KAJIAN PENGGEROMBOLAN DATA TIDAK LENGKAP
DENGAN ALGORITMA KHUSUS TANPA IMPUTASI
(Studi kasus : Penggerombolan kabupaten/kota di Provinsi Aceh)
WINNY DIAN SAFITRI
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa tesis berjudul “Kajian Penggerombolan Data Tidak Lengkap dengan Algoritma Khusus Tanpa Imputasi” adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apapun kepada perguruan tinggi manapun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Juni 2015
Winny Dian Safitri
RINGKASAN
WINNY DIAN SAFITRI. Kajian Data Tidak Lengkap dengan Algoritma Khusus Tanpa Imputasi. Dibimbing oleh ERFIANI dan BAGUS SARTONO.
Analisis gerombol merupakan suatu metode statistika yang bertujuan untuk mengelompokkan n satuan objek ke dalam k kelompok, sehingga objek-objek dalam satu kelompok mempunyai ciri-ciri yang lebih homogen dibandingkan unit pengamatan dalam kelompok lain (Mattjik & Sumertajaya 2002). Tujuan utama teknik ini adalah melakukan pengelompokan berdasarkan kriteria tertentu sehingga objek-objek tersebut mempunyai variasi di dalam gerombolrelatif kecil dibandingkan variasi antar gerombol. Metode penggerombolan yang sering digunakan hanya dapat digunakan untuk data set lengkap. Permasalahan yang dihadapi dalam kehidupan, sering ditemukan keadaan sekumpulan data yang ingin digerombolkan tidak lengkap, hal tersebut dapat disebabkan karena ketidaktersedian dari data tersebut.
Penanganan penggerombolan data tidak lengkap dapat dilakukan dengan 2 pendekatan, yaitu preprocessing dan penerapan algoritma khusus. Preprocessing
adalah suatu proses yang dilakukan untuk menyelesaikan masalah data tidak lengkap dengan menerapkan hasilnya pada metode data lengkap yang umum digunakan (Grzymała & Hu 2001). Dua teknik yang dapat dilakukan dalam
prepocessing, yaitu : teknik marginalisasi (penghapusan) data yang tidak lengkap dan teknik imputasi. Wagstaff dan Laidler (2005) menjelaskan bahwa pendekatan
preporcessing sering digunakan, baik dengan metode marginalisasi atau metode imputasi dengan alasan mudah dan sederhana.
Metode marginalisasi merupakan teknik yang paling sederhana untuk dijadikan solusi yang dilakukan untuk menangani penggerombolan data tidak lengkap. Ada 2 kemungkinan yang dilakukan dengan metode marjinalisasi yaitu dengan menghapus objek yang tidak lengkap dari kumpulan data atau menghapus peubah yang tidak lengkap, akan tetapi perlu diperhatikan bahwa marginalisasi dapat menyebabkan informasi data yang ada akan hilang.
Metode Imputasi dilakukan untuk menduga nilai data yang tidak lengkap dalam penggerombolan dengan berbagai teknik, seperti imputasi dengan nilai konstan, angka nol, nilai acak, nilai median, nilai rata-rata dan lainnya. Troyanskaya et al (2001) dalam penelitianya menyimpulkan bahwa data tidak lengkap yang diperhitungkan dengan metode imputasi tidak teruji kehandalannya dan menghasilkan informasi yang tidak akurat.
Algoritma khusus dilakukan untuk menutupi kekurangan dari metode marjinalisasi dan metode imputasi. Ada beberapa algoritma khusus untuk data hilang yang murni tanpa imputasi, diantaranya metode partial distance strategy
(PDS) dan k-means soft constraints (KSC). PDS dan KSC mengadopsi tahapan dari algoritma k-means untuk data lengkap. Wagstaff (2004) melakukan penelitian penggerombolan untuk data tidak lengkap tanpa imputasi dengan pendekatan k-means soft constraints (KSC). Matyja dan Simiński (2014) juga melakukan penelitian penggerombolan untuk data tidak lengkap tanpa imputasi dengan membandingkan partial distance stategy (PDS) dengan optimal completion strategy (OCS), nearest prototype strategy (NPS), fuzzy c-mean (FCM) dan
sebelumnya membuat peneliti tertarik mengkaji pengerombolan data tidak lengkap tanpa imputasi. Kajian penggerombolan data tidak lengkap tanpa imputasi dilakukan dengan data simulasi dan data terapan. Penelitian ini bertujuan mengkaji metode partial distance strategy (PDS) dan metode k-means soft constraints (KSC) untuk penggerombolan data tidak lengkap.
Data simulasi merupakan data bangkitan dengan jumlah populasi sebanyak
N = 1200 dengan tipe data numerik yang ditinjau dari beberapa aspek simulasi yaitu jumlah contoh (n), pusat antar gerombol (µ) dan korelasi antar peubah (�). Data simulasi dilakukan dengan membangkitkan tiga populasi yang menyebar normal ganda � �,� yang terdiri dari 7 peubah. Tiga populasi tersebut disimulasikan menjadi 3 model rancangan populasi yaitu rancangan model populasi yang tidak terpisah (rancangan I), rancangan model populasi terpisah (rancangan II), rancangan model yang terpisah dengan sempurna (rancangan III).
Data sekunder yang digunakan dalam penelitian ini berasal dari BPS yaitu data indikator kesejahteraan rakyat Provinsi Aceh tahun 2006 sebanyak 10 peubah. Pemilihan peubah indikator kesejahteraan rakyat yang digunakan dalam penelitian ini ditinjau dari berbagai sumber, seperti RPJP (rencana pembangunan jangka panjang), MDGs (millenium development goals) dan indikator kesejahteraan yang dipublikasikan oleh BPS yang bekerja sama dengan instansi pemerintah lainnya. Secara garis besar, ketiga sumber indikator kesejahteraan rakyat tersebut mempublikasikan unsur indikator kesejahteraan rakyat yang sama (BAPPENAS, 2010).
Kajian penggerombolan data tidak lengkap tanpa imputasi terhadap data simulasi dari kombinasi n, µ, ρ dan besarnya persentase data tidak lengkap yang dicobakan menunjukkan bahwa semakin besar n, kondisi populasi saling terpisah,
korelasi antar peubah kecil dan persentase data tidak lengkap kecil maka akan menyebabkan rata-rata persentase ketepatan gerombol yang dihasilkan dengan menggunakan metode PDS dan KSC akan semakin tinggi. Kajian penggerombolan data tidak lengkap tanpa imputasi terhadap data terapan menyatakan hasil penggerombolan kabupaten/kota di Provinsi Aceh menunjukan bahwa anggota dari setiap gerombol memiliki keragaman yang homogen didalam gerombol tersebut, sedangkan keragaman antar gerombol lebih heterogen. Hal ini menunjukkan bahwa kabupaten/kota yang berada dalam satu gerombol tersebut memiliki tingkat kemiripan yang tinggi, sehingga memiliki hubungan kesamaan ciri yang ditinjau dari indikator kesejahteraan rakyat.
SUMMARY
WINNY DIAN SAFITRI. Study of Incomplete Data with Special Algorithm without Imputation. Supervised by ERFIANI and BAGUS SARTONO.
Cluster analysis is a statistical method that aims to classify the n unit objects into k groups, so that the characteristic of objects in a group is more homogeneous than in other groups (Mattjik & Sumertajaya 2002). The main purpose of this technique is to clustering the objects based on specific criteria so that these objects have relatively small variations in the cluster compared to the variation among clusters. The common clustering method can only be used for the complete data set. However, sometimes problems occur when data is incomplete, due to the data not available.
Handling of incomplete data clustering can be done with two approaches, namely preprocessing and application of a special algorithm. Preprocessing is a process to solve the problem of incomplete data by applying the results on the complete data (Grzymała & Hu 2001). Two techniques that can be done in preprocessing, namely: engineering marginalization (deletion) of incomplete data and imputation techniques. Wagstaff and Laidler (2005) explain that preprocessing approach is often used, either by the method of marginalization or the imputation method which are easy and simple.
Marginalization method is the simplest technique to be used as a solution of incomplete data clustering. There are two possibilities to do with marginalization method; remove objects from the data collection or delete the incomplete, but it should be noted that marginalization can lead to data information loss.
Imputation methods performed to estimate the value of incomplete data in clustering with various techniques, such as imputation with constant values, zeros, random values, the median value, average value and others. Troyanskaya et al (2001) in his research concluded that calculation of incomplete data by imputation method is reliable and yield inaccurate information.
A special algorithm is done to cover the shortage of marginalization methods and imputation methods. There are some special algorithm for missing data without imputation, such as method of Partial Distance Strategy (PDS) and K-means Soft Constraints (KSC). PDS and KSC adopt the stages of K-means algorithm for complete data. Wagstaff (2004) conducted a study of clustering for incomplete data without imputation with approach Of K-Means Soft Constraints (KSC). Matyja and Simiński (2014) also conducted research of clustering for incomplete data without imputation by comparing Partial Distance Strategy (PDS) with Optimal Completion Strategy (OCS), Nearest Prototype Strategy (NPS), Fuzzy C-Mean (FCM) and Nearest Cluster Strategy (NCS). The development of research has been done before is success to make researchers interested in reviewing the incomplete data clustering without imputation. Study of incomplete data clustering without imputation is done by data simulation and application data. This study aims to assess the method of Partial Distance Strategy (PDS) and the method of K-Means Soft Constraints (KSC) for incomplete data clustering.
variables (ρ). Data simulation performed by generating three population of normal multivariate ~ N (μ, Σ), which is consists of 7 variables. Three population are simulated into three population model, they are the population model that does not separate (design I), a separate populations model (design II), a perfect separate model (design III).
The secondary data of this study is BPS data of people's welfare indicator as many as 10 variables at Aceh Province in 2006. Selection of those indicator variables is evaluated from various sources, such as RPJP (Long Term Development Plan), the MDG (Millennium Development Goals) and indicators of well-being published by BPS in cooperation with other government agencies. Broadly speaking, all sources of are publish the same indicator of public welfare (Bappenas, 2010).
Study of incomplete data clustering without imputation against simulated data from a combination of n, μ, ρ and the percentage of incomplete data that were tested are showed when the larger the n, the condition of the population separated from each other, the correlation between the variables is small and tiny percentage of incomplete data, it will cause the average percentage of accuracy of cluster produced by using PDS and KSC will be higher. Study of incomplete data clustering without imputation of data applied declares that the members of each cluster have a homogeneous variance within cluster, whereas, the variation among clusters is more heterogeneous. This result shows that the districts / cities that are in one cluster have a high degree of similarity, so they have the common feature in terms of the indicators of people's welfare.
© Hak Cipta Milik IPB, Tahun 2015
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada
Program Studi Statistika
KAJIAN PENGGEROMBOLAN DATA TIDAK LENGKAP
DENGAN ALGORITMA KHUSUS TANPA IMPUTASI
(Studi kasus : Penggerombolan kabupaten/kota di Provinsi Aceh)SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
BOGOR
2015
Judul Tesis : Kajian Penggerombolan Data Tidak Lengkap dengan Algoritma Khusus Tanpa Imputasi
Nama : Winny Dian Safitri NIM : G151130181
Disetujui oleh Komisi Pembimbing
Dr. Ir. Erfiani, M.Si Ketua
Dr. Bagus Sartono Anggota
Diketahui oleh
Ketua Program Studi Statistika
Dr. Ir. Anik Djuraidah, MS
Dekan Sekolah Pascasarjana
Dr. Ir. Dahrul Syah, M.Sc.Agr
PRAKATA
Puji dan syukur kehadirat Allah SWT yang telah melimpahkan rahmat dan hidayah-Nya, sehingga penulis dapat menyelesaikan tesis yang berjudul “Kajian Penggerombolan Data Tidak Lengkap dengan Algoritma Khusus Tanpa Imputasi”. Keberhasilan penulisan tesis ini tidak lepas dari bantuan, bimbingan, dan petunjuk dari berbagai pihak.
Terima kasih penulis ucapkan kepada Ibu Dr. Ir. Erfiani, M.Si dan Bapak Dr. Bagus Sartono selaku pembimbing, atas kesediaan dan kesabaran untuk membimbing dan membagi ilmunya kepada penulis dalam penyusunan tesis ini.Terimakasih kepada Prof. Khairil Anwar Notodiputro selaku penguji luar komisi pembimbing atas masukan yang diberikan.Ucapan terima kasih juga penulis sampaikan sebesar-besarnya kepada seluruh Dosen Departemen Statistika IPB yang telah mengasuh dan mendidik penulis selama di bangku kuliah hingga berhasil menyelesaikan studi, serta seluruh staf Departemen Statistika IPB atas bantuan, pelayanan, dan kerjasamanya selama ini.
Ucapan terima kasih yang tulus dan penghargaan yang takterhingga juga penulis ucapkan kepada kedua orangtuaku Bapak (Alm) Sabirin dan Ibu Silawaty yang telah membesarkan, mendidik dan memberikan semangat penulis disetiap langkahnya dengan penuh kasih sayang demi keberhasilan penulis selama menjalani proses pendidikan, juga kedua abangku tersayang Riky Pramayoga dan Riyan Antony serta seluruh keluargaku atas doa dan semangatnya.
Terakhir tak lupa penulis juga menyampaikan terima kasih kepada seluruh mahasiswa Pascasarjana Departemen Statistika atas segala bantuan dan kebersamaannya selama menghadapi masa-masa terindah maupun tersulit dalam menuntut ilmu, serta semua pihak yang telah banyak membantu dan tak sempat penulis sebutkan satu per satu.
Semoga tesis ini dapat bermanfaat bagi semua pihak yang membutuhkan. Bogor, Juni 2015
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 2
TINJAUAN PUSTAKA 3
Penggerombolan Data Tidak Lengkap 3
Partial Distance Strategy (PDS) 3
K-means Soft Constraints (KSC) 4
METODE PENELITIAN 5
Data 5
Metode Analisis 7
HASIL DAN PEMBAHASAN 9
Kajian Simulasi 9
Penerapan Metode Penggerombolan Data Tidak Lengkap 12
KESIMPULAN DAN SARAN 14
DAFTAR PUSTAKA 15
DAFTAR TABEL
1 Kombinasi rancangan simulasi dan % data tidak lengkap 6
2 Daftar peubah indikator kesejahteraan rakyat 7
3 Hasil rata-rata ketepatan penggerombolan data lengkap 9
4 Hasil rata-rata ketepatan penggerombolan rancangan I 10
5 Hasil rata-rata ketepatan penggerombolan rancangan II 10
6 Hasil rata-rata ketepatan penggerombolan rancangan III 11
7 Hasil gerombol kabupaten/kota di Provinsi Aceh 12
8 Karakteristik kabupaten/kota di Provinsi Aceh 13
DAFTAR GAMBAR 1 Diagram alir penelitian 8
2 Peta Provinsi Aceh berdasarkan hasil gerombol kabupaten/kota menggunakan PDS dan KSC 13
1
PENDAHULUAN
Latar Belakang
Analisis gerombol merupakan suatu metode statistika yang bertujuan untuk mengelompokkan n satuan objek ke dalam k kelompok, sehingga objek-objek dalam satu kelompok mempunyai ciri-ciri yang lebih homogen dibandingkan unit pengamatan dalam kelompok lain (Mattjik & Sumertajaya 2002). Tujuan utama teknik ini adalah melakukan pengelompokan berdasarkan kriteria tertentu sehingga objek-objek tersebut mempunyai variasi di dalam gerombol relatif kecil dibandingkan variasi antar gerombol. Metode penggerombolan umumnya hanya dapat digunakan untuk data set lengkap. Permasalahan yang dihadapi dalam kehidupan, sering ditemukan keadaan sekumpulan data yang ingin digerombolkan tidak lengkap, hal tersebut dapat disebabkan karena ketidaktersedian dari data tersebut. Misalkan ingin menggerombolkan siswa berdasarkan nilai ujian akhir semester mata pelajaran matematika, ada seorang siswa yang tidak mengikuti ujian akhir mata pelajaran tersebut, tetapi siswa tersebut tetap akan dimasukan dalam penggerombolan. Kasus lain, misalkan melakukan penggerombolan kabupaten/kota berdasarkan indikator kemiskinan, untuk kabupaten/ kota yang baru terbentuk (pemekaran) ada beberapa item dari peubah yang digunakan belum tersedia untuk kabupaten/kota tersebut, tetapi kabupaten/kota tersebut tetap dapat dimasukkan dalam proses penggerombolan, sehingga penggerombolan akan dilakukan dengan teknik khusus untuk kasus data yang tidak lengkap.
imputasi ini dengan memodifikasikan pada perhitungan jarak dari objek ke pusat gerombol.
Penelitian ini mengkaji metode penggerombolan untuk data tidak lengkap dengan algoritma khusus tanpa imputasi. Pendekatan ini diharapkan menjadi solusi untuk masalah yang muncul pada metode marjinalisasi dan metode imputasi yaitu kehilangan informasi dari data dan hasil estimasi yang tidak berarti. Wagstaff (2004) melakukan penelitian penggerombolan untuk data tidak lengkap tanpa imputasi dengan pendekatan k-means soft constraints (KSC). Hasil penelitiannya menunjukkan nilai persentase ketepatan yang tinggi dari metode KSC dalam penggerombolan data tidak lengkap. Matyja dan Simiński (2014) juga melakukan penelitian penggerombolan untuk data tidak lengkap tanpa imputasi dengan membandingkan partial distance strategy (PDS) dengan optimal completion strategy (OCS), nearest prototype strategy (NPS), fuzzy c-mean
(FCM) dan nearest gerombol strategy (NCS). Hasil penelitiaan perbandingan tersebut memperoleh kesimpulan bahwa metode tanpa imputasi lebih unggul dari pada metode imputasi.
Tujuan Penelitian
Tujuan dari penelitian ini yaitu mengkaji metode partial distance strategy
(PDS) dan metode k-means soft constraints (KSC) untuk penggerombolan data tidak lengkap.
2
TINJAUAN PUSTAKA
Penggerombolan Data Tidak Lengkap
Penggerombolan merupakan salah satu metode yang dilakukan untuk membagi kumpulan data menjadi beberapa kelompok sehingga objek-objek yang memiliki tingkat kesamaan yang tinggi satu sama lainnya akan berada dalam satu kelompok yang sama serta akan memiliki tingkat perbedaan yang tinggi dengan kelompok yang lainnya. Setiap kelompok yang terbentuk disebut gerombol. Metode penggerombolan yang sering digunakan hanya dapat digunakan untuk data set lengkap tetapi tidak dapat menangani data yang tidak lengkap.
Penggerombolan data tidak lengkap merupakan suatu teknik mengelompokkan data dengan item yang tidak lengkap. Penanganan penggerombolan data tidak lengkap dapat dilakukan dengan 2 pendekatan, yaitu
Metode marginalisasi merupakan teknik yang paling sederhana untuk dijadikan solusi yang dilakukan untuk menangani penggerombolan data tidak lengkap. Ada 2 kemungkinan yang dilakukan dengan metode marjinalisasi yaitu dengan menghapus objek yang tidak lengkap dari kumpulan data atau menghapus peubah tidak lengkap, akan tetapi perlu diperhatikan bahwa marginalisasi dapat menyebabkan informasi data yang ada akan hilang.
Metode Imputasi dilakukan untuk menduga nilai data yang tidak lengkap dalam penggerombolan dengan berbagai teknik, seperti imputasi dengan nilai konstan, angka nol, nilai acak, nilai median, nilai rata-rata dan lainnya. Troyanskaya et al. (2001) dalam penelitianya menyimpulkan bahwa data tidak lengkap yang diperhitungkan dengan metode imputasi tidak teruji kehandalannya dan menghasilkan informasi yang tidak akurat.
Algoritma khusus dilakukan untuk menutupi kekurangan dari metode marjinalisasi dan metode imputasi. Ada beberapa algoritma khusus untuk data hilang yang murni tanpa imputasi, diantaranya metode partial distance strategy
(PDS) dan k-means soft constraints (KSC). PDS dan KSC mengadopsi tahapan dari algoritma k-means untuk data lengkap. Penggerombolan dengan metode PDS dan KSC untuk data tidak lengkap dilakukan dengan memaksimalkan kemiripan data dalam satu gerombol dan meminimalkan kemiripan data antar gerombol.
Partial Distance Strategy (PDS)
Partial distance strategy (PDS) merupakan suatu algoritma pengelompokan untuk data tidak lengkap dengan menghitung jarak objek ke pusat gerombol berdasarkan data yang ada (Matyja & Simiński 2014). Tahapan awal pada proses penggerombolan data dengan menggunakan algoritma PDS adalah pembentukan titik awal pusat gerombol. Pembentukan pusat gerombol awal, umumnya dibangkitkan secara acak. Jumlah pusat gerombol yang dibangkitkan sesuai dengan jumlah gerombol yang ditentukan di awal. Total jarak yang digunakan dimodifikasi oleh jumlah dimensi. Berikut algoritma metode PDS :
1. Menentukan pusat gerombol ke-c.
2. Mencari jarak dari suatu objek ke-k ke pusat gerombol ke-c dengan metode
partial distance strategy (PDS) digunakan formula sebagai berikut:
dengan fungsi indikator �� didefenisikan sebagai berikut :
�� = 1, Jika peubah ke0, selainnya− � ada pada objek ke−
ck
dengan pembobot eksponensial m>0.
3. Mengalokasikan objek ke dalam suatu gerombol berdasarkan jarak minimum 4. Ulangi langkah 1 hingga 3 dan berhenti sampai
() ( 1) 4
dengan r merupakan total dari iterasi.
K-means Soft Constraints (KSC)
Wagstaff et al. (2001) menjelaskan bahwa latar belakang informasi data dapat dijadikan bekal untuk mengefektifkan algoritma penggerombolan dengan membuat soft constraints. Soft constraints merupakan sebuah fungsi yang dibuat sebagai informasi awal dari anggota suatu gerombol.
MacQueen (1967) menjabarkan bahwa penggerombolan dengan metode
k-means merupakan sebuah algoritma yang paling tepat digunakan untuk melakukan penggerombolan dengan soft constraints, sehingga Wagstaff (2004) mengkombinasikan sebuah algorima penggerombolan untuk data tidak lengkap dengan soft constraints yang dibentuk dari anggota peubah data tidak lengkap.
Soft constraints ini digunakan sebagai informasi dalam pengelompokan. Soft constraints dari suatu objek ke objek lainnya dapat dihitung dengan syarat bahwa anggota dari objek tersebut memiliki nilai pada peubah data tidak lengkap.
K-means dengan soft constraints dilakukan dengan membagi 2 bagian himpunan dari data, yaitu himpunan dengan peubah data lengkap (Fo) dan
himpunan dengan peubah data tidak lengkap (Fm). Misalkan sc merupakan simbol
untuk soft constraints, Fmadalah himpunan dari peubah data tidak lengkap, �
merupakan item objek ke-i dari peubah data tidak lengkap ke- m, � merupakan item objek ke-j dari peubah data hilang ke-m, � merupakan anggota peubah tidak lengkap. Soft constraints dari � dan � adalah: lainnya memiliki gerombol yang berbeda. Algoritma k-means soft constraints
(KSC) mengadopsi tahapan dari algoritma k-means dalam membagi k objek ke dalam c gerombol yang sesuai. Tahapan dari algoritma KSC adalah :
1. Menentukan pusat gerombol ke-c.
2. Menentukan anggota dari gerombol ke-c dengan menghitung jarak minimum suatu objek ke–k ke pusat gerombol ke-c peubah data lengkap ke-d adalah sebagai berikut :
2
w =
faktor pembobotan yang ditentukan secara subjektif dengan nilai
∈ 0,1 , dalam penelitian ini menggunakan nilai w = 0.5
max
v = jarak maksimum dari seluruh objek ke pusat gerombol pada peubah data lengkap
cv
= jumlah kuadrat dari soft constraints yang memuat nilai sc max
cv = jumlah kuadrat dari seluruh softconstraints
3. Ulangi langkah 1 hingga 2 sampai
( ) ( 1) 4
Data dalam penelitian ini terdiri dari dua sumber yaitu data sekunder dan data simulasi. Data sekunder digunakan untuk menggerombolkan kabupaten/kota di Provinsi Aceh dan data simulasi berguna untuk mengukur kinerja metode PDS dan KSCdalam mengelompokkan data tidak lengkap.
Data Simulasi
Data simulasi merupakan data bangkitan dengan jumlah populasi sebanyak
N = 1200 dengan tipe data numerik yang ditinjau dari beberapa aspek simulasi yaitu banyaknya contoh (n), pusat antar gerombol (µ), korelasi antar peubah (�). Data simulasi dilakukan dengan membangkitkan tiga populasi yang menyebar normal ganda �� �,� yang terdiri dari 7 peubah dengan matriks ragam
Tiga populasi tersebut disimulasikan menjadi 3 model rancangan populasi berikut:
1. Rancangan model populasi I (populasi yang tidak terpisah) dibangkitkan dengan sebaran normal ganda �� �,� dengan � merupakan pusat gerombol ke-c sebagai berikut :
2. Rancangan model populasi II (populasi yang terpisah) dibangkitkan dengan
3. Rancangan model populasi III (populasi yang terpisah sempurna) dibangkitkan dengan sebaran normal ganda �� �,� dengan � merupakan pusat gerombol ke-c sebagai berikut :
Gerombol 1 : � = [2, 2, 2, 2, 2, 2, 2]
Gerombol 2 : � = [10, 10, 10, 10, 10, 10, 10] Gerombol 3 : � = [18, 18, 18, 18, 18, 18, 18]
Tabel 1 Rancangan simulasi dan % data tidak lengkap
Model populasi n � % data tidak lengkap
Rancangan I, II, III 60, 120 0, 0.3, 0.9 0, 5, 10, 15, 20, 25, 30
Data Sekunder
Data sekunder yang digunakan dalam penelitian ini berasal dari BPS yaitu data indikator kesejahteraan rakyat Provinsi Aceh tahun 2006 yang terdiri dari 10 peubah (Tabel 2). Pemilihan peubah indikator kesejahteraan rakyat yang digunakan dalam penelitian ini ditinjau dari berbagai sumber, seperti RPJP (rencana pembangunan jangka panjang), MDGs (millenium development goals) dan indikator kesejahteraan yang dipublikasikan oleh BPS yang bekerja sama dengan instansi pemerintah lainnya. Secara garis besar, ketiga sumber indikator kesejahteraan rakyat tersebut mempublikasikan unsur indikator kesejahteraan rakyat yang sama (BAPPENAS, 2010).
Tabel 2 Daftar peubah indikator kesejahteraan rakyat Peubah indikator kesejahteraan rakyat Simbol
Persentase laju pertumbuhan penduduk (%) X1
Kepadatan penduduk per km2 (jiwa) Angka beban ketergantungan (jiwa) Rata-rata lama sakit (bulan/ tahun)
Persentase penduduk usia 10 tahun ke atas dengan pendidikan tertinggi SLTP atau lebih (%)
X2
X3
X4
X5
Pengeluaran rata-rata perkapita sebulan (Rp)
Persentase rumah tangga dengan luas lantai kurang dari 10 m2 (%)
X6
X7
Persentase rumah tangga dengan sumber air minum ledeng (%) X8
Persentase penduduk usia muda 0 – 14 tahun (%) X9
Metode Analisis
Tahapan analisis data yang dilakukan berkaitan dengan tujuan penelitian dilakukan melalui langkah-langkah sebagai berikut:
1. Membangkitkan data populasi sebanyak N = 1200 yang terbagi ke dalam 3 gerombol
2. Mengambil contoh sebanyak n = 60 dan n =120
3. Menghilangkan sebagian data dengan persentase data tidak lengkap dari
total keseluruhan data yang dicobakan (0%, 5%, 10%, 15%, 20%, 25%, 30%)
4. Menggerombolkan data tidak lengkap dengan menerapkan metode PDS dan KSC
5. Menghitung persentase ketepatan gerombol metode PDS dan metode KSC 6. Mengulangi 1000 kali tahap ke-2 sampai tahap ke-5, untuk melihat
kekonsistenan ketepatan hasil gerombol metode PDS dan KSC
7. Membandingkan rata – rata hasil ketepatan gerombol metode PDS dan metode KSC dari 1000 kali ulangan
8. Penerapan metode PDS dan KSC pada data empirik dengan tahapan berikut : a. Menstandardisasikan gugus peubah data kesejahteraan rakyat Provinsi
Aceh
b. Menggerombolkan kabupaten/kota di Provinsi Aceh dengan metode PDS dan KSC ke dalam 4 gerombol yang dicobakan
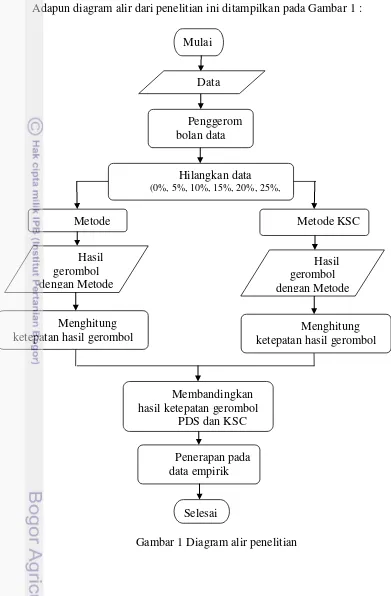
Adapun diagram alir dari penelitian ini ditampilkan pada Gambar 1 :
Gambar 1 Diagram alir penelitian Membandingkan
hasil ketepatan gerombol PDS dan KSC
Selesai
Penerapan pada data empirik Metode
PDS
Metode KSC
Hasil gerombol dengan Metode
Hilangkan data
(0%, 5%, 10%, 15%, 20%, 25%, 30%)
Penggerom bolan data
lengkap
Hasil gerombol dengan Metode Mulai
Data simulasi
Menghitung ketepatan hasilgerombol
PDS
Menghitung ketepatan hasilgerombol
4
HASIL DAN PEMBAHASAN
Kajian penggerombolan pada data tidak lengkap ini ditinjau dari kajian simulasi dan kajian terapan. Kajian simulasi terdiri dari 126 kasus simulasi dari 3 model rancangan model populasi. Simulasi dilakukan untuk mengevaluasi ketepatan penggerombolan yang dihasilkan dengan menggunakan metode PDS dan KSC dalam menggerombolkan data yang tidak lengkap dengan melihat rata-rata persentase ketepatan gerombol. Rata-rata-rata persentase ketepatan gerombol tersebut diperoleh dari hasil simulasi yang diulang sebanyak 1000 kali.
Kajian Simulasi
Penggerombolan data tidak lengkap dilakukan dengan menggunakan data bangkitan. Simulasi dilakukan dengan mengambil contoh sebanyak n = 60 dan n = 120 dari populasi N =1200 untuk berbagai kondisi yang dicobakan yaitu µ, korelasi antar peubah (ρ) serta berbagai macam persentase dari data tidak lengkap. Dari data bangkitan yang diperoleh, kemudian diterapkan pada metode penggerombolan data tidak lengkap. Dalam penelitian ini, dilakukan kajian metode penggerombolan data tidak lengkap yaitu metode partial distance strategy
(PDS) dan k-means soft constraints (KSC). Kedua metode penggerombolan tidak lengkap dievaluasi ketepatannya, kekonsistenan serta efektifitas dari metode tersebut dengan melihat rata dari persentase ketepatan gerombol. Hasil rata-rata ketepatan penggerombolan metode PDS dan KSC di sajikan pada tabel di bawah ini :
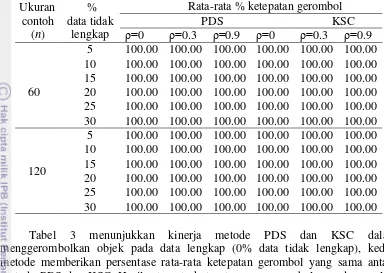
Tabel 3 Hasil rata-rata ketepatan penggerombolan menggunakan metode PDS dan KSC pada data lengkap ( 0% data tidak lengkap) Ukuran
contoh (n)
ρ Rancangan I Rata-rata % ketepatan gerombol rancanganII rancangan III
PDS KSC PDS KSC PDS KSC
60
0 99.16 99.16 100.00 100.00 100.00 100.00 0.3 86.66 86.66 100.00 100.00 100.00 100.00 0.9 75.00 75.00 90.00 90.00 100.00 100.00 120
Tabel 4 Hasil rata-rata ketepatan penggerombolan menggunakan metode PDS dan KSC pada rancangan I (populasi tidak terpisah)
Tabel 6 Hasil rata-rata ketepatan penggerombolan menggunakan metode PDS dan KSC pada rancangan III (populasi terpisah dengan sempurna)
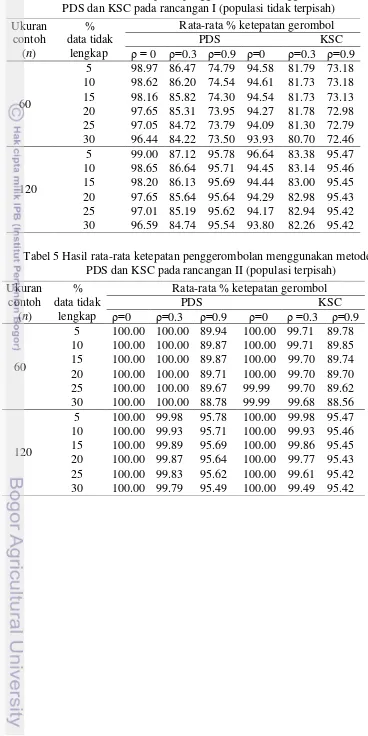
Tabel 3 menunjukkan kinerja metode PDS dan KSC dalam menggerombolkan objek pada data lengkap (0% data tidak lengkap), kedua metode memberikan persentase rata-rata ketepatan gerombol yang sama antara metode PDS dan KSC. Hasil rata–rata ketepatan penggerombolan pada populasi yang terpisah dengan sempurna yaitu rancangan populasi III (Tabel 6) terlihat bahwa kedua metode mengelompokkan objek dengan rata-rata ketepatan penggerombolan 100% untuk berbagai persentase kehilangan data. Metode PDS maupun KSC dapat menggerombolkan objek dengan tingkat kesalahan gerombol 0% pada kondisi populasi yang terpisah tegas atau jarak antar pusat gerombol sangat jauh.
Pada Tabel 5 menyajikan hasil rata-rata ketepatan penggerombolan pada kondisi populasi yang terpisah (rancangan II), kedua metode tersebut memberikan hasil yang cukup baik dalam menggerombolkan objek. Rancangan ini memperlihatkan dengan jelas pengaruh dari jumlah contoh (n), korelasi antar peubah (ρ) yang dicobakan dan besarnya persentase data tidak lengkap, sangat berpengaruh terhadap persentase ketepatan penggerombolan untuk kedua metode. Hasil rata-rata persentase ketepatan penggerombolan pada rancangan II menunujukkan bahwa semakin besar jumlah contoh (n), korelasi yang rendah antar peubah dan persentase data tidak lengkap, maka secara umum meningkatkan rata-rata persentase ketepatan penggerombolan dengan menggunakan metode PDS dan KSC.
Dengan demikian, hasil dari kedua metode ini memiliki kemampuan untuk mengelompokkan data dengan baik yang diperlihatkan dari rata-rata hasil ketepatan gerombol yang tinggi. Rata-rata hasil ketepatan metode PDS dan KSC tidak jauh berbeda yang tergambarkan dari selisih persentase ketepatannya yang relatif kecil, namun PDS memberikan hasil gerombol yang lebih baik dibandingkan dengan KSC. Selain itu, juga terlihat bahwa rata-rata persentase ketepatan hasil gerombol sangat dipengaruhi oleh jarak antar gerombol, besarnya persentase data tidak lengkap serta korelasi antar peubah. Secara umum dapat disimpulkan bahwa rata-rata ketepatan hasil gerombol menggunakan PDS dan KSC akan semakin besar jika jumlah contoh (n) yang digunakan besar, kondisi populasi saling terpisah, korelasi antar peubah kecil dan persentase data tidak lengkap kecil. Hasil gerombol metode PDS sangat bergantung pada pusat gerombol awal yang diberikan, sedangkan KSC memberikan hasil gerombol yang sama untuk berbagai macam pusat gerombol, hal ini disebabkan karena metode KSC telah terbagi kedalam 2 himpunan peubah yaitu peubah dengan elemen lengkap dan peubah dengan elemen tidak lengkap, juga sangat dipengaruhi oleh nilai pembobot (w) yang diberikan.
Penerapan Metode PDS Pada Data Tidak Lengkap
Hasil kajian simulasi menunjukan bahwa metode PDS memberikan hasil rata-rata ketepatan gerombol yang tinggi dibandingkan dengan hasil rata-rata ketepatan penggerombolan yang dihasilkan dengan menggunakan metode KSC, oleh karena itu akan dibahas penerapan metodePDS untuk penggerombolandata tidak lengkap untuk menggerombolkan dan mengidentifikasi kabupaten/kota di Provinsi Aceh berdasarkan data indikator kesejahteraan rakyat tahun 2006.
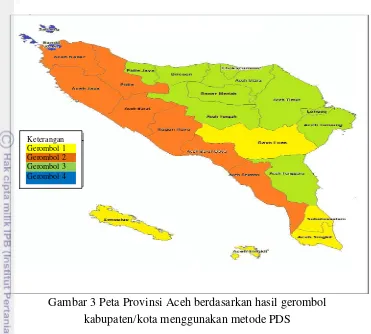
Tahapan awal dilakukan standardisasi terhadap peubah. Penggerombolan objek dengan metode PDS yaitu dengan menggerombolkan objek berdasarkan jarak minimum suatu objek ke pusat gerombol yang telah ditentukan. Kabupaten/kota di Provinsi Aceh dikelompokkan ke dalam empat gerombol. Pusat gerombol awal ditentukan dari nilai rataan kabupaten/kota yang saling berdekatan yang ditinjau dari letak geografis dari kabupaten/kota tersebut. Hasil gerombol kabupaten/kota di Provinsi Aceh berdasarkan data indikator kesejahteraan rakyat menggunakan metode PDS disajikan pada Tabel 7 dan Gambar 3.
Tabel 7 Hasil gerombol kabupaten/kota di Provinsi Aceh dengan metode PDS dan karakteristik gerombol Gerombol Karakteristik peubah kabupaten/kota Anggota
penduduk usia
Gambar 3 Peta Provinsi Aceh berdasarkan hasil gerombol kabupaten/kota menggunakan metode PDS
Hasil penggerombolan kabupaten/kota di Provinsi Aceh menunjukkan bahwa letak geografis dan struktur pemerintahan dari kabupaten/kota sangat mempengaruhi hasil dari gerombol yang dihasilkan dengan menggunakan metode PDS. Karakteristik yang dihasilkan setiap gerombol telah sesuai dengan kenyataan dilapangan. Informasi yang diperoleh dari anggota gerombol pertama yaitu merupakan kabupaten/ kota yang mengalami pemekaran dan baru berkembang. Anggota gerombol kedua merupakan kabupaten/kota yang letak wilayahnya berada disekitar pesisir pantai. Anggota gerombol ketiga merupakan kabupaten/kota yang berada pada wilayah dataran tinggi. Anggota dari gerombol keempat merupakan pusat dari perekonomian, pemerintahan dan wisata dari Provinsi Aceh.
Dari hasil gerombol dengan metode PDS dikatakan bahwa kabupaten/kota yang berada pada gerombol dengan tingkat kesejahteraan masih sangat rendah yaitu anggota gerombol pertama. Tingkat kesejahteraan sedang yaitu anggota gerombol kedua dan ketiga dan kabupaten/kota dengan tingkat kesejahteraan tinggi yaitu gerombol keempat. Penyebab dari tinggi dan rendahnya tingkat kesejahteraan rakyat dari anggota gerombolantara lain letak geografis kabupatern/kota, keadaan sosial budaya, sumber daya manusia (SDM), sumber daya alam (SDA) dan kemajuan dari pembangunan daerah yang mencakup struktur pemerintahan.
5
KESIMPULAN DAN SARAN
Kesimpulan
Berdasarkan hasil penggerombolan dari data simulasi dapat disimpulkan bahwa :
1. Rata-rata persentase hasil ketepatan gerombol yang dihasilkan dengan menggunakan metode PDS dan KSC sangat dipengaruhi oleh jarak antar gerombol, jumlah contoh (n), korelasi (ρ) dan persentase data tidak lengkap.
2. Metode PDS dan KSC memiliki kemampuan menggerombolkan objek dengan tingkat kesalahan penggerombolan kecil (tingkat kesalahan ≤ 30 %).
3. Metode PDS lebih unggul dari metode KSC dalam menggerombolkan data tidak lengkap. Hal ini disebabkan karena metode PDS mampu memberikan hasil rata-rata ketepatan gerombol yang tinggi pada kondisi gerombol yang tidak terpisah
Berdasarkan hasil penggerombolan kabupaten/kota di Provinsi Aceh menggunakan metode PDS menunjukkan bahwa anggota dari masing-masing gerombol sangat dipengaruhi oleh karakteristik tinggi rendahnya indikator kesejahteraan kabupaten/kota tersebut. Penyebab dari tinggi rendahnya indikator kesejahteraan rakyat yang paling utama yaitu letak geografis kabupatern/kota, keadaan sosial budaya, sumber daya manusia (SDM), sumber daya alam (SDA) dan kemajuan dari pembangunan daerahyang mencakup struktur pemerintahan.
Saran
DAFTAR PUSTAKA
BPS. 2007. Indikator Kesejahteraan Rakyat 2007. BPS Provinsi Aceh. Aceh. BAPPENAS. 2010. Ringkasan Peta Jalan Percepatan Pencapaian Tujuan
Pembangunan Milenium di Indonesia. BAPPENAS.
Grzymała B. J., Hu M. 2001. A Comparison of Several Approaches to Missing Attribute Values in Data Mining. USA.
MacQueen J. B. (1967). Some methods for classification and analysis of multivariate observations. Proceedings of the Fifth Symposium on Math, Statistics and Probability : 281–297. University of California Press.
Mattjik A., Sumertajaya, I. 2002. Aplikasi Analisis Peubah Ganda. Bogor.
Matyja A., Simiński K. 2014. Comparison of algorithms for clustering incomplete data. Journal Foundations of Computing and Decision Sciences 39 : 107– 127.
Troyanskaya O., Cantor M., Sherlock G., Brown P., Hastie T., Tibshirani R., Botstein D., Altman RB. 2001. Missing value estimation methods for DNA microarrays. Journal Bioinformatics 17 : 520–525. USA.
Wagstaff K., Laidler V. 2005. Making the most of missing values: Object clustering with partial data in astronomy. Proceedings of Astronomical Data Analysis Software and Systems XIV 347: 172–176. California,USA.
Wagstaff K. 2004. Clustering with missing values: No imputation required.
Proceedings of the Meeting of the International Federation of Classification Societies : 649–658. California.
Lampiran 1 Plot data skor komponen Rancangan I
(a) korelasi 0 (b) korelasi 0.3 (c) korelasi 0.9 Rancangan II
(a)korelasi 0 (b) korelasi 0.3 (c) korelasi 0.9 Rancangan III
Lampiran 2 Hasil gerombol Kabupaten/kota di Provinsi Aceh menggunakan metode KSC
Gerombol Kabupaten/kota
1 Simeulue, Aceh Tenggara, Aceh Tengah, Aceh Besar, Pidie, Aceh Utara, Nagan Raya, Bener Meriah, Pidie Jaya
2 Aceh Selatan, Aceh Jaya
3 Aceh Singkil, Aceh Timur, Aceh Barat, Bireuen, Aceh Barat Daya, Aceh Tamiang, Gayo Lues, Sabang, Kota Langsa, Lhokseumawe, Subulussalam
4 Banda Aceh
Keterangan Gerombol 1 Gerombol 2 Gerombol 3 Gerombol 4
RIWAYAT HIDUP
Penulis dilahirkan di Meulaboh pada tanggal 24 Mei 1990 merupakan anak bungsu dari tiga bersaudara dari pasangan (Alm) Sabirin dan Silawaty. Pendidikan sekolah dasar di SD Negeri 18 Meulaboh, dan lulus pada tahun 2002. Pendidikan sekolah menengah pertama ditempuh di SMP Negeri 2 Meulaboh, lulus pada tahun 2005. Pendidikan sekolah menengah atas ditempuh di SMA Negeri 1 Meulaboh Program IPA, lulus pada tahun 2008. Pada tahun yang sama penulis diterima di program studi Matematika Universitas Syiah Kuala dan menyelesaikannya pada tahun 2012.
Selanjutnya penulis melanjutkan program master (S2) pada program studi Statistika, Sekolah Pascasarjana IPB pada tahun 2012 dengan program Beasiswa BPPDN dari Direktorat Jendral Pendidikan Tinggi (Dikti). Selama perkuliahan penulis juga aktif di organisasi HIMMPAS (Himpunan Mahasiswa Pasca Sarjana) dan penulis juga aktif pada komunitas kongkrit. Motivasi dan semangat dalam hidup penulis adalah “Ibu”, Motto hidup penulis “Tetap bersemangat dalam berbagi”