SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
ZAQISYAH 10107346
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS TEKNIK DAN ILMU KOMPUTER
UNIVERSITAS KOMPUTER INDONESIA BANDUNG
v
KATA PENGANTAR ... iii
DAFTAR ISI ... v
DAFTAR GAMBAR ... viii
DAFTAR TABEL ... ix
DAFTAR SIMBOL ... xi
DAFTAR LAMPIRAN ... xv
BAB 1 PENDAHULUAN... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 2
1.3 Maksud dan tujuan ... 2
1.4 Batasan masalah ... 2
1.5 Metodologi penelitian... 3
1.6 Sistematika penulisan ... 4
BAB 2 TINJAUAN PUSTAKA ... 5
2.1 Analisis sentimen ... 5
2.2 Review Literatur ... 5
2.3 Dokumen Pelatihan ... 6
2.4 Preprocessing text ... 6
2.4.1 Lexical Analysis of The Text ... 7
2.4.1.1 Case folding ... 7
2.4.1.2 Tokenizing ... 7
2.4.2 Stemming ... 8
2.4.3 Penghapusan Stopwords ... 12
2.5 Klasifikasi Dokumen ... 12
2.6 Naive Bayes... 12
2.7 Evaluasi ... 15
2.7.1 Accuracy and Error Rate ... 15
2.8 Konsep Dasar Pemrograman Objek ... 16
BAB 3 ANALISIS MASALAH DAN PERANCANGAN ... 21
vi
3.5.1 Dokumen input ... 24
3.5.2 Case folding ... 24
3.5.3 Tokenizing ... 26
3.5.4 Stemming ... 28
3.5.5 Penghapusan Stopwords ... 31
3.6 Analisis Algoritma ... 34
3.7 Evaluasi Akurasi ... 39
3.8 Analisa kebutuhan non fungsionalitas ... 39
3.8.1 Analisa Kebutuhan Perangkat Lunak ... 40
3.8.2 Analisa kebutuhan perangkat keras ... 40
3.9 Analisis kebutuhan fungsional ... 40
3.9.1 Use Case ... 40
3.9.1.1 Definisi Use Case ... 42
3.9.1.2 Skenario Use Case ... 42
3.9.2 Class diagram ... 45
3.9.3 Activity Diagram ... 46
3.9.4 Sequence Diagram ... 47
3.9.5 Perancangan Antarmuka Perangkat Lunak ... 52
BAB 4 IMPLEMENTASI DAN PENGUJIAN ... 53
4.1 Implementasi Sistem ... 53
4.1.1 Implementasi Perangkat Keras ... 53
4.1.2 Implementasi Perangkat Lunak... 53
4.2 Implementasi kelas pada sistem ... 53
4.2.1 Implementasi Kelas BayesFrame Tokenizing ... 53
4.2.2 Implementasi BayesFrame Case Folding ... 54
4.2.3 Implementasi Kelas BayesFrame potongan kode stemming ... 54
4.2.4 Implementasi Kelas BayesFrame potongan kode Stopwords ... 54
4.2.5 Implementasi kelas BayesClassifier ... 55
4.3 Implementasi Sistem ... 56
vii
4.3.6 Implementasi Data uji ... 66
4.3.7 Implementasi Klasifikasi Naive Bayes ... 67
4.4 Pengujian Sistem ... 67
4.4.1 Skenario Pengujian Proporsi Dokumen ... 68
4.4.2 Pengujian Alpha ... 69
4.4.2.1 Skenario Pengujian Aplikasi ... 69
4.4.2.2 Kasus dan Hasil Pengujian Black Box ... 70
4.4.2.3 Kesimpulan pengujian Alpha... 73
BAB 5 Kesimpulan dan Saran ... 75
5.1 Kesimpulan ... 75
5.2 Saran ... 75
77
Computer Science University of California Irvine, 2011
[2] Rozi Fahrur Imam, dkk. Implementasi Opinion Mining (Analisis Sentimen) untuk Ekstraksi Data Opini Publik pada Perguruan Tinggi. Electrical Power Electronic Comunication Control Information Seminar, Vol. 6(No 1), 2012.
[3] Samodra Joko, dkk. Klasifikasi Dokumen teks berbahasa indonesia dengan Menggunakan Naive Bayes. Seminar Nasional Electrical, Informatics and it’s Educations. 2009.
[4] Wibisono Yudi. Klasifikasi Berita Berbahasa Indonesia menggunakan Naïve Bayes Classifier. FPMIPA UPI, 2013
[5] Hamzah, Amir. Klasifikasi Teks dengan Naive Bayes untuk Pengelompokkan Teks Berita dan Abstract Akademis. Prosiding Seminar Nasional Aplikasi Sains & Teknologi (SNAST) Periode III. 2012. Prosiding Seminar Nasional Aplikasi Sains & Teknologi (SNAST) Periode III. 2012
[6] Baeza Yates, dkk. Modern Information Retrieval. New york: Addision-Wesley, 1999
[7] Mitchell M. Tom : Machine Learning, Mc-Graw-Hill, 1997
[8] Khodra, Leylia Masayu, dkk. Clustering Berita Berbahasa Indonesia, Bandung: KK Informatika Sekolah Teknik Elektro dan Informatika ITB, 2005
78 Addison-Wesley, 2011
[12] B.sakur, Stendy. PHP5 Pemrograman berorientasi objek Konsep & Implementasi. Yogyakarta: Andi. 2010
iii
hadirat sang Maha Pintar Allah SWT, karena dengan izin-Nya dan setitik ilmu
pengetahuan yang dipinjamkan kepada mahluk-Nya, penulis dapat menyelesaikan
laporan tugas akhir ini.
Laporan tugas akhir/skripsi dengan judul “OPTIMASI AKURASI
ANALISIS SENTIMEN PADA POSTING TWITTER MENGGUNAKAN
METODE NAIVE BAYES DAN STEMMING” ini disusun guna memenuhi salah
satu syarat dalam menyelesaikan studi jenjang strata satu (S1) di Program Studi
Teknik Informatika, Universitas Komputer Indonesia. Selama menulis laporan
tugas akhir ini, penulis telah mendapatkan banyak sekali bimbingan dan bantuan
dari berbagai pihak yang telah dengan segenap hati dan keikhlasan yang penuh
membantu dan membimbing penulis dalam menyelesaikan laporan ini. Dengan
kesadaran hati, penulis ucapkan terima kasih kepada :
1. Ayahanda dan Ibunda, dukungan lahir maupun batin, beserta do’anya
senantiasa mengiri setiap perjalanan hidupku.
2. Dr. Ir. Eddy Soeryanto Soegoto, M.Sc., selaku Rektor Universitas Komputer
Indonesia.
3. Dekan Prof. Dr. H. Denny Kurniadie, Ir., M.Sc., selaku Dekan Fakultas
Teknik dan Ilmu Komputer Universitas Komputer Indonesia
4. Pak Alif Finandhita, S.Kom. sebagai dosen pembimbing terima kasih telah
banyak meluangkan waktu untuk memberikan bimbingan, saran dan
nasehatnya selama penyusunan skripsi ini.
5. Ibu Ednawati Rainarli, S.Si., M.Si. sebagai penguji yang telah banyak
iv
8. Sahabat-sahabatku. Terima kasih telah menemani dalam suka dan duka
kepada penulis serta semangat yang diberikan selama perjalanan
penyelesaian skripsi ini.
9. Teman-teman di jurusan teknik Informatika UNIKOM angkatan 2007 dan
2009, yang telah sama-sama melakukan perkuliahan dan skripsi di
UNIKOM, semoga kita selalu menjadi orang yang sukses.
10. Semua pihak yang turut memberikan dukungan dalam penulisan skripsi ini
yang tidak bisa disebutkan satu persatu.
Penulis sadar bahwa dalam penulisan skripsi ini masih terdapat banyak
kekurangan baik dari segi teknik penyajian penulisan, maupun materi penulisan
mengingat keterbatasan ilmu yang dimiliki penulis. Oleh karena itu, penulis
sangat mengharapkan segala bentuk saran dan kritik dari semua pihak demi
penyempurnaan skripsi ini. Akhir kata, semoga Allah SWT senantiasa
melimpahkan karunia-Nya dan membalas segala amal budi serta kebaikan
pihak-pihak yang telah membantu penulis dalam penyusunan laporan ini dan semoga
tulisan ini dapat memberikan manfaat bagi pihak-pihak yang membutuhkan.
Bandung, Agustus 2013
1
Analisis sentimen dilakukan untuk melihat pendapat atau kecenderungan
opini terhadap sebuah masalah atau objek oleh seseorang, apakah cenderung
berpandangan atau beropini negatif atau positif. Salah satu contoh penggunaan
analisis sentimen dalam dunia nyata adalah identifikasi opini publik terhadap
kandidat capres. Akibatnya timbul kebutuhan untuk mengatur dan
mengelompokkan opini berdasarkan sentimennya agar seseorang dapat mencari
dan menilai kualitas kandidat capres dari opini publik, akan tetapi jika
pengelompokkan berita dilakukan secara manual memakan waktu yang lama dan
mahal maka dari itu diperlukan klasifikasi dokumen.
Klasifikasi dokumen secara otomatis sekiranya diperlukan untuk
mengurangi biaya dan mempercepat pengaturan informasi. Salah satu metode
yang dapat digunakan dalam pengklasifikasian yaitu Naive Bayes. Naive Bayes
merupakan metode klasifikasi dengan tingkat keakuratan tinggi dan penghitungan
yang sederhana. Metode ini mengasumsikan kemunculan suatu kata tidak
mempengaruhi kemunculan kata yang lain. Walaupun asumsi ini melanggar
aturan disetiap bahasa, asumsi ini tidak berpengaruh besar terhadap tingkat
keakuratan metode ini [1].
Pada metode Naive Bayes yang menjadi masalah adalah keberadaan kata
berperan penting pada proses klasifikasi. Salah satu faktor yang mempengaruhi
keberadaan kata yaitu stemming. Dengan stemming bentuk kata baku yang
beragam akan menjadi seragam (kata dasar). Namun faktanya pada posting twitter
ditemukan banyak kata-kata yang tidak baku seperti kata “tidak” yang mempunyai
variasi “tdk”, “gak”, “ngga”, “kagak”, “ga”, “nda”, “gag” yang tidak dapat
ditangani oleh praproses Stopwords. Keberadaan kata yang tidak baku akan
mempengaruhi akurasi hasil perhitungan Naive Bayes. Oleh karena itu diperlukan
Berdasarkan masalah di atas maka dibutuhkan optimasi preprocessing text
yaitu stemming dalam analisis sentimen pada posting twitter.
1.2 Rumusan Masalah
Bagaimana penerapan preprocessing teks yaitu stemming sebelum melakukan klasifikasi pada metode Naïve Bayes dilakukan untuk menghilangkan
variasi kata yang tidak baku dan menggantinya dengan kata yang baku.
1.3 Maksud dan tujuan
Berdasarkan masalah yang diteliti maka maksud dari penelitian tugas akhir
ini adalah mengoptimasi analisis sentimen pada posting twitter menggunakan metode Naive Bayes.
Sedangkan tujuan yang akan dicapai dalam penelitian ini adalah untuk
mengetahui pengaruh, performansi yang dihasilkan dengan melihat persentase
akurasi dalam implementasi metode Naive bayes pada sentimen analisis dengan
melakukan stemming.
1.4 Batasan masalah
Penelitian yang dilakukan untuk implementasikan Naive Bayes maka
memiliki batasan masalah sebagai berikut :
1. Studi kasus yang digunakan kandidat Capres 2014 yaitu Jokowi dan
Prabowo.
2. Klasifikasi sentimen yang digunakan 3 kategori positif, negatif dan non
opini.
3. Informasi yang didapatkan adalah jumlah sentimen dari masing-masing
kelas, akurasi dan kecepatan proses.
4. Tweets yang digunakan hanya berbahasa indonesia.
5. Metode Stemming menggunakan Algoritma Nazief dan Adriani
6. Evaluasi kinerja menggunakan Accuracy and Error rate
7. Variasi kata tidak baku yang ada pada kamus sama dengan variasi kata tidak
1.5 Metodologi penelitian
Metodologi penelitian yang digunakan pada penelitian ini yaitu metodologi
penelitian untuk mengumpulkan dasar dan data penelitian yaitu berupa ekstraksi
informasi dari tweets. Metodologi yang digunakan untuk mengumpulkan dasar
dan data penelitian, yaitu :
1. Studi masalah dan solusi
Melakukan eksplorasi terhadap masalah yang akan dilakukan observasi dan
menentukan solusi yang mungkin. Menentukan hipotesa yang mungkin
dihasilkan dari solusi yang diambil terhadap masalah yang ada.Sehingga
masalah tersebut dapat diselesaikan dan mendapatkan detail hasil eksplorasi
dengan melakukan eksperimen dari penerapan solusi tersebut terhadap
masalah yang diambil dan mendapatkan hasil secara kuantitatif dari efisiensi
solusi hingga efektifitas yang dihasilkan dari penerapan solusi tersebut.
2. Pengumpulan data
Pengumpulan data yang akan digunakan dalam penelitian ini adalah dengan
mengambil tweets masyarakat mengenai salah satu capres 2014 secara
random dari twitter.
3. Learning Modeling
Membangun learning modeling yaitu model probabilistik yang dihasilkan
dari data pelatihan sebagai hipotesis awal.
4. Eksperiment
Merupakan tahap eksplorasi terhadap objek penelitian yang berupa teks,
dengan melakukan processing terhadap teks tersebut dan menerapakan
metode learning yang akan diuji coba. Eksplorasi dilakukan dengan
membangun perangkat lunak yang mengimplementasikan metoda dibuat.
Mengambil hasil dari uji coba tersebut dan melakukan analisis terhadap
hasil uji tersebut. Dengan melakukan implementasi program yang dibangun
1.6 Sistematika penulisan
Sistematika penulisan tugas akhir ini disusun untuk memberikan gambaran
umum tentang permasalahan dan pemecahannya. Sistematika penulisan tugas
akhir ini adalah sebagai berikut :
BAB 1 PENDAHULUAN
Bab ini berisi tentang latar belakang masalah, identifikasi masalah, maksud dan
tujuan, batasan masalah dan metode penelitian yang dipergunakan dalam
penelitian mengimplementasikan analisis sentimen pada posting twitter menggunakan metode Naive Bayes.
BAB II TINJAUAN PUSTAKA
Menguraikan tinjauan terhadap berbagai literatur pendukung yang digunakan
untuk mengoptimasi analisis sentimen pada posting twitter menggunakan Metode
Naive Bayes dan Stemming.
BAB III ANALISIS METODE
Pada bagian ini dijelaskan secara rinci mengenai tahapan pengerjaan dengan
menggunakan metode yang digunakan penulis dalam mengerjakan penelitian
sesuai dengan pendekata analisis orientasi berbasis objek, yaitu dengan analisis
kebutuhan fungsionalitas atau Use case, Class diagram, Sequence Diagram.
Selain itu terdapat juga perancangan untuk sistem yang akan dibangun sesuai
dengan hasil analisis dan antarmuka untuk sistem yang akan dibangun.
BAB IV PENGUJIAN
Pada bagian dilakukan pengujian terhadap prototipe dari program dengan
menggunakan data uji yang belum diketahui kategorinya agar diketahui apakah
sudah optimal akurasi yang diteliti.
BAB V KESIMPULAN DAN SARAN
Bab ini berisi kesimpulan yang diperoleh dari tujuan dan permasalahan yang
5
Analisis sentimen atau opinion mining merupakan proses memahami,
mengekstrak dan mengolah data tekstual secara otomatis untuk mendapatkan
informasi sentimen yang terkandung dalam suatu kalimat opini. Analisis sentimen
dilakukan untuk melihat pendapat atau kecenderungan opini terhadap sebuah
masalah atau objek oleh seseorang, apakah cenderung berpandangan atau beropini
negatif atau positif. Salah satu contoh penggunaan analisis sentimen dalam dunia
nyata adalah identifikasi kecenderungan pasar dan opini pasar terhadap suatu
objek barang. Besarnya pengaruh dan manfaat dari analisis sentimen
menyebabkan penelitian semakin berkembang pesat[2].
Salah satu metode dari text mining yang bisa digunakan untuk
menyelesaikan masalah opinion mining adalah Naïve Bayes (NB). Naïve Bayes
bisa digunakan untuk mengklasifikasikan opini ke dalam opini positif dan negatif.
Naïve Bayes bisa berfungsi dengan baik sebagai metode pengklasifikasi teks.
Tahapan yang dilakukan analisis sentimen yaitu mengumpulkan tweets
positif, negatif dan netral lalu memisahkan menjadi tiga kategori yaitu positif,
negatif dan netral tahap selanjutnya mencari kata kunci yang terkait dengan
sekumpulan tweet positif, negatif dan netral. Kata kunci ini terutama untuk menggambarkan aspek apa yang mendapat opini.
2.2 Review Literatur
Samodra Joko et al [3] Melakukan Klasifikasi untuk teks berbahasa
indonesia menggunakan data dari situs www.tempointeraktif.com dengan jumlah
dokumen sebanyak 2400 yang dibagi menjadi 4 kategori. Pada tahap awal dengan
melakukan preprocessing dan file HTML diedit secara manual untuk diambil
teksnya saja lalu dokumen dipisahkan kedalam 4 kategori. Pengujian yang
didapat menunjukkan penghilangan kata-kata yang tidak penting tidak
berpengaruh besar terhadap hasil klasifikasi.
Yudi Wibisono [4] dalam Klasifikasi Berita Berbahasa Indonesia
menggunakan Naïve Bayes telah melakukan klasifikasi pada 582 dokumen
berbahasa Indonesia menggunakan metode NB. Hal yang menarik adalah akurasi
tidak menunjukkan peningkatan yang signifikan walaupun dokumen contoh telah
meningkat banyak dari 70% menjadi 90% serta akurasi masih relative tinggi
walaupun dokumen contoh secara ekstrim dikurangi hanya 58 dokumen (10%).
Amir Hamzah [5] melakukan pengelompokkan teks berita dan abstrak
akademis. Pada setiap koleksi dokumen diformat dalam bentuk <DOC></DOC>
untuk membedakan dokumen yang satu dengan dokumen yang lain, tag
<DOCNO>..</DOCNO> untuk identifikasi nomor dokumen dan tag
<CATNO>..</CATNO> untuk identifikasi dari nomor kategori dokumen.
2.3 Dokumen Pelatihan
Satu set pelatihan adalah seperangkat dokumen yang digunakan dalam
berbagai bidang ilmu informasi untuk menemukan hubungan yang berpotensi
prediktif. Set pelatihan yang digunakan dalam kecerdasan buatan, pembelajaran
mesin, pemrograman genetik, sistem cerdas, dan statistik. Dalam semua bidang
tersebut, satu set pelatihan memiliki banyak peran yang sama dan sering
digunakan dalam hubungannya dengan satu set [7].
2.4 Preprocessing text
Data uji diproses terlebih dahulu sebelum digunakan dalam program. Proses
ini disebut preprocessing text. preprocessing text bertujuan untuk mengurangi
volume kosakata, menyeragamkan kata dan menghilangkan noise. preprocessing text meliputi lexical analysis of the text yang terdiri dari case folding dan
tokenizing kemudian dilanjutkan dengan penghapusan stopwords dan stemming
2.4.1 Lexical Analysis of The Text
Lexical analysis merupakan proses mengubah kumpulan karakter menjadi
kumpulan kata [6]. Tujuan utama dari fase ini adalah mengidentifikasi kata-kata
pada dokumen. Fase ini terdiri dari dua langkah yaitu case folding yaitu
penyeragaman bentuk huruf serta penghilangan tanda baca dan parsing yang
bertujuan untuk memecah kalimat menjadi kata-kata yang independen.
2.4.1.1Case folding
Dokumen mengandung beragam variasi dari bentuk huruf sampai tanda
baca. Variasi huruf harus diseragamkan (menjadi huruf besar saja atau huruf kecil
saja) dan tanda baca harus dihilangkan untuk menghilangkan noise pada saat
informasi. Hal ini dapat dilakukan dengan case folding. Case folding adalah
proses mengubah huruf dalam dokumen menjadi huruf kecil [8]. Hanya huruf 'a'
sampai dengan 'z' yang diterima. Karakter selain huruf dihilangkan dan dianggap
sebagai delimiter.
Karakter-karakter simbol yang akan dihapus atau dianggap sebagai pemisah
kata, dapat dilihat di tabel 2.1 dibawah ini.
Tabel 2.1 Karakter Simbol
Karakter Simbol
^ , :
@ ( ;
% ) |
$ - ]
# < }
„ > {
~ + \
& = /
. ! “
2.4.1.2 Tokenizing
Dalam tahap ini dilakukan pemecahan atau pemotongan dokumen menurut
filtering. Hasil pemotongan (tokenizing) terhadap kata-kata tunggal tersebut
dijadikan kumpulan token dan membentuknya menjadi sebuah daftar atau list[6].
2.4.2 Stemming
Stemming berfungsi mengubah kata menjadi kata dasar. Pada umumnya kata dalam dokumen memiliki variasi kombinasi imbuhan kata yang beragam. Variasi
imbuhan dapat berupa prefix (awalan), suffix (akhiran), infix (sisipan) dan confix
(kombinasi antara awalan dan akhiran). Dengan menggunakan stemming dapat
mengurangi variasi kata yang sebenarnya memiliki kata dasar yang sama. Salah
satu algoritma stemming yaitu Algoritma Nazief dan Adriani.
Algoritma stemming Nazief dan Adriani (1996) dikembangkan berdasarkan
aturan morfologi Bahasa Indonesia yang mengelompokkan imbuhan menjadi
awalan (prefix), sisipan (infix), akhiran (suffix) dan gabungan awalan-akhiran
(confixes). Algoritma ini menggunakan kamus kata dasar dan mendukung
recoding, yakni penyusunan kembali kata-kata yang mengalami proses stemming
berlebih.
Algoritma stemming Nazief dan Adriani menggunakan morfologi imbuhan
sebagai berikut :
1. Inflection suffixes merupakan kumpulan akhiran (suffixes) yang tidak
merubah kata dasar. Misalnya kata ‘duduk’+’-lah’-> ’duduklah’. Inflection
suffixes terbagi menjadi :
a. Particles (P) termasuk ‘-lah’ dan ‘-kah’. Contoh : pergilah, pernahkah.
b. Possesive pronouns (PP) termasuk ‘-ku’,’-mu’ dan ‘nya’. Contoh : diriku,
dirimu, dirinya.
2. Derivation suffixes (DS) merupakan kumpulan akhiran (suffixes) yang langsung menempel pada kata dasar. Misalnya kata dasar ‘lapor’ ditambah
derivation suffix ‘-kan’ menjadi ‘laporkan’. Setelah itu ditambah inflection
suffix ‘-lah’ menjadi ‘laporkanlah’.
3. Derivation prefixes (DP) merupakan himpunan awalan (prefixes) yang
mempunyai sampai dua derivation prefixes. Misalnya derivation prefixes
‘mem-’ dan ‘per-’ + ‘-perindahkannya’->’memperindahkannya.
Dibawah ini adalah urutan pemakaian imbuhan sebagai inflections dan
derivations:
[DP+[DP+[DP+]]] kata dasar [[+DS][+PP][+P]]
Kurung siku menandakan bahwa imbuhan bersifat optional [14]. Pada penelitian
ini, algoritma yang digunakan untuk stemming bahasa Indonesia adalah algoritma
Adriani dan Nazief. Algoritma dimulai dengan pembacaan tiap kata dari file input
sehingga input berupa sebuah kata. Algoritma ini menggunakan kamus berisi
kata-kata dasar sebagai pedoman pengecekan jika proses stemming telah
mencapai kata dasar. Selain itu, pengecekan juga dilakukan pada panjang kata.
Jika panjang kata kurang dari dua karakter, maka proses stemming tidak
dilanjutkan. Setiap kata yang akan di-stemming akan menjalankan
langkah-langkah sebagai berikut :
1. Kata yang belum di-stemming dicari di kamus kata dasar. Jika ditemukan,
maka kata tersebut dianggap sebagai kata dasar. Algoritma mengembalikan
kata tersebut dan berhenti.
2. Inflection suffixes (‘-lah’,’-ku’,’-kah’,’-mu’ atau ‘-nya’) dihapus. Awalnya
penghapusan dilakukan pada akhiran particles (‘-lah’ atau ‘-kah’) kemudian
disusul dengan penghapusan akhiran possessive pronoun (‘-ku’,’-mu’ atau ‘-
nya’).
3. Derivation suffixes (‘-i’ atau ‘-an’) dihapus. Jika sukses, langkah 4
dijalankan. Jika langkah 4 tidak sukses
a. Jika ‘-an’ dihapus dan huruf terakhir dari kata tersebut ‘-k’, maka ‘-k’ juga
dihapus dan langkah 4 kembali dijalankan. Jika gagal, maka langkah 3b
dijalankan.
b. Hapus akhiran (‘-i’,‘-an’ atau ‘-kan’) kemudian simpan.
4. Derivation previx dihapus. Proses ini memiliki beberapa langkah yaitu :
a. Jika akhiran dihapus pada langkah 3, maka cek kombinasi awalan akhiran
berdasarkan Tabel 2.1. Jika ada yang cocok, maka algoritma
b. Jika awalan sekarang sama dengan awalan sebelumnya, maka algoritma
mengembalikan kata tersebut dan berhenti.
c. Jika tiga awalan telah dihapus sebelumnya, maka algoritma
mengembalikan kata tersebut dan berhenti.
d. Jenis awalan ditentukan dengan langkah berikut.
i. Jika awalan merupakan ‘di-‘,’ke-‘ atau ‘se-‘, maka jenis awalan tetap
‘di-‘,’ke-‘ atau ‘se-‘.
ii. Jika awalan adalah ‘te-’,’be-‘,’me-‘ atau ‘pe-‘, maka diperlukan
proses tambahan untuk mengekstrak karakter yang berawalan ‘te-‘
berdasarkan Tabel 2.2. Misalnya, kata ‘terlambat’, setelah
menghapus ‘te-‘ menghasilkan ‘rlambat’. Ekstraksi pertama
dilakukan menurut aturan ‘Set 1’ dan hal yang serupa terjadi pada
lima baris pertama. Setelah itu, terdapat karakter ‘-l-‘ (Set 2), hal
yang serupa terjadi pada baris tiga sampai lima. Sehingga kata
menjadi ‘ambat’ sesuai dengan ‘Set 3’ dan buang kemungkinan baris
tiga dan empat. Hasilnya ditunjukan pada kolom terakhir bahwa
akhiran dari kata ‘terlambat’ berjenis awalan ‘ter-‘.
iii. Jika dua karakter pertama tidak sama dengan ‘di-‘,’ke-‘,’se- ‘,’te-‘,
‘be-‘,’me-‘ atau ‘pe-‘, maka algoritma mengembalikan kata tersebut
dan berhenti.
e. Jika jenis awalan ‘none’ atau tidak ada, maka algoritma mengembalikan
kata tersebut dan berhenti. Jika awalan tidak ‘none’, maka jenis awalan
ditemukan pada Tabel 2.3. Awalan yang ditemukan akan dihapus.
Jika kata dasar tidak ditemukan pada kamus, langkah 4 secara rekursif
dijalankan untuk penghapusan lebih lanjut. Jika kata dasar ditemukan pada kamus,
maka algoritma mengembalikan kata tersebut dan berhenti.
Tabel 2.2 Kombinasi awalan dan akhiran yang tidak diperbolehkan
Prefiks Disallowed Suffixes
be- -i
di- -an
ke- -i, -kan
me- -an
se- -i, -kan
te- -an
Pada Tabel 2.1 terdapat satu pengecualian, kata dasar ‘tahu’ diperbolehkan
untuk kombinasi awalan ‘ke-‘ dan akhiran ‘i-’.
Tabel 2.3 Penentuan tipe awalan untuk kata dengan awalan ‘te-‘.
Following characters
Prefix type
Set 1 Set 2 Set 3 Set 4
‘-r’ ‘-r’ - - None
‘-r’ vowel - - ter-luluh
‘-r’ Not (‘-r’ or vowel) ‘-er-’ vowel Ter
‘-r’ Not (‘-r’ or vowel) ‘-er-’ Not vowel None
‘-r’ Not (‘-r’ or vowel) Not ‘-er-‘ - Ter
Not (vowel or ‘-r’) ‘-er-’ vowel - None
Not (vowel or ‘-r’) ‘-er-’ Not vowel - Te
Keterangan : Jika awalan ‘te-‘ tidak sesuai dengan salah satu dari aturan
pada tabel, maka dikembalikan ke ‘none’. Aturan yang sama berlaku untuk ‘be-‘,
‘me-‘ dan ‘pe-‘.
Tabel 2.4 Penentuan awalan dari jenis awalan
Prefix type Prefix to be removed
di di-
ke ke-
se se-
te te-
ter-luluh ter- 2.4.3 Penghapusan Stopwords
Kata yang terlalu sering muncul pada setiap dokumen tidak terlalu baik
digunakan sebagai kata kunci. Faktanya, kata yang muncul sampai 80% pada
setiap dokumen tidak berguna untuk pengambilan informasi [6]. Kata-kata yang
sering muncul tersebut dikenal sebagai stopwords. Stopwords adalah kata-kata
yang sering muncul dan tidak memiliki arti. Daftar kata stopword yaitu kumpulan
seluruh kata-kata yang sering muncul dan tidak memiliki arti yang disimpan
dalam bank kata khusus stopword yang terdiri dari 810 stopword bahasa indonesia
Contoh dari stopwords untuk bahasa indonesia yaitu adalah, adanya, akhirnya,
bahkan, bagaimanapun. Dengan dibuangnya stopwords, ukuran kosakata menjadi
berkurang sehingga hanya kata-kata penting yang terdapat dalam dokumen dan
diharapkan akan menjadi kata-kata yang memiliki bobot yang tinggi.
2.5 Klasifikasi Dokumen
Klasifikasi merupakan proses mengidentifikasi objek ke dalam kelas, grup
atau kategori berdasarkan prosedur, karakteristik dan definisinya [3]. Salah satu
bentuk klasifikasi yang diterapkan dalam penelitian ini adalah klasifikasi Tweets.
Pada penelitian ini, setiap tweets dipetakan tepat satu ke kategori yang
paling sesuai dengan isinya. Klasifikasi dokumen terbagi menjadi dua salah
satunya yaitu supervised document classification yaitu klasifikasi yang melibatkan
mekanisme external (seperti human feedback) guna menyediakan informasi
klasifikasi yang benar. Klasifikasi tipe ini biasanya menggunakan dokumen
pembelajaran. Salah satu contoh supervised document classification adalah Naive Bayes yang akan diulas pada penelitian ini.
2.6 Naive Bayes
Naive Bayes tergolong supervised classification document. Metode ini memiliki tingkat keakuratan tinggi dengan penghitungan yang sederhana [7].
Metode ini mengasumsikan kemunculan suatu kata tidak mempengaruhi
bahasa, asumsi ini tidak berpengaruh besar terhadap tingkat keakuratan metode ini
[1].
Teorema Bayes berawal dari persamaan 2.1, yaitu:
(2.1)
Di mana P(A|B) artinya peluang A(Kata) pada data uji jika diketahui keadaan
B(Kelas) positif, negatif dan netral. Kemudian dari persamaan 2.1 didapatkan
persamaan 2.2
(2.2)
Sehingga didapatkan teorema Bayes seperti persamaan yang ditunjukkan pada
persamaan 2.3
(2.3)
Algoritma pembelajaran bayes menghitung probabilitas eksplisit untuk
menggambarkan hipotesa yang dicari. Sistem dilatih menggunakan data latih
lengkap berupa pasangan nilai-nilai atribut dan nilai target kemudian sistem akan
diberikan sebuah data baru dalam bentuk <a1, a2, a3,....an> dan sistem diberi tugas
untuk menebak nilai fungsi target dari data tersebut [7].
Naive Bayes memberi nilai target kepada data baru menggunakan nilai Vmap,
yaitu nilai kemungkinan tertinggi dari seluruh anggota himpunan set domain V
yang ditunjukkan pada persamaan 2.4.
Vmap = (2.4)
a = kata dalam dokumen
Vj = Kategori ke j
j = 1, 2, 3
V1 = Kategori Positif
V3 = Kategori Netral
Teorema Bayes kemudian digunakan untuk menulis ulang persamaan 2.4
menjadi persamaan 2.5
(2.5)
Karena P(a1,a2,a3,....,an) nilainya konstan untuk semua Vj sehingga
persamaan 2.5 dapat ditulis dengan persamaan 2.6.
Vmap = P(a1,a2,a3...an |Vj) P(Vj) (2.6)
Tingkat kesulitan menghitung P(a1,a2,a3,....an|Vj) P(Vj) menjadi tinggi karena
jumlah kata P(a1,a2,a3,....an|Vj) P(Vj) bisa menjadi sangat besar. Ini disebabkan
jumlah kata tersebut sama dengan jumlah kombinasi posisi kata dikali dengan
jumlah kategori. Metode klasifikasi Naive Bayes menyederhanakan hal ini dengan
bekerja dengan asumsi bahwa atribut-atribut yang digunakan bersifat
conditionally independent antara satu dan yang lainnya, dengan kata lain dalam
setiap kategori, setiap kata independent satu sama lain. Sehingga menjadi
persamaan 2.7.
(2.7)
Subtitusi persamaan 2.7 dengan persamaan 2.6 menjadi persamaan 2.8.
(2.8)
VMap adalah nilai probabilitas hasil perhitungan Naive Bayes. Untuk nilai
fungsi target yang bersangkutan. Frekuensi kemunculan kata menjadi dasar
ini berkorespondensi dengan hipotesa yang ingin dipelajari. Hipotesa kemudian
digunakan untuk mengklasifikasikan data-data baru. Pada pengklasifikasikan teks,
perhitungan persamaan 2.7 dapat didefinisikan :
(2.9)
(2.10)
Keterangan :
1. Docsj : Kumpulan dokumen yang memiliki kategori vj.
2. |D| : Jumlah dokumen yang digunakan dalam pelatihan (kumpulan
data latih).
3. n : jumlah total kata yang terdapat di dalam kata tekstual yang
memiliki nilai fungsi target yang sesuai.
4. nk : Jumlah kemunculan kata wk pada semua data tekstual yang
memilliki nilai fungsi target yang sesuai.
5. |kata| : Jumlah kata yang berbeda yang muncul dalam seluruh data
tekstual yang digunakan.
2.7 Evaluasi
Hasil klasifikasi teks dengan menggunakan metode Naive Bayes akan
dievaluasi keakuratannya menggunakan pendekatan Accuracy and Error rate.
2.7.1 Accuracy and Error Rate
Untuk mengevaluasi kinerja klasifikasi teks, Accuracy and Error rate secara
luas digunakan. Definisi akurasi dan kesalahan tingkat untuk masing-masing
kategori adalah sebagai berikut [10]:
(2.11)
(2.12)
TN = True Negative, jumlah data uji yang benar klasifikasikan ke kategori yang salah
FP = False Positive, jumlah data uji yang salah diklasifikasikan ke kategori yang benar
FN = False Negative, jumlah data uji yang salah diklasifikasikan ke kategori yang salah
Mirip dengan penyaringan spam, klasifikasi yang salah dari dokumen ke
kategori memiliki konsekuensi berat. Kedua langkah sederhana cukup intuitif dan
menyatakan nilai persentase untuk hasil kategorisasi baik benar dan salah.
Namun, dalam situasi di mana TN lebih besar dari TP untuk beberapa kategori,
mereka bisa menyesatkan. Dalam hal ini, akurasi yang tinggi dapat diperoleh,
sebagai dokumen yang umumnya tidak relevan dengan kategori tertentu. Namun,
dua kesalahan set FB dan FN dapat dibandingkan dengan set yang relevan TP.
2.8 Konsep Dasar Pemrograman Objek
Pemrograman berorientasi objek berarti sebuah teknik pemrograman yang
dalam proses pengembangannya menggunakan terminologi objek, di mana setiap
objek memiliki atribut beserta dengan fungsi yang dapat saling berinteraksi satu
dengan yang lain. Contohnya objek makhluk hidup – baik manusia ataupun
binatang maka akan mengenalinya dari bentuk, ukuran, beratnya kemudian dari
perilakunya dapat dilihat bahwa makhluk hidup dapat melihat, makan, berjalan,
berlari dan selain itu terdapat fungsi lainnya seperti fungsi peredaran darah yang
berhubungan dengan fungsi pernapasan atau fungsi pencernaan.
Ciri-ciri inilah yang menjadi ide dasar bagaimana mengembangkan sebuah
perangkat lunak yang kompleks dengan menggunakan model objek tersebut.
Dengan demikian, proses pengembangan perangkat lunak akan lebih mudah
karena hanya akan menyesuaikan model pemrograman dengan objek yang kita
buat. PBO memiliki tujuan untuk memberikan pemahaman sistem kepada user
atau client. Hal ini karena user/client dapat lebih mudah memahami alur
pemrograman dengan kasus yang dihadapi, hal ini berbeda dengan pemrograman
terstruktur karena lebih berorientasi kepada programmer untuk menyelesaikan
Pengertian UML ( Unified Modeling Language)
UML singkatan dari Unified Modeling Language yang berarti bahasa
pemodelan standar. Ketika akan membuat model menggunakan konsep UML ada
aturan-aturan yang harus diikuti. Bagaimana elemen pada model-model yang
dibuat berhubungan satu dengan lainnya dan harus mengikuti standar yang ada.
UML bukan hanya sekedar diagram, tetapi juga menceritakan konteksnya [14].
UML adalah himpunan struktur danteknik untuk pemodelan desain program
berorientasi objek (OOP) serta aplikasinya. UML adalah metodologi untuk
mengembangkan sistem OOP dan sekelompok perangkat tool untuk mendukung
pengembangan sistem tersebut UML mulai diperkenalkan oleh Object
Management Group, sebuah organisasi yang telah mengembangkan model,
teknologi, dan standar OOP sejak tahun 1980-an. Sekarang UML sudah mulai
banyak digunakan oleh para praktisi OOP. UML merupakan dasar bagi perangkat
(tool) desain berorientasi objek dari IBM.
UML diaplikasikan untuk maksud tertentu, biasanya antara lain untuk :
1. Merancang perangkat Lunak
2. Sarana Komunikasi antara perangkat lunak dengan proses bisnis
3. Menjabarkan sistem secara rinci untuk analisa dan mencari apa yang
diperlukan sistem.
4. Mendokumentasi sistem yang ada, proses-proses dan organisasinya.
Beberapa literature menyebutkan bahwa UML menyediakan Sembilan jenis
diagram, yang lain menyebutkan sepuluh karena ada beberapa diagram yang
digabung, misalnya diagram komunikasi, diagram urutan dan diagram perwaktuan
digabung menjadi diagram interaksi. Namun demikian model-model itu dapat
dikelompokkan menjadi 10 macam diagram untuk memodelkan aplikasi
berorientasi objek, yaitu :
1. Diagram Kelas. Bersifat statis. Diagram ini memperlihatkan himpunan
kelas-kelas, antarmuka-antarmuka, kolaborasi-kolaborasi, serta relasi-relasi.
Diagram ini umum dijumpai pada pemodelan sistem berorientasi objek.
2. Diagram Paket (Package Diagram). Bersifat statis. Diagram ini
memperlihatkan kumpulan kelas-kelas, merupakan bagian dari diagram
komponen.
3. Diagram Use-Case. Bersifat statis. Diagram ini memperlihatkan himpunan
use-case dan aktor-aktor (suatu jenis khusus dari kelas). Diagram ini terutama
sangat penting untuk mengordinasikan dan memodelkan perilaku suatu sistem
yang dibutuhkan serta diharapkan pengguna.
4. Diagram interaksi dan sequence (urutan). Bersifat dinamis. Diagram urutan
adalah diagram interaksi yang menekankan pada pengiriman pesan dalam
suatu waktu tertentu.
5. Diagram Komunikasi (Communication Diagram). Bersifat dinamis. Diagram
sebagai pengganti diagramkolaborasi UML 1.4 yang menekankan organisasi
struktural dari objek-objek yang menerima serta mengirim pesan.
6. Diagram Statechart (Statechart Diagram). Bersifat dinamis. Diagram status
memperlihatkan keadaan-keadaan pada sistem, memuat status (state), transisi,
kejadian serta aktifitas. Diagram ini terutama penting untuk memperlihatkan
sifat dinamis dari antarmuka (interface), kelas, kolaborasi dan terutama
penting pada pemodelan sistem-sistem yang reaktif.
7. Diagram Aktivitas (Activity Diagram). Bersifat dinamis. Diagram aktivitas
adalah tipe khusus dari diagram status yang memperlihatkan aliran dari suatu
aktivitas ke aktivitas lainnya dalam suatu sistem. Diagram ini terutama
penting dalam pemodelan fungsi-fungsi suatu sistem dan memberi tekanan
pada aliran kendali antar objek.
8. Diagram komponen (Component Diagram). Bersifat statis. Diagram
komponen ini memperlihatkan organisasi serta kebergantungan
sistem/perangkat lunak pada komponen-komponen yang telah ada
sebelumnya. Diagram ini berhubungan dengan diagram kelas dimana
komponen secara tipikal dipetakan kedalam satu atau lebih kelas-kelas,
antaramuka-antarmuka serta kolaborasi-kolaborasi.
Diagram Deployment (Deployment Diagram). Bersifat statis. Diagram ini
simpul-simpul beserta komponen-komponen yang ada di dalamnya. Diagram deployment
berhubungan erat dengan diagram komponen dimana diagram ini memuat satu
atau lebih komponen-komponen. Diagram ini sangat berguna saat aplikasi kita
berlaku sebagai aplikasi yang dijalankan pada banyak mesin (distributed
21
BAB 3
ANALISIS MASALAH DAN PERANCANGAN
3.1 State of the Art
Pada penelitian sebelumnya sudah ada yang menggunakan metode
Stemming untuk preprocessing text dalam mengolah data pelatihan dan data uji
untuk kasus kata yang baku seperti pada tabel 3.1
Tabel 3.1 Analisis penelitian sebelumnya
Penelitian
Fitur Stemming
Bahasa
Indonesia Dokumen
Klasifikasi Dokumen Teks berbahasa Indonesia dengan menggunakan Naive Bayes
Spam Filtering with Naive
Bayesian Classication
Bayesian Learning for
Automatic Arabic Text
Categorization
Dari penelitian yang sudah simpulkan pada tabel 3.1 maka akan dibuat
penelitian optimasi akurasi untuk metode Naive Bayes dengan penambahan
tahapan Nazief dan Adriani stemmer pada preprocessing text untuk menangani
keberagaman bahasa sehari-hari(kata tidak baku) pada bahasa indonesia.
3.2 Analisis Masalah
Beragamnya penggunaan kata dalam bahasa Indonesia seperti kata baku
yang berimbuhan (peninggalan, mendukung) dan kata yang tidak baku (tdk, ga,
ngga, brp, knp) pada posting twitter menjadi faktor yang mempengaruhi akurasi
dalam klasifikasi dokumen. Maka diperlukan optimasi stemming untuk menangani
kata-kata yang tidak baku
3.3 Arsitektur Sistem
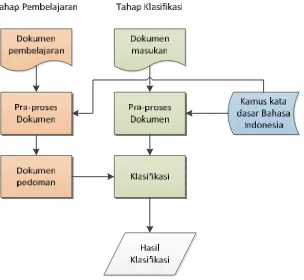
Gambar 3.1 memperlihatkan arsitektur sistem yang akan dikembangkan.
dilakukan tahap pembelajaran dan tahap klasifikasi. Data teks dari posting twitter
ini akan di praproses terlebih dulu sebelum diproses lebih lanjut.
Gambar 3.1 Arsitektur Sistem Klasifikasi Posting Twitter
Text mining mempunyai definisi sebagai menambang data berupa teks
dimana sumber data biasanya didapat dari suatu dokumen dengan tujuan mencari
kata-kata yang dapat mewakili isi dari dokumen sehingga dapat dilakukan analisa
keterhubungan antar dokumen. Secara umum sistem ini dibagi menjadi beberapa
tahapan proses, pada gambar 3.1 blok diagram proses kerja pada text mining
klasifikasi objek wisata sebagai berikut.
1. Optimasi analisis sentimen ini memiliki dua tahap yaitu tahap pembelajaran
dan tahap klasifikasi.
2. Tahap pembelajaran harus dijalankan terlebih dahulu dengan melalui
pra-proses yaitu case folding, tokenizing, stemming dan stopwords untuk
menghasilkan dokumen pembelajaran sebagai pedoman untuk setiap kategori
3. Tahap pembelajaran memiliki modul yang hampir sama dengan tahap
klasifikasi. Bedanya hanya pada tahap pembelajaran tidak menjalankan
modul klasifikasi, tetapi hanya menghasilkan dokumen yang mengandung
kata-kata untuk mengkarakteristik suatu kategori
4. Setelah memiliki data pembelajaran, maka tahap klasifikasi baru dapat
dijalankan.
5. Tahap klasifikasi dapat dispesifikasi mulai dari sistem menerima input berupa
teks dokumen posting twitter sampai menampilkan hasil klasifikasi yaitu
positif, negatif dan netral.
6. Modul praproses dokumen dimulai dengan melakukan pembacaan kalimat
dari teks dokumen posting twitter.
7. Kalimat yang sudah dibaca akan menjalani proses case folding dan tokenizing
sehingga berbentuk kata yang independent.
8. Kata yang mempunyai imbuhan, variasi dan kata yang tidak baku akan masuk
ke tahapan stemming dengan bantuan kamus kata dasar bahasa Indonesia.
Kata yang cocok dengan daftar stopwords dihilangkan.
9. Selanjutnya modul Klasifikasi melakukan penghitungan berdasarkan metode
Naive Bayes untuk menentukan kategori yang akan dipetakan ke dokumen
input dan menampilkan hasil klasifikasi, kecepatan dan akurasinya.
3.4 Analisis Data Masukan
Data masukan berupa tweets diambil dari seluruh timeline pengguna twitter.
Ada beberapa tweets mengenai salah satu kandidat capres 2014 yang ada pada
timeline, untuk penelitian ini data diambil secara random sehingga komposisi
tweet yang mengandung selain teks dan angka dihapus dengan tahapan preprocessing teks. Contoh tweet dari pengguna twitter mengenai salah satu
kandidat capres 2014 :
“Bagaimanapun jg dukung ==> jokowi jd presiden agar INDONESIA
3.5 Praproses dokumen
Tahap praproses dokumen merupakan tahap yang seharusnya dilakukan
sebelum metode klasifikasi. Tujuan dari tahap ini adalah menghilangkan noise,
menyeragamkan bentuk kata dan mengurangi volume kosakata. Tahap ini
meliputi case folding, tokenizing, penghapusan stopword dan stemming. Berikut
penerapan pada tahap praproses dokumen pada sistem klasifikasi :
3.5.1 Dokumen input
Contoh tweet yang akan memasuki tahap document preprocessing dapat
dilihat di bawah ini
“Bagaimanapun jg dukung ==> jokowi jd presiden agar INDONESIA hebat
\(´▽`)/”
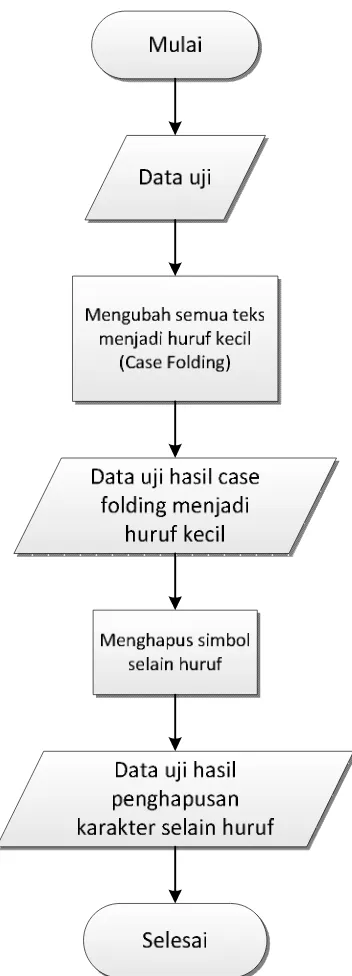
3.5.2 Case folding
Pada tahap ini dilakukan pengubah huruf dalam dokumen menjadi huruf
kecil. Hanya huruf ‘a’ sampai dengan ‘z’ yang diterima. Karakter selain huruf
dihilangkan dan dianggap sebagai delimiter. Contoh hasil case folding terlihat
Gambar 3.2 Flowchart tahapan case folding
Pada tahapan ini, ada beberapa aturan proses agar hasil case folding dapat
sesuai dengan yang diharapkan. Adapun aturan-aturan tersebut dapat dilihat pada
Tabel 3.2 Aturan tahapan case folding
Kondisi Aksi
Inputan data latih memiliki huruf kapital [A…..Z].
Maka akan mengubah semua inputan tersebut menjadi huruf kecil [a……z] semua.
Inputan data latih memiliki karakter simbol
Maka akan menghapus karakter simbol tersebut dari inputan
Inputan data latih memiliki huruf kecil Tidak ada aksi Inputan data latih memiliki spasi Tidak ada aksi
Berikut ini adalah contoh tahapan case folding yang akan di ilustrasikan pada
tabel 3.3 :
Tabel 3.3 Ilustrasi tahapan Case folding
Contoh Data
Data Uji Tahapan Case Folding
Input
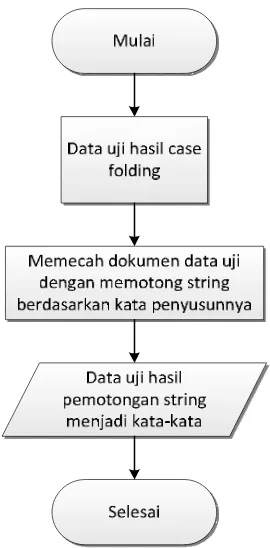
Tokenizing merupakan proses pemotongan string input berdasarkan tiap kata
yang menyusunya serta membedakan karakter-karakter tertentu yang dapat
diperlakukan sebagai pemisah kata atau bukan. Tahapan ini dilakukan setelah
inputan data uji melewati tahap Case Folding. Proses tokenizing ini mempunyai
Gambar 3.3 Flowchart Tahapan Parsing
Pada tahapan ini dilakukan pemecahan deskripsi dari data latih menjadi
bab-bab, paragrap, kalimat, dan menjadi kata-kata dengan memotong string dari
penyusunnya. Ada beberapa aturan proses agar hasilnya sesuai dengan yang
diinginkan. Adapun aturan-aturan tersebut pada tabel 3.3 :
Tabel 3.4 Aturan tahapan Parsing
Kondisi Aksi
Jika inputan data uji bertemu spasi Maka akan memecah dari deskripsi data latih menjadi bab-bab per bagian kata atau string.
Jika Inputan data latih memiliki huruf.
Tabel 3.5 dibawah ini merupakan contoh tahapan Tokenizing sebagai berikut :
Tabel 3.5 Ilustrasi Tokenizing
Contoh Data
Data Latih hasil Case Folding Tahapan Tokenizing
Input
bagaimanapun jg dukung jokowi jd presiden agar indonesia hebat
Output
bagaimanapun jg
dukung jokowi jd presiden agar indonesia hebat
3.5.4 Stemming
Pada tahap ini dilakukan pembuangan imbuhan kata. Misalnya kata
“bagaimanapun” maka langkah yang dilakukan stemming dijalankan selanjutnya
mengecek kata "bagaimanapun" pada kamus kata dasar, jika tidak ada maka akan
masuk ke tahap penghapusan partikel yaitu "-pun" pada akhiran kata dasar
selanjutnya pengecekan awalan jika tidak ada maka algoritma mengembalikan
kata menjadi "bagaimana" dan stemming berhenti. Untuk stemming kata "jg" dan
"jd" maka sistem akan mengecek pada kamus yang berisi singkatan dari kata-kata
dasar anomali yang sudah didaftarkan contoh yang terdapat pada kamus kata
"jg"="juga", "jd"="jadi". Sehingga semua kata tidak yang terdaftar pada kamus
yang berisi singkatan dari kata-kata dasar akan diganti ke kata dasar yang baku.
Proses stemming ini mempunyai alur yang digambarkan pada gambar 3.4 sebagai
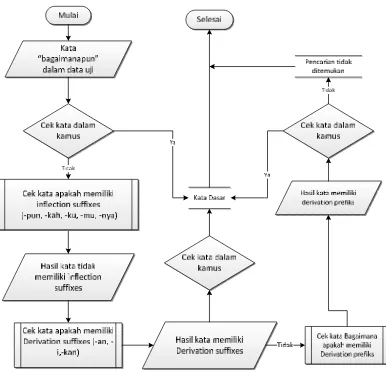
Gambar 3.4 Flowchart Stemming kata baku
pada flowchartstemming di atas tahapan yang dilakukan adalah sebagai berikut
:
1. Kata yang hendak di stemming dicari terlebih dahulu pada kamus. Jika ditemukan, maka kata tersebut adalah kata dasar, jika tidak maka langkah 2
yang dilakukan.
2. Pada kata dalam data uji akan dicek apakah memiliki inflectional suffixes,
yaitu akhiran(“-lah”,“-kah”,“-tah”,“-pun”) dan kata ganti kepunyaan atau
possessive pronoun PP (“-ku”, “-mu”, “-nya”) ternyata pada kata dalam data
uji tidak terdapat inflectional suffixes dan possessive pronoun kemudian
3. Pada kata dalam data uji akan dicek apakah memiliki Derivation suffixes,
yaitu akhiran(“-an”, ”-i”, “-kan”) ternyata pada kata dalam data uji terdapat
Derivation suffixes maka sistem menghapus akhiran derivation suffixes lalu
sistem mengecek ke kamus kata dasar jika kata hasil derivation suffixes ada
di dalam kamus kata dasar maka sistem berhenti jika tidak ditemukan akan
dilakukan proses selanjutnya.
4. Kata dalam data uji akan dicek, apakah memiliki derivation prefixes,
ternyata kata dalam data uji mengandung derivation prefiixes kemudian
sistem mencari kata ke kamus kata dasar jika ditemukan maka kata dalam
data uji adalah kata dasar dan proses berhenti, jika tidak maka kata
dikembalikan dan proses berhenti.
Pada tweet uji terdapat dua kata yang tidak baku yaitu jg dan jd. Maka
kedua kata tersebut harus diubah ke dalam bentuk kata yang baku melalui proses
stemming yang menggunakan kamus yang berisi daftar kata-kata anomali dari
kata dasarnya begitu juga untuk singkatan-singkatan dari kata dasar. Berikut
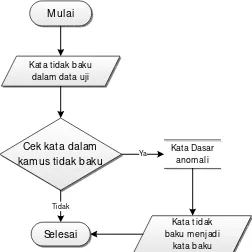
contoh proses stemming untuk salah satu kata yang tidak baku :
Kat a t idak baku dalam dat a uji
Cek kat a dalam kamus tidak baku
M ulai
Selesai
Kat a Dasar anomali
Tidak
Ya
Kat a t idak baku m enjadi
kat a baku
1. Kata tidak baku yang akan di-stemming langsung dicek dalam kamus apakah
termasuk ke dalam kata anomali atau singkatan dari kata dasar.
2. Ternyata kata tidak baku termasuk dalam kata anomali dari kata dasarnya
maka hasilnya diganti menjadi kata baku dan proses berhenti.
3. Jika kata tidak baku atau kata singkatan dari kata dasar tidak terdapat dalam
kamus kata tidak baku maka proses akan berhenti.
Adapun isi dari sebagian daftar kata anomali pada kamus kata dasar anomali
yang disajikan tabel 3.6 :
Tabel 3.6 Kamus kata dasar anomali
Kata anomali Kata dasarnya
jg juga
jd jadi
wkt waktu
brp berapa
jml jumlah
Berikut ini merupakan contoh tahapan stemming pada tabel 3.7 :
Tabel 3.7 Ilustrasi Stemming
Contoh Data
Data Latih hasil Tokenizing Tahapan Stemming
Input
Kata-kata yang terkandung pada daftar stopwords yang terdapat pada daftar
kata khusus stopword bahasa indonesia terdiri berisi 810 kata-kata yang sering
dan “jadi” terdapat di bank kata stopwords sehingga kata tersebut harus
dihilangkan. Kata yang tertinggal dapat dilihat pada Gambar 3.6 berikut :
Gambar 3.6 Flowchart Stopword
Pada tahapan ini, ada beberapa aturan proses agar hasil stopword sesuai apa
yang diharapkan. Adapun aturan-aturan tersebut disajikan pada tabel 3.8.
Tabel 3.8 Aturan tahapan Stopword
Kondisi Aksi
Jika Inputan data latih mengandung kata pada database stopword
Maka akan menghapus kata atau string dalam data latih.
Jika Inputan data latih tidak mengandung kata pada kamus stopword
Adapun isi dari sebagian daftar kata stopword yang disajikan pada tabel 3.9
:
Tabel 3.9 Daftar sebagian Kata-kata Stopword
Data Stopword
telah punya mendapatkan dari
untuk setiap pernah lain
agar memang lakukan melakukannya
jadi seperti ada antara
juga hampir semua setelah
Tabel 3.10 merupakan contoh tahapan stopword sebagai berikut.
Tabel 3.10 Ilustrasi Stopword
Contoh Data
Data Latih hasil stemming Tahapan Stopword
Input
bagaimanapun juga
dukung jokowi jadi presiden agar indonesia hebat
Output
dukung jokowi presiden indonesia hebat
Dari tweet “Bagaimanapun jg dukung ==> jokowi jd presiden agar
indonesia hebat \(´▽`)/” setelah melalui proses preprocessing text hasilnya
menjadi ”dukung, jokowi, presiden, indonesia, hebat” dan ini belum diketahui
kategori kelasnya sehingga harus melalui proses perhitungan dengan metode
3.6 Analisis Algoritma
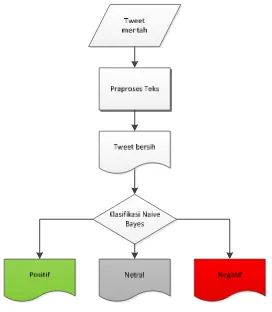
Gambar 3.7 Flowchart Naive bayes
Gambar 3.7 memperlihatkan arsitektur sistem yang akan dikembangkan.
Sistem ini menerima masukan berupa data tweet mentah. Data ini akan di
praproses terlebih dulu sebelum diproses lebih lanjut.
Dari gambar diagram alur Algoritma Naive Bayes di atas dapat jelaskan
sebagai berikut :
1. Tweet mentah yaitu kumpulan tweet yang belum dilakukan preprocessing text yaitu dengan parsing, case folding, penghapusan stopword dan stemming
contoh ”dukung jokowi jd presiden wujud indonesia maju
jg hebat \(´▽`)/”
2. Koleksi tweet diproses terlebih dahulu sebelum digunakan dalam program.
Proses ini disebut preprocessing text. Preprocessing text bertujuan untuk
mengurangi volume kosakata, menyeragamkan kata dan menghilangkan
3. Tweet bersih yaitu kumpulan tweet yang sudah dihilang noise, variasi kata
dari kata contoh “dukung jokowi jadi presiden wujud
indonesia maju hebat”
4. Klasifikasi naive Bayes yaitu mengklasifikasikan apakah tweet yang
dijadikan data uji hasilnya sentimen positif atau negatif.
5. Total masing-masing tweet positif, tweet negatif dan tweet netral hasil akhir dari klasifikasi
Algoritma Naive Bayes merupakan pengklasifikasian dengan metode
probabilitas, yaitu memprediksi peluang di masa depan berdasarkan pengalaman di
masa sebelumnya sehingga dikenal sebagai teorema Bayes. Dari contoh tweet yang
telah dibersihkan melalui tahapan preprocessing text maka hasil kata disajikan pada
tabel 3.11 :
Tabel 3.11 Indeks kata data uji
Kata pada data uji
dukung presiden indonesia hebat
dari data uji diatas maka didapat fitur kemunculan yang penting diantaranya
dukung, presiden, maju, hebat. Setelah mendapat fitur yang diperlukan maka
dilakukan proses klasifikasi dengan algoritma Naive Bayes.
Gambar 3.8 Algoritma Naive Bayes
Dari Algoritma Naive Bayes pada gambar 3.7 tahapan yang dilakukan adalah
sebagai berikut :
1. Data pelatihan : Tweet yang akan dijadikan sebagai data pelatihan untuk data
testing contoh dari kumpulan training data yang sudah melalui tahapan
preprocessing text dari masing-masing kategori
2. Bentuk Vocabulary : Kumpulkan semua kata yang unik dari tweet pada tabel
training data, contoh : tolak, jangan, salah, dukungan, maju, hebat, presiden,
cawapres, jakarta.
3. Hitung P(Vj) : Total kelas ada tiga yaitu positif, negatif dan non opini maka
kemungkinannya adalah :
Tabel 3.12 Nilai P(Vj) untuk setiap kategori
Kategori P(Vj)
Positif
Negatif
4. Bentuk Teksj : untuk kelas positif contoh kata uniknya yaitu “dukung”,
“maju”, “hebat”. Untuk kelas negatif contoh yaitu “tolak”, “jangan”, “salah”.
Untuk kelas non opini contohnya “presiden”, “cawapres”, “jakarta”
Tabel 3.13 Data pelatihan
Kategori Hasil keyword data latih
Positif dukung(8), maju(2), hebat(2)
Negatif tolak(3), jangan(4), salah(4)
Netral presiden(10), cawapres(3), jakarta(5)
5. Setelah dilakukan pembuangan kata yang tidak relevan pada setiap karakter,
maka proses selanjutnya pembelajaran data latih akan dimasukakan ke dalam
model probabilitas naïve bayes (learning), ditentukan dengan persamaan 2.10.
Tabel 3.14 Model probabilistik
Kategori
Dokumen
cawapres dukung hebat jangan maju presiden salah tolak jakarta Positif
Negatif
Netral
6. Klasifikasi Naïve Bayes Untuk Data Uji
Selanjutnya, setelah didapatkan data latih, maka tahapan dilanjutkan ke dalam
proses pengklasifikasian untuk menguji model yang telah dibangun kepada data
uji untuk mengukur ketepatan atau performa model probabilitas dari data latih
Kasus : Berapa nilai klasifikasi jika terdapat data uji yang belum diketahui kategori
jika memiliki kemunculan kosakata pada tabel 3.14.
Tabel 3.15 Data uji
Doc ke-n
Hasil Kemunculan
Kosakata Kategori
Baru
“dukung”(3), “presiden”(1),
“maju”(2), “hebat”(3)
?
Selanjutnya, Pada tahap ini kemunculan kata yang pada data uji akan dilihat
pada model probabilitas pada tabel 3.14 untuk dicari Vmap pada setiap kategori
berikut ini :
Tabel 3.16 Nilai Vmap
Kategori P(Vj)
Dokumen
Nilai Vmap
dukung presiden maju hebat Positif
Negatif
Non opini
Berdasarkan tabel 3.15 dapat dilihat peluang kemunculan kata yag nilainya telah
diperoleh dari model probabilitas kemunculan kata pada data latih di tabel 3.13.
Peluang kemunculan kata yang besar akan menghasilkan Vmap yang tinggi,
sehingga dokumen data uji akan terklasifikasi ke dalam karakter dengan Vmap
yang paling tinggi. Pada kasus data uji diatas, dapat disimpulkan bahwa dokumen
terklasifikaasi ke dalam kategori positif. Pada penelitian jumlah data yang
benar adalah dan yang salah. Dari hasil klasifikasi didapat jumlah True Positif 50,
True Negatif 90 dan True Netral 63.
3.7 Evaluasi Akurasi
Untuk menghitung akurasi dan error dari hasil klasifikasi maka diperlukan
data hasil klasifikasi dengan keseluruhan data yang sebenarnya atau aktual berikut
perhitungan akurasi Naive Bayes :
True Positif = 50
True Negatif = 90
True Netral = 63
False Positif = 17
False Negatif = 68
False Netral = 12
Jumlah data uji yang benar dari hasil perhitungan = 203
Jumlah data uji yang salah dari hasil perhitungan = 97
Total data uji keseluruhan : 300
Accuracy= = = 67,67%
Error rate = = 32,32%
Hasil uji coba sistem stopword dengan stemming menggunakan proporsi
dokumen uji disajikan pada tabel 3.17 :
Tabel 3.17 Tabel hasil klasifikasi
Proporsi Dokumen Uji Penggunaan stemming dengan
Stopwords
300 Data 67,67%
3.8 Analisa kebutuhan non fungsionalitas
Analisis kebutuhan non fungsional adalah langkah dimana seorang
pembangun perangkat lunak menganalisis sumber daya yang akan digunakan dan
lunak yang dimiliki harus sesuai dengan kebutuhan, sehingga dapat ditentukan
kompabilitas aplikasi yang dibangun terhadap sumber daya yang ada.
3.8.1 Analisa Kebutuhan Perangkat Lunak
Adapun perangkat lunak yang digunakan untuk optimasi analisis sentimen
pada posting twitter menggunakan metode Naive Bayes :
1. Netbeans
2. Visual paradigm
3. Ms Visio
3.8.2 Analisa kebutuhan perangkat keras
Adapun perangkat keras yang digunakan untuk optimasi analisis sentimen
pada posting twitter menggunakan metode Naive Bayes :
1. Prosesor Intel Core i3 (2,2 GHz).
2. Memori 2.00 GB DDR2.
3. Harddisk 500 GB
4. Monitor 14.1 inch
3.9 Analisis kebutuhan fungsional
Analsis kebutuhan fungsional mendefinisikan aksi dasar yang ada dalam
perangkat lunak yang dibangun untuk menerima dan memproses masukan dan
menghasilkan keluaran.
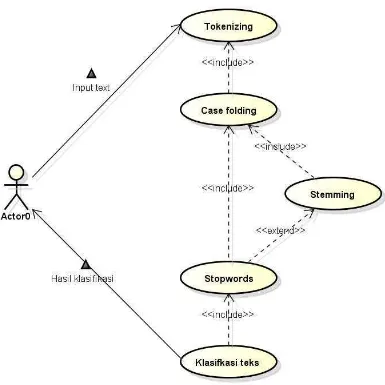
3.9.1 Use Case
Diagram use case adalah diagram yang menggambarkan secara umum yang
menjadi masukkan, proses, dam keluaran yang terjadi pada sebuah sistem. Diagram
Gambar 3.9 Use CaseDiagram
Definisi Aktor berfungsi untuk menjelaskan actor yang terlibat pada use
case diagram. Berikut ini adalah tabel 3.18 yang menerangkan definisi actor.
Tabel 3.18 Definisi Aktor
No Aktor Deskripsi
3.9.1.1Definisi Use Case
Tabel 3.19 Deskripsi Use Case
No Use Case Deskripsi
1 Tokenizing Melakukan pemotongan
kalimat menjadi kata-kata
2 Case Folding Mengubah karakter menjadi
huruf kecil dan menghapus delimiter pada kata-kata
3 Stemming Mengubah kata yang
berimbuhan dan kata tidak baku menjadi kata dasarnya
4 Stopwords Menghilangkan kata yang
tidak memiliki arti
5 Klasifikasi teks Menghitung seluruh data uji ke dalam masing-masing kelas kategori
3.9.1.2Skenario Use Case
Skenario use case menggambarkan alur penggunaan sistem dimana setiap
skenario digambarkan dari sudut pandang aktor, seseorang atau peranti yang
berinteraksi dengan perangkat lunak dalam berbagai cara.
Tabel 3.20 Tabel Skenario Use Case Tokenizing
Identifikasi
Nomor 1.
Nama Tokenizing
Tujuan Melakukan pemotongan kalimat menjadi per kata
Aktor
SkenarioUtama
Kondisi Awal Pengguna menginput data testing
AksiAktor ReaksiSistem
Menginput teks Melakukan pemotongan seluruh kalimat
Tabel 3.21 Skenario Use Case Case Folding
Identifikasi
Nomor 2.
Nama Case folding.
Tujuan Mengubah karakter menjadi huruf kecil dan menghapus delimiter pada kata-kata
Aktor
SkenarioUtama
Kondisi Awal Seluruh kalimat sudah menjadi potongan kata per kata
AksiAktor ReaksiSistem
Sistem melakukan pembersihan setiap karakter dari delimiter dan mengubah setiap karakter menjadi huruf kecil
KondisiAkhir Seluruh kata sudah menjadi karakter yang bersih dari delimiter menjadi huruf kecil.
Tabel 3.22 Skenario Use Case Stemming
Identifikasi
Nomor 3.
Nama Stemming.
Tujuan Mengubah kata berimbuhan menjadi kata dasarnya
Aktor
SkenarioUtama
Kondisi Awal Seluruh kata sudah bersih dari delimiter dan menjadi huruf kecil
AksiAktor ReaksiSistem
Sistem menghilangkanimbuhan dan mengubah menjadi kata dasarnya
Tabel 3.23 Skenario Use Case Stopwords
Identifikasi
Nomor 4.
Nama Stopwords.
Tujuan Menghilangkan kata yang tidak memiliki arti
Aktor
SkenarioUtama
Kondisi Awal Seluruh kata sudah menjadi kata dasarnya
AksiAktor ReaksiSistem
Menghilangkan setiap kata dasar yang tidak memiliki arti
KondisiAkhir Terkumpul kata dasar yang memiliki arti.
Tabel 3.24 Klasfikasi Teks
Identifikasi
Nomor 5.
Nama Klasifikasi teks.
Tujuan Menghitung seluruh data uji ke dalam masing-masing kelas kategori
Aktor
SkenarioUtama
Kondisi Awal Terkumpul kata dasar yang memiliki arti.
AksiAktor ReaksiSistem
Menghitung seluruh data uji
3.9.2 Class diagram
Diagram kelas menggambarkan struktur sistem dari segi pendefinisian kelas-kelas yang akan dibuat untuk membangun sistem.
Kelas-kelas yang terdapat pada klasifikasi teks adalah kelas BayesClassifier, Classification, Classifier, IfeatureProbability,
BayesFrame, fmain, BayesFrame
3.9.3 Activity Diagram
Diagram aktivitas atau activity diagram menggambarkan workflow (aliran
kerja) atau aktivitas dari sebuah sistem atau proses bisnis. Dalam diagram
aktivitas yang terlibat adalah antara user dan sistem. Terdapat tujuh aktivitas yang
tergambar sesuai prosesnya masing-masing yaitu Activity diagram classifying
text.
3.9.4 Sequence Diagram
Diagram sekuen atau sequence diagram menggambarkan kelakuan objek
pada use case dengan mendeskripsikan waktu hidup objek dan message yang
dikirimkan dan diterima antar objek.
Gambar 3.14 Sequence Diagram Stemming
Gambar 3.17 Sequence Diagram BayesClassifier
3.9.5 Perancangan Antarmuka Perangkat Lunak
Perancangan antarmuka merupakan salah satu bagian penting dalam
perancangan sistem karena nantinya antarmuka tersebut akan menjadi fasilitas yang
menjembatani interaksi manusia dengan sistem.