PENERAPAN
LEARNING VECTOR QUANTIZATION
UNTUK
IDENTIFIKASI PEMBICARA DENGAN MENGGUNAKAN
EKSTRAKSI CIRI
PRINCIPAL COMPONENT ANALYSIS
ENDRIK SUGIYANTO
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Penerapan Learning Vector Quantization untuk Identifikasi Pembicara dengan Menggunakan Ekstraksi Ciri Principal Component Analysis adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
ENDRIK SUGIYANTO. Penerapan Learning Vector Quantization untuk Identifikasi Pembicara dengan Menggunakan Ekstraksi Ciri Principal Component Analysis. Dibimbing oleh AGUS BUONO.
Keunikan manusia yang banyak digunakan sebagai identifikasi adalah sidik jari, wajah, retina, suara, dan DNA. Hingga saat ini, penelitian tentang suara sebagai identifikasi masih banyak diminati. Tujuan penelitian ini adalah mengembangkan metode Learning Vector Quantization (LVQ) untuk identifikasi pembicara dan mengetahui akurasi identifikasi pembicara dengan ekstraksi cirri Principal Component Analysis (PCA). Data yang digunakan adalah suara pembicara sebanyak 10 orang yang direkam selama 2 detik dengan sampling rate 11000 Hz. Perekaman dilakukan sebanyak 50 kali untuk masing-masing pembicara kemudian dinormalisasi. Setelah itu dilakukan ekstraksi ciri menggunakan PCA. Penelitian ini menunjukan bahwa akurasi tertinggi sebesar 96% dari (1) 100 dan 150 epoch dengan learning rate 0.0009, (2) 70 epoch dengan learning rate 0.001. Penurunan learning rate yang digunakan adalah 0.977 dan nilai eigen sebesar 95%. Hasil percobaan menunjukan bahwa, model LVQ dapat mengenali individu dan membedakan individu yang mirip.
Kata kunci: identifikasi pembicara, LVQ, PCA.
ABSTRACT
ENDRIK SUGIYANTO.Application of Learning Vector Quantization for Speaker Identification with Feature Extraction Using Principal Component Analysis. Supervised by AGUS BUONO.
The uniqueness of humans that is widely used as identification includes fingerprints, faces, retinas, voices, and DNA’s. Until now, research on sound as identification is still much on demand. The purpose of this research is to develop Learning Vector Quantization (LVQ) for speaker identification. Feature extraction is conducted using Principal Component Analysis (PCA). The data 2-second voices taken from 10 speakers with sampling rate of 11000 Hz. The recording is perfomed 50 times for each speaker. Afterward, the recording is normalized and extracted using PCA to obtain its features. The results show that we obtain the highest accuracy of 96% with (1) learning rate 0.0009 with 100 epoch and 150 epoch, (2) learning rate 0.001 and 70 epoch. We used the eigen value of 95% and the learning-rate descrease-rate of 0.977. The results suggest the LVQ can recognize individuals and distinguises similar ones.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
PENERAPAN
LEARNING VECTOR QUANTIZATION
UNTUK
IDENTIFIKASI PEMBICARA DENGAN MENGGUNAKAN
EKSTRAKSI CIRI
PRINCIPAL COMPONENT ANALYSIS
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2015
Penguji:
1 Karlisa Priandana, ST MEng
Judul Skripsi : Penerapan Learning Vector Quantization untuk Identifikasi Pembicara dengan Menggunakan Ekstraksi Ciri Principal Component Analysis
Nama : Endrik Sugiyanto
NIM : G64114046
Disetujui oleh
Dr Ir Agus Buono, MSi MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis ucapkan kepada Allah subhanahu wata’ala atas segala rahmat karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Solawat serta salam selalu tercurahkan kepada Nabi Muhammad Shalallahu
‘alaihi wa sallam. Tema yang dipilih dalam penelitian ini ialah Penerapan Learning Vector Quantization untuk Identifikasi Pembicara dengan Menggunakan Ekstraksi Ciri Principal Component Analysis.
Terima kasih penulis ucapkan kepada:
1 Bapak Dr Ir Agus Buono, MSi MKom selaku dosen pembimbing yang telah banyak memberikan pengarahan, saran dan masukannya.
