ANALISIS KLASTER K-
MEANS
DAN K-
MEDIAN
PADA
DATA INDIKATOR KEMISKINAN
(Studi Kasus Data Indikator Kemiskinan Kabupaten di Indonesia Tahun 2009)
Febriyana
PROGRAM STUDI MATEMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI
SYARIF HIDAYATULLAH
ANALISIS KLASTER K-
MEANS
DAN K-
MEDIAN
PADA
DATA INDIKATOR KEMISKINAN
(Studi Kasus Data Indikator Kemiskinan Kabupaten di Indonesia Tahun 2009)
Skripsi
Sebagai Satu Syarat Untuk Memperoleh
Gelar Sarjana Sains
Fakultas Sains dan Teknologi
Universitas Islam Negeri Syarif Hidayatullah Jakarta
Oleh
Febriyana
107094002893
PROGRAM STUDI MATEMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI
SYARIF HIDAYATULLAH
ii
PENGESAHAN PEMBIMBING
ANALISIS KLASTER K-MEANS DAN K-MEDIAN PADA DATA INDIKATOR KEMISKINAN
(Studi Kasus Data Indikator Kemiskinan Kabupaten di Indonesia Tahun 2009)
Skripsi
Sebagai satu syarat untuk memperoleh Gelar sarjana sains
Fakultas Sains dan Teknologi
Universitas Islam Negeri Syarif Hidayatullah Jakarta
iii
PENGESAHAN UJIAN
Skripsi berjudul “Analisis Klaster K-Means dan K-Median Pada Data Indikator Kemiskinan” yang ditulis oleh Febriyana, NIM 107094002893 telah di uji dan dinyatakankan lulus dalam sidang Munaqosyah Fakultas Sains dan Teknologi Universitas Islam Negeri Syarif Hidayatullah Jakarta pada tanggal 8 Juni 2011 Skripsi ini telah diterima sebagai salah satu syarat untuk memperoleh gelar sarjana strata satu (S1) Program Matematika.
Dekan Fakultas Sains dan Teknologi, Ketua Program Studi Matematika,
DR. Syopiansyah Jaya Putra, M. Sis Yanne Irene, M. Si
iv
PERNYATAAN
DENGAN INI SAYA MENYATAKAN BAHWA SKRIPSI INI
BENAR-BENAR HASIL KARYA SENDIRI YANG BELUM PERNAH DIAJUKAN
SEBAGAI SKRIPSI PADA PERGURUAN TINGGI ATAU LEMBAGA
MANAPUN.
Jakarta, Juni 2011
K a r y a i n i ku per sem ba hka n un t uk
Or a n gt ua ku t er ci n t a y a n g t ela h ba n y a k m en cur a hka n
ka si h sa y a n g da n dukunga n ba i k m or i l m a upun m a t er i
F i t r i a n a F a dhi lla h
K edua a di kku
M ot t o
Sesun gguhn y a set ela h kesuli t a n t er da pa t kem uda ha n . Set ela h
t a n gi sa n t er da pa t sen y um a n . D a n sega la kesuli t a n a ka n
v ABSTRAK
Analisis klaster merupakan salah satu metode multivariate yang bertujuan untuk mengelompokkan objek berdasarkan kemiripan atau ketidakmiripan karakteristiknya, sehingga objek yang terletak pada satu klaster memiliki kemiripan yang lebih besar dibandingkan dengan objek pengamatan yang terletak pada klaster lain. K-means merupakan salah satu metode pengklasteran tidak berhirarki yang paling banyak digunakan, namun karena menggunakan rataan sebagai pusat klasternya, metode ini lebih sensitif terhadap keberadaan pencilan pada data. Metode K-median yang menggunakan median sebagai nilai pusat klasternya dinilai dapat mengatasi adanya pencilan. Penelitian ini bertujuan untuk membandingkan hasil analisis klaster k-means dengan k-median dari data indikator kemiskinan kabupaten di Indonesia tahun 2009.
Hasil pengklasteran menunjukkan bahwa pada metode k-means klaster pertama terdapat 395 kabupaten dan pada klaster kedua terdapat 76 kabupaten. Sedangkan pada metode k-median pada klaster pertama terdapat 99 kabupaten dan pada klaster kedua terdapat 372 kabupaten. Berdasarkan nilai ketepatan klasifikasi klaster K-means memiliki tingkat ketepatan klasifikasi yang lebih baik yaitu sebesar 98,51 Sedangkan pada k-median tingkat ketepatan klasifikasi sebesar 97,57%. Sehingga dapat disimpulkan bahwa pada kasus ini metode pengklasteran k-means lebih baik dibandingkan dengan k-median.
ABSTRACT
Cluster analysis is one of the multivariate method which aims to classify objects based on similarity or dissimilarity its characteristics, so that objects located in one cluster has a similarity larger than the object of observation is located in another cluster. K-means clustering is one method does not berhirarki the most commonly used, but because it uses the mean as the center of the cluster, this method is more sensitive to the presence of outliers in the data. K-medians method that uses the median as a central value can cope with the outliers. This study aimed to compare the results of k-means cluster analysis with k-median of district poverty indicators in Indonesia in 2009.
Clustering results show that the method of k-means clustering, the first cluster there are 395 districts and the second cluster there are 76 districts. While the k-median method, the first cluster there are 99 districts and the second cluster there are 372 districts. Based on the classification accuracy of K-means cluster has the level of a better classification accuracy that is equal to 98.51, while the k-median level of classification accuracy of 97.57%. So it can be concluded that in this case k-means clustering method is better than the k-median.
vii
KATA PENGANTAR
Segala puji dan syukur yang sebesar-besarnya penulis panjatkan kehadirat
Allah SWT, karena dengan rahmat dan karunia-Nya penulis dapat menyelesaikan
tugas akhir ini tepat pada waktunya. Shalawat serta salam semoga selalu tercurah
kepada Nabi Muhammad SAW, keluarga, sahabat serta segenap umatnya.
Penulis sadar bahwa skripsi ini tidak akan selesai bila penulis tidak
mendapat bantuan dari berbagai pihak, baik bantuan secara langsung maupun
dukungan moril dan doa. Oleh karena itu penulis ingin mengucapkan terima kasih
yang sebesar-besarya kepada:
1. Dr. Syopyansyah Jaya Putra, M.Si, Dekan Fakultas Sains dan Teknologi UIN
Syarif Hidayatullah Jakarta.
2. Ibu Yanne Irene, M.Si, Ketua Program Studi Matematika dan Ibu Suma’inna,
M.Si, Sekretaris Program Studi Matematika.
3. Ibu Suma’inna, M.Si, sebagai Dosen Pembimbing I, yang telah meluangkan
waktunya untuk memberikan bimbingan dan pengarahan hingga
terselesaikannya skripsi ini.
4. Bapak Bambang Ruswandi, M.Stat, sebagai Dosen Pembimbing II, atas
bimbingan, saran dan bantuannya dari awal hingga terselesaikannya skripsi
ini.
5. Ayahanda tercinta yang telah menghabiskan waktu dan tenaga tanpa
mengenal batas untuk memberikan yang terbaik bagi penulis agar dapat
viii 6. Ibunda tercinta yang selalu memberikan semagat dan dukungan kepada
penulis, atas doa, kasih sayang, dorongan, pengertian dan kesabaran yang tak
terkira hingga penulis dapat menyelesaikan skripsi ini.
7. Seluruh dosen jurusan Matematika, Fakultas Sains dan Teknologi UIN Syarif
Hidayatullah Jakarta yang telah memberikan segenap ilmu.
8. Fitriana Fadhillah yang telah meluangkan banyak waktunya untuk membantu
menyelesaikan skripsi ini serta memberikan dukungan moril dan kesabaran.
9. Dua adikku, seluruh keluarga besarku dan keluarga Dhila yang telah
memberikan perhatian, dukungan dan doanya.
