PENGENALAN POLA DALAM FUZZY CLUSTERING
DENGAN PENDEKATAN ALGORITMA GENETIKA
TESIS
OlehAYU NURIANA SEBAYANG
097038005/TINF
PROGRAM STUDI MAGISTER (S2) TEKNIK INFORMATIKA FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
M E D A N
PENGENALAN POLA DALAM FUZZY CLUSTERING
DENGAN PENDEKATAN ALGORITMA GENETIKA
TESIS
Diajukan sebagai salah satu syarat untuk memperoleh
gelar Magister Sains dalam Program Studi Magister Teknik Informatika pada Program Studi Magister (S2) Teknik Informatika Fakultas MIPA
Universitas Sumatera Utara
Oleh
AYU NURIANA SEBAYANG
097038005/TINF
PROGRAM STUDI MAGISTER (S2) TEKNIK INFORMATIKA FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
M E D A N
PENGESAHAN TESIS
Judul Tesis : PENGENALAN POLA DALAM
FUZZY CLUSTERING DENGAN
PENDEKATAN ALGORITMA
GENETIKA
Nama Mahasiswa : Ayu Nuriana Sebayang
Nomor Induk Mahasiswa : 097038005
Program Studi : Magister Teknik Informatika
Fakultas : Matematika dan Ilmu Pengetahuan Alam
Universitas Sumatera Utara
Menyetujui
Komisi Pembimbing
Syahril Effendi, S.Si, MIT Prof. Dr. Tulus
Anggota Ketua
Ketua Program Studi
Dekan
Prof. Dr. Muhammad Zarlis
PERNYATAAN ORISINALITAS
PENGENALAN POLA DALAM FUZZY CLUSTERING
DENGAN PENDEKATAN ALGORITMA GENETIKA
TESIS
Dengan ini saya nyatakan bahwa saya mengakui semua karya
tesis ini adalah hasil kerja saya sendiri kecuali kutipan dan
ringkasan yang tiap satunya dijelaskan sumbernya dengan benar.
Medan, 23 Juli 2011
PERNYATAAN PERSETUJUAN PUBLIKASI
KARYA ILMIAH UNTUK KEPENTINGAN
AKADEMIS
Sebagai sivitas akademis Universitas Sumatera Utara, saya yang bertanda tangan dibawah ini:
Nama : Ayu Nuriana Sebayang NIM : 097038005
Program Studi : Magister Teknik Informatika Jenis Karya Ilmiah : Tesis
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Sumatera Utara Hak Bebas Royalti Non-Eksklusif (Non-Exclusive
Royalty Free Right ) atas Tesis saya yang berjudul:
PENGENALAN POLA DALAM FUZZY CLUSTERING
DENGAN PENDEKATAN ALGORITMA GENETIKA
Beserta perangkat keras yang ada (jika diperlukan). Dengan Hak Bebas Royalti Non-Ekslusif ini, Universitas Sumatera Utara berhak menyimpan, mengalihkan media, memformat, mengelola dalam bentuk data-base, merawat dan mempublikasikan Tesis saya tanpa meminta izin dari saya selama tetap mencatumkan nama saya sebagai penulis dan sebagai pemegang dan atau sebagai pemilik hak cipta.Demikian pernyataan ini dibuat dengan sebenarnya.
Medan, 23 Juli 2011
Telah diuji pada Tanggal : 27 Juli 2011
PANITIA PENGUJI TESIS
KETUA : Prof. Tulus
RIWAYAT HIDUP
DATA PRIBADI
Nama lengkap berikut gelar : Ayu Nuriana Sebayang, S.Kom Tempat dan Tanggal Lahir : Medan, 17 September 1985
Alamat Rumah : Jl. Puskesmas I gg. Mawar No. 11 Medan Telepon/Faks/HP : 085261744566
Instansi Tempat Bekerja : STMIK/AMIK Logika Medan Alamat kantor : Jl. Yosudarso No. 374 C Medan Telepon/Faks/HP : 061-6618572
DATA PENDIDIKAN
KATA PENGANTAR
Puji Syukur Penulis ucapkan kepada Allah SWT atas segala limpahan rahmat dan karunia-Nya sehingga penulis dapat menyelesikan tesis ini dengan judul: PENGENALAN POLA DALAM FUZZY CLUSTERING DENGAN PENDEKATAN ALGORITMA GENETIKA.
Dengan selesainya tesis ini, penulis menyampaikan terima kasih sebesar-besarnya kepada:
Prof. Dr. dr. Syahril Pasaribu, DTM&H, M.Sc (CTM), Sp.A(K) selaku Rektor Universitas Sumatera Utara yang telah memberikan kesempatan kepada penulis untuk mengikuti dan menyelesaikan pendidikan Program Magister.
Dr. Sutarman, M.Sc selaku Dekan FMIPA USU atas kesempatan penulis menjadi mahasiswa pada Program Studi Magister Teknik Informatika.
Prof. Dr. Muhammad Zarlis, selaku Ketua Program Studi Magister Teknik Informatika FMIPA Universitas Sumatera Utara.
M. Andri Budiman, S.T., M.Comp Sc., M.E.M., selaku Sekretaris Program Studi Magister Teknik Informatika.
Prof. Dr. Tulus, selaku Pembimbing Utama yang telah banyak memberikan bimbingan dan arahan serta motivasi kepada penulis.
Syahril Effendi, S.Si, M.I.T., selaku Pembimbing Kedua yang telah banyak memberikan bimbingan dan arahan serta motivasi kepada penulis.
Seluruh Staff Pengajar yang telah banyak memberikan ilmu pengetahuan selama masa perkuliahan serta
Seluruh Staff Pegawai pada Program Magister Teknik Informatika FMIPA Universitas Sumatera Utara.
Ucapan terima kasih juga penulis ucapkan kepada sahabat-sahabat terbaik, Raihan, Ari Eka, Silvia, Tetty, Rosita, Yani Maulita, Ramliana dan rekan-rekan kuliah angkatan ’09 yang telah memberikan semangat kepada penulis.
Akhir kata penulis hanya berdoa kepada Allah SWT semoga Allah memberikan limpahan karunia kepada semua pihak yang telah memberikan bantuan, perhatian, serta kerja samanya kepada penulis dalam menyelesaikan tesis ini.
Medan, 23 Juli 2011 Penulis
PENGENALAN POLA DALAM FUZZY CLUSTERING
DENGAN PENDEKATAN ALGORITMA GENETIKA
ABSTRAK
Masalah mengelompokkan data dengan suatu pola dalam cluster untuk menentukan pusat cluster berdasarkan derajat kesamaan yang diukur dari fungsi jarak. Dengan menggunakan mekanisme operator genetik yaitu persilangan dan mutasi populasi dievolusikan melalui fungsi fitness yang diarahkan pada kondisi konvergensi. Algoritma ini dapat diterapkan dalam banyak area fungsi-fungsi optimasi, penerapannya adalah fungsi objektif berbasis fuzzy clustering. Penulis menggunakan Fuzzy C-Means yaitu algoritma pengklusteran untuk mengkluster IPM (Indeks Pembangunan Manusia) dari setiap Propinsi di Indonesia dengan membagi Propinsi dalam beberapa cluster. Pada pendekatan algoritma genetika untuk penyelesaian fuzzy clustering ditempuh pilihan untuk menggunakan pendekatan Prototype-based algorithms, yaitu mengevolusikan matrik pusat cluster dengan menentukan fungsi fitness
∑∑
= = −
= c i
n
k
k i ik ikD v 1 1
2
) x ( )
V U, (
Jm µ .
INTRODUCTION OF PATTERN IN FUZZY CLUSTERING
BY GENETIC ALGORITHM APPROACH
ABSTARCT
The classification of data by pattern in a cluster to determine the cluster center based on the equality level measured by distance function. By using genetic operator mechanism, i.e. crossing and population mutation in evolution through the fitness function that directed to the convergence condition. This algorithm can be applied in any optimization function area, its application is fuzzy clustering based objective function. The writer using the Fuzzy C-Means, i.e. clustering algorithm for IPM clustering (Human Development Index) in each Province in Indonesia by classified the provinces into any clusters. In the genetic algorithm approach in solving the fuzzy clustering is conducted by alternative for using the Prototype based algorithm approach, i.e. evolution of cluster center matrix by
determining the fitness function
∑∑
= = −
= c i
n
k
k i ik ikD v 1 1
2
) x ( )
V U, (
Jm µ .
