ANALISIS PERBANDINGAN ALGORITMA ZERO COMPRESION DENGAN DIFFERENCE CODING PADA KOMPRESI FILE AUDIO
DRAFT SKRIPSI
DESSY FEBRIANI TRIAJIWATI 111421022
PROGRAM STUDI EKSTENSI S1 ILMU KOMPUTER
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEDAN
ANALISIS PERBANDINGAN ALGORITMA ZERO COMPRESION DENGAN DIFFERENCE CODING PADA KOMPRESI FILE AUDIO
SKRIPSI
Diajukan untuk melengkapi dan memenuhi syarat memperoleh ijazah
Sarjana Ilmu komputer
DESSY FEBRIANI TRIAJIWATI 111421022
PROGRAM STUDI EKSTENSI S1 ILMU KOMPUTER
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEDAN
PERSETUJUAN
Judul : ANALISIS PERBANDINGAN ZERO COMPRESION
DENGAN DIFFERENCE CODING PADA
KOMPRESI FILE AUDIO
Kategori : SKRIPSI
Nama : DESSY FEBRIANI TRIAJIWATI
Nomor Induk Mahasiswa : 111421022
Program Studi : EKSTENSI S1 ILMU KOMPUTER
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Handrizal.S.Si.M.Comp.Sc Prof.Dr.Muhammad Zarlis
NIP. 19570701 198601 1 003
Diketahui/disetujui oleh
Program Studi S1 Ilmu Komputer
Ketua,
Dr. Poltak Sihombing, M.Kom
PERNYATAAN
ANALISIS PERBANDINGAN ZERO COMPRESION DENGAN DIFFERENCE CODING PADA KOMPRESI FILE AUDIO
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa
kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, Maret 2014
Dessy Febriani Triajiwati
PENGHARGAAN
Alhamdulillahirrabbil’alamin. Segala puji dan syukur penulis panjatkan kepada Allah SWT, Tuhan semesta alam karena atas rahmat, taufik dan hidayah-Nya penulis
mampu menyelesaikan skripsi ini. Tidak lupa juga shalawat beriring salam penulis
ucapkan kepada Nabi Besar Muhammad SAW.
Skripsi ini diselesaikan sebagai salah satu syarat guna memperoleh gelar
Sarjana Ilmu Komputer Fakultas Ilmu Komputer dan Teknologi Informasi Universitas
Sumatera Utara. Penulis menyadari bahwa terselesaikannya penulisan skripsi ini
tentunya tidak terlepas dari dorongan berbagai pihak. Oleh karena itu, pada
kesempatan ini dengan kerendahan hati penulis mengungkapkan rasa terima kasih dan
penghargaan kepada:
1. Bapak Prof.Dr.dr Syahril Pasaribu,DTM&M.Sc(CTM),Sp.A(K) selaku Rektor
Universitas Sumatera Utara.
2. Bapak Prof.Dr.Muhammad Zarlis S.Kom selaku Dosen Dekan Program Studi
Ilmu Komputer sekaligus Pembimbing I yang telah memberikan banyak sekali
arahan, masukan serta motivasi yang membuat penulis memperoleh
pengetahuan sehingga dapat menyelesaikan skripsi ini dengan baik.
3. Bapak Dr. Poltak Sihombing, M.Kom selaku Ketua Program Studi Ilmu
Komputer sekaligus sebagai Dosen Pembanding I, yang telah memberikan
kritik dan saran yang membangun bagi penulis.
4. Ibu Maya Silvi Lydia B.Sc,M.Sc selaku Sekretaris Program Studi Ilmu
Komputer .
5. Bapak Handrizal.S.Si.M.Comp.Sc selaku Dosen Pembimbing II yang telah
memberikan banyak sekali arahan, masukan serta motivasi yang membuat
penulis memperoleh pengetahuan sehingga dapat menyelesaikan skripsi ini
dengan baik.
6. Ibu Dian Rachmawati selaku Dosen Pembanding II, yang telah memberikan
7. Orang tua tercinta, Mama,Papa dan Ayah serta Mama kisaran atas semua do’a,
dukungan dan motivasi yang tidak ternilai harganya.
8. Untuk Suami tercinta, Fahrurrozy Syahputra makasih atas doa serta
dukungannya
9. Serta Abang-abang dan Adik-adik tersayang yang telah mendo’akan dan
mendukung penulis.
10.Dan sahabat tersayang Qurbani, Nadra , Team Shop Sun Plaza(Telkomsel)
terima kasih atas dukungannya .
11.Keluarga Besar Ekstensi Ilmu Komputer, kawan-kawan angkatan 2011 yang
telah banyak membantu memotivasi penulis selama ini.
Semoga Allah SWT membalas semua kebaikan yang telah kalian berikan.
Penulis,
ANALISIS PERBANDINGAN ZERO COMPRESION DENGAN
DIFFERENCE CODING PADA KOMPRESI FILE AUDIO
ABSTRAK
Ukuran file audio khususnya berformat.Wav relatif besar dibandingkan file dengan format teks,yang membutuhkan memori yang besar dalam melakukan penyimpanan maupun dalam hal transmisi (pengiriman) melalui media komunikasi. Hal ini sangat mempengaruhi ketersediaan tempat (space) maupun pengolahan data khususnya data audio.Untuk itu perlu dikembangkan aplikasi untuk kompresi data yang bertujuan untuk minimalisasi memori menggunakan algoritma Zero Compression dan
Difference Coding. Pada metode Zero Compression, kompresi file audio dilakukan pada sampel audio yang bernilai nol (0) berurutan. Ada dua tahap utama kompresi dengan metode Zero Compression untuk data audio, yaitu reading redudance data
dan coding. Readingredudance data adalahmerepresentasikan frekuensi kemunculan setiap sampel audio kedalam bilangan eksak sedangkan Coding adalah menuliskan kode yang berisi nilai sampel dengan frekuensi kemunculannya.Sedangkan kompresi dengan metode Difference Coding adalah data difference yaitu adalah pengurangan nilai sampel audio dengan nilai sampel audio sebelumnya serta coding. Hasil kompresi file wav dengan kedua algoritma di atas dapat memberikan ukuran file yang lebih kecil yaitu dengan algoritma Zero Compression rata-rata rasio kompresi sebesar 24.43 % dan Difference Coding adalah 25.48 %.
.
ANALYSIS COMPARISON ZERO COMPRESION ALGORITHM
WITH DIFFERENCE CODING
COMPRESSION FOR FILE AUDIO
ABSTRACT
The Size of .wav audio file format in particular is relatively large compared with the text format file, which requires a large memory to perform in terms of storage and transmission (delivery) through the medium of communication. This greatly affects the availability of a place (space) as well as data processing, especially the audio data . so it is necessary to develop applications for data compression that aims to minimize memory by using Zero Compression Algorithm and Difference Coding. At Zero Compression method, the compression of audio files is done on the audio sample which has a value of zero sequentially .There are two main stages of compression using Zero compression method for audio data, that is reading redudance the data and coding. Reading redudance the data is representing the frequency of occurrence of each audio sample into exact numbers, while coding is to write code that contains the value of the sample with the frequency of occurrence. While the method of Difference Coding compression is data that difference is a reduction in the value of an audio sample with previous audio sample values and coding. Wav file compression Results with both algorithms above can give you a smaller file size that is used Zero Compression algorithms with an average compression ratio about 24.43% and 25.48% Difference Coding is.
keywords : Audio, Compression, Zero Compression, and Difference Coding .
