Jenis Kelamin : Perempuan
Umur : 24 Tahun
Tinggi, Berat Badan : 160 cm, 45 Kg
Agama : Kristen
Alamat : Jl. Kihapit Timur No 09
RT 09 RW 10 Kota Cimahi
Status : Mahasiswa
Telepon : 082126633691
Email : jademp.it@gmail.com
PENDIDIKAN
1998 – 2004 : SDN Santo Yusup Kota Cimahi 2004 – 2007 : SMPN 3 Cimahi Kota Cimahi
2007 – 2011 : SMKN 1 Cimahi Kota Cimahi Program Studi RPL
SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
JADEQUELINE MARSHA PRICILA 10112965
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
iii
skripsi ini tepat pada waktunya. Maksud dan tujuan penulis menyusun penulisan skripsi ini yaitu untuk memenuhi syarat dalam menyelesaikan program Strata Satu (S1) jurusan Teknik Informatika pada Fakultas Teknik dan Ilmu Komputer Universitas Komputer Indonesia (UNIKOM) dengan judul Perbandingan Beberapa Pendekatan Multiclass SVM Untuk Klasifikasi Artikel Berbahasa Indonesia.
Penulis sangat menyadari bahwa dalam penulisan skripsi ini masih jauh dari kesempurnaan, baik dalam metode penulisan, penyajian maupun pembahasan materi, sehingga kiranya masih banyak yang perlu diperbaiki. Oleh karena itu, penulis sangat mengharapkan saran dan kritik yang bersifat membangun sehingga dapat memperbaiki kekurangan dikemudian hari.
Dalam proses penyusunan skripsi ini, penulis banyak mendapatkan bantuan, dukungan dari banyak pihak. Oleh karena itu penulis mengucapkan banyak terima kasih dengan penuh rasa hormat kepada yang terhormat Ibu Ken Kinanti Purnamasari, S.Kom, M.T., selaku dosen pembimbing yang telah meluangkan waktu, tenaga dan pikirannya untuk membimbing penulis dalam penulisan skripsi ini. Selain itu, penulis juga ingin mengucapkan banyak terima kasih kepada :
1. Yth. Bapak Prof. Dr. Ir. Eddy Suryanto Soegoto, M.Sc., selaku Rektor Universitas Komputer Indonesia (UNIKOM) Bandung.
2. Yth. Ibu Prof. Dr. Hj. Ria Ratna Ariawati, M.S, Ak, selaku Pembantu Rektor I Universitas Komputer Indonesia (UNIKOM) Bandung.
3. Yth. Bapak Prof. Dr. Moh Tadjuddin, M.A., selaku Pembantu Rektor II Universitas Komputer Indonesia (UNIKOM) Bandung.
iv Bandung.
6. Yth. Bapak Irawan Afrianto, M.T. selaku ketua program studi Teknik Informatika Universitas Komputer Indonesia (UNIKOM) Bandung. 7. Yth. Segenap tim dosen dan staf program studi Teknik Informatika
Universitas Komputer Indonesia (UNIKOM) Bandung.
8. Yth. Segenap staf front office Universitas Komputer Indonesia (UNIKOM) Bandung.
Selain itu penulis ingin mengucapkan terimakasih sebesar-besarnya kepada Ayah dan Ibu tercinta, Juliana, Joanna, teman – teman komunitas, dan dukungan selama ini kepada penulis, untuk keluarga dan keluarga besarku diseluruh penjuru tanah air yang telah memberikan doa dan dukungan untukku, terima kasih ya. Untuk teman-teman IF Goceng 2012 dan segenap teman seperjuangan di prodi Teknik Informatika yang tidak dapat penulis sebutkan satu persatu, terima kasih atas semua kerja sama dan dukungan selama ini, mohon maaf apabila selama ini banyak kesalahan yang penulis perbuat, baik sengaja atau tidak.
Bandung, 25-Agustus-2016
v
DAFTAR ISI
ABSTRAK ... i
ABSTRACT ... ii
KATA PENGANTAR ... iii
DAFTAR ISI ... v
DAFTAR GAMBAR ... x
DAFTAR TABEL ... xii
DAFTAR SIMBOL ... xvi
DAFTAR LAMPIRAN ... xix
BAB 1 PENDAHULUAN ... 1
1.1 Latar Belakang Masalah ... 1
1.2 Identifikasi Masalah ... 3
1.3 Maksud dan Tujuan ... 3
1.4 Batasan Masalah... 3
1.5 Metodologi Penelitian ... 4
1.5.2 Metode Pembangunan Perangkat Lunak ... 5
1.6 Sistematika Penulisan... 7
BAB 2 LANDASAN TEORI ... 9
2.1 Berita ... 9
2.2 Klasifikasi ... 11
2.2.1 Model ... 12
vi
2.3 Praproses Dokumen ... 15
2.3.1 Case Folding ... 15
2.3.2 Tokenisasi ... 15
2.3.3 Stopwords ... 15
2.4 Text Feature Extraction ... 15
2.4.1 TF-IDF ... 15
2.5 Support Vector Machine (SVM) ... 16
2.5.1 Konsep SVM ... 16
2.5.2 SVM pada Linearly Separable Data... 18
2.5.3 Hyperplane SVM... 21
2.5.4 SVM pada NonLinearly Separable Data ... 24
2.5.5 Contoh Aplikasi Klasifikasi dengan SVM ... 28
2.5.6 Karakteristik Support Vector Machine ... 29
2.6.1 Metode one-against-all ... 31
2.6.2 Metode one-against-one ... 32
2.6.3 Metode error correcting output code ... 34
2.7 Python ... 34
2.7.1 Python 2.7 ... 35
2.8 NoSQL ... 36
2.8.1 MongoDB ... 37
2.8.2 Data model... 38
2.9 Pemrograman Terstruktur ... 38
vii
2.9.2 Kamus Data ... 39
2.10 Scikit – Learn ... 40
2.11 NLTK ... 40
BAB 3 ANALISIS DAN PERANCANGAN SISTEM ... 42
3.1.1 Analisis Sistem ... 43
3.1.2 Analisis Data Masukan ... 47
3.1.3 Analisis Proses ... 48
3.1.3.1 Preprocessing ... 48
3.1.3.2 Case Folding ... 49
3.1.3.3 Filtering... 51
3.1.3.4 Tokenizing... 55
3.1.3.5 Stopword ... 58
3.1.3.6 Analisis Feature Extraction dengan TF-IDF ... 61
3.1.4 Analisis Klasifikasi menggunakan Metode SVM ... 69
3.1.4.1 Representasi Data ... 69
3.1.4.2 Analisis Proses SVM Training ... 71
3.1.4.2.1 Analisis Training one vs all... 75
3.1.4.2.2 Analisis Training one vs one ... 83
3.1.4.2.3 Analisis Training ECOC ... 89
3.1.4.3 Analisis Proses SVM Testing... 94
3.1.4.3.1 Analisis MulticlassOne vs All ... 95
3.1.4.3.2 Analisis MulticlassOne vs One ... 103
viii
3.1.5 Analisis kebutuhan non fungsionalitas ... 112
3.1.5.1 Analisis Kebutuhan Perangkat Lunak ... 112
3.1.5.2 Analisis kebutuhan perangkat keras ... 113
3.1.5.3 Analisis Pengguna ... 113
3.1.6 Analisis Kebutuhan Fungisional... 113
3.1.6.1 Diagram Konteks ... 114
3.2.1 Data Model ... 124
3.2.2 Perancangan Struktur Menu ... 126
3.2.3 Perancangan Antarmuka ... 126
3.2.4 Perancangan Pesan ... 131
3.2.5 Perancangan Semantik... 132
BAB 4 IMPLEMENTASI DAN PENGUJIAN ... 133
4.1 Implementasi Sistem ... 133
4.1.1 Implementasi Perangkat Keras ... 133
4.1.2 Implementasi Perangkat Lunak ... 133
4.1.3 Implementasi Database ... 133
4.1.4 Implementasi Antar Muka ... 135
4.2 Pengujian Sistem ... 137
4.2.1 Pengujian Fungisionalitas ... 138
4.2.2 Pengujian Performansi... 139
4.3 Hasil Pengujian Sistem ... 139
4.3.1 Hasil Pengujian Fungisionalitas ... 139
ix
4.3.3 Analisis Hasil Pengujian... 155
5.1 Kesimpulan ... 156
5.2 Saran ... 156
161
[2] Chih-Wei Hsu dan Chih-Jen Lin. 2002. A Comparison of Methods For Multi-class
Support Vector Machines, IEEE Transactions on Neural Networks, vol 3,ISSN:1045-9227.
[3] Sommerville, Ian. 2011. Software Engineering, 9th: Pearson.
[4] Barus , Willing Sedia. 2011. Jurnalistik Petunjuk Teknis Menulis Berita. Jakarta: Erlangga.
[5] Sembiring,Kristantus. 2007. Penerapan Teknik Support Vector Machine untuk
Pendeteksian Intrusi pada Jaringan.
[6] Rolly,Intan. 2006. HARD:Subject-based Search Engine menggunakan TF-IDF dan Jaccard’s Coefficient.
[7] Raharjo, Budi. 2015. Mudah Belajar Python untuk Aplikasi Dekstop dan Web. Bandung: Informatika.
[8] Rosa A. S dan M. Shalahuddin. 2013. Rekayasa Perangkat Lunak. Bandung: Informatika.
[9] Robert Laython. 2015. Learning Data Mining with Python Cookbook: Pact.
[10] MongoDB, https://docs.mongodb.com/
[11] Perkins, Jacob., 2010, Python Text Processing with NLTK 2.0 Cookbook: Pact.
[12] Santosa, Budi., 2007, Data Mining Teknik Pemanfaatan Data untuk Keperluan Bisnis. Yogyakarta: Graha Ilmu.