10. Seluruh karyawan dan murid Primagama Pondok Cabe yang selalu
memberikan dorongan motivasi kepada penulis hingga terselesaikan skripsi
ini.
11. Seluruh teman-teman Matematika 2007 yang penuh kekeluargaan dan selalu
memberikan motivasi kepada penulis dalam menyelesaikan skripsi ini.
Penulis menyadari dalam skripsi ini masih terdapat banyak kekurangan.
Penulis mengharapkan kritik dan saran agar penulis dapat memperbaiki
kekurangan yang ada. Penulis berharap semoga tugas akhir ini bermanfaat bagi
penulis khususnya, dan pihak lain umumnya.
Jakarta, Juni 2011
ix DAFTAR ISI
HALAMAN JUDUL ... i
PENGESAHAN PEMBIMBING ... ii
PENGESAHAN UJIAN ... iii
PERNYATAAN ... iv
PERSEMBAHAN DAN MOTTO ABSTRAK ... v
ABSTRACT ... vi
KATA PENGANTAR ... vii
DAFTAR ISI ... ix
DAFTAR TABEL ... xi
DAFTAR LAMPIRAN ... xii
BAB I PENDAHULUAN ... 1
1.1. Latar Belakang ... 1
1.2. Permasalahan ... 3
1.3. Pembatasan Masalah ... 3
1.4. Tujuan Penelitian ... 4
1.5. Manfaat Penelitian ... 4
BAB II LANDASAN TEORI ... 6
2.1. Kesejahteraan ... 6
2.2. Kemiskinan ... 6
x
2.4. Ukuran Kemiripan ... 10
2.5. K-means Klaster ... 11
2.6. K-median Klaster ... 12
2.7. Analisis Diskriminan ... 13
BAB III METODOLOGI PENELITIAN ... 16
3.1. Sumber Data ... 16
3.2. Variabel Penelitian ... 16
3.3. Uji Multikolinieritas ... 18
3.4. Uji Normal Multivariate ... 18
3.5. Metode Kerja ... 19
3.6. Alur Penelitian ... 23
BAB IV HASIL DAN PEMBAHASAN ... 24
4.1. Deskripsi Data ... 24
4.2. Pengujian Asumsi Multikolinieritas ... 25
4.3. Pembentukan Klaster K-means ... 25
4.4. Pembentukan Klaster K-median ... 29
4.5. Analisis Diskriminan ... 33
BAB V KESIMPULAN DAN SARAN ... 37
5.1. Kesimpulan ... 37
5.2. Saran ... 38
DAFTAR PUSTAKA ... 39
xi DAFTAR TABEL
Tabel 4.1 : Deskripsi Data ... 24
Tabel 4.2 : Nilai VIF Setiap Variabel ... 25
Tabel 4.3 : Jumlah Anggota Setiap Klaster K-means... 25
Tabel 4.4 : Rata-rata Setiap Variabel Pada Klaster 1 ... 26
Tabel 4.5 : Rata-rata Setiap Variabel Pada Klaster 2 ... 27
Tabel 4.6 : Variansi Setiap Variabel ... 28
Tabel 4.7 : Jumlah Anggota Setiap Klaster K-median... 29
Tabel 4.8 : Rata-rata Setiap Variabel Pada Klaster 1 ... 30
Tabel 4.9 : Rata-rata Setiap Variabel Pada Klaster 2 ... 31
Tabel 4.10 : Variansi Setiap Variabel ... 32
Tabel 4.11 : Ketepatan Klasifikasi K-means ... 34
xii DAFTAR LAMPIRAN
Lampiran 1 : Hasil Pengklasteran ... 41
Lampiran 2 : Output Nilai Variance Inflation Factor (VIF) ... 54
Lampiran 3 : Perhitungan Nilai Pada K-means ... 54
Lampiran 4 : Perhitungan Nilai Pada K-median ... 55
Lampiran 5 : Ketepatan Klasifikasi K-means ... 56
Lampiran 6 : Ketepatan Klasifikasi K-median ... 57
Lampiran 7 : Perhitungan rata-rata setiap variabel pada klaster k-means ... 57
Lampiran 8 : Perhitungan rata-rata setiap variabel pada klaster k-median ... 57
1 BAB I
PENDAHULUAN
1.1 Latar belakang
Kesejahteraan merupakan tumpuan harapan dan menjadi cita-cita
luhur perjuangan bangsa Indonesia sejak proklamasi kemerdekaan. Selain
itu kesejahteraan merupakan hal yang menentukan suatu pembangunan di
suatu daerah. Kesejahteraan masyarakat diharapkan meningkat dari tahun ke
tahun.
Salah satu masalah di bidang kesejahteraan adalah kemiskinan.
Kemiskinan menjadi permasalahan yang dihadapi oleh semua negara di
dunia, terutama di negara yang sedang berkembang seperti halnya
Indonesia. Hingga tahun 2010, BPS memperkirakan hampir 13,33% dari
total penduduk Indonesia masih hidup dalam kondisi miskin.
Indonesia memiliki potensi yang luar biasa dengan segala sumber
daya yang ada. Seharusnya hal ini dapat dimanfaatkan dengan baik oleh
pemerintah dalam meningkatkan kesejahteraan masyarakat Indonesia.
Namun kenyataannya permasalahan kemiskinan menjadi salah satu
permasalahan yang cukup penting di Indonesia. Kondisi ini menggambarkan
bahwa kemiskinan merupakan masalah sosial, baik di tingkat nasional
maupun regional dan perlu mendapatkan penanganan yang serius dari
seluruh masyarakat. Oleh karena itu permasalahan kemiskinan harus segera
2 Kemiskinan terjadi bukan hanya karena rendahnya pendapatan tetapi
juga karena keterbatasan sarana dan prasarana rumah tangga. Suatu rumah
tangga tidak memiliki fasilitas buang air besar belum tentu dapat dikatakan
miskin karena tingkat perekonomiannya cukup tinggi. Hal ini terjadi karena
rumah tangga tersebut menerapkan pola kehidupan tempat tinggalnya.
Selama ini pemerintah telah berupaya mengatasi permasalahan
kemiskinan. Salah satunya yaitu dengan memberikan bantuan kepada rumah
tangga miskin antara lain dengan memberikan bantuan langsung tunai
(BLT), pemberian kartu jaminan kesehatan dan lain sebagainya. Namun
permasalahan mendasar yang sangat penting dan dapat mengganggu
keberhasilan program ini adalah salah sasaran (mis-targeting). Salah satu
penyebabnya adalah belum adanya informasi mengenai kondisi aktual
kemiskinan pada setiap kabupaten.
Untuk mengatasi hal tersebut, pemerintah memerlukan gambaran
kondisi sosial ekonomi kabupaten/kota di Indonesia berupa kegiatan
evaluasi dan studi kasus yang dapat mengelompokkan kabupaten-kabupaten
di Indonesia untuk mengetahui karakteristik kabupaten tersebut dalam
bidang kemiskinan. Sehingga dapat menentukan kabupaten mana saja yang
diprioritaskan untuk mendapatkan bantuan dari pemerintah.
Dalam statistika, salah satu metode yang digunakan untuk
mengelompokkan variabel atau objek adalah analisis klaster. Analisis
klaster merupakan suatu metode untuk mengelompokkan variabel atau
3 kelompok akan mempunyai ciri yang relatif sama sedangkan antar
kelompok unit pengamatan memiliki sifat yang berbeda [1].
Ada beberapa metode pengelompokkan dalam analisis klaster, antara
lain k-means klaster dan k-median klaster. Berdasarkan penelitian Yanne
Flowrensia (2010) pada kasus pengelompokkan karakteristik tanaman bunga
iris, metode pengelompokkan k-median lebih baik dibandingkan k-means
dalam pengelompokkan data yang mengandung outlier [5].
