BAB 2
LANDASAN TEORI
2.1. Accurate Learning
Training sample diasumsikan sebagai distribusi dari testing sampel termasuk distribusi dari data baru (unclassifies sample) yang ingin diduga kelas labelnya. Untuk mendapat akurasi yang baik saat mengklasifikasi testing data, training set harus merepresentasikan keadaan data tes . Jika tidak, maka akurasi biasanya rendah. (Figliola, 2011).
Dari proses pengenalan pola jaringan syaraf tiruan Learning Vector Quantization (LVQ) menggunakan algoritma genetika, dapat dianalisa dengan persamaan berikut :
% �������= ��ℎ������ℎ�������� ���������������������� × 100% ………..(2.1)
2.2. Learning Vector Quantization (LVQ)
Salah satu metode dari jaringan syaraf tiruan adalah Learning vector quantization
(LVQ) yang mana digunakan untuk klasifikasi pengenalan pola. Masing-masing output mewakili kelas tertentu atau kategori. Beberapa unit output harus digunakan untuk masing-masing kelas. Bobot vektor untuk unit output sering disebut sebagai
vektor referensi (codebook) yang mana untuk mewakili unit kelas kategori. Selama
pelatihan, unit ouput diposisikan dengan mngatur bobot mereka melalui spelatihan
diawasi (supervised training). Setelah pelatihan, jaringan LVQ mengklasifikasikan
vektor masukan dengan menetapkan ke kelas yang sama sebagai unit output yang
memiliki vektor bobot (vektor referensi) terdekatnya untuk vektor input. (Fausett,
2.2.1. Arsitektur Jaringan
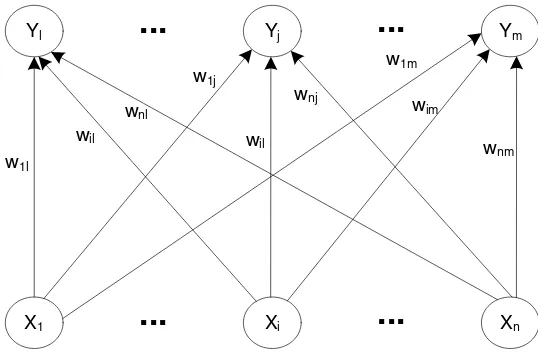
Pada dasarnya, arsitektur jaringan syaraf tiruan LVQ sama seperti arsitektur jaringan Kohenen – Self Organizing Map (SOM), tanpa struktur topologi yang diasumsikan untuk unit output). Selain itu, setiap unit output mewakili kelas yang diwakilinya.
Yl Yj Ym
X1 Xi Xn
w1l
wil
wnl
w1j
wil
w1m
wnj
wim
wnm
...
...
...
...
Gambar 2.1. Arsitektur Jaringan Learning Vector Quantization (LVQ) (Fausett, 1993)
2.2.2. Algoritma Learning Vector Quantization (LVQ)
Algoritma jaringan LVQ adalah untuk menentukan unit output yang paling dekat dengan vektor input. Sehingga, jika vektor input dan vektor bobot memiliki kelas yang sama, maka bobot baru akan menjadi vektor input yang selanjutnya. Tetapi jika vektor input dan vektor bobot memiliki kelas yang berbeda, maka perubahan bobot baru dikurang dengan bobot yang lama. Adapun tahap-tahap algoritma adalah sebagai berikut :
1. Tetapkan vektor bobot (w), iterasi maksimum (epoch maksimum), error
minimum (eps) dan learning rate (α).
2. Jika kondisi berhenti False, lakukan tahap 3 – 7.
3. Untuk masing-masing vektor input x, lakukan tahap 4 – 6.
4. Hitung nilai J, yang mana �� − ��� = minimum (terkecil). (2.2) 5. Hitung perubahan �� sebagai berikut
Jika T ≠ J, maka ��(���) =��(���)− ��� − ��(���)�. (2.4)
6. Kurangi nilai learning rate (α).
7. Pengujian berhenti, kondisi ini dapat menentukan jumlah tetap iterasi, yaitu eksekusi tahap – 1 atau learning rate (α) mencapai nilai yang cukup kecil.
Keterangan :
x = vektor training (�1, … ,��, … ,��) T = target atau kelas target
�� = vektor bobot untuk unit ouput ke – j ��1�, … ,���, … ,���� J = kategori atau kelas yang diperoleh dari unit output ke – j �� − ��� = jarak Euclidean antara vektor input dan vektor bobot untuk unit output ke – j.
