PEMBOBOTAN DALAM PROSES PENGINDEKSAN DOKUMEN BAHASA
INDONESIA MENGGUNAKAN FRAMEWORK INDRI
HENDREX HERDI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
PEMBOBOTAN DALAM PROSES PENGINDEKSAN DOKUMEN BAHASA
INDONESIA MENGGUNAKAN FRAMEWORK INDRI
HENDREX HERDI
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
HENDREX HERDI. Weighting in Indexing Process for Document in Bahasa Indonesia Using Indri Framework. Under direction of JULIO ADISANTOSO.
A very large amount of information has stimulated the development of information search engine to help users in finding information they need. To retrieve the information according to the user’s needs, information search engine should be able to work well. One of the factors that can affect the performance of search engines is indexing. The purpose of this research is to implement automatic indexing process using Indri framework with tf-idf and BM25 term weighting. This testing used 30 queries and 2000 documents. The testing result showed that the performance of information search engine is better when we use the BM25 term weighting than tf-idf term weighting. However, the performance of information search engine with BM25 term weighting and tf-idf term weighting gave good results with around 64% average precision. The number of indexed documents for indexing will affect the indexing time. Increasing of the number of indexed documents will increase the indexing time.
Judul Penelitian : Pembobotan dalam Proses Pengindeksan Dokumen Bahasa Indonesia dengan Menggunakan Framework Indri
Nama : Hendrex Herdi NRP : G64060900
Menyetujui:
Pembimbing,
Ir. Julio Adisantoso, M.Kom NIP. 19620714 198601 1 002
Mengetahui:
Ketua Departemen Ilmu Komputer,
Dr. Ir. Sri Nurdiati, M.Sc. NIP. 19601126 198601 2 001
KATA PENGANTAR
Puji syukur Penulis panjatkan kepada Tuhan Yang Maha Esa, karena berkat rahmat dan karunia-Nya sehingga skripsi ini berhasil diselesaikan. Skripsi ini merupakan hasil penelitian yang dilakukan dari Februari sampai Agustus 2010 dengan bidang kajian Pembobotan dalam Proses Pengindeksan Dokumen Bahasa Indonesia Menggunakan Framework Indri.
Penulis mengucapkan terima kasih kepada Bapak Ir. Julio Adisantoso M.Kom selaku pembimbing yang telah memberi saran, masukan, dan ide-ide kepada Penulis dalam menyusun skripsi ini. Terima kasih juga Penulis ucapkan kepada Bapak Ahmad Ridha S.Kom, MS dan Bapak Sony Hartono Wijaya S.Kom, M.Kom sebagai dosen penguji. Penulis juga mengucapkan terima kasih kepada:
1 Ibu dan Bapak serta kakak yang selalu memberikan doa, nasihat, dukungan, semangat, dan kasih sayang yang luar biasa kepada Penulis sehingga dapat menyelesaikan tugas akhir ini.
2 Aditya Wahyu Baskoro, Rio Ramadhan, Eka Yuliani Simanjuntak, dan Kartina yang telah banyak membantu penulis dalam menyelesaikan tugas akhir ini serta teman-teman satu bimbingan lainnya Maryam Noviana B, Sri Rahayu I, Awet Samana, dan Wildan Rachman yang selalu memberi semangat dan motivasi.
3 Ario Hakim Wicaksono yang memberikan motivasi kepada Penulis.
4 Tri Cahya Uthari, Indyastari C, Riferson S, Yohan, dan teman-teman Ilkom angkatan 43 yang telah banyak membantu Penulis.
5 Departemen Ilmu Komputer, staf, dan dosen yang telah banyak membantu baik selama penelitian maupun pada masa perkuliahan.
Kepada semua pihak lainnya yang telah memberikan kontribusi yang besar selama pengerjaan penelitian ini yang tidak dapat disebutkan satu-persatu, Penulis ucapkan terima kasih banyak.
Semoga penelitian ini dapat memberikan manfaat.
Bogor, September 2010
RIWAYAT HIDUP
Penulis dilahirkan di Siak Riau pada tanggal 13 April 1989 dari ayah Herdi Kasmadi dan ibu Nati. Penulis merupakan putra terakhir dari enam bersaudara.
Tahun 2006 penulis lulus dari SMA Negeri 1 Siak dan pada tahun yang sama lulus seleksi masuk IPB melalui jalur Beasiswa Utusan Daerah (BUD). Tahun 2007 penulis diterima di Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam.
iv
DAFTAR ISI
Halaman
DAFTAR TABEL ... v
DAFTAR GAMBAR ... v
DAFTAR LAMPIRAN ... v
PENDAHULUAN Latar Belakang ... 1
Tujuan ... 1
Ruang Lingkup ... 1
Manfaat Penelitian ... 1
TINJAUAN PUSTAKA Information Retrieval (Temu-Kembali Informasi) ... 1
Indri ... 2
Pembobotan Tf-Idf ... 2
Pembobotan BM25... 3
Recall dan Precision ... 3
METODE PENELITIAN Gambaran Umum Sistem ... 3
Evaluasi Sistem ... 4
Asumsi ... 4
Lingkungan Implementasi ... 4
HASIL DAN PEMBAHASAN Koleksi Dokumen... 4
Pengindeksan ... 5
Pemrosesan Kueri... 5
Hasil Temu-Kembali ... 6
Evaluasi Sistem ... 7
Kelebihan dan Kekurangan Sistem ... 9
KESIMPULAN DAN SARAN Kesimpulan ... 9
Saran ... 10
DAFTAR PUSTAKA ... 10
v
DAFTAR TABEL
Halaman
1 Hasil perhitungan average precision ... 8
2 Waktu pengindeksan Indri ... 8
DAFTAR GAMBAR
Halaman1 Proses penulisan
MemoryIndex ke dalam disk (DiskIndex) secara bertahap ... 22 Pengukuran Recall dan Precision ... 3
3 Gambaran Umum Sistem ... 4
4 Format dokumen dengan struktur
tag XML ... 55 Format dokumen setelah dilakukan pembuangan
tagging ... 56 Kurva
recall-precision 1000 dokumen ... 77 Kurva
recall-precision 2000 dokumen ... 88 Waktu pengindeksan Indri untuk berbagai jumlah koleksi dokumen ... 9
DAFTAR LAMPIRAN
Halaman 1 Daftar kata buang (stoplist) ... 122 Daftar kueri yang digunakan ... 15
3 Contoh hasil perolehan 30 dokumen teratas ... 16
4 Hasil perhitungan
precision pada elevent standard recall ... 171
PENDAHULUANLatar Belakang
Pada saat ini informasi dapat diperoleh dengan mudah dan cepat. Salah satunya adalah menggunakan mesin pencariyang memberikan informasi kepada penggunanya berdasarkan kueri tertentu. Informasi yang diberikan berupa dokumen yang terurut sesuai relevansinya dengan kueri. Namun kadang kala dokumen yang diberikan tidak sesuai dengan yang diinginkan pengguna. Untuk itu, telah banyak dikembangkan sistem temu-kembali informasi dengan berbagai metode dan sistem pengindeksan.