Pengelompokkan ini bermanfaat bagi pemerintah dalam menentukan
kabupaten mana saja yang diprioritaskan untuk mendapatkan bantuan. Oleh
karena itu penulis tertarik untuk melakukan penelitian mengenai hal tersebut
dengan judul “ Analisis Klaster K-Means dan K-Median pada data
indikator kemiskinan studi kasus data indikator kemiskinan kabupaten
di Indonesia Tahun 2009”.
1.2 Permasalahan
Rumusan masalah penelitian ini dapat dirinci ke dalam beberapa
pertanyaan penelitian sebagai berikut :
1. Bagaimana hasil pengklasifikasian K-Means dan K-Median.
2. Kabupaten mana saja di Indonesia yang diprioritaskan untuk
mendapatkan bantuan dari pemerintah untuk periode 2010 hingga 2015.
1.3 Pembatasan Masalah
Agar dalam pembahasan tidak terlalu luas dan hasilnya dapat
mendekati pokok permasalahan, maka dalam penelitian ini hanya
4 tahun 2009 serta analisis yang dilakukan berdasarkan data-data yang
diperoleh pada waktu penelitian.
1.4 Tujuan Penelitian
Penelitian ini dilakukan dengan tujuan sebagai berikut :
1. Untuk membandingkan hasil klasifikasi K-Means dengan hasil
klasifikasi K-Median.
2. Mengelompokkan kabupaten-kabupaten di Indonesia berdasarkan
indikator kemiskinan untuk mengetahui kabupaten mana yang perlu
mendapatkan prioritas bantuan dari pemerintah agar program
pemerintah tepat sasaran.
1.5 Manfaat Penelitian
Hasil penelitian ini diharapkan dapat digunakan untuk :
1. Manfaat Teoritis
Dapat digunakan sebagai bahan referensi untuk penelitian lanjutan,
dengan tema yang sama akan tetapi dengan metode dan teknik analisa
yang berbeda. Sehingga dapat dilakukan proses verifikasi demi kemajuan
ilmu pengetahuan.
2. Manfaat Praktis
a. Bagi pemerintah
Sebagai dasar untuk menentukan kabupaten mana saja yang harus
diprioritaskan untuk mendapat bantuan, sehingga tidak terjadi lagi
5 b. Bagi penulis
Hasil penelitian ini dapat dijadikan bahan temuan awal untuk
melakukan penelitian lebih lanjut mengenai indikator-indikator
kemiskinan, serta dapat menerapkan ilmu-ilmu yang telah didapat
selama kuliah.
c. Bagi pembaca
Hasil penelitian diharapkan dapat digunakan sebagai bahan bacaan
dan acuan bagi pembaca yang sedang melakukan penelitian di bidang
6 BAB II
TINJAUAN PUSTAKA
2.1 Kesejahteraan
Kesejahteraan mencakup bidang-bidang kehidupan yang sangat luas
dan semua aspeknya tidak dapat diukur. Sebuah keluarga dapat dikatakan
sejahtera apabila seluruh kebutuhan jasmani dan rohani dari keluarga
tersebut dapat terpenuhi sesuai dengan tingkat hidup masing-masing
keluarga [2].
Kesejahteraan dalam konsep dunia modern adalah sebuah kondisi
dimana seorang dapat memenuhi kebutuhan pokok, baik itu kebutuhan akan
makanan, pakaian, tempat tinggal, air minum yang bersih serta kesempatan
untuk melanjutkan pendidikan dan memiliki pekerjaan yang memadai yang
dapat menunjang kualitas hidupnya sehingga memiliki status sosial yang
mengantarkan pada status sosial yang sama terhadap sesama warga lainnya
[2].
2.2 Kemiskinan
Masalah sosial bersifat relatif, namun secara pasti banyak sekali
permasalahan sosial yang terjadi dalam masyarakat Indonesia. Untuk
memudahkan penanganannya, pemerintah mengklasifikasikan masalah
sosial dalam lima masalah utama, yaitu kemiskinan, kecacatan,
7 masalah sosial tersebut, kemiskinan merupakan akar utama terjadinya
seluruh permasalahan sosial.
BPS mendasarkan pada besarnya Rupiah yang dibelanjakan
perkapita perbulan untuk memenuhi kebutuhan minimum makanan dan non
makanan. Kebutuhan minimum makanan menggunakan patokan 2100 kalori
perhari. Kebutuhan non makanan meliputi perumahan, sandang, aneka
barang dan jasa. Pengeluaran bukan makanan dibedakan antara perkotaan
dan pedesaan. Pola ini telah dianut oleh BPS sejak tahun 1976.
Kemiskinan adalah keadaan dimana terjadi kekurangan hal-hal yang
biasa untuk dimiliki seperti makanan, pakaian, tempat berlindung, dan air
minum, hal ini berhubungan erat dengan kualitas hidup. Secara konseptual,
kemiskinan dapat dikategorikan menjadi dua, yaitu :
1. Kemiskinan kronis (chronic poverty) yang terjadi secara simultan atau
disebut juga sebagai kemiskinan struktural. Fakir miskin atau rumah
tangga miskin memerlukan penanganan yang menyeluruh, terpadu secara
lintas sektor, dan berkelanjutan.
2. Kemiskinan sementara (transient poverty) yang ditandai dengan
menurunnya pendapatan dan kesejahteraan masyarakat secara sementara
sebagai akibat dari perubahan kondisi normal menjadi kondisi kritis,
bencana alam dan bencana sosial, seperti korban konflik sosial.
Kemiskinan sementara jika tidak ditangani secara serius dapat menjadi
8 Kemiskinan memiliki beberapa ciri sebagai berikut :
1. Ketidakmampuan memenuhi kebutuhan konsumsi dasar (pangan,
sandang dan papan).
2. Ketiadaan akses terhadap kebutuhan hidup dasar lainnya (kesehatan,
pendidikan, sanitasi, air bersih dan transportasi).
3. Ketiadaan jaminan masa depan (karena tiadanya investasi untuk
pendidikan dan keluarga).
4. Kerentanan terhadap goncangan yang bersifat individual maupun massal.
5. Rendahnya kualitas sumber daya manusia dan keterbatsaan sumber alam.
6. Ketidakterlibatan dalam kegiatan sosial masyarakat.
7. Ketiadaaan akses terhadap lapangan kerja dan mata pencaharian yang
berkesinambungan.
8. Ketidakmampuan untuk berusaha karena cacat fisik maupun mental.
9. Ketidakmampuan dan ketidaksinambungan sosial (anak terlantar, wanita
korban tindak kekerasan rumah tangga, janda miskin, kelompok marjinal
dan terpencil).
Terdapat 14 indikator kemiskinan yaitu luas lantai, jenis lantai, jenis
dinding, fasilitas buang air besar, sumber air minum, sumber penghasilan
kepala rumah tangga, sumber penerangan rumah tangga, jenis bahan bakar
untuk memasak setiap hari, frekuensi pembelian pakaian baru dalam
9 frekuensi makan dalam sehari, biaya kesehatan, pendidikan tertinggi kepala
rumah tangga, dan tabungan [12].
2.3 Analisis Klaster
Analisis klaster merupakan teknik multivariate (banyak variabel)
yang berfungsi mengelompokkan beberapa variabel atau objek [9]. Dalam
analisis klaster, ingin mengetahui pengaruh dari setiap variabel bebas, baik
secara individu maupun bersama terhadap variabel tidak bebas.
Tujuan utama analisis klaster adalah mengklasifikasi objek seperti
orang, produk atau barang, perusahaan, ke dalam kelompok-kelompok yang
homogeny dan didasarkan pada suatu set variabel yang dipertimbangkan
untuk diteliti. Pembentukan klaster didasarkan pada kuat tidaknya hubungan
antar variabel. Suatu objek dimasukkan ke dalam suatu klaster atau
kelompok sehingga lebih berhubungan (berkorelasi) dengan objek lainnya
di dalam klasternya dibandingkan dengan objek di klaster lain.
