DALAM KLASIFIKASI RISIKO KREDIT
TESIS
OLEH
ADITIARNO MANIK 187038053
PROGRAM STUDI S-2 TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN
2021
DALAM KLASIFIKASI RISIKO KREDIT
TESIS
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Magister Teknik Informatika
ADITIARNO MANIK 187038053
PROGRAM STUDI S-2 TEKNIK INFORMATIKA
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN
2021
Judul : PENINGKATAN KINERJA SVM DENGAN PSO DALAM
KLASIFIKASI RISIKO KREDIT
Kategori : TESIS
Nama : ADITIARNO MANIK
Nomor Induk Mahasiswa : 187038053
Program Studi : MAGISTER (S-2) TEKNIK INFORMATIKA
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Prof. Dr. Tulus Dr. Erna Budhiarti Nababan, M.IT
PENINGKATAN KINERJA SVM DENGAN PSO DALAM KLASIFIKASI RISIKO KREDIT
TESIS
Saya mengakui bahwa tesis ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, 12 Agustus 2021
Aditiarno Manik 187038053
KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Sebagai sivitas akademika Universitas Sumatera Utara, saya yang bertanda tangan di bawah ini :
Nama : Aditiarno Manik
NIM : 187038053
Program Studi : Magister (S-2) Teknik Informatika Jenis Karya ilmiah : Tesis
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Sumatera Utara Hak Bebas Royalti Non-Eksklusif (Non-Exclusive Royalty Free Right) atas tesis saya yang berjudul :
PENINGKATAN KINERJA SVM DENGAN PSO DALAM KLASIFIKASI RISIKO KREDIT
Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti Non-Eksklusif ini, Universitas Sumatera Utara berhak menyimpan, mengalih media, memformat, mengelola dalam bentuk database, merawat dan mempublikasikan tesis saya tanpa meminta izin dari saya selama tetap mencantumkan nama saya sebagai penulis dan sebagai pemegang dan/atau sebagai pemilik hak cipta.
Demikian pernyataan ini dibuat dengan sebenarnya.
Medan, 12 Agustus 2021
Aditiarno Manik
187038053
Tanggal : 12 Agustus 2021
PANITIA PENGUJI TESIS :
Ketua : Prof. Dr. Opim Salim Sitompul Anggota : 1. Prof. Dr. Saib Suwilo
2. Dr. Erna Budhiarti Nababan, M.IT 3. Prof. Dr. Tulus
DATA PRIBADI
Nama Lengkap : Aditiarno Manik, S.Kom, M.Kom Tempat dan Tanggal Lahir : Medan, 18 Pebruari 1984
Alamat Rumah : Jl. Gurilla Gg.Cangak Merah No.14 Medan Telepon/Faks/HP : 082278005374
Email : tiarnoaditia@gmail.com
Instansi Tempat Bekerja : AMIK Medicom Medan Alamat Kantor : Jl. Darat No.74 Medan
DATA PENDIDIKAN
SD : SD Negeri 060860 Medan TAMAT : 1996
SLTP : SLTP HKBP Sidorame Medan TAMAT : 1999
SLTA : SMK Negeri 5 Medan TAMAT : 2002
D3 : AMIK Medicom Medan TAMAT : 2005
S1 : STMIK BUDIDARMA Medan TAMAT : 2011
S2 : Teknik Informatika USU TAMAT : 2021
UCAPAN TERIMA KASIH
Puji dan Syukur atas kehadirat Tuhan Yang Maha Esa berkat kasih dan karunia-Nya yang melimpah penulis dapat menyelesaikan tesis yang berjudul “PENINGKATAN KINERJA SVM DENGAN PSO DALAM KLASIFIKASI RISIKO KREDIT” sebagai salah satu kelengkapan tugas dan syarat untuk memperoleh ijazah Magister pada Program Studi Magister (S-2) Teknik Informatika Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara.
Selama proses penyusunan tesis ini mulai dari awal sampai pada akhir pengerjaan penulis mendapatkan banyak sekali pengetahuan, pelajaran, serta pengalaman yang sangat berharga dari berbagai pihak, penulis menyadari bahwa penyusunan tesis ini tentulah karena adanya dukungan dari banyak pihak tersebut. Untuk itu penulis menyampaikan ucapan terima kasih yang sebesar besarnya kepada :
1. Bapak Dr. Muryanto Amin, S.Sos., M.Si, selaku Rektor Universitas Sumatera Utara.
2. Ibu Dr. Maya Silvi Lydia B.Sc.,M.Sc, selaku Dekan Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara.
3. Bapak Prof. Dr. Muhammad Zarlis, selaku Ketua Program Studi Magister (S-2) Teknik Informatika Universitas Sumatera Utara
4. Bapak Dr. Syahril Efendi, S.Si, M.IT, selaku Sekretaris Program Studi Magister (S-2) Teknik Informatika Universitas Sumatera Utara
5. Ibu Dr. Erna Budhiarti Nababan, M.IT, selaku Dosen Pembimbing I yang telah banyak meluangkan waktu, pikiran dalam bentuk diskusi, arahan serta bimbingan untuk menyusun Tesis ini dengan baik.
