KOVARIAT DARI FUNGSIONAL PRINSIPAL
KOMPONEN ANALISIS UNTUK DATA
LONGITUDINAL
TESIS
Oleh
AGUSMAN
097021053/MT
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
KOVARIAT DARI FUNGSIONAL PRINSIPAL
KOMPONEN ANALISIS UNTUK DATA
LONGITUDINAL
TESIS
Diajukan Sebagai Salah Satu Syarat
Untuk Memperoleh Gelar Magister Sains dalam Program Studi Magister Matematika pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Universitas Sumatera Utara
Oleh
AGUSMAN
097021053/MT
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
Judul Tesis : KOVARIAT DARI FUNGSIONAL PRINSIPAL KOMPONEN ANALISIS UNTUK
DATA LONGITUDINAL Nama Mahasiswa : Agusman
Nomor Pokok : 097021053 Program Studi : Matematika
Menyetujui,
Komisi Pembimbing
(Dr. Sutarman, M.Sc) (Prof. Dr. Herman Mawengkang)
Ketua Anggota
Ketua Program Studi, Dekan
(Prof. Dr. Herman Mawengkang) (Dr. Sutarman, M.Sc)
Telah diuji pada Tanggal 15 Juni 2011
PANITIA PENGUJI TESIS
Ketua : Dr. Sutarman, M.Sc
Anggota : 1. Prof. Dr. Herman Mawengkang
2. Prof. Dr. Tulus, M.Si
ABSTRAK
Analisa komponen utama multivariat klasik diperluas untuk data fungsional dan disebut dengan istilah fungsional prinsipal komponen analisis (FPCA). Sebagian besar pendekatan FPCA yang ada tidak mengakomodir informasi kovariat, dan tujuan dari tulisan ini adalah untuk mengembangkan dua metode yang mengako-modir informasi tersebut. Dengan pendekatan ini, baik fungsi mean maupun fungsi kovariansi tergantung pada kovariat Z dan skala waktu t sementara dengan dekatan kedua hanya fungsi mean yang tergantung pada kovariat Z. Kedua pen-dekatan baru mengakomodir kesalahan pengukuran tambahan dan data fungsional sampelnya diambil pada kisi waktu yang teratur dan juga data longitudinal yang jarang diambil sampelnya pada kisi waktu yang tidak teratur. Pendekatan per-tama untuk menyesuaikan sepenuhnya baik fungsi mean maupun fungsi kovariansi beradaptasi lebih besar terhadap data tetapi lebih intensif perhitungan daripada pendekatan untuk menyesuaikan efek kovariat hanya pada fungsi mean. Di kem-bangkan teori asymptot umum untuk kedua pendekatan dan dibandingkan kinerja keduanya secara numerik melalui studi simulasi dan suatu kumpulan data.
Kata kunci : Estimasi, Seleksi Bandwidth dan jumlah eigen fungsi, Hasil-hasil asimtot
ABSTRACT
Classical multivariate principal component analysis has been extended to functional data and termed functional principal componentanalysis (FPCA). Most existing FPCA approaches do not accommodate covariate information, and it is the goal of this paper to develop two methods that do. In the ?rst approach, both the mean and covariance functions depend on the covariate Z and time scale t while in the second approach only the mean function depends on the covariate Z .Both new approaches accommodate additional measurement errors and functional data sampled at regular time grids as well as sparse longitudinal data sampled at irregular time grids. The first approach to fully adjust both the mean and covariance functions adapts more to the data but is computationally more intensive than the approach to adjust the covariate effects on the mean function only. We develop general asymptotic theory for both approaches and compare their performance numerically through simulation studies and a data set.
KATA PENGANTAR
Puji syukur penulis ucapkan kepada Sang Maha Pencipta,Allah SWT yang telah memberikan begitu banyak nikmat sehingga tesis ini dapat terselesaikan de-ngan baik.
Dalam menyelesaikan pendidikan di Sekolah Pasca Sarjana USU ini penulis banyak mendapat dukungan dari berbagai pihak, maka pada kesempatan ini penulis mengucapakan terimakasih dan penghargaan yang sebesar-besarnya kepada:
Dr. Sutarman, MSc, selaku Dekan F.MIPA dan selaku Dosen Pembimbing I yang telah memberikan bimbingan dan petunjuk sehingga tesis ini dapat tersele-saikan dengan baik.
Prof. Dr. Herman Mawengkang, selaku Ketua Program Studi Magister Ma-tematika FMIPA USU dan selaku Dosen Pembimbing II yang banyak memberikan banyak bimbingan dan motivasi kepada penulis sehingga pendidikan ini dapat terse-lesaikan dengan baik.
Seluruh Dosen pada Program Studi Magister Matematika FMIPA USU, yang telah memberikan ilmu pengetahuan kepada penulis selama perkuliahan hingga selesai.
Drs. Lukman Hakim, MPd, selaku Kepala Sekolah SMA Swasta Al-Ulum Medan yang telah memberikan kesempatan kepada penulis untuk mengikuti Pro-gram Studi Magister Matematika di ProPro-gram Studi Magister Matematika FMIPA USU ini.
Dr. Hasratudin, MPd, selaku Bapak angkat saya dan selaku Dosen MIPA Unimed Medan yang telah memberikan dukungan dan motivasi kepada penulis untuk mengikuti Program Studi Magister Matematika di FMIPA USU ini.
Secara khusus penulis menyampaikan terima kasih yang tak terhingga kepada Ayahanda tercinta yaitu Jakiman dan Ibunda tercinta Sanis yang doa-doanya se-lalu menyertai penulis. Kepada Papa Dr. Irwan Fahri Rangkuti,SpKK yang sese-lalu menjadi motivator penulis dan selalu membantu moril dan materil yang tak ter-hingga selama perkuliahan dan sampai tesis ini dapat terselesaikan.
Kepada semua pihak yang telah turut membantu baik langsung maupun tidak langsung yang penulis dapatkan selama ini.
Semoga tesis ini bermanfaat bagi pembaca dan pihak-pihak yang membu-tuhkannya.
Medan, 15 Juni 2011
Penulis,
RIWAYAT HIDUP
Agusman dilahirkan di Tanjung Morawa Kabupaten Deli Serdang pada tang-gal 17 Oktober 1982 dan merupakan anak ke sembilan dari sembilan bersaudara dari ayah Jakiman dan Ibu Sanis. Menamatkan Sekolah Dasar di SD Negeri No. 106179 Desa Limau Manis Kecamatan Tanjung Morawa Kabupaten Deli Serdang pada tahun 1994, Sekolah Lanjutan Tingkat Pertama pada SLTP Negeri 2 Tan-jung Morawa Deli Serdang pada tahun 1997, Sekolah menengah Umum pada SMU Swasta Dwitunggal Tanjung Morawa Deli Serdang pada tahun 2000. Pada tahun 2000 memasuki Perguruan Tinggi pada Universitas Muslim Nusantara ( UMN ) Al Washliyah Medan dan memperoleh gelar Sarjana Pendidikan pada tahun 2006. Pada tahun 2009 mengikuti Program Studi Magister Matematika di Sekolah Pas-casarjana Universitas Sumatera Utara.