2 Ibu Karlisa Priandana, ST MEng dan Bapak Muhammad Asyhar Agmalaro, SSi MKom selaku penguji.
3 Emak, Bapak, Kakang, Ayuk serta seluruh keluarga yang telah memberikan dukungan,dan doanya sehingga penulis dapat menyelesaikan karya ilmiah ini. 4 Teman-temansatu bimbingan dan teman-teman Alih Jenis Ilmu Komputer IPB
angkatan 6 atas kerjasamanya.
5 Teman-teman Asrama IPB Sukasari dan KAMUS atas persaudaraan yang telah diberikan.
Semoga karya ilmiah ini bermanfaat.
DAFTAR ISI
Pelatihan dan Pengujian ... 9
Evaluasi ... 10
SIMPULAN DAN SARAN ... 12
Simpulan ... 12
Saran ... 12
DAFTAR PUSTAKA ... 13
DAFTAR TABEL
1 Parameter pengujian LVQ 10
2 Matrik confusion suara pembicara 12
DAFTAR GAMBAR
1 Tahapan penelitian 2
2 Blok diagram proses sinyal 3
3 Alur proses pemotongan suara 4
4 Ilustrasi proses frame blocking 5
5 Arsitektur LVQ 7
6 Ilustrasi cara kerja LVQ. (a) Bobot mendekati data, (b) Bobot
menjauhi data (Desylvia 2013) 8
7 Ilustrasi silence removing. (a) suara yang belum silence, (b) suara
yang sudah silence 9
8 Rata-rata akurasi PCA 80% berdasarkan epoch 10
9 Rata-rata akurasi PCA 95% berdasarkan epoch 11
10 Rata-rata akurasi berdasarkan learning rate 11
DAFTAR LAMPIRAN
1 Hasil percobaan dengan PCA 80% 14
PENDAHULUAN
Latar Belakang
Keunikan manusia yang banyak digunakan sebagai identifikasi adalah sidik jari, wajah, retina, suara, dan DNA. Hingga saat ini, penelitian tentang suara sebagai identifikasi masih banyak diminati. Perkembangan penelitian pada bidang identifikasi suara memicu banyak metode baru. Pada penelitian ini akan dilakukan identifikasi pembicara dengan menggunakan metode learning vector quantization (LVQ) yang merupakan suatu metode klasifikasi pola yang masing-masing unit output mewakili kategori atau kelas tertentu. Vektor bobot untuk unit output sering disebut vektor referensi untuk kelas yang dinyatakan oleh unit tersebut. LVQ mengklasifikasikan vektor input dalam kelas yang sama dengan unit output yang memiliki vektor bobot yang paling dekat dengan vektor input.
Identifikasi pembicara memerlukan sebuah ekstraksi ciri, yang merupakan proses untuk menentukan satu nilai atau vektor yang dapat dipergunakan sebagai penciri dari suatu objek. Pada penelitian Susanto (2007), identifikasi suara dilakukan dengan menggunakan model jaringan saraf tiruan resilient backpropagation. Akurasi terbaik diperoleh dengan data yang menggunakan noise 30 dB sebesar 92.8%. Selanjutnya, Fansuri (2011) menggunakan LVQ untuk mengklasifikasi genre musik menghasilkan akurasi tertinggi 93.75% untuk durasi 10 detik.
Pemilihan untuk ekstraksi ciri principal component analysis (PCA) diajukan karena menghasilkan akurasi 96% dengan menggabungkan metode MFCC pada penelitianPramiyanti (2011).
Tujuan Penelitian Tujuan dari penelitian ini adalah:
1 Mengembangkan metode LVQ untuk identifikasi pembicara.
2 Menghasilkan akurasi identifikasi pembicara dengan menggunakan ekstraksi ciri PCA.
Manfaat Penelitian
Penelitian ini diharapkan dapat memberikan informasi mengenai akurasi metode LVQ dengan ekstraksi ciri PCA.
