ALGORITMA GENETIKA: STUDI KASUS MASALAH
MULTI-CRITERIA DECISION ANALYSIS
(MCDA)
DALAM HAL ADA DATA KOSONG
SEPTIAN RAHARDIANTORO
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Algoritma Genetika: Studi Kasus Masalah Multi-Criteria Decision Analysis (MCDA) dalam Hal Ada Data Kosong adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Juni 2013
Septian Rahardiantoro
ABSTRAK
SEPTIAN RAHARDIANTORO. Algoritma Genetika: Studi Kasus Masalah
Multi-Criteria Decision Analysis (MCDA) dalam Hal Ada Data Kosong. Dibimbing oleh TOTONG MARTONO dan BAGUS SARTONO.
Berbagai metode pada Multi-Criteria Decision Analysis (MCDA) digunakan untuk mengurutkan alternatif berdasarkan pada kriteria
Data MCDA dapat disajikan dalam matriks keputusan dengan , nilai alternatif ke- untuk kriteria ke- . Solusi pada metode-metode MCDA diperoleh dengan memberikan pembobot pada kriteria ke-sesuai dengan peranannya. Konsep pengoptimuman korelasi Spearman setiap pasangan kandidat solusi dengan semua kriteria sebagai ukuran kebaikan solusi melalui algoritma genetika tampaknya dapat menjadi suatu metode alternatif untuk solusi MCDA, meskipun ada asumsi bahwa setiap pasang vektor kriteria harus berkorelasi positif. Hal ini terindikasikan dari hasil simulasi terhadap 30 alternatif dengan 15 kriteria dengan algoritma genetika memberikan solusi yang berkorelasi cukup tinggi dengan hasil yang menggunakan metode AHP, korelasinya sebesar 0.94. Di samping itu, perlakuan terhadap data kosong lebih sederhana dengan menggunakan algoritma genetika dan hasilnya berupa korelasi tinggi antara peringkat alternatif simulasi terhadap data lengkap dengan peringkat alternatif dengan data kosong sebanyak 10% sampai 40%; semua korelasi itu bernilai lebih dari 0.85. Studi kasus terhadap data 29 merek mobil dengan 11 kriteria dan sekitar 20% data kosong menghasilkan Model-Y, Model-1, dan Model-3 sebagai tiga mobil urutan terbaik pilihan konsumen.
Kata kunci: algoritma genetika, data kosong, korelasi, MCDA
ABSTRACT
SEPTIAN RAHARDIANTORO. Genetic Algorithms: Case Study of Multi-Criteria Decision Analysis (MCDA) on the Data Contained Missing Value. Supervised by TOTONG MARTONO and BAGUS SARTONO.
result will be a high correlation between the ranking of alternative simulation from the complete data with alternative rankings contained missing value as much as 10% to 40%; all correlations were worth more than 0.85. A case study of 29 automobile brands with 11 criteria and contains 20% of missing value resulting Model-Y, Model-1, and Model-3 as the best sequence of three consumer preferred brands.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Statistika pada
Departemen Statistika
ALGORITMA GENETIKA: STUDI KASUS MASALAH
MULTI-CRITERIA DECISION ANALYSIS
(MCDA)
DALAM HAL ADA DATA KOSONG
SEPTIAN RAHARDIANTORO
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Judul Skripsi : Algoritma Genetika: Studi Kasus Masalah Multi-Criteria Decision Analysis (MCDA) dalam Hal Ada Data Kosong
Nama : Septian Rahardiantoro NIM : G14090020
Disetujui oleh
Dr. Totong Martono Pembimbing I
Dr. Bagus Sartono, M.Si Pembimbing II
Diketahui oleh
Dr. Ir. Hari Wijayanto, M.Si Ketua Departemen
PRAKATA
Puji syukur penulis panjatkan kehadirat Allah SWT karena hanya dengan lindungan, rahmat dan karuniaNya-lah penulis telah menyelesaikan karya ilmiah yang berjudul Algoritma Genetika: Studi Kasus Masalah Multi-Criteria Decision Analysis (MCDA) dalam Hal Ada Data Kosong.
Terselesainya penyusunan karya ilmiah ini tidak lepas dari dukungan, motivasi, saran, dan kerjasama dari berbagai pihak. Oleh karena itu, penulis mengucapkan terima kasih kepada :
1. Bapak Dr. Totong Martono selaku ketua komisi pembimbing yang telah bersabar dalam memberikan nasihat kepada penulis untuk dapat menghasilkan karya ilmiah yang impresif.
2. Bapak Dr. Bagus Sartono, M.Si selaku anggota komisi pembimbing atas kesempatan yang telah diberikan kepada penulis untuk dapat mengembangkan diri pada topik yang ingin penulis teliti. Selain itu juga atas bantuan sumber data yang digunakan dalam karya ilmiah ini.
3. Rekan-rekan statistika angkatan 2009, terutama Wahyu Bodromurti, Fajrianza Adi N, Casia Nursyifa, Muhammad Hafid, Devi Fitri Yani, Azyl Yunia K, serta Miko Novri A yang telah membantu penulis dalam diskusi untuk menyelesaikan karya tulis ini.
4. Staf Tata Usaha Departemen Statistika atas bantuannya dalam kelancaran administrasi.
5. Bapak, ibu, serta seluruh keluarga, atas segala doa dan kasih sayangnya, yang selalu mendukung penulis untuk mewujudkan cita-citanya.
Demi penyempurnaan karya ilmiah ini, penulis sangat mengharapkan saran, kritik, dan masukan dari para pembaca. Besar harapan penulis semoga karya ilmiah ini bermanfaat.
Bogor, Juni 2013
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
MULTI CRITERIA DECISION ANALYSIS (MCDA) 1
ALGORITMA GENETIKA 2
Algoritma Genetika Suatu Pilihan Solusi MCDA 3
Deskripsi Algoritma Genetika pada Software R 6
IMPLEMENTASI FUNGSI GENMCDA 7
Simulasi Masalah MCDA 7
Simulasi Data Kosong 10
Pilihan Mobil Berdasarkan Selera Konsumen 11
SIMPULAN 12
Simpulan 12
DAFTAR PUSTAKA 13
LAMPIRAN 14
DAFTAR TABEL
1 Solusi hasil simulasi algoritma genetika 8
2 Bobot acak pada metode AHP (dibulatkan dalam 3 desimal) 8 3 Peringkat alternatif dengan algoritma genetika dan metode AHP 9
4 Masukan fungsi DATAKOSONG 10
5 Rataan korelasi Spearman solusi data lengkap dengan solusi ada data kosong, dan antar solusi dengan ada data kosong 10
6 Skala kriteria mobil 11
7 Hasil peringkat merek mobil berdasarkan penilaian konsumen 11
DAFTAR GAMBAR
1 Ilustrasi pindah silang 5
2 Kurva rataan minimum korelasi Spearman solusi urutan alternatif
terhadap peluang mutasi 5
3 Ilustrasi mutasi 6
4 Plot hubungan peringkat alternatif dengan algoritma genetika dan
metode AHP 9
DAFTAR LAMPIRAN
1 Algoritma genetika untuk MCDA pada R berbentuk fungsi GENMCDA 14
2 Matriks keputusan (simulasi) 18
3 Matriks korelasi Spearman kriteria matriks keputusan (simulasi) 19
4 Keluaran solusi matriks keputusan (simulasi) 20
5 Simulasi data kosong dengan fungsi DATAKOSONG 21
6 Daftar merek mobil dan skala kriterianya 22
7 Matriks keputusan untuk merek mobil 23
1
PENDAHULUAN
Berbagai masalah dalam bidang sains, teknik, ilmu komputer, ekonomi, bisnis, dan manajemen seringkali dihadapkan pada pengambilan keputusan untuk menentukan satu atau beberapa pilihan terbaik di antara pilihan berdasarkan parameter. Hal ini dapat diselesaikan dengan berbagai metode pada Multi-Criteria Decision Analysis (MCDA) yang menggunakan konsep pembobotan pada setiap parameter berdasarkan peranannya.
Adakalanya data kosong dijumpai pada gugus data MCDA. Metode yang biasa digunakan untuk menangani kondisi tersebut melalui hot-deck imputation,
subtitution, cold deck imputation, unconditional mean/ median/ mode imputation
dan multiple imputation. Pilihan metode apa yang tepat ketika ada data kosong disesuaikan dengan karakteristik parameternya agar terhindar dari bias (Nardo et al. 2005).
Algoritma genetika merupakan metode pengoptimuman berdasarkan pada prinsip-prinsip genetika dan seleksi alam. Kaidah dalam algoritma ini merefleksikan sebuah populasi yang dibentuk dari banyak individu yang berkembang di bawah aturan seleksi tertentu (Haupt dan Haupt 2004). Individu dalam populasi dipilih secara acak dan banyaknya terbatas. Pengacakan ini memberikan peluang yang sama terhadap setiap individu untuk masuk ke dalam populasi. Selain itu, konsep pengacakan juga dilakukan pada proses pindah silang (crossover) dan mutasi terhadap populasi untuk membentuk generasi baru. Individu terbaik pada generasi terakhir inilah yang nantinya menjadi solusi dalam algoritma genetika.
Pada implementasi algoritma genetika, individu dapat direpresentasikan oleh bilangan biner atau pun bilangan real (Haupt dan Haupt 2004). Penelitian ini akan menelaah representasi individu dalam bentuk peringkat pada algoritma genetika dan memanfaatkan koefisien korelasi Spearman untuk kriteria optimumnya sebagai alternatif pilihan dalam mencari solusi pada data MCDA baik data lengkap maupun ada data kosong. Implementasi algoritma tersebut dilakukan pada software R dengan ilustrasinya menggunakan data simulasi dan aplikasinya dalam menentukan pilihan terbaik merek mobil berdasarkan berbagai kriteria selera konsumen.
MULTI CRITERIA DECISION ANALYSIS
(MCDA)
Misalkan adalah himpunan buah alternatif yang akan ditentukan peringkatnya atau urutannya berdasarkan pada penilaian terhadap himpunan buah kriteria Hasil penilaian terhadap kriteria tersebut dapat direpresentasikan dalam matriks [ ]
berordo dengan menyatakan nilai alternatif ke- , untuk kriteria ke- , ; matriks ini dikenal sebagai matriks keputusan (Steele et al. 2008).
Menurut Triantaphyllou et al. (1998), ada 6 metode yang dapat digunakan pada MCDA, yaitu Weighted Sum Model (WSM), Weighted Product Model
2
(RAHP), ELECTRE Method, dan TOPSIS Method. Keenam metode tersebut memanfaatkan sebagai bobot kriteria ke- , dalam penyelesaiannya. Bobot ini mencerminkan tingkat kepentingan kriteria dalam menentukan peringkat alternatif dan didefinisikan oleh pembuat keputusan dengan batasan
dan ∑ .
ALGORITMA GENETIKA
Algoritma genetika mengikuti perilaku dalam proses evolusi yang dialami makhluk hidup dari generasi ke generasi, hanya individu yang mampu bertahan yang dapat hidup. Konsep dasar algoritma ini melibatkan pengertian gen, individu, populasi, nilai fitness, pindah silang (crossover), mutasi, dan kriteria konvergensi.
Pada awalnya populasi terdiri dari individu-individu dengan karakteristik yang heterogen. Individu ini merupakan kumpulan dari buah gen yang membentuk suatu kesatuan berupa dengan merupakan gen ke- . Populasi tersebut merupakan himpunan sebanyak individu,
{ } dan dianggap sebagai generasi pertama yang terbentuk pada algoritma genetika. Kondisi lingkungan menyebabkan hanya individu terbaik yang mampu bertahan. Kriteria penentuan individu yang dapat bertahan dilihat dari nilai fitness yang dihasilkan. Misalkan , maka selanjutnya individu terbaik pada populasi tersebut satu per satu masuk ke dalam himpunan Hal ini menyebabkan himpunan menjadi { } , dengan baru tergantung pada pendefinisian pindah silang. Pembangkitan generasi baru
, sebagai pengganti generasi sebelumnya, terjadi melalui proses yang sama dengan sebelumnya dan mungkin terjadi proses mutasi yang berupa perubahan gen karena pengaruh eksternal dengan tingkat kejadian sangat rendah. Pembangkitan generasi selesai ketika nilai fitness individu-individu pada generasi
konvergen ke suatu nilai tertentu atau banyaknya generasi yang dibangkitkan, mencapai nilai tertentu. Pada akhirnya solusi algoritma genetika merupakan individu dengan nilai fitness terbaik pada generasi terakhir yang dibangkitkan.
Oleh karena itu pada praktiknya algoritma genetika dapat dirangkum dalam bentuk langkah-langkah sebagai berikut (Sivanandam dan Deepa 2008).
1. Definisikan individu/kromosom, nilai fitness, peluang mutasi dan kriteria konvergensi yang sesuai dengan permasalahan.
2. Bangkitkan satu atau beberapa generasi , dengan langkah :
Ulangi :
3 Bangkitkan secara acak sebuah populasi sebagai generasi awal
yang berisi individu dalam hal lainnya
mulai
Pilih individu induk dari populasi yang memiliki nilai
fitness terbaik;
Lakukan pindah silang;
Lakukan mutasi dengan peluang hasilnya berupa keturunan baru;
Tempatkan keturunan baru ke populasi baru ; selesai
Hitung nilai fitness masing-masing individu dari populasi
Sampai diperoleh generasi yang memenuhi kriteria konvergensi yang diinginkan.
Solusi algoritma genetika merupakan individu dengan nilai fitness terbaik pada generasi terakhir apabila nilai fitness-nya konvergen ataukah generasi terakhir yang telah ditetapkan pada awal iterasi.
Algoritma Genetika Suatu Pilihan Solusi MCDA
Pada algoritma ini alternatif terbaik dinyatakan dengan peringkat terakhir, , dan tentunya alternatif terburuk oleh peringkat pertama Semua data numerik pada setiap kriteria matriks ditransformasi menjadi data peringkat dan ditempatkan pada matriks [ ] selanjutnya notasi indeks p digunakan untuk menyatakan objek yang bersesuaian berisi peringkat. Oleh karena itu digunakan koefisien korelasi peringkat Spearman. Nilai fitness
didefinisikan sebagai nilai korelasi terkecil antara masing-masing individu dengan setiap kriteria. Kemudian penentuan solusinya memanfaatkan operator maximin
untuk mencari sebanyak individu dengan nilai fitness dalam urutan terbesar. Konsep maximin digunakan dengan tujuan untuk menghindari pengambilan solusi terburuk yang terjadi (Linkov et al. 2004). Berdasarkan hal ini, algoritma genetika dalam mencari solusi masalah MCDA akan valid apabila korelasi Spearman dari setiap pasangan kriteria ( ) untuk Karena adanya nilai korelasi negatif akan berakibat nilai fitness yang dihasilkan berupa nilai korelasi negatif tersebut. Kriteria konvergensi algoritma ini ialah jangkauan nilai fitness setiap generasi kurang dari . Tahapan algoritma genetika untuk mencari solusi dalam permasalahan MCDA ialah :
Misalkan dan vektor individu berordo
dengan berarti berisi hasil permutasi bilangan asli pertama.
1. Pembangkitan populasi awal
4
maka populasi awal sebanyak individu dibangkitkan secara acak dengan persamaan
dengan menyatakan vektor bilangan acak ke- Namakan individu hasil pemeringkatan dari dengan , sehingga populasi generasi pertama sebanyak individu dengan alternatif diekspresikan sebagai matriks
[ | ] 2. Periksa asumsi validitas algoritma pada setiap generasi
Misalkan { | } untuk merupakan himpunan korelasi Spearman antara individu ke- dengan vektor kriteria. Berdasarkan data empiris terungkap bahwa 30% atau 0.3 dari himpunan ini harus himpunan bagian dari himpunan bilangan positif
Apabila kriteria ini belum terpenuhi maka ulangi pembangkitan populasi awal pada butir (1).
3. Evaluasi generasi
Evaluasi dilakukan dengan menggunakan konsep maximin korelasi Spearman yang dihasilkan antara setiap individu pada dengan semua kriteria, Misalkan matriks dengan
Sebanyak induk individu dipilih berdasarkan urutan tertinggi pada melalui { } Hasilnya berupa matriks induk individu, namakanlah
[ ] berisi sebanyak induk individu dengan alternatif. b. Pindah silang (crossover)
Operasi pindah silang dilakukan kepada setiap kombinasi pasangan induk sebanyak yang didefinisikan sebagai peringkat rataan terboboti pada setiap gen di dalam individunya. Bobot yang digunakan ialah nilai maximin korelasi Spearman antara sepasang induk yang akan dilakukan pindah silang. Induk yang memiliki nilai maximin ini diberi bobot dengan nilai tersebut, sedangkan induk pasangannya diberi bobot
5
[ ( )]
Selanjutnya, agar sifat dari induk tidak hilang, maka hasil dari pindah silang digabungkan dengan matriks induk sebelumnya, , sehingga hasilnya dinamakan sebagai [ | | | | ] Ilustrasi mengenai pindah silang ini dapat dilihat pada Gambar 1.
c. Mutasi
Mutasi dilakukan dengan peluang pada untuk menjadi . Hal ini berdasarkan data empiris hubungan minimum korelasi dengan peluang mutasi (Gambar 2) ketika diperoleh minimum korelasinya relatif tinggi dan cenderung stabil.
Misalkan merupakan unsur (gen) dari matriks , operasi mutasi dilakukan dengan mengganti pada dan tertentu dengan bilangan acak, yang kemudian diperingkatkan kembali berdasarkan kolomnya. Banyaknya gen yang akan dilakukan mutasi dicari melalui perkalian antara peluang mutasi dengan jumlah kolom dan baris matriks
yang telah dibulatkan hasilnya, ( ) Gambar 11 Ilustrasi pindah silang
6
dengan menyatakan himpunan bilangan asli. Setelah itu didefinisikan bilangan bulat acak yang mewakili baris dan kolom sebanyak hasil , ( ) untuk baris, dan mengenai mutasi dapat dilihat pada Gambar 3.
Deskripsi Algoritma Genetika pada Software R
Implementasi algoritma genetika berupa fungsi GENMCDA yang melibatkan 5 buah fungsi lain dalam mencari solusi MCDA dengan software R. Ekspresi pernyataan fungsi GENMCDA tercantum dalam Lampiran 1 dan dengan batasan seperti tercantum di bawah ini.
1. Nilai masukan fungsi GENMCDA
e. alpha : batasan terbesar jangkauan dari nilai fitness (korelasi minimum)
2. Deskripsi fungsi-fungsi bagian dari fungsi GENMCDA
a. Fungsi rperm dan fungsi nselect berperan sebagai pembangkit populasi awal berukuran . Populasi dengan individu dan alternatif ini telah memenuhi kriteria 30% korelasi bernilai positif antara individu dengan kriteria. Hasilnya ditempatkan pada matriks
[ | ]
b. Fungsi eval berperan menghasilkan induk individu terbaik berdasarkan konsep maximin terhadap korelasi Spearman antara setiap individu dengan masing-masing kriteria. Hasilnya berupa matriks
7
alpha. Jika kriteria ini tidak terpenuhi, maka akan ditampilkan pesan untuk melakukan eksekusi ulang fungsi GENMCDA dengan masukan yang sama ataukah mengubah , , , atau alpha.
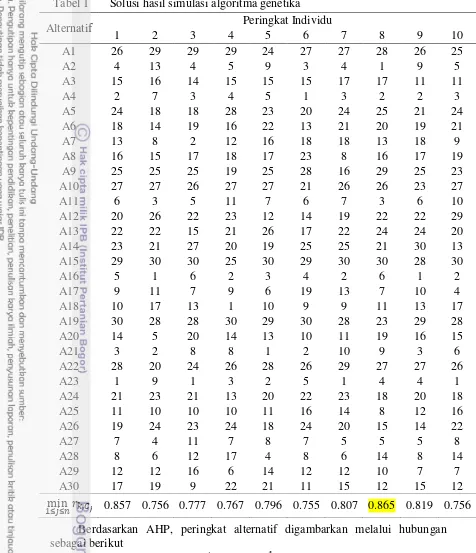
Pada bagian ini akan diulas seberapa dekat solusi simulasi masalah MCDA dengan algoritma genetika dan metode pembobotan AHP, serta solusinya ketika ada data kosong dengan acuan korelasi antar solusinya dan menggunakan fungsi GENMCDA. minimum korelasinya dapat dilihat pada Tabel 1 dan dengan keluaran solusi pada Lampiran 4.
8
Berdasarkan AHP, peringkat alternatif digambarkan melalui hubungan sebagai berikut
dengan [ ]
[ ] dan adalah delta kronecker. Unsur tertinggi pada menyatakan alternatif padanannya berada pada peringkat pertama yang tentunya sebagai alternatif terbaik.
Tabel 23 Bobot acak pada metode AHP (dibulatkan dalam 3 desimal)
Kode w1 w2 w3 w4 w5 w6 w7 w8 w9 w10 w11 w12 w13 w14 w15
Bobot 0.012 0.086 0.029 0.162 0.014 0.037 0.064 0.062 0.135 0.042 0.018 0.007 0.184 0.056 0.091
Tabel 11 Solusi hasil simulasi algoritma genetika
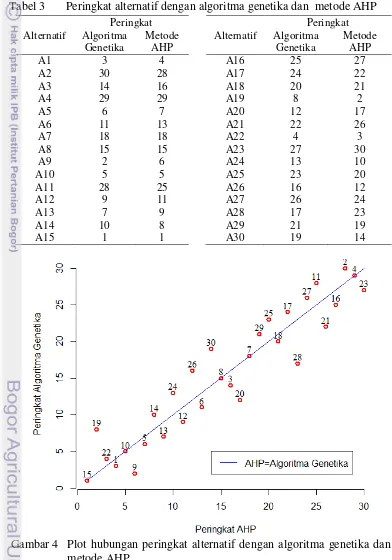
9 Besaran bobot yang digunakan merupakan bilangan acak yang dibangkitkan melalui software R (Tabel 2), dengan dan . Pada Tabel 3 terlihat bahwa ada 25 alternatif yang berbeda peringkatnya tetapi tidak menyimpang terlalu jauh. Hal tersebut diindikasikan pula oleh koefisien korelasi antara kedua solusi tersebut sebesar 0.944 yang bermakna hubungannya hampir linear seperti tampilan pada Gambar 4. Hal ini berarti ada konsistensi antara solusi dengan algoritma genetika dan solusi dengan metode AHP. Dengan perkataan lain masalah MCDA dapat pula diselesaikan dengan algoritma genetika.
Tabel 34 Peringkat alternatif dengan algoritma genetika dan metode AHP
Alternatif
10
Simulasi Data Kosong
Matriks keputusan [ ]
pada simulasi sebelumnya disisihkan isinya secara acak sebanyak 10, 15, 20, 25, 30, 35, dan 40 persen dengan menggunakan fungsi yang bernama DATAKOSONG (Lampiran 5). Masukan pada fungsi DATAKOSONG ialah x, data yang sebagian isinya akan disisihkan sebagai data kosong, alpha, persentase data kosong, dan seed, nilai acak komputer agar diperoleh kondisi data kosong yang sama. Pada masing-masing persentase data kosong dilakukan simulasi sebanyak lima kondisi letak data kosong yang berbeda dengan ulangan sebanyak 50 kali, agar diperoleh solusi terbaiknya. Pada Tabel 4 ditampilkan nilai masukan untuk membuat data kosong pada matriks keputusan dengan fungsi DATAKOSONG. Data yang terbentuk ini selanjutnya digunakan pada fungsi GENMCDA untuk memperoleh urutan alternatif optimum.
Gambaran keterandalan fungsi GENMCDA diukur dari korelasi Spearman solusi urutan alternatif pada setiap persentase data kosong dengan urutan alternatif pada data lengkap. Selain itu juga korelasi Spearman antar solusi urutan alternatif pada persentase data kosong yang sama. Rataan korelasi tersebut disajikan pada Tabel 5.
Rataan korelasi Spearman antara solusi data lengkap dengan solusi ada data kosong diperoleh nilai yang cenderung stabil dalam kisaran 0.8702 hingga 0.8988. Selain itu nilai yang cenderung stabil dalam kisaran 0.8519 hingga 0.9074 pada rataan korelasi Spearman antara sesama solusi yang ada data kosong. Kestabilan nilai rataan korelasi ini menandakan bahwa algoritma genetika dengan menggunakan konsep korelasi terandalkan sebagai solusi masalah MCDA dengan data lengkap maupun ada data kosong tak lebih dari 40%.
Tabel 56 Rataan korelasi Spearman solusi data lengkap dengan solusi ada data kosong, dan antar solusi dengan ada data kosong
Data Kosong
Tabel 45 Masukan fungsi DATAKOSONG
11 Pilihan Mobil Berdasarkan Selera Konsumen
Data primer penilaian 7654 konsumen terhadap 29 merek mobil berdasarkan pada 11 kriteria diolah dengan algoritma genetika untuk memperoleh peringkat mobil dari yang paling disukai sampai yang paling tidak disukai. Data ini bersifat kategorik dengan 3 jenis skala penilaian, dari 1-5, 1-7, dan 1-10 (Lampiran 6). Nilai tertinggi dari ketiga jenis skala penilaian tersebut menyatakan bahwa mobil paling disukai. Persepsi tingkat selera konsumen terhadap merek mobil yang paling disukai terwakili pada matriks keputusan [ ]
yang ditetapkan dengan merupakan persentase responden yang memilih 0.4 sampai 0.5 bagian tertinggi dari setiap jenis skala kriteria seperti tercantum pada Tabel 6. Matriks keputusan ini memiliki sekitar 20% data kosong (Lampiran 7), serta memiliki nilai korelasi positif untuk setiap pasang kriteria (Lampiran 8).
Pada matriks keputusan , dapat dilihat Model-Y, Model-1 dan Model-3 memiliki nilai yang cenderung besar di semua kriteria, sedangkan Model-A memiliki nilai yang cenderung kecil di semua kriteria. Dugaan sementara bahwa Model-Y, Model-1 dan Model-3 berada peringkat teratas, sedangkan Model-A berada pada peringkat terbawah.
Pengolahan data tersebut dengan fungsi GENMCDA diperoleh hasil urutan alternatifnya yang dapat dilihat pada Tabel 7. Hasilnya sesuai dengan dugaan awal bahwa Model-Y, Model-1 dan Model-3 berada pada tiga peringkat teratas, dan Model-A berada pada peringkat terbawah.
Tabel 67 Skala kriteria mobil No. Jangkauan
Tabel 78 Hasil peringkat merek mobil berdasarkan penilaian konsumen Peringkat Merek Mobil Peringkat Merek Mobil
12
SIMPULAN
Simpulan
Melalui simulasi terungkap adanya konsistensi solusi masalah MCDA dengan metode AHP dan solusinya dengan algoritma genetika. Indikatornya ialah koefisien korelasi Spearman kedua solusi ini sebesar 0.94 atau plotnya hampir linear. Selain itu tampak pula algoritma genetika juga terandalkan untuk mengatasi adanya data kosong hingga 40% dalam masalah MCDA, sebagaimana diindikasikan oleh tingginya rataan korelasi Spearman solusi data lengkap dengan solusi ada data kosong maupun di antara solusi yang ada data kosongnya; nilainya lebih dari 0.85.
13
DAFTAR PUSTAKA
Haupt RL, Haupt SE. 2004. Practical Genetic Algorithms Second Edition. New Jersey(US) : John Wiley and Sons, Inc
Linkov I, Varghese A, Jamil S, Seager TP, Kiker G, Bridges T. 2004. Multi-Criteria Decision Analysis: A Framework for Structuring Remedial Decisions at Contaminated Sites. Comparative Risk Assessment and Environmental Decision Making. 15-54
Nardo M, Saisana M, Saltelli A, Tarantola S, Hoffman A, Giovannini E.2005. Handbook on Constructing Composite Indicators: Methodology and User Guide. OECD Statistics Working Paper. STD/DOC(2005)3:12-30
Sivanandam SN, Deepa SN. 2008. Introductions to Genetic Algorithms. New York(US) : Springer
Steele K, Carmel Y, Cross J, Wilcox C. 2008. Uses and Misuses of Multi-Criteria Decision Analysis (MCDA) in Environmental Decision-Making. Australian Centre of Excellence for Risk Analysis.1-19
14
Lampiran 1 Algoritma genetika untuk MCDA pada R berbentuk fungsi GENMCDA
GENMCDA <- function(data, N, k, pmutation, alpha) #masukan {
stop("Ukuran induk dari populasi (k) minimal 3.") }
rperm <- function(data, column=2) #pembangkitan populasi {
nselect <- function(data,y) #seleksi populasi
15
e <- tryCatch(eval(data,y),finally=print("Eksekusi fungsi GENMCDA kembali"))
crossover <- function(data,e) #pindah silang
17 solusi2 <- (nrow(data)+1)-solusi1
msolusi <- as.matrix(solusi2)
hmsolusi <- data.frame(msolusi,rownames(data)) d <- hmsolusi
for(i in 1:nrow(data)) {
j<-0
repeat { j<-j+1
if(hmsolusi[j,1]==i) {d[i,] <-hmsolusi[j,] break }
}}
colnames(d)<-c("peringkat","alternatif")
list(populasiawal=y,hasilakhir=ydata ,minKorelasi=e[[2]],
18
Lampiran 2 Matriks keputusan (simulasi)
C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 C11 C12 C13 C14 C15
19 Lampiran 33 Matriks korelasi Spearman kriteria matriks keputusan (simulasi)
r C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 C11 C12 C13 C14 C15
C1 1
20
21 Lampiran 55 Simulasi data kosong dengan fungsi DATAKOSONG
#x = data yang akan disisihkan isinya sebagai data kosong #alpha = persentase data kosong yang diinginkan
#seed = nilai acak komputer
DATAKOSONG <- function(x,alpha,seed) {
kolom <- ncol(x) baris <- nrow(x) set.seed(seed)
A <- matrix(rbinom(kolom*baris,1,alpha),baris,kolom) D <- ifelse(A==1,NA,1)
DataNA <- x*D DataNA
22
Lampiran 66 Daftar merek mobil dan skala kriterianya
Merek Mobil B B1 B2 B5 C C2 C3 D E2 F15 F19
B Penampilan keseluruhan dari depan B1 Desain lampu utama
B2 Desain kisi-kisi depan B5 Desain bemper depan
C Penampilan keseluruhan dari samping C2 Desain roda/pelek/lingkaran roda C3 Desain kaca samping
D Penampilan keseluruhan dari belakang E2 Kemenarikan ukuran badan mobil F15 Kenyamanan tempat duduk depan
23 Lampiran 77 Matriks keputusan untuk merek mobil
Merek Mobil B B1 B2 B5 C C2 C3 D E2 F15 F19
Model-1 0.947 0.953 0.913 0.880 0.847 0.773 0.733 0.800 0.913 0.940 0.887 Model-2 0.823 0.839 0.661 0.742 0.774 0.468 0.694 0.806 0.016 0.806 0.790 Model-3 0.933 0.933 0.893 0.887 0.933 0.880 0.933 0.927 0.893 0.973 0.953
Model-A 0.170 0.080 0.100 NA 0.240 0.200 0.250 0.220 NA 0.420 0.390
Model-B 0.630 0.770 0.280 NA 0.700 0.690 0.780 0.710 NA 0.690 0.710
Model-C 0.810 0.830 0.800 NA 0.620 0.390 0.930 0.690 NA 0.900 0.640
Model-G 0.829 0.838 0.721 0.658 0.829 0.586 NA 0.685 NA NA 0.523
Model-H 0.559 0.580 0.478 0.466 0.571 0.466 NA 0.494 0.728 0.742 0.590 Model-J 0.765 0.812 0.587 0.662 0.671 0.493 NA 0.685 0.671 0.850 0.822 Model-K 0.645 0.651 0.623 0.614 0.611 0.586 NA 0.491 0.728 0.859 0.775
Model-L 0.450 0.676 0.477 0.486 0.441 0.468 NA 0.514 NA NA 0.874
Model-M 0.724 0.897 0.755 0.787 0.631 0.581 0.826 0.689 0.376 0.903 0.852 Model-N 0.694 0.761 0.695 0.667 0.656 0.555 0.252 0.643 0.251 0.753 0.613 Model-O 0.854 0.929 0.826 0.742 0.787 0.787 0.923 0.799 0.221 0.755 0.697 Model-P 0.793 0.656 0.582 0.577 0.772 0.771 0.517 0.703 0.505 0.819 0.827
Model-Q 0.727 0.425 0.222 0.288 0.534 NA NA 0.667 0.472 0.817 0.915
Model-R 0.790 0.431 0.327 0.360 0.772 0.543 0.039 0.697 0.688 0.726 0.653
Model-S 0.732 NA NA NA 0.665 NA NA 0.751 0.883 NA NA
Model-T 0.907 NA NA NA 0.782 NA NA 0.821 0.837 NA NA
Model-U 0.662 NA NA NA 0.539 NA NA 0.544 NA NA NA
Model-V 0.640 NA NA NA 0.548 NA NA 0.522 NA NA NA
Model-W 0.531 0.477 0.369 0.468 0.572 0.387 NA 0.490 NA NA 0.757
Model-X 0.726 0.860 0.520 NA 0.546 0.360 0.250 0.631 NA 0.730 0.680
Model-Y 0.833 NA NA NA 0.838 NA NA 0.873 NA NA NA
Model-Z 0.443 NA NA NA 0.439 NA NA 0.447 NA NA NA
Model-4 0.900 0.913 0.853 0.807 0.853 0.667 0.833 0.807 0.853 0.807 0.760 Model-5 0.806 0.629 0.774 0.726 0.806 0.968 0.629 0.839 0.323 0.968 0.919 Model-6 0.803 0.656 0.754 0.836 0.705 0.574 0.541 0.770 0.066 0.689 0.623 Model-7 0.705 0.656 0.541 0.721 0.705 0.492 0.836 0.803 0.033 0.902 0.705
24
Lampiran 88 Matriks korelasi Spearman kriteria untuk merek mobil
r B B1 B2 B5 C C2 C3 D E2 F15 F19
B 1
B1 0.654 1
B2 0.794 0.752 1
B5 0.679 0.806 0.911 1
C 0.869 0.561 0.710 0.675 1
C2 0.598 0.404 0.606 0.568 0.780 1
C3 0.490 0.614 0.640 0.613 0.380 0.381 1
D 0.838 0.513 0.631 0.725 0.875 0.659 0.546 1
E2 0.281 0.162 0.215 0.046 0.220 0.329 0.070 0.066 1
F15 0.447 0.383 0.595 0.346 0.394 0.477 0.589 0.438 0.300 1
25
RIWAYAT HIDUP
Penulis dilahirkan di Rembang pada tanggal 6 September 1991 dari bapak Iman Sugiyantoro dan ibu Sudarti. Penulis adalah putra pertama dari dua bersaudara. Tahun 2009 penulis lulus dari SMA Negeri 1 Rembang dan pada tahun yang sama diterima sebagai mahasiswa baru pada Departemen Statistika, Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor (IPB) melalui jalur Undangan Seleksi Masuk IPB.
Selama mengikuti perkuliahan, penulis menjadi asisten praktikum Fisika TPB pada semester ganjil dan genap tahun ajaran 2010/2011, asisten Kalkulus II dan Metode Statistika pada semester ganjil tahun ajaran 2011/2012, asisten Kalkulus III dan Metode Penarikan Contoh pada semester genap tahun ajaran 2011/2012, serta asisten Komputasi Statistika dan Analisis Data Kategorik pada semester ganjil tahun ajaran 2012/2013. Penulis juga aktif mengajar mata kuliah TPB dan Statistika di bimbingan belajar dan privat mahasiswa Klinik Studi Expert. Penulis pernah menjadi ketua panitia Komstat Jr dalam rangkaian acara Pesta Sains Nasional IPB 2012. Bulan Februari-Maret 2013 penulis melaksanakan praktik lapang di PT. Ewaysindo Makmur.