2.3. Algoritma Genetika
Salah satu algoritma pencarian (searching algorithm) adalah algoritma genetika yang
mana berdasarkan pada mekanisme seleksi alam dan genetika (Goldberg, 1989).
Algoritma genetika merupakan adalah algoritma perncarian (search algorithm)
stokastik yang berdasarkan pada evolusi biologi. Secara umum, algoritma genetika mengelola suatu populasi yang dibangkitkan secara random dan solusi dibangkitkan sesudah tahapan konsekutif dari proses, selection, crossover dan mutasi. Untuk menyelesaikan suatu permasalahan, setiap individu dari populasi memiliki nilai yang dibentuk ke dalam suatu nilai fitness. (Cagnoni et al, 2007).
Urutan langkah-langkah algoritma genetika direpresentasikan berdasarkan prosedur kromosom buatan, seleksi alami, dan teknik ini dikenal sebagai crossover
dan mutasi. Satu individu terdiri dari beberapa kromosom, dan kromosom terdiri dari sejumlah ‘gen’, dan setiap gen nilainya dapat berupa bilangan numeric, biner, symbol ataupun tergantung dari permasalahan yang ingin diselesaikan. (Negnevitsky, 2005).
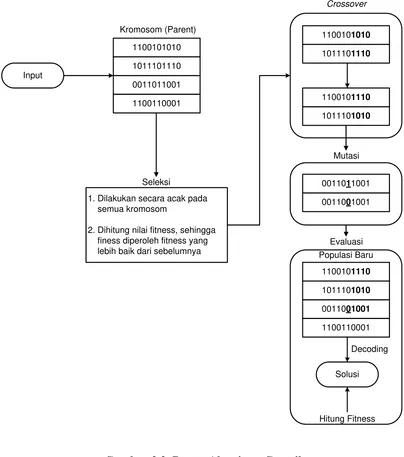
Tahapan proses dari algoritma genetika secara umum diperlihatkan pada Gambar 2.2. Kromosom direpresentasi dari solusi, yang mana operator genetika terdiri dari crossover dan mutasi, dilakukan bersamaan atau hanya salah satu saja. Evolusi yaitu proses seleksi kromosom dari parent (generasi induk) dan offspring
Diharapkan akan lebih baik dalam memperkirakan solusi yang optimum, selanjutnya proses iterasi dilakukan yang mana disesuaikan dengan jumlah generasi yang ditetapkan.
Input
1100101010
1011101110
1100110001 0011011001
1. Dilakukan secara acak pada semua kromosom
2. Dihitung nilai fitness, sehingga finess diperoleh fitness yang lebih baik dari sebelumnya
1100101010
1011101110
1011101010
1100101110
0011001001
0011011001
1100110001 0011001001
1011101010
1100101110
Solusi Evaluasi
Decoding
Hitung Fitness Mutasi
Crossover
Seleksi Kromosom (Parent)
Populasi Baru
Gambar 2.2. Proses Algoritma Genetika
2.3.1. Struktur Algoritma Genetika
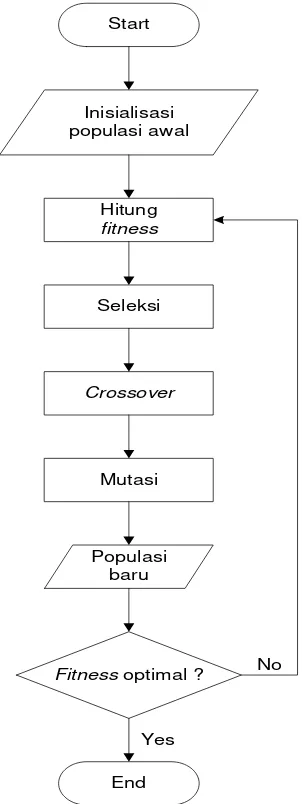
Nilai parameter algoritma genetika menduplikasi cara reproduksi genetika, pembentukan kromosom baru, proses migrasi gen, serta seleksi, sehingga terbentuk generasi baru yang diharapkan.
Start
Inisialisasi populasi awal
Hitung fitness
Seleksi
Crossover
Mutasi
Populasi baru
Fitness optimal ?
End Yes
No
Gambar 2.3. Struktur Umum Algoritma Genetika (Goldberg, 1989)
membedakan prosedur pencarian atau optimasi yang lain, maka perlu diketahui karakterstik berikut (Goldberg, 1989) :
1. Bekerja dengan pengkodean dari himpunan solusi permasalahan.
2. Pencarian populasi merupakan solusi permasalahan bukan hanya dari satu individu.
3. Informasi dari fungsi objektif untuk mengevaluasi individu yang mempunyai solusi terbaik, tetapi bukan turunan dari satu fungsi saja.
