KLASIFIKASI SPAMMER PADA TWITTER BERDASARKAN
PERILAKU PENGGUNA MENGGUNAKAN
ALGORITME C5.0
TANTRIYANA PUSPA ANGGITASARI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Klasifikasi Spammer pada Twitter Berdasarkan Perilaku Pengguna Menggunakan Algoritme C5.0 adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
TANTRIYANA PUSPA ANGGITASARI. Klasifikasi Spammer pada Twitter Berdasarkan Perilaku Pengguna Menggunakan Algoritme C5.0. Dibimbing oleh IMAS SUKAESIH SITANGGANG dan HUSNUL KHOTIMAH.
Twitter menjadi salah satu media sosial yang populer di dunia maya. Twitter dapat dijadikan sarana penyebaran informasi dalam status pengguna, hal ini membuka peluang bagi beberapa pihak untuk menyebarkan spam. Penelitian ini bertujuan untuk mengidentifikasi karakteristik perilaku spammer di Twitter. Penelitian ini difokuskan terhadap perilaku pengguna bukan pada isi konten tweet pada Twitter. Algoritme klasifikasi yang digunakan adalah algoritme C5.0 yang menghasilkan model klasifikasi pohon keputusan dan berbasis aturan. Klasifikasi dilakukan dengan data Twitter pada periode Januari 2015–Agustus 2015. Penelitian ini menggunakan 11 atribut yang menunjukan perilaku pengguna Twitter. Klasifikasi spammer menggunakan algoritme C5.0 telah berhasil dilakukan. Untuk model berbasis pohon keputusan menghasilkan 4 aturan dengan akurasi 91%, sedangkan model berbasis aturan menghasilkan 3 buah aturan dengan akurasi 91%. Atribut yang muncul pada aturan pohon keputusan dan berbasis aturan adalah usia akun dan rataan tweet per hari.
Kata kunci: C5.0, klasifikasi spammer, perilaku spammer, spammer, Twitter
ABSTRACT
TANTRIYANA PUSPA ANGGITASARI. Classification of Spammers on the Twitter Based on User Behaviour using C5.0 Algorithm. Supervised by IMAS SUKAESIH SITANGGANG and HUSNUL KHOTIMAH.
Twitter has became one of the most popular social media in the internet. Twitter could be used as a facility to spread message in the form of user status. This situation opens the chance for some people to spread spam. The purpose of this research is to identify the spammer‟s behaviors on Twitter. This research focused on user‟s behavior rather than the tweet content of Twitter. The classification algorithm used is C5.0 that produces tree-based classification model and rule based model. Classification was performed on the Twitter data in the period of January 2015–August 2015. This research used 11 attributes that indicate user‟s behavior. Spammer classification that uses the C5.0 algorithm was successfully performed. Decision tree based models produce 4 classification rules with accuracy 91%, whereas the rule based model produce 3 classification rules with accuracy 91%. The attributes that appeared on the tree and the rule based model are user‟s age and average tweet per day.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
KLASIFIKASI SPAMMER PADA TWITTER BERDASARKAN
PERILAKU PENGGUNA MENGGUNAKAN
ALGORITME C5.0
TANTRIYANA PUSPA ANGGITASARI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Penguji:
Judul Skripsi : Klasifikasi Spammer pada Twitter Berdasarkan Perilaku Pengguna Menggunakan Algoritme C5.0
Nama : Tantriyana Puspa Anggitasari NIM : G64134036
Disetujui oleh
Dr Imas Sukaesih Sitanggang, SSi, MKom Pembimbing I
Husnul Khotimah, SKomp, MKom Pembimbing II
Diketahui oleh
Dr Ir Agus Buono, MSi, MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga penulis dapat menyelesaikan skripsi yang berjudul “Klasifikasi Spammer pada Twitter Berdasarkan Perilaku Pengguna Menggunakan Algoritme C5.0”.
Skripsi ini disusun sebagai syarat mendapatkan gelar Sarjana Komputer (SKomp) pada Program Sarjana Ilmu Komputer di Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor (IPB). Penulis menyadari bahwa selama mengerjakan tugas akhir ini mengalami berbagai kendala. Akan tetapi berkat kerja sama dan bimbingan dari berbagai pihak dan atas berkat rahmat Allah subhanahu wa ta’ala kendala yang dihadapi dapat diselesaikan dengan baik. Untuk itu penulis ucapkan terima kasih kepada mamah, papah, serta seluruh keluarga atas segala dukungan, doa dan kasih sayangnya. Penulis juga ucapkan terima kasih kepada Ibu Dr Imas Sukaesih Sitanggang, SSi, MKom dan Ibu Husnul Khotimah, SKomp, MKom selaku pembimbing yang telah sabar, tulus, dan ikhlas meluangkan waktu, tenaga, dan pikiran dalam memberikan bimbingan, motivasi, arahan dan saran yang bermanfaat bagi penulis. Penulis juga ucapkan terima kasih kepada Bapak Muhammad Asyhar Agmalaro, SSi, MKom selaku penguji atas saran dan masukan yang diberikan. Begitu pula rasa terima kasih penulis kepada rekan-rekan Program Alih Jenis angkatan 8 yang menjadi bagian hidup penulis selama menempuh pendidikan di Program Alih Jenis Ilmu Komputer FMIPA IPB.
Semoga karya ilmiah ini bermanfaat.
DAFTAR ISI
DAFTAR TABEL ix
DAFTAR GAMBAR ix
DAFTAR LAMPIRAN ix
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
TINJAUAN PUSTAKA 3
Microblogging 3
Twitter 3
Spammer Detection 3
Algoritme C5.0 4
METODE 5
Tahapan Penelitian 5
Pengumpulan Data 6
Praproses Data 6
Pembangunan Model Klasifikasi menggunakan Algoritme C5.0 7
Perhitungan Akurasi 7
Analisis dan Evaluasi Model Klasifikasi 8
Lingkungan Pengembangan 8
HASIL DAN PEMBAHASAN 8
Pengumpulan Data 8
Praproses Data 10
Pembuatan Model Klasifikasi menggunakan Algoritme C5.0 14
Karakteristik Spammer 15
Analisis dan Evaluasi Model Klasifikasi 17
SIMPULAN DAN SARAN 18
Saran 18
DAFTAR PUSTAKA 18
DAFTAR TABEL
1 Confusion matrix hasil klasifikasi 7
2 Hasil seleksi pada fungsi getUser 11
3 Contoh beberapa dataset pada fungsi userTimeline 11
4 Hasil seleksi pada fungsi userTimeline 11
5 Hasil penggabungan fungsi getUser dan userTimeline 12
6 Penggunaan atribut dalam model klasifikasi 15
7 Confusion matrix untuk model deteksi spammer 17
DAFTAR GAMBAR
1 Tahapan penelitian 6 2 Tahapan praproses data 6 3 Tampilan aplikasi pengelolaan pada Twitter 9 4 Model pohon keputusan untuk klasifikasi spammer dan nonspammer 15 5 Sebaran usia akun 16 6 Sebaran rataan tweet per hari 17DAFTAR LAMPIRAN
1 Fungsi pada package twitteR yang digunakan pada penelitian 20 2 Dataset sebanyak 120 akun Twitter yang digunakan pada penelitian 21 3 Contoh penggunaan algoritme C5.0 23PENDAHULUAN
Latar Belakang
Twitter merupakan sebuah situs microblogging yang populer (Hu et al. 2013). Twitter menjadi salah satu media sosial yang populer di Indonesia. Kemenkominfo (2013) menyatakan bahwa pengguna Internet di Indonesia mencapai 63 juta orang, 95% di antaranya mengakses media sosial. Indonesia menempati peringkat ke-5 untuk pengguna terbanyak Twitter. Twitter digandrungi oleh semua usia mulai dari remaja hingga dewasa. Twitter dapat mengirimkan pesan pendek dengan jumlah karakter maksimal 140 karakter. Pesan tersebut biasa disebut dengan tweet. Twitter dikategorikan sebagai microblogging service. Microblogging merupakan blog yang memungkinkan penggunanya untuk mengirimkan sebuah pesan teks (status) yang singkat, baik untuk dilihat semua orang atau kelompok terbatas yang dipilih oleh pengguna tersebut.
