ANALISIS REGRESI LOGISTIK UNTUK MENGETAHUI FAKTOR – FAKTOR YANG MEMPENGARUHI FREKUENSI KEDATANGAN PELANGGAN DI PUSAT
PERBELANJAAN “X”
Erna Hayati
Fakultas Ekonomi Universitas Islam Lamongan
ABSTRAKSI
Kepuasan pelanggan adalah salah satu kunci keberhasilan suatu usaha. Demikian juga pada pusat perbelanjaan, kepuasan pelanggan adalah satu hal yang selalu diutamakan. Ada berbagai faktor yang mempengaruhi frekuensi kedatangan pelanggan di suatu pusat pebelanjaan, beberapa diantaranya adalah kenyamanan area berbelanja, kelengkapan fasilitas dan harga produk. Untuk mengukur frekuensi kedatangan pelanggan di pusat perbelanjaan, maka digunakan skala sering (1) dan jarang (0). Untuk mengetahui apakah ada pengaruh variabel kenyamanan area berbelanja, kelengkapan fasilitas dan harga produk terhadap frekuensi kedatangan pelanggan di pusat perbelanjaan “X”, dimana variabel frekuensi kedatangan pelanggan berupa data kategori yang terdiri dari 2 kategori (biner), maka metode statistika yang digunakan adalah analisis regresi logistik biner. Setelah dilakukan analisis regresi logistik biner, diperoleh kesimpulan bahwa hanya variabel kenyamanan area berbelanja dan kelengkapan fasilitas yang berpengaruh signifikan terhadap frekuensi kedatangan pelanggan, sedangkan harga produk tidak berpengaruh signifikan. Sehingga model logit yang diperoleh adalah sebagai berikut:
)
(
ˆ x
g
= -28,068 + 1,475 * Nyaman + 2,652 *FasilitasKata kunci : biner, regresi logistik biner, model logit
PENDAHULUAN 1.1 Latar Belakang
Pelanggan merupakan salah satu factor penentu kesuksesan suatu pusat perbelanjaan. Persepsi pelanggan terhadap pusat perbelanjaan yang mereka datangi menentukan seberapa besar frekuensi kedatangan mereka di pusat perbelanjaan tersebut. Oleh karena itu pelanggan harus dibuat senyaman mungkin ketika melakukan aktifitas belanja di pusat perbelanjaan tersebut, agar persepsi pelanggan terhadap pusat perbelanjaan tersebut baik, sehingga frekuensi kedatangan mereka ke pusat perbelanjaan tersebut semakin meningkat.
Dengan demikian pihak pusat perbelanjaan tersebut harus mampu memahami apa saja yang menjadi keinginan pelanggan sehingga membuat mereka merasa nyaman melakukan aktifitas belanja di pusat perbelanjaan tersebut dan akhirnya nanti membuat pelanggan selalu ingin kembali berbelanja di pusat perbelanjaan tersebut. Salah satu cara untuk mengetahui apa yang diinginkan dan diharapkan oleh pelanggan adalah dengan mengetahui faktor-faktor yang mempengaruhi frekuensi kedatangan pelanggan di suatu pusat perbelanjaan.
1.2
1.3 Permasalahan
Pelanggan merupakan factor penentu keberhasilan dari pusat perbelanjaan. Oleh karena itu pihak pengelola pusat perbelanjaan harus mampu megetahui apa yang menjadi keinginan dari pelanggan sehingga membuat pelanggan selalu ingin kembali mengunjungi pusat perbelanjaan tersebut. Permasalahan yang diangkat dalam penetitian ini adalah faktor-faktor yang mempengaruhi frekuensi kedatangan pelanggan di pusat perbelanjaan „X‟.
1.4 Tujuan Penelitian
Tujuan dari penelitian ini adalah untuk mengetahui faktor-faktor yang secara signifikan mempengaruhi frekuensi kedatangan pelanggan di pusat perbelanjaan „X‟.
1.5 Manfa‟at Penelitian
Dari penelitian ini diharapkan dapat memberikan informasi kepada pusat perbelanjaan „X‟ mengenai faktor-faktor mempengaruhi frekuensi kedatangan pelanggan sehingga bisa dijadikan bahan referensi untuk pihak pengelola pusat perbelanjaan „X‟ untuk lebih meningkatkan kembali pelayanannya terhadap pelanggan.
Obyek penelitian yang digunakan adalah pelanggan yang datang di pusat perbelanjaan „X‟.
TINJAUAN PUSTAKA
2.1 Pengantar umum model Regresi Logistik.
Regresi Logistik adalah suatu analisis regresi yang digunakan untuk menggambarkan hubungan antara variabel respon (outcome atau dependent) dengan sekumpulan variabel prediktor (explanatory
atau independent), dimana variabel respon
bersifat biner atau dikotomus. Variabel dikotomus adalah variabel yang hanya mempunyai dua kemungkinan nilai, misalnya sukses dan gagal. Sedangkan variabel prediktor sering disebut juga dengan covariate.
Untuk memudahkan, maka variabel respon diberi notasi Y dan variabel prediktor dinotasikan dengan X. Apabila Y menghasilkan dua kategori, misalnya “1” jika berhasil dan “0” jika gagal, maka variabel Y tersebut mengikuti distribusi Bernoulli, dengan fungsi probabilitasnya adalah :
f(yi) = piyi (1 – pi)1-yi , yi = 0,1 ...(2.1)
jika yi = 0 maka f(yi) = 1 - pi dan jika yi = 1 maka f(yi) = pi
Distribusi dari variabel respon ini merupakan pembeda antara regresi logistik dengan regresi linier. Pada regresi linier variabel responnya diasumsikan berdistribusi normal sedangkan untuk variabel respon pada regresi logistik bersifat dikotomus. Dan fungsi Logistik tersebut adalah sebagai berikut :
f(x) = X
e
1
1
...(2.2)dimana nilai x berkisar antara -∞ sampai +∞. Jika x = -∞, maka
lim
(
)
0
f
x
x
Jika x = +∞, maka
lim
(
)
1
f
x
x
Dengan melihat kemungkinan nilai f(x) yang berkisar antara 0 dan 1 ini, menunjukkan bahwa regresi logistik sebenarnya menggambarkan probabilitas terjadinya suatu kejadian. Kurva fungsi logistik dapat dilihat pada gambar 2.1 1 /2 - ∞ 0 ∞ x
Gambar 2.1 Gambar fungsi Logistik
Kurva tersebut bentuknya mirip dengan huruf S. Nilai x dalam hal ini bisa dianggap sebagai kombinasi dari berbagai penyebab timbulnya suatu kejadian, dimana efek x dapat minimal dengan rendahnya nilai x sampai batas tertentu, dan kemudian pengaruhnya akan meningkat dengan cepat dan probabilitasnya akan tetap tinggi mendekati 1.
