PERBANDINGAN METODE KLASIFIKASI ANTARA
ANALISIS
DISKRIMINAN VERTEKS
DAN DISKRIMINAN FISHER
NURMALENI
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa tesis berjudul Perbandingan Metode Klasifikasi antara Analisis Diskriminan Verteks dan Diskriminan Fisher adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apapun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Februari 2015
RINGKASAN
NURMALENI. Perbandingan Metode Klasifikasi antara Analisis Diskriminan Verteks dan Diskriminan Fisher. Dibimbing oleh I MADE SUMERTAJAYA dan BAGUS SARTONO.
Permasalahan klasifikasi banyak dijumpai dalam bidang sosial, bidang perbankkan dan bidang kedokteran. Metode klasifikasi terus berkembang sebagai cabang penting dari statistika. Salah satu metode klasifikasi yang berkembang adalah analisis diskriminan. Analisis diskriminan adalah salah satu metode terbaik yang digunakan dalam pengklasifikasian objek. Analisis diskriminan bertujuan untuk mengenali faktor apa saja yang dapat membedakan dua kelompok atau lebih yang digunakan sebagai cara terbaik untuk memisahkan kelompok individu.
Johnson dan Wichern (2007) menjelaskan bahwa fungsi diskriminan pertama kali diperkenalkan oleh Ronald A. Fisher pada tahun 1936. Analisis diskriminan Fisher (ADF) tidak dapat mengklasifikasikan objek pada saat matriks X berpangkat tidak penuh, karena matriks ragam-peragam bersifat singular sehingga tidak memiliki matriks kebalikan. Lange dan Wu (2008) memperkenalkan metode pembelajaran untuk klasifikasi multikategori yang dikenal dengan analisis diskriminan verteks (ADV). ADV dapat mengklasifikasikan objek pada saat matriks X berpangkat penuh dan matriks X berpangkat tidak penuh. Klasifikasi pada ADV dilakukan dengan meminimumkan fungsi tujuan yang melibatkan
-insensitive loss dan penalti kuadrat. Penelitian ini mengkaji kinerja metode ADV pada saat matriks X berpangkat penuh, dimana kondisi ini tercapai pada saat banyak observasi n jauh lebih besar dari banyak peubah p. Hasil kesalahan klasifikasi (nilai APER) metode ADV dibandingkan dengan nilai APER yang dihasilkan metode ADF untuk melihat kinerja dua metode.
Data dalam penelitian ini terdiri dari dua sumber yaitu data simulasi dan data kasus terapan. Pada kajian simulasi ada 8 kelompok skenario simulasi yaitu berdasarkan korelasi antar peubah, berdasarkan jarak nilai tengah antar kelompok dan nilai keragaman. Hasil simulasi menujukan pada saat ukuran observasi n jauh lebih besar dari banyak peubah p, dengan asumsi kenormalan dan kehomogenan matriks ragam-peragam terpenuhi, pada saat peubah berkorelasi ADF lebih baik dalam pengklasifikasian daripada ADV. Jika peubah tidak ada korelasi metode ADF dan ADV memiliki kemampuan sama dalam klasifikasi. Metode ADF lebih baik dari ADV jika jarak nilai tengah antar kelompok berjauhan dan metode ADV dan ADF memiliki kemampuan klasifikasi yang sama jika nilai tengah antar kelompok berdekatan. Berdasarkan keragaman memperlihatkan pola yaitu semakin besar nilai keragaman maka kesalahan klasifikasi juga akan meningkat, tetapi kesalahan klasifikasi pada metode ADV dan ADF tidak jauh berbeda dalam pengklasifikasian. Oleh karena itu dapat disimpulkan bahwa metode ADV dan ADF mempunyai kemampuan yang sama dalam pengklasifikasian.
klasifikasi yang sama. Sedangkan untuk matriks X berpangkat tidak penuh diambil dari data kabupaten/kota yang ada di Provinsi Riau yang terdiri dari 12 kabupaten/kota dan 19 peubah. Metode ADV lebih baik dari ADF dalam pengklasifikasian, karena pada kondisi ini ADF tidak dapat digunakan.
SUMMARY
NURMALENI. Comparison of Classification Method of Analisis diskriminan verteks and Fisher‟s Discriminant Analysis. Supervised by I MADE SUMERTAJAYA and BAGUS SARTONO.
Classification problems are often found in the social sector, a banking field, and the field of medicine. Classification methods continue to evolve as an important branch of statistics. One method of classification is developed discriminant analysis. Discriminant analysis is one of the best methods used in object classification. Discriminant analysis aims to identify factors that can differentiate two or more groups are used as the best way to separate groups of individuals.
Johnson dan Wichern (2007) explained that the first of discriminant function was introduced by Ronald A. Fisher in 1936. Fisher‟s discriminant analysis (FDA) can not classify object if the matrix X not full rank. In this case, FDA gives singularity in the variance-covariance matrix that affecting the existence of invers. Lange and Wu (2008) introduced a new method of supervised learning control for multicategory classification. It is called the vertex discriminant analysis (VDA). VDA can classify object when the matrix X full rank and matrix X not full rank. VDA classifications is performed by minimizing the objective of functions involving -insensitive loss and quadratic penalty. In this study, we will be showed the performance of the VDA when the matrix X full rank. This condition is reached at a time when observations n larger than variables p. The performance of Fisher discriminant analysis and Multicategory Analisis diskriminan verteks were compared by value of APER.
Research data, there are two types of data are simulated data and case data. In the simulation study, there are 8 groups of simulation scenarios are based on the correlation between variables, based on the distance of the midpoint between the group and the value of diversity. The results of simulation showed that Fisher‟s discriminant analysis was better than VDA when the assumption of normality and homogeneity of variance-covariance matrix were satisfied, variables have correlation. If there is no correlation variables, FDA and VDA have the same ability in classification. If the centriod between the groups apart, FDA is better than VDA, but VDA and FDA have the same ability on the apposite. Based on the variaty of data simulation, VDA and FDA have the same ability in the classification. It can be seen the classification error on VDA and FDA are not much different in the classification.
matrix X not full rank. In this case, FDA gives singularity in the variance-covariance matrix that affecting the existence of invers.
© Hak Cipta Milik IPB, Tahun 2015
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains
pada
Program Studi Statistika
PERBANDINGAN METODE KLASIFIKASI ANTARA
ANALISIS
DISKRIMINAN VERTEKS DAN DISKRIMINAN FISHER
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
Judul Tesis : Perbandingan Metode Klasifikasi antara Analisis diskriminan verteks dan Diskriminan Fisher
Nama : Nurmaleni
NIM : G151120171
Disetujui oleh Komisi Pembimbing
Dr Ir I Made Sumertajaya, MSi Ketua
Dr Bagus Sartono, SSi, MSi Anggota
Diketahui oleh
Ketua Program Studi Statistika
Dr Ir Anik Djuraidah, MS
Dekan Sekolah Pascasarjana
Dr Ir Dahrul Syah, MScAgr
PRAKATA
Puji dan syukur penulis ucapkan kehadirat Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga penulis dapat menyelesaikan karya ilmiah ini. Shalawat serta salam semoga tetap tercurah kepada junjungan kita Nabi besar Muhammad Shalallahu „Alaihi Wassallam beserta keluarga Beliau, para Shahabat, para tabi‟in, tabi‟ut tabi‟in dan para penerus perjuangan Beliau hingga akhir zaman. Karya ilmiah ini berjudul “Perbandingan Metode Klasifikasi antara Analisis diskriminan verteks dan Diskriminan Fisher”.
Keberhasilan penulisan karya ilmiah ini tidak lepas dari bantuan, bimbingan, dan petunjuk dari berbagai pihak. Oleh karena itu, penulis menyampaikan penghargaan dan ucapan terima kasih yang sebesar-besarnya khususnya kepada:
1. Bapak Dr Ir I Made Sumertajaya, MSi selaku pembimbing I dan Bapak Dr Bagus Sartono, SSi, MSi selaku pembimbing II yang dengan kesabaran telah banyak memberi bimbingan, arahan, serta saran kepada penulis selama penyusunan karya ilmiah ini.
2. Bapak Dr Anang Kurnia SSi, MSi selaku penguji luar komisi yang telah banyak memberikan kritikan, masukan, dan arahan yang sangat membangun dalam penyusunan karya ilmiah ini.
3. Seluruh staf pengajar pascasarjana Departemen Statistika IPB yang telah banyak memberikan ilmu dan arahan selama perkuliahan sampai dengan penyusunan karya ilmiah ini.
4. Teman-teman statistika angkatan 2012 atas kebersamaan, kekompakannya, bantuan dan masukannya selama bersama-sama menempuhkuliah.
5. Kedua orang tua serta seluruh keluarga atas do‟a, dukungan, dan kasih sayangnya.
6. Seluruh pihak yang namanya tidak dapat disebutkan satu per satu, terima kasih atas bantuannya.
Atas segala bantuan yang diberikan, penulis hanya bisa berdoa dengan harapan semoga semua kebaikan yang penuh keikhlasan tersebut dicatat sebagai amal ibadah dan mendapatkan balasan berupa pahala disisi Allah Subhanahu wa
ta’ala, Aamiin Ya Rabbal Alamin. Semoga karya ilmiah ini bermanfaat serta dapat menambah wawasan bagi para pembaca. Kritikan yang membangun sangat penulis harapkan demi perbaikan karya ilmiah ini dimasa yang akan datang.
