndroid dibentuklah Open
HandsetAlliance konsorsium dari 34 perusahaan hardware, software dan
telekomunikasi,termasuk Google, HTC, Intel, Motorola, Qualqomm, T-Mobile dan
Nividia.Saat inisudah banyak bermunculan vendor-vendor untuk smartphone yang
memakai OS Android. (Chistie, 2012)
Kelebihan Android :
a. Lengkap (Complete Platform) : Android dikatakan lengkap karena Android menyediakan tools untuk membangun software yang sangat lengkap dibanding dengan platform lain.
b. Terbuka (Open Source Platform) : Platform Android diciptakan dibawah lisensi open source, dimana para pengembang bebas untuk mengembangkan aplikasi pada platform ini.
c. Bebas (Free Platform) : Android adalah platform mobile yang tidak memiliki batasan dalam mengembangkan aplikasinya. Tidak ada lisensi dalam mengembangkan aplikasi Android. Android dapat didistribusikan dan diperdagangkan dalam bentuk apapun. (Eko, 2012)
2.5Jenis-jenis OS Android
16
1. Android versi 1.
Gambar 2.1. Android versi 1.1
Pada gambar 2.1. Andoid versi 1.1 di rilis pada 9 Maret 2009 oleh Google. Android versi ini dilengkapi disupport oleh Google Mail Service dengan pembaruan estetis pada aplikasi, jam alarm, voice search (pencarian suara), pengirimanpesan dengan Gmail, dan pemberitahuan email.
2. Android versi 1.5 Cup Cake
Gambar 2.2 Android versi 1.5 Cup Cake
Pada gambar 2.2. Android Cup Cake di rilis pada pertengahan Mei 2009, masih oleh Google Inc. Android ini dilengkapi softwaredevelopment kit dengan berbagai pembaharuan termasuk penambahan beberapa fitur antara lain yakni kemampuan merekam dan menonton video dengan modus kamera, mengunggah video ke Youtube, upload gambar ke Picasa langsung dari telepon, serta mendapat dukungan
3. Android versi 1.6 Donut
Gambar 2.3. Android versi 1.6 Donut
Pada gambar 2.3. Android Donut di rilis pada September 2009 menampilkan proses pencarian yang lebih baik dibandingkan versi-versi sebelumnya. Selain itu Android Donut memiliki fitur-fitur tambahan seperti galeri yang memungkinkan pengguna untuk memilih foto yang akan dihapus, kamera, camcorder dan galeri yang dintegrasikan text-to-speech engine, kemampuan dial kontak, dan teknologi text to
change speech. Android Donut juga dilengkapi baterai indikator, dan kontrol applet
VPN.
4. Android versi 2.0/2.1 Eclair
Gambar 2.4. Android versi 2.0/2.1 Eclair
Pada gambar 2.4. Android Eclair dirilis pada 3 Desember 2009. Perubahan yang ada antara lain adalah pengoptimalan hardware, peningkatan Google Maps 3.1.2, perubahan UI dengan browser baru dan dukungan HTML5, daftar kontak yang baru, dukungan flash untuk kamera 3,2 MP, digital Zoom, dan Bluetooth 2.1. Android Eclair merupakan Android pertama yang mulai dipakai oleh banyak smartphone, fitur utama
Eclair yaitu perubahan total struktur dan tampilan user interface.
18
[image:51.595.286.386.142.248.2]5. Android versi 2.2 Froyo (Frozen Yogurt)
Gambar 2.5. Android versi 2.2 Froyo
Pada gambar 2.5. Android Froyo dirilis pada 20 mei 2012. Adroid versi ini memiliki kecepatan kinerja dan aplikasi 2 sampai 5 kali dari versi-versi sebelumnya. Selain itu ada penambahan fitur-fitur baru seperti dukungan Adobe Flash 10.1, intergrasi V8 JavaScript engine yang dipakai Google Chrome yang mempercepat kemampuan rendering pada browser, pemasangan aplikasi dalam SD Card, kemampuan WiFi Hotspot portabel, dan kemampuan auto update dalam aplikasi
Android Market.
6. Android versi 2.3 Gingerbread
Gambar 2.6. Android versi 2.3 Gingerbread
Pada gambar 2.6. Andoid Gingerbread di rilis pada 6 Desember 2010. Perubahan-perubahan umum yang didapat dari Android versi ini antara lain peningkatan kemampuan permainan (gaming), peningkatan fungsi copy paste, layar antar muka (User Interface) didesain ulang, dukungan format video VP8 dan WebM, efek audio baru (reverb, equalization, headphone virtualization, dan bass boost), dukungan kemampuan Near Field Communication (NFC), dan dukungan jumlah kamera yang lebih dari satu.
