IMPLEMENTASI ALGORITMA LEARNING VECTOR QUANTIZATION PADA
PREDIKSI PRODUKSI KELAPA SAWIT DI
PT. PERKEBUNAN NUSANTARA I
PULAU TIGA
SKRIPSI
EDGAR AUDELA BATUBARA
101402111
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
IMPLEMENTASI ALGORITMA LEARNING VECTOR QUANTIZATION PADA PREDIKSI PRODUKSI KELAPA SAWIT DI
PT. PERKEBUNAN NUSANTARA I PULAU TIGA
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana Teknologi Informasi
EDGAR AUDELA BATUBARA 101402111
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : IMPLEMENTASI ALGORITMA LEARNING VECTOR
QUANTIZATION PADA PREDIKSI PRODUKSI KELAPA SAWIT DI
PT. PERKEBUNAN NUSANTARA I PULAU TIGA
Kategori : SKRIPSI
Nama : EDGAR AUDELA BATUBARA
Nomor Induk Mahasiswa : 101402111
Program Studi : S1 TEKNOLOGI INFORMASI
Departemen : TEKNOLOGI INFORMASI
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Dedy Arisandi, ST.,M.Kom Prof. Dr. Opim Salim Sitompul, M.Sc NIP 19790831 200912 1 002 NIP 19610817 198701 1 001
Diketahui/Disetujui oleh
Program Studi S1 Teknologi Informasi Ketua
iii
PERNYATAAN
IMPLEMENTASI ALGORITMA LEARNING VECTOR QUANTIZATION PADA PREDIKSI PRODUKSI KELAPA SAWIT DI
PT. PERKEBUNAN NUSANTARA I PULAU TIGA
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, 23 Maret 2015
UCAPAN TERIMA KASIH
Puji dan syukur penulis panjatkan kehadirat Tuhan Yang Maha Esa yang telah melimpahkan berkat, rahmat serta karuniaNya sehingga penulis dapat menyelesaikan skripsi ini sebagai syarat untuk memperoleh gelar Sarjana Teknologi Informasi, Program Studi (S1) Teknologi Informasi, Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara.
Ucapan terima kasih penulis sampaikan kepada semua pihak yang telah membantu penulis dalam menyelesaikan skripsi ini baik secara langsung maupun tidak langsung. Pada kesempatan ini penulis ingin mengucapkan terima kasih yang sebesar-besarnya kepada:
1. Kedua orang tua penulis, yaitu ayahanda Muda Bincara Batubara dan ibunda tercinta Sri Susilawati yang telah membesarkan penulis dengan sabar serta penuh kasih sayang. Kepada saudara/i kandung, Eggy Anggia Batubara, Alm. Elvan andrian Batubara, Chandra Amelia Batubara yang juga selalu memberikan dukungan dan doa sehingga dapat menyelesaikan skripsi ini. 2. Kepada Bapak Prof. Dr. Opim Salim Sitompul, M.Sc dan Bapak Dedy
Arisandi, ST., M.Kom. selaku dosen pembimbing penulis yang telah memberikan saran dan masukkan serta bersedia meluangkan waktu, tenaga dan pikiran untuk membantu penulis dalam menyelesaikan skripsi ini.
3. Bapak Romi Fadillah Rahmat, B.Comp.,Sc.,M.Sc. dan Ibu Dr. Erna budhiarti Nababan, M.Sc sebagai dosen penguji yang telah memberikan kritik dan saran dalam penyempurnaan skripsi ini.
4. Bapak Muhammad Anggia Muchtar, ST., MM.IT. selaku Ketua Program Studi S1 Teknologi Informasi dan Bapak Mohammad Fadly Syahputra, B.Sc., M.Sc.IT. selaku Sekretaris Program Studi S1 Teknologi Informasi.
5. Seluruh Dosen Program Studi S1 Teknologi Informasi yang telah memberikan ilmu yang bermanfaat bagi penulis dari awal perkuliahan.
v
7. Sahabat - sahabat penulis, Ape, abi, Ibnu, Balsa, Rizki Khairunnisa, Imam, Tri Andika, Ricky feri, Udin yang terus menanyakan kapan wisuda, serta memberikan banyak pelajaran dalam hidup kepada penulis.
8. Sahabat – sahabat terdekat penulis yang tergabung dalam Foya members Akira, Muslim, Eka, Dian Pomta, Rozy, Galih, bunda Dian, Desi, Fezan , Baim, Desi, Heri, Joko, Chairul dan seluruh teman-teman angkatan 2010 Teknologi Informasi yang tidak dapat disebutkan satu persatu, yang telah membantu dan bersama-sama dengan penulis melewati seluruh proses perkuliahan di Universitas Sumatera Utara ini. Kalian semua luar biasa.
9. Seluruh staf TU (Tata Usaha) terutama bang faisal serta pegawai di Program Studi S1 Teknologi Informasi.
ABSTRAK
Kelapa sawit merupakan salah satu komoditas ekspor perkebunan terbesar di Indonesia. Indonesia mempunyai struktur tanah serta curah hujan yang cocok untuk perkebunan kelapa sawit. Kelapa sawit menjadi tanaman yang bernilai ekonomi, sejalan dengan meningkatnya kebutuhan kelapa sawit di pasar dunia. Pada lingkup perkebunan negara, tiap tahunnya akan diadakan Rencana Kerja dan Anggaran Perusahaan (RKAP). Ini dilakukan untuk merencanakan target produksi dan anggaran yang akan digunakan untuk tahun berikutnya. Pada PT. Perkebunan Nusantara I (PTPN I) pulau tiga, target produksi dilakukan secara manual dengan melihat hasil produksi tahun-tahun sebelumnya. Namun kendala terjadi karena hasil produksi rencana yang telah ditargetkan berbeda dengan hasil produksi realisasi. Atas dasar hal ini, prediksi kelapa sawit sangatlah penting. Algoritma yang diajukan pada penelitian ini adalah Learning vector quantization. Pada penelitian ini ditunjukkan bahwa algoritma learning vector quantization mampu memprediksi hasil produksi kelapa sawit sehingga hasil prediksi dapat digunakan untuk menjadi acuan target produksi perusahaan.
vii
IMPLEMENTATION LEARNING VECTOR QUANTIZATION ALGORITHM TO PRODUCTION PREDICTED PALM OIL IN
PT. PERKEBUNAN I PULAU TIGA
ABSTRACT
Palm oil is one of the largest export commodites in indonesia. Indonesia soil structure and rainfall are suitable for palm plantations. Palm oil plans for further economic value for the future, are in line with the increasing demand of oil in the world market. The scope of country estates, held each year workplan & budget of company (RKAP). This is done to plan production and budgets that are used to scan the next year. The PTPN I Pulau tiga, the production target manual is done by reviewing at the output of the previous year. However constraint occurs because the targeted production plans are different from actual production results. On the basis of this, it’s very important for future prediction of palm oil. Algorithm proposed in this study is learning vector quantization. In this research it is indicated that the prediction results can be used for a references targeting of production of PT. Perkebunan I Pulau Tiga.
DAFTAR ISI
Hal.