6. Bapak Prof. Dr. Tulus, selaku Dosen Pembimbing II yang dengan sabar mengarahkan dan membimbing pengerjaan tesis ini sehingga dapat diselesaikan dengan baik.
7. Bapak Prof. Dr. Opim Salim Sitompul, selaku Dosen Pembanding I yang selalu memberikan arahan dan bimbingan dalam pengerjaan tesis ini.
saran untuk perbaikan dan penyelesaian tesis ini.
9. Bapak/Ibu Staf Pegawai Program Studi Magister (S-2) Teknik Informatika yang banyak membantu penulis dalam menyelesaikan studi Magister di Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara.
10. Ibunda tercinta L. Munte yang terus mendoakan dan memberikan semangat
11. Istri Vlorina Heniati Tinambunan telah menjadi penolong yang dikirim Tuhan dalam keluarga, serta anak-anak Cain Arsen Manik, Rain Edbert Manik, Tri Alvernia Manik yang menjadi sumber semangat dan sukacita untuk selalu optimis dalam memperjuangkan harapan, sehingga penulis dapat menyelesaikan tesis ini.
12. Seluruh keluarga besar penulis yang selalu mendoakan dan memberikan dukungan kepada penulis.
13. Rekan-rekan seperjuangan mahasiswa Magister Teknik Informatika sebagai tempat saling bertukar pikiran dan berdiskusi khususnya Angkatan 2018 Kom-C Dalam menyusun tesin ini penulis menyadari masih banyak terdapat kekurangan.
Untuk itu penulis mengharapkan saran dan kritik yang membangun untuk kesempurnaan tesis ini.
Akhir kata kiranya Tuhan selalu melindungi dan melimpahkan rahmat-Nya kepada kita semua, dan semoga tesis ini dapat memberikan manfaat khususnya kepada penulis, dan kepada para pembaca umumnya.
Medan, 12 Agustus 2021
Penulis,
Aditiarno Manik
187038053
Pada Klasifikasi menggunakan SVM, setiap kernel mempunyai parameter-parameter yang mempengaruhi hasil akurasi klasifikasi. Penelitian ini meninjau peningkatan kinerja SVM dengan pemilihan parameter menggunakan PSO pada klasifikasi risiko kredit yang hasilnya dibandingkan dengan SVM dengan pemilihan parameter secara random. Kinerja klasifikasi dievaluasi dengan menerapkan klasifikasi SVM pada set data privat yang merupakan set data kredit yang dikeluarkan dari suatu Bank lokal yang ada di Sumatera Utara. Walaupun membutuhkan waktu eksekusi yang lebih lama untuk mencapai nilai akurasi yang optimal, penggabungan SVM dan PSO cukup efektif dan lebih sistematis dibandingkan dengan teknik trial and error dalam mencari nilai parameter SVM, sehingga mampu menghasilkan akurasi yang lebih baik. Secara umum, hasil pengujian mendapatkan bahwa kernel RBF mampu menghasilkan akurasi dan f1-score yang lebih tinggi dibandingkan kernel linear dan polynomial. Akurasi klasifikasi SVM pada kernel RBF meningkat dengan pencapaian terbaik 92.31%, dengan nilai parameter terbaiknya c dan berturut-turut adalah 8.9540 dan 3.5291.
Kata Kunci: Klasifikasi SVM, Pencarian parameter SVM, PSO, Data Kredit
CLASSIFICATION ABSTRACT
SVM classification, in each kernel has parameters that affect the results of classification accuracy. This study examines the improvement of SVM performance by selecting parameters using PSO in credit risk classification, the results of which are compared with SVM by randomly selecting parameters. Classification performance was evaluated by applying SVM classification to private data sets, which are credit data sets issued from a local bank in North Sumatra, Indonesia. Although it requires a longer execution time to achieve optimal accuracy values, combining SVM and PSO is quite effective and more systematic compared to trial and error techniques in finding SVM parameter values, so that it can produce better accuracy. In general, the test results show that the RBF kernel is capable of producing higher accuracy and higher f1-score than linear and polynomial kernels. The SVM classification accuracy of the RBF kernel increased with the best achievement of 92.31%, with the best parameter values of c and respectively are being 8,9540 and 3,5291.