Twitter menyediakan informasi begitu besar. Ada banyak informasi dalam Twitter yang sifatnya up to date dan informasi tersebut sangat bermanfaat bagi sebagian orang. Namun, meskipun menarik dengan adanya kemudahan dalam penyebaran berita dan memungkinkan pengguna untuk membahas berita tersebut dalam status mereka, layanan ini juga membuka peluang adanya spam (Benevenuto et al. 2010).
Penelitian deteksi spammer pada Twitter dapat dilakukan 2 cara yaitu berdasarkan perilaku pengguna dan berdasarkan konten isi dari tweet. Penelitian yang menyajikan deteksi spammer berdasarkan konten terdapat pada penelitian Ghosh et al. (2012) mengenai fungsi search pada Twitter yang memudahkan pencarian trending topic dan berita terkini yang menarik perhatian spammer. Tweet spammer biasanya mendorong pengguna untuk menyebarkan informasi dengan cara mengirim tautan URL dengan tujuan agar pengguna Twitter mengunjungi URL (Song et al. 2011) selain itu spammer juga melakukan banyak mention ke akun non followers. Hasil penelitian Grier et al. (2011) juga menyebutkan bahwa Twitter spam lebih berhasil memaksa pengguna untuk mengklik URL dibanding email spam dengan rasio klik 0.13%. Perkembangan spamming tidak terhenti hanya mengirimkan tweet sampah, tetapi sudah menjurus ke arah penipuan. Spam yang terkirim kepada pengguna dapat menimbulkan ketidaknyamanan bagi penerimanya. Hal ini dapat diantisipasi dengan mendeteksi akun yang merupakan spammer.
2
mudah dan lebih cepat dibandingkan penyeleksian berdasarkan konten atribut. Penyeleksian berdasarkan konten atribut perlu memperhatikan satu per satu kata dalam teks yang di posting oleh user, sedangkan penyeleksian berdasarkan perilaku hanya melihat sifat dari user seperti jumlah followers, jumlah following, jumlah tweet, rasio followers per following, usia akun pengguna, rataan tweet per hari, jumlah reply, rataan, median, minimum, dan maksimum selang waktu antara tweet. Model klasifikasi dibangun dengan menggunakan bahasa R dengan package C50. Algoritme C5.0 adalah salah satu algoritme data untuk melakukan klasifikasi dengan pemodelan pohon keputusan (decision tree) dan pemodelan berbasis aturan (rule based). Model klasifikasi ini diharapkan dapat memberikan informasi karakteristik perilaku pengguna spammer dan nonspammer.
Perumusan Masalah
Perumusan masalah dalam penelitian ini adalah:
1 Bagaimana mengklasifikasikan spammer atau nonspammer pada Twitter degan menggunakan algoritme C5.0?
2 Bagaimana karakteristik perilaku spammer pada akun Twitter? Tujuan Penelitian
Tujuan penelitian ini adalah:
1 Membuat model klasifikasi perilaku akun spammer atau nonspammer di Twitter menggunakan metode pohon keputusan dan berbasis aturan.
2 Menentukan karakteristik perilaku spammer berdasarkan pemodelan algoritme C5.0.
Manfaat Penelitian
Penelitian ini bisa menghasilkan pemodelan klasifikasi spammer dan dapat mengetahui karakteristik perilaku pengguna akun spammer atau nonspammer pada Twitter.
Ruang Lingkup Penelitian
Ruang lingkup pada penelitian ini antara lain:
1 Penelitian ini dilakukan pada media sosial Twitter dengan jumlah 120 akun Twitter.
2 Penelitian ini fokus terhadap perilaku user, bukan pada isi konten tweet pada Twitter dan menggunakan 11 atribut yaitu jumlah followers, jumlah following, jumlah tweet, rasio followers per following, usia akun pengguna, rataan tweet per hari, jumlah reply, rataan, median, minimum, dan maksimum selang waktu antara tweet.
3
TINJAUAN PUSTAKA
Microblogging
Microblogging adalah salah satu jenis komunikasi. Pengguna dapat menulis dan mempublikasikan status (kurang dari 200 karakter) yang dikirim melalui instant messaging, email atau web (Java et al. 2007). Salah satu microblog yang banyak dipakai oleh pengguna adalah Twitter. Situs web jejaringan sosial yang memiliki fitur microblog selain Twitter adalah Facebook dan MySpace. Beberapa layanan microblogging menawarkan fitur seperti pengaturan privasi untuk mengontrol siapa saja yang dapat membaca microblog pengguna. Penelitian ini hanya mengambil data yang bersifat publik.
Twitter merupakan salah satu contoh microblogging yang banyak dipakai. Pada Twitter, pengguna tidak hanya bisa membaca tweet tetapi pengguna bisa memberi tautan tweet melalui antarmuka situs web, pesan singkat, atau melalui aplikasi untuk perangkat lunak seluler. Twitter mengalami perkembangan yang sangat pesat. Twitter dapat mengirimkan pesan pendek dengan jumlah karakter maksimal 140 karakter untuk setiap tweet (Benevenuto et al. 2010).
Twitter menyediakan Application Programming Interface (API) yang memudahkan setiap orang untuk mengambil data dari Twitter. Twitter API terdiri dari dua komponen yang berbeda: REST dan SEARCH API. REST API memungkinkan developer Twitter untuk mengakses data core Twitter (tweet, timeline, user data). SEARCH API digunakan untuk membuat query tweet, termasuk menyediakan informasi tentang trending topics (Wang 2010).
Spammer Detection
Spam adalah pesan atau email yang dikirimkan secara massal tanpa dikehendaki oleh penerimanya. Arti dari “secara massal“ yaitu pesan yang merupakan bagian dari sekumpulan pesan yang memiliki isi yang sama (Spamhaus 2004). Tindakan menyebarkan spam disebut dengan spamming, sedangkan orang yang melakukan spamming disebut spammer.