Terdapat dua metode dalam analisis klaster, yaitu metode hirarki dan
metode non-hirarki. Pada metode non-hirarki umumnya digunakan jika
banyaknya satuan pengamatan besar dan banyaknya klaster telah ditentukan
sebelumnya. Sedangkan pada metode hirarki banyaknya satuan pengamatan
10 2.4 Ukuran Kemiripan
Ukuran kemiripan yang biasa digunakan dalam analisis klaster
adalah jarak Euclidean dan jarak Mahalanobis [4]. Jarak Euclidean
digunakan jika variabel amatan saling bebas atau tidak berkorelasi satu
sama lain (tidak terjadi multikolinieritas). Namun jika terjadi
multikolinieritas, dapat diatasi dengan mentransformasi data menggunakan
Principle Component Analysis (PCA) karena bila data yang digunakan
dalam analisis klaster adalah data skor komponen dari hasil PCA, maka
tidak akan ditemukan lagi adanya Multikolinieritas [7]. Jarak Euclidean
dirumuskan sebagai berikut :
d(i,j) = ∑ ( − ) i= 1...471 ; j = 1 ... 7 (2.1)
dimana d(i,j) = jarak antara objek i dan objek j
xik = nilai objek i pada variabel ke k
xjk = nilai objek j pada variabel ke k
p = banyak variabel yang diamati
Jika terjadi multikolinieritas selain dengan mentransformasi data
dengan PCA dapat juga menggunakan ukuran jarak Mahalanobis. Jarak
Mahalanobis dirumuskan sebagai berikut :
d(i,j) = − ( − ) = 1,2,3, . .471; = 1,2,3, . . ,7 (2.2)
dengan xi dan xj sebagai vektor dari nilai objek i dan j, sedangkan S
11 2.5 K-Means Klaster
K-Means merupakan metode pengelompokkan yang paling terkenal
dan banyak digunakan di berbagai bidang karena sederhana dan mudah
diimplementasikan. K-means merupakan metode pengklasteran secara
partitioning yang memisahkan data ke dalam kelompok yang berbeda.
K-means merupakan salah satu metode pengelompokkan data
nonhirarki yang berusaha membagi data yang ada ke dalam bentuk dua atau
lebih kelompok [13]. Metode ini dikembangkan oleh Mac Queen pada tahun
1967.
Tujuan dari pengelompokkan data ini adalah untuk
meminimalisasikan fungsi objektif dalam proses pengelompokkan, yang
pada umumnya berusaha meminimalisasikan ragam di dalam suatu
kelompok dan memaksimalkan ragam antar kelompok.
Dasar algoritma K-means adalah sebagai berikut :
1. Diberikan nilai k sebagai jumlah klaster yang ingin dibentuk.
2. Bangkitkan k centroid (titik pusat klaster) awal secara random.
3. Hitung jarak setiap data ke masing-masing pusat klaster yaitu
menggunakan Euclidean Distance.
4. Kelompokkan setiap data berdasarkan jarak terdekat antara data dengan
pusatnya.
5. Tentukan posisi pusat klaster baru (Ckj) dengan cara menghitung nilai
rata-rata dari data-data yang ada pada pusat klaster yang sama.
12 = pusat klaster ke-k pada variabel ke-j
= banyak data pada klaster ke-k
2.6 K-Median Klaster
K-median merupakan salah satu metode dalam pengelompokkan.
Namun jika pada K-means pengelompokkan berdasarkan nilai rataannya,
pada K-median pengelompokkan didasarkan pada nilai mediannya [8].
Misalkan terdapat N buah data, jarak antara objek ke-i, dan objek
ke-j, dinotasikan dengan . Dalam pemilihan suatu objek yang
representatif dalam suatu klaster (median awal), didefinisikan sebagai
variabel biner 0 dan 1, dimana y = 1 jika objek ke-i dipiih sebagai median
awal. Penempatan setiap objek ke-j ke salah satu median awal dituliskan
sebagai , dengan bernilai 0 dan 1. Jika objek j ditempatkan ke klaster
dimana objek i sebagai median maka = 1.
Berdasarkan definisi di atas, maka :
min ∑ ∑ (2.4)
dengan ` ∑ = 1 , ∀ ∈ (2.5)
≤ ∀ , ∈ (2.6)
∑ = , = jumlah klaster (2.7)
∈{0,1} ,∀ , ∈ (2.8)
13 Persamaan (2.4) menyatakan bahwa klaster yang terbentuk dengan
menempatkan setiap objek ke median yang terdekat. Persamaan (2.5)
menyatakan bahwa setiap objek ditempatkan pada sebuah median.
Persamaan (2.6) menyatakan bahwa penempatan objek didasarkan pada
median. Persamaan (2.7) menyatakan bahwa hanya terdapat sebuah objek
yang akan dipilih median.
Dasar algoritma K-median adalah sebagai berikut :
1. Diberikan nilai k sebagai jumlah klaster yang ingin dibentuk.
2. Bangkitkan k centroid (titik pusat klaster) awal secara random.
3. Hitung jarak setiap data ke masing-masing pusat klaster yaitu
menggunakan Euclidean Distance.
4. Kelompokkan setiap data berdasarkan jarak terdekat antara data dengan
pusatnya.
5. Tentukan posisi pusat klaster baru (Ck) dengan cara menghitung nilai
median data-data yang ada pada pusat klaster yang sama.
2.7 Analisis Diskriminan
Analisis Diskriminan merupakan suatu analisis dengan tujuan
membentuk sejumlah fungsi melalui kombinasi linear variabel-variabel asal,
yang dapat digunakan sebagai cara terbaik untuk memisahkan
kelompok-kelompok individu. Fungsi yang terbentuk melalui analisis ini selanjutnya
dinamakan fungsi diskriminan [11].
Analisis diskriminan dapat digunakan jika variabel terikat terdiri dari
14 maka teknik yang digunakan adalah analisis diskriminan multipel (multiple
discriminant analysis).
Analisis diskriminan menghubungkan satu variabel terikat (non
metrik, nominal atau ordinal) dengan satu atau beberapa variabel bebas
sebagai prediktor yang merupakan metrik (interval atau rasio).
Tujuan analisis diskriminan adalah sebagai berikut :
1. Membuat suatu fungsi diskriminan atau kombinasi linier dari prediktor
atau variabel bebas yang bisa mendiskriminasi atau membedakan
kategori variabel terikat atau kelompok. Artinya mampu membedakan
suatu objek masuk kelompok atau kategori yang mana.
2. Menguji apakah ada perbedaan signifikan antar kelompok dikaitkan
dengan variabel bebas atau prediktor.
3. Menentukan prediktor atau variabel bebas mana yang memberikan
sumbangan terbesar terhadap terjadinya perbedaan antar kelompok.
4. Mengklasifikasi objek ke dalam suatu kelompok didasarkan pada nilai
variabel bebas.
5. Mengevaluasi keakuratan klasifikasi.
Adapun dalam penelitian ini tujuan yang ingin dicapai yaitu untuk
15 Untuk menghitung seberapa besar ketepatan klasifikasi terdapat
beberapa metode, salah satunya adalah Appearent Error Rate (APER).
APER adalah persentase kesalahan yang dikelompokkan salah. APER
dihitung berdasarkan persamaan sebagai berikut :
(2.10)
1
1 l
jM j
l
j j
n APER
n
16
BAB III
METODOLOGI PENELITIAN
3.1 Sumber Data
Data yang digunakan dalam penelitian ini adalah data sekunder hasil
Survei Sosial Ekonomi Nasional (SUSENAS) tahun 2009 yang
dilaksanakan oleh Badan Pusat Statistik (BPS). Data yang digunakan berupa
data indikator kemiskinan untuk seluruh kabupaten/kota di seluruh
Indonesia, yang terdiri dari 471 kabupaten atau kota. Data tersebut
disesuaikan dengan ketersediaan data yang ada.
