APLIKASI REGRESI BINOMIAL NEGATIF DAN
GENERALIZED POISSON DALAM MENGATASI
OVERDISPERSION PADA REGRESI POISSON
(Studi Kasus Data Kemiskinan Provinsi di Indonesia Tahun 2009)
Fitriana Fadhillah
PROGRAM STUDI MATEMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI
SYARIF HIDAYATULLAH
i
APLIKASI REGRESI BINOMIAL NEGATIF DAN
GENERALIZED POISSON DALAM MENGATASI
OVERDISPERSION PADA REGRESI POISSON
(Studi Kasus Data Kemiskinan Provinsi di Indonesia Tahun 2009)
Skripsi
Sebagai Satu Syarat Untuk Memperoleh
Gelar Sarjana Sains
Fakultas Sains dan Teknologi
Universitas Islam Negeri Syarif Hidayatullah Jakarta
Oleh :
Fitriana Fadhillah
107094002808
PROGRAM STUDI MATEMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI
SYARIF HIDAYATULLAH
iii
PENGESAHAN UJIAN
Skripsi berjudul “Aplikasi Regresi Binomial Negatif dan Generalized Poisson
Dalam Mengatasi Overdispersion Pada Regresi Poisson” yang ditulis oleh Fitriana
Fadhillah, NIM 107094002808 telah di uji dan dinyatakankan lulus dalam sidang
Munaqosyah Fakultas Sains dan Teknologi Universitas Islam Negeri Syarif Hidayatullah Jakarta pada tanggal 7 Juni 2011. Skripsi ini telah diterima sebagai salah satu syarat untuk memperoleh gelar sarjana strata satu (S1) Program Matematika.
Menyetujui,
Gustina Elfiyanti, M.Si Taufik Edy Sutanto, M.ScTech
NIP. 19820820 200901 2006 NIP. 19790530 200604 1002
Dekan Fakultas Sains dan Teknologi Ketua Program Studi Matematika
DR. Syopiansyah Jaya Putra, M. Sis Yanne Irene, M. Si
iv
PERNYATAAN
DENGAN INI SAYA MENYATAKAN BAHWA SKRIPSI INI BENAR-BENAR
HASIL KARYA SENDIRI YANG BELUM PERNAH DIAJUKAN SEBAGAI
SKRIPSI PADA PERGURUAN TINGGI ATAU LEMBAGA MANAPUN.
Jakarta, Juni 2011
K a r y a i n i ku per sem ba hka n un t uk
Or a n gt ua ku t er ci n t a y a n g t ela h ba n y a k m en cur a hka n
ka si h sa y a n g da n dukunga n ba i k m or i l m a upun m a t er i K edua ka ka kku da n kepon a ka n ku (Sa lsa )
F ebr i y a n a
M ot t o
T i da k a ka n a da r a sa kecew a ji ka sega la n y a di la kuka n den ga n ket ulusa n . T i da k a ka n di t em uka n ka t a sa kit ha t i ji ka ki t a m ur n i m ela kuka n n y a un t uk A llah da n a t a s n a m a A lla h.
“Ja n ga n la h ka li a n ber sika p lem a h da n ja n ga n la h pula ka li a n ber sedi h ha t i , pa da ha l ka li a n la h or a ng-or a n g y a n g pa li n g t i n ggi (der a ja t n y a ) ji ka ka lia n or a n g-or a n g y a n g ber i m a n ”
v ABSTRAK
Model Regresi Poisson secara umum digunakan untuk menganalisis data cacah yang diasumsikan menyebar Poisson dimana nilai rata-rata dan variansinya sama (equidispersion). Namun seringkali terjadi masalah nilai variansi melebihi nilai rataannya atau lebih dikenal dengan overdispersion. Regresi Poisson yang diterapkan pada data yang mengandung overdispersion akan menghasilkan nilai
standard error yang menjadi underestimate. Model yang sering digunakan untuk
mengatasi masalah overdispersion adalah Regresi Binomial Negatif dan
Generalized Poisson. Regresi Binomial Negatif dan Generalized Poisson dapat
digunakan baik dalam keadaan equidispersion maupun overdispersion. Penaksiran
parameter dapat diperoleh dengan menggunakan metode maximum likelihood
melalui iterasi Newton-Raphson. Beberapa ukuran perbandingan dapat digunakan
untuk membandingkan model Regresi Poisson, Binomial Negatif dan Generalized
Poisson. Kajian yang digunakan dalam penelitian ini adalah mengetahui faktor-faktor yang mempengaruhi angka kemiskinan provinsi di Indonesia tahun 2009.
Data Jumlah penduduk miskin menunjukkan terjadi overdispersion.
Sehingga pemodelan yang tepat adalah menggunakan Regresi Binomial Negatif
dan Generalized Poisson. Hasil analisis dalam penelitian ini menunjukkan bahwa
faktor yang berpengaruh terhadap jumlah penduduk miskin adalah jumlah penduduk. Model Regresi Generalized Poisson memenuhi kriteria kesesuaian model regresi dibandingkan dengan model Regresi Poisson dan Binomial Negatif. Sehingga dapat disimpulkan bahwa untuk kasus data kemiskinan provinsi di Indonesia tahun 2009, Regresi Generalized Poisson merupakan salah satu solusi yang dapat digunakan untuk mengatasi permasalahan overdispersion.
vi ABSTRACT
Poisson regression model is commonly used to analyze count data that is assumed to spread Poisson where the average and variance values are equal (equidispersion). But often there are problems with the variance value exceeds the average or better known as overdispersion. Poisson regression is applied to the data that contains overdispersion will generate the value of standard error becomes underestimate. Models are often used to solve problem of overdispersion are Negative Binomial and Generalized Poisson regression. Negative Binomial and Generalized Poisson regression can be used either in a state equidispersion or overdispersion. Estimation of parameters can be obtained by using maximum likelihood method via Newton-Raphson iteration. Some size comparison can be used to compare the model Poisson, Negative Binomial and Generalized Poisson regression. Studies used in this research was to determine the factors that affect poverty rate in provinces of Indonesia 2009.
Data on the number of poor people show that there were overdispersion. So that proper modeling is to use Negative Binomial and Generalized Poisson Regression. The results showed that the factors which affects the number of poor people is the population, unemployment, number of illiterate population, population who complete elementary, junipr and senior high school. Generalized Poisson Regression model criteria fullfilment regression model compared with Poisson and Negative Binomial Regression models. It can be concluded that for the case of data poverty rate in provinces of Indonesia 2009, Generalized Poisson regression is one solution that can be used to solve problems of overdispersion.
vii
KATA PENGANTAR
Segala puji dan syukur yang sebesar-besarnya penulis panjatkan kehadirat
Allah SWT, karena dengan rahmat dan karunia-Nya penulis dapat menyelesaikan
tugas akhir ini tepat pada waktunya. Shalawat serta salam semoga selalu tercurah
kepada Nabi Muhammad SAW, keluarga, sahabat serta segenap umatnya.
Penulis sadar bahwa skripsi ini tidak akan selesai bila penulis tidak
mendapat bantuan dari berbagai pihak, baik bantuan secara langsung maupun
dukungan moril dan doa. Oleh karena itu penulis ingin mengucapkan terima kasih
yang sebesar-besarya kepada:
1. Dr. Syopyansyah Jaya Putra, M.Si, Dekan Fakultas Sains dan Teknologi UIN
Syarif Hidayatullah Jakarta.
2. Ibu Yanne Irene, M.Si, Ketua Program Studi Matematika dan Ibu Sumainna,
M.Si, Sekretaris Program Studi Matematika.
3. Bapak Hermawan Setiawan, M.Kom, sebagai Dosen Pembimbing I, yang
telah meluangkan waktunya untuk memberikan bimbingan dan pengarahan
hingga terselesaikannya skripsi ini.
4. Bapak Bambang Ruswandi, M.Stat, sebagai Dosen Pembimbing II, atas
bimbingan, saran dan bantuannya dari awal hingga terselesaikannya skripsi
ini.