Ruang Lingkup Penelitian Ruang lingkup penelitian ini adalah:
2
METODE PENELITIAN
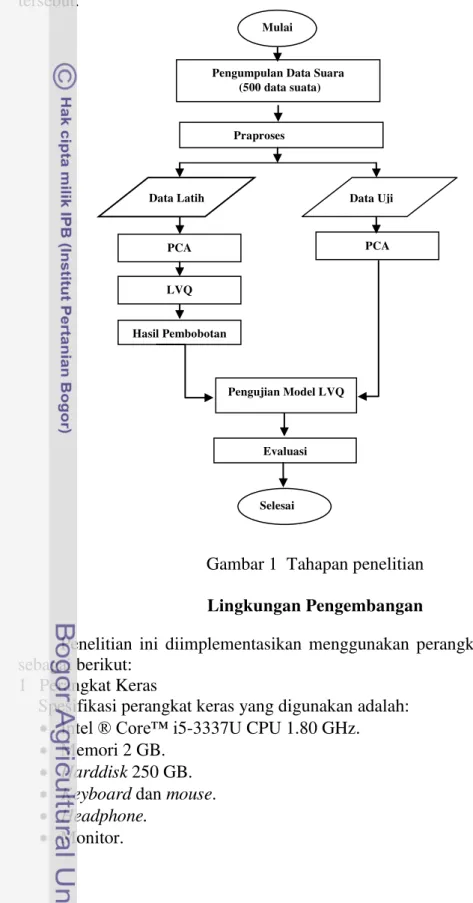
Penelitian ini dilakukan dengan beberapa tahapan, yaitu pengumpulan data, normalisasi, ekstraksi ciri dan pengenalan pola, Gambar 1 menunjukkan tahapan tersebut.
Gambar 1 Tahapan penelitian Lingkungan Pengembangan
Penelitian ini diimplementasikan menggunakan perangkat keras dan lunak sebagai berikut:
1 Perangkat Keras
Spesifikasi perangkat keras yang digunakan adalah:
3 2 Perangkat Lunak
Sistem operasi Windows 7 Profesional 32 bit. Matlab 7.7.0 (R2008b).
Pengumpulan Data
Data suara didapatkan dari 10 pembicara yang mengucapkan kata
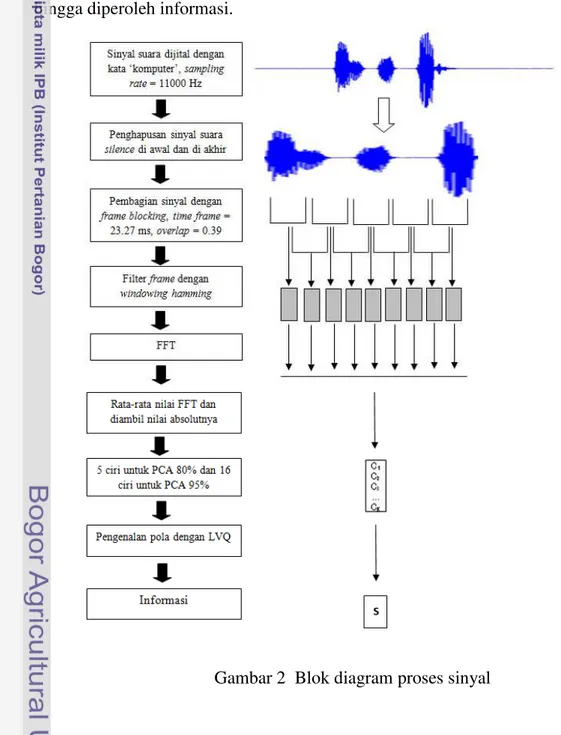
“KOMPUTER” masing-masing pembicara mengucapkan sebanyak 50 kali. Setiap suara direkam pada durasi waktu 2 detik dengan sampling rate 11000 Hz dalam fail berekstensi WAV sehingga diperoleh total data suara sebanyak 500 suara, 390 suara digunakan untuk data latih, 10 untuk bobot dan 100 suara sebagai data uji. Gambar 2 menunjukkan blok diagram proses sinyal dari awal suara diakusisi hingga diperoleh informasi.