DAFTAR ISI
Halaman
PENGESAHAN iii
PERNYATAAN ORISINALITAS iv
PERNYATAAN PERSETUJUAN PUBLIKASI KARYA
ILMIAH UNTUK KEPENTINGAN AKADEMIS v PENETAPAN PANITIA PENGUJI TESIS vi
RIWAYAT HIDUP vii
KATA PENGANTAR viii
ABSTRAK x
ABSTRACT xi
DAFTAR ISI xii
DAFTAR GAMBAR xiv
DAFTAR TABEL xv
BAB I PENDAHULUAN 1
1.1 Latar Belakang Masalah 1
1.2 Perumusan Masalah 3
1.3 Batasan Masalah 4
1.4 Tujuan Penelitian 4
1.5 Manfaat Penelitian 4
BAB II TINJAUAN PUSTAKA 5
2.1 Pengenalan Pola 5
2.2 Teknik Pengenalan Pola 5
2.2.1. Evaluasi Ciri Melalui Ukuran-Ukuran Fuzzy 6 2.2.2. Pendekatan Teoritik Keputusan 7
2.3.1 Pengertian Algoritma genetika 8
2.3.2 Encoding 9
2.3.3 Fungsi fitness 10
2.3.4 Seleksi 11
2.3.5 Crossover 11
2.3.6 Mutasi 11
2.3.7 Konsep Penggunaan Algoritma Genetika 11
2.4 Logika Fuzzy 12
2.4.1 Pengertian Logika Fuzzy 12
2.4.2 Fungsi Keanggotaan 13
2.4.3 Proses Sistem Fuzzy 14
2.5 Fuzzy Cluestering 14
2.5.1 Algoritma Fuzzy Clustering dengan Pendekatan Algoritma genetika (Genetic Guided Algorithm for
Fuzzy C-Means = GGA-FCM) 15 2.5.2. Parameter dalam Algoritma Genetika 18 2.5.3. Validitas Clustering dan Classification Rate 18 2.5.4. Algoritma Fuzzy clustering konvensional 19
2.5.5. Fuzzy C-Means 19
BAB III METODOLOGI PENELITIAN 22
3.1. Rancangan 22
3.2. Pelaksanaan Penelitian 22
3.3. Variabel Yang Diamati 22
3.3.1. Ukuran Fuzzy 23
3.3.2. Diagram Alir 23
BAB IV ANALISIS DAN PEMBAHASAN 26
4.1. Data Perkembangan Indeks Pembangunan
Manusia untuk tingkat propinsi Indonesia 26
4.1.1. Metode Perhitungan IPM 26
4.2.1. Pengolahan Data 28
4.2.2. Analisis dengan algoritma genetika 35
A. Penentuan populasi 35
B. Penentuan Fitness 35
BAB V KESIMPULAN DAN SARAN 38
5.1. Kesimpulan 38
5.2. Saran 38
PENGENALAN POLA DALAM FUZZY CLUSTERING
DENGAN PENDEKATAN ALGORITMA GENETIKA
ABSTRAK
Masalah mengelompokkan data dengan suatu pola dalam cluster untuk menentukan pusat cluster berdasarkan derajat kesamaan yang diukur dari fungsi jarak. Dengan menggunakan mekanisme operator genetik yaitu persilangan dan mutasi populasi dievolusikan melalui fungsi fitness yang diarahkan pada kondisi konvergensi. Algoritma ini dapat diterapkan dalam banyak area fungsi-fungsi optimasi, penerapannya adalah fungsi objektif berbasis fuzzy clustering. Penulis menggunakan Fuzzy C-Means yaitu algoritma pengklusteran untuk mengkluster IPM (Indeks Pembangunan Manusia) dari setiap Propinsi di Indonesia dengan membagi Propinsi dalam beberapa cluster. Pada pendekatan algoritma genetika untuk penyelesaian fuzzy clustering ditempuh pilihan untuk menggunakan pendekatan Prototype-based algorithms, yaitu mengevolusikan matrik pusat cluster dengan menentukan fungsi fitness
∑∑
= = −
= c i
n
k
k i ik ikD v 1 1
2
) x ( )
V U, (
Jm µ .
INTRODUCTION OF PATTERN IN FUZZY CLUSTERING
BY GENETIC ALGORITHM APPROACH
ABSTARCT
The classification of data by pattern in a cluster to determine the cluster center based on the equality level measured by distance function. By using genetic operator mechanism, i.e. crossing and population mutation in evolution through the fitness function that directed to the convergence condition. This algorithm can be applied in any optimization function area, its application is fuzzy clustering based objective function. The writer using the Fuzzy C-Means, i.e. clustering algorithm for IPM clustering (Human Development Index) in each Province in Indonesia by classified the provinces into any clusters. In the genetic algorithm approach in solving the fuzzy clustering is conducted by alternative for using the Prototype based algorithm approach, i.e. evolution of cluster center matrix by
determining the fitness function
∑∑
= = −
= c i
n
k
k i ik ikD v 1 1
2
) x ( )
V U, (
Jm µ .
BAB I
PENDAHULUAN
1.1. Latar Belakang Masalah
Indeks Pembangunan Manusia (IPM) / Human Development Index (HDI) adalah pengukuran perbandingan dari mengklasifikasikan apakah sebuah negara adal kebijaksanaan ekonomi terhadap kualitas hidup.
Sejak tahun 1969 Indonesia menerapkan planned economy dengan pola
growth first then distribution of wealth. Planned economy ini menunjukkan
keberhasilan terutama dilihat dari indikator makro ekonomi yaitu tingkat pertumbuhan ekonomi yang tinggi, pertumbuhan pendapatan yang tinggi, tingkat inflasi yang rendah, kestabilan nilai tukar rupiah, rendahnya tingkat pengangguran dan perbaikan sarana perekonomian. Data ekonomi periode 1970-1980 mengenai ekonomi dan distribusi pendapatan terutama di LDC (Less Developing Country), khususnya dinegara-negara yang mempunyai tingkat pertumbuhan ekonomi yang cukup pesat antara pertumbuhan ekonomi dan tingkat kesenjangan ekonomi. Semakin tinggi pendapatan per kapita maka semakin besar perbedaan si miskin dan si kaya.
Berdasarkan fakta tersebut muncul pertanyaan mengapa terjadi trade off antara pertumbuhan dan kesenjangan ekonomi dan berapa lama akan terjadi?. Kerangka pemikiran tersebut melandasi Hipotesis Kuznetz, yaitu dalam jangka pendek ada korelasi yang positif antara pertumbuhan pendapatan per kapita dan kesenjangan pendapatan. Namun dalam jangka panjang hubungan keduanya menjadi korelasi negatif. Sebagai indicator pembangunan manusia, UNDP(United
Nations Development Programme) mengembangkan Human Development Index
menghasilkan suatu ukuran untuk merefleksikan upaya pembangunan manusia wilayah, yaitu:
1. hidup yang sehat dan panjang umur yang diukur dengan saat kelahiran
2. Pengetahuan yang diukur dengan angka dewasa (bobotnya dua per tiga) dan kombinasi pendidikan dasar, menengah, atas
3. standard kehidupan yang layak diukur dengan logaritma natural dari
Pengenalan pola serta ajar mesin (mesin learning) dewasa ini telah membentuk suatu bidang yang sangat luas dari kegiatan riset serta pengembangan yang meliputi pemrosesan gambar, serta informasi bukan-numerik lainnya yang diperoleh dari interaksi antara ilmu pengetahuan, teknik, dan masyarakat. Motivasi kedua yang mendorong kegiatan dalam bidang ini adalah kebutuhan manusia untuk berkomunikasi dengan mesin komputer dalam modus-modus komunikasi alami. Perhatian yang muncul telah menciptakan suatu kebutuhan yang meningkat akan metode serta teknik yang lebih baru untuk mendesain teknik yang lebih baru untuk desain pengenalan pola dan system ajar (learning system). Dari beberapa pendekatan yang telah diusulkan serta diteliti, dua teknik yang dibahas untuk pemecahan masalah dalam pengenalan pola serta ajar mesin adalah teori keputusan dan estimasi statistic, serta pendekatan sintatik (linguistic) sebagai bentuk asli dari teori linguistic matematik (Pal dan Majumder 1989).
Algoritma genetika (AG) adalah algoritma pencarian heuristik yang didasarkan atas mekanisme evolusi biologis. Keberagaman pada evolusi biologis adalah variasi dari kromosom antar individu organisme. Variasi kromosom ini akan mempengaruhi laju reproduksi dan tingkat kemampuan organisme untuk tetap bertahan hidup (Kusumadewi 2005).
oleh Holland tahun 1975, algoritma genetika (Genetic Algoritms=GA) terus mengalami perkembangan dalam banyak aplikasi (Gen dan Cheng 2000).
Pesatnya perkembangan aplikasi GA pada berbagai problem optimasi dipacu oleh perkembangan teknologi komputer dan mikro prosessor. Salah satu minat dalam aplikasi genetic-fuzzy system adalah genetic-fuzzy clustering. Pada fuzzy clustering berbasis fungsi tujuan persoalan mencari kluster terbaik akan identik dengan persoalan optimasi fungsi tujuan algoritma genetika untuk fuzzy clustering dimungkinkan dapat meningkatkan unjuk kerja fuzzy clustering. John Holland menyatakan bahwa setiap masalah yang berbentuk adaptasi (alami maupun buatan) dapat diformulasikan ke dalam terminologi genetika. Sifat algoritma genetika adalah mencari kemungkinan-kemungkinan dari calon solusi untuk mendapatkan yang optimal bagi penyelesaian masalah.
Fuzzy clustering adalah salah satu teknik untuk menentukan kluster optimal dalam suatu ruang vektor yang didasarkan pada bentuk normal Euclidian untuk jarak antar vektor. Fuzzy clustering sangat berguna bagi pemodelan fuzzy terutama dalam mengidentifikasi atura-aturan fuzzy (Kusumadewi 2004)..
Ada beberapa algoritma clustering data, salah satu diantaranya adalah Fuzzy C-Means (FCM). Fuzzy C-Means adalah suatu teknik pengklusteran data yang mana keberadaan tiap-tiap titik data dalam suatu kluster ditentukan oleh derajat keanggotaan. Teknik ini pertama kali diperkenalkan oleh Jim Bezdek pada tahun 1981. Konsep dasar FCM adalah menentukan pusat kluster yang akan menandai lokasi rata-rata untuk tiap-tiap kluster. Pada kondisi awal, pusat cluser masih belum akurat. Dengan cara memperbaiki pusat kluster dan nilai keanggotaan tiap-tiap data secara berulang, maka akan dapat dilihat bahwa pusat kluster akan bergerak menuju lokasi yang tepat (Kusumadewi 2004).