5. Alm. Ayahanda tercinta yang telah menghabiskan waktu dan tenaga tanpa
mengenal batas untuk memberikan yang terbaik bagi penulis agar dapat
viii 6. Ibunda tercinta yang selalu memberikan semagat dan dukungan kepada
penulis, atas doa, kasih sayang, dorongan, pengertian dan kesabaran yang tak
terkira hingga penulis dapat menyelesaikan skripsi ini.
7. Seluruh dosen jurusan Matematika, Fakultas Sains dan Teknologi UIN Syarif
Hidayatullah Jakarta yang telah memberikan segenap ilmu.
8. Febriyana yang telah meluangkan banyak waktunya untuk membantu
menyelesaikan skripsi ini serta memberikan dukungan moril dan kesabaran.
9. Dua kakakku, keponakanku (Salsa) dan seluruh keluarga besarku tercinta
yang telah memberikan perhatian, dukungan dan doanya.
10. Seluruh karyawan dan murid Primagama Mayestik yang selalu memberikan
dorongan motivasi kepada penulis hingga terselesaikan skripsi ini.
11. Seluruh teman-teman Matematika 2007 yang selalu memberikan motivasi
kepada penulis dalam menyelesaikan skripsi ini.
Penulis mengharapkan kritik dan saran agar penulis dapat memperbaiki
kekurangan yang ada. Penulis berharap semoga tugas akhir ini bermanfaat bagi
penulis khususnya, dan pihak lain umumnya.
Jakarta, Juni 2011
x
2.4. Regresi Binomial Negatif ... 10
2.5. Regresi Generalized Poisson ... 13
2.6. Penaksiran Parameter ... 15
2.7. Kesesuaian Model Regresi ... 17
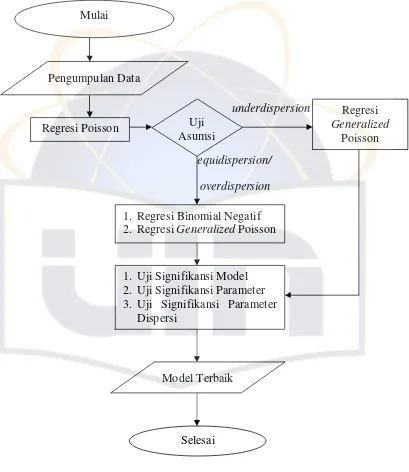
BAB III METODOLOGI PENELITIAN ... 19
3.1. Sumber Data ... 19
3.2. Pengujian Signifikansi Model dan Parameter ... 21
3.3. Alur Penelitian ... 25
BAB IV HASIL DAN PEMBAHASAN ... 26
4.1. Deskripsi Data ... 26
4.2. Regresi Poisson ... 27
4.3. Overdispersion ... 32
4.4. Regresi Binomial Negatif ... 33
4.5. Regresi Generalized Poisson ... 38
4.6. Kesesuaian Model Regresi ... 43
BAB V KESIMPULAN DAN SARAN ... 46
5.1. Kesimpulan ... 46
5.2. Saran ... 47
DAFTAR PUSTAKA... 48
xi
DAFTAR TABEL
Tabel 4.1 : Statistik Deskriptif ... 26
Tabel 4.2 : Nilai Parameter Regresi Poisson... 27
Tabel 4.3 : Hasil Uji Overdispersion ... 32
Tabel 4.4 : Nilai Parameter Regresi Binomial Negatif ... 33
Tabel 4.5 : Nilai Parameter Regresi Generalized Poisson ... 38
xii
DAFTAR LAMPIRAN
Lampiran 1 : Syntax Pengolahan Data Stata Versi Trial ... 49
Lampiran 2 : Output Statistik Deskriptif ... 51
Lampiran 3 : Output Regresi Poisson ... 51
Lampiran 4 : Output Kesesuaian Model Regresi Poisson ... 52
Lampiran 5 : Output Pendeteksian Overdispersion ... 52
Lampiran 6 : Output Regresi Binomial Negatif ... 53
Lampiran 7 : Output Kesesuaian Model Regresi Binomial Negatif ... 53
Lampiran 8 : Output Regresi Generalized Poisson ... 54
Lampiran 9 : Output Kesesuaian Model Regresi Generalized Poisson ... 54
1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Model regresi Poisson merupakan salah satu model yang digunakan
untuk memodelkan hubungan antara variabel dependent berupa data cacah
dengan variabel independent berupa data kontinu, diskrit, kategori atau
campuran. Dalam model regresi Poisson terdapat beberapa asumsi. Salah satu
asumsi yang harus terpenuhi adalah variansi dari variabel dependent sama
dengan rataannya (equidispersion), yaitu:
( ) = ( ) =
Namun, dalam analisis data cacah sering dijumpai data yang variansinya lebih
kecil atau lebih besar dari rataan. Keadaan ini lebih dikenal dengan
underdispersion atau overdispersion. Regresi Poisson yang diterapkan pada
data yang mengandung overdispersion akan menghasilkan nilai standard
error yang menjadi turun atau underestimate [4]. Pendekatan yang dapat
digunakan untuk menangani overdispersion pada regresi Poisson adalah
regresi Binomial Negatif dan regresi Generalized Poisson.
Hasil penelitian Dimas Haryo Pamungkas (2003) menyatakan bahwa
saat terjadi overdispersion pada data, regresi Binomial Negatif lebih baik
digunakan dibandingkan regresi Poisson [7]. Sedangkan pada penelitian Ega
Prihastari (2008), saat terjadi underdispersion dan overdispersion pada data,
regresi Generalized Poisson lebih baik digunakan dibandingkan regresi
2 membandingkan regresi Poisson, Binomial Negatif dan Generalized Poisson
pada data yang mengandung overdispersion. Model yang digunakan dalam
penelitian ini untuk mengetahui faktor eksternal yang berpengaruh terhadap
kemiskinan penduduk Indonesia tahun 2009.
Tingginya tingkat kemiskinan di Indonesia membuat pemerintah
memberikan perhatian lebih terhadap upaya pengentasan kemiskinan. Untuk
menurunkan tingkat kemiskinan terlebih dahulu perlu diketahui faktor-faktor
yang mempengaruhi tingkat kemiskinan, sehingga dapat dirumuskan
kebijakan yang efektif untuk menurunkan angka kemiskinan di Indonesia.
Faktor-faktor yang mempengaruhi tingkat kemiskinan di Indonesia antara lain
Pertumbuhan Ekonomi, Jumlah Penduduk dan Pendidikan [10].
Dalam penelitian ini akan dijelaskan hubungan antara jumlah
penduduk miskin (variabel dependent) dengan faktor-faktor yang
berpengaruh (variabel independent) yaitu jumlah penduduk, pengangguran,
angka melek huruf penduduk, penduduk tamat SD/sederajat, penduduk tamat
SMP/sederajat dan penduduk tamat SM/sederajat.
Jumlah penduduk miskin di Indonesia dapat dikatakan masih cukup
tinggi namun jarang sekali terjadi dalam ruang sampel besar. Sehingga
hubungan antara jumlah penduduk miskin dengan faktor-faktor yang
3 1.2 Permasalahan
Rumusan masalah penelitian ini dapat dirinci ke dalam beberapa
pertanyaan penelitian sebagai berikut:
a. Bagaimana pengaruh overdispersion pada regresi Poisson dalam data
kemiskinan Indonesia tahun 2009.
b. Bagaimana penerapan Regresi Poisson, regresi Binomial Negatif dan
regresi Generalized Poisson pada data kemiskinan Indonesia tahun 2009
yang mengandung overdispersion.
c. Faktor-faktor apa saja yang mempengaruhi angka kemiskinan di Indonesia
tahun 2009.