Keywords: SVM Classification, SVM parameters, PSO, Credit Data Set
Halaman Judul ... i
Persetujuan ... ii
Pernyataan Orisinalitas ... iii
Persetujan Publikasi ... iv
Panitia Penguji ... v
Riwayat Hidup ... vi
Ucapan Terima Kasih... vii
Abstrak ... ix
Abstract ... x
Daftar Isi ... xi
Daftar Tabel ... xii
Daftar Gambar... xiii
BAB 1 PENDAHULUAN ... 1
1.1 Latar Belakang Masalah ... 1
1.2 Rumusan Masalah ... 4
1.3 Tujuan dan Manfaat Penelitian ... 5
1.3.1 Tujuan Penelitian ... 5
1.3.2 Manfaat Penelitian ... 5
1.4 Ruang Lingkup Penelitian ... 5
1.5 Metodologi Penelitian ... 6
1.6 Sistematika Penulisan ... 7
BAB 2 LANDASAN TEORI ... 8
2.1 Data Mining ... 8
2.2 Support Vector Machine ... 11
2.3 Pencarian Parameter Terbaik SVM Menggunakan PSO ... 12
2.4 Evaluasi Klasifikasi... 15
2.5 k-Fold Cross Validation ... 17
2.6.1 Transformasi Data Kategorial ... 19
2.6.2 Pembersihan Data (Data Cleaning) ... 20
2.6.3 Normalisasi Data ... 23
2.7 Penelitian Terkait ... 24
BAB 3 METODE PENELITIAN ... 27
3.1 Data yang digunakan ... 27
3.1.1 Set Data Benchmark Credit German ... 27
3.1.2 Set Data Privat dari Bank lokal ... 31
3.2 Metodologi Penelitian ... 33
3.2.1 Preprocessing Data ... 35
3.2.2 Klasifikasi SVM ... 52
3.2.3 Klasifikasi SVM + PSO ... 56
3.2.4 Akurasi ... 61
3.3 Alat Penelitian ... 61
BAB 4 HASIL DAN PEMBAHASAN ... 62
4.1 Hasil ... 62
4.1.1 Hasil Klasifikasi SVM ... 62
4.1.2 Hasil Klasifikasi SVM + PSO ... 66
4.2 Pembahasan ... 75
BAB 5 KESIMPULAN DAN SARAN ... 82
5.1 Kesimpulan ... 82
5.2 Saran... 82
DAFTAR PUSTAKA
LAMPIRAN PROGRAM MATLAB
Tabel 2.1 Confusion Matrix ... 16
Tabel 3.1 Informasi Atribut Set Data Kredit German ... 28
Tabel 3.2 Tampilan sebagian Set Data Kredit German ... 30
Tabel 3.3 Informasi Atribut Set Data Kredit Privat ... 32
Tabel 3.4 Tampilan sebagian Set Data Kredit Privat ... 33
Tabel 3.5 Set Data Kredit German Memiliki Data Bertipe Kategorial ... 45
Tabel 3.6 Transformasi Data Kategorial ke Numerik Set Data Kredit German ... 45
Tabel 3.7 Tampilan Set Data Kredit German Setelah Transformasi ... 47
Tabel 3.8 Set Data Kredit Privat Memiliki Data Bertipe Kategorial ... 48
Tabel 3.9 Transformasi Data Kategorial ke Numerik Set Data Kredit Privat ... 48
Tabel 3.10 Tampilan Set Data Kredit Privat Setelah Transformasi ... 49
Tabel 4.1 Hasil Klasifikasi SVM Kernel Linier ... 62
Tabel 4.2 Hasil Klasifikasi SVM Kernel RBF ... 64
Tabel 4.3 Hasil Klasifikasi SVM Kernel Polynomial ... 65
Tabel 4.4 Hasil Akurasi SVM+PSO Kernel Linier Set Data Kredit Privat ... 68
Tabel 4.5 Hasil Akurasi SVM+PSO Kernel Linier Set Data Kredit German ... 69
Tabel 4.6 Hasil Akurasi SVM+PSO Kernel RBF Set Data Kredit Privat ... 69
Tabel 4.7 Hasil Akurasi SVM+PSO Kernel RBF Set Data Kredit German ... 71
Tabel 4.8 Hasil Akurasi SVM+PSO Kernel Polynomial Set Data Kredit Privat ... 73
Tabel 4.9 Hasil Akurasi SVM+PSO Kernel Polynomial Set Data Kredit German ... 73
Tabel 4.10 Akurasi Tertinggi yang dihasilkan Klasifikasi SVM ... 75
Tabel 4.11 Perbandingan Akurasi Klasifikasi Pada Set Data Kredit Privat ... 78
Tabel 4.12 Peningkatan Akurasi Klasifikasi SVM dengan Metode Optimisasi ... 78
Tabel 4.13 Perbandingan Akurasi dengan Optimisasi dan tanpa Optimisasi ... 79
Tabel 4.14 F1-Score Klasifikasi SVM Berbasis PSO ... 80
Tabel 4.15 Waktu Proses Klasifikasi SVM dengan Optimisasi PSO ... 80