Persetujuan ii
Pernyataan iii
Ucapan Terima Kasih iv
Abstrak vii
Abstract viii
Daftar Isi viiii
Daftar Tabel x
Daftar Tabel xi
BAB 1 Pendahuluan 1
1.1 Latar Belakang 1
1.2 Rumusan Masalah 2
1.3 Tujuan Penelitian 2
1.4 Batasan Masalah 2
1.5 Manfaat Penelitian 3
1.6 Metodologi Penelitian 3
1.7 Sistematika Penulisan 4
BAB 2 Landasan Teori 6
2.1 Jaringan Saraf Biologi Manusia 6
2.2 Jaringan Saraf Tiruan 7
2.2.1. Latar Belakang 7
2.2.2.Pengertian Jaringan Saraf Tiruan 8
2.2.3.Arsitektur Jaringan 8
2.2.4.Manfaat Meggunakan Jaringan Saraf Tiruan 10
2.2.5.Paradigma Pembelajaran 11
2.3 Learning Vector Quantization 13
ix
BAB 3 Analisis dan Perancangan Sistem 17
3.1 Pengambilan Data 18
3.2 Pendefinisian Input 19
3.3 Penetapan Target Kelas 21
3.4 Flowchart Training 22
3.5 Flowchart Prediksi 24
3.6 Perhitungan Training 24
3.7 Perhitungan Prediksi 28
BAB 4 Implementasi dan Pengujian Sistem 30
4.1 Implementasi 30
4.2 Pengujian 33
BAB 5 Kesimpulan dan Saran 40
5.1 Kesimpulan 40
5.2 Saran 40
DAFTAR TABEL
Hal. Tabel 2.1. Perbedaan Saraf Biologi dengan Jaringan Saraf Tiruan
(Medsker & Liebowitz, 1994) 8
Tabel 3.1. Tabel Data Produksi Kelapa Sawit tahun 2010 19 Tabel 3.2. Tabel Pertumbuhan Jumlah Produksi Kelapa Sawit 21
Tabel 3.3. Tabel Produksi Kelapa Sawit tahun 2010 25
Tabel 3.4. Tabel Pembelajaran Training 25
Tabel 3.5. Tabel Bobot Training 26
Tabel 3.6. Tabel Bobot baru pertama 27
Tabel 3.7. Tabel Bobot baru kedua 28
Tabel 3.8. Inisialisasi input Prediksi 29
Tabel 3.9. Hasil Prediksi 29
Tabel 4.1. Hasil Produksi Kelapa Sawit tahun 2014 33
Tabel 4.2. Hasil Produksi Kelapa Sawit tahun 2014 menurut kelasnya 34
Tabel 4.3. Hasil Pengujian Epoch 5000 35
Tabel 4.4. Hasil Pengujian Epoch 5200 36
Tabel 4.5. Hasil Pengujian Epoch 5500 37
Tabel 4.6. Hasil Pengujian Learning rate 0.06 37
xi
DAFTAR GAMBAR
Hal. Gambar 2.1. Neuron biologi manusia (Medsker & Liebowitz, 1994) 6
Gambar 2.2. Single Layer Network (Fausett, 1994) 9
Gambar 2.3. Multi Layer Network (Fausett, 1994) 10
Gambar 2.4. Proses Supervised Learning (Bird et al, 2014) 12 Gambar 2.5. Arsitektur Jaringan Learning Vector Quantization (Fausett, 1994) 13
Gambar 3.1. Arsitektur umum training 17
Gambar 3.2. Arsitektur umum prediksi 18
Gambar 3.3. Arsitektur Jaringan Learning Vector Quantization 20
Gambar 3.4. Flowchart Training 22
Gambar 3.5. Flowchart Prediksi 24
Gambar 4.1. Tampilan Halaman Awal 30
Gambar 4.2. Tampilan Halaman Help 31
Gambar 4.3. Tampilan Halaman Input Data 31
Gambar 4.4. Tampilan Halaman saat proses training 32
vi
ABSTRAK
Kelapa sawit merupakan salah satu komoditas ekspor perkebunan terbesar di Indonesia. Indonesia mempunyai struktur tanah serta curah hujan yang cocok untuk perkebunan kelapa sawit. Kelapa sawit menjadi tanaman yang bernilai ekonomi, sejalan dengan meningkatnya kebutuhan kelapa sawit di pasar dunia. Pada lingkup perkebunan negara, tiap tahunnya akan diadakan Rencana Kerja dan Anggaran Perusahaan (RKAP). Ini dilakukan untuk merencanakan target produksi dan anggaran yang akan digunakan untuk tahun berikutnya. Pada PT. Perkebunan Nusantara I (PTPN I) pulau tiga, target produksi dilakukan secara manual dengan melihat hasil produksi tahun-tahun sebelumnya. Namun kendala terjadi karena hasil produksi rencana yang telah ditargetkan berbeda dengan hasil produksi realisasi. Atas dasar hal ini, prediksi kelapa sawit sangatlah penting. Algoritma yang diajukan pada penelitian ini adalah Learning vector quantization. Pada penelitian ini ditunjukkan bahwa algoritma learning vector quantization mampu memprediksi hasil produksi kelapa sawit sehingga hasil prediksi dapat digunakan untuk menjadi acuan target produksi perusahaan.
IMPLEMENTATION LEARNING VECTOR QUANTIZATION ALGORITHM TO PRODUCTION PREDICTED PALM OIL IN
PT. PERKEBUNAN I PULAU TIGA
ABSTRACT
Palm oil is one of the largest export commodites in indonesia. Indonesia soil structure and rainfall are suitable for palm plantations. Palm oil plans for further economic value for the future, are in line with the increasing demand of oil in the world market. The scope of country estates, held each year workplan & budget of company (RKAP). This is done to plan production and budgets that are used to scan the next year. The PTPN I Pulau tiga, the production target manual is done by reviewing at the output of the previous year. However constraint occurs because the targeted production plans are different from actual production results. On the basis of this, it’s very important for future prediction of palm oil. Algorithm proposed in this study is learning vector quantization. In this research it is indicated that the prediction results can be used for a references targeting of production of PT. Perkebunan I Pulau Tiga.
BAB 1 PENDAHULUAN
1.1. Latar Belakang
Kelapa sawit (Elaeis Guineensis) merupakan salah satu komoditas ekspor perkebunan terbesar di Indonesia. Indonesia mempunyai struktur tanah serta curah hujan yang cocok untuk perkebunan kelapa sawit. Di Indonesia penyebaran kelapa sawit berada di daerah Aceh, Sumatera, Jawa, hingga Sulawesi.
Selain menjadi bahan baku minyak goreng, hasil produksi kelapa sawit juga menjadi bahan baku industri, serta bahan bakar. Kelapa sawit menjadi tanaman yang bernilai ekonomi, sejalan dengan meningkatnya kebutuhan kelapa sawit di pasar dunia. Kelapa sawit memberikan kontribusi yang besar terhadap devisa negara. Selain itu, industri kelapa sawit juga membuka banyak lapangan pekerjaan dibandingkan industri lainnya. Seluruh area perkebunan kelapa sawit di indonesia, dikelola dalam bentuk perkebunan rakyat dan perkebunan besar. Perkebunan besar terdiri dari perkebunan negara seperti Perseroan Terbatas Perkebunan Nusantara (PTPN) dan perkebunan swasta.
Pada lingkup perkebunan negara, tiap tahunnya akan diadakan Rencana Kerja dan Anggaran Perusahaan (RKAP). Ini dilakukan untuk merencanakan target produksi dan anggaran yang akan digunakan untuk tahun berikutnya. Pada PT. Perkebunan Nusantara I (PTPN I) pulau tiga, target produksi dilakukan secara manual dengan melihat hasil produksi tahun-tahun sebelumnya. Namun kendala terjadi karena hasil produksi rencana yang telah ditargetkan berbeda dengan hasil produksi realisasi.
Dari banyak metode untuk prediksi, salah satu metode yang diakui keunggulannya adalah Jaringan Saraf Tiruan. Jaringan saraf tiruan merupakan rekayasa dari jaringan saraf biologi (Yadav, et al. 2013). Jaringan saraf tiruan dapat menyelesaikan masalah perhitungan yang rumit, seperti prediksi dan pemodelan, klasifikasi, pola pengenalan, pengklasteran serta optimasi. Jaringan saraf tiruan bersifat fleksibel terhadap masukan data serta menghasilkan respon yang konsisten (Pham, 1994).
Dalam hal ini metode jaringan saraf tiruan yang akan penulis terapkan adalah metode Learning Vector Quantization. Learning vector quantization telah dipelajari agar menghasilkan vector acuan yang optimal karena sederhana dan cepat (Kohonen, 1989). Jaringan learning vector quantization merupakan suatu jaringan pelatihan kompetitif dan pada masing-masing outputnya akan dihubungkan dengan suatu kelas tertentu.
1.2. Rumusan Masalah
Berdasarkan uraian latar belakang permasalahan yang ada, bahwa prediksi produksi kelapa sawit sangatlah penting. Maka dibutuhkan suatu metode prediksi yang dapat memberikan informasi hasil produksi kelapa sawit tiap bulannya untuk dijadikan acuan perusahaan dalam merencanakan target produksi kelapa sawit untuk tahun selanjutnya.
1.3. Tujuan Penelitian
Tujuan penelitian ini adalah untuk memprediksi produksi kelapa sawit di PT. Perkebunan Nusantara I (PTPN I) Pulau Tiga tiap bulannya dengan menggunakan algoritma Learning vector quantization.
1.4. Batasan masalah
Untuk mencegah meluasnya pembahasan, maka akan dilakukan pembatasan masalah. Batasan-batasan tersebut sebagai berikut:
1. Data produksi kelapa sawit yang digunakan adalah data produksi kelapa sawit dari tahun 2010-2013 untuk tahun tanam sawit 2003.
3
jumlah pupuk, jumlah produksi sebelumnya dan output berjumlah dua yaitu produksi rendah atau produksi tinggi.
1.5. Manfaat Penelitian
Manfaat penelitian ini antara lain:
1. Diperolehnya sebuah Aplikasi yang dapat memprediksi produksi kelapa sawit. 2. Diperoleh informasi mengenai kemampuan algoritma Learning vector
quantization dalam memprediksi produksi kelapa sawit.
3. Penelitian dapat dijadikan sebagai bahan rujukan untuk penelitian lain.
1.6. Metodologi Penelitian
Dalam penelitian ini, tahapan-tahapan yang akan dilalui adalah sebagai berikut: 1. Studi Literatur
Pada tahap ini dilakukan studi kepustakaan terhadap buku-buku yang relevan maupun artikel-artikel, e-book dan juga journal international yang didapat melalui internet.
2. Analisis Permasalahan
Tahap ini digunakan untuk mengolah data dari hasil studi literatur dan kemudian melakukan analisis sehingga menjadi suatu informasi.
3. Pembangunan Program
Parameter-parameter yang digunakan pada metode Learning vector quantization ini adalah sebagai berikut:
a. Alfa (Learning rate)
Alfa didefinisikan sebagai tingkat pembelajaran. Jika alfa terlalu besar, maka algoritma akan menjadi tidak stabil sebaliknya jika alfa terlalu kecil, maka prosesnya akan terlalu lama. Nilai alfa adalah 0 < α < 1.
b. Dec alfa (Penurunan Learning rate)
Dec Alfa yaitu penurunan tingkat pembelajaran. c. Min Alfa (Minimum Learning rate)
d. Max Epoch (Maksimum epoch)
Max epoch aitu jumlah epoch maksimum yang boleh dilakukan selama pelatihan. Iterasi akan dihentikan jika nilai epoch melebihi epoch maksimum. Misalkan terdapat n buah data dengan m buah variabel input. Data-data tersebut terbagi dalam K kelas. Hasil dari algoritma Learning vector quantization adalah menemukan unit output yang paling dekat dengan vektor input.