[13] I. A.Muis dan M. Muhammad Affandes., 2010, Penerapan Metode Support Vector
Machine (SVM) Menggunakan Kernel Radial Basis Function (RBF) Pada Klasifikasi Tweet,
Jurnal Sains, Teknologi dan Industri, vol. 12, pp. 189-197,.
[16] Sujarweni,Wiratna V., 2015, Metodologi Penelitian Bisnis & Ekonomi. Yogyakarta: Pustaka Baru Press.
[17] Trisedya Bayu Distiawan., 2007, Pemanfaatan Dokumen Unlabeled Pada Klasifikasi Topik Berbasis Naïve Bayes dengan Algoritma Expectation Maximitation.
[18] B. Nazief. Spelling Checker Facility and The Analysis of the Word Frequency.
Proceedings of Computer and Arts Conference, 1995.
[19] C. Fox. Lexical Analysis and Stoplists. In Frakes and Baeza [11], pages 102–130. [20] Zuherman Rustam, et al., 2003, Pendeteksian Jenis dan Kelas Aroma dengan
Menggunakan Metode One-vs-One dan Metode One-vs-Rest. Makara, Sains, Vol. 7, N0.3,
Desember 2003.
[21] Kikuchi Tomonori and Abe Shigeo., Error Correcting Output Codes vs. Fuzzy Support
Vector Machines.
[22] Santosa, B. and Trafalis, T., 2004, Multiclass procedure for minimax probability
machine, Intelligent Engineering Systems Through Artficial Neural Networks 14, (eds).
1
Penyebaran dan kebutuhan akan informasi digital di Indonesia dalam bentuk teks atau dokumen semakin meningkat dan setiap waktu terus mengalami pertumbuhan seiring dengan perkembangan teknologi. Salah satu sumber informasi tersebut adalah portal berita elektronik. Suatu portal berita elektronik mengklasifikasi artikel – artikel ke dalam kategori. Selama ini pengklasifikasian berita masih menggunakan tenaga manusia atau manual. Kategori yang banyak beserta waktu yang cepat akan menyulitkan editor untuk mengklasifikasikan artikel, terutama pada artikel yang isinya tidak terlalu berbeda secara jelas. Beberapa kategori yang penggunaan bahasanya tidak berbeda terlalu jauh seperti olahraga, sains, ekonomi, teknologi dan kesehatan mengharuskan seorang editor mengetahui isi artikel secara keseluruhan untuk selanjutnya dimasukkan ke dalam kategori yang tepat. Akan lebih efesien apabila kategori berita dimasukkan secara otomatis dengan menggunakan metode tertentu.Pengklasifikasian juga dilakukan untuk mempermudah para pengguna dalam mengakses artikel.
Support Vector Machine (SVM) adalah sistem pembelajaran yang menggunakan ruang hipotesis berupa fungsi-fungsi linier dalam sebuah ruang fitur (feature space) berdimensi tinggi, dilatih dengan algoritma pembelajaran yang didasarkan pada teori optimasi dengan mengimplementasikan learning bias yang berasal dari teori pembelajaran statistik [1]. SVM memiliki kelebihan yaitu mampu menemukan fungsi pemisah (klasifier) yang optimal yang bisa memisahkan dua set
dan error correcting output code (ECOC).
Pada penelitian sebelumnya sudah ada yang melakukan perbandingan
pendekatan Multiclass SVM. Pendekatan yang digunakan adalah one vs one, one
vs all [20]. Data yang digunakan dalam penelitian sebelumnya adalah data aroma
yang terdiri dari 3 jenis aroma. Dari hasil percobaan memberikan hasil bahwa
metode One-vs-One telah mampu 100% mengklasifikasikan data aroma
berdasarkan kelas yang tepat. Semakin banyak data training yang digunakan, metode One-vs-One akan lebih cepat mengklasifikasikan data dibandingkan dengan metode One-vs-Rest [20].
Selain metode One vs One dan One vs All, ada metode error correcting output code (ECOC). Pendekatan error correcting output code (ECOC) merupakan
pendekatan yang terinspirasi dari pendekatan teori informasi untuk mengirimkan pesan melalui saluran yang ber-noise [1]. Metode error correcting output code (ECOC) dianggap sebagai varian dari metode One vs All classification [21]. Tetapi belum ada penelitian yang membandingkan performansi pada metode One vs One dan One vs All dengan metode ECOC khususnya pada data berbahasa Indonesia, padahal ECOC merupakan salah satu metode yang paling popular [10].
Berdasarkan uraian diatas dapat disimpulkan bahwa penggunaan ECOC pada data berbahasa Indonesia belum ada, maka perlu diadakan penelitian untuk membandingkan metode One-vs-One, One-vs-All, dan error correcting output code (ECOC) untuk mengetahui akurasi dari masing – masing metode agar dapat mengetahui metode mana yang lebih sesuai untuk kasus pengklasifikasian artikel dan diharapkan dapat membantu penelitian lebih lanjut dalam pengembangan pendekatan Multiclass SVM.
1.2Identifikasi Masalah
1.3Maksud dan Tujuan
Penelitian ini bermaksud untuk melakukan perbandingan beberapa pendekatan Multiclass SVM pada klasifikasi artikel berbahasa Indonesia.Adapun tujuan dari penelitian ini adalah untuk mengetahui perbedaan nilai akurasi antara multiclass svm one vs one, one vs all dan error correcting output code , dari aspek penggunaan precision, recall dan F-measure.
1.4 Batasan Masalah
Batasan masalah dalam penelitian yang dilakukan antara lain : 1. Input
a. Dokumen yang digunakan sebagai inputan adalah dokumen
berbahasa indonesia dengan ekstensi *.txt, *.csv dan bersifat plain text.
b. Dokumen yang digunakan diambil dari kompas
(www.kompas.com), tempo (www.tempo.com), merdeka
(www.merdeka.com) dan tribunnews (www.tribunnews.com). c. Teks artikel tidak disertai gambar.
d. Teks artikel tidak disertai tag html. 2. Proses
a. Proses preprocessing yang dilakukan adalah case folding, filtering, tokenisasi, stopword dan feature extraction.
b. Library yang digunakan untuk implementasi SVM mwnggunakan
Sklearn.
3. Output
a. Kelas target pada berita ada 5 yaitu : Ekonomi, Teknologi, Kesehatan, Pariwisata dan Olahraga. Pemilihan kelas target dilihat dari segi persoalan menurut Sedia Willing Barus[4].
b. Kernel yang digunakan adalah kernel RBF dengan gamma 0.5.
1.5 Metodologi Penelitian
tujuan untuk menjelaskan hubungan sebab – akibat antara satu variabel dengan lainnya [16]. Hasil akhir dari penelitian ini adalah berupa grafik persentase klasifikasi teks pada artikel berbahasa Indonesia.
Langkah-langkah yang dilakukan selama melakukan penelitian dapat dilihat pada Gambar 1.1
Gambar 1.1 Langkah – langkah penelitian
Metode yang digunakan dalam penulisan tugas akhir ini menggunakan dua metode, yaitu metode pengumpulan data dan pembangunan perangkat lunak.
1.5.1 Metode Pengumpulan Data
Metode pengumpulan data yang digunakan dalam penelitian ini adalah studi literatur, yaitu dengan mencari jurnal, e-book, buku, serta artikel-artikel mengenai Text Mining, metode Multiclass SVM, kernel – based methods, serta penelitian-penilitian sebelumnya yang terkait dengan topik penelitian.
1.5.2 Metode Pembangunan Perangkat Lunak
menggunakan model waterfall sommerville [3] yang melakukan pendekatan secara sistematis dan berurutan dalam pembangunan perangkat lunak yang dirubah sesuai dengan kebutuhan penelitian meliputi proses sebagai berikut.
Gambar 1.2 Diagram Waterfall
a. Kebutuhan
Langkah ini merupakan analisa terhadap kebutuhan sistem. Pada tahap ini dilakukan pengumpulan kebutuhan penelitian secara lengkap tentang klasifikasi teks menggunakan Multiclass SVM. Data yang digunakan dalam format *.txt atau *.csv. Semua hal tersebut akan ditetapkan secara rinci dan berfungsi sebagai spesifikasi sistem.
b. Analisis
c. Desain
Pada tahapan ini dilakukan penuangan pikiran dan perancangan sistem terhadap solusi dari permasalahan yang ada dengan menggunakan perangkat pemodelan sistem seperti diagram alir data (Data Flow Diagram), perancangan struktur menu, perancangan antarmuka dan perancangan jaringan semantik.
d. Pengkodean
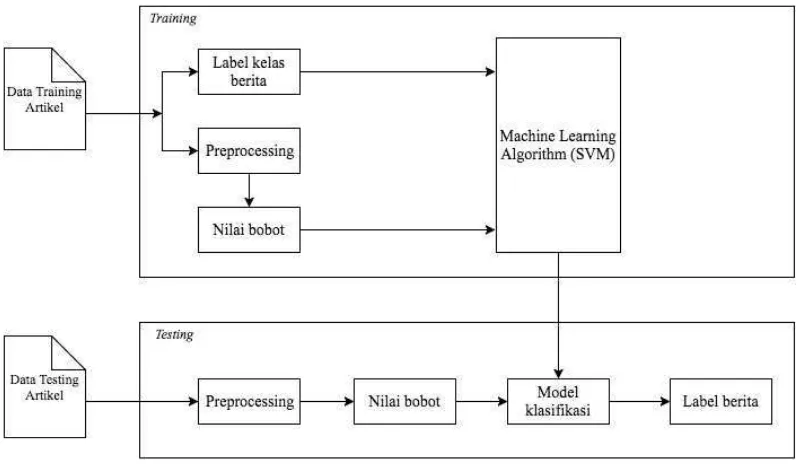
Pada tahap ini desain program yang telah dibuat kemudian diimplementasikan ke dalam bentuk kode bahasa pemrograman diantaranya adalah tahap preprocessing (case folding, filtering,tokenisasi,dan stopwords) yang kemudian akan dilakukan feature extraction menggunakan TF-IDF. Hasil dari pembobotan TF-IDF ini akan dirubah ke dalam bentuk vektor untuk dilakukan pelatihan. Dari pelatihan ini akan menghasilkan model prediksi yang akan digunakan dalam klasifikasi teks. Setiap yang telah
dirancang pada DFD akan diimplementasikan pada coding. Pada penelitian
ini menggunakan bahasa pemrograman python 2.7
e. Pengujian
Dalam tahap ini, sistem sudah siap digunakan. Selain itu juga memperbaiki error yang tidak ditemukan pada tahap pembuatan. Dalam tahap ini juga dilakukan pengembangan sistem seperti penambahan fitur dan fungsi baru yang mungkin muncul kemudian sesuai dengan kebutuhan pengguna.