Bogor, Februari 2015
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi PENDAHULUAN 1 Latar Belakang 1 Tujuan Penelitian 2 TINJAUAN PUSTAKA 2 Analisis Diskriminan Verteks (ADV) 2
Fungsi Tujuan pada ADV 3
Algoritma MM (Majorize-Minimize) 3
Mayorisasi Fungsi Kerugian dan Fungsi Tujuan 4
Ukuran Kesalahan Pengklasifikasian dalam Analisis Diskriminan 5
METODE PENELITIAN 6
Data 6
Metode Analisis 8
HASIL DAN PEMBAHASAN 9
Kajian Simulasi 10
Kajian Terapan 13
SIMPULAN DAN SARAN 21
Simpulan 21
Saran 21
DAFTAR PUSTAKA 22
LAMPIRAN 23
DAFTAR TABEL
1 Contoh nilai titik simpul 3
2 Perbedaan delapan kelompok skenario 7
3 Deskripsi data simulasi untuk banyak kelompok 3 10 4 Rata-rata APER dari semua rata-rata simulasi berdasarkan hubungan
antar peubah 12
5 Rata-rata APER dari semua rata-rata simulasi berdasarkan jarak nilai
tengah antar kelompok 12
6 Rata-rata APER dari semua rata-rata simulasi berdasarkan kergaman
data 13
7 Deskripsi data persentase penduduk per-kabupaten/kota di Pulau
Sumatera untuk masing-masing peubah pada setiap kelompok 15 8 Deskripsi data tingkat kemiskinan Kabupaten/Kota untuk
masing-masing kelompok 15
9 Kebaikan model diskriminan untuk metode ADV untuk 106 data training pada kasus matriks X berpangkat penuh 16 10 Nilai peubah untuk objek pertama data testing ( Kepulauan Mentawai) 17 11 Titik simpul, jarak antara objek dan titik simpul 17 12 Hasil klasifikasi model diskriminan ADV untuk 45 data testing pada
kasus matriks X berpangkat penuh 18
13 Kebaikan model diskriminan untuk metode ADF untuk 106 data training pada kasus matriks X berpangkat penuh 19 14 Hasil klasifikasi model diskriminan Fisher untuk 45 data testing pada
kasus matriks X berpangkat penuh 19
15 Kebaikan model diskriminan ADV untuk 12 data training pada kasus
matriks X berpangkat tidak penuh 20
DAFTAR GAMBAR
1 Diagram alir perbandingan efisiensi motode ADV dan ADF 8 2 Nilai APER antara metode ADF dan ADV dengan berbagai nilai S2
pada kelompok skenario 1 11
3 Histogram dan kurva normal data tingkat kemiskinan kabupaten/kota di
Pulau Sumatera 14
DAFTAR LAMPIRAN
1 Ringkasan simulasi 24
2 Nilai APER antara metode ADF dan metode ADV untuk 100 ulangan dengan berbagai nilai S2 pada kelompok skenario 2 27 3 Nilai APER antara metode ADF dan metode ADV untuk 100 ulangan
dengan berbagai nilai S2 pada kelompok skenario 5 28 4 Nilai APER antara metode ADF dan metode ADV untuk 100 ulangan
dengan berbagai nilai S2 pada kelompok skenario 6 28 5 Nilai APER antara metode ADF dan metode ADV untuk 100 ulangan
6 Nilai APER antara metode ADF dan metode ADV untuk 100 ulangan dengan berbagai nilai S2 pada kelompok skenario 8 29 7 Rangkuman hasil analisis kedelapan kelompok skenario 30 8 Data persentase penduduk kabupaten/kota di Pulau Sumatera dengan 19
peubah indikator kesejahteraan masyarakat 31
9 Output ADV untuk data training 35
10 Dugaan koefisien fungsi diskriminan yang dibentuk oleh ADV 35 11 Kabupaten/kota, Jarak objek ketitik simpul, kelompok awal, dugaan
kelompok dengan ADV 36
12 Output analisis diskriminan Fisher untuk data training 37 13 Output ADV untuk data ukuran objek n besar dari banyak peubah p
(Provinsi Riau) 38
14 Deskripsi data simulasi untuk banyak kelompok 8 40 15 Perbandingan persentase antara metode ADV dan ADF dalam
melakukan pengklasifikasian dengan nilai APER lebih kecil dari 100
kali ulangan 41
16 Data persentase penduduk per kabupaten/kota berdasarkan indikator
PENDAHULUAN
Latar Belakang
Metode klasifikasi banyak digunakan di berbagai bidang ilmu seperti sosial, ekonomi, perbankan, dan kedokteran. Metode klasifikasi adalah sebuah metode dari data mining yang digunakan untuk memprediksi kelompok suatu data pada kelompok kelas yang sudah ada sebelumnya (Izenman 2008). Metode klasifikasi terus berkembang sebagai cabang penting dari statistika. Salah satu metode klasifikasi yang banyak digunakan untuk pengklasifikasian objek (observasi) adalah analisis diskriminan. Analisis diskriminan yang berkembang sampai saat ini ada beberapa yaitu analisis diskriminan linier Fisher (ADF), analisis diskriminan kuadratik, analisis diskriminan kanonik dan analisis diskriminan linier yang terbaru adalah analisis diskriminan verteks (ADV). Pada karya ilmiah ini, peneliti membandingkan dua metode diskriminan linier yaitu ADF dan ADV.
Analisis diskriminan merupakan teknik statistika yang umum digunakan dalam pengklasifikasian (memisahkan) suatu objek dan mengalokasikan objek baru ke dalam suatu kelompok yang telah didefinisikan sebelumnya. Analisis diskriminan menghasilkan fungsi pembeda yang digunakan untuk memisahkan kelompok. Menurut Mattjik dan Sumertajaya (2011), analisis diskriminan adalah salah satu teknik statistik yang digunakan pada kasus peubah respon berupa data kualitatif dan peubah penjelas berupa data kuantitatif. Menurut Rencher (2002), fungsi diskriminan merupakan kombinasi linier peubah asal yang akan menghasilkan cara terbaik dalam pemisahan kelompok. Fungsi ini memberikan nilai sedekat mungkin bagi objek-objek dalam kelompok yang sama dan sejauh mungkin bagi objek-objek antar kelompok.
Johnson dan Wichern (2007) menjelaskan bahwa fungsi diskriminan pertama kali diperkenalkan oleh Ronald A. Fisher pada tahun 1936. Analisis diskriminan Fisher (ADF) dapat digunakan untuk klasifikasi dua kategori dan klasifikasi multikategori dengan mensyaratkan beberapa asumsi. ADF memiliki keterbatasan dalam penggunaannya yaitu tidak dapat mengklasifikasikan objek pada saat matriks X berpangkat tidak penuh. Kondisi tersebut biasanya tercapai jika ukuran observasi n kecil dari banyak peubah p. Pada kondisi ini pembentukan fungsi diskriminan tidak dapat dilakukan karena matriks ragam-peragam akan bersifat singular sehingga tidak memiliki matriks kebalikan.
Lange dan Wu (2008) memperkenalkan metode klasifikasi multikategori yang dikenal dengan ADV. Dibandingkan dengan ADF, ADV dapat mengklasifikasikan objek pada saat matriks X berpangkat tidak penuh. Masing-masing verteks pada ADV mewakili kategori yang berbeda pada Masing-masing-Masing-masing kelompok. Klasifikasi pada ADV dilakukan dengan meminimumkan fungsi tujuan yang melibatkan -insensitive loss dan penalti kuadrat. Penambahan penalti kuadrat digunakan dalam seleksi peubah dengan cara memperkecil koefisien parameter yang berkorelasi, yakni menuju nilai nol (Hastie et al. 2008).
2
Pada penelitian ini dikaji kinerja dari metode ADV untuk matriks X berpangkat penuh. Kondisi ini biasanya tercapai pada saat banyaknya observasi n jauh lebih besar dari banyak peubah p. Hasil kesalahan klasifikasi (nilai APER) metode ADV akan dibandingkan dengan nilai APER yang dihasilkan metode ADF. Selain itu, pada data kasus akan dilakukan analisis metode ADV untuk banyak observasi n jauh lebih kecil dari banyak peubah p.
Tujuan Penelitian
Tujuan dari penelitian ini, antara lain :
1. Mendapatkan tahapan proses dan salah pengklasifikasian suatu objek ke dalam suatu kelompok menggunakan ADF dan ADV.
2. Membandingkan hasil salah klasifikasi antara metode ADF dengan ADV untuk memperoleh hasil terbaik berdasarkan salah klasifikasi yang minimum.
TINJAUAN PUSTAKA
ADV
ADV merupakan metode pembelajaran untuk klasifikasi multikategori seperti yang telah dijelaskan oleh Lange dan Wu (2008). Verteks adalah suatu titik simpul berjarak sama pada ruang simplek dalam ruang Euclide yang digunakan untuk pengkodean atau pelabelan indikator kelas dari masing-masing kelompok. Masing-masing titik simpul menunjukan kategori yang berbeda.
Titik Berjarak Sama di
Proposisi 1. Sangat mungkin untuk memilih k+1 titik berjarak sama di tetapi tidak untuk k+2 titik berjarak sama di bawah Norm Euclide.
Kasus yang paling sederhana dari analisis diskriminan adalah klasifikasi biner (klasifikasi dua kategori). Indikator kelompok umumnya dilabelkan dengan titik -1 dan 1 pada garis nyata untuk membedakan kedua kelompok. Pemilihan tiga titik simpul berjarak sama dilakukan pada bidang datar (segitiga sama sisi). Hal ini disebabkan karena pemilihan tiga titik tidak dapat dilakukan dalam satu garis. Secara umum, kita dapat memilih (k+1) titik simpul ( 1,..., k+1) pada
simpleks regular dalam k (ruang dimensi k) dan banyak kategori (k+1)>3. Penentuan titik simpul pada simpleks reguler menurut Lange dan Wu (2008) salah satunya adalah sebagai berikut:
{ , untuk c d , untuk
(1)
3 Beberapa contoh nilai titik simpul untuk beberapa kategori di ruang k disajikan pada Tabel 1.
Tabel 1 Contoh nilai titik simpul
: titik simpul kelompok ke-j
Memaksimumkan atau meminimumkan fungsi tujuan merupakan suatu proses optimasi. Fungsi tujuan sama dengan nilai harapan dari fungsi kerugian. Meminimumkan fungsi tujuan sama dengan meminimumkan nilai harapan kerugian. Analisis diskriminan juga bertujuan meminimumkan nilai harapan kerugian , , | dengan y dan x masing-masing menunjukan indikator kelas dan vektor penciri untuk kasus acak, dan , adalah fungsi kerugian. Hal ini sulit dilakukan, sehingga untuk pendugaan parameter dilakukan dengan cara meminimumkan rata-rata kondisi kerugian
n∑ni dengan menambahkan batas penalti. Pengklasifikasian ADV
dilakukan dengan meminimumkan fungsi tujuan yang melibatkan fungsi kerugian untuk mengukur kesalahan empirik dalam fungsi tujuan, dan penalti kuadrat bertujuan memperkecil nilai dugaan menuju nol untuk peubah-peubah yang berkorelasi.
