ABSTRAK
PEMETAAN SEBARAN ASAL SISWA DAN KLASIFIKASI JARAK ASAL SISWA SMA NEGERI DI KABUPATEN PRINGSEWU
MENGGUNAKAN METODENAÏVE BAYES
Oleh RISKA APRILIA
Jarak siswa dapat diketahui dari data asal siswa yang tersimpan. Asal siswa yang berbeda-beda akan menghasilkan jarak yang berbeda pula. Penelitian ini dilakukan untuk mengetahui klasifikasi jarak asal siswa yang tersimpan di SMA negeri di Kabupaten Pringsewu. Jarak asal siswa diklasifikasikan untuk mendapatkan lima class/kategori yaitu sangat dekat, dekat, sedang, cukup jauh, dan jauh dengan menggunakan atribut nomor, SMA, kabupaten, kecamatan, kelurahan, jarak, asal SMP, danclass. Klasifikasi dilakukan dengan menggunakan metode Naive Bayes dengan menggunakan tool Weka. Pembagian data training dan data testing yang berbeda sebanyak 20 kali pengujian menghasilkan akurasi Naïve Bayes tertinggi yaitu 89.329% pada pembagian datatraining 60% dan data testing 40%. Data asal siswa dan informasi hasil klasifikasi ditampilkan dalam bentuk peta digital yaitu peta sebaran asal siswa SMA negeri di Kabupaten Pringsewu.
ABSTRACT
DISTRIBUTION MAPPING OF STUDENTS ADDRESS AND CLASSIFICATION DISTANCE HIGH SCHOOL STUDENTS IN THE
PRINGSEWU DISTRICT USING NAÏVE BAYES METHOD
By
RISKA APRILIA
Distance students can be seen from the data stored student's address. Address high school students in the Pringsewu District have different distances. This research was conducted to determine the classification of the distance stored in high school students in the Pringsewu District. Distance students are classified to obtain five
categories: “sangat dekat”, “dekat”, “sedang”, “cukup jauh”, and “jauh” by using
eight attributes are “nomor”, “SMA”, “kabupaten”, “kecamatan”, “kelurahan”, “jarak”, “asal SMP”, and “class”. The classification performed by using Naive
Bayes using Weka tool. Distribution of training data and testing data is different as much as 20 times of testing, resulting in the highest accuracy Naïve Bayes is 89.329% on distribution of 60% training data : 40% testing data. The data of students address and information classification results displayed in the form of digital map that is mapping of student’s address in high school in the Pringsewu
District.
PEMETAAN SEBARAN ASAL SISWA DAN KLASIFIKASI JARAK ASAL SISWA SMA NEGERI DI KABUPATEN PRINGSEWU
MENGGUNAKAN METODENAÏVE BAYES
(Skripsi)
Oleh : RISKA APRILIA
JURUSAN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS LAMPUNG
ABSTRAK
PEMETAAN SEBARAN ASAL SISWA DAN KLASIFIKASI JARAK ASAL SISWA SMA NEGERI DI KABUPATEN PRINGSEWU
MENGGUNAKAN METODENAÏVE BAYES
Oleh RISKA APRILIA
Jarak siswa dapat diketahui dari data asal siswa yang tersimpan. Asal siswa yang berbeda-beda akan menghasilkan jarak yang berbeda pula. Penelitian ini dilakukan untuk mengetahui klasifikasi jarak asal siswa yang tersimpan di SMA negeri di Kabupaten Pringsewu. Jarak asal siswa diklasifikasikan untuk mendapatkan lima class/kategori yaitu sangat dekat, dekat, sedang, cukup jauh, dan jauh dengan menggunakan atribut nomor, SMA, kabupaten, kecamatan, kelurahan, jarak, asal SMP, danclass. Klasifikasi dilakukan dengan menggunakan metode Naive Bayes dengan menggunakan tool Weka. Pembagian data training dan data testing yang berbeda sebanyak 20 kali pengujian menghasilkan akurasi Naïve Bayes tertinggi yaitu 89.329% pada pembagian datatraining 60% dan data testing 40%. Data asal siswa dan informasi hasil klasifikasi ditampilkan dalam bentuk peta digital yaitu peta sebaran asal siswa SMA negeri di Kabupaten Pringsewu.
ABSTRACT
DISTRIBUTION MAPPING OF STUDENTS ADDRESS AND CLASSIFICATION DISTANCE HIGH SCHOOL STUDENTS IN THE
PRINGSEWU DISTRICT USING NAÏVE BAYES METHOD
By
RISKA APRILIA
Distance students can be seen from the data stored student's address. Address high school students in the Pringsewu District have different distances. This research was conducted to determine the classification of the distance stored in high school students in the Pringsewu District. Distance students are classified to obtain five
categories: “sangat dekat”, “dekat”, “sedang”, “cukup jauh”, and “jauh” by using
eight attributes are “nomor”, “SMA”, “kabupaten”, “kecamatan”, “kelurahan”, “jarak”, “asal SMP”, and “class”. The classification performed by using Naive
Bayes using Weka tool. Distribution of training data and testing data is different as much as 20 times of testing, resulting in the highest accuracy Naïve Bayes is 89.329% on distribution of 60% training data : 40% testing data. The data of students address and information classification results displayed in the form of digital map that is mapping of student’s address in high school in the Pringsewu
District.
PEMETAAN SEBARAN ASAL SISWA DAN KLASIFIKASI JARAK ASAL SISWA SMA NEGERI DI KABUPATEN PRINGSEWU
MENGGUNAKAN METODENAÏVE BAYES
Oleh : RISKA APRILIA
Skripsi
Sebagai Salah Satu Syarat untuk Memperoleh Gelar SARJANA KOMPUTER
pada
Jurusan Ilmu Komputer
Fakultas Matematika dan Ilmu Pengetahuan Alam
JURUSAN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS LAMPUNG
PERNYATAAN
Saya yang bertanda tangan di bawah ini, menyatakan bahwa skripsi saya yang
berjudul “Pemetaan Sebaran Asal Siswa dan Klasifikasi Jarak Asal Siswa SMA Negeri di Kabupaten Pringsewu Menggunakan Metode Naïve Bayes” merupakan
karya saya sendiri dan bukan karya orang lain. Semua tulisan yang tertuang di skripsi ini telah mengikuti kaidah penulisan karya ilmiah Universitas Lampung. Apabila dikemudian hari terbukti skripsi saya merupakan hasil penjiplakan atau dibuat orang lain, maka saya bersedia menerima sanksi berupa pencabutan gelar yang telah saya terima.
Bandar Lampung, 2 Februari 2017
RIWAYAT HIDUP
Penulis dilahirkan pada tanggal 26 April 1994 di Gumukmas Kecamatan Pagelaran, Kabupaten Pringsewu sebagai anak kedua dari dua bersaudara dengan Ayah bernama Rinto Riyadi dan Ibu bernama Poniyati.