1.6 Sistematika Penulisan
Sistematika penulisan laporan ini disusun untuk memberikan gambaran umum tentang penelitian dalam tugas akhir yang dilaksanakan. Sistematika penulisan tugas akhir ini adalah sebagai berikut :
BAB I PENDAHULUAN
BAB II LANDASAN TEORI
Pada bab ini berisi tentang landasan teori dan metode yang digunakan pada tugas akhir ini dalam melakukan klasifikasi teks pada artikel berbahasa Indonesia. Pembahasan dimulai dengan penjelasan mengenai berita dan jenis – jenis berita, dilanjutkan dengan penjelasan tentang klasifikasi teks dan metode – metode yang digunakan dalam melakukan klasifikasi teks.
BAB III ANALISIS DAN PERANCANGAN
Pada bab ini berisi mengenai perancangan untuk melakukan klasifikasi teks pada artikel. Klasifikasi dilakukan dengan menentukan kategori dari semua dokumen artikel testing yang ada. Perancangan klasifikasi teks ini meliputi persiapan dokumen artikel, tahap case folding, filtering, tokenisasi, stopword, pembuatan term documents matrix dan klasifikasi teks menggunakan machine learning Multiclass SVM. Pendekatan Multiclass SVM yang digunakan, yaitu one-against-all, one-against-one, dan error correcting output code.
BAB IV IMPLEMENTASI DAN PENGUJIAN
Pada bab ini berisi tentang tahapan yang dilakukan dalam penelitian secara garis besar dimulai dari tahap persiapan sampai pada penarikan kesimpulan, pada tahap ini klasifikasi teks akan diuji dengan menggunakan data testing.
BAB V KESIMPULAN DAN SARAN
8 BAB 2
LANDASAN TEORI
2.1Berita
Untuk dapat mengenal informasi, dibutuhkan upaya menuntun ke mana dan
bagaimana memperoleh fakta yang diperlukan. Berita adalah segala laporan
mengenai peristiwa, kejadian, gagasan, fakta yang menarik perhatian dan penting
untuk disampaikan atau dimuat dalam media massa agar diketahui atau menjadi
kesadaran umum [4].
Dengan demikian, jika diamati dari semua definisi tersebut pada dasarnya
berita mengandung beberapa unsur antara lain :
1. Suatu peristiwa, kejadian, gagasan, pikiran, fakta yang aktual.
2. Menarik perhatian karena ada factor yang luar biasa (extraordinary) di
dalamnya.
3. Penting.
4. Dilaporkan, diumumkan, atau dibuat untuk menjadi kesadaran umum
supaya menjadi pengetahuan bagi orang banyak (massa).
5. Laporan itu dimuat di media tertentu.
Dari kelima unsur di atas dapat disimpulkan bahwa suatu peristiwa, kejadian,
gagasan, atau yang disebut dengan “fakta” betapa pun aktual, menarik, dan
pentingnya, jika tidak dilaporkan atau diberitakan melalui media massa dan tidak
disampaikan kepada umum untuk diketahui, hal tersebut bukanlah berita. Artinya,
fakta menjadi berita bila dilaporkan [4].
Berita yang didasarkan pada topik masalah mencakup berbagai bidang yang
sangat kompleks. Secara besarannya biasa dikelompokan menjadi berita politik,
ekonomi, sosial budaya, hukum , olahraga, militer, kriminal, atau kejahatan dan
sebagainya. Bidang – bidang tersebut masih bisa dirinci lagi [4].
Demikian rumitnya, demi menggali unsur daya tariknya, pengelompokan
bidang di atas dibuat semacam rubrikasi dalam surat kabar dan majalah. Mulai
dari persoalan wanita, gaya hidup, menu makanan, agama, hingga rubrik anak dan
Dalam dunia maya, sebagai media baru dalam komunikasi massa, untuk situs
web beritadibuat dengan nama manajemen konten yang berlapis – lapis jendela
atau navigasi untuk masuk kepada menunya (feeding) atau bahkan lokasi
beritanya.
Berikut dibahas beberapa bidang yang menyangkut berita dilihat dari segi
persoalan sebagai gambaran tentang luasnya bidang – bidang pemberitaan dan
sumber – sumber yang harus diliput oleh seorang wartawan.
1. Politik
Berita politik adalah berita yang menyangkut kegiatan politik atau
peristiwa disekitar masalah – masalah ketatanegaraan dan segala hal yang
berhubungan dengan urusan pemerintah dan negara. Politik di sini harus
diartikan sebagai upaya manusia untuk menata kehidupan rakyat,
pemerintahan, dan Negara demi mencapai suatu tujuan dan cita – cita
bersama yang luhur, yaitu perbaikan hidup atau nasib bangsanya.
Berita politik menjadi menu pokok isi media karena pengaruhnya
cukup luas dan mendalam bagi kehidupan rakyat sehari-hari. Berita politik
akan terasa meninggi intensitas dan gemanya tatkala menjelang, saat, dan
pasca – pemilihan umum, siding – siding DPR/MPR, pembentukan
cabinet, krisis lembaga legislative, pemilihan kepala daerah, kongres
partai, dan sebagainya.
2. Ekonomi
Selain berita politik, masalah ekonomi juga memiliki pengaruh
besar terhadap kehidupan kita. Masalah ekonomi sering kali memberi
dampak nyata bagi kehidupan manusia. Berita ekonomi sebenarnya
mencakup aspek yang sangat luas, yaitu perdagangan, finansial,
perindustrian, perdagangan, pertambangan, perbankan, tenaga kerja, dunia
usaha, valuta asing, dan pasar modal.
3. Teknologi
Pada dasarnya manusia menyukai kemajuan. Oleh karena itu, berita
tentang perkembangan atau kemajuan teknologi juga menarik perhatian
telepon genggam, alat transportasi, robot, hingga gaya hidup. Semuanya
merupakan produk dari ilmu pengetahuan dan teknologi.
4. Kesehatan
Kesehatan merupakan keadaan dimana setiap manusia mampu
untuk hidup produktif tanpa adanya gangguan dalam kesehatan. Bertia
kesehatan meliputi seluruh kegiatan dalam pemeliharaan kesehatan.
Pencegahan, pengobatan, perawatan, kebiasaan yang merusak kesehatan,
dan sebagainya.
5. Pariwisata
Berita periwisata meliputi seluruh kegiatan yang berhubungan
dengan perjalanan wisata, daya tarik wisata, pengusaha objek wisata,
keindahan tempat wisata, dan sebagainya.
6. Olahraga
Berita olahraga meliputi seluruh kegiatan olahraga termasuk
cabang – cabang olahraga seperti atletik, renang, senam, balap sepeda,
balap mobil/motor, tinju, gulat, renang, yudo, karate, silat, tennis, bulu
tangkis, bola, polo air, golf, tenis meja, dan sebagainya, baik yang berskala
local, regional, nasional, maupun internasional.
2.2Klasifikasi
Klasifikasi merupakan suatu pekerjaan menilai objek data untuk
memasukannya ke dalam kelas tertentu dari sejumlah kelas yang tersedia.
Dalam klasifikasi ada dua pekerjaan utama yang dilakukan. Pertama,
pembangunan model sebagai prototipe untuk disimpan sebagai memori. Kedua,
penggunaan model untuk melakukan pengenalan/klasifikasi/prediksi pada suatu
objek lain, agar diketahui di kelas mana objek data tersebut dalam model yang
sudah disimpannya [1].
Contoh aplikasi yang sering ditemui adalah pengklasifikasian jenis hewan,
yang mempunyai sejumlah atribut. Dengan atribut tersebut, jika ada hewan
baru, kelas hewannya dapat langsung diketahui. Contoh lain adalah bagaimana
yaitu dengan melakukan pembangunan model berdasarkan data latih yang ada,
kemudian menggunakan model tersebut untuk mengidentifikasi penyakit pasien
baru sehingga diketahui apakah pasien tersebut menderita kanker atau tidak [1].
2.2.1 Model
Klasifikasi dapat didefinisikan sebagai perkerjaan yang melakukan
pelatihan/pembelajaran terhadap fungsi target f yang memetakan setiap set
atribut (fitur) x ke satu dari sejumlah label kelas y yang tersedia. Pekerjaan
pelatihan tersebut akan menghasilkan suatu model yang kemudian disimpan
sebagai memori [1].
Model dalam klasifikasi mempunyai arti yang sama dengan kotak
hitam, di mana ada suatu model yang menerima masukan, kemudian mampu
melakukan pemikiran terhadap masukan tersebut, dan memberikan jawaban
sebagai keluaran dari hasil pemikirannya. Kerangka kerja klasifikasi ditunjukan
pada Gambar 2.1. Pada gambar tersebut disediakan sejumlah data latih (x,y)
untuk digunakan sebagai data pembangunan model. Model tersebut kemudian
diapakai untuk memprediksi kelas dari data uji (x,?) sehingga diketahui kelas y
yang sesungguhnya.