Aturan-aturan yang digunakan yaitu transisi peluang.
2.3.2. Operator Algoritma Genetika
Untuk menghindari konvergensi prematur yang mana solusi optimum belum waktunya, solusi yang diperoleh adalah hasil local optima. Sehingga ada operator algoritma genetika yang perlu diperhatikan, yaitu: (Goldberg, 1989).
1. Populasi, ukuran tergantung masalah yang akan diselesaikan. Jika masalah lebih kompleks, diperlukan ukuran populasi yang lebih besar, untuk menghasilkan lokal optima dan mencegah.
2. Probabilitas crossover (��), Setiap generasi, sebanyak �� �, individu dalam populasi mengalami pindah silang. Makin besar nilai ��, maka makin cepat struktur individu baru diperkenalkan ke dalam populasi. Jika nilai �� diberikan terlalu besar, individu merupakan solusi terbaik yang dapat hilang lebih cepat dibanding seleksi untuk peningkatan kerja. Sebaliknya nilai ��yang rendah dapat mengakibatkan stagnasi karena rendahnya angka eksplorasi.
3. Probabilitas mutasi (�� ), setiap posisi bit string dalam populasi baru mengalami perubahan secara acak setelah proses seleksi. Dalam satu generasi panjang struktur (L), kemungkinan terjadi mutasi sebanyak �� ��.
2.3.3. Pengenalan Pola (Pattern Recognition)
Pengenalan pola (pattern recognition) adalah proses klasifikasi dari suatu objek atau pola menjadi beberapa kategori atau kelas, yang mana bertujuan untuk memberikan informasi. Pola merupakan bentuk atau model yang dapat dipakai untuk membuat atau menghasilkan suatu bagian dari sesuatu yang ingin dikenal.
Pengenalan pola dapat dilakukan secara sintkas, statistik, dan jaringan syaraf tiruan. Pengenalan pola yang dilakukan secara sintaks dengan menggunakan aturan-aturan tertentu. Pengenalan pola yang dilakukan secara statistik yaitu menggunakan data-data dari statistik, seperti pasar saham, curah hujan, dan lain-lain. Sedangkan pengenalan pola dengan menggunakan jaringan syaraf tiruan, yangitu dengan menggabungkan pengenalan pola statistic dan sintaks, dimana cara kerja jaringan syaraf tiruan meniru cara kerja otak manusia. Pada pola ini, dasar untuk pengambilan keputusan digunakan data statistik yang mana membuat rule-rule tertentu. Media pengenalan pola bias berupa citra digital, audio, video, pola matriks biner, dan lain-lain.
2.4. Penelitian-pelenelitian Terkait 2.4.1. Penelitian Terdahulu
Emnida (2014), dengan mengkombinasikan LVQ dan self organizing Kohonen terdapat peningkatan kecepatan komputasi pelatihan dalam pengenelan pola tanda tangan. Kombinasi LVQ dan self organizing Kohonen, yaitu membentuk bobot vektor yang nantinya dimasukkan kembali ke dalam vektor bobot pada LVQ.
Blachnik dan Duch (2011), pada LVQ algorithm with instance weighting for generation of prototype-based rules, dengan memanfaatkan parameter fungsi pelatihan pada metode LVQ dapat membentukan prototipe berdasarkan modifikasi aturan pada logika fuzzy.
Munjal (2011), pada ANN paradigms for Audio Recognition, dengan membandingkan tiga metode jaringan syaraf tiruan Learning Vector Quantization
Basu et al (2010), pada Use of Artificial Neural Network in Pattern Network, meskipun ada beberapa kelebihan dan kekurangan pada penerapan kecerdasan buatan dalam pengenalan pola, selalu diperoleh hasil yang lebih baik dari pada tanpa menggunakan jaringan syaraf tiruan.