Penulis menyelesaikan pendidikan formal di TK Dharma Wanita Gumukmas pada tahun 2000, kemudian melanjutkan pendidikan dasar di SD Negeri 1 Gumukmas dan selesai tahun 2006. Pendidikan menengah pertama diselesaikan di SMP Negeri 1 Pagelaran pada tahun 2009, kemudian melanjutkan ke pendidikan menengah atas di SMA Negeri 1 Pringsewu dan lulus di tahun 2012.
Tahun 2012, penulis terdaftar sebagai mahasiswa Jurusan Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Lampung. Selama menjadi mahasiswa beberapa kegiatan yang dilakukan penulis antara lain:
1. Bulan Januari 2013 melaksanakan Karya Wisata Ilmiah di Desa Sukoharjo IV Kabupaten Pringsewu.
2. Tahun 2014 bergabung menjadivolunteerdi Sahabat Pulau Lampung. 3. Bulan Januari 2015 melaksanakan kerja praktek di Badan Pusat Statistik
(BPS) Kabupaten Pesawaran.
PERSEMBAHAN
Teruntuk
Bapak Rinto Riyadi
dan
Ibu Poniyati
yang sangat kucintai, kupersembahkan
skripsi ini.
Terimakasih untuk kasih sayang, perhatian, pengorbanan, usaha, dukungan moril maupun
materi, motivasi dan do a-do a mu yang tak akan terbalaskan.
Teruntuk
Kakakku Rudianto
Terikasih untuk kasih sayang, doa, pengorbanan, usaha, dukungan moril maupun materi
MOTTO
FA BIAYYI ALAA I RABBI KUMA TUKADZDZI BAN Maka nikmat Tuhanmu yang manakah yang kamu dustakan.
(Q.S. Ar Rahman: 13)
FAINNAMA AL USRI YUSRO. INNAMA AL USRI YUSRO
Sesungguhnya bersama dengan kesulitan ada kemudahan. Bersama dengan kesulitan ada kemudahan.
(Q.S.Al-Insyirah:6-7)
Tak perlu menjelaskan dirimu kepada siapapun, karena yang menyukaimu tidak membutuhkannya, dan yang membencimu tidak akan
mempercayainya
SANWACANA
Alhamdulillahirabbil’alamin, puji syukur kehadirat Allah SWT atas berkat
rahmat, hidayah, dan karunia-Nya sehingga penulis dapat menyelesaikan skripsi ini.
Skripsi ini disusun sebagai syarat untuk memperoleh gelar Sarjana Komputer di Jurusan Ilmu Komputer Universitas Lampung. Penyelesaian skripsi ini tidak terlepas dari bantuan banyak pihak yang membantu baik secara materi, moril, saran, dan bimbingan. Oleh karena itu, penulis mengucapkan terimakasih kepada:
1. Kedua orang tua tercinta, Bapak Rinto Riyadi dan Ibu Poniyati, serta Kakakku Rudianto yang selalu memberi dukungan berupa materi, doa, motivasi dan kasih sayang yang tak terhingga.
2. Bapak Dr. Ir. Kurnia Muludi, M.S.Sc., sebagai pembimbing utama, yang telah membimbing penulis dan memberikan ide, kritik serta saran sehingga penulisan skripsi ini dapat diselesaikan.
3. Bapak Aristoteles, S.Si., M.Si., sebagai pembimbing kedua, yang telah membimbing penulis dan memberikan bantuan, kritik serta saran dalam pembuatan skripsi ini.
4. Bapak Rico Andrian, S.Si., M.Kom., sebagai pembahas, yang telah memberikan masukan yang bermanfaat dalam perbaikan skripsi ini.
5. Bapak Prof. Warsito, S.Si., D.E.A., Ph.D., selaku Dekan FMIPA Universitas Lampung.
selama penulis menjadi mahasiswa Ilmu Komputer dan Bapak Didik Kurniawan, S.Si.,MT., selaku Sekretaris Jurusan Ilmu Komputer FMIPA Universitas Lampung.
7. Bapak dan Ibu Dosen Jurusan Ilmu Komputer yang telah memberikan ilmu dan pengalaman dalam hidup untuk menjadi lebih baik.
8. Eko Ibrahim Ahmad yang selalu mendengarkan keluh, memberi motivasi doa, dan semangat, serta Fenti Visiamah dan Ana Rianti yang selalu memberikan semangat dan doa.
9. Winda, Eka, Mei, Lutfi, Aul, dan teman KKN (Mona, Guntur, Khorik, Citra, Gio, Iko) yang telah memberi doa dan semangat.
10. Kawan seperjuangan: Nafi, Erlina, Anita, Qonitati, Yuni, Maya, Puja, Nila, Cindona, Ciwo, Taqiya, Dian, Afriska, Nurul, Erika, Haryati, Indah, Lia, Deby, Qiqin, Roni, Dipa, Juan, Shandy, Abet, Moko, Bintang, Ridwan dan seluruh keluarga besar Ilmu Komputer 2012.
11. Teman-teman Sahabat Pulau Lampung.
12. Ibu Ade Nora Maela dan Mas Irsan yang telah membantu segala urusan administrasi, dan Mas Nurhollis yang telah menyiapkan ruang seminar selama penulis kuliah di Jurusan Ilmu Komputer.
