ANALISIS DAN PREDIKSI PADA PERILAKU MAHASISWA
DIPLOMA UNTUK MELANJUTKAN STUDI KE
JENJANG SARJANA MENGGUNAKAN
TEKNIK DECISION TREE DAN
SUPPORT VEKTOR MACHINE
TESIS
Oleh
HERI SANTOSO
097038017/TINF
PROGRAM STUDI MAGISTER (S2) TEKNIK INFORMATIKA FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA MEDAN
ANALISIS DAN PREDIKSI PADA PERILAKU MAHASISWA
DIPLOMA UNTUK MELANJUTKAN STUDI KE
JENJANG SARJANA MENGGUNAKAN
TEKNIK DECISION TREE DAN
SUPPORT VEKTOR MACHINE
TESIS
Diajukan sebagai salah satu syarat untuk memperoleh gelar
Magister Komputer dalam Program Studi Magister
Teknik Informatika pada Program Pascasarjana
Fakultas Ilmu Komputer dan Teknologi Informasi
Universitas Sumatera Utara
Oleh
HERI SANTOSO 097038017/TINF
PROGRAM STUDI MAGISTER (S2) TEKNIK INFORMATIKA FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA MEDAN
PENGESAHAN TESIS
Judul Tesis : ANALISIS DAN PREDIKSI PADA PERI LAKU MAHASISWA DIPLOMA UNTUK MELANJUTKAN STUDI KE JENJANG
SARJANA MENGGUNAKAN TEKNIK
DECISION TREE DAN SUPPORT VEKTOR MACHINE
Nama Mahasiswa : HERI SANTOSO Nomor Induk Mahasiswa : 097038017
Program Studi : MAGISTER TEKNIK INFORMATIKA
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI
INFORMASI
UNIVERSITAS SUMATERA UTARA
Menyetujui Komisi Pembimbing
Dr. Marwan Ramli
Anggota Ketua
Prof. Dr. Muhammad Zarlis
Ketua Program Studi Dekan
Prof. Dr. Muhammad Zarlis Prof. Dr. Muhammad Zarlis NIP : 195707011986011003 NIP :
PERNYATAAN ORISINALITAS
ANALISIS DAN PREDIKSI PADA PERILAKU MAHASISWA
DIPLOMA UNTUK MELANJUTKAN STUDI KE
JENJANG SARJANA MENGGUNAKAN
TEKNIK DECISION TREE DAN
SUPPORT VEKTOR MACHINE
TESIS
Dengan ini saya nyatakan bahwa saya mengakui semua karya tesis ini adalah hasil kerja saya sendiri kecuali kutipan dan ringkasan yang tiap bagiannya telah di jelaskan sumbernya dengan benar.
Medan, Juli 2012
PERNYATAAN PERSETUJUAN PUBLIKASI
KARYA ILMIAH UNTUK KEPENTINGAN
AKADEMIS
Sebagai sivitas akademika Universitas Sumatera Utara, saya yang bertanda tangan
di bawah ini:
Nama : HERI SANTOSO
Nim : 097038017
Program Studi : Magister ( S2) Teknik Informatika
Jenis Karya Ilmiah : TESIS
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada
Universitas Sumatera Utara Hak Bebas Royalti Non-Eksklusif (Non-Exclusive Royalty free Right) atas Tesis saya yang berjudul:
ANALISIS DAN PREDIKSI PADA PERILAKU MAHASISWA
DIPLOMA UNTUK MELANJUTKAN STUDI KE JENJANG
SARJANA MENGGUNAKAN TEKNIK DECISION TREE
DAN SUPPORT VEKTOR MACHINE
Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti Non-Eksklusif ini, Universitas Sumatera Utara berhak menyimpan, mengalih media,
memformat, mengelola dalam bentuk database, merawat dan mempublikasikan
Tesis saya tanpa meminta izin dari saya selama tetap mencantumkan nama saya
sebagai penulis dan sebagai pemegang dan atau sebagai pemilik hak cipta.
Demikian pernyataan ini dibuat dengan sebenarnya.
Medan, Juli 2012
Telah diuji pada
Tanggal : 10 Juli 2012
PANITIA PENGUJI TESIS
Ketua : Prof. Dr. Muhammad Zarlis Anggota : 1. Prof. Dr. Herman Mawengkang
2. Prof. Dr. Tulus
RIWAYAT HIDUP
DATA PRIBADI
Nama lengkap berikut gelar : Heri Santoso, SKom
Tempat dan Tanggal Lahir : Medan, 19 Nopember 1967
Alamat Rumah : Jl. Besitang No. 54 P. Brandan
Telepon / HP : 0821 6700 5000
Instansi Tempat Bekerja : AMIK Tunas Bangsa
Alamat Kantor : Jl. Jendral Sudirman Blok A No. 1,2,3
Pematangsiantar
Telepon : (0622) 22431
DATA PENDIDIKAN
SD : SD NEGERI No. 050747 Tamat : 1980
SMP : SMP BABALAN Tamat : 1983
SMA : SMU NEGERI 1 Tamat : 1986
D3 : AMIK LOGIKA MEDAN Tamat : 2005
Strata-1 : STMIK LOGIKA Medan Tamat : 2006
KATA PENGANTAR
Pertama-tama kami panjatkan puji syukur kehadirat Allah SWT Tuhan
Yang Maha Esa atas segala limpahan rakhmad dan karunia-Nya sehingga Tesis ini
dapat diselesaikan melalui bimbingan, arahan dan bantuan yang diberikan
berbagai pihak khususnya pembimbing, pembanding, para dosen, teman teman
mahasiswa, khususnya mahasiswa Program Studi Magister (S2) Teknik
Informatika di Fasilkom-TI Universitas Sumatera Utara.
Tesis dengan judul: ” Analisis dan prediksi pada perilaku mahasiswa
diploma untuk melanjutkan studi ke jenjang sarjana menggunakan teknik decision
tree dan support vektor machine ” adalah merupakan Tesis dan syarat untuk
memperoleh gelar Magister Komputer dalam Program Studi Magister (S2) Teknik
Informatika pada Program Pascasarjana Fasilkom-TI Universitas Sumatera Utara
Dengan selesainya tesis ini, perkenankanlah penulis mengucapkan terima
kasih yang sebesar-besarnya kepada:
Ketua Yayasan Muhammad Nasir AMIK Tunas Bangsa Pematangsiantar
H. Maulia Ahmad Ridwan Syah , Direktur AMIK Tunas Bangsa Pematangsiantar
Dedi Hartama yang telah memberikan izin, bantuan moril dan materil dan
kesempatan kepada penulis untuk mengikuti pendidikan lanjutan pada Program
Pascasarjana Fasilkom-TI USU.
Rektor Universitas Sumatera Utara, Prof. Dr. dr. Syahril Pasaribu,
DTM&H, M,Sc (CTM), Sp. A(K) atas kesempatan yang diberikan kepada penulis
untuk mengikuti dan menyelesaikan pendidikan Program Magister (S2).
Dekan Fasilkom-TI Universitas Sumatera Utara, Ketua Program Studi
Program Studi Magister (S2) Teknik Informatika M. Andri Budiman, ST, M.
Comp. Sc, M.EM beserta seluruh Staff dan Staff Pengajar pada Program Studi
Magister (S2) Teknik Informatika Program Pascasarjana Fasilkom-TI Universitas
Sumatera Utara, yang telah bersedia membimbing penulis, sehingga dapat
menyelesaikan pendidikan tepat pada waktunya.
Terimakasih yang tak terhingga dan penghargaan setinggi-tingginya kami
ucapkan kepada Prof. Dr. Muhammad Zarlis selaku Pembimbing Utama dan Dr.
Marwan Ramli selaku Pembimbing Anggota yang dengan penuh kesabaran
membimbing, memotivasi, memberikan dukungan moril, kritik dan saran serta
memberikan bahan-bahan yang berkaitan dengan penyusunan tesis ini sehingga
penulis dapat menyelesaikan tesis ini dengan baik.
Terimakasih yang tak terhingga dan penghargaan setinggi-tingginya kami
ucapkan kepada Prof. Dr. Herman Mawengkang, Prof. Dr. Tulus, dan Dr.
Zakarias Situmorang sebagai pembanding, yang telah memberikan saran,
masukan dan arahan yang baik demi penyelesaian tesis ini.
Orangtua tercinta Ibunda, serta Bapak dan Ibu Mertua dan semua keluarga
yang senantiasa mendoakan, dan memberikan dorongan kepada penulis.
Istri tercinta, Marina Artha, Amd yang selalu mendoakan, memberikan
semangat, dengan kasih, sabar dan bantuan selama penulis mengikuti pendidikan,
budi baik ini tidak dapat dibalas hanya diserahkan kepada Allah SWT, Tuhan
Yang maha Esa. Sekali lagi terima kasih.
Rekan Mahasiswa Angkatan Kedua Program Studi Magister (S2) Teknik
Informatika Komputer Fasilkom-TI Universitas Sumatera Utara dan Rekan
Sejawat di AMIK Tunas Bangsa Pematangsiantar yang telah banyak membantu
Dengan segala kekurangan dan kerendahan hati, semoga kiranya Allah
SWT Tuhan Yang Maha Kuasa membalas segala bantuan, kebaikan yang telah
diberikan.
Medan, Juli 2012 Penulis,
ANALISIS DAN PREDIKSI PADA PERILAKU MAHASISWA
DIPLOMA UNTUK MELANJUTKAN STUDI KE JENJANG
SARJANA MENGGUNAKAN TEKNIK DECISION TREE
DAN SUPPORT VEKTOR MACHINE
ABSTRAK
Tesis ini mengusulkan sebuah model prediksi keinginan mahasiswa diploma untuk melanjutkan studi ke jenjang sarjana di perguruan tinggi swasta. Faktor-faktor mana yang lebih dominan yang mempengaruhi keinginan mahasiswa belum dapat diketahui dengan pasti. Data diperoleh dari database Akademik AMIK Tunas Bangsa dan hasil survei terhadap mahasiswa semester IV tahun ajaran 2009 dan 2010. Dalam tesis ini algoritma C 4.5 decision tree diaplikasikan agar mendapatkan suatu model prediksi yang dapat memperlihatkan keinginan mahasiswa diploma melanjutkan kejenjang sarjana dengan jurusan yang sama atau jurusan yang berbeda dan bahkan tidak ada keinginan untuk melanjutkan studinya . Faktor-faktor yang mempengaruhi adalah kepercayaan diri, dukungan orang tua , minat belajar, perilaku belajar dan waktu belajar terhadap mahasiswa. Model prediksi yang diperoleh menunjukkan bahwa variabel terbaik dari prediktor yang digunakan adalah faktor kepercayaan diri yang memberikan kontribusi sebesar 79,8% terhadap keinginan mahasiswa melanjutkan studi ke jenjang sarjana.
Prediction Analysis on Diploma Student Behaviour
In Pursuing Bachelor Degree Using DecisionTree
Technique And Support Vector Machine
ABSTRACT
This thesis proposes a model to predict the desire of diploma student to pursue education to bachelor degree in private college. The more dominant factors which influence this desire are not known yet. Data was obtained from Academy of Management and Information Tunas Bangsa in Pematangsiantar database and of survey result of 2009 and 2010 fourth semester students.. In this thesis The C 4.5 algorithm decision tree was applied to obtain a prediction model which may indicate the desire of diploma degree students to pursue a bachelor‘s degree whether in the same department or in a different one, or no desire at all. Influencing factoris include self confidence, parental support, study interest, study behavior, and study duration. The prediction model obtained indicated that the best variable from the predictors used was self confidence which contributed 79,8 % to the desire of students to pursue the bachelor degree.
DAFTAR ISI
Halaman
KATA PENGANTAR i
ABSTRAK ii
ABSTRACT iii
DAFTAR ISI iv
BAB I PENDAHULUAN 1
1.1 Latar Belakang 1
1.2 Perumusan Masalah 4
1.3 Batasan Masalah 4
1.4 Tujuan Penelitian 5
1.5 Manfaat Penelitian 5
BAB II TINJAUAN PUSTAKA 6
2.1 Pengertian Data Mining 6
2.2 Pengelompokan Data Mining 13
2.3 Decision Tree 15
2.4 Algoritma C 4.5 16
2.5 Ekstraksi Rule dari Decision Tree 24
2.6 Support Vektor Machine 25
2.7 Riset- riset Terkait 26
2.8 Kontribusi Riset 27
BAB III METODE PENELITIAN 29
3.1. Pendahuluan 29
3.2 Lokasi dan Waktu Penelitian 29
3.3 Rancangan Penelitian 30
3.4 Prosedur Pengumpulan Data 31
3.5 Validitas dan Reabilitas (Keakuratan Data) 31
3.6 Preprocessing Data 32
3.6.1 Preprocessing Data Kuesioner 32
3.7.1 Paket Statitik Untuk Ilmu Sosial 33
3.7.2 Komunitas Rapid Miner 34
3.8 Instrument Penelitian 34
3.9 Diagram Aktifitas Kerja Penelitian 35
3.10 Model Decision Tree 36
3.11 Model Support Vektor Machine 38
BAB IV HASIL DAN PEMBAHASAN 40
4.1. Pendahuluan 40
4.2 Hasil Percobaan 40
4.2.1 Hasil Percobaan Sampel Data 40
4.2.2 Hasil Percobaan Descriptive Data 42
4.2.3 Hasil Percobaan Frekuensi Data 43
4.2.3.1 Statistik Frekuensi Faktor Kepercayaan Diri 43
4.2.3.2 Statistik Frekuensi Faktor DukunganOrang Tua 44
4.2.3.3 Statistik Frekuensi Faktor Minat Belajar 44
4.2.4 Signifikan dan Multicollinearity 46
4.2.4.1 Signifikan 46
4.2.4.2 Multicollinearity 48
4.2.5 Hasil Percobaan Decision Tree 49
4.2.6.Validasi Decision Tree 51
4.2.7.Hasil Percobaan Support Vektor Machine 52
BAB V KESIMPULAN DAN SARAN 56
5.1. Kesimpulan 56
5.2 Saran 57
DAFTAR PUSTAKA 58
ANALISIS DAN PREDIKSI PADA PERILAKU MAHASISWA
DIPLOMA UNTUK MELANJUTKAN STUDI KE JENJANG
SARJANA MENGGUNAKAN TEKNIK DECISION TREE
DAN SUPPORT VEKTOR MACHINE
ABSTRAK
Tesis ini mengusulkan sebuah model prediksi keinginan mahasiswa diploma untuk melanjutkan studi ke jenjang sarjana di perguruan tinggi swasta. Faktor-faktor mana yang lebih dominan yang mempengaruhi keinginan mahasiswa belum dapat diketahui dengan pasti. Data diperoleh dari database Akademik AMIK Tunas Bangsa dan hasil survei terhadap mahasiswa semester IV tahun ajaran 2009 dan 2010. Dalam tesis ini algoritma C 4.5 decision tree diaplikasikan agar mendapatkan suatu model prediksi yang dapat memperlihatkan keinginan mahasiswa diploma melanjutkan kejenjang sarjana dengan jurusan yang sama atau jurusan yang berbeda dan bahkan tidak ada keinginan untuk melanjutkan studinya . Faktor-faktor yang mempengaruhi adalah kepercayaan diri, dukungan orang tua , minat belajar, perilaku belajar dan waktu belajar terhadap mahasiswa. Model prediksi yang diperoleh menunjukkan bahwa variabel terbaik dari prediktor yang digunakan adalah faktor kepercayaan diri yang memberikan kontribusi sebesar 79,8% terhadap keinginan mahasiswa melanjutkan studi ke jenjang sarjana.
Prediction Analysis on Diploma Student Behaviour
In Pursuing Bachelor Degree Using DecisionTree
Technique And Support Vector Machine
ABSTRACT
This thesis proposes a model to predict the desire of diploma student to pursue education to bachelor degree in private college. The more dominant factors which influence this desire are not known yet. Data was obtained from Academy of Management and Information Tunas Bangsa in Pematangsiantar database and of survey result of 2009 and 2010 fourth semester students.. In this thesis The C 4.5 algorithm decision tree was applied to obtain a prediction model which may indicate the desire of diploma degree students to pursue a bachelor‘s degree whether in the same department or in a different one, or no desire at all. Influencing factoris include self confidence, parental support, study interest, study behavior, and study duration. The prediction model obtained indicated that the best variable from the predictors used was self confidence which contributed 79,8 % to the desire of students to pursue the bachelor degree.
BAB I
PENDAHULUAN
1.1 Latar Belakang
Data mining adalah suatu konsep yang digunakan untuk menemukan pengetahuan yang tersembunyi di dalam database. Data mining merupakan proses semi otomatik yang menggunakan teknik statistik, matematika, kecerdasan buatan, dan
machine learning untuk mengekstraksi dan mengidentifikasi informasi pengetahuan potensial dan berguna yang tersimpan di dalam database besar.
(Turban et al, 2005 ). Data mining adalah bagian dari proses KDD ( Knowledge Discovery in Databases) yang terdiri dari beberapa tahapan seperti pemilihan data, pra pengolahan, transformasi, data mining, dan evaluasi hasil (Maimon dan Last, 2000). KDD secara umum juga dikenal sebagai pangkalan data.
Teknik data mining secara garis besar dapat dibagi dalam dua kelompok: verifikasi dan discovery. Metode verifikasi umumnya meliputi teknik-teknik statistik seperti goodness of fit, dan analisis variansi. Metode discovery lebih lanjut dapat dibagi atas model prediktif dan model deskriptif. Teknik prediktif
melakukan prediksi terhadap data dengan menggunakan hasil-hasil yang telah
diketahui dari data yang berbeda. Model ini dapat dibuat berdasarkan penggunaan
data historis lain. Sementara itu, model deskriptif bertujuan mengidentifikasi
pola-pola atau hubungan antar data dan memberikan cara untuk mengeksplorasi
karakteristik data yang diselidiki (Dunham, 2003).
Masih menjadi isu sentral di dunia pendidikan tinggi khususnya program
diploma dalam hal faktor prediktor dan teknik yang digunakan untuk memprediksi
keinginan mahasiswa diploma dalam melanjutkan studinya ke jenjang sarjana
setelah menyelesaikan studi pada tingkat diploma. Hingga saat ini masih jarang
ditemukan prediktor-prediktor serta teknik yang cukup handal dan akurat dalam
memprediksi tingkat keinginan mahasiswa diploma untuk melanjutkan studinya
yang sama atau melanjukan studinya tapi kebidang ilmu yang berbeda atau tidak
malanjutkan studinya.
Dewasa ini kemajuan teknologi informasi dan komputer telah
menyediakan fasilitas penyimpanan data dalam format elektronik sehingga
penyimpanan data bukan lagi menjadi satu pekerjaan yang sulit. Sebagai
konsekuensinya jumlah data yang disimpan mengalami peningkatan yang sangat
cepat dari segi kuantitas dan kualitas. Pada institusi pendidikan tinggi data dapat
diperoleh dari data historis dan data kegiatan operasional sebuah perguruan
tinggi, dimana data ini akan bertambah secara terus menerus, sehingga proses
eksplorasi data dalam menentukan hubungan antar variabel didalam data menjadi
sangat lambat dan memiliki proses yang subjektif. Salah satu Solusi yang
mungkin digunakan untuk menangani masalah ini adalah konsep menemukan
pengetahuan di dalam pangkalan data.
Beberapa tahun belakangan ini telah terjadi peningkatan penelitian di area
pendidikan dengan menggunakan teknik-teknik penambangan data. Aplikasi dari
teknik penambangan data ini difokuskan untuk membangun metode-metode untuk
mengungkapkan pengetahuan yang tersimpan didalam data dan digunakan untuk
membuka informasi yang tersembunyi didalam data yang tidak nampak
dipermukaan tetapi potensial untuk digunakan. Pengungkapan pengetahuan ini
juga dapat digunakan untuk lebih mengetahui bagaimana prilaku belajar seorang
mahasiswa di tingkat diploma, sehingga dapat membantu para dosen untuk lebih
mengenal situasi para mahasiswanya, dapat dijadikan sebagai pengetahuan dini
untuk mengambil tindakan preventif dalam hal mengantisipasi mahasiswa
drop-out, untuk memicu meningkatkan prestasi mahasiswa, untuk meningkatkan
kurikulum, termasuk juga untuk memprediksi keinginan mahasiswa dalam
melanjutkan studinya kejenjang yang lebih tinggi dan banyak lagi keuntungan lain
yang bisa diperoleh dari hasil penambangan data.
Dalam beberapa penelitian yang telah dilakukan oleh peneliti yang
data mining dalam bidang pendidikan antara tahun 1995 sampai 2005, hasil penelitian yang dilakukan menyimpulkan bahwa data mining yang berhubungan dengan pendidikan sangat baik untuk diteliti terutama di bidang e-learning, multimedia, artificial intelligent dan web database. Merceron dan Yacep, (2005) melakukan penelitian menggunakan data mining untuk mengidentifikasi perilaku mahasiswa yang cenderung gagal pada prestasi akademik sebelum ujian akhir.
Waiyamai, (2003) menggunakan data mining untuk membantu dalam pengembangan kurikulum baru. Ogor, (2007) menggunakan teknik data mining
yang digunakan untuk membangun prototipe Penilaian Kinerja Monitoring System
(PAMS) untuk mengevaluasi kinerja mahasiswa. Sembiring, et al., (2009)
menggunakan teknik data mining dalam pemantauan dan memprediksi peningkatan prestasi mahasiswa berdasarkan minat, prilaku belajar, pemanfaatan
waktu dan dukungan orang tua di perguruan tinggi.
Dalam penelitian ini akan di teliti tentang perilaku mahasiswa diploma
untuk melanjutkan studi ke jenjang sarjana akan digunakan teknik decision tree
(C 4.5) untuk menganalisis dan membangun sebuah model prediksi berdasarkan
perilaku belajar mahasiswa diploma dan menggunakan teknik Support Vector
Machine untuk mengklasifikasi mahasiwa tersebut berdasarkan model prediksi
yang diperoleh oleh decision tree. Kedua metode ini dipilih karena metode
decision tree ini cukup sederhana dan banyak dipergunakan oleh peneliti lain
dalam mengembangkan sebuah model. Metode Support Vector Machine (SVM)
merupakan teknik yang relative baru dalam pattern recognition dan merupakan
state of art dalam pattern recognition dan machine learning karena kehandalannya dalam memproses data berdimensi banyak.
Penelitian ini mengambil area pendidikan tinggi sebagai sebagai salah satu
domain penelitian dalam bidang penambangan data dengan sumber data dari
database akademik AMIK Tunas Bangsa Pematang Siantar dan melakukan
survey terhadap 1300 orang mahasiswa D3 Manajemen Informatika AMIK Tunas
Penelitian ini diharapkan dapat memberikan kontribusi bagi perguruan
tinggi swasta khususnya Akademi Manajemen Informatika dan Komputer
(AMIK) Tunas Bangsa Pematangsiantar.
1.2 Perumusan Masalah
Berdasar pada latar belakang di atas, maka dapat dirumuskan masalah dalam tesis
ini sebagai berikut:
1.Bagaimana membangun model yang dapat digunakan untuk memprediksi
keinginan para alumni diploma untuk melanjutkan studinya ke jenjang
sarjana ?
2.Bagaimana menggunakan model untuk memprediksi keinginan para
alumni diploma unutk melanjutkan studinya ke jenjang sarjana ?
1.3 Batasan Masalah
Mengingat luasnya ruang lingkup penelitian dalam implemantasi teknik -
teknik data mining di area pendidikan , khususnya pada pendidikan tinggi,
maka penelitian ini dibatasi pada:
1. Sumber data untuk penelitian ini, diperoleh dari database akademik dan
hasil survey secara acak yang dilakukan terhadap mahasiswa program
diploma tiga bidang informatika dan komputer di AMIK Tunas Bangsa
Pematang Siantar.
2. Pendekatan dalam analisis data dalam penelitian ini akan menggunakan
teknik Multi variant analisis untuk menguji tingkat korelasi faktor-faktor
prediktor yang akan diusulkan dan Decision tree (Algoritma C.4.5) untuk
membangun model prediksi serta teknik SVM untuk memprediksi
keinginan mahasiswa program diploma tiga yang akan melanjutkan
studinya ke jenjang sarjana.
3. Untuk mendukung analisis data dalam penelitian ini akan menggunakan
bantuan perangkat lunak data mining yang berbasis open source seperti
1.4 Tujuan Penelitian
Beranjak dari latarbelakang permasalahan, tujuan penelitian ini adalah sebagai
berikut:
1. Untuk mendapatkan apa saja factor-faktor yang berpengaruh terhadap
keinginan mahasiswa program diploma 3 bidang informatika dan
komputer untuk melanjutkan pendidikannya ke jenjang yang lebih tinggi.
2. Untuk membangun sebuah model prediksi mahasiswa program diploma 3
bidang informatika dan komputer yang akan melanjutkan studinya ke
jenjang sarjana.
1.5 Manfaat Penelitian
Penelitian ini secara teoritis diharapkan akan bermanfaat bagi menambah
khasanah dan variasi penelitian dalam penerapan teknik-teknik data mining pada
area pendidikan. Hasil dari penelitian ini diharapkan dapat dijadikan sebagai
perbandingan bagi peneliti lain yang tertarik dalam penerapan teknik-teknik data
mining pada area pendidikan.
Secara praktis hasil penelitian ini juga dapat bermanfaat bagi institusi pendidikan
tinggi sebagai referensi dan sebagai informasi pendukung dalam mengambil
kebijakan strategis.
Model prediksi yang diperoleh dari penelitian ini juga dapat dipergunakan oleh
institusi-institusi pendidikan tinggi yang memiliki program sarjana, sebagai sistem
informasi pendukung untuk promosi dengan sasaran mahasiswa yang sedang
BAB II
TINJAUAN PUSTAKA
2.1 Pengertian Data Mining
Data mining adalah suatu istilah yang digunakan untuk menemukan pengetahuan yang tersembunyi di dalam database. Data mining merupakan proses semi otomatik yang menggunakan teknik statistik, matematika, kecerdasan buatan, dan
machine learning untuk mengekstraksi dan mengidentifikasi informasi pengetahuan potensial dan berguna yang bermanfaat yang tersimpan di dalam
database besar. (Turban et al, 2005 ). Menurut Gartner Group data mining adalah suatu proses menemukan hubungan yang berarti, pola, dan kecenderungan dengan
memeriksa dalam sekumpulan besar data yang tersimpan dalam penyimpanan
dengan menggunakan teknik pengenalan pola seperti teknik statistik dan
matematika (Larose, 2006).
Selain definisi di atas beberapa definisi juga diberikan seperti, “data mining adalah serangkaian proses untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara
manual.” (Pramudiono, 2006). “Data mining adalah analisis otomatis dari data yang berjumlah besar atau kompleks dengan tujuan untuk menemukan pola atau
kecenderungan yang penting yang biasanya tidak disadari keberadaannya.”
(Pramudiono, 2006).
“Data mining merupakan analisis dari peninjauan kumpulan data untuk menemukan hubungan yang tidak diduga dan meringkas data dengan cara yang
berbeda dengan sebelumnya, yang dapat dipahami dan bermanfaat bagi pemilik
data.” (Larose, 2006). “Data mining merupakan bidang dari beberapa keilmuan yang menyatukan teknik dari pembelajaran mesin, pengenalan pola, statistik,
database, dan visualisasi untuk penanganan permasalahan pengambilan informasi
dari database yang besar.” (Larose, 2006).
Kemajuan luar biasa yang terus berlanjut dalam bidang data mining
1. Pertumbuhan yang cepat dalam kumpulan data.
2. Penyimpanan data dalam data warehouse, sehingga seluruh perusahaan memiliki akses ke dalam database yang baik.
3. Adanya peningkatan akses data melalui navigasi web dan intranet.
4. Tekanan kompetisi bisnis untuk meningkatkan penguasaan pasar dalam
globalisasi ekonomi.
5. Perkembangan teknologi perangkat lunak untuk data mining
(ketersediaan teknologi).
6. Perkembangan yang hebat dalam kemampuan komputasi dan
pengembangan kapasitas media penyimpanan.
Berdasarkan definisi-definisi yang telah disampaikan, hal penting yang
terkait dengan data mining adalah :
1. Data mining merupakan suatu proses otomatis terhadap data yang sudah ada.
2. Data yang akan diproses berupa data yang sangat besar.
3. Tujuan data mining adalah mendapatkan hubungan atau pola yang mungkin memberikan indikasi yang bermanfaat.
Hubungan yang dicari dalam data mining dapat berupa hubungan antara dua atau lebih dalam satu dimensi. Misalnya dalam dimensi produk, dapat di lihat
keterkaitan pembelian suatu produk dengan produk yang lain. Selain itu,
hubungan juga dapat dilihat antara dua atau lebih atribut dan dua atau lebih objek.
(Ponniah, 2001).
Sementara itu, penemuan pola merupakan keluaran lain dari data mining. Misalkan sebuah perusahaan yang akan meningkatkan fasilitas kartu kredit dari
pelanggan, maka perusahaan akan mencari pola dari pelanggan-pelanggan yang
ada untuk mengetahui pelanggan yang potensial dan pelanggan yang tidak
potensial.
terhadap data dalam jumlah besar dengan tujuan menemukan pola atau aturan
yang berarti (Larose, 2006).
Tiga tahun kemudian, dalam buku Mastering Data Mining mereka memberikan definisi ulang terhadap pengertian data mining dan memberikan pernyataan bahwa “jika ada yang kami sesalkan adalah frasa secara otomatis
maupun semi otomatis, karena kami merasa hal tersebut memberikan fokus
berlebih pada teknik otomatis dan kurang pada eksplorasi dan analisis”. Hal
tersebut memberikan pemahaman yang salah bahwa data mining merupakan produk yang dapat dibeli dibandingkan keilmuan yang harus dikuasai
(Larose, 2006).
Pernyataan tersebut menegaskan bahwa dalam data mining otomatisasi tidak menggantikan campur tangan manusia. Manusia harus ikut aktif dalam
setiap fase dalam proses data mining. Kehebatan kemampuan algoritma data mining yang terdapat dalam perangkat lunak analisis yang terdapat saat ini memungkinkan terjadinya kesalahan penggunaan yang berakibat fatal. Pengguna
mungkin menerapkan analisis yang tidak tepat terhadap kumpulan data dengan
menggunakan pendekatan yang berbeda. Oleh karenanya, dibutuhkan pemahaman
tentang statistik dan struktur model matematika yang mendasari kerja perangkat
lunak (Larose, 2006).
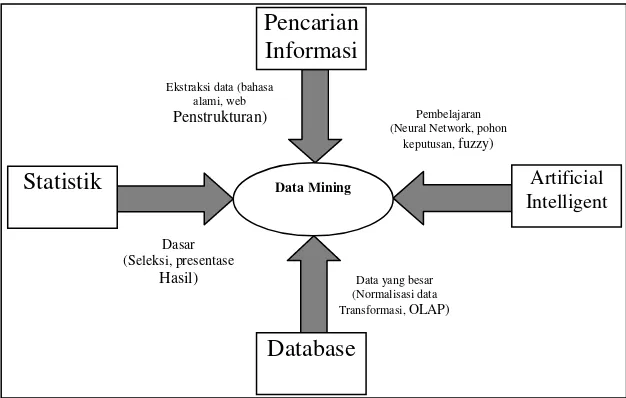
Gambar 2.1 Bidang Ilmu Data Mining
Pencarian Informasi
Database
Artificial Intelligent
Statistik Data Mining Ekstraksi data (bahasa
alami, web
Penstrukturan)
Dasar (Seleksi, presentase
Hasil) Data yang besar
(Normalisasi data Transformasi, OLAP)
Pembelajaran (Neural Network, pohon
Data mining bukanlah suatu bidang yang sama sekali baru. Salah satu kesulitan untuk mendefinisikan data mining adalah kenyataan bahwa data mining
mewarisi banyak aspek dan teknik dari bidang-bidang ilmu yang sudah mapan
terlebih dahulu. Gambar 2.1 menunjukkan bahwa data mining memiliki akar yang panjang dari bidang ilmu seperti kecerdasan buatan (artificial intelligent),
machine learning, statistik, database, dan juga information retrieval
(Pramudiono, 2006).
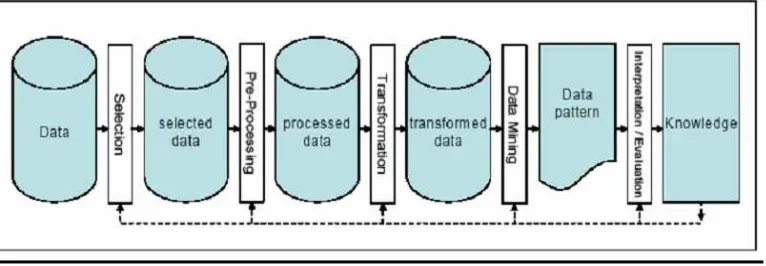
Istilah data mining dan Knowledge Discovery in Database (KDD) sering kali digunakan secara bergantian untuk menjelaskan proses penggalian informasi
tersembunyi dalam suatu basis data yang besar. Sebenarnya kedua istilah tersebut
memiliki konsep yang berbeda, tetapi berkaitan satu sama lain. Dan salah satu
tahapan dalam keseluruhan proses KDD adalah data mining. Proses KDD secara garis besar dapat dijelaskan sebagai berikut (Fayyad, 1996).
1. Data Selection
Pemilihan (seleksi) data dari sekumpulan data operasional perlu
dilakukan sebelum tahap penggalian informasi dalam KDD dimulai.
Data hasil seleksi yang akan digunakan untuk proses data mining,
disimpan dalam suatu berkas, terpisah dari basis data operasional.
2. Pre-processing/Cleaning
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses
cleaning pada data yang menjadi fokus KDD. Proses cleaning
mencakup antara lain membuang duplikasi data, memeriksa data yang
inkonsisten, dan memperbaiki kesalahan pada data, seperti kesalahan
cetak (tipografi). Juga dilakukan proses enrichment, yaitu proses “memperkaya” data yang sudah ada dengan data atau informasi lain
yang relevan dan diperlukan untuk KDD, seperti data atau informasi
eksternal.
3. Transformation
dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis
atau pola informasi yang akan dicari dalam basis data.
4. Data mining
Data mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik,
metode, atau algoritma dalam data mining sangat bervariasi. Pemilihan metode dan algoritma yang tepat sangat bergantung pada tujuan dan
proses KDD secara keseluruhan.
5. Interpretation/Evalution
Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang
berkepentingan. Tahap ini merupakan bagian dari proses KDD yang
disebut interpretation. Tahap ini mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesis
yang ada sebelumnya. Penjelasan di atas dapat direfresentasikan pada
Gambar 2.2
Gambar 2.2 Proses dari Data Mining
Sumber: SPSS, 2004
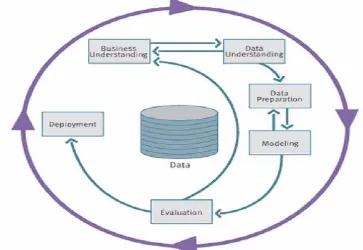
Cross-Industry Standart Process for Data Mining (CRISP-DM) yang di kembangkan tahun 1996 oleh analisis dari beberapa industri seperti Daimler
Chrysler, SPSS dan NCR. CRISP-DM menyediakan standar proses data mining
Dalam CRISP-DM sebuah proyek data mining memiliki siklus hidup yang terbagi dalam enam fase Gambar 2.3. Keseluruhan fase berurutan yang ada
tersebut bersifat adaptif. Fase berikutnya dalam urutan bergantung kepada
keluaran dari fase sebelumnya. Hubungan penting antar fase digambarkan dengan
panah. Sebagai contoh, jika proses berada pada fase modeling. Berdasar pada perilaku dan karakteristik model, proses mungkin kembali kepada fase data preparation untuk perbaikan lebih lanjut terhadap data atau berpindah maju kepada fase evaluation.
Gambar 2.3 Proses Data Mining Menurut CRISP-DM Sumber: CRISP, 2005
Enam fase CRISP-DM ( Cross Industry Standard Process for Data Mining) (Larose, 2006).
1. Fase Pemahaman Bisnis ( Business Understanding Phase )
a. Penentuan tujuan proyek dan kebutuhan secara detail dalam lingkup
bisnis atau unit penelitian secara keseluruhan.
b. Menerjemahkan tujuan dan batasan menjadi formula dari
c. Menyiapkan strategi awal untuk mencapai tujuan.
2. Fase Pemahaman Data ( Data Understanding Phase ) a. Mengumpulkan data.
b. Menggunakan analisis penyelidikan data untuk mengenali lebih
lanjut data dan pencarian pengetahuan awal.
c. Mengevaluasi kualitas data.
d. Jika diinginkan, pilih sebagian kecil kelompok data yang mungkin
mengandung pola dari permasalahan
3. Fase Pengolahan Data ( Data Preparation Phase )
a. Siapkan dari data awal, kumpulan data yang akan digunakan untuk
keseluruhan fase berikutnya. Fase ini merupakan pekerjaan berat
yang perlu dilaksanakan secara intensif.
b. Pilih kasus dan variabel yang ingin dianalisis dan yang sesuai
analisis yang akan dilakukan.
c. Lakukan perubahan pada beberapa variabel jika dibutuhkan.
d. Siapkan data awal sehingga siap untuk perangkat pemodelan.
4. Fase Pemodelan ( Modeling Phase )
a. Pilih dan aplikasikan teknik pemodelan yang sesuai.
b. Kalibrasi aturan model untuk mengoptimalkan hasil.
c. Perlu diperhatikan bahwa beberapa teknik mungkin untuk
digunakan pada permasalahan data mining yang sama.
d. Jika diperlukan, proses dapat kembali ke fase pengolahan data
untuk menjadikan data ke dalam bentuk yang sesuai dengan
spesifikasi kebutuhan teknik data mining tertentu. 5. Fase Evaluasi ( Evaluation Phase )
a. Mengevaluasi satu atau lebih model yang digunakan dalam fase
pemodelan untuk mendapatkan kualitas dan efektivitas sebelum
disebarkan untuk digunakan.
b. Menetapkan apakah terdapat model yang memenuhi tujuan pada
c. Menentukan apakah terdapat permasalahan penting dari bisnis atau
penelitian yang tidak tertangani dengan baik.
d. Mengambil keputusan berkaitan dengan penggunaan hasil dari data mining.
6. Fase Penyebaran (Deployment Phase)
a. Menggunakan model yang dihasilkan. Terbentuknya model tidak
menandakan telah terselesaikannya proyek.
b. Contoh sederhana penyebaran: Pembuatan laporan.
c. Contoh kompleks Penyebaran: Penerapan proses data mining
secara paralel pada departemen lain. Informasi lebih lanjut
mengenai CRISP-DM dapat dilihat di
2.2 Pengelompokan Data Mining
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat di lakukan, yaitu (Larose, 2006).
1.Deskripsi
Terkadang peneliti dan analisis secara sederhana ingin mencoba mencari
cara untuk menggambarkan pola dan kecendrungan yang terdapat dalam
data. Sebagai contoh, petugas pengumpulan suara mungkin tidak dapat
menemukan keterangan atau fakta bahwa siapa yang tidak cukup
profesional akan sedikit didukung dalam pemilihan presiden. Deskripsi
dari pola dan kecendrungan sering memberikan kemungkinan penjelasan
untuk suatu pola atau kecendrungan.
2.Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali variabel target estimasi
lebih ke arah numerik dari pada ke arah kategori. Model dibangun
menggunakan record lengkap yang menyediakan nilai dari variabel target sebagai nilai prediksi. Selanjutnya, pada peninjauan berikutnya estimasi
nilai dari variabel target dibuat berdasarkan nilai variabel prediksi.
Sebagai contoh, akan dilakukan estimasi tekanan darah sistolik pada
dan level sodium darah. Hubungan antara tekanan darah sistolik dan nilai
variabel prediksi dalam proses pembelajaran akan menghasilkan model
estimasi. Model estimasi yang dihasilkan dapat digunakan untuk kasus
baru lainnya.
3.Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa
dalam prediksi nilai dari hasil akan ada di masa mendatang.
Contoh prediksi dalam bisnis dan penelitian adalah:
a. Prediksi harga beras dalam tiga bulan yang akan datang.
b. Prediksi presentase kenaikan kecelakaan lalu lintas tahun depan jika
batas bawah kecepatan dinaikan.
Beberapa metode dan teknik yang digunakan dalam klasifikasi dan
estimasi dapat pula digunakan (untuk keadaan yang tepat) untuk prediksi.
4.Klasifikasi
Dalam klasifikasi, terdapat target variabel kategori. Sebagai contoh,
penggolongan pendapatan dapat dipisahkan dalam tiga kategori, yaitu
pendapatan tinggi, pendapatan sedang, dan pendapatan rendah.
Contoh lain klasifikasi dalam bisnis dan penelitian adalah:
a. Menentukan apakah suatu transaksi kartu kredit merupakan
transaksi yang curang atau bukan.
b. Memperkirakan apakah suatu pengajuan hipotek oleh nasabah
merupakan suatu kredit yang baik atau buruk.
c. Mendiagnosa penyakit seorang pasien untuk mendapatkan
termasuk kategori apa.
5.Pengklusteran
Pengklusteran merupakan pengelompokan record, pengamatan, atau memperhatikan dan membentuk kelas objek-objek yang memiliki
kemiripan.
Pengklusteran berbeda dengan klasifikasi yaitu tidak adanya variabel
target dalam pengklusteran. Pengklusteran tidak mencoba untuk
melakukan klasifikasi, mengestimasi, atau memprediksi nilai dari
variabel target. Akan tetapi, algoritma pengklusteran mencoba untuk
melakukan pembagian terhadap keseluruhan data menjadi
kelompok-kelompok yang memiliki kemiripan (homogen), yang mana kemiripan
dengan record dalam kelompok lain akan bernilai minimal. Contoh pengklusteran dalam bisnis dan penelitian adalah:
a. Mendapatkan kelompok-kelompok konsumen untuk target
pemasaran dari suatu produk bagi perusahaan yang tidak memiliki
dana pemasaran yang besar.
b. Untuk tujuan audit akutansi, yaitu melakukan pemisahan terhadap
prilaku finansial dalam baik dan mencurigakan.
c. Melakukan pengklusteran terhadap ekspresi dari gen, dalam jumlah
besar.
6.Asosiasi
Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul dalam suatu waktu. Dalam dunia bisnis lebih umum disebut
analisis keranjang belanja.
Contoh asosiasi dalam bisnis dan penelitian adalah:
a. Meneliti jumlah pelanggan dari perusahaan telekomunikasi seluler
yang diharapkan untuk memberikan respon positif terhadap
penawaran upgrade layanan yang diberikan.
b. Menemukan barang dalam supermarket yang dibeli secara
bersamaan dan barang yang tidak pernah dibeli bersamaan.
Untuk mendukung penelitian ini penulis menggunakan Algoritma C4.5
decision tree.
2.3 Decision Tree
cabangnya merepresentasikan nilai dari atribut, dan daun merepresentasikan
kelas. Node yang paling atas dari decision tree disebut sebagai root.
Decision tree merupakan metode klasifikasi yang paling populer digunakan. Selain karena pembangunannya relatif cepat, hasil dari model yang
dibangun mudah untuk dipahami.
Pada decision tree terdapat 3 jenis node, yaitu:
a. Root Node, merupakan node paling atas, pada node ini tidak ada input
dan bisa tidak mempunyai output atau mempunyai output lebih dari satu.
b. Internal Node , merupakan node percabangan, pada node ini hanya terdapat satu input dan mempunyai output minimal dua.
c. Leaf node atau terminal node , merupakan node akhir, pada node ini hanya terdapat satu input dan tidak mempunyai output.
2.4 Algoritma C 4.5
Algoritma C 4.5 adalah salah satu metode untuk membuat decision tree
berdasarkan training data yang telah disediakan. Algoritma C 4.5 merupakan
pengembangan dari ID3. Beberapa pengembangan yang dilakukan pada C 4.5
adalah sebagai antara lain bisa mengatasi missing value, bisa mengatasi continue data, dan pruning.
Pohon keputusan merupakan metode klasifikasi dan prediksi yang sangat
kuat dan terkenal. Metode pohon keputusan mengubah fakta yang sangat besar
menjadi pohon keputusan yang merepresentasikan aturan. Aturan dapat dengan
mudah dipahami dengan bahasa alami. Dan mereka juga dapat diekspresikan
dalam bentuk bahasa basis data seperti Structured Query Language untuk mencari
record pada kategori tertentu. Pohon keputusan juga berguna untuk mengeksplorasi data, menemukan hubungan tersembunyi antara sejumlah calon
variabel input dengan sebuah variabel target.
Karena pohon keputusan memadukan antara eksplorasi data dan
pemodelan, pohon keputusan sangat bagus sebagai langkah awal dalam proses
Sebuah pohon keputusan adalah sebuah struktur yang dapat digunakan untuk
membagi kumpulan data yang besar menjadi himpunan-himpunan record yang lebih kecil dengan menerapkan serangkaian aturan keputusan. Dengan
masing-masing rangkaian pembagian, anggota himpunan hasil menjadi mirip satu dengan
yang lain (Berry dan Linoff, 2004).
Sebuah model pohon keputusan terdiri dari sekumpulan aturan untuk
membagi sejumlah populasi yang heterogen menjadi lebih kecil, lebih homogen
dengan memperhatikan pada variabel tujuannya. Sebuah pohon keputusan
mungkin dibangun dengan seksama secara manual atau dapat tumbuh secara
otomatis dengan menerapkan salah satu atau beberapa algoritma pohon keputusan
untuk memodelkan himpunan data yang belum terklasifikasi.
Variabel tujuan biasanya dikelompokkan dengan pasti dan model pohon
keputusan lebih mengarah pada perhitungan probability dari tiap-tiap record
terhadap kategori-kategori tersebut atau untuk mengklasifikasi record dengan mengelompokkannya dalam satu kelas. Pohon keputusan juga dapat digunakan
untuk mengestimasi nilai dari variabel continue meskipun ada beberapa teknik yang lebih sesuai untuk kasus ini.
Banyak algoritma yang dapat dipakai dalam pembentukan pohon
keputusan,antara lain ID3, CART, dan C4.5 (Larose, 2006).
Data dalam pohon keputusan biasanya dinyatakan dalam bentuk tabel
dengan atribut dan record. Atribut menyatakan suatu parameter yang dibuat sebagai kriteria dalam pembentukan pohon. Misalkan untuk menentukan main
tenis, kriteria yang diperhatikan adalah cuaca, angin, dan temperatur.
Salah satu atribut merupakan atribut yang menyatakan data solusi per item data yang disebut target atribut. Atribut memiliki nilai-nilai yang dinamakan dengan
instance. Misalkan atribut cuaca mempunyai instance berupa cerah, berawan, dan hujan (Basuki dan Syarif, 2003)
Proses pada pohon keputusan adalah mengubah bentuk data (tabel)
menjadi model pohon, mengubah model pohon menjadi rule, dan menyederhanakan rule (Basuki dan Syarif, 2003).
Input : sampel training, label training, atribut
1. Membuat simpul akar untuk pohon yang dibuat
2. Jika semua sampel positif, berhenti dengan suatu pohon dengan satu simpul akar, beri tanda (+)
3. Jika semua sampel negatif, berhenti dengan suatu pohon dengan satu simpul akar, beri tanda (-)
4. Jika atribut kosong, berhenti dengan suatu pohon dengan suatu simpul akar, dengan label sesuai nilai yang terbanyak yang ada pada label training 5. Untuk yang lain, Mulai
a. A --- atribut yang mengklasifikasikan sampel dengan hasil terbaik (berdasarkan Gain rasio)
b. Atribut keputusan untuk simpul akar --- A c. Untuk setiap nilai, vi, yang mungkin untuk A
1) Tambahkan cabang di bawah akar yang berhubungan dengan A= vi
2) Tentukan sampel Svi sebagai subset dari sampel yang mempunyai nilai vi untuk atrribut A
3) Jika sampel Svi
i. Di bawah cabang tambahkan simpul daun dengan label = nilai yang terbanyak yang ada pada label training
kosong
ii. Yang lain tambah cabang baru di bawah cabang yang sekarang C4.5 (sampel training, label training, atribut-[A])
d. Berhenti
Mengubah tree yang dihasilkan dalam beberapa rule. Jumlah rule sama dengan jumlah path yang mungkin dapat dibangun dari root sampai leafnode.
Tree Pruning dilakukan untuk menyederhanakan tree sehingga akurasi dapat bertambah. Pruning ada dua pendekatan, yaitu :
a. Pre-pruning, yaitu menghentikan pembangunan suatu subtree lebih awal (yaitu dengan memutuskan untuk tidak lebih jauh mempartisi data
training). Saat seketika berhenti, maka node berubah menjadi leaf (node
akhir). Node akhir ini menjadi kelas yang paling sering muncul di antara
subset sampel.
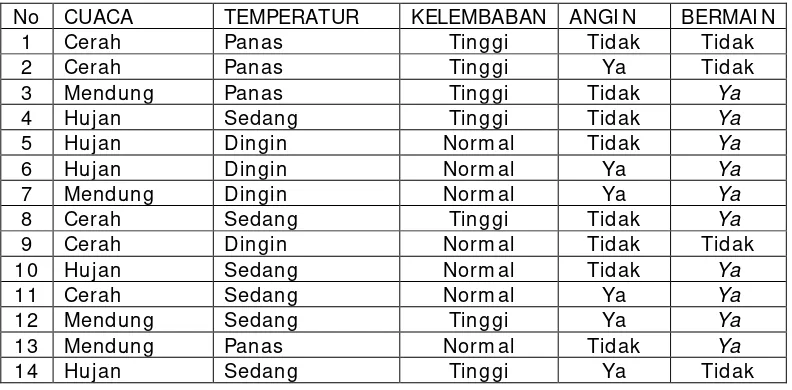
Untuk memudahkan penjelasan mengenai algoritma C 4.5 berikut ini
[image:35.595.120.516.174.369.2]disertakan contoh kasus yang dituangkan dalam Tabel 2.1
Tabel 2.1 Keputusan Bermain Tenis
No CUACA TEMPERATUR KELEMBABAN ANGI N BERMAI N
1 Cerah Panas Tinggi Tidak Tidak
2 Cerah Panas Tinggi Ya Tidak
3 Mendung Panas Tinggi Tidak Ya
4 Huj an Sedang Tinggi Tidak Ya
5 Huj an Dingin Norm al Tidak Ya
6 Huj an Dingin Norm al Ya Ya
7 Mendung Dingin Norm al Ya Ya
8 Cerah Sedang Tinggi Tidak Ya
9 Cerah Dingin Norm al Tidak Tidak
10 Huj an Sedang Norm al Tidak Ya
11 Cerah Sedang Norm al Ya Ya
12 Mendung Sedang Tinggi Ya Ya
13 Mendung Panas Norm al Tidak Ya
14 Huj an Sedang Tinggi Ya Tidak
Dalam kasus yang tertera pada Tabel 2.1 akan dibuat pohon keputusan
untuk menentukan main tenis atau tidak dengan melihat keadaan cuaca,
temperatur, kelembaban dan keadaan angin.
Secara umum algoritma C4.5 untuk membangun pohon keputusan adalah
sebagai berikut:
1. Pilih atribut sebagai akar
2. Buat cabang untuk masing-masing nilai
3. Bagi kasus dalam cabang
4. Ulangi proses untuk masing-masing cabang sampai semua kasus pada
cabang memiliki kelas yang sama.
Untuk memilih atribut sebagai akar, didasarkan pada nilai Gain tertinggi dari atribut-atribut yang ada. Untuk menghitung Gain digunakan rumus seperti tertera dalam Rumus 1 (Craw, 2005).
Gain(S,A) = Entrropy(S) – * Entropy(Si) Dengan
S : Himpunan Kasus A : Atribut
|Si| : Jumlah kasus pada partisi ke i |S| : Jumlah kasus dalam S
Sedangkan perhitungan nilai Entropy dapat dilihat pada rumus 2 berikut (Craw, 2005):
Entropy(A) = Dengan
S : Himpunan Kasus
A : Fitur
n : Jumlah partisi S
pi : Proporsi dari Si terhadap S
Berikut ini adalah penjelasan lebih rinci mengenai masing-masing langkah
dalam pembentukan pohon keputusan dengan menggunakan algoritma C4.5 untuk
menyelesaikan permasalahan pada Tabel 2.1
1. Menghitung jumlah kasus, jumlah kasus untuk keputusan Ya, jumlah
kasus untuk keputusan Tidak, dan Entropy dari semua kasus dan kasus yang dibagi berdasarkan atribut cuaca, temperatur, kelembaban dan
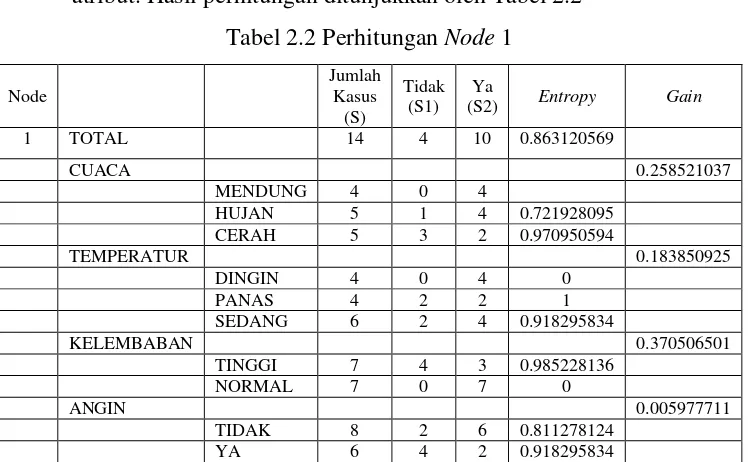
[image:36.595.127.502.492.723.2]angin. Setelah itu lakukan penghitungan Gain untuk masing-masing atribut. Hasil perhitungan ditunjukkan oleh Tabel 2.2
Tabel 2.2 Perhitungan Node 1
Node Jumlah Kasus (S) Tidak (S1) Ya
(S2) Entropy Gain
1 TOTAL 14 4 10 0.863120569
CUACA 0.258521037
MENDUNG 4 0 4
HUJAN 5 1 4 0.721928095
CERAH 5 3 2 0.970950594
TEMPERATUR 0.183850925
DINGIN 4 0 4 0
PANAS 4 2 2 1
SEDANG 6 2 4 0.918295834
KELEMBABAN 0.370506501
TINGGI 7 4 3 0.985228136
NORMAL 7 0 7 0
ANGIN 0.005977711
TIDAK 8 2 6 0.811278124
Baris total kolom Entropy pada Tabel 2.2 dihitung dengan rumus 2, sebagai berikut:
Entropy(Total) = (- *Log2( ))+(- *Log2( ))
Entropy(Total) =0.863120569
Sementara itu nilai Gain pada baris cuaca dihitung dengan menggunakan rumus 1, sebagai berikut :
Gain(Total,Cuaca) = Entropy(Total) - * Entropy(Cuaca)
Gain(Total,Cuaca) = 0.863120569 – (( *0)+ (( *0.723)+ (( *0.97))
Gain(Total,Cuaca) = 0.23
Dari hasil pada Tabel 2.2 dapat diketahui bahwa atribut dengan Gain
tertinggi adalah kelembaban yaitu sebesar 0.37. Dengan demikian kelembaban
dapat menjadi node akar. Ada 2 nilai atribut dari kelembaban yaitu tinggi dan normal. Dari kedua nilai atribut tersebut, nilai atribut normal sudah
mengklasifikasikan kasus menjadi 1 yaitu keputusannya Ya, sehingga tidak perlu
dilakukan perhitungan lebih lanjut, tetapi untuk nilai atribut tinggi masih perlu
dilakukan perhitungan lagi.
Dari hasil tersebut dapat digambarkan pohon keputusan sementara,
[image:37.595.202.431.507.652.2]tampak seperti Gambar 2.4
Gambar 2.4 Pohon Keputusan Hasil Perhitungan Node 1
2. Menghitung jumlah kasus, jumlah kasus untuk keputusan Ya, jumlah kasus
untuk keputusan Tidak, dan Entropy dari semua kasus dan kasus yang dibagi berdasarkan atribut cuaca, temperatur dan angin yang dapat menjadi node akar
1.
Kelembaban
Ya ?
Normal
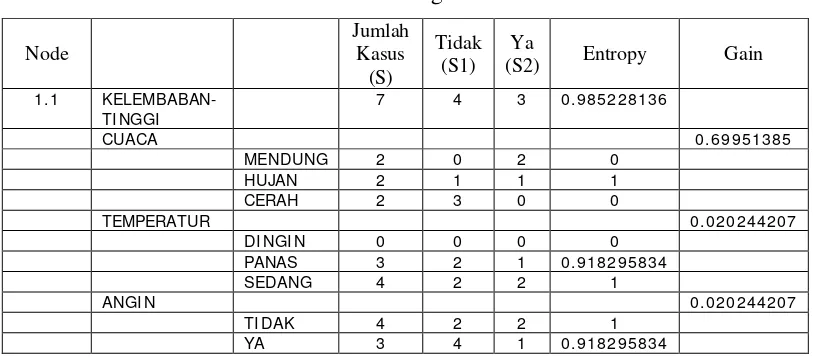
dari nilai atribut tinggi. Setelah itu lakukan penghitungan Gain untuk masing-masing atribut. Hasil perhitungan ditunjukkan oleh Tabel 2.3
Tabel 2.3 Perhitungan Node 1.1
Node Jumlah Kasus (S) Tidak (S1) Ya
(S2) Entropy Gain
1.1
KELEMBABAN-TI NGGI
7 4 3 0.985228136
CUACA 0.69951385
MENDUNG 2 0 2 0
HUJAN 2 1 1 1
CERAH 2 3 0 0
TEMPERATUR 0.020244207
DI NGI N 0 0 0 0
PANAS 3 2 1 0.918295834
SEDANG 4 2 2 1
ANGI N 0.020244207
TI DAK 4 2 2 1
YA 3 4 1 0.918295834
Dari hasil pada Tabel 2.3 dapat diketahui bahwa atribut dengan Gain
tertinggi adalah cuaca yaitu sebesar 0.699. Dengan demikian cuaca dapat menjadi
node cabang dari nilai atribut tinggi. Ada 3 nilai atribut dari cuaca yaitu mendung, hujan dan cerah. dari ketiga nilai atribut tersebut, nilai atribut mendung sudah
mengklasifikasikan kasus menjadi 1 yaitu keputusannya Ya dan nilai atribut cerah
sudah mengklasifikasikan kasus menjadi satu dengan keputusan Tidak, sehingga
tidak perlu dilakukan perhitungan lebih lanjut, tetapi untuk nilai atribut hujan
masih perlu dilakukan perhitungan lagi.
[image:38.595.176.456.554.728.2]Pohon keputusan yang terbentuk sampai tahap ini ditunjukkan pada
Gambar 2.5 berikut:
3. Menghitung jumlah kasus, jumlah kasus untuk keputusan Ya, jumlah kasus
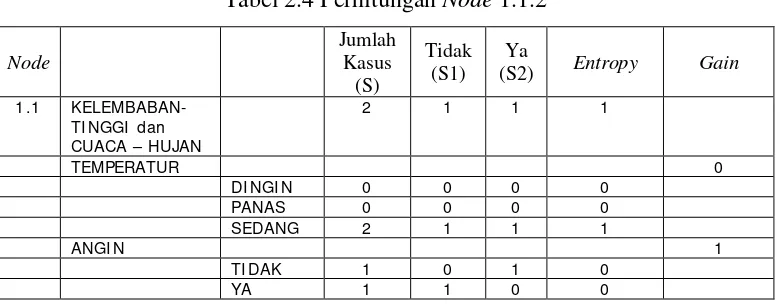
[image:39.595.119.510.245.397.2]untuk keputusan Tidak, dan Entropy dari semua kasus dan kasus yang dibagi berdasarkan atribut temperatur dan angin yang dapat menjadi node cabang dari nilai atribut hujan. Setelah itu lakukan penghitungan Gain untuk masing-masing atribut. Hasil perhitungan ditunjukkan oleh Tabel 2.4
Tabel 2.4 Perhitungan Node 1.1.2
Node
Jumlah Kasus
(S)
Tidak (S1)
Ya
(S2) Entropy Gain
1.1
KELEMBABAN-TI NGGI dan CUACA – HUJAN
2 1 1 1
TEMPERATUR 0
DI NGI N 0 0 0 0
PANAS 0 0 0 0
SEDANG 2 1 1 1
ANGI N 1
TI DAK 1 0 1 0
YA 1 1 0 0
Dari hasil pada Tabel 2.4 dapat diketahui bahwa atribut dengan Gain
tertinggi adalah angin yaitu sebesar 1. Dengan demikian angin dapat menjadi node
cabang dari nilai atribut hujan. Ada 2 nilai atribut dari angin yaitu Tidak dan Ya.
Dari kedua nilai atribut tersebut, nilai atribut Tidak sudah mengklasifikasikan
kasus menjadi 1 yaitu keputusannya Ya dan nilai atribut Ya sudah
mengklasifikasikan kasus menjadi satu dengan keputusan Tidak, sehingga tidak
perlu dilakukan perhitungan lebih lanjut untuk nilai atribut ini. Pohon keputusan
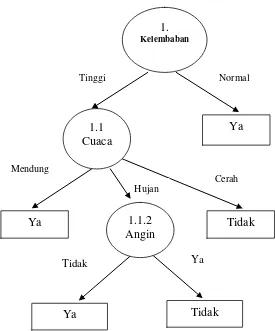
Gambar 2.6 Pohon Keputusan Hasil Perhitungan Node 1.1.2
Dengan memperhatikan pohon keputusan pada Gambar 2.6 diketahui
bahwa semua kasus sudah masuk dalam kelas. Dengan demikian, pohon
keputusan pada Gambar 2.6 merupakan pohon keputusan terakhir yang terbentuk.
2.5 Ekstraksi Rule dari Decision Tree
Pengetahuan yang diperoleh dari decision tree dapat direpresentasikan dalam bentuk klasifikasi IF-THEN rules. Nilai suatu atribut akan menjadi bagian
anticendent (bagian IF), sedang daun (leaf) dari sebuah decision tree akan menjadi bagian consequent (THEN). Aturan seperti ini akan menjadi sangat membantu manusia dalam memahami model klasifikasi terutama jika ukuran
decisiontree terlalu besar .
Ya Tidak
Tidak Ya
1.
Kelembaban
Ya 1.1
Cuaca
Normal Tinggi
Tidak 1.1.2
Angin Ya
Cerah Hujan
2.6 Support Vector Machine (SVM)
Pattern Recognition merupakan salah satu bidang dalam komputer sains, yang
memetakan suatu data ke dalam konsep tertentu yang telah didefinisikan
sebelumnya. Konsep tertentu ini disebut class atau category. Aplikasi pattern recognition sangat luas, di antaranya mengenali suara dalam sistem sekuriti,
membaca huruf dalam OCR, mengklasifikasikan penyakit secara otomatis
berdasarkan hasil diagnosa kondisi medis pasien dan sebagainya. Berbagai
metode dikenal dalam pattern recognition, seperti linear discrimination analysis,
hidden markov model hingga metode kecerdasan buatan seperti artificial neural
network. Salah satu metode yang akhir-akhir ini banyak mendapat perhatian
sebagai state of the art dalam pattern recognition adalah Support Vector Machine (SVM). Support Vector Machine (SVM) dikembangkan oleh Boser, Guyon,
Vapnik, dan pertama kali dipresentasikan pada tahun 1992 di Annual Workshop
on Computational Learning Theory. Konsep dasar SVM sebenarnya merupakan
kombinasi harmonis dari teori-teori komputasi yang telah ada puluhan tahun
sebelumnya, seperti margin hyperplane (Duda & Hart tahun 1973, Cover tahun 1965, Vapnik 1964), kernel diperkenalkan oleh Aronszajn tahun 1950, dan
demikian juga dengan konsep-konsep pendukung yang lain. Akan tetapi hingga
tahun 1992, belum pernah ada upaya merangkaikan komponen-komponen
tersebut. Berbeda dengan strategi neural network yang berusaha mencari
hyperplane pemisah antar class, SVM berusaha menemukan hyperplane yang
terbaik pada input space. Prinsip dasar SVM adalah linear classifier, dan
selanjutnya dikembangkan agar dapat bekerja pada problem non-linear. dengan
memasukkan konsep kernel trick pada ruang kerja berdimensi tinggi. Perkembangan ini memberikan rangsangan minat penelitian di bidang pattern
recognition untuk investigasi potensi kemampuan SVM secara teoritis maupun
dari segi aplikasi. Dewasa ini SVM telah berhasil diaplikasikan dalam problema
dunia nyata (real-world problems), dan secara umum memberikan solusi yang
lebih baik dibandingkan metode konvensional seperti misalnya artificial neural
Tulisan ini memperkenalkan konsep dasar SVM, dan membahas aplikasinya di
Educational data mining, yang akhir-akhir ini merupakan salah satu bidang yang
berkembang cukup pesat.
2.7 Riset-Riset Terkait
Terdapat beberapa riset yang telah dilakukan oleh banyak peneliti berkaitan
dengan domain pendidikan, seperti yang akan dijelaskan di bawah ini :
Yu et al. (2010) dalam risetnya menjelaskan mengenai sebuah pendekatan
data mining dapat diaplikasikan untuk meneliti faktor-faktor yang mempengaruhi tingkat daya ingat mahasiswa. Sunjana (2010a) juga menyampaikan hasil risetnya
mengenai aplikasi data mining mahasiswa dengan metode klasifikasi decision tree. Dengan kesimpulan sebagai berikut :
1. Penentuan data training sangat menentukan tingkat akurasi tree yang dibuat.
2. Besar prosentase kebenaran tree sangat dipengaruhi oleh data training yang digunakan untuk membangun model tree tersebut.
3. Nilai IPK seorang mahasiswa terlihat sangat terpengaruh dengan 9
(Sembilan) mata kuliah yang dianggap pokok.
Quadri dan Kalyankar (2010) juga menjelaskan tentang penggunaan teknik
decision tree untuk mengidentifikasi berbagai faktor yang meyebabkan mahasiswa melakukan drop out untuk meningkatkan kinerja akademik.
She et al. (2010) dalam risetnya menjelaskan mengenai prediksi penurunan
sifat sifat manusia secara cepat dan akurat dengan klasifikasi decisiontree .
Rocha dan Junior (2010) juga dalam risetnya menjelaskan tentang
bagaimana mengidentifikasi kecurangan-kecurangan yang terjadi di bidang
Nogroho, (2008) menjelaskan dalam risetnya mengenai Implementasi
decision tree berbasis analisis teknikal untuk pembelian dan penjualan saham, menyimpulkan sistem pendukung keputusan decision tree yang dibangun berdasarkan analisis teknikal mampu memberikan gambaran saat saham
diperdagangkan hanya berdasarkan pergerakan trend. Perdagangan berdasarkan
pergerakan trend ini bersifat spekulasi namun cukup mampu memberikan
keuntungan.
Sunjana (2010b) menjelaskan dalam risetnya tentang klasifikasi data
nasabah sebuah asuransi menggunakan algoritma C 4.5, berikut adalah
kesimpulan yang dapat diambil dari data nasabah asuransi setelah dilakukan
análisis menggunakan metode algoritma C 4.5:
1. Aplikasi dapat menyimpulkan bahwa rata-rata nasabah memiliki status
L dikarenakan pembayaran premi yang melebihi 10% dari penghasilan.
2. Dengan persentase atribut premi_dasar dan penghasilan, maka dapat
diketahui rata-rata status nasabah memiliki nilai P atau L.
Bhargavi at al. (2008) menjelaskan dalam risetnya tentang menguraikan
pengetahuan menggunakan aturan aturan dengan pendekatan decision tree.
Al-Radaideh et al. (2006) menjelaskan dalam risetnya tentang pemanfaatan
data mining terhadap data mahasiswa menggunakan decision tree.
Adeyemo dan Kuye (2006) menjelaskan dalam risetnya untuk
memprediksi kinerja mahasiswa di bidang akademik menggunakan algoritma
decision tree.
2.8 Kontribusi Riset
Penelitian ini memberikan kontribusi pada pemahaman kita tentang hubungan
tingkat keinginan mahasiswa diploma untuk melanjutkan ke jenjang yang lebih
tinggi yaitu jenjang sarjana.
Beberapa kemungkinan lain dianggap penting adalah pimpinan perguruan
tinggi ataupun yayasan dapat menggunakan informasi yang diberikan dalam
mengambil beberapa tindakan untuk meningkatkan keinginan mahasiswa dalam
melanjutkan pendidikan nya. Pembuat keputusan bisa menggunakan model
prediksi seberapa besar keinginan mahasiswa diploma nya unutk melanjutkan
pendidikannya ke jenjang sarjana. Penelitian ini memperkenalkan aplikasi
BAB III
METODOLOGI PENELITIAN
3.1 Pendahuluan
Tujuan dari tesis ini adalah untuk membuat model keterhubungan data
mahasiswa menggunakan algoritma C 4.5 dan Support Vektor Machine untuk
mengetahui seberapa besar keinginan mahasiswa diploma untuk melanjutkan
pendidikan ke jenjang sarjana dengan menyediakan data prilaku sehari-hari
mahasiswa diploma yang dapat digunakan sebagai pedoman analisis dalam
pembuatan keputusan.
Pada bagian ini di mulai dengan menggambarkan studi kasus data mining
pada jumlah mahasiswa diploma di perguruan tinggi dan prosedur bagaimana
mengumpulkan data yang dapat digunakan pada penelitian ini.
Data dikumpulkan dari database pendidikan akademik dan mensurvei
mahasiswa diploma yang telah menempuh semester 4 dan semester 6 sampai
dengan tahun 2012 di Akademi Manajemen Informatika Komputer (AMIK) Tunas
Bangsa Pematangsiantar. Instrumen penelitian yang digunakan harus mempunyai
ukuran yang akurat. Secara terperinci, bagaimana mendapatkan input yang lebih baik dalam proses data mining yang digambarkan pada bagian sebelum pemprosesan data. Penulis memberikan tinjauan singkat dari beberapa analysis
data yang digunakan pada penelitian ini.
3.2
Lokasi dan Waktu PenelitianPenelitian dilakukan di Akademi Manajemen Informatika Komputer (AMIK)
Tunas Bangsa, Jl. Jendral Sudirman Blok A No. 1,2,3 Pematangsiantar. Lamanya
waktu yang dibutuhkan untuk menyelesaikan penelitian ini selama 4 bulan yang
dimulai pada awal Maret 2012 sampai dengan akhir bulan Juni 2012.
3.3 Rancangan Penelitian
Rancangan penelitian ini pertama kali dilakukan dengan melakukan pengamatan
kemudian dibuat percobaan yang mendukung, selanjutnya dilakukan eksperimen
data dengan menggunakan rapidminer yang merupakan software open source
untuk membuat model aturan data yang diambil dari database mahasiswa
Akademi Manajemen Informatika Komputer (AMIK) Tunas Bangsa dan data
demografi mahasiswa. Hasil dari eksperimen data ini merupakan pengembangan
dari ilmu pengetahuan yang nantinya dapat merupakan masukan bagi pemecahan
masalah yang ada di lembaga pendidikan, dalam hal ini di Akademi Manajemen
Informatika Komputer (AMIK) Tunas Bangsa Pematangsiantar.
Secara garis besar metodologi penelitian ini dilaksanakan adalah sebagai berikut:
1. Studi literatur yang berkaitan dengan permasalahan dan teknik-teknik yang
akan dipergunakan untuk analisis data, yang bersumber dari
journal-journal, makalah-makalah, buk1
2. Berdasarkan teoritis yang sudah eksis dan tinjauan pustaka, akan dibangun
kuesioner untuk melihat tingkat korelasi dari faktor-faktor prediktor yang
akan diusulkan.
u-buku dan sumber-sumber lain yang
berkaitan termasuk internet.
3. Pengambilan data mahasiswa program diploma tiga dari Database AMIK
Tunas Bangsa Pematang Siantar.
4. Penyebaran kuesioner terhadap mahasiswa program diploma tiga bidang
informatika dan komputer di AMIK Tunas Bangsa Pematang Siantar.
5. Pemeriksaan kelengkapan data dan pembersihan terhadap data-data yang
tidak lengkap.
6. Melakukan proses Data Preparation ( Data cleaning, and Transformation) untuk persiapan sebagai input analisis data.
7. Pengujian dan Analisis data menggunakan bantuan prangkat lunak yang
ada
8. Pembahasan dan analisis terhadap hasil pengolahan data
9. Pendokumentasian proses dan hasil pengolahan data
10.Perumusan kesimpulan
3.4 Prosedur Pengumpulan Data
Dalam studi kasus ini, untuk data set pertama, penulis mengumpulkan data dari
mengembangkan kuesioner (Lampiran A) untuk mengukur keterhubungan data
demografi yang sesungguhnya dari mahasiswa. 5 (lima) pertanyaan menghasilkan
informasi demografi untuk responden. Pertanyaan pertanyaan yang dibuat adalah
tipe skala point linker 5 yang disusun dari “ sangat setuju” sampai “ sangat tidak setuju”. yang berkenaan untuk membuat prediksi perilaku mahasiswa. Data set
[image:47.595.166.458.318.415.2]pertama dapat dilihat pada Tabel 3.1
Tabel 3.1 Tampilan Data Set Pertama
No Role Name Type
1 Label Lanjut Studi Nominal
2 Regular Minat Belajar Nominal
3 Regular Kepercayaan Diri Nominal
4 Regular Perilaku Belajar Nominal
5 Regular Dukungan Orangtua Nominal
6 Regular Waktu Belajar Nominal
Pada Tabel 3.1 atribut Lanjut Studi sebagai label yang merupakan tujuan dari
atribut Minat Belajar, Kepercayaan Diri, Perilaku Belajar, Dukungan Orangtua,
dan Waktu Belajar.
3.5 Validitas dan Reliabilitas (Keakuratan) Data
Akurasi instrumen yang digunakan pada penelitian ini adalah penting. Akurasi
mengacu apakah instrumen yang digunakan mengukur secara konsisten setiap
waktu dan populasi ( Gall et al., 1996 ).
Survei dalam studi ini diuji dalam jangka waktu dan ukuran internal yang
terpercaya yang memiliki keterkaitan antara bagian bagian tes ( Brown and
Alexander, 1991 ). Hal ini menjamin apakah pengukuran instrumen secara akurat
dimaksudkan untuk mengukur.
Cronbach’s Alpha diberikan survei untuk mengukur konsistensi internal. Menurut Mitchell dan Jolley ( 1999 ), Cronbach’s Alpha pada atau di atas 0.60 diterima sebagai bukti realibilitas internal. Validitas dan Realibilitas dari
kuesioner dengan jumlah data sebanyak 75 item, seperti pada Tabel 3.4
Tabel 3.2 Statistik Reliabilitas Data
No Variabel dalam Skala Cronbach's alpha
Jumlah Data
1 Faktor Kepercayaan Diri .669 75
2 Faktor Dukungan Orang Tua .655 75
3 Faktor Minat Belajar .663 75
Dari Tabel di atas Cronbach's alpha dari ke tiga variabel berjumlah di atas 0.60 ini menunjukkan bahwa data yang diolah adalah valid dan dipercaya.
3.6 Preprocessing Data
3.6.1 Preprocessing Data Kuesioner
Data survei dalam bentuk kuesioner yang dibagikan kepada mahasiswa terdiri dari
[image:48.595.112.517.237.306.2]beberapa field. Data yang dikumpulkan dapat dilihat pada Tabel 3.7 Tabel 3.3 Data Kuesioner
Nim Nama IP Q Q Q Q Q R Q Q Q Q Q R Q Q Q Q Q R
1 2 3 4 5 E 6 7 8 9 10 O 11 12 13 14 15 F
… … … …
Data pada Tabel 3.3 di atas dapat dijelaskan bahwa :
1. Q1 sampai dengan Q5 adalah pertanyaan untuk minat belajar.
2. RE adalah rata-rata minat dari pertanyaan Q1 sampai dengan
Q5
3. Q6 sampai dengan Q10 adalah pertanyaan untuk kepercayaan
diri.
4. RO adalah rata-rata kepercayaan diri dari pertanyaan Q6
sampai dengan Q10
5. Q11 sampai dengan Q15 adalah pertanyaan untuk perilaku
6. RF adalah rata-rata perilaku belajar dari pertanyaan Q11
sampai dengan Q15
7. Q16 sampai dengan Q20 adalah pertanyaan untuk dukungan
orang tua.
8. RD adalah rata-rata dukungan orang tua dari pertanyaan Q16
sampai dengan Q20
9. Q21 sampai dengan Q25 adalah pertanyaan untuk waktu
belajar
10. RW adalah rata-rata waktu belajar dari pertanyaan Q21 sampai
dengan Q25
Dari keterangan tabel 3.3 di atas, pengolahan data penelitian dibagi dua,
yaitu jumlah minat belajar, kepercayaan diri, perilaku belajar, dukungan orang tua
dan waktu belajar digunakan pada software rapidminer sedangkan nilai dari pertanyaan digunakan pada software SPSS 18.
3.7 Alat Analisis Data
3.7.1 Paket Statistik untuk Ilmu Sosial
SPSS (Statistical Package for the Social Sciences) dianggap timer (alat pengukur waktu) tertua di bidang data mining. Ini awalnya dirancang untuk digunakan oleh ilmuwan sosial untuk menganalisa data dari survei. SPPS mengizinkan pengguna
untuk menarik data dan menampilkan operasi analisis statistik yang rumit, seperti
komputasi regresi dan menampilkan presentasi data grafis. Ini juga menggunakan
inferensial yang rumit dan prosedur statistik yang multi variasi, seperti analisis
varians (ANOVA), analisis faktor, analisis kluster,dan analisis data katerogikal. SPSS terutama sekali sangat cocok digunakan untuk survei penelitian.
SPPS 18.0 digunakan pada studi ini untuk menampilkan analisis regresi
pada data set yang dijelaskan pada Tabel 3.2 Keduanya merupakan langkah yang
bijak dan penuh model regresi yang dijalankan untuk menentukan model yang
3.7.2 Komunitas Rapidminer
Rapidminer dahulu YALE Mierswa et al. (2006 ) ini adalah permulaan yang
bebas dan terbuka untuk KDD dan Machine Learning, yang menyediakan
beraneka ragam metode yang mengizinkan bentuk dasar dari aplikasi baru.
Rapidminer (dahulu nya YALE ) dan propagandanya membuktikan lebih dari 400
operator dari segala aspek data mining. Operator meta sec