Gambar 2.1 Proses Pekerjaan Klasifikasi
Kerangka kerja seperti yang ditunjukan pada Gambar 2.1 meliputi dua
membangun model klasifikasi dari data latih yang diberikan, disebut juga
proses pelatihan, sedangkan deduksi merupakan langkah untuk menerapkan
model tersebut pada data uji sehingga kelas yang sesungguhnya dari data uji
dapat diketahui [1].
2.2.2 Pengukuran Kinerja Klasifikasi
Sebuah sistem yang melakukan klasifikasi diharapkan dapat melakukan
klasifikasi semua set data dengan benar, tetapi tidak dapat dipungkiri bahwa
kinerja suatu sistem tidak dapat 100% benar sehingga sebuah sistem klasifikasi
juga harus diukur kinerjanya. Umumnya, pengukuran kinerja klasifikasi
dilakukan dengan matriks konfusi[1].
Matriks konfusi merupakan tabel pencatat hasil kerja klasifikasi. Tabel
2.1 merupakan contoh matriks konfusi yang melakukan klasifikasi masalah
biner (dua kelas), hanya ada dua kelas, yaitu kelas 0 dan kelas 1. Setiap sel !"#
dalam matriks menyatakan jumalah data dari kelas I yang hasil prediksinya
masuk ke kelas j. Misalnya, sel !$$ adalah jumlah data dalam kelas 1 yang
secara benar dipetakan ke kelas 1, dan !$% adalah data dalam kelas 1 yang
dipetakan secara sah ke kelas 0.
Tabel 2.1 Matriks Konfusi untuk klasifikasi dua kelas
!"#
Kelas hasil prediksi (j)
Kelas = 1 Kelas = 0
Kelas asli (i)
Kelas = 1 !$$ !$%
Kelas = 0 !%$ !%%
Dengan mengetahui jumlah data yang diklasifikasikan secara benar, kita
dapat mengetahui akurasi hasil prediksi, dan dengan mengetahui jumlah data
yang diklasifikasikan secara sah, kita dapat mengetahui laju eror dari prediksi
yang dilakukan. Dua kuantitas ini digunakan sebagai metric kinerja klasifikasi.
Akurasi
=
&'()*+ -*.* /*01 -2345-2672 758*4* 950*4 :'()*+ 345-2672 /*01 -2)*6'6*0=
;<< = ;>>
;<< = ;<>= ;><= ;>>
Untuk menghitung lahu error (kesalahan prediksi) digunakan formula
Laju eror = &'()*+ -*.* /*01 -2345-2672 758*4* 7*)*+ :'()*+ 345-2672 /*01 -2)*6'6*0
=
;<> = ;><
;<< = ;<>= ;><= ;>>
Semua algoritma klasifikasi berusaha membentuk model yang
mempunyai akurasi tinggi atau laju eror yang rendah. Umumnya, model yang
dibangun dapat memprediksi dengan benar pada semua data yang menjadi data
latihnya, tetapi ketika model berhadapan dengan data uji, barulah kinerja model
dari sebuah algoritma klasifikasi ditentukan [1].
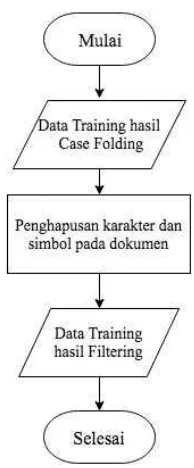
2.3Praproses Dokumen
Dokumen Preparation atau bisa disebut juga dengan dokumen preprocessing
adalah suatu proses/langkah yang dilakukan untuk membuat data mentah menjadi
data yang berkualitas. Proses persiapan dokumen meliputi case folding,
tokenisasi, dan stopwords. Keempat proses ini perlu dilakukan sebelum proses
feature extraction.
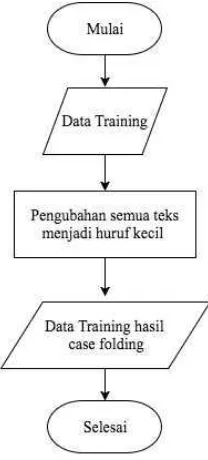
2.3.1 Case Folding
Case folding adalah mengubah semua huruf dalam dokumen menjadi
huruf kecil. Hanya huruf “a‟ sampai dengan “z‟ yang diterima. Karakter selain
huruf dihilangkan dan dianggap delimiter.
2.3.2 Tokenisasi
Secara garis besar tokenisasi adalah tahap memecah sekumpulan karakter
dalam suatu teks kedalam satuan kata. Sekumpulan karakter tersebut dapat berupa
karakter whitespace, seperti enter, tabulasi, spasi.
2.3.3 Stopwords
Stopword adalah katakata yang tidak deskriptif yang dapat dibuang dalam
pendekatan bag-of-words. Contoh stopwords adalah “yang”, “dan”, “di”, “dari”
2.4Text Feature Extraction
Text Feature Extraction adalah sebuah proses untuk mengambil atau
mengekstrak karakteristik atau informasi yang penting dari suata data
untukdigunakan dalam proses klasifikasi.
2.4.1 TF-IDF
Metode TF-IDF merupakan metode untuk menghitung bobot setiap kata
yang paling umum digunakan pada information retrieval. Metode ini juga terkenal
efisien, mudah dan memiliki hasil yang akurat [6]. Metode ini akan menghitung
nilai Term Frequency (TF) dan Inverse Document Frequency (IDF) pada setiap
token (kata) di setiap dokumen dalam korpus. Metode ini akan menghitung bobot
setiap token t di dokumen d dengan rumus:
idf (t) = Log
?@;
(2.1)
tf-idf
(t) =
tf
(t,d) *
idf
(t)
(2.2)Dimana :
d : dokumen ke-d
t : kata ke-t dari kata kunci
tf-idf
(t)
: bobot dokumen ke-d terhadap kata ke-ttf : banyaknya kata yang dicari pada sebuah dokumen
IDF : Inversed Document Frequency
D : total dokumen
df : banyak dokumen yang mengandung kata yang dicari
Berdasarkan rumus diatas, berapapun besarnya nilai tf (t,d), apabila D = df
maka akan didapatkan hasil 0 (nol) untuk perhitungan idf. Untuk itu dapat
ditambahkan nilai 1 pada sisi idf, sehingga perhitungan bobotnya menjadi sebagai
berikut:
idf (t) = Log
?@;
+ 1
(2.1)Rumus (2.1) dapat dinormalisasi dengan Rumus (2.2) dengan tujuan untuk
menstandarisasi nilai bobot ke dalam interval 0 s.d. 1, sbb:
A
"#=
B;∗()E1 F
GH =$)
(B;JK)L∗ [()E1 GHF =$)]L O
KP<
(2.3)
2.5Support Vector Machine (SVM)
2.5.1 Konsep SVM
Ide dasar SVM adalah memaksimalkan batas hyperlane, yang
diilustrasikan pada Gambar 2.2. Pada gambar (a) ada sejumlah pilihan hyperlane
yang mungkin untuk set data, sedangkan gambar (b) merupakan hyperlane dengan
margin maksimal. Meskipun sebenarnya pada gambar (a) bisa juga menggunakan
hyperlane sembarang, tetapi hyperlane dengan margin yang maksimal akan
memberikan generalisasi yang lebih baik pada metode klasifikasi[1].
Gambar 2.2 Batas keputusan yang mungkin untuk set data
Konsep klasifikasi dengan SVM dapat dijelaskan secara sederhana sebagai
usaha mencari hyperlane terbaik yang berfungsi sebagai pemisah dua buah kelas
data pada input space (Nugroho, 2007). Gambar 2.2 memperlihatkan beberapa
data yang merupakan anggota dari duah buah kelas data, yaitu +1 dan -1. Data
yang tergabung pada kelas -1 disimbolkan dengan bentuk lingkaran, sedangkan
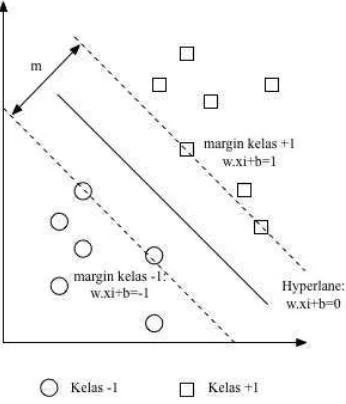
Hyperlane ( batas keputusan ) pemisah terbaik antara kedua kelas dapat
ditemukan dengan mengukur margin hyperlane tersebut dan mencari titik
maksimalnya. Margin adalah jarak antara hyperlane tersebut dengan data terdekat
dari masing – masing kelas. Data yang paling dekat ini disebut sebagai support
vector. Garis solid pada gambar 2.2 (b) sebelah kanan menunjukan hyperlane
yang terbaik, yaitu yang terletak tepat ditengah – tengah kedua kelas, sedangkan
data lingkaran dan bujur sangkar yang dilewati garis batas margin (garis
putus-putus) adalah support vector. Usaha untuk mencari lokasi hyperlane ini
[image:30.595.260.433.307.509.2]merupakan inti dari proses pelatihan pada svm[1].