DAFTAR ISI
PERSETUJUAN iii
PERNYATAAN iv
PENGHARGAAN v
ABSTRAK vii
ABSTRACT viii
DAFTAR ISI ix
DAFTAR GAMBAR xi
DAFTAR TABEL xii
BAB 1 PENDAHULUAN 1
1.1 Latar Belakang 1
1.2 Rumusan Masalah 3
1.3 Batasan Masalah 3
1.4 Tujuan Penelitian 3
1.5 Manfaat Penelitian 3
1.6 Metodologi Penelitian 4
1.7 Sistematika Penulisan 5
BAB 2 LANDASAN TEORI 6
2.1Pengertian Audio Digital 6
2.2 Kelebihan Audio Digital 8
2.3 Istilah dalam Audio Digital 9
2.3.1 Channel (Jumlah Kanal) 9
2.3.2 Sampling Rate (Laju Pencuplikan) 9
2.3.3 Bandwidth 10
2.3.4 Bit Per Sample (Banyaknya Bit Dalam Satu Sampel) 10
2.3.5 Bit Rate (Laju Bit) 11
2.4Data Audio 12
2.5 StrukturFile Wave 13
2.5.1 Header File Wave 15
2.5.2 Chunk FileWAVE 15
2.5.4 Chunk Data 19
2.5.5 Format Wave PCM 20
2.6 Hubungan Multimedia dengan Aplikasi Windows 24
2.7Kompresi Data 25
2.7.1 Teori Kompresi Data 25
2.7.2 Pemodelan Sumber (Source Modeling) 26
2.7.3 Entropi Rate Dari Suatu Sumber 29
2.7.4 Dalil Shannon Mengenai Lossless Source Coding 30 2.7.5 Perbedaan Antara Lossless dan Lossy Compression 33 2.7.6 Perbedaan Antara Compression Rate Dan Compression Ratio 32
2.8Kompresi Metode Zero Compression 34
2.9Kompresi Metode Difference Coding 35
BAB 3 ANALISIS DAN PERANCANGAN 37
3.1Analisis 35
3.1.1 Sampel Audio WAV 35
3.1.2 Kompresi dengan Algoritma Zero Compression 39 3.1.3 Kompresi dengan Algoritma Difference Coding 40
3.2Perancangan 41
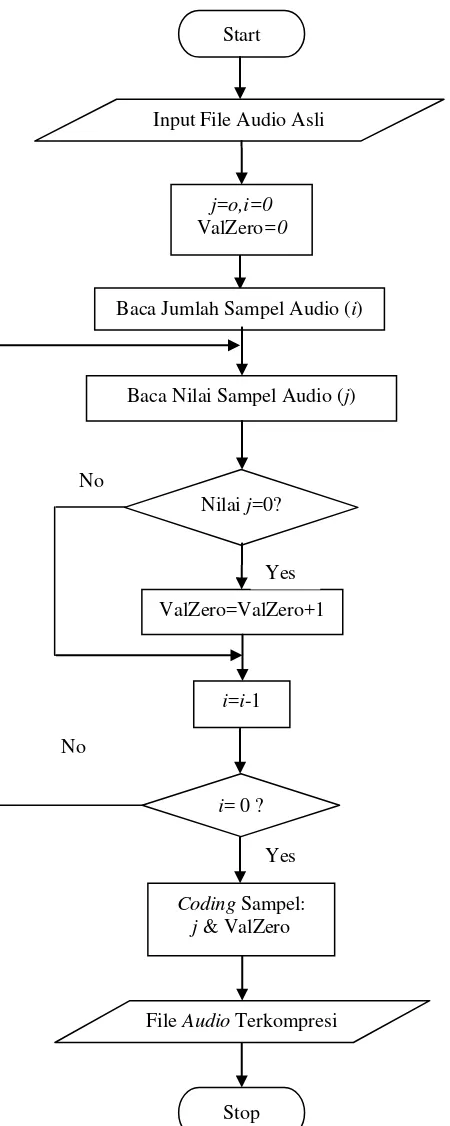
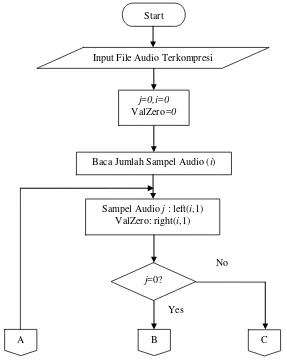
3.2.1 Flow Chart Kompresi Algoritma Zero Compression 42 3.2.2 Flow Chart Dekompresi Algoritma Zero Compression 43 3.2.3 Flow Chart Kompresi Algoritma Difference Coding 45 3.2.4 Flow Chart Dekompresi Algoritma Difference Coding 46 3.2.5 Pemodelan Persyaratan Sistem dengan Use Case 47
3.2.6 Analisis Proses Sistem 55
3.2.7 Rancangan Antarmuka 57
3.2.7.1Rancangan Menu Utama 57
3.2.7.2Rancangan Kompresi 58
3.2.7.3Rancangan Help 59
3.2.7.4Rancangan About 60
3.2.9 Rancangan Hasil Pengujian 60
3.2.9.1Rancangan Grafik Hasil Kompresi 62
BAB 4 IMPLEMENTASI DAN PENGUJIAN 64
4.1Implementasi 64
4.1.1 Tampilan Menu Utama 64
4.1.2 Tampilan Zero Compression (Kompresi) 65
4.1.3 Tampilan Zero Compression (Dekompresi) 66
4.1.4 Tampilan Difference Coding (Kompresi) 66 4.1.5 Tampilan Difference Coding (Dekompresi) 67
4.1.6 Tampilan Help 68
4.1.7 Tampilan About 68
4.2Pengujian Sistem 69
4.2.1 Tampilan Hasil Pengujian Kompresi
Algoritma Zero Compression 69
4.2.2 Tampilan Hasil Pengujian Dekompresi
Algoritma Zero Compression 69
4.2.3 Tampilan Hasil Pengujian Kompresi
Algoritma Difference Coding 70
4.2.4 Tampilan Hasil Pengujian Dekompresi
Algoritma Difference Coding 71
4.2.5 Tampilan Grafik Hasil Kompresi Algoritma Zero Compression 72 4.2.6 Grafik Hasil Kompresi Algoritma Difference Coding 73 4.2.7 Grafik Hasil Perbandingan Rasio Algoritma Zero Compression 74
Dengan Difference Coding
BAB 5 KESIMPULAN DAN SARAN 75
5.1 Kesimpulan 75
5.2 Saran 76
DAFTAR GAMBAR
Gambar 2.1 Konversi Sinyal Analog ke Digital 7
Gambar 2.2 Konversi Sinyal Digital ke Analog 8
Gambar 2.3 Layout File Wave 14
Gambar 2.4 Diagram Format File Wave 20
Gambar 2.5 Interpretasi Tiap Byte pada File Wave 22 Gambar 2.6 Lapisan-Lapisan Multimedia dengan Windows 24
Gambar 2.7 Nilai Sample Audio 35
Gambar 3.1 Data Audio Wav dalam Hexa 38
Gambar 3.2 Flow Chart Kompresi File Audio Algoritma Zero Compression 42 Gambar 3.3 Flow Chart Dekompresi File Audio Algoritma Zero Compression 43 Gambar 3.4 Flow Chart Dekompresi File Audio Algoritma Zero Compression
(Lanjutan) 44
Gambar 3.5 Flow Chart Kompresi File Audio Algoritma Difference Coding 45 Gambar 3.6 Flow Chart Dekompresi File Audio Algoritma Difference Coding 46 Gambar 3.7 Flow Chart Dekompresi File Audio Algoritma Difference Coding
(Lanjutan) 47
Gambar 3.8 Use Case Diagram Sistem yang akan dikembangkan 48 Gambar 3.9 Activity Diagram Kontrol Proses Watermarking(Kompresi) 51 Gambar 3.10 Activity Diagram Kontrol Proses Watermarking(Dekompresi) 54 Gambar 3.11 Sequence Diagram Proses Kompresi 55 Gambar 3.12 Sequence Diagram Proses Dekompresi 56
Gambar 3.15 Rancangan Menu Utama 57
Gambar 3.16 Rancangan Kompresi 58
Gambar 3.17 Rancangan Help 59
Gambar 3.18 Rancangan About 60
Gambar 3.19 Rancangan Grafik Hasil Kompresi 62
Gambar 3.20 Rancangan Grafik Hasil Dekompresi 63
Gambar 4.1 Tampilan Menu Utama 64
Gambar 4.2 Tampilan Kompresi Zero Compression 65 Gambar 4.3 Tampilan Dekompresi Zero Compression 66 Gambar 4.4 Tampilan Kompresi Difference Coding 66 Gambar 4.5 Tampilan Dekompresi Difference Coding 67
Gambar 4.6 Tampilan Help 68
Gambar 4.7 Tampilan About 68
Gambar 4.8 Tampilan Grafik Hasil Kompresi Algoritma Zero Compression 72 Gambar 4.9 Tampilan Grafik Hasil Kompresi Algoritma Difference Coding 73 Gambar 4.10 Tampilan Grafik Hasil Perbandingan Rasio Kompresi Algoritma 74
DAFTAR TABEL
Tabel 2.1 Frekuensi Sampling dan Kualitas Suara yang Dihasilkan 10 Tabel 2.2 Tabel Penyimpanan Berbagai Konfigurasi Audio Digital 11
Tabel 2.3 Nilai Jenis Chunk RIFF 15
Tabel 2.4 Format Chunk RIFF 16
Tabel 2.5 Nilai-Nilai Chunk Format File Wave 16
Tabel 2.6 Kode Kompresi Wave 17
Tabel 2.7 Format Data Chunk 19
Tabel 2.8 Penjelasan Struktur File Wave 21
Tabel 2.9 Penambahan Chunk Lain Pada File Wave 23 Tabel 3.1 Hasil Kompesi Zero Compresion per Sampel Audio 40 Tabel 3.2 Hasil Kompesi Difference Coding per Sampel Audio 41 Tabel 3.3 Dokumentasi Naratif Use Case Kompresi 49 Tabel 3.4 Dokumentasi Naratif Use Case Dekompresi 52
Tabel 3.5 Rancangan Hasil Pengujian Kompresi 61
Tabel 3.4. Rancangan Hasil Pengujian Dekompresi 61 Tabel 4.1. Rancangan Hasil Pengujian kompresi Zero Compression 69 Tabel 4.2. Rancangan Hasil Pengujian Dekompresi Zero Compression 70
ANALISIS PERBANDINGAN ZERO COMPRESION DENGAN
DIFFERENCE CODING PADA KOMPRESI FILE AUDIO
ABSTRAK
Ukuran file audio khususnya berformat.Wav relatif besar dibandingkan file dengan format teks,yang membutuhkan memori yang besar dalam melakukan penyimpanan maupun dalam hal transmisi (pengiriman) melalui media komunikasi. Hal ini sangat mempengaruhi ketersediaan tempat (space) maupun pengolahan data khususnya data audio.Untuk itu perlu dikembangkan aplikasi untuk kompresi data yang bertujuan untuk minimalisasi memori menggunakan algoritma Zero Compression dan
Difference Coding. Pada metode Zero Compression, kompresi file audio dilakukan pada sampel audio yang bernilai nol (0) berurutan. Ada dua tahap utama kompresi dengan metode Zero Compression untuk data audio, yaitu reading redudance data
dan coding. Readingredudance data adalahmerepresentasikan frekuensi kemunculan setiap sampel audio kedalam bilangan eksak sedangkan Coding adalah menuliskan kode yang berisi nilai sampel dengan frekuensi kemunculannya.Sedangkan kompresi dengan metode Difference Coding adalah data difference yaitu adalah pengurangan nilai sampel audio dengan nilai sampel audio sebelumnya serta coding. Hasil kompresi file wav dengan kedua algoritma di atas dapat memberikan ukuran file yang lebih kecil yaitu dengan algoritma Zero Compression rata-rata rasio kompresi sebesar 24.43 % dan Difference Coding adalah 25.48 %.