1.3 Pembatasan Masalah
Agar dalam pembahasan tidak terlalu luas dan hasilnya dapat
mendekati pokok permasalahan, maka dalam penulisan hanya akan
membahas overdispersion pada data kemiskinan, faktor-faktor yang
mempengaruhi angka kemiskinan di Indonesia tahun 2009 serta analisis yang
dilakukan berdasarkan data yang diperoleh pada waktu penelitian.
1.4 Tujuan Penelitian
Tujuan dari penelitian ini adalah:
a. Untuk menganalisa adanya pengaruh overdispersion pada regresi Poisson
dalam data kemiskinan Indonesia tahun 2009.
b. Untuk membandingkan penerapan regresi Poisson, regresi Binomial
Negatif dan regresi Generalized Poisson pada data kemiskinan Indonesia
4
c. Untuk mengetahui faktor-faktor yang mempengaruhi angka kemiskinan di
Indonesia tahun 2009.
1.5 Manfaat Penelitian
Manfaat penelitian terdiri dari manfaat teoritis serta manfaat praktis
digunakan untuk perbaikan bagi pemerintah dan/atau Pemerintah Daerah
(Pemda) yang bersangkutan. Manfaat penelitian dijelaskan sebagai berikut:
1. Manfaat Teoritis
Hasil penelitian ini dapat dijadikan bahan studi lanjutan yang
relevan dan bahan kajian ke arah pengembangan, serta kultur yang
berkembang. Pembahasan tentang indikator yang berkaitan dengan angka
kemiskinan, diharapkan dapat menjadi masukan untuk peningkatan
pembangunan sosial di Indonesia.
2. Manfaat Praktis
Penelitian ini secara praktis diharapkan dapat memiliki kontribusi
sebagai berikut:
a. Bagi Pemerintah
1) Sebagai dasar perencanaan terutama yang terkait dengan masalah
faktor-faktor yang mempengaruhi angka kemiskinan di Indonesia
tahun 2009.
2) Dapat memberikan sumbangan penelitian dalam membantu
mengatasi angka kemiskinan yang dihadapi, melalui kebijakan yang
5 b. Bagi Penulis
Hasil penelitian ini dapat dijadikan bahan untuk melakukan penelitian
lebih lanjut mengenai model pengembangan faktor-faktor yang
mempengaruhi angka kemiskinan. Serta menambah pengetahuan bagi
penulis dan menerapkan ilmu-ilmu yang telah di dapat selama kuliah.
c. Bagi Pembaca
Hasil penelitian ini diharapkan dapat digunakan sebagai bahan bacaan
6
BAB II
LANDASAN TEORI
2.1 Kemiskinan
Masalah kemiskinan merupakan salah satu persoalan mendasar yang
harus menjadi perhatian pemerintah di negara manapun. Secara umum,
kemiskinan adalah ketidakmampuan seseorang untuk memenuhi kebutuhan
dasar pada setiap aspek kehidupan [2]. Badan Pusat Statistik (BPS)
mendasarkan pada besarnya rupiah yang dibelanjakan perkapita/bulan untuk
memenuhi kebutuhan minimum makanan dan non makanan [1].
Kualitas dan kuantitas sumber daya manusia akan berpengaruh
terhadap pembangunan ekonomi suatu wilayah. Kualitas dan kuantitas
sumber daya manusia dapat dilihat dari jumlah penduduknya [2].
Perkembangan jumlah penduduk dapat menjadi faktor pendorong dan
penghambat pembangunan. Faktor pendorong karena memungkinkan
semakin banyaknya tenaga kerja. Sedangkan penduduk disebut faktor
penghambat pembangunan karena akan terdapat banyak pengangguran.
Dalam kaitannya dengan kemiskinan, jumlah penduduk yang besar justru
akan menambah tingkat kemiskinan. Fakta menunjukkan, beberapa Negara
dengan jumlah penduduk yang besar, tingkat kemiskinannya juga lebih besar
7 Kualitas sumber daya manusia dapat dilihat dari tingkat
pendidikannya. Dengan melakukan investasi pendidikan, maka akan
meningkatkan produktivitas. Peningkatan produktivitas akan meningkatkan
pendapatan. Pendapatan yang cukup akan mampu mengangkat kehidupan
seseorang dari kemiskinan.
2.2 Regresi Poisson
Regresi Poisson termasuk ke dalam Generalized Linear Models dan
merupakan salah satu bentuk regresi yang digunakan untuk model data cacah.
Variabel dependent dalam persamaan tersebut menyatakan data cacah [4].
Jika ingin diketahui hubungan antara variabel dependent dan buah
variabel independent , , …, . Diberikan sampel sebesar pengamatan
yaitu , , …, , ; = 1, 2, …, dan = 1, 2, …, . Pengamatan
ke- dari variabel , , …, adalah , , …, . Pengamatan ke- dari
variabel adalah .
Jika merupakan variabel acak untuk data cacah dengan = 1, 2, ...,
, dimana menyatakan banyaknya data dan mengikuti distribusi Poisson.
Maka fungsi kepadatan peluangnya adalah:
( ; ) =
! (2.1)
Untuk > 0, dengan merupakan rataan dari variabel dependent .
Fungsi peluang Poisson termasuk keluarga eksponensial, sehingga
dapat dituliskan dalam bentuk:
( ; ) = [ ( ) − ]
8 Berdasarkan fungsi peluang di atas, maka diperoleh fungsi penghubung (Link
Function) yaitu:
= ( ) = (2.3)
Asumsi yang harus dipenuhi pada model regresi Poisson yaitu:
( ) = ( ) = = ( ) (2.4)
Dengan adalah vektor yang berukuran x1 yang menjelaskan variabel
independent dan adalah vektor berukuran x1 merupakan parameter
regresi. Sehingga fungsi kepadatan peluang regresi Poisson adalah sebagai
berikut:
( ; ) = [ − ( ) ]
! (2.5)
Nilai harapan yang bergantung pada variabel independent adalah .
Taksiran parameter koefisien regresi Poisson dapat dilakukan dengan
menggunakan Maximum Likelihood Estimation (MLE). Fungsi log likelihood
untuk regresi Poisson dapat ditulis sebagai:
ℓ( ; ) = ∑ [ ( )− − ( !) ] (2.6)
dimana = ( )
ℓ( ; ) = ∑ [ ( ) − ( ) − ( !) ] (2.7)
Dengan demikian, penaksir maximum likelihood dapat diselesaikan
dengan memaksimumkan model log likelihoodℓ( ; ), yaitu:
ℓ( ; ) = ∑ ( − ) = 0 , = 1, 2, …, (2.8)
dan
9 2.3 Overdispersion
Pada model regresi Poisson terdapat asumsi yang harus dipenuhi.
Salah satunya adalah asumsi kesamaan antara rataan dan variansi dari
variabel dependent, yang disebut juga equidispersion. Namun, dalam analisis
data cacah seringkali dijumpai data yang variansinya lebih besar dari
rataannya (overdispersion).
Jika pada data cacah terjadi overdispersion namun tetap digunakan
regresi Poisson, akan berpengaruh pada nilai standard error yang menjadi
turun atau underestimate, sehingga kesimpulannya menjadi tidak valid [4].
Fenomena overdispersion dapat dituliskan:
( ) > ( )
Overdispersion dapat diindikasikan dengan nilai deviance dan
pearson chi-squares yang dibagi dengan derajat bebasnya. Jika kedua nilai
tersebut lebih dari 1, maka dikatakan terjadi overdispersion pada data [6].
Terdapat dua cara yang dapat digunakan untuk mendeteksi
overdispersion, yaitu:
1. Deviance
= ; = 2∑ −( − ) (2.10)
Dimana = − dengan merupakan banyaknya parameter
termasuk konstanta, merupakan banyaknya pengamatan dan adalah
10
2. Pearson Chi-Squares
= ; = ∑ ( )
( ) (2.11)
Dimana = − dengan merupakan banyaknya parameter
termasuk konstanta, merupakan banyaknya pengamatan dan
adalah Pearson Chi-Squares [5].
Jika dan bernilai lebih dari 1 maka terjadi overdispersion pada data.