DAFTAR ISI
Halaman
ABSTRAK i
ABSTRACT ii
KATA PENGANTAR iii
RIWAYAT HIDUP v
DAFTAR ISI vi
DAFTAR TABEL viii
DAFTAR GAMBAR ix
BAB 1 PENDAHULUAN 1
1.1 Latar Belakang 1
1.2 Rumusan Masalah 2
1.3 Tujuan Penelitian 2
1.4 Manfaat Penelitian 2
1.5 Metodologi 3
BAB 2 BEBERAPA KAJIAN TENTANG FUNGSIONAL PRINSIPAL
KOM-PONEN ANALISIS 4
BAB 3 PENGERTIAN TEORITIS FPCA 7
3.1 Estimasi 9
3.1.1 fFPCA 10
3.1.2 mFPCA 13
3.2 Hasil-hasil Asymtot untuk Fungsi Mean dan Fungsi Kovarian 15
BAB 4 PENERAPAN KOVARIAT PADA FUNGSIONAL PRINSIPAL
KOM-PONEN ANALISIS 19
4.1 Aplikasi Data 23
BAB 5 KESIMPULAN DAN SARAN 27
5.1 Kesimpulan 27
5.2 Saran 27
DAFTAR PUSTAKA 28
DAFTAR TABEL
Nomor Judul Halaman
4.1 Hasil Simulasi fFPCA 21
4.2 Rata-rata MISE dan MSFE dalam 100simulasi berjalan untuk tiga 22
DAFTAR GAMBAR
Nomor Judul Halaman
4.1 Dua eigenfunctions kovariansi dan estimasi dengan. mFPCA 21
4.2 Dari dua eigenfunctions pertama diperkirakan melalui fFPCA
pada lima nilai yang berbeda dari covarite tersebut 22
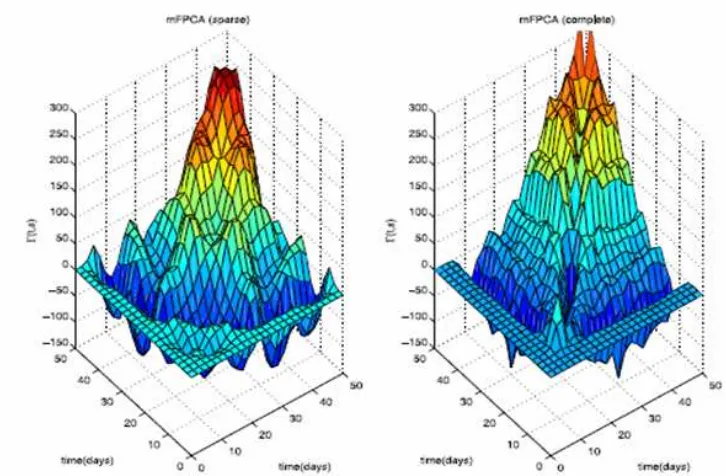
4.3 Estimasi rata-rata permukaan untuk data jarang dan lengkap 25
4.4 Estimasi kovarians permukaan mFPCA untuk jarang dan 26
ABSTRAK
Analisa komponen utama multivariat klasik diperluas untuk data fungsional dan disebut dengan istilah fungsional prinsipal komponen analisis (FPCA). Sebagian besar pendekatan FPCA yang ada tidak mengakomodir informasi kovariat, dan tujuan dari tulisan ini adalah untuk mengembangkan dua metode yang mengako-modir informasi tersebut. Dengan pendekatan ini, baik fungsi mean maupun fungsi kovariansi tergantung pada kovariat Z dan skala waktu t sementara dengan dekatan kedua hanya fungsi mean yang tergantung pada kovariat Z. Kedua pen-dekatan baru mengakomodir kesalahan pengukuran tambahan dan data fungsional sampelnya diambil pada kisi waktu yang teratur dan juga data longitudinal yang jarang diambil sampelnya pada kisi waktu yang tidak teratur. Pendekatan per-tama untuk menyesuaikan sepenuhnya baik fungsi mean maupun fungsi kovariansi beradaptasi lebih besar terhadap data tetapi lebih intensif perhitungan daripada pendekatan untuk menyesuaikan efek kovariat hanya pada fungsi mean. Di kem-bangkan teori asymptot umum untuk kedua pendekatan dan dibandingkan kinerja keduanya secara numerik melalui studi simulasi dan suatu kumpulan data.
ABSTRACT
Classical multivariate principal component analysis has been extended to functional data and termed functional principal componentanalysis (FPCA). Most existing FPCA approaches do not accommodate covariate information, and it is the goal of this paper to develop two methods that do. In the ?rst approach, both the mean and covariance functions depend on the covariate Z and time scale t while in the second approach only the mean function depends on the covariate Z .Both new approaches accommodate additional measurement errors and functional data sampled at regular time grids as well as sparse longitudinal data sampled at irregular time grids. The first approach to fully adjust both the mean and covariance functions adapts more to the data but is computationally more intensive than the approach to adjust the covariate effects on the mean function only. We develop general asymptotic theory for both approaches and compare their performance numerically through simulation studies and a data set.
Keywords : Estimation, Bandwidth selection and number of eigenfunctions, Asymtotic results
BAB 1
PENDAHULUAN
1.1 Latar Belakang
Dalam beberapa penelitian tentang Fungsional Prinsipal Component Analisis (FPCA) tidak banyak yang melibatkan informasi kovariat. Kovariat yang digu-nakan dalam FPCA dengan asumsi bahwa fungsi keseluruhan dari fungsi acak bisa diamati tanpa kesalahan, kovariat digunakan untuk memprediksi status dari satu atau lebih variabel terikatnya.
Ada dua cara untuk memperluas pendekatan FPCA untuk mengakomodir informasi kovariat. Kedua pendekatan terdiri dari dua bagian: bagian sistematik yang bersesuaian dengan fungsi mean (mFPCA) dan bagian stokastik yang ter-diri dari komponen-komponen acak yang mencerminkan struktur kovariansi data longitudinal (fFPCA).
Fungsional prinsipal komponen analisis (FPCA) merupakan alat pengurangan dimensi standar untuk data multivariat dan diperluas untuk data fungsional yang diberikan dalam bentuk kurva acak. Karena data fungsional pada hakekatnya berdimensi tak hingga, pengurangan dimensi penting untuk menganalisa data demikian. Selain Ferraty dan Vieu (2006) dan Wu dan Zhang (2006), rangka-ian tulisan Ramsay dan Silverman (2002, 2005) memberikan kajrangka-ian khusus tentang metodologi dan aplikasi ”Analisa Data Fungsional” (FDA).
Kneip dan Utikal (2001) menggunakan metode FDA untuk menilai variabil-itas kepadatan bagi kumpulan-kumpulan data dari populasi yang berbeda-beda. Apabila data fungsional diamati pada beberapa titik waktu, misalnya hanya be-berapa titik waktu per subjek, maka data demikian ini disebut data longitudinal kartena timbul dari kajian longitudinal. Rice (2004) dan Hall et al. (2006) memba-has persamaan dan perbedaan intrinsik antara FDA dan analisa data longitudinal.
2
dimungkinkan melaksanakan FPCA. [lihat; Shi et al (1996), Yao et al (2005), Paul dan Peng (2009), serta Peng dan Paul (2009)].
Mengingat pentingnya metode ini maka penulis ingin meneliti dan men-jabarkannya pada ” Kovariat Dari Fungsional Prinsipal Komponen Analisis Untuk Data Longitudinal ”.
1.2 Rumusan Masalah
Asumsi kunci yang diajukan para peneliti dalam menyelesaikan FPCA adalah bahwa trajektori data fungsional lengkap teramati atau tercatat padat terhadap waktu, Asumsi demikian ini jarang terpenuhi dalam kajian data longitudinal oleh karena itu masalahnya adalah bagaimana mengikutsertakan informasi kovariat dalam FPCA untuk data longitudinal jarang.
1.3 Tujuan Penelitian
Tujuan dari penelitian ini adalah untuk Memadukan informasi kovariat yang berlaku pada data fungsional dan data longitudinal dengan mengembangkan dua pendekatan yang mengakomodir informasi tersebut yaitu pendekatan fFPCA dan mFPCA.
1.4 Manfaat Penelitian
Manfaat dalam Penelitian ini adalah
1. Sebagai bahan informasi bagi peneliti dalam menyesuaikan efek kovariat un-tuk data longitudinal.
2. Untuk menambah wawasan dan literatur dalam berbagai bidang, dalam bi-dang matematika secara umum, bibi-dang Tekhnik, dan kesehatan.