Penulis menyadari bahwa laporan ini masih jauh dari kata sempurna. Secara pribadi penulis mohon maaf yang sebesar-besarnya atas segala kekurangannya. Besar harapan agar skripsi ini dapat berguna bagi penulis dan semua pembacanya
Bandar Lampung, 2 Februari 2017 Penulis
xii
DAFTAR ISI
Halaman
DAFTAR ISI... xii
DAFTAR GAMBAR ...xiv
DAFTAR TABEL... xv
BAB I PENDAHULUAN 1.1 Latar Belakang 1 1.2 Rumusan Masalah 3 1.3 Batasan Masalah 3 1.4 Tujuan 3 1.5 Manfaat 4 BAB II TINJAUAN PUSTAKA 2.1 Klasifikasi ...5
2.1.1 Komponen Klasifikasi...5
2.1.2 Kerangka Klasifikasi...7
2.2 Probabiitas...8
2.2.1 Data Probabilitas ...8
2.3Naïve Bayes...9
2.3.1 PerhitunganNaïve Bayes...11
2.4 Pengukuran Kinerja...13
xiii
3.1 Metode Penelitian...17
3.2 Waktu dan Tempat Penelitian ...18
3.3 Tahap Penelitian...18
3.4 Pengukuran Kinerja Algoritma Klasifikasi ...26
3.5 Analisis Hasil Pengujian ...26
3.6 Visualisasi Data...27
BAB IV HASIL DAN PEMBAHASAN 4.1 Pra-proses Klasifikasi ...28
4.2 Pembagian DataTrainingdan DataTesting...32
4.3 Format Klasifikasi ...32
4.4 Proses Klasifikasi ...34
4.4.1 Klasifikasi denganNaïve Bayes...34
4.5 Pengukuran Kinerja Algoritma ...35
4.6 Pra-proses Visualisasi Data ...40
4.7 Visualisasi Data ...41
4.8.1 Visualisasi Jarak Asal Siswa SMA Negeri di Kabupaten Pringsewu...42
4.9 Pembahasan...44 BAB V KESIMPULAN DAN SARAN
5.1 Kesimpulan 46
5.2 Saran 46
DAFTAR PUSTAKA 48
xiv
DAFTAR GAMBAR
Halaman
Gambar 2.1 Proses Klasifikasi ... 7
Gambar 3.1 Diagram Alir Penelitian ... 17
Gambar 4.1 Proses Perapihan Data Asal Siswa SMAN 1 Gadingrejo ... 29
Gambar 4.2 DataTrainingFormat .csv ... 33
Gambar 4.3 DataTrainingFormat .arff ... 33
Gambar 4.4 Rata-rata akurasi denganNaïve Bayes ...35
Gambar 4.5 Rata-Rata PresentasePrecision dan RecallmetodeNaïve BayesuntukClassJauh... 39
Gambar 4.6 Data Sebelum Visualisasi... 40
Gambar 4.7 Visualisasi Data dengan Quantum Gis... 41
Gambar 4.8 Visualisasi Hasil Klasifikasi dengan Naïve Bayes... 42
Gambar 4.9 Perbedaan Warna Visualisasi Perbedaan Hasil Klasifikasi denganNaïve Bayes ...43
xv
DAFTAR TABEL
Halaman Tabel 1.1 Banyaknya Murid SMA Dirinci Menurut Jenis Kelamin Per
Kecamatan di Kabupaten Pringsewu Tahun 2015... 1
Tabel 2.1Confusion Matrix... 14
Tabel 2.2 Kategori Jarak Jangkauan dan Waktu Tempuh ... 15
Tabel 3.1 SMA Negeri di Kabupaten Pringsewu... 18
Tabel 3.2 Atribut Klasifikasi... 19
Tabel 3.3 DataTraining... 20
Tabel 3.4 Hasil PerhitunganMeandan Standar Deviasi, dan Densitas Gauss jarak siswa ... 24
Tabel 3.5 Hasil PerhitunganMeandan Standar deviasi, dan Densitas Gauss jarak no siswa ... 25
Tabel 3.6 Probabilitas dari setiapclassuntuk atribut data diskrit... 25
Tabel 4.1 Data SMAN 1 Gadingrejo Sebelum Pra-proses... 28
Tabel 4.2 Data SMAN 1 Gadingrejo Setelah Pra-proses ... 30
Tabel 4.3 Rincian Jumlah Perubahan Data ... 30
Tabel 4.4 Contoh Data yang MempunyaiMissing Value... 31
Tabel 4.5 Akurasi Hasil Pengujian Setiap Percobaan denganNaïve Bayes.. 34
Tabel 4.6Confusion MatrixKlasifikasi Jarak Siswa dengan MetodeNaïve Bayespada pembagian datatraining:testing60:40 pada pengujian ke-20 ... 36
Tabel 4.7Confusion MatrixKlasifikasi Jarak untuk MenghitungPrecision, Recall,dan Akurasi pada pembagian datatraining:testing60:40 pada pengujian ke-20 dengan MetodeNaïve Bayes... 37
1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Pringsewu merupakan kabupaten baru hasil pemekaran dari Kabupaten Tanggamus yang disahkan pada tanggal 3 April 2009. Kabupaten Pringsewu mempunyai 262 SD, 25 SMP, 10 SMA, 3 SMK berstatus negeri dan 5 SD, 32 SMP, 11 SMA, 25 SMK berstatus swasta (Tim BPS Pringsewu, 2015). Jumlah SMA yang sedikit berpeluang mempunyai siswa dari berbagai daerah di kecamatan yang ada di Kabupaten Pringsewu. Banyak siswa di Kabupaten Pringsewu untuk Sekolah Menengah Atas ditunjukkan oleh Tabel 1.1 berikut.
Tabel 1.1 Banyaknya Murid SMA Dirinci Menurut Jenis Kelamin Per Kecamatan di Kabupaten Pringsewu Tahun 2015
No Kecamatan
2 Ambarawa 215 544 49 95 903
3 Pagelaran 258 457 147 236 1098
4 Pagelaran Utara - - - -
-5 Pringsewu 560 1010 496 715 2781
6 Gadingrejo 432 782 70 48 1332
7 Sukoharjo 251 456 11 26 744
8 Banyumas 142 232 - - 374
9 Adiluwih 138 169 - - 307
Jumlah 2047 3700 773 1120 7640
2
Berdasarkan Tabel 1.1, terlihat siswa SMA negeri berjumlah 5747 dan siswa SMA swasta berjumlah 1893. Data tersebut menunjukkan bahwa siswa di Kabupaten Pringsewu lebih cenderung memilih SMA berstatus negeri meskipun siswa harus menempuh jarak yang jauh.
Jarak siswa dapat diketahui dari data asal siswa yang tersimpan. Asal siswa yang berbeda-beda akan menghasilkan jarak yang berbeda pula. Data tersebut dapat menunjukkan kepopuleran sekolah. Data jarak siswa akan dijadikan salah satu atribut untuk klasifikasi jarak asal siswa SMA negeri di Kabupaten Pringsewu, seperti penelitian Satoto dan Yasid (2015) tentang aplikasi sales report untuk klasifikasi area penjualan menggunakan K-Nearest Neighbor dan Naive Bayes berbasis android. Menggunakan jarak sebagai salah satu atribut dan menghasilkan akurasi sebesar 86%.
Penelitian yang akan dilakukan diharapkan dapat mengklasifikasikan jarak asal siswa dengan menggunakanNaive Bayes.Klasifikasi jarak asal siswa SMA negeri di Kabupaten Pringsewu dilakukan untuk mendapatkan lima class yaitu sangat dekat, dekat, sedang, cukup jauh, dan jauh. Selain itu, data asal siswa akan divisualisasikan dalam bentuk peta digital seperti penelitian Rodiyansyah dan Winarko (2013) tentang klasifikasi posting twitter kemacetan lalu lintas kota Bandung menggunakan Naive Bayesian Classification. Penelitian tersebut melakukan klasifikasi posting twitter kemudian data divisualisasikan pada peta kota Bandung. Data yang ditampilkan di peta adalah data jumlah tweet yang mengandung informasi kemacetan di suatu jalan.
3
SMA negeri di Kabupaten Pringsewu. Selain itu, hasil klasifikasi menggunakan Naïve Bayesakan ditambahkan sebagai informasi pada peta sebaran asal siswa.
Hasil penelitian diharapkan dapat membantu pihak sekolah dalam mengambil keputusan dan dapat digunakan sebagai penunjuk bagi pihak pemerintah kota dalam pemenuhan dan perbaikan sarana dan prasarana seperti kondisi jalan, pemerataan sekolah, dan tersedianya transportasi.
1.2 Rumusan Masalah
Berdasarkan latar belakang di atas rumusan masalah dalam penelitian ini adalah Bagaimana mengklasifikasikan jarak siswa di masing-masing SMA Negeri di Kabupaten Pringsewu?