2.4 Regresi Binomial Negatif
Model Regresi Binomial Negatif merupakan suatu model regresi yang
digunakan untuk menganalisis hubungan antara sebuah variabel dependent
yang berupa data cacah dengan satu atau lebih variabel independent. Regresi
Binomial Negatif dapat digunakan baik dalam keadaan equidispersion
ataupun overdispersion [5].
Jika ingin diketahui hubungan antara variabel dependent dan buah
variabel independent , , …, . Diberikan sampel sebesar pengamatan
yaitu , , …, , ; = 1, 2, …, dan = 1, 2, …, . Pengamatan
ke- dari variabel , , …, adalah , , …, . Pengamatan ke- dari
11
Jika menyebar Poisson dengan parameter dan terdapat variabel
12
Jika = 0, maka rataan dan variansinya akan sama, ( ) =
( ). Jika > 0, maka variansinya akan melebihi rataannya, ( ) >
( ) [5].
Jika diasumsikan bahwa ( | ) = = ( ). Dengan
adalah vektor yang berukuran x1 yang menjelaskan variabel independent
dan adalah vektor berukuran x1 merupakan parameter regresi. Maka
model log likelihood untuk regresi Binomial Negatif dapat dituliskan sebagai:
ℓ( ; , ) =
Dengan demikian, penaksir maximum likelihood dapat diselesaikan dengan
13
ℓ ; ,
= ∑ − ( ) ( ) ( )
( ) + 2 ( 1 + ) +
+ − (2.18)
Fungsi digamma merupakan turunan pertama dari fungsi log-gamma Γ( ).
Fungsi trigamma merupakan turunan kedua dari Γ( ) [4].
2.5 Regresi Generalized Poisson
Model Regresi Generalized Poisson merupakan suatu model regresi
yang digunakan untuk menganalisis hubungan antara sebuah variabel
dependent yang berupa data cacah dengan satu atau lebih variabel
independent. Regresi Generalized Poisson dapat digunakan baik dalam
keadaan underdispersion, equidispersion ataupun overdispersion [5].
Jika ingin diketahui hubungan antara variabel dependent dan buah
variabel independent , , …, . Diberikan sampel sebesar pengamatan
yaitu , , …, , ; = 1, 2, …, dan = 1, 2, …, . Pengamatan
ke- dari variabel , , …, adalah , , …, . Pengamatan ke- dari
variabel adalah .
Fungsi kepadatan peluang distribusi Generalized Poisson adalah:
14
Generalized Poisson merupakan perluasan dari Poisson. Dengan
merupakan parameter dispersi. Jika = 0, maka ( ) = ( ). Jika
> 0 maka ( ) > ( ). Jika < 0 maka ( ) < ( ) [5].
Jika diasumsikan bahwa ( | ) = = ( ). Dengan
adalah vektor yang berukuran x1 yang menjelaskan variabel independent
dan adalah vektor berukuran x1 merupakan parameter regresi. Maka
model log likelihood untuk regresi Generalized Poisson dapat dituliskan
sebagai:
Dengan demikian, penaksir maximum likelihood, dapat diselesaikan
15 2.6 Penaksiran Parameter
Penaksiran parameter untuk regresi Poisson, Binomial Negatif dan
Generalized Poisson menggunakan iterasi Newton-Raphson [4]. Penurunan
algoritma didasarkan pada modifikasi dua orde deret taylor dengan fungsi log
likelihood. Bentuk dari deret Taylor yaitu:
Untuk menentukan nilai dapat menggunakan perluasan deret Taylor
berupa ( ) = 0 [9].
0 = ( ) + ( − ) ′( ) (2.28)
atau
= − ( )
( ) (2.29)
Metode Newton-Raphson menerapkan estimasi di atas dengan
menggunakan nilai turunan pertama dan kedua dari fungsi log likelihood
16 Turunan kedua dari fungsi log likelihood, ℓ( ), untuk regresi Poisson,
Binomial Negatif dan Generalized Poisson terdapat pada Persamaan (2.9),
(2.16) dan (2.23).
Penaksiran parameter dispersi, untuk memaksimumkan ℓ( ; , )
terhadap pada regresi Binomial Negatif dapat menggunakan iterasi
Newton-Raphson.
= − ℓ( −1)
ℓ( ) (2.31)
Untuk memaksimumkan ℓ( ; , ) terhadap pada regresi Binomial Negatif
dapat menggunakan iterasi Newton-Raphson.
= − ℓ( −1)
ℓ( ) (2.32)
Turunan pertama dari fungsi ℓ( ) dan ℓ( ) untuk regresi Binomial Negatif dan Generalized Poisson terdapat pada Persamaan (2.17) dan (2.24).
Turunan kedua dari fungsi ℓ( ) dan ℓ( ) untuk regresi Binomial
Negatif dan Generalized Poisson terdapat pada Persamaan (2.18) dan (2.25).
17 Nilai residual didefinisikan sebagai perbedaan antara nilai yang diamati ( )
dengan nilai hasil prediksi atau ( ). Sehingga, Residual = − atau
Residual = ( − ) .
2.7 Kesesuaian Model Regresi
Ketika ketiga model regresi telah didapatkan, selanjutnya adalah
membandingkan model tersebut untuk mencari model yang terbaik yang
dapat digunakan. Pengukuran yang sering digunakan adalah likelihood ratio
tests, Akaike Information Criteria (AIC) dan Bayesian Schwartz Information
Criteria (BIC) [4].
Uji likelihood ratio tests ( ) biasa digunakan untuk uji perbandingan
model. Uji nilai likelihood ratio tests ( ) yang menunjukkan penolakan H0
berarti model tersebut lebih baik, karena mengindikasikan terjadinya
overdispersion pada data.
Nilai AIC dapat didefinisikan sebagai:
AIC = −2 ℓ − (2.35)
Nilai log likelihood untuk model yang mengandung seluruh variabel
independent adalah ℓ . Banyaknya parameter termasuk konstanta dinyatakan
dengan . Dalam pengukuran ini, jika nilai AICA < AICB, maka model A
18 Nilai BIC dapat didefinisikan sebagai:
BIC = −2ℓ + ( ) (2.36)
Nilai log likelihood untuk model yang mengandung seluruh variabel
independent adalah ℓ . Banyaknya parameter termasuk konstanta dinyatakan
19
BAB III
METODOLOGI PENELITIAN
3.1 Sumber Data
Penelitian ini dilaksanakan pada bulan Februari 2011. Jenis data yang
digunakan adalah data sekunder. Data berasal dari hasil Survey Sosial
Ekonomi Nasional (SUSENAS) yang diselenggarakan oleh Badan Pusat
Statistik (BPS) tahun 2009.
Variabel yang digunakan dalam penelitian ini adalah sebagai berikut:
a. Variabel dependent
Dalam penelitian ini adalah jumlah penduduk miskin dengan ukuran
jiwa.
b. Variabel independent
Adapun variabel independent dalam penelitian ini adalah:
1. Jumlah penduduk ( ) yang diukur dalam satuan jiwa.
Adalah jumlah penduduk yang berdomisili di wilayah geografis
Republik Indonesia selama 6 bulan atau lebih atau mereka yang
berdomisili kurang dari 6 bulan tetapi bertujuan untuk menetap serta
yang sudah diakui secara sah sebagai Warga Negara Indonesia
20 2. Pengangguran ( ) yang diukur dalam ukuran persentase.
Adalah penduduk usia 15 tahun ke atas yang tidak bekerja tetapi
berharap mendapatkan pekerjaan. Terdiri dari penduduk yang
mencari pekerjaan, penduduk yang mempersiapkan usaha, penduduk
yang tidak mencari pekerjaan karena merasa tidak mungkin
mendapatkan pekerjaan dan penduduk yang sudah punya pekerjaan
tetapi belum mulai bekerja.
3. Angka Melek Huruf Penduduk ( ) yang diukur dalam ukuran
persentase.