.
ANALYSIS COMPARISON ZERO COMPRESION ALGORITHM
WITH DIFFERENCE CODING
COMPRESSION FOR FILE AUDIO
ABSTRACT
The Size of .wav audio file format in particular is relatively large compared with the text format file, which requires a large memory to perform in terms of storage and transmission (delivery) through the medium of communication. This greatly affects the availability of a place (space) as well as data processing, especially the audio data . so it is necessary to develop applications for data compression that aims to minimize memory by using Zero Compression Algorithm and Difference Coding. At Zero Compression method, the compression of audio files is done on the audio sample which has a value of zero sequentially .There are two main stages of compression using Zero compression method for audio data, that is reading redudance the data and coding. Reading redudance the data is representing the frequency of occurrence of each audio sample into exact numbers, while coding is to write code that contains the value of the sample with the frequency of occurrence. While the method of Difference Coding compression is data that difference is a reduction in the value of an audio sample with previous audio sample values and coding. Wav file compression Results with both algorithms above can give you a smaller file size that is used Zero Compression algorithms with an average compression ratio about 24.43% and 25.48% Difference Coding is.
keywords : Audio, Compression, Zero Compression, and Difference Coding .
BAB 1 PENDAHULUAN
Pada bab ini dijelaskan latar belakang permasalahan serta tujuan dari penelitian,
metodologi serta sistematika penulisan. Bab ini merupakan dasar dari penelitian
mengenai kompresi dan dekompresi file audio berformat wav.
1.8Latar Belakang
Perkembangan teknologi informasi yang pesat telah menjadi peran yang sangat
penting untuk pertukaran informasi yang cepat. Kecepatan pengiriman informasi
dalam bentuk perpaduan teks, audio maupun citra secara nyata akan menjadi bagian utama dalam pertukaran informasi. Kecepatan pengiriman ini sangat bergantung
kepada ukuran dari informasi tersebut. Salah satu solusi untuk masalah di atas adalah
dengan melakukan kompresi data sebelum ditransmisikan dan kemudian penerima
akan melakukan dekompresi yaitu merekonstruksinya kembali menjadi data aslinya.
Pada umumnya file audio digital memiliki ukuran (size) yang lebih besar dibandingkan dengan file teks. Jadi untuk mengurangi ukurannya dapat dilakukan
dengan cara kompresi. File Audio dengan format WAV memiliki data yang tidak terkompres sehingga seluruh sampel audio disimpan semuanya di harddisk (tidak di
coding). File audio ini jarang sekali digunakan di internet karena ukurannya yang relatif besar dengan batasan maksimal pada media player yang optimum adalah 2GB.
Seperti pada teknik kompresi pada umumnya, kompresi data audio, baik
lossy maupun lossless, memanfaatkan adanya redundansi informasi dengan
pengkodean, pengenalan pola, maupun prediksi linear seperti pada kompresi video.
Pada kompresi lossless, hasil kompresi dapat dikembalikan seperti data asli tanpa ada perubahan, maka rasio kompresi pun tidak dapat terlalu besar untuk memastikan
Kompresi lossy pada data audio berdasarkan pada psikoakustik, sebagaimana kompresi lossy pada gambar yang berdasarkan pada redundansi psikovisual. Keduanya memanfaatkan keterbatasan indera manusia yang hanya dapat menangkap
(perceive) kondisi lingkungannya dalam rentang tertentu, misalnya telinga manusia hanya dapat menangkap suara dengan frekuensi di antara 20 Hz hingga 20000 Hz.
Kompresi lossless pada data audio berarti bahwa hasil kompresi dari data tersebut dapat di-dekompres untuk menghasilkan data yang sama persis dengan data
asli, tanpa ada penurunan kualitas sama sekali. Kompresi lossless untuk data audio
agak mirip dengan algoritma kompresi lossless generik, dengan rasio kompresi sekitar 50% hingga 60%, meskipun dapat mencapai 35% pada data musik orkestra atau
paduan suara yang tidak terlalu banyak noise.
Kompresi lossless utamanya digunakan untuk pengarsipan, dan penyuntingan. Untuk keperluan pengarsipan, tentu kualitas yang diinginkan adalah kualitas
terbaik. Menyunting data yang terkompresi secara lossy menyebabkan turunnya kualitas suara pada setiap penyimpanan. Maka kompresi lossless selalu digunakan dalam sound engineering. Selain kedua kegunaan itu, kompresi lossless juga biasa digunakan oleh para audiophile, yaitu penggemar musik yang senang mendengarkan musik dengan kualitas tinggi dengan perangkat keras yang berkualitas tinggi pula.
Data audio yang terkompresi secara lossless juga digunakan untuk menghasilkan data audio versi lossy untuk didistribusikan. Saat ini, dengan semakin murahnya media penyimpanan data digital dan bandwidth, kompresi lossless pun
menjadi semakin populer di kalangan konsumen. Ada dua tahap utama dalam
kompresi lossless untuk data audio, yaitu prediction dan coding. Prediction
memanfaatkan sample-sample sebelumnya untuk memprediksi sample berikutnya. Kemudian selisih antara sample hasil prediksi dengan sample sebenarnya dikodekan (coding). Untuk setiap format, biasanya perbedaan hanya terdapat pada teknik
prediction dan/atau coding.
Teknik kompresi diperlukan karena ukuran dari data semakin lama semakin
besar, tetapi belum optimal karena tidak didukung oleh perkembangan dari teknologi
diperlukan kualitas kompresi yang baik yaitu ukuran yang minimum dengan tidak
mengurangi kualitas data tersebut. Melihat masalah-masalah tadi, maka
pemecahannya adalah maksimalisasi kompresi yaitu mengurangi ukuran data.
Algoritma Zero Compression adalah melakukan kompresi file audio untuk sampel audio yang bernilai nol (0) berurutan sedangkan Difference Coding adalah dengan mengurangi nilai sampel audio dengan nilai sampel audio sebelumnya. Sampel audio yang bernilai nol atau mendekati nol adalah sampel audio tidak dapat didengar telinga manusia jadi melakukan reduksi nilai nol pada sampel audio tidak akan mempengaruhi kualitas suaranya.
Berdasarkan hal yang telah diuraikan diatas maka penulis berniat membuat
skripsi dengan judul analisis perbandingan algoritma zero compression dengan
difference coding pada kompresi file audio.
1.9Rumusan Masalah
Berdasarkan latarbelakang di atas maka masalah yang akan di bahas pada penelitian
ini adalah bagaimana cara mendapatkan hasil perbandingan kompresi file audio
menggunakan algoritma Zero Compression dan Difference Coding.
1.10 Batasan Masalah
Agar tujuan penelitian ini dapat tercapai, maka penulis membuat batasan-batasan
antara lain adalah:
a. File audio yang dikompresi adalah berformat WAV.
b. Algoritma yang digunakan adalah Zero Compresion dan Difference Coding. c. Bahasapemrograman yang digunakan adalah Visual Basic .NET 2010.
1.11 Tujuan Penelitian
Pada penelitian ini yang menjadi tujuan adalah untuk menganalisis serta
membandingkan kompresi file audio dengan menggunakan algoritma Zero Compresion dan Difference Coding.
1.12 Manfaat Penelitian
Manfaat penelitian ini adalah:
a. Untuk memberi informasi hasil kompresi file audio terhadap masing-masing
algoritma diatas.
b. Untuk lebih memahami teknik kompresi file audio.
c. Sebagai bahan perbandingan untuk algoritma kompresi lossless yang lainnya.
1.13 Metodologi Penelitian
Dalam penelitian ini, tahapan-tahapan yang akan dilalui adalah sebagai berikut:
a. Studi Literatur
Metode ini dilaksanakan dengan melakukan studi tentang audio digital, teknik kompresi dan dekompresi serta algoritma Zero dan Difference Coding.
b. Analisis
Pada tahap ini digunakan untuk mengolah data yang ada dan kemudian
melakukan analisis terhadap hasil studi literatur yang diperoleh sehingga menjadi
suatu informasi.
c. Perancangan Perangkat Lunak
Pada tahap ini, digunakan seluruh hasil analisa terhadap studi literatur yang
dilakukan untuk merancang perangkat lunak yang akan dihasilkan. Dalam
tahapan ini juga dilakukan perancangan bagan arus proses kerja sistem (flow chart) serta antarmuka (user interface) untuk memudahkan dalam penulisan kode program.
Pada tahap ini dilakukan pemasukan data serta memproses data untuk
mendapatkan hasil apakah sudah sesuai dengan tujuan.
e. Implementasi
Pada tahap ini dilakukan pemanfaatan program dalam melakukan proses
kompresi file audio.
f. Dokumentasi serta Laporan Akhir
Tahap ini dilakukan pembuatan dokumen dari penelitian serta laporan dalam
bentuk skripsi.
1.14 Sistematika Penulisan
Sistematika penulisan skripsi ini adalah sebagai berikut:
BAB 1 PENDAHULUAN membahas latar belakang, rumusan masalah, batasan
masalah, tujuan penelitian, manfaat penelitian serta sistematika penulisan.
BAB 2 LANDASAN TEORI membahas tentang landasan teori tentang kompresi
audio, algoritma Zero dan Difference Coding, bahasa pemrograman VB NET
serta flow chart.
