SEARCH ENGINE
DUA BAHASA BERBASIS KAMUS
MENGGUNAKAN SPHINX
SEARCH
WANODYA EKA PRAMESTI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
SEARCH ENGINE
DUA BAHASA BERBASIS KAMUS
MENGGUNAKAN SPHINX
SEARCH
WANODYA EKA PRAMESTI
Skripsi
sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Program Studi Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRAK
WANODYA EKA PRAMESTI. Bilingual Dictionary-based Search Engine Using Sphinx Search. Supervised by JULIO ADISANTOSO.
Cross Language Information Retrieval (CLIR) systems allow users to input the keywords in their own language and then the system will retrieve the relevant documents that written in the other language from database. This research implements a CLIR system that will retrieve relevant documents in Bahasa Indonesia and English by entering the query in Bahasa Indonesia or English. In order to translate the query, we use bilingual dictionaries. For indexing and retrieval process, we use BM25 and proximity algorithms from Sphinx. Performance of the system is determined using recall and precision with maximum interpolation. In the evaluation we conduct comparisons among Bahasa Indonesia search engine, English search engine, and Bilingual search engine. The test results show that the performance of monolingual search engine is better than bilingual search engine. The influence factors are the amount of translations, the combination of the wrong translation, and the amount of the document collections.
Judul Skripsi : Search Engine Dua Bahasa Berbasis Kamus Menggunakan Sphinx Search
Nama : Wanodya Eka Pramesti
NRP : G64076056
Disetujui:
Pembimbing
Ir. Julio Adisantoso, M.Kom. NIP 19620714 198601 1 002
Diketahui:
Ketua Departemen Ilmu Komputer
Dr. Ir. Agus Buono, M.Si., M.Kom. NIP 19660702 199302 1 001
RIWAYAT HIDUP
Penulis dilahirkan di Bogor, pada tanggal 8 Januari 1986 dan memiliki nama lengkap Wanodya Eka Pramesti. Penulis merupakan anak kedua dari tiga bersaudara, pasangan Bapak Joni Firman dan Ibu Maani Umar.
Penulis menyelesaikan pendidikan Sekolah Menengah Umum di SMU Negeri 1 Bogor pada tahun 2004. Pada tahun 2004 penulis diterima di Institut Pertanian Bogor sebagai mahasiswa Fakultas Matematika dan Ilmu Pengetahuan Alam, Departemen Ilmu Komputer Program Studi D3 Informatika melalui jalur reguler.
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah Subhanahu Wa Taala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Shalawat dan salam semoga Allah limpahkan kepada Nabi Muhammad Salallahu Alaihi Wasalam, keluarganya, sahabatnya, serta umatnya.
Judul yang dipilih dalam penelitian yang dilaksanakan sejak Juli 2009 sampai dengan November 2009 ialah Search Engine Dua Bahasa Berbasis Kamus Menggunakan Sphinx Search.
Terima kasih penulis ucapkan kepada:
1. Kedua orang tua tercinta, kakak, dan adik penulis, atas segala doa, kasih sayang, perhatian, semangat, dan dukungannya.
2. Bapak Ir. Julio Adisantoso, M.Kom., selaku dosen pembimbing yang telah membantu memberikan bimbingan, nasehat, dan motivasi kepada penulis.
3. Imam Prasetio Utomo atas semangat yang selalu diberikan.
4. Teman-teman Ekstensi Ilkom Angkatan 2 terima kasih atas keceriaan, dukungan, dan bantuan yang selalu diberikan disaat masa-masa sulit.
5. Bapak Andi Pramurjadi dan Suci yang selalu menjadi teman bimbingan yang baik. 6. Seluruh staf pengajar dan karyawan Departemen Ilmu Komputer FMIPA IPB.
Semoga karya ilmiah ini bermanfaat.
Bogor, Juli 2012
DAFTAR ISI
Halaman
DAFTAR TABEL ... vi
DAFTAR GAMBAR ... vi
DAFTAR LAMPIRAN ... vi
PENDAHULUAN ... 1
Latar Belakang ... 1
Tujuan ... 1
Ruang Lingkup ... 1
TINJAUAN PUSTAKA ... 1
Sistem Temu-kembali Informasi ... 1
Mesin Pencari ... 1
Cross Language Information Retrieval (CLIR) ... 1
Sphinx ... 2
Pembobotan BM25 ... 2
Pengujian ... 2
METODE PENELITIAN ... 3
Dokumen ... 3
Koleksi Pengujian ... 3
Metodologi ... 3
1. Corpus ... 4
2. Indexing ... 4
3. Query ... 4
4. Proses Terjemahan ... 4
5. Database Frase ... 4
6. Kamus ... 4
7. Proses Stemming ... 4
8. Lingkungan Implementasi ... 4
HASIL DAN PEMBAHASAN ... 5
Deskripsi Dokumen ... 5
Kamus ... 5
Struktur Sphinx ... 5
Hasil Pengujian ... 6
Evaluasi Kinerja ... 6
KESIMPULAN DAN SARAN ... 7
Kesimpulan ... 7
Saran ... 8
DAFTAR PUSTAKA ... 8
DAFTAR TABEL
Halaman
1 Ilustrasi perhitungan recall precision. ... 3
2 Pasangan query dan dokumen yang relevan. ... 3
3 Hasil keluaran search engine dua bahasa berbasis kamus. ... 6
DAFTAR GAMBAR
Halaman 1 Ilustrasi CLIR. ... 22 Alur metode penelitian. ... 3
3 Grafik recall dan precision menggunakan interpolasi maksimum search engine bahasa Indonesia. ... 6
4 Grafik recall dan precision menggunakan interpolasi maksimum search engine bahasa Inggris ... 6
5 Grafik recall dan precision menggunakan interpolasi maksimum search engine dua bahasa berbasis kamus. ... 7
6 Grafik recall dan precision menggunakan interpolasi maksimum. ... 7
DAFTAR LAMPIRAN
Halaman 1 Contoh kamus yang terdapat pada Laboratorium IR ... 102 Contoh kamus yang telah mengalami pengubahan ... 11
3 Recall dan precisionquery bahasa Indonesia pada searchengine bahasa Indonesia ... 12
4 Recall dan precision dengan interpolasi maksimum searchengine bahasa Indonesia ... 13
5 Recall dan precision query bahasa Inggris pada search engine bahasa Inggris ... 14
6 Recall dan precision dengan interpolasi maksimum search engine bahasa Inggris ... 15
7 Recall dan precision pada search engine dua bahasa berbasis kamus ... 16
1
PENDAHULUAN
Latar Belakang
Teknologi yang semakin canggih di bidang komputasi dan telekomunikasi pada masa kini, membuat informasi dapat dengan mudah didapatkan oleh banyak orang (Mandala & Setiawan 2002). Saat ini pengguna tidak hanya mencari informasi pada satu bahasa tertentu, tetapi beragam bahasa agar informasi yang didapat bisa lebih akurat dan relevan.
Pencarian dan pemilihan atau penemuan kembali informasi tidak mungkin dilakukan secara manual karena kumpulan informasi yang sangat besar. Diperlukan suatu sistem otomatis yang dapat membantu pengguna untuk mendapatkan informasi yang relevan dengan kebutuhan pengguna tanpa terhalang faktor bahasa. Sistem berbasis Cross Language Information Retrieval (CLIR) adalah sistem Information Retrieval yang mengizinkan pengguna memasukkan query
dalam bahasanya dan sistem akan menemukembalikan dokumen yang relevan dalam bahasa yang berbeda.
Penelitian di bidang CLIR telah dilakukan oleh Firdestawati (2008), yang membuat suatu sistem menerjemahkan query bahasa Indonesia menjadi bahasa Inggris dan mengembalikan dokumen bahasa Inggris yang relevan dengan query. Pada kenyataannya dokumen dalam koleksi tidak hanya monolingual (bahasa Indonesia atau bahasa Inggris), melainkan campuran dari keduanya.
Ada tiga pendekatan utama dalam CLIR, yaitu mesin penerjemah, corpus setara atau paralel, dan kamus (Aljlayl & Frieder 2001), belum dilakukan penelitian menggunakan dokumen bilingual (bahasa Indonesia dan bahasa Inggris) dengan query bahasa Indonesia maupun bahasa Inggris.
Oleh karena itu penelitian ini akan mengimplementasikan metode CLIR yang mengembalikan dokumen relevan dalam bahasa Indonesia dan bahasa Inggris berdasarkan query yang dimasukkan oleh pengguna.
Tujuan
Tujuan penelitian ini adalah merancang dan membangun sistem CLIR untuk dokumen bilingual (bahasa Indonesia dan bahasa Inggris).
Ruang Lingkup
Mesin pencari difokuskan pada dua bahasa, yaitu bahasa Indonesia dan bahasa Inggris.
Sistem yang dikembangan pada penelitian ini adalah sistem translingual Indonesia Inggris, dimana query dapat menemukan dokumen bahasa Indonesia dan bahasa Inggris.
TINJAUAN PUSTAKA
Sistem Temu-kembali Informasi
Temu-kembali Informasi/Information Retrieval (IR) adalah menemukan materi (biasanya dokumen) dengan struktur tidak teratur untuk memenuhi kebutuhan informasi dari koleksi dokumen yang sangat besar dan biasanya tersimpan dalam komputer (Manning
et al. 2009).
Pada sistem IR, pengguna merepresentasikan kebutuhan informasi dalam bentuk query, kemudian sistem akan mengembalikan dokumen yang dianggap relevan dengan query yang dimasukkan. Hal yang menjadi masalah adalah kebutuhan informasi yang berbeda untuk setiap pengguna meski query yang dimasukkan adalah query
yang sama. Untuk mengatasi hal ini, sistem IR akan memberikan peringkat bagi dokumen yang dianggap paling relevan.
Mesin Pencari
Mesin pencari berbasis web umumnya terdiri atas tiga unit utama, yaitu: penjelajah
web, modul pengindeks dan temu-kembali, serta fasilitas antarmuka untuk pengguna (Vega & Bressan 2001). Penjelajah web, seperti namanya, bertugas untuk menjelajahi
web dan mengumpulkan dokumen-dokumen yang diinginkan.
Modul temu kembali akan membentuk daftar dokumen-dokumen yang diperkirakan relevan dengan query yang diberikan pengguna. Dokumen-dokumen tersebut kemudian diurutkan berdasarkan bobot kemiripan masing-masing dokumen dengan
query pengguna.
Cross Language Information Retrieval (CLIR)
Pada Cross Information Information Retrieval (CLIR), baik dokumen atau query
2
corpus setara atau paralel, dan kamus (Aljlayl & Frieder 2001).
Teknik CLIR berbasis kamus adalah teknik menerjemahkan kata dari satu bahasa ke bahasa lainnya dengan menggunakan kamus. Ada dua strategi utama dalam CLIR berbasis kamus, yaitu dengan menerjemahkan dokumen ke dalam bahasa query dan dengan menerjemahkan query ke dalam bahasa dokumen. Menerjemahkan query ke dalam bahasa dokumen lebih efisien karena tidak memerlukan biaya yang lebih mahal untuk menerjemahkan seluruh dokumen, khususnya ketika ada dokumen baru yang sering ditambahkan.
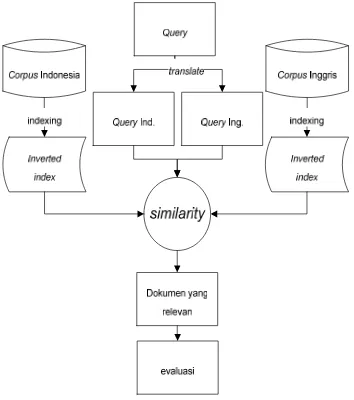
Perbedaan antara monolingual IR dan CLIR terletak pada dokumen yang ditemukembalikan. Monolingual IR menemukembalikan dokumen yang bahasanya sama dengan query sedangkan CLIR bahasa antara hasil dan query berbeda. Ilustrasi CLIR dapat dilihat pada Gambar 1 pengguna memasukkan query bahasa Indonesia kemudian query diterjemahkan ke dalam bahasa Inggris, dan sistem akan menemukembalikan dokumen bahasa Inggris yang relevan dengan hasil terjemahan query.
Gambar 1 Ilustrasi CLIR
.
Sphinx
Sphinx adalah mesin pencari yang menggunakan sistem fulltext indexing agar kinerja pencarian cepat dan efisien. Sphinx dirancang dapat diitegrasikan dengan DBMS (MySQL dan PostgreSQL) dan bahasa pemrograman web (Aksyonoff, 2009).
Fasilitas utama Sphinx, yaitu:
1. indexer, untuk membuat indeks dalam format fulltext.
2. search, command line untuk melakukan (mencoba) query terhadap hasil indeks. 3. searchd, daemon untuk memproses
pencarian dari perangkat lunak lain, misalnya skrip web.
4. sphinxapi, pustaka API untuk bahasa pemrograman berbasis web, baru tersedia untuk PHP.
Pembobotan BM25
Algoritme BM25 diperkenalkan di Text Retrieval Conference (TREC) 3. Fungsi bobot dari sebuah dokumen dan query dapat dilihat pada Persamaan 1, idft menunjukan inverse document frequency (idf) untuk sebuah kata t
(Persamaan 2). Rumus untuk K dapat dilihat pada Persamaan 3, tf adalah jumlah kemunculan kata t dalam dokumen d, qtf
adalah jumlah kemunculan kata t dalam query
Q, N merupakan jumlah seluruh dokumen dalam koleksi, n adalah jumlah dokumen yang mengandung sebuah kata t, dl adalah panjang dokumen, adl adalah rata-rata panjang dokumen untuk corpus, dan b, k1 dan
k3 adalah parameter yang didefinisikan (Lily & Spitery 2002).
Nilai parameter yang digunakan untuk
k1 = 1.2, k3 = 7, dan b = 0.75 (Robertson & Walker 1999)
Pengujian
Kinerja sistem IR berhubungan dengan relevansi dokumen yang dihasilkan dari suatu
query. Pengukuran kinerja atau evaluasi sistem IR tidak dapat dilakukan bila seluruh dokumen yang relevan terhadap suatu query
tidak diketahui sebelumnya. Seluruh dokumen relevan hampir tidak pernah diketahui, terutama untuk koleksi dokumen yang besar. Untuk mengatasi permasalahan ini maka dibuatlah koleksi pengujian.
Koleksi pengujian merupakan suatu kumpulan dokumen yang ditentukan dari sekumpulan query. Beberapa ahli yang mengenal kumpulan dokumen tersebut menentukan relevansi dokumen berdasarkan
3
Recall dan precision mengukur kemampuan sistem dalam menemu-kembalikan dokumen yang relevan. Recall
merupakan rasio jumlah dokumen relevan yang ditemu-kembalikan terhadap jumlah seluruh dokumen relevan di dalam koleksi.
Precision merupakan rasio jumlah dokumen relevan yang ditemu-kembalikan terhadap jumlah seluruh dokumen yang ditemu-kembalikan. Ilustrasi perhitungan nilai recall precision dapat dilihat pada Tabel 1 (Manning
et al. 2009).
Tabel 1 Ilustrasi perhitungan recall precision.
Relevant Nonrelevant
Pengukuran kinerja dengan mempertimbangkan aspek keterurutan atau
ranking dapat dilakukan dengan melakukan interpolasi antara precision dan recall. Nilai rata-rata interpolated precision dapat mencerminkan urutan dari dokumen-dokumen relevan pada perangkingan. Standar yang biasa digunakan adalah 11 tingkat recall
standar, yaitu 0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, dan 1.0. Rumus interpolasi maksimum recall dan precision dapat dilihat pada (6):
Koleksi dokumen yang digunakan dalam penelitian ini adalah Jurnal Makara Universitas Indonesia tahun 2002 sampai dengan 2010 yang dapat di-download di http://journal.ui.ac.id. Jumlah artikel yang akan digunakan sebanyak 270 file, yaitu 157
file bahasa Indonesia dan 113 file bahasa Inggris.
Koleksi Pengujian
Jumlah query dalam koleksi pengujian ini sebanyak 10 query yaitu, teknologi, kesehatan, fuzzy, sastra, kebudayaan, Support Vector Machines, perairan, politik, perangkat lunak, dan sistem informasi geografis. Dari setiap query tersebut akan diterjemahkan ke dalam bahasa Inggris kecuali Support Vector Machines dan fuzzy. Dari setiap query dan terjemahannya akan ditentukan dokumen yang relevan dengan query tersebut. Pasangan
query dan dokumen yang relavan dapat dilihat pada Tabel 2.
Tabel 2 Pasangan query dan dokumen yang relevan.
No. Query Banyaknya
Dok. Relevan
1. Teknologi 24
2 Kesehatan 23
3. Fuzzy 7
4. Sastra 11
5. Kebudayaan 15
6. Support Vector
Machines 3
7. Perairan 16
8. Politik 7
9. Perangkat lunak 7
10. Sistem informasi
geografis 3
Metodologi
Diagram alir metode penelitian dapat dilihat pada Gambar 2.
4
Corpus
Jurnal Makara sebanyak 270 dokumen dibagi menjadi dua, 157 file untuk bahasa Indonesia dan 113 file untuk bahasa Inggris. Abstrak dan judul dari setiap dokumen disimpan ke dalam database corpus pada tabel ‘corpus’. Tabel ‘corpus’ terbagi atas lima field yaitu ‘id_dokumen’, ‘id_jenis’, ‘judul’, ‘abstrak’, dan ‘nama_file’.
Indexing
Proses indexing pada dokumen dilakukan dengan menggunakan Sphinx Search mulai dari tokenisasi, menghilangkan stopword, pembobotan, dan pembuatan inverted index. Pembobotan yang digunakan adalah pembobotan BM25 yang dapat dilihat pada Persamaan 1. Hasil dari indexing akan disimpan pada suatu binary file. Sedangkan proses indexing pada query dibuat modul sendiri untuk proses parsing, membuang
stopword, dan stemming tanpa menggunakan modul pada Sphinx Search.
Query
Query yang diinputkan oleh pengguna dapat berupa bahasa Indonesia atau bahasa Inggris, baik berupa kata tunggal, frase, atau kalimat.
Proses Terjemahan
Query yang dimasukkan oleh pengguna akan diperiksa apakah frase atau kata. Jika frase akan dicari terjemahannya ke dalam kamus frase. Jika query yang dimasukkan oleh pengguna tidak terdapat di kamus frase, maka
query tersebut akan diperiksa dalam kamus bahasa Indonesia – bahasa Inggris dan diambil kata terjemahannya. Jika tidak ada di dalam kamus, diasumsikan kata tersebut memiliki imbuhan dan dilakukan proses stemming. Jika setelah kata di-stemming terdapat pada KBBI maka akan dicari terjemahannya kedalam kamus Indonesia – Inggris. Dan selanjutnya akan diproses dengan Sphinx untuk mendapatkan dokumen yang relevan.
Jika setelah di-stemming kata tersebut tidak ada pada KBBI, query yang dimasukkan oleh pengguna akan diperiksa ke kamus Inggris – Indonesia kemudian akan diambil terjemahannya dan selanjutnya akan diproses dengan Sphinx untuk mendapatkan dokumen yang relevan.
Database Frase
Database frase adalah kumpulan frase yang terdapat di dalam dokumen. Frase dicari
secara manual oleh penulis. Frase yang dicari dan dimasukan ke dalam database hanya yang berbahasa Indonesia. Database frase digunakan untuk memeriksa apakah query
yang dimasukkan pengguna berupa frase atau kata.
Kamus
Database kamus yang digunakan pada penelitian ini diperoleh dari laboratorium IR dengan melakukan pengubahan field pada
database. Proses pengubahan dilakukan untuk mempermudah proses terjemahan kata. Kamus yang ada di laboratorium IR terdapat dua field yaitu kata dan terjemahannya. Seluruh terjemahan disimpan pada satu field
sehingga untuk mendapatkan satu per satu kata terjemahannya akan sulit dan mengakibatkan terjadinya salah terjemah.
Proses Stemming
Stemming dilakukan dengan menggunakan KBBI untuk mengambil kata dasar pada query
yang dimasukkan oleh pengguna. Pada KBBI kata dasar untuk awalan me-, ke-, ter-, pe-
sudah tersedia, sedangkan untuk awalan di-
tidak semua kata ada. Menurut Alwi et al
(2003) imbuhan di- dapat bergabung dengan akhiran –kan dan -i, dan awalan per- dan
ber-. Oleh karena itu pada penelitian ini dibuat stemming untuk pola imbuhan di-kata dasar-kan, di-kata dasar-i, diber-kata
dasar-kan, diper-kata dasar, diper-kata dasar-kan,
diper-kata dasar-i.
Lingkungan Implementasi
Lingkungan implementasi menggunakan
notebook dengan spesifikasi sebagai berikut: Perangkat keras
Processor Intel Core 2 Duo 2.1 GHz
Random Access Memory (RAM) 2 GB
Harddisk 320 GB
Perangkat lunak
Sistem operasi Microsoft Windows XP Professional Service Pack 2
Bahasa pemrograman PHP 5.1.1
Apache 2.0.55
Database MySQL 5.0.16
5
HASIL DAN PEMBAHASAN
Deskripsi Dokumen
Koleksi dokumen yang digunakan pada penelitian ini adalah abstrak dan judul Jurnal Makara Universitas Indonesia yang terdiri atas empat seri yaitu, seri teknologi, seri kesehatan, seri sains, dan seri sosial humaniora. Dari empat seri tersebut dibagi ke dalam dua bagian, 157 dokumen bahasa Indonesia dan 113 dokumen bahasa Inggris.
Jumlah kata dalam koleksi dokumen sebanyak 38.189 kata (25.635 kata untuk dokumen bahasa Indonesia dan 12.554 kata untuk bahasa Inggris). Rata-rata jumlah kata setiap dokumen sebanyak 164 kata untuk dokumen bahasa Indonesia dan 111 kata untuk dokumen bahasa Inggris. Koleksi dokumen bahasa Indonesia mempunyai ukuran sebesar 199.247 bytes dan bahasa Inggris 138.065 bytes.
Kamus
Pada penelitian ini terjemahan kata dipecah-pecah ke dalam terjemahan 1, terjemahan 2, dan seterusnya tergantung banyaknya terjemahan setiap kata. Kamus bahasa Indonesia-bahasa Inggris akan disusun dalam tabel kamus_ina dan kamus bahasa Inggris-bahasa Indonesia akan disusun pada tabel kamus_eng.
Proses pengubahan kamus dilakukan dengan menggunakan regular expression, setelah itu dilakukan proses pengeditan secara manual. Contoh kamus yang belum diubah dapat dilihat pada Lampiran 1 dan kamus yang sudah diubah dapat dilihat pada Lampiran 2.
Struktur Sphinx
Sphinx merupakan sebuah search engine
yang digunakan dalam membangun aplikasi ini, untuk proses indexing, perangkingan, dan pencarian. Pengguna memasukkan query yang selanjutnya akan diproses oleh skrip Sphinxapi.php.
Sphinxapi.php dijalankan ketika terdapat
query yang ingin dicari ke dalam koleksi dokumen. File Sphinxapi.php akan memproses query yang diberikan untuk selanjutnya diproses melalui search engine
Sphinx. Setelah query diproses Sphinx akan menemukembalikan dokumen yang relevan berdasarkan urutan yang tertinggi.
Untuk melakukan indexing, dokumenyang akan di-index disimpan dalam sebuah
database. Database yang akan di-index perlu didefinisikan pada file konfigurasi Sphinx
Search. Konfigurasi Sphinx Search dapat dilihat di bawah ini.
source artikelEng { type = mysql sql_host = localhost sql_user = root sql_pass =
sql_db = corpus sql_port = 3306
sql_query= SELECT id_dokumen, judul, abstrak, nama_file FROM corpus_backup WHERE id_jenis = 2 }
index artikelEng { source = artikelEng
path= d:/Sphinx/data/artikelEng stopwords =
d:/Sphinx/data/stopwordsEng.txt }
Setelah dilakukan konfigurasi kemudian dilakukan indexing dengan perintah d:Sphinx\bin\indexer.exe --config d:Sphinx\config.conf artikelEng. Hasil
indexing akan disimpan pada suatu binary file
yang terdapat pada folder d:Sphinx/data/. Pada penelitian ini tidak dilakukan pengubahan atau penambahan modul Sphinx. Proses penerjemahan kata, stemming,
kombinasi terjemahan kata, dan mengurutkan hasil penggabungan dokumen relevan dilakukan oleh program yang dibuat terpisah dari modul Sphinx.
Pada penelitian ini digunakan pembobotan BM25. Pseudocode pembobotan BM25 pada Sphinx dapat dilihat di bawah ini.
Hasil akhir dari pembobotan BM25 pada Sphinx merupakan hasil penjumlahan dari
phrase rank dan pembobotan BM25 yang dibulatkan. Bobot akhir dapat dilihat pada
pseudocode di bawah ini. field_weight = 0
foreach (field in matching_fields) field_weights += user_weigth (field) weight=
6
Setelah dilakukan proses indexing, dapat dilakukan searching. Sphinx akan me-retrieve
dokumen yang relevan beserta bobotnya.
Hasil Pengujian
Pada Tabel 3 disajikan hasil keluaran
search engine dua bahasa berbasis kamus. Dari Tabel 3 terlihat bahwa query dengan kata “kebudayaan” dan kata “fuzzy”
menemukembalikan dokumen yang tidak relevan paling banyak, dan terjemahan yang dihasilkan banyak yang tidak relevan dengan konteks kata yang dimaksud.
Untuk kata “sistem informasi geografis” terjadi kesalahan terjemahan dan struktur kata terjemahan yang salah. “Sistem informasi geografis” diterjemahkan menjadi “system information geographycal”. Kesalahan terjemahan terjadi untuk kata yang jumlahnya lebih dari satu. Sedangkan untuk kata “perangkat lunak”, sistem menerjemahkan kata sesuai dengan yang dimaksud, karena “perangkat lunak” masuk ke dalam frase yang sudah didefinisikan di dalam database. Tabel 3 Hasil keluaran search engine dua
bahasa berbasis kamus.
No. Query Dokumen
10. Sistem informasi
geografis 2 -
Keterangan:
R : Relevan
TR : Tidak Relevan
Evaluasi Kinerja
Evaluasi kinerja search engine dua bahasa ini akan menggunakan interpolasi maksimum
recall dan precision dari hasil pengujian terhadap 10 pasangan query dan dokumen relevan. Untuk perbandingan kinerja dilakukan antara search engine dua bahasa dengan menggunakan kamus, search engine
bahasa Indonesia, dan search engine bahasa Inggris. Setiap query akan dihitung nilai recall
dan precision-nya.
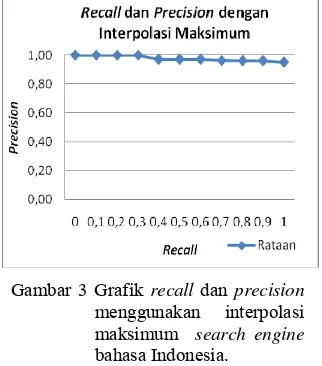
Nilai recall dan precision search engine
bahasa Indonesia dapat dilihat pada Lampiran 3 dan nilai interpolasinya dapat dilihat pada Gambar 3 dan Lampiran 4. Pengujian search engine bahasa Indonesia menggunakan 10 pasangan query dan dokumen relevan yang sama untuk menguji search engine dua bahasa. Jumlah koleksi dokumen yang digunakan sebanyak 157 dokumen.
Gambar 3 Grafik recall dan precision
menggunakan interpolasi maksimum search engine
bahasa Indonesia.
Nilai recall dan precision search engine
bahasa Inggris dapat dilihat pada Lampiran 4 dan nilai interpolasinya dapat dilihat pada Gambar 4 dan Lampiran 5. Pengujian search engine bahasa Inggris menggunakan 10 pasangan query dan dokumen relevan yang merupakan terjemahan dari query untuk menguji search engine dua bahasa. Jumlah koleksi dokumen yang digunakan sebanyak 113 dokumen.
Gambar 4 Grafik recall dan precision
menggunakan interpolasi maksimum search engine
7
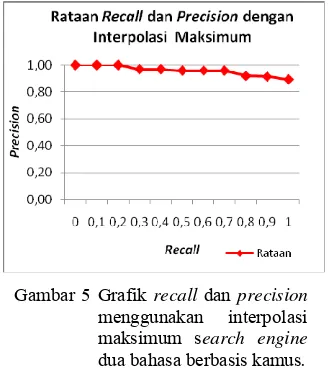
Pengujian search engine dua bahasa dilakukan menggunakan 10 pasangan query
dan dokumen relevan beserta terjemahannya. Koleksi dokumen yang digunakan merupakan hasil penggabungan dokumen bahasa Indonesia dan dokumen bahasa Inggris. Jumlah koleksi dokumen hasil penggabungan sebanyak 270 dokumen. Nilai recall dan
precision search engine bahasa Inggris dapat dilihat pada Lampiran 6 dan nilai interpolasinya dapat dilihat pada Gambar 5 dan Lampiran 7.
Gambar 5 Grafik recall dan precision
menggunakan interpolasi maksimum search engine
dua bahasa berbasis kamus.
Perbandingan dari ketiga hasil pengujian dapat dilihat pada Gambar 6. Dari grafik terlihat bahwa search engine dua bahasa mempunyai kinerja yang lebih rendah dari
search engine bahasa Indonesia. Hal ini disebabkan karena hasil terjemahan query
menghasilkan banyak terjemahan dan beberapa diantara terjemahannya tidak relevan dengan query, seperti kata kebudayaan yang memiliki terjemahan culture dan practice. Terjemahan practice tidak sesuai dengan yang dimaksud oleh penulis, sehingga terdapat beberapa dokumen yang tidak relevan.
Kesalahan struktur hasil kombinasi terjemahan dan terjemahan kata yang salah juga menjadi penyebab berkurangnya dokumen yang relevan seperti pada kata sistem informasi geografis, sistemdua bahasa mengeluarkan hasil terjemahan system information geographycal yang seharusnya adalah geographic information system.
Terjemahan yang salah terjadi karena kamus yang digunakan untuk menerjemahkan kata tidak lengkap.
Gambar 6 Grafik recall dan precision
menggunakan interpolasi maksimum.
Jumlah koleksi dokumen juga mempengaruhi kinerja search engine. Search engine bahasa Inggris mempunyai kinerja yang paling rendah, karena jumlah dokumen bahasa Inggris hanya 113 dokumen sehingga untuk beberapa query pengujian sistem hanya mengembalikan sedikit dokumen, bahkan tidak sama sekali. Hal tersebut mempengaruhi kinerja sistem.
Semakin banyak koleksi dokumen, akan semakin banyak juga dokumen relevan yang ditemukembalikan, meskipun akan semakin banyak juga dokumen tidak relevan yang ditemukembalikan oleh sistem.
KESIMPULAN DAN SARAN
Kesimpulan
Penelitian ini telah mengimplementasikan
search engine dua bahasa berbasis kamus dengan menggunakan Sphinx Search. Berdasarkan nilai recall dan precision dengan interpolasi maksimum terlihat bahwa search engine monolingual (bahasa Indonesia) memiliki kinerja yang lebih baik dari search engine bilingual.
Ada beberapa faktor yang mempengaruhi kinerja search engine dua bahasa berbasis kamus, yaitu hasil terjemahan query yang banyak dan tidak sesuai dengan konteks yang dimaksud, struktur kombinasi kata terjemahan yang salah, dan jumlah koleksi dokumen.
Sphinx Search menggunakan metode
fulltext indexing sehingga pada penelitian ini proses indexing dan pencarian data lebih optimal. Hasil proses indexing Sphinx Search
disimpan pada sebuah external indexer. Hasil
8
sehinga proses pencarian dan indexing tidak mengganggu kinerja database. Akan tetapi karena data disimpan pada dua tempat yang berbeda, apabila terjadi proses penambahan atau pengubahan, maka harus dilakukan pada keduanya.
Saran
Penelitian ini masih terdapat kelemahan dalam proses penerjemahan. Untuk penelitian selanjutkan query yang memiliki banyak terjemahan dicari terlebih dahulu bobot setiap kata, bobot kata yang terbesar pada koleksi dokumen akan dijadikan kata terjemahan. Struktur kombinasi hasil terjemahan juga perlu diperbaiki sesuai dengan kaidah bahasa yang ada. Saran lain adalah menggunakan kamus yang lebih lengkap agar hasil terjemahan sesuai dengan yang dimaksud.
DAFTAR PUSTAKA
[Sphinx]. 2009. About Sphinx.
http://sphinxsearch.com/about.html [9 Juli 2009].
Aljlayl M, Frieder O. 2001. Effective arabic-english cross-language information retrieval via machine readable dictionaries and machine translation. Proceedings of the ACM Tenth Conference on Information and Knowledge Management. CIKM ’01; 10 (11) : 295 – 302. doi:
http://ir.iit.edu/publications/downloads/En glishArabicCrossLanguageCIKM2001.pdf
Alwi H, Dardjowidjojo S, Lapowila H, Moeliono AM. 2003. Tata Bahasa Baku Bahasa Indonesia. Ed ke-3. Jakarta: Balai Pustaka.
Firdestawati I. 2008. Implementasi model ruang vektor sebagai penerjemah query
pada cross-language information retrieval. [skripsi]. Bandung: Institut Teknologi Telkom.
Kantostathis A, Lily A, Spitery RJ. 2008. Distributed EDLSI, BM25, and power norm at TREC 2008. The Seventeenth Text Retrieval Conference (TREC 2008) Proceedings. Maryland: NIST.
Manning C, Raghavan P, Schűtze H. 2008.
Introduction to Information Retrieval. Cambridge: Cambridge University Press.
Mandala R, Setiawan H. 2002. Peningkatan Kinerja Sistem Temu-Kembali Informasi
dengan Perluasan Query Secara Otomatis. Bandung : Institut Teknologi Bandung.
Robertson SE, S. Walker. 1999. Okapi/Keenbow at TREC-8. Proc. Of the 8th Text REtrieval Conference. London: Microsoft Research Ltd.
10
Lampiran 1 Contoh kamus yang terdapat pada Laboratorium IR
id Inggris
aberikos see ABRIKOS.
Abet 1 appearrance. 2 behavior.
Abib (in families of Arabic descent) grandfather.
Abid 1 pious, devout. 2 see ABADI.
Abiding /abidun/ (Islam) the faithful.
Abil see HABIL.
Abis see HABIS.
abiturien o. who went as far as high school. Abjad alphabet.
abjadiah alphabetical.
Ablak (Jakarta) open wide.
Ablative (Ling.) ablative.
Ablur see HABLUR.
Abn (Anggaran Belanja Negara) national budget.
abnormal abnormal. abnormalitas abnormality.
Abnus (Lit.) ebony.
Abolisi abolition.
Abon shredded meat that has been boiled and fried.
Abone subscriber.
abonemen subscription (to a magazine, etc.).
Aborsi /abortus/ abortion.
Abrak mica.
Abrek 1 very much. 2 see AMBREG.
Abri [Angkatan Bersenjata Republik Indonesia] Indonesian Armed Forces.
abrikos apricot.
abrit-abritan see APRIT-APRITAN.
Abruk (Jakarta) slam or set s.t. down with a crash.
Abs [Asal Bapak Senang] as long as the boss is happy.
11
Lampiran 2 Contoh kamus yang telah mengalami pengubahan
Kata Terjemahan 1
Terjemahan 2
Terjemahan 3
Terjemahan 4
Terjemahan 5
aberikos apricot NULL NULL NULL NULL
Abet appearrance behavior NULL NULL NULL Abib grandfather NULL NULL NULL NULL
Abid pious devout Eternal lasting enduring
abidin the faithful NULL NULL NULL NULL
Abil Abel
of Adam's
sons NULL NULL NULL
Abis finished used up Completed through concluded
Abjad alphabet NULL NULL NULL NULL
abjadiah alphabetical NULL NULL NULL NULL
ablak open wide NULL NULL NULL NULL
ablatif ablative NULL NULL NULL NULL
ablur crystal NULL NULL NULL NULL
abn
national
budget NULL NULL NULL NULL
abnormal abnormal NULL NULL NULL NULL
abnormalitas abnormality NULL NULL NULL NULL
abnus ebony NULL NULL NULL NULL
abolisi abolition NULL NULL NULL NULL
abone subscriber NULL NULL NULL NULL
abonemen subscription NULL NULL NULL NULL
12
Lampiran 3 Recall dan precision pada searchengine bahasa Indonesia
Rangking
Query
Teknologi Kesehatan Fuzzy Sastra kebudayaan Support Vector
Machine Perairan Politik
Perangkat Lunak
Sistem Informasi Geografis
R P R P R P R P R P R P R P R P R P R P
1 0.17 1.00 0.08 1.00 0.25 1.00 0.13 1.00 1.00 1.00 0.50 1.00 0.09 1.00 0.33 1.00 0.50 1.00 0.50 1.00 2 0.33 1.00 0.15 1.00 0.50 1.00 0.25 1.00 1.00 1.00 0.18 1.00 0.67 1.00 1.00 1.00 1.00 1.00 3 0.50 1.00 0.16 1.00 0.75 1.00 0.38 1.00 0.27 1.00 1.00 1.00
4 TR TR 0.21 1.00 1.00 1.00 0.50 1.00 0.36 1.00 5 0.67 0.80 0.26 1.00 0.63 1.00 0.45 1.00 6 TR TR 0.32 1.00 0.75 1.00 0.55 1.00 7 0.83 0.71 TR TR 0.88 1.00 0.64 1.00 8 1.00 0.75 0.54 0.88 1.00 1.00 0.73 1.00
9 TR TR 0.62 0.89 0.82 1.00
10 TR TR 0.91 1.00
11 0.69 0.82 TR TR
12 0.77 0.83 1.00 0.92
13 TR TR
13
Lampiran 4 Recall dan precision dengan interpolasi maksimum searchengine bahasa Indonesia
Recall
Query
Rataan Teknologi Kesehatan Fuzzy Sastra Kebudayaan Support Vector Machine Perairan Politik Perangkat Lunak Sistem Informasi Geografis
0 1 1 1 1 1 1 1 1 1 1 1.00
0.1 1 1 1 1 1 1 1 1 1 1 1.00
0.2 1 1 1 1 1 1 1 1 1 1 1.00
0.3 1 1 1 1 1 1 1 1 1 1 1.00
0.4 0.89 0.83 1 1 1 1 1 1 1 1 0.97
0.5 0.89 0.83 1 1 1 1 1 1 1 1 0.97
0.6 0.89 0.83 1 1 1 1 1 1 1 1 0.97
0.7 0.83 0.83 1 1 1 1 1 1 1 1 0.97
0.8 0.81 0.81 1 1 1 1 1 1 1 1 0.96
0.9 0.81 0.81 1 1 1 1 1 1 1 1 0.96
14
Lampiran 5 Recall dan precision pada search engine bahasa Inggris
Rangking
Query
Technology Health Fuzzy Literature Culture Support Vector
Machine Waters Political Software
Geographics Information System
R P R P R P R P R P R P R P R P R P R P
1 0.10 1.00 0.08 1.00 0.33 1.00 0.20 1.00 0.33 1.00 0.25 1.00 0.25 1.00 0.33 1.00 0.33 1.00 2 0.20 1.00 0.15 1.00 0.67 1.00 TR TR 0.67 1.00 0.50 1.00 0.50 1.00 0.67 1.00 0.67 1.00 3 0.30 1.00 0.23 1.00 1.00 1.00 0.40 0.67 1.00 1.00 0.75 1.00 0.75 1.00 1.00 1.00 1.00 1.00 4 0.40 1.00 0.31 1.00 0.60 0.75 1.00 1.00 TR TR
5 0.50 1.00 0.38 1.00 TR TR 1.00 0.80 6 0.60 1.00 0.46 1.00 0.80 0.67
7 0.70 1.00 0.54 1.00 TR TR 8 0.80 1.00 0.62 1.00 TR TR 9 0.90 1.00 0.69 1.00 1.00 0.56 10 TR TR 0.77 1.00
11 1.00 0.91 0.85 1.00 12 0.92 1.00 13 1.00 1.00 14
15
Lampiran 6 Recall dan precision dengan interpolasi maksimum search engine bahasa Inggris
Recall
Query
Rataan
Technology Health Fuzzy Literature Culture Support Vector Machine Waters Political Software Geographics Information System
0 1 1 1 0 1 1 1 1 1 1 0.9
0.1 1 1 1 0 1 1 1 1 1 1 0.9
0.2 1 1 1 0 1 1 1 1 1 1 0.9
0.3 1 1 1 0 0.75 1 1 1 1 1 0.875
0.4 1 1 1 0 0.75 1 1 1 1 1 0.875
0.5 1 1 1 0 0.75 1 1 1 1 1 0.875
0.6 1 1 1 0 0.75 1 1 1 1 1 0.875
0.7 1 1 1 0 0.67 1 1 1 1 1 0.867
0.8 1 1 1 0 0.67 1 1 0.8 1 1 0.847
0.9 1 1 1 0 0.56 1 1 0.8 1 1 0.836
16
Lampiran 7 Recall dan precision pada search engine dua bahasa berbasis kamus
Rangking
Query
Teknologi Kesehatan Fuzzy Sastra Kebudayaan Support Vector
Machine Perairan Politik
Perangkat Lunak
Sistem Informasi Geografis
R P R P R P R P R P R P R P R P R P R P
1 0.05 1.00 0.04 1.00 0.33 1.00 0.13 1.00 0.14 1.00 0.33 1.00 0.06 1.00 0.14 1.00 0.20 1.00 0.50 1.00 2 0.11 1.00 0.07 1.00 0.67 1.00 0.25 1.00 TR TR 0.67 1.00 0.13 1.00 0.29 1.00 0.40 1.00 1.00 1.00 3 0.16 1.00 0.11 1.00 1.00 1.00 0.38 1.00 0.29 0.67 1.00 1.00 0.19 1.00 TR TR 0.60 1.00
4 0.21 1.00 0.14 1.00 0.50 1.00 TR TR 0.25 1.00 0.43 0.75 0.80 1.00 5 0.26 1.00 0.18 1.00 0.63 1.00 TR TR 0.31 1.00 0.57 0.800 1.00 1.00 6 0.32 1.00 0.21 1.00 0.75 1.00 0.43 0.50 0.38 1.00 TR TR
7 0.37 1.00 0.25 1.00 0.88 1.00 0.57 0.57 0.44 1.00 0.71 0.71 8 0.42 1.00 0.29 1.00 1.00 1.00 0.71 0.63 0.50 1.00 0.86 0.75 9 0.47 1.00 0.32 1.00 TR TR 0.56 1.00 TR TR 10 0.53 1.00 0.36 1.00 0.86 0.60 0.63 1.00 TR TR 11 0.58 1.00 0.39 1.00 TR TR 0.69 1.00 TR TR 12 0.63 1.00 0.43 1.00 1.00 0.58 0.75 1.00 TR TR 13 0.68 1.00 0.46 1.00 TR TR 0.81 1.00 TR TR 14 0.74 1.00 0.50 1.00 0.88 1.00 1.00 0.50
15 TR TR 0.54 1.00 0.94 1.00
16 TR TR 0.57 1.00 1.00 1.00
17
Lanjutan Lampiran 8 Recall dan precision pada search engine dua bahasa berbasis kamus
Rangking
Query
Teknologi Kesehatan Fuzzy Sastra Kebudayaan Support Vector
Machine Perairan Politik
Perangkat Lunak
Sistem Informasi Geografis
R P R P R P R P R P R P R P R P R P R P
21 0.95 0.86 0.75 1.00 22 1.00 0.86 0.79 1.00 23 0.82 1.00 24 0.86 1.00 25 0.89 1.00
26 TR TR
18
Lampiran 9 Recall dan precision dengan interpolasi maksimum search engine dua bahasa berbasis kamus
Recall
Query
Rataan Teknologi Kesehatan Fuzzy Sastra Kebudayaan Support Vector
Machine Perairan Politik
Perangkat lunak
Sistem Informasi Geografis
0 1 1 1 1 1 1 1 1 1 1 1.00
0.1 1 1 1 1 1 1 1 1 1 1 1.00
0.2 1 1 1 1 1 1 1 1 1 1 1.00
0.3 1 1 1 1 0.67 1 1 1 1 1 0.97
0.4 1 1 1 1 0.67 1 1 1 1 1 0.97
0.5 1 1 1 1 0.63 1 1 0.8 1 1 0.96
0.6 1 1 1 1 0.63 1 1 0.75 1 1 0.96
0.7 1 1 1 1 0.63 1 1 0.75 1 1 0.96
0.8 0.86 1 1 1 0.6 1 1 0.75 1 1 0.92
0.9 0.86 0.97 1 1 0.58 1 1 0.75 1 1 0.92