1.2. Perumusan Masalah
1.3. Batasan Masalah
Adapun batasan masalah dari penulisan ini adalah:
1. Parameter yang digunakan dalam proses pengklusteran dengan menggunakan algoritma FCM.
2. Data yang dianalisis sebanyak 33 terdiri atas tiap-tiap Propinsi di Indonesia.
1.4. Tujuan Penelitian
Berdasarkan uraian pada latar belakang masalah dan perumusan masalah diatas, maka tujuan yang ingin dicapai dalam penelitian ini adalah untuk mengidentifikasi unsur IPM yang kuat dan masih lemah untuk tiap-tiap propinsi di Indonesia dalam penentuan kluster yang merupakan persoalan optimasi fungsi tujuan pada algoritma genetika.
1.5. Manfaat Penelitian
Manfaat yang diperoleh dari penelitian ini adalah sebagai berikut:
a. Memberikan kontribusi bagi penelitian lanjutan dalam bidang pengenalan pola dalam peningkatan kinerja fuzzy clustering.
b. Hasil penelitian ini diharapkan dapat memberikan masukan pada manajemen perusahan sebagai dasar untuk menentukan pusat kluster yang akan menandai lokasi rata-rata untuk tiap-tiap kluster.
BAB II
TINJAUAN PUSTAKA
2.1. Pengenalan Pola
Sebuah pola adalah setiap antar hubungan data (analog atau digital), kejadian atau konsep yang dapat dibedakan. Pengenalan pola merupakan bidang dalam pembelajaran mesin dan dapat diartikan sebagai tindakan mengambil data mentah dan bertindak berdasarkan klasifikasi data. Dengan demikian, pengenalan pola merupakan himpunan kaidah bagi pembelajaran diselia (supervised learning).
Ada beberapa definisi lain tentang pengenalan pola, di antaranya:
1. Penentuan suatu objek fisik atau kejadian ke dalam salah satu atau beberapa kategori.
2. Ilmu pengetahuan yang menitikberatkan pada deskripsi dan klasifikasi (pengenalan) dari suatu pengukuran.
3. Suatu pengenalan secara otomatis suatu bentuk, sifat, keadaan, kondisi, susunan tanpa keikutsertaan manusia secara aktif dalam proses pemutusan. Berdasarkan beberapa definisi di atas, pengenalan pola dapat didefinisikan sebagai cabang kecerdasan yang menitik-beratkan pada metode pengklasifikasian objek ke dalam klas-klas tertentu untuk menyelesaikan masalah tertentu. Salah satu aplikasinya adalah pengenalan suara, klasifikasi teks dokumen dalam kategori (contoh. surat-E spam/bukan-spam), pengenalan tulisan tangan, pengenalan kode pos secara otomatis pada sampul surat, atau sistem pengenalan wajah manusia. Aplikasi ini kebanyakan menggunakan analisis citra bagi pengenalan pola yang berkenaan dengan citra digital sebagai input ke dalam sistem pengenalan pola.
2.2. Teknik Pengenalan Pola
teks dll.), pengiraan ciri-ciri, pengkelasan dan akhirnya post-pemrosesan berdasarkan kelas pengenalan dan aras keyakinan. Pengenalan pola itu sendiri khususnya berkaitan dengan langkah pengkelasan. Dalam kasus tertentu, sebagaimana dalam pengambilan juga boleh dilaksanakan secara semi otomatis atau otomatis sepenuhnya. Untuk penyelesaian masalah dengan pengkelasan dapat dilakukan dengan tiga cara .
Pertama adalah mencari peta ruang ciri (feature space) (biasanya berbagai dimensi membagi ruang ciri menjadi kawasan-kawasan, kemudian meletakkan label kepada setiap kaw probabilitas, sebelum diterapkannya post-processing.
Masalah kedua adalah dengan menganggap masalah sebagai suatu kemungkinan, dimana konsepnya adalah kondisi probabilitas bagi bentuk
... (2.1) dimana input vektor ciri adalah , dan fungsi f biasanya diparameter oleh sebagian parameter . Dalam pendekata berlainan dengan memilih satu vektor parameter , hasil dibentuk bagi kesemua kelas yang mungkin, sesuai urutan berdasarkan data latihan D:
... (2.2) Masalah ketiga terkait dengan masalah kedua, tetapi masalahnya adalah untuk kondisi probabilitas bersyarat (conditional probability) dan kemudian menggunaka sebagaimana dalam masalah kedua.
2.2.1. Evaluasi Ciri Melalui Ukuran-Ukuran Fuzzy
berguna untuk mencapainya yaitu transformasi kluster yang memaksimum dan meminimumkan jarak dengan menggunakan transformasi diagonal sehingga bobot-bobot yang lebih kecil memiliki variansi yang lebih besar.
Data-data atau pola yang terpilih akan di kelompokkan menjadi beberapa kluster dengan parameter yang digunakan untuk proses pengklusteran yaitu:
1. Jumlah kluster yang akan dibentuk. 2. Pembobot.
3. Maksimum iterasi. 4. Kriteria penghentian.
2.2.2. Pendekatan Teoritik Keputusan
Pengenalan pola komputer dapat dipandang sebagai tugas yang berisikan ajar (learning) perilaku-perilaku invarian dan lazim dari sekumpulan sampel yang mencirikan sebuah kelas, dan memutuskan sebuah sampel baru. Langkah pengoperasian yang perlu dalam mengembangkan serta melaksanakan aturan keputusan dalam sistem pengenalan pola praktis, ditunjuk dalam blok-blok sebagai berikut:
Gambar 2.1. Tahap Pengoperasian Suatu sistem pengenalan pola
Sebuah sistem fisis untuk tujuan pengenalan pola ditandai oleh beberapa perwujudan fisisnya yang dinyatakan secara numerik yang membentuk ruang pengukuran. Pemilihan dan ekstraksi feature dalam pengenalan pola merupakan proses pemilihan sebuah pemetaan bentuk X = f(Y) yang berasal dari sampel Y(y1,
y2,...., yQ) dalam ruang dimensi yang ditransformasi ke suatu titik X (x1, x2,....,
xN). Fungsi f(Y) akan meminimumkan jarak dan memaksimumkan jarak dalam ruang feature. Proses penurunan sebuah aturan keputusan berdasarkan sekumpulan sampel untuk mengklasifikasi suatu titik dalam ruang feature terhadap sampel.
SISTEM FISIS RUANG
PENGUKURAN
RUANG KEPUTUSAN RUANG CIRI
2.3. Algoritma Genetika
2.3.1. Pengertian Algoritma Genetika
Menurut Desiani dan Arhami (2005), Algoritma genetika (AG) merupakan suatu algoritma pencarian yang berbasis pada mekanisme yang memanfaatkan proses seleksi alamiah yang dikenal dengan proses evolusi. Dalam proses evolusi, individu secara terus-menerus mengalami perubahan gen untuk menyesuaikan dengan lingkungan hidupnya dan hanya individu yang kuat yang mampu bertahan. Proses seleksi alamiah ini melibatkan perubahan gen yang terjadi pada individu melalui proses perkembangbiakan. Dalam algoritma genetika ini, proses perkembang-biakan ini menjadi proses dasar yang menjadi tujuan untuk mendapatkan keturunan yang lebih baik.
Algoritma genetika (AG) adalah algoritma pencarian heuristik yang didasarkan atas mekanisme evolusi biologis. Keberagaman pada evolusi biologis adalah variasi dari kromosom antar individu organisme. Variasi kromosom ini akan mempengaruhi laju reproduksi dan tingkat kemampuan organisme untuk tetap bertahan hidup. Yang membedakan algoritma genetika dengan berbagai algoritma konvensional lainnya adalah bahwa algoritma memulai dengan suatu himpunan penyelesaian acak awal yang disebut populasi (Kusumadewi 2005).
Algoritma genetika digunakan untuk penyelesaian masalah optimasi yang kompleks dan sukar diselesaikan dengan menggunakan metode yang konvensional. Sebagaimana halnya proses evolusi di alam, suatu algoritma genetika yang sederhana umumnya terdiri dari tiga operator yaitu: operator reproduksi, operator crossover (persilangan) dan operator mutasi. Struktur umum dari suatu algoritma genetika dapat didefinisikan dengan langkah-langkah sebagai berikut:
2. Membentuk generasi baru, Dalam membentuk digunakan tiga operator yang telah disebut di atas yaitu operator reproduksi/seleksi, crossover dan mutasi. Proses ini dilakukan berulang-ulang sehingga didapatkan jumlah kromosom yang cukup untuk membentuk generasi baru dimana generasi baru ini merupakan representasi dari solusi baru.
3. Evaluasi solusi, Proses ini akan mengevaluasi setiap populasi dengan menghitung nilai fitness setiap kromosom dan mengevaluasinya sampai terpenuhi kriteria berhenti. Bila kriteria berhenti belum terpenuhi maka akan dibentuk lagi generasi baru dengan mengulangi langkah 2.