3.2 Variabel Penelitian
Variabel-variabel yang digunakan pada penelitian ini dibagi dalam
beberapa bidang sebagai berikut :
a. Variabel Bidang Pekerjaan
Pengelompokkan pekerjaan dibedakan dalam dua kelompok yaitu
bekerja di bidang formal dan informal. Pekerja sektor formal adalah
seseorang yang bekerja dengan dibantu karyawan/pegawai tetap atau
bekerja sebagai karyawan/pegawai. Sedangkan pekerja di sektor
informal adalah seseorang yang berusaha sendiri, berusaha dengan
buruh tidak tetap atau buruh tidak dibayar.
b. Variabel Fasilitas Perumahan
Sebuah rumah dikategorikan rumah sehat apabila luas lantai
17 Rumah tangga pengguna air bersih adalah persentase rumah
tangga yang menggunakan air minum yang berasal dari air mineral, air
leding atau PAM, pompa air, sumur atau mata air terlindung dengan
jarak ke penampungan lebih dari 10 meter.
c. Variabel Program Pemerintah
Beras untuk masyarakat miskin (Raskin) adalah salah satu
program pemerintah untuk membantu rakyat miskin dalam memenuhi
kebutuhan makanan sehari-hari. Raskin diselenggarakan oleh Badan
Urusan Logistik (Bulog) dengan cara menjual beras dengan harga
murah bersubsidi.
Variabel yang digunakan dalam penelitian ini disesuaikan dengan
ketersediaan data. Berikut adalah variabel-variabel yang digunakan:
X1 : jumlah penduduk miskin yang bekerja di bidang formal.
X2 : jumlah penduduk miskin bekerja di bidang informal.
X3 : jumlah rumah tangga dengan luas lantai kurang dari 8 m2.
X4 : jumlah rumah tangga dengan luas lantai lebih dari 8 m2.
X5 : jumlah rumah tangga menggunakan air bersih.
X6 : jumlah rumah tangga menggunakan jamban sendiri.
18 3.3 Uji Multikolinieritas
Uji multikolinieritas dilakukan untuk mengetahui ada tidaknya
korelasi antar variabel. Uji multikolinieritas dilakukan dengan
menggunakan nilai Variance inflation factor (VIF). Jika nilai VIF lebih
besar dari 5, maka variabel tersebut mempunyai permasalahan
multikolinieritas dengan variabel bebas lainnya [10].
3.4 Uji Normal Multivariate
Pengujian asumsi normal multivariate dilakukan pada
masing-masing data tiap klaster untuk mengetahui apakah data pada tiap klaster
tersebut menyebar mengikuti sebaran normal multivariate, dengan
langkah-langkah sebagai berikut :
a. Menghitung jarak Mahalanobis (di2) pada kelompok ke-i dengan
persamaan :
di2 = (xi - )TS-1 (xi - ) i = 1, 2, ..., n (3.1)
di2 = jarak Mahalanobis
xi = vektor kolom berisi nilai-nilai pengamatan
= vektor kolom berisi rataan kelompok ke-i
S= matriks kovarians
b. Mengurutkan di2 dari yang terkecil ke terbesar sehingga d12 < d22 < .... <
dn2 dengan n menyatakan jumlah amatan.
c. Untuk setiap nilai di2, dihitung
( , )
d. Mencari nilai χ2 untuk setiap persentil dari sebaran χ2 dengan p derajat
19 e. Membuat plot antara χ2 dengan di2
Jika x ~ Np ( , ) maka (xi - )tS-1 (xi - ) ~ χ2 (p)
Apabila plot antara jarak Mahalanobis dan Khi-kuadrat mengikuti
pola garis lurus maka dapat dikatakan bahwa data berdistribusi normal
multivariate [6].
3.5 Metode Kerja
Setelah data diperoleh, langkah selanjutnya adalah melakukan
analisis data dengan menggunakan metode K-Means klaster dan K-Median
klaster. Tahapan analisis yang dilakukan sebagai berikut :
1. Menentukan banyaknya klaster yang akan dibentuk.
Dalam penelitian ini klaster yang ingin dibentuk adalah 2 klaster.
2. Lakukan metode pengklasteran K-Means dan K-Median dengan k klaster
yang didapat pada langkah 1. Tahapan yang dilakukan pada metode
k-means adalah sebagai berikut :
a. Menentukan pusat klaster awal secara acak.
b. Menghitung jarak antara setiap objek dengan pusat klaster
c. Masukkan tiap objek ke satu klaster yang memiliki jarak terdekat
dengan pusat klasternya.
d. Menghitung kembali pusat klaster yang terbentuk.
e. Ulangi dari langkah b sampai tidak ada perpindahan objek antar
20 3. Mendeskripsikan karakteristik klaster.
Dalam mendeskripsikan klaster digunakan persamaan
X =∑ i = 1,2,3...n j=1,2,3...q (3.2)
dengan X = Rata-rata sampel (rata-rata variabel pada klaster tertentu).
nj = banyak anggota pada klaster ke-j.
xij = nilai data ke-i pada variabel ke-j
4. Uji Variance
Uji Variance dilakukan untuk melihat apakah variabel-variabel yang
telah membentuk klaster memiliki perbedaaan pada tiap klaster, serta
untuk melihat variabel yang paling berpengaruh terhadap pembentukan
klaster [9]. Hal ini dapat dilihat dengan menggunakan konsep sebagai
berikut :
= = 1,2 (3.3)
= rata-rata setiap variabel pada klaster ke-i
= jumlah anggota pada klaster ke-i
= ∑ ∑ (3.4)
= rataan populasi dari variabel
= banyaknya klaster
= (3.5)
= rata-rata populasi
21
= ∑ ( ) = 1,2 (3.6)
= variansi pada klaster ke-i
= nilai data ke-j pada klaster ke-i
Internal homogenity variance within cluster ( ).
= ∑ (3.7)
= variansi dalam klaster
External homogenity variance between cluster ( ).
= ∑ ( ) (3.8)
= variansi antar klaster
= (3.9)
Semakin besar nilai suatu variabel, maka semakin besar perbedaan
variabel tersebut pada ketiga klaster yang terbentuk. Hal ini dapat
digunakan sebagai metode pembanding untuk mengetahui metode
pengelompokkan mana yang lebih baik. Semakin besar nilai pada
setiap variabel maka semakin baik metode pengelompokkan tersebut.
5. Analisis Diskriminan
Analisis Diskriminan digunakan sebagai metode pembanding dalam
mengetahui seberapa besar ketepatan pengklasteran antara metode
k-means dengan k-median. Hal ini dapat dilihat dari besar nilai ketepatan
22 pengklasteran semakin baik. Sedangkan jika nilai ketepatan klasifikasi
semakin kecil, maka pengklasteran kurang baik.