Dalam sistem temu-kembali informasi tahapan pengindeksan merupakan tahapan yang sangat penting peranannya dalam menemukembalikan informasi sesuai keinginan pengguna. Oleh karena itu, telah banyak dilakukan penelitian untuk menentukan metode dan sistem pengindeksan yang baik dalam sistem temu-kembali informasi. Salah satunya adalah penentuan metode pembobotan yang digunakan dalam pengindeksan.
Donald Metzler et al. (2004) pada TREC 2004 menggunakan mesin pencari Indri untuk mengindeks koleksi dokumen berukuran 426 GB (25 juta dokumen) selama 6 jam. Donald Metzler et al. (2005) melanjutkan penelitiannya untuk menentukan seberapa efisien dan efektif mesin pencari Indri dalam menemukembalikan
named page pada koleksi dokumen web. Hasil yang diperoleh menunjukan bahwa dengan menggunakan pseudo-relevance feedback dan
dependece modeling, Indri akan lebih efektif dalam menemukembalikan named page.
Selanjutnya Donald Metzler et al. (2006) melakukan penelitian untuk mendapatkan kesimpulan akhir dari kinerja Indri. Hasil yang diperoleh adalah Indri sangat efektif dan efisien dalam mengindeks dokumen dalam jumlah yang besar. Berbeda dengan penelitian yang dilakukan sebelumnya, Xing Yi dan James Allan (2007) melakukan penelitian untuk menguji kinerja dari mesin pencariIndri dalam menangani kueri dalam jumlah yang besar pada dokumen web. Pada penelitian ini digunakan pendekatan koreksi ejaan pada kueri yang diuji.
Penelitian yang telah dilakukan dengan menggunakan mesin pencari Indri baru diterapkan untuk koleksi dokumen Bahasa Inggris. Untuk itu, penelitian kali ini akan digunakan mesin pencari Indri dalam mengindeks dokumen Bahasa Indonesia dengan
format dokumen yang ada yaitu dokumen teks dengan struktur tag XML.
Tujuan
Tujuan dari penelitian ini adalah:
1. Mengimplementasikan pengindeksan secara otomatis pada dokumen Bahasa Indonesia dengan menggunakan framework
Indri.
2. Menganalisis kinerja Indri dalam mengindeks dokumen.
3. Menganalisis pengaruh pembobotan dalam pengindeksan menggunakan Indri.
Ruang Lingkup
Ruang lingkup penelitian ini adalah:
1. Menggunakan korpus yang terdiri atas 2000 dokumen Bahasa Indonesia dengan struktur tag XML.
2. Menggunakan 30 kueri yang tersedia di Laboratorium Temu-Kembali Informasi Departemen Ilmu Komputer IPB.
Manfaat Penelitian
Kinerja framework Indri diharapkan dapat meningkatkan efisiensi waktu dalam proses pengindeksan dokumen berbahasa Indonesia. Pengindeksan yang lebih efisien diharapkan dapat meningkatkan kinerja sistem temu-kembali informasi.
TINJAUAN PUSTAKA
Information Retrieval (Temu-Kembali
Informasi)
2 Indri
Indri merupakan suatu Application Programming Interface (API) yang digunakan untuk melakukan pengindeksan dan pencarian teks yang dapat diintegrasikan ke dalam sebuah aplikasi. Indri merupakan bagian dari proyek Lemur, yaitu sebuah kerja sama antara
University of Massachusetts dan Carnegie Mellon University dalam pengembangan sistem temu-kembali informasi.
Indri dapat mengolah dokumen dalam berbagai format, seperti dokumen TREC dengan format text, XML, HTML, dan dokumen plain text (Strohman 2005).
Indri memiliki dua tipe pengindeksan yaitu
MemoryIndex dan DiskIndex. MemoryIndex
melakukan pengindeksan di dalam RAM sedangkan DiskIndex di dalam disk. Pada saat pembentukan tempat penyimpanan dari suatu koleksi dokumen teks (inverted index), Indri menambahkan dokumen yang masuk ke
MemoryIndex yang aktif. Ketika dokumen tersebut masuk ke dalam MemoryIndex, maka akan dilakukan langsung proses tokenisasi terhadap dokumen tersebut. Proses tokenisasi ini akan dilakukan sampai semua isi dokumen telah ditokenisasi sebelum menambahkan dokumen baru ke dalam MemoryIndex.
Gambar 1 Proses penulisan MemoryIndex ke dalam disk (DiskIndex) secara bertahap.
Untuk koleksi dokumen teks yang kecil, pengindeksan hanya dilakukan dalam
MemoryIndex. Akan tetapi untuk koleksi yang besar MemoryIndex akan menuliskan hasil pengindeksannya ke dalam disk (DiskIndex)
karena melebihi dari batas memori yang dimiliki. Pada saat penulisan ke dalam disk,
MemoryIndex baru akan dibuat dan akan berfungsi sebagai active index yang siap melakukan pengindeksan terhadap dokumen selanjutnya. Proses penulisan ke dalam disk
dapat dilihat pada Gambar 1.
Hasil pengindeksan yang disimpan di dalam
memory berupa sebuah tabel hash, sedangkan hasil pengindeksan yang disimpan di dalam disk
berupa dua B-Tree, yaitu B-Tree untuk frequent term dan B-Tree untuk infrequent term. Untuk keseluruhan informasi term (inverted index) Indri menyimpannya dalam satu file yang terurut berdasarkan term tersebut (Strohman & Croft 2006).
Pada proses pengindeksan, Indri menghasilkan beberapa struktur data (Metzler 2004):
1. Inverted index untuk koleksi, termasuk informasi posisi term,
2. Inverted index untuk setiap field dalam koleksi,
3. Vektor dokumen untuk setiap dokumen dalam koleksi, termasuk informasi posisi
term dan informasi posisi field,
4. Isi koleksi yang telah dikompresi.
Pembobotan Tf-Idf
Term frequency (tf) merupakan frekuensi kemunculan suatu term t pada dokumen d.
Document frequency (df) merupakan banyaknya dokumen di dalam korpus yang mengandung kata tertentu (Manning et al. 2008).
Pembobotan tf-idf memberikan bobot pada
term t dalam dokumen d dengan nilai:
���,�����
3. N merupakan jumlah dokumen dalam koleksi
4. dft merupakan jumlah dokumen yang
mengandung term t.
Kesamaan antara kueri dan dokumen dapat ditentukan dengan menghitung cosine similarity
dari vektor istilah kueri (��⃗(�)) dan vektor istilah dokumen (��⃗(��)) (Manning et al. 2008):
3 dengan pembilang merupakan dot product
(dikenal juga sebagai inner product) antara
��⃗(�) dan ��⃗(��). Dot product antara dua vektor
�⃗.�⃗ didefinisikan sebagai ∑��=1����, sedangkan penyebut merupakan perkalian panjang Euclidean. Panjang Euclidean d didefinisikan
sebagai �∑ ��⃗��=1 �2(�).
Pembobotan BM25
Pembobotan BM25, disebut juga sebagai pembobotan Okapi, merupakan pembobotan yang digunakan sejak TREC ketiga. Pembobotan BM25 menggabungkan bobot idf dengan koleksi pengskalaan khusus untuk dokumen dan kueri (Kontostathis 2008). Pembobotan BM25 dengan dokumen dan kueri yang diberikan dapat dilihat pada persamaan berikut (Manning et al. 2008):
Di dan rata-rata panjang dokumen dalam
koleksi
4. k1 dan b merupakan parameter-parameter pengskalaan terhadap tf dokumen dan panjang dokumen.
Pada pembobotan BM25, bobot istilah-istilah kueri merupakan nilai statistik dokumen yang ada dalam koleksi (Song 2009).
Nilai parameter yang digunakan adalah masing-masing k1 = 1,2 dan b = 0,75 (Jones
1999).
Recall dan Precision
Recall merupakan perbandingan antara dokumen relevan yang ditemukembalikan (|Ra|) dengan dokumen relevan yang ada pada korpus (|R|).
������= |��| |�|
Precision adalah perbandingan antara dokumen relevan yang ditemukembalikan (|Ra|) dengan dokumen yang ditemukembalikan (|A|) (Baeza-Yates & Ribeiro-Neto 1999).
���������= |��| |�|
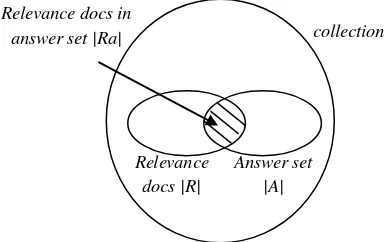
Gambar 2 menjelaskan recall dan precision
yang disebutkan diatas.
Gambar 2 Pengukuran Recall dan Precision.
Average precision adalah suatu ukuran evaluasi kinerja temu-kembali yang diperoleh dengan menghitung rata-rata precision pada berbagai tingkat recall, biasanya digunakan sebelas tingkat recall standar yaitu 0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1 (Baeza-Yates & Ribeiro-Neto 1999).
METODE PENELITIAN
Gambaran Umum Sistem
Gambaran umum sistem pengindeksan otomatis yang dikembangkan dapat dilihat pada Gambar 3.
Proses pengindeksan otomatis dimulai dengan mengambil koleksi dokumen berekstensi text (*.txt) yang tedapat pada satu direktori kemudian dilakukan indexing terhadap dokumen dengan Indri. Dari hasil pengindeksan dilakukan pembentukan inverted index oleh Indri. Setelah inverted index terbentuk pencarian dokumen dengan kueri yang diberikan dapat dilakukan. Untuk melakukan pencarian, kueri dilakukan proses parsing
terlebih dahulu. Kemudian hasil dari pencarian yang sudah terurut berdasarkan bobot yang dimiliki, dilakukan evaluasi terhadap sistem. Evaluasi dilakukan terhadap 30 dokumen teratas dari setiap hasil temu-kembali sistem berdasarkan kueri yang diberikan.
collection Relevance docs in
answer set |Ra|
Relevance docs |R|
4
Documents
Indexing with
Indri
.Gambar 3 Gambaran umum sistem.
Evaluasi Sistem
Pengujian sistem dilakukan dengan melakukan perhitungan terhadap recall dan
precision. Dalam perhitungan recall, digunakan
elevent standard recall yaitu 0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, dan 1.0. Perhitungan ini dilakukan untuk masing-masing tipe pembobotan.
Hasil perhitungan recall dan precision untuk masing-masing pembobotan akan dibandingkan dalam bentuk grafik recall-precision. selain itu juga akan dihitung average precision dari kedua tipe pembobotan tersebut untuk memperoleh tipe pembobotan yang baik dalam pengindeksan menggunakan Indri.
Untuk melihat tipe pembobotan yang baik dalam pengindeksan menggunakan Indri dilakukan empat kali pengujian yakni:
1. Pengujian 1000 dokumen dengan pembobotan tf-idf
2. Pengujian 2000 dokumen dengan pembobotan tf-idf
3. Pengujian 1000 dokumen dengan pembobotan BM25
4. Pengujian 2000 dokumen dengan pembobotan BM25.
Selain menguji kinerja temu-kembali dengan pengindeksan menggunakan Indri, dilakukan juga pengujian terhadap kinerja Indri dalam
mengindeks dokumen yang besar dengan melihat waktu yang dibutuhkan Indri dalam melakukan pengindeksan. Pengindeksan dilakukan dengan menggunakan jumlah koleksi dokumen yang berbeda-beda yakni jumlah koleksi dokumen dengan kelipatan 200. Penentuan dokumen dalam menguji kinerja Indri dilakukan secara acak. Pengujian kinerja Indri juga dilakukan dengan menggunakan berbagai ukuran memori dalam mengindeks dokumen. Ukuran memori yang digunakan adalah 512 KB, 256 MB, 512 MB, dan 1 GB.
Asumsi
Asumsi-asumsi yang digunakan dalam pembangunan sistem ini adalah:
1. Perhitungan recall dan precision dilakukan dengan manual oleh penulis,
2. Stoplist yang digunakan sama seperti yang digunakan pada penelitian Anbiana (2009), 3. Tidak ada kesalahan dalam pengetikan
kueri,
4. Setiap kata pada kueri dipisahkan oleh
whitespace atau spasi.
Lingkungan Implementasi
Lingkungan implementasi yang akan digunakan adalah sebagai berikut:
Perangkat lunak:
1. Sistem operasi Windows 7 Profesional sebagai sistem operasi,
2. Netbeans IDE 6.8 sebagai IDE untuk pembangunan sistem,
3. JDK Update 17 sebagai compiler yang digunakan untuk pengembangan sistem, 4. Indri 2.7 sebagai framework yang
digunakan untuk melakukan pengindeksan automatis dan proses pencarian,
5. Microsoft Excel 2007 sebagai aplikasi yg digunakan untuk melakukan perhitungan
recall dan precision.
Perangkat keras:
1. Prosesor Intel Core 2 duo 2.2 GHz 2. RAM 3 GB
3. Harddisk 160 GB
HASIL DAN PEMBAHASAN
Koleksi Dokumen
5 dokumen uji yang digunakan, ukuran dokumen
terkecil adalah 1 KB dan terbesar 53 KB, sedangkan jumlah kata terbesar adalah 6942 kata yaitu pada dokumen jurnal000000-001 dan jumlah kata terkecil adalah 53 kata pada dokumen situshijau030603-003.
Koleksi dokumen memiliki format teks (*.txt) dengan struktur tag XML, yaitu setiap file terdiri atas satu dokumen yang ditunjukkan dengan tag <DOC>. Setiap dokumen memiliki nomor dokumen yang unik yang ditunjukkan dengan tag <DOCNO>, judul dokumen (<TITLE>), dan pengarang (<AUTHOR>). Untuk isi dari dokumen sendiri terletak diantara
tag <TEXT>. Gambar 4 menunjukkan format dokumen yang digunakan.
Koleksi dokumen memiliki Struktur tag
XML yang berbeda-beda. Sebagian besar strukturnya seperti yang ditunjukkan Gambar 4, sedangkan untuk koleksi dokumen yang lain memiliki tambahan tag yaitu <DATE> yang menunjukkan tanggal dokumen.
Gambar 4 Format dokumen dengan struktur tag
XML.
Sebelum dilakukan proses pengindeksan koleksi dokumen terlebih dahulu dilakukan pembuangan tagging. Pembuangan tagging ini dilakukan karena tagging bukan merupakan suatu penciri dari dokumen. Gambar 5 menunjukkan format dokumen setelah dilakukan pembuangan tagging.
Gambar 5 Format dokumen setelah dilakukan pembuangan tagging.
Pengindeksan
Pengindeksan dokumen dimulai dengan melakukan parsing terhadap dokumen, kemudian dilakukan proses pembuangan
stopword, pembuangan tanda baca, dan mengubah term ke lower case. Daftar kata buang (stoplist) yang digunakan dapat dilihat pada Lampiran 1. Setelah itu Indri akan melakukan perhitungan statistik sehingga diperoleh suatu inverted index dan df setiap dokumen.
Pengindeksan koleksi dokumen dengan menggunakan Indri menghasilkan beberapa file
biner seperti:
1. invertedFile: berisi inverted index dan df serta posisi term pada dokumen,
2. frequentID: berisi daftar pemetaan dari
termID ke term string,
3. frequentString: berisi daftar pemetaan dari
term string ke termID,
4. infrequentID: berisi daftar pemetaan dari
termID ke term string,
5. infrequentString: berisi daftar pemetaan dari term string ke termID.
File biner ini akan digunakan dalam proses pencarian teks. Untuk dapat membaca file biner tersebut, digunakan suatu fungsi yang ada pada Indri yakni IndexManager.openIndex (indexPath) dengan indexPath merupakan direktori tempat file biner disimpan.
Dari file biner invertedFile yang dihasilkan dari proses pengindeksan, pengindeksan 1000 dokumen menghasilkan ukuran file sebesar 1,613 MB dan pengindeksan 2000 dokumen sebesar 2,399 MB. Dari masing-masing file invertedFile tersebut, jumlah kata unik yang dihasilkan untuk pengindeksan 1000 dokumen adalah 27127 kata dengan frekuensi total 548701 kata dan untuk pengindeksan 2000 dokumen adalah 35517 kata dengan frekuensi total 859130 kata.
Pemrosesan Kueri
Jumlah kueri yang digunakan pada penelitian ini adalah 30 yang tersedia di Laboratorium Temu-Kembali Informasi Departemen Ilmu Komputer IPB. Daftar kueri yang digunakan dapat dilihat pada Lampiran 2.
Pemrosesan kueri dilakukan dengan mengubah kueri terlebih dahulu ke lowercase, kemudian kueri (Q) ditokenisasi dengan menggunakan fungsi yang tersedia oleh
java.util yaitu StringTokenizer(Q, delimeter)
dan disimpan dalam array tokenQuery.
Delimeter yang digunakan untuk tokenisasi balaipenelitian000000-001 PRODUKTIVITAS SOM
JAWA Ireng Darwati Som Jawa merupakan tanaman yang menghasilkan umbi. Untuk menghasilkan umbi yang optimal, diperlukan tanah yang sifat-sifat fisik dan kesuburannya baik . Kondisi tersebut dapat dicapai dengan penggunaan bahan organik (kasting, kompos daun bambu dan pupuk kandang).
<DOC>
<DOCNO>balaipenelitian000000-001</DOCNO> <TITLE>PRODUKTIVITAS SOM JAWA </TITLE> <AUTHOR>Ireng Darwati </AUTHOR>
<TEXT>
Som Jawa merupakan tanaman yang menghasilkan umbi. Untuk menghasilkan umbi yang optimal, diperlukan tanah yang sifat-sifat fisik dan kesuburannya baik . Kondisi tersebut dapat dicapai dengan penggunaan bahan organik (kasting, kompos daun bambu dan pupuk kandang).
6 kueri adalah whitespace atau spasi. Dalam tahap
pemrosesan kueri ini tidak dilakukan penghilangan stopwords, karena term kueri yang berupa stopwords secara automatis tidak akan digunakan dalam proses pemilihan n dokumen teratas.
Isi dari array tokenQuery adalah berupa suatu nilai integer, yaitu nilai urutan token pada hasil indexing koleksi dokumen. Perubahan
term kueri (t) yang berupa string menjadi suatu
integer dilakukan dengan menggunakan fungsi yang tersedia pada Indri yaitu term(t). Array tokenQuery ini akan digunakan dalam proses perolehan n dokumen teratas. Berikut ini adalah contoh perolehan array tokenQuery yang berupa suatu nilai integer dengan kueri, “Penerapan bioteknologi di Indonesia”
Array(
Nilai array tokenQuery ini tergantung pada koleksi dokumen yang digunakan. Pada contoh diatas, koleksi dokumen yang digunakan adalah koleksi 1000 dokumen yang ada di Laboratorium Temu-Kembali Informasi Departermen Ilmu Komputer IPB. Jika koleksi dokumen ditambahkan dengan dokumen yang baru, maka hasil yang diperoleh dengan kueri yang sama ditunjukkan pada ilustrasi di bawah ini (dengan penambahan 1000 dokumen).
Array(
Pada saat proses perolehan n dokumen teratas array tokenQuery berfungsi untuk pemilihan dokumen dalam koleksi yang memiliki salah satu atau lebih term kueri di dalamnya, sehingga dalam pemilihan n dokumen teratas hanya dokumen yang memiliki
term kueri saja yang akan dilakukan proses perolehan n dokumen teratas.
Hasil Temu-Kembali
Perolehan n dokumen teratas tergantung pada tipe pembobotan yang digunakan. Pada penelitian ini tipe pembobotan yang digunakan yaitu pembobotan tf-idf dan pembobotan BM25. Jumlah dokumen teratas yang diambil adalah 30. Contoh hasil perolehan 30 dokumen
teratas untuk kueri “perdagangan hasil pertanian” dengan jumlah koleksi dokumen adalah 1000 pada pembobotan tf-idf dapat dilihat pada Lampiran 3.
1. Pembobotan tf-idf
Untuk memperoleh n dokumen teratas dengan pembobotan dilakukan dengan langkah-langkah berikut:
1. Melakukan pembobotan tf-idf terhadap kata pada kueri yang diberikan kemudian dilakukan perhitungan terhadap panjang kueri.
2. Menyimpan informasi kata unik yang ada pada dokumen.
3. Menghitung idf dan tf-idf untuk setiap kata unik dokumen dengan menggunakan df dan tf yang diperoleh pada proses indexing. 4. Menghitung panjang dokumen.
5. Menjumlahkan perkalian antara tf-idf kata kueri dengan tf-idf kata dokumen (yang akhirnya menjadi nilai dotproduct antara kueri dan dokumen).
6. Menghitung bobot dokumen dengan cosine similarity antara dokumen dengan kueri. Kemudian menyimpan hasilnya dalam
array dokScoring dan menyimpan nama dokumen dalam array docName.
7. Melanjutkan proses untuk dokumen berikutnya hingga seluruh koleksi telah dibandingkan dengan kueri.
8. Melakukan proses sorting terhadap array dokScoring dan docName untuk memperoleh n dokumen teratas dengan menggunakan fungsi Sort(dokScoring).
Array dokScoring dan docName berisi bobot dokumen dan nama dokumen dari dokumen yang memiliki nilai dotproduct lebih besar dari nol (0). Berikut ini adalah contoh dari isi 10 teratas dari array dokScoring dan docName
dengan kueri, ”gagal panen” pada pengindeksan 1000 koleksi dokumen
7
docName(
[0] => republika060804-001.txt [1] => kompas030704.txt
[2] => indosiar140204.txt [3] => indosiar130504.txt [4] => indosiar260803-001.txt [5] => suaramerdeka120104.txt [6] => situshijau280404-002.txt [7] => republika090804-01.txt [8] => indosiar040903.txt [9] => gatra190902-02.txt )
2. Pembobotan BM25
Pembobotan BM25 untuk memperoleh n dokumen teratas dilakukan dengan langkah-langkah sebagai berikut:
1. Menghitung rata-rata panjang koleksi dokumen dengan docLengthAvg().
2. Menghitung panjang dokumen dengan
docLength (idDoc) untuk setiap koleksi dokumen.
3. Menyimpan setiap kata unik pada dokumen.
4. Menghitung similarity (pembobotan BM25)dokumen dengan kueri untuk setiap kata yang sama, kemudian dilakukan penjumlahan setiap similarity tersebut. Kemudian menyimpan hasilnya dalam
array dokScoring dan menyimpan nama dokumen dalam array docName.
5. Melanjutkan proses untuk dokumen berikutnya hingga seluruh koleksi telah dibandingkan dengan kueri.
6. Melakukan proses sorting terhadap array dokScoring dan docName untuk memperoleh n dokumen teratas dengan menggunakan fungsi Sort(dokScoring).
Isi dari array dokScoring dan array docName sama seperti yang ada pada perolehan n dokumen teratas dengan pembobotan tf-idf.
Evaluasi Sistem
Pada penelitian ini pengujian sistem dilakukan dengan menguji kinerja temu-kembali dan menguji kinerja Indri dalam mengindeks dokumen dalam jumlah yang besar.
1. Kinerja Temu-Kembali
Pada tahapan evaluasi digunakan 30 kueri seperti yang ada pada Lampiran 2. Untuk setiap kueri dilakukan perhitungan recall dan
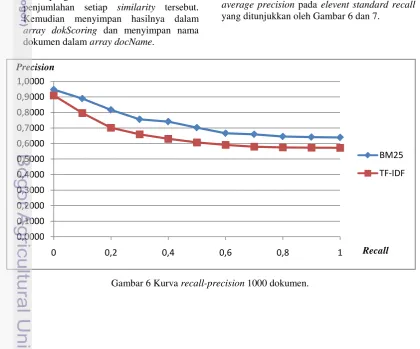
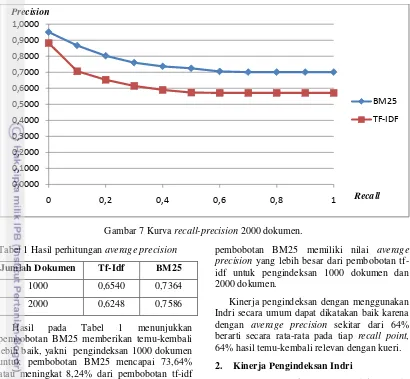
precision untuk 30 dokumen teratas yang ditemukembalikan oleh sistem. Hasil perhitungan precision pada elevent standard recall dapat dilihat pada Lampiran 4. Average precision masing-masing pembobotan dan jumlah koleksi dokumen ditunjukkan pada Tabel 1. Untuk melihat kinerja temu-kembali sistem maka diilustrasikan dengan kurva
average precision pada elevent standard recall
yang ditunjukkan oleh Gambar 6 dan 7.
Gambar 6 Kurva recall-precision 1000 dokumen.
8 Gambar 7 Kurva recall-precision 2000 dokumen.
Tabel 1 Hasil perhitungan average precision
Jumlah Dokumen Tf-Idf BM25
1000 0,6540 0,7364
2000 0,6248 0,7586
Hasil pada Tabel 1 menunjukkan pembobotan BM25 memberikan temu-kembali lebih baik, yakni pengindeksan 1000 dokumen untuk pembobotan BM25 mencapai 73,64% atau meningkat 8,24% dari pembobotan tf-idf dan untuk pengindeksan 2000 dokumen untuk pembobotan BM25 mencapai 75,86% atau meningkat sebesar 13,38% dari pembobotan tf-idf. Hasil uji yang dilakukan juga menunjukkan bahwa untuk pembobotan tf-idf dan BM25 memiliki perbedaan yang signifikan dengan
pembobotan BM25 memiliki nilai average precision yang lebih besar dari pembobotan tf-idf untuk pengindeksan 1000 dokumen dan 2000 dokumen.
Kinerja pengindeksan dengan menggunakan Indri secara umum dapat dikatakan baik karena dengan average precision sekitar dari 64% berarti secara rata-rata pada tiap recall point, 64% hasil temu-kembali relevan dengan kueri.
2. Kinerja Pengindeksan Indri
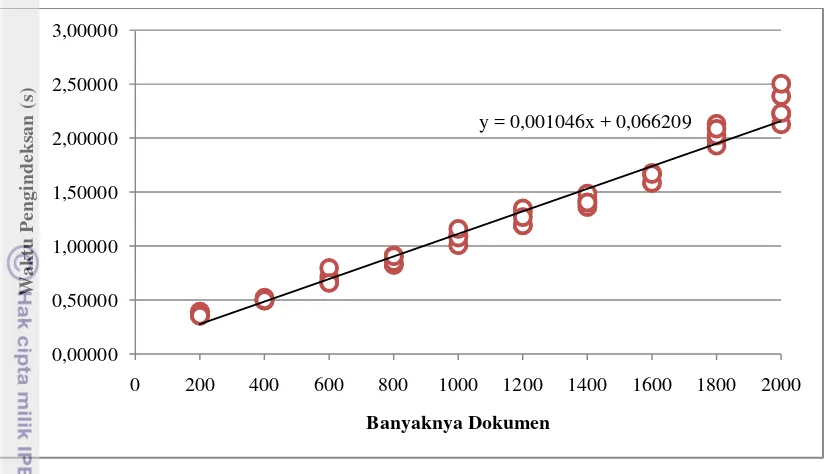
Hasil pengujian kinerja pengindeksan Indri dengan menggunakan jumlah koleksi dokumen yang berbeda-beda yakni 200, 400, 600, 800, 1000, 1200, 1400, 1600, 1800, dan 2000 dapat dilihat pada Tabel 2 dan diilustrasikan pada Gambar 8.
Tabel 2 Waktu pengindeksan Indri
Jumlah Dokumen Waktu Pengindeksan Ke-n (s) Rata-rata
9 Gambar 8 Kurva waktu pengindeksan Indri untuk berbagai jumlah koleksi dokumen.
Pengujian kinerja dilakukan dengan melakukan analisis regresi linear dan uji korelasi untuk memperoleh hubungan antara waktu pengindeksan dan banyaknya dokumen. Hasil pengujian korelasi menunjukkan bahwa waktu pengindeksan dan banyaknya dokumen memiliki korelasi yang sangat kuat dengan nilai korelasinya (r) adalah 0,98622, sedangkan dari hasil analisis regresi linear diperoleh:
�= 0,001046� + 0,066209
dengan
1. y = waktu pengindeksan dokumen 2. x = banyaknya dokumen
yang menunjukkan bahwa waktu pengindeksan dan jumlah dokumen memiliki hubungan yang positif (+) pada taraf nyata 5% yaitu semakin besar jumlah dokumen maka semakin lama proses pengindeksan.
Pengujian kinerja pengindeksan Indri yang telah dilakukan di atas menggunakan memori sebesar 256 MB dalam melakukan pengindeksan. Hasil pengujian tersebut menunjukkan untuk setiap dokumen membutuhkan waktu pengindeksan sebesar 0,001046 detik.
Pengujian kinerja pengindeksan Indri juga dilakukan untuk ukuran memori yang lebih kecil yaitu 512 KB. Pengujian ini dilakukan untuk melihat waktu pengindeksan pada saat
memoryIndex harus menuliskan hasil
pengindeksan ke dalam disk karena melebihi dari kapasitas memori. Pengujian juga dilakukan untuk ukuran memori 512 MB dan 1 GB. Hasil pengujian dapat dilihat pada Lampiran 5.
Hasil uji pengindeksan Indri dengan ukuran memori 512 KB, 256 MB, 512 MB, dan 1 GB menunjukkan bahwa tidak terdapat perbedaan waktu pengindeksan untuk keempat ukuran memori tersebut.
Kelebihan dan Kekurangan Sistem
Kelebihan dan kekurangan automatic indexing menggunakan Indri adalah sebagai berikut:
Kelebihan:
1. Pengindeksan dokumen hanya dilakukan satu kali yaitu pada awal pembangunan sistem.
2. Jika terdapat dokumen baru, maka pengindeksan dapat di-update langsung tanpa harus melakukan pengindeksan ulang.
3. Penggunaan n dokumen teratas yang memudahkan pengguna untuk menentukan jumlah dokumen yang harus dikembalikan.
Kekurangan:
1. Tidak dilakukan proses stemming sehingga jumlah kata unik yang dihasilkan lebih banyak.
2. Tidak dilakukan kajian terhadap makna semantik pada kueri.
y = 0,001046x + 0,066209
0,00000
0 200 400 600 800 1000 1200 1400 1600 1800 2000
10 KESIMPULAN DAN SARAN
Kesimpulan
Berdasarkan penelitian dan pengujian yang dilakukan, dapat disimpulkan bahwa pembobotan BM25 yang digunakan untuk temu-kembali dengan pengindeksan menggunakan Indri memberikan hasil yang lebih baik. Hal ini terlihat pada pengindeksan dengan pembobotan BM25 untuk 1000 dokumen memiliki nilai average precision
0,7364 sedangkan untuk pembobotan tf-idf 0,6540 dan untuk 2000 dokumen dengan pembobotan BM25 memiliki nilai average precision 0,7586 sedangkan pembobotan tf-idf 0,6248.
Pengujian kinerja pengindeksan dengan melakukan uji korelasi dan analisis regresi linear menunjukkan jumlah dokumen dan waktu pengindeksan memiliki hubungan yang kuat dengan nilai korelasi (r) adalah 0,98622 dan positif yaitu semakin banyak jumlah dokumen maka semakin lama (tinggi) waktu pengindeksan. Penggunaan ukuran memori yang berbeda-beda dalam pengindeksan akan menghasilkan waktu pengindeksan yang berbeda pula. Akan tetapi, hasil uji menunjukkan untuk ukuran memori 512 KB, 256 MB, 512 MB, dan 1 GB tidak terdapat perbedaan waktu pengindeksan.
Saran
Terdapat beberapa hal yang dapat ditambahkan atau diperbaiki untuk penelitian ke depan seperti:
1. Menggunakan dokumen dalam berbagai format seperti HTML, doc, ppt, pdf, dan XML.
2. Menggunakan stemming untuk melihat pengaruh stemming terhadap kinerja pengindeksan Indri untuk masing-masing pembobotan.
DAFTAR PUSTAKA
Anbiana ED. 2009. Pseudo-Relevance Feedback pada Temu-Kembali Menggunakan Segmentasi Dokumen [skripsi]. Bogor: Fakultas Matemetika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Baeza-Yates R, Ribeiro-Neto B. 1999. Modern Information Retrieval. Addison-Wesley.
Jones K S. 1999. A probabilistic model of information retrieval: development and comparative experiments Part 2. Cambridge: Cambridge University.
Kontostathis. April. 2008. Distributed EDLSI, BM25, and Power Norm at TREC 2008. USA, Department of Mathematics and Computer Science, Ursinus College.
Manning CD, Prabhakar R, Hinrich S. 2008.
Introduction to Information Retrieval. Cambridge University Press.
Metzler et al. 2004. Indri at Trec 2004: Terabyte Track. USA.
Metzler et al. 2005. Indri at Trec 2005: Terabyte Track. USA.
Metzler et al. 2006. Indri at Trec 2006: Lessons Learned From Three Terabyte Tracks. USA
Song Jin. 2009. DUTIR at TREC 2009: Chemical IR Track. China, Information Retrieval Lab, Dalian University of Technology.
Strohman T. 2005. Dynamic Collection in Indri. USA.
Strohman T, W. Bruce C. 2006. Low Latency Index Maintenance in Indri. USA.
12 Lampiran 1 Daftar kata buang (stoplist)
acapkali apanya begitupula berkesempatan contohkan diberinya
ada apapun begitupun berkesimpulan contohnya dibiarkan adakah arti belakang berlalu cukup dibiasakan adakan artian belakangan berlalunya Cuma dibilang adalah artinya belum berlama daerah dicontoh
adanya asalan belumlah berlangsung dahulu dicontohkan adapun asalkan benar bermula dalam dicontohkannya
aduh asumsi benarkah bersama dan didapat
agak asumsinya benarnya bersamaan dapat didapati
agaknya atas berada bertepatan dapatkah didapatkan agar atasnya berakhir beruntun dapatkan didapatnya aja atau berakhirnya berupa dapatlah didasarkan akalan ataukah berakibat besarnya dari digolongkan
akan ataupun berakibatkan beserta darinya digunakan akankah awal beralasan besok daripada diharapkan akhir bagai beralih besoknya dekat dijadikan akhirnya bagaikan beralihnya betapa dekatnya dijadikannya
akibat bagaimana beranggapan biar demi dikarenakan akibatkan bagaimanakah berapa biarlah demikian dikasih akibatnya bagaimanapun berapanya biasa demikianlah dikata aku bagi berapapun biasanya dengan dikatakan
ala baginya berarti bicarakan dengannya dikatakannya alangkah bagus berasumsi bicaranya depan dikategorikan alasan bagusnya berbagai bila depannya dikembangkan alasannya bahkan berbagi bilamana di diketahui
alih bahwa berbanding bilang dia diketahuinya alihkan baik berbeda bisa dialah dilaksanakan amat baiknya berdampak bisakah dialami dilakukan amatlah balik berdasarkan bisanya dialihkan dimana
ambil banding berhadapan boleh diambil dimulai anda bandingkan berharap boro diambilkan dimulailah andai banyak berhubung buat diambilnya dimulainya anggap banyaknya berhubungan buatnya dianggap dimungkinkan
anggapan barangkali beri bukan diantara dipaparkan antar baru berikan bukankah diantaranya dipersilahkan antara bawah berikanlah bukanlah diapakan disaat antaranya bawahnya berikut bukannya dibagi disebabkan
apa beberapa berikutnya buktikan dibagikan disejumlah apabila begini berjumlah cara dibeberapa diseluruh apakah beginilah berkat cerita diberbagai disertai apalagi begitu berkenaan ceritanya diberi disertakan
13 Lanjutan Lampiran 1 Daftar kata buang (stoplist)
disitulah itupun kemana manalagi mengaku mulanya
ditanggapi iya kemanakah manapun mengalami muncul ditanya jadi kembali masa mengalihkan mungkin ditanyakan jadikan kemudian masih mengambil mungkinkah dituturkan jadilah kemungkinan masihkah mengambilnya namun
diucapkan jadinya kemungkinannya masing menganggap nanti dkk jangan kenapa masuk menganggapnya negara dll jarang kenapakah masyarakat mengapa nilai
dsb jauh kepada mau mengatakan nyaris
dua jelaskan kepadanya maupun mengembangkan nyiakan
dulu jika kepala melainkan mengenai oleh
dulunya jikalau ketika melakukan menggunakan orang empat juga ketimbang melalui mengungkapkan pada
enggak jumlah khususnya melihat meningkat padahal engkau jumlahnya kini memang meningkatkan padanannya
esok justru kita memaparkan menjadi paling
gimana juta kondisi membagi menjadikan panjangnya
habis kabupaten kurang membagikan menjadikannya papar habisan kadang lagi memberi menjelang paparan habiskan kalau lagian memberikan menjelaskan paparkan habisnya kalaupun lagipula memberinya menuju paparnya
hal kali lain membiarkan menunjukkan para
hampir kalian lainnya membolehkan menurut pasti hanya kami laksana membuat menurutnya pastilah hanyalah kamu lakukan memeperoleh menuturkan pastinya
hari kan lalu memiliki menyatakan pelak
harus kapan lalui meminta menyebabkan pelbagai haruskah karena lama memperbolehkannya menyebutkan pemaparan haruslah karenanya lanjut mempersilahkan menyia pembagian
harusnya kata lantaran mempunyai mereka pembagiannnya hendak katakan lantas memungkinkan merupakan pendapat hendaklah katakanlah lebih menanggapi meski pengalihan hendaknya katanya lepas menanggapinya meskipun pengambil
hingga kau lewat menanyakan mesti pengambilan
how kayak lokasi mencapai mestinya pengandaian ialah kayaknya maka mencontohkan misal per
ingin ke makin mendapat misalkan peralihan
ini kebanyakan mampu mendapati misalnya percuma inilah kebetulan mampukah mendapatkan mudah peri inipun kebiasaan mampunya mendapatkannya mula perihal
itu kecil mana menerus mulai perlahan
14 Lanjutan Lampiran 1 Daftar kata buang (stoplist)
pernah sebenarnya semakin sesungguhnya tentunya umum
persen seberapa semampunya setelah tepatnya umumnya pertamanya seberat semenjak setelahnya terbagi ungkap pinggir sebesar sementara seterusnya terbalik ungkapan pula sebetulnya semestinya setiap terbiasa ungkapkan
pulalah sebuah semisal setidak terbilang ungkapnya pun secara semoga setidaknya terdapat untuk
rata sedalam semua seusai terdapat usah
relevankah sedang semuanya sewaktu tergolong usahlah
rendah sedangkan semula seyogyanya terhadap usai
saat sedapat seolah sia terjadi usianya
saatnya sedemikian seorang sialnya terjadilah waktu saatnyalah sedikit seorangpun siap terjadinya waktulah
saja sedikitnya sepadan siapa terkadang waktunya salah segera sepanjang siapakah terkait walau sama sehabis sepasang siapapun terkecuali walaupun sambil seharusnya sepele silahkan terlalu warga
sambutannya seharusnyalah sependapat singkatnya terlebih yaitu sampai sehingga seperti sini termasuk yakni sana sehubungan sepertinya sinilah ternyata yang
sang sejak seputar situ tersebut
sangat sejauhmana seraya sosok tertentu sangatlah sejumlah serba sosoknya terus satunya sekalian serentak suatu tetap saya sekaligus sering sudah tetapi
sayangnya sekalipun seringkali sulit tiap seakan sekarang seringkalinya sungguh tiba seandainya sekata seringlah sungguhpun tidak seantero sekedar seringnya supaya tidaklah
sebab sekeliling serta tak tidaknya sebabkan seketika sertanya tambahnya tiga sebabnya sekian sesaat tanggapan tinggi sebagai sekitar sesama tanggapannya tutur
sebagaimana selagi sesamamu tanggapnya tuturnya sebagainya selain sesedikit tanpa ucap sebagian selalu seseorang tapi ucapan sebaik selama sesuai tatkala ucapannya
sebaiknya selanjutnya sesuatu telah ucapkan sebaliknya selesai sesuatunya tempat ucapnya sebanyak selesaikah sesudah tengah ujar sebelum seluruh sesudahnya tentang ujarnya
15 Lampiran 2 Daftar kueri yang digunakan
No Kueri
1 gagal panen/puso 2 petani tebu 3 industri gula
4 perdagangan hasil pertanian 5 penerapan teknologi pertanian 6 pupuk organik
7 penyakit hewan ternak/penyakit ternak
8 penerapan bioteknologi di indonesia/penerapan bioteknologi/bioteknologi di indonesia 9 laboratorium pertanian
10 riset pertanian
11 harga komoditas pertanian 12 tanaman pangan
13 kelompok masyarakat tani/kelompok tani 14 musim panen
15 tanaman obat 16 gabah kering giling 17 impor beras indonesia
18 pertanian organik/sistem pertanian organik 19 swasembada pangan
20 penyuluhan pertanian 21 tadah hujan
22 bencana kekeringan
23 peternak unggas/peternak ayam/peternak burung 24 flu burung
25 institut pertanian bogor
26 pembangunan untuk sektor pertanian
27 upaya peningkatan pendapatan petani/peningkatan pendapatan petani 28 produk usaha peternakan rakyat/produk peternakan
29 kelangkaan pupuk
16 Lampiran 3 Contoh hasil perolehan 30 dokumen teratas
Bobot Dokumen Nama Dokumen Relevansi*
0.4409062 kompas121099.txt R
0.37065294 jurnal000000-017.txt R
0.34840918 jurnal000000-011.txt R
0.3094563 republika230704-08.txt R
0.22601162 jurnal000000-008.txt NR
0.20682736 jurnal000000-013.txt R
0.20426403 suarakarya000000-019.txt NR
0.19835569 suarapembaruan020603.txt NR
0.19834284 situshijau030603-001.txt R
0.1981379 suarapembaruan020603_-_No.txt R
0.19081329 jurnal000000-018.txt NR
0.18973437 republika260803.txt R
0.18528064 mediaindonesia030203.txt NR
0.1742558 kompas290402.txt R
0.1575037 situshijau140903-003.txt R
0.13596562 republika140604-001.txt R
0.13584645 republika180504-001.txt R
0.13310817 wartapenelitian000000-007.txt R
0.1312325 republika201103.txt NR
0.12934998 situshijau180803-002.txt R
0.12574962 indosiar201103.txt NR
0.121523835 situshijau080103.txt R
0.11676065 puslitbang000000-001.txt NR
0.11427295 situshijau140903-001.txt R
0.11374518 situshijau130503-002.txt NR
0.11259709 suarakarya000000-037.txt NR
0.10716234 situshijau110603-001.txt NR
0.10676231 republika220604-003.txt R
0.10556391 situshijau180603-003.txt R
0.10502637 situshijau270703-005.txt R
17 Lampiran 4 Hasil perhitungan precision pada elevent standard recall
Recall
Precision
1000 dokumen 2000 dokumen
Tf-Idf BM25 Tf-Idf BM25
0 0,9094 0,9472 0,8821 0,9504
0,1 0,7960 0,8890 0,7063 0,8664
0,2 0,7015 0,8164 0,6528 0,8019
0,3 0,6589 0,7551 0,6144 0,7593
0,4 0,6300 0,7404 0,5895 0,7365
0,5 0,6070 0,7023 0,5729 0,7246
0,6 0,5911 0,6662 0,5709 0,7046
0,7 0,5792 0,6589 0,5709 0,7003
0,8 0,5750 0,6453 0,5709 0,7003
0,9 0,5732 0,6413 0,5709 0,7003
1 0,5722 0,6386 0,5709 0,7003
18 Lampiran 5 Kinerja pengindeksan Indri dengan menggunakan berbagai ukuran memori
Tabel Pengindeksan menggunakan memori 512 MB
Jumlah Dokumen Waktu Pengindeksan Ke-n Rata-rata
1 2 3 4 5
200 0,35861 0,42362 0,34603 0,39007 0,35441 0,37455 400 0,50121 0,51171 0,47605 0,60398 0,49912 0,51841
600 0,70044 0,81579 0,68157 0,67528 0,68367 0,71135 800 0,91855 0,84305 0,79691 0,89128 0,96049 0,88206 1000 1,10519 1,08213 1,04438 1,02760 1,07164 1,06619 1200 1,38202 1,20795 1,26248 1,25619 1,22054 1,26584
1400 1,42396 1,37573 1,38412 1,37782 1,43025 1,39838 1600 1,59593 1,65675 1,65045 1,61900 1,66094 1,63661 1800 1,77419 1,90840 1,89582 1,95035 2,03004 1,91176 2000 2,09924 2,06150 2,12231 2,17474 2,36978 2,16551
Tabel Pengindeksan menggunakan memori 1 GB
Jumlah Dokumen Waktu Pengindeksan Ke-n Rata-rata
1 2 3 4 5
200 0,37329 0,37958 0,3649 0,34393 0,34603 0,36155
400 0,50541 0,51380 0,51799 0,49912 0,49283 0,50583 600 0,78014 0,83676 0,69625 0,70044 0,6564 0,73400 800 0,92903 0,91435 0,92274 0,85773 0,90177 0,90512 1000 1,06325 1,21425 1,0255 1,09890 1,07583 1,09555
1200 1,20586 1,20166 1,19747 1,21215 1,23312 1,21005 1400 1,48478 1,41138 1,40089 1,35266 1,44913 1,41977 1600 1,67143 1,59383 1,53721 1,58125 1,67981 1,61271 1800 1,84339 1,84759 1,87904 1,81193 1,86227 1,84884
2000 2,06779 2,06988 2,05311 2,06988 2,16635 2,08540
Tabel Pengindeksan menggunakan memori 512 KB
Jumlah Dokumen Waktu Pengindeksan Ke-n Rata-rata
1 2 3 4 5
200 0,41733 0,36700 0,38377 0,50541 0,37539 0,40978 400 0,76336 0,74239 0,60817 0,65431 0,91435 0,73652 600 1,09890 1,30233 1,23522 1,37573 1,45122 1,29268 800 1,42396 1,50994 1,55189 1,64626 1,31491 1,48939
1000 1,42396 1,50994 1,55189 1,64616 1,31491 1,48937 1200 2,25443 1,98600 2,03423 2,06779 1,84129 2,03675 1400 2,77662 2,13490 2,22927 2,18102 2,28170 2,32070 1600 2,94020 2,51448 2,46625 2,44947 2,28589 2,53126
19 Lanjutan Lampiran 5 Kinerja pengindeksan Indri dengan menggunakan berbagai ukuran memori
Kurva waktu pengindeksan Indri untuk berbagai ukuran memori
0 0,5 1 1,5 2 2,5 3 3,5
0 500 1000 1500 2000
W
a
k
u P
e
ng
inde
k
sa
n
(s
)
Banyaknya Dokumen
512 KB
256 MB
512 MB