Sejak dikembangkan sampai saat ini GA ini terus menjadi objek riset dalam berbagai aplikasi. Alasan mengapa GA banyak menjanjikan, antara lain banyak problem dibidang sains dan teknik tidak dapat dipecahkan dengan algoritma deterministik biasa meskipun dengan waktu yang meningkat secara polynomial. Secara umum algoritma ini memiliki prosedur yang dapat dirumuskan sebagai berikut
Procedure Genetic Algorithms Begin t←0 initialize P(t) evaluate P(t) while (not termination condition ) do begin recombine P(t) to yield C(t) evaluate C(t)
select P(t+1) from P(t) and C(t) t ← t+1
end end
Dengan t = generasi, P(t)= Populasi pada generasi t, dan C(t)=Populasi tambahan atau individu baru (offspring) dari hasil proses operasi genetik Crossover dan Mutasi.
2.3.2. Encoding
dibangkitkan secara random yang menjangkau keseluruhan ruang solusi. Proses evolusi dilakukan dengan melakukan operasi genetik (cross-over dan mutasi) dan melakukan seleksi kromosom untuk generasi berikutnya sampai sejumlah generasi yang dikehendaki dengan panduan fungsi fitness.
Algoritma genetika pada dua ruang, yaitu ruang solusi (disebut phenotip) dan ruang coding (disebut genotip). Operasi genetika (cross over dan mutasi) dilakukan pada ruang genotip sementara operasi seleksi dilakukan pada ruang phenotip. Dalam binary encoding variabel keputusan diwakili oleh deretan bit 0,1 yang panjangnya disesuaikan dengan ruang pencarian. Tiap bit 0,1 dapat dianggap sebagai sebuah gen. Untuk optimasi 2 variabel misalnya, maka solusi adalah x1 dan x
Integer dan literal permutation encoding adalah kode terbaik untuk problem combinatorial optimization karena inti dari problem ini adalah mencari kombinasi atau permutasi terbaik dari item solusi terhadap kendala yang ada. Untuk problem yang lebih komplek encoding menggunakan data struktur yang lebih sesuai.
2.
2.3.3. Fungsi Fitness
Fungsi fitness adalah fungsi yang digunakan untuk menentukan apakah suatu kromosom layak bertahan. Pada setiap generasi dipilih kromosom yang mendekati solusi dengan mengevaluasi fungsi kecocokan dari kromosom tersebut. Fungsi ini didefinisikan sedemikian sehingga semakin besar nilai fitness semakin besar probabilitas untuk terseleksi pada generasi berikutnya. Untuk maksimasi maka fungsi tujuan dapat dijadikan sebagai fungsi fitness, sehingga kromosom yang mewakili nilai fungsi besar akan memiliki probabilitas terseleksi yang besar juga. Untuk minimasi dapat dirumuskan sedemikian sehingga fungsi tujuan yang semakin kecil maka memiliki fungsi fitness yang besar (Fadlisyah 2009).
fitness(x) = f(x)+p(x)
2.3.4. Seleksi
Setiap anggota populasi diwakili deretan string (disebut kromosom) dengan panjang tertentu. Elemen string tersebut dapat berupa digit 0,1 (untuk binary encoding), bilangan real (untuk real encoding), atau elemen lain. Untuk ukuran populasi N yang biasanya dipertahankan tetap prosedur seleksi diperlukan untuk memilih anggota populasi yang mana yang akan tetap eksis pada generasi berikutnya.
Fungsi fitness digunakan untuk menentukan apakah kromosom layak dipertahankan atau tidak dalam generasi berikutnya. Sebelum dilakukan seleksi jumlah anggota populasi ditambah dengan hasil offspring dari proses operasi genetik yang dapat berupa cross over dan mutasi. Hasil operasi genetik dan populasi semula selanjutnya diseleksi dengan metode tertentu untuk diambil n anggota populasi yang terbaik. Untuk kasus minimasi maka yang terpilih adalah n anggota populasi dengan nilai fitness yang terkecil.
2.3.5. Crossover
Proses operasi crossover dirancang untuk mencari kemungkinan yang lebih baik dari anggota populasi yang telah ada. Dari pasangan induk yang terpilih berdasarkan seleksi fungsi fitness diambil sejumlah pasangan dengan probabilitas Pc untuk dikenakan operasi crossover.
2.3.6. Mutasi
2.3.7. Konsep Penggunaan Algoritma Genetika (GA)
GA bekerja dengan modalitas coding dari set parameter, tetapi tidak menghitung parameter sendiri. Setiap langkah di GA adalah mencari solusi dari suatu kelompok ke kelompok lain dalam ruang solusi bukan dari solusi untuk solusi lain. GA memanfaatkan probabilitas transisi dari aturan kepastian. GA hanya memanfaatkan informasi fungsi objek tetapi tidak proses derivasi dan informasi tambahan lainnya.
GA disediakan dengan paralelisme operasi, dan dapat menilai beberapa data atau titik pada waktu yang sama dalam ruang pencarian yang rumit, yang hasilnya adalah tepat untuk mencari solusi optimal global dalam ruang solusi multi-nilai. Hal ini merawat kualitas individu kelompok berkembang setiap kali dalam proses GA, yaitu kualitas solusi masalah, yang berbeda dari algoritma optimasi banyak yang membutuhkan informasi rekursif atau semua informasi dari masalah seperti struktur dan parameter. Sehingga, GA sangat cocok untuk solusi masalah waktu yang tidak terbatas atau masalah nonlinier yang rumit (Wang 2008).
2.4. Logika Fuzzy
2.4.1 Pengertian Logika Fuzzy
Logika fuzzy digunakan untuk menterjemahkan suatu besaran yang diekspresikan menggunakan bahasa (linguistic), misalkan besaran kecepatan laju kendaraan yang diekspresikan dengan pelan, agak cepat, cepat, dan sangat cepat. Dan logika fuzzy menunjukan sejauh mana suatu nilai itu benar dan sejauh mana suatu nilai itu salah. Tidak seperti logika klasik (scrisp)/tegas, suatu nilai hanya mempunyai 2 kemungkinan yaitu merupakan suatu anggota himpunan atau tidak. Derajat keanggotaan 0 (nol) artinya nilai bukan merupakan anggota himpunan dan 1 (satu) berarti nilai tersebut adalah anggota himpunan.
Logika fuzzy adalah suatu cara yang tepat untuk memetakan suatu ruang input kedalam suatu ruang output, mempunyai nilai kontiniu. Fuzzy dinyatakan dalam derajat dari suatu keanggotaan dan derajat dari kebenaran. Oleh sebab itu sesuatu dapat dikatakan sebagian benar dan sebagian salah pada waktu yang sama (Kusumadewi 2006).
Kelebihan dari teori logika fuzzy adalah kemampuan dalam proses penalaran secara bahasa (linguistic reasoning). Sehingga dalam perancangannya tidak memerlukan persamaan matematik dari objek yang akan dikendalikan.
2.4.2. Fungsi Keanggotaan
Dalam penelitian ini untuk mendapatkan derajat keanggotaan adalah dengan pendekatan fungsi keanggotaan yang direpresentasikan dalam bentuk kurva bahu. Membership function ditentukan dari awal yang direpresentasikan menggunakan kurva bahu.
1. Cosinus antara dua titik x dan y didefinisikan sebagai:
y
x
y
x
T=
θ
cos
... (2.3)dimana x didefinisikan sebagai
∑
= n i i x 1 2 2. Kovarian
Kovarian antara dua data didefinisikan sebagai berikut: cov( , ) 1 ( )( )
1 Υ − − =
∑
= i n ii X Y
X n y
x ... (2.4) dimana x adalah data pertama dan y data kedua.
3. Koefisien korelasi y x
y
x
y
x
r
σ
σ
)
,
cov(
)
,
(
=
... (2.5)2.4.3. Proses Sistem Fuzzy
Sebuah sistem fuzzy akan memiliki struktur proses sebagai berikut:
1. Fuzzification (fuzzifikasi), yaitu proses memetakan crisp input ke dalam himpunan fuzzy. Hasil dari proses ini berupa fuzzy input dalam bentuk rule fuzzy.
2. Rule evaluation (rule evaluasi), yaitu proses melakukan penalaran terhadap fuzzy input yang dihasilkan oleh proses fuzzification berdasarkan aturan fuzzy yang telah dibuat. Proses ini menghasilkan fuzzy output.
digunakan adalah metode centroid dan metode largest of maximum (LOM).
2.5. Fuzzy Clustering
Fuzzy clustering adalah salah satu teknik untuk menentukan kluster optimal dalam suatu ruang vektor yang didasarkan pada bentuk normal euclidian untuk jarak antar vektor. Fuzzy clustering sangat berguna bagi pemodelan fuzzy terutama dalam mengindentifikasi aturan-aturan fuzzy. Metode clustering merupakan pengelompokkan data beserta parameternya dalam kelompok-kelompok sesuai kecenderungan sifat dari masing-masing data tersebut (kesamaan sifat) (Kusumadewi 2004).
Ada dua pendekatan dalam clustering yaitu partisioning dan hirarki. Dalam postioning, dengan mengelompokkan obyek x1, x2,...,xn kedalam c kluster. Hal ini dilakukan untuk menentukan pusat kluster awal, lalu dilakukan realokasi obyek berdasarkan kriteria tertentu sampai dicapai pengelompokkan yang optimum. Sedangkan dalam kluster hirarki yaitu dengan membuat m kluster dimana setiap kluster beranggotakan satu obyek dan berakhir dengan satu kluster dimana anggotanya adalah m obyek. Pada setiap tahap prosedurnya, satu kluster digabung dengan satu kluster yang lain. Lalu dengan memilih berapa jumlah kluster yang diinginkan dengan menentukan cut-off pada tingkat tertentu.