Gambar 2.3 Margin Hyperplane
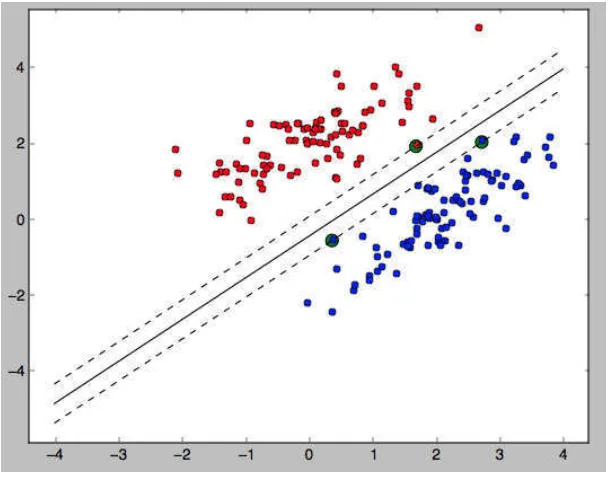
2.5.2 SVM pada Linearly Separable Data
Linearly separable data merupakan data yang dapat dipisahkan secara linier.
Misalkan {x1 ,..., xn }adalah dataset dan yi {+ 1,−1} adalah label kelas dari
data xi.. Pada Gambar 2.4 dapat dilihat berbagai alternatif bidang pemisah yang
dapat memisahkan semua data set sesuai dengan kelasnya. Namun, bidang
pemisah terbaik tidak hanya dapat memisahkan data tetapi juga memiliki margin
Gambar 2.4 Alternatif bidang pemisah (kiri) dan bidang pemisah terbaik
dengan margin (m) terbesar (kanan).
Gambar 2.5 diagram plot data linear
Setiap data latih dinyatakan oleh (xi,yi), di mana i = 1,2, ..., N, dan xi =
{RS1, RS2, . . . , RSX}Z merupakan atribut (fitur) set untuk data latih ke –i.
yi {-1,+1} menyatakan label kelas. Kelas 1 merupakan kelas -1 dan kelas 2
merupakan kelas +1. Hyperplane klasifikasi linear SVM, seperti pada Gambar
2.4, dinotasikan dengan
w.
[
\+ b = 0
(2.4)koordinat. W . ]\ merupakan inner product dalam antara w dan R". Data R" yang
masuk ke dalam kelas -1 adalah data yang memenuhi pertidaksamaan berikut:
w.
[
\+ b
≤
-1
(2.5)Sementara data R" yang masuk ke dalam kelas +1 adalah data yang
memenuhi pertidaksamaan berikut:
w.
[
\+ b
≥
+1
(2.6)Sesuai dengan Gambar 2.4, jika ada dalam kelas -1 (misalnya, R`) yang
bertempat di hyperplane, Persamaan 2.2 akan terpenuhi. Untuk data kelas -1
dinotasikan dengan
w.
[
a+ b = 0
(2.7)Sementara kelas +1 (misalnya, Rb) akan memenuhi persamaan
w.
[
c+ b = 0
(2.8)Rb - R` adalah vektor paralel di posisi hyperplane dan diarahkan dari R` ke
Rb. Karena inner produk dalam bernilai 0, arah w harus tegak lurus terhadap
hyperplane (bidang pemisah Gambar 2.4).
Dengan memberikan label -1 untuk kelas 1 dan +1 untuk kelas 2, prediksi
semua data uji akan menggunakan formula
y = +1
, jikaw.
x
2+ b > 0
y = -1
, jikaw.
x
2+b < 0
(2.9)Sesuai dengan Gambar 2.4, hyperplane untuk kelas -1 (garis putus –
putus) adalah data pada support vector yang memenuhi persamaan
w.
R
`+ b = -1
(2.10)Sementara hyperplane untuk kerlas +1 (garis putus – putus) memenuhi
persamaan
w.
R
b+ b = 1
(2.11)Dengan demikian margin dapat dihitung dengan mengurangi Persamaan
2.8 dengan 2.7, didapatkan
w.(
R
b-
R
`) = 2
(2.12)Notasi di atas diringkas menjadi
A
x d
ataud =
ef
(2.13)
2.5.3 Hyperplane SVM
Klasifikasi kelas data pada SVM pada Persamaan 2.5 dan 2.6 dapat
digabungkan dengan notasi
g
"(w.
R
"+ b)
≥
1,
i
= 1,2, ..., N
(2.14)Margin optimal dihitung dengan memaksimalkan jarak antara hyperplane
dan data terdekat. Jarak ini dirumuskan dengan Persamaan 2.10 ( A adalah
vektor bobot w). Selanjutnya, masalah ini diformulasikan ke dalam quadratic
programming (QP) problem, dengan meminimalkan invers Persamaan 2.10,
$ e A
e, dibawah kendala(syarat), seperti berikut:
Minimalkan : $
e A
e (2.15)
dengan syarat seperti pada notasi Persamaan 2.11
Optimalisasi ini dapat diselesaikan dengan Lagrange Multiplier:
(2.16)
h" adalah Lagrange Multiplier yang berkorespondensi dengan R". Nilai h"
adalah nol atau positif. Untuk meminimalkan Lagrangian, Persamaan 2.13 harus
diturunkan pada w dan b, dan diset dengan nilai 0 untuk syarat optimalisasi di
atas.
Syarat 1:
ijk
if
=
0, w =
h
"l
"m$
g
"R
"(2.17)
Syarat 2:
ijk
if
=
0
,
h
"l
"m$
g
"= 0
(2.18)N adalah jumlah data yang menjadi support vector. Karena Lagrange
Multiplier (α) tidak diketahui nilainya, persamaan di atas tidak dapat diselesaikan
tersebut, modifikasilah Persamaan 2.13 menjadi kasus pemaksimalan, syarat
optimal untuk dualitasnya menggunakan kendala (constraint)
Karush-Kuhn-Tucker (KKT) berikut:
Syarat 1:
h
"g
"A. R
"+ o − 1 = 0
(2.19)
Syarat 2:
h
"≥
0, i = 1,2, ...,N
(2.20)Dengan menerapkan kendala pada Persamaan 2.16 dan 2.17, dipastikan
bahwa nilai Lagrange Multiplier sama banyaknya dengan data latih, tetapi
sebenarnya banyak dari data latih yang Lagrange Multiplier-nya sama dengan nol
(karena hanya beberpa saja yang akan menjadi support vector) ketika menerapkan
syarat pertama. Kendala diatas menyatakan bahwa Lagrange Multiplier
h
"harus
nol, kecuali untuk data latih R" yang memenuhi persamaan
g
"A. R
"+ o = 1
(2.21)
Data latih itu, dengan h" > 0, terletak pada hyperplane o"$ atau o"e, dan
disebut support vector. Data latih yang tidak terletak di hyperplane tersebut
mempunyai h" = 0. Persamaan 2.14 dan 2.15 juga menyarankan parameter w dan
b, yang mendefinisikan hyperplane, hanya tergantung support vector.
Walaupun bisa diselesaikan, masalah optimalisasi di atas masih sulit
karena banyaknya parameter: w, b, dan h". Untuk menyederhanakannya,
persamaan optimalisasi 2.13 harus ditransformasi ke dalam fungsi Lagrange
Multiplier itu sendiri (disebut dualitas masalah).
Persamaan Lagrange Multiplier 2.13 dapat dijabarkan menjadi
(2.22)
Syarat optimal 2.15 ada dalam suku ketiga di ruas kanan dalam Persamaan
2.18, dan memaksa suku ini menjadi sama dengan 0. Dengan mengganti w dari
syarat 2.14, dan suku
A
e =A
".
A
#,
persamaan di atas akan berubah menjadidualitas Lagrange Multiplier yang berupa Ld, didapatkan
:
(2.23)
Syarat 1:
(2.24)
Syarat 2:
h
"≥
0,
i = 1,2, ..., N (2.25)[
\.
[
s merupakan dot – product dua data dalam data latih. Hyperplane(batas keputusan atau pemisah) didapatkan dengan formula
(2.26)
N adalah jumlah data yang menjadi support vector,
R
" merupakan supportvector, z merupakan data uji yang akan diprediksi kelasnya, dan
R
".z
merupakaninner-product antara
R
" danz.
Untuk nilaib
didapatkan dari Persamaan 2.16pada support vector. Karena
h
" dihitung dengan metode numerik dan mempunyaieror numerik, nilai yang dihitung untuk b bisa jadi tidak sama. Hal ini disebabkan
oleh support vector yang digunakan dalam Persamaan 2.16, biasanya diambil nilai
rata – rata dari b yang didapat untuk menjadi parameter hyperplane. Untuk
mendapatkan b. Persamaan 2.16 dapat disederhanakan menjadi
o
"= 1 -
g
"(w.
R
")
(2.27)Penjelasan di atas berdasarkan asumsi bahwa kedua kelas dapat terpisah
secara sempurna oleh hyperplane. Akan tetapi, pada umumnya kedua kelas
tersebut tidak dapat terpisah secara sempurna. Hal ini menyebabkan proses
optimalisasi tidak dapat diselesaikan karena tidak ada w dan b yang memenuhi
Pertidaksamaan 2.11. Untuk itu pertidaksamaan itu dimodifikasi dengan
memasukan variabel slack t (t" ≥ 0). Penambahan variabel t sering juga disebut
soft margin hyperplane.Hasilnya adalah
g
"A. R
"+ o ≥ 1
-
t
"(2.28)
(2.29)
Metode untuk mengoptimalisasi hyperplane SVM umumnya dipakai untuk
menyelesaikan pemrograman kuadratik dengan kendala yang ditetapkan.
Beberapa pilihan metode yang bisa digunakan adalah chunking (Vapnik, 1982),
metode dekomposisi (Osuna, 1997), dan sequential minimal optimization
(SMO)(Plat, 1999).