Adalah perbandingan antara jumlah penduduk usia 15 tahun ke atas
yang dapat membaca dan menulis, dengan jumlah penduduk usia 15
tahun ke atas.
4. Penduduk Tamat SD/Sederajat ( ) yang diukur dalam ukuran
persentase.
Adalah penduduk yang tamat pada jenjang pendidikan Sekolah
Dasar, Madrasah Ibtidaiyah dan sederajat yang ditandai dengan
sertifikat/ijazah.
5. Penduduk tamat SMP/Sederajat ( ) yang diukur dalam ukuran
persentase.
Adalah penduduk yang tamat pada jenjang pendidikan SMP Umum,
Madrasah Tsanawiyah, SMP kejuruan dan sederajat yang ditandai
21
6. Penduduk tamat SM/Sederajat ( ) yang diukur dalam ukuran
persentase.
Adalah penduduk yang tamat pada jenjang pendidikan Sekolah
Menengah Atas (SMA), Sekolah Menengah Kejuruan (SMK),
Madrasah Aliyah dan sederajat yang ditandai dengan
sertifikat/ijazah.
3.2 Pengujian Signifikansi Model dan Parameter
a. Pengujian Signifikansi Model
Setelah taksiran parameter dari model regresi diketahui,
selanjutnya dilakukan pengujian signifikansi model. Pengujian yang
dilakukan adalah uji rasio likelihood, dengan hipotesis:
H0 : = = . . . = = 0
H1 : ∃ ≠0 = 1, 2, 3, …,
Statistik uji yang dilakukan adalah:
= 2 ℓ − ℓ (3.1)
Dengan ℓ adalah log likelihood untuk model yang mengandung seluruh
variabel independent dan ℓ adalah log likelihood untuk model yang
tidak mengandung variabel independent.
Pada kondisi H0 statistik uji mendekati distribusi chi-square
( ) dengan derajat bebas . Aturan keputusannya adalah H0 ditolak
pada tingkat signifikansi 0.05 jika > . ; . Penolakan H0 pada
22
parameter di antara , , . . ., yang signifikan pada tingkat
signifikansi 0.05 atau dapat dikatakan bahwa model regresi tersebut
cocok untuk menjelaskan hubungan antara variabel independent dengan
variabel dependent pada tingkat signifikansi 0.05.
b. Pengujian Signifikansi Parameter dalam Model
Setelah dilakukan pengujian signifikansi model, selanjutnya
dilakukan pengujian signifikansi masing-masing parameter dari model.
Pengujian yang dilakukan adalah uji Wald, dengan hipotesis:
H0 : = 0
H1 : ∃ ≠0 = 1, 2, …,
Statistik uji yang digunakan adalah:
= (3.2)
Dengan adalah nilai taksiran parameter dan adalah nilai
taksiran standard error dari .
Pada kondisi H0, statistik uji mendekati distribusi chi-square
( ) dengan derajat bebas 1. Aturan keputusannya adalah H0 ditolak
pada tingkat signifikansi 0.05 jika > . ; . Penolakan H0 pada
tingkat signifikansi 0.05 berarti bahwa variabel independent untuk
suatu tertentu dengan = 1, 2, …, memiliki kontribusi terhadap
23
c. Pengujian Signifikansi Parameter Dispersi pada Model
Pengujian signifikansi untuk parameter dispersi dilakukan untuk
menentukan apakah kondisi kesamaan rataan dan variansi
(equidispersion) terpenuhi atau tidak. Kondisi equidispersion terjadi
apabila nilai = 0 dan = 0 terpenuhi.
Untuk pengujian parameter dispersi pada regresi Binomial
Negatif hipotesis yang digunakan adalah:
H0 : = 0
H1 : > 0
Untuk pengujian parameter dispersi pada regresi Generalized
Poisson hipotesis yang digunakan adalah:
H0 : = 0
H1 : ≠ 0
Dengan merupakan parameter dispersi untuk regresi Binomial
Negatif dan merupakan parameter dispersi untuk Generalized Poisson.
Misalkan taksiran log likelihood untuk model yang mengandung seluruh
variabel independent pada regresi Poisson, Binomial Negatif dan
Generalized Poisson adalah ℓ , ℓ dan ℓ .
Pada model regresi Binomial Negatif, statistik uji yang digunakan
adalah:
24 Pada model regresi Generalized Poisson, statistik uji yang
digunakan adalah:
= 2 ℓ − ℓ (3.4)
Pada kondisi H0, statistik uji mendekati distribusi chi-square
( ) dengan derajat bebas 1. Aturan keputusannya adalah H0 ditolak
pada tingkat signifikansi 0.05 jika > . ; . Penolakan H0 berarti pada
tingkat signifikansi 0.05 berarti bahwa model regresi Binomial Negatif
atau Generalized Poisson lebih tepat digunakan dibandingkan model
26
BAB IV
PEMBAHASAN
4.1 Deskripsi Data
Untuk melihat karakteristik dari masing-masing variabel maka
ditampilkan statistika deskriptif yang dapat dilihat pada tabel berikut ini:
Tabel 4.1 Statistika Deskriptif
Variabel Rata-rata Variansi Min Maks
Penduduk Miskin ( ) 985756.4 2.35x1012 76630 6022590
Jumlah Penduduk ( ) 7011197 1.04x1014 743860 4.15x107
Pengangguran ( ) 7.235758 7.072094 3.13 14.97
Persentase jumlah penduduk miskin di Indonesia pada tahun 2009
tercatat sebesar 14.15% atau 32.529.970. Distribusi jumlah penduduk
miskin tertinggi tahun 2009 untuk setiap provinsi di Indonesia terjadi pada
provinsi Jawa Timur dengan jumlah penduduk miskin sebesar 6.022.590
jiwa. Sedangkan jumlah penduduk miskin terendah pada tahun 2009 terjadi
pada provinsi Bangka Belitung dengan jumlah penduduk miskin sebesar
27 4.3 Regresi Poisson
a. Hasil Pengolahan Data
Setelah melakukan pengolahan data, diperoleh nilai untuk
parameter , , , , , , pada tabel berikut:
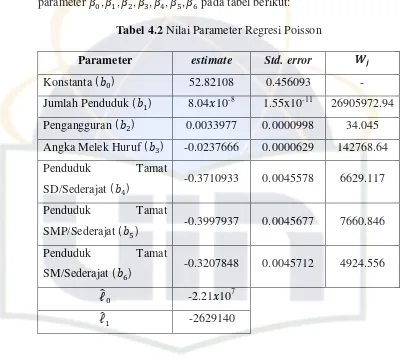
Tabel 4.2 Nilai Parameter Regresi Poisson
Parameter estimate Std. error
Konstanta ( ) 52.82108 0.456093 -
Jumlah Penduduk ( ) 8.04 10-8 1.55x10-11 26905972.94
Pengangguran ( ) 0.0033977 0.0000998 34.045
Angka Melek Huruf ( ) -0.0237666 0.0000629 142768.64
Penduduk Tamat
SD/Sederajat ( ) -0.3710933 0.0045578 6629.117
Penduduk Tamat
SMP/Sederajat ( ) -0.3997937 0.0045677 7660.846
Penduduk Tamat
SM/Sederajat ( ) -0.3207848 0.0045712 4924.556
28 Pada model terlihat bahwa nilai taksiran parameter model untuk
angka melek huruf, penduduk tamat SD/sederajat, penduduk tamat
SMP/sederajat dan penduduk tamat SM/sederajat bernilai negatif. Hal ini
menunjukkan bahwa hubungan antara variabel tersebut dengan log
rata-rata dari jumlah penduduk miskin berbanding terbalik. Jika terjadi
kenaikan angka melek huruf, penduduk tamat SD/sederajat, penduduk
tamat SMP/sederajat dan penduduk tamat SM/sederajat maka log rata-rata
penduduk miskin akan menurun. Sedangkan nilai taksiran parameter
model untuk jumlah penduduk dan pengangguran bernilai positif. Hal ini
menunjukkan bahwa hubungan antara variabel tersebut dengan log
rata-rata dari jumlah penduduk miskin berbanding lurus. Jika terjadi kenaikan
jumlah penduduk dan pengangguran maka log rata-rata penduduk miskin
akan meningkat.
b. Uji Signifikansi Model
Pengujian signifikansi model dilakukan untuk mengetahui apakah
model regresi Poisson tersebut dapat digunakan untuk menggambarkan
hubungan antara jumlah penduduk miskin dengan jumlah penduduk,
pengangguran, angka melek huruf, penduduk tamat SD/sederajat,
penduduk tamat SMP/sederajat serta penduduk tamat SM/sederajat.