1.3 Batasan Masalah
Batasan masalah dari sistem ini adalah sebagai berikut.
1. Klasifikasi jarak asal siswa dilakukan menggunakan MetodeNaïve Bayes. 2. Data siswa untuk klasifikasi adalah data siswa kelas XII tahun ajaran
2013/2014, 2014/2015, dan 2015/2016.
1.4 Tujuan Penelitian
Tujuan penelitian ini adalah sebagai berikut.
1. Mengklasifikasikan jarak asal siswa di setiap SMA negeri di Kabupaten Pringsewu dengan menggunakan metodeNaive Bayes.
4
1.5 Manfaat Penelitian
Manfaat yang dapat diperoleh dari penelitian ini adalah sebagai berikut.
1. Mengetahui kategori jarak siswa di setiap SMA negeri di Kabupaten Pringsewu.
5
BAB II
TINJAUAN PUSTAKA
2.1Klasifikasi
Classification adalah proses untuk menemukan model atau fungsi yang
menjelaskan atau membedakan konsep atauclass data, dengan tujuan untuk dapat
memperkirakan class dari suatu objek yang labelnya tidak diketahui (Han dkk.,
2011).
Klasifikasi merupakan fungsi pembelajaran yang memetakan (mengklasifikasi)
sebuah unsur (item) data ke dalam salah satu dari beberapa class yang sudah
didefinisikan. Data input untuk klasifikasi adalah koleksi dari record. Setiap
record dikenal sebagai instance atau contoh yang ditentukan oleh sebuah tuple
(x,y), dimana x adalah himpunan atribut dan y adalah atribut tertentu, yang
dinyatakan sebagai label class (juga dikenal sebagai kategori atau atribut target)
(Andri dkk., 2013).
2.1.1 Komponen Klasifikasi
6
Klasifikasi adalah algoritma yang menggunakan data dengan target (class/label) yang berupa nilai kategorikal/nominal. Proses klasifikasi didasarkan pada empat komponen mendasar (Gorunescu, 2011), yaitu:
1. Kelas (Class)
Variabel dependen dari model, merupakan variabel kategorikal yang
merepresentasikan “label” pada objek setelah klasifikasinya. Contoh: adanya kelas penyakit jantung, loyalitas pelanggan, dan kelas gempa bumi (badai).
2. Prediktor (Predictor)
Variabel independen dari model, direpresentasikan oleh karakteristik (atribut) dari data yang akan diklasifikasikan dan berdasarkan klasifikasi yang telah dibuat. Contoh: tekanan darah, status perkawinan, catatan geologi yang spesifik, kecepatan dan arah angin, musim, dan lokasi terjadinya fenomena .
3. Pelatihan dataset (Training dataset)
Kumpulan data yang berisi nilai-nilai dari kedua komponen sebelumnya dan digunakan untuk melatih model dalam mengenali class yang cocok/sesuai, berdasarkan prediktor yang tersedia. Contoh: kelompok pasien yang diuji pada serangan jantung, kelompok pelanggan supermarket (diselidiki oleh intern dengan jajak pendapat), database yang berisi gambar untuk monitoring teleskopik dan pelacakan objek astronomi, database badai.
4. Dataset Pengujian (Testing Dataset)
7
2.1.2 Kerangka Klasifikasi
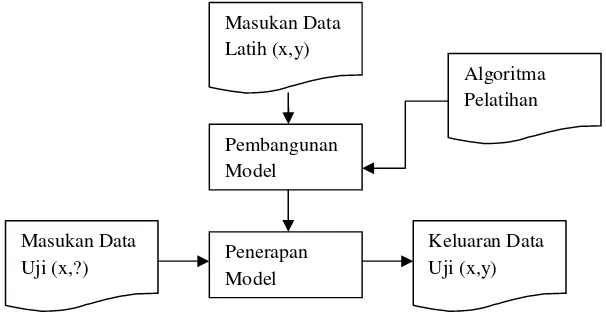
Kerangka kerja (framework) klasifikasi ditunjukkan pada Gambar 2.1. Disediakan sejumlah data latih (x,y) untuk digunakan sebagai data pembangun model. Model tersebut kemudian digunakan untuk memprediksi class dari data uji (x,y), sehingga diketahuiclassyang sesungguhnya.
Gambar 2.1 Proses Klasifikasi (Afriana, 2014)
Model yang sudah dibangun pada saat pelatihan dapat digunakan untuk memprediksi label class baru yang belum diketahui. Dalam pembangunan model selama pelatihan diperlukan suatu algoritma untuk membangunnya, yang disebut algoritma pelatihan.
8
2.2 Probabilitas
Probabilitas adalah suatu nilai yang digunakan untuk mengukur tingkat terjadinya suatu kejadian yang acak. Probabilitas dapat diartikan pula sebagai hasil banyaknya peristiwa yang dimaksud dengan seluruh peristiwa yang mungkin. Dirumuskan:
( )= ( )
( )……….. (1)
dengan:
( )= probabilitas terjadinya peristiwa A
( )= jumlah peristiwa A
( )= jumlah peristiwa yang mungkin
Nilai probabilitas berkisar antara 0 dan 1. Semakin dekat nilai probabilitas, ke nilai 0, semakin kecil kemungkinan suatu kejadian akan terjadi. Sebaliknya, Semakin dekat nilai probabilitas, ke nilai 1, semakin besar kemungkinan suatu kejadian akan terjadi (Supranto, 2000).
2.2. 1 Data Probabilitas
Salah satu jenis data adalah data kuantitatif yan terdiri dari data diskrit dan data
kontinu (Budiarto, 2001).
- Data diskrit adalah data yang diperoleh dari hasil perhitungan atau membilang (bukan mengukur) hingga hasilnya selalu positif dan dapat dipisahkan satu dengan yang lain secara jelas.
9
jumlah responden yang menjawab ya atau tidak, pengelompokan bunga berdasarkan warnanya.
- Data kontinu adalah data yang dihasilkan dari pengukuran dapat berupa bilangan desimal atau bilangan bulat. Misalnya, data skor tes, hasil pengukuran tinggi badan seseorang, luas daerah A sebesar 425,7 km, kecepatan mobil 60/km jam, dan sebagainya.
Apabila unsur probabilitas adalah diskrit maka mengunakan istilah fungsi massa. Apabila unsur probabilitas adalah kontinu maka mengunakan istilah fungsi Densitas (Naga, 2008).
2.3 Naïve Bayes
Naïve Bayes merupakan sebuah pengklasifikasian probabilistik sederhana yang
menghitung sekumpulan probabilitas dengan menjumlahkan frekuensi dan
kombinasi nilai dari dataset yang diberikan. Algoritma ini mengasumsikan semua
atribut independen atau tidak saling ketergantungan yang diberikan oleh nilai pada
variabel class. Pengklasifikasian dengan metode probabilitas dan statistik yang
dikemukan oleh ilmuwan Inggris Thomas Bayes, yaitu memprediksi peluang di
masa depan berdasarkan pengalaman di masa sebelumnya. Naïve Bayes
didasarkan pada asumsi penyederhanaan bahwa nilai atribut secara kondisional
saling bebas jika diberikan nilai output (Ridwan dkk., 2013).