Fungsi Tujuan pada ADV
Pendugaan parameter pada ADV untuk proses klasifikasi diduga dengan cara meminimumkan fungsi tujuan yang didefinisikan dengan persamaan:
∑ ∑ ‖ ‖ ∑ ‖ ‖ , (2)
Dengan n = n1+n2 … nj, i ,…,n1,n2,…,n1+1,…,n2,…,nj,…,n, θ(A,b) adalah himpunan semua parameter yang tidak diketahui, b matriks berukuran k 1, A
matriks berukuran k p dengan p adalah banyaknya peubah X dan k adalah banyak kategori dikurangi 1, adalah tugas titik simpul ke-j pada observasi ke-i (k 1), ∑ ‖ ‖ adalah penalti pada matriks A dari parameter slope ( baris ke-j dari matriks A(kxp)), ‖ ‖ adalah fungsi kerugian, dan konstansta
pemulus λ≥0. Fungsi kerugian yang digunakan adalah -insensitive jarak Euclid yang didefinisikan sebagai berikut:
Banyak kategori (k+1) Keterangan
2
= 1.000
c √
√ , d √ =-1.000
3
=[0. 0. ]
c - √
√ , d √ , [0], [
0]
=[0 -0. ]
=[-0.
4
‖ ‖ ‖ ‖ { ‖ ‖ ‖ ‖ ‖ ‖ (3)
dengan = √ .
Algoritma MM
Algoritma MM (Majorize-Minimize) memiliki potensi dalam memecahkan masalah optimasi dan estimasi dimensi tinggi. Algoritma MM berhasil menyederhanakan masalah optimasi yang sulit dengan cara iterasi (Hunter & Lange, 2003; Lange dan Wu, 2010). Algoritma MM melibatkan majorize (mayorisasi) fungsi tujuan f dengan fungsi pengganti g | m . Fungsi g | m dikatakan mayorisasi fungsi f pada m apabila
Fungsi g | m minimize (minimisasi) dari f pada m jika –g | m mayorisasi f ). Mencari fungsi pengganti g | m yang optimum diperoleh dari tahapan mayorisasi dan diminimumkan pada tahap minimisasi yang menghasilkan nilai dugaan m . Mengoptimalkan fungsi pengganti akan mendorong fungsi tujuan keatas atau kebawah sampai optimum lokal. Jika m meminimalkan g | m maka tahapan minimisasi memaksa sifat turun f( m ) f m . Fakta ini mengikuti bentuk pertidaksamaan
f( m ) g( m | m) f( m ) g( m | m) g m| m f m g m| m ,
yang menjelaskan g( m | m) g m| m dan persamaan (4). Sifat turun ini membuat algoritma MM sangat stabil.
Fungsi pengganti yang sangat ideal digunakan untuk tujuan komputasi adalah fungsi kuadrat (Lange dan Wu, 2008). Algoritma MM diharapkan dapat mencapai konvergen minimum global untuk fungsi tujuan yang sangat cembung sehingga dapat menghasilkan solusi yang unik.
Mayorisasi Fungsi Kerugian dan Fungsi Tujuan
Mayorisasi fungsi kerugian ‖ ‖ yang didefinisikan pada persamaan (3) dihasilkan dari penggunaan pertidaksamaan Cauchy-Schwarz. Pertidaksamaan Cauchy-Schwarz g | m untuk mayorisasi fungsi ‖ ‖ (Lange dan Wu, 2008) adalah sebagai berikut:
f m g m| m (4)
5
Berdasarkan persamaan (6) mayorisasi fungsi tujuan dapat ditulis sebagai berikut:
∑ ‖ ‖ ∑‖ ‖
dan d adalah konstanta yang bergantung pada residual pada iterasi ke-m.
Golud dan Van Loan (1996) menjelaskan bahwa minimalisasi pada fungsi pengganti memperkecil dugaan pembobot kuadrat terkecil. Meminimumkan fungsi pengganti pada algoritme MM dilakukan untuk mendapatkan penduga
pada iterasi (m+1) yang dilakukan dengan memecahkan k
6
Bentuk persamaan (11) jika diperhatikan sama dengan model regresi multivariat untuk n observasi. Klasifikasi respon untuk kasus baru pada metode ADV diprediksi dengan
̂ argmin ‖ ̂ ̂‖ (10)
Ukuran Kesalahan Pengklasifikasian dalam Analisis Diskriminan
Apparent error rate (APER) adalah salah satu metode untuk mengevaluasi Analisis Diskriminan dalam pengklasifikasian. Nilai APER menurut Johnson dan Wichern (2002) adalah banyaknya persentase yang salah dalam pengelompokannya oleh fungsi klasifikasi.
A jumlah total objek ang salah dalam pengklasifikasianjumlah total objek
METODE PENELITIAN
Data
Data dalam penelitian ini terdiri dari dua sumber yaitu data simulasi dan data kasus terapan. Lang dan Wu (2008) telah menjelaskan bahwa metode ADV dapat mengklasifikasikan objek pada saat matriks X berpangkat tidak penuh. Pada kondisi tersebut metode ADF tidak dapat mengklasifikasikan objek karena matriks ragam-peragamnya bersifat singular, sehingga tidak memiliki matriks kebalikan. Tujuan dari peneltian ini adalah melihat kinerja dari metode ADV pada saat matriks X pangkat penuh dan membandingkan dengan metode ADF. Oleh karena itu, data simulasi dibangkitkan dengan kondisi banyak objek n jauh lebih besar dari p. Masing-masing simulasi diulang 100 kali. Data simulasi digunakan untuk mengukur dan membandingkan kinerja antara metode ADV dan ADF dengan menggunakan nilai kesalahan klasifikasi (APER). Data kasus terapan digunakan sebagai penerapan contoh kasus untuk metode ADV dan ADF.
Data Simulasi
Langkah-langkah analisis data pada proses pembangkitan data simulasi terbagi atas 2 tahap, yaitu:
Tahap I : Membangkitkan data
Langkah dalam membangkitkan data adalah sebagai berikut:
7 matriks diagonal yang elemen diagonalnya merupakan simpangan baku masing-masing peubah X, berdimensi 3 3
f. Membangkitkan peubah acak normal baku Z1,Z2,Z3 untuk banyak
kelompok 3 dan Z1,Z2,Z3,Z4,Z5,Z6,Z7,Z8untuk banyak kelompok 8 dengan Zj~N3(0,1) sebanyak 50 untuk masing-masing kelompok dengan j=1, 2, 3
dan j , , …,
g. Menguraikan setiap matriks j menjadi HTH
h. Membangkitkan peubah acak normal ganda Gjsebanyak nj untuk kelompok ke-j, dengan Gj ~ Np(µj,j) dan Gj=ZjH+1 µjT
i. Menggabungkan data semua kelompok menjadi satu data simulasi. Tahap II: Menyusun skenario simulasi
Ada 8 kelompok skenario simulasi yang akan dilakukan. Pada setiap simulasi, data dibangkitkan secara acak mengukuti normal ganda. banyak observasi 50 untuk masing-masing kelompok dan banyak peubah bebas 3. Perbedaan kedelapan kelompok skenario tersaji pada Tabel 2.
Tabel 2 Perbedaan kedelapan kelompok skenario
Kelompok
Masing-masing skenario diulang sebanyak 100 kali ulangan. Secara lengkap skenario simulasi dapat dilihat pada Lampiran 1.
Data Kasus Terapan
Tingkat kemiskinan adalah persentase penduduk miskin dari seluruh penduduk pada suatu daerah (Berita Resmi Statistik, 2014). Semakin besar persentase tingkat kemiskinan maka jumlah penduduk miskin pada daerah tersebut semakin banyak, sehingga dapat dikatakan daerah tersebut adalah daerah dengan masalah kemiskinan terparah dan begitu juga sebaliknya.
8
masyarakat di Pulau Sumatera yang digunakan sebagai peubah X untuk mengukur tingkat kemiskinan Y. Data diambil pada level provinsi di Pulau Sumatera yang terdiri dari 9 provinsi dan 151 kabupaten/kota. Data terapan pada penelitian ini terdiri dua jenis kasus yaitu data terapan untuk kasus matriks X berpangkat penuh dan data terapan untuk matriks X berpangkat tidak penuh.
Matriks X berpangkat penuh seperti yang telah dijelaskan biasanya tercapai pada saat banyak observasi n jauh lebih besar dari banyak peubah p. Oleh karena itu, data terapan untuk matriks X berpangkat penuh diambil dari data kabupaten/kota untuk seluruh provinsi yang ada di Pulau Sumatera yang terdiri dari 151 kabupaten/kota dan 19 peubah.
Sedangkan untuk matriks X berpangkat tidak penuh biasanya tercapai pada saat banyak observasi n lebih kecil dari banyak peubah p. Berdasarkan hal tersebut, data terapan untuk kasus matriks X berpangkat tidak penuh diambil dari data kabupaten/kota yang ada di Provinsi Riau yang terdiri dari 12 kabupaten/kota dan 19 peubah.