BAB 3 ANALISIS DAN PERANCANGAN pembahasan mengenai kompresi audio
dengan algoritma Zero Compression dan Difference Coding, flow chart
sistem serta perancangan antar muka aplikasi (user interface).
BAB 4 IMPLEMENTASI DAN PENGUJIAN membahas tentang implementasi dari
perancangan sistem yang dirancang pada BAB 3.
BAB 5 KESIMPULAN DAN SARAN merupakan kesimpulan dari semua
pembahasan yang ada dengan saran-saran yang ditujukan bagi para pembaca
BAB 2
LANDASAN TEORI
Sebelum melakukan penelitian, penulis mengumpulkan informasi berupa teori-teori
yang berkenaan atau yang relevan dengan objek penelitian yaitu kompresi file audio
berformat Wav serta algoritma kompresi yang digunakan. Adapun teori-teori yang
menyangkut penelitian ini adalah sebagai berikut.
2.10 Pengertian Audio Digital
Suara yang kita dengar sehari-hari adalah merupakan gelombang analog. Gelombang ini berasal dari tekanan udara yang ada di sekeliling kita, yang dapat kita dengar
dengan bantuan gendang telinga. Gendang telinga ini bergetar, dan getaran ini dikirim
dan diterjemahkan menjadi informasi suara yang dikirimkan ke otak, sehingga kita
dapat mendengarkan suara. Suara yang kita hasilkan sewaktu berbicara berbentuk
tekanan suara yang dihasilkan oleh pita suara. Pita suara ini akan bergetar, dan getaran
ini menyebabkan perubahan tekanan udara, sehingga kita dapat mengeluarkan suara
(Binanto,2010).
Komputer hanya mampu mengenal sinyal dalam bentuk digital. Bentuk digital
yang dimaksud adalah tegangan yang diterjemahkan dalam angka “0” dan “1”, yang
juga disebut dengan istilah “bit”. Tegangan ini berkisar 5 volt bagi angka “1” dan mendekati 0 volt bagi angka “0”. Dengan kecepatan perhitungan yang dimiliki
komputer, komputer mampu melihat angka “0” dan “1” ini menjadi kumpulan bit-bit
dan menerjemahkan kumpulan bit-bit tersebut menjadi sebuah informasi yang bernilai.
Bagaimana caranya memasukkan suara analog ini sehingga dapat dimanipulasi oleh peralatan elektronik yang ada? Alat yang diperlukan untuk melakukan ini adalah
transducer. Dalam hal ini, transducer adalah istilah untuk menyebut sebuah peralatan yang dapat mengubah tekanan udara (yang kita dengar sebagai suara) ke dalam
Contoh transducer adalah mikrofon dan speaker. Mikrofon dapat mengubah tekanan udara menjadi tegangan elektrik, sementara speaker melakukan pekerjaan sebaliknya.
Tegangan elektrik diproses menjadi sinyal digital oleh sound card. Ketika Anda merekam suara atau musik ke dalam komputer, sound card akan mengubah gelombang suara (bisa dari mikrofon atau stereo set) menjadi data digital, dan ketika suara itu dimainkan kembali, sound card akan mengubah data digital menjadi suara yang kita dengar (melalui speaker), dalam hal ini gelombang analog. Proses pengubahan gelombang suara menjadi data digital ini dinamakan Analog-to-Digital Conversion (ADC), dan kebalikannya, pengubahan data digital menjadi gelombang suara dinamakan Digital-to-Analog Conversion (DAC).
Proses pengubahan dari tegangan analog ke data digital ini terdiri atas beberapa tahap yang ditunjukkan pada Gambar 2.1, yaitu:
1. Membatasi frekuensi sinyal yang akan diproses dengan Low Pass Filter.
2. Mencuplik sinyal analog ini (melakukan sampling) menjadi beberapa potongan waktu.
3. Cuplikan-cuplikan ini diberi nilai eksak, dan nilai ini diberikan dalam bentuk data
digital.
Gambar 2.1 Konversi Sinyal Analog ke Digital (Binanto, 2010)
Proses sebaliknya, yaitu pengubahan dari data digital menjadi tegangan analog juga terdiri atas beberapa tahap, yang ditunjukkan pada gambar 2.2, yaitu:
1. Menghitung data digital menjadi amplitudo-amplitudo analog. 2. Menyambung amplitudo analog ini menjadi sinyal analog.
Gambar 2.2 Konversi Sinyal Digital ke Analog (Binanto, 2010)
Proses pengubahan sinyal analog menjadi digital harus memenuhi sebuah kriteria, yaitu kriteria Nyquist. Kriteria ini mengatakan bahwa untuk mencuplik
sebuah sinyal yang memiliki frekuensi X Hertz, maka harus mencupliknya minimal
dua kali lebih rapat, atau 2X Hertz. Jika tidak, sinyal tidak akan dapat dikembalikan
ke dalam bentuk semula.
2.11Kelebihan Audio Digital
Kelebihan audio digital adalah kualitas reproduksi yang sempurna. Kualitas reproduksi yang sempurna yang dimaksud adalah kemampuannya untuk
menggandakan sinyal audio secara berulang-ulang tanpa mengalami penurunan kualitas suara.
Kelebihan lain dari audiodigital adalah ketahanan terhadap noise (sinyal yang tidak diinginkan). Pada saat transmisi data dan pemrosesan dengan
komponen-komponen elektrik, pada sinyal analog sangat mudah sekali terjadi gangguan-gangguan berupa noise. Suara desis pada kaset rekaman merupakan salah satu contoh terjadinya noise berupa gangguan pada frekuensi tinggi.
2.12 Istilah dalam Audio Digital
Dalam dunia audio digital, ada beberapa istilah yaitu channel (jumlah kanal),
sampling rate (laju pencuplikan), bandwidth, bit per sample (banyaknya bit dalam satu sample), bit rate (laju bit) (Dangarwala, 2010).
2.12.1 Channel (Jumlah Kanal)
Jumlah kanal menentukan banyaknya kanal audio yang digunakan. Audio satu kanal dikenal dengan mono, sedangkan audio dua kanal dikenal dengan stereo. Saat ini untuk audio digital standar, biasanya digunakan dua kanal, yaitu kanal kiri dan kanal kanan. Audio untuk penggunaan theater digital menggunakan lebih banyak kanal. Ada yang menggunakan tiga kanal, yaitu 2 kanal depan dan surround. Ada yang menggunakan 6 kanal (dikenal dengan format audio 5.1) yaitu terdiri dari 2 kanal depan dan 2 kanal surround, 1 kanal tengah dan 1 kanal subwoofer. Bahkan ada yang menggunakan 8 kanal (formataudio 7.1) yaitu terdiri dari 2 kanal depan dan 2 kanal
surround, 1 kanal tengah dan 1 kanal subwoofer dan ditambah 2 buah speaker EX (Environmental Extended) untuk menghasilkan suara dari belakang.
2.12.2 Sampling Rate (Laju Pencuplikan)
Ketika sound card mengubah audio menjadi data digital, sound card akan memecah suara tadi menurut nilai menjadi potongan-potongan sinyal dengan nilai tertentu.
Proses sinyal ini bisa terjadi ribuan kali dalam satuan waktu. Banyak pemotongan
dalam satu satuan waktu ini dinamakan sampling rate (laju pencuplikan). Satuan
sampling rate yang biasa digunakan adalah KHz (kilo Hertz) (Binanto, 2010).
Kerapatan laju pencuplikan ini menentukan kualitas sinyal analog yang akan diubah menjadi data digital. Makin rapat laju pencuplikan ini, kualitas suara yang dihasilkan akan makin mendekati suara aslinya. Sebagai contoh, lagu yang disimpan
dalam Compact Disc Audio (CDA) memiliki sampling rate 44.1 KHz, yang berarti lagu ini dicuplik sebanyak 44100 kali dalam satu detik untuk memastikan kualitas
Tabel 2.1 Frekuensi Sampling dan Kualitas Suara yang Dihasilkan
Sampling Rate (KHZ) Aplikasi
8 Telepon
11,025 Radio AM
16 Kompromi antara 11,025 dan 22,025 KHz
22,025 Mendekati Radio FM
32,075 Lebih baik dari Radio FM
44,1 Compact Disc Audio (CDA)
48 Digital Audio Tape (DAT)
Sampling rate yang umumnya digunakan antara lain 8 KHz, 11 KHz, 16 KHz, 22 KHz, 24 KHz, 44 KHz, 88 KHz. Makin tinggi sampling rate, semakin baik kualitas audio. Teori Nyquist menyatakan bahwa sampling rate yang diperlukan minimal 2 kali bandwidth sinyal. Hal ini berkaitan dengan kemampuan untuk merekonstruksi ulang sinyal audio.
2.12.3 Bandwidth
Bandwitdth adalah selisih antara frekuensi tertinggi dan frekuensi terendah yang akan diolah. Misalnya sinyal audio pada telepon yang digunakan untuk menyampaikan sinyal dengan frekuensi 300 – 3400 Hz (ucapan manusia), berarti bandwidth-nya adalah 3100 Hz (3400 dikurangi 300). Maka sampling rate minimum yang diperlukan adalah 2 kali yaitu 6,2 KHz. Demikian pula dengan frekuensi suara secara umum,
frekuensi yang dapat didengar manusia adalah 20 – 20.000 Hz, dengan bandwidth
19.980. Berarti sampling rate minimum yang digunakan adalah 39.960 Hz. Jadi frekuensi sampling yang mencukupi adalah 44.100 Hz.