Keuntungan penggunan Naïve Bayes adalah hanya membutuhkan jumlah data
pelatihan (training data) yang kecil untuk menentukan estimasi parameter yang
10
Naïve Bayes merupakan salah satu algoritma klasifikasi yang sederhana namun
memiliki kemampuan dan akurasi tinggi (Rodiyansyah dan Winarko, 2013).
Persamaan dari teorema Bayes adalah
( | ) = ( | ) ( )
( ) ………..(2) (Kusrini dan Luthfi, 2009)
Di mana:
: Data denganclassyang belum diketahui. : Hipotesis data merupakan suatu class spesifik.
( | ): Probabilitas hipotesis H berdasarkan kondisi X (posterior probabilitas).
( ): Probabilitas hipotesis H (prior probabilitas) terjadi tanpa memandang bukti apapun.
( | ): Probabilitas X berdasarkan kondisi pada hipotesis H .
( ): Probabilitas kondisi X (prior probabilitas) terjadi tanpa memandang kondisi yang lain.
Ide dasar dari aturan Bayes adalah bahwa hasil dari hipotesis atau peristiwa (H) dapat diperkirakan berdasarkan pada beberapa bukti atau kondisi (X) yang diamati. Hal penting dari aturan Bayes (Afriana, 2014) adalah sebagai berikut.
1. Sebuah probabilitas awal/prior H atau P(H) adalah probabilitas dari suatu hipotesis sebelum bukti/kondisi diamati.
2. Sebuah probabilitas akhir/ posterior H atau P(H|X) adalah probabilitas dari suatu hipotesis setelah bukti/kondisi diamati.
Proses klasifikasi memerlukan sejumlah petunjuk untuk menentukan class apa yang cocok bagi sampel yang dianalisis tersebut. Karena itu, metode Naive Bayes di atas disesuaikan sebagai berikut:
( | 1 ) = ( ) ( | )
11
Di mana Variabel C merepresentasikan class, sementara variabel F1 ... Fn
merepresentasikan karakteristik petunjuk yang dibutuhkan untuk melakukan
klasifikasi. Maka rumus tersebut menjelaskan bahwa peluang masuknya sampel
karakteristik tertentu dalam classC (Posterior) adalah peluang munculnyaclassC
(sebelum masuknya sampel tersebut, seringkali disebut prior), dikali dengan
peluang kemunculan karakteristik-karakteristik sampel padaclass C (disebut juga
likelihood), dibagi dengan peluang kemunculan karakteristik - karakteristik
sampel secara global (disebut juga evidence). Dapat pula ditulis secara sederhana
sebagai berikut:
= ………(4)
Nilai Evidence selalu tetap untuk setiap class pada satu sampel. Nilai dari
posterior tersebut nantinya akan dibandingkan dengan nilai-nilai posterior class
lainnya untuk menentukan keclassapa suatu sampel akan diklasifikasikan (Saleh,
2015).
2.3.1 PerhitunganNaïve Bayes
Perhitungan Naïve Bayes memerlukan beberapa parameter sebagai berikut (Heksaputra, 2013).
a. Mean
Adapun persamaan yang digunakan untuk menghitung nilai rata – rata (mean) dapat dilihat sebagai berikut:
=
………..(5)atau
12
di mana:
: rata–rata hitung (mean) : nilai sample ke -i
: jumlah sampel
b. Standar Deviasi
Persamaan untuk menghitung nilai simpangan baku (standar deviasi) dapat dilihat sebagai berikut: Keterangan: /Exp =2,718282
d. Menghitung Nilai Likelihood
Dilakukan perhitungan menggunakan metode Naïve Bayes sebelum mengetahui hasil akhir, dengan menggunakan rumus likelihood.
Persamaan likelihood :
( | ) = ( | ) × ( 1| ) × × ( | )………. (9)
Di mana :
13
e. Normalisasi Nilai Probabilitas
Berdasarkan perhitungan likelihood maka dapat diperoleh nilai probabilitas akhir sebagai berikut :
( | ) = ( | )
( | ) ………..(10)
2.4 Pengukuran Kinerja
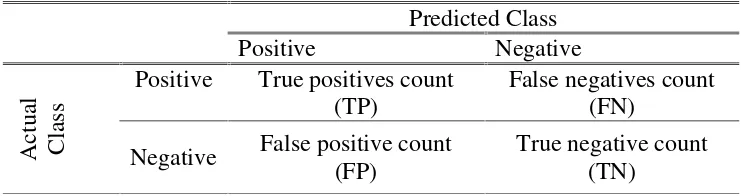
Confusion matrix merupakan tabel pencatat hasil kerja klasifikasi. Confusion matrix melakukan pengujian untuk memperkirakan objek yang benar dan salah (Gorunescu, 2011). Dengan mengetahui jumlah data yang diklasifikasikan secara benar, dapat diketahui akurasi hasil prediksi dan dengan mengetahui jumlah data yang diklasifikasikan secara salah, dapat diketahui laju error dari prediksi yang dilakukan (Afriana, 2014).
Akurasi dapat dihitung mengunakan persamaan:
= ……..………... (15)
laju eror (kesalahan prediksi) dapat dihitung menggunakan persamaan:
= ………(16)
14
True positives adalah jumlah record positif yang diklasifikasikan sebagai positif, false positives adalah jumlah record positif yang diklasifikasikan sebagai negatif, false negativesadalah jumlahrecordnegatif yang diklasifikasikan sebagai positif, true negativesadalah jumlahrecordnegatif yang diklasifikasikan sebagai negatif, Data uji yang dimasukkan ke dalam confusion matrix, akan dihitung nilai-nilai recall,precisiondanaccuracy(Defiyanti, 2013).
= ………..(17)
= ………..(18)
Precision (p) = jumlah sampel berkategori positif diklasifikasi benar dibagi dengan total sampel yang diklasifikasi sebagai sample positif.
Recall (r) = jumlah sampel diklasifikasi positif dibagi total sampel dalam testing set berkategori positif.
Akurasi juga dapat diperoleh dengan persamaan di bawah ini:
= ……….(19)
2.5 Jarak
15
dalam satuan unit ukuran fisik seperti mil, km, meter, dan sebagainya (Daldjoeni, 1997).
Jarak dari tempat tinggal ke setiap prasarana mempunyai standar yang berbeda. Standar jarak dan waktu tempuh untuk sarana fasilitas pendidikan menurut konsep Neighborhood Unit dapat dibagi menjadi lima kategori yang ditunjukkan pada Tabel 2.2 berikut.