4
Praproses
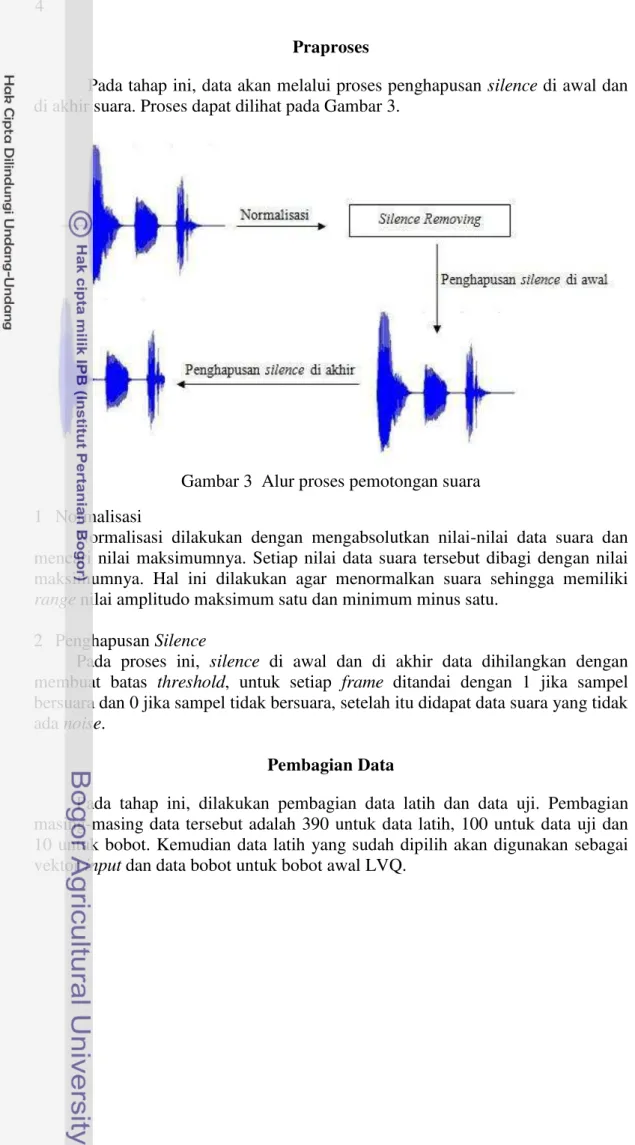
Pada tahap ini, data akan melalui proses penghapusan silence di awal dan di akhir suara. Proses dapat dilihat pada Gambar 3.
Gambar 3 Alur proses pemotongan suara 1 Normalisasi
Normalisasi dilakukan dengan mengabsolutkan nilai-nilai data suara dan mencari nilai maksimumnya. Setiap nilai data suara tersebut dibagi dengan nilai maksimumnya. Hal ini dilakukan agar menormalkan suara sehingga memiliki range nilai amplitudo maksimum satu dan minimum minus satu.
2 Penghapusan Silence
Pada proses ini, silence di awal dan di akhir data dihilangkan dengan membuat batas threshold, untuk setiap frame ditandai dengan 1 jika sampel bersuara dan 0 jika sampel tidak bersuara, setelah itu didapat data suara yang tidak ada noise.
Pembagian Data
5 Ekstraksi Ciri
1 Frame Blocking
Pembagian sinyal suara menjadi beberapa frame yang akan mempermudah perhitungan dan analisa sinyal, setiap frame dengan lebar tertentu yang saling tumpang tindih. Tiap hasil frame dipresentasikan dalam sebuah vektor, panjang frame merupakan bilangan yang bernilai 256, frame dibuat secara tumpang tindih. Pada Gambar 4 di bawah, sinyal suara dibagi ke dalam 9 frame dengan tumpang tindih sebesar 50%.
Gambar 4 Ilustrasi proses frame blocking 2 Windowing
N : jumlah sampel pada setiap frame N : frame ke-n
W(n) : fungsi window hamming 3 Fast Fourier Transform (FFT)
FFT merupakan algoritme yang mengimplementasikan Discrete Fourier Transform (DFT), terdiri dari nilai real dan imajiner. DFT mengubah tiap frame dari domain waktu kedalam domain frekuensi yang didefinisikan pada persamaan berikut (Do 1994):
Xk : magnitude frekuensi
Xn : nilai sampel yang akan diproses pada domain waktu k : N/2 + 1 ,j = bilangan imajiner
N : jumlah data
4 Principal Components Analysis (PCA)
6
berdasarkan informasi yang kandungnya disebut sebagai vektor eigen atau nilai komponen utama (Pramiyanti 2011). PCA merupakan teknik multivariate yang paling banyak digunakan pada hampir semua bidang (Abdi dan Williams 2010).