2.5.1. Algoritma Fuzzy Clustering dengan Pendekatan Algoritma Genetika (Genetic Guided Algorithm for Fuzzy C-Means = GGA-FCM)
Pada pendekatan algoritma genetika untuk penyelesaian fuzzy clustering ditempuh pilihan untuk menggunakan pendekatan Prototype-based algorithms, yaitu mengevolusikan matrik pusat kluster V. Beberapa hal yang ditentukan adalah:
∑∑
= = − = c i n k k i ik ikD v 1 1 2 ) x ( ) V U, ( [image:32.595.165.465.244.301.2]Jm µ ... (2.6) Encoding dan Struktur kromosom: Encoding yang digunakan adalah real encoding. Struktur kromosom untuk V dalam populasi yang dievolusikan adalahvektor real beranggotakan cxp elemen (c=cacah kluster dan p cacah elemen dalam objek).
Gambar 2.2. Struktur Kromosom untuk Encoding V
Berdasarkan Algoritma Genetika digunakan fuzzy clustering untuk mengatasi 6 hal yaitu (Wang 2008):
1. Menghasilkan kelompok awal.
Populasi awal terdiri dari individu awal yang dihasilkan secara acak yang jumlahnya popsize. Delegasi kromosom A data titik, yaitu berisi lokasi setiap data dalam pengelompokan ruang. Jika jumlah popsize terlalu kecil, situasi akan keluar keragaman, jika jumlah popsize terlalu besar, clustering akan menghabiskan banyak waktu.
2. Menentukan pengkodean.
memilih coding, pengkodean dan operasi crossover dan kemudian proses pengkodean biner.
3. Menentukan fungsi fitness.
Hal ini mencerminkan bahwa seberapa kuat kemampuan pas individu untuk keadaan adalah dengan fungsi fitness.
4. Untuk menentukan metode operasi GA.
Dalam operasi GA, metode yang harus ditentukan adalah terutama pemilihan, metode metode crossover dan mutasi.
5. Seleksi operator.
Dalam rangka warisan biologis dan evolusi alam, spesies yang memiliki daya adaptasi lebih tinggi untuk lingkungan hidup, akan memperoleh lebih banyak kesempatan untuk menyebarkan ke generasi berikutnya, sedangkan yang lebih rendah akan mendapatkan lebih sedikit. Meniru kursus ini, GA membuat individu dari grup diproses "kelangsungan bagi yang terkuat" dengan memanfaatkan operator seleksi.
6. Crossover operator.
Dalam tesis ini, operator crossover menerapkan metode persimpangan dua-titik. Probabilitas crossover tidak boleh terlalu kecil karena operasi crossover adalah pencarian global, mungkin dari 90 % menjadi 100 %.
2.5.2. Parameter dalam Algoritma Genetika
Parameter dalam dalam algoritma genetika adalah hal yang harus ditentukan dalam mengimplementasikan algoritma genetika ke dalam penyelesaian masalah. Parameter ini menentukan ukuran populasi, probabilitas penyilangan (Pc), dan probabilitas mutasi.
Probabilitas mutasi (Pm) dalam algoritma genetika seharusnya diberi nilai yang kecil karena tujuan mutasi adalah untuk menjaga perbedaan kromosom dalam populasi sehingga dapat menghindari konvergensi prematur.
terlalu sedikit maka algoritma genetika hanya mempunyai probabilitas yang kecil untuk melakukan penyilangan. Sebaliknya, jika jumlah kromosom dalam populasi terlalu banyak, maka algoritma genetika akan cenderung lambat dalam menemukan solusi.
Algoritma Genetika Untuk Fuzzy Clustering
Algoritma genetika (GA) sebagai teknik optimasi dapat diterapkan pada clustering yang berbasis optimasi fungsi tujuan. Pada pendekatan GA untuk fuzzy clustering fungsi fitness diambil dari fungsi objektif yang diminimumkan, yaitu Jm (U,V) (Widyastuti dan Hamzah 2007).
2.5.3. Validitas Clustering dan Classification Rate
Hasil akhir FCM atau GGA-FCM adalah V,U dan Rm tertentu untuk suatu c yang diinputkan. Pada beberapa kasus c yang tepat mungkin tidak diketahui. Untuk itu beberapa pendekatan telah diusulkan untuk menentukan berapa sebaiknya c sehingga hasil clustering dapat dianggap terbaik. Ukuran ini dikenal sebagai validitas clustering.
2.5.4. Algoritma Fuzzy Clustering konvensional
Berikut diuraikan algoritma fuzzy clustering konvensional, yaitu penyelesaian fuzzy clustering dengan cara iteratif dengan melakukan update pada matrik keanggotan U dan matrik prototipe kluster V. Dalam algoritma diperlukan sampel objek sebanyak n1
X ={x
, tiap objek p parameter, dituliskan :
1, x2,.... ,xn} xi R∈
I = 1,2,…,n. Ditentukan dalam proses penyelesaian melalui iterasi : P
U = [µικ
Berikut adalah algoritma yang diajukan : 1. Initialization step:
Tentukan: n = cacah objek yang akan dikluster; p = cacah parameter dalam tiap objek; c = cacah kluster; t = 0 (iterasi ke); m = derajat fuzziness = dipilih 2;
ε =nilai yang cukup kecil mendekati 0 Tentukan secara acak : U(0) dan V
2.
Iteration step :(0)
a) Dengan menggunakan U(t), hitung pusat kluster V(t)menurut rumus :
∑
==
n k ik m ik m ik ix
11
V
µ
µ
... Untuk i=1,2,...,c. (2.7)b) Dengan menggunakan V(t)
∑
= −
−
−
=
c j m j k m i k ikv
x
v
x
1 2 ) 1 /( 1 21
1
µ
, hitung derajat keanggotaan dengan rumus:
... (2.8)
c) Jika max (µik(t) − µik(t−1) ) < ε berhenti, Jika tidak ulangi langkah 2.a.
2.5.5. Fuzzy C-Means
Ada beberapa algoritma clustering data, salah satu diantaranya adalah Fuzzy C-Means. Fuzzy C-Means adalah suatu teknik pengklusteran yang mana keberadaannya tiap-tiap titik data dalam suatu kluster ditentukan oleh derajat keanggotaan. Teknik ini pertama kali diperkenalkan oleh Jim Bezdek pada tahun 1981.
sehingga data dapat menjadi anggota dari semua kelas atau kluster terbentuk dengan derajat atau tingkat keanggotaan yang berbeda antara 0 hingga 1.
Konsep dari Fuzzy C-Means pertama kali adalah menentukan pusat kluster, yang akan menandai lokasi rata-rata untuk tiap-tiap kluster. Pada kondisi awal, pusat kluster ini masih belum akurat. Tiap-tiap titik data memiliki derajat keanggotaan untuk tiap-tiap kluster. Dengan cara memperbaiki pusat kluster dan derajat keanggotaan tiap-tiap titik data secara berulang, maka akan dapat dilihat bahwa pusat kluster akan bergerak menuju lokasi yang tepat. Perulangan ini didasarkan pada minimasi fungsi obyektif yang menggambarkan jarak dari titik data yang diberikan kepusat kluster yang terbobot oleh derajat keanggotaan titik data tersebut.
Output dari Fuzzy C-Means merupakan deretan pusat kluster dan beberapa derajat keanggotaan untuk tiap-tiap titik data. Informasi ini dapat digunakan untuk membangun suatu fuzzy inference system.
Algoritma Fuzzy C-Means
Algoritma Fuzzy C-Means adalah sebagai berikut (Ross, 2005):
1. Input data yang akan dikluster X, berupa matriks berukuran n x m (n=jumlah sample data, m=atribut setiap data).
X = data sample kei (i=1,2,…,n), atribut ke-j (j=1,2,…,m).
2. Tentukan:
a. Jumlah kluster = c; b. Pangkat = w;
c. Maksimum iterasi = MaxIter; d. Error terkecil yang diharapkan = ζ; e. Fungsi obyektif awal = P=0; f. Iterasi awal = t=1;
BAB III
METODOLOGI PENELITIAN
3.1. Rancangan
Penelitian yang dilaksanakan adalah berupa penelitian eksplanatif artinya penelitian yang menjelaskan secara keseluruhan dari obyek yang diteliti dalam batas-batas tertentu. Penelitian ini menjelaskan kondisi pembangunan manusia untuk meningkatkan partisipasi masyarakat dalam proses pembangunan. Keberhasilan pembangunan dewasa ini sering dilihat dari pencapaian kualitas sumber daya manusia untuk meningkatkan kualitas SDM, baik aspek fisik (kesehatan), aspek intelektualitas (pendidikan) dan aspek ekonomi (berdaya beli) sehingga partisipasi masyarakat dalam pembangunan akan dengan sendirinya meningkat.
3.2. Pelaksanaan Penelitian 1. Studi Literatur
Merupakan sumber yang dapat sajikan rujukan dari sumber data. 2. Pengumpulan Data
Data diambil dari jurnal atau buku yang bersangkutan. 3. Analisis Data
Melakukan analisis terhadap data untuk mengenali lebih lanjut data yang mengandung pola permasalahan.
3.3. Variabel Yang Diamati
Berdasarkan pembahasan diatas yang dikemukakan atribut penelitian adalah data yang merupakan sampel dalam beberapa variabel.