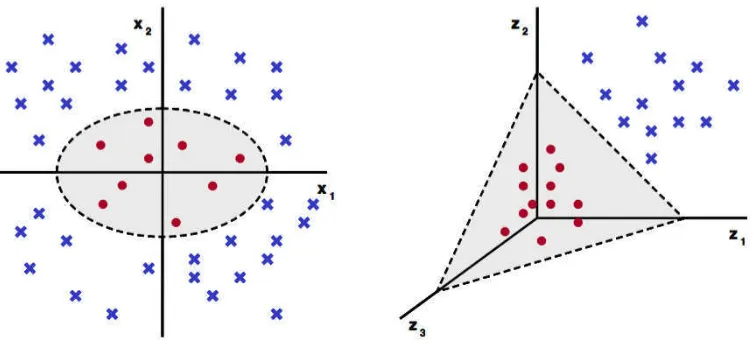
2.5.4 SVM pada NonLinearly Separable Data
SVM sebenarnya adalah hyperplane linear yang hanya bekerja pada data
yang dapat dipisahkan secara linear. Untuk data yang distribusi kelasnya tidak
linear biasanya digunakan pendekatan kernel pada fitur data dari awal set data.
Kernel dapat di definisikan sebagai suatu fungsi yang memetakan fitur data dari
dimensi awal (rendah) ke fitur lain yang berdimensi lain yang lebih tinggi (bahkan
jauh lebih tinggi). Pendekatan ini berbeda dengan metode klasifikasi pada
umumnya yang justru mengurangi dimensi awal untuk menyederhanakan proses
komputasi dan memberikan akurasi prediksi yang lebih baik.
[image:36.595.127.504.469.643.2]a. Data dalan fitur dimensi rendah b. Data dalam fitur dimensi tinggi
Gambar 2.6 Dimensi Data
Ilustrasi kernel yang digunakan untuk memetakan dimensi awal (yang
2.5. Algoritma pemetaan kernel ditunjukan pada algoritma 2.1.
Algoritma 2.1 Pemetaan dengan kernel
∅
:
v
wv
xx
∅
(x)
∅ merupakan fungsi kernel yang digunakan untuk pemetaan, D merupakan
data latih, q merupakan set fitur dalam satu data yang lama, dan r merupakan set
fitur yang baru sebagai hasil pemetaan untuk setiap data latih. Sementara x
merupakan data latih, di mana x1, x2, ..., Ry ∈ vw merupakan fitur – fitur yang
akan dipetakan ke fitur berdimensi tinggi r, jadi untuk set data yang digunakan
sebagai pelatihan dengan algoritma yang ada dari dimensi fitur yang lama D ke
dimensi baru r. Misalnya, untuk n sample data:
(
∅
(
R
$),
g
$,
∅
(
R
e),
g
e, ...,
∅
(
R
y),
g
y)
∈v
x(2.30)
Selanjutnya dilakukan proses pelatihan yang sama sebagaimana pada SVM
linear. Proses pemetaan pada fase ini memerlukan perhitungan dot – product dua
buah data pada ruang fitur baru. Dot – product kedua buah vektor (R") dan (R#)
dinotasikan sebagai ∅(R") . ∅(R#). Nilai dot – product kedua buah vektor ini dapat
dihitung secara tidak langsung, yaitu tanpa mengetahui fungsi transformasi ∅.
Teknik komputasi seperti ini kemudian disebut trik kernel, yaitu menghitung dot –
product dua buah vektor di ruang dimensi baru dengan memakai komponen kedua
buah vektor tersebut di ruang dimensi asal, seperti berikut:
K(
[
\,
[
s) =
∅
(
[
\) .
∅
(
[
s)
(2.31)Dan prediksi pada set data dengan dimensi fitur yang baru diformulasikan
dengan
(2.32)
N adalah jumlah data yang menjadi support vector, R" adalah support
vector, dan z adalah data uji yang akan diprediksi. Untuk pilihan fungsi kernel
Tabel 2.2 Fungsi Kernel
Nama Kernel Definisi Fungsi
Linear K(x,y) = x.y
Polinomial K(x,y) = (R. g + {)@
Gausian RBF exp −| R − g e , | > 0
Sigmoid (tangen hiperbolik) K(x,y) = tanh(~(x.y) + c)
Invers Multikuadratik K(x,y) = $
ÄÅ L= ÇL
X dan y adalah pasangan dua data dari semua bagian data latih. Parameter
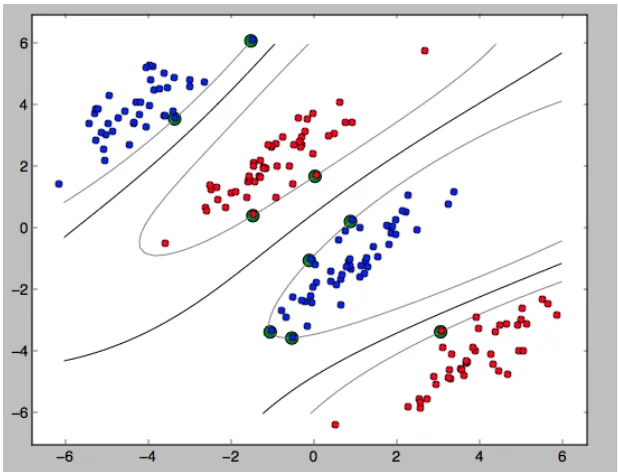
~, c, d, | > 0, merupakan konstanta.
[image:38.595.174.483.428.664.2]Gambar 2.8 Diagram plot non-linear dengan kernel Polinomial
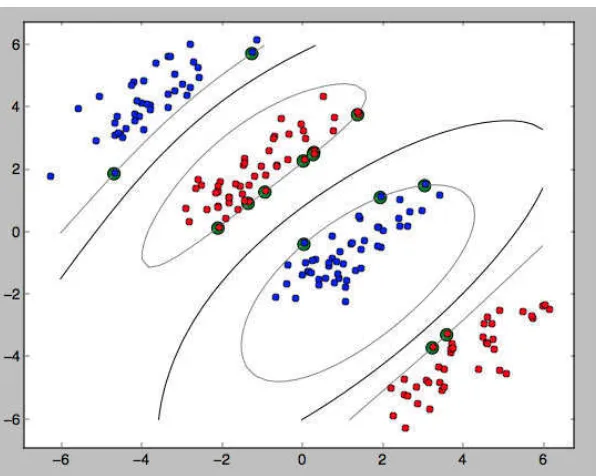
berderajat 2
Fungsi kernel yang sah diberikan oleh teori Mercer ([Vapnik,1995] dan
[Haykin,1999]) di mana fungsi kernel harus memenuhi syarat kontinu dan pasti
positif.
2.5.5 Contoh Aplikasi Klasifikasi dengan SVM
SVM pada kasus operasi AND. Dilakukan pencarian hyperplane yang
tepat untuk menyelesaikan kasus operasi logika AND. Operasi logika AND
merupakan contoh pemetaan data linear dengan distribusi data yang jelas dan
sederhana, seperti yang ditunjukanoleh Gambar 2.9. Pertama – tama, jangkauan
set data dan kelas yang digunakan dikonversi dulu agar sesuai dengan format
SVM karena SVM mensyaratkan bahwa kelas yang digunakan memakai nilai -1
Gambar 2.9 Diagram plot data latih operasi logika AND
Tabel 2.3 merupakan contoh masalah operasi logika AND yang
merupakan masalah linear sehingga tidak diperlukan fungsi kernel didalamnya.
Tabel 2.3 Operasi logika AND dengan format bipolar
[É [Ñ Kelas(y)
1 1 1
1 -1 -1
-1 1 -1
-1 -1 -1
Dengan menggunakan Tabel 2.3, karena ada dua fitur (x1 dan x2), w juga
akan memiliki dua fitur (w1 dan w2). Formulasi yang bisa digunakan adalah
sebagai berikut:
Minimalkan: $ e
(
A
$e
+
A
ee)
Syarat:
g
"(w.
R
"+ b)
≥
1,
i
= 1,2, ..., N
1. (A$ + Ae + b) ≥ 1, untuk y1 = 1; x1 = 1; x2 = 1
2. (-A$ + Ae - b) ≥ 1, untuk y1 = -1; x1 = 1; x2 = -1
3. (A$ - Ae - b) ≥ 1, untuk y1 = -1; x1 = -1; x2 = 1
4. (A$ + Ae - b) ≥ 1, untuk y1 = -1; x1 = -1; x2 = -1
dengan menjumlahkan persamaan syarat (1) dan (3) didapatkan w1 = 1. Dengan
menjumlahkan persamaan syarat (2) dan (3) didapatkan b = -1 sehingga
persamaan hiperbolik yang didapatkan adalah
f(x) = A$R$ + AeRe + b
f(x) = R$ + Re -1
2.5.6 Karakteristik Support Vector Machine
Karakteristik klasifikasi SVM dapat diringkas menjadi seperti berikut [1] :
1. SVM sebenarnya bisa dikatakan sebagai teknik klasifikasi yang
semi-eager-learner karena selain memerlukan proses pelatihan, SVM juga
menyimpan sebagian kecil data latih untuk digunakan kembali pada
saat proses prediksi. Sebagian data yang masih disimpan ini adalah
support vector.
2. Untuk parameter yang sama yang digunakan dalam klasifikasi, SVM
memberikan model klasifikasi yang solusinya adalah global optima,
tidak seperti ANN yang solusinya sering masuk pada wilayah local
optima. Hal ini berarti SVM selalu memberikan model yang sama dan
solusi dengan margin maksimal, sedangkan ANN memberikan model
dengan nilai yang berbeda dengan margin yang tidak selalu sama.
3. SVM membutuhkan komputasi pelatihan dan prediksi yang rumit
karena dimensi data yang digunakan dalam proses pelatihan dan
prediksi lebih besar daripada dimensi yang sesungguhnya. Hal ini
bertentangan dengan metode lain yang umumnya mengurangi dimensi
untuk memberikan kinerja yang lebih cepat dan akurasi yang lebih baik.
4. Untuk set data berjumlah besar, SVM membutuhkan memori yang
sangat besar untuk alokasi matriks kernel yang digunakan. Misalnya,
data latih dengan ukuran 1.000 x 1.000. Metode pelatihan SVM yang
membutuhkan memori besar adalah chunking (Vapnik, 1982) dan
atau SMO (Platt,1999) dikembangkan untuk mempercepat proses
pelatihan dan mengurangi memori.
5. Penggunaan matriks kernel mempunyai keutungan lain, yaitu kinerja set
data dengan dimensi besar tetapi jumlah datanya sedikit akan lebih
cepat karena ukuran data pada dimensi baru berkurang banyak.
Misalnya, data latih berukuran 10 data 1.000 kolom fitur akan berubah
menjadi matriks kernel berukuran 10x10 saja.
2.6Multiclass Support Vector Machine (SVM)
Metode – metode klasifikasi seperti Decison Tree, Artficial Neural Network,
Nearest Neighbor didesan untuk dapat melakukan klasifikasi multikelas sekaligus,
tetatpi SVM tidak. SVM hanya dapat melakukan klasifikasi biner (dua kelas).
Sementara masalah di dunia nyata umumnya mempunyai banyak kelas seperti
pengenalan karakter, pengenalan wajah, atau diagnosis pasien, di mana data
masukan terbagi menjadi lebih dari dua kelas[1].
2.6.1 Metode one-against-all
Dengan metode ini, dibangun k buah model SVM biner (k adalah jumlah
kelas). Setiap model klasifikasi ke-i dilatih dengan menggunakan keseluruhan
data, untuk mencari solusi permasalahan[5].
(2.30)
Contohnya, terdapat permalasahan klasifikasi dengan 4 buah kelas. Untuk
Tabel 2.4 Contoh 4 SVM biner dengan metode One-against-all
g" = 1 g" = -1 Hipotesis
Kelas 1 Bukan kelas 1
f 1 (x) = (w1 )x + b1
Kelas 2 Bukan kelas 2
f 2 (x) = (w2 )x + b2
Kelas 3 Bukan kelas 3
f 3 (x) = (w3 )x + b3
Kelas 4 Bukan kelas 4
f 3 (x) = (w3 )x + b3
Gambar 2.10 Contoh klasifikasi dengan metode One-against-all 2.6.2 Metode one-against-one
Dengan menggunakan metode ini, dibangun Ö(ÖÄ$)
e buah model
klasifikasi biner ( k adalah jumlah kelas ). Setiap model klasifikasi dilatih pada
data dari dua kelas[5]. Untuk data pelatihan dari kelas ke-i dan kelas ke-j,
(2.31)
Terdapat beberapa metode untuk melakukan pengujian setelah keseluruhan k
(
k −1)
/ 2 model klasifikasi selesai dibangun.Tabel 2.5 Contoh 4 SVM biner dengan metode One-against-one
g" = 1 g" = -1 Hipotesis
Kelas 1 Kelas 2
f 12 (x) = (w12 )x + b12 Kelas 1 Kelas 3
f 13 (x) = (w13 )x + b13 Kelas 1 Kelas 4
f 14 (x) = (w14 )x + b14 Kelas 2 Kelas 3
f 23 (x) = (w23 )x + b23 Kelas 2 Kelas 4
f 24 (x) = (w24 )x + b24 Kelas 3 Kelas 4
f 34 (x) = (w34 )x + b34
Gambar 2.11 Contoh klasifikasi dengan metode One-against-one
φ(x)+ b ) dan hasilnya menyatakan menyatakan x adalah kelas i, maka suara untuk kelas i ditambah satu. Kelas dari data x akan ditentukan dari jumlah suara
terbanyak. Jika terdapat dua buah kelas yang jumlah suaranya sama, maka kelas
yang indeksnya lebih kecil dinyatakan sebagai kelas dari data. Jadi pada pendekatan ini terdapat k(k −1)/ 2 buah permasalahan quadratic programming
yang masing- masing memiliki 2n / k variabel (n adalah jumlah data pelatihan)
[5].
2.6.3 Metode error correcting output code
Pendekatan error correcting output code (ECOC) memberikan hasil
prediksi yang lebih handal daripada one-against-all. Pendekatan ini diinspirasi
dari pendekatan teori informasi untuk mengirimkan pesan melalui saluran yang
ber-noise. Idenya adalah dengan menambahkan data redudan ke dalam pesan yang
dikirimkan dalam bentuk codeword sehingga di sisi penerima dapat mendeteksi
kesalahan dalam pesan yang diterima dan bahkan memulihkan pesan asli jika ada
sejumlah kesalahan yang kecil. Pendekatan tersebut adalah kode Hamming.
Untuk masalah multikelas, setiap kelas yi dipresentasikan oleh string bit
dengan panjang n yang disebut codeword. Selanjutnya harus dibentuk n
klasifikator biner untuk memprediksi setiap bit sesuai string codeword. Kelas
vektor uji hasil prediksi diberikan oleh codeword dengan jarak hammingyang
paling dekat terhadap codeword yang dihasilkan oleh klasifikator biner.
Sementara definisi jarak hamming adalah jumlah bit berbeda dari semua bit yang
digunakan dalam representasinya.
2.7Python
Python adalah bahasa pemrograman computer, samalayaknya seperti
bahasa pemrograman lain, misalnya C, C++, Pascal, Java, PHP, Perl dan lain –
lain. Sebagai bahasa pemrograman, Python tentu memiliki dialek, kosakata atau
kata kunci, dan aturan tersendiri yang jelas berbeda dengan bahasa pemrograman
lainnya [7].
Bahasa pemrograman Python disusun di akhir tahun 1980-an dan
implementasinya baru dimulai pada Desember 1989 oleh Guido Van Rossum di
matematika dan sains, Amsterdam – Belanda; sebagai suksesor atau pengganti
dari bahasa pemrograman pendahulunya, bahasa pemrograman ABC, yang juga
dikembangkan di CWI oleh Leo Geurts, Lambert Meertens, dan Steven
Pemberton [7].
Secara umum, para programmer banyak yang menjatuhkan pilihannya ke
bahasa Python karena alasan – alasan berikut [7]:
• Python memiliki konsep design yang bagus dan sederhana, yang berfokus
pada kemudahan dalam penggunaan. Kode Python dirancang untuk mudah
dibaca, dipelajari, digunakan ulang, dan dirawat. Selain itu, Python juga
mendukung pemrograman berorientasi objek dan pemrograman
fungisional.
• Python dapat meningkatkan produktivitas dan menghemat waktu bagi para
programmer. Untuk memperoleh hasil program yang sama, kode Python
jauh lebih sedikit dibandingkan dengan kode yang ditulis menggunakan
bahasa – bahasa pemrograman lain.
• Program yang ditulis menggunakan Python dapat dijalankan di hamper
semua sistem operasi (Linux, Windows, Mac, dan lain – lain), termasuk
untuk perangkat – perangkat mobile
• Python bersifat gratis atau bebas (free) dan open-source, meskipun
digunakan untuk kepentingan komersil.
2.7.1 Python 2.7
Sejak versi 2.7, Python 2 dan Python 3 dirilis secara simultan (paralel).
Python 2.7 masih terus dipertahankan dan diperbaharui sebagai rilis terakhir dari
python 2, karena banyak programmer Python yang enggan beralih dari Python 2
ke Python 3. Alasannya adalah karena mereka pada umumnya sudah merasa
nyaman menggunakan Python 2 sehingga proses pengembangan aplikasi
diharapkan jauh lebih mudah [7].
Sejak Python 2.6, komunitas Python menyertakan modul _ future_ ke
dalam Python 2. Dengan menggunakan modul ini, para pengguna Python 2 masih
dilengkapi dengan tool bernama 2to3, yang digunakan untuk mengkonversi kode
Python 2 ke Python 3[7].
2.7.2 Python 3
Python 3 dikembangkan dengan tujuan jangka panjang. Fasilitas – fasilitas
baru yang saat ini ditambahkan ke dalama bahasa Python hanya
diimplementasikan ke dalam Python 3 dengan harapan para programmer yang
masih menggunakan Python 2 secara bertahap bisa beralih ke Python 3.
2.8NoSQL
NoSQL adalah konsep mengenail penyimpanan data non – relasional. NoSQL
sangat berguna pada data-data yang terus - menerus berkembang, dimana data
tersebut sangat kompleks sehingga sebuah database relational tidak lagi bisa
mengakomodir. Salah satu bentuknya adalah ketika suatu data saling berhubungan
satu sama lain, maka akan muncul proses duplikasi data. Dimana data saling
memanggil ke beberapa permintaan, tambahan data baru, perubahan data, dan
lain-lain dengan key yang sama. Karena faktor hubungan antar data yang sama
terjadi terus-menerus, mendorong faktor redudansi data, data menjadi
berlipat-lipat, dan pada akhirnya akan menyebabkan crash pada database berkonsep
RDBMS. Tipe – tipe database dalam NoSQL, yaitu [10]:
• Document Databases : contohnya MongoDB, setiap satu object data
disimpan dalam satu dokumen. Dokumen sendiri bisa terdiri dari
key-value, dan value sendiri bisa berupa array atau key-value bertingkat.
• Graph Stores : Format penyimpanan data dalam struktur graph. Format ini
sering dipakai untuk data yang saling berhubungan seperti jejaring social.
Contoh database noSQL dengan format ini adalah Neo4J dan FlockDB.
FlockDB dipakai oleh twitter.
• Key – value Stores : are the simplest NoSQL databases. Every single item
in the database is stored as an attribute name (or 'key'), together with its
value. Examples of value stores are Riak and Berkeley DB. Some
key-value stores, such as Redis, allow each key-value to have a type, such as
• Wide – column Stores : Column stores in NO SQL are actually hybrid
row/column store unlike pure relational column databases. Although it
shares the concept of column-by-column storage of columnar databases
and columnar extensions to row-based databases, column stores do not
store data in tables but store the data in massively distributed
architectures.
2.8.1 MongoDB
MongoDB adalah database open source berbasis dokumen
(Document-Oriented Database) yang awalnya dibuat dengan bahasa C++. MongoDB sendiri
sudah dikembangkan oleh 10gen sejak Oktober 2007, namun baru dipublikasikan
pada Februari 2009. Selain karena performanya 4 kali lebih cepat dibandingkan
MySQL serta mudah diaplikasikan, karena telah tergabung juga sebagai modul
PHP.
Dalam konsep MongoDB tidak ada yang namanya tabel, kolom ataupun
baris yang ada hanyalah collection (ibaratnya tabel), document (ibaratnya record).
Data modelnya sendiri disebut BSON dengan struktur mirip dengan JSON.
Strukturnya cukup mudah dibaca, contohnya seperti ini.
{
"nama" : "Jadequeline Marsha Pricila", "kontak" : {
"alamat" : "Jl. Kihapit Timur", "kota" : "Cimahi",
"kodepos" : "40532", "telp" : "0812xxxxxx", }
}
Dengan konsep key-value yang ada pada MongoDB, setiap document
otomatis memiliki index id yang unik. Hal ini membantu mempercepat proses
pencarian data secara global.
MongoDB merupakan basis data yang tidak relasional, hal ini membuat
MongoDB sangat cepat saat melakukan proses manipulasi data dibandingkan
dengan sistem basis data relasional, selain itu MongoDB berbasis dokumen tidak
memiliki struktur data yang teratur seperti tabel. MongoDB biasanya digunakan
networking, dan website yang tidak membutuhkan proses transaksi seperti sistem
bank.
2.8.2 Data model
Data model adalah cara formal menggambarkan data yang digunakan dan
diciptakan dalam sistem. Data di mongoDB memiliki skema yang fleksibel. Tidak
seperti database SQL yang harus menentukan skema tabelnya terlebih dahulu
sebelum memasukan data. MongoDB’s collection tidak memaksakan struktur
dokumen. Fleksibilitas ini memfasilitasi pemetaan dokumen ke sebuah entitas
atau objek. Setiap dokumen dapat memiliki kecocokan dengan field data yang
merepresentasi entitas, bahkan jika data memiliki variasi yang banyak. Pada
penggunaanya dokumen – dokumen pada collection berbagi struktur yang
sama[10].
Kundi dalam merancang data model pada aplikasi MongoDB berkisar
pada struktur dokumen dan bagaimana aplikasi mewakili hubungan antar data.
Ada dua tool yang memungkinkan aplikasi untuk merepresentasikan hubungan
ini, yaitu [10]:
1. References
References menyimpan hubungan antara data dengan memasukan link
atau references untuk mengakses data yang terkait. Secara umum, ini
adalah model data yang dinormalisasi. Data model ini yang digunakan
pada penelitian ini.
2. Embedded Data
Embedded Documents menangkap hubungan antara data dengan
meyimpan data yang terkait dalam struktur dokumen tunggal.
Dokumen MongoDB memungkinkan untuk struktur embedded
documents atau array dalam dokumen. Model – model data yang
denormalized data model memungkinkan aplikasi untuk mengambil
2.9Pemrograman Terstruktur
Pemrograman terstruktur adalah konsep atau paradigma atau sudut pandang
pemrograman yang membagi – bagi program berdasarkan fungsi – fungsi atau
prosedur – prosedur yang dibutuhkan program komputer. Modul – modul
(pembagian program) biasanya dibuat dengan mengelompokan fungsi – fungsi
dan prosedur – prosedur yang diperlukan sebuah proses tertentu [8].
Fungsi – fungsi dan prosedur – prosedur ditulis secara sekuensial atau terurut
dari atas ke bawah sesuai dengan kebergantungan antar fungsi atau prosedur
(fungsi atau prosedur yang dapat dipakai oleh fungsi atau prosedur dibawahnya
harus yang sudah ditulis atau dideklarasikan di atasnya) [8].
2.9.1 DFD (Data Flow Diagram)
Data Flow Diagram (DFD) awalnya dikembangkan oleh Chris Gane dan
Trish Sarson pada tahun 1979 yang termasuk dalam Structured Systems Analysis
and Design Methodology (SSADM) yang ditulis oleh Chris Gane dan Trish
Sarson Sistem yang dikembangkan ini berbasis pada dekomposisi fungisional dari
sebuah sistem [8].
Edward Yourdon dan Tom DeMarco memperkenalkan metode yang lain
pada tahun 1980-an di mana mengubah persegi dengan sudut lengkung dengan
lingkaran untuk menotasikan. DFD Edward Yourdon dan Tom DeMarco populer
digunakan sebagai model analisis sistem perangkat lunak untuk sistem perangkat
lunak yang akan diimplementasikan dengan pemrograman terstruktur [8].
DFD dapat digunakan untuk merepresentasikan sebuah sistem atau
perangkat lunak pada beberapa level abstraksi. DFD dapat dibagi menjadi
beberapa level yang lebih detail untuk mereprentasikan aliran informasi atau
fungsi yang lebih detail [8].
2.9.1.1Kamus Data
Kamus data dipergunakan untuk memperjelas aliran data yang
digambarkan pada DFD. Kamus data adalah kumpulan daftar elemen data yang
mengalir pada sistem perangkat lunak sehingga masukan (input) dan keluaran
dapat menjadi parameter masukan atau keluaran dari sebuah fungsi atau prosedur
[8]. Kamus data biasanya berisi:
• nama – nama dari data
• Digunakan pada - merupakan proses – proses yang terkait data
• Deskripsi – merupakan deksripsi data
• Informasi tambahan = seperti tipe data, nilai data, batas nilai data,
dan komponen membentuk data
2.10 Scikit – Learn
Modul Sklearn merupakan machine learning library ditulis dalam python.
Modul ini menyediakan banyak sekali algoritma, datasets, utilities, dan
frameworks machine learning. Libraries numpy dan scipy yang ada dalam
sklearn, biasanya dioptimasi untuk kecepatan. Ini yang membuat sklearn fast dan
scalable, serta sangat berguna untuk research users [9].
The library is built upon the SciPy (Scientific Python) that must be installed
before you can use scikit-learn. This stack that includes [9]:
• NumPy: Base n-dimensional array package
• SciPy: Fundamental library for scientific computing • Matplotlib: Comprehensive 2D/3D plotting
• IPython: Enhanced interactive console • Sympy: Symbolic mathematics
• Pandas: Data structures and analysis 2.11NLTK
Modul Natural Language Toolkit (NLTK) menyediakan berbagai fungsi dan
wrapper, serta corpora standar baik itu mentah atau pun pre-processed yang
digunakan dalam materi pengajaran Natural Language Processing (NLP) [11].
Pustaka NLTK menyediakan beberapa corpora teks yang sering digunakan
dalam komunitas penelitian NLP. Berikut ini, contoh corpora yang ada di dalam
NLTK:
• Brown Corpus: The Brown Corpus of Standard American English dinilai
pemrosesan computational linguistic. Corpus ini terdiri dari sekitar sejuta
kata dalam bahasa Inggris Amerika yang dicetak pada tahun 1961. Agar
corpus ini dapat mewakili bahasa Inggris seoptimal mungkin, corpus ini
dibagi kedalam 15 genre tulisan, misalnya fiksi, berita dan teks agama.
Berikutnya versi POS-tagged dari corpus ini juga dibuat menggunakan
teknik-teknik manual.
• Gutenberg Corpus: The Gutenberg Corpus terdiri dari 14 teks pilihan dari
Project Gutenberg - koleksi ebook gratis terbesar. Corpus ini terdiri dari
1,7 juta kata.
• Treebank Corpus: Kumpulan teks yang sudah di-parsing dari Penn
treebank.
• StopwordsCorpus: Selain kata-kata umum, ada juga kelompok kata yang
disebut dengan stop words yang memiliki posisi penting dalam grammar
namun tidak bisa berdiri sendiri, seperti prepositions, complementizers,
dan determiners. Pustaka NLTK menyediakan Stopword Corpus yang
39
Penyebaran dan kebutuhan akan informasi digital di Indonesia dalam bentuk
teks atau dokumen semakin meningkat dan setiap waktu terus mengalami
pertumbuhan seiring dengan perkembangan teknologi. Salah satu sumber informasi
tersebut adalah portal berita elektronik. Suatu portal berita elektronik
mengklasifikasi artikel – artikel ke dalam kategori. Selama ini pengklasifikasian
berita masih menggunakan tenaga manusia atau manual. Kategori yang banyak
beserta waktu yang cepat akan menyulitkan editor untuk mengklasifikasikan
artikel, terutama pada artikel yang isinya tidak terlalu berbeda secara jelas.
Beberapa kategori yang penggunaan bahasanya tidak berbeda terlalu jauh seperti
olahraga, sains, ekonomi, teknologi dan kesehatan mengharuskan seorang editor
mengetahui isi artikel secara keseluruhan untuk selanjutnya dimasukkan ke dalam
kategori yang tepat. Akan lebih efesien apabila kategori berita dimasukkan secara
otomatis dengan menggunakan metode tertentu. Pengklasifikasian juga dilakukan
untuk mempermudah para pengguna dalam mengakses artikel.
Support Vector Machine (SVM) adalah sistem pembelajaran yang
menggunakan ruang hipotesis berupa fungsi-fungsi linier dalam sebuah ruang fitur
(feature space) berdimensi tinggi, dilatih dengan algoritma pembelajaran yang
didasarkan pada teori optimasi dengan mengimplementasikan learning bias yang
berasal dari teori pembelajaran statistik [1]. SVM memiliki kelebihan yaitu mampu m