Hipotesis:
H0 : = = ... = 0
29
Berdasarkan tabel chi-squares dengan tingkat signifikansi 0.05 dan derajat
bebas 6 diperoleh nilai . ; = 12.59. Nilai = 38941720 > . ; =
12.59, maka H0 ditolak pada tingkat signifikansi 0.05. Sehingga, model
tersebut dapat digunakan untuk menggambarkan hubungan antara jumlah
penduduk miskin dengan jumlah penduduk, pengangguran, angka melek
huruf, penduduk tamat SD/sederajat, penduduk tamat SMP/sederajat serta
penduduk tamat SM/sederajat.
c. Uji Signifikansi Parameter
Selanjutnya dilakukan pengujian signifikansi masing-masing
30
Berdasarkan tabel chi-squares dengan tingkat signifikansi 0.05 dan derajat
bebas 1 diperoleh nilai . ; = 3.841.
Artinya, pada tingkat signifikansi 0.05 jumlah penduduk, pengangguran,
angka melek huruf, penduduk tamat SD/sederajat, penduduk tamat
SMP/sederajat serta penduduk tamat SM/sederajat memiliki kontribusi
31
d. Interpretasi Parameter
Karena seluruh parameter dalam model regresi Poisson signifikan
pada tingkat signifikansi 0.05, maka seluruh parameter dapat
diinterpretasi.
1) Interpretasi = 8.04x10-8
Untuk setiap kenaikan jumlah penduduk sebanyak 1 jiwa, dengan
asumsi nilai variabel lainnya tetap, maka rata-rata jumlah penduduk
miskin cenderung bertambah sebesar (8.04 10-8) ≈ 1 jiwa.
2) Interpretasi = 0.0033977
Untuk setiap kenaikan pengangguran sebanyak 1 persen, dengan
asumsi nilai variabel lainnya tetap, maka rata-rata jumlah penduduk
miskin cenderung bertambah sebesar (0.0033977) ≈ 1 jiwa.
3) Interpretasi = -0.0237666
Untuk setiap kenaikan angka melek huruf penduduk sebanyak 1
persen, dengan asumsi nilai variabel lainnya tetap, maka rata-rata
jumlah penduduk miskin cenderung berkurang sebesar
(-0.0237666) ≈ 1 jiwa.
4) Interpretasi = -0.3710933
Untuk setiap kenaikan penduduk yang tamat SD/sederajat sebanyak 1
persen, dengan asumsi nilai variabel lainnya tetap, maka rata-rata
jumlah penduduk miskin cenderung berkurang sebesar
32
5) Interpretasi = -0.3997937
Untuk setiap kenaikan penduduk tamat SMP/Sederajat sebanyak 1
persen, dengan asumsi nilai variabel lainnya tetap, maka rata-rata
jumlah penduduk miskin cenderung bertambah sebesar
(-0.3997937) ≈ 1 jiwa.
6) Interpretasi = -0.3207848
Untuk setiap kenaikan penduduk tamat SM/Sederajat sebanyak 1
persen, dengan asumsi nilai variabel lainnya tetap, maka rata-rata
jumlah penduduk miskin cenderung berkurang sebesar
(-0.3207848) ≈ 1 jiwa.
4.4 Overdispersion
Overdispersion pada data kemiskinan tahun 2009 ditunjukkan pada
Tabel 4.1 dimana variansi lebih besar dari rataan . Selain itu, fenomena
overdispersion pada data kemiskinan tahun 2009 dapat dilihat berdasarkan
nilai Pearson Chi-Squares dan Deviance yang dibagi dengan derajat
Berdasarkan Persamaan (2.10) dan (2.11) didapatkan =
238992.409 dan = 239347.818 atau jauh di atas 1. Sehingga dapat
33 4.5 Regresi Binomial Negatif
a. Hasil Pengolahan Data
Setelah melakukan pengolahan data, diperoleh nilai untuk
parameter , , , , , , pada tabel berikut:
Tabel 4.4 Nilai Parameter Regresi Binomial Negatif
Parameter estimate Std. error
Konstanta ( ) 100.7498 196.8678 -
Jumlah Penduduk ( ) 9.18 10-8 1.19 10-8 59.51
Pengangguran ( ) 0.0259301 0.045808 0.32
Angka Melek Huruf ( ) -0.0308432 0.0282524 1.192
Penduduk Tamat
SD/Sederajat ( ) -0.8454549 1.969745 0.184
Penduduk Tamat
SMP/Sederajat ( ) -0.8791235 1.972733 0.199
34 Pada model terlihat bahwa nilai taksiran parameter model untuk
angka melek huruf, penduduk tamat SD/sederajat, penduduk tamat
SMP/sederajat dan penduduk tamat SM/sederajat bernilai negatif. Hal ini
menunjukkan bahwa hubungan antara variabel tersebut dengan log
rata-rata dari jumlah penduduk miskin berbanding terbalik. Jika terjadi
kenaikan angka melek huruf, penduduk tamat SD/sederajat, penduduk
tamat SMP/sederajat dan penduduk tamat SM/sederajat maka log
rata-rata penduduk miskin akan menurun. Sedangkan nilai taksiran parameter
model untuk jumlah penduduk dan pengangguran bernilai positif. Hal ini
menunjukkan bahwa hubungan antara variabel tersebut dengan log
rata-rata dari jumlah penduduk miskin berbanding lurus. Jika terjadi kenaikan
jumlah penduduk dan pengangguran maka log rata-rata penduduk miskin
akan meningkat.
b. Uji Signifikansi Model
Pengujian signifikansi model dilakukan untuk mengetahui apakah
model regresi Binomial Negatif tersebut dapat digunakan untuk
menggambarkan hubungan antara jumlah penduduk miskin dengan
jumlah penduduk, pengangguran, angka melek huruf, penduduk tamat
SD/sederajat, penduduk tamat SMP/sederajat serta penduduk tamat
SM/sederajat.
Hipotesis:
H0 : = = ... = 0
35
Berdasarkan tabel chi-squares dengan tingkat signifikansi 0.05
dan derajat bebas 6 diperoleh nilai . ; = 12.59. Nilai = 48.083 >
. ; = 12.59, maka H0 ditolak pada tingkat signifikansi 0.05. Sehingga,
model tersebut dapat digunakan untuk menggambarkan hubungan antara
jumlah penduduk miskin dengan jumlah penduduk, pengangguran, angka
melek huruf, penduduk tamat SD/sederajat, penduduk tamat
SMP/sederajat serta penduduk tamat SM/sederajat.
c. Uji Signifikansi Parameter
Selanjutnya dilakukan pengujian signifikansi masing-masing
36
Berdasarkan tabel chi-squares dengan tingkat signifikansi 0.05 dan
derajat bebas 1 diperoleh nilai . ; = 3.841.
Parameter signifikan pada tingkat signifikansi 0.05. Artinya, pada
tingkat signifikansi 0.05 jumlah penduduk memiliki kontribusi terhadap
37
d. Uji Signifikansi Parameter Dispersi
Hipotesis:
H0 : = 0
H1 : > 0
Statistik uji yang digunakan untuk pengujian tersebut berdasarkan
Persamaan (3.3) adalah:
= 2 ℓ − ℓ
= 2(-407.2713 – (-2629140))
= 2(2628732.729)
= 5257465.457
Berdasarkan tabel chi-squares dengan tingkat signifikansi 0.05 dan
derajat bebas 1 diperoleh nilai . ; = 3.841. Nilai = 5257465.457 >
. ; = 3.841, maka tolak H0 pada tingkat signifikansi 0.05.