3.3.1. Ukuran Fuzzy
Ukuran fuzzy menunjukkan derajat kekaburan dari himpunan fuzzy. Secara umum ukuran kekaburan dapat ditulis sebagai fungsi (Yan,1994):
f : P(X) →R
Dengan P(X) adalah himpunan semua subset dari X. f(A) adalah suatu fungsi yang memetakan subset A ke karakteristik derajat kekaburannya. Dalam mengukur nilai kekaburan, fungsi f harus mengikuti hal-hal sebagai berikut:
1. f(A) = 0 jika dan hanya jika A adalah himpunan Crisp.
2. Jika A < B, maka f(A) ≤ B berarti B lebih kabur dibandingkan A (atau A lebih tajam dibanding B). Relasi ketajaman A < B didefinisikan dengan:
µA[X] ≤µB[X], jika µB[X] ≤ 0,5; dan
µA[X] ≥µB[X], jika µB[X] ≥ 0,5.
3. f(A) akan mencapai maksimum jika dan hanya jika A benar-benar kabur
secara maksimum. Tergantung pada interpetasi derajat kekaburan, nilai fuzzy maksimal biasanya terjadi pada saat µA[X] = 0,5 untuk setiap x.
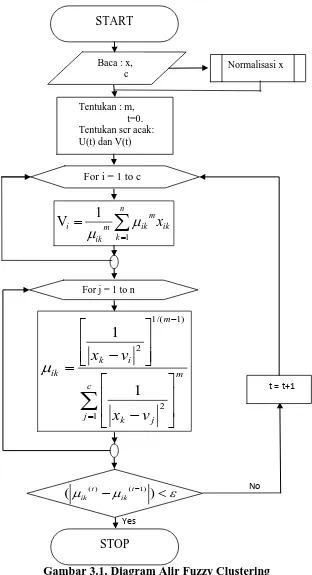
3.3.2. Diagram Alir
START
Normalisasi x
Tentukan : m, t=0. Tentukan scr acak: U(t) dan V(t)
For i = 1 to c
For j = 1 to n
STOP
t = t+1
Yes
No
Baca : x, c
∑
==
n k ik m ik m ik ix
11
V
µ
µ
∑
= −
−
−
=
c j m j k m i k ikv
x
v
x
1 2 ) 1 /( 1 21
1
µ
ε µµ − − <
[image:40.595.155.467.108.683.2]) ( ik(t) ik(t 1)
Gambar 3.1. Diagram Alir Fuzzy Clustering
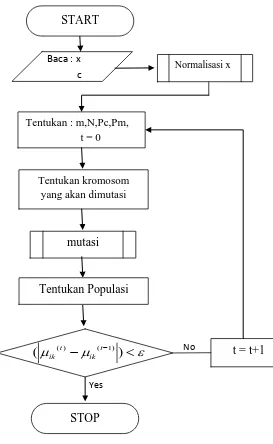
dimutasi, penentuan populasi sehingga akan diperoleh fungsi obyektif dari tiap-tiap data.
Gambar 3.2. Diagram Alir Algoritma Genetika
Baca : x c
Tentukan : m,N,Pc,Pm, t = 0
Tentukan kromosom yang akan dimutasi
mutasi
Tentukan Populasi
ε µ
µ − − <
)
( ik(t) ik(t 1) t = t+1
STOP
No
Yes
START
BAB IV
HASIL DAN PEMBAHASAN
4.1. Data Perkembangan Indeks Pembangunan Manusia untuk tingkat propinsi Indonesia.
Pembangunan nasional Indonesia sesungguhnya menurut GBHN yang kemudian dijabarkan ke dalam repelita adalah pembangunan yang menganut konsep pembangunan manusia. Konsep pembangunan manusia seutuhnya merupakan konsep yang menghendaki peningkatan kualitas hidup penduduk baik secara fisik, mental maupun dilakukan menitikberatkan pada pembangunan sumber daya manusia secara fisik dan mental mengandung makna peningkatan kapasitas dasar penduduk yang kemudian akan memperbesar kesempatan untuk dapat berpartisipasi dalam proses pembangunan yang berkelanjutan.
4.1.1. Metode Perhitungan IPM
Adapun komponen IPM disusun dari tiga komponen yaitu lamanya hidup diukur dengan harapan hidup pada saat lahir, tingkat pendidikan diukur dengan kombinasi antara angka melek huruf pada penduduk dewasa (dengan bobot dua per tiga) dan rata-rata lama sekolah (dengan bobot sepertiga), dan tingkat kehidupan yang layak yang diukur dengan pengeluaran perkapita yang telah disesuaikan (PPP rupiah), indeks ini merupakan rata-rata sederhana dari ketiga komponen tersebut diatas :
IPM = 1/3(indeks X1 + indeks X2 + indeks X3 Dimana:
)
X1 X
= Lamanya hidup 2
X
= Tingkat pendidikan 3
Dari hasil perhitungan tersebut maka diperoleh data indeks pembangunan manusia untuk tiap propinsi di Indonesia seperti tabel dibawah ini:
Tabel 4.1. Data IPM Tingkat propinsi Indonesia (1996-2008)
No Propinsi IPM
199 6 199 9 200 2 200 4
2005 2006 2007 2008
Indonesia 67.7 64.3 65.8 68.7 69.57 70.10 70.59 71.17
1. Nanggroe Aceh
Darussalam
69.4 65.3 66.0 68.7 69.05 69.41 70.35 70.76
2. Sumatera Utara 70.5 66.6 68.8 71.4 72.03 72.46 72.78 73.29
3. Sumatera Barat 69.2 65.8 67.5 70.5 71.19 71.65 72.23 72.96
4. Riau 67.6 67.3 69.1 72.2 73.63 73.81 74.63 75.09
5. Jambi 69.3 65.4 67.1 70.1 70.95 71.29 71.46 71.99
6. Sumatera Selatan 68.0 63.9 66.0 69.6 70.23 71.09 71.4 72.05
7. Bengkulu 68.4 64.8 66.2 69.9 71.09 71.28 71.57 72.14
8. Lampung 67.6 63.0 65.8 68.4 68.85 69.38 69.78 70.3
9. Bangka Belitung - - 65.4 69.6 70.68 71.18 71.62 72.19
10. Kepulauan Riau - - - 70.8 72.23 72.79 73.68 74.18
11. DKI Jakarta 76.1 72.5 75.6 75.8 76.07 76.33 76.59 77.03
12. Jawa Barat 68.2 64.6 65.8 69.1 69.93 70.32 70.71 71.12
13. Jawa Tengah 67.0 64.6 66.3 68.9 69.78 70.25 70.92 71.6
14. Yogyakarta 71.8 68.7 70.8 72.9 73.5 73.7 74.15 74.88
15. Jawa Timur 65.5 61.8 64.1 66.8 68.42 69.18 69.78 70.38
16. Banten - - 66.6 67.9 68.80 69.11 69.29 69.7
17. Bali 70.1 65.7 67.5 69.1 69.78 70.07 70.53 70.98
18. Nusa Tenggara Barat 56.7 54.2 57.8 60.6 62.42 63.04 63.71 64.12
19. Nusa Tenggara
Timur
60.9 60.4 60.3 62.7 63.59 64.83 65.36 66.15
20. Kalimantan Barat 63.6 60.6 62.9 65.4 66.2 67.08 67.53 68.17
21. Kalimantan Tengah 71.3 66.7 69.1 71.7 73.22 73.4 73.49 73.88
22. Kalimantan Selatan 66.3 62.2 64.3 66.7 67.44 67.75 68.01 68.72
23. Kalimantan Timur 71.4 67.8 70.0 72.2 72.94 73.26 73.77 74.52
24. Sulawesi Utara 71.8 67.1 71.3 73.4 74.21 74.37 74.68 75.16
25. Sulawesi Tengah 66.4 62.8 64.4 67.3 68.47 68.85 69.34 70.09
26. Sulawesi Selatan 66.0 63.6 65.3 67.8 68.06 68.81 69.62 70.22
27. Sulawesi Tenggara 66.2 62.9 64.1 66.7 67.52 67.8 68.32 69.0
28. Gorontalo - - 64.1 65.4 67.46 68.01 68.83 69.29
29. Sulawesi Barat - - - 64.4 65.72 67.06 67.72 68.55
30. Maluku 68.2 67.2 66.5 69.0 69.24 69.69 69.96 70.38
31. Maluku Utara - - 65.8 66.4 66.95 67.51 67.82 68.18
32. Irian Jaya Barat - - - 63.7 64.83 66.08 67.28 67.95
33. Papua 60.2 58.8 60.1 60.9 62.08 62.75 63.41 64.0
4.2. Analisis Kluster IPM
Dari tabel 4.1. akan diolah dengan teknik fuzzy clustering untuk beberapa kluster, yaitu c = 3. Untuk pengolahan data dengan teknik ini digunakan software Matlab 2009A dan PowerISO.