Data masukan pada metode PCA adalah berupa matriks. Dari matriks dihitung kovarian S dengan menggunakan persamaan:
S : matrik kovarian
n : unit sampel Xi : jumlah vektor
X : rata-rata vektor
(X)T : transpose dari x
Setelah diperoleh matriks kovarian, ditentukan eigen vektor dan nilai eigen. Nilai eigen yang didapat diurutkan mulai yang terbesar sampai yang terkecil. Selanjutnya, penentuan nilai proporsi yang akan digunakan dalam PCA, besaran nilai proporsi ini berguna untuk menentukan besarnya komponen utama yang digunakan. Komponen utama nantinya akan digunakan sebagai masukan kedalam metode learning vector quantization.
Ada beberapa parameter input yang dibutuhkan dalam proses ektraksi ciri, pada penelitian ini adalah inputan berupa suara digital dan disimpan dengan ekstensi fail WAV, time frame yang digunakan pada penelitian ini sebesar 23.27 ms, window hamming merupakan window yang digunakan pada tahapan windowing, overlapping yang digunakan sebesar 0.39 untuk penelitian ini. Overlapping digunakan untuk mengurangi kehilangan informasi pada saat proses frame blocking, nilai eigen sebesar 80% dengan 5 penciri dan 95% dengan 16 penciri.
Pelatihan dan Pengujian
Jaringan syaraf tiruan LVQ digunakan untuk pelatihan dan pengujian. LVQ merupakan suatu metode klasifikasi pola yang masing-masing unit output mewakili kategori atau kelas tertentu. Vektor bobot untuk unit output sering disebut vektor referensi untuk kelas yang dinyatakan oleh unit tersebut. LVQ mengklasifikasikan vektor input dalam kelas yang sama dengan unit output yang mewakili vektor bobot paling dekat dengan vektor input. Gambar 5 merupakan arsitektur LVQ dalam penelitian ini.
7
Gambar 5 Arsitektur LVQ Algoritme dari LVQ adalah (Fausett, 1994):
1 Tentukan vektor referensi dan learning rate, α(0).
2 Selama kondisi berhenti belum terpenuhi, lakukan langkah 3-6. 3 Untuk setiap vektor masukan X, lakukan langkah 4-5.
4 Temukan j sehingga ||X - Wj|| bernilai minimum.
5 Update nilai Wj sesuai ketentuan berikut:
Jika T = Cj,
7 Cek kondisi berhenti: jumlah iterasi mencapai nilai yang ditentukan. dengan:
X : vektor pelatihan atau vektor masukan ( X1,…,Xi,…Xn)
T : kategori atau kelas yang benar untuk vektor masukan Wj : vektor bobot untuk unit keluaran j (W1j,…,Wij,…,Wnj)
Cj : kategori atau kelas direpresentasikan oleh unit keluaran ke j
||X - Wj|| : jarak euclidean antara vektor masukandan unit keluaran ke j
Menentukan vektor referensi (vektor bobot) yaitu dengan cara mengambil sebanyak satu baris pertama atau terakhir pada vektor data latih dan menggunakannya untuk vektor bobot. Sisa vektor data latih digunakan untuk proses pelatihan.
Cara kerja LVQ secara sederhana, yaitu membarui bobot agar lebih mendekati data, jika target samadengan kelas. Jika target tidak sama dengan kelas, bobot yang baru dijauhkan dari data (Desylvia 2013). Hal ini diilustrasikan pada Gambar 6.
8
Gambar 6 Ilustrasi cara kerja LVQ. (a) bobot mendekati data, (b) bobot menjauhi data (Desylvia 2013)
Evaluasi
Evaluasi merupakan tahap terakhir pada metode untuk menentukan apakah proses klasifikasi sudah tepat atau belum. Perhitungan dilakukan dengan membandingkan banyaknya hasil kata pembicara yang benar dengan kata pembicara yang diuji. Hasil dari tahap ini yaitu akurasi yang didapat dengan cara.
HASIL DAN PEMBAHASAN
Pengambilan Data Suara
Data suara yang digunakan pada penelitian ini direkam dari 10 pembicara yang mengucapkan kata “KOMPUTER”. Agar suara yang dihasilkan tidak banyak noise perekaman dilakukan di ruangan tertutup. Perekaman suara pembicara dilakukan dengan menggunakan fungsi wavrecord pada Matlab yang tidak dibatasi panjang pendek serta tekanan dalam pengucapannya. Suara direkam dengan rentang waktu 2 detik dengan sampling rate 11000 Hz dalam bentuk berekstensi WAV. Dari 10 pembicara masing-masing mengucapkan sebanyak 50 data, sehingga total suara yang dihasilkan sebanyak 500 data.