Tabel 4.16 Waktu Proses Klasifikasi SVM tanpa Optimisasi PSO ... 81
Gambar 2.1 Beberapa metode data mining (Ridwal et al, 2013) ... 10
Gambar 2.2 Diagram Alir PSO (Xiao et al, 2018) ... 14
Gambar 2.3 Validasi 10 fold Cross dalam perulangan Iterasi (Prasetyo, 2014) ... 18
Gambar 2.4 Tampilan Outlier yang Terdeteksi pada Data ... 23
Gambar 3.1 Bagan Metodologi Penelitian ... 34
Gambar 3.2 Matrix Set Data Kredit Privat ... 36
Gambar 3.3 Program Matlab untuk Mendeteksi Data Redundant ... 37
Gambar 3.4 Tampilan Set Data Kredit Privat dibersihkan dari Redundant ... 37
Gambar 3.5 Tampilan Kode Program Matlab Penanganan Missing Value ... 38
Gambar 3.6 Tampilan Set Data Kredit Privat dibersihkan dari Missing Value ... 39
Gambar 3.7 Pendeteksian Outlier pada Data Atribut-2 ... 40
Gambar 3.8 Pendeteksian Outlier pada Data Atribut-4 ... 41
Gambar 3.9 Pendeteksian Outlier pada Data Atribut-8 ... 41
Gambar 3.10 Pendeteksian Outlier pada Data Atribut-9 ... 42
Gambar 3.11 Pendeteksian Outlier pada Data Atribut-10 ... 42
Gambar 3.12 Pendeteksian Outlier pada Data Atribut-11 ... 43
Gambar 3.13 Pendeteksian Outlier pada Data Atribut-12 ... 43
Gambar 3.14 Pendeteksian Outlier pada Data Atribut-13 ... 44
Gambar 3.15 Input Matrix Set Data Kredit yang akan dinormalisasi ... 50
Gambar 3.16 Hasil Normalisasi Set Data ... 51
Gambar 3.17 Sampel Data Training Set Data Kredit Privat ... 53
Gambar 3.18 Sampel Data Testing Set Data Kredit German ... 54
Gambar 3.19 Flowchart Pencarian Parameter SVM dengan PSO ... 56
Gambar 3.20 Pengujian Matlab SVM+PSO Kernel RBF Set Data Kredit Privat ... 60
Gambar 4.1 Klasifikasi SVM+PSO Kernel Linier Set Data Kredit Privat ... 67
Gambar 4.2 Klasifikasi SVM+PSO Kernel Linier Set Data Kredit German ... 68
Gambar 4.3 Klasifikasi SVM+PSO Kernel RBF Set Data Kredit Privat ... 72
Gambar 4.5 Klasifikasi SVM+PSO Kernel Polynomial Set Data Kredit Privat ... 74 Gambar 4.6 Klasifikasi SVM+PSO Kernel Polynomial Set Data Kredit German .... 74
BAB 1 PENDAHULUAN
1.1 Latar Belakang Masalah
Kredit telah menjadi stimulus penting dalam mendorong ekonomi untuk bertumbuh juga menjadi kegiatan utama dari setiap bank dimana pun (Mukid et al., 2018).
Pemberian kredit memberikan peluang kepada masyarakat dalam memperbaiki maupun meningkatkan konsumsinya serta memberikan peluang kepada perusahaan dalam menanam investasi yang sebelumnya sulit dilakukan jika menggunakan dana sendiri. Dalam mengalokasikan atau memberikan pinjaman kepada pelanggan atau peminjam potensial, bank komersial dan lembaga keuangan harus mempertimbangkan risiko kredit yang akan diberikan, apakah pelanggan akan membayar kreditnya atau tidak (kredit bermasalah). Risiko kredit (biasa disebut juga dengan default risk) adalah risiko yang muncul disebabkan gagalnya atau tidak mampunya nasabah melakukan pengembalian kredit yang diberikan pihak perbankan termasuk bunga kreditnya pada jangka waktu yang sudah disepakati atau ditentukan.
Apabila kredit yang gagal dibayarkan terlalu besar, dapat menyebabkan aliran kas pada perusahaan pemberi kredit menjadi terhambat serta semua manfaat positif yang diharapkan dari pemberian kredit tersebut menjadi tidak terjadi (Leidiyana, 2013).
Oleh karena itu, perusahaan pemberi kredit memerlukan analisis yang baik dalam perencanaan kreditnya sehingga kemungkinan terjadinya kredit macet dapat diketahui sebelumnya.