Chen et al (2006), pada An Approach to Seafloor Classification with GA-Based Neural Network. Dengan mengklasifikasikan komponen-komponen dasar laut sebagai objek penelitian dengan menggunakan pendekatan algoritma genetika berdasarkan jaringan syaraf tiruan Learning Vector Quantization (LVQ), dengan memasukkan parameter-parameter algoritma genetika yaitu selection, crossover dan mutasi ke dalam pelatihan jaringan LVQ, diperoleh hasil yang cepat dan akurat dalam mengklasifikasi komponen-komponen dasar laut. Salah satu titik kelemahan LVQ adalah sensitifitas inisialisasi, yang berpengaruh terhadap akurasi klasifikasi dasar laut, sehingga algoritma genetika digunakan untuk mengoptimasi nilai inisialisasi LVQ. Pendeketan algoritma genetika ini diterapkan ke dalam pengklasifikasian komponen-komponen dasar laut dengan menggunakan Multibeam Echo Sounder
(MBES) .
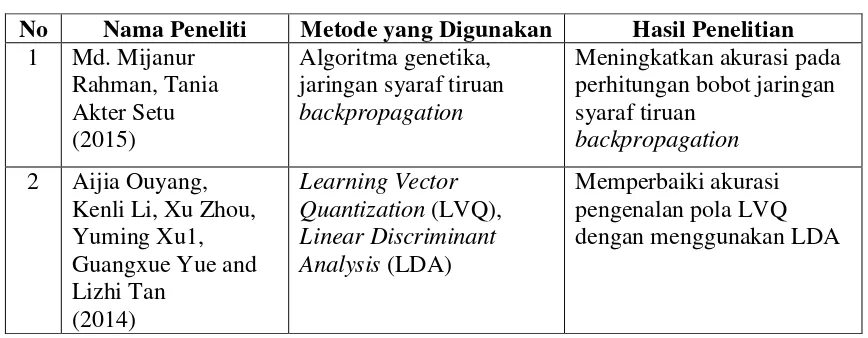
Adapun beberapa penelitian-penelitian yang telah dilakukan oleh peneliti yang lain dapat dilihat pada Tabel 2.1.
Tabel 2.1. Perbedaan penelitian yang dilakukan oleh peneliti yang lain No Nama Peneliti Metode yang Digunakan Hasil Penelitian
1 Md. Mijanur Rahman, Tania Akter Setu (2015)
Algoritma genetika, jaringan syaraf tiruan
backpropagation
Meningkatkan akurasi pada perhitungan bobot jaringan syaraf tiruan
backpropagation
2 Aijia Ouyang, Kenli Li, Xu Zhou, Yuming Xu1, Guangxue Yue and Lizhi Tan
(2014)
Learning Vector Quantization (LVQ),
Linear Discriminant Analysis (LDA)
Tabel 2.1. Perbedaan penelitian yang dilakukan oleh peneliti yang lain (Lanjutan)
No Nama Peneliti Metode yang Digunakan Hasil Penelitian 3 Eminta Br Ginting,
(SOM), Learning Vector Quantization (LVQ)
Mengkombinasikan jaringan syaraf tiruan LVQ dengan SOM untuk meningkatkan akurasi pengenalan pola tanda tangan menggunakan citra digital
4 Gilang Ananggadip, Achmad Hidayatno, dan Ajub Ajulian Zahra
(2014)
Learning Vector Quantization (LVQ), tujuh moment invariant Hu
Membandingkan LVQ dan tujuh moment invariant
5 Saeed Balochian, Emad Abbasi
Seidabad and Saman Zahiri Rad
(2013)
Algoritama genetika,
Multilayer Perceptron
(MLP)
Optimasi perhitungan bobot pada jaringan syaraf tiruan
Multi Layer Perceptron
(MLP) 6 Geetika Munjal
(2011)
Learning Vector
Quantization (LVQ), Self Organizing Map (SOM), dan Multi Layer
Perceptron (MLP)
Membandingkan metode LVQ, SOM, dan MLP pada pengenalan pola audio
7 Marcin Blachnik,
Włodzisław Duch
(2011)
Learning Vector Quantization (LVQ),
Fuzzy Logic
Menganalisa akurasi pembelajaran jaringan syaraf tiruan LVQ dengan mengkombinasikan fuzzy logic
Analisa pengenalan pola dengan menggunakan jaringan syaraf tiruan Multi Layer Perceptron (MLP) 9 Okko Johannes
Räsänen, Unto Kalervo Laine, and Toomas Altosaar (2009)
Learning Vector
Quantization (LVQ), Self Organizing Map (SOM)
Mengkombinasikan LVQ dengan SOM untuk meningkatkan akurasi pembelajaran pada pengenalan pola suara 10 Yongqi CHEN,
Xinghua ZHOU, Yongting WU, and Qinhua TANG (2006)
Algoritma genetika,
Learning Vector Quantization (LVQ)
2.4.2. Perbedaan Penelitian
![[6] program tahunan bina sma](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)