9 Praproses
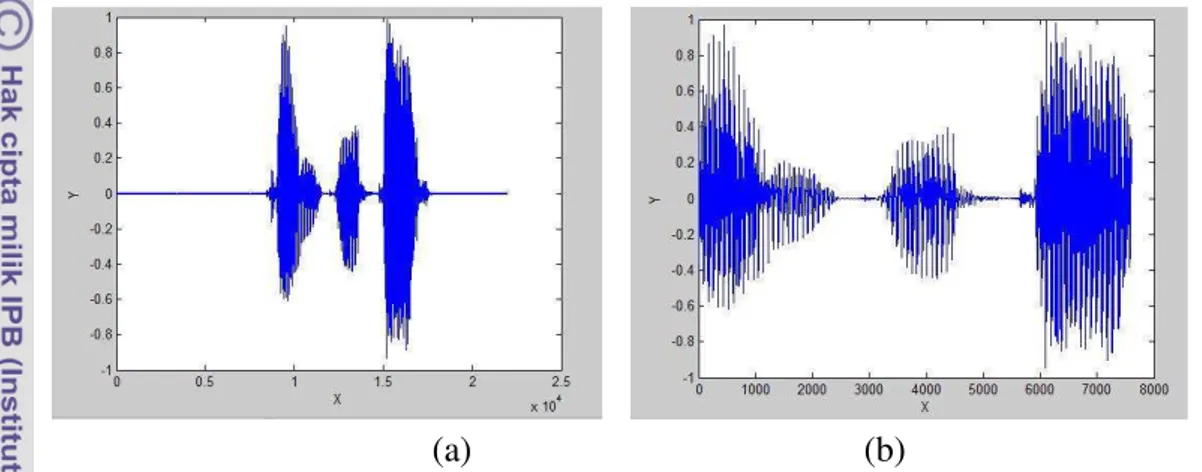
Data yang telah direkam akan dinormalisasi dengan mengabsolutkan dan memaksimumkan nilai data suara agar memiliki nilai amplitudo maksimum satu dan minimum minus satu. Data yang sudah diabsolutkan akan dihapus bagian awal dan akhirnya untuk menghilangkan noise yang adadengan algoritma silence removing. Contoh hasil dari silence removing yang dilakukan dapat dilihat pada Gambar 7.
(a) (b)
Proses selanjutnya adalah pembagian data. Data suara diambil sebanyak 500 suara dari 10 pembicara yang terbagi sebanyak 390 data latih, 100 data uji dan 10 untuk bobot. Pada penentuan bobot diambil dari data suara yang ke-40. Selanjutnya penentuan data uji diambil dari rekaman suara yang ke-41 sampai 50 dan sisanya menjadi data latih.
Pelatihan dan Pengujian
Data yang digunakan untuk proses pelatihan dan pengujian adalah data yang sudah dibagi manjadi data latih, data uji dan data bobot. Parameter yang diperlukan untuk LVQ adalah jumlah neuron input yang disesuaikan dengan nilai eigen PCA 80% yaitu sebanyak 5 penciri dan 95% sebanyak 16 penciri. Jumlah neuron output ditentukan berdasarkan jumlah kelas sebanyak 10 kelas. Learning rate yang digunakan adalah 0.0001, 0.0003, 0.0005, 0.0007, 0.0009, 0.001, 0.003, 0.005, 0.007, 0.009, 0.01, 0.03, 0.05, 0.07, dan 0.09. Penurunan learning rate yang digunakan sebesar 0.977. Jumlah epoch adalah pengulangan yang dilakukan utuk setiap iterasi. Bobot yang digunakan sebagai inisialisasi LVQ didapat dari salah satu data suara yang masing-masing mewakili tiap kelas. Data yang digunakan untuk bobot ini dipisahkan dari dari uji dan data latih. Tabel 1 menunjukkan parameter yang dimasukkan pada LVQ.