4
Algoritme C5.0
Algoritme C5.0 merupakan perluasan dari algoritme C4.5. Algoritme C5.0 adalah salah satu algoritme klasifikasi yang terdapat dalam data mining yang khususnya diterapkan pada decision tree. C5.0 adalah algoritme klasifikasi yang dapat menangani kumpulan data besar. Govindarajan (2007) menyatakan bahwa algoritme C5.0 meningkatkan kecepatan sekitar 90% antara 5.7 sampai dengan 240 kali lebih cepat daripada C4.5. Algoritme C5.0 lebih baik daripada C4.5 dalam hal akurasi, kecepatan dan memori (Rulequest 2012). Menurut Patil et al. (2012) pemilihan atribut dalam algoritme C5.0 diproses dengan menghitung besarnya nilai information gain. Dalam memilih atribut untuk memecahkan objek harus dipilih atribut yang menghasilkan information gain paling besar.
Model klasifikasi yang digunakan adalah pohon keputusan (decision tree) dan berbasis aturan (rule based). Model pohon keputusan merupakan suatu diagram yang mirip dengan struktur pohon seperti flowchart yang masing-masing simpul merupakan atribut, masing-masing cabang menunjukan nilai dari atribut, dan masing-masing simpul daun menunjukan label kelas. Pada model berbasis aturan terdiri atas kondisi if-then yang merupakan penurunan dari model pohon keputusan (Han et al. 2012).
Algoritme Generate_decision_tree adalah sebagai berikut: 1 D, merupakan dataset yang telah ditentukan label kelasnya.
2 Attribute_list, merupakan atribut kandidat yang menggambarkan suatu dataset. 3 Attribute_selection_method, merupakan suatu prosedur untuk memilih atribut
yang mengolah tuple yang diberikan berdasarkan kelas masing-masing. Algoritme klasifikasi pohon keputusan adalah sebagai berikut (Han et al. 2012): 1 Buat simpul N.
2 Jika tuple di D memiliki kelas yang sama yaitu C maka jadikan N sebagai simpul daun dan beri label C.
3 Jika attribute_list kosong, maka jadikan simpul N sebagai simpul daun dan diberi label dengan kelas yang terbanyak.
4 Terapkan attribute_selection_attribute untuk mendapatkan atribut split yang terbaik.
5 Beri label simpul N dengan atribut split.
6 Jika atribut split bernilai diskret dan dapat dipisahkan, maka 7 Attribute_list <- attribute_list – atribut split
8 Untuk setiap nilai j dari atribut split, yaitu
Buat Dj menjadi kumpulan data tuple untuk memenuhi hasil j.
Jika Dj kosong, maka tambahkan simpul daun dengan label dari kelas yang terbanyak.
Selainnya, tambah cabang baru dengan memanggil fungsi Generate_decision_tree (Dj, attribute_list) ke simpul N.
9 Kembali ke N.
5 atribut yang didefinisikan pada atribut A dapat dilihat pada Persamaan 1 (Han et al. 2012):
Info(D) = -∑ l (1) dimana Pi adalah peluang kelas dalam output seperti pada kelas |Ci.D|/|D|. Atribut A memiliki nilai tertentu (a1, a2, …, av). Atribut A dapat digunakan pada partisi D ke dalam v subset (D1,D2,…,Dv), dimana Dj berisi sample pada D yang bernilai aj pada A. Jika A dipilih sebagai atribut tes (sebagai contoh atribut untuk split), maka subset ini akan berhubungan pada cabang dari node himpunan D, untuk mendapatkan informasi nilai subset dari atribut A tersebut maka digunakan formula pada Persamaan 2 (Han et al. 2012):
InfoA(D) = -∑
D
D D
(2)
Untuk mendapatkan nilai gain yang diperoleh pada atribut A dapat dilihat pada Persamaan 3 sebagai berikut:
Gain (A) = Info(D) – InfoA(D) (3) Gain(A) menyatakan bahwa ada berapa banyak cabang yang akan diperoleh pada A. Atribut A dengan information gain tertinggi, maka Gain(A) dipilih sebagai atribut pada node.
METODE
Penelitian ini difokuskan terhadap perilaku pengguna sebanyak 11 atribut, dan tidak menggunakan isi konten tweet pada Twitter. Data yang digunakan dalam penelitian ini adalah data yang diambil dari Twitter menggunakan Twitter API. Akun yang digunakan terdiri dari 99 akun perorangan dan 21 akun instansi atau lembaga. Data berjumlah 120 data dan diperoleh selama periode Januari 2015 sampai dengan Agustus 2015.
Tahapan Penelitian
6
Gambar 1 Tahapan penelitian
Pengumpulan Data
Tahap pertama adalah pengumpulan data. Data Twitter digunakan untuk mendapatkan informasi yang dibutuhkan pada penelitian. Pengambilan data Twitter menggunakan perangkat lunak Rstudio 0.98.1102 yang didukung dengan package twitteR. Package twitteR merupakan sebuah package yang dapat terhubung dengan Twitter API. Package twitteR memerlukan beberapa nilai atribut yang dibutuhkan yaitu consumer key, consumer secret, acces token, dan acces token secret, untuk mendapatkan nilai atribut tersebut harus melakukan koneksi R terlebih dahulu pada Twitter. Setelah berhasil membuat koneksi dari R ke Twitter API, langkah yang dilakukan selanjutnya adalah:
1 Mencari akun spammer dan nonspammer sebanyak 120 data akun pengguna yang terdiri dari 99 akun perorangan dan 21 akun instansi atau lembaga pada Twitter.
2 Setiap akun diberi label secara manual yaitu spammer dan nonspammer.
3 Mengambil data dari R yang sudah terhubung dengan Twitter API. Fungsi pada package twitteR yang digunakan pada penelitian ini dapat dilihat pada Lampiran 1.
Praproses Data
Tahapan ini melakukan pemilihan data yang digunakan pada penelitian. Tahapan praproses data dapat dilihat pada Gambar 2.
Gambar 2 Tahapan praproses data
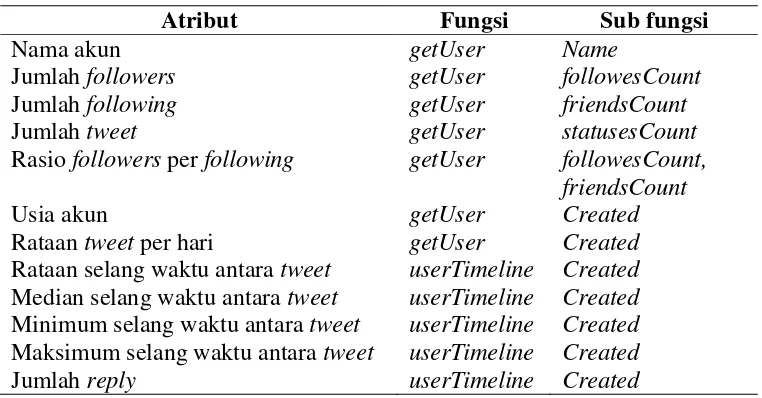
7 tentang suatu akun seperti nama akun dan jumlah tweet, sedangkan fungsi userTimeline menyediakan data tentang status yang pernah di posting oleh pengguna. Data dari kedua fungsi ini diseleksi dan dilakukan transformasi untuk mendapatkan atribut perilaku pengguna. Untuk setiap akun akan memiliki atribut seperti jumlah followers, jumlah following, jumlah tweet, rasio followers per following, usia akun pengguna, rataan tweet per hari, jumlah reply, rataan, median, minimum, dan maksimum selang waktu antara tweet dengan memiliki 2 macam label yaitu spammer dan nonspammer.