2.12.4 Bit Per Sample (Banyaknya Bit Dalam Satu Sampel)
Bit per sample menyatakan seberapa banyak bit yang diperlukan untuk menyatakan hasil sample tersebut, hal ini berkaitan dengan proses kuantisasi. Bit rate yang digunakan adalah 8 bit per sample atau 16 bit per sample. Proses kuantisasi akan mengubah amplitudo sinyal audio menjadi suatu level sinyal tertentu. Dengan 8 bit per sample akan ada 256 level pilihan sedangkan 16 bit per sample akan ada 65.536
ini, penggunaan 16 bit per sample dibandingkan penggunaan 8 bit per sample akan mempertinggi ketelitian kualitas kuantisasi sebanyak 256 kali.
2.12.5 Bit Rate (Laju Bit )
Istilah bit rate merupakan gabungan dari istilah sampling rate dan bit per sample. Bit rate menyatakan banyaknya bit yang diperlukan untuk menyimpan audio selama satu detik, satuannya adalah bit per detik. Bit rate (dengan satuan bit per detik) diperoleh dengan rumus yang sederhana yaitu perkalian antara jumlah kanal, sampling rate
(dengan satuan Hertz) dan bit per sample (dengan satuan bit).Seperti dapat dilihat di Tabel 2.2 di bawah ini
Tabel 2.2 Tabel Penyimpanan Berbagai Konfigurasi Audio Digital
Sampling rate
Bit per sample
Jumlah kanal
Bit rate Byte rate (1 byte = 8 bit)
Byte rate per menit
12 kHz 8 1 96.000 12.000 720 KB
12 kHz 8 2 192.000 24.000 1,44 MB
12 kHz 16 1 192.000 24.000 1,44 MB
12 kHz 16 2 348.000 48.000 2,88 MB
24 kHz 8 1 192.000 24.000 1,44 MB
24 kHz 8 2 348.000 48.000 2,88 MB
24 kHz 16 1 348.000 48.000 2,88 MB
24 kHz 16 2 768.000 96.000 5,76 MB
44.1 kHz 8 1 352.800 44.100 2,646 MB
44.1 kHz 8 2 705.600 88.200 5,292 MB
44.1 kHz 16 1 705.600 88.200 5,292 MB
44.1 kHz 16 2 1.411.200 176.400 10,584 MB
Audio sekualitas CD Audio menggunakan sampling rate 44,1 kHz, 16 bit per
menyimpan data audio lagu tersebut jika diasumsikan 1 KB = 1.000 byte dan 1 MB = 1.000 KB = 1.000.000 byte.
2.13 Data Audio
Salah satu tipe data multimedia adalah audio yang berupa suara ataupun bunyi, data
audio sendiri telah mengalami perkembangan yang cukup pesat seiring dengan semakin umumnya orang dengan perangkat multimedia. Tentunya yang merupakan syarat utama supaya komputer mampu menjalankan tipe data tersebut adalah adanya
speaker yang merupakan output untuk suara yang dihasilkan dan untuk menghasilkan maupun mengolah data suara yang lebih kompleks seperti *.WAV, *.MIDI tersebut
tentunya sudah diperlukan perangkat yang lebih canggih lagi yaitu sound card.
Tipe dari pelayanan audio memerlukan format yang berbeda untuk informasi
audio dan teknologi yang berbeda untuk menghasilkan suara. Windows menawarkan beberapa tipe dari pelayanan audio :
1. Pelayanan audio Waveform menyediakan playback dan recording untuk perangkat keras digital audio. Waveform digunakan untuk menghasilkan non -musikal audio seperti efek suara dan suara narasi. Audio ini mempunyai keperluan penyimpanan yang sedang dan keperluan untuk tingkat transfer paling
kecil yaitu 11 K/detik.
2. Midi Audio, menyediakan pelayanan file MIDI dan MIDI playback melalui
synthesizer internal maupun eksternal dan perekaman MIDI. MIDI digunakan untuk aplikasi yang berhubungan dengan musik seperti komposisi musik dan
program MIDI sequencer. Karena memerlukan tempat penyimpanan lebih kecil dan tingkat transfer yang lebih kecil daripada Waveform audio, maka sering digunakan untuk keperluan background.
3. Compact Disc Audio (CDA) menyediakan pelayanan untuk playback informasi
Red Book Audio dalam CD dengan drive CD-ROM pada komputer multimedia. CD menawarkan kualitas suara tertinggi, namun juga memerlukan daya
penyimpanan yang paling besar pula, sekitar 176 KB/detik.
ini telah menjadi standar format file audio komputer dari suara sistem dan
games sampai CD Audio. File Wave diidentifikasikan dengan nama yang berekstensi *.WAV. Format asli dari tipe file tersebut sebenarnya berasal dari bahasa C.
2.14 Struktur File Wave
Aplikasi multimedia seperti diketahui memerlukan manajemen penyimpanan dari sejumlah jenis data yang bervariasi, termasuk bitmap, data audio, data video, informasi mengenai kontrol device periperal. Rule Interchange File Format (RIFF) menyediakan suatu cara untuk menyimpan semua jenis data tersebut (Dangarwala,
2010). Tipe data pada sebuah file RIFF dapat diketahui dari ekstensi filenya. Sebagai contoh jenis-jenis file yang disimpan dalam bentuk format RIFF adalah sebagai berikut:
1. Audio/visual interleaved data (.AVI) 2. Waveform data (.WAV)
3. Bitmapped data (.RDI) 4. MIDI information (.RMI) 5. Color palette (.PAL) 6. Multimedia Movie (.RMN) 7. Animated cursor (.ANI)
Pada saat ini, file *.AVI merupakan satu-satunya jenis file RIFF yang telah secara penuh diimplementasikan menggunakan spesifikasi RIFF. Meskipun file
*.WAV juga menggunakan spesifikasi RIFF, karena struktur file *.WAV ini begitu sederhana maka banyak perusahaan lain yang mengembangkan spesifikasi dan standar
mereka masing-masing.
lingkungan Windows yang menggunakan prosesor Intel, maka format data dari file
WAVE disimpan dalam format urutan little-endian (least significant byte) dan sebagian dalam urutan big-endian.
File WAVE menggunakan struktur standar RIFF yang mengelompokkan isi
file (sampel format, sampel digital audio, dan lain sebagainya) menjadi “chunk” yang terpisah, setiap bagian mempunyai header dan byte data masing-masing. Header chunck menetapkan jenis dan ukuran dari byte data chunk. Dengan metoda pengaturan seperti ini maka program yang tidak mengenali jenis chunk yang khusus dapat dengan mudah melewati bagian chunk ini dan melanjutkan langkah memproses
chunk yang dikenalnya. Jenis chunk tertentu mungkin terdiri atas sub-chunk. Sebagai contoh, pada gambar 2.3 dapat dilihat chunk “fmt ” dan “data” sebenarnya merupakan
sub-chunk dari chunk “RIFF”.
Chunk pada file RIFF merupakan suatu string yang harus diatur untuk tiap kata. Ini berarti ukuran total dari chunk harus merupakan kelipatan dari 2 byte (seperti 2, 4, 6, 8 dan seterusnya). Jika suatu chunk terdiri atas jumlah byte yang ganjil maka harus dilakukan penambahan byte (extra padding byte) dengan menambahkan sebuah nilai nol pada byte data terakhir. Extra padding byte ini tidak ikut dihitung pada ukuran chunk. Oleh karena itu sebuah program harus selalu melakukan pengaturan kata untuk menentukan ukuran nilai dari header sebuah chunk untuk mengkalkulasi
offset dari chunk berikutnya. Layoutfile wave dapat dilihat seperti pada Gambar 2.3.
2.14.1 Header File Wave
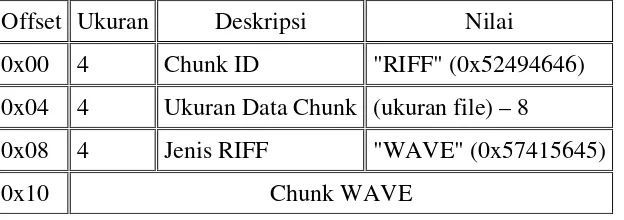
Header file Wave mengikuti struktur format file RIFF standar. Delapan byte pertama dalam file adalah header chunk RIFF standar yang mempunyai chunk ID “RIFF” dan ukuran chunk didapat dengan mengurangkan ukuran file dengan 8 byte yang digunakan sebagai header. Empat byte data yaitu kata “RIFF” menunjukkan bahwa
file tersebut merupakan file RIFF. File Wave selalu menggunakan kata “WAVE” untuk membedakannya dengan jenis file RIFF lainnya sekaligus digunakan untuk mendefinisikan bahwa file tersebut merupakan file audio waveform
(Dangarwala,2010). Seperti terlihat pada Tabel 2.3.