Parameter signifikan pada tingkat signifikansi 0.05. Artinya,
model regresi Binomial Negatif lebih baik digunakan dibandingkan
dengan model regresi Poisson.
e. Interpretasi Parameter
Parameter yang signifikan pada tingkat signifikansi 0.05 dalam
model regresi Binomial Negatif hanyalah parameter , maka interpretasi
38 1) Interpretasi = 9.18 10-8
Untuk setiap kenaikan jumlah penduduk sebanyak 1 jiwa, dengan
asumsi nilai variabel lainnya tetap, maka rata-rata jumlah penduduk
miskin cenderung bertambah sebesar (9.04 10-8) ≈ 1 jiwa.
2) Interpretasi = 0.2972525
Nilai taksiran yang diperoleh adalah positif. Hal ini
mengindikasikan terjadinya overdispersion.
4.6 Regresi Generalized Poisson
a. Hasil Pengolahan Data
Setelah melakukan pengolahan data, diperoleh nilai untuk
parameter , , , , , , pada tabel berikut:
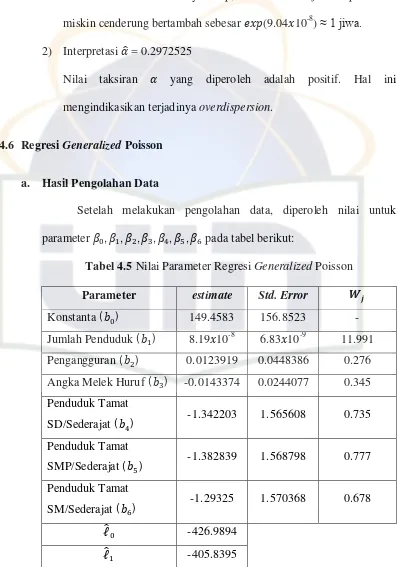
Tabel 4.5 Nilai Parameter Regresi Generalized Poisson
Parameter estimate Std. Error
Konstanta ( ) 149.4583 156.8523 -
Jumlah Penduduk ( ) 8.19 10-8 6.83 10-9 11.991
Pengangguran ( ) 0.0123919 0.0448386 0.276
Angka Melek Huruf ( ) -0.0143374 0.0244077 0.345
Penduduk Tamat
SD/Sederajat ( ) -1.342203 1.565608 0.735
Penduduk Tamat
SMP/Sederajat ( ) -1.382839 1.568798 0.777
Penduduk Tamat
SM/Sederajat ( ) -1.29325 1.570368 0.678
ℓ -426.9894
39 Model regresi Generalized Poisson yang dihasilkan adalah:
̂( , , …, ) = 149.4583 + 8.19 10-8 + 0.0123919 –
0.0143374 - 1.342203 – 1.382839 –
1.29325
Pada model terlihat bahwa nilai taksiran parameter model untuk
angka melek huruf, penduduk tamat SD/sederajat, penduduk tamat
SMP/sederajat dan penduduk tamat SM/sederajat bernilai negatif. Hal ini
menunjukkan bahwa hubungan antara variabel tersebut dengan log
rata-rata dari jumlah penduduk miskin berbanding terbalik. Jika terjadi
kenaikan angka melek huruf, penduduk tamat SD/sederajat, penduduk
tamat SMP/sederajat dan penduduk tamat SM/sederajat maka log
rata-rata penduduk miskin akan menurun. Sedangkan nilai taksiran parameter
model untuk jumlah penduduk dan pengangguran bernilai positif. Hal ini
menunjukkan bahwa hubungan antara variabel tersebut dengan log
rata-rata dari jumlah penduduk miskin berbanding lurus. Jika terjadi kenaikan
jumlah penduduk dan pengangguran maka log rata-rata penduduk miskin
akan meningkat.
b. Uji Signifikansi Model
Pengujian signifikansi model dilakukan untuk mengetahui apakah
model regresi Generalized Poisson tersebut dapat digunakan untuk
menggambarkan hubungan antara jumlah penduduk miskin dengan
40 SD/sederajat, penduduk tamat SMP/sederajat serta penduduk tamat
SM/sederajat.
Berdasarkan tabel chi-squares dengan tingkat signifikansi 0.05
dan derajat bebas 6 diperoleh nilai . ; = 12.59. Nilai = 42.2998 >
. ; = 12.59, maka H0 ditolak pada tingkat signifikansi 0.05. Sehingga,
model tersebut dapat digunakan untuk menggambarkan hubungan antara
jumlah penduduk miskin dengan jumlah penduduk, pengangguran, angka
melek huruf, penduduk tamat SD/sederajat, penduduk tamat
SMP/sederajat serta penduduk tamat SM/sederajat.
c. Uji Signifikansi Parameter
Selanjutnya dilakukan pengujian signifikansi masing-masing
parameter dari model regresi Generalized Poisson.
Hipotesis:
H0 : = 0 = 1, 2, …, 6
41
Berdasarkan tabel chi-squares dengan tingkat signifikansi 0.05 dan
derajat bebas 1 diperoleh nilai . ; = 3.841.
Parameter signifikan pada tingkat signifikansi 0.05. Artinya, pada
tingkat signifikansi 0.05 jumlah penduduk memiliki kontribusi terhadap
42
d. Uji Signifikansi Parameter Dispersi
Hipotesis:
H0 : = 0
H1 : ≠ 0
Statistik uji yang digunakan untuk pengujian tersebut berdasarkan
Persamaan (3.3) adalah:
= 2 ℓ − ℓ
= 2(-405.8395 – (-2629140))
= 2(2628734.161)
= 5257468.321
Berdasarkan tabel chi-squares dengan tingkat signifikansi 0.05
dan derajat bebas 1 diperoleh nilai . ; = 3.841. Nilai =
5257468.321 > . ; = 3.841, maka tolak H0 pada tingkat signifikansi
0.05.
Parameter signifikan pada tingkat signifikansi 0.05. Artinya,
model regresi Generalized Poisson lebih baik digunakan dibandingkan
43
e. Interpretasi Parameter
Parameter yang signifikan pada tingkat signifikansi 0.05 dalam
model regresi Generalized Poisson hanyalah parameter , maka
interpretasi yang diperlukan adalah interpretasi untuk parameter serta
untuk parameter .
1) Interpretasi = 8.19 10-8
Untuk setiap kenaikan jumlah penduduk sebanyak 1 jiwa, dengan
asumsi nilai variabel lainnya tetap, maka rata-rata jumlah penduduk
miskin cenderung bertambah sebesar (8.19 10-8) ≈ 1 jiwa.
2) Interpretasi = 0.9979845
Nilai taksiran yang diperoleh adalah positif. Hal ini
mengindikasikan terjadinya overdispersion.
4.7 Kesesuaian Model Regresi
Untuk membandingkan model regresi Poisson, regresi Binomial
Negatif dan regresi Generalized Poisson dapat dilihat pada tabel berikut ini:
44 Berdasarkan nilai likelihood ratio tests antara regresi Poisson dan
regresi Binomial Negatif, nilai likelihood ratio statistics dari regresi Binomial
Negatif sebesar = 5767616.842 dinyatakan signifikan. Hal ini menunjukkan
bahwa model regresi Binomial Negatif merupakan model yang lebih baik.
Untuk perbandingan lebih lanjut dapat menggunakan nilai AIC dan BIC yang
ditunjukkan pada Tabel 4.6. Berdasarkan nilai likelihood ratio, AIC dan BIC,
maka pada penelitian ini regresi Binomial Negatif merupakan model yang
lebih baik dari regresi Poisson.