3
1.5 Metodologi
Adapun langkah-langkah yang dilakukan pada penelitian ini adalah:
1. Mengestimasi fungsi mean dan fungsi kovarian.
2. Memilih jumlah eigen fungsi.
3. Menentukan asymtot untuk fungsi mean dan fungsi kovarian.
BAB 2
BEBERAPA KAJIAN TENTANG FUNGSIONAL PRINSIPAL KOMPONEN ANALISIS
Banyak penelitian ilmiah menghasilkan data longitudinal dengan pengukuran ulang dijumlah titik waktu, dan data peristiwa yang mempertimbangkan peruba-han dari waktu ke peristiwa, yaitu, ” kegagalan ” atau ” bertaperuba-han hidup ”, serta informasi kovariat tambahan.Sebuah contoh adalah bahwa uji klinis HIV, di mana biomarker seperti jumlah limfosit CD4 diukur sesekali waktu dan untuk pengem-bangan menjadi AIDS atau kematian juga dicatat, dengan kemungkinan awal DO atau kegagalan. Hal ini penting dan diperlukan untuk menyelidiki pola perubahan CD4, dan untuk menandai hubungan antara CD4 dan waktu untuk pengembangan atau kematian (Pawitan dan Self (1993), Tsiatis et al. (1995), Wulfsohn dan Tsiatis (1997).
Dalam prakteknya proses longitudinal yang tersembunyi sering tidak teramati karena kesalahan pengukuran dan tidak tersedia pada saat diperlukan, terutama bila terjadi kegagalan. Diketahui bahwa sebagian kemungkinan pendekatan kon-vensional yang digunakan untuk model Cox tidak dapat menghindari kesimpulan yang memihak dari proses tersembunyi longitudinal, seperti nilai terakhir dilakukan ke depan metode (Prentice (1982)), teknik pemulusan (Raboud et al. (1993)), atau pendekatan ” dua tahap ” (Bycott dan Taylor (1998), Tsiatis et al. (1995)). Ini disebut perhitungan longitudinal dan proses secara bersamaan, yaitu, ” yang disebut ” pemodelan bersama. Pendekatan standar pemodelan bersama adalah karakterisasi proses longitudinal dengan model efek parametric acak yang berfokus pada kelancaran perkembangan yang ditentukan oleh sejumlah kecil efek acak dan yang telah digunakan untuk menggambarkan lintasan CD4 (Tsiatis et al. (1995), Wulfsohn dan Tsiatis (1997), Bycott dan Taylor (1998), Dafni dan Tsiatis (1998)) Selain perbaikan penyimpangan, pemodelan bersama juga berpotensi meningkat-kan efisiensi estimasi parameter karena inferensi simultan pada kedua model longi-tudinal dan model survival, lihat Faucett dan Thomas (1996); Slasor dan Laird (2003), Hsieh et al. (2006) untuk diskusi lebih lanjut tentang masalah ini.
5
Meskipun model parametrik yang disebutkan di atas menemukan fitur-fitur dalam data yang sudah tergabung secara apriori dalam model, model ini mungkin tidak cukup jika program waktu tidak didefinisikan dengan baik dan tidak masuk ke dalam bagian yang terbentuk sebelumnya dari fungsi. Dalam situasi analisis melalui metode nonparametric. Telah ada peningkatan kepentingan analisis non-parametrik data yang berupa sampel untuk kurva atau lintasan, yaitu, ” analisis data fungsional”, lihat Ramsay dan Silverman (1997) untuk ringkasan. Fungsional Analisis komponen utama (FPCA) mencoba untuk menemukan modus dominan variasi sekitar fungsi secara keseluruhan, dan dengan demikian merupakan kunci dalam teknik analisis data fungsional (Berkey dan Kent (1983); Besse dan Ramsay (1986), Castro et al. (1986), Rice dan Silverman (1991); Silverman (1996), James et al. (2000), Yao et al. (2003, 2005); Yao dan Lee (2006).
Sebaliknya, model berkaitan erat yang diajukan oleh Rice dan Wu (2000) tidak memperhatikan dimensi pengurangan dan mungkin tidak berlaku jika data jarang, lihat James et al. (2000) untuk perbandingan dari dua pendekatan. Hal ini membuat perbedaan antara yang diusulkan model dan yang dalam Brown et al. (2005 ) eksplisit. Keuntungan lain dari model gabungan dengan FPCs adalah efisiensi perhitungan dicapai dengan pengurangan dimensi menggunakan FPCs de-ngan matriks kovarians diagonal, sementara model bersama dalam Brown et al. (2005) dengan B-splines biasanya berisi koefisien yang lebih acak dengan kova-rian matriks terstruktur. Interpretasi yang tepat dari eigenfunctions orthogonal dan nilai FPC sering menyediakan lebih wawasan dari model B-spline. Wang dan Taylor (2001) mendirikan sebuah proses stokastik Integrated Ornstein Uhlenbeck (IOU) untuk model yang tidak ditentukan arah lintasan longitudinal dalam kon-teks model bersama, dalam semangat yang sama dengan lintasan splines. Se-cara khusus, proses IOU menyajikan struktur kovariansi gabungan dengan model efek acak dan Brown motion sebagai kasus yang khusus. Keterkaitan keberhasilan lainnya yang dimasukkan angka nol berarti proses untuk model fluktuasi individu meliputi Henderson et al. (2000), Xu dan Zeger (2001)
de-6
ngan mengabaikan informasi kovariat. Ini menghasilkan ekspansi Karhunen-Loeve [lihat (3.1)] untuk setiap subjek X(t) yang mana ekspektasi bersyarat dari X(t) yang memberikan kovariat Z diperoleh dan selanjutnya ditaksir melalui pendekatan semiparametrik. Suatu pendekatan yang berbeda ada diajukan Cardot (2006), yang mengkaji FPCA bersyarat melalui estimator kernal nonparametrik atas fungsi mean bersyarat dan fungsi variansi bersyarat.
Asumsi utama untuk kedua pendekatan adalah bahwa trayektori data fung-sional diamati secara total atau dicatat secara padat seiring berjalannya waktu. Kedua asumsi jarang dipenuhi dalam studi medis atau sosial longitudinal. Pada prinsipnya, pendekatan dalam Chiou et al. (2003) tidak cocok untuk perluasan pada data longitudinal yang tidak padat karena komponen utama bersyarat tidak bisa ditaksir atau diaproksimasi dengan konsisten untuk data longitudinal yang tidak padat. Diajukan suatu pendekatan gabungan untuk memodelkan fungsi mean dan dua pendekatan yang berbeda untuk memodelkan fungsi kovariansi.
BAB 3
PENGERTIAN TEORITIS FPCA
Prosedur FPCA pada dasarnya adalah bertujuan untuk menyederhanakan variable yang diamati dengan cara menyusutkan ( mereduksi ) dimensinya. Hal ini dilakukan dengan cara menghilangkan korelasi diantara variable bebas melalui transformasi variable bebas asal ke variable baru yang tidak berkorelasi sama sekali atau biasa disebut dengan principal component analysis.
Ada dua cara untuk memperluas pendekatan FPCA untuk mengakomodir informasi kovariat. Kedua pendekatan terdiri dari dua bagian : bagian sistema-tik yang bersesuaian dengan fungsi mean dan bagian stokassistema-tik yang terdiri dari komponen-komponen acak yang mencerminkan struktur kovariansi data lingitudi-nal. Pada kedua pendekatan tidak mengasumsikan bahwa tidak diketahui struk-tur µ(t,z) selain bahwa µ(t,z) adalah fungsi mulus, karenanya perlu menaksirnya secara nonparametrik. Perbedaan antara kedua pendekatan adalah dalam pena-nganan struktur kovariansi. Secara konseptual, kovariat Z bisa berupa suatu vektor yang mempunyai distribusi kontinu, tetapi karena aturan dimensionalitas hanya Z berdimensi-rendah yang bisa digunakan. Akan diperlukan beberapa pendekatan penurunan dimensi untuk Z berdimensi-tinggi dan sudah di luar ruang lingkup tulisan ini.