Pembangunan Model Klasifikasi menggunakan Algoritme C5.0
Tahap ini membangun model klasifikasi menggunakan algoritme C5.0. Algoritme C5.0 bekerja untuk menghasilkan aturan-aturan klasifikasi dalam bentuk pohon keputusan (decision tree) dan berbasis aturan (rule based). Algoritme ini menggunakan ukuran information gain dalam membuat pohon keputusan. Pembagian dataset pada penelitian ini sebesar 90% data latih dan 10% data uji. Setelah pembagian dataset selesai dilakukan, pembangunan model klasifikasi dilakukan menggunakan package C50.
Perhitungan Akurasi
Penelitian ini dibutuhkan beberapa alat ukur antara lain confusion matrix. Confusion matrix mengandung informasi tentang hasil aktual dan prediksi dari proses klasifikasi yang dilakukan oleh sistem (Han et al. 2012). Tabel 1 merupakan bentuk dari confusion matrix.
Tabel 1 Confusion matrix hasil klasifikasi
Kelas aktual Kelas prediksi
Nonspammer Spammer
Nonspammer TP FN
Spammer FP TN
Keterangan sel dalam confusion matrix sebagai berikut:
True Positive (TP), yaitu akun dari kelas nonspammer yang benar diklasifikasikan sebagai nonspammer.
True Negative (TN), yaitu akun dari kelas spammer yang benar diklasifikasikan sebagai spammer.
False Positive (FP), yaitu akun dari kelas spammer yang salah diklasifikasikan sebagai nonspammer.
False Negative (FN), yaitu akun dari kelas nonspammer yang salah diklasifikasikan sebagai spammer.
8
Akurasi = N
N N (4)
Selain dari pengukuran akurasi, evaluasi juga dilakukan terhadap sensitivity dan specificity. Sensitivity adalah kemampuan model untuk mengenal kelas nonspammer untuk mendapatkan nilai sensitivity adalah (Han et al. 2012)
Sensitivity = N (5) Specificity adalah kemampuan model untuk mengenal kelas spammer untuk mendapatkan nilai specificity adalah (Han et al. 2012)
Specificity = N
N (6)
Analisis dan Evaluasi Model Klasifikasi
Tahap ini menganalisis dan mengevaluasi dataset Twitter dengan menggunakan data Twitter yang baru. Data tersebut merupakan lapisan penjelas yang diprediksi menggunakan algoritme C5.0.
Lingkungan Pengembangan
Spesifikasi perangkat keras dan perangkat lunak yang digunakan untuk penelitian ini adalah sebagai berikut:
1 Perangkat keras berupa komputer personal dengan spesifikasi sebagai berikut
Processor Intel® CoreTM i5-2410M CPU @2.30GHz
RAM 6 GB
Monitor LCD 14.0” HD
Harddisk 512 GB HDD 2 Perangkat lunak:
Sistem Operasi Windows 8.1
Bahasa pemograman R versi 3.12
RStudio versi 0.98.1102 dengan memanfaatkan package twitteR untuk menghubungkan dengan Twitter API, package C5.0 untuk klasifikasi data, package Caret untuk pembagian data latih dan data uji.
HASIL DAN PEMBAHASAN
Pengumpulan Data
9 dibuat. Key tersebut diperlukan untuk melakukan authorization. Tampilan aplikasi pengelolaan pada Twitter dapat dilihat pada Gambar 3.
Gambar 3 Tampilan aplikasi pengelolaan pada Twitter
Setelah tahap pembuatan aplikasi pengelolaan Twitter selesai dilakukan, koneksi R ke Twitter API memerlukan package twitteR. Package twitteR memerlukan 3 package yaitu RCurl, ROAuth, dan rjson. Koneksi ke Twitter dilakukan melalui langkah-langkah:
Ketika pengguna mengakses R melalui jaringan internet, server R akan merespon dan memanggil library twitteR, untuk mengambil data Twitter.
Library(twitteR)
Library twitteR melakukan otorisasi terlebih dahulu sebelum memanggil RCurl untuk meminta sertifikasi hak otoritas. Package RCurl digunakan untuk mengunduh fail pada „http://curl.haxx.se/ca/cacert.pem‟ dan mengembalikan pada library twitteR dalam bentuk fail.
download.file(url=’http://curl.haxx.se/ca/cacert.pem’
,destfile=’cacert.pem’)
Library ROAuth melakukan otorisasi dengan Twitter menggunakan sertifikat yang telah dipanggil oleh library RCurl. Package ROAuth diperlukan untuk proses authorization. Proses authorization memerlukan consumer key dan consumer secret. Pada saat proses authorization, R secara otomatis membuka browser untuk melakukan verifikasi dengan aplikasi Twitter dan muncul kode numerik secara acak. Kode pada R untuk melakukan proses authorization sebagai berikut:
requestURL<-“https://api.twitter.com/oauth/request_token”
accesURL<-“https://api.twitter.com/oauth/acces_token” #proses authorization
authURL<-https://api.twitter.com/oauth/authorize consumerKey <- “Your Consumer Key”
10
Pengguna memasukkan kode acak kemudian server menerima verifikasi tersebut maka terhubunglah server dengan Twitter. Tahap verifikasi selesai, fail disimpan dengan nama twitter_credentials. Setelah semua tahap selesai, fail dapat langsung dipanggil tanpa harus melakukan tahapan dari awal. Kode pada R sebagai berikut:
twitCred$handshake(cainfo=”cacert.pem”)
registerTwitterOAuth(twitCred)
save(list=”twitCred”,file=”twitteR_credentials”)
Tahap membuat koneksi R ke Twitter selesai dilakukan, kemudian mencari akun spammer dan nonspammer sebanyak 120 data akun Twitter yang dapat dilihat pada Lampiran 2. Data tersebut diambil secara manual kemudian setiap akun diberi label secara manual yaitu spammer dan nonspammer.
Untuk menentukan label spammer atau nonspammer pada penelitian ini hanya melihat 1 halaman pertama dari timeline pengguna tersebut, jika user mengirimkan tweet ke banyak orang dengan teks yang sama dalam waktu yang singkat, isi tweet hanya promosi, dan tweet berisi URL yang tidak jelas maka user tersebut diberi label sebagai spammer. Setiap akun akan memiliki 11 atribut seperti jumlah followers, jumlah following, jumlah tweet, rasio followers per following, usia akun pengguna, rataan tweet per hari, jumlah reply, rataan, median, minimum, dan maksimum selang waktu antara tweet. Data ini akan digunakan untuk mendapatkan informasi yang dibutuhkan pada penelitian, data tersebut diperoleh dari Twitter API.
Praproses Data
Tahap pengumpulan data selesai dilakukan, kemudian dilakukan praproses data. Tahap ini melakukan pemilihan atribut pada package twitteR yang terdapat di R dan atribut tersebut digunakan pada penelitian. Tahap praproses data terdiri atas 2 tahap, yaitu seleksi data dan transformasi data.