Oleh karena tidak adanya teori atau penelitian sebelumnya yang mendasari pengelompokan tingkat kemiskinan per-kabupaten/kota, maka peneliti mengelompokan tingkat kemiskinan Y menjadi 3 kelompok berdasarkan sebaran empirik data. Kelompok 1 adalah kabupaten/kota dengan tingkat kemiskinan di bawah 7.5% (daerah tidak miskin), kelompok 2 adalah kabupaten/kota dengan tingkat kemiskinan antara 7.5% sampai dengan 22.5% (daerah dengan masalah kemiskinan sedang) dan kelompok 3 adalah kabupaten/kota dengan tingkat kemiskinan di atas 22.5% (daerah dengan masalah kemiskinan terparah). Peubah yang digunakan dalam penelitian ini adalah (BPS, 2010):
X1 : tingkat pengangguran terbuka (%)
X2 : angka partisipasi angkatan kerja (%)
X3 : pekerja yang bekerja selama kurang dari 14 jam seminggu (%)
X4 : pekerja yang bekerja selama kurang dari 35 jam seminggu (%)
X5 : pekerja disektor informal (%)
X6 : persentase balita kekurangan gizi (%)
X7 : angka kematian bayi per 1000 kelahiran hidup
X8 : kelahiran ditolong oleh tenaga medis (%)
X9 : penduduk dengan keluhan kesehatan (%)
X10 : angka morbiditas (terkena penyakit) (%)
X11 : rata-rata lama sakit (%)
X12 : penduduk yang melakukan pengobatan sendiri (%)
X13 : angka putus sekolah penduduk usia (7-15) tahun (%)
X14 : angka partisipasi pendidikan sekolah dasar (APM)
X15 : angka partisipasi pendidikan sekolah menengah pertama (APM)
X16 : angka partisipasi pendidikan sekolah menengah atas (APM)
X17 : proporsi rumah tangga dengan akses air bersih (%)
X18 : proporsi rumah tangga tanpa akses sanitasi (%)
X19 : angka harapan hidup per tahun (%)
Metode Analisis
9
Gambar 1 Diagram alir untuk membandingkan efisiensi metode ADV dab ADF
a. Pembentukan fungsi ADV dengan tahapan: (Lange dan Wu 2008) 1. Menetapkan iterasi awal m=0 dengan A(0)=0 dan b(0)=0
2. Menentukan nilai titik simpul dari masing-masing kelompok dengan persamaan (1) dan mendefinisikan
3. Majorize fungsi kerugian yang diregularisasi pada persamaan (7) dengan residual ke-i
4. Meminimumkan fungsi pengganti dengan menentukan A(m+1) dan b(m+1)
yang diperoleh dari memecahkan k pasang persamaan linier
5. Jika ‖ ‖ dan | | dengan maka stop, Jika tidak ulangi langkah 3 sampai 5
6. Setelah mendapatkan fungsi diskriminan untuk membedakan masing-masing kelompok dilakukan tahapan pengklasifikasian metode ADV dengan persamaan 10.
7. Menghitung nilai APER
b. Pembentukan fungsi diskriminan Fisher dengan tahapan: (Johnson dan Wichern 2002)
1. Mengecek asumsi ADF
a. Pengecekan asumsi data berdistribusi normal ganda menggunakan plot kuantil khi kuadrat
b. Menguji kehomogenan matriks ragam-peragam ( ) menggunakan statistik Bo ‟s M
10
2. Membentuk fungsi diskriminan Fisher , vektor koefisien pembobot fungsi diskriminan a(px1) adalah vektor ciri dari , x adalah vektor
peubah bebas yang diidentifikasi dalam fungsi diskriminan.
∑
∑( ̅ ̅)
( ̅ ̅) ∑ ̅
̅
dengan ;
3. Mengklasifikasikan observasi baru berdasarkan persamaan diskriminan linier Fisher, alokasikan x ke kelompok j jika
∑ ̂ ̅ ∑ [ ̂ ( ̅)] ∑ [ ̂ ̅̅̅ ]
4. Menghitung nilai APER untuk semua data simulasi.
5. Membandingkan hasil kesalahan klasifikasi dari kedua metode, yaitu ADV dan ADF menggunakan APER untuk masing-masing metode.
2. Penerapan data kasus untuk metode ADV dengan tahapan analisis:
1. Membagi data kemiskinan menjadi dua, yaitu data training dan data testing dengan persentase masing-masing 70% dan 30%. Data training digunakan untuk membentuk fungsi diskriminan dan data testing digunakan untuk evaluasi kesalahan pengklasifikasian.
2. Melakukan proses pembentukan fungsi diskriminan dengan metode ADV seperti diagram alir tahapan metode ADV
3. Mengklasifikasikan objek berdasarkan fungsi diskriminan 4. Menghitung kesalahan klasifikasi berdasarkan nilai APER
HASIL DAN PEMBAHASAN
11
Kajian Simulasi
Pada kajian simulasi ada 8 kelompok skenario simulasi. Masing-masing kelompok skenario simulasi terdiri dari 5 simulasi. Masing-masing simulasi dianalisis dengan metode ADV dan ADF dengan 100 kali ulangan. Metode ADV dan ADF menghasilkan 100 nilai APER. Selajutnya nilai APER masing-masing metode dirata-ratakan dan dibandingkan untuk melihat kinerja dari metode ADV dan ADF. Gambaran data hasil bangkitan untuk semua simulasi dengan banyak kelompok 3 dapat dilihat pada Tabel 3 dan banyak kelompok 8 tersaji pada Lampiran 14.
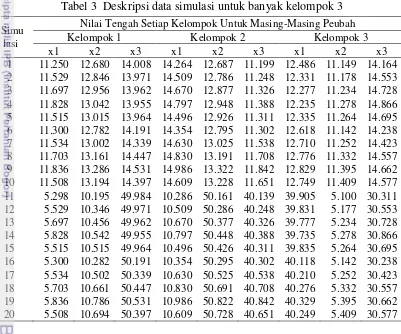
Tabel 3 Deskripsi data simulasi untuk banyak kelompok 3
Simu lasi
Nilai Tengah Setiap Kelompok Untuk Masing-Masing Peubah
Kelompok 1 Kelompok 2 Kelompok 3
x1 x2 x3 x1 x2 x3 x1 x2 x3
1 11.250 12.680 14.008 14.264 12.687 11.199 12.486 11.149 14.164
2 11.529 12.846 13.971 14.509 12.786 11.248 12.331 11.178 14.553
3 11.697 12.956 13.962 14.670 12.877 11.326 12.277 11.234 14.728
4 11.828 13.042 13.955 14.797 12.948 11.388 12.235 11.278 14.866
5 11.515 13.015 13.964 14.496 12.926 11.311 12.335 11.264 14.695
6 11.300 12.782 14.191 14.354 12.795 11.302 12.618 11.142 14.238
7 11.534 13.002 14.339 14.630 13.025 11.538 12.710 11.252 14.423
8 11.703 13.161 14.447 14.830 13.191 11.708 12.776 11.332 14.557
9 11.836 13.286 14.531 14.986 13.322 11.842 12.829 11.395 14.662
10 11.508 13.194 14.397 14.609 13.228 11.651 12.749 11.409 14.577
11 5.298 10.195 49.984 10.286 50.161 40.139 39.905 5.100 30.311
12 5.529 10.346 49.971 10.509 50.286 40.248 39.831 5.177 30.553
13 5.697 10.456 49.962 10.670 50.377 40.326 39.777 5.234 30.728
14 5.828 10.542 49.955 10.797 50.448 40.388 39.735 5.278 30.866
15 5.515 10.515 49.964 10.496 50.426 40.311 39.835 5.264 30.695
16 5.300 10.282 50.191 10.354 50.295 40.302 40.118 5.142 30.238
17 5.534 10.502 50.339 10.630 50.525 40.538 40.210 5.252 30.423
18 5.703 10.661 50.447 10.830 50.691 40.708 40.276 5.332 30.557
19 5.836 10.786 50.531 10.986 50.822 40.842 40.329 5.395 30.662
20 5.508 10.694 50.397 10.609 50.728 40.651 40.249 5.409 30.577
Berdasarkan deskripsi data simulasi pada Tabel 3 terlihat bahwa untuk kelompok skenario1,2,3,4 nilai tengah setiap kelompok mendekati nilai tengah masing-masing kelompok pada skenario simulasi yang dibentuk. Hal ini menunjukan bahwa simulasi yang dibentuk sudah sesuai.
Kelompok Skenario 1
12
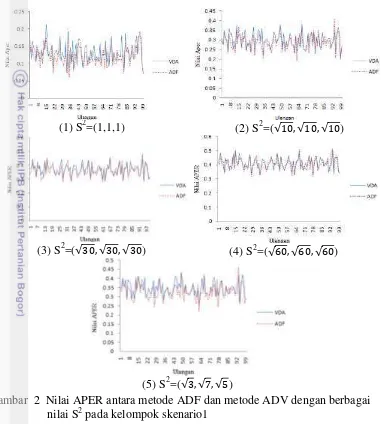
tidak ada korelasi antar peubah. Hasil analisis data untuk kelompok skenario 1 tersaji pada Gambar 2.