Tabel 3.1. Tabel klasifikasi
Menghitung seberapa besar ketepatan klasifikasi dengan
menggunakan Correct Classification Rate (CCR). CCR merupakan
persentase ketepatan nilai amatan dan dugaannya, CCR dihitung dengan
persamaan sebagai berikut :
CCR = Jumlah prediksi yang tepat x 100% Jumlah data
CCR = , ,
∑ ∑ x 100% (3.10)
Menghitung persentase kesalahan dalam klasifikasi dihitung
menggunakan APER yaitu sebagai berikut :
APER = , ,
∑ ∑ x 100% (3.11)
Semakin kecil nilai APER maka tingkat ketepatan klasifikasi
23 3.6 Alur Penelitian
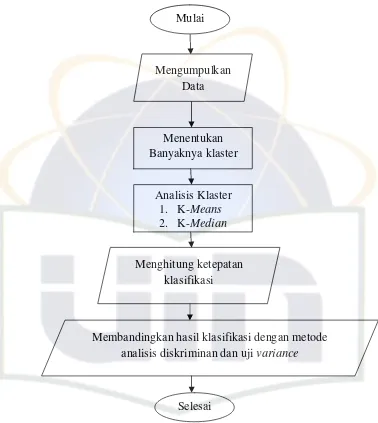
Gambar 3.1 Alur penelitian
Setelah data diperoleh langkah selanjutnya adalah menentukan
banyaknya klaster yang ingin dibentuk, kemudian dilakukan analisis
klaster k-means dan k-median, dan membandingkan nilai ketepatan
klasifikasi kedua metode tersebut dengan menggunakan metode analisis
diskriminan dan uji variance. Mulai
Mengumpulkan Data
Analisis Klaster
1. K-Means
2. K-Median
Menghitung ketepatan klasifikasi Menentukan Banyaknya klaster
Selesai
24 BAB IV
HASIL DAN PEMBAHASAN
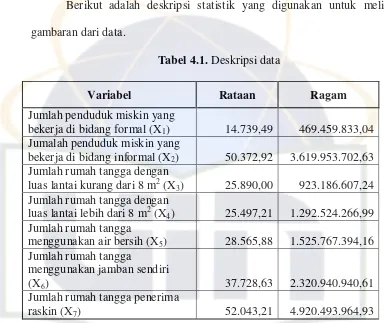
4.1 Deskripsi data
Berikut adalah deskripsi statistik yang digunakan untuk melihat
gambaran dari data.
Tabel 4.1. Deskripsi data
Variabel Rataan Ragam
Jumlah penduduk miskin yang
bekerja di bidang formal (X1) 14.739,49 469.459.833,04 Jumalah penduduk miskin yang
bekerja di bidang informal (X2) 50.372,92 3.619.953.702,63 Jumlah rumah tangga dengan
luas lantai kurang dari 8 m2 (X3) 25.890,00 923.186.607,24 Jumlah rumah tangga dengan
luas lantai lebih dari 8 m2 (X4) 25.497,21 1.292.524.266,99 Jumlah rumah tangga
menggunakan air bersih (X5) 28.565,88 1.525.767.394,16 Jumlah rumah tangga
menggunakan jamban sendiri
(X6) 37.728,63 2.320.940.940,61
Jumlah rumah tangga penerima
raskin (X7) 52.043,21 4.920.493.964,93
Berdasarkan Tabel 4.1 terlihat bahwa secara rata-rata sebagian besar
penduduk miskin di indonesia bekerja di bidang informal yaitu sebesar
50.372 jiwa. Selain itu jumlah penerima raskin juga masih cukup tinggi
25 4.2 Pengujian Asumsi Multikolinieritas
Sebelum dilakukan pengklasteran, dilakukan uji asumsi
Multikolinieritas untuk mengetahui ukuran kemiripan apa yang dapat
digunakan. Pengujian multikolinieritas didapat hasil sebagai berikut :
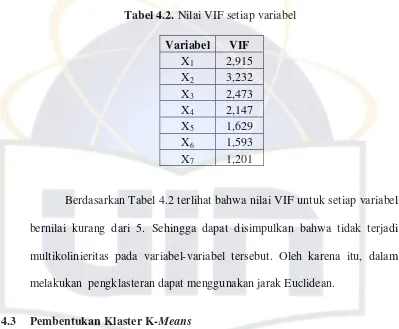
Tabel 4.2. Nilai VIF setiap variabel
Variabel VIF
Berdasarkan Tabel 4.2 terlihat bahwa nilai VIF untuk setiap variabel
bernilai kurang dari 5. Sehingga dapat disimpulkan bahwa tidak terjadi
multikolinieritas pada variabel-variabel tersebut. Oleh karena itu, dalam
melakukan pengklasteran dapat menggunakan jarak Euclidean.
4.3 Pembentukan Klaster K-Means
Hasil pengklasteran dengan menggunakan metode K-means adalah
sebagai berikut :
a. Jumlah Anggota Klaster
Tabel 4.3. Jumlah anggota pada setiap klasterk-means
Klaster jumlah anggota
1 395
2 76
26 Berdasarkan Tabel 4.3 hasil pengklasteran didapat 2 klaster dengan
jumlah anggota pada klasterpertama adalah 395 kabupaten, klasterkedua
adalah 76 kabupaten dari jumlah kabupaten se-Indonesia sebanyak 471
kabupaten.
b. Karakteristik Klaster
Interpretasi karakteristik dari setiap klaster yang terbentuk adalah
sebagai berikut :
1. Klaster satu
Berdasarkan persamaan 3.2 didapat nilai rata-rata setiap variabel
pada klaster pertama adalah sebagai berikut :
Tabel 4.4 Rata-rata variabel pada klaster 1
Variabel Rata-rata pada
Berdasarkan Tabel 4.4 terlihat bahwa pada klaster satu sebagian
besar penduduk miskin bekerja di bidang informal yaitu sebesar
28.020 jiwa, sedangkan pada bidang fasilitas rumah tangga klaster
satu beranggotakan kabupaten/kota yang sebagian besar memiliki
rumah dengan luas lantai kurang dari 8 m2 yaitu sebesar 19.954 rumah
27 Anggota klaster satu antara lain Kabupaten Simeuleu, Aceh
Tamiang, Aceh Selatan, Aceh Tenggara, Aceh Timur, Sabang,
Jakarta Selatan, Jakarta Utara, Jakarta Barat, dan untuk selengkapnya
terdapat pada lampiran 1.
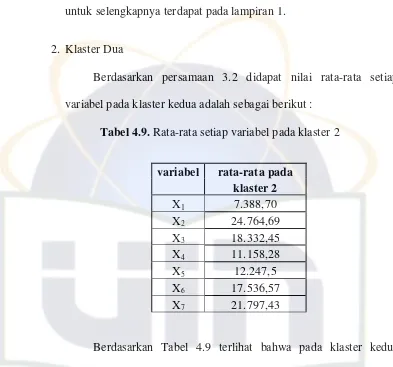
2. Klaster Dua
Berdasarkan persamaan 3.2 didapat nilai rata-rata setiap variabel
pada klaster kedua adalah sebagai berikut :
Tabel 4.5. Rata-rata variabel pada klaster 2
variabel rata-rata pada
Berdasarkan Tabel 4.5 terlihat bahwa pada klaster dua sebagian
besar penduduk miskin bekerja di bidang informal yaitu sebesar
166.545 jiwa, sedangkan pada bidang fasilitas rumah tangga klaster
dua beranggotakan kabupaten/kota yang sebagian besar memiliki
rumah dengan luas lantai lebih dari 8 m2 yaitu sebesar 90.007 rumah
tangga. Namun rumah tangga dengan luas lantai kurang dari 8 m2 pun
masih cukup tinggi yaitu sebesar 58.609 rumah tangga dan masih
banyaknya penduduk miskin yang menerima raskin yaitu sebesar
28 Anggota klaster dua antara lain adalah Aceh Utara, Lampung
Selatan, Cianjur, Garut, Banyumas, Lombok Barat dan untuk
selengkapnya terdapat pada lampiran 1.
Berdasarkan interpretasi kedua klaster tersebut, dapat
disimpulkan bahwa klaster pertama yaitu klaster pekerja informal
dengan fasilitas rumah tangga cukup memadai. Sedangkan klaster
kedua yaitu klaster pekerja informal dengan fasilitas rumah tangga
kurang memadai. Sehingga kabupaten yang ada pada klaster kedua
lebih membutuhkan bantuan dibandingkan dengan kabupaten yang
ada pada klaster pertama.
c. Uji Variance Klaster K-means
Berdasarkan persamaan (3.7), (3.8), dan (3.9) didapat hasil sebagai
berikut :
Tabel 4.6. Variansi setiap variabel
Variabel
X1 718.054.355 611.664.319 1,17393533
X2 9.594.606.413 2.024.722.791 4,73872594 X3 761.100.700 1.641.170.185 0,46375489 X4 2.958.515.061 1.180.758.363 2,50560585 X5 3.567.228.316 1.090.978.948 3,26974991 X6 5.590.002.996 1.555.498.689 3,59370473 X7 13.334.040.132 2.846.127.209 4,68497687
Berdasarkan Tabel 4.6 terlihat bahwa nilai
terbesar ada pada variabel X2 yaitu sebesar 4,73872594, sehingga
29 perbedaan paling berarti pada klaster 1 dan klaster 2 serta merupakan
variabel yang paling berpengaruh terhadap pembentukan klaster.