Metode klasifikasi tingkat risiko kredit sudah berperan penting pada praktik kegiatan manajemen risiko perkreditan kontemporer dan memberikan kontribusi kepada keputusan utama persetujuan pemberian kredit sehingga secara efisien dan akurat mengukur tingkat risiko kredit yang diajukan oleh calon peminjam. Metode
klasifikasi risiko kredit dilakukan dengan maksud untuk mengetahui aktifitas di kemudian hari terkait risiko kredit berdasarkan catatan kejadian sebelumnya (masa
lalu) pelanggan dengan karakteristik serupa. Tingkat risiko kredit peminjam dikaitkan dengan kemungkinan risiko gagal bayar atas kredit yang mendapat persetujuan untuk dilunasi pada waktu yang sudah ditetapkan. Tujuan penting dari metode klasifikasi kredit yaitu melakukan pemisahan dari kelompok peminjam yang tidak mampu mengembalikan dan kelompok peminjam yang mampu mengembalikan kredit.
Keberhasilan pemisahan menjadi ukuran utama keberhasilan suatu metode. Saat ini, kinerja klasifikasi telah menjadi semakin penting untuk penilaian kredit, karena bahkan sebagian kecil dari persentase peningkatan sudah dapat memberikan sejumlah besar keuntungan untuk lembaga keuangan (Abellán & Castellano, 2017).
SVM yang termasuk dalam supervised learning mampu memodelkan suatu klasifikasi dengan memanfaatkan data latih dan digunakan dalam melakukan prediksi data uji yang merupakan data baru hasil pengamatan dan kemudian untuk selanjutnya model divalidasi. Model klasifikasi yang dibangun berdasarkan minimasi risiko menggunakan SVM mampu memberikan keluaran yang baik untuk melakukan generalisasi persoalan sebaik mungkin serta dapat menghindari munculnya overfitting. SVM dapat memberikan hasil akurasi yang optimal serta tingkat error yang cenderung kecil karena memiliki kemampuan menggeneralisasi.
Baesens et al., (2003) mempelajari model penilaian kredit yang dibangun dengan Support Vector Machines (SVM) dan membandingkan performanya dengan metode canggih lainnya. Mereka bereksperimen dengan SVM standar dan SVM Least Squares (LS-SVM) dan melaporkan bahwa LS-SVM menghasilkan kinerja yang baik dibandingkan dengan metode lain. SVM dalam perkembangannya sudah berhasil diaplikasikan dalam penyelesaian masalah pada banyak bidang, diantaranya yaitu pengklasifikasian data risiko kredit dan telah menjadi teknik data mining yang sangat sering penggunaanya dalam menyusun model klasifikasi penilaian kredit. Studi review terbaru dari Alaka et al. (2018) dan Moro et al. (2016) juga telah mengidentifikasi SVM sebagai alat penting untuk dipilih di antara para peneliti untuk mendapatkan pengembangan model kredit.
Kelemahan yang dimiliki oleh metode SVM adalah SVM menghadapi tantangan penentuan nilai parameternya yang terbaik. Yenaeng et al. (2014) telah mempelajari bahwa tantangan terbesar pada pembentukan model klasifikasi SVM yaitu dalam hal penentuan nilai hyper parameternya. Sedangkan diketahui bahwa penentuan nilai parameter yang tepat dapat memperbaiki akurasi dari kinerja pada model klasifikasi SVM (Huang & Wang, 2006). Oleh karena itu, dalam tujuannya memperoleh nilai parameter yang dapat memberikan hasil kinerja yang paling baik pada model klasifikasi SVM, maka diperlukan pencarian parameter SVM yang diharapkan dapat mengoptimalkan kinerja klasifikasi. Pencarian parameter SVM yang dimaksud merupakan kegiatan penentuan hyperparameter dari model klasifikasi SVM yang dapat memberikan hasil kinerja yang optimal.