Tabel 2.2 Kategori Jarak Jangkauan dan Waktu Tempuh
No Kategori jarak Jarak tempuh (meter) Waktu tempuh
1 Sangat Dekat 0-300 meter 0-5 menit
2 Dekat 300-600 meter 5-10 menit
3 Sedang / Cukup 600-1200 meter 10-20 menit
4 Cukup Jauh 1200-3000 meter 20-40 menit
5 Jauh >3000 meter >40 menit
Sumber : Udjianto, 1994 dalam Takumangsang 2010
Takumangsang juga menyebutkan bahwa standar fasilitas pendidikan departemen pendidikan dan kebudayaan untuk SMA adalah sebagai berikut.
• Wilayah Kerja
Sebuah SMA didirikan setidaknya untuk melayani penduduk satu kabupaten (30.000 jiwa). Pada wilayah perkotaan jumlah fasilitas SMA ini dapat lebih dari satu, tergantung pada jumlah murid lulusan sokolah menengah pertama.
• Lokasi
Lokasi sebuah SMA harus memenuhi ketentuan sebagai berikut. - mudah dicapai dari setiap bagian kecamatan.
16
Neighboorhood unit diadaptasi oleh Clarence Perry pada tahun 1929 untuk merencanakan suatu lingkungan yang berlandaskan suatu pemikiran sosial psikologis agar dapat menjawab optimasi dengan mengatasi penurunan kualitas kehidupan masyarakat di negara-negara industri saat itu. Perry mengidentifikasi neighborhood unitsebagai suatu unit pemukiman yang mempunyai batasan yang jelas yaitu: (1) ukuran atas dasar keefektifan jarak jangkau pejalan kaki dan (2) adanya kontak langsung individual serta ketersediaan fasilitas pendukung kebutuhan pemukiman.
Dalam konsepneighborhood unitini, dapat disimpulkan bahwa Perry mempunyai tujuan utama bagi sebuah lingkungan permukiman yang baik untuk membuat interaksi sosial di antara penghuni lingkungan permukiman, sedangkan penataan fisik lingkungan merupakan cara untuk tujuan utama tersebut.
17
BAB III
METODOLOGI PENELITIAN
3.1 Metode Penelitian
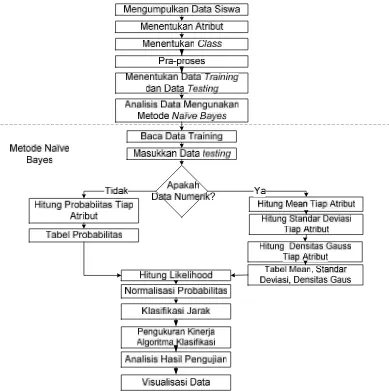
Metode penelitian dalam penelitian ini mengunakan Metode Naïve Bayes. Diagram alir penelitian untuk menjelaskan penelitian ini ditunjukkan pada Gambar 3.1.
18
3.2 Waktu dan Tempat Penelitian
Penelitian ini dilaksanakan mulai dari semester genap tahun ajaran 2015/2016 sampai selesai, bertempat di Jurusan Ilmu Komputer Fakultas Matematika Dan Ilmu Pengetahuan Alam, Universitas Lampung.
3.3 Tahap Penelitian
Penjelasan dari setiap tahap penelitian berdasarkan diagram alir penelitian adalah sebagai berikut.
1. Pengumpulan Data Siswa
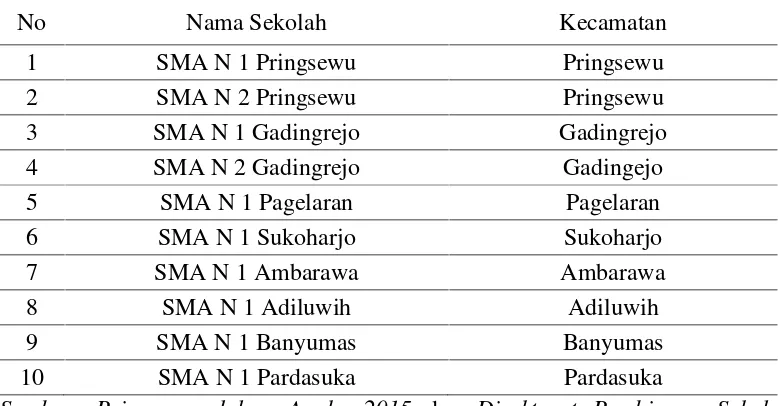
Pengumpulan data siswa pada penelitian ini menggunakan metode wawancara. Data diperoleh dengan cara datang ke sepuluh SMA negeri yang ada di Kabupaten Pringsewu. Tabel 3.1 menunjukkan daftar SMA negeri di Kabupaten Pringsewu. Data siswa yang diperoleh berupa alamat siswa, asal SMP, dan titik koordinat SMA, serta jarak siswa dengan bantuan Google Maps.
Tabel 3.1 SMA Negeri di Kabupaten Pringsewu.
No Nama Sekolah Kecamatan
1 SMA N 1 Pringsewu Pringsewu
2 SMA N 2 Pringsewu Pringsewu
3 SMA N 1 Gadingrejo Gadingrejo
4 SMA N 2 Gadingrejo Gadingejo
5 SMA N 1 Pagelaran Pagelaran
6 SMA N 1 Sukoharjo Sukoharjo
7 SMA N 1 Ambarawa Ambarawa
8 SMA N 1 Adiluwih Adiluwih
9 SMA N 1 Banyumas Banyumas
10 SMA N 1 Pardasuka Pardasuka
19
2. Penentuan Atribut
Data yang sudah terkumpul akan dibentuk atribut klasifikasi yang ditunjukkan pada Tabel 3.2.
Tabel 3.2 Atribut Klasifikasi
Atribut Klasifikasi Keterangan
NO Berisi nomor sebagai pembeda pada setiap data. SMA Berisi nama SMA negeri di Kabupaten Pringsewu. Kabupaten (Kab) Berisi kabupaten asal siswa di SMA negeri di Kabupaten
Pringsewu.
Kecamatan (Kec) Berisi kecamatan asal siswa di SMA negeri di Kabupaten Pringsewu.
Kelurahan (Kel) Berisi kelurahan asal siswa di SMA negeri di Kabupaten Pringsewu.
Jarak
Berisi jarak asal siswa dari rumah ke masing-msing sekolah dengan berjalan kaki dalam satuan kilometer (km).
Jarak yang digunakan adalah jarak mutlak. Asal SMP Berisi asal SMP siswa di SMA negeri di Kabupaten
Pringsewu.
Class Berisiclass/ label yang merepresentasikan jarak asal siswa.
3. PenentuanClassatau Label Klasifikasi
Atribut yang sudah terbentuk akan dilakukan pe-label-an sesuai denganclassyang telah ditentukan, yaitu “sangat dekat”, “dekat”, “sedang”, “cukup jauh”, dan “jauh” untuk jarak siswa dari rumah kemasing-masing sekolah.
4. Pra-proses Klasifikasi
Pra-proses klasifikasi yang dilakukan adalah proses pembersihan dan perapihan data yaitu sebagai berikut.