Kerangka penerapan teori dalam kasus yang dibahas pada tesis ini adalah:
1. Banyaknya objek yang dikaji adalah ke-33 Propinsi Indonesia, jadi n = 33, 2. Jumlah kluster yang akan dicoba adalah c = 3,
3. Pangkat (pembobot) = w = 2, 4. Maksimum iterasi = 100, 5. Kriteria penghentian = ε = 10-5
6. Setiap propinsi akan dicirikan sebagai vektor kolom. ,
4.2.1. Pengolahan Data
Sesuai dengan kerangka penerapan teori, tiap propinsi akan dikelompokkan kedalam 3 kluster, jadi nilai c adalah 3. Misalkan data pada tabel 4.1. dimasukan dari notepad dan disimpan dengan nama “ipm.dat” pada drive D, lalu pada Matlab browser directory file kemudian import file hingga muncul ke workspace. kemudian gunakan perintah berikut:
>> X = load('ipm.dat')
>> [center,U,obj_fcn]=fcm(X,3)
Perintah X = Load('ipm.dat') akan membaca file dengan nama “ipm.dat” dan komputer akan menyimpannya dalam variable X. Perintah
“[center,U,obj_fcn]=fcm(X,3)” akan memasukkan nilai variabel X kedalam fungsi fcm (fuzzy C-Means) dan data pada variabel akan dibagi kedalam 3 kluster, adapun besarnya pangkat bobot dipilih w = 2, iterasi maksimum padaperhitungan adalah 100, criteria penghentian iterasi adalah bila selisih antara 2 solusi yang berurutan yang bernilai kurang dari 10-5, hasil dari perhitungan didapat dari pusat
kluster atau center, derajat keanggotaan atau matriks U serta nilai fungsi tujuan
Setelah kedua perintah tersebut digunakan pada matlab, didapat 3 (tiga) hasil yaitu:
1. Hasil perhitungan fungsional, sebagai berikut:
Iteration count = 12, obj. fcn = 5004.376093
Interpretasinya, sotware Matlab 2009A memerlukan iterasi 12 kali sebelum memperoleh solusi optimal bagi nilai fungsional Jm(U,V) pada persamaan (2.6), yaitu sebesar = 5004.376093
2. Perhitungan nilai-nilai Vij center =
yaitu
71.1780
69.8445
70.1744
Nilai-nilai ini merupakan titik pusat kelima kluster dan memberikan garis besar citra tiap kluster.
U =
Columns 1 through 8
0.9991 0.9909 0.9958 0.9825 0.9974 0.6498 0.9979 0.9990
0.0005 0.0055 0.0025 0.0106 0.0015 0.2011 0.0013 0.0006
0.0003 0.0036 0.0017 0.0069 0.0010 0.1491 0.0008 0.0004
Columns 9 through 16
0.0034 0.0073 0.9396 0.9995 0.9996 0.9778 0.9950 0.0005
0.9896 0.0221 0.0363 0.0003 0.0003 0.0133 0.0030 0.9986
0.0070 0.9706 0.0242 0.0002 0.0002 0.0088 0.0020 0.0009
Columns 17 through 24
0.9982 0.8710 0.9470 0.9807 0.9859 0.9926 0.9832 0.9747
0.0011 0.0779 0.0317 0.0117 0.0085 0.0044 0.0101 0.0153
Columns 25 through 32
0.9969 0.9980 0.9937 0.0010 0.0011 0.9983 0.0012 0.0022
0.0019 0.0012 0.0038 0.9969 0.0034 0.0010 0.9963 0.0066
0.0012 0.0008 0.0025 0.0021 0.9956 0.0007 0.0025 0.9912
Column 33
0.9158
0.0505
0.0337
Nilai-nilai ini menggambarkan derajat keanggotaan suatu objek (IPM tingkat propinsi Indonesia) terhadap ketiga kluster, misalnya untuk propinsi Nanggroe Aceh Darussalam :
= 0.0003 0.0005 0.9991 3 2 1 µ µ µ
Interpretasinya, Propinsi Nanggroe Aceh Darussalam dapat menjadi anggota dari:
a. Kluster-1 dengan derajat keanggotaan 0.9991
b.
Kluster-2 dengan derajat keanggotaan 0.0005c.
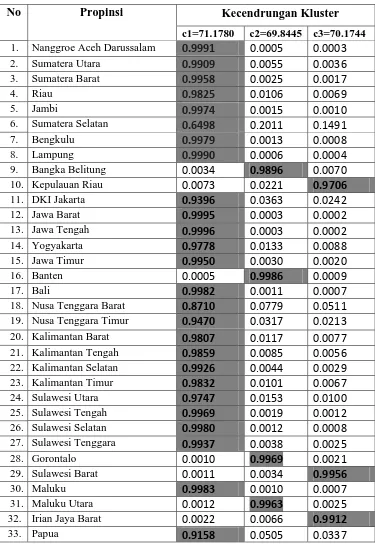
Kluster-3 dengan derajat keanggotaan 0.0003Tabel 4.2. Kecendrungan Kluster Tiap Propinsi di Indonesia
No Propinsi
c1=71.1780 c2=69.8445 c3=70.1744
1. Nanggroe Aceh Darussalam 0.9991 0.0005 0.0003
2. Sumatera Utara 0.9909 0.0055 0.0036
3. Sumatera Barat 0.9958 0.0025 0.0017
4. Riau 0.9825 0.0106 0.0069
5. Jambi 0.9974 0.0015 0.0010
6. Sumatera Selatan 0.6498 0.2011 0.1491
7. Bengkulu 0.9979 0.0013 0.0008
8. Lampung 0.9990 0.0006 0.0004
9. Bangka Belitung 0.0034 0.9896 0.0070
10. Kepulauan Riau 0.0073 0.0221 0.9706
11. DKI Jakarta 0.9396 0.0363 0.0242
12. Jawa Barat 0.9995 0.0003 0.0002
13. Jawa Tengah 0.9996 0.0003 0.0002
14. Yogyakarta 0.9778 0.0133 0.0088
15. Jawa Timur 0.9950 0.0030 0.0020
16. Banten 0.0005 0.9986 0.0009
17. Bali 0.9982 0.0011 0.0007
18. Nusa Tenggara Barat 0.8710 0.0779 0.0511
19. Nusa Tenggara Timur 0.9470 0.0317 0.0213
20. Kalimantan Barat 0.9807 0.0117 0.0077
21. Kalimantan Tengah 0.9859 0.0085 0.0056
22. Kalimantan Selatan 0.9926 0.0044 0.0029
23. Kalimantan Timur 0.9832 0.0101 0.0067
24. Sulawesi Utara 0.9747 0.0153 0.0100
25. Sulawesi Tengah 0.9969 0.0019 0.0012
26. Sulawesi Selatan 0.9980 0.0012 0.0008
27. Sulawesi Tenggara 0.9937 0.0038 0.0025
28. Gorontalo 0.0010 0.9969 0.0021
29. Sulawesi Barat 0.0011 0.0034 0.9956
30. Maluku 0.9983 0.0010 0.0007
31. Maluku Utara 0.0012 0.9963 0.0025
32. Irian Jaya Barat 0.0022 0.0066 0.9912
33. Papua 0.9158 0.0505 0.0337
Hasil lengkap pengklusteran 33 Propinsi Indonesia kedalam 3kluster adalah sebagai berikut:
a. Kluster-1 dengan center 71.1780 terdiri atas propinsi nomor urut: 1,2,3,4,5,6,7,8,11,12,13,14,15,17,18,19,20,21,22,23,24,25,26,27,30,33. b. Kluster-2 dengan center 69.8445 terdiri atas propinsi nomor urut:
9,16,28,31.
c. Kluster-3 dengan center 70.1744 terdiri atas propinsi nomor urut: 10,29,32.
[image:48.595.177.450.342.554.2]Untuk melihat antarmuka dari hasil pengklusteran dengan menggunakan perintah “findkluster” pada command line maka pada layar akan muncul seperti gambar:
Gambar 4.1. Kluster Interface
Tekan Load Data untuk mengambil file data yang akan dikluster. Kemudian pilih method fcm untuk metode kluster yang akan digunakan dan ganti kluster number menjadi 3. Lalu pilih vektor data yang akan ditampilkan pada sumbu X dan sumbu Y.
didapat hasil seperti gambar 4.2. untuk sumbu-x adalah variabel indeks pembangunan manusia pada tahun 2006 (data-6) dan sumbu-y adalah variabel indeks pembangunan manusia pada tahun 1996 (data-1) kemudian tekan start sehingga tampak seperti gambar 4.2.
Gambar 4.2. Perbandingan data 6 dengan data 1
Dari interface diatas terlihat dua buah lingkaran yaitu lingkaran merah dan lingkaran hitan. Lingkaran merah adalah data yang akan dikluster, data ini dapat bersifat multidimensi yang ditampilkan hanya pemetaan antara dua vektor data yaitu sumbu x dan sumbu y. Sedangkan lingkaran hitam adalah pusat vektor untuk tiap-tiap kluster.