Seleksi Data
Seleksi data dilakukan untuk memilih atribut yang digunakan pada fungsi getUser. Langkah pertama yang harus dilakukan adalah memasukkan satu per satu nama user pada sintaks R. Kode pada sintaks R untuk memperoleh nilai atribut yaitu getUser(“nama_akun”,cainfo=”cacert.pem), nama_akun
merupakan nama user yang dicari dan cacert.pem merupakan fail yang berisi sertifikasi otoritas publik.
11 Tabel 2 Hasil seleksi pada fungsi getUser
Fungsi Atribut Keterangan
Tahap ini dilakukan penyeleksian atribut pada fungsi userTimeline. Kode
pada sintaks R untuk memperoleh atribut yaitu
userTimeline(“nama_akun”,n,cainfo=”cacert.pem). n adalah
banyaknya tweet yang diambil, maksimal jumlah tweet yang dapat dimasukkan sebanyak 3200 tweets dan cacert.pem merupakan fail yang berisi otoritas publik. Contoh hasil fungsi userTimeline seperti pada Tabel 3.
Tabel 3 Contoh beberapa dataset pada fungsi userTimeline
Text Favorite favoriteC replyToS created Truncated replyTo
1 Selamat Pa FALSE 4 NA 4/12/201 FALSE NA
Fungsi userTimeline memiliki 16 atribut, namun tidak semua atribut dibutuhkan pada penelitian ini sehingga dipilih 2 atribut. Atribut tersebut dapat dilihat pada Tabel 4.
Tabel 4 Hasil seleksi pada fungsi userTimeline
Fungsi Atribut Keterangan
userTimeline Created Waktu status dibuat
12
Tabel 5 Hasil penggabungan fungsi getUser dan userTimeline Atribut Fungsi Sub fungsi
Nama akun getUser Name
Jumlah followers getUser followesCount
Jumlah following getUser friendsCount
Jumlah tweet getUser statusesCount
Rasio followers per following getUser followesCount, friendsCount
Usia akun getUser Created
Rataan tweet per hari getUser Created
Rataan selang waktu antara tweet userTimeline Created Median selang waktu antara tweet userTimeline Created Minimum selang waktu antara tweet userTimeline Created Maksimum selang waktu antara tweet userTimeline Created
Jumlah reply userTimeline Created
Atribut nama akun, jumlah followers, jumlah following, dan jumlah tweet didapat secara otomatis ketika memanggil fungsi getUser, sedangkan 8 atribut lainnya harus dilakukan pencarian dengan menggunakan fungsi getUser atau userTimeline. Cara perhitungan nilai dari 8 atribut tersebut adalah:
Menghitung rasio followers per following
Langkah pertama yang harus dilakukan adalah menghitung jumlah followers dan jumlah following, kedua atribut tersebut bisa didapatkan secara otomatis ketika memanggil fungsi getUser. Setelah mendapatkan kedua atribut lakukan perhitungan rasio followers per following. Perhitungannya menggunakan rumus pada Persamaan 7.
Rasio followers per following = la ll la ll
(7)
Menghitung usia akun
Tahap ini membutuhkan atribut created pada fungsi getUser, untuk menghitung usia akun menggunakan tipe data POSIXct. Langkah pertama yang harus dilakukan adalah melihat waktu akun pengguna dibuat pada atribut created, kemudian lakukan perhitungan selisih waktu. Perhitungan untuk mendapatkan usia akun menggunakan rumus pada Persamaan 8.
Usia akun = a – b (8)
dimana a adalah waktu melakukan pencarian data, sedangkan b adalah waktu akun pengguna dibuat. Untuk mempermudah dilakukan operasi tanggal untuk mendapatkan data usia akun yaitu as.POSIXct(“YYYY-MM-DD”).
Menghitung rataan tweet per hari
13 tanggal unik yang ada pada atribut created. Setelah itu dilakukan perhitungan rataan tweet per hari menggunakan rumus pada Persamaan 9.
Rataan tweet per hari = ∑ (9) dimana n(ti) adalah banyaknya tweet pada tanggal ke-i, i merupakan indeks dari tanggal dan n adalah jumlah tanggal unik.
Menghitung nilai rataan, median, minimum, dan maksimum selang waktu antara tweet
Atribut yang digunakan untuk menghitung selang waktu adalah created pada fungsi userTimeline, kemudian hitung selisih tweet awal dan tweet akhir, setelah nilai selisih didapat dilakukan perhitungan rataan selang waktu antara tweet. Cara yang sama juga dilakukan untuk mendapatkan nilai median, minimum, dan maksimum selang waktu antara tweet. Perhitungan rataan selang waktu antara tweet menggunakan rumus pada Persamaan 10 sebagai berikut:
Rataan selang waktu antara tweet = ∑ -
-(10)
dimana tj adalah waktu status di posting, j merupakan indeks dari tanggal, dan m merupakan banyaknya tweet dari pengguna.
Perhitungan minimum selang waktu antara tweet menggunakan rumus pada Persamaan 11 sebagai berikut:
Minimum selang waktu antara tweet = a - - (11) Perhitungan maksimum selang waktu antara tweet menggunakan rumus pada Persamaan 12 sebagai berikut:
Minimum selang waktu antara tweet = a a - - (12) Perhitungan median selang waktu antara tweet dapat dilihat dari nilai selisih yang sudah didapat. Nilai median merupakan nilai tengah.
Kode untuk mendapatkan nilai rataan, median, minimum dan maksimum selang waktu antara tweet, dengan menggunakan sintaks R yaitu:
#mencari nilai selisih
#mencari nilai rataan, median, minimum, maksimum Summary(jeda[i:n])
Menghitung banyaknya jumlah reply
14
berapa banyak yang berisi screen name pengguna lain. Kode untuk menghitung jumlah reply dengan menggunakan sintaks R yaitu
length(which(“nama_akun”$replyToSN!=”NA”)).
Pembuatan Model Klasifikasi menggunakan Algoritme C5.0
Algoritme C5.0 diterapkan pada dataset Twitter dengan menghasilkan model klasifikasi berupa pohon keputusan (decision tree) dengan 4 aturan dan berbasis aturan (rule based) dengan 3 aturan, contoh penggunaan algoritme C5.0 seperti pada Lampiran 3. Algoritme C5.0 terdapat pada perangkat lunak RStudio dengan package C50. Jumlah dataset pada Twitter sebanyak 120 data, sebelum dibentuk klasifikasi dengan package C50 dilakukan partisi data latih dan data uji secara acak dengan 90% dataset dijadikan sebagai data latih dan 10% dataset dijadikan sebagai data uji.