Nilai likelihood ratio tests antara regresi Poisson dan regresi
Generalized Poisson sebesar = 5767616.842 dinyatakan signifikan. Hal ini
menunjukkan bahwa model regresi Generalized Poisson merupakan model
yang lebih baik. Untuk perbandingan lebih lanjut dapat menggunakan nilai
AIC dan BIC yang ditunjukkan pada Tabel 4.6. Berdasarkan nilai likelihood
ratio, AIC dan BIC, maka pada penelitian ini regresi Generalized Poisson
merupakan model yang lebih baik dari regresi Poisson.
Berdasarkan pengujian di atas, regresi Binomial Negatif dan
Generalized Poisson lebih baik dibandingkan model regresi Poisson. Maka
langkah selanjutnya adalah membandingkan model regresi Binomial Negatif
dan Generalized Poisson berdasarkan nilai AIC dan BIC.
Pada Tabel 4.6 terlihat bahwa nilai AIC dan BIC untuk regresi
Generalized Poisson lebih kecil dibandingkan regresi Binomial Negatif.
Sehingga, pada penelitian ini model regresi Generalized Poisson lebih baik
45
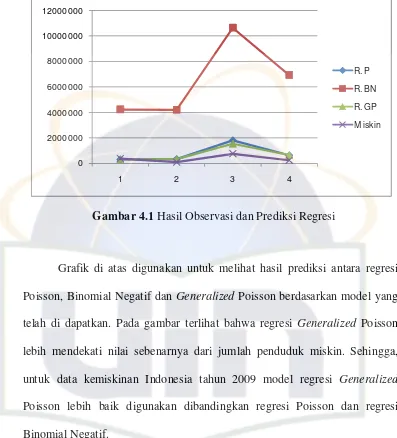
Gambar 4.1 Hasil Observasi dan Prediksi Regresi
Grafik di atas digunakan untuk melihat hasil prediksi antara regresi
Poisson, Binomial Negatif dan Generalized Poisson berdasarkan model yang
telah di dapatkan. Pada gambar terlihat bahwa regresi Generalized Poisson
lebih mendekati nilai sebenarnya dari jumlah penduduk miskin. Sehingga,
untuk data kemiskinan Indonesia tahun 2009 model regresi Generalized
Poisson lebih baik digunakan dibandingkan regresi Poisson dan regresi
Binomial Negatif. 0 2000000 4000000 6000000 8000000 10000000 12000000
1 2 3 4
R. P
R. BN
R. GP
46
BAB V
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Jika pada data cacah terjadi overdispersion namun tetap digunakan
regresi Poisson akan berpengaruh pada nilai standard error yang menjadi
turun atau underestimate seperti yang terlihat pada Tabel 4.2. Sehingga
kesimpulannya menjadi tidak valid.
Ketika model telah didapatkan, dilakukan pembandingan model untuk
mencari model terbaik yang dapat digunakan. Berdasarkan nilai likelihood
ratio tests, AIC dan BIC, model regresi Generalized Poisson lebih baik
digunakan dibandingkan model regresi Poisson dan Binomial Negatif untuk
kasus jumlah penduduk miskin di Indonesia tahun 2009.
Model untuk regresi Generalized Poisson yang dihasilkan adalah:
̂( , , …, ) = 149.4583 + 8.19 10-8 + 0.0123919 –
0.0143374 - 1.342203 – 1.382839 –
1.29325
Setelah taksiran parameter dari model regresi Generalized Poisson diperoleh,
dilakukan pengujian signifikansi untuk kebaikan model dan parameter yang
terdapat dalam model. Pada model regresi Generalized Poisson, variabel
47 5.2 Saran
Dalam penelitian ini telah dibahas mengenai model regresi Poisson,
Binomial Negatif dan Generalized Poisson dengan metode penaksiran
parameter maximum likelihood. Berdasarkan model regresi Binomial Negatif
dan Generalized Poisson yang dihasilkan masih terdapat parameter yang
dinyatakan tidak signifikan, sehingga model tersebut dirasa kurang tepat.
Selain menggunakan metode penaksiran maximum likelihood, dapat
digunakan metode penaksiran lain yaitu moment. Oleh karena itu, penelitian
selanjutnya disarankan untuk membahas metode penaksiran parameter
48
DAFTAR PUSTAKA
[1] Badan Pusat Statistik. Data dan Informasi Kemiskinan 2009, Buku 2:
Kabupaten/Kota. Jakarta: BPS. 2009.
[2] Chamsyah, Bachtiar. Pembangunan Sosial untuk Kesejahteraan Masyarakat
Indonesia. Jakarta: Trisakty University Press. 2008.
Binomial and Generalized Poisson Regression Model. Malaysia: Causalty
Actuarial Society Forum. 2007.
[6] McCullagh, P. and J.A. Nelder. Generalized Linear Models 2nd edition.
London: Chapman and Hall. 1989.
[7] Pamungkas, Dimas Haryo. Kajian Pengaruh Overdispersi Dalam Regresi
Poisson. Bogor: Institut Pertanian Bogor. 2003.
[8] Prihastari, Ega. Model Regresi Generalized Poisson I. Depok: Universitas
Indonesia. 2008.
[9] Munir, Rinaldi. Metode Numerik Revisi Kedua. Bandung: Informatika.
2003.
[10] Usman, Sunyoto. Pembangunan dan Pemberdayaan Masyarakat.
49 LAMPIRAN
Lampiran 1 Syntax STATA versi Trial
Syntax Statistik Deskriptif
tabstat Penduduk Pengangguran AMH SD SMP SM, statistics( mean var min
max ) columns(statistics)
Syntax Regresi Poisson
poisson Miskin Penduduk Pengangguran AMH SD SMP SM, nolog technique(nr)
Syntax Kesesuaian Model Regresi Poisson
estat ic, n(29)
Syntax Deviance
. estat gof
SyntaxPearson Chi-Squares
. estat gof, pearson
Syntax Regresi Binomial Negatif
nbreg Miskin Penduduk Pengangguran AMH SD SMP SM, dispersion(mean)
50
Syntax Kesesuaian Model Regresi Binomial Negatif
estat ic, n(29)
Syntax Regresi Generalized Poisson
gpoisson Miskin Penduduk Pengangguran AMH SD SMP SM, nolog
technique(nr)
Syntax Kesesuaian Model Regresi Generalized Poisson
52 Lampiran 4 Output Kesesuaian Model Regresi Poisson
Lampiran 5 Output Pendeteksian Overdispersion
Deviance
Pearson Chi-Squares
Not e: N=29 used i n cal cul at i ng BI C
. 29 - 2. 21e+07 - 2629140 6 5258293 5258301 Model Obs l l ( nul l ) l l ( model ) df AI C BI C
Pr ob > chi 2(
22
) =
0. 0000
Goodness- of - f i t chi 2 =
5257833
53 Lampiran 6 Output Regresi Binomial Negatif
Lampiran 7 Output Kesesuaian Model Regresi Binomial Negatif
54 Lampiran 8 Output Regresi Generalized Poisson
Lampiran 9 Output Kesesuaian Model Regresi Generalized Poisson
Nama : Fitriana Fadhillah
NIM : 107094002808
Tempat Tanggal Lahir : Bogor, 27 April 1990
Alamat Rumah : Komp. Pelni Blok H1 No.5
Rt 004 Rw 019
Baktijaya – Depok 16418
Phone / Hand Phone : 08998944011/08567171007
Email : [email protected]
Jenis Kelamin : Perempuan
1. S1 : Program Studi Matematika Fakultas Sains dan Teknologi Universitas Islam Negeri (UIN) Syarif Hidayatullah Jakarta, Tahun 2007 – 2011 2. SMA : SMA Islam PB Soedirman, Tahun 2004 – 2007
3. SMP : SMP Islam PB Soedirman, Tahun 2002 – 2004 4. SD : SD Islam PB Soedirman, Tahun 1996 – 2002
DAFTAR RIW AYAT HIDUP
Data Pribadi