(1) S2=(1,1,1) (2) S2=(√ √ √ )
(3) S2=(√ √ √ ) (4) S2=(√ √ √ )
(5) S2=(√ √ √ )
Gambar 2 Nilai APER antara metode ADF dan metode ADV dengan berbagai nilai S2 pada kelompok skenario1
13 menunjukan bahwa sebanyak 35% dari 100 kali ulangan nilai APER metode ADV lebih kecil dalam pengklasifikasian dari ADF, 55% ADF lebih kecil dari ADV, dan 10% memiliki kemampuan klasifikasi yang sama. Rata-rata nilai APER untuk metode ADV 0.39 dan ADF 0.39. Begitu juga pada simulasi (5) S2=(3,7,5) dengan ulangan 100 kali, perbandingan nilai APER metode ADV 21% lebih kecil dari ADF, 73% nilai APER dengan metode ADF lebih kecil dari ADV, dan 6% memiliki kemampuan klasifikasi yang sama. Rata-rata nilai APER utnuk metode ADV 0.40 dan ADF 0.40. Dari kelima simulasi rata-rata kesalahan klasifikasi dari kedua metode hampir sama, sehingga dapat disimpulkan bahwa jika asumsi kenormalan dipenuhi dan peubah X tidak berkorelasi, maka metode ADF dan ADV memiliki kemampuan klasifikasi yang sama. Semakin besar ragam data nilai APER juga semakin besar. Nilai APER dari metode ADF dan metode ADV dengan berbagai nilai S2 dengan 100 kali ulangan pada kelompok skenario 2,3,4,5,6,7,dan 8 tersaji dalam bentuk gambar pada Lampiran 2,3,4,5,dan 6. Gambaran rata-rata hasil analisis data dari kedelapan kelompok skenario simulasi secara umum tersaji pada Tabel 4, Tabel 5, Tabel 6, dan gambaran rata-rata hasil analisis data dari kedelapan kelompok skenario untuk masing-masing simulasi secara lengkap tersaji pada Lampiran 7.
Tabel 4 Gambaran rata-rata APER dari semua rata-rata simulasi berdasarkan ADV (0.32) pada saat peubah berkorelasi. Jika peubah tidak ada korelasi rata-rata nilai APER kedua metode sama. Hal ini berarti metode ADF dan ADV memiliki kemampuan sama dalam klasifikasi.
Jika dilihat dari rata-rata APER untuk masing-masing skenario simulasi yang terdapat pada Lampiran 7. Pada saat peubah berkorelasi ADV dan ADF memiliki kemampuan klasifikasi yang sama jika nilai tengah berdekatan. Jika nilai tengah berjauhan maka ada 2 kemungkinan yaitu kedua metode dapat mengklasifikasikan dengan sempurna untuk banyak kelompok 3 dan metode ADF lebih baik dari ADV dalam pengklasifikasian untuk banyak kelompok 8.
14
Jarak nilai tengah antar kelompok mempengaruhi nilai kesalahan klasifikasi dari metode ADV dan ADF. Berdasarkan jarak nilai tengah antar kelompok dari kedelapan kelompok skenario simulasi disimpulkan metode ADF lebih baik dari ADV jika jarak nilai tengah antar kelompok berjauhan. Hal ini ditunjukan pada Tabel 5 bahwa rata-rata APER metode ADF (0.04) dan ADV (0.14). Rata-rata APER metode ADF (0.47) dan ADV (0.53) pada saat nilai tengah antar kelompok berdekatan. Oleh karena itu dapat disimpulkan pada saat nilai tengah antara kelompok dekat metode ADV dan ADF memiliki kemampuan klasifikasi yang sama. Lampiran 7 menunjukkan untuk masing-masing skenario jika jarak nilai tengah berjauhan maka ada terdapat 2 kesimpulan yang dapat kita ambil yaitu untuk banyak kelompok ada 3 maka ADV dan ADF dapat mengklasifikasikan objek dengan sempurna tanpa ada salah klasifikasi. Tetapi untuk banyak kelompok 8 ADF lebih baik dari ADV dalam pengklasifikasian.
Tabel 6 Gambaran rata-rata APER dari semua rata-rata simulasi berdasarkan keragaman data
Keragaman data Rata-rata dari rata-rata nilai APER untuk ADV
Rata-rata dari rata-rata nilai APER untuk ADF
1,1,1 0.26 0.18
10,10,10 0.39 0.24
30,30,30 0.33 0.27
60,60,60 0.35 0.30
3,7,5 0.33 0.27
Berdasarkan keragaman data kedelapan kelompok skenario simulasi memperlihatkan pola yaitu semakin besar nilai keragaman maka kesalahan klasifikasi juga akan meningkat. Tetapi kesalahan klasifikasi pada metode ADV dan ADF tidak jauh berbeda dalam pengklasifikasian. Oleh karena itu dapat disimpulkan bahwa metode ADV dan ADF mempunyai kemampuan yang sama dalam pengklasifikasian.
Dari rata-rata untuk masing-masing skenario simulasi yang terdapat pada Lampiran 7 dapat disimpulkan bahwa pada saat nilai tengah berdekatan untuk semua nilai ragam yang telah dicobakan ADV dan ADF memiliki kemampuan klasifikasi yang sama. Jika nilai tengah antara kelompok berjauhan ada 2 simpulan yang dapat kita ambil yaitu ADV dan ADF dapat mengklasifikasikan objek dengan sempurna untuk banyak kelompok 3 dan ADF lebih baik dari ADV dalam mengklasifikasikan objek untuk banyak kelompok 8.
Perbandingan persentase nilai APER antara metode ADV dan ADF dalam melakukan pengklasifikasian dari 100 kali ulangan data simulasi dapat dilihat pada Lampiran 15.
Pembentukan Model Diskriminan pada Kasus Terapan
15 kesejahteraan masyarakat di Pulau Sumatera tersebut dapat dilihat pada Lampiran 8 dengan penentuan kelompok awal dari masing-masing kabupaten/kota dilakukan berdasarkan sebaran data. Gambar 3 menyajikan histogram dengan kurva normal dari tingkat kemiskinan kabupaten/kota di Pulau Sumatera.
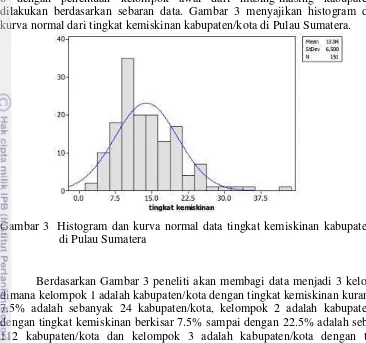
Gambar 3 Histogram dan kurva normal data tingkat kemiskinan kabupaten/kota di Pulau Sumatera
Berdasarkan Gambar 3 peneliti akan membagi data menjadi 3 kelompok, dimana kelompok 1 adalah kabupaten/kota dengan tingkat kemiskinan kurang dari 7.5% adalah sebanyak 24 kabupaten/kota, kelompok 2 adalah kabupaten/kota dengan tingkat kemiskinan berkisar 7.5% sampai dengan 22.5% adalah sebanyak 112 kabupaten/kota dan kelompok 3 adalah kabupaten/kota dengan tingkat kemiskinan lebih dari 22.5% adalah sebanyak 15 kabupaten/kota. Secara lengkap tersaji pada Lampiran 8. Selain itu, Gambar 3 juga menjelaskan rata-rata tingkat kemiskinan kabupaten/kota di Sumatera adalah 13.85 dan standar deviasi 6.5.
Deskripsi data persentase per kabupaten/Kota berdasarkan indikator kesejahteraan masyarakat di Pulau Sumatera untuk masing-masing peubah pada setiap kelompok dapat dilihat pada Tabel 7.
Tabel 7 menjelaskan bahwa rata-rata peubah X1 untuk kelompok 1 pada
data persentase penduduk per kabupaten/kota di Pulau Sumatera adalah 7.86 dengan standar deviasi sebesar 3.76, sampai dengan rata-rata dan standar deviasi peubah X19 untuk kelompok 3. Deskripsi data tingkat kemiskinan kabupaten/kota
untuk masing-masing kelompok tersaji pada Tabel 8.
16
Tabel 7 Deskripsi data persentase penduduk per-kabupaten/kota di Pulau Sumatera untuk masing-masing peubah pada setiap kelompok
Kelompok 1 Kelompok 2 Kelompok 3
Peubah Rata-rata Standar
deviasi
Rata-rata Standar
deviasi
Rata-rata Standar
deviasi
X1 7.86 3.76 6.42 3.23 5.50 3.56
X2 64.80 5.09 68.73 7.57 67.54 7.54
X3 3.79 2.24 4.76 2.60 5.71 2.46
X4 28.21 12.72 37.32 12.13 44.88 9.29
X5 50.79 14.37 65.03 15.89 69.39 11.69
X6 17.48 4.98 20.51 6.80 25.55 7.24
X7 29.27 5.37 34.07 7.18 35.78 7.59
X8 83.98 15.46 81.16 14.08 80.36 12.83
X9 33.61 7.62 32.90 7.71 32.53 5.23
X10 18.63 4.73 18.92 5.31 20.41 3.75
X11 5.37 0.69 5.56 0.86 5.27 0.55
X12 66.29 8.62 72.70 8.91 74.57 8.14
X13 2.15 1.64 2.33 1.43 1.55 1.19
X14 92.34 4.77 94.91 2.82 95.86 2.82
X15 65.45 8.36 70.38 8.41 75.13 5.24
X16 54.82 14.14 50.54 12.42 60.13 8.23
X17 56.62 17.60 46.59 19.73 40.15 10.12
X18 16.80 12.14 28.10 18.99 33.76 16.64
X19 69.56 2.60 68.78 1.84 68.27 1.90
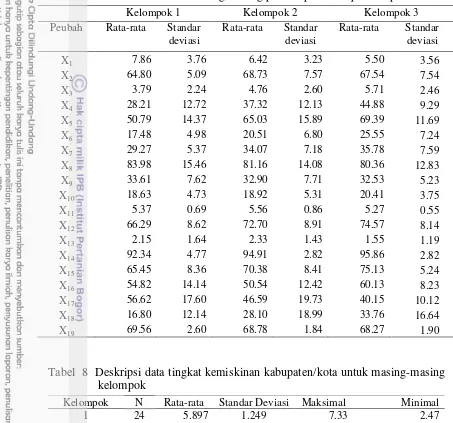
Tabel 8 Deskripsi data tingkat kemiskinan kabupaten/kota untuk masing-masing kelompok
Kelompok N Rata-rata Standar Deviasi Maksimal Minimal
1 24 5.897 1.249 7.33 2.47
2 112 13.742 3.849 21.68 7.60
3 15 27.324 5.497 42.46 22.62
Total 151
Kasus Terapan untuk Matriks X Berpangkat Penuh
17 kabupaten/kota. Data training digunakan untuk pembentukan fungsi diskriminan dan data testing digunakan untuk mengevaluasi model diskriminan.
Pembentukan Model Diskriminan Verteks
Metode ADV membentuk fungsi diskriminan dengan bentuk dan hasil analisis dapat dilihat pada Lampiran 9. ADV membentuk 2 fungsi diskriminan untuk membedakan 3 kelompok berdasarkan banyak objek 106 kabupaten/kota, banyak kelompok 3, dan besar lamda 0.009434. Dugaan koefisien yang dibentuk oleh ADV disajikan pada Lampiran 10 .
Berdasarkan dugaan koefisien pada Lampiran 10 didapatkan bentuk fungsi diskriminan pertama (Y1) dan fungsi diskriminan kedua (Y2) sebagai berikut:
Y1= 0.094 + 0.109X1 + 0.073X2 - 0.036X3 + 0.018X4 - 0.073X5 - 0.015X6 -
0.021X7 - 0.043X8 – 0.031X9 + 0.027X10 + 0.049X11 - 0.053X12 + 0.015X13 –
0.008X14 - 0.115X15 + 0.009X16 - 0.004X17 - 0.061X18 - 0.026X19
Y2= -0.165 - 0.028X1 - 0.024X2 -0.029X3 + 0.027X4 - 0.002X5 + 0.009X6–
0.039X7 - 0.017X8 + 0.00007X9 + 0.013X10 + 0.004X11 - 0.035X12 -0.017X13
-0.006X14 - 0.043X15 + 0.021X16 + 0.009X17 - 0.041X18 - 0.028X19
Kebaikan model diskriminan untuk metode ADV dapat dilihat dari ketepatan klasifikasi masing-masing kelompok yang dapat dilihat pada Tabel 9.
Tabel 9 Kebaikan model diskriminan untuk metode ADV untuk 106 data training pada kasus matriks X berpangkat penuh
Klasifikasi Model
Kelompok 1 2 3 Banyak objek
Klasifikasi Sebenarnya
1 11 7 0 18
2 2 78 0 80
3 0 4 4 8
Banyak objek 13 89 4 106
Tabel 9 memperlihatkan bahwa banyak objek yang diklasifikasikan secara tepat oleh kedua model diskriminan untuk metode ADV adalah sebanyak 93 objek (88%), dan banyak objek yang salah klasifikasi sebanyak 13 objek (12%). Nilai persentase probabilita pengelompokan awal sebesar 17%. Evaluasi tingkat akurasi fungsi diskriminan dilakukan dengan memperhatikan persentase tepat pengklasifikasian dan probabilita pengelompokan awal. Model diskriminan dikatakan cukup baik karena persen tepat klasifikasi (88%) besar dari (1.25 kali persen probabilita pengelompokan awal) yaitu sebesar 21.2 %. Dari Lampiran 9 terlihat bahwa kesalahan klasifikasi (nilai APER) metode ADV sebesar 0.1226415. Hal ini menunjukan bahwa metode ADV memiliki kemampuan dalam mengklasifikasian objek dengan tepat pada kasus data training sebesar 0.877359.
18
klasifikasi model dan klasifikasi sebenarnya untuk kedua metode memiliki korelasi yang kuat.
Setelah fungsi diskriminan terbentuk, selanjutnya dilakukan evaluasi pada metode ADV menggunakan 45 data testing dengan melihat besar kesalahan klasifikasi (nilai APER). Misalkan untuk objek pertama data testing (Kepulauan Mentawai) dengan klasifikasi awal adalah kelompok 2. Nilai untuk masing-masing peubah dan nilai standarisasi tersaji pada Tabel 10.
Tabel 10 Nilai peubah untuk objek pertama data testing (Kepulauan Mentawai)
Peubah Data Data yang dibakukan
X1 4.03 -0.7406
X2 74.21 0.7678
X3 2.81 -0.8151
X4 58.09 1.5555
X5 92.07 1.6070
X6 19.75 -0.0311
X7 35.00 0.0850
X8 44.50 -2.6026
X9 27.84 -0.6153
X10 21.46 0.4459
X11 4.35 -1.3929
X12 76.88 0.5630
X13 1.80 -0.2693
X14 87.92 -2.3020
X15 58.20 -1.3050
X16 45.37 -0.4802
X17 4.30 -2.1987
X18 75.00 2.6255
X19 68.45 -0.1243
Nilai masing-masing peubah disubtitusi ke dalam fungsi diskriminan pertama dan fungsi diskriminan kedua pada model diskriminan ADV untuk kasus n>p sehingga diperoleh nilai Y1=0.065385 dan Y2= -0.13688. Nilai titik simpul
untuk 3 kelompok, jarak antara objek dengan titik simpul, dan dugaan klasifikasi dengan menggunakan persamaan (10) tersaji pada Tabel 11.
Tabel 11 Titik simpul, jarak antara objek dan titik simpul, dan dugaan klasifikasi
Kelompok ‖ ̂ ̂‖
1 0.707 1.050287
0.707
2 0.258 0.850226
-0.965
3 -0.965 1.103459
19 Berdasarkan nilai jarak terkecil antara objek dan titik simpul pada Tabel 11 dari ketiga kelompok, Kepulauan Mentawai diklasifikasikan ke dalam kelompok 2. Hasil analisis klasifikasi untuk 45 data testing secara lengkap dapat disajikan pada Lampiran 11. Hasil klasifikasi metode ADV untuk semua data testing dapat dilihat pada Tabel 12.
Tabel 12 Hasil klasifikasi model diskriminan ADV untuk 45 data testing pada kasus matriks X berpangkat penuh
Klasifikasi Model
Kelompok 1 2 3
Banyak objek
Klasifikasi Sebenarnya
1 2 4 0 6
2 4 27 1 32
3 0 5 2 7
Banyak objek 6 36 3 45
Tabel 12 menjelaskan bahwa banyak objek yang diklasifikasikan secara tepat untuk kedua model diskriminan pada data testing adalah sebanyak 31 objek (68.9%) dan banyak objek yang salah klasifikasi sebanyak 14 objek (31.1%). Nilai persentase probabilita pengelompokan awal sebesar 13.3%. Karena persen tepat klasifikasi (68.9%) besar dari (1.25 kali persen peluang pengelompokan awal) yaitu sebesar 16.7 % dapat disimpulkan model diskriminan cukup baik dalam membedakan kelompok. Besar kesalahan klasifikasi yang dihasilkan metode ADV pada data testing berkisar 31.1%.
Pembentukan Model Diskriminan Fisher
Pembentukan model diskriminan dengan menggunakan metode ADF juga dilakukan pada data terapan (data persentase penduduk per-kabupaten/kota berdasarkan indikator kesejahteraan masyarakat di Pulau Sumatera). Pembentukan model diskriminan menggunakan data training sebanyak 106 kabupaten/kota, dan data testing sebanyak 45 kabupaten/kota digunakan untuk mengevaluasi model diskriminan.
Metode ADF membentuk fungsi diskriminan dengan bentuk dan hasil analisis dapat dilihat pada Lampiran 12. ADF membentuk 2 fungsi diskriminan untuk membedakan 3 kelompok berdasarkan banyak objek 106 kabupaten/kota, banyak kelompok 3. Berdasarkan dugaan koefisien pada Lampiran 12 didapatkan bentuk fungsi diskriminan pertama (Y1) dan fungsi diskriminan kedua (Y2)
sebagai berikut:
Y1 = 0.001X1 - 0.218X2 + 0.379X3 - 0.281X4 + 0.629X5 + 0.122X6 + 0.644X7 +
0.358X8 + 0.106X9 - 0.157X10 + 0.006X11 + 0.629X12 + 0.155X13 + 0.361X14
+ 0.520X15 - 0.201X16 - 0.018X17 + 0.209X18 + 0.759X19
Y2 = -0.819 X1 - 0.897 X2 - 0.475X3 + 0.664X4- 0.186X5 + 0.357X6 +0.609X7 –
0.071X8 + 0.373X9 - 0.258X10 - 0.341X11 - 0.277X12 + 0.162X13 + 0.101X14
+ 0.164 X15 + 0.547X16 - 0.099X17 + 0.103X18 - 0.317X19
20
Tabel 13 Kebaikan model diskriminan untuk metode ADF untuk 106 data training pada kasus matriks X berpangkat penuh
Klasifikasi Model
Tabel 13 menunjukan bahwa banyak objek yang diklasifikasikan secara tepat oleh model diskriminan untuk metode ADF adalah sebanyak 89 objek (84%), dan banyak objek yang salah klasifikasi sebanyak 17 objek (16%). Nilai persentase probabilita pengelompokan awal sebesar (16.98%). Karena persen tepat klasifikasi (84%) besar dari (1.25 kali persen peluang pengelompokan awal) yaitu sebesar 20% dapat disimpulkan model diskriminan cukup baik.
Setelah fungsi diskriminan terbentuk, selanjutnya dilakukan evaluasi pada metode ADF menggunakan 45 data testing dengan melihat besar kesalahan klasifikasi (nilai APER). Misalkan untuk objek pertama data testing (Kepulauan Mentawai) dengan klasifikasi awal adalah kelompok 2. Nilai untuk masing-masing peubah distandarisasi, nilai ini tersaji pada Tabel 10.
Nilai masing-masing peubah disubtitusi ke dalam fungsi diskriminan pertama dan fungsi diskriminan kedua pada model diskriminan ADF untuk kasus pangkat matriks data X lebih besar dari banyak peubah p, sehingga diperoleh nilai nilai Y1=-1.53667 dan Y2= 0.910714. Pengklasifikasian berdasarkan persamaan
diskriminan linier Fisher untuk Kepulauan Mentawai diklasifikasikan ke dalam kelompok 1. Hasil klasifikasi metode ADF untuk semua data testing dapat dilihat pada Tabel 14.
Tabel 14 Hasil klasifikasi model diskriminan Fisher untuk 45 data testing pada kasus matriks X berpangkat penuh
21 awal) yaitu sebesar 38.89% dapat disimpulkan model diskriminan cukup baik. Nilai APER metode ADF menunjukan angka 48.9 %. Hal ini berarti untuk data testing model diskriminan memiliki kemampuan dalam mengklasifikasian objek dengan tepat sebesar 51.1%.
Kasus Terapan untuk Matriks X Berpangkat Tidak Penuh
Data terapan untuk kasus matriks X berpangkat tidak penuh diambil dari data kabupaten/kota yang ada di Provinsi Riau yang terdiri dari 12 kabupaten/kota. Data yang digunakan adalah data persentase penduduk per-kabupaten/kota berdasarkan indikator kesejahteraan masyarakat di Provinsi Riau yang tersaji pada Lampiran 16.
Metode ADF memiliki keterbatasan pada saat matriks X berpangkat tidak penuh, sehingga dalam penerapan data ini metode ADF tidak dapat dilakukan. Metode ADV dapat mengatasi keterbatasan dari metode ADF tersebut. Metode ADV membentuk 2 fungsi diskriminan untuk membedakan 3 kelompok yaitu fungsi diskriminan pertama (Y1) dan fungsi diskriminan kedua (Y2). Hasil analisis
metode ADV tersaji pada Lampiran 13. Bentuk fungsi diskriminan ADV untuk membedakan 3 kelompok sebagai berikut:
Y1 = 0.026 0.023X1 - 0.011X2 - 0.006X3 -0.017X4 - 0.014X5 + 0.013X6 - 0.019X7
+ 0.011X8 + 0.014 X9 + 0.008X10 + 0.009X11 0.015X12 -0.001X13 +
0.034X14 + 0.012X15 0.006 X16 + 0.005X17 - 0.001X18 + 0.0189X19
Y2 = -0.098 - 0.003X1 + 0.021X2 - 0.003X3 -0.008X4 - 0.017X5 - 0.018X6 -
0.008X7 + 0.0037X8 + 0.015X9 + 0.003X10 - 0.023X11 -0.018X12 +
0.0007X13 - 0.045X14 + 0.012X15 0.008X16 + 0.010X17 - 0.011X18 +
0.008X19
Kebaikan model diskriminan untuk metode ADV dapat dilihat dari ketepatan klasifikasi masing-masing kelompok yang tersaji pada Tabel 15.
Tabel 15 Kebaikan model diskriminan ADV untuk 12 data training pada kasus matriks X berpangkat tidak penuh
Klasifikasi Model
Kelompok 1 2 3 Banyak
Klasifikasi sebenarnya
1 3 0 0 3
2 0 8 0 8
3 0 0 1 1
Banyak 3 8 1 12
22
SIMPULAN DAN SARAN
Simpulan
Berdasarkan hasil dan pembahasan dari 8 kelompok skenario data simulasi dan data kasus terapan (data tingkat kemiskinan per-kabupaten/kota berdasarkan indikator kesejahteraan masyarakat di Pulau Sumatera) yang digunakan untuk membandingkan kinerja antara kedua metode (ADV, ADF) dapat disimpulkan: a. Pada saat matriks X berpangkat penuh, asumsi kenormalan dan kehomogenan
matriks ragam-peragam terpenuhi, dan banyak kelompok 3 dan 8. Metode ADF dan ADV memiliki kemampuan klasifikasi yang sama, tetapi kedua metode ini sangat sensitif terhadap besarnya keragaman. Semakin besar nilai keragaman maka kesalahan klasifikasi juga akan meningkat.
b. Pada data kasus terapan untuk matriks X berpangkat tidak penuh, ADV memiliki kemampuan klasifikasi yang lebih baik dari ADF. Pada kondisi ini ADV mampu melakukan klasifikasi objek dengan tepat tanpa ada salah klasifikasi, sedangkan metode ADF tidak dapat digunakan.
Saran
Pada penelitian ini baru dilakukan perbandingan kinerja metode analisis diskriminan linier ADF dan ADV, dan dievaluasi untuk data yang menyebar normal ganda dan matriks ragam-peragam antar kelompok homogen. Selain itu pada penelitian ini belum dilakukan pengujian signifikansi pada fungsi diskriminan yang dibentuk.
Peneliti berikutnya dapat mengkaji kinerja metode ADV pada kondisi data tidak menyebar normal ganda dan matriks ragam-peragam antar kelompok tidak homogen, selanjutnya dapat dibandingkan dengan analisis diskriminan kuadratik dan diskriminan kanonik. Pengujian signifikansi pada model diskriminan dapat dilakukan dengan pendekatan resampling.
DAFTAR PUSTAKA
Berita Resmi Statistika. 2014. Tingkat Kemiskinan di Daerah Istimewa Yogyakarta. Yokyakarta (ID): BPS
BPS[Badan Pusat Statistika]. 2010. Survei Sosial Ekonomi Nasional Tahun 2010. Jakarta (ID): BPS.
Golub GH, Van Loan CF. 1996. Matrix Computations. Baltimore (MD): Johns Hopkins University Pr. Ed ke-3.
Hastie T, Tibshirani R, Friedman J. 2008. The Elements Of Statistical Learning. Data Mining, Inference, and Prediction. Standford California (US): Springer. Ed ke-2.
23 Izenman AJ. 2008. Modern Multivariate Statistical Techniques. New York (US):
Springer.
Johnson RA, Wichern DW. 2007. Applied Multivariate Statistical Analysis. New Jersey (US): Pearson Prentice Hall. Ed ke-6.
Lange K. 2004. Optimization. New York (US): Springer-Verlag.
Lange K, Wu TT. 2008. An MM Algoritm For Multicategory Vertex Discriminant Analysis. J Comput Graph Stat. 17(3) : 527-544
Lange K, Wu TT. 2010. The MM alternative to EM. Statistical Science. 25: 492-505.
Mattjik AA, Sumertajaya IM. 2011. Sidik Peubah Ganda. Bogor (ID): IPB Pr. Rencher AC. 2002. Methods of Multivariate Analysis. New York (US): Wiley. Ed
24
25 Lampiran 1 Ringkasan simulasi
Simulasi Jumlah
kelompok Nilai Tengah (µ) Ragam Keterangan
1 3
keragam kecil dan sama, centroid antar kelompok berdekatan, tidak ada korelasi antar peubah
keragam besar dan sama, centroid antar kelompok berdekatan, tidak ada korelasi antar peubah
keragam besar dan sama, centroid antar kelompok berdekatan, tidak ada korelasi antar peubah
keragam besar dan sama, centroid antar kelompok berdekatan, tidak ada korelasi antar peubah
keragam tidak sama, centroid antar kelompok berdekatan, tidak ada korelasi antar peubah
6 3
keragam kecil dan sama, centroid antar kelompok berdekatan, ada korelasi antar
keragam besar dan sama, centroid antar kelompok berdekatan, ada korelasi antar
keragam besar dan sama, centroid antar kelompok berdekatan, ada korelasi antar
keragam besar dan sama, centroid antar kelompok berdekatan, ada korelasi antar
keragam tidak sama, centroid antar kelompok berdekatan, ada korelasi antar peubah
keragam kecil dan sama, centroid antar kelompok jauh, tidak ada korelasi antar peubah
keragam besar dan sama, centroid antar kelompok jauh, tidak ada korelasi antar peubah
keragam besar dan sama, centroid antar kelompok jauh, tidak ada korelasi antar peubah
keragam besar dan sama, centroid antar kelompok jauh, tidak ada korelasi antar peubah
keragam tidak sama, centroid antar kelompok berdekatan, tidak ada korelasi antar peubah
16 3
keragam kecil dan sama, centroid antar kelompok jauh, ada korelasi antar peubah
17 3
keragam besar dan sama, centroid antar kelompok jauh, ada korelasi antar peubah
18 3
26
Lampiran 1 Ringkasan simulasi
Simulasi kelompok Jumlah Nilai Tengah (µ) Ragam Keterangan
19 3
keragam besar dan sama, centroid antar kelompok jauh, ada korelasi antar peubah
20 3
keragam tidak sama, centroid antar kelompok berdekatan, ada korelasi antar peubah
keragam kecil dan sama, centroid antar kelompok berdekatan, tidak ada korelasi antar peubah
keragam besar dan sama, centroid antar kelompok berdekatan, tidak ada korelasi antar peubah
keragam besar dan sama, centroid antar kelompok berdekatan, tidak ada korelasi antar peubah
keragam besar dan sama, centroid antar kelompok berdekatan, tidak ada korelasi antar peubah
keragam tidak sama, centroid antar kelompok berdekatan, tidak ada korelasi antar peubah
26 8
keragam kecil dan sama, centroid antar kelompok berdekatan, ada korelasi antar
27 Lampiran 1 Ringkasan simulasi
Simulasi kelompok Jumlah Nilai Tengah (µ) Ragam Keterangan
µ5=(2.5,2.7,2.8)
keragam besar dan sama, centroid antar kelompok berdekatan, ada korelasi antar
keragam besar dan sama, centroid antar kelompok berdekatan, ada korelasi antar
keragam tidak sama, centroid antar kelompok berdekatan, ada korelasi antar peubah
keragam kecil dan sama, centroid antar kelompok jauh, tidak ada korelasi antar peubah
keragam besar dan sama, centroid antar kelompok jauh, tidak ada korelasi antar peubah
keragam besar dan sama, centroid antar kelompok jauh, tidak ada korelasi antar peubah
28
Lampiran 1 Ringkasan simulasi
Simulasi kelompok Jumlah Nilai Tengah (µ) Ragam Keterangan
µ7=(11,15,5)
keragam tidak sama, centroid antar kelompok berdekatan, tidak ada korelasi antar peubah
36 8
keragam kecil dan sama, centroid antar kelompok jauh, ada korelasi antar peubah
37 8
keragam besar dan sama, centroid antar kelompok jauh, ada korelasi antar peubah
38 8
keragam besar dan sama, centroid antar kelompok jauh, ada korelasi antar peubah
39 8
keragam besar dan sama, centroid antar kelompok jauh, ada korelasi antar peubah
40 8
29 Lampiran 2 Nilai APER antara metode ADF dan metode VDA untuk 100
ulangan dengan berbagai nilai S2 pada kelompok skenario 2
(6) S2=(1,1,1) (7) S2=(√ √ √ ))
(8) S2=(√ √ √ ) (9) S2=(√ √ √ )
(10) S2=(√ √ √ )
Lampiran 3 Nilai APER antara metode ADF dan metode ADV untuk 100 ulangan dengan berbagai nilai S2 pada kelompok skenario 5
(21) S2=(1,1,1) (22) S2
=(√ √ √ )
(23) S2=(√ √ √ ) (24) S2=(√ √ √ )
30
Lampiran 4 Nilai APER antara metode ADF dan metode ADV untuk 100 ulangan dengan berbagai nilai S2 pada kelompok skenario 6
(26) S2=(1,1,1) (27) S2
=(√ √ √ )
(28) S2=(√ √ √ ) (29) S2
=(√ √ √ )
(30) S2=(√ √ √ )
Lampiran 5 Nilai APER antara metode ADF dan metode ADV untuk 100 ulangan dengan berbagai nilai S2 pada kelompok skenario 7
(31) S2=(1,1,1) (32) S2=(√ √ √ )
(33) S2=(√ √ √ ) (34) S2=(√ √ √ )
31 Lampiran 6 Nilai APER antara metode ADF dan metode ADV untuk 100
ulangan dengan berbagai nilai S2 pada kelompok skenario 8
(36) S2=(1,1,1) (37) S2=(√ √ √ )
(38) S2=(√ √ √ ) (39) S2=(√ √ √ )
(40) S2=(√ √ √ )
Lampiran 7 Rangkuman hasil analisis kedelapan kelompok skenario
32
Lampiran 7 Rangkuman hasil analisis kedelapan kelompok skenario
Simulasi Hubungan
33 Lampiran 8 Data persentase penduduk kabupaten/kota di ulau Sumatera dengan 19
peubah indikator kesejahteraan masyarakat Daerah
Kode Daer-ah
X1 X2 X3 X4 … X16 X17 X18 X19 Kelo-mpok
Kota Padang 13 14.67 54.95 2.92 17.66 66.08 80.10 7.60 70.89 1
Kota Solok 14 3.04 58.85 2.70 14.09 65.34 94.90 11.60 69.69 1
Kota Sawah Lunto 15 14.39 58.63 2.82 29.58 67.60 66.30 18.30 71.65 1 Koto Padang
Panjang 16 9.23 64.47 3.77 23.53 73.28 77.90 10.30 71.30 2 Koto Bukittinggi 17 7.15 69.22 2.23 19.79 71.21 80.60 3.50 71.53 1
Koto Payakumbuh 18 6.50 69.17 5.92 29.14 68.62 83.60 14.60 70.62 2
Koto Pariaman 19 7.02 63.96 7.25 38.41 67.52 47.30 13.30 69.02 1
Nias 20 2.57 77.10 4.93 46.90 40.77 20.99 55.86 69.60 2
Mandailing Natal 21 4.21 71.30 3.49 42.06 40.61 22.96 70.95 63.62 2
Tapanuli Selatan 22 3.35 80.48 6.77 58.30 45.04 34.74 65.51 67.21 2
Tapanuli Tengah 23 6.24 73.55 7.60 40.09 44.43 31.17 63.94 68.11 2
Tapanuli Utara 24 2.26 84.16 10.46 46.16 65.52 37.21 41.15 69.70 2
Toba Samosir 25 2.56 80.78 8.64 45.62 67.35 40.54 31.50 70.68 2
Labuhan Batu 26 7.04 59.93 6.38 38.63 49.08 41.72 15.30 69.54 2
Asahan 27 8.91 63.39 4.80 32.31 45.50 53.32 7.76 68.98 2
Simalungun 28 6.43 69.81 3.13 33.46 65.16 55.07 24.94 68.96 2
Dairi 29 2.06 90.46 5.67 44.72 62.63 34.85 29.94 68.40 2
Karo 30 1.55 85.47 2.19 35.45 58.79 54.93 28.15 72.19 2
Deli Serdang 31 9.02 69.96 2.04 19.65 61.57 71.74 5.15 70.65 1
Langkat 32 8.69 67.76 4.66 35.74 46.01 46.85 9.43 69.07 2
Nias Selatan 33 2.43 82.59 0.86 29.69 37.69 24.69 59.23 70.01 2 Humbang
Hasundutan 34 0.69 89.93 9.79 59.02 74.65 32.30 41.78 67.87 2 Pakpak Bharat 35 1.48 89.37 7.13 35.82 67.97 41.32 39.69 67.60 2
Samosir 36 0.56 92.32 6.67 43.81 67.76 20.73 53.46 69.73 2
Serdang Bedagai 37 6.32 68.64 3.38 31.57 55.60 57.93 4.89 68.98 2
Batu Bara 38 7.95 64.48 5.98 37.56 53.51 65.33 7.57 68.58 2 Padang Lawas
Utara 39 3.34 79.88 11.53 68.70 45.33 21.73 68.20 66.57 2 Padang Lawas 40 7.05 72.76 6.80 54.31 45.75 24.91 59.61 67.03 2 Labuhan Batu
Selatan 41 5.50 63.80 4.64 39.00 56.93 48.57 29.74 69.95 2 Labuhan Batu
Utara 42 5.95 60.57 6.48 39.33 56.93 48.57 29.74 69.62 2 Nias Utara 43 3.29 75.04 5.33 52.89 56.93 48.57 29.74 69.15 3
Nias Barat 44 0.59 79.18 9.06 47.94 56.93 48.57 29.74 69.15 3
34
35 Lampiran 8 Data persentase penduduk kabupaten/kota di pulau Sumatera dengan
19 peubah indikator kesejahteraan masyarakat Daerah
Kode
Daer-ah
X1 X2 X3 X4 … X16 X17 X18 X19 Kelo-mpok
Bangka Barat 80 4.19 71.06 3.91 40.65 40.48 50.30 35.46 67.78 1
Bangka Tengah 81 6.65 67.20 2.46 30.20 30.78 59.60 24.80 67.92 2
Bangka Selatan 82 4.07 66.53 2.30 27.63 22.49 50.90 30.29 67.72 1
Belitung Timur 83 3.98 62.03 1.89 20.34 34.46 39.40 44.47 68.83 2 Kota Pangkal
Pinang 84 9.37 64.47 2.68 15.75 43.79 81.80 3.13 70.43 1 Simeulue 85 12.25 63.72 6.02 45.63 74.00 30.38 36.18 62.98 3
Aceh Singkil 86 9.31 64.15 2.67 37.10 56.74 32.53 38.39 64.92 2
Aceh Selatan 87 11.38 58.87 6.11 35.87 51.83 32.60 50.82 66.93 2
Aceh Tenggara 88 9.90 63.76 7.29 68.10 70.51 36.68 65.84 69.22 2
Aceh Timur 89 6.13 64.20 5.31 41.54 49.15 32.94 23.29 69.74 2
Aceh Tengah 90 2.55 79.06 5.33 57.25 53.14 64.13 26.40 69.64 2
Aceh Barat 91 3.52 58.98 2.37 26.55 65.52 40.79 39.50 69.97 3
Aceh Besar 92 11.60 61.22 5.61 36.16 63.99 58.64 27.00 70.75 2
Pidie 93 7.57 64.89 4.50 45.41 64.34 42.67 69.81 69.53 3
Bireuen 94 7.32 67.34 7.39 39.82 65.57 46.88 24.27 72.35 2
Aceh Utara 95 12.78 59.94 5.39 41.14 65.42 43.53 34.59 69.74 3
Aceh Barat Daya 96 6.14 58.90 6.43 44.98 65.54 36.99 67.01 66.99 2
Gayo Lues 97 4.72 74.99 2.53 39.19 69.21 57.84 53.44 67.08 3
Aceh Tamiang 98 8.03 63.62 6.22 41.90 60.64 64.64 7.14 68.37 2
Nagan Raya 99 3.94 61.38 4.98 42.52 56.82 35.19 47.95 69.64 3
Aceh Jaya 100 7.78 66.49 2.69 32.88 54.87 39.78 33.79 68.02 2
Bener Meriah 101 2.25 78.31 4.93 49.99 64.89 52.71 19.84 67.63 3
Pidie Jaya 102 5.81 63.09 9.21 61.83 60.88 28.36 52.18 69.24 3
Banda Aceh 103 11.56 53.65 2.74 17.44 64.11 95.41 0.63 70.88 2
Sabang 104 10.02 67.81 4.82 33.39 73.84 91.78 15.79 71.02 2
Langsa 105 12.98 61.22 3.68 36.13 69.75 68.99 8.93 70.58 2
Lhokseumawe 106 11.83 57.73 3.22 24.38 67.79 78.16 12.96 70.81 2
Subulussalam 107 4.28 54.99 10.37 48.18 54.52 28.50 16.41 65.89 3
Kuantansingingi 108 4.86 59.97 15.10 67.20 58.02 24.10 33.81 68.33 2
Indragirihulu 109 8.28 61.58 4.80 42.38 48.12 54.40 17.64 68.81 2
Indragirihilir 110 5.41 68.23 2.70 43.95 27.45 8.50 14.19 71.39 2
Pelalawan 111 8.17 61.36 5.65 41.94 38.06 47.20 19.06 68.82 2
Siak 112 9.37 66.31 7.25 30.18 60.95 45.70 6.88 71.69 1
Kampar 113 9.23 60.30 5.93 38.38 50.85 47.60 13.89 68.52 2
Rokanhulu 114 8.61 59.57 14.09 58.72 52.98 34.90 21.04 67.17 2
36