10
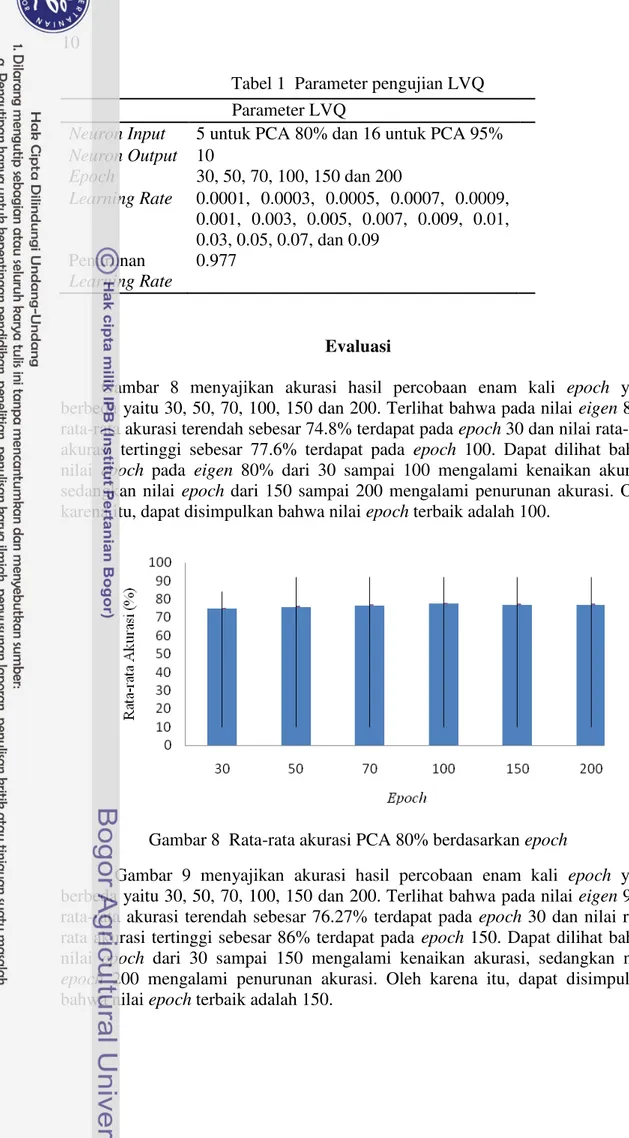
Tabel 1 Parameter pengujian LVQ Parameter LVQ berbeda yaitu 30, 50, 70, 100, 150 dan 200. Terlihat bahwa pada nilai eigen 80% rata-rata akurasi terendah sebesar 74.8% terdapat pada epoch 30 dan nilai rata-rata akurasi tertinggi sebesar 77.6% terdapat pada epoch 100. Dapat dilihat bahwa nilai epoch pada eigen 80% dari 30 sampai 100 mengalami kenaikan akurasi, sedangkan nilai epoch dari 150 sampai 200 mengalami penurunan akurasi. Oleh karena itu, dapat disimpulkan bahwa nilai epoch terbaik adalah 100.
Gambar 8 Rata-rata akurasi PCA 80% berdasarkan epoch
11
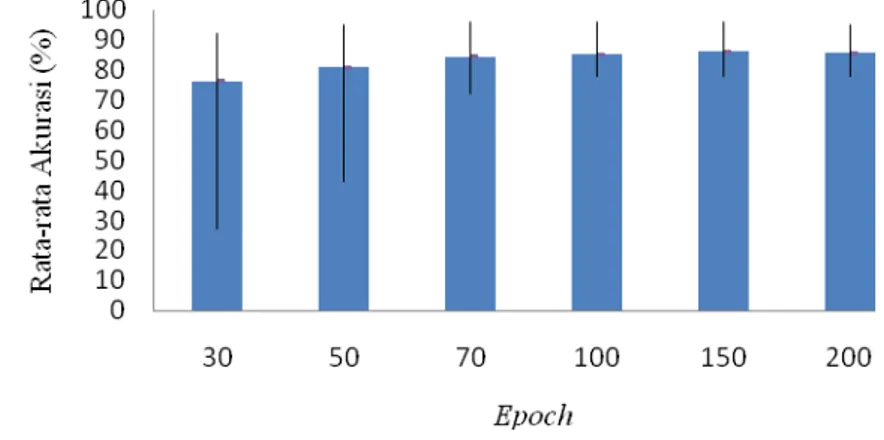
Gambar 9 Rata-rata akurasi PCA 95% berdasarkan epoch
Gambar 10 menyajikan hasil rata-rata akurasi percobaan nilai learning rate 0.0001, 0.0003, 0.0005, 0.0007, 0.0009, 0.001, 0.003, 0.005, 0.007, 0.009, 0.01, 0.03, 0.05, 0.07, dan 0.09. Terlihat hasil rata-rata akurasi pada nilai eigen 80% akurasi terendah didapat pada learning rate 0.09 sebesar 10% dan akurasi tertinggi sebesar 89.67% pada learning rate 0.0009 dan 0.001. Pada nilai eigen 95% rata-rata akurasi terendah sebesar 62.67% terdapat pada learning rate 0.09 dan nilai rata-rata akurasi tertinggi sebesar 94.5% terdapat pada learning rate 0.0009. Dapat dilihat bahwa nilai learning rate dari 0.0001 sampai 0.0009 mengalami kenaikan akurasi, sedangkan nilai learning rate dari 0.001 sampai 0.09 mengalami penurunan akurasi. Oleh karena itu, dapat disimpulkan bahwa nilai learning rate terbaik adalah 0.0009. Tabel perhitungan hasil percobaan untuk PCA 80% dan 95% dapat dilihat pada Lampiran 1 dan 2.