Tabel 2.3 Nilai Jenis Chunk RIFF
Offset Ukuran Deskripsi Nilai
0x00 4 Chunk ID "RIFF" (0x52494646)
0x04 4 Ukuran Data Chunk (ukuran file) – 8
0x08 4 Jenis RIFF "WAVE" (0x57415645)
0x10 Chunk WAVE
2.14.2 Chunk File WAVE
Ada beberapa jenis chunk untuk menyatakan file Wave. Kebanyakan file Wave hanya terdiri atas 2 buah chunk, yaitu Chunk Format dan Chunk Data. Dua jenis chunk ini diperlukan untuk menggambarkan format dari sampel digital audio. Meskipun tidak diperlukan untuk spesifikasi file Wave yang resmi, lebih baik menempatkan Chunk Format sebelum Chunk Data. Kebanyakan program membaca chunk tersebut dengan urutan di atas dan jauh lebih mudah dilakukan streaming digital audio dari sumber yang membacanya secara lambat dan linear seperti Internet. Jika Chunk Format lebih dulu ditempatkan sebelum Chunk Data maka semua data dan format harus di-stream
Tabel 2.4 Format Chunk RIFF
Offset Ukuran (byte) Deskripsi
0x00 4 Chunk ID
0x04 4 Ukuran Data Chunk
0x08 Byte Data Chunk
2.14.3 Chunk Format
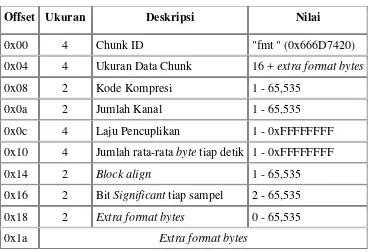
Chunk format terdiri atas informasi tentang bagaimana suatu data waveform disimpan dan cara untuk dimainkan kembali, termasuk jenis kompresi yang digunakan, jumlah
kanal, laju pencuplikan (sampling rate), jumlah bit tiap sampel dan atribut lainnya.
Chunk format ini ditandai dengan chunnk ID “fmt“ (Kadhim, 2012). Seperti dapat kita lihat Tabel 2.5.
Tabel 2.5 Nilai-Nilai Chunk Format File Wave (Kadhim, 2012)
Offset Ukuran Deskripsi Nilai
0x00 4 Chunk ID "fmt " (0x666D7420)
0x04 4 Ukuran Data Chunk 16 + extra format bytes
0x08 2 Kode Kompresi 1 - 65,535
0x0a 2 Jumlah Kanal 1 - 65,535
0x0c 4 Laju Pencuplikan 1 - 0xFFFFFFFF
0x10 4 Jumlah rata-rata byte tiap detik 1 - 0xFFFFFFFF
0x14 2 Block align 1 - 65,535
0x16 2 Bit Significant tiap sampel 2 - 65,535
0x18 2 Extra format bytes 0 - 65,535
A. Chunk ID dan Ukuran Data
Chunk ID selalu ditandai dengan kata “fmt “ (0x666D7420) dan ukurannya sebesar data format Wave (16 byte) ditambah dengan extra format byte yang diperlukan untuk format Wave khusus, jika tidak terdiri atas data PCM tidak terkompresi. Sebagai catatan string chunk ID ini selalu diakhir dengan karakter spasi (0x20). Chunk ID “fmt “ digunakan sebagai informasi file Wave, informasi ini berupa: Compression Code, Number of Channels, Sample Rate, Average Bytes perSecond, Block Align, Significant Bits per Sample, Extra Format Bytes.
B. Compression Code
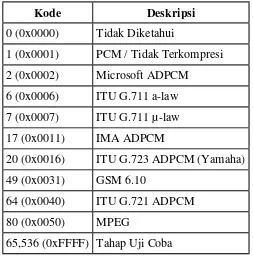
Setelah chunk ID dan ukuran data chunk maka bagian pertama dari format data file Wave menyatakan jenis kompresi yang digunakan pada data Wave. Seperti terlihat pada Table 2.6.
Tabel 2.6 Compression Code Wave (Gunawan, 2005)
Kode Deskripsi
0 (0x0000) Tidak Diketahui
1 (0x0001) PCM / Tidak Terkompresi
2 (0x0002) Microsoft ADPCM
6 (0x0006) ITU G.711 a-law
7 (0x0007) ITU G.711 µ-law
17 (0x0011) IMA ADPCM
20 (0x0016) ITU G.723 ADPCM (Yamaha)
49 (0x0031) GSM 6.10
64 (0x0040) ITU G.721 ADPCM
80 (0x0050) MPEG
65,536 (0xFFFF) Tahap Uji Coba
C. Number of Channels
Jumlah kanal menyatakan berapa banyak signal audio terpisah yang di-encode
D. Sampling Rate
Menyatakan jumlah potongan sampel tiap detik. Nilai ini tidak dipengaruhi oleh
jumlah kanal.
E. Average Bytes Per Second
Nilai ini mengindikasikan berapa besar byte data Wave harus di-stream ke konverter D/A (Digital Audio) tiap detik sewaktu suatu file Wave dimainkan. Informasi ini berguna ketika terjadi pengecekan apakah data dapat di-stream
cukup cepat dari suatu sumber agar sewaktu playback pembacaan data tidak terhenti. Nilai ini dapat dihitung dengan menggunakan rumus di bawah ini:
... (2.1)
F. Block Align
Menyatakan jumlah byte tiap potongan sampel. Nilai ini tidak dipengaruhi oleh jumlah kanal dan dapat dikalkulasi dengan rumus di bawah ini:
... (2.2)
G. Significant Bits Per Sample
Nilai ini menyatakan jumlah bit yang digunakan untuk mendefinisikan tiap sampel. Nilai ini biasanya berupa 8, 16, 24 atau 32 (merupakan kelipatan 8). Jika
jumlah bit tidak merupakan kelipatan 8 maka jumlah byte yang digunakan tiap sampel akan dibulatkan ke ukuran byte paling dekat dan byte yang tidak digunakan akan diset 0 (nol) dan diabaikan.
H. Extra Format Byte
Nilai ini menyatakan berapa banyak format byte tambahan. Nilai ini tidak ada jika kode kompresi adalah 0 (file PCM yang tidak terkompresi). Jika terdapat suatu nilai pada bagian ini maka ini digunakan untuk menentukan jenis file Wave yang memiliki kompresi dan ini memberikan informasi mengenai jenis kompresi apa
yang diperlukan untuk men-decode dataWave. Jika nilai ini tidak dilakukan word aligned (merupakan kelipatan 2), penambahan byte (padding) pada bagian akhir data ini harus dilakukan.
AvgBytesPerSec = SampleRate * BlockAlign
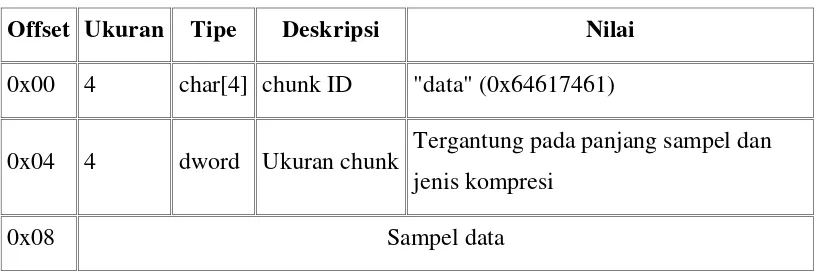
2.14.4 Chunk Data
Chunk ini ditandai dengan adanya string “data”. Chunk Data pada file Wave terdiri atas sampel digital audio yang mana dapat didecode kembali menggunakan metode kompresi atau format biasa yang dinyatakan dalam chunk format Wave. Jika kode kompresinya adalah 1 (jenis PCM tidak terkompresi), maka “Data Wave” terdiri atas nilai sampel mentah (raw sample value).Seperti terlihat pada Tabel 2.7.
Tabel 2.7 Format Data Chunk (Gunawan,2005)
Offset Ukuran Tipe Deskripsi Nilai
0x00 4 char[4] chunk ID "data" (0x64617461)
0x04 4 dword Ukuran chunk Tergantung pada panjang sampel dan jenis kompresi
0x08 Sampel data
Sampel digital audio multi-channel disimpan dalam bentuk data wave Interlaced. File wave multi-channel (seperti stereo dan surround) disimpan dengan mensiklus tiap kanal sampel audio sebelum melakukan pembacaan lagi untuk tiap waktu cuplik berikutnya. Dengan cara seperti ini maka file audio tersebut dapat dimainkan atau di-stream tanpa harus membaca seluruh isi file. Lebih praktis dengan cara seperti ini ketika sebuah filewave dengan ukuran yang besar dimainkan dari disk (mungkin tidak dapat dimuat seluruhnya ke dalam memori) atau ketika melakukan
streaming sebuah file wave melalui jaringan internet.
2.14.5 Format Wave PCM
Jenis format Wave ini merupakan jenis file Wave yang paling umum dan hampir dikenal oleh setiap program. Format Wave PCM (Pulse Code Modulation) adalah file wave yang tidak terkompresi, akibatnya ukuran file sangat besar jika file mempunyai durasi yang panjang. Berikut ini diagram (Gambar 2.4) yang menggambarkan format
file Wave PCM. (Kadhim,2012).
Berikut ini penjelasan mengenai struktur file Wave yang dimulai dengan header RIFF: Seperti terlihat pada Tabel 2.8.
Tabel 2.8 Penjelasan Struktur File Wave (Gunawan,2005)
Offset Size Nama Field Deskripsi
0 4 ChunkID Terdiri atas kata “RIFF” dalam bentuk ASCII
(0x52494646 dalam bentuk big-endian). 4 4 Chunksize 36 + SubChunk2Size atau lebih tepatnya:
4 + (8 + SubChunk1Size) + (8 + SubChunk2Size).
Ini adalah besar seluruh file dalam byte dikurangi 8
byte untuk 2 field yang tidak termasuk dalam hitungan: ChunkID dan ChunkSize
8 4 Format Terdiri atas kata “WAVE” (0x57415645 dalam
bentuk big-endian).
12 4 SubChunk1ID Terdiri atas kata “fmt “ (0x666d7420 dalam bentuk
big-endian).
16 4 SubChunk1Size 16 untuk jenis PCM.
20 2 AudioFormat PCM = 1 (Linear quantization). Nilai lebih dari 1 mengindikasikan fileWave kompresi.