Penulis mengusulkan metode Particle Swarm Optimization (PSO) untuk mencari nilai parameter SVM yang optimal dengan beberapa keunggulannya. PSO sebagai teknik komputasi evolusioner, mampu memperoleh solusi optimal secara global dalam ruang pencarian dengan mempertimbangkan interaksi antar individu pada sekawanan partikel. Setiap partikel memberikan informasi posisi terbaiknya kepada partikel yang lain sekaligus menyesuaikan posisi serta kecepatan perubahan posisi berdasarkan informasi yang diperoleh terkait posisi yang terbaik tersebut (Nurelasari, 2016). Jika dilakukan perbandingan dengan algoritma sejenis, seperti Algoritma Genetika (GA), maka PSO termasuk model yang lebih sederhana dengan tidak membutuhkan lebih banyak langkah prosedur, misalnya langkah seleksi, mutasi ataupun crossover yang dimiliki metode GA. Tidak hanya itu, teknik PSO juga berhasil dalam pencarian parameter optimal pada metode pembelajaran mesin lainnya yang diketahui dari beberapa penelitian sebelumnya. Abolhassani & Yaghoobi (2010) dalam peramalan pasar saham mengusulkan algoritma berdasarkan SVM dioptimalkan oleh PSO untuk pemilihan atribut terbaik di antara atribut yang tersedia yang berasal dari bagian analisis teknis dan menghasilkan PSO-SVM mengungguli metode SVM tunggal. Tang & Zhou (2015) dalam penelitian telah menggabungkan PSO-SVM untuk memprediksi konsumsi air pertanian, dimana PSO-SVM dinilai
lebih sederhana untuk menyesuaikan dibandingkan dengan metode lain seperti GA dengan penyesuaian minimum pada parameternya, dan hasil penelitian menunjukkan bahwa model SVM-PSO paling optimal. Pada penilaian kredit sendiri, PSO sangat cocok dikombinasikan dengan SVM (Danenas & Garsva, 2010) dan PSO juga cocok dikombinasikan dengan metode Jaringan Syaraf Tiruan (Li & Xiao, 2013).
Pengaplikasian PSO pada riset-riset tersebut telah memberikan hasil yang menggambarkan peningkatan akurasi klasifikasi dalam menentukan parameter SVM yang mengoptimalkan akurasi. Melihat kemampuan dari metode PSO inilah yang mendasari penelitian ini menggunakan metode PSO untuk diterapkan dalam pencarian parameter SVM sehingga akan diperoleh peningkatan kinerja klasifikasi.
Penelitian ini akan meninjau kinerja SVM dengan pemilihan parameter menggunakan PSO untuk mengklasifikasi risiko kredit yang akan dibandingkan dengan SVM yang menggunakan parameter default. Masalah model pemberian skor kredit yang perlu diperhatikan adalah sulitnya mendapatkan data kredit dunia nyata, karena data kredit pelanggan bersifat rahasia di sebagian besar lembaga keuangan dan para peneliti tidak bisa mendapatkan akses ke data ini. Untuk mengevaluasi kinerja klasifikasi, penelitian ini akan menerapkan klasifikasi SVM menggunakan privat data yang merupakan set data kredit yang diterbitkan suatu Bank lokal yang ada di Sumatera Utara.
Dari uraian latar belakang diatas, maka diusulkan sebuah penelitian dengan mengambil topik “Peningkatan Kinerja SVM Dengan PSO Dalam Klasifikasi Risiko Kredit”.
1.2 Rumusan Masalah
Persoalan pada aplikasi metode SVM adalah tantangan dalam mencari nilai parameternya yang dapat memberikan hasil yang optimal. Penentuan nilai hyperparameter dari SVM menjadi permasalahan terbesar dalam mengatur model SVM, padahal akurasi dari model klasifikasi SVM dapat ditingkatkan melalui
penentuan nilai parameter yang tepat. Maka diperlukan suatu metode untuk diaplikasikan dalam pencarian parameter yang tepat dimana dapat memberikan luaran SVM yang optimal dengan hasil akurasi yang paling baik dalam klasifikasi risiko kredit.
1.3 Tujuan dan Manfaat Penelitian 1.3.1 Tujuan Penelitian
Tujuan yang diharapkan dari penelitian ini yaitu untuk meningkatkan kinerja SVM dalam klasifikasi risiko kredit.
1.3.2 Manfaat Penelitian
Adapun manfaat dilakukannya penelitian ini adalah:
1. Bermanfaat untuk menambah khasanah dan variasi penelitian dalam penerapan klasifikasi SVM dengan kinerja yang ditingkatkan melalui penentuan parameter terbaik menggunakan PSO pada klasifikasi data risiko kredit.
2. Menjadi rujukan perbandingan oleh peneliti lainnya yang membahas persoalan terkait penggunaan klasifikasi SVM dengan kinerja yang ditingkatkan melalui penentuan parameter terbaik menggunakan PSO pada klasifikasi data risiko kredit.
1.4 Ruang Lingkup Penelitian
Berikut ini akan dijelaskan ruang lingkup penelitian dalam penulisan tesis ini antara lain:
1. Penelitian ini akan menggunakan data privat yang merupakan set data pinjaman (kredit) yang diperoleh dari bank lokal yang terdiri dari 390 instance dan 16 atribut. Serta Set data Benchmark Credit German merupakan set data
kredit diterbitkan oleh University of California Irivine (UCI) yang tersedia di UCI Machine Learning Repository
2. Metode klasifikasi yang diaplikasikan adalah Metode SVM dengan kinerja yang ditingkatkan melalui pencarian parameter menggunakan PSO.