4. Implementasi dan Pengujian Sistem
Pada tahap ini dilakukan pemasukan data serta memprosesnya untuk mendapatkan hasil apakah sesuai dengan yang diharapkan.
5. Dokumentasi
Tahap dokumentasi adalah pembuatan laporan berupa skripsi berdasarkan tahap-tahap diatas.
1.7. Sistematika Penulisan
Sistematika penulisan skripsi ini adalah sebagai berikut: BAB 1 : Pendahuluan
Bab ini berisikan konsep dasar untuk penyusunan penelitian yang terdiri dari latar belakang penelitian yang dilaksanakan, rumusan masalah, tujuan penelitian, batasan masalah, manfaat penelitian, metodologi penelitian, serta sistematika penulisan.membahas latar belakang, rumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian serta sistematika penulisan.
BAB 2 : Landasan Teori
Pada bab ini membahas beberapa teori pendukung untuk bab selanjutnya. Teori tentang jaringan saraf buatan, kelapa sawit, algoritma Learning vector quantization yang akan digunakan akan dibahas pada bab ini.
BAB 3 : Analisis dan Perancangan Perangkat Lunak
5
BAB 4 : Implementasi dan Pengujian Perangkat Lunak
Bab ini berisi pembahasan tentang iimplementasi dari perancangan penerapan yang telah dijabarkan pada bab 3. Selain itu, hasil yang didapat dari pengujian yang dilakukan terhadap implementasi juga akan dijabarkan pada bab ini.
BAB 5 : Kesimpulan dan Saran
BAB 2
LANDASAN TEORI
2.1. Jaringan Saraf Biologi Manusia
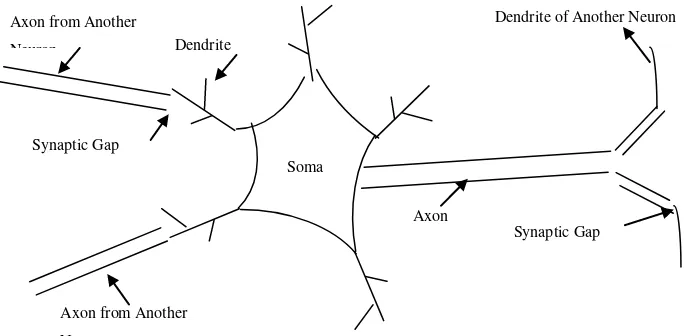
Otak manusia memiliki struktur yang sangat kompleks, serta memiliki kemampuan yang luar biasa. Otak terdiri dari neuron-neuron dan penghubung yang disebut sinapsis. Seperti dapat dilihat pada gambar 2.1 Neuron biologi manusia. Neuron bekerja berdasarkan impuls/sinyal yang diberikan oleh neuron lain. Diperkirakan manusia memiliki 109 neuron dan 6x1018 sinapsis. Dengan jumlah yang begitu banyak, otak mampu mengenali pola, melakukan perhitungan, dan mengontrol organ-organ tubuh dengan kecepatan yang lebih tinggi dibandingkan komputer digital (Puspitaningrum, 2006). Sebagai perbandingan, pengenalan wajah seseorang yang sedikit berubah misal memakai topi, memiliki jenggot dan lainnya akan lebih cepat dilakukan manusia dibandingkan komputer. Pada waktu lahir, otak mempunyai struktur yang menakjubkan karena kemampuannya membentuk sendiri aturan-aturan/pola berdasarkan pengalaman yang diterima. Jumlah dan kemampuan neuron berkembang seiring dengan pertumbuhan fisik manusia, terutama pada umur 0-2 tahun. Pada 2 tahun pertama umur manusia, terbentuk 1 juta sinapsis per detiknya.
Gambar 2.1 Neuron biologi manusia (Medsker & Liebowitz, 1994) Axon
Synaptic Gap
Dendrite of Another Neuron
Axon from Another Neuron
Axon from Another Neuron
Synaptic Gap
7
Neuron memiliki 3 komponen penting yaitu dendrit, soma dan axon. Dendrit memiliki fungsi menerima sinyal dari neuron lain. Sinyal tersebut berupa impuls elektrik yang dikirim melalui celah sinaptik melalui proses kimiawi. Sinyal tersebut dimodifikasi (diperkuat/diperlemah) di celah sinaptik. Berikutnya, soma menjumlahkan semua sinyal-sinyal yang masuk. Kalau jumlahan tersebut cukup kuat dan melebihi batas ambang (threshold), maka sinyal tersebut akan diteruskan ke sel lain melalui axon. Frekuensi penerusan sinyal berbeda-beda antara satu sel dengan yang lain.
Neuron biologi merupakan sistem yang "fault tolerant" dalam 2 hal. Pertama, manusia dapat mengenali sinyal input yang agak berbeda dari yang pernah kita terima sebelumnya. Sebagai contoh, manusia sering dapat mengenali seseorang yang wajahnya pernah dilihat dari foto, atau dapat mengenali seseorang yang wajahnya agak berbeda karena sudah lama tidak dijumpainya. Kedua, otak manusia tetap mampu bekerja meskipun beberapa neuronnya tidak mampu bekerja dengan baik. Jika sebuah neuron rusak, neuron lain kadang-kadang dapat dilatih untuk menggantikan fungsi sel yang rusak tersebut.
2.2. Jaringan Saraf Tiruan 2.2.1. Latar belakang
Jaringan saraf tiruan dibuat pertama kali pada tahun 1943 oleh Neurophysiologist McCulloch dan Logician Walter Pits. McCulloch dan Pits menyimpulkan bahwa kombinasi beberapa neuron sederhana menjadi sebuah sistem neural akan meningkatkan kemampuan komputasinya. Bobot dalam jaringan yang diusulkan oleh McCulloch dan Pits diatur untuk melakukan fungsi logika sederhana. Pada tahun 1958, Rosenblatt memperkenalkan dan mulai mengembangkan model jaringan yang disebut Perceptron. Metode pelatihan diperkenalkan untuk mengoptimalkan hasil iterasinya.
(single layer). Pada tahun 1986, Rumelhart mengembangkan perceptron menjadi backpropagation, yang memungkinkan jaringan diproses melalui beberapa layer.
2.2.2. Pengertian jaringan saraf tiruan
Jaringan saraf tiruan adalah pemrosesan suatu informasi yang memiliki karakteristik mirip dengan jaringan saraf biologi (Fausett, 1994). Jaringan Saraf Tiruan dibentuk untuk memecahkan suatu masalah tertentu seperti pengenalan pola atau klasifikasi karena proses pembelajaran (Smith, 1996).
Jaringan saraf tiruan dibentuk sebagai generalisasi model matematika dari jaringan saraf biologi, dengan asumsi bahwa :
a. Pemrosesan informasi terjadi pada banyak elemen sederhana (neuron).
b. Sinyal dikirirnkan diantara neuron-neuron melalui penghubung-penghubung. c. Penghubung antar neuron memiliki bobot yang akan memperkuat atau
memperlemah sinyal
d. Untuk menentukan output, setiap neuron menggunakan fungsi aktivasi (biasanyabukan fungsi linier) yang dikenakan pada jumlahan input yang diterima. Besarnya output ini selanjutnya dibandingkan dengan suatu batas ambang
Dapat dilihat pada tabel 2.1 perbedaan antara jaringan saraf tiruan dengan jaringan saraf biologi (Medsker & Liebowitz, 1994).
Tabel 2.1 Perbedaan Saraf Biologi dengan Jaringan Saraf Tiruan (Medsker & Liebowitz, 1994)
Jaringan Saraf Biologi (Manusia) Jaringan Saraf Tiruan (JST)
Soma Node (simpul)
Dendrit Input
Axon Output
Synapse Weight (bobot)
Slow speed Fast speed
Terdiri dari banyak Neuron (109) Beberapa Neuron
2.2.3. Arsitektur jaringan
9
Neuron-neuron pada jaringan diatur menjadi layer-layer. Di dalam tiap layer, neuron-neuron biasanya memiliki fungsi aktivasi yang sama serta pola hubungan yang sama dengan neuron-neuron yang lain. Pengaturan neuron-neuron ke dalam layer dan pola hubungan antar layer dinamakan arsitektur jaringan saraf tiruan. Jaringan saraf tiruan umumnya diklasifikasikan sebagai single layer network dan multilayer network.
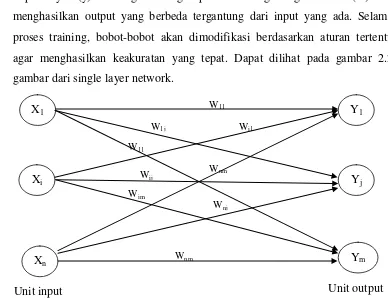
a. Single Layer Network
Dalam jaringan single layer, input layer (x) berhubungan langsung dengan ouput layer (y). Masing- masing input terhubung dengan bobot (w) dan menghasilkan output yang berbeda tergantung dari input yang ada. Selama proses training, bobot-bobot akan dimodifikasi berdasarkan aturan tertentu agar menghasilkan keakuratan yang tepat. Dapat dilihat pada gambar 2.2 gambar dari single layer network.
Gambar 2.2 Single Layer Network (Fausett, 1994)
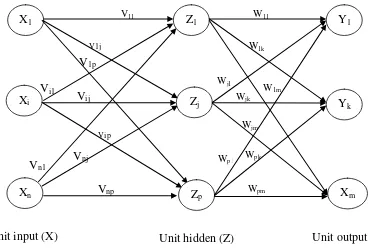
b. Multilayer Network
Jaringan ini merupakan pengembangan dari single layer network. Pada model ini, jaringan mempunyai layer tambahan atau yang sering disebut dengan hidden layer (Z). Keunggulan model ini adalah adalah kemampuannya untuk menghasilkan output yang lebih akurat dari model pertama. Dapat dilihat pada gambar 2.3 gambar multilayer network.
X1 Y1
Xi Yj
Xn Ym
V11
Gambar 2.3 Multilayer Network (Fausett, 1994)
2.2.4. Manfaat Menggunakan Jaringan Saraf Tiruan Berikut manfaat menggunakan Jaringan saraf tiruan.
a. Bersifat adaptif terhadap perubahan parameter yang mempengaruhi karakteristik system.
b. Dapat dilatih untuk memberikan keputusan dengan memberikan set pelatihan sebelumnya untuk mencapai target tertentu, sehingga jaringan saraf tiruan mampu membangun dan memberikan jawaban sesuai dengan informasi yang diterima pada proses pelatihan.
c. Mempunyai struktur paralel yang terdistribusi. Artinya, komputasi dapat dilakukan oleh lebih dari satu elemen pemroses yang bekerja secara simultan. d. Mampu mengklasifikasi pola masukan dan pola keluaran. Melalui proses penyesuaian, pola keluaran dihubungkan dengan masukan yang diberikan oleh jaringan saraf tiruan. Jaringan saraf tiruan ditentukan oleh 3 hal.
1. Pola hubungan antar neuron
Neuron adalah unit pemroses informasi yang menjadi dasar dalam pengoperasian jaringan saraf tiruan. Neuron terdiri dari 3 elemen pembentuk. Elemen-elemen pembentuk neuron tersebut sebagi yaitu, Himpunan unit-unit yang dihubungkan dengan jalur koneksi, unit
11
penjumlah yang akan menjumlahkan input-input sinyal yang sudah dikalikan dengan bobotnya, fungsi aktivasi yang akan menentukan apakah sinyal dari input neuron akan diteruskan ke neuron lain atau tidak.
2. Metode menentukan bobot penghubung 3. Fungsi aktivasi
Fungsi aktivasi merupakan suatu fungsi yang akan mentransformasikan suatu inputan menjadi suatu output tertentu. Pada jaringan saraf tiruan suatu informasi akan diterima oleh inputan. Inputan ini akan diproses melalui suatu fungsi perambatan. Fungsi ini akan menjumlahkan sejumlah inputan, hasil dari penjumlahan ini kemudian akan dibandingkan dengan nilai ambang (threshold) tertentu melalui fungsi aktivasi terhadap setiap neuron. Jika nilai yang dihasilkan melewati nilai ambang maka neuron tersebut akan diaktifkan jika tidak maka neuron tidak diaktifkan. Artinya neuron akan menghasilkan suatu nilai output jika threshold dilewati.
2.2.5. Paradigma pembelajaran
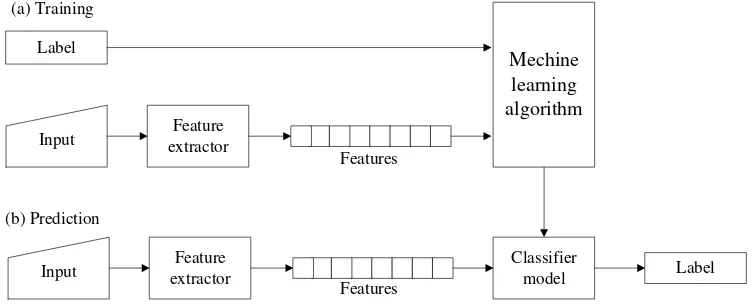
Berikut 2 macam paradigma pembelajaran yang dikenal a. Supervised learning
Input extractorFeature
Mechine learning algorithm
Label
Input extractorFeature Classifier model Label Features
Features (a) Training
(b) Prediction
Gambar 2.4 proses supervised learning (Bird et al, ,2014)
Berdasarkan proses yang dilakukan, kita perlu memperhatikan beberapa hal dalam menyusun set pelatihan, yaitu:
1. Pemberian urutan pola yang akan diajarkan 2. Kriteria perhitungan error
3. Kriteria proses belajar
4. Jumlah iterasi yang harus dilalui 5. Inisialisasi bobot dan parameter awal
Contoh jaringan saraf tiruan supervised learning backpropagation, learning vector quatization.
b. Unsupervised learning
Pada pelatihan unsupervised learning, jaringan tidak mendapatkan target, sehingga jaringan saraf tiruan mengatur bobot interkoneksi sendiri. Unsupervised learning mempelajari bagaimana sistem dapat belajar untuk mewakili pola masukan tertentu dengan cara yang mencerminkan struktur statistik keseluruhan pola masukan (Dayan, 1999). Contoh jaringan saraf tiruan unsupervised learning adalah jaringan Kohonen.
2.3.Learning Vector Quantization
13
digunakan untuk pengklasifikasian (Biehl, 2006). Hal ini diterapkan dalam berbagai praktis masalah, termasuk medis dan analisis data. Learning vector quantization merupakan salah satu jaringan saraf tiruan, dan merupakan versi supervised learning dari algoritma Kohonen Self-Organizing Map (SOM). Algoritma learning vector quantization bertujuan akhir mencari nilai bobot yang sesuai untuk mengelompokkan vektor-vektor kedalam kelas tujuan yang telah diinisialisasi pada saat pembentukan jaringan Learning vector quantization. Pemrosesan yang terjadi pada setiap vektor adalah mencari jarak antara suatu vektor input ke bobot yang bersangkutan (w1 dan
w2). Untuk lebih jelasnya dapat dilihat pada gambar 2.5 Arsitektur jaringan Learning
vector quantization.
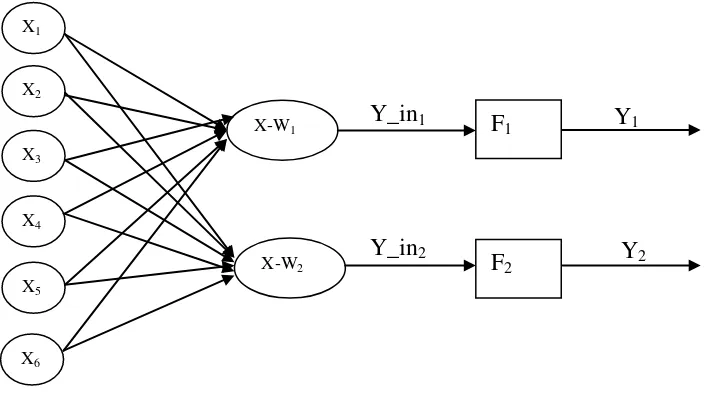
Gambar 2.5 Arsitektur Jaringan Learning Vector Quantization (Fausett, 1994) Keterangan:
1. X1, X2 - X6 merupakan vektor inputan. Kemudian vektor-vektor input tersebut
dihubungkan ke vektor W1 dan W2.
2. W1 dan W2 merupakan vektor bobot pertama dan kedua. W1 merupakan vektor
bobot yang menghubungkan setiap neuron pada lapisan input ke neuron
pertama pada lapisan output, sedangkan W2 merupakan vektor bobot yang
menghubungkan setiap neuron pada lapisan input ke neuron yang kedua pada
memetakan y_in2 ke y2 = 2 apabila ||X – w2|| < ||X – w1||, dan y2 = 0 jika
sebaliknya.
4. Y1 dan Y2 merupakan output pertama dan kedua.
Algoritma training learning vector quantization (Kusumadewi, 2004).
1. Tetapkan
a. Bobot awal variabel input ke-j menuju kelas (cluster) ke-i.
b. Parameter learning rate (α)
c. Pengurangan learning rate (Dec α)
d. Minimal learning rate yang diperbolehkan (min α)
2. Masukkan:
a. Data input:Xij
Dengan i = 1, 2, ..., n; dan j = 1, 2, ..., m.
b. Target berupa kelas: Tk;
Dengan k = 1, 2, ..., n.
3. Tetapkan kondisi awal epoch
4. Kerjakan jika (α >=min α)
a. Epoch = epoch + 1;
b. Kerjakan untuk i = 1 sampai n
i. Tentukan j sedemikian hingga ||Xi - Wj||
ii. Perbaiki Wj dengan ketentuan:
o Jika T = Cj maka:
Setelah dilakukan pelatihan, akan diperoleh bobot-bobot akhir. Bobot-bobot ini
nantinya akan digunakan untuk melakukan simulasi atau pengujian.
Algoritma simulasi (pengujian)
1. Masukkan data yang akan diuji, misal: Xij dengan i = 1, 2, ..., np; dan
j = 1, 2, ..., m.
15
a. Tentukan J sedemikian hingga ||Xi - Wj|| minimum; dengan
J = 1, 2, ..., k.
b. J adalah kelas untuk Xi.
2.4. Penelitian Terdahulu
Terdapat beberapa penelitian terdahulu yang berkaitan dengan learning vector quantization dan produksi kelapa sawit dalam metode prediksi. Beberapa penelitian terdahulu dalam penelitian ini akan dijadikan sebagai bahan acuan agar peneliti dapat memperoleh informasi mengenai topik pembahasan penelitian yang akan dilakukan. Pada tahun 2009, Hermantoro & Purnawan melakukan penelitian dengan judul pemodelan dan simulasi produktivitas perkebunan kelapa sawit berdasarkan kualitas lahan dan iklim menggunakan model Artificial Neural Network.
Data yang akan dijadikan parameter diambil dari beberapa afdeling PT.Sawit Sumbermas Sarana Kalimantan Tengah. Penelitian ini menggunakan 7 data parameter yaitu curah hujan, ketinggian dari permukaan laut, kelerengan, umur tanaman, batuan, solum, dan keasaman tanah. Pada saat training dicoba berbagai struktur model ANN yaitu model :7-3-1, model 7-4-1, dan model 7-51 dengan koefisien laju pembelajaran 0.9, konstanta omentum 0.9 dan konstanta gain 0.9. Berdasarkan hasil penelitian tersebut saat dilakukan test dan dari test tersebut diperoleh model terbaik adalah model 7-3-1, dengan iterasi 30000, laju pembelajaran = 0.9, momentum = 0.9 dan konstanta gain = 0.9 dengan hasil pelatihan (training) R2 = 0.9998 dan RSME = 0.0709 dan pengujian (testing) R2 = 0.8901 dan RSME = 2.2196.
nilai 3 jika jenis angina adalah variant pectoris, Diberi nilai 4 jika jenis angina adalah myocardiac infarction. Pada data variabel Kadar gula darah > 120 mg/dl, nilai 0 jika kadar gula darah tidak > 120 mg/dl, diberi nilai 1 jika kadar gula darah > 120 mg/dl. Pada data variabel merokok, diberi nilai 0 jika tidak merokok, Diberi nilai 1 jika merokok kurang dari 3 kali sehari, Diberi nilai 2 jika merokok lebih dari 4 kali sehari.Pada data variabel keturunan diberi nilai 0 jika tidak mempunyai sejarah keluarga yang sakit jantung, dan diberi nilai 1 jika mempunyai sejarah keluarga yang sakit jantung. Pada data variabel olahraga ini, yang dimaksud olah raga adalah olahraga jalan kaki dengan jarak yang ditempuh kurang lebih 4 km. Sedangkan yang dimaksud 0, 1, 2, 3, 4 dan 5 dalam data pasien penyakit jantung adalah frekuensi olah raga tiap minggunya. Pada metode Learning vector quantization, target/sasaran (Y) yang diinginkan juga harus dituliskan. Dalam hal ini targetnya berupa kategori terjangkit penyakit jantung dan tidak terjangkit penyakit jantung. Agar dapat dikenali oleh jaringan, kategori harus diubah ke dalam bentuk numerik, yaitu diiberi nilai 1 jika orang tersebut tidak terjangkit penyakit jantung dan diberi nilai 2 jika orang tersebut terjangkit penyakit jantung. Parameter – parameter yang digunakan pada penelitian tersebut saat melakukan training dengan nilai Alfa (Learning rate), α = 0.25 , DecAlfa (Penurunan Learning rate), Decα = 0.1, MinAlfa (Minimum Learning rate),
BAB 3
ANALISIS DAN PERANCANGAN
Analisis Dan Perancangan Prediksi Produksi Kelapa Sawit
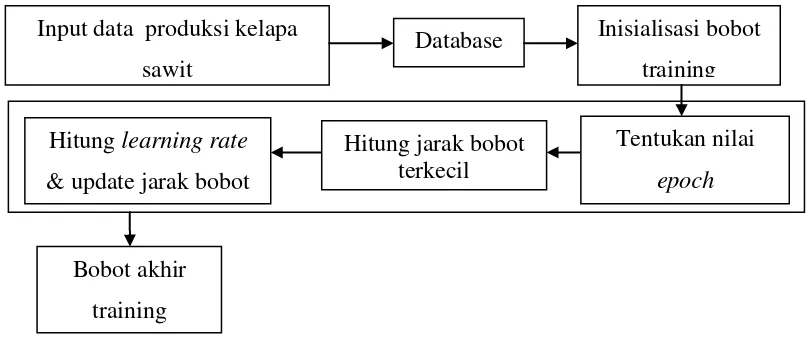
Dalam merancang prediksi produksi kelapa sawit, penulis menerapkan algoritma Learning Vector Quantization. Bentuk perancangan prediksi produksi kelapa sawit ini dapat dilihat pada gambar 3.1 yang menunjukkan arsitektur umum dari rangkaian yang dilakukan pada proses training.
Gambar 3.1 Arsitektur umum Training
Proses dimulai dari penginputan data. Data yang di input berupa tahun produksi, tahun tanam, jumlah pokok, luas, umur, bulan, jumlah pupuk, jumlah hari panen dan jumlah produksi. Data-data tersebut akan disimpan ke database training. Setelah semua data diinput dan disimpan maka proses selanjutnya adalah proses training. Proses training dimulai dari penginisialisasian data-data input. Dua input akan di inisialisasi menjadi bobot training ke-1 dan ke-2, yaitu jumlah produksi kelapa sawit paling kecil dan jumlah produksi kelapa sawit yang paling besar. Sedangkan sisanya akan dijadikan input pembelajaran.
Setelah nilai epoch ditentukan, pada epoch ke-1 hitung jarak terpendek dengan bobot training ke-1 dan ke-2. Setelah jarak terpendek pada bobot ke-1 dan ke-2
Database Input data produksi kelapa
sawit
Inisialisasi bobot training Hitung learning rate
& update jarak bobot
Prediksi Output
didapat, pilih jarak yang terkecil untuk proses perkalian dengan nilai learning rate. Hasil dari perhitungan tersebut akan digunakan sebagai nilai bobot yang baru. Proses dilakukan hingga nilai input pembelajaran terakhir didapat pada epoch ke-1. Sebelum masuk ke epoch selanjutnya, nilai learning rate(α) akan diupdate dengan cara dec alpha dikalikan learning rate yang lama. Setelah didapat nilai learning rate yang baru akan dilakukan proses perhitungan yang sama seperti epoch ke-1 hingga sampai nilai epoch yang ditentukan dicapai. Setelah nilai epoch yang ditentukan dicapai maka akan didapat bobot akhir training. Bobot akhir training akan digunakan pada proses selanjutnya yakni proses prediksi. Dapat dilihat pada gambar 3.2 gambar arsitektur umum prediksi.
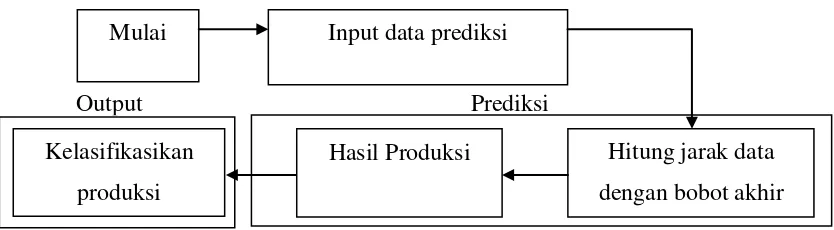
Gambar 3.2 Arsitektur umum Prediksi
Proses prediksi dimulai dari penginputan data yang akan diprediksi. Setelah data yang ingin diprediksi di input, proses selanjutnya adalah menghitung jarak terkecil dengan menggunakan bobot akhir hasil training. Hasil dari perhitungan jarak terkecil akan digunakan sebagi pengkelasifikasian apakah hasil perhitungan masuk kedalam kelas produksi rendah atau kelas produksi tinggi.
3.1. Pengambilan Data
Dalam perancangan prediksi produksi kelapa sawit, variabel yang akan digunakan sebagai parameter adalah tahun produksi, tahun tanam, bulan, umur tanaman, luas, jumlah pokok, jumlah hari panen, jumlah pupuk, jumlah produksi sebelumnya dan sebagai outputnya yaitu prediksi produksi kelapa sawit rendah dan prediksi produksi kelapa sawit tinggi.
Data yang diambil untuk ditraining merupakan data produksi kelapa sawit selama empat tahun yaitu tahun 2010, 2011, 2012 dan 2013 dengan tahun tanam sawit
19
tahun tanam 2003. Sedangkan untuk data prediksi, akan digunakan data tahun 2014 dengan tahun tanam sawit 2003. Dapat dilihat pada tabel 3.1 tabel data produksi kelapa sawit tahun 2010 sebagai salah satu data produksi kelapa sawit yang akan digunakan untuk proses training.
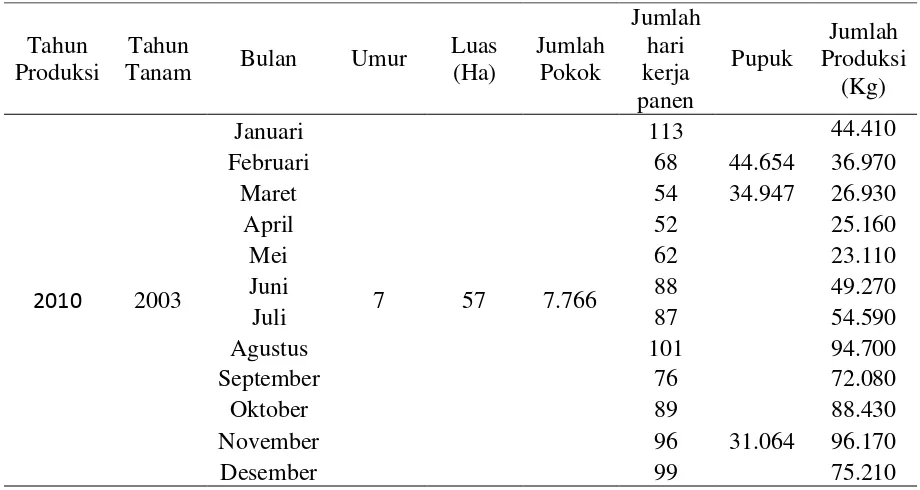
Tabel 3.1 Data produksi kelapa sawit tahun 2010
Tahun sebagai input pembelajaran training dan bobot training.
3.2. Pendefinisian Input
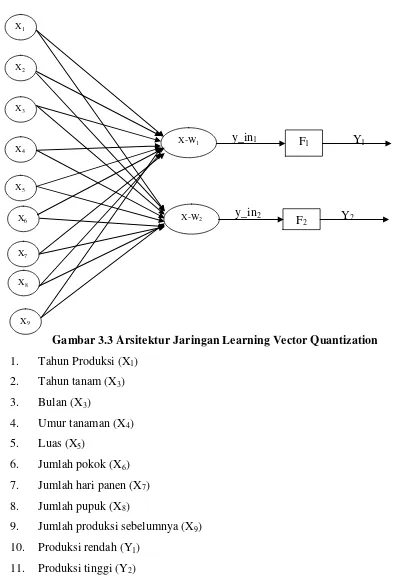
Data parameter produksi kelapa sawit yang diambil, selanjutnya akan diolah oleh jaringan. Dapat dilihat pada gambar 3.3 arsitektur jaringan learning vector quantization dengan 9 unit (neuron) pada lapisan input, dan 2 unit (neuron) pada
lapisan output. Lapisan neuron-neuron input tersebut dihubungkan ke vektor W1 dan
W2. W1 dan W2 merupakan vektor bobot pertama dan kedua. W1 merupakan vektor
bobot yang menghubungkan setiap neuron pada lapisan input ke neuron pertama pada
lapisan output, sedangkan W2 merupakan vektor bobot yang menghubungkan setiap
neuron pada lapisan input ke neuron yang kedua pada lapisan output. F1 dan F2
merupakan fungsi aktivasi pertama dan kedua. Fungsi aktivasi F1 akan memetakan
pula dengan yang terjadi pada fungsi aktivasi F2, akan memetakan y_in2 ke y2 = 2
apabila ||X – w2|| < ||X – w1||, dan y2 = 0 jika sebaliknya.Y1 dan Y2 merupakan output
pertama dan kedua.
Gambar 3.3 Arsitektur Jaringan Learning Vector Quantization 1. Tahun Produksi (X1)
21
3.3. Penetapan Target Kelas
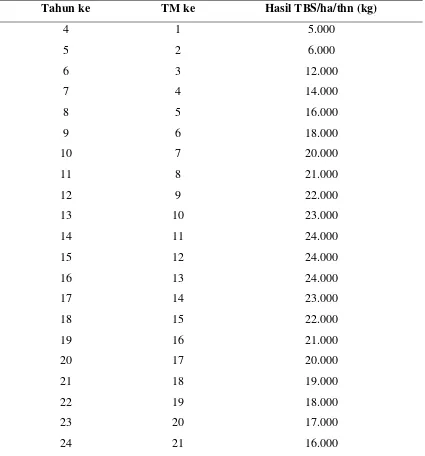
Terdapat 2 kelas yang akan menjadi output dari prediksi. Yaitu kelas produksi rendah (kelas 1) dan kelas produksi tinggi (kelas 2). Produksi kelapa sawit tinggi di dapat apabila hasil produksi kelapa sawit diatas hasil data produksi kelapa sawit yang telah ditetapkan. Sebaliknya jika hasil produksi kelapa sawit dibawah dari data produksi kelapa sawit yang telah ditentukan maka produksi kelapa sawit tersebut masuk ke kelas 1 yakni produksi kelapa sawit rendah. Dapat dilihat pada tabel 3.2 pertumbuhan jumlah produksi kelapa sawit.
No
Yes
Tabel 3.2 Tabel Pertumbuhan jumlah produksi kelapa sawit (lanjutan)
Tahun ke TM ke Hasil TBS/ha/thn (kg)
25 22 15.000
26 23 14.000
27 24 13.000
28 25 12.000
Keterangan:
1. Tahun ke memiliki pengertian berapa usia tanaman sawit tersebut.
2. TM (tahun menghasilkan) ke merupakan penjabaran dari tahun menghasilkan yang keberapa produksi kelapa sawit tersebut.
3. Hasil TBS(tandan buah segar)/ha/thn merupakan data hasil produksi kelapa sawit yang nantinya akan digunakan sebagai kelasifikasi output dari hasil prediksi. Hasil prediksi tersebut
3.4. Flowchart Training
Flowchart Training adalah proses pembelajaran data input oleh jaringan dengan algoritma Learning vector quantization. Dapat dilihat pada gambar 3.4. flowchart learning vector quantization.
Gambar 3.4 Flowchart Training Start
Input (Xi) dan Target Inisialisasi bobot awal dan
Epoch=1
Epoch ≤ Max epoch
23
Gambar 3.4 Flowchart Training (lanjutan) 3.5. Flowchart Prediksi
Adapun flowchart Prediksi adalah proses penetapan kelas hasil produksi kelapa sawit yang didapat dari data input ke jaringan. Berikut gambar 3.5 gambar flowchart prediksi learning vector quantization.
Hitung jarak data xi dengan bobot ||X-Wj|| indeks vektor bobot sebagai j
Gambar 3.5 Flowchart Prediksi Learning Vector Quantization
3.6. Perhitungan Training
Pada perhitungan training produksi kelapa sawit data inputan sebanyak 48 data selama 4 tahun yakni tahun 2010, 2011, 2012, 2013. Pada kali ini penulis mengambil sampel untuk untuk perhitungan training tahun produksi 2010. Dapat dilihat pada tabel 3.3 tabel produksi kelapa sawit tahun 2010. Diketahui 12 data tahun 2010 dengan variabel yang digunakan sebagai parameter mulai dari tahun produksi, tahun tanam, bulan, umur tanaman, luas, jumlah pokok, jumlah hari panen, jumlah pupuk, jumlah produksi sebelumnya dan sebagai outputnya yaitu kelas 1 sebagi prediksi produksi kelapa sawit rendah dan kelas 2 sebagai prediksi produksi kelapa sawit tinggi.
Tabel 3.3 Produksi kelapa sawit tahun 2010
No X1 X2 X3 X4 X5 X6 X7 X8 X9 Kelas
1 2010 2003 1 7 57 7766 113 0 44,410 1
2 2010 2003 2 7 57 7766 68 44655 36,970 1
3 2010 2003 3 7 57 7766 52 34947 26,930 1
Start
Masukkan input & Bobot akhir
Hitung Jarak
Pilih neuron dengan jarak minimum
Selesai Penetapan
25
Tabel 3.3 Produksi kelapa sawit tahun 2010 (lanjutan)
No X1 X2 X3 X4 X5 X6 X7 X8 X9 Kelas
4 2010 2003 4 7 57 7766 62 0 25,160 1
5 2010 2003 5 7 57 7766 195 0 23,110 1
6 2010 2003 6 7 57 7766 88 0 49,270 1
7 2010 2003 7 7 57 7766 87 0 54,590 1
8 2010 2003 8 7 57 7766 101 0 94,700 2
9 2010 2003 9 7 57 7766 76 0 72,080 1
10 2010 2003 10 7 57 7766 89 0 88,430 2
11 2010 2003 11 7 57 7766 96 31064 96,170 2
12 2010 2003 12 7 57 7766 99 0 75,210 1
Sepuluh inputan akan dijadikan input pembelajaran. Dapat dilihat pada tabel 3.4 tabel pembelajaran training.
Tabel 3.4 Tabel pembelajaran training
No X1 X2 X3 X4 X5 X6 X7 X8 X9 Kelas
1 2010 2003 2 7 57 7766 68 44655 36,970 1
2 2010 2003 3 7 57 7766 52 34947 26,930 1
3 2010 2003 4 7 57 7766 62 0 25,160 1
4 2010 2003 5 7 57 7766 195 0 23,110 1
5 2010 2003 6 7 57 7766 88 0 49,270 1
6 2010 2003 7 7 57 7766 87 0 54,590 1
7 2010 2003 8 7 57 7766 101 0 94,700 2
8 2010 2003 9 7 57 7766 76 0 72,080 1
9 2010 2003 11 7 57 7766 96 31064 96,170 2
10 2010 2003 12 7 57 7766 99 0 75,210 1
Tabel 3.5 Tabel bobot training
No X1 X2 X3 X4 X5 X6 X7 X8 X9 Kelas
1 2010 2003 1 7 57 7766 113 0 44,410 1
2 2010 2003 10 7 57 7766 89 0 88,430 2
Sebagai Nilai awal dipilih Learning rate (α) = 0.05, epoch = 500, penurunan α = 0.1*
α (lama). Epoch ke-1 :
Data Ke-1 : (2010, 2003, 2, 7, 57, 7766, 68, 44655, 36970) Bobot ke-1: (2010, 2003, 1, 7, 57, 7766, 113, 0, 44410) Jarak pada bobot ke – 1
= – – –
= – – – =
=
= = 45270,571
Bobot ke-2: (2010, 2003, 10, 7, 57, 7766, 89, 0, 88430) Jarak pada bobot ke – 2
= – – –
= – – –
=
= = 68133,700
Jarak terkecil pada bobot ke-1 Target data ke-1 = 1
Bobot ke-1 baru:
W13 = W13 + α * (X13– W13) = 2010 + 0.05*(2010-2010) = 2010 W14 = W14 + α * (X14– W14) = 2003 + 0.05*(2003-2003) = 2003 W15 = W14 + α * (X14– W14) = 1 + 0.05*(2-1) = 1.05
27
W18 = W16 + α * (X16 – W16) = 7766+ 0.05*(7766-7766) = 7766 W19 = W17 + α * (X17 – W17) = 113 + 0.05*(68-113) = 110.75 W20 = W18 + α * (X18 – W18) = 0 + 0.05*(44655-0) = 2232.75
W21 = W19 + α * (X19 – W19) = 44410 + 0.05*(36970-44410) = 44038 W1(baru) = (2010, 2003, 1.05, 7, 57, 7766, 110.75, 2232.75, 44038)
Untuk melakukan update bobot yang baru, maka nilai W1 dimasukkan ke tabel bobot baru ke-1. Dapat dilihat pada tabel 3.6. tabel bobot baru pertama.
Tabel 3.6 Tabel bobot baru pertama
No X1 X2 X3 X4 X5 X6 X7 X8 X9 Kelas
1 2010 2003 1.05 7 57 7766 110.75 2232.75 44,038 1
2 2010 2003 10 7 57 7766 89 0 88,430 2
Data Ke-2 : (2010, 2003, 3, 7 , 57, 7766, 52, 34947, 26930)
Bobot ke-1: (2010, 2003, 1.05, 7, 57, 7766, 110.75, 2232.75, 44038) Jarak pada bobot ke – 1
= – – –
= – – – =
=
= = 36917.6011
Bobot ke-2: (2010, 2003, 10, 7, 57, 7766, 89, 0, 88430) Jarak pada bobot ke – 2
= – – –
= – – – =
=
= = 70735.7351
Bobot ke-1 baru:
W13 = W13 + α * (X13 – W13) = 2010 + 0.05 * (2010 - 2010) = 2010 W14 = W14 + α * (X14 – W14) = 2003 + 0.05 * (2003 - 2003) = 2003 W15 = W14 + α * (X14 – W14) = 1.05 + 0.05 * (3 - 1.05) = 1.1475 W16 = W15 + α * (X15 – W15) = 7 + 0.05 * (7 - 7) = 7
W17 = W14 + α * (X14 – W14) = 57+ 0.05 * (57 - 57) = 57
W18 = W16 + α * (X16 – W16) = 7766+ 0.05 * (7766 - 7766) = 7766 W19 = W17 + α * (X17 – W17) = 110.75 + 0.05 * (52 - 110.75) = 107.8125
W20 = W18 + α * (X18– W18) = 2232.75 + 0.05 * (34947 - 2232.75) = 3862.4625 W21 = W19 + α * (X19 – W19) = 44038 + 0.05 * (26930 - 44038) = 43182.6 W1(baru) = (2010, 2003, 1.1475, 7, 57, 7766, 107.8125, 3862.4625, 43182.6)
Untuk melakukan update bobot yang baru, maka nilai W1 dimasukkan ke tabel bobot baru ke-1. Dapat dilihat pada tabel 3.7. bobot baru kedua.
Tabel 3.7 Tabel bobot baru kedua
No X1 X2 X3 X4 X5 X6 X7 X8 X9 Kelas
1 2010 2003 1.14 7 57 7766 107.81 3862.46 43182 1
2 2010 2003 10 7 57 7766 89 0 88,430 2
Proses ini diteruskan sampai dengan data ke 10. Kemudian akan dilanjutkan ke epoch ke-2. Namus sebelum masuk epoch ke-2, nilai learning rate akan diupdate terlebih dahulu dengan cara nilai dec alpha dikalikan dengan nilai learning rate.
New learning rate = dec alpha * learning rate lama New learning rate = 0.1 ** 0.05
New learning rate = 0. 005.
Setelah nilai learning rate baru didapat, proses yang berjalan akan dilanjutkan seperti proses-proses sebelumnya hingga mencapai epoch yang ditentukan yakni epoch ke-500.
3.7. Perhitungan Prediksi
29
Tabel 3.8 Inisialisasi input prediksi
No X1 X2 X3 X4 X5 X6 X7 X8 X9 Kelas
1 2014 2003 1 7 57 7766 78 32000 0
Setelah input di inisialisasi, maka langkah selanjutnya cari jarak terpendek menggunakan bobot terakhir dari proses training. Disini kita akan mencoba menggunakan tabel 3.7 tabel bobot baru kedua sebagai bobot akhir training. Hasil dari perhitungan bobot dengan jarak terpendek akan menjadi kelasnya.
Jarak pada bobot ke – 1
= – –
= – – – – =
=
= = 51639.3335
Bobot ke-2: (2010, 2003, 10, 7, 57, 7766, 89, 0, 88430) Jarak pada bobot ke – 2
= – – –
= – – – =
=
= = 88430.0011
Jarak terkecil pada bobot ke-1
Sehingga input prediksi tersebut termasuk kedalam kelas 1 yakni kelas produksi rendah. Jika diupdate maka dapat dilihat pada tabel 3.9 hasil prediksi.
Tabel 3.9 hasil Prediksi
No X1 X2 X3 X4 X5 X6 X7 X8 X9 Kelas
BAB 4
IMPLEMENTASI DAN PENGUJIAN
4.1Implementasi
Setelah melalui tahap analisis dan perancangan, tahap selanjutnya yaitu implementasi serta pengujian. Implementasi dan pengujian diperlukan untuk mengetahui apakah prediksi produksi kelapa sawit yang dibangun berjalan sesuai yang diharapkan. Berikut hasil implementasi dari aplikasi yang telah dibangun
1. Pada halaman awal, program akan menampilkan berupa nama aplikasi yang dibangun serta beberapa sub menu yang terdiri dari file, help, exit. Dapat dilihat pada gambar 4.1 tampilan halaman awal program prediksi produksi kelapa sawit.
Gambar 4.1 Tampilan halaman awal
31
2. Menu help menampilkan bagaimana tata cara pengoperasian aplikasi. Dapat dilihat pada gambar 4.2. tampilan halaman help.
Gambar 4.2 Tampilan halaman help
3. Halaman input data berfungsi untuk menginput data produksi. Data produksi selanjutnya akan disimpan ke dalam database. Data-data yang diinput kedalam database berupa data tahun produksi, tahun tanam, luas area, jumlah pokok, bulan, jumlah hari panen, jumlah pupuk dan yang terakhir jumlah produksi kelapa sawit. Untuk kolom umur akan otomastis didapat setelah melalui proses pengurangan tahun produksi dengan tahun tanam. Dapat dilihat pada gambar 4.3 menunjukkan tampilan halaman input data.
Ada beberapa tombol yang dapat digunakan dalam input data. Tombol– tombol tersebut adalah tombol add, save, cari, edit, delete, clear, training. Tombol add berfungsi apabila ingin menambahka data baru ke database. Fungsi tombol save untuk menyimpan data, baik data yang baru ataupun data yang telah di edit. Tombol cari berguna untuk mencari data yang ingin di ubah. Tombol delete berfungsi untuk menghapus sebuah data. Tombol clear berguna apabila kita akan membatalkan data yang akan kita ubah inputnya. Tombol training berfungsi untuk melanjutkan ke tahap selanjutnya yakni tahap training.
4. Halaman proses training dan prediksi ditampilkan pada halaman yang sama. Dapat dilihat pada gambar 4.4 tampilan halaman training dan prediksi saat melakukan proses training.
Gambar 4.4 Tampilan halaman saat proses training
33
Pada tampilan prediksi user di minta untuk memasukkan data yang akan di prediksi. Mulai dari data tahun produksi, tahun tanam, bulan, perkiraan jumlah hari panen, perkiraan jumlah pupuk. Sedangkan untuk kolom umur pokok, luas kebun, jumlah pokok akan otomatis ditampilkan sesuai dengan data yang terdapat di database. Setelah semua kolom terisi dengan benar maka user dapat melakukan prediksi. Dapat dilihat pada gambar 4.5 tampilan halaman training dan prediksi saat melakukan proses prediksi
Gambar 4.5 Tampilan halaman saat proses prediksi
4.2Pengujian
Pengujian berfungsi untuk menampilkan informasi hasil pengujian prediksi produksi kelapa sawit. Pada pengujian kali ini, produksi yang akan di prediksi adalah produksi kelapa sawit tahun 2014. Produksi kelapa sawit tahun 2014 telah diketahui.Dapat dilihat pada tabel 4.1 hasil produksi kelapa sawit tahun 2014.
Tabel 4.1 Hasil produksi kelapa sawit tahun 2014
Bulan Jumlah
Hari panen
Jumlah Pupuk(kg)
Jumlah Produksi Kelapa Sawit (kg)
Januari 99 0 27.490
Februari 52 0 41.500
Maret 79 0 55.090
Tabel 4.1 Hasil produksi kelapa sawit tahun 2014 (lanjutan)
Pada tahun 2014, tanaman sawit berarti telah berumur 11 tahun, karena tahun tanam sawit adalah tahun 2003 dan dengan luas 57 ha. Sesuai dengan tabel pertumbuhan jumlah produksi, sawit yang telah berumur 11 tahun dapat menghasilkan 21.000 kg/ha/tahun. Jika dihitung maka akan terlihat seperti berikut.
Produksi per tahun = 57 ha x 21.000 kg/ha = 1.197.000 kg/tahun Produksi per bulan = 1.197.000 / 12
= 99.750 kg/bln
Hasil yang didapat dari perhitungan, normalnya sawit akan menghasilkan 99.750 kg tiap bulannya. Jika produksi kelapa sawit kurang dari jumlah (< 99.750 kg) tersebut maka sawit dikategorikan kelas produksi rendah. Sebaliknya jika jumlah produksi sawit lebih (< 99.750 kg) dari jumlah normal maka sawit dikategorikan kelas produksi tinggi. Dapat dilihat pada tabel 4.2 hasil produksi kelapa sawit menurut kelasnya.
Tabel 4.2 Hasil produksi kelapa sawit tahun 2014 menurut kelasnya
35
Tabel 4.2 Hasil produksi kelapa sawit tahun 2014 menurut kelasnya (lanjutan)
Bulan Jumlah
Selanjutkan akan dilakukan pengujian dengan menggunakan aplikasi prediksi produksi kelapa sawit yang telah dirancang. Hasil prediksi produksi kelapa sawit akan dibandingkan dengan hasil produksi kelapa sawit yang sebenarnya. Prediksi akan dilakukan dengan mengubah nilai epoch. Nilai epoch yang akan digunakan mulai dari learning rate 5000, 5200, dan 5500.
Dapat dilihat tabel 4.3 tabel hasil pengujian dengan epoch 5000 , learning rate 0.06 dan penurunan alfa tiap epochnya sebesar 0.01. Jumlah neuron yang digunakan 9 neuron.
Tabel 4.3 Hasil pengujian epoch 5000
Tabel 4.3 Hasil pengujian epoch 5000 (lanjutan)
Dari tabel 4.3 hasil pengujian epoch 5000 didapatkan 8 bulan dengan hasil pengujian yang sukses. Bulan-bulan yang sukses yakni bulan Januari, Februari, Maret, April, Mei, Agustus, September, Oktober. Pengertian sukses dalam tabel yaitu hasil prediksi kelapa sawit sama dengan hasil jumlah produksi kelapa sawit yang sebenarnya. Sebaliknya pengertian hasil pengujian yang gagal artinya hasil prediksi kelapa sawit tidak sama dengan hasil produksi kelapa sawit yang sebenarnya. Di tabel 4.3 terdapat 4 bulan dengan hasil pengujian yang gagal. Bulan-bulan yang gagal tersebut adalah bulan Juni, Juli, November, Desember.
37
Tabel 4.4 Hasil pengujian epoch 5200
Bulan pengujian yang sukses. Bulan-bulan yang sukses yakni bulan Januari, Maret, April, Mei, Agustus, September, Oktober. Kemudian didapat 5 hasil pengujian yang gagal. Bulan-bulan yang gagal tersebut adalah bulan Februari, Juni, Juli, November, Desember.
Tabel 4.5 Hasil pengujian epoch 5500 agustus, september, oktober. Kemudian didapat 6 hasil pengujian yang gagal. Bulan-bulan yang gagal tersebut adalah Bulan-bulan Februari, Maret, Juni, Juli, November, Desember.
39
4.6 Tabel hasil pengujian learning rate sebesar0.06
Bulan
Dari tabel 4.6 pengujian learning rate sebesar 0.06 didapatkan 8 bulan dengan hasil pengujian yang sukses. Bulan-bulan yang sukses yakni bulan Januari, Februari, Maret, April, Mei, Agustus, September, Oktober. Dan juga di tabel 4.6 terdapat 4 bulan dengan hasil pengujian yang gagal. Bulan-bulan yang gagal tersebut adalah bulan Juni, Juli, November, Desember.
4.7 Tabel hasil pengujian learning rate sebesar0.07
Bulan
Jmlh Hari panen
Produksi kelapa sawit sebenarnya
Prediksi produksi kelapa
sawit Keterangan Jumlah
produksi(kg) Kelas
Jumlah
produksi(kg) Kelas
Jan 99 27.490 Rendah < 99.750 Rendah Sukses
Feb 52 41.500 Rendah > 99.750 Tinggi Gagal
Mar 79 55.090 Rendah > 99.750 Rendah Sukses
Apr 103 80.480 Rendah < 99.750 Rendah Sukses Mei 114 97.910 Rendah < 99.750 Rendah Sukses
Jun 98 86.910 Rendah > 99.750 Tinggi Gagal
Jul 93 87.200 Rendah > 99.750 Tinggi Gagal
Agu 112 182.940 Tinggi > 99.750 Tinggi Sukses Sep 101 121.150 Tinggi > 99.750 Tinggi Sukses Okt 116 110.010 Tinggi > 99.750 Tinggi Sukses Nov 105 87.170 Rendah > 99.750 Tinggi Gagal
Des 112 72.340 Rendah > 99.750 Tinggi Gagal
BAB 5
KESIMPULAN DAN SARAN
5.1Kesimpulan
Setelah merancang serta mengaplikasikan Algoritma Learning Vector Quantization pada Prediksi produksi kelapa sawit di Perkebunan Kelapa Sawit Pulau Tiga, maka diperoleh kesimpulan sebagai berikut:
1. Aplikasi dapat melakukan prediksi produksi kelapa sawit dengan inputan berupa tahun produksi, tahun tanam, jumlah pokok, luas, umur, bulan, jumlah pupuk, jumlah hari panen dan jumlah produksi.
2. Hasil prediksi terbaik diperoleh dari prediksi produksi kelapa sawit tahun 2014 dengan epoch 5000 dan learning rate 0.06 yakni pada bulan Januari, Maret, April, Mei, Juni, September, Oktober.
5.2Saran
Adapun saran-saran penulis untuk pengembangan penelitian berikutnya sebagai berikut:
1. Menambah parameter inputan seperti curah hujan, PH tanah serta kemiringan pohon agar diperoleh hasil yang lebih akurat.
DAFTAR PUSTAKA
Biehl, M., Ghosh, A., & Hammer, B. 2006. Learning Vector Quantization : The Dynamics of Winner-Takes-All Algorithms. (Online)
http://www.cs.rug.nl/~biehl/Preprints/ncprep.pdf (07 Februari 2015).
Bird, S., Klein, E., & Loper, E. 2014. Natural Language Processing with Python. (Online)
http://www.victoria.lviv.ua/html/fl5/NaturalLanguageProcessingWithPython (29 Maret 2015).
Dayan, P. 1999b .Unsupervised Learning. The MIT Encyclopedia of the Cognitive Sciences. (Online) http://www.gatsby.ucl.ac.uk/~dayan/papers/dun99b.pdf (07 Februari 2015).
Estimasi Pendapatan. 2014. (Online)
http://www.investasikelapasawit.com/estimasi-pendapatan.(3 Desember 2014). Fausett, L. 1994. Fundamental of Neural Network: Architectures, Algorithm, and
Applications. Englewood Cliffs, New Jersey. Prentice Hall. Gray, R. M. 1984. Vector quantization, IEEE ASSP Mag. 1 : 4–29.
Gonzalez, I. A., Grana, M., & D’Anjou, A. 1995. An analysis of the GLVQ Algorithm. IEEE Trans. of Neural Networks, Vol. 6, No. 4, pp. 1012-1016. Hermantoro & Purnawan, W. R. 2009. Prediksi Produksi Kelapa Sawit
Berdasarkan Kualitas Lahan Menggunakan Model Artificial Neural Network. Agroteknose, 4(2). pp. 1-6.
Hermawan, A. 2006. Jaringan Saraf Tiruan Teori dan Aplikasi. Yogyakarta: ANDI. Hidayati, N. & Warsito, B. 2010. Prediksi Terjangkitnya Penyakit Jantung Dengan
Metode Learning Vector Quantization. Media Statistika, 3 (1). pp. 21-30. ISSN 1979-3693.
Kotsiantis, B. S. 2007. Supervised Machine Learning: A Review of Classification Techniques. (Online) http://www.informatica.si/PDF/31-3/11_Kotsiantis (07 Februari 2015)
Kusumadewi, S. & Hartati. 2010. Neuro-Fuzzy Integrasi Sistem Fuzzy & Jaringan Syaraf. Yogyakarta : GRAHA ILMU.
Kusumadewi, S. 2004. Membangun Jaringan Syaraf Tiruan Menggunakan Matlab & Excel Link. Yogyakarta : GRAHA ILMU.
Ladjamuhddin, A. 2005. Analisis dan Desain Sistem Informasi. Yogyakarta : GRAHA ILMU
Medsker, L. & Liebowitz, J. 1994. Design and Development of Expert Systems and Neural Network. New York. Prentice Hall.
Neuron. 2015. (Online)
http://www.biologyreference.com/Mo-Nu/Neuron.html.(29 Maret 2015).
Patterson D.W. 1996. Artificial Neural Networks Theory and Application. New York. Prentice Hall
Pham, D. T. 1994. Neural Network for Chemical Engineers. Amsterdam. Elsevier Press.
Puspitaningrum, D. 2006. Pengantar Jaringan Saraf Tiruan. Yogyakarta : ANDI.
Risza, S. 1994. Upaya Peningkatan Produktivitas Kelapa Sawit. Yogyakarta. Kanisius. Risza, S. 1994. Kelapa Sawit. Yogyakarta: Kanisus.
Siang, J.J. 2005. Jaringan Syaraf Tiruan dan Pemrogramannya Menggunakan Matlab. Yogyakarta: ANDI.
Smith, L. 1996. An Introduction to Neural Networks. Department of Computing
and Mathematics University of Stirling Scotland. (Online) http://www.cs.stir.ac.uk/~lss/NNIntro/InvSlides.html (16 Desember 2014).
Sutojo & Mulyanto, E. 2010. Kecerdasan Buatan. Yogyakarta : ANDI.