4.4 Pembentukan Klaster K-Median
Hasil pengklasteran dengan menggunakan metode K-median adalah
sebagai berikut :
a. Jumlah Anggota Klaster
Tabel 4.7. Jumlah anggota pada setiap klaster k-median
Klaster Jumlah anggota
1 99
2 372
jumlah 471
Berdasarkan Tabel 4.7 hasil pengklasteran didapat 2 klaster dengan
jumlah anggota pada klaster pertama adalah 99 kabupaten dan pada
klaster 2 terdapat 372 kabupaten dari jumlah kabupaten se-Indonesia
30 b. Karakteristik Klaster
Interpretasi karakteristik dari setiap klaster yang terbentuk adalah
sebagai berikut :
1. Klaster 1
Berdasarkan persamaan 3.2 didapat nilai rata-rata setiap
variabel pada klaster pertama adalah sebagai berikut :
Tabel 4.8. Rata-rata setiap variabel pada klaster 1
variabel rata-rata pada
Berdasarkan Tabel 4.8 klaster pertama beranggotakan
kabupaten yang sebagian besar penduduknya bekerja di bidang
informal yaitu sebesar 146.597 jiwa, sedangkan pada bidang fasilitas
rumah tangga klaster pertama beranggotakan kabupaten yang
sebagian besar rumah tangganya memiliki rumah dengan luas lantai
lebih dari 8 m2 yaitu sebesar 79.376 rumah tangga. Namun rumah
tangga dengan luas lantai kurang dari 8 m2 pun masih cukup tinggi
yaitu sebesar 54.288 rumah tangga dan masih banyaknya rumah
tangga yang berstatus sebagai penerima raskin yaitu sebesar 165.693
31 Anggota klaster satu antara lain adalah Kabupaten Aceh Utara,
Subang, Banyumas, Lamongan, Lombok Barat, Lombok Timur dan
untuk selengkapnya terdapat pada lampiran 1.
2. Klaster Dua
Berdasarkan persamaan 3.2 didapat nilai rata-rata setiap
variabel pada klaster kedua adalah sebagai berikut :
Tabel 4.9. Rata-rata setiap variabel pada klaster 2
variabel rata-rata pada
beranggotakan kabupaten yang sebagian besar penduduknya bekerja
di bidang informal yaitu sebesar 24.764 jiwa, sedangkan pada bidang
fasiltas rumah tangga sebagian besar rumah tangga memiliki rumah
dengan luas lantai kurang dari 8 m2, dan rumah tangga penerima
raskin relatif rendah yaitu sebesar 21.797 rumah tangga.
Anggota klaster dua antara lain adalah Kabupaten Simeuleu,
Sabang, Padang, Jakarta Timur, Jakarta Pusat, Kota Bogor dan untuk
32 Berdasarkan interpretasi kedua klaster tersebut, dapat disimpulkan
bahwa klaster pertama adalah klaster pekerja informal dengan fasilitas
rumah tangga kurang memadai, sedangkan klaster kedua adalah klaster
pekerja informal dengan fasilitas rumah tangga cukup memadai. Sehingga
kabupaten yang ada pada klaster pertama lebih membutuhkan bantuan
dibandingkan dengan kabupaten yang ada pada klaster kedua.
c. Uji Variance Klaster K-median
Berdasarkan persamaan (3.7), (3.8), dan (3.9) didapat hasil sebagai
berikut :
Tabel 4.10. Variansi setiap variabel
Variabel
X1 611.518.110,1 528.972.334,1 1,156049326
X2 7.421.645.859 2.229.769.775 3,328435941 X3 646.402.449,2 1.376.121.469 0,469727756 X4 2.326.885.700 1.100.203.573 2,114959228 X5 3.013.667.582 1.011.294.993 2,980008408 X6 4.614.265.706 1.498.189.586 3,079894393 X7 10.353.109.573 3.063.649.882 3,379338361
Berdasarkan Tabel 4.10 terlihat bahwa nilai
terbesar terdapat pada variabel X7 yaitu sebesar 3,379338361.
Sehingga variabel jumlah penerima raskin adalah variabel yang memiliki
perbedaan paling berarti pada klaster 1, dan klaster 2 serta merupakan
33 4.5 Analisis Diskriminan
Untuk mengetahui hasil pengklasteran mana yang lebih baik antara
metode klaster k-means dan k-median dilakukan analisis diskriminan
dengan langkah-langkah sebagai berikut :
a. Pengujian Asumsi Normal Multivariate
Sebelum melakukan analisis diskriminan terlebih dahulu melakukan
pengujian asumsi normal multivariate. Hasil pengujian asumsi normal
multivariate adalah sebagai berikut :
C26
Scatterplot of khi-kuadrat vs jarak mahalanobis (iterasi 1)
Gambar 4.1. Scatter plot khi-kuadrat dengan jarak Mahalonobis
Berdasarkan grafik tersebut, terlihat bahwa terdapat satu nilai yang
dideteksi sebagai outlier yaitu data ke 471, maka data tersebut dihilangkan
34 Pada iterasi kedua, setelah menghilangkan data ke 471, didapat hasil
sebagai berikut :
Scatterplot khi-kuadrat vs jarak mahalanobis (iterasi 2)
Gambar 4.2. Scatter plot khi-kuadrat dengan jarak Mahalonobis
Pada grafik tersebut terlihat bahwa data berkumpul pada suatu garis.
Sehingga dapat dikatakan asumsi normalmultivariate sudah terpenuhi.
b. Menghitung ketepatan klasifikasi
1. K-means
Tabel 4.11. Ketepatan klasifikasi k-means
D Prediksi Total
1 2
Aktual 1 390 4 394
2 3 73 76
Berdasarkan persamaan 3.10 maka didapat persentase ketepatan
klasifikasi klaster k-means sebagai berikut :
35 Berdasarkan persamaan 3.11 persentase kesalahan dalam
pengklasifikasian adalah sebagai berikut :
APER = x 100 % = 1,49 %
Berdasarkan perhitungan tersebut dapat terlihat bahwa nilai
ketepatan klasifikasi k-means sangat tinggi dengan tingkat kesalahan
sebesar 1,49%.
2. K-median
Tabel 4.12. Ketepatan klasifikasi k-median
D Prediksi Total
1 2
Aktual 1 89 10 99
2 0 371 371
Berdasarkan persamaan 3.10 maka didapat persentase ketepatan
klasifikasi klaster k-median adalah sebagai berikut :
CCR = x 100 % = 97,87%
Berdasarkan persamaan 3.11 persentase kesalahan dalam
pengklasifikasian adalah sebagai berikut :
36 Berdasarkan perhitungan tersebut dapat terlihat bahwa nilai
ketepatan klasifikasi k-median sangat tinggi dengan tingkat kesalahan
sebesar 2,13%.
Berdasarkan tingkat ketepatan klasifikasi terlihat bahwa nilai
ketepatan klasifikasi k-means (98,51 %) lebih baik dibandingkan k-median
37 BAB V
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Pada metode klaster k-means nilai ketepatan klasifikasi adalah
sebesar 98,51% sedangkan pada metode klaster k- median nilai ketepatan
klasifikasi sebesar 97,87%. Selain itu pada uji variance terlihat bahwa pada
beberapa variabel yaitu jumlah pekerja di bidang informal, jumlah rumah
tangga dengan luas lantai lebih dari 8 m2, jumlah rumah tangga
menggunakan air bersih, jumlah rumah tangga menggunakan jamban sendiri
dan jumlah rumah tangga penerima raskin nilai
pada pengelompokkan k-means lebih besar dibandingkan dengan
k-median. Sehingga disimpulkan bahwa pada kasus ini metode
pengelompokkan k- means lebih baik dibandingkan dengan metode
pengelompokkan k-median.