3. Kernel yang akan digunakan dalam metode SVM adalah Linear, RBF dan Polynomial.
4. Nilai k untuk fold yang dipakai dalam validasi k-fold cross adalah 10.
5. Pengukuran hasil pengujian model menggunakan confusion matrix, dengan membandingkan nilai akurasi dan f1 score.
1.5 Metodologi Penelitian
Metodologi penelitian yang dipakai dalam penelitian ini yaitu sebagai berikut:
1. Studi literature
Yang dilakukan pada tahap Studi literature yaitu memahami bagaimana konsep SVM, masalah yang ada pada SVM, dan PSO sebagai solusi penentuan nilai parameter SVM terbaik, proses klasifikasi tingkat resiko kredit dan metode yang sudah ada.
2. Analisis masalah
Pada tahap ini dilakukan analisis berdasarkan hasil studi literatur untuk mengidentifikasi masalah yang harus diselesaikan, data yang dibutuhkan, dan menentukan metode yang diusulkan untuk menyelesaikan masalah.
3. Perancangan model
Tahap perancangan model yaitu kegiatan merancang activity diagram yang menggambarkan proses penerapan SVM dan PSO pada klasifikasi data risiko kredit.
4. Pengujian
Melakukan pengujian penerapan SVM dan PSO pada data risiko kredit dengan memperhatikan nilai validasi menggunakan k-fold cross validation.
5. Menarik kesimpulan dari hasil pengujian 6. Menyusun laporan Tesis
1.6 Sistematika Penulisan
Sistematika penulisan ditujukan untuk memudahkan pemahaman terkait laporan penelitian yang ditulis. Laporan tesis ini menyajikan beberapa bagian sebagai berikut.
BAB 1 PENDAHULUAN
Bab ini menyajikan pendahuluan yang mencakup terkait topik yang diriset, termasuk didalamnya latar belakang masalah, rumusan masalah penelitian, tujuan serta manfaat yang diinginkan, ruang lingkup penelitian, metodologi penelitian serta sistematika dalam penulisan.
BAB 2 TINJAUAN PUSTAKA
Bab ini menyajikan tinjauan pustaka serta teori yang melandasi penelitian serta yang menunjang dalam pembuatan tesis.
BAB 3 METODE PENELITIAN
Bab ini berisikan tahapan-tahapan metode penelitian yang digunakan dalam penelitian.
BAB 4 HASIL DAN PEMBAHASAN
Bab ini berisikan hasil maupun pembahasan hasil penelitian yang diharapkan dapat menyelesaikan permasalahan.
BAB 5 PENUTUP
Bab ini berisikan penutup yang mencakup kesimpulan penelitian dan termasuk juga saran.
8
BAB 2
LANDASAN TEORI
2.1 Data Mining
Pada proses pengolahan data menjadi informasi, data mining sangat diperlukan yang kemudian diharapkan dapat diperoleh hasil berupa informasi baru terkait dari data yang sudah ada dimana luaran keputusan tersebut bisa dimanfaatkan sebagai acuan pada pengambilan kebijakan dimasa yang akan datang. Data mining mengaitkan temuan pola baru yang dapat digali, serta memiliki potensi untuk dimanfaatkan dari sekumpulan informasi besar serta mempraktikkan algoritma dalam ekstraksi data tersembunyi. Banyak istilah lain yang digunakan untuk data mining, misalnya, penemuan pengetahuan (mining) dalam database (KDD), ekstraksi pengetahuan, analisis data/pola, arkeologi data, pengerukan data, dan pengumpulan informasi (Han et al., 2011).
Tujuan dari setiap proses data mining adalah untuk membangun model prediktif atau deskriptif yang efisien dari sejumlah besar data yang tidak hanya paling cocok atau menjelaskannya, tetapi juga dapat menggeneralisasi ke data baru (Mukhopadhyay et al., 2013). Berdasarkan tampilan luas dari fungsionalitasnya, data mining dapat diartikan sebagai kegiatan mencari informasi yang dapat digali dari sejumlah data yang besar dan tersimpan dengan aman di database, tempat penyimpanan data, maupun repositori informasi dalam bentuk lainnya.
Berdasarkan penjelasan definisi dari data mining serta terkait kegunaannya, umumnya kegiatan terkait data mining mencakup tahapan-tahapan diantaranya sebagai berikut (Chen et al., 2015):
1. Persiapan data: siapkan data untuk penambangan. Ini mencakup tiga langkah berikut: pengintegrasian data di berbagai sumber data dan melakukan
9
pembersihan gangguan dari data; mengekstrak sebagian dari data untuk selanjutnya di proses pada sistem data mining.
2. Penambangan data: yaitu melakukan menerapkan algoritma pada data yang digali untuk mendapatkan suatu atau beberapa pola serta melakukan evaluasi pola informasi yang telah ditemukan.
