lxi
Formulir Persetujuan Menjadi Responden Penelitian
ANALISIS FAKTOR PENGARUH TINGKAT KECEMASAN MAHASISWA DALAM MENYELESAIKAN TUGAS AKHIR/SKRIPSI
DI FMIPA USU
Oleh
DELVINA TRI ASWARA
Saya adalah mahasiswa Fakultas Matematika dan IPA Universitas
Sumatera Utara Medan. Penelitian ini dilaksanakan sebagai salah satu kegiatan
dalam menyelesaikan skripsi.
Tujuan penelitian ini adalah untuk mengetahui pengaruh tingkat
kecemasan mahasiswa FMIPA USU dalam menyelesaikan tugas akhir/skripsi.
Saya mengharapkan jawaban yang Ibu/Bapak, Saudara/I berikan sesuai dengan
kenyataan yang terjadi dan kami akan menjamin kerahasiaan pendapat dan
identitas responden.
Partisipasi Ibu/Bapak, Saudara/I dalam penelitian ini bersifat bebas.
Ibu/Bapak, Saudara/I bebas untuk ikut menjadi responden penelitian atau menolak
tanpa sanksi apapun.
Jika Ibu/Bapak, Saudara/I bersedia menjadi responden penelitian ini,
silahkan Ibu/Bapak, Sauadar/I menandatangani kolom dibawah ini.
Terima Kasih
Tanda Tangan :
Tanggal Penelitian :
lxii
Angket /Kuisioner
ANALISIS FAKTOR PENGARUH TINGKAT KECEMASAN MAHASISWA DALAM MENYELESAIKAN TUGAS AKHIR/SKRIPSI
DI FMIPA USU
Data Demografi Responden
Petunjuk :
- Jawablah semua pernyataan yang tersedia dengan memberikan tanda ( √ )
pada tempat yang telah disediakan
- Semua pernyataan diisi dengan satu jawaban
- Ajukan pertanyaan jika ada pernyataan yang tidak dimengerti
Jenis Kelamin : L/P (Lingkari salah satu)
Umur : … Tahun
Agama : Islam Kristen (K/P) Budha
Hindu Lain-lain : … (sebutkan)
Stambuk :
Status Perkawinan : Menikah Belum Menikah
Status Pekerjaan : Bekerja
Belum Bekerja
lxiii
No Pernyataan Skala
5 4 3 2 1
1 Saya tidak mengalami kesulitan dalam mengumpulkan sampel atau data yang saya butuhkan dalam penelitian
2 Saya meluangkan waktu untuk beristirahat dengan cukup agar tubuh saya tetap sehat selama proses menyelesaikan tugas akhir/skripsi
3 Saya selalu hadir tepat waktu saat perkuliahan dan tidak pernah meningggalkan perkuliahan untuk menyelesaikan perbaikan tugas akhir/skripsi atau konsultasi dengan pembimbing
4 Saya tidak merasa keberatan dengan semua prosedur yang harus dilakukan saat pengajuan proposal
5 Dukungan dan motivasi dari keluarga membuat saya bersemangat dalam mengerjakan tugas akhir/skripsi
6 Saya tidak mengalami kesulitan untuk menjumpai dosen pembimbing dan saya merasa senang selama masa bimbingan juga tidak tertekan dengan revisi-revisi yang diberikan oleh dosen pembimbing
7 Saya tidak memiliki masalah dengan biaya yang dibutuhkan selama proses menyelesaikan tugas akhir/skripsi dan saya menyediakan dana untuk membeli buku yang tidak saya jumpai di perpustakaan
8 Saya merasa memiliki cukup banyak waktu untuk bimbingan dengan dosen pembimbing
Keterangan :
5 = Selalu atau sangat tinggi
4 = Sering atau tinggi
3 = kadang-kadang atau cukup tinggi
2 = jarang atau rendah
lxviii
lxix
Lampiran 3
Perhitungan Korelasi Product Moment Variabel X1 Dengan Total Variabel (Y)
Nomor
Responden X X X X X X X X Y XY X² Y²
1 4,638 3,237 3,157 1,838 3,674 1,872 2,735 1,859 18,372 85,209,336 21,511,044 337,530,384
2 1,829 1,477 2,050 1,838 2,518 3,760 2,735 3,624 18,002 32,925,658 3,345,241 324,072,004
3 3,522 3,237 4,931 3,566 2,518 2,757 2,732 2,661 22,402 78,899,844 12,404,484 501,849,604
4 3,522 3,237 4,931 1,000 3,674 3,760 2,735 3,624 22,961 80,868,642 12,404,484 527,207,521
5 3,522 1,477 4,035 2,650 1,570 2,757 4,686 3,624 20,799 73,254,078 12,404,484 432,598,401
6 3,522 2,355 4,035 3,566 1,570 3,760 4,686 1,859 21,831 76,888,782 12,404,484 476,592,561
7 3,522 2,355 3,157 3,566 3,674 1,872 1,732 1,000 17,356 61,127,832 12,404,484 301,230,736
8 2,667 2,355 4,035 2,650 1,570 4,913 4,686 1,859 22,068 58,855,356 7,112,889 486,996,624
9 4,638 3,237 2,050 4,669 1,000 3,760 1,732 3,624 20,072 93,093,936 21,511,044 402,885,184
10 3,522 3,237 2,050 3,566 2,518 1,000 2,735 3,624 18,730 65,967,060 12,404,484 350,812,900
11 4,638 1,477 3,157 4,669 3,674 2,757 2,735 4,795 23,264 107,898,432 21,511,044 541,213,696
12 1,829 3,237 4,035 2,650 1,000 4,913 4,686 3,624 24,145 44,161,205 3,345,241 582,981,025
13 2,667 2,355 2,050 3,566 2,518 1,872 2,735 2,661 17,757 47,357,919 7,112,889 315,311,049
14 2,667 2,355 3,157 2,650 1,953 2,757 2,757 2,735 18,364 48,976,788 7,112,889 337,236,496
15 3,522 1,477 3,157 1,838 3,674 2,757 1,732 1,859 16,494 58,091,868 12,404,484 272,052,036
16 3,522 1,477 4,931 4,669 3,674 2,757 2,735 2,735 22,978 80,928,516 12,404,484 527,988,484
17 1,829 3,237 4,035 2,650 3,674 1,872 2,735 2,661 20,864 38,160,256 3,345,241 435,306,496
18 3,522 3,237 3,157 4,669 3,674 1,872 1,732 1,859 20,200 71,144,400 12,404,484 408,040,000
lxx
20 2,667 3,237 3,157 2,650 3,674 1,872 2,735 2,661 19,986 53,302,662 7,112,889 399,440,196
21 4,638 3,237 3,157 1,838 1,000 3,760 2,735 1,859 17,586 81,563,868 21,511,044 309,267,396
22 3,522 2,355 4,931 3,566 3,674 3,760 4,686 4,795 27,767 97,795,374 12,404,484 771,006,289
23 2,667 4,338 3,157 2,650 3,674 1,872 2,735 2,661 21,087 56,239,029 7,112,889 444,661,569
24 1,829 3,237 4,931 3,566 3,674 2,757 2,735 2,661 23,561 43,093,069 3,345,241 555,120,721
25 1,829 1,477 3,157 1,000 3,674 3,760 3,744 1,000 17,812 32,578,148 3,345,241 317,267,344
26 2,667 1,000 3,157 2,650 3,674 2,757 2,735 1,859 17,832 47,557,944 7,112,889 317,980,224
27 4,638 3,237 1,000 4,669 3,674 3,760 2,735 3,624 22,699 105,277,962 21,511,044 515,244,601
28 4,638 3,237 3,157 4,669 3,674 2,757 1,000 3,624 22,118 102,583,284 21,511,044 489,205,924
29 1,000 3,237 3,157 4,669 3,674 3,760 3,744 3,624 25,865 25,865,000 1,000,000 668,998,225
30 2,667 3,237 3,157 3,566 3,674 3,760 3,774 2,661 23,829 63,551,943 7,112,889 567,821,241
31 3,522 1,477 4,035 2,650 2,518 2,757 3,744 3,624 20,805 73,275,210 12,404,484 432,848,025
32 2,667 1,477 3,157 4,669 3,674 2,757 3,744 3,624 23,102 61,613,034 7,112,889 533,702,404
33 2,667 4,338 3,157 2,650 3,674 2,757 2,735 3,624 22,935 61,167,645 7,112,889 526,014,225
34 4,638 3,237 3,157 2,650 1,953 2,757 2,735 2,661 19,150 88,817,700 21,511,044 366,722,500
35 2,667 2,355 4,035 2,650 1,953 1,872 1,000 1,000 14,865 39,644,955 7,112,889 220,968,225
36 4,638 3,237 3,157 1,838 1,000 1,000 1,732 3,624 15,588 72,297,144 21,511,044 242,985,744
37 3,522 2,355 3,157 2,650 1,953 2,757 2,735 1,859 17,466 61,515,252 12,404,484 305,061,156
38 3,522 2,355 2,050 3,566 1,953 1,872 3,744 1,859 17,399 61,279,278 12,404,484 302,725,201
39 2,667 2,355 3,157 2,650 1,953 2,757 2,735 2,661 18,268 48,720,756 7,112,889 333,719,824
40 3,522 4,338 4,931 3,566 3,674 3,760 3,744 2,661 26,674 93,945,828 12,404,484 711,502,276
41 3,522 4,338 4,931 3,566 3,674 3,760 3,744 3,624 27,637 97,337,514 12,404,484 763,803,769
42 3,522 4,338 4,931 3,566 3,674 2,757 3,744 4,795 27,805 97,929,210 12,404,484 773,118,025
43 3,522 4,338 4,035 3,566 3,674 3,760 3,744 3,624 26,741 94,181,802 12,404,484 715,081,081
lxxi
45 3,522 4,338 4,035 3,566 3,674 2,757 3,744 3,624 25,738 90,649,236 12,404,484 662,444,644
46 3,522 4,338 3,157 3,566 3,674 3,760 3,744 2,661 24,900 87,697,800 12,404,484 620,010,000
47 3,522 4,338 3,157 3,566 3,674 3,760 3,744 2,661 24,900 87,697,800 12,404,484 620,010,000
48 1,829 3,237 2,050 1,838 2,518 1,872 1,732 2,661 15,908 29,095,732 3,345,241 253,064,464
49 3,522 4,338 4,035 3,566 2,518 3,760 2,735 3,624 24,576 86,556,672 12,404,484 603,979,776
50 2,667 3,237 3,157 2,650 1,953 3,760 2,735 2,661 20,153 53,748,051 7,112,889 406,143,409
51 3,522 4,338 4,035 3,566 1,953 3,760 3,774 3,624 25,050 88,226,100 12,404,484 627,502,500
52 4,638 3,237 4,931 4,669 3,674 3,760 3,774 4,795 28,840 133,759,920 21,511,044 831,745,600
53 3,522 2,355 4,035 2,650 3,674 2,757 2,735 3,624 21,830 76,885,260 12,404,484 476,548,900
54 1,829 3,237 2,050 1,838 2,518 2,757 2,735 2,661 17,796 32,548,884 3,345,241 316,697,616
55 3,522 4,338 4,931 3,566 2,518 3,760 2,735 3,624 25,472 89,712,384 12,404,484 648,822,784
56 3,522 4,338 4,931 3,566 3,674 2,757 3,774 3,624 26,664 93,910,608 12,404,484 710,968,896
57 2,667 2,355 4,035 3,566 3,674 2,757 2,735 3,624 22,746 60,663,582 7,112,889 517,380,516
58 2,667 3,237 3,157 3,566 2,518 2,757 2,735 3,624 21,594 57,591,198 7,112,889 466,300,836
59 2,667 2,355 3,157 1,838 2,518 2,757 1,732 2,661 17,018 45,387,006 7,112,889 289,612,324
60 2,667 2,355 4,931 3,566 3,674 2,757 4,686 3,624 25,593 68,256,531 7,112,889 655,001,649
61 2,667 4,338 4,035 2,650 3,674 3,760 2,735 2,661 23,853 63,615,951 7,112,889 568,965,609
62 1,000 2,355 3,157 4,669 3,674 1,000 3,744 1,859 20,458 20,458,000 1,000,000 418,529,764
63 2,667 2,355 3,157 3,566 2,518 3,760 2,735 2,661 20,752 55,345,584 7,112,889 430,645,504
64 2,667 3,237 3,157 2,650 2,518 3,760 1,000 3,624 19,946 53,195,982 7,112,889 397,842,916
65 1,000 4,338 4,035 1,000 1,000 2,757 2,735 2,661 18,526 18,526,000 1,000,000 343,212,676
66 3,522 2,355 3,157 1,838 3,674 4,913 2,735 1,859 20,531 72,310,182 12,404,484 421,521,961
67 2,667 2,355 4,931 2,650 3,674 2,757 2,735 2,661 21,763 58,041,921 7,112,889 473,628,169
68 4,638 2,355 3,157 2,650 1,953 4,913 4,686 1,000 20,714 96,071,532 21,511,044 429,069,796
lxxii
70 2,667 3,237 4,035 3,566 2,518 3,760 3,744 3,624 24,484 65,298,828 7,112,889 599,466,256
71 2,667 2,355 3,157 3,566 3,674 4,913 4,686 4,795 27,146 72,398,382 7,112,889 736,905,316
72 1,829 3,237 4,035 3,566 3,674 3,760 2,735 3,624 24,631 45,050,099 3,345,241 606,686,161
73 3,522 4,338 4,931 4,669 2,518 3,760 2,735 3,624 26,575 93,597,150 12,404,484 706,230,625
74 1,000 3,237 3,157 4,669 3,674 3,760 2,735 2,661 23,893 23,893,000 1,000,000 570,875,449
75 4,638 4,338 4,931 4,669 3,674 4,913 4,686 4,795 32,006 148,443,828 21,511,044 1,024,384,036
76 1,829 3,237 4,931 3,566 3,674 2,757 2,735 2,661 23,561 43,093,069 3,345,241 555,120,721
77 2,667 3,237 3,157 3,566 2,518 3,760 2,735 2,661 21,634 57,697,878 7,112,889 468,029,956
78 1,829 4,338 3,157 2,650 3,674 4,913 1,000 2,661 22,393 40,956,797 3,345,241 501,446,449
lxxiii
Lampiran 4
Perhitungan Korelasi Antara Variabel X1 dan X2
lxxiv
lx
DAFTAR PUSTAKA
Ade,f. 2007. Aplikasi SPSS untuk Penyusunan Skripsi dan Tesis. USU, Medan
Anton H. 1984. Aljabar Linier. Erlangga, Bandung
Juliansyah.2011. Metodologi Penelitian. Prenadamedia Group, Jakarta
Riduan.2002. Skala pengukuran variabel-variabel Penelitian. Alfabeta, Bandung
Santoso, Singgih 2010. Statistik Multivariat Konsep dan Aplikasi dengan SPSS. Jakarta: PT. Elex Media Komputindo, Jakarta
Seymour Lipschutz.2004. Aljabar Linier. Erlangga, Bandung
Supranto, J. 2010. Analisis Multivariat. PT.Rineka Cipta, Jakarta
Supranto, J. 1997. Pengantar Matrix. PT.Rineka Cipta, Jakarta
http;//www.jogjapress.com/index.php/EMPATHY/article/download/…/904
xxxv
BAB 3
PEMBAHASAN DAN HASIL
3.1 Populasi, Sampel, dan Teknik Pengambilan Sampel
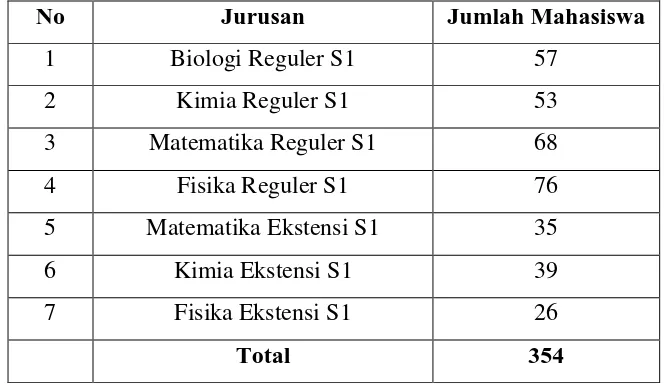
Populasi dalam penelitian ini adalah Mahasiswa FMIPA USU yang sedang
menyelesaikan skripsi. Jumlah mahasiswa yang menyelesaikan skripsi untuk
tahun ajaran 2015 adalah 354 orang (data diperoleh dari Direktori USU)
Tabel 3.1 Daftar jumlah mahasiswa yang menyelesaikan tugas skripsi Tahun 2015
No Jurusan Jumlah Mahasiswa
1 Biologi Reguler S1 57
2 Kimia Reguler S1 53
3 Matematika Reguler S1 68
4 Fisika Reguler S1 76
5 Matematika Ekstensi S1 35
6 Kimia Ekstensi S1 39
7 Fisika Ekstensi S1 26
Total 354
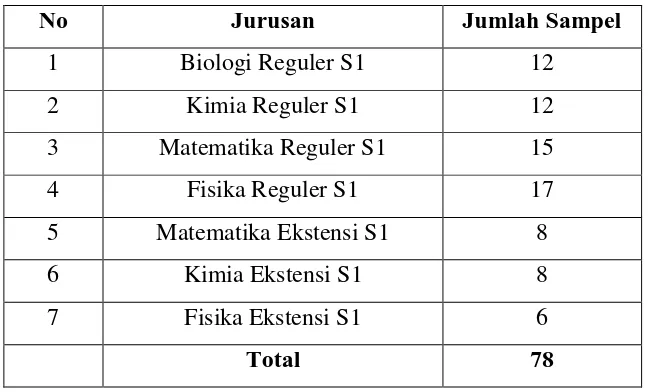
Jumlah sampel dalam penelitian ini adalah 78 responden. Langkah –
langkah dalam penentuan sampel, tahap pertama adalah menentukan banyaknya
jumlah sampel dari seluruh populasi yang telah diketahui dan kemudian tentukan
tingkat presisi yang ditetapkan yaitu 10% dengan rumus slovin sebagai berikut :
n =
n =
n =
= 77, 97
n = 78 responden
xxxvi
Kemudian menentukan sampel secara proporsional dengan rumus :
ni = . n
n1 = . 78 = 12 responden
n2 = . 78 = 12 responden
n3 = . 78 = 15 responden
n4 = . 78 = 17 responden
n5 = . 78 = 8 responden
n6 = . 78 = 8 responden
n7 = . 78 = 6 responden
Sesuai dengan perhitungan manual diatas diperoleh jumlah sampel pada tiap-tiap
jurusan sebagai berikut :
Tabel.3.2 Jumlah Sampel pada tiap-tiap jurusan
No Jurusan Jumlah Sampel
1 Biologi Reguler S1 12
2 Kimia Reguler S1 12
3 Matematika Reguler S1 15
4 Fisika Reguler S1 17
5 Matematika Ekstensi S1 8
6 Kimia Ekstensi S1 8
7 Fisika Ekstensi S1 6
Total 78
Prosedur pengambilan sampel yang dapat menghilangkan kemungkinan bias
xxxvii
proses pengambilan sampel dapat menggunakan lotere dengan langkah-langkah
sebagai berikut:
1. Populasi diberi nomor urut dari 1 sampai N
2. Buat lotere dengan nomor 1 sampai N
3. Kocok lotere supaya setiap nomor mempunyai kemungkinan yang sama
untuk terambil
4. Ambil lotere sebanyak n (pengambilan dilakukan satu persatu), nomor
yang terpilih merupakan nomor polulasi yang terambil menjadi sampel.
3.2 Variabel Penelitian
Variabel yang digunakan dalam penelitian ini adalah :
X1= Metodologi Penelitian
X2 = Kesehatan
X3 = Penurunan Motivasi
X4 = Prosedur Pengajuan Proposal
X5 = Keluarga
X6 = Proses Bimbingan
X7 = Biaya Pembuatan Skripsi
X8 = Kuliah Sambil Bekerja
3.3 Pengolahan Data
3.3.1 Tabulasi Data
Input data mentah yang terdiri dari 78 sampel observasi (responden) dan 8
variabel awal penelitian. Kuesioner terdiri dari beberapa pernyataan yang disertai
skor jawaban 1 -5 dengan menngunakan skala likert yaitu :
5 = Selalu atau sangat tinggi
4 = Sering atau tinggi
3 = Kadang-kadang atau cukup
2 = Jarang atau rendah
xxxviii
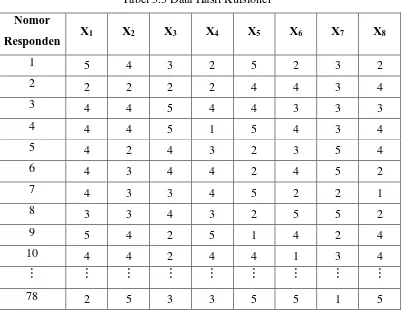
Berikut data yang diperoleh dari hasil penyebaran kuisioner pada mahasiswa yang
sedang menyelesaikan skripsi pada tahun 2015
Tabel 3.3 Data Hasil Kuisioner
Nomor
Responden X1 X2 X3 X4 X5 X6 X7 X8
1 5 4 3 2 5 2 3 2
2 2 2 2 2 4 4 3 4
3 4 4 5 4 4 3 3 3
4 4 4 5 1 5 4 3 4
5 4 2 4 3 2 3 5 4
6 4 3 4 4 2 4 5 2
7 4 3 3 4 5 2 2 1
8 3 3 4 3 2 5 5 2
9 5 4 2 5 1 4 2 4
10 4 4 2 4 4 1 3 4
78 2 5 3 3 5 5 1 5
Data secara keseluruhan dapat dilihat dalam lampiran 2A
3.3.2 Penskalaan Data Ordinal Menjadi Data Interval
Dari data mentah hasil kuisioner dibuat suatu matriks data Xpxn yang telah
dilakukan penskalaan data ordinasl menjadi skala interval. Teknik penskalaan
yang digunakan dalam penelitian ini adalah Methode Successive interval.
Langkah-langkah Methods Successive Interval :
1. Mengitung frekuensi skor jawaban dalam skala ordinal
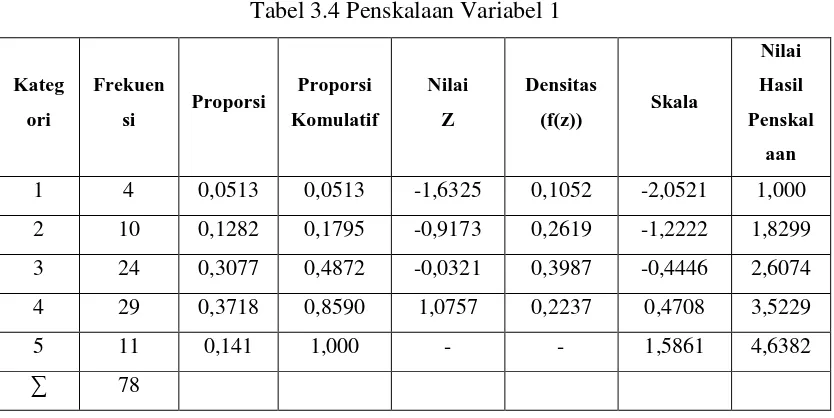
Untuk contoh diatas :
Frekuensi skor jawaban 1 sebanyak 4 responden
Frekuensi skor jawaban 2 sebanyak 10 responden
Frekuensi skor jawaban 3 sebanyak 24 responden
Frekuensi skor jawaban 4 sebanyak 29 responden
xxxix
2. Menghitung proporsi dan proporsi komulatif untuk masing-masing skor
jawaban.
Proporsi dihitung dengan membagi setiap frekuensi dengan jumlah
responden.
P1 = 0,051
P2 = 0,128
P3 = 0,308
P4 = 0,372
P5 = 0,141
Menghitung Proporsi Komulatif (PK)
PK1 = 0,051
PK2 = 0,179
PK3 = 0,487
PK4 = 0,859
PK5 = 1,000
3. Menentukan nilai Z untuk setiap katagori, dengan asumsi bahwa proporsi
komulatif dianggap mengikuti distribusi normal baku. Nilai Z diperoleh dari
Tabel Distribusi Normal Baku
Contoh PK1 = 0,051, nilai P yang akan dihitung adalah : 0,5-0,051 = 0,449
Nilai 0,449 ada diantara : 1,64+1,65 = 3,29/2,004454343 = 1,64134
4. Menghitung nilai densitas dari nilai Z yang diperoleh dengan cara
memasukkan nilai Z tersebut kedalam fungsi densitas normal baku sebagai
berikut :
f(z) =
√ (
xl
=
√ (
)
=
√ (
)
=
=
(3,845899449)
= 1,534680955
5. Menghitung Scale Value (SV) dengan rumus :
SV =
SV1 = = = -2,05212
SV2 = = -1,22
SV3 = = -0,44
SV4 = = 0,47
SV5 = = 1,58
6. Menentukan Scala Value min sehingga SVterkecil + SVmin = 1
Scale Value terkecil = -2,05212
-2,05212 + SVmin = 1
SVmin = 3,05212
7. Menentukan nilai skala dengan menggunakan rumus :
Y = SV + SVmin
xli
Y2 = -1,22416 + 3,06347 = 1,8299
Y3 = -0,44417+ 3,06347 = 2,6075
Y4 = -0,47057 + 3,06347 = 3,523
Y5 = 1,58639 + 3,06347 = 4,6382
Perhitungan diatas adalah penskalaan data ordinal menjadi data interval pada
variabel 1 dengan menggunakan Methode Successive Interval, penskalaan variabel
1 dilakukan juga dengan bantuan Microsoft Excel 2007. Diperoleh data sebagai
Dengan melakukan cara yang sama seperti diatas untuk memperoleh hasil
penskalaan dari 8 variabel dengan bantuan Microsoft Exel 2007 diperoleh hasil
penskalaan data ordinal menjadi skala interval sebagai berikut :
xlii
3.3.3 Uji Validitas
Validitas merupakan sejauh mana ketepatan dan kecermatan melakukan fungsi
ukurnya. Suatu test atau instrument pengukur dapat dikatakan mempunyai
validitas yang tinggi apabila alat ukur tersebut menjalankan fungsi ukurnya, atau
memberikan hasil ukur yang sesuai dengan maksud dilakukannya pengukuran
tersebut
Pengujian validitas dilakukan pada 78 responden. Setelah dilakukan uji validitas
dengan bantuan SPSS diperoleh hasil sebagai berikut :
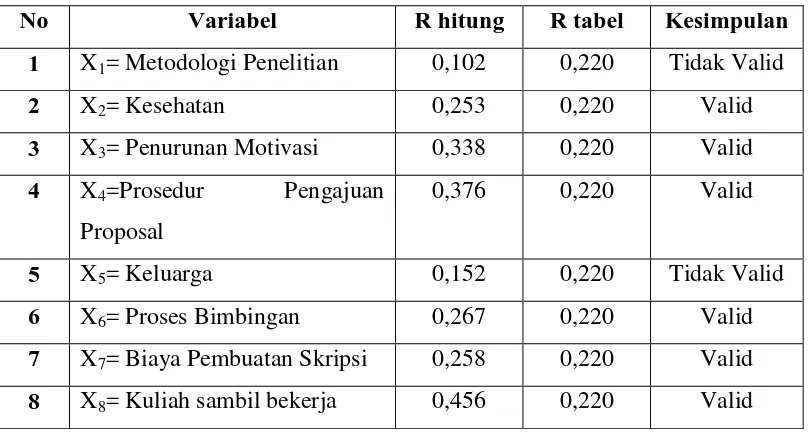
Tabel 3.6 Uji Validitas Variabel Penelitian
No Variabel R hitung R tabel Kesimpulan
1 X1= Metodologi Penelitian 0,102 0,220 Tidak Valid
2 X2= Kesehatan 0,253 0,220 Valid
3 X3= Penurunan Motivasi 0,338 0,220 Valid
4 X4=Prosedur Pengajuan
Proposal
0,376 0,220 Valid
5 X5= Keluarga 0,152 0,220 Tidak Valid
6 X6= Proses Bimbingan 0,267 0,220 Valid
7 X7= Biaya Pembuatan Skripsi 0,258 0,220 Valid
8 X8= Kuliah sambil bekerja 0,456 0,220 Valid
Untuk mengetahui valid atau tidak dapat dilihat dari nilai korelasi hitung
dibandingkan dengan tabel korelasi product moment untuk N = 78 dan α = 0,5 %
adalah 0,220. Dari hasil uji validitas, terlihat bahwa seluruh variabel dinyatakan
valid karena nilai r-hitung > r-tabel, r-hitung > 0,220, maka selanjutnya dilakukan
uji reliabilitas.
Untuk memudahkan perhitungan manual korelasi product moment antara variabel
X2 dengan skor total variabel lainnya Y diperlukan tabel perhitungan korelasi
xliii
Tabel.3.7 Perhitungan Korelasi Product Moment
Nomor
Responden X Y XY X
2
Y2
1 4,638 18,372 85,209,336 21,511,044 337,530,384
2 1,829 18,002 32,925,658 3,345,241 324,072,004
3 3,522 22,402 78,899,844 12,404,484 501,849,604
4 3,522 22,961 80,868,642 12,404,484 527,207,521
5 3,522 20,799 73,254,078 12,404,484 432,598,401
6 3,522 21,831 76,888,782 12,404,484 476,592,561
7 3,522 17,356 61,127,832 12,404,484 301,230,736
8 2,667 22,068 58,855,356 7,112,889 486,996,624
9 4,638 20,072 93,093,936 21,511,044 402,885,184
10 3,522 18,730 65,967,060 7,112,889 350,812,900
. . . .
. . . .
. . . .
78 1,829 22,393 40,956,797 3,345,241 501,446,449
Jumlah 239,454 1,716,176 5,299,187 804,513,226 38,725,225
Tabel perhitungan secara lengkap dapat dilihat pada lampiran 3
Dari tabel perhitungan diatas maka dapat dihitung korelasi product moment antara
variabel X2 dengan skor total variabel lainnya (Y) sebagai berikut :
rxy = √
rxy = √
rxy =
√
rxy =
xliv
rxy = √
rxy = = 0,101
3.3.4 Uji Reliabilitas
Uji reliabilitas menunjukkan sejauh mana hasil suatu pengukuran dapat dipercaya.
Pengukuran yang memiliki reliabilitas tinggi disebut pengukuran yang reliabel.
Metode yang digunakan untuk menguji reliabilitas adalah metode Alpha
Cronbach. Variabel dikatakan reliabel jika memberikan nilai Alpha Cronbach >
0,6 (Ghozali, 2005).
Cara perhitungan reliabilitas dengan SPSS for Windows 17.0 adalah sebagai
berikut :
- Klik analyze, pilih scale dan reliability analysis
- Setelah muncul kotak dialog reliability analysis, pindahkan (X1-X8) ke
dalam item statistic
- Klik kotak dialog statistic, pilih descriptive for (item, scale, da, scale if
item deleted)
- Klik continue dan klik OK
- Pada output kolom Cronbach’s Alpha if item deleted adalah hasil uji
reliabilitas
Dengan bantuan SPSS diperoleh nilai Alpha Cronbach dari 8 variabel penelitian
sebagai berikut :
Reliability Statistics
Cronbach's
Alpha N of Items
xlv
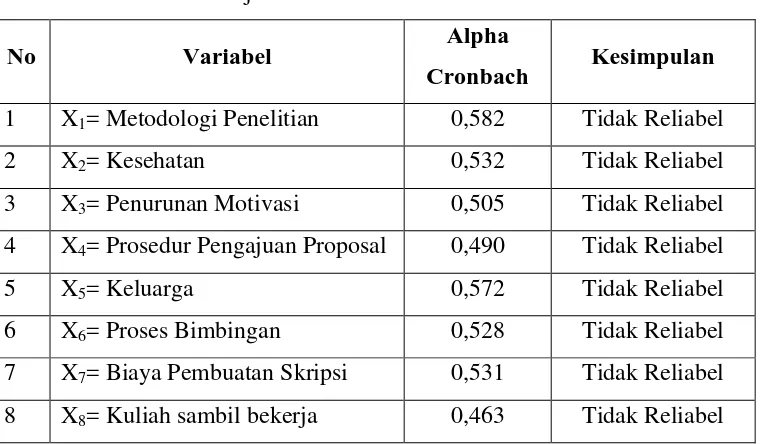
Tabel 3.8 Uji Reliabilitas Variabel Penelitian
No Variabel Alpha
Cronbach Kesimpulan
1 X1= Metodologi Penelitian 0,582 Tidak Reliabel
2 X2= Kesehatan 0,532 Tidak Reliabel
3 X3= Penurunan Motivasi 0,505 Tidak Reliabel
4 X4= Prosedur Pengajuan Proposal 0,490 Tidak Reliabel
5 X5= Keluarga 0,572 Tidak Reliabel
6 X6= Proses Bimbingan 0,528 Tidak Reliabel
7 X7= Biaya Pembuatan Skripsi 0,531 Tidak Reliabel
8 X8= Kuliah sambil bekerja 0,463 Tidak Reliabel
Dari tabel diatas hasil ujireliabilitas terhadap variabel-variabel penelitian
menunjukkan bahwa data mempunyai tingkat reliabilitas yang rendah karena nilai
Alpha Cronbach untuk ke-8 variabel < 0,6. Dengan demikian data dapat
memberikan hasil pengukuran yang kurang konsisten (tidak reliabel).
3.4 Analisis Data
Prinsip utama analisis faktor adalah korelasi, maka asumsi-asumsi yang terkait
dengan korelasi akan digunakan, yaitu :
Besar korelasi atau korelasi antar variabel independen harus cukup kuat
diatas 0,5.
Besar korelasi antara dua variabel dengan menganggap tetap variabel lain
justru harus lebih kecil. Pada SPSS data dari 8 variabel yang berasal dari
78 responden kemudian dianalisa pada anti image correlation.
Pengujian seluruh matriks korelasi (korelasi antar variabel), yang diukur dengan besaran BARLETT TEST OF SPHERRICITY dan MEASURE
SAMPLING ADEQUACY (MSA) berkisar antara 0 sampai dengan 1
dengan kriteria nilai (santoso, 2005) :
MSA = 1, artinya variabel dapat diprediksi tanpa kesalahan oleh variabel
lain.
xlvi
lanjut.
MSA < 0,5, artinya variabel tidak dapat diprediksi dan tidak dapat
dianalisis lebih lanjut.
Berikut matriks korelasi antar variabel yang diperoleh dengan bantuan SPSS
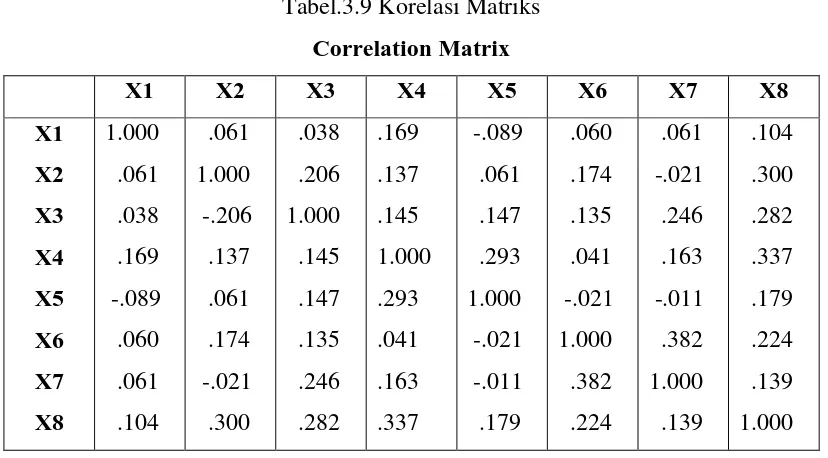
Tabel.3.9 Korelasi Matriks
Pada penelitian ini matriks korelasi yang dibentuk dari data yang diperoleh untuk
mengetahui seberapa besar korelasi antar 8 variabel tersebut. Terlihat korelasi
yang cukup kuat antar variabel X1 dan X2 sehingga diharapkan nantinya bahwa
variabel - variabel lainnya akan berkorelasi dengan faktor yang sama.
Data mengenai 8 variabel yang berasal dari jawaban 78 orang responden
kemudian dianalisa pada anti image correlation. Uji ini dilakukan dengan
memperhatikan angka KMO dan MSA. Kriteria kesesuaian dalam pemakaian
analisis faktor adalah :
Jika harga KMO sebesar 0,9 berarti sangat memuaskan, Jika harga KMO sebesar 0,8 berarti memuaskan, Jika harga KMO sebesar 0,7 berarti harga menengah, Jika harga KMO sebesar 0,6 berarti cukup
xlvii
Tabel 3.10 Kaiser –Meyes-Olkin (KMO) dan Barlett’s Test
KMO and Bartlett's Test
Kaiser-Meyer-Olkin Measure of Sampling Adequacy. .597
Bartlett's Test
of Sphericity
Approx. Chi-Square 59.627
df 28
Sig. .000
Hasil output SPSS seperti tabel diatas menunjukkan angka KMO dan Barlett’s test
adalah 0,597 lebih besar dari 0,5 dengan signifikansi 0,000 lebih kecil dari 0,5,
maka variabel dan sampel sudah layak dianalisis lebih lanjut.
Tabel 3.11 Nilai Measure of Sampling Adequecy (MSA)
xlviii
Hipotesis untuk uji diatas adalah :
H0 = sampel belum memadai untuk dianalisis lebih lanjut
H1 = sampel sudah memadai untuk dianalisis lebih lanjut
Kriteria dengan melihat probabilitas (tingkat signifikansi) :
Angka Sig. ≥ 0,5 maka H0 diterima
Angka Sig. < 0,5 maka H0 ditolak
3.4.1 Memilih metode analisis faktor
a. Pada tahap ini, akan dilakukan proses inti dari analisis faktor, yaitu melakukan
ekstraksi terhadap sekumpulan variabel yang ada KMO > 0,5 sehingga
terbentuk satu atau lebih faktor
b. Metode yang digunakan untuk tahap ini adalah Principal Component Analysis
(Analisis Komponen Utama). Didalam Principal Component Analysis, jumlah
varians dalam data dipertimbangkan, diagonal matriks korelasi terdiri dari
angka satu (1).
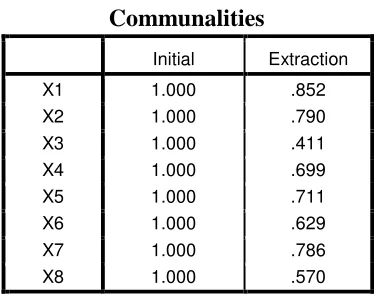
Communality ialah jumlah varian yang disumbangkan oleh suatu variabel dengan
seluruh variabel lainnya dalam analisis. Dengan bantuan SPSS diperoleh
komunalitas sebagai berikut :
Tabel.3.12 Tabel Komunalitas
Communalities
Initial Extraction
X1 1.000 .852
X2 1.000 .790
X3 1.000 .411
X4 1.000 .699
X5 1.000 .711
X6 1.000 .629
X7 1.000 .786
X8 1.000 .570
xlix
Dari tabel 3.12 menunjukkan bahwa variabel diuji memenuhi persyaratan
komunalitas, yaitu lebih besar dari 0,5.
Komunalitas pada dasarnya adalah jumlah varians (bisa dalam persentase) dari
suatu variabel mula-mula yang bisa dijelaskan oleh faktor yang terbentuk. Bisa
juga disebut proporsi atau bagian varian yang dijelaskan oleh komponen faktor
atau besarnya sumbangan suatu faktor terhadap varian seluruh variabel.
a. Untuk variabel Metodologi Penelitian, nilai komunalitasnya adalah 0,852
atau sekitar 85,2% varians dari variabel metodologi penelitian bisa
dijelaskan oleh faktor yang terbentuk.
b. Untuk variabel Kesehatan, nilai komunalitasnya adalah 0,790 atau sekitar
79% varians dari variabel Kesehatan bisa dijelaskan oleh faktor yang
terbentuk.
c. Untuk variabel Penurunan Motivasi, nilai komunalitasnya adalah 0,411
atau sekitar 41,1% varians dari variabel Penurunan Motivasi bisa
dijelaskan oleh faktor yang terbentuk.
d. Untuk variabel Prosedur Pengajuan Proposal, nilai komunalitasnya adalah
0,699 atau sekitar 69,9% varians dari variabel Prosedur Pengajuan
Proposal bisa dijelaskan oleh faktor yang terbentuk.
e. Untuk variabel Keluarga, nilai komunalitasnya adalah 0,711 atau sekitar
71,1% varians dari variabel Keluarga bisa dijelaskan oleh faktor yang
terbentuk.
f. Untuk variabel Proses Bimbingan, nilai komunalitasnya adalah 0,629 atau
sekitar 62,9% varians dari variabel Proses Bimbingan bisa dijelaskan oleh
faktor yang terbentuk.
g. Untuk variabel Biaya Pembuatan Skripsi, nilai komunalitasnya adalah
0,786 atau sekitar 78,6% varians dari variabel Biaya Pembuatan Skripsi
bisa dijelaskan oleh faktor yang terbentuk.
h. Untuk variabel Kuliah Sambil Bekerja, nilai komunalitasnya adalah 0,570
atau sekitar 57,0% varians dari variabel Kuliah Sambil Bekerja bisa
l
Dalam tahap ekstraksi faktor selanjutnya adalah melihat nilai eigen-nya. Nilai
eigen merupakan total varian yang dijelaskan oleh setiap faktor atau merupakan
sumbangan (share) dari faktor tertentu terhadap seluruh variance dari variabel
awal atau variabel asli. Dengan SPSS diperoleh nilai eigen untuk setiap faktor
sebagai berikut :
Tabel 3.13 Nilai eigen untuk setiap faktor
Total Variance Explained
Component
Initial Eigenvalues
Total % of Variance Cumulative %
1 2.084 26.050 26.050
2 1.286 16.076 42.126
3 1.062 13.277 55.403
4 1.015 12.684 68.087
5 .812 10.151 78.238
6 .661 8.258 86.496
7 .611 7.643 94.139
8 .469 5.861 100.000
Tabel.3.13 dengan tabel initial eigen value menunjukkan nilai eigen untuk setiap
faktor, yang pada awalnya terdiri dari 8 faktor yaitu sebanyak variabel aslinya.
Kemudian didalam proses berikutnya dipilih faktor-faktor yang nilai eigennya
minimal 1. Oleh karena itu tidak semua faktor mempunyai nilai eigen lebih besar
atau sama dengan 1, maka akan terjadi banyak faktor yang berguguran, karena
tidak memenuhi persyaratan untuk menjadi faktor yang nilai eigennya besar 1 atau
lebih.
Untuk mengetahui seberapa besar total seluruh varians yang mempengaruhi
tingkat kecemasan mahasiswa menyelesaikan skripsi diperoleh sumbangan
li
Tabel. 3.14 Nilai eigen faktor terhadap varians seluruh variabel asli
Component Extraction Sums of Squared Loadings
Nilai eigen % of Variance Cumulative %
1
Berdasarkan tabel 3.14 diperoleh empat faktor yang memiliki nilai eigen lebih
besar dari 1,0 yaitu kita sebut faktor 1 dengan nilai eigen 2,084, faktor 2 dengan
nilai eigen 1,286, faktor 3 dengan nilai eigen 1,062, faktor 4 dengan nilai eigen
1,015. Keempat faktor tersebut menjelaskan (68,087)% total varians variabel yang
mempengaruhi tingkat kecemasan mahasiswa dalam menyelesaikan skripsi di
FMIPA USU.
3.4.2 Menentukan Banyaknya Faktor
Penentuan banyaknya faktor yang dilakukan dalam analisis faktor maksudnya
adalah mencari variabel terakhir yang disebut faktor yang saling tidak berkorelasi,
bebas satu sam lainnya, lebih sedikit jumlahnya daripada variabel awal akan tetapi
dapat menyerap sebagian besar informasi yang terkandung dalam variabel awal
atau yang dapat memberikan sumbangan terhadap varians seluruh variabel. Ada
beberapa prosedur yang dapat dipergunakan dalam menentukan banyaknya faktor,
antara lain adalah sebagai berikut :
1. Dilihat dari total nilai eigen
Untuk menentukan banyaknya faktor dari total nilai eigen dilihat dengan metode
pendekatan, hanya faktor dengan eigen value lebih besar dari satu yang
dipertahankan, jika lebih kecil dari satu, faktornya tidak diikutsertakan dalam
model. Suatu nilai eigen menunjukkan besarnya sumbangan dari faktor terhadap
lii
Berdasarkan tabel. 3.13 ternyata diperoleh banyaknya faktor yang
mempengaruhi tingkat kecemasan mahasiswa menyelesaikan skripsi menurut
responden adalah 4, karena ada 4 faktor atau komponen yang nilai eigennya lebih
dari 1,0 yaitu faktor 1 dengan nilai eigen 2,084, faktor 2 dengan nilai eigen 1,286,
faktor 3 dengan nilai eigen 1,062, faktor 4 dengan nilai eigen 1,015.
Berdasarkan tabel 3.14 dapat diketahui bahwa besarnya sumbangan yang
diberikan dari masing-masing faktor terhadap varians seluruh variabel asli. Faktor
pertama memberikan sumbangan varians sebesar 26,050 %, faktor kedua
16,076%, faktor ketiga 13,277%, faktor keempat 12,684%. Sehingga total
sumbangan varians dari ketiga faktor tersebut adalah 68,087%.
2. Menentukan Banyaknya Faktor dengan Scree Plot
Suatu scree plot adalah plot dari eigen value melawan banyaknya faktor yang
bertujuan untuk melakukan ekstraksi agar diperoleh jumlah faktor.
Jika tabel total varians menjelaskan dasar jumlah faktor yang di dapat
dengan perhitungan angka, maka scree plot memperlihatkan hal tersebut dengan
grafik. Terlihat bahwa dari satu kedua faktor (garis dari sumbu komponen 1 ke 2),
arah garis cukup menurun tajam. Kemudian dari 2 ke 3 garis juga menurun. Pada
faktor 5 sudah dibawah angka 1 dari sumbu nilai eigen. Hal ini menunjukkan
bahwa ada 4 faktor yang mempengaruhi tingkat kecemasan mahasiswa
menyelesaikan skripsi, yang dapat di ekstraksi berdasarkan scree plot.
liii
3.4.3 Melakukan Rotasi Faktor
Output terpenting dalam analisis faktor adalah Matriks Faktor atau yang disebut
juga dengan Komponen Matriks. Matriks faktor memuat koefsien yang
dipergunakan untuk mengekspresikan variabel yang dibakukan dinyatakan dalam
faktor. Koefsien ini merupakan factor loading, mewakili koefsien korelasi antara
faktor dengan variabel. Koefsien dengan nilai mutlak (absolute) yang besar
menunjukkan bahwa faktor dan variabel sangat terkait. Koefsien dari matriks
faktor dapat dipergunakan untuk menginterpretasi faktor. Matriks faktor atau
matriks komponen dapat dilihat sebagai berikut :
Tabel 3.15 Matriks Faktor (Sebelum Dirotasi)
Component Matrix
Component
1 2 3 4
Metodologi_penelitian .234 .128 .827 .311
Kesehatan .486 -.127 .230 -.697
Penurunan_motivasi .583 .026 -.221 -.146
Prosedur_pengajuan_proposal .583 -.389 .150 .429
Keluarga .348 -.622 -.389 .228
Proses_bimbingan .498 .595 -.134 -.097
Biaya_pembuatan_skripsi .487 .577 -.274 .374
Kuliah_sambil_bekerja .712 -.164 .100 -.158
Extraction Method: Principal Component Analysis.
Walaupun matriks faktor atau matriks komponen awal sebelum dirotasi
menunjukkan hubungan antara faktor (komponen) dengan variabel secara
individu, akan tetapi masih sulit diambil kesimpulannya tentang banyaknya faktor
yang dapat diekstraksi. Hal ini disebabkan karena faktor (komponen) berkorelasi
dengan banyak variabel lainnya atau sebaliknya variabel tertentu masih
berkorelasi dengan banyak faktor. Sehingga dalam keadaan ini terkadang
liv
Misalkan matriks faktor (sebelum dirotasi) diatas dapat dilihat bahwa F1 memiliki
korelasi kuat dengan 5 variabel, yakni X2,X3,X4,X5 dan X8 sedangkan F2
memiliki korelasi kuat dengan X6 dan X7 dan F3 memiliki korelasi kuat dengan
X1.
Untuk dapat dilakukan proses rotasi faktor yang terbentuk agar
memperjelas posisi sebuah variabel, akankah dimasukkan pada faktor yang satu
ataukah ke faktor lainnya. Beberapa metode rotasi yang bisa digunakan adalah
orthogonal rotation, varimax rotation, dan oblique rotation.
Proses rotasi terhadap faktor pada penelitian ini menngunakan metode
varimax rotation, yaitu rotasi orthogonal dengan meminimumkan banyaknya
variabel yang memiliki loading tinggi pada sebuah faktor, sehingga lebih mudah
mengiterpretasi faktor.
Tabel 3.16 Matriks Faktor (setelah dirotasi)
Rotated Component Matrixa
Component
1 2 3 4
Metodologi_penelitian .026 -.009 .050 .921
Kesehatan -.051 -.055 .885 .029
Penurunan_motivasi .385 .269 .417 -.127
Prosedur_pengajuan_proposal .093 .733 .116 .372
Keluarga -.078 .795 .053 -.263
Proses_bimbingan .734 -.149 .261 .020
Biaya_pembuatan_skripsi .866 .119 -.127 .068
Kuliah_sambil_bekerja .213 .379 .596 .160
Extraction Method: Principal Component Analysis.
Rotation Method: Varimax with Kaiser Normalization.
Tujuan dilakukan rotasi adalah untuk memperlihatkan dirtribusi variabel yang
lebih jelas dan nyata. Dapat dilihat perbedaan antara matriks faktor sebelum
lv
3.4.4 Interpretasi Faktor
Setelah dirotasi dilakukan langkah selanjutnya adalah interpretasi faktor.
Interpretasi faktor dipermudah dengan mengidentifikasi variabel yang loadingnya
besar pada faktor yang sama. Faktor tersebut kemudian diinterprtasi menurut
variabel-variabel yang memiliki loading tinggi dengan faktor tersebut. Ataupun
penentuan variabel yang dimasukkan ke dalam faktor dengan cara melihat factor
loading yang terbesar.
a. Variabel metodologi penelitian: Korelasi antara variabel dengan faktor 3
sebelum dirotasi adalah 0,827; dengan rotasi korelasi menjadi 0,921 dengan
faktor 4. Jadi variabel ini masuk faktor 4.
b. Variabel kesehatan: Korelasi antara variabel dengan faktor 1 sebelum dirotasi
adalah 0,486; dengan rotasi korelasi menjadi 0,885 dengan faktor 3. Jadi
variabel ini masuk faktor 3.
c. Variabel penurunan motivasi: Korelasi antara variabel dengan faktor 1
sebelum dirotasi adalah 0,583; dengan rotasi korelasi menjadi 0,417 dengan
faktor 3. Jadi variabel ini masuk faktor 1.
d. Variabel prosedur pengajuan proposal: Korelasi antara variabel dengan faktor
1 sebelum dirotasi adalah 0,583; dengan rotasi korelasi menjadi 0,733 dengan
faktor 2. Jadi variabel ini masuk faktor 2.
e. Variabel keluarga: Korelasi antara variabel dengan faktor 1 sebelum dirotasi
adalah 0,348; dengan rotasi korelasi menjadi 0,795 dengan faktor 2. Jadi
variabel ini masuk faktor 2.
f. Variabel proses bimbingan: Korelasi antara variabel dengan faktor 2 sebelum
dirotasi adalah 0,595; dengan rotasi korelasi menjadi 0,734 dengan faktor 1.
Jadi variabel ini masuk faktor 1.
g. Variabel biaya pembuatan skripsi: Korelasi antara variabel dengan faktor 2
sebelum dirotasi adalah 0,577; dengan rotasi korelasi menjadi 0,866 dengan
faktor 1. Jadi variabel ini masuk faktor 1.
h. Variabel kuliah sambil bekerja: Korelasi antara variabel dengan faktor 1
sebelum dirotasi adalah 0,712; dengan rotasi korelasi menjadi 0,596 dengan
lvi
Tabel 3.17 Korelasi antara variabel sebelum dan setelah dirotasi
Variabel
Dengan demikian ke 8 variabel telah direduksi menjadi empat faktor yang dapat
mempengaruhi tingkat kecemasan mahasiswa dalam menyelesaikan tugas
akhir/skripsi, yaitu :
1. Faktor 1 (F1) terdiri atas variabel x3 = penurunan motivasi, x6 = proses
bimbingan, x7 = biaya pembuatan skripsi, x8 = kuliah sambil bekerja.
Faktor ini diberi nama FAKTOR KEMALASAN
2. Faktor 2 (F2) terdiri atas variabel x4 = prosedur pengajuan proposal, x5 =
keluarga.
Faktor ini diberi nama FAKTOR EMOSIONAL
3. Faktor 3 (F3) terdiri atas variabel x2 = kesehatan
Faktor ini diberi nama FAKTOR FISIK
4. Faktor 4 (F4) terdiri atas variabel x1 = metodologi penelitian.
Faktor ini diberi nama FAKTOR ILMU
Interpretasi variabel :
1. Faktor 1 adalah faktor kemalasan memberikan sumbangan varians sebesar
26,050% dan merupakan faktor dominan yang memberikan nilai varians
lvii
kemalasan merupakan faktor utama yang mempengaruhi tingkat kecemasan
mahasiswa dalam menyelesaikan skripsi.
2. Faktor 2 adalah faktor emosional yang memberikan sumbangan varians
sebesar 16,076% dan merupakan faktor kedua menurut persepsi mahasiswa
dalam menyelesaikan skripsi.
3. Faktor 3 adalah faktor fisik yang memberikan sumbangan varians sebesar
13,277% dimana menurut persepsi mahasiswa faktor fisik merupakan faktor
ketiga yang mempengaruhi tingkat kecemasan mahasiswa dalam
menyelesaikan skripsi.
4. Faktor 4 adalah faktor ilmu yang memberikan sumbangan varians sebesar
12,684%, dan merupakan faktor terkecil yang mempengaruhi tingkat
kecemasan mahasiswa dalam menyelesaikan skripsi.
5. Keempat faktor yang mempengaruhi tingkat kecemasan mahasiswa dalam
menyelesaikan tugas akhir/skripsi tersebut memberikan komulatif varians
sebesar 68,087%, artinya sebesar 68,087% faktor yang terbentuk
mempengaruhi mahasiswa dalam menyelesaikan skripsi dan sisanya adalah
faktor-faktor lain yang tidak terangkum dalam model penelitian ini.
3.4.5 Menghitung factor scores atau surrogate variables
Kalau analisis faktor akan dilanjutkan menjadi regresi linear berganda, perlu
dihitung faktor score. Akan tetapi kalau tujuan analisis faktor hanya untuk
mereduksi, dari variabel asli menjadi sedikit variabel yang disebut faktor atau
komponen maka nilai/skor tidak diperlukan.
Dalam hal principal component analysis dimungkinkan untuk menghitung Factor
score.
3.4.6 Menentukan ketepatan Model (model fit)
Proses akhir dari analisis faktor adalah menguji ketepatan model, dengan
menggunakan output program SPSS. Perbedaan antara korelasi yang diobservasi
(pada matriks korelasi sebelum analisis faktor) dengan korelasi analisis faktor
(yang diestimasi dari matriks faktor) yaitu yang disebut dengan residual. Kalau
lviii
model tidak tepat, model dipertimbangkan kembali. Sebaliknya jika banyak
residual yang nilainya lebih kecil dari 0,05 (residual < 0,05), berarti model sudah
tepat.
Untuk mengetahui ketepatan model analisis faktor dapat dilihat dengan
nilai residual pada Tabel 3.18
Tabel 3.18 Selisih (Residual) antara observed correlation dengan Reproduced Correlation
Sisaan atau residual (ei) didefinisikan sebagai selisih antara korelasi sebelum
analisis faktor dan setelah analisis faktor
Contoh :
e2 = 0,061-(-0,021) = 0,082
lix
BAB 4
KESIMPULAN DAN SARAN
4.1 Kesimpulan
Dari hasil penelitian 78 orang dan 8 variabel pernyataan kepada mahasiswa,
dengan menggunakan metode analisis faktor penulis diperoleh proporsi
keragaman komulatif sebesar 68,087% yang diperoleh dari jumlah keempat faktor
dominan yang mempengaruhi tingkat kecemasan mahasiswa dalam
menyelesaikan skripsi yaitu faktor kemalasan (26,050%), faktor emosional
(16,076%), faktor fisik (13,277%), faktor ilmu (12,684%).
4.2 Saran
Adapun sebagai saran dari hasil ini yaitu :
1. Perlu diteliti kembali, mengapa mahasiswa malas meyelesaikan skripsi,
apakah karena kerja, ikut organisasi, urus rumah tangga atau lain-lain.
2. Perlu diteliti kembali faktor lain yang menyebabkan mahasiswa lama
menyelesaikan skripsi.
3. Bagi peneliti selanjutnya hasil penelitian ini masih bisa diteruskan dengan
mengembangkan penelitian, seperti menambah variabel-variabel baik yang
bersifat data kualitatif maupun data kuantitatif dan dengan metode lain
xvii
BAB 2
LANDASAN TEORI
2.1Pengertian Kecemasan
Kecemasan atau dalam Bahasa Inggrisnya “anxiety” berasal dari bahasa latin “angustus” yang berarti kaku, dan “ango,anci” yang berarti mencekik. Menurut Freud (dalam Alwisol, 2005:28) mengatakan bahwa kecemasan adalah fungsi ego
untuk memperingatkan individu tentang kemungkinan datangnya suatu bahaya
sehingga dapat disiapkan reaksi adaptif yang sesuai. Kecemasan berfungsi sebagai
mekanisme yang melindungi ego karena kecemasan memberi sinyal bahwa ada
bahaya dan kalau tidak dilakukan tindakan yang tepat maka bahaya itu akan
meningkat sampai ego dikalahkan.
Kecemasan adalah suatu keadaan aprehensi atau keadaan khawatir yang
mengeluhkan bahwa sesuatu yang buruk akan terjadi. Kecemasan adalah respon
yang cepat terjadi ancaman tetapi akan menjadi abnormal apabila tingkatannya
tidak sesuai dengan proporsi ancaman, atau bila datang tanpa ada penyebab
(Nevid, 2005).
Menurut Nevid (2005) kecemasan terdiri dari tiga aspek yaitu :
a. Simptom fisik adalah gangguan yang terjadi pada fisik, seperti badan
gemetar, keluar banyak keringat, jantung berdetak kencang, sulit bernafas,
pusing, tangan dingin, mual, panas dingin, lebih sensitive, kegelisahan,
kegugupan, pingsan, merasa lemas, sering buang air kecil, dan diare.
b. Simptom perilaku adalah kecemasan yang mengakibatkan perilaku
seseorang menjadi berbeda dan mengarah kepada hal yang kurang biasa,
seperti perilaku menghindar, perilaku ketergantungan atau melekat,
perilaku terguncang, dan meninggalkan situasi yang menimbulkan
kecemasan.
c. Simptom kognitif yaitu khawatir tentang sesuatu, keyakinan bahwa
sesuatu yang mengerikan akan segera terjadi tanpa ada penjelasan yang
jelas, merasa terancam oleh orang atau peristiwa, kebingungan, dan
xviii
2.2 Populasi dan Sampel 2.2.1 Populasi
Menurut Juliansyah (2011:147) Populasi adalah seluruh elemen/anggota dari
suatu wilayah yang menjadi sasaran penelitian atau merupakan keseluruhan objek
penelitian dipelajari kemudian ditarik kesimpulannya. Populasi yang digunakan
dalam penelitian ini mahasiswa FMIPA yang sedang menyelesaikan skripsi tahun
ajaran 2014/2015.
2.2.2 Sampel
Sampel adalah sejumlah anggota yang dipilih dari populasi (Juliansyah, 2011 :
147). Pada penelitian ini, peneliti mengambil sampel di wilayah Fakultas
Matematika dan IPA Universitas Sumatera Utara.
Teknik pengambilan sampel dilakukan dengan metode penyebaran kuesioner pada
mahasiswa FMIPA USU dengan beberapa pertanyaan yang diberi skor jawaban
dengan menggunakan skala likert yaitu mulai dari 1-5 dengan keterangan :
5 = Selalu atau sangat tinggi
4 = Sering atau tinggi
3 = Kadang-kadang atau cukup
2 = Jarang atau rendah
1 = Tidak pernah atau rendah sekali
Metode yang digunakan dalam menentukan jumlah sampel menggunakan rumus
Slovin yaitu :
N
n = (2.1)
1+Ne2
Keterangan :
n = Jumlah Sampel
N = Jumlah Populasi
xix
Pemilihan sampel dilakukan dengan probability sampling yaitu metode
proportionate stratified random sampling yaitu pengambilan sampel dari anggota
populasi secara acak dan berstrata secara proporsional.
2.3 Variabel Penelitian
Variabel ialah sesuatu yang nilainya berubah-ubah menurut waktu atau berbeda
menurut elemen/tempat (Suprapto : 2004). Umumnya nilai karakteristik
merupakan variabel, diberi simbol huruf X. variabel yang digunakan dalam
penelitian ini adalah: Metodologi Penelitian, Kesehatan, Penurunan Motivasi,
Prosedur Pengajuan Proposal, Keluarga, Proses Bimbingan, Biaya Pembuatan
Skripsi, Kuliah Sambil Bekerja.
2.4 Jenis Sumber Data
Data merupakan komponen utama dalam statistika. Data adalah bahan baku yang
jika diolah melalui berbagai analisis dapat melahirkan informasi, dimana
informasi tersebut dapat diambil suatu keputusan. Sumber data yang dipakai
dalam penelitian ini adalah Data Primer, yaitu data yang diperoleh melalui studi
dokumentasi, baik dari buku, jurnal majalah dan situs internet yang mendukung
penelitian ini.
2.5 Skala Pengukuran
Maksud dari skala pengukuran ini untuk mengklasifikasikan variabel yang akan
diukur supaya tidak terjadi kesalahan dalam menentukan analisis data dan langkah
penelitian selanjutnya. Jenis-jenis skala pengukuran ada empat yaitu :
a. Skala Nominal
Skala nominal yaitu skala yang paling sederhana disusun menurut jenis
(kategorinya) atau fungsi bilangan hanya sebagai symbol untuk membedakan
sebuah karakteristik dengan karakteristik lainnya. Adapun ciri-ciri skala nominal
antara lain : Hasil penghitungan dan tidak dijumpai bilangan pecahan, angka yang
tertera hanya label saja, tidak mempunyai urutan (rangking), tidak mempunyai
xx
Contoh :
Agama yang dianut : Islam = 1, Kristen = 2, Hindu = 3, Budha = 4, dan
lain-lainya.
b. Skala Ordinal (Rangking)
Skala ordinal ialah skala yang didasarkan pada rangking, diurutkan pada rangking,
diurutkan dari jenjang yang lebih tinggi sampai jenjang terendah atau sebaliknya.
Contoh :
- Mengukur tingkat prestasi kerja
- Mengkur gaji pegawai
- Mengukur rangking kelas : I,II,III
- Kepangkatan militer : Jenderal>Mayor>Kapten>Letnan
c. Skala Interval
Skala interval adalah skala yang menunjukkan jarak antara satu data dengan data
yang lain yang mempunyai bobot yang sama.
Contoh :
1. Skor ujian perguruan tinggi : A,B,C,D dan E
2. Skor IQ
3. Waktu : menit, jam, hari, minggu, bulan, tahun
4. Temperatur atau suhu
5. Mengurutkan : Kualitas pelayanan, keadaan persepsi pegawai dan sikap
pimpinan
Sangat Puas = 5
Puas = 4
Cukup Puas = 3
Kurang Puas = 2
Tidak Puas = 1
d. Skala ratio
Skala ratio adalah skala pengukuran yang mempunyai nilai nol mutlak dan
xxi
keduanya tidak memiliki angka nol negative, artinya seseorang tidak dapat
berumur dibawah nol tahun dan seseorang harus memiliki timbangan diatas nol
pula.
2.6 Skala untuk Instrumen (Model Skala Sikap)
Bentuk-bentuk skala sikap yang sering digunakan dalam penelitian ada 5 macam,
yaitu :
1. Skala Likert
Skala Likert digunakan untuk mengukur sikap, pendapat dan persepsi
seseorang atau sekelompok tentang kejadian atau gejala sosial. Dalam
penelitian gejala sosial ini telah ditetapkan secara spesifik oleh peneliti, yang
selanjutnya disebut sebagai variabel penelitian.
Dengan menggunakan skala likert, maka variabel yang akan diukur dijabarkan
menjadi dimensi, dimensi dijabarkan menjadi sub variabel kemudian sub
variabel dijabarkan lagi menjadi indikator-indikator yang dapat diukur.
Akhirnya indikator-indikator yang terukur ini dapat dijadikan titik tolak untuk
membuat item instrument yang berupa pernyataan atau pernyataan yang perlu
dijawab oleh responden. Setiap jawaban dihubungkan dengan bentuk
pernyataan atau dukungan sikap yang diungkapkan dengan kata-kata.
Misalnya :
Sangat Setuju (SS) = 5
Setuju (S) = 4
Ragu-ragu/Tidak Tahu (TT) = 3
Tidak Setuju (TS) = 2
Sangat Tidak Setuju (STS) = 1
Sangat Puas = 5
Puas = 4
Cukup Puas = 3
Kurang Puas = 2
xxii
2. Skala Guttman
Skala Guttman merupakan skala kumulatif. Skala Guttman mengukur suatu
dimensi saja dari suatu variabel yang multidimensi. Skala Guttman adalah
skala yang digunakan untuk jawaban yang bersifat jelas (tegas) dan konsisten.
Misalnya : Yakin – Tidak Yakin, Ya – Tidak, Salah – Benar, Positif –
Negatif, Pernah – Belum Pernah, Setuju – Tidak Setuju, dan lain sebagainya.
3. Skala Diferensial Semantik
Skala Diferensial Semantik atau skala perbedaan semantik berisikan
serangkaian karakteristik bipolar (dua kutup). Responden diminta untuk
menilai suatu objek atau konsep pada suatu skala yang mempunyai 2 ejektif
yang bertentangan.
Seperti : Panas – Dingin, Populer – Tidak Populer, Bagus – Buruk, dan
sebagainya.
4. Rating Scale
Rating Scale yaitu data mentah yang didapat berupa angka kemudian
ditafsirkan dalam pengertian kualitatif.
Misalnya : ketat – longgar, lemah – kuat, positif – negative
5. Skala Thurstone
Skala Thurstone meminta responden untuk memilih jawaban yang ia setujui
dari beberapa pertanyaan yang menyajikan pandangan – pandangan berbeda –
beda. Pada umumnya asosiasi antara 1 sampai 9 tetapi nilainya tidak
diketahui oleh responden.
2.7 Metode Pengumpulan Data
Pengumpulan data penelitian dimaksudkan sebagai pencatatan peristiwa atau
karakteristik dari sebagian peristiwa atau seluruh elemen proposal penelitian.
Pengumpulan data penelitian dapat dilakukan berdasarkan cara-cara tertentu.
xxiii
a. Metode dokumentasi
Metode dokumentasi adalah mencari data mengenai hal-hal atau variabel yang
berupa catatan, transkip, buku, surat kabar, majalah, prasasti, notulen rapat,
agenda dan sebagainya. Metode dokumentasi dalam penelitian ini digunakan
untuk mengumpulkan data tentang kecemasan mahasiswa dalam menyelesaikan
skripsi.
b. Metode Angket (kuisioner)
Kuisioner adalah pertanyaan tertulis yang digunakan untuk memperoleh informasi
dari respoden dalam arti laporan tentang pribadinya atau hal-hal yang ia ketahui.
Untuk mengetahui distribusi frekuensi masing-masing variabel yang
pengumpulan datanya menggunakan angket (kuisioner), setiap indikator dari data
yang dikumpulkan terlebih dahulu diklasifikasikan dan diberi skor atau nilai yaitu:
Skor 5 jika jawaban responden selalu atau sangat tinggi
Skor 4 jika jawaban responden sering atau tinggi
Skor 3 jika jawaban kadang-kadang atau cukup tinggi
Skor 2 jika jawaban jarang atau rendah
Skor 1 jika jawaban tidak pernah atau rendah sekali
c. Wawancara
Wawancara merupakan teknik pengumpulan data dalam metode survey yang
menggunakan pertanyaan secara lisan kepada subjek penelitian. Teknik
wawancara dilakukan jika peneliti memerlukan komunikasi atau hubungan
dengan responden.
2.8Uji Dalam Pengolahan Data
2.8.1 Uji Validitas
Validitas menunjukkan sejauh mana ketepatan dan kecermatan suatu alat ukur
dalam melakukan fungsi ukurnya. Suatu test atau instrument pengukur dapat
dikatakan mempunyai validitas yang tinggi apabila alat ukur tersebut menjalankan
xxiv
dilakukannya pengukuran tersebut. Metode yang digunakan untuk menguji
validitas adalah dengan korelasi product moment yang rumusnya sebagai berikut :
rxy =
√ (2.2)
Keterangan :
rxy = Koefsien korelasi
X = Skor Variabel
Y = Skor Total
n = Jumlah Sampel
Untuk menentukan valid tidaknya variabel adalah dengan cara mengkonsultasikan
hasil perhitungan koefsien korelasi dengan tabel nilai koefsien (r) pada taraf
kepercayaan 95%.
Apabila rxy≥ rtabel valid
Apabila rxy < rtabel tidak valid (Ade Fatma, 2007)
2.8.2. Uji Reliabilitas
Reliabilitas menunjukkan sejauh mana hasil pengukuran dapat dipercaya.
Pengukuran yang memiliki reliabilitas tinggi disebut sebagai pengukuran yang
reliabilitas. Metode yang digunakan untuk menguji reliabilitas adalah metode
Alpha Cronbach. Variabel dikatakan reliabel jika memberikan nilai Alpha
Cronbach > 0,60 (Ade Fatma, 2007).
r =
(2.3)
Keterangan :
r = nilai (koefsien) Alpha Cronbach
k = Banyaknya variabel penelitian
xxv
2.9Analisis Faktor
2.9.1 Pengertian Analisis Faktor
Yang dimaksud dengan analisis faktor ialah suatu analisis yang mensyaratkan
adanya keterkaitan antar variabel. Tujuan utama teknik ini ialah untuk membuat
ringkasan informasi yang dikandung dalam sejumlah besar variabel kedalam suatu
kelompok faktor yang lebih kecil.
Teknik ini bermanfaat untuk mengurangi jumlah data dalam rangka untuk
mengidentifikasi sebagian kecil faktor yang dapat menerangkan varians yang
sedang diteliti secara lebih jelas dalam suatu kelompok variabel yang jumlahnya
besar. Kegunaan utama analisis faktor ialah untuk melakukan pengurangan data
atau dengan kata lain melakukan peringkasan sejumlah variabel menjadi lebih
kecil jumlahnya. Pengurangan dilakukan dengan melihat interdependensi
beberapa variabel yang dapat dijadikan satu yang disebut dengan faktor sehingga
diketemukan variabel-variabel atau faktor-faktor yang dominan atau penting
untuk dianalisa lebih lanjut.
Untuk menggunakan teknik ini persyaratan yang sebaiknya dipenuhi ialah :
a. Data yang digunakan ialah data kuantitatif berskala interval atau ratio
b. Data harus mempunyai distribusi normal bivariate untuk masing-masing
pasangan variabel
c. Model ini mengkhususkan bahwa semua variabel ditentukan oleh
faktor biasa (faktor yang diestimasikan oleh model) dan
faktor-faktor unik (yang tidak tumpang tindih antara variabel-variabel yang
sedang diobservasi)
d. Estimasi yang dihitung didasarkan pada asumsi bahwa semua faktor unik
tidak saling berkorelasi satu dengan lainnya dan dengan faktor-faktor
biasa.
e. Persyaratan dasar untuk melakukan penggabungan ialah besarnya korelasi
antar variabel independen setidak-tidaknya 0,5 karena prinsip analisis
xxvi
Analisis faktor dapat digunakan di dalam situasi sebagai berikut :
1. Mengenali atau mengidentifikasi dimensi yang mendasari (underlying
dimensions) atau faktor, yang menjelaskan korelasi antara suatu set
variabel.
2. Mengenali atau mengidentifikasi suatu set variabel baru yang tidak
berkorelasi (independen) yang lebih sedikit jumlahnya untuk
menggantikan suatu set variabel asli yang saling di dalam analisis
multivariat selanjutnya, misalnya analisis regresi berganda dan analisis
diskriminan.
3. Mengenali atau mengidentifikasi suatu set variabel yang penting dari suatu
set variabel yang lebih banyak jumlahnya untuk dipergunakan di dalam
analisis multivariat selanjutnya.
2.9.2 Model Analisis Faktor
Secara matematis, analisis faktor hamper sama dengan analisis regresi, yaitu
dalam hal bentuk fungsi linier. Jumlah varians yang dikontribusi dari sebuah
variabel dengan seluruh variabel lainnya lebih dikelompokkan sebagai
komunalitas. Kovarians diantara variabel dijelaskan terbatas dalam sejumlah kecil
komponen ditambah sebuah faktor unik untuk setiap variabel. Faktor-faktor
tersebut tidak secara eksplisit diamati. Jika variabel distandarisasi, maka model
analisis faktor dapat dilihat dari persamaan (1.1).
Faktor yang unik tidak berkorelasi dengan sesama faktor yang unik dan juga tidak
berkorelasi dengan komponen faktor. Komponen faktor sendiri bisa dinyatakan
sebagai kombinasi linier dari variabel-variabel yang terlihat/terobservasi hasil
penelitian lapangan.
Fi = Wi1 X1 + Wi2 X2 + Wi3 X3+ … + Wik Xk (2.4)
Dimana
Fi = Perkiraan faktor ke-i (didasarkan pada nilai variabel X dengan koefsiennya
xxvii
Wi = Koefsien nilai faktor ke-i
k = Banyaknya variabel (ada 8 variabel)
Xi= Variabel ke i ; i = 1,2,3 … k
2.9.3. Statistik yang berkaitan dengan Analisis Faktor
Statistik yang berkaitan dengan analisis faktor adalah :
a. Uji Barlett
Pengujian ini digunakan untuk melihat apakah variabel yang digunakan
berkorelasi dengan variabel lainnya. Jika variabel-variabel yang digunakan sama
sekali tidak mempunyai korelasi dengan variabel lainnya, sudah tentu analisis
faktor tidak dapat dilakukan.
Dalam hal ini pengujian dilakukan dengan menggunakan Statistik Chi Square,
sebagaimana dapat dilihat dibawah ini :
X2 = - | | (2.5)
Keterangan :
N = Jumlah Populasi
| |= Determinan matriks korelasi k = jumlah variabel
b. Correlation matrix (Matriks Korelasi)
Matriks ialah suatu kumpulan angka-angka (sering disebut elemen-elemen) yang
disusun menurut baris dan kolom sehingga berbentuk empat persegi panjang,
dimana panjangnya dan lebarnya ditunjukkan oleh banyaknya kolom-kolom dan
baris-baris.
Matriks korelasi adalah matriks yang menunjukkan korelasi sederhana (r)
antara seluruh kemungkinan pasangan variabel yang dilibatkan dalam analisis.
Apabila suatu matriks A terdiri dari m baris dan n kolom, maka matriks A
xxviii
Komunalitas adalah jumlah varian yang dikontribusi dari sebuah variabel dengan
seluruh variabel lainnya dalam analisis. Ini juga merupakan proporsi dari varians
yang diterangkan oleh komponen faktor.
Nilai eigen merupakan jumlah varians yang dijelaskan oleh setiap faktor-faktor
yang mempunyai nilai eigen > 1, maka faktor tersebut akan dimasukkan ke dalam
model. (J.Supranto, 2010).
Definisi :
Jika A adalah sebuah matriks nxn, maka sebuah vector tak nol x pada Rn disebut
eigenvector dari A jika Ax adalah sebuah kelipatan scalar dari x; jelasnya,
Ax = λx
Untuk scalar sebarang λ, scalar λ disebut nilai eigen dari A, dan x disebut sebagai
xxix
e. Faktor Loadings(Faktor Muatan)
Faktor muatan adalah korelasi sederhana antara variabel dengan faktor
f. Faktor Loading Plot(Plot Faktor Muatan)
Plot faktor muatan adalah suatu plot dari variabel asli dengan menggunakan factor
loading sebagai koordinat.
g. Faktor Matrix(Faktor Matriks)
Matriks faktor mengandung factor loading dari seluruh variabel dalam seluruh
faktor yang dikembangkan.
h. Kaiser – Meyer – Olkin (KMO) measure of sampling adequency
Kaiser – Meyer – Olkin (KMO) merupakan suatu indeks yang digunakan untuk
menguji ketepatan analisis faktor. Nilai yang tinggi (antara 0,5 – 1,0)
mengidentifikasi analisis faktor tepat. Apabila dibawah 0,5 menunjukkan bahwa
analisis faktor tidak tepat untuk diaplikasikan.
KMO =
(2.7)
Keterangan :
rik = koefsien korelasi sederhana antara variabel ke-I dan ke-k
aik = koefsien korelasi parsial antara variabel ke-i dan ke-k
Measure of sampling adequacy (MSA) yaitu suatu indeks perbandingan antara
koefsien korelasi parsial untuk setiap variabel. MSA digunakan untuk mengukur
kecukupan sampel.
i. Percentage of variance(Persentase Varians)
Persentase varians adalah persentase total varians yang disumbangkan oleh setiap