20
2. Konversi menjadi huruf kapital.
Contoh : Pringsewu BaratPRINGSEWU BARAT
3. Melakukan perbaikan data apabila ada kata yang diperlukan tetapi data tidak sesuai.
Contoh: ada kata“gemuk mas”kemudian diubah menjadi“GUMUKMAS”. 4. Melakukan penghapusan spasi
Contoh : PRINGSEWU BARATPRINGSEWUBARAT
5. Penentuan DataTrainingdan DataTesting
Data yang sudah di lakukan pembersihan dan perapihan data dipisahkan menjadi dua bagian, yaitu data training dan data testing. Setiap data dalam training tidak boleh ada di dalamtesting.
6. Analisa MetodeNaïve Bayes
Metode Naïve Bayes digunakan untuk menentukanclass dari atribut-atribut jarak asal siswa dengan bantuan aplikasi Weka. Analisis MetodeNaïve Bayesmemiliki tahap sebagai berikut..
1. Baca datatraining Contoh:
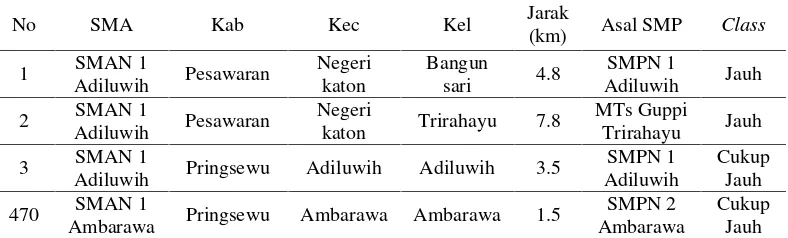
Tabel 3.3 DataTraining
No SMA Kab Kec Kel Jarak
(km) Asal SMP Class
Adiluwih Pringsewu Adiluwih Adiluwih 3.5
SMPN 1 Adiluwih
Cukup Jauh
470 SMAN 1
Ambarawa Pringsewu Ambarawa Ambarawa 1.5
SMPN 2 Ambarawa
21
Lanjutan Tabel 3.3 DataTraining
No SMA Kab Kec Kel Jarak
(km) Asal SMP Class
Banyumas Pringsewu Banyumas Sriwungu 1
SMPN 1
Pardasuka Pringsewu Pardasuka Kedaung 9.5
SMPN 1
Sukoharjo Pringsewu Sukoharjo Siliwangi 9.2
SMP PGRI
1 Sukoharjo Jauh
2028 SMAN 1
Sukoharjo Pringsewu Adiluwih Adiluwih 4.2
SMPN 1
Pringsewu Pringsewu Pringsewu Podosari 0.3
MTsN 1
Dicariclassdari datatestingberikut:
22
3. Perhatikan jenis data pada datatesting • Data non-numerik/diskrit
Cari nilai probabilistik pada data testing yang bersifat non-numerik/diskrit dengan cara menghitung jumlah data yang sesuai dari kategori yang sama dibagi dengan jumlah data pada kategori tersebut.
Contoh :
Probabilitas dari setiap kelas.
- P(class= “Sangat Dekat” )= = 0.05
-P(class= “Dekat”)= = 0.1
-P(class= “Sedang”)= = 0.10 -P(class= “Cukup Jauh”)= = 0.2
-P(class= “Jauh”)= = 0.55
Probabilitas dari setiapclassuntuk atribut data diskrit.
-P(SMA = “SMAN 1 Gadingrejo” | class= “Sangat Dekat”)= = 0
- P(SMA = “SMAN 1 Gadingrejo” | class= “Dekat”)= = 0
- P(SMA = “SMAN 1 Gadingrejo” | class= “Sedang”) = = 0.5
- P(SMA = “SMAN 1 Gadingrejo” | class= “Cukup Jauh”)= = 0
- P(SMA = “SMAN 1 Gadingrejo” | class= “Jauh”)= = 0.090
- P(Kab= “Pringsewu” | class= “Sangat Dekat”)= = 1
- P(Kab= “Pringsewu” | class= “Dekat”)= = 1
- P(Kab= “Pringsewu” | class= “Sedang”)= = 0.5
- P(Kab= “Pringsewu” | class= “Cukup Jauh”)= = 1
- P(Kab= “Pringsewu” | class= “Jauh”) = = 0.636
23
- P(Kec = “Gadingrejo” | class= “Dekat”)= = 0
- P(Kec = “Gadingrejo” | class= “Sedang”)= = 0.5
- P(Kec = “Gadingrejo” | class= “Cukup Jauh”)= = 0.25
- P(Kec = “Gadingrejo” | class= “Jauh”)= = 0.090
-P(Kel = “Tegalsari” | class= “Sangat Dekat”)= = 0
- P(Kel = “Tegalsari” | class= “Dekat”)= = 0
- P(Kel = “Tegalsari” | class= “Sedang”)= = 0.5
- P(Kel = “Tegalsari” | class= “Cukup Jauh”)= = 0.25
-P(Kel = “Tegalsari” | class= “Jauh”)= = 0
-P(AsalSMP= “SMPN 1Gadingrejo” | class= “Sangat Dekat”)= = 0
- P(AsalSMP= “SMPN1 Gadingrejo” | class= “Dekat”)= = 0
- P(AsalSMP= “SMPN1 Gadingrejo” | class= “Sedang”)= = 0.5
- P(AsalSMP= “SMPN1 Gadingrejo” | class= “Cukup Jauh”)= = 0
-P(AsalSMP= “SMPN1 Gadingrejo” | class= “Jauh”)= = 0
• Data numerik/kontinu
Cari nilai mean, standar deviasi, dan densitas gauss dari masing-masing parameter yang merupakan data numerik/kontinu.
• Persamaan menghitungmean:
=
……….………... (1)atau
=
………
(2)Contoh :
24
•
Persamaan untuk menghitung nilai simpangan baku (standar deviasi):=
( ) ..….………...(3)Contoh :
Jarak = ( . . ) ( . ) = 0.071
• Persamaan fungsi Densitas Gauss:
( ) =
Nilai Densitas Gauss yang didapat digunakan dalam perhitungan likelihood. 4. Mendapatkan nilai dalam tabelmean, standar deviasi, densitas gauss dan
probabilitas.
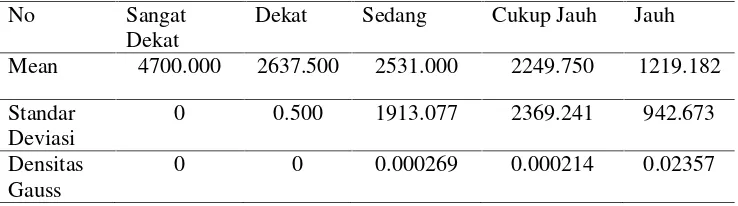
Hasil mean, standar deviasi, densitas gauss menggunakan persamaan (2), (3), dan (4) dapat dilihat pada Tabel 3.4 dan Tabel 3.5 berikut.
Tabel 3.4 Hasil PerhitunganMeandan Standar deviasi, dan Densitas Gauss jarak siswa.
Jarak Sangat Dekat
Dekat Sedang Cukup Jauh Jauh
Mean 0.300 0.550 1.050 2.450 11.063
Standar Deviasi
0 0.071 0.071 0.954 10.286
Densitas
Gauss 0
25
Tabel 3.5 Hasil PerhitunganMeandan Standar deviasi, dan Densitas Gauss no siswa.
No Sangat Dekat
Dekat Sedang Cukup Jauh Jauh
Mean 4700.000 2637.500 2531.000 2249.750 1219.182
Standar Deviasi
0 0.500 1913.077 2369.241 942.673
Densitas Gauss
0 0 0.000269 0.000214 0.02357
Tabel 3.6 Probabilitas dari setiapclassuntuk atribut data diskrit.
Atribut Sangat Dekat Dekat Sedang Cukup
Jauh Jauh
26
P(X|Jauh)= 0.069176 × 0.02357 × × × × × × =0
6. Normalisasi Probabilitas
Mengambil keputusan sebuah data testing masuk ke dalamclass apa, perlu dilakukan normalisasi probabilitas.
Probabilitas Sangat Dekat =
( . ) = 0
Probabilitas Dekat =
( . ) = 0
Probabilitas Sedang = ( .. ) = 1
Probabilitas Cukup Jauh = ( . ) = 0
Probabilitas Jauh = ( . ) = 0
Kesimpulanclassdari datatestingyang diberikan adalah Sedang.
Jadi klasifikasi jarak asal siswa dari datatestingyang diberikan adalahclass Sedang.
3.4 Pengukuran Kinerja Algoritma Klasifikasi
Pengujian algoritma klasifikasi dilakukan dengan pengukuran kinerja algoritma menggunakan confusion matrix. Data uji yang dimasukkan akan membentuk tabel, dan akan dihitungprecision, recall, dan akurasi dari data tersebut.
3.5 Analisis Hasil Pengujian
27
3.6 Visualisasi Data
6
BAB V
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Kesimpulan yang didapat dari klasifikasi jarak siswa SMA negeri di kabupaten Pringsewu dengan MetodeNaïve Bayesadalah sebagai berikut.
1. Metode Naïve Bayes berhasil mengklasifikasikan jarak asal siswa SMA negeri di Kabupaten Pringsewu.
2. Setelah 20 kali pengujian diperoleh rata-rata akurasi tertinggi pada Naïve Bayessebesar 89.329% pada pembagian datatrainingdan datatesting60:40. 3. Pada proses klasifikasi dengan Naïve Bayes jumlah data training tidak
mempengaruhi tingginya nilai akurasi.
4. Hasil visualisasi data asal siswa menunjukkan SMAN 1 Pringsewu dan SMAN 1 Gadingrejo lebih dikenal luas di masyarakat karena asal siswa lebih beragam.
5.2 Saran
Saran yang diajukan dalam penelitian tentang klasifikasi jarak siswa SMA negeri di kabupaten Pringsewu adalah sebagai berikut.
✁ ✂
2. Penelitian selanjutnya dapat menggunakan metode klasifikasi lainnya untuk mengetahui metode yang lebih cocok untuk klasifikasi jarak asal siswa SMA negeri di Kabupaten Pringsewu.
DAFTAR PUSTAKA
Afriana, Fikri. 2014. Klasifikasi Kendaraan Roda Empat Menggunakan Metode Naïve Bayes [online] url: http://repository.widyatama.ac.id/xmlui/handle /123456 789/3523.pdf. Diakses tanggal 13 Mei 2016.
Andri, Kunang, Y. M. dan Murniati, S. 2013. Implementasi Teknik Data Mining untuk Memprediksi Tingkat Kelulusan Mahasiswa pada Universitas Bina Darma Palembang. Seminar Nasional Informatika (semnasIF 2013) UPN ”Veteran” Yogyakarta. ISSN: 1979-2328.
Budiarto, Eko. 2001. Biostatistika untuk Kedokteran dan Kesehatan Masyarakat. Jakarta: Penerbit Buku Kodekteran CEGC.
Daldjoeni. 1997. Geografi Baru-Organisasi Keruangan dalam Teori dan Praktek. Alumni. Bandung.
Defiyanti, Sofi. 2013. Analisis dan Prediksi Kinerja Mahasiswa Menggunakan TeknikData Mining.Syntax Vol. 2 Ed. 1.
Gorunescu, F. 2011.Data Mining Concept Model Technique.Romania: Springer. Han, J., Kamber, M. dan Pei, J. 2011.Data Mining Concept and Techniques Third
Edition. SanFrancisco: Morgan Kauffman.
Heksaputra, D., Azani, Y., Naimah, Z. dan Iswari, L. 2013. Penentuan Pengaruh Iklim Terhadap Pertumbuhan Tanaman dengan Naïve Bayes. Seminar Nasional Aplikasi Teknologi Informasi (SNATI), ISSN: 1907–5022. Kusrini dan Luthfi, E.T. 2009. Algoritma data mining. Yogyakarta: Andi Offset.
Nasution, N., Djahara, K. dan Zamsuri, A. 2015. Evaluasi Kinerja Akademik Mahasiswa Menggunakan Algoritma Naïve Bayes (Studi Kasus: Fasilkom Unilak). Jurnal Teknologi Informasi & Komunikasi Digital Zone. Vol.6, No.2.
Rodiyansyah, S. F. dan Winarko, E. 2013. Klasifikasi Posting Twitter Kemacetan Lalu Lintas Kota Bandung Menggunakan Naive Bayesian Classification. IndonesianJournalof Computing and Cybernetics Systems (IJCCS).Vol.7, No.1. ISSN: 1978-1520.
Saleh, Alfa. 2015. Implementasi Metode Klasifikasi Naïve Bayes Dalam Memprediksi Besarnya Penggunaan Listrik Rumah Tangga. Creative Information Technology Journal. Vol. 2, No. 3. ISSN:2354-5771.
Satoto, B. D,. dan Yasid, A. 2015. Aplikasi Sales Report untuk Klasifikasi Area Penjualan Menggunakan K-Nearest Neighbor dan Naive Bayes Berbasis Android. Seminar Nasional Teknologi Informasi dan Komunikasi 2015 (SENTIKA 2015). ISSN: 2089-9815.
Supranto, J. 2000. Statistik: Teori & Aplikasi, edisi 6, jilid 1. Jakarta: Erlangga. Takumangsang, Esli D. 2010. Kajian Penempatan Fasilitas Pendidikan Dasar dan
Menengah dalam Aspek Sistem Informasi Geografis. TEKNO Vol. 08 No.54.
Tim BPS Pringsewu, 2015. Pringsewu dalam Angka 2015. Badan Pusat Statistik Pringsewu.
Tim BPS Pringsewu, 2015. Kecamatan dalam Angka 2015. Badan Pusat Statistik Pringsewu.
Utoro, R. I, 2006. Kajian Optimasi Pola dan Tingkat Pelayanan Sarana Dasar di Kota Kecamatan Jalancagak–Subang. Tesis, Semarang: Perencanaan Pembangunan Wilayah Dan Kota, Universitas Diponegoro.