Untuk mempermudah notasi maka digunakan nilai π(x) = E(Y|X) untuk menyatakan rata-rata bersyarat dari Y jika
diberikan nilai x. Bentuk model regresi logistik adalah :
)
(
exp
1
)
(
exp
)
(
1 1x
x
x
o o
...(2.3)Untuk mempermudah menaksir parameter regresinya, maka π(x) pada persamaan (2.3) ditransformasi dengan menggunakan transformasi logit. Uraian tentang transformasi logit adalah sebagai berikut :
)
(
exp
1
)
(
exp
)
(
1 1x
x
x
o o
(
x
)
1
exp
(
o
1x
)
=
exp
(
o
1x
)
(
x
)
(
x
)
exp(
o
1x
)
=
exp
(
o
1x
)
(x
)
=
exp
(
o
1x
)
(
x
)
exp(
o
1x
)
(x
)
=
1
(
x
)
exp(
o
1x
)
)
(
1
)
(
x
x
=exp(
o
1x
)
(
)
1
)
(
ln
x
x
=ln
exp
(
o
1x
)
g (x) =
o
1x
...(2.4) g(x) disebut dengan bentuk logit.Pada model regresi linier diasumsikan bahwa pengamatan pada variabel respon dinyatakan sebagai Y = E(Y|X) + e, dimana e adalah error yang mengikuti distribusi normal dengan mean sama dengan nol dan varians konstan. Sedangkan pada regresi logistik, pola distribusi bersyarat variabel responnya
adalah Y = π(x) + e, yang memiliki dua macam nilai error yaitu :
Untuk y = 1 maka e = 1 - π(x), dengan peluang π(x)
Untuk y = 0 maka e = - π(x), dengan peluang 1 - π(x)
Untuk lebih jelasnya dapat dilihat pada tabel 2.1
Tabel 2.1 Nilai Error untuk respon Biner
Y Error P(e(x)) = y
1 1 – π (x) π (x)
0 π (x) 1 – π (x),
Sehingga distribusi errornya mempunyai mean sama dengan nol dan varians
(
x
)
(
1
(
x
)
, yang mengikuti distribusi binomial.Model regresi logistik pada persamaan (2.3) adalah model univariate karena banyaknya variabel prediktor hanya satu. Pada regresi logistik ini dapat juga
disusun suatu model yang terdiri dari banyak variabel prediktor dengan skala pengukuran data yang berbeda. Model dengan banyak variabel prediktor ini disebut dengan model regresi logistik multiple. Model regresi logistik multiple dengan k variabel prediktor adalah :
)
(
exp
1
)
(
exp
)
(
1 1 1 1 k k o k k ox
x
x
x
x
...(2.5) dimana k adalah banyaknya variabelprediktor.
Apabila model pada persamaan (2.5) ditransformasikan dengan transformasi logit,
maka dengan cara transformasi logit pada model univariate, dan didapatkan bentuk logit :
g(x) = β0 + β1x1 + ... + βkxk ...(2.6) 2.2 Estimasi Parameter
Dalam regresi linier, metode yang sering digunakan untuk menaksir parameter yang belum diketahui adalah dengan metode
Least Square. Dengan metode ini dapat
ditentukan nilai β0 dan β1 yang meminimumkan jumlah kuadrat deviasi (error) nilai observasi Y dari nilai dugaannya. Tetapi cara least square ini tidak dapat diterapkan pada model dengan variabel respon yang dikotomus. Nilai taksiran parameternya akan berbeda dengan nilai taksiran yang didapat dari regresi linier .
Penaksiran parameter pada regresi logistik mengunakan cara lain, yaitu
Maximum Likelihood. Metode ini merupakan dasar pendekatan dalam menaksir parameter pada model regresi logistik. Pada dasarnya metode maximum likelihood memberikan nilai taksiran parameter dengan memaksimalkan fungsi
likelihood .
Jika Y dikodekan 0 dan 1, maka
π(x) pada persamaan (2.3) menyatakan
probabilitas bersyarat untuk Y sama dengan 1 jika diberikan nilai x. Hal ini dapat dinyatakan sebagai P(Y=1|x). Demikian juga untuk 1-π(x) menyatakan probabilitas bersyarat untuk Y sama dengan nol jika diberikan nilai x, yaitu P(Y=0|x). Sehingga untuk pasangan (xi,yi) dimana y1=1
kontribusi pada fungsi likelihoodnya adalah π(xi) dan untuk yi=0 kontribusi pada fungsi likelihoodnya adalah 1-π(xi), dimana π(xi)
menyatakan nilai π(x) yang dihitung pada xi . kontribusi pada fungsi likelihood untuk (xi,yi) adalah : ζ(xi) = i yi i y i
x
x
)
[
1
(
)]
1(
...(2.7) Misalkan ada variabel responsebanyak N yang berdistribusi Bernoulli dan saling independent. Kemudian ada juga xi = (xi0, xi1, ... , xik ) yang menyatakan nilai ke-i
untuk sejumlah k variabel prediktor dan i = 1, 2, .... , I, dimana xi0 = 1 maka model regresi logistiknya adalah :
k j ij j k j ij j ix
x
x
0 0)
exp(
1
)
exp(
)
(
...(2.8) 2.3 Pengujian Estimasi ParameterSetelah menaksir parameter maka langkah selanjutnya yang dilakukan terhadap model adalah menguji signifikansi dari variabel yang ada dalam model. Untuk itu digunakan uji dan hipotesis statistik untuk menentukan apakah variabel prediktor dalam model signifikan atau berpengaruh secara nyata terhadap variabel respon. Pengujian signifikansi parameter dilakukan sebagai berikut :
1. Uji parsial
Dalam uji parsial ini, pengujian dilakukan dengan menguji setiap βi secara individual. Hasil pengujian secara individual akan menunjukkan apakah suatu variabel prediktor layak untuk masuk dalam model atau tidak. Hipotesis :
Ho : βi = 0 i = 1, 2, 3, ..., k H1 : βi ≠ 0
Statistik uji yang digunakan adalah Uji Wald, yaitu :
Wi =
)
(
i iSE
...(2.9) Statistik uji Wald ini mengikutidistribusi normal, sehingga untuk memperoleh keputusan pengujian dibandingkan dengan distribusi normal (Z). Kriteria penolakan (tolak Ho) jika nilai W lebih besar dari
2
Z
.
2. Uji serentak
Uji serentak disebut juga dengan uji Model Chi-Square yaitu digunakan untuk menguji parameter
hasil dugaan secara bersama-sama atau dengan kata lain untuk memeriksa keberartian koefisien β secara keseluruhan atau serentak. Dan hipotesa pengujiannya adalah : Ho : βo = β1 = ... = βk
H1 : Paling sedikit ada satu βk yang tidak sama dengan nol.
Adapun statistik uji yang dilakukan adalah statistik uji G atau Likelihood
Ratio Test, yaitu
: G = -2 Ln
n i y i y i n o n i in
n
n
n
1 ) 1 ( 1ˆ
1
ˆ
2 1
...(2.10) Dimana : no =
I i I i i iy
n
y
1 1);
1
(
dan n = no + n1Statistik uji G ini mengikuti distribusi Chi-Square (χ2 ) dengan derajat bebas v (banyaknya parameter dalam model), karena itu untuk memperoleh keputusan pengujian nilai G ini dibandingkan dengan nilai χ2
α, v .
kriteria penolakan (tolak Ho) jika nilai G lebih besar dari χ2
α, v.
2.4 Interpretasi Koefisien Parameter Interpretasi koefisien parameter dari suatu model adalah inferensi dan pengambilan kesimpulan berdasarkan pada
koefisien parameter. Koefisien menggambarkan slope atau perubahan pada variabel respon perunit untuk setiap perubahan variabel prediktor. Interpretasi koefisien parameter ini menyangkut dua hal, yaitu :
1. Perkiraan mengenai hubungan fungsional antara variabel respon dengan variabel prediktor.
2. Menentukan pengaruh dari setiap unit perubahan variabel prediktor terhadap variabel respon.
- Variabel Prediktor yang dikotomus. Variabel prediktor x dikategorikan kedalam dua kategori yang dinyatakan dengan kode 0 dan 1. dalam hal ini kategori pertama dibandingkan terhadap kategori kedua berdasarkan nilai Odds ratio (ψ) yang menyatakan kategori pertama berpengaruh ψ kali dari kategori kedua terhadap variabel respon. Karena itu ada dua nilai π(x) dan dua nilai 1- π(x). Nilai-nilai ini dapat dinyatakan pada tabel 2.2 berikut ini.
Tabel 2.2 Nilai-nilai dalam model regresi logistik dengan variabel predikor yang dikotomus.
X = 1 X = 0 Y = 1 1 1
1
)
1
(
o oe
e
o oe
e
1
)
0
(
Y = 0 11
1
)
1
(
1
oe
1
e
o1
)
0
(
1
Odds ratio didefinisikan sebagai :Ψ =
)
0
(
1
/
)
0
(
)
1
(
1
/
)
1
(
...(2.11) =
1
(
1
)
)
0
(
)
0
(
1
)
1
(
...(2.12) = 0 1 0 e
e
...(2.13) =e
1 ...(2.14)Log odds ratio adalah : Ln ψ = ln
)
0
(
1
/
)
0
(
)
1
(
1
/
)
1
(
...(2.15) = ln [π(x)/1-π(x)] – ln [π(x)/1-π(x)] = g(1)-g(0) ...(2.16) yang disebut perbedaan logit.Sehingga Odds ratio untuk model regresi logistik adalah : Ψ =
e
1Dengan log odds rationya adalah :
ln (ψ) = ln (eβ 1) = β1 METODOLOGI PENELITIAN
3.1 Sumber Data
Data yang digunakan dalam penelitian ini merupakan data primer yang diperoleh dari hasil survey pelanggan di pusat perbelanjaan „X‟. Jumlah responden yang digunakan sebanyak 50 orang responden.
3.2 Identifikasi Variabel
Variabel-variabel yang digunakan dalam penelitian ini adalah:
1. Variabel Respon (Y) adalah frekuensi kedatangan pelanggan di
pusat perbelanjaan „X‟ dengan kategori:
1 = sering 0 = jarang
2. Variabel-variabel yang diduga mempengaruhi frekuensi kedatangan pelanggan di pusat perbelanjaan „X‟ yaitu:
a) Kenyamanan area berbelanja (X1)
b) Kelengkapan fasilitas (X2) c) Harga produk (X3) 3.3 Langkah-langkah Penelitian
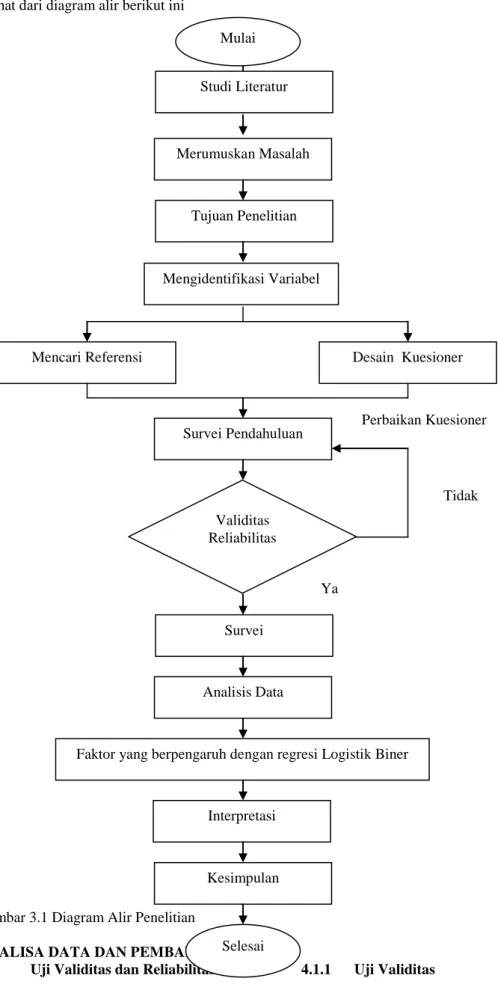
Langkah-langkah penelitian dapat dilihat dari diagram alir berikut ini
Gambar 3.1 Diagram Alir Penelitian ANALISA DATA DAN PEMBAHASAN
4.1 Uji Validitas dan Reliabilitas 4.1.1 Uji Validitas Mulai
Studi Literatur
Merumuskan Masalah
Tujuan Penelitian
Mengidentifikasi Variabel
Mencari Referensi Desain Kuesioner
Survei Pendahuluan
Validitas Reliabilitas
Survei
Analisis Data
Faktor yang berpengaruh dengan regresi Logistik Biner
Interpretasi Kesimpulan Selesai Perbaikan Kuesioner Tidak Ya
Uji validitas ini hanya dilakukan pada variabel-variabel yang dianggap mempengaruhi frekuensi kedatangan
pelanggan di pusat perbelanjaan „X‟. Dengan demikian hasil uji validitas tersaji dalam Tabel 4.1.
Tabel 4.1 Nilai total koreksi korelasi
Variabel Total koreksi korelasi
Kenyamanan Area Berbelanja Kelengkapan Fasilitas Harga 0,466 0,559 0,300
Hipotesis yang digunakan untuk masing-masing pertanyaan adalah :
Ho : Pertanyaan tidak mengukur aspek yang sama
H1 : pertanyaan mengukur aspek yang sama
Jika dibandingkan maka angka-angka total koreksi korelasi yang diperoleh dengan angka kritik pada tabel korelasi r (produk
moment) dengan α = 0,05 dan n = 50 dengan
derajat bebas sebesar 50 – 2 = 48, diperoleh angka kritik sebesar 0,284. Karena total koreksi korelasi yang diperoleh dari masing-masing pertanyaan yang terdapat dalam Tabel 4.1 berada diatas nilai kritik dengan taraf 5% maka semua pertanyaan tersebut mengukur aspek yang sama dan dapat digunakan untuk mencari pola hubungan selanjutnya.
4.1.2 Uji Reliabilitas
Untuk menguji apakah pertanyaan-pertanyaan tersebut konsisten, maka dilakukan pengujian reliabilitas. Dengan hipotesis sebagai berikut :
Ho : Hasil pengukuran tidak konsisten
H1 : Hasil pengukuran konsisten Berdasarkan output pada reliabiliti analisis pada Lampiran maka diperoleh nilai alpha sebesar 0,627. Ternyata nilai alpha yang diperoleh berada diatas nilai kritik (0,6), sehingga dapat dikatakan skala pengukur yang disusun adalah reliabel dan hasil pengukuran masing-masing pertanyaan konsisten.
4.2 Faktor-faktor yang Berpengaruh Terhadap Frekuensi Kedatangan Pelanggan di Pusat Perbelanjaan „X‟.
Untuk mengetahui faktor-faktor yang berpengaruh terhadap frekuensi kedatangan pelanggan di pusat perbelanjaan „X‟, maka dilakukan analisis regresi logistik baik secara univariate maupun multiple.
Analisis regresi logistik univariate (individu) digunakan untuk mengetahui pengaruh dari masing-masing variabel prediktor terhadap frekuensi kedatangan secara individu. Caranya adalah dengan membuat regresi logistik untuk masing-masing variabel prediktor terhadap frekuensi kedatangan. Hasil dari analisis regresi logistik univariate terhadap frekuensi kedatangan pelanggan adalah sebagai berikut :
a. Pengaruh Kenyamanan Area Berbelanja terhadap Frekuensi Kedatangan Pelanggan
Untuk mengetahui apakah variabel kenyamanan area berbelanja berpengaruh terhadap frekuensi kedatangan pelanggan, maka dilakukan uji parsial dengan hipotesis :
Ho : β = 0, artinya kenyamanan area berbelanja tidak berpengaruh terhadap frekuensi kedatangan pelanggan
H1 : β ≠ 0, artinya kenyamanan area berbelanja berpengaruh terhadap frekuensi kedatangan pelanggan
Hasil dari analisis regresi logistik antara variabel kenyamanan area berbelanja itu sendiri dengan frekuensi kedatangan pelanggan dapat dilihat pada Tabel 4.2 .
Tabel 4.2 Hasil regresi logistik antara variabel kenyamanan area berbelanja itu sendiri dengan frekuensi kedatangan pelanggan
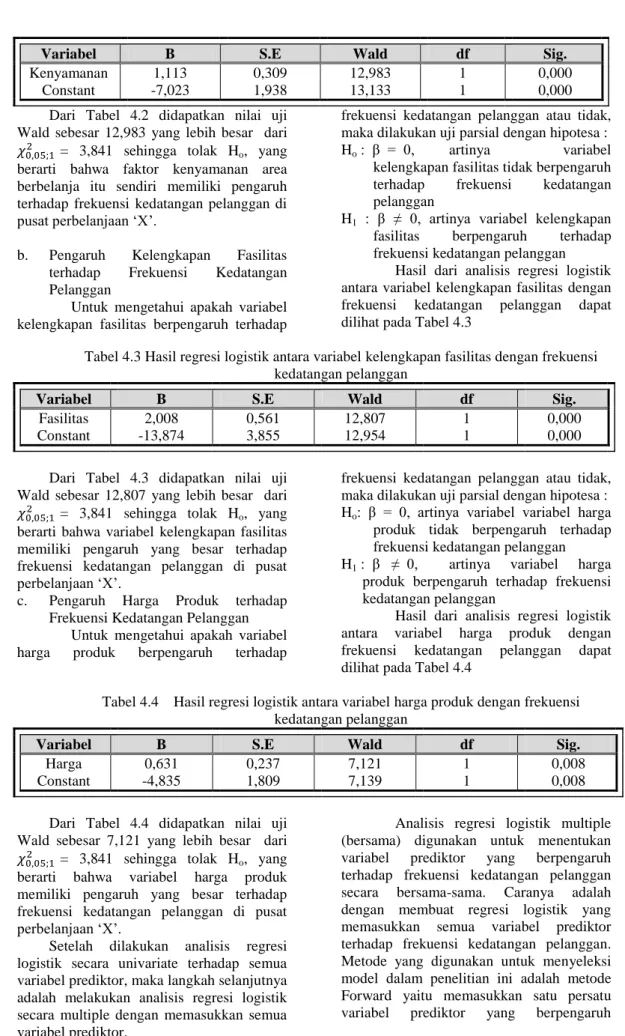
Variabel B S.E Wald df Sig. Kenyamanan Constant 1,113 -7,023 0,309 1,938 12,983 13,133 1 1 0,000 0,000 Dari Tabel 4.2 didapatkan nilai uji
Wald sebesar 12,983 yang lebih besar dari
= 3,841 sehingga tolak Ho, yang berarti bahwa faktor kenyamanan area berbelanja itu sendiri memiliki pengaruh terhadap frekuensi kedatangan pelanggan di pusat perbelanjaan „X‟.
b. Pengaruh Kelengkapan Fasilitas terhadap Frekuensi Kedatangan Pelanggan
Untuk mengetahui apakah variabel kelengkapan fasilitas berpengaruh terhadap
frekuensi kedatangan pelanggan atau tidak, maka dilakukan uji parsial dengan hipotesa : Ho : β = 0, artinya variabel
kelengkapan fasilitas tidak berpengaruh terhadap frekuensi kedatangan pelanggan
H1 : β ≠ 0, artinya variabel kelengkapan fasilitas berpengaruh terhadap frekuensi kedatangan pelanggan
Hasil dari analisis regresi logistik antara variabel kelengkapan fasilitas dengan frekuensi kedatangan pelanggan dapat dilihat pada Tabel 4.3
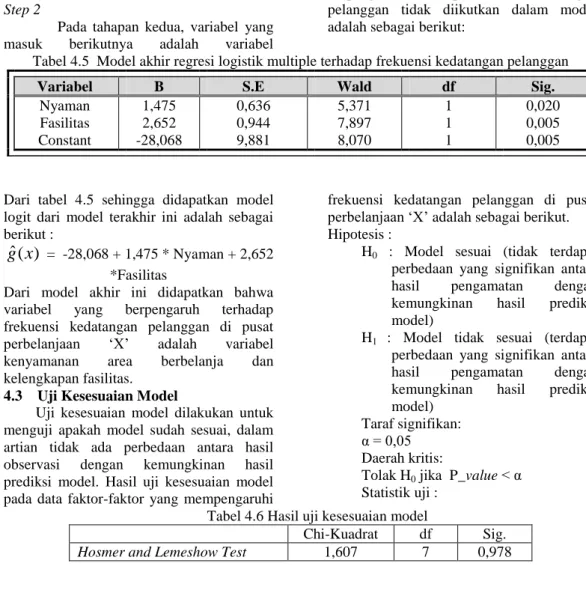
Tabel 4.3 Hasil regresi logistik antara variabel kelengkapan fasilitas dengan frekuensi kedatangan pelanggan
Variabel B S.E Wald df Sig.
Fasilitas Constant 2,008 -13,874 0,561 3,855 12,807 12,954 1 1 0,000 0,000
Dari Tabel 4.3 didapatkan nilai uji Wald sebesar 12,807 yang lebih besar dari
= 3,841 sehingga tolak Ho, yang berarti bahwa variabel kelengkapan fasilitas memiliki pengaruh yang besar terhadap frekuensi kedatangan pelanggan di pusat perbelanjaan „X‟.
c. Pengaruh Harga Produk terhadap Frekuensi Kedatangan Pelanggan
Untuk mengetahui apakah variabel harga produk berpengaruh terhadap
frekuensi kedatangan pelanggan atau tidak, maka dilakukan uji parsial dengan hipotesa : Ho: β = 0, artinya variabel variabel harga
produk tidak berpengaruh terhadap frekuensi kedatangan pelanggan H1 : β ≠ 0, artinya variabel harga
produk berpengaruh terhadap frekuensi kedatangan pelanggan
Hasil dari analisis regresi logistik antara variabel harga produk dengan frekuensi kedatangan pelanggan dapat dilihat pada Tabel 4.4
Tabel 4.4 Hasil regresi logistik antara variabel harga produk dengan frekuensi kedatangan pelanggan
Variabel B S.E Wald df Sig.
Harga Constant 0,631 -4,835 0,237 1,809 7,121 7,139 1 1 0,008 0,008 Dari Tabel 4.4 didapatkan nilai uji
Wald sebesar 7,121 yang lebih besar dari
= 3,841 sehingga tolak Ho, yang berarti bahwa variabel harga produk memiliki pengaruh yang besar terhadap frekuensi kedatangan pelanggan di pusat perbelanjaan „X‟.
Setelah dilakukan analisis regresi logistik secara univariate terhadap semua variabel prediktor, maka langkah selanjutnya adalah melakukan analisis regresi logistik secara multiple dengan memasukkan semua variabel prediktor.
Analisis regresi logistik multiple (bersama) digunakan untuk menentukan variabel prediktor yang berpengaruh terhadap frekuensi kedatangan pelanggan secara bersama-sama. Caranya adalah dengan membuat regresi logistik yang memasukkan semua variabel prediktor terhadap frekuensi kedatangan pelanggan. Metode yang digunakan untuk menyeleksi model dalam penelitian ini adalah metode Forward yaitu memasukkan satu persatu variabel prediktor yang berpengaruh
(signifikan) terhadap frekuensi kedatangan pelanggan.
Langkah-langkah pembentukan model dengan menggunakan metode Forward adalah sebagai berikut:
Step 1
Pada tahapan pertama ini, variabel predictor yang masuk terlebih dahulu adalah variabel kelengkapan fasilitas. Hal ini bisa dilihat dari nilai score kelengkapan fasilitas yang paling besar dibandingkan dua variabel yang lain yaitu sebesar 27,438. Ketika di uji secara parsial, nilai Wald dari variabel kelengkapan fasilitas sebesar 12,807, dimana nilai ini lebih besar daripada nilai
= 3,841, sehingga tolak H0 yang
artinya bahwa variabel kelengkapan fasilitas berpengaruh terhadap frekuensi kedatangan pelanggan.
Step 2
Pada tahapan kedua, variabel yang masuk berikutnya adalah variabel
kenyamanan area berbelanja, karena nilai score dari variabel kenyamanan area berbelanja sebesar 8,791 lebih besar daripada nilai score dari variabel harga produk yang hanya sebesar 2,507. Jika di uji secara parsial, maka variabel kenyamanan area berbelanja ini memiliki nilai Wald sebesar 5,371, dimana nilai ini lebih besar daripada nilai = 3,841, sehingga tolak
H0 yang artinya bahwa variabel kenyamanan area berbelanja berpengaruh terhadap frekuensi kedatangan pelanggan. Untuk variabel harga produk tidak dimasukkan di dalam model, karena nilai score yang kecil dan tidak signifikan berpengaruh terhadap frekuensi kedatangan pelanggan.
Dan model terakhir yang didapatkan setelah variabel yang tidak berpengaruh terhadap frekuensi kedatangan pelanggan tidak diikutkan dalam model adalah sebagai berikut:
Tabel 4.5 Model akhir regresi logistik multiple terhadap frekuensi kedatangan pelanggan
Variabel B S.E Wald df Sig.
Nyaman Fasilitas Constant 1,475 2,652 -28,068 0,636 0,944 9,881 5,371 7,897 8,070 1 1 1 0,020 0,005 0,005
Dari tabel 4.5 sehingga didapatkan model logit dari model terakhir ini adalah sebagai berikut :
)
(
ˆ x
g
= -28,068 + 1,475 * Nyaman + 2,652 *FasilitasDari model akhir ini didapatkan bahwa variabel yang berpengaruh terhadap frekuensi kedatangan pelanggan di pusat perbelanjaan „X‟ adalah variabel kenyamanan area berbelanja dan kelengkapan fasilitas.
4.3 Uji Kesesuaian Model
Uji kesesuaian model dilakukan untuk menguji apakah model sudah sesuai, dalam artian tidak ada perbedaan antara hasil observasi dengan kemungkinan hasil prediksi model. Hasil uji kesesuaian model pada data faktor-faktor yang mempengaruhi
frekuensi kedatangan pelanggan di pusat perbelanjaan „X‟ adalah sebagai berikut. Hipotesis :
H0 : Model sesuai (tidak terdapat perbedaan yang signifikan antara hasil pengamatan dengan kemungkinan hasil prediksi model)
H1 : Model tidak sesuai (terdapat perbedaan yang signifikan antara hasil pengamatan dengan kemungkinan hasil prediksi model)
Taraf signifikan: α = 0,05 Daerah kritis:
Tolak H0 jika P_value < α Statistik uji :
Tabel 4.6 Hasil uji kesesuaian model
Chi-Kuadrat df Sig.
Hosmer and Lemeshow Test 1,607 7 0,978
Tabel 4.6 menunjukkan bahwa dengan derajat bebas sebesar 7, didapatkan nilai chi-kuadrat untuk uji kesesuaian model sebesar
1,607. Dengan P-value sebesar 0,978 dapat diambil keputusan gagal tolak H0 karena 0,978 > α (0,05) sehingga dapat ditarik
kesimpulan bahwa model sesuai. Hal itu berarti tidak terdapat perbedaan yang signifikan antara hasil pengamatan dengan kemungkinan hasil prediksi model.
4.4 Ketepatan Klasifikasi Model Dari hasil regresi multiple terdapat tabel klasifikasi untuk frekuensi kedatangan
pelanggan. Tabel ini menggambarkan seberapa tepat model yang diperoleh dapat memprediksi variabel respon (frekuensi kedatangan pelanggan) dan dapat pula dilihat pada Tabel 4.7.
Tabel 4.7 Tabel klasifikasi untuk frekuensi kedatangan pelanggan
Prediksi Percent correct Jarang Sering Observed Jarang 25 2 92,6% Sering 2 21 91,3% Overall 92,0%
Dari Tabel 4.7 terlihat bahwa, dari 27 responden yang jarang datang ke pusat perbelanjaan „X‟, ada 25 responden diprediksi dengan benar oleh model. Dan dari 23 responden yang sering datang ke pusat perbelanjaan „X‟, ada sebanyak 21 responden yang diprediksi dengan benar oleh model. Untuk kolom yang lain adalah kesalahan klasifikasi, sehingga secara keseluruhan ada sebesar 46 dari 50 responden dapat diprediksi dengan tepat oleh model yaitu sebesar 92%.
4.5 Interpretasi Koefisien Parameter Setelah didapatkan model terbaik maka langkah selanjutnya adalah melakukan interpretasi dari koefisien parameter. Untuk model regresi logistik dengan variabel prediktor yang berskala kategori, maka odds rasionya dinyatakan dengan
e
. Nilai odds ratio untuk masing-masing variabel prediktor pada model akhir dapat dilihat pada Tabel 4.8.Tabel 4. 8 Odds ratio untuk model akhir
Variabel B Exp(B) Nyaman Fasilitas 1,475 2,652 4,369 14,186
Interpretasi dari odds ratio untuk masing– masing variabel prediktor adalah :
a. Variabel kenyamanan area berbelanja Jika factor kelengkapan fasilitas adalah konstan, maka odds frekuensi pelanggan yang sering datang ke pusat perbelanjaan „X‟ akan naik sebesar 4,369 kali dari frekuensi pelanggan yang jarang datang untuk setiap kenaikan terhadap persepsi kenyamanan area berbelanja.
b. Variabel Kelengkapan Fasilitas Jika factor kenyamanan area berbelanja dianggap konstan, maka odds frekuensi pelanggan yang datang ke pusat perbelanjaan „X‟ akan naik 14,186 kali dari pelanggan yang jarang datang untuk setiap kenaikan persepsi kelengkapan fasilitas.
KESIMPULAN DAN SARAN 5.1 Kesimpulan
Berdasarkan hasil analisis data dan pembahasan diperoleh kesimpulan sebagai berikut :
1. Dari hasil analisis regresi logistik secara univariate didapatkan bahwa faktor yang berpengaruh terhadap frekuensi kedatangan pelanggan di pusat perbelanjaan „X‟ adalah variabel kenyamanan area berbelanja, kelengkapan fasilitas dan harga produk. Namun dengan menggunakan analisis regresi logistik serentak diperoleh model akhir yang hanya ada dua variabel yang berpengaruh terhadap frekuensi kedatangan pelanggan yaitu variabel variabel kenyamanan area berbelanja dan kelengkapan fasilitas.
2. Bentuk logit dari model akhir adalah :
)
(
ˆ x
g
= -28,068 + 1,475 * Nyaman + 2,652 *Fasilitas5.2 Saran
Sesuai dengan hasil analisa mengenai faktor-faktor yang berpengaruh terhadap frekuensi kedatangan pelanggan maka saran yang dapat disampaikan kepada pusat perbelanjaan‟X‟ adalah agar lebih meningkatkan lagi kenyamanan area berbelanja dan kelengkapan fasilitas, serta lebih memperhitungkan kembali harga produk-produk yang dijual agar lebih terjangkau oleh pelanggan.
DAFTAR PUSTAKA
Agresti, Alan. (1990), Categorical Data
Analysis, John Wiley and Sons, Inc,
New York.
Lenny, S. (2000), Pengaruh Waktu Temupuh
dan Luasan Terhadap Frekuensi Kunjungan Orang ke Pusat Perbelanjaan, Universitas Kristen
Petra, Surabaya.
Singgih,S. dan F.Tjiptono.(2001), Riset
Pemasaran Konsep dan Aplikasi dengan SPSS, Elex Media Komputindo, Jakarta.
LAMPIRAN
Lampiran A. Uji Validitas dan Reliabilitas Lampiran A.1 UJi Validitas
Item-Total Statistics Scale Mean if Item Deleted Scale Variance if Item Deleted Corrected Item-Total Correlation Cronbach's Alpha if Item Deleted Kenyamanan Area Berbelanja 14.06 6.017 .466 .483 Kelengkapan Fasilitas 13.42 5.881 .559 .350 Harga Produk 12.88 7.455 .300 .706
Lampiran A.2 Uji Reliabilitas
Reliability Statistics Cronbach's
Alpha N of Items
.627 3
Lampiran B Regresi Logistik Univariate
Lampiran B.1 Regresi Logistik Pengaruh Kenyamanan Area Berbelanja terhadap Frekuensi Kedatangan Pelanggan
Variables in the Equation
B S.E. Wald df Sig. Exp(B)
95% C.I.for EXP(B) Lower Upper Step 1a Nyaman 1.113 .309 12.983 1 .000 3.044 1.661 5.578
Constant -7.023 1.938 13.133 1 .000 .001 a. Variable(s) entered on step 1: Nyaman.
Lampiran B.2 Regresi Logistik Pengaruh Kelengkapan Fasilitas terhadap Frekuensi Kedatangan Pelanggan
Variables in the Equation
B S.E. Wald df Sig. Exp(B)
95% C.I.for EXP(B) Lower Upper Step 1a Fasilitas 2.008 .561 12.807 1 .000 7.448 2.480 22.366
Constant -13.874 3.855 12.954 1 .000 .000 a. Variable(s) entered on step 1: Fasilitas.
Lampiran B.3 Regresi Logistik Pengaruh Harga Produk terhadap Frekuensi Kedatangan Pelanggan
Variables in the Equation
B S.E. Wald df Sig. Exp(B)
95% C.I.for EXP(B) Lower Upper Step 1a Harga .631 .237 7.121 1 .008 1.880 1.183 2.989
Constant -4.835 1.809 7.139 1 .008 .008 a. Variable(s) entered on step 1: Harga.
Lampiran C Regresi Logistik Multiple dengan Metode Forward
Case Processing Summary
Unweighted Casesa N Percent
Selected Cases Included in Analysis 50 100.0
Missing Cases 0 .0
Total 50 100.0
Unselected Cases 0 .0
Total 50 100.0
a. If weight is in effect, see classification table for the total number of cases.
Dependent Variable Encoding Original
Value Internal Value
Jarang 0
Sering 1
Block 0: Beginning Block
Classification Tablea,b
Observed
Predicted
Jarang Sering Correct
Step 0 Frekuensi Kedatangan Jarang 27 0 100.0
Sering 23 0 .0
Overall Percentage 54.0
a. Constant is included in the model. b. The cut value is .500
Variables in the Equation
B S.E. Wald df Sig. Exp(B)
Step 0 Constant -.160 .284 .319 1 .572 .852
Variables not in the Equation
Score df Sig.
Step 0 Variables Nyaman 18.881 1 .000
Fasilitas 27.438 1 .000
Harga 8.159 1 .004
Overall Statistics 31.946 3 .000
Block 1: Method = Forward Stepwise (Wald)
Omnibus Tests of Model Coefficients
Chi-square df Sig. Step 1 Step 36.455 1 .000 Block 36.455 1 .000 Model 36.455 1 .000 Step 2 Step 10.750 1 .001 Block 47.205 2 .000 Model 47.205 2 .000 Model Summary Step -2 Log likelihood
Cox & Snell R Square
Nagelkerke R Square
1 32.539a .518 .692
2 21.789b .611 .816
a. Estimation terminated at iteration number 6 because parameter estimates changed by less than .001.
b. Estimation terminated at iteration number 8 because parameter estimates changed by less than .001.
Hosmer and Lemeshow Test
1 4.739 4 .315
2 1.607 7 .978
Contingency Table for Hosmer and Lemeshow Test Frekuensi Kedatangan = Jarang
Frekuensi Kedatangan = Sering
Total Observed Expected Observed Expected
Step 1 1 3 2.991 0 .009 3 2 8 7.831 0 .169 8 3 11 10.336 1 1.664 12 4 3 5.003 8 5.997 11 5 2 .705 5 6.295 7 6 0 .133 9 8.867 9 Step 2 1 7 6.999 0 .001 7 2 5 4.993 0 .007 5 3 5 4.970 0 .030 5 4 4 4.445 1 .555 5 5 4 3.221 1 1.779 5 6 1 1.603 4 3.397 5 7 1 .661 5 5.339 6 8 0 .102 5 4.898 5 9 0 .006 7 6.994 7 Classification Tablea Observed Predicted Frekuensi Kedatangan Percentage Correct Jarang Sering
Step 1 Frekuensi Kedatangan Jarang 22 5 81.5
Sering 1 22 95.7
Overall Percentage 88.0
Step 2 Frekuensi Kedatangan Jarang 25 2 92.6
Sering 2 21 91.3
Overall Percentage 92.0
a. The cut value is .500
Variables in the Equation
Lower Upper Step 1a Fasilitas 2.008 .561 12.807 1 .000 7.448 2.480 22.366 Constant -13.874 3.855 12.954 1 .000 .000 Step 2b Nyaman 1.475 .636 5.371 1 .020 4.369 1.255 15.206 Fasilitas 2.652 .944 7.897 1 .005 14.186 2.231 90.203 Constant -28.068 9.881 8.070 1 .005 .000
a. Variable(s) entered on step 1: Fasilitas. b. Variable(s) entered on step 2: Nyaman.
Variables not in the Equation
Score df Sig.
Step 1 Variables Nyaman 8.791 1 .003
Harga 2.507 1 .113
Overall Statistics 11.274 2 .004
Step 2 Variables Harga 3.778 1 .052
Overall Statistics 3.778 1 .052
Casewise List
Case Selected Statusa
Observed Predicted Predicted Group Temporary Variable Frekuensi
Kedatangan Resid ZResid
1 S S 1.000 S .000 .011 2 S J .008 J -.008 -.092 3 S J .000 J .000 -.012 4 S S .908 S .092 .318 5 S S .753 S .247 .572 6 S S .993 S .007 .084 7 S J .002 J -.002 -.044 8 S J .000 J .000 -.001 9 S S .694 S .306 .664 10 S J .035 J -.035 -.191 11 S S .998 S .002 .047 12 S J .001 J .000 -.024 13 S S .977 S .023 .152 14 S J .008 J -.008 -.092 15 S S .881 S .119 .368 16 S J .002 J -.002 -.044 17 S S .694 S .306 .664 18 S S .881 S .119 .368 19 S S .999 S .001 .022 20 S J .138 J -.138 -.400 21 S J .342 J -.342 -.721 22 S J .138 J -.138 -.400
23 S J .000 J .000 -.012 24 S J .001 J .000 -.024 25 S J .003 J -.003 -.051 26 S J** .881 S -.881 -2.715 27 S S .960 S .040 .204 28 S S .881 S .119 .368 29 S S .999 S .001 .022 30 S J .342 J -.342 -.721 31 S J .411 J -.411 -.836 32 S J .003 J -.003 -.051 33 S S .628 S .372 .770 34 S J .000 J .000 -.012 35 S S .991 S .009 .098 36 S J** .628 S -.628 -1.299 37 S J .002 J -.002 -.044 38 S J .000 J .000 -.006 39 S S** .342 J .658 1.387 40 S J .138 J -.138 -.400 41 S J .008 J -.008 -.092 42 S S** .106 J .894 2.900 43 S S .998 S .002 .047 44 S J .342 J -.342 -.721 45 S S .999 S .001 .022 46 S J .000 J .000 -.012 47 S S .908 S .092 .318 48 S S .999 S .001 .022 49 S S .977 S .023 .152 50 S J .000 J .000 -.003
a. S = Selected, U = Unselected cases, and ** = Misclassified cases. Lampiran D. Kuesioner
Pertanyaan 1:
Seberapa sering Bapak/Ibu/Saudara mengunjungi pusat perbelanjaan „X‟ dalam seminggu? 1. > 2 kali (sering)
2. 1 kali (jarang) Pertanyaan 2:
Berikan skor untuk setiap atribut berikut yang menunjukkan tingkat persepsi Bapak/Ibu/ Saudara terhadap pusat perbelanjaan „X‟!
Atribut Skor Kenyamanan area berbelanja Sangat Tidak Nyaman 1 2 3 4 5 6 7 8 9 10 Sangat Nyaman Kelengkapan fasilitas Sangat Tidak
Lengkap
1 2 3 4 5 6 7 8 9 10 Sangat Lengkap
Harga Produk Sangat Tidak
Terjangkau
1 2 3 4 5 6 7 8 9 10 Sangat Terjangkau Lampiran E. Data
N0. Responden Nyaman Fasilitas Harga Frekuensi Kedatangan 1 9 9 8 1 2 5 6 8 0 3 4 5 5 0 4 8 7 9 1 5 9 6 8 1 6 8 8 9 1 7 4 6 8 0 8 3 4 9 0 9 7 7 8 1 10 6 6 7 0 11 7 9 9 1 12 5 5 8 0 13 9 7 9 1 14 5 6 5 0 15 6 8 9 1 16 4 6 7 0 17 7 7 8 1 18 6 8 9 1 19 8 9 6 1 20 7 6 8 0 21 6 7 9 0 22 7 6 8 0 23 4 5 6 0 24 5 5 6 0 25 6 5 4 0 26 6 8 9 0 27 5 9 8 1 28 6 8 9 1 29 8 9 8 1 30 6 7 7 0 31 8 6 6 0 32 6 5 8 0 33 5 8 8 1 34 4 5 6 0 35 6 9 7 1 36 5 8 6 0 37 4 6 5 0 38 5 4 8 0 39 6 7 9 1 40 7 6 5 0 41 5 6 7 0 42 5 7 9 1
43 7 9 5 1 44 6 7 7 0 45 8 9 9 1 46 4 5 6 0 47 8 7 8 1 48 8 9 6 1 49 9 7 5 1 50 4 4 4 0