[image:51.595.297.371.466.555.2]Gambar 2.7. Android versi 3.0/3.1 Honeycomb
Pada gambar 2.7. Android Honeycomb di rilis pada awal 2012. Merupakan versi Android yang dirancang khusus untuk device dengan layar besar seperti Tablet PC. Fitur baru yang ada pada Android Honeycomb antara lain yaitu dukungan terhadap prosessor multicore dan grafis dengan hardware acceleration. User Interface pada Honeycomb juga berbeda karena sudah didesain untuk tablet. Tablet pertama yang memakai Honeycomb adalah tablet Motorola Xoom yang dirilis bulan Februari 2011. Selain itu sebuah perangkat keras produksi Asus bernama Eee Pad Transformer juga menggunakan OS Android honeycomb.
[image:52.595.298.372.397.487.2]8. Android versi 4.0 ICS (Ice Cream Sandwich)
Gambar 2.8. Android versi 4.0 Ice Cream Sandwich
Pada gambar 2.8. Android Ice Cream Sandwich diumumkan secara resmi pada 10 Mei 2011 di ajang Google I/O Developer Conference (San Francisco), pihak Google mengklaim Android Ice Cream Sandwich akan dapat digunakan baik di
smartphone ataupun tablet. Android Ice Cream Sandwich membawa fitur Honeycomb
untuk smartphone serta ada penambahan fitur baru seperti membuka kunci dengan pengenalan wajah, jaringan data pemantauan penggunaan dan kontrol, terpadu kontak jaringan sosial, perangkat tambahan fotografi, mencari email secara offline, dan berbagi informasi dengan menggunakan NFC. Ponsel pertama yang menggunakan sistem operasi ini adalah Samsung Galaxy Nexus.
9. Android versi 4.1 Jelly Bean
20
Gambar 2.9. Android versi 4.1 Jelly Bean
Pada gambar 2.9. Android Jelly Bean juga diluncurkan pada acara Google I/O 10 Mei 2011 yang lalu. Android versi ini membawa sejumlah keunggulan dan fitur baru, diantaranya peningkatkan input keyboard, desain baru fitur pencarian, UI yang baru dan pencarian melalui Voice Search yang lebih cepat. Versi ini juga dilengkapi Google Now yang dapat memberikan informasi yang tepat pada waktu yang tepat pula. Salah satu kemampuannya adalah dapat mengetahui informasi cuaca, lalu-lintas, ataupun hasil pertandingan olahraga. Sistem operasi Android Jelly Bean 4.1 pertama kali digunakan dalam produk tablet Asus, yakni Google Nexus 7.
[image:53.595.296.367.425.509.2]10. Android versi 4.4 KitKat
Gambar 2.10. Android versi 4.4 KitKat
11. Android versi 5.0 Lolipop
Gambar 2.11. Android versi 5.0 Lolipop
Pada gambar 2.11. Android Lollipop adalah versi stabil terbaru dari sistem operasi Android yang dikembangkan oleh Google, yang pada saat ini mencakup versi antara 5.0 dan 5.1. Diresmikan pada 25 Juni 2014 saat Google I / O, dan tersedia secara resmi melalui over-the-air (OTA) update pada tanggal 12 November 2014, untuk memilih perangkat yang menjalankan distribusi Android dilayani oleh Google (seperti perangkat Nexus dan Google Play edition). Kode sumbernya dibuat tersedia pada 3 November 2014.
Salah satu perubahan yang paling menonjol dalam rilis Lollipop adalah user
interface yang didesain ulang dan dibangun dengan yang dalam bahasa desain disebut
sebagai "material design". Perubahan lain termasuk perbaikan pemberitahuan, yang dapat diakses dari lockscreen dan ditampilkan pada banner di bagian atas screen. Google juga membuat perubahan internal untuk platform, dengan Android Runtime (ART) secara resmi menggantikan Dalvik untuk meningkatkan kinerja aplikasi, dan dengan perubahan yang ditujukan untuk meningkatkan dan mengoptimalkan penggunaan baterai, yang dikenal secara internal sebagai Project Volta.
2.6Eclipse
Eclipse adalah sebuah IDE (Integrated Development Environment) untuk
mengembangkan perangkat lunak dan dapat dijalankan di semua platform
22
(platformindependent). Berikut ini adalah sifat dari Eclipse: Multi-platform,
Mulit-language dan Multi-role.Sejarah Eclipse awalnya dikembangkan oleh IBM
(International Business Machines) untuk menggantikan perangkat lunak pengembangan IBM Visual Age for Java 4.0. Produk Eclipse ini diluncurkan oleh IBM pada tanggal 5 November 2001. IBM menginvestasikan US$ 40 juta untuk pengembangannya. Sejak 5 November 2001.
2.7SQLite
SQLite merupakan sebuah Database yang bersifat ACID-compliant dan memiliki
ukuran pustaka kode yang relatif kecil, ditulis dalam bahasa C. SQLite merupakan proyek yang bersifat public domain yang dikerjakan oleh D. Richard Hipp. SQLite adalah sebuah open source database yang telah ada cukup lama, cukup stabil, dan sangat terkenal pada perangkat kecil, termasuk Android. Android menyediakan database relasional yang ringan untuk setiap aplikasi menggunakan SQLite. Aplikasi dapat mengambil keuntungan dari itu untuk mengatur relational database engine untuk menyimpan data secara aman dan efiesien. Untuk Android, SQLite dijadikan satu di dalam Android runtime, sehingga setiap aplikasi Android dapat membuat basis data
SQLite. Karena SQLite menggunakan antarmuka SQL, cukup mudah untuk digunakan
orang orang dengan pengalaman lain yang berbasis databases. Terdapat beberapa alasan mengapa SQLite sangat cocok untuk pengembangan aplikasi Android, yaitu:
Database dengan konfigurasi nol. Artinya tidak ada konfigurasi database untuk para
developer. Ini membuatnya relatif mudah digunakan. Tidak memiliki server. Tidak ada proses database SQLite yang berjalan. Pada dasarnya satu set libraries menyediakan fungsionalitas database. Single-file database. Ini membuat keamanan database secara langsung. Open source. Hal ini membuat developer mudah dalam pengembangan aplikasi.
BAB 3
BAB 1
PENDAHULUAN 1.1 Latar Belakang
Pada era komputerisasi, informasi telah berkembang dengan pesat. Terdapat sistem operasi yang berkembang antara lain mobile phone dan smartphone. Smartphone sebagai product mobile phone dewasa ini lebih berkembang dan lebih diminati penggunaannya oleh masyarakat karena beragam fitur dapat ditampilkan untuk memenuhi kebutuhan dan daya tarik tersendiri bagi masyarakat penggunannya.
Kebutuhan masyarakat terhadap layanan teknologi berbasis IT sangat bervariatif, salah satu kebutuhan adalah kebutuhan akan ketersediaan kamus dengan berbagai kepentingan mulai dari kamus yang bersifat umum seperti kamus bahasa hingga kamus istilah-istilah khusus seperti kamus politik, kamus ekonomi, kamus bahasa dan sebagainya. Kamus bahasa Mandarin merupakan salah satu kamus yang di perlukan oleh masyarakat, kamus istilah bahasa Mandarin yang saat ini banyak beredar dalam bentuk buku, namun banyak penggunaannya menyulitkan karena pengguna harus mencari arti dan istilah bahasa Mandarin secara manual, disisi lain buku sangat sulit untuk dibawa dan tidak dapat di update setiap saat sesuai dengan kebutuhan dan perkembangan pada saat ini. Oleh karena itu di butuhkan ketersediaan kamus istilah bahasa Mandarin yang dapat memudahkan semua orang mencari dan memahami arti kata bahasa Mandarin dengan mudah dan cepat dimana pun kita berada. Mengingat masyarakat dewasa ini sangat akrab dengan layanan smartphone maka jika salah satu layanannya dapat menyediakan fitur kamus tentunyaakan sangat bermanfaat dan menarik serta diminati oleh penggunanya.
Berkembangnya platform Android sekarang,membuat saya ingin mencoba memberikan perhatian lebih untuk dapat memaksimalkan kemajuan dari platform Android.Jenis-jenis sistem operasi smartphone diantarannya Windows phone,
Blackberry OS,Android, Sysmbian, IOS, dan sebagainya. Sistem operasi Android
merupakan salah satu sistem operasi yang tengah berkembang di masyarakat. Terdapat
2
keunggulan dari sistem operasi ini antara lain sistem operasinya yang open
source,dapat diubah sesuai dengan keinginan kita sendiri, banyaknya aplikasi
komputer yang sudah tersedia untuk smartphone android dan harganya yang terjangkau.
String match adalah suatu algoritma yang digunakan untuk memecahkan masalah
pencocokan suatu teks terhadap suatu teks lain. Ada beberapa algoritma yang dapat digunakan dalam pencarian string matching contohnya ialah algoritma Brute Force dan Boyer Moore yang memiliki cara kerja berbeda, mengakibatkan kecepatan pencocokan yang berbeda.
Dengan adanya perbedaan tersebut, maka perlu diadakan perbandingan langsung terhadap aplikasi yang akan dirancang.
1.2Rumusan Masalah
Adapun masalah yang akan dibahas dalam penelitian ini adalah :
1. Bagaimana merancang Algoritma Boyer Moore dan Algoritma Brute Force dalam pembuatan kamus Bahasa Mandarin – Indonesia - Inggris
2. Bagaimana melakukan perbandingan Algoritma Booyer Moore dan Algoritma
Brute Force dalam pembuatan kamus Bahasa Mandarin – Indonesia – Inggris.
1.3 Batasan Masalah
Berdasarkan latar belakang diatas maka aplikasi kamus berbasis android yang dapat menjadi acuan batasan masalah yakni :
1. Inputan langsung berupa kata, tidak berupa kalimat. 2. Hasil terjemahan hanya berupa bentuk kata (kata dasar).
3. Aplikasi ini hanya kompatibel dengan ponsel berbasis android 4.2 Jelly
Bean sampai Android 5.0 Lollipop
5. Manajemen Sistem Database yang digunakan dalam program kamus berbasis android adalah SQlite.
6. Jumlah kata yang tersedia dalam database hanya 500 kata pada Kamus Bahasa Mandarin – Indonesia – Inggris.
7. Parameter yang digunakan dalam perbandingan Algoritma Brute Force dan
Boyer Moore adalah Running Time
1.4Tujuan Penelitian
Tujuan dari penelitian ini adalah sebagai berikut :
1. Merancang aplikasi Kamus Bahasa Mandarin – Indonesia – Inggris.
2. Melakukan perbandingan Algoritma Boyer Moore dan Algoritma Brute Force.
1.5 Manfaat Penelitian
Manfaat dari penelitian ini adalah sebagai berikut:
1. Manfaat bagi penulis adalah menambah pengetahuan penulis dalam merancang aplikasi berbasis android dan pengetahuan tentang algoritma Boyer Moore dan Algoritma Brute Force.
2. Manfaat bagi bidang ilmu adalah sebagai acuan agar dapat dikembangkan algoritma string matching dan dikembangkan aplikasi android dalam bidang yang lain.
3. Manfaat bagi masyarakat adalah agar pemilik sistem operasi yang berbasis android dapat menggunakan aplikasi Bahasa Mandarin untuk mempermudah dalam pengenalan bahasa .
4
1.6 Metode Penelitian
Penelitian ini menerapkan beberapa metode penelitian sebagai berikut: 1. Studi Pustaka
Pada tahap ini, dilakukan peninjauan terhadap buku-buku, jurnal-jurnal, artikel-artikel yang pembahas tentang algoritma Boyer Moore, Algoritma Brute Force dan beberapa tutorial pembuatan aplikasi Android.
2. Analisis dan Perancangan
Melakukan analisis terhadap permasalahan, batasan sistem, kinerja sistem, cara kerja sistem disertai pembuatan Flowchart, Unified Modeling Language (UML),
Design Interface
3. Implementasi
Pada tahap ini pengimplementasian Algoritma Brute Force dan Boyer-Moore untuk mencari kata hasil terjemahan berbasis Android dan menunjukkan perbandingan antara algoritma tersebut.
4. Pengujian
Aplikasi yang telah diimplementasikan diuji berdasarkan hasil analisis dan perancangan pencarian kata serta menunjukkan perbandingan dari Algoritma Brute
Force dan Boyer Moore dari segi Running Time
5. Dokumentasi
1.7Sistematika Penulisan
BAB I PENDAHULUAN
Bab ini berisi latar belakang masalah, rumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian, metodologi penelitian, dan sistematika penulisan skripsi.
BAB II TINJAUAN PUSTAKA
Bab ini berisi teori-teori yang berkaitan dengan penelitian tugas akhir, antara lain Algoritma Booyer Moore, Algoritma Brute Force, Bahasa Mandarin, Sejarah dan jenis jenis A