Gambar 4.3. Perbandingan Data-6 dengan Data-6
Untuk memperoleh grafik dari pengklusteran tiap-tiap propinsi dapat menggunakan perintah “plot(ipm, 'DisplayName', 'ipm', 'YDataSource', 'ipm')”; figure(gcf)” sehingga akan tampil sebuah layar grafik seperti gambar dibawah ini:
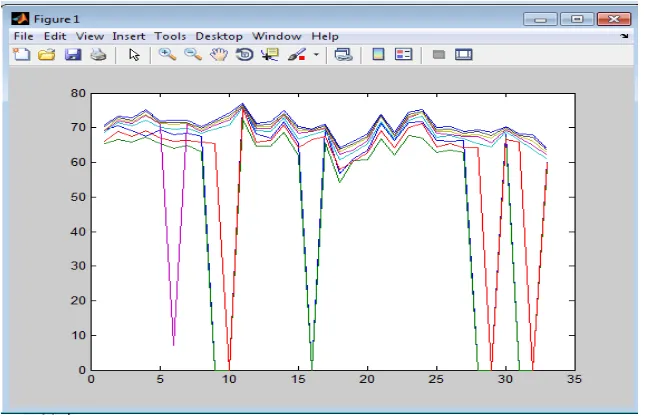
Gambar 4.4. Grafik kluster tiap-tiap Propinsi
4.2.2. Analisis dengan algoritma genetika A. Penentuan Populasi
Untuk melihat populasi dengan menggunakan perintah “Population = rand(1,33)”
[image:50.595.152.475.402.612.2]Populasi=
Columns 1 through 8
0.9347 0.3605 0.9477 0.0301 0.4411 0.7007 0.7030 0.5102
Columns 9 through 16
0.6122 0.7464 0.8014 0.3367 0.5641 0.8553 0.5892 0.5082
Columns 17 through 24
0.8534 0.6838 0.1063 0.5020 0.0192 0.4426 0.9072 0.0447
Columns 25 through 32
0.9452 0.1804 0.3699 0.2052 0.0956 0.4327 0.2776 0.1009
Column 33
0.4989
B. Penentuan fitness
Untuk mencari nilai fitness maka gunakan perintah “[x,fval] = ga(@simple_fitness,33)” sehingga akan menghasilkan 33 nilai x, yaitu:
x =
Columns 1 through 8
0.9326 0.8797 0.1866 0.0149 0.6270 -0.3085 -0.7164 0.2599
Columns 9 through 16
0.5068 0.0787 -0.3470 0.5579 0.5925 0.7130 0.2776 -0.1951
Columns 17 through 24
0.9897 -2.9610 -2.0417 1.4071 0.4670 -0.2849 0.2294 0.3370
Columns 25 through 32
0.1444 0.6614 1.1441 1.3181 0.2700 0.8885 -0.0269 0.4378
Column 33
0.2141
Jika menggunakan perintah ”gafitness” di command line pada workspace akan muncul “FitnessFunction, U, X, a, b, center, fval, ipm, numberOfVariables, obj_fcn, options, x”.
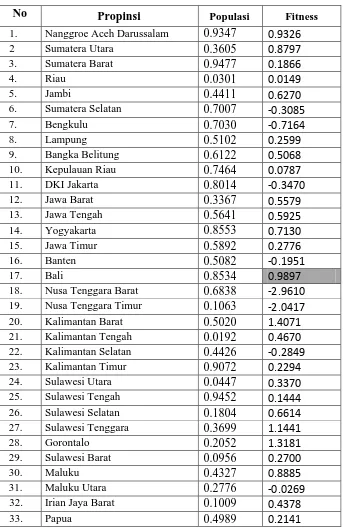
Tabel 4.3. Tabel Nilai Fitness tiap-tiap Propinsi
No Propinsi Populasi Fitness
1. Nanggroe Aceh Darussalam 0.9347 0.9326
2 Sumatera Utara 0.3605 0.8797
3. Sumatera Barat 0.9477 0.1866
4. Riau 0.0301 0.0149
5. Jambi 0.4411 0.6270
6. Sumatera Selatan 0.7007 -0.3085
7. Bengkulu 0.7030 -0.7164
8. Lampung 0.5102 0.2599
9. Bangka Belitung 0.6122 0.5068
10. Kepulauan Riau 0.7464 0.0787
11. DKI Jakarta 0.8014 -0.3470
12. Jawa Barat 0.3367 0.5579
13. Jawa Tengah 0.5641 0.5925
14. Yogyakarta 0.8553 0.7130
15. Jawa Timur 0.5892 0.2776
16. Banten 0.5082 -0.1951
17. Bali 0.8534 0.9897
18. Nusa Tenggara Barat 0.6838 -2.9610
19. Nusa Tenggara Timur 0.1063 -2.0417
20. Kalimantan Barat 0.5020 1.4071
21. Kalimantan Tengah 0.0192 0.4670
22. Kalimantan Selatan 0.4426 -0.2849
23. Kalimantan Timur 0.9072 0.2294
24. Sulawesi Utara 0.0447 0.3370
25. Sulawesi Tengah 0.9452 0.1444
26. Sulawesi Selatan 0.1804 0.6614
27. Sulawesi Tenggara 0.3699 1.1441
28. Gorontalo 0.2052 1.3181
29. Sulawesi Barat 0.0956 0.2700
30. Maluku 0.4327 0.8885
31. Maluku Utara 0.2776 -0.0269
32. Irian Jaya Barat 0.1009 0.4378
Dari tabel diatas terlihat nilai fittnes tertinggi adalah 0.9897 pada populasi 0.8534 yang terletak di propinsi Bali. Sehingga dapat disimpulkan bahwa pembangunan manusia di Bali termasuk tingkat yang baik. Sedangkan nilai minus pada nilai fitness tabel diatas merupakan propinsi yang harus diperhatikan tingkat pembangunannya.
Untuk melihat gambar algoritma genetika dapat menggunakan perintah
[image:53.595.138.483.272.535.2]“gamultiobjoptionsdemo” sehingga akan muncul layar baru seperti pada gambar dibawah ini:
Gambar 4.5. nilai fitness dengan algoritma genetika
Dari gambar diatas terlihat nilai fitness dari tiap-tiap Propinsi di Indonesia. Dari gambar terdapat titik-titik yang merupakan nilai fitness dari tiap-tiap propinsi yang terletak pada sumbu x (objective 1) dan sumbu y (objective 2).
Dilihat dari tabel (4.2.), diantara data-data tersebut terdapat kluster yang terendah yaitu dengan kluster 0.8710 dan 0.9158 terletak pada tingkat
BAB V
KESIMPULAN DAN SARAN
A. Kesimpulan
1. Clustering merupakan proses pengelompokan obyek atau data tidak berlabel kedalam suatu kelas atau kluster dengan obyek yang memiliki kesamaan. Clustering dengan menggunakan metode Fuzzy C-Means terhadap data indeks pembangunan manusia dapat memunculkan beberapa kluster untuk mengetahui cluster tertinggi dan kulster terendah.
2. Dari data yang di analisis diperoleh nilai fitness tertinggi di Propinsi Bali sehingga dapat dinyatakan bahwa Bali merupakan Propinsi yang memiliki tingkat pembangunan manusia yang tinggi.
B. Saran
1. Agar data akan lebih akurat sebaiknya bila melakukan analisis terhadap unsur-unsur pembentukan Indeks Pembangunan Manusia (IPM) untuk tiap Propinsi secara berkesinambungan dari tahun ke tahun.
DAFTAR KEPUSTAKAAN
Cominetti, O., Matzavinos, A., Samarasinghe, A., Kulasiri, D., Liu, S., Maini, P. dan Erban, R. Diffuzzy: A fuzzy clustering algorithm for complex data sets. International Journal of Computational Intelligence in Bioinformatics and Systems Biology 1(4) pp. 402-417 (2010).
Desiani, A. dan Arhami, M. 2005. Konsep Kecerdasan Buatan. Andi Yogyakarta. Fadlisyah, Arnawan, dan Faisal. 2009. Algoritma genetika. Graha Ilmu.
Gen, M. and Cheng, R., 2000. Genetic Algorithms and Engineering Optimization, John Wiley & Sons, New York.
H., Rahila, Raghuwanshi, M. dan Jaisawal, N. Genetic Algorithm Based
Clustering. International Journal of Information System. 16 Juli 2008.
Hamzah, A, 2001, Pengenalan Pola dengan Fuzzy Clustering, ACADEMIA ISTA, Vol.4.No.1., Lembaga Penelitian, Institut Sains dan Teknologi AKPRIND, Yogayakarta.
Kusumadewi, S. dan Purnomo, H. 2004. Aplikasi Logika Fuzzy Untuk Pendukung
Keputusan. Graha Ilmu. Yogyakarta.
Kusumadewi, S. dan Purnomo, H. 2005. Penyelesaian Masalah Optimasi dengan
teknik-teknik Heuristik. Graha Ilmu. Yogyakarta.
Kusumadewi, S., Hartati, S., Harjoko, A., dan Wardoyo, R. 2006. Fuzzy
Multi-Attribute Decesion making (Fuzzy MADM). Graha Ilmu. Yogyakarta.
Kusumadewi, S. 2002. Analisis dan Desain Sistem Fuzzy Menggunakan Tool Box
Matlab. Graha Ilmu. Yogyakarta. 159-192
Luthfi, E. Fuzzy C-Means untuk Clustering Data. Jurnal teknik Informatika. Yogyakarta. 24 November 2007.
Pal, K. dan Majumder, D. K. 1989. Fuzzy Pendekatan Matematik untuk
Ross, Timothy J. Fuzzy Logic With Engginering Applications. Edisi ke-2. John Wiley & Sons Inc. Inggris.
Wang, Yingjie. Fuzzy Clustering Analysis by Using Genetic Algorithm. ICIC International 2008 ISSN 1881-803X. Volume 2, Number4, December 2008. 331-337.
Widyastuti, N. dan Hamzah, A. Penggunaan Algoritma Genetika Dalam
Peningkatan Kinerja Fuzzy Clustering Untuk Pengenalan Pola (Application
of Genetic Algorithm to Enhance the Performance of Clustering Fuzzy in
Pattern Recognition). Jurnal Teknik Informatika. 3 April 2007.
________________. 1994. Optimizing of Fuzzy C-Means Clustering Algorithm