12
Berdasarkan pada Tabel 2 matrik confusion dengan kontribusi nilai eigen 95%, parameter learning rate 0.0009 dan epoch 100 menghasilkan nilai akurasi pembicara sebesar 96%. Pembicara yang menghasilkan akurasi tertinggi yaitu 100% adalah Aji, Buldani, Chandra, Endrik, Janan, dan Uci. Pembicara tersebut dapat teridentifikasi dengan baik karena memiliki noise lebih kecil daripada pembicara lainnya. Pembicara yang menghasilkan akurasi 90% adalah Allan, Janan, Restu dan Vikhy. Kesalahan terdapat pada kelas pembicara. Dari 10 percobaan, Allan teridentifikasi sebagai Restu, Janan teridentifikasi sebagai Chandra, Restu 1 teridentifikasi sebagai Allan dan Vickhy teridentifikasi sebagai Buldani. Kesalahan identifikasi tersebut disebabkan oleh banyaknya noise yang ada pada data suara dan kemiripan suara pembicara.
Tabel 2 Matrik confusion suara pembicara
Aktual Prediksi
Rata-Penelitian ini telah berhasil menerapkan LVQ untuk identifikasi pembicara dengan menggunakan ekstraksi ciri PCA. Akurasi tertinggi yang diperoleh adalah 96% dari 100 dan 150 epoch dengan learning rate 0.0009 dan 70 epoch dengan learning rate 0.001. Penurunan learning rate yang digunakan adalah 0.977 dan nilai eigen sebesar 95%. Hasil percobaan menunjukan bahwa, model LVQ dapat mengenali individu dan membedakan individu yang mirip.
Saran
Saran untuk pengembangan selanjutnya, yaitu:
1 Penambahan jumlah data training untuk memberikan hasil yang maksimal. 2 Penggunaan metode ekstraksi ciri yang lain untuk memperoleh akurasai yang
lebih baik.
3 Pencarian kombinasi nilai parameter dari LVQ yang lain untuk pengenalan pembicara.
13
DAFTAR PUSTAKA
Abdi H, Williams LJ. 2010. Principal component analysis. Wiley Interdisciplinary Reviews: Computational Statistics 2. 2: 433–459.
Desylvia SN. 2013. Perbandingan SOM dan LVQ pada identifikasi citra wajah dengan wavelet sebagai ekstraksi ciri [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Do MN. 1994. Digital signal processing mini-project: an automatic speaker recognition system. Lausanne (CH): Swiss Federal Institute of Technology. Fansuri MR. 2011. Klasifikasi genre musik menggunakan learning vector
quantization (LVQ) [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Fausett L. 1994. Fundamental of Neural Network: Architectures, Algorithm, and Application. United States (US): Prentice-Hall.
Pramiyanti T. 2011. Pengembangan model sistem identifikasi pembicara dengan kombinasi teknik ekstraksi ciri suara mel-frequency cepstral coefficients (MFCC) dan principal component analysis (PCA). Jakarta (ID): UPNVJ. Susanto N. 2007. Pengembangan model jaringan syaraf tiruan resilent
14
LAMPIRAN
Lampiran 1 Hasil percobaan dengan PCA 80%
Learning
Lampiran 2 Hasil percobaan dengan PCA 95%
15