Tahapan pembuatan model klasifikasi menggunakan algoritme C5.0 menggunakan sintaks R adalah sebagai berikut:
1 Membaca dataset menggunakan sintaks R yaitu
data <- read.csv(“D://hasil4.csv”) set.seed(800)
2 Partisi data latih dan data uji
inTrain<-createDataPartition(data$Label,p.90,list=FALSE) training <- data[inTrain,]
testing <- data[-inTrain,]
3 Penerapan algoritme C5.0 untuk mendapatkan model tree dan model rule based. Langkah selanjutnya membangun model tree sebagai berikut :
oneTree<-C5.0(Label~., data=training) oneTree
summary(oneTree)
4 Melakukan prediksi menggunakan data uji untuk mendapatkan nilai akurasi, sensitivity, dan specificity dari model pohon keputusan
oneTreePred<-predict(oneTree, testing)
oneTreeProbs<-predict(oneTree,testing,type=”prob”) postResample(oneTreePred, testing$Label)
confusionMatrix(oneTreePred, testing$Label)
5 Membuat model berbasis aturan (rule based)
rules<-C5.0(Label~.,data=training,rules=TRUE) Summary(rules)
6 Menghitung nilai akurasi menggunakan data uji, untuk melakukan prediksi dengan model berbasis aturan (rule based)
postResample(predict(rules,testing),testing$Label)
15
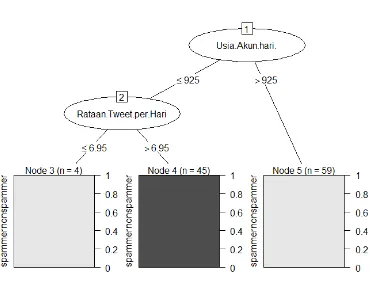
Gambar 4 Model pohon keputusan untuk klasifikasi spammer dan nonspammer Klasifikasi menggunakan algoritme C5.0 selain menghasilkan aturan pohon keputusan (tree) juga menghasilkan aturan berbasis aturan (rule based) sebagai berikut:
IF usia akun > 925 hari(59) THEN Class nonspammer
IF rataan tweet per hari ≤ 6.950495(46) THEN Class nonspammer
I usia akun ≤ 925 hari AND rataan tweet per hari > 6.950495(45) THEN Class spammer
Karakteristik Spammer
Hasil klasifikasi dari model pohon keputusan (tree) dan model berbasis aturan (rule based) memiliki persamaan atribut dengan presentase yang berbeda. Atribut tersebut dapat dilihat pada Tabel 6.
Tabel 6 Penggunaan atribut dalam model klasifikasi
Atribut Model
Tree Rule based
Usia akun 100% 96.30%
Rataan tweet per hari 45.37% 84.26%
16
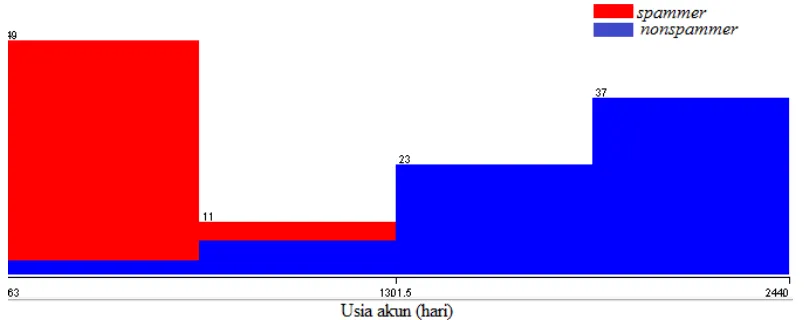
keputusan (tree), atribut usia akun sebesar 100%. Atribut ini menandakan bahwa setiap pengecekan pada model pohon keputusan (tree) harus dimulai dari atribut usia akun, dengan kata lain pada model tree sepenuhnya memerlukan atribut usia akun. Pada atribut rataan tweet per hari tidak mencapai 100%, karena pada waktu pengecekan lihat atribut usia akun terlebih dahulu, jika atribut usia akun ≤925 hari maka dilakukan pengecekan pada rataan tweet per hari sebesar 45.37% dan sisanya atribut usia akun >925 hari. Pada model berbasis aturan (rule based) kedua atribut tidak mencapai 100% yang menandakan bahwa setiap aturan tidak sepenuhnya memerlukan atribut usia akun atau rataan tweet per hari. Pada saat melakukan deteksi spammer tidak perlu 11 atribut tetapi cukup dengan 2 atribut yaitu usia akun dan rataan tweet per hari karena kelas nonspammer pada atribut usia akun memiliki usia jauh lebih lama dan memiliki jumlah yang lebih sedikit pada atribut rataan tweet per hari.
Grafik sebaran usia akun dapat dilihat pada Gambar 5 dan rataan tweet per hari dapat dilihat pada Gambar 6. Dari gambar tersebut dapat dilihat bahwa usia akun merupakan atribut yang cukup baik untuk memisahkan kelas spammer dan nonspammer. Untuk visualisasi 9 atribut lainnya dapat dilihat pada Lampiran 4, terlihat bahwa atribut-atribut tersebut tidak dapat memisahkan kelas spammer dan nonspammer dengan baik. Contohnya pada visualisasi pada atribut jumlah following, terlihat pada satu batang diagram histogram terjadi pencampuran warna antara spammer dan nonspammer. Hal tersebut memperlihatkan bahwa terjadi kemiripan antara nilai atribut tersebut pada kelas spammer dan nonspammer.
17
Gambar 6 Sebaran rataan tweet per hari
Analisis dan Evaluasi Model Klasifikasi
Evaluasi dilakukan terhadap algoritme C5.0 dengan menggunakan confusion matrix. Presentase klasifikasi sesuai dengan kelasnya. Confusion matrix deteksi spammer dengan menggunakan algoritme C5.0 dapat dilihat pada Tabel 7.
Tabel 7 Confusion matrix untuk model deteksi spammer
Kelas aktual Kelas prediksi
Nonspammer Spammer
Nonspammer 7 0
Spammer 1 4
Pada Tabel 7, terdapat 1 data Twitter yang diklasifikasikan tidak benar. Pada dataset Twitter telah diberi label sebagai spammer tetapi setelah dilakukan klasifikasi data diprediksi sebagai nonspammer.
Evaluasi model juga dilakukan terhadap sensitivity dan specificity. Sensitivity adalah kemampuan model dalam mengenal kelas nonspammer, nilai sensitivity hasil klasifikasi adalah:
Sensitivity = 0 100 100 (11) Specificity adalah kemampuan model untuk mengenal kelas spammer, nilai specificity hasil klasifikasi adalah:
18
lebih lama daripada kelas spammer dan memiliki jumlah yang lebih sedikit pada rataan tweet per hari.
SIMPULAN DAN SARAN
Simpulan
Berdasarkan penelitian yang telah dilakukan, dapat disimpulkan beberapa hal sebagai berikut:
1 Akurasi model keputusan dari data uji untuk klasifikasi akun spammer atau nonspammer sebesar 91% dengan 4 aturan, sedangkan akurasi model berbasis aturan (rule based) adalah sebesar 91% dengan 3 aturan.
2 Berdasarkan perilaku spammer yang mempengaruhi karakteristik klasifikasi spammer adalah usia akun dan rataan tweet per hari.
Saran
Penelitian ini masih memiliki beberapa kekurangan. Penelitian selanjutnya dapat melakukan deteksi spammer pada konten atribut, kemudian jumlah data bisa ditambahkan untuk memaksimalkan hasil akurasi yang akan didapat. Pada proses pelabelan spammer dan nonspammer diperlukan proses pembangunan sistem identifikasi spammer dan nonspammer, untuk meningkatkan ketelitian dan keakurasian hasil dan pengambilan data bisa melalui akun @spam.
DAFTAR PUSTAKA
Benevenuto F, Magno G, Rodrigues T, Almeida V. 2010. Detecting spammers on twitter. Di dalam: CEAS 2010-Seventh annual Collaboration, Electronic messaging, Anti Abuse and Spam Conference; 2010 July 13-14; Redmond,
Ghosh S, Viswanath B, Kooti F, Sharma N, Korlam G, Benevenuto V, Ganguly N, Gummadi K. 2012. Understanding and combating link farming in the twitter social network. Di dalam: In Proceedings of World Wide Web Conference Committee; 2012 April 16-20; Lyon, France.
Govindarajan M. 2007. Text Mining Technique for Data Mining Application. Di dalam: International Journal of Computer, Electrical, Automation, Control and Information Engineering.
19 Han J, Kamber M, Pei J. 2012. Data Mining: Concepts and Techniques. 3rd ed.
United States of America: Morgan Kaufman Publisher.
Hu X, Tang J, Zhang Y, Liu H. 2013. Social Spammer Detection in Microblogging. Di dalam: Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence.
Java A, Finin T, Tseng B, Song X. 2007. Why We Twitter: Understanding Microblogging Usage and Communities.
[Kemenkominfo] Kementerian Komunikasi Informatika. 2013. Kominfo: pengguna internet di Indonesia 63 juta orang. [Internet]. [diunduh 2015 Juni
27]. Tersedia pada:
http://kominfo.go.id/index.php/content/detail/3415/%20Kominfo+:+Pengguna+ Internet+di+Indonesia+63+Juta+Orang/0/berita_satker.
Patil N, Lathi R, Chitre V. 2012. Customer card classification based on C5.0 and CART algorithms. Di dalam: International Journal of Enggineering Research and Applications ; 2012 July-August. 2 (4):164-167.
Rulequest. 2012. C5.0: An Informal Tutorial. [Internet]. [diunduh 2015 November 23]. Tersedia pada: https://www.rulequest.com/see5-unix.html.
Song J, Lee S, Kim J. 2011. Spam Filtering in Twitter using Sender Receiver Relationship. Di dalam: Dept. of CSE, POSTECH; Republic of Korea.
Spamhaus. 2004. The Definition of Spam. [Internet]. [diunduh 2015 Mei 27]. Tersedia pada: https://www.spamhaus.org/consumer /definition.
20
Lampiran 1 Fungsi pada package twitteR yang digunakan pada penelitian
Fungsi Atribut Keterangan Tipe data
getUser description Deskripsi pengguna Char
getUser statusesCount Jumlah status pengguna Numerik getUser followersCount Jumlah followers pengguna Numerik getUser favoritesCount Jumlah status yang difavoritkan Numerik getUser friendsCount Jumlah following pengguna Numerik
getUser URL URL yang terkait dengan
pengguna
Char
getUser name Nama akun pengguna Char
getUser created Waktu akun pengguna dibuat Datetime
getUser screenname Screen name pengguna Char
getUser location Lokasi pengguna Char
getUser id ID pengguna Char
getUser listedCount Berapa kali pengguna muncul dalam daftar umum
Char
getUser followRequestCount Jumlah pengguna lain yang mem-follow
Numerik
userTimeline text Status pengguna Char
userTimeline favorite Apakah status ini menjadi favorit
Boolean
userTimeline favoritedCount Jumlah favorit terhadap status tersebut
Numerik userTimeline replyToSN Screenname pengguna lain yang
membalas status
Char
userTimeline created Waktu status dibuat Datetime userTimeline truncated Apakah status ini terpotong Char userTimeline replyToUID ID pengguna lain yang
membalas status
Char
userTimeline id ID status Char
userTimeline statusSource Perantara sumber pengguna untuk tweet
Char
userTimeline screenname Screenname pengguna yang memasang status
Char
userTimeline retweetCount Berapa kali status tersebut di retweet
Numerik userTimeline isRetweet True jika merupakan status yang
me-retweet
Boolean
userTimeline retweeted True jika merupakan status yang di-retweet
Boolean
userTimeline longitude Koordinat garis bujur dari status yang di posting
Char
userTimeline latitude Koordinat garis lintang dari status yang di posting
Char
userTimeline replyToSID ID pengguna lain yang membalas status
21 Lampiran 2 Dataset sebanyak 120 akun Twitter yang digunakan pada penelitian
No Akun Label No Akun Label
1 Aisadip Nonspammer 61 CoecuCahyati Spammer
2 Arya_permadi Nonspammer 62 kemendag Nonspammer 3 ariza_fajar Nonspammer 63 gilangmsp Nonspammer 4 adhit_yap Nonspammer 64 DelinaFauziah Spammer 5 kompascom Nonspammer 65 TelkomPromo Nonspammer
6 IcaHans Spammer 66 EgaAuliania Spammer
7 Anditaaaw Nonspammer 67 TinnaSintia Spammer
8 sayna_az Spammer 68 Goodgrow_Ks Spammer
9 BernataLatipah Spammer 69 kaskus Nonspammer
10 Cheppiiyy Nonspammer 70 HariTerlanjur Spammer 11 chesariapuspan Nonspammer 71 meida_adinda Spammer
12 CintaCllara Spammer 72 infoBMKG Nonspammer
13 DennySaputro16 Nonspammer 73 kiran_chandra1 Spammer
14 dindin_pril Nonspammer 74 KAI121 Nonspammer
15 danitapratiwi Nonspammer 75 Mmelani2 Spammer
16 ebehebeh Nonspammer 76 deanMukti Nonspammer
17 estimulyawati Nonspammer 77 Mutilestarii Spammer 18 faikarzakky Nonspammer 78 Fathyanurul Nonspammer 19 meyrenata27 Spammer 79 NidaSri_Andini Spammer 20 firdaushuda Nonspammer 80 Shaunshata Nonspammer 21 GalangMeilasa Nonspammer 81 NadiraPermana Spammer
22 CucuTresna Spammer 82 NaddaYullia Spammer
23 gitalistyaa Nonspammer 83 PanggilVina1 Spammer 24 galaratama Nonspammer 84 MittaDwinda Nonspammer 25 Itothagam Nonspammer 85 rizma_rohima1 Spammer 26 juliusGdimas Nonspammer 86 Allendiar Nonspammer 27 litarindiani Nonspammer 87 sonialunna88 Spammer 28 panggilpipi1 Spammer 88 Wputrasejati Nonspammer 29 MhdYons_ Nonspammer 89 Veronicawrlta Spammer 30 MarieaLiem Nonspammer 90 Vitaplankton Spammer
31 DiyaanaAullia Spammer 91 Wolf_X9 Spammer
32 MenikNugraeny Nonspammer 92 Ambimannyu Spammer
33 fw6955 Spammer 93 Nessyalvioriza Nonspammer
34 nurshintaaa Nonspammer 94 Pradityareza Nonspammer 35 nundaayu Nonspammer 95 MRanoTryAstra Nonspammer 36 purnomo_eko Nonspammer 96 Sheilashabilaa Nonspammer
37 Fany_Herliani Spammer 97 YulliYr Spammer
22
No Akun Label No Akun Label
43 JogjaUpdate Nonspammer 103 liputan6dotcom Nonspammer 44 shellanurandika Nonspammer 104 Am67Riska Spammer 45 tentrioktaviani Nonspammer 105 detikcom Nonspammer 46 TommySetyono Nonspammer 106 EmaMatina Spammer
47 tio_staycool Nonspammer 107 tvOneNews Nonspammer 48 VanoDaniel Nonspammer 108 okezonenews Nonspammer 49 Azizah_Rhma222 Spammer 109 blogger_jateng Spammer 50 zmachmobile Nonspammer 110 azizah_rhma31 Spammer 51 zanukoston Nonspammer 111 Metro_TV Nonspammer 52 alya_putri25 Spammer 112 AuraMaheera Spammer 53 tribunjogja Nonspammer 113 KompasTV Nonspammer
54 AliisaTina Spammer 114 lenaunna Spammer
23 Lampiran 3 Contoh penggunaan algoritme C5.0
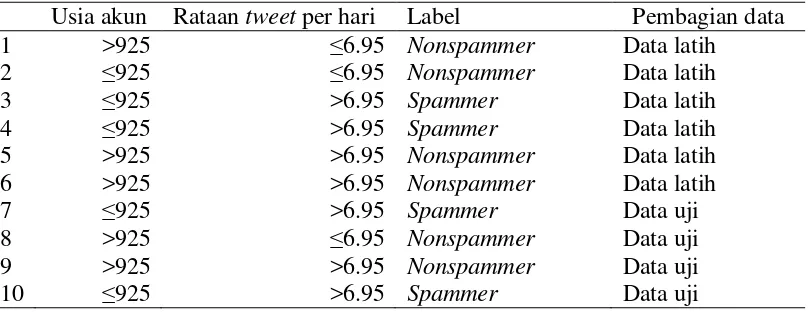
Langkah pertama yang harus dilakukan dalam klasifikasi menggunakan algoritme C5.0 yaitu siapkan dataset Twitter yang akan diklasifikasikan. Dataset dapat dilihat pada Tabel L3.1.