3. Penyajian data: yaitu menampilkan data termasuk hasil analisis serta menggambarkan informasi yang digali untuk digunakan oleh para pengguna.
Kita bisa melihat data mining dalam tampilan multidimensi (Han et al., 2011), yaitu:
1. Dalam tampilan pengetahuan atau tampilan fungsi data mining, ini mencakup karakterisasi, diskriminasi, klasifikasi, pengelompokan, analisis asosiasi, analisis deret waktu, dan analisis pencilan.
2. Dalam tampilan teknik yang digunakan, itu termasuk pembelajaran mesin, statistik, pengenalan pola, data besar, mesin vektor pendukung, himpunan kasar, jaringan saraf, dan algoritma evolusioner.
3. Dalam tampilan aplikasi, ini mencakup industri, telekomunikasi, perbankan, analisis penipuan, penambangan biodata, analisis pasar saham, penambangan teks, penambangan web, jaringan sosial, dan e-commerce.
Konsep pembelajaran dalam Data mining dibagi dalam dua 2 jenis pembelajaran (Oded & Lior, 2010), pertama yaitu Supervised Learning yaitu algoritma yang menghasilkan fungsi objektif berdasarkan kajian data latih yang sudah tersedia, dimana dengan kata lain untuk algoritma ini sudah terdapat sejumlah data yang digunakan untuk latihan yang lengkap dan mendetil dan sudah diklasifikasikan atau dikelompokkan yang nantinya membentuk suatu model dari data ketika proses ujicoba akan dilakukan dengan suatu data uji yang lain sehingga memberikan hasil luaran sebagaimana sebelumnya diharapkan.
Beberapa algoritma dari Unsupervised Learning
10
diantaranya adalah: K-Means Clustering, Fuzzy C-Means, maupun Hierarchical Clustering.
Kedua yaitu Unsupervised Learning merupakan suatu algoritma yang digunakan dalam melakukan suatu penggambaran atau mewakili bentuk suatu masukan yang bersumber dari suatu data latih dan yang menjadi salah satu pembedanya dibandingkan dengan Supervised Learning yaitu tidak terdapatnya input data yang diklasifikasi. Pada proses pembelajaran tidak terdapat role model yaitu informasi termasuk juga contoh yang tersedia yang akan dimanfaatkan sebagai model ketika proses ujicoba melakukan dalam menyelesaikan suatu masalah dengan data tes yang diuji (Shalev-Shwartz & Ben-David, 2014).
Beberapa algoritma Supervised Learning diantaranya adalah Decision tree, Naive Bayes Classifier, K-Nearest Neighbor Classifier, Artificial Neural Network, dan Support Vector Machine. Beberapa metode yang bisa dimanfaatkan berdasarkan pengelompokan data mining ditunjukkan pada Gambar 2.1.
Gambar 2.1 Beberapa metode data mining (Ridwan et al., 2013)
11 2.2 Support Vector Machine
Dalam sistem kerjanya, Support Vector Machine (SVM) merupakan suatu algoritma dimana sistem kerjanya yaitu dengan melakukan nonlinear mapping dimana fungsinya yaitu data training awal ditransformasikan ke dalam dimensi yang baru dan tentunya lebih tinggi. Dimensi baru yang dimaksud, di dalamnya SVM berfungsi untuk membentuk suatu hyperplane linear yang memberikan hasil optimal. Nonlinear mapping yang dilakukan ke dalam dimensi yang lebih tinggi, dimana pada data yang terdiri dari dua kelas nantinya dapat dilakukan pemisahan oleh suatu hyperplane yang telah dibentuk. Metode SVM dapat membentuk suatu hyperplane optimal dengan memanfaatkan margins dan support vectors (Han et al., 2011). SVM dapat memecahkan masalah nonlinier dan dapat menangani kumpulan data berdimensi tinggi, tetapi interpretasinya tidak kuat. Dengan adanya sekumpulan contoh pelatihan, setiap contoh pelatihan ditandai sebagai milik satu atau yang lain dari dua kategori, SVM membuat model yang menetapkan contoh baru ke salah satu dari dua kategori, menjadikannya pengklasifikasi linier biner non-probabilistik (Zhang, 2020).
SVM untuk pertama kalinya diperkenalkan oleh Vapnik, Boser, dan Guyon pada tahun 1992. Pada teori SVM, strategi baru diperkenalkan yaitu untuk menemukan hyperplane optimal dari data masukan. Pada awalnya, prinsip SVM merupakan klasifikasi yang linier, kemudian selanjutnya SVM dikembangkan lagi sehingga diharapkan dapat melakukan klasifikasi pada persoalan non-linear dengan memasukkan suatu kernel. Dengan berkembangnya SVM, akhirnya mