I. PENDAHULUAN
1.1. Latar Belakang
Berbicara mengenai statistika maka erat kaitannya dengan analisis data penelitian. Secara umum tahapan suatu penelitian meliputi pengumpulan data dan analisis data. Beberapa penelitian yang ada, seringkali data yang dikumpulkan tidak berupa data numerik. Misalkan pekerjaan seseorang, jenis kelamin, atau pendapat seseorang mengenai suatu kebijakan. Variabel-variabel demikian tidak dapat dihitung dengan angka karena bersifat kualitatif. Dalam statistik, variabel yang demikian disebut variabel data kategori (categorical data).
Variabel data kategori adalah variabel data yang diklasifikasikan menurut kriteria tertentu. Variabel data kategori digunakan dalam suatu penelitian karena tidak semua objek dalam suatu penelitian dapat diukur dengan menggunakan alat ukur yang ada. Misalkan, pekerjaan seseorang tidak dapat diukur dengan suatu alat ukur melainkan hanya bisa dikelompokan berdasarkan kategori tertentu. Data kategori diklasifikasikan menurut kriteria tertentu dalam skala pengukuran nominal atau ordinal, dan data kategori diolah berdasarkan nilai frekuensi
Selain itu, seringkali dalam suatu penelaahan penelitian melibatkan lebih dari satu variabel yang antar variabel tidak diketahui ada tidaknya hubungan atau asosiasi yang signifikan. Sedangkan hubungan atau asosiasi antar variabel sangat
berpengaruh terhadap penentuan metode analisis yang akan digunakan selanjutnya serta mempengaruhi keabsahan hasil penelitian. Oleh karena itu, Analisis
hubungan atau pola asosiasi antar variabel ini perlu dilakukan terlebih dahulu. Analisis hubungan antarvariabel dari suatu variabel numerik tentu tidak sama dengan analisis antarvariabel yang bersifat kategori.
1.2. Rumusan Masalah
Metode-metode analisis pola asosiasi antarvariabel dari data numerik telah kita kenal sebelumnya seperti analisis regresi sederhana ataupun analisis regresi berganda. Sedangkan untuk data kategori berskala nominal maupun ordinal pendekatan regresi tidak dapat dilakukan karena asumsi-asumsi model regresi tidak dapat dipenuhi. Maka diperlukan pendekatan lain untuk mengatasi masalah ini.
1.3. Batasan Masalah
Dalam penelitian ini hanya akan disampaikan mengenai analisis data kategori dengan metode Analisis Konfigurasi Frekuensi. Sedangkan sampling data, ukuran pemusatan, atau ukuran penyebaran data tidak dibahas dalam skripsi ini.
1.4. Tujuan Penelitian
Adapun yang menjadi tujuan penelitian ini adalah : 1. Mendeskripsikan Analisis Konfigurasi Frekuensi.
2. Mengaplikasikan Analisis Konfigurasi Frekuensi pada suatu data kategori guna mengetahui :
a. Perbandingan antara frekuensi hasil pengamatan dengan frekuensi yang diharapkan.
b. Signifikansi perbedaan hasil pengamatan dengan frekuensi yang diharapkan.
c. Ada tidaknya hubungan (korelasi) antara variabel bebas (predictor) dan variabel tak bebas (criterion).
3. Membentuk model log-linear dengan langkah Analisis Model Log-linear
1.5. Manfaat Penelitian
II. LANDASAN TEORI
2.1. Data Kategori
Wallpole (1995), mendefinisikan data kategori sebagai data yang diklasifikasikan menurut kriteria tertentu. Data kategori disebut juga data nonmetrik atau data yang bukan merupakan hasil pengukuran. Data kategori merupakan data kualitatif sehingga untuk dapat dianalisis dengan menggunakan rumus matematika/statistika perlu diberi kode (coding) berupa angka. Analisis matematika/statistika terhadap data kategori dilakukan berdasarkan hasil membilang (counting) pada setiap kategori/pasangan kategori.
Klasifikasi data kategori adalah : 1. Kategori Nominal.
2. Kategori Ordinal.
2.2. Tabel Kontingensi
Watson (1993) menerangkan bahwa jika data dari suatu variabel acak yang diambil dari suatu populasi diklasifikasikan dalam dua variabel kategori atau kriteria, maka salah satu kelas dapat direpresentasikan sebagai baris dalam tabel dan kelas yang lain direpresentasikan sebagai kolom. Secara umum tabel dengan r baris dan c kolom dikenal dengan tabel kontingensi (contingency table) atau
tabulasi silang (cross tabulation).
Baris Kolom Total
Baris
1 2 3 … c
1 Y11 Y12 Y13 … Y1c R1 2 Y21 Y22 Y23 … Y2c R2 3 Y31 Y32 Y33 … Y3c R3
r Yr1 Yr2 Yr3 … Yrc Rr Total
Kolom C1 C2 C3 … Cc n Keterangan :
ij
Y : frekuensi observasi (f0) yaitu nilai observasi sampel acak pada baris ke-i dan
kolom ke- j
n : ukuran sampel
c
j j r
i i r
i c
j
ij R C
Y
1 1
1 1
Jika f0 adalah frekuensi observasi, f0 dapat diduga oleh frekuensi harapan
(expected frequency) fe, frekuensi harapan dari observasi baris ke-i dan kolom ke-j
dirumuskan dengan :
fe ij=
n C R
sampel ukuran
kolom total
baris
total i j
) )(
(
(Watson, et.al., 1993).
2.3. Distribusi Multinomial
population). Jika proporsi dari elemen-elemen yang termasuk dalam setiap kelas
tidak dipengaruhi oleh pemilihan sampel maka model yang tepat adalah distribusi multinomial (multinomial distribution). Distribusi multinomial adalah distribusi bersama untuk suatu peubah acak Y1,Y2,,Yk, yang beranggotakan suatu sampel acak berukuran n yang termasuk dalam tiap k kelas populasi multinomial, Yj
adalah anggota kelas ke-j. Parameter dalam suatu distribusi multinomial terdiri dari n yang bersifat tetap dan p1,p2,,pk adalah proporsi kelas ke-i. Dengan
asumsi Y n k
i i
1
dan 1
1
k i i p .Fungsi Distribusi Peluang (Probability Distribution Function) untuk distribusi multinomial Y1,Y2,,Ykanggota k kelas adalah :
k i i Y i k k Y k Y Y k Y p n Y Y Y p p p n Y Y Y P i 1 2 1 2 1 2 1 ! ! ! ! ! ! ) , , , ( 2 1 (Watson,et.al, 1993).Dengan mengetahui sebaran dari suatu variabel kategori, maka pendugaan terhadap nilai frekuensi observasi dalam suatu tabel kontingensi dapat dilakukan dengan menggunakan Maximum Likelihood Estimation.
2.4. Metode Pendugaan Maksimum (Maximum Likelihood Estimation)
Salah satu metode pendugaan parameter dari suatu fungsi distribusi adalah metode pendugaan maksimum (maximum likelihood estimation). Misalkan X1, X2,..., Xn adalah sampel acak dari suatu distribusi f(xi,) dimana adalah
) , ( ) , ( ) ,
(x1 f x2 f xn
f . Fungsi kepekatan peluang bersama ini dilihat sebagai fungsi , yang selanjutnya disebut dengan fungsi likelihood (L) sampel acak dan ditulis :
n i i nn
f
x
f
x
f
x
f
x
x
x
x
L
1 2 1 21
,
,
,
(
,
)
(
,
)
(
,
)
(
,
)
;
Melalui fungsi likelihood ini, dapat ditentukan suatu fungsi nontrivial dari
n x x
x1, 2,, yaitu u(x1,x2,,xn), sehingga dapat digantikan oleh
) , , ,
(x1 x2 xn
u yang mengakibatkan fungsi likelihood (L( )) akan maksimum.
Fungsi (L()) akan dapat maksimum dengan menentukan derivatif pertama dari logaritma fungsi (L( )) terhadap yang sama dengan nol.
0 , , , ;ln 1 2
x x xn
L
Selanjutnya dengan melakukan penurunan matematis maka akan didapat
) , , , ( ˆ 2 1 x xn x
u
.
ˆ disebut dengan penduga maksimum likelihood (Hoog dan Craig, 1995).
2.5. Model Log-Linear
kontingensi yang terdiri dari tiga atau lebih variabel (multi-way contingency tables) ( Angela, 2009).
Strategi dasar dalam pemodelan log-linear adalah membentuk model berdasarkan frekuensi pengamatan dalam tabel silang dari suatu variabel kategori. Model yang dihasilkan akan merepresentasikan frekuensi harapan yang mungkin berbeda atau menyerupai frekuensi pengamatan.
Bentuk umum model log-linear :
ijk jk
ik ij k j i ijk
Y
E( ) log
Keterangan :
E(Yijk) = frekuensi harapan dalam setiap sel
= Intercept atau konstanta atau rata-rata umum
i
= parameter pengaruh tingkat ke-i dari faktor
j
= parameter pengaruh tingkat ke-j dari faktor
k
= parameter pengaruh tingkat ke-k dari faktor
ij
= parameter pengaruh interaksi tingkat ke-i dan ke-j dari faktor
dan faktor
ik
= parameter pengaruh interaksi tingkat ke-i dan ke-k dari faktor
dan faktor
jk
= parameter pengaruh interaksi tingkat ke-j dan ke-k dari faktor
ijk
= parameter pengaruh interaksi tingkat ke-i, ke-j dan ke-k dari
faktor , dan faktor
Dimana penduga parameternya adalah :
IJK Y E i j k
ijk
) ( log
IJ Y E IK Y E JK Y E I Y E J Y E K Y E Y IJ Y E IK Y E I Y E IJ Y E JK Y E J Y E IK Y E JK Y E K Y E IJ Y E IK Y E JK Y E i j ijk i k ijk j k ijk i ijk j ijk k ijk ijk ijk i j ijk i k ijk i ijk jk i j ijk j k ijk j ijk ik i k ijk j k ijk k ijk ij i j ijk k i k ijk j j k ijk i ) ( log ) ( log ) ( log ) ( log ) ( log ) ( log ˆ log ) ( log ) ( log ) ( log ) ( log ) ( log ) ( log ) ( log ) ( log ) ( log ) ( log ) ( log ) ( logJumlah dari parameter untuk semua index adalah nol, yaitu :
k ijk j ij i ij k k j j ii
= 0
Model umum diatas disebut juga Model Jenuh (Saturated Model) karena model tersebut memuat kemungkinan pengaruh setiap faktor beserta interaksinya.
Selain itu, ada pula model independen sebagai partisi dari model jenuh log-linear yaitu model log-linear yang hanya melibatkan parameter pengaruh faktor utama dan tidak melibatkan parameter interaksi antar faktor. Model ini digunakan jika tidak ada interaksi antar variabel. Bentuk umumnya sebagai berikut :
k j i ijkl
Y
E( ) log
Selain model independen dan model jenuh, dikenal pula model hirarki log-linear, Model tersebut adalah partisi dari model jenuh. Model hirarki menghilangkan parameter-parameter faktor yang tidak signifikan berpengaruh dan hanya melibatkan faktor yang signifikan berpengaruh. Contohnya :
ik k j i ijk
Y
E( ) log
Pembentukan model statistika adalah mencari model sesederhana mungkin yang dapat mencocokkan data tanpa harus melibatkan parameter faktor yang komplek dan berlebihan (Agus, 2005). Pada model log-linear jenuh (saturated model)
ijk jk
ik ij k j i ijk
Y
E( ) log
Sebagai indikasi apakah suatu parameter faktor atau parameter interaksi faktor itu signifikan berpengaruh terhadap model, diperlukan suatu statistik yang dikenal dengan Rasio Kesamaan Chi-kuadrat (Likelihood Ratio Chi-square)
dilambangkan dengan G2. Statistika G2 berdistribusi Chi-kuadrat (Agung, 2004).
Rasio Kesamaan Chi-kuadrat (G2 ) dapat dihitung secara manual berdasarkan rumus :
i j k ijk
ijk ijk
fe fo fo
G2 2 ln
( Agung, 2004).
Dengan hipotesis
Ho : tidak ada pengaruh faktor interaksi H1 : ada pengaruh faktor interaksi
Pengambilan keputusan berdasarkan perbandingan nilai G2 terhadap nilai 2
tabel atau berdasarkan nilai p-value. Jika nilai statistik G2 lebih besar dari
nilai 2
tabel atau p-value < (taraf nyata) maka disimpulkan bahwa interaksi tersebut signifikan berpengaruh dan perlu dimasukkan dalam model
2.6. Pengujian Chi Square
Pengujian mengenai keindependenan variabel kategori atau kriteria klasifikasi baris dan kolom pada tabel kontingensi dihitung berdasarkan frekuensi harapan dari tiap cell (fe) dan menggunakan pengujian statistik 2.
Uji ini digunakan untuk menguji apakah ada hubungan antara dua variabel kategori (data kualitatif). Pada uji ini digunakan tabel kontingensi dengan banyaknya baris r dan banyaknya kolom c (tabel kontingensi r x c).
Pengujian hipotesis yang dilakukan adalah:
Ho : tidak ada hubungan antara baris dan kolom H1 : ada hubungan antara baris dan kolom
Statistik Ujinya adalah: 2=
r
i ij
ij ij c
j fe
fe fo
1
2
1
keterangan:
ij
fo : frekuensi observasi pada baris ke-i dan kolom ke-j
ij
fe : frekuensi harapan pada baris ke-i dan kolom ke-j, n : ukuran sampel
dengan derajat bebas v(c1)(r1)
Pengambilan keputusan didasarkan pada hal dibawah ini : a. Berdasarkan perbandingan 2 hitung dan tabel
b. Berdasarkan probabilitas (p-value)
Jika probabilitas > α maka H0 tidak ditolak
Jika probabilitas < α maka H0 ditolak
(Sanders & Smidt, 2000)
2.7. Uji z
Dua hal penting dalam statistika inferensia adalah pendugaan paramater dan pengujian hipotesis statistika. Pengujian hipotesis dilakukan untuk menjawab suatu pertanyaan hipotesis yang merupakan suatu dugaan sementara.
Salah satu cara pengujian hipotesis statistik yang umum digunakan adalah dengan menggunakan Pengujian nilai z (z-test). Uji z didasarkan pada pendekatan nilai pengamatan terhadap nilai z. Suatu pengamatan dari suatu populasi yang mempunyai nilai tengah dan simpangan baku ,
mempunyai nilai z yang didefinisikan sebagai :
z
Dengan perumusan hipotesis :
0 0
1
0 : :
atau H
Ho
atau dikenal dengan uji satu arah.
0 1
0 : :
H Ho
Dengan taraf nyata sebesar maka pengambilan keputusan tolak Ho dilakukan jika zzatau zz untuk pengujian satu arah. Sedangkan tolak Ho jika
2 /
z
z untuk pengujian dua arah. didefinisikan sebagai nilai peluang tolak
Ho padahal Ho benar, oleh karena itu nilai dibuat sekecil mungkin. Nilai
III. METODOLOGI PENELITIAN
3.1. Waktu dan Tempat Penelitian
Penelitian skripsi ini dilakukan di Jurusan Matematika Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Lampung pada tahun akademik 2009/2010.
3.2. Metode Penelitian
Secara umum, pelaksanaan penelitian skripsi ini adalah melakukan tahapan-tahapan analisis sebagai berikut :
1. Menentukan data kategori dengan n-variabel (n adalah bilangan bulat positif, n >1) yang ingin diteliti, dimana masing-masing variabel terdiri dari beberapa kategori. Dalam hal ini, digunakan tabel kategori berukuran 2 x 2 x 2 x 2.
2. Melakukan langkah-langkah Analisis Konfigurasi Frekuensi untuk mengetahui ada tidaknya interaksi antar variabel.
3. Melakukan analisis pemodelan log-linear untuk mendapatkan model yang tepat.
3.3. Analisis Konfigurasi Frekuensi
Misalkan terdapat suatu data kategori dengan lebih dari satu variabel yang dinyatakan dalam tabel kontingensi sebagai berikut :
baris Kolom Total
Baris
X1 X2 1 2 3 … c
1 1 Y111 Y112 Y113 … Y11c R1 2 2 Y221 Y222 Y223 … Y22c R2 3 3 Y331 Y332 Y333 … Y33c R3
q r Yqr1 Yqr2 Yqr3 … Yqrc Rr
Total Kolom C1 C2 C3 … Cc n
Analisis model log-linear dapat menjelaskan pola asosiasi antar variabel baris dan kolom, baris dan kolom dalam tabel kontingensi tersebut menyatakan variabel yang terlibat. Selain Analisis Model Log-Linear, untuk mengetahui pola asosiasi antarvariabel data kategori pada tabel kontingensi terdapat metode lain yang akan diperkenalkan yaitu Analisis Konfigurasi Frekuensi (Configural Frequency Analysis). Analisis Konfigurasi Frekuensi adalah suatu metode yang digunakan
untuk mengidentifikasi pola (konfigurasi) dari variabel kategori apakah terjadi ketidakcocokan (discrepancies) dengan apa yang telah diekspektasikan
melalui pola (konfigurasi) frekuensi yang terjadi apakah menyangkal dari model dasar.
Penyangkalan model dasar yang dimaksud ditandai dengan munculnya data type atau antitype. Resa (2008) mendefinisikan ketidakcocokan (discrepancies) terjadi jika :
1. Suatu peristiwa lebih sering terjadi atau jumlah peristiwa yang terjadi lebih besar dari yang diharapkan atau diekspektasikan (disebut data Type), dan 2. Suatu peristiwa lebih jarang terjadi atau jumlah peristiwa yang terjadi
lebih kecil dari yang diharapkan atau diekspektasikan (disebut data antitype)
Parameter bukanlah fokus dari pengujian Analisis Konfigurasi Frekuensi, tetapi yang difokuskan dalam Analisis Konfigurasi Frekuensi adalah penyimpangan yang terjadi pada model ditandai dengan munculnya type dan antitype.
Von eye (2002) menjelaskan langkah-langkah dalam pengujian dengan menggunakan Analisis Konfigurasi Frekuensi adalah sebagai berikut :
1. Pemilihan model dasar untuk Analisis Konfigurasi Frekuensi dan pendugaan frekuensi harapan dari suatu sel.
2. Pemilihan konsep penyimpangan dari suatu model. 3. Pemilihan pengujian untuk melihat signifikansi.
4. Penjabaran hasil pengujian signifikansi dan pengidentifikasian apakah konfigurasi masuk ke dalam type atau anitype.
3.3.1. Pemilihan Model Dasar dan Pendugaan Frekuensi Harapan dari Suatu Sel.
Dalam Analisis Konfigurasi Frekuensi, base model atau yang selanjutnya disebut model dasar, digunakan untuk merefleksikan asumsi teorikal dari sifat suatu parameter yaitu apakah semua variabel mempunyai status yang sama, ataukah terbagi menjadi prediktor dan kriteria. Selain itu, model dasar juga berfungsi untuk mempertimbangkan rencana pengambilan sampel yang nantinya berguna untuk menentukan dugaan dari nilai frekuensi harapan suatu sel. (Resa, 2008)
Model Log-Linear umum digunakan sebagai model dasar dalam Analisis
Konfigurasi Frekuensi. Hal ini dikarenakan Log-linier sebagai suatu model dasar dapat menjelaskan asumsi teorikal mengenai sifat suatu parameter serta
keterbagian variabel menjadi prediktor dan kriteria.
Dalam model log-linear, terdapat suatu asumsi bahwa model tersebut mengasumsikan semua variabel mempunyai status yang sama sebagai suatu respon (Resa, 2008). Namun jika ternyata pada suatu penelitian diasumsikan bahwa variabel-variabel tersebut terbagi menjadi prediktor dan kriteria maka model log-linear dapat pula memodelkannya.
Beberapa bentuk umum model log-linear sebagai model dasar dalam analisis konfigurasi frekuensi adalah sebagai berikut :
Model interaksi :
ijk jk
ik ij l k j i ijkl
Y
E( )
Model first order :
k j i ijk
Y
E( )
log ...(3.2)
Model zero order :
) (
logE Yijkl ...(3.3)
Dimana :
E(Yijkl) = frekuensi harapan dalam setiap sel
= Intercept atau konstanta atau rata-rata umum
i
= parameter pengaruh tingkat ke-i dari faktor
j
= parameter pengaruh tingkat ke-j dari faktor
k
= parameter pengaruh tingkat ke-k dari faktor
l
= parameter pengaruh tingkat ke-l dari faktor sebagai kriteria
(respon)
ij
= parameter pengaruh interaksi tingkat ke-i dan ke-j dari faktor
dan faktor
ik
= parameter pengaruh interaksi tingkat ke-i dan ke-k dari faktor
dan faktor
jk
= parameter pengaruh interaksi tingkat ke-j dan ke-k dari faktor
dan faktor
ijk
= parameter pengaruh interaksi tingkat ke-i, ke-j dan ke-k dari
Misalkan terdapat suatu kasus dengan variabel ,, , dan dimana diasumsikan bahwa ,, sebagai prediktor dan sebagai respon. Maka model 3.1. digunakan untuk menganalisis atau mengetahui ada tidaknya interaksi antara prediktor (,, ) terhadap kriteria ( ), Analisis konfigurasi frekuensi akan memberikan informasi tersebut melalui pola (konfigurasi) frekuensi yang terjadi.
Sedangkan untuk mengetahui ada tidaknya keterkaitan atau interaksi antar prediktor ,dan dapat digunakan model log-linear dengan hanya melibatkan faktor utamanya saja (first order model ) sebagai model dasar yaitu seperti model 3.2.
Untuk mengetahui apakah semua variabel baik prediktor maupun kriteria
mempengaruhi model, maka digunakan model log-linear zero order (model 3.3) yaitu tanpa melibatkan parameter pengaruh variabel apapun namun hanya parameter rata-rata umumnya sebagai model dasar.
Pengujian dengan analisis konfigurasi frekuensi difokuskan pada konfigurasi kategori antar variabel dan tidak difokuskan pada nilai dari parameternya dan kecocokan model, yaitu perbandingan antara frekuensi sel hasil observasi terhadap frekuensi sel hasil ekspektasi. Frekuensi hasi ekspektasi ini diperoleh melalui pendugaan. Metode dugaan yang umum digunakan adalah maximum likelihood estimator dengan bergantung pada sebaran peluang dari data kategori.
Fungsi dari distribusi multinomial dengan frekuensi Y1,Y2,,Yk, dengan peluang
tiap sel adalah p1,p2,,pk adalah :
k i i Y i k k Y k Y Y Y p n Y Y Y p p p n n p y f i 1 2 1 2 1 ! ! ! ! ! ! ) ; ( 2 1
k i i Y n 1adalah banyaknya sampel yang telah ditentukan sebelumnya.
Pendugaan nilai E(Yi) dengan menggunakan metode maksimum likelihood
adalah:
k i i Y i Y p n n p y f i 1 ! ! ) ; (
k i i i k i i i i k i i Y i p Y k L Y p Y n L Y p n n p y f L i 1 1 1 log ) ! log log ( ! log ! ! log ) ; ( logDimana
k i i Y n 1
dan 1
1
k i ip dan k adalah konstanta.
Untuk memaksimalkan model, penaksir maksimum likelihood dari parameter pi
diperoleh dengan memaksimalkan fungsi likelihood dengan constraintnya yaitu
1 1
k i ip dan
k i i Y n 1
, yang dapat dilakukan dengan menambahkan n ke dalam
persamaan maka diperoleh :
k i i k i i k i ii p n p n Y n
Akan ditaksir nilai parameter pi dan diperoleh :
i i
i i
i i i
Y p n
n Y p
n p Y p
t
0
Jadi dapat disimpulkan bahwa maksimum likelihood estimator dari Yˆi adalah :
i i
i E Y np
Yˆ ( )
Dengan pi adalah peluang dari suatu kategori. Dua variabel kategori dalam tabel kontingensi adalah independen. Maka peluang untuk dua variabel kategori adalah
ij
p dimana pij pi.pj
Penduga maksimum likelihood untuk untuk pij adalah pˆij pˆi.pˆj
Dengan demikian dugaan frekuensi suatu sel dalam tabel kontingensi :
n Y Y
n Y
n Y n p p n Y Y
E i j i j
j i ij
ij) ˆ .ˆ ˆ .
(
ij
Yˆ disebut juga frekuensi harapan untuk sel pada tabel kontingensi baris ke-i
kolom ke-j ( feij). Sedangkan foij adalah frekuensi hasil observasi pada baris
ke-i dan kolom ke-j.
3.3.2. Pemilihan Suatu Konsep Penyimpangan dari Suatu Model.
Uji hipotesis yang digunakan adalah dengan menggunakan uji independensi yaitu dengan hipotesis sebagai berikut :
H1 : Frekuensi suatu sel hasil observasi tidak sama dengan frekuensi yang diekspektasikan
Penolakan H0 berarti akan memunculkan data type atau antitype pada sel konfigurasinya. Pengujian hupotesis dilakukan dengan menggunakan uji chi-square.
3.3.3. Pemilihan pengujian untuk melihat signifikansi
Uji signifikansi ini dilakukan untuk melihat apakah perbedaan antara frekuensi sel hasil observasi terhadap frekuensi yang diekspektasikan dalam suatu sel bersifat signifikan. Karena jika tidak signifikan maka dianggap tidak mengalami
perbedaan sehingga type dan antitype tidak muncul pada sel. Uji signifikansi ini dapat dilakukan dengan uji-z dua arah.
3.3.4. Penjabaran hasil pengujian signifikansi dan pengidentifikasian apakah konfigurasi masuk ke dalam type atau antitype.
Munculnya type atau antitype merupakan tanda adanya penyimpangan sel dari frekuensi yang telah diekspektasikan sebelumnya. Jika pengujian hipotesis
3.3.5. Penginterpretasian type dan antitype.
Type atau antitype yang muncul mendeskripsikan bahwa :
1. Adanya interaksi antar prediktor
IV. PEMBAHASAN
4.1. Pendahuluan
Sebagai bentuk kajian lebih lanjut maka pada bab ini akan disampaikan studi kasus dalam menyelesaikan analisis data kategori menggunakan langkah-langkah analisis konfigurasi frekuensi. Data yang digunakan diambil dari buku
Categorical Data Analysis oleh Agresti, A. tahun 1990 yang memuat tentang
frekuensi terjadinya korban luka-luka dalam kecelakaan di lokasi yang berbeda.
Data penelitan terdiri dari empat variabel kategori yaitu jenis kelamin, lokasi, penggunaan sabuk pengaman, dan keterjadian luka-luka. Variabel jenis kelamin dilambangkan sebagai faktor dengan level angka 1 menunjukkan perempuan dan angka 2 menunjukkan laki-laki. Variabel lokasi dilambangkan dengan dengan level angka 1 sebagai simbol lokasi perkotaan dan angka 2 sebagai simbol pedesaan. melambangkan penggunaan sabuk pengaman dengan level angka 1 menunjukkan bahwa korban tidak menggunakan sabuk pengaman dan angka 2 jika menggunakan sabuk pengaman. Selanjutnya keterjadian korban luka-luka dilambangkan dengan dimana 1 menunjukkan korban tidak mengalami
Tabel 1. Data frekuensi terjadinya korban luka-luka dalam kecelakaan
berdasarkan jenis kelamin, lokasi, dan penggunaan sabuk pengaman.
Jenis
Kelamin Lokasi
Penggunaan Sabuk Pengaman
Keterjadian Luka-Luka
(l) total
i
j k 1 2
1 1 1 7287 996 8283
1 1 2 11587 759 12346
1 2 1 3246 973 4219
1 2 2 6134 757 6891
2 1 1 10381 812 11193
2 1 2 10969 380 11349
2 2 1 6123 1084 7207
2 2 2 6693 513 7206
total 62420 6274 68694
Sumber : Agresti, Alan. 1990. Categorical Data Analysis : 379 4.2. Langkah-Langkah Analisis Konfigurasi Frekuensi
Pada skripsi ini akan dilakukan pengkajian ada tidaknya interaksi atau pengaruh jenis kelamin, lokasi, dan penggunaan sabuk pengaman terhadap frekuensi keterjadian korban luka-luka dalam kecelakaan, ada tidaknya interaksi antar variabel jenis kelamin, lokasi, dan penggunaan sabuk pengaman, serta untuk mengetahui apakah keempat variabel secara bersama-sama akan mempengaruhi model yang ditentukan. Metode yang digunakan adalah metode Analisis
Konfigurasi Frekuensi dengan mengidentifikasi pola (konfigurasi) dari variabel kategori apakah terjadi ketidakcocokan dengan apa yang diekspektasikan sebelumnya.
4.2.1. Pemilihan Model Dasaruntuk Analisis Konfigurasi Frekuensi dan pendugaan frekuensi harapan suatu sel.
Base model atau yang selanjutnya disebut model dasar merupakan bentuk
pemodelan secara umum dari data kategori pada suatu tabel kontingensi. Dengan adanya model dasar, maka dapat tergambarkan mengenai status suatu variabel apakah sebagai prediktor (variabel bebas) atau kriteria (variabel tak bebas). Analisis Konfigurasi Frekuensi memfokuskan pengujian pada ketidakcocokan antara frekuensi observasi dengan frekuensi harapan. Model dasar dapat
digunakan untuk merefleksikan frekuensi harapan suatu sel dengan diketahuinya penduga parameter pengaruh suatu variabel. Dalam analisis konfigurasi frekuensi ini penduga parameter tersebut tidak akan menjadi fokus pengujian. Model dasar yang digunakan dalam Analisis Konfigurasi Frekuensi adalah Model Log-Linear. Model log-linear dipilih karena model log-linear merupakan bentuk pemodelan data yang didalamnya turut dilibatkan parameter pengaruh interaksi antar variabel.
Pada penelitian kali ini model log-linear yang digunakan membagi variabel data penelitian menjadi prediktor dan kriteria. Prediktor yang dimaksud adalah variabel jenis kelamin (), Lokasi () dan penggunaan sabuk pengaman ( ). Sedangkan kriteria model adalah frekuensi keterjadian korban luka-luka ( ). Model log-linear untuk data tersebut adalah sebagai berikut :
ijk jk
ik ij l k j i ijkl
Y
E( )
log ...(4.1)
Dimana :
E(Yijkl) = frekuensi diharapkan dalam setiap sel
= Intercept atau konstanta atau rata-rata umum
i
= parameter pengaruh tingkat ke-i (i=1 untuk perempuan dan i=2 untuk
laki-laki ) dari faktor jenis kelamin ()
j
= parameter pengaruh tingkat ke-j (j=1 untuk perkotaan dan j=2 untuk
pedesaan ) dari faktor lokasi ()
k
= parameter pengaruh tingkat ke-k (k=1 jika tidak menggunakan sabuk
pengaman dan k=2 jika menggunakan sabuk pengaman ) dari faktor penggunaan sabuk pengaman ( )
l
= parameter pengaruh tingkat ke-l dari faktor (l=1 jika korban tidak
mengalami luka-luka dan l=2 jika korban mengalami luka-luka) sebagai kriteria (respon)
ij
= parameter pengaruh interaksi tingkat ke-i dan ke-j dari faktor dan
ik
= parameter pengaruh interaksi tingkat ke-i dan ke-k dari faktor dan
faktor
jk
= parameter pengaruh interaksi tingkat ke-j dan ke-k dari faktor dan
faktor
ijk
= parameter pengaruh interaksi tingkat ke-i, ke-j dan ke-k dari faktor
, dan faktor
Model log linear 4.1 ini digunakan untuk menganalisis atau mengetahui ada tidaknya pengaruh prediktor terhadap kriteria, yaitu antara variabel jenis kelamin, lokasi dan penggunaan sabuk pengaman terhadap keterjadian korban luka-luka. Analisis konfigurasi frekuensi akan memberikan informasi tersebut melalui pola (konfigurasi) frekuensi yang terjadi.
Sedangkan untuk mengetahui ada tidaknya keterkaitan atau interaksi antar prediktor dapat digunakan model log-linear dengan hanya melibatkan faktor utama dari prediktornya saja disebut juga first order model sebagai berikut :
k j i ijk
Y
E( )
log ...(4.2)
Dimana :
E(Yijk) = frekuensi diharapkan dalam setiap sel
= Intercept atau konstanta atau rata-rata umum
i
= parameter pengaruh tingkat ke-i (i=1 untuk perempuan dan i=2 untuk
j
= parameter pengaruh tingkat ke-j (j=1 untuk perkotaan dan j=2 untuk
pedesaan ) dari faktor lokasi ( )
k
= parameter pengaruh tingkat ke-k (k=1 jika tidak menggunakan sabuk
pengaman dan k=2 jika menggunakan sabuk pengaman ) dari faktor penggunaan sabuk pengaman ( )
Untuk mengetahui apakah keempat variabel baik prediktor maupun kriteria mempengaruhi model secara bersama-sama, maka digunakan model log-linear zero order yaitu tanpa melibatkan parameter pengaruh jenis kelamin, lokasi,
penggunaan sabuk pengaman maupun faktor keterjadian korban luka-luka. Model tersebut sebagai berikut :
) (
logE Yijkl ...(4.3)
Dimana = Intercept atau konstanta atau rata-rata umum
Selanjutnya adalah pendugaan frekuensi konfigurasi suatu sel. Pendugaan (E(Yijk)) dilakukan dengan menggunakan metode penaksiran Maksimum
Likelihood berdasarkan distribusi data kategori. Diketahui sebaran dari suatu data
kategorik ini merupakan distribusi multinomial.
Dari pendugaan yang telah dilakukan pada bab sebelumnya diketahui rumusan umum dugaan dari suatu frekuensi adalah :
j i ij
ij Y np p Y
E( ) ˆ ˆ ˆ
Dengan demikian frekuensi harapan dari konfigurasi prediktor dan kriteria adalah:
E(Yijkl)=
Frekuensi harapan dan konfigurasi antar prediktor saja adalah :
) (Yijk
E =
k j i p p p n
dan frekuensi harapan dari konfigurasi yang hanya melibatkan konstanta rata-rata umumnya adalah :
) (Yijk
E =
ijkl p n
4.2.2. Pemilihan suatu konsep penyimpangan dari suatu model
Uji hipotesis umum yang digunakan pada kasus ini adalah :
Ho : Frekuensi suatu sel hasil observasi sama dengan frekuensi yang diekspektasikan ( fo fe )
H1 : Frekuensi suatu sel hasil observasi tidak sama dengan frekuensi yang diekspektasikan ( fo fe )
Untuk mengetahui ada tidaknya interaksi antara prediktor dan kriteria maka Model log-linear dibawah Ho adalah :
ijk jk
ik ij l k j i ijkl
Y
E( ) log
Dengan hipotesis :
Ho : E(Yijk)=
ijk l p p n
H1 :E(Yijk)
ijk l p p n
Statistik uji yang digunakan adalah :
ijkl ijkl ijkl I
i J
j K
k L
l fe
fe
fo 2
1 1 1 1
2
Dengan foijkl = frekuensi observasi pada ijkl
feijkl= frekuensi ekspektasi pada ijkl
Dan 2
tabel adalah 2
(IJK-1)(L-1), derajat bebas (IJK 1)(L1) Dengan kriteria uji :
Tolak Ho jika 2hitung 2 dengan kata lain akan muncul type atau antitype
pada sel konfigurasi dan terima Ho jika 2hitung <2 dengan kata lain model
ijk jk
ik ij k j i ijkl
Y
E( )
log diterima. Munculnya
type atau antitype mendefinisikan bahwa terdapat interaksi antar prediktor dan
kriteria , yaitu terdapat hubungan antara jenis kelamin, lokasi dan penggunaan sabuk pengaman terhadap keterjadian korban luka-luka.
Untuk pengujian ada tidaknya keterkaitan atau interaksi antar prediktor maka model log linear dibawah Ho adalah
k j i ijk
Y
E( ) log
Dengan hipotesisi uji :
Ho : E(Yijk)=
k j i p p p n
H1 :E(Yijk)
k j i p p p n
Statistik uji yang digunakan adalah :
ijk ijk ijk I
i J
j K
k fe
fe
fo 2
1 1 1
2
Dengan foijk = frekuensi observasi pada ijk
Dan 2tabel adalah 2 (i1)(j1)(k1)derajat bebas (i1)(j1)(k1)
Dengan kriteria uji :
Tolak Ho jika 2hitung 2 dengan kata lain akan muncul type atau antitype
pada sel konfigurasi dan terima Ho jika 2hitung <2 dengan kata lain model
k j i ijkl
Y
E( )
log diterima. Munculnya type atau antitype
mendefinisikan bahwa terdapat interaksi antar prediktor, yaitu terdapat hubungan antara jenis kelamin, lokasi dan penggunaan sabuk pengaman.
Untuk pengujian ada tidaknya pengaruh variabel jenis kelamin, lokasi,
penggunaan sabuk pengaman dan keterjadian korban luka-luka terhadap model maka model log-linear dibawah Ho adalah :
) ( logE Yijkl
Dengan hipotesisi uji :
Ho : E(Yijk)=
ijkl p n
H1 :E(Yijk)
ijkl p n
Statistik uji yang digunakan adalah :
ijkl ijkl ijkl I
i J
j K
k L
l fe
fe
fo 2
1 1 1 1
2
Dengan foijkl = frekuensi observasi pada ijkl
feijkl= frekuensi ekspektasi pada ijkl
Dengan kriteria uji :
Tolak Ho jika 2hitung 2 dengan kata lain akan muncul type atau antitype
pada sel konfigurasi dan terima Ho jika 2
hitung <2
dengan kata lain model
) (
logE Yijkl diterima. Munculnya type atau antitype mendefinisikan bahwa jenis kelamin, lokasi dan penggunaan sabuk pengaman serta variabel keterjadian korban luka-luka mempengaruhi model.
4.2.3. Pengujian Signifikansi Konfigurasi
Analisis konfigurasi frekuensi menjadikan pola konfigurasi sebagai fokus pengujian, apakah frekuensi observasi (fo) signifikan berbeda dengan frekuensi sel yang telah diekspektasikan (fe). Pemilihan konsep penyimpangan ini
merupakan bentuk uji hipotesis statistik yang alternatifnya bersifat dua-arah, oleh karena itu, uji z dua arah merupakan salah satu pilihan untuk melihat signifikansi perbedaan antara frekuensi observasi.
Dengan rumus pendekatan normal yaitu
e e o
f f f
z
Jika suatu data yang sama dianalisis beberapa kali dengan =0,05 maka nominal
tersebut hanya dapat digunakan pada pengujian pertama. Jika pada pengujian
itu, total nilai untuk semua konfigurasi harus kurang dari atau sama dengan keseluruhan, serta nilai untuk setiap konfigurasi adalah sama. Hal ini bertujuan untuk melindungi nilai . Dengan demikian nilai untuk setiap konfigurasi merupakan nilai keseluruhan dibagi dengan banyaknya konfigurasi yang terjadi.
Untuk mengetahui ada tidaknya interaksi antara jenis kelamin, lokasi, dan penggunaan sabuk pengaman maka nilai yang digunakan adalah
00625 , 0 8
05 , 0
*
i konfiguras jumlah
dan untuk melihat ada tidaknya pengaruh prediktor terhadap kriteria serta melihat pengaruh keempat variabel terhadap model, maka yang digunakan adalah :
003125 , 0 16
05 , 0
*
i konfiguras jumlah
Tolak Ho jika z -hitung < z2*dengan kata lain frekuensi hasil observasi berbeda dengan frekuensi ekspektasi sehingga akan muncul type atau antitype pada sel konfigurasi.
4.2.4. Penjabaran hasil pengujian signifikansi dan pengidentifikasian apakah konfigurasi masuk ke dalam type atau antitype.
Untuk melihat ada tidaknya interaksi antara prediktor terhadap kriteria dengan model log-linear dibawah Ho adalah
ijk jk ik ij l k j i ijkl Y
E( )
log ,
Didapat bahwa
ijkl ijkl ijkl I i J j K k L l fe fe fo 2
1 1 1 1
2
=2074,402
Nilai 2hitung = 2074,402 > dari 2v, 27,0,05 = 20,3 Maka keputusan tolak Ho, artinya model
ijk jk ik ij l k j i ijkl Y
E( )
log belum dapat
[image:36.595.115.513.375.680.2]diterima sehingga akan muncul data type atau antitype pada konfigurasinya. Sedangkan hasil analisis konfigurasi frekuensinya adalah :
Tabel 2. Hasil Analisis Konfigurasi Frekuensi untuk model interaksi Konfigurasi fo fe Statistik
z Nilai z2* Keputusan Identifikasi
1 1 1 1
7287 7526,492 -2,76054 2,95517 terima Ho
2 1 1 1
996 756,508 8,707315 2,95517 tolak Ho type
1 2 1 1
11587 11218,41 3,479989 2,95517 tolak Ho type
2 2 1 1
759 1127,592 -10,9767 2,95517 tolak Ho antitype
1 1 2 1
3246 3833,668 -9,49128 2,95517 tolak Ho antitype
2 1 2 1
973 385,332 29,93743 2,95517 tolak Ho type
1 2 2 1
6134 6261,627 -1,61287 2,95517 terima Ho
2 2 2 1
757 629,373 5,087314 2,95517 tolak Ho type
1 1 1 2
10381 10170,71 2,085177 2,95517 terima Ho
2 1 1 2
812 1022,286 -6,57694 2,95517 tolak Ho antitype
1 2 1 2
10969 10312,47 6,46507 2,95517 tolak Ho type
2 2 1 2
380 1036,533 -20,3922 2,95517 tolak Ho antitype
1 1 2 2
6123 6548,766 -5,26128 2,95517 tolak Ho antitype
2 1 2 2
1084 658,234 16,59514 2,95517 tolak Ho antitype
1 2 2 2
6693 6547,857 1,793686 2,95517 terima Ho
2 2 2 2
513 658,143 -5,65765 2,95517 tolak Ho antitype
Didapat bahwa
ijk ijk ijk I i J j K k fe fe fo 21 1 1
2
= 872,7086
Nilai 2
hitung = 872,7086> dari 2v, 21,0,05 = 7,88
[image:37.595.119.515.248.413.2]Maka keputusan tolak Ho, artinya model logE(Yijkl)ij k belum dapat diterima sehingga akan muncul data type atau antitype pada konfigurasinya. , hasil analisis konfigurasi frekuensinya adalah :
Tabel 3. Hasil Analisis Konfigurasi Frekuensi untuk model independen
konfigurasi fo fe nilai z Nilai z2* hasil uji identifikasi
1 1 1
8283 8972,931 -7,28347 2,73437 tolak ho antitype
2 1 1
12346 10973,56 13,10146 2,73437 tolak ho type
1 2 1
4219 5304,86 -14,9086 2,73437 tolak ho antitype
2 2 1
6891 6487,65 5,007701 2,73437 tolak ho type
1 1 2
11193 10447,55 7,293085 2,73437 tolak ho type
2 1 2
11349 12776,96 -12,6329 2,73437 tolak ho antitype
1 2 2
7207 6176,66 13,11003 2,73437 tolak ho type
2 2 2
7206 7553,83 -4,00206 2,73437 tolak ho antitype
Untuk pengujian ada tidaknya pengaruh variabel jenis kelamin, lokasi,
penggunaan sabuk pengaman dan keterjadian korban luka-luka terhadap model, digunakan model dasar log E(Yijkl).
Nilai perhitungan yang didapat
ijkl ijkl ijkl I i J j K k L l fe fe fo 2
1 1 1 1
2
= 59695,15
Nilai 2hitung = 59695,15 > 2v, 27,0,05 = 20,3
Berikut adalah hasil analisis konfigurasi frekuensinya :
Tabel 4. Hasil Analisis Konfigurasi Frekuensi untuk model konstan Konfigurasi fo fe Statistik
z Nilai z2* Keputusan Identifikasi
1 1 1 1
7287 4293,375 45,68756 2,95517 Tolak Ho type
2 1 1 1
996 4293,375 -50,3233 2,95517 Tolak Ho antitype
1 2 1 1
11587 4293,375 111,3125 2,95517 Tolak Ho type
2 2 1 1
759 4293,375 -53,9403 2,95517 Tolak Ho antitype
1 1 2 1
3246 4293,375 -15,9846 2,95517 Tolak Ho antitype
2 1 2 1
973 4293,375 -50,6743 2,95517 Tolak Ho antitype
1 2 2 1
6134 4293,375 28,09092 2,95517 Tolak Ho type
2 2 2 1
757 4293,375 -53,9708 2,95517 Tolak Ho antitype
1 1 1 2
10381 4293,375 92,90701 2,95517 Tolak Ho type
2 1 1 2
812 4293,375 -53,1314 2,95517 Tolak Ho antitype
1 2 1 2
10969 4293,375 101,8808 2,95517 Tolak Ho type
2 2 1 2
380 4293,375 -59,7244 2,95517 Tolak Ho antitype
1 1 2 2
6123 4293,375 27,92304 2,95517 Tolak Ho type
2 1 2 2
1084 4293,375 -48,9803 2,95517 Tolak Ho antitype
1 2 2 2
6693 4293,375 36,62216 2,95517 Tolak Ho type
2 2 2 2
513 4293,375 -57,6946 2,95517 Tolak Ho antitype
4.2.5. Penginterpretasian type dan antitype
Dari hasil pengujian siginifikansi yang dilakukan nampak bahwa ternyata muncul type atau antitype pada beberapa sel menunjukkan bahwa ada pengaruh jenis
kelamin, lokasi kejadian dan penggunaan sabuk pengaman terhadap frekuensi keterjadian korban luka-luka. Selain itu, masing-masing antara jenis kelamin, lokasi dan penggunaan sabuk pun memiliki interaksi. Munculnya type dan antitype pada pengujian dengan menggunakan model konstanta sebagai model
pembentukan model. Jika tujuan penelitian hanya ingin melihat hubungan antar variabel dan keterkaitannya terhadap model, maka Analisis Konfigurasi Frekuensi telah memberi jawaban meski menyimpulkan penolakan terhadap beberapa model log-linear yang dijadikan model dasar. Sedangkan jika peneliti menginginkan pemodelan log-linear yang mampu menggambarkan data sebenarnya, langkah Analisis Model Log-linear perlu dilakukan.
4.3. Pembentukan Model Log-linear
Untuk menyempurnakan hasil penelitian ini, maka perlu dilakukan analisis lanjutan yaitu pembentukan model log-linear yang bertujuan untuk mendapatkan model sederhana yang dapat menggambarkan data dengan baik.
Pembentukan model log-linear ini dilakukan dengan langkah mundur atau backward search dengan bantuan software SAS Sytem for windows versi 9.
Secara statistik pembentukan model ini dilakukan dengan menghipotesiskan model jenuh log-linear (saturated models) sebagai model awal. Model jenuh ini melibatkan semua parameter faktor beserta parameter interaksi faktor secara lengkap. Kemudian akan dilihat signifikansi pengaruh interaksi dimulai dari pengujian parameter interaksi 4 faktor dan dilanjutkan dengan interaksi 3 faktor dan seterusnya.
Tabel 5. Hasil analisis model log-linear untuk model jenuh ijkl jkl ikl ijl ijk kl jl jk il ik ij l k j i ijkl Y E ) ( log
Interaksi Derajat Bebas
Statistik G2 2tabel pvalue 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1.94 287.69 49.03 26365.03 85.50 299.04 383.56 4.51 728.70 851.26 1.74 2.93 0.06 2.42 1.32 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 0.1640 <.0001 <.0001 <.0001 <.0001 <.0001 <.0001 0.0336 <.0001 <.0001 0.1865 0.0867 0.7989 0.1197 0.2497
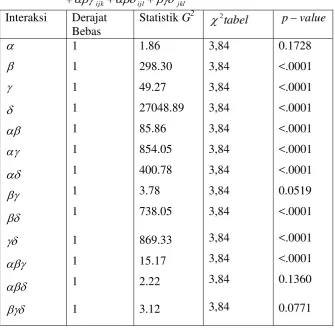
Dari tabel d iatas, untuk parameter interaksi empat faktor yang terlibat nampak tidak signifikan karena nilai Statistik G2 <2tabel atau pvalue>. Oleh karena itu , interaksi empat faktor tidak perlu dimasukkan ke dalam model.
Tabel 6. Hasil analisis model log-linear untuk model jkl ikl ijl ijk kl jl jk il ik ij l k j i ijkl Y E ) ( log
Interaksi Derajat Bebas
Statistik G2 2tabel pvalue 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1.88 298.09 26403.79 48.23 85.85 298.44 382.97 3.81 738.01 852.66 14.79 2.24 0.04 3.05 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 0.1707 <.0001 <.0001 <.0001 <.0001 <.0001 <.0001 0.0510 <.0001 <.0001 0.0001 0.1349 0.8382 0.0808
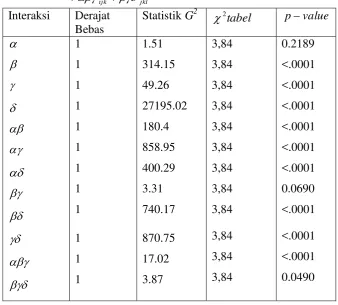
Tabel 7. Hasil analisis model log-linear untuk model jkl ijl ijk kl jl jk il ik ij l k j i ijkl Y E ) ( log
Interaksi Derajat Bebas
Statistik G2 2tabel pvalue 1 1 1 1 1 1 1 1 1 1 1 1 1 1.86 298.30 49.27 27048.89 85.86 854.05 400.78 3.78 738.05 869.33 15.17 2.22 3.12 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 0.1728 <.0001 <.0001 <.0001 <.0001 <.0001 <.0001 0.0519 <.0001 <.0001 <.0001 0.1360 0.0771
[image:42.595.145.481.127.457.2]Tabel 8. Hasil analisis model log-linear untuk model jkl ijk kl jl jk il ik ij l k j i ijkl Y E ) ( log
Interaksi Derajat Bebas
Statistik G2 2tabel pvalue 1 1 1 1 1 1 1 1 1 1 1 1 1.51 314.15 49.26 27195.02 180.4 858.95 400.29 3.31 740.17 870.75 17.02 3.87 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 0.2189 <.0001 <.0001 <.0001 <.0001 <.0001 <.0001 0.0690 <.0001 <.0001 <.0001 0.0490
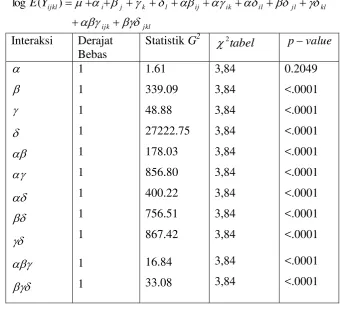
[image:43.595.142.481.129.434.2]Tabel 9. Hasil analisis model log-linear untuk model jkl ijk kl jl il ik ij l k j i ijkl Y E ) ( log
Interaksi Derajat Bebas
Statistik G2 2tabel pvalue 1 1 1 1 1 1 1 1 1 1 1 1.61 339.09 48.88 27222.75 178.03 856.80 400.22 756.51 867.42 16.84 33.08 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 3,84 0.2049 <.0001 <.0001 <.0001 <.0001 <.0001 <.0001 <.0001 <.0001 <.0001 <.0001
Dalam bentuk model ini, nampak bahwa semua interaksi signifikan berpengaruh. Sehingga dapat disimpulkan bahwa model log-linear yang tepat untuk
menggambarkan data keterjadian korban luka-luka dalam suatu kecelakaan adalah
jkl ijk kl jl il ik ij l k j i ijkl Y E ) ( log Dimana :
E(Yijkl) = frekuensi diharapkan dalam setiap sel
= Intercept atau konstanta atau rata-rata umum
i
= parameter pengaruh tingkat ke-i (i=1 untuk perempuan dan i=2 untuk
[image:44.595.142.481.123.414.2]j
= parameter pengaruh tingkat ke-j (j=1 untuk perkotaan dan j=2 untuk
pedesaan ) dari faktor lokasi ()
k
= parameter pengaruh tingkat ke-k (k=1 jika tidak menggunakan sabuk
pengaman dan k=2 jika menggunakan sabuk pengaman ) dari faktor penggunaan sabuk pengaman ( )
l
= parameter pengaruh tingkat ke-l (l=1 jika korban tidak mengalami
luka-luka dan l=2 jika korban mengalami luka-luka) dari faktor (keterjadian korban luka-luka)
ij
= parameter pengaruh interaksi tingkat ke-i dan ke-j dari faktor dan
faktor
ik
= parameter pengaruh interaksi tingkat ke-i dan ke-k dari faktor dan
faktor
il
= parameter pengaruh interaksi tingkat ke-i dan ke-l dari faktor dan
faktor
jl
= parameter pengaruh interaksi tingkat ke-j dan ke-l dari faktor dan
faktor
kl
= parameter pengaruh interaksi tingkat ke-k dan ke-l dari faktor dan
faktor
ijk
= parameter pengaruh interaksi tingkat ke-i, ke-j dan ke-k dari faktor
, dan faktor
jkl
= parameter pengaruh interaksi tingkat ke-j, ke-k dan ke-l dari faktor,
V. PENUTUP
5.1. Kesimpulan
Berdasarkan pada hasil penelitian dan studi literatur yang dituangkan dalam bab-bab sebelumnya maka dapat diambil beberapa kesimpulan, yaitu :
1. Analisis Konfigurasi Frekuensi merupakan metode alternatif untuk mengetahui pola asosiasi dari beberapa variabel kategori. Analisis ini memfokuskan pengujian pada pola konfigurasi data kategori apakah terjadi penyangkalan terhadap model dasar. Penyangkalan model dasar terjadi karena terdapat perbedaan signifikan antara frekuensi observasi dan frekuensi yang diharapkan, yang selanjutnya memunculkan data type dan antitype.
2. Hasil pengujian analisis konfigurasi frekuensi dapat menjelaskan ada tidaknya hubungan antara prediktor dan kriteria, hubungan antar prediktor, serta ada tidaknya pengaruh prediktor dan kriteria secara bersama-sama terhadap model. Sedangkan model log-linear yang dapat menggambarkan data dengan baik, tidak dapat dijelaskan melalui analisis konfigurasi frekuensi.
jenis kelamin, lokasi dan penggunaan sabuk pengaman. Serta keempat variabel tersebut mempengaruhi model.
4. Hasil pembentukan model dengan menggunakan langkah pemodelan log-linear menghasilkan model
jkl ijk
kl jl il ik ij l k j i ijkl
Y E
) ( log
untuk menggambarkan data keterjadian luka-luka dalam kecelakaan.
5.2. Saran
ABSTRAK
ANALISIS KONFIGURASI FREKUENSI DATA KATEGORI
Oleh
Muharofah
Variabel kategori adalah variabel penelitian yang bersifat kualitatif,
sehingga untuk melakukan analisis matematika atau statistika digunakan frekuensi pada setiap kategori atau pasangan kategori. Jika beberapa variabel kategori terlibat secara bersamaan dalam suatu penelitian, maka perlu diketahui ada tidaknya hubungan atau asosiasi antar variabel. Untuk mengetahui pola asosiasi antar variabel kategori dapat digunakan suatu metode pemodelan yang dikenal dengan Analisis Model Log-Linear. Dalam penelitian ini akan dipaparkan sebuah metode lain untuk mengetahui pola asosiasi antar variabel kategori, yaitu metode Analisis Konfigurasi Frekuensi. Analisis Konfigurasi Frekuensi adalah suatu metode yang digunakan untuk mengidentifikasi pola (konfigurasi) dari variabel kategori apakah terjadi ketidakcocokan (discrepancies) dengan apa yang telah diekspektasikan sebelumnya. Ketidakcocokan ini ditandai dengan munculnya data type atau data antitype. Analisis Konfigurasi Frekuensi dapat menjelaskan ada tidaknya perbedaan antara frekuensi hasil observasi dengan frekuensi yang diharapkan, ada tidaknya interaksi antar variabel respon dan variabel prediktor, serta mengetahui apakah variabel-variabel tersebut berpengaruh terhadap model. Namun Analisis Konfigurasi Frekuensi tidak mampu menggambarkan model yang dapat menjelaskan data sebenarnya, maka penelitian ini dilanjutkan dengan
DAFTAR ISI
Halaman
DAFTAR TABEL ... i
I. PENDAHULUAN ... 1
1.1.Latar Belakang Masalah ... 1
1.2.Rumusan Masalah ... 2
1.3.Batasan Masalah ... 3
1.4.Tujuan Penelitian ... 3
1.5.Manfaat Penelitian ... 3
II. LANDASAN TEORI ... 4
2.1.Data Kategori ... 4
2.2.Tabel Kontingensi ... 4
2.3.Distribusi Multinomial ... 5
2.4.Metode Pendugaan Maksimum (Maximum Lihelihood Estimation) ... 6
2.5.Model Log-Linear ... 7
2.6.Pengujian Chi-Square ... 12
2.7.Uji z ... 13
III. METODOLOGI PENELITIAN ... 15
3.1. Waktu dan Tempat Penelitian ... 15
3.2. Metode Penelitian... 15
3.3. Analisis Konfigurasi Frekuensi ... 16
3.3.1. Pemilihan model dasar dan pendugaan frekuensi harapan dari suatu sel. ... 18
3.3.2. Pemilihan suatu konsep penyimpangan dari suatu model. ... 22
3.3.3. Pemilihan pengujian untuk melihat signifikansi. ... 23
3.3.4. Penjabaran hasil pengujian signifikansi dan pengidentifikasian apakah konfigurasi masuk ke dalam type atau antitype. ... 23
3.3.5. Penginterpretasian type dan antitype. ... 24
IV. PEMBAHASAN ... 25
4.1. Pendahuluan ... 25
4.2. Langkah-Langkah Analisis Konfigurasi Frekuensi ... 26
4.2.1. Pemilihan model dasar untuk Analisis Konfigurasi Frekuensi dan pendugaan frekuensi harapan dari suatu sel. ... 27
4.2.5. Penginterpretasian type dan antitype. ... 38
4.3. Pembentukan Model Log-linear ... 39
V. PENUTUP ... 46
5.1. Kesimpulan ... 46
5.2. Saran ... 47 DAFTAR PUSTAKA
Tabel Halaman 1. Data frekuensi terjadinya korban luka-luka dalam kecelakaan berdasarkan
jenis kelamin, lokasi, dan penggunaan sabuk pengaman. ... 26
2. Hasil Analisis Konfigurasi Frekuensi untuk model interaksi ... 36
3. Hasil Analisis Konfigurasi Frekuensi untuk model independen ... 37
4. Hasil Analisis Konfigurasi Frekuensi untuk model konstan ... 38
5. Hasil analisis model log-linear untuk model jenuh ijkl jkl ikl ijl ijk kl jl jk il ik ij l k j i ijkl Y E ) ( log ... 40
6. Hasil analisis model log-linear untuk model jkl ikl ijl ijk kl jl jk il ik ij l k j i ijkl Y E ) ( log ... 41
7. Hasil analisis model log-linear untuk model jkl ijl ijk kl jl jk il ik ij l k j i ijkl Y E ) ( log ... 42
8. Hasil analisis model log-linear untuk model jkl ijk kl jl jk il ik ij l k j i ijkl Y E ) ( log ... 43
DAFTAR PUSTAKA
Agresti, A. 1990. Categorical Data Analysis. John Wiley and Son. New york. Agung, I.G.N. 2004. Statistika Penerapan Metode Analisis untuk Tabulasi
Sempurna dan Tak Sempurna dengan SPSS. Grafindo Persada, Jakarta.
Hoog, R.V and Craig, A.T. 1995. Introduction to Mathematical Statistics. Fifth Edition. Prentice-hall, New Jersey.
Jeansonne, A. Log-linear Models. www.google.com. Diakses tanggal 14 Desember 2009.
Pontoh, R.S. 2008. Configural Frekuency Analysis untuk Melihat Karakteristik Calon Investor Saham Retail PT Bursa Efek Jakarta. Laporan Penelitian Mandiri. Jurusan Statistika FMIPA Universitas Padjadjaran, Bandung. Sanders and Smidt. 2000. A First Course Statistics. Sixth Edition. McGraw-Hill
Companies. USA.
Suwondo, A. 2005. Analisis Log Linier Pada Study Kasus Penyakit Anak. Skripsi. Jurusan Matematika FMIPA Universitas Lampung, Bandar Lampung. Von Eye, A. 2002. Configural Frequency Analysis Methods, Models, and
Applications. Psychology Press.
Wallpole, R. E. 1995. Pengantar Statistika. Edisi ke-3. Gramedia Pustaka, Jakarta.
Watson, C.J.,et.al. 1993. Statistics for Management and Economics. Fifth Edition. Allyn and Bacon, USA.
ANALISIS KONFIGURASI FREKUENSI DATA KATEGORI
(Skripsi)
Oleh
M
UHAROFAH
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS LAMPUNG
ANALISIS KONFIGURASI FREKUENSI DATA KATEGORI
Oleh
Muha-rofah
Skripsi
Sebagai Salah Satu Syarat untuk Memperoleh Gelar SARJANA SAINS
pada
Jurusan Matematika
Fakultas Matematika dan Ilmu Pengatahuan Alam
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS LAMPUNG
Judul Skripsi : ANALISIS KONFIGURASI FREKUENSI DATA KATEGORI
Nama Mahasiswa :
Muharofah
No. Pokok