22 2 NumChannels Mono = 1, Stereo = 2 dan seterusnya
24 4 SampleRate 8000, 44100, dan seterusnya dalam satuan Hz
28 4 ByteRate = SampleRate * NumChannels * BitsPerSample / 8
32 2 BlockAlign = NumChannels * BitsPerSample / 8
Jumlah byte untuk satu sampel termasuk semua
channel.
34 2 BitsPerSample 8 bits = 8, 16 bits = 16, dan seterusnya.
36 4 SubChunk2ID Terdiri atas kata “data” (0x64617461 dalam bentuk
big-endian).
40 4 SubChunk2Size = NumSamples * NumChannels * BitsPerSample / 8
Keterangan: Format “WAVE” terdiri atas 2 buah SubChunk2: “fmt ” dan “data”.
SubChunk “fmt “ menggambarkan format data sound.
SubChunk “data” terdiri atas ukuran besar data dan data sound
sebenarnya.
Sebagai contoh, berikut ini merupakan 72 byte pertama dari sebuah file Wave
yang ditampilkan dalam heksadesimal:
52 49 46 46 24 08 00 00 57 41 56 45 66 6d 74 20 10 00 00 00 01 00 02 00 22 56 00 00 88 58 01 00 04 00 10 00 64 61 74 61 00 08 00 00 00 00 00 00 24 17 1e f3 3c 13 3c 14 16 f9 18 f9 34 e7 23 a6 3c f2 24 f2 11 ce 1a 0d
Berikut ini (Gambar 2.5) interpretasi dari tiap byte pada fileWave di atas:
Gambar 2.5 Interpretasi tiap Byte pada File Wave (Gunawan, 2005)
Selain bentuk standar dari file Wave di atas, seperti yang dikemukakan sebelumnya file Wave dapat ditambahkan chunk-chunk lain. Penambahan ini tidak berpengaruh sebab suatu program yang membaca file Wave jika tidak memerlukan informasi pada chunk ini akan mengabaikannya dan mencari chunk lain yang diperlukannya. Sebagai contoh berikut ini ditampilkan suatu tabel sebuah file Wave
Tabel 2.9 Penambahan Chunk Lain Pada File Wave(Gunawan,2010)
Start
Byte
Chunk Chunk Field Name contents contents
(HEX)
bytes Format
0 RIFF Name "RIFF" 52 49 46 46 4 ASCII
4 Size 176444 3C B1 02
00
4 uInt32
8 WAVE Name "WAVE" 57 41 56 45 4 ASCII
12 Fmt Name "fmt " 66 6D 74
20
4 ASCII
16 Size 16 10 00 00 00 4 uInt32
20 wFormatTag 1 01 00 2 uInt16
22 nChannels 2 02 00 2 uInt16
24 nSamplesPerSec 44100 44 AC 00
00
4 uInt32
28 nAvgBytesPerSec 176400 10 B1 02
00
4 uInt32
32 nBlockAlign 4 04 00 2 uInt16
34 nBitsPerSample 16 10 00 2 uInt16
36 Rgad name "rgad" 72 67 61 64 4 ASCII
40 size 8 08 00 00 00 4 uInt32
44 fPeakAmplitude 1 00 00 80 3F 4 float32
48 nRadioRgAdjust 10822 46 2A 2 uInt16
50 nAudiophileRgAdjust 18999 37 4A 2 uInt16
52 Data name "data" 64 61 74 61 4 ASCII
56 size 176400 10 B1 02
00
4 uInt32
2.15 Hubungan Multimedia dengan Aplikasi Windows
Arsitektur dari pelayanan multimedia dirancang berdasarkan konsep dari extensibilitas (ekstensibility) dan device independence (kebebasan alat). Berdasarkan kata
multimedia dapat diasumsikan bahwa multimedia merupakan suatu wadah atau penyatuan beberapa media menjadi satu. Elemen-elemen dalam pembentukan aplikasi
multimedia adalah teks, gambar, suara dan video. Untuk itu ekstensibilitas memungkinkan arsitektur perangkat lunak dengan mudah mengakomodasikan lebih
canggih dalam teknologi tanpa perubahan pada arsitektur itu sendiri (Santi,2010).
Kebebasan alat memungkinkan aplikasi multimedia menjadi lebih mudah dikembangkan yang akan berjalan pada perangkat keras yang berbeda-beda. 3 (tiga)
elemen desain dari perangkat lunak sistem mendukung ekstensibilitas dan kebebasan
alat yaitu:
1. Lapisan translasi (MMSystem) yang mengisolasikan aplikasi dari driver peralatan dan memusatkan pada kode kebebasan alat.
2. Hubungan run-time yang memungkinkan lapisan translasi untuk menghubungkan dengan driver yang dibutuhkan.
3. Suatu bentuk yang diatur sesuai dan driver konsisten interface yang meminimalkan kode khusus dan membuat instalasi dan meningkatkan proses
menjadi lebih mudah.
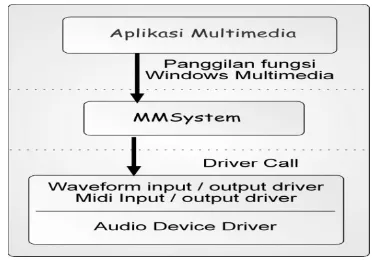
Untuk lebih jelasnya maka digambarkan bagaimana lapisan translasi
menterjemahkan sebuah fungsi multimedia menjadi panggilan kepada driver alat
audio:
Gambar 2.6 Lapisan-Lapisan Multimedia dengan Windows
Level Aplikasi
Level Translasi
2.7 Kompresi Data
Kompresi data dilakukan untuk mereduksi ukuran data atau file. Dengan melakukan kompresi atau pemadatan data maka ukuran file atau data akan lebih kecil sehingga dapat mengurangi waktu transmisi sewaktu data dikirim dan tidak banyak
menghabiskan ruang media penyimpan (Nadarajan, 2008).
2.7.1 Teori Kompresi Data
Dalam makalahnya di tahun 1948, “A Mathematical Theory of Communication”,
Claude E. Shannon merumuskan teori kompresi data. Shannon membuktikan adanya
batas dasar (fundamental limit) pada kompresi data jenis lossless. Batas ini, disebut dengan entropy rate dan dinyatakan dengan simbol H. Nilai eksak dari H bergantung pada informasi data sumber, lebih terperinci lagi, tergantung pada statistikal alami dari
data sumber. Adalah mungkin untuk mengkompresi data sumber dalam suatu bentuk
lossless, dengan laju kompresi (compression rate) mendekati H. Perhitungan secara matematis memungkinkan ini dilakukan lebih baik dari nilai H (Adhitama, 2009).
Shannon juga mengembangkan teori mengenai kompresi data lossy. Ini lebih dikenal sebagai rate-distortion theory. Pada kompresi data lossy, proses dekompresi data tidak menghasilkan data yang sama persis dengan data aslinya. Selain itu, jumlah
distorsi atau nilai D dapat ditoleransi. Shannon menunjukkan bahwa, untuk data sumber (dengan semua properti statistikal yang diketahui) dengan memberikan
pengukuran distorsi, terdapat sebuah fungsi R(D) yang disebut dengan rate-distortion function. Pada teori ini dikemukakan jika D bersifat toleransi terhadap jumlah distorsi, maka R(D) adalah kemungkinan terbaik dari laju kompresi (Dangarwala, 2010).
Ketika kompresi lossless (berarti tidak terdapat distorsi atau D = 0), kemungkinan laju kompresi terbaik adalah R(0) = H (untuk sumber alphabet yang
Teori kompresi data lossless dan teori rate-distortion dikenal secara kolektif sebagai teori pengkodean sumber (source coding theory). Teori pengkodean sumber menyatakan batas fundamental pada unjuk kerja dari seluruh algoritma kompresi data.
Teori tersebut sendiri tidak dinyatakan secara tepat bagaimana merancang dan
mengimplementasikan algoritma tersebut. Bagaimana pun juga algoritma tersebut
menyediakan beberapa petunjuk dan panduan untuk memperoleh unjuk kerja yang
optimal. Dalam bagian ini, akan dijelaskan bagaimana Shannon membuat model dari
sumber informasi dalam istilah yang disebut dengan proses acak (random process). Di bagian selanjutnya akan dijelaskan mengenai teorema pengkodean sumber lossless
Shannon, dan teori Shannon mengenai rate-distortion. Latar belakang mengenai teori probabilitas diperlukan untuk menjelaskan teori tersebut.
2.7.2 Pemodelan Sumber (Source Modeling)
Pada umumnya perpustakaan mempunyai pilihan buku-buku yang banyak, misalnya
terdapat 100 juta buku dalam perpustakaan tersebut. Tiap buku dalam perpustakaan ini
sangat tebal, sebagai contoh tiap buku mempunyai 100 juta karakter (atau huruf).
Ketika anda pergi ke perpustakaan tersebut, mengambil sebuah buku secara acak dan
meminjamnya. Buku yang dipilih tersebut merupakan informasi sumber yang akan
dikompresi. Buku yang terkompresi tersebut disimpan pada zip disk untuk dibawa pulang, atau ditransmisi secara langsung melalui internet ke rumah anda ataupun
bagaimana kasusnya.