Berdasarkan hasil penelitian pada metode k-means terdapat 2 klaster
yaitu :
Klaster 1 : kabupaten pekerja informal dengan fasilitas rumah tangga
cukup memadai.
Klaster 2 : kabupaten pekerja informal dengan fasilitas rumah tangga
38 Sedangkan pada metode k-median terdapat 2 klaster yaitu :
Klaster 1 : kabupaten pekerja informal dengan fasilitas rumah tangga
kurang memadai.
Klaster 2 : kabupaten pekerja informal dengan fasilitas rumah tangga
cukup memadai.
Berdasarkan hasil pengklasteran dengan metode k-means dapat
dikatakan bahwa kabupaten yang ada pada klaster kedua lebih
membutuhkan bantuan dibandingkan dengan kabupaten yang ada pada
klaster pertama. Sedangkan pada metode k-median dapat dikatakan bahwa
kabupaten yang ada pada klaster pertama lebih membutuhkan bantuan
dibandingkan dengan kabupaten yang ada pada klaster kedua.
5.2 Saran
Selain menggunakan metode k-means dan k-median,
pengelompokkan data juga dapat menggunakan metode klaster k-error.
Penelitian selanjutnya disarankan untuk menambahkan indikator
kemiskinan lainnya untuk hasil pengelompokkan yang lebih baik dan
39
DAFTAR PUSTAKA
[1] Agusta, Yudi. K-Means - Penerapan Permasalahan dan Metode Terkait.
Bali : STMIK STIKOM Bali. 2007.
[2] Badan Pusat Statistik. Data dan Informasi Kemiskinan 2009, Buku 2:
Kabupaten/Kota. Jakarta: BPS. 2009.
[3] Budiono, Agung. Analisis komponen utama dan analisis gerombol untuk
pengelompokkan propinsi di Indonesia berdasar peubah industri kecil.
[Skripsi]. Bogor : Jurusan Statistika Fakultas MIPA IPB. 1987.
[4] Durran BS, Odell PL. Cluster Analysis. New York : Springer-Verlay.
Berlin. 1974.
[5] Flowrensia, Yanne. Perbandingan Penggerombolan K-means dan
K-medoidPada Data Yang Mengandung Pencilan. [Skripsi]. Bogor : Jurusan
Statistika Fakultas MIPA IPB. 2010.
[6] Jhonson, Richard A. Dan Dean W Wichern. Applied multivariate
statistical anlysis. Edisi keempat. New York: Prentice-Hall International,
inc. 1998.
[7] Kaufma L and Peter JR. Findings Group in Data, An Introduction to
Cluster Analysis. New York : Jhon Willey and Sons Inc. 1990.
[8] Kumar, Mahesh dan Nithin R Patel. Clustering data with measurement
40 [9] Ruswandi, Bambang. Diktat Perkuliahan Praktikum Statistika Multivariat.
Jakarta : Program Studi Matematika Fakultas Sains dan Teknologi UIN
Jakarta. 2008.
[10] Setyoko, Mahmud. Uji Asumsi Klasik Statistik Pengaruh Kewenangan,
Kemitraan dan Konflik Terhadap Efektivitas Saluran Distribusi Minyak
Tanah Menggunakan SPSS Versi 13. Semarang : Politeknik Negeri
Semarang. 2008.
[11] Sharma, S. Applied Multivariate Techniques. Jhon Willey & Sons : New
York. 1996.
[12] Sidabutar, Drs. Albert. 14 indikator kemiskinan di rumah tangga, berhak
menerima bantuan langsung tunai.
http://barsamatoba.com/tobasa/berita/14-indikator-kemiskinan-di-rumah-tangga-berhak-menerima-bntuan-langsung-tunai.html. [24 Februari 2011].
[13] Supranto, Johanes. Analisis Multivariat Arti dan Interpretasi. Rineka Cipta
41 LAMPIRAN Lampiran 1. Hasil Pengklasteran
kabupaten Kode k-means k-median
42 Kabupaten Kode K-means K-median
43 Kabupaten Kode K-means K-median
44 Kabupaten Kode K-means K-median
45 Kabupaten Kode K-means K-median
46 Kabupaten Kode K-means K-median
47 Kabupaten Kode K-means K-median
48 Kabupaten Kode K-means K-median
49 Kabupaten Kode K-means K-median
50 Kabupaten Kode K-means K-median
51 Kabupaten Kode K-means K-median
52 Kabupaten Kode K-means K-median
53 Kabupaten Kode K-means K-median
Puncak Jaya 3308 1 2
Mimika 3309 1 2
Boven Digoel 3310 1 2
Mappi 3311 1 2
Asmat 3312 1 2
Yahukimo 3313 1 2
Pegunungan Bintang 3314 1 2
Tolikara 3315 1 2
Sarmi 3316 1 2
Keerom 3317 1 2
Waropen 3318 1 2
Supiori 3319 1 2
Mamberamo Raya 3320 1 2
Nduga 3321 1 2
Lanny Jaya 3322 1 2
Mamberamo Tengah 3323 1 2
Yalimo 3324 1 2
Puncak 3325 1 2
Dogiyai 3326 1 2
54 Lampiran 2. Output Nilai Variance Inflation Factor (VIF)
56 Lampiran 5. Ketepatan klasifikasi K-means.
Classification Resultsb,c
k_means
Predicted Group Membership
Total
1 2
Original Count 1 390 4 394
2 3 73 76
% 1 99.0 1.0 100.0
2 3.9 96.1 100.0
Cross-validateda Count 1 390 4 394
2 3 73 76
% 1 99.0 1.0 100.0
2 3.9 96.1 100.0
a. Cross validation is done only for those cases in the analysis. In cross validation,
each case is classified by the functions derived from all cases other than that case.
b. 98,5% of original grouped cases correctly classified.
57 Lampiran 6. Ketepatan klasifikasi k-median.
Classification Resultsb,c
k_medi
an
Predicted Group Membership
Total
1 2
Original Count 1 89 10 99
2 0 371 371
% 1 89.9 10.1 100.0
2 .0 100.0 100.0
Cross-validateda Count 1 87 12 99
2 0 371 371
% 1 87.9 12.1 100.0
2 .0 100.0 100.0
a. Cross validation is done only for those cases in the analysis. In cross validation,
each case is classified by the functions derived from all cases other than that case.
b. 97,9% of original grouped cases correctly classified.
c. 97,4% of cross-validated grouped cases correctly classified.
Lampiran 7. Perhitungan Rata-rata setiap Variabel pada klaster k-means.
Nama : Febriyana
NIM : 107094002893
Tempat Tanggal Lahir : Pandeglang, 5 Februari 1989
Alamat Rumah : Jalan Raya Labuan Km 6
Kp. Kadukanas Rt 01 Rw 01
Desa Sukasari Kec. Kaduhejo
Kab. Pandeglang - Banten
Phone / Hand Phone : 08998944001
Email : febri.2497@gmail.com
Jenis Kelamin : Laki-laki
1. S1 : Program Studi Matematika Fakultas Sains dan Teknologi Universitas
Islam Negeri (UIN) Syarif Hidayatullah Jakarta, Tahun 2007 – 2011
2. SMA : SMAN 1 Pandeglang, Tahun 2004 – 2007
3. SMP : SMPN 1 Pandeglang, Tahun 2001 – 2004
4. SD : SDN 1 Pandeglang, Tahun 1995 – 2001
DAFTAR RIW AYAT HIDUP
Data Pribadi