Tabel L3.1Contoh dataset kecil
Usia akun Rataan tweet per hari Label Pembagian data
1 >925 ≤6.95 Nonspammer Data latih
2 ≤925 ≤6.95 Nonspammer Data latih
3 ≤925 >6.95 Spammer Data latih
4 ≤925 >6.95 Spammer Data latih
5 >925 >6.95 Nonspammer Data latih
6 >925 >6.95 Nonspammer Data latih
7 ≤925 >6.95 Spammer Data uji
8 >925 ≤6.95 Nonspammer Data uji
9 >925 >6.95 Nonspammer Data uji
10 ≤925 >6.95 Spammer Data uji
Data dibagi menjadi 6 data latih dan 4 data uji secara acak, kemudian tentukan label dari Tabel L3.1, selanjutnya tentukan nilai information gain total dari atribut tersebut. Nilai information gain total yaitu
Information gain total = l l
dimana 4 didapatkan dari jumlah nonspammer, 2 didapatkan dari jumlah spammer dari label dan 6 didapatkan dari jumlah total atribut kelas.
24
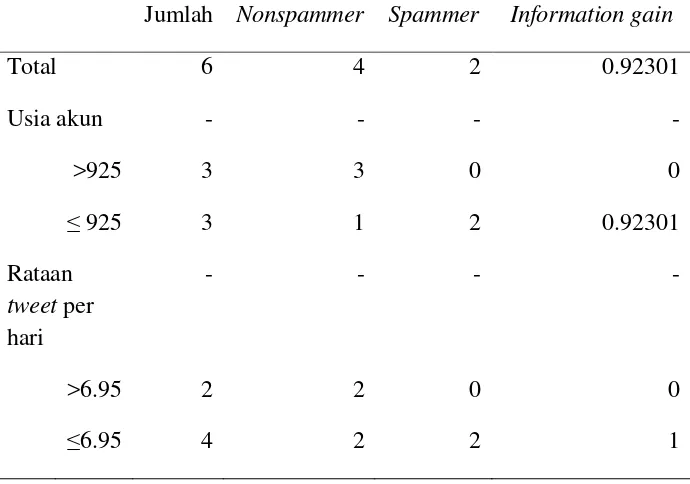
Lampiran 3 Lanjutan
Table L3.2 Hasil information gain pada masing-masing atribut Jumlah Nonspammer Spammer Information gain
Total 6 4 2 0.92301
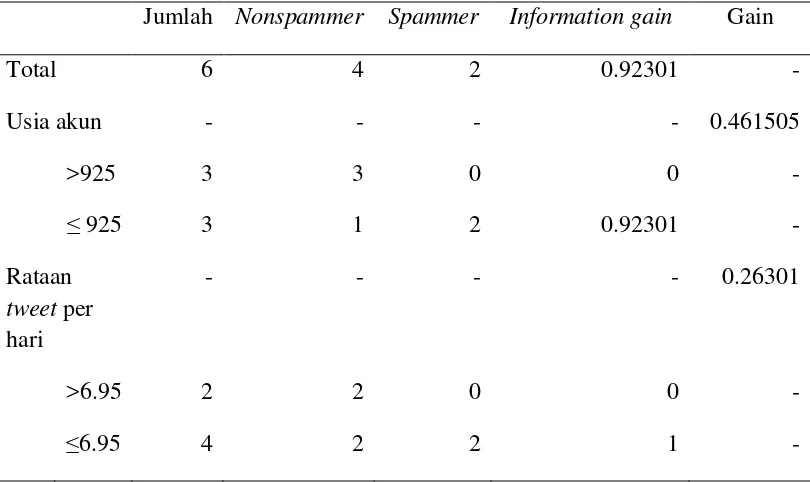
Selanjutnya mencari gain dari masing-masing atribut, untuk menentukan akar utama dari decision tree. Nilai gain sebagai berikut:
Gain = - - Keterangan:
0.92301 merupakan nilai information gain total
3/6, 3 didapatkan dari jumlah nonspammer, dan 6 dari jumlah label
3/6, 3 didapatkan dari jumlah spammer, dan 6 dari jumlah label
3/6 × 0.92301, 0.92301 didapatkan dari nilai information gain dari rataan tweet per hari
Dan seterusnya
25 Lampiran 3 Lanjutan
Akurasi = N N N
Table L3.3 Hasil gain masing-masing atribut
Jumlah Nonspammer Spammer Information gain Gain
Total 6 4 2 0.92301 -
Usia akun - - - - 0.461505
>925 3 3 0 0 -
≤ 925 3 1 2 0.92301 -
Rataan tweet per hari
- - - - 0.26301
>6.95 2 2 0 0 -
≤6.95 4 2 2 1 -
26
Lampiran 4 Visualisasi sebaran data 9 atribut yang tidak muncul pada tree
Gambar L4.1 Sebaran data atribut jumlah followers berdasarkan kelas
Gambar L4.2 Sebaran data atribut jumlah following berdasarkan kelas
27 Lampiran 4 Lanjutan
Gambar L4.4 Sebaran data atribut rasio followers per following berdasarkan kelas
Gambar L4.5 Sebaran data atribut maksimum selang waktu antara tweet berdasarkan kelas
28
Lampiran 4 Lanjutan
Gambar L4.7 Sebaran data atribut minimum selang waktu antara tweet berdasarkan kelas
Gambar L4.8 Sebaran data atribut rataan selang waktu antara tweet berdasarkan kelas
29