Secara matematis buku yang dipilih tersebut didenotasikan sebagai:
X = (X1, X2, X3, X4, …)
Dimana X merepresentasikan seluruh buku, dan X1 merepresentasikan karakter pertama dari buku tersebut, X2 merepresentasikan karakter kedua, dan seterusnya. Meskipun pada kenyataannya panjang karakter dalam buku tersebut terbatas, secara
matematis diasumsikan mempunyai panjang karakter yang tidak terbatas. Alasannya
adalah buku tersebut terlalu tebal dan dapat dibayangkan jumlah karakternya terlalu
banyak. Untuk menyederhanakan hal tersebut, misalkan diasumsi semua karakter
dalam buku tersebut terdiri atas huruf kecil (‘a’ hingga ‘z’) atau SPACE. Sumber
A={a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z, SPACE}
Sekarang jika seorang yang ingin merancang suatu algoritma kompresi maka
sangat sulit baginya untuk mengetahui buku yang mana yang akan dipilih. Orang
tersebut hanya mengetahui bahwa seseorang akan memilih sebuah buku dari
perpustakaan tersebut. Dengan cara pandangnya, karakter-karakter dalam buku
merupakan (Xi, i = 1, 2 , …) merupakan variabel acak yang diambil dari nilai alphabet A. Keseluruhan buku, X merupakan urutan tak berhingga dari variabel acak, makanya X merupakan suatu proses acak. Ada beberapa cara untuk menyatakan model statistik dari buku tersebut:
A. Zero-Order Model. Tiap karakter distatistik secara bebas dari semua karakter dan 27 kemungkinan nilai dalam alphabet A dinyatakan sama seperti yang muncul. Jika model tersebut akurat, maka cara tipikal untuk membuka sebuah
buku adalah seperti berikut (Dangarwala, 2010)
rxkhrjffjuj zlpwcfwkcyj ffjeyvkcqsghyd qpaamkbzaacibzlhjqd
B. First-Order Model. Dalam bahasa Inggris diketahui beberapa huruf muncul lebih sering dibandingkan huruf yang lain. sebagai contoh, huruf ‘a’ dan ‘e’
lebih umum daripada huruf ‘q’ dan ‘z’. Jadi dalam model ini karakter masih
secara bebas terhadap satu sama lain, tetapi distribusi probabilitas dari
karakter-karakter tersebut menurut distribusi statistikal urutan pertama dari
teks bahasa Inggris. Teks yang secara tipikal dari model ini berbentuk seperti
ini:
ocroh hli rgwr nmielwis eu ll nbnesebya th eei alhenhttpa oobttva nah brl
C. Second-Order Model. Dua model sebelumnya diasumsi menurut statistik secara bebas dari satu karakter hingga karakter berikutnya. Ini tidak begitu
akurat dibandingkan dengan bahasa alami Inggris. Sebagai contoh, beberapa
huruf dalam kalimat tersebut hilang. Bagaimanapun juga, kita masih dapat
menerka huruf-huruf tersebut dengan mencarinya pada konteks kalimat. Ini
mengimplikasikan beberapa ketergantungan antara karakter-karakter. Secara
daripada karakter yang berhubungan jauh satu sama lainnya. Pada model ini,
karakter yang ada Xi bergantung pada karakter sebelumnya Xi−1, tetapi secara kondisional tidak bergantung dengan semua karakter (X1, X2, …, Xi−2). Menurut model ini, distribusi probabilitas dari karakter Xi beragram menurut karakter sebelumnya Xi−1. Sebagai contoh, huruf ‘u’ jarang muncul (probabilitas = 0.022). Bagaimanapun juga, jika dinyatakan karakter
sebelumnya adalah ‘q’ maka probabilitas dari ‘u’ dalam karakter berikutnya
lebih tinggi (probabilitas = 0.995). Teks tipikal untuk model ini terlihat seperti
berikut:
on ie antsoutinys are t inctore st be s deamy achin d ilonasive tucoowe at teasonare fuso tizin andy tobe seace ctisbe
D. Third-Order Model. Ini merupakan pengembangan model sebelumnya. Berikut ini merupakan karakter Xi yang bergantung pada dua karakter sebelumnya (Xi−2, Xi−1) tetapi secara kondisional tidak bergantung pada semua karakter sebelumnya sebelum: (X1, X2,…, Xi−3). Pada model ini, distribusi dari
Xi beragam menurut (Xi−2, Xi−1). Teks tipikal dari model ini seperti bentuk
berikut ini:
in no ist lat whey cratict froure birs grocid pondenome of demonstures of the reptagin is regoactiona of cre
Penyusunan kembali menjadi teks Inggris asli akan memudahkan tiap teks di
atas dapat dibaca.
E. General Model. Pada model ini, buku X merupakan proses acak seimbang yang berubah-ubah. Properti statistikal pada model seperti ini terlalu kompleks
untuk dipertimbangkan sebagai tujuan praktikal. Model ini disukai hanya
dalam sudut pandang teoritikal saja.
Model A di atas merupakan kasus khusus dari model B. Model B merupakan
kasus spesial dari Model C. Model C merupakan kasus spesial dari model D. Model D
2.7.3 Entropi Rate Dari Suatu Sumber
Entropy rate dari suatu sumber adalah suatu bilangan yang bergantung hanya pada statistik alami sumber. Jika sumber mempunyai suatu model sederhana, maka nilai
tersebut dapat dengan mudah dikalkulasi. Berikut ini, contoh dari sumber yang
berubah-ubah:
X = (X1, X2, X3, X4, ...),
Dimana X merupakan teks dalam bahasa Inggris. Maka model statistik sumber di atas adalah sebagai berikut:
A. Zero-Order Model. Karakter-karakter secara statistik bersifat bebas untuk setiap alphabet A dan secara bersamaan muncul. Misalkan m merupakan ukuran dari alphabet. Dalam kasus ini, entropy rate dapat dinyatakan dengan persamaan:
H= log2m bits/char ... (2.3) Untuk teks dalam bahasa Inggris, ukuran alphabet m = 27. Jadi, jika ini merupakan model akurat untuk teks dalam bahasa Inggris, maka entropy rate
akan bernilai H = log2 27 = 4,75 bits/character.
B. First-Order Model. Karakter-karakter secara statistik bersifat bebas. Misalkan
m adalah ukuran dari alphabet dan misalkan Pi merupakan probabilitas dari huruf ke-i dalam alphabet.
Entropy ratenya adalah: H= ∑��=1�����2�� bits/char ... (2.4) Dengan menggunakan first-order distribution, entropy rate dari teks Inggris sebesar 4,07 bits/character.
A. Second-Order Model. Misalkan Pji adalah probabilitas yang berkondisi untuk karakter yang berlaku saat ini dan merupakan huruf ke-j dalam alphabet yang
merupakan karakter sebelumnya yaitu huruf ke-i. maka entropy ratenya adalah:
H= ∑�=1� ��∑�=1� ��|����2��|� bits/char ... (2.5)
D. Third-Order Model. Misalkan Pkj,i adalah probabilitas berkondisi yang berlaku untuk karakter saat ini dan merupakan karakter ke-k dalam alphabet
yang didapat dari karakter sebelumnya yaitu huruf ke-j dan satu karakter
sebelum huruf ke-i. Entropy rate untuk model tersebut adalah:
H= ∑��=1��∑�=1� ��|�∑�=1� ��|�,����2��|�,� bits/char ... (2.6)
Dengan menggunakan third-order distribution, entropy rate dari teks Inggris dengan model di atas adalah 2,77 bits/character.
B. General Model. Misalkan Bn merepresentasikan karakter n pertama. Entropy
rate dalam kasus yang umum dinyatakan dengan persamaan berikut ini:
H = lim�→∞1
�∑ �(�)����2�(�)� bits/char ... (2.7) Dimana seluruh jumlah dari semua mn merupakan kemungkinan nilai dari Bn.
Adalah tidak mungkin untuk menghitung entropy rate menurut persamaan di atas. Dengan menghitung metoda prediksi, Shannon mampu memperkirakan
entropy rate dari ke-27 teks Inggris adalah 2,3 bits/character.
Hanya terdapat satu entropy rate untuk suatu sumber yang diberikan. Semua definisi di atas untuk entropy rate saling bersesuaian satu sama lainnya.
2.7.4 Dalil Shannon Mengenai Lossless Source Coding
Dalil Shannon mengenai Lossless Source Coding berdasarkan pada konsep dari block coding. Untuk mengilustrasikan konsep tersebut, diperkenalkan suatu sumber informasi khusus dimana suatu alphabet terdiri atas hanya dua huruf:
A = {a,b}
Di sini, huruf ‘a’ dan ‘b’ sama-sama mempunyai kemungkinan untuk muncul.
Bagaimanapun juga, misalkan ‘a’ muncul dalam karakter sebelumnya, probabilitas ‘a’
untuk muncul lagi dalam karakter saat ini adalah 0,9. Sama halnya dengan ‘b’ muncul
sebagai karakter sebelumnya, probabilitas ‘b’ akan muncul sekali lagi sebagai karakter
saat ini adalah 0,9. Ini dikenal sebagai Binary Symmetric Markov Source.
1. First-Order Block Code. Tiap karakter dipetakan sebagai suatu bit tunggal.
B1 P(B1) Codeword
a 0.5 0
b 0.5 1
R =1 bit/character
Contoh:
Original Data : a a a a a a a b b b b b b b b b b b b b a a a a
Compressed Data : 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0
Sebagai catatan 24 bit dipakai untuk merepresentasi 24 karakter − rata-rata 1
bit / karakter.
2. Second-Order Block Code. Tiap pasangan karakter dipetakan dengan satu, dua, atau tiga bit.
B2
P(B2) Codeword
aa 0.45 0
bb 0.45 10
ab 0.05 110
ba 0.05 111
R=0.825 bits/character
Contoh:
Original Data : a a a a a a a b b b b b b b b b b b b b a a a a
Compressed Data : 0 0 0 110 10 10 10 10 10 10 10 10
Sebagai catatan 20 bit dipakai untuk merepresentasi 24 karakter − rata-rata
0,83 bit / karakter.