Dalam pendekatan pertama, diasumsikan bahwa eigenfungsi dari Γ(t, s, z) bervariasi sesuai dengan z sehingga terdapat ekspansi ortogonal Γ (dalam artian
L2) dalam bentuk eigenfungsi φk(t, z) dan eigenvalue tak naik λk(z) : Γ(t, s, z) =k
λk(z)φk(t, z)φk (s, z).Dengan demikian, trayektori acakX(t,z) dapat dituliskan
sebagai
X(t,z) =µ(t, z) + X
k=1
8
di mana Ak(z) adalah variabel-variabel acak tidak berkorelasi dengan mean 0 dan variansi λk(z).Selain itu, akan dimodelkan permukaan kovariansi secara non-parametrik, dengan mengasumsikan bahwa permukaan kovariansi tersebut adalah fungsi mulus dari t, s dan z. Karena fungsi mean maupun fungsi kovariansi dise-suaikan oleh kovariat Z, ini disebut fully adjusted functional principal component analysisdan disingkat fFPCA.
Pendekatan untuk menyesuaikan efek kovariat ini ekuivalen secara konseptual dengan pendekatan FPCA bersyarat dalam Cardot (2006) tetapi berbeda secara berarti dalam cara penaksiran disebabkan perbedaan dalam rancangan data yang dikaji. Perbedaan penting dalam rancangan data juga memicu kerangka teoritis yang sangat berbeda. Untuk Z satu-dimensi, hanya pemulusan satu-dimensi dibu-tuhkan dalam Cardot (2006) untuk menaksir fungsi mean maupun fungsi kovari-ansi sepanjang arah-Z pada masing-masing lokasi waktu karena fungsi keseluruhan X(t,z) diamati.
Bila µ(t,z) = β(t)z dan komponen-komponen stokastik Pk=1Ak(z)∅k(t, z)
dalam model X(t,z)=µ(t, z) + Pk=1Ak(z)∅k(t, z) mengadopsi struktur linier bervariasi-waktu b(t)z untuk fungsi β dan fungsi acak b yang tidak diketahui,
model X(t,z)=µ(t, z) + Pk=1Ak(z)∅k(t, z) menghasilkan model efek acak koe-fisien bervariasi dalam Guo (2002). Bila µ(t,z) berbentuk linier parsial f(t) +
βz dan komponen stokastik jua berbentuk linier parsial u(t) + bZ, untuk fungsi tak diketahui f dan u, parameter β dan variabel acak b, model X(t,z)=µ(t, z) +
P
k=1Ak(z)∅k(t, z) direduksi menjadi model campuran linier parsial dalam Zhang et al. (1998).
Dalam pendekatan kedua, bisa mengambil keuntungan dari faktaZ bahwa ko-variatZ adalah variabel acak dan mengumpulkan semua subjek setelah memusatkan masing-masing kurva pada nol. Ini menghasilkan fungsi kovariansi gabungan Γ*(t,s) = z E{(X(t,z) – µ(t,z))(X(s,z) – µ(s,z))}g(z)dz di mana g adalah pdf dari Z atasZ, dan Γ*(t,s) diasumsikan merupakan fungsi mulus dari t dan s. Akibatnya, terdapat ekspansi ortogonal (dalam artian L2) dalam bentuk eigenfungsi φ
k∗ dan eigenvalue tak naik λk∗ sedemikian sehingga
Γ∗(t, s) =k φ∗
9
X(t, z) =µ(t, z) + X k=1
A∗k∅∗k(t) (3.2)
Di mana A∗
k adalah variabel acak yang tidak berkorelasi dengan E{A∗k} = 0 dan
var{A∗k} = λ∗
k. Pendekatan ini mempunyai keuntungan bahwa fungsi kovariansi bisa ditaksir dengan pemulus berdimensi lebih rendah, yang mempercepat laju
konvergensi dibandingkan dengan fFPCA disingkatmean adjusted functional prin-cipal component analysis ini atas X(t,z) –µ(t,z) sebagai ”mFPCA” di mana ”m” menyatakan operasi penyesuaian mean.
Prosedur penaksiran untuk mFPCA dijelaskan pada bagian selanjutnya Se-cara konseptual, pendekatan fFPCA akan mencocokkan data dengan lebih baik apabila beradaptasi terhadap informasi kovariat dalam penaksiran kovariansi se-mentara mFPCA tidak.
Keuntungan ini bisa diimbangi dengan kinerja praktis yang lebih buruk jika data tidak padat. Hasil simulasi mencerminkan keuntungan terbatas dari fFPCA, oleh karenanya mungkin lebih menyukai pendekatan mFPCA dalam banyak ap-likasi atau mencoba kedua pendekatan, kecuali eigenfungsi bervariasi secara berarti atas nilai-nilai kovariat.
3.1 Estimasi
Dalam banyak situasi hanya bisa mengamati proses X(t,z) secara tak kontinu dan kemungkinan dengan kesalahan pengukuran. MisalkanYij adalah pengamatan ke-j atas fungsi acakXi,yang dilakukan atas waktu acakTij ∈T dengan kovariat Zi ∈ Z dan kesalahan pengukuran ǫij di mana i = 1, . . . , n dan j = 1, . . .,Ni. Dalam hal ini di asumsikan bahwa skedul pengukuran Tij adalah sampel acak berukuran Ni dan Ni diasumsikan dan tak tergantung pada variabel acak lain-nya. Juga di asumsikan bahwa kesalahan pengukuran dengan mean 0 dan variansi konstanσ2dan tidak tergantung pada koefisien acakA
10
Dengan demikian, data yang diamati adalah
Yij= Xi(Tij,Zi) + ∈ij. (3.3)
Tahap-tahap utama dalam pendekatan FPCA adalah untuk menaksir fungsi mean dan fungsi kovariansi. Eigenvalue dan eigenfungsi yang bersesuaian bisa diperoleh dengan mudah melalui persamaan-eigen setelah fungsi kovariansi di-taksir. Fungsi mean untuk fFPCA dan mFPCA sama dan bisa ditaksir dengan menggunakan pemulus diagram-pencar dua-dimensi Yij terhadap (Tij,Zi), untuk
j = 1, . . . , Ni, i = 1, . . . , n. Diberikan sifat-sifat asymptot umum dari pemulus diagram-pencar linier dari fungsi meanµ(t,z) dan membuktikan sifat-sifat asymp-tot ini atas dua pemulus linier, estimator Nadaraya-Watson (3.8) dan estimator linear lokal (3.9)
Sama halnya, estimator kovariansi juga bisa dinyatakan sebagai pemulus diagram-pencar dari apa yang disebut dengan ”kovarian Baku” yang didefinisikan di bawah ini terhadap (Tij,Tik):
Cijk = (Yij − µb(Tij, Zi)) (Yik−µb(Tik, Zi)) (3.4)
Estimator kovariansi berbeda untuk fFPCA dan mFPCA. Untuk Z satu di-mensi, yang pertama melibatkan pemulus tiga-dimensi Cijk terhadap (Tij,Tik.Zi) untuk j,k = 1,. . .,Ni, i = 1,. . .,n sementara yang disebut terakhir hanya mem-butuhkan pemulus dua-dimensi Cijk terhadap (Tij,Tik) untuk j,k = 1,. . .,Ni, i = 1,. . .,n. Pada prinsipnya, bisa menggunakan pemulus linier.
3.1.1 fFPCA
11
dan K3 adalah fungsi kernel tiga-dimensi yang memenuhi
RR
Tujuan selanjutnya menaksir variansi V(t,z) = Γ(t,t,z) +σ2 dari Y(t) untuk
z tertentu. Misalkan K2 adalah fungsi kernel dua-dimensi yang memenuhi
RR
dan V(t,z) adalah pemulus linier lokal yang hanya menggunakan elemen-elemen waktu diagonal; maka
Variansiσ2dari kesalahan pengukuran bisa ditaksir dengan merata-ratakan (V(t,z)
12
waktu. Ditemukan rekomendasi dalam Yao et al.(2005) untuk menggunakan pe-motongan mean yang didasarkan pada 50% pusat domain waktu yang memuaskan. Pada prinsipnya, ini menghasilkan
dengan notasiImenotasikan panjang interval umumI. Jika variansi dari kesalahan pengukuran bervariasi seiring berjalannya waktu dan z , fungsi variansiσ2(t,s) bisa
ditaksir secara langsung sebagaiV(t,z) – Γ(t,t,z). gunakan untuk menaksir eigenfungsi dan eigenvalue. Sekarang masih harus ditaksir skor komponen utama RAik(Zi) = R ∅k(t, Zi) [Xi(t, Zi)−µ(t, Zi)]dt untuk sub-jekke-i. Karena kesalahan pengukuran dan skedul pengukuran tak kontinu, pen-dekatan dalam Chiou et al.(2003) dan Cardot (2006) tidak berlaku untuk menaksir skor ini. Sebagai gantinya, pendekatan dalam Yao et al.(2005) yang bertujuan menaksir ekspektasi bersyarat E(Aik(Zi)Yi) cukup cocok untuk menaksir skor komponen utama di manaYi = (Yi1, . . .,YiN i)T. Dengan asumsi bahwa Yi adalah normal multivariat, ini menghasilkan taksiran
13
3.1.2 mFPCA
Penaksiran Γ*(s,t) serupa dengan prosedur dalam Yao, Muller dan Wang (2005) kecuali bahwa kita gunakan Cijk sebagai kovariansi mentah. Misalkan ˆ
Γ∗(t, s) adalah estimator kovariansi yang didasarkan pada pemulus linier lokal, maka ˆΓ∗ (t, s) menjadi estimator kovarian berdasarkan linear lokal yang halus, maka Γ∧∗(t, s) = β0
Dimana t,s∈ T dan K2 didefinisikan dalam
ZZ
Misalkan ˆV ∗(t) adalah pemulus linier lokal yang fokus pada nilai-nilai diagonal
di mana K1 adalah fungsi kernel dengan pendukung kompak, simetris dan kontinu.
Sekali lagi, mean ”terpotong” dari ( ˆV ∗(t) - ˆΓ∗(t, t)) digunakan untuk menaksir untuk menaksir eigenfungsi dan eigenvalue. Skor komponen utama A∗
14
Subjek ke-i ditaksir seperti dalam Yao et al.(2005) melalui
ˆ
di mana Yi dan µi didefinisikan seperti dalam Bagian 3.1.1, dan
ik(t) didefinisikan sebagai
(Xˆ
3.1.3 Seleksi Bandwidth dan Jumlah Eigenfungsi
Bandwidth untuk taksiran fungsi mean dipilih melalui pengesahan silang menyisakan satu kurva yang diajukan Rice dan Silverman (1991). Akan tetapi bandwidth dari estimator fungsi kovariansi dipilih melalui prosedur pengesahan-silang k-fold untuk menghemat waktu penghitungan. Di bawah ini di definisikan metode pengesahan-silang k-fold untuk seleksi bandwidth dari Γ*(t,s). Rumus untuk Γ(t,s,z) sama.
Andaikan bahwa subjek dialokasikan secara acak ke k himpunan (S1, S2, . . . , Sk).
h= arghmin
ij, Tim) adalah taksiran fungsi kovariansi pada (Tij,Tim) bila subjek-subjek di dalam Sl tidak digunakan untuk menaksir Γ*(t,s). Ditemukan metode
Ten-fold (k = 10) yang mempunyai kinerja yang memuaskan.
15
(fFPCA) ˆXK
i (t, z) =µbL(t, z) +PKk=1Aˆik(z)b∅k(t, z),
(mFPCA) ˆXK
i (t, z) = bµL(t, z) +PKk=1Aˆ∗ikb∅∗k(t),
3.2 Hasil-hasil Asymtot untuk Fungsi Mean dan Fungsi Kovarian
Untuk penyederhanaan, kovariat Z dalam bagian ini berupa univariat, dan N1,...Nnadalah dari suatu variabel acak N. Mula-mula fokus pada distribusi
asym-tot dari pemulus-pemulus linier fungsi mean.
Teori umum untuk estimator berbobot kernel dua dimensi:
Lemma 1: Misal H:RQ →R suatu fungsi dengan orde kontinu turunan pertama
DH(v)=(∂x∂1H (v), . . . ,∂x∂
2. Jumlah observasi Ni (n) untuk subjek i adalah variabel acak dengan Ni (n)˜ N (n) dimana N(n) adalah bilangan bulat positif-nilai acak variabel dengan
lim supn→∞[ENEN((nn))]22dan lim supn→∞
EN(n)4
(EN(n)2
)2keduanya terbatas. Selain itu,
Ni(n), i= 1, ..., N
3. Observasi waktu Tij dan pengukuran Yij independen terhadap jumlah
16
dari teori di atas diperoleh normalitas asymptot dari estimator kernel Nadaraya-Watson ˆµN W(t, z) dan estimator linier lokal ˆµL(t, z) dari µ(t,z).
Hasil asymptot untuk fungsi kovariansi,Perlu mempertimbangkan pemulus tiga-dimensi untuk menaksir fungsi kovariansi. Selain itu, normalitas asymptot dari estimator kernel Nadaraya-Watson dan estimator linier lokal dari fungsi kovariansi diperoleh dari Lemma 2. ( Misalkan H:RQ → R menjadi fungsi dengan urutan pertama yang kontinu Derivative
i=1Ni.Di sini estimator kernel
17
Untuk kemudahan notasional, kita fokus pada kasus kernel konvensional berorde (0,2) dan di notasikan
σ2
Hasil-hasil asymptot di atas menunjukkan bahwa angka konvergen optimal standar untuk data independen dicapai untuk semua estimator bila E(N) berhingga. Sebagai contoh misalnya, laju konvergensi untuk taksiran Nadaraya-Watson dan taksiran linier lokal untuk fungsi mean adalah n1/3 yang merupakan laju
konver-gensi optimal untuk pemulus dua-dimensi dengan syarat keteraturan serupa, dan laju konvergensi untuk kedua estimator fungsi kovariansi adalah n2/7, juga optimal
untuk pemulus tiga-dimensi serupa.
Laju konvergen dari semua estimator lebih cepat bila perkiraan jumlah pen-gukuran per subjek E(N) → ∞apabila semakin banyak data tersedia per subjek. Sebagai contoh misalnya, laju konvergensi untuk kedua taksiran fungsi mean dan kedua taksiran fungsi kovariansi bisa secara sebarang mendekati n2/5 bila E(N) →
∞. Catat bahwa n2/5 adalah laju optimal konvergensi bila proses longitudinal
18
Normalitas asymptot dari estimator kovariansi mFPCA bisa ditangani seperti dalam Teorema 1. Dengan asumsi
1. hµ,t≍hµ,z ≍ h, h→0, nE(N)h|v|+2 → ∞, E(N)h→0dan nE(N) x h2k+2 < ∞
2. Jumlah observasi Ni (n) untuk subjek i adalah variabel acak dengan Ni (n)˜ N (n) di mana N (n) adalah bilangan bulat positif-nilai acak variabel dengan
lim?supn→∞[ENEN((nn))]22dan lim?supn→∞
EN(n)4
(EN(n)2
)2 keduanya terbatas. Selain itu,
Ni (n), i = 1,. . . , N
3. Observasi waktu Tij dan pengukuran Yij independen terhadap jumlah
pen-gukuran N (n).
4. dtk1ddzk k2f2(t, z) dan kontinu pada (t, z) untuk k1 + k2 = k,0 ≤ k1,k2 ≤
k,dan f2(t, z)>0
5. dk
dtk1dzk2µ(t, z) dan kontinu pada {(t, z)}, untuk k1 +k2 = k, 0≤ k1,k2 ≤ k.
dan dengan mengasumsikan hµ,s
hµ,t → ρµdan nE(N)h
BAB 4
PENERAPAN KOVARIAT PADA FUNGSIONAL PRINSIPAL KOMPONEN ANALISIS
Perbandingan kinerja kedua pendekatan FPCA yang disesuaikan kovariat de-ngan estimator dalam Yao, Muller dan Wang (2005) yang disebut dede-ngan istilah uFPCA dengan awalan “u” yang menunjukkan bahwa itu adalah FPCA “tak dise-suaikan” suatu contoh simalusi yang terdiri dari 100 putaran, dan jumlah subjek adalah 100 pada setiap putaran.
Skema simulasi adalah sebagai berikut: untuk setiap subjek, kovariat z di-hasilkan dariU(0,1),fungsi mean-nya adalahµ(t,z) = t + z sin(t)+ (1 – z)cos(t) dan fungsi variansi-kovariansi diperoleh dari dua eigenfungsi φ1(t,z) = -cos(π(t + z/2))√2 dan φ2(t,z) = sin(π(t + z/2))√2, untuk 0 = t = 1 dengan eigenvalue
λ1(z) = z/9, λ2(z) = z/36 dan λk = 0 untuk k = 3. Skor komponen utama spesifik Aik(z) dihasilkan dari N(0,λk(z)), dan kesalahan pengukuran tambahan di-asumsikan berdistribusi normal dengan mean 0 dan variansi (0,05)2. Untuk skema
pengukuran{tij}digunakan rancangan “jittered” nonequidistant. Pada pokoknya, kisi berjarak sama {c0,...,c50} atas [0,1] dengan c0 = 0 dan c50 = 1 dipilih dan
jittered menurut rencana si = ci + ǫi di mana ǫi adalah i.i.d. dengan N(0, 0,0001) dan kemudian dibatasi menjadi si = 0 jika si < 0 dan si = 1 jika si > 1. Setiap kurva diambil sampelnya atas sejumlah acak titik,
{tij}, j = 1,...,Ni, di mana Ni dipilih dari distribusi bilangan acak {2,...,10}, dan lokasi pengukuran dipilih secara acak dari {s1,...,s49} tanpa penggantian.
20
Metode FVE didefinisikan sebagai jumlah minimum komponen yang dibu-tuhkan untuk menjelaskan setidaknya suatu fraksi yang ditetapkan dari total vari-asi. Dalam simulasi, kami pilih K untuk uFPCA dan mFPCA sebagai bilangan minimum k yang memenuhi (Pki=1λi)/(Pi=1λi) = 0,80, dan untuk pendekatan fFPCA, ini bersesuaian dengan pemilihan k terkecil yang memenuhiPki=1λi(z)/Pi=1 λi(z) = 0,80 untuk setiap subjek dengan nilai kovariat z. Perbedaan utama adalah bahwa FVE tipe ini akan memungkinkan pilihan spesifik-subjek untuk jumlah kom-ponen utama dalam fFPCA. Masalahnya adalah bahwa taksiran kovariansi yang didasarkan pada jumlah komponen utama yang dipilih secara individual mungkin tidak menghasilkan permukaan kovariansi mulus. Untuk meluruskan hal ini dan untuk mempermudah platform seragam guna membandingkan ketiga pendekatan, kami ajukan pilihan global K yang didasarkan pada persentil ke-90 dari k yang dipilih secara individual untuk fFPCA. Pilihan global ini bersifat objektif dan bisa memberikan sedikit keuntungan untuk fFPCA dalam pencocokan data yang diamati sebagaimana dibandingkan dengan menggunakan nilai mean atau median dari k sebagai pilihan global. Pendekatan AIC dan BIC cenderung memilih terlalu banyak eigenfungsi sehingga bisa memprediksi data dengan baik, sementara FVE adalah yang terbaik untuk memilih model yang tepat. Akan tetapi, pendekatan ini diungguli oleh pendekatan lain untuk prediksi seperti yang tampak jelas dalam Tabel 2.
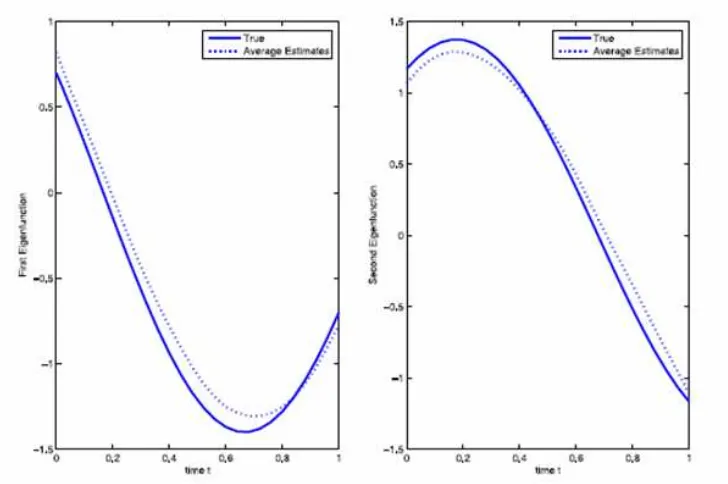
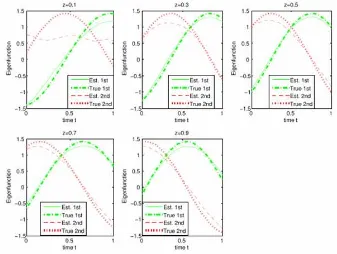
Kuadrat kesalahan terpadu mean dari estimator kovariansi untuk mFPCA adalah 0,00046, bias dan standard error dari kedua eigenvalue masing-masing adalah -0,0102 (s.d. = 0,0121) dan -0,0035 (s.d. = 0,0052). Taksiran eigenfungsi rata-rata dari 100 simulasi mendekati eigenfungsi yang sebenarnya seperti yang diperlihatkan dalam Gambar 1. Ini menunjukkan bahwa estimator kovariansi dari mFPCA cukup akurat. Dari Tabel 1 dan Gambar 2, kinerja fFPCA umumnya memuaskan walaupun akurasi bervariasi dengan kovariat. Taksiran untuk eigen-fungsi kedua pada Z = 0,1 buruk disebabkan eigenvalue kecil 0,0028, karenanya mungkin tidak perlu memasukkan lebih dari satu eigenfungsi untuk Z = 0,1.
21
MISE = n1 Pni=1R01(Xi(t, zi)−XˆiK(t, zi))2dt
sebagai kriteria di mana K adalah jumlah eigenfungsi yang digunakan untuk mem-prediksi trayektori setiap subjek. Kuadrat error pencocokan mean yang bersesuaian
Gambar 4.1 Dua eigenfunctions kovariansi dan estimasi dengan. mFPCA (Sumber : C.-R. Jiang and J.-L Wang 2010)
MSFE = n1 Pni=1 N1
i
PNi
j=1(Yij −Yˆij)2
Sebuah outlier terdeteksi dalam jangka 6 untuk mFPCA diprediksi trayektori, se-hingga termasuk dua hasil dalam Tabel 4.2
Tabel 4.1 Hasil Simulasi fFPCA
Covariate z 0.1 0.3 0.5 0.7 0.9
LSE untuk ˆΓL 0.00015 0.00025 0.00071 0.0014 0.0030 LSE untuk ˆφ1(t, z) 0.0294 0.0076 0.0071 0.0074 0.0112
LSE untuk ˆφ2(t, z) 0.2720 0.0305 0.0242 0.0179 0.0300
ˆ
λ1(z) 0.0047 -0.0041 -0.0113 -0.0202 -0.0242
(0.0073) (0.0106) (0.0181) (0.0205) (0.0333) ˆ
λ2(z) 0.0034 0.0001 0.0005 -0.0002 -0.0037
22
Tabel 4.2 Rata-rata MISE dan MSFE dalam 100simulasi berjalan untuk tiga pendekatan
MISE MSFE
FVE AIC BIC FVE AIC BIC
uFPCA 0.0339 0.0215 0.0215 0.0047 0.0035 0.0036
(0.0325) (0.0198) (0.0197) 0.0067) (0.0065) 0.0025
mFPCA 0.1075 0.0077 0.0076 0.0039 0.0024 0.0025
(0.0103) (0.0063) (0.0063) (0.0050) (0.0017) (0.0017)
fFPCA 0.0085 0.0077 0.0077 0.0039 (0.0027) 0.0027
(0.0085) (0.0077) (0.0077) (0.0022) (0.0015) (0.0015) (Sumber : C.-R. Jiang and J.-L Wang 2010)
Outlier terdeteksi pada putaran ke-6 untuk trayektori yang diprediksi mFPCA, karenanya kita masukkan dua hasil dalam Tabel 4.2, satu dengan semua simulasi dan satu dengan putaran outlier ini dicoret. Tidak aneh, uFPCA lebih unggul pada umumnya dengan kedua pendekatan yang disesuaikan kovariat. Bila meng-gunakan metode FVE sebagai kriteria dalam memilih K, fFPCA sedikit lebih baik daripada mFPCA. Akan tetapi, bila menggunakan AIC atau BIC sebagai kriteria dalam memilih K,di tampilkan dari
Gambar 4.2 Dari dua eigenfunctions pertama diperkirakan melalui fFPCA pada lima nilai yang berbeda dari covarite tersebut
23
Kinerja mFPCA sebanding, jika tidak lebih baik dari kinerja fFPCA. akibat-nya, jika tujuannya adalah untuk memprediksi trayektori subjek, direkomendasikan mFPCA dengan BIC karena kesederhanaannya. Untuk tujuan pemodelan, fFPCA dengan metode FVE lebih diinginkan.
4.1 Aplikasi Data
Dijelaskan suatu pendekatan FPCA yang disesuaikan-kovariat melalui data reproduksi untuk lalat buah Mexico. Studi dilaksanakan di fasilitas penangkaran lalat buah di dekat Metapa, Chiapas, Mexico. Produksi telur (jumlah telur) per hari dicatat untuk sebanyak 1151 betina sampai lalatnya mati. Tujuannya di sini adalah untuk mengkaji pengaruh reproduksi dini, sebagaimana diukur menurut total reproduksi hingga usia 30 (dalam hari), pada pola reproduksi hingga usia 50. Dikesampingkan lalat yang mandul dan lalat yang hidup kurang dari 50 hari. ini memberikan platform seragam untuk melaksanakan FPCA dan hanya mengkaji lalat yang hidup setidaknya sekitar lama hidup rata-rata (≈ 50,9 hari) lalat yang subur. Dari 567 lalat tersisa, di pilih secara acak 2 sampai 10 pengamatan dalam 50 hari pertama, karenanya bisa dibandingkan hasil-hasil untuk data yang jarang
dengan data lengkap untuk mengesahkan pendekatan mFPCA dan fFPCA yang baru.
24
struktur geometrik dari eigenfungsi begitu berada di manifol Stiefel. Karena rFPCA berfungsi sebagai taksiran awal untuk gFPCA, kode awal untuk rFPCA meningkat dan dimasukkan dalam paket R, fpca, yang tersedia pada proyek CRAN.
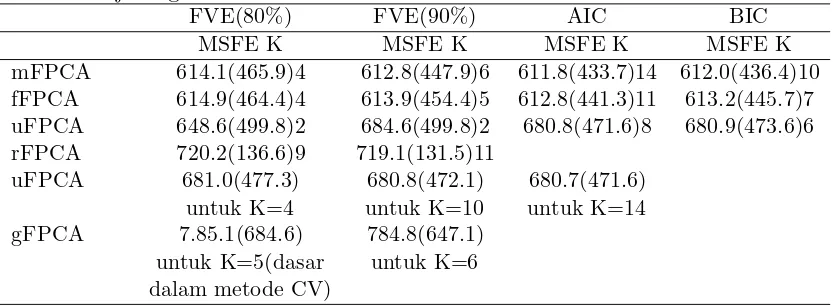
Seperti yang diajukan dalam James et al.(2000), jumlah basis di dalam rFPCA dipilih dengan likelihood pengesahan-silang Ten-fold dan jumlah eigenfungsi diku-rangi dengan metode FVE yang biasa (fraksi dari variasi yang dijelaskan). Untuk data Medfly, dipilih 15 basis dan jumlah eigenfungsi yang dihasilkan bersesuaian dengan 80% dan 90% FVE, seperti yang dilaporkan dalam Tabel 3, masing-masing adalah 9 dan 11. Pilihan fungsi basis B-spline dan jumlah eigenfungsi untuk gFPCA dipilih dengan metode likelihood disahkan-silang baru yang diajukan dalam Peng dan Paul (2009) dan ini menghasilkan 8 basis dan 5 eigenfungsi.
Tabel 4.3 MSFEs dari mFPCA, fFPCA, uFPCA dan rFPCA berdasarkan data jarang
FVE(80%) FVE(90%) AIC BIC
MSFE K MSFE K MSFE K MSFE K
mFPCA 614.1(465.9)4 612.8(447.9)6 611.8(433.7)14 612.0(436.4)10 fFPCA 614.9(464.4)4 613.9(454.4)5 612.8(441.3)11 613.2(445.7)7 uFPCA 648.6(499.8)2 684.6(499.8)2 680.8(471.6)8 680.9(473.6)6 rFPCA 720.2(136.6)9 719.1(131.5)11
uFPCA 681.0(477.3) 680.8(472.1) 680.7(471.6)
untuk K=4 untuk K=10 untuk K=14
gFPCA 7.85.1(684.6) 784.8(647.1)
untuk K=5(dasar untuk K=6 dalam metode CV)
(Sumber : C.-R. Jiang and J.-L Wang 2010)
25
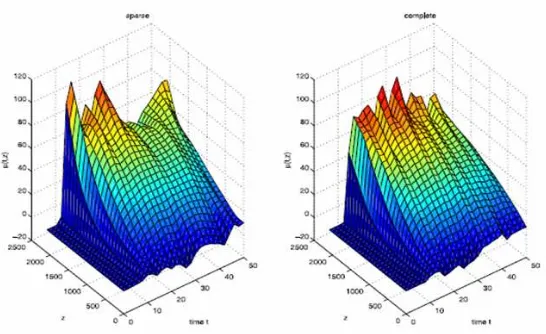
Kuadrat error dicocokkan mean untuk ke lima pendekatan dilaporkan dalam Tabel 4.1.1 Kinerja uFPCA, mFPCA dan fFPCA sama dengan yang diperoleh dari studi simulasi,mFPCA umumnya sedikit lebih baik daripada fFPCA untuk data jarang, dan keduanya mengungguli uFPCA dan gFPCA. Peningkatan mFPCA dan fFPCA dibanding uFPCA tampaknya marginal untuk data jarang, tetapi hal ini disebabkan error pengukiuran yang besar (taksiran σ dengan mFPCA, fFPCA, uFPCA masing-masing adalah 25,34, 25,44, 24,81) ada di dalam data. Karena uFPCA hanya memilih dua eigenfungsi, dan berusaha memeriksa apakah bisa meningkatkannya dengan meningkatkan jumlah eigenfungsi. digunakan mFPCA sbeagai ukuran, dan bagian bawah dari Tabel 3 melaporkan hasil tambahan untuk uFPCA yang menggunakan jumlah komponen yang sama (K = 4, 10 dan 14) de-ngan mFPCA. Akan dimasukkan hasil tambahan untuk gFPCA untuk dibanding-kan dengan mFPCA; adibanding-kan tetapi, CV memilih 8 basis dan karenanya membatas K pada K = 8. Ini hanya menghasilkan satu kasus tambahan bila K = 6 karena algoritma menemukan situasi singuleritas untuk kasus dengan K = 8.
Fenomena yang menarik adalah kinerja rFPCA, yang sampai sejauh ini meng-ungguli semua prosedur lainnya untuk data jarang tetapi tidak untuk data lengkap di mana uFPCA, mFPCA dan fFPCA semuanya mempunyai error pencocokan yang lebih kecil.
26
Gambar 4.4 Estimasi kovarians permukaan mFPCA untuk jarang dan Sumber : C.-R. Jiang and J.-L Wang 2010
Ini menunjukkan adanya masalah pencocokan berlebihan dan membutuhkan penelitian lebih lanjut. hal ini dapat diselidiki dengan simulasi tetapi tidak bisa mencapai kesimpulan dengan menggunakan simulasi, Algoritma pada rFPCA mau-pun gFPCA menemukan situasi singuleritas atau tidak bisa konvergen dalam ban-yak putaran dengan masalah divergen yang lebih serius untuk gFPCA. Tam-pak bahwa parameter-parameter pemulusan untuk kedua metode sensitif terhadap data.
BAB 5
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Pendekatan-pendekatan sekarang ini untuk FPCA mungkin tidak lagi co-cok untuk data fungsional bila informasi kovariat tersedia. Diajukan dua alter-natif untuk memadukan efek kovariat pada data respon fungsional, dengan menye-suaikan efek kovariat hanya pada fungsi mean (mFPCA) atau menyemenye-suaikan efek kovariat juga untuk kovariansi (fFPCA). Bukti numerik mendukung pendekatan disesuaikan-mean yang lebih sederhana terutama bila tujuannya adalah untuk memprediksi trayektori Y(t).
Akan tetapi, fFPCA memakan waktu dan mFPCA hanya sedikit kurang efisien dibandingkan dengan fFPCA dalam pencocokan X(t) tetapi bisa lebih efisien daripada fFPCA dalam memprediksi Y(t), karenanya mFPCA bisa menjadi pen-dekatan yang menarik untuk mengakomodir kovariat.
Kedua pendekatan FPCA adalah bebas model dan memberikan taksiran non-parametrik untuk efek tetap maupun efek acak. Keuntungan dari pendekatan berbasis komponen utama adalah: (1) Lebih sedikit efek acak dibutuhkan untuk mencocokkan data; (2) Mempunyai nilai tambah untuk menunjukkan mode vari-asi data dan (3) Memberikan petunjuk untuk model hemat lainnya seperti model koefisien bervariasi atau model efek campuran linier. Mengembangkan prosedur kesimpulan formal dengan menggunakan pendekatan mFPCA atau fFPCA untuk pengesahan model akan menjadi proyek penting di masa mendatang.
5.2 Saran
DAFTAR PUSTAKA
Berkey, C. S. and Kent, R. L. J. (1983). Longitudinal principal components and non-linear regression models of early childhood growth. Annals of Human Biology 10, 523-536.
Besse, P. and Ramsay, J. O. (1986). Principal components analysis of sampledfunc-tions. Psychometrika 51, 285-311.
Brown, E. R., Ibrahim, J. G. and DeGruttola, V. (2005). A flexible B-spline model for multiple longitudinal biomarkers and survival. Biometrics 61, 64-73.
Bycott, P. and Taylor, J. (1998). A comparison of smoothing techniques for CD4 data measured with error in a time-dependent cox proportional hazard model. Statistics in Medicine 17, 2061-2077.
Cardot, H. (2006). Conditional functional principal components analysis. Scand. J. Statist. 34 317-335.
Castro, P. E., Lawton, W. H. and Sylvestre, E. A. (1986). Principal modes of variation for processes with continuous sample curves. Technometrics 28, 329-337.
Chiou, J.-M., Muller, H.-G. and Wang, J.-L. (2003). Functional quasi-likelihood regression models with smooth random effects. J. R. Stat. Soc. Ser. B Stat. Methodol. 65 405-423.
Dafni, U. G. and Tsiatis, A. A. (1998). Evaluating surrogate markers if clinical outcomes measured with error. Biometrics 54, 1445-1462.
Fan, J. and Gijbels, I. (1996). Local Polynomial Modelling and Its Applications. Chapman and Hall, London.
Faucett, C. L. and Thomas, D. C. (1996). Simultaneously modelling censored sur-vival data and repeatedly measured covariates: a Gibbs sampling approach. Statistics in Medicine 15, 1663-1685.
Ferraty, F. and Vieu, P. (2006). Nonparametric Functional Data Analysis: Theory and Practice. Springer, New York. Guo, W. (2002). Funcitonal mixed effects models. Biometrics 58 121-128.
Henderson, R., Diggle, P. J. and Dobson, A. (2000). Joint modelling of longitudinal measurements and event time data. Biostatistics 4, 465-480.18
Hsieh, F., Tseng, Y. K. and Wang, J. L. (2006). Joint modelling of survival and longitudinal data: likelihood approach revisited. Biometrics, to appear
James, G. M., Hastie, T. J. and Suger, C. A. (2000). Principal components models for sparse functional data. Biometrika 87 587-602.
Kneip, A. and Utikal, K. (2001). Inference for density families using functional principal component analysis. J. Amer. Statist. Assoc. 96 519-532.
Pawitan, Y. and Self, S. (1993). Modelling disease marker processes in AIDS. Journal of the American Statistical Association 88, 719-726.
29
Prentice, R. (1982). Covariate measurement errors and parameter estimates in a failure time regression model. Biometrika 69, 331-342.
Raboud, J., Reid, N., Coates, R. A. and Farewell, V. T. (1993). Estimating risks of progressing to AIDS when covariates are measured with error. Journal of the Royal Statistical Society A 156, 396-406.
Ramsay, J. O. and Silverman, B. W. (1997). Functional Data Analysis. Springer, New York
Ramsay, J. O. and Silverman, B.W. (2002). Applied Functional Data Analysis: Methods and Case Studies. Springer, New York.
Ramsay, J. O. and Silverman, B. W. (2005). Functional Data Analysis, 2nd ed. Springer, New York.
Rice, J. and Silverman, B. (1991). Estimating the mean and covariance structur nonparametrically when the data are curves. J. Roy. Statist. Soc. Ser. B 53 233-243.
Rice, J. and Wu, C. (2000). Nonparametric mixed effects models for unequally sampled noisy curves. Biometrics 57, 253-259.
Rice, J. A. (2004). Functional and longitudinal data analysis: Prospectives on smoothing. Statist. Sinica 14 631-647.
Wang, Y. and Taylor, J. M. G. (2001). Jointly modelling longitudinal and event time data with application to acquired immunodeficiency syndrome. Journal of the American Statistical Association, 96, 895-905.
Wu, H. and Zhang, J.-T. (2006). Nonparametric Regression Methods for Longitu-dinal Data Analysis: Mixed-Effects Modeling Approaches. Wiley, Hoboken, NJ.
Xu, J. and Zeger, S. L. (2001b). Joint analysis of longitudinal data comprising repeated measures and times to event. Applied Statistics 50, 375-387
Silverman, B. W. (1996). Smoothed functional principal components analysis by choice of norm. The Annals of Statistics 24, 1-24.
Slasor, P. and Laird, N. (2003). Joint models for efficient estimation in proportional hazards regression models. Statistics in Medicine 22, 2137-2148.
Tsiatis, A. A., Degruttola, V. and Wulfsohn, M. S. (1995). Modelling the rela-tionship of survival to longitudinal data measured with error. Applications to survival and cd4 counts in patients with AIDS. Journal of the American Statistical Association, 90, 27-37.
Wulfsohn, M. S. and Tsiatis, A. A. (1997). A joint model for survival and longitu-dinal data measured with error. Biometrics 53, 330-339.
Yao, F., Muller, H.-G. and Wang, J.-L. (2005). Functional data analysis for sparse longitudinal data. J. Amer. Statist. Assoc. 100 577-590
30
Yao, F. (2007). Asymptotic distributions of nonparametric regression estimators for longitudinal of functional data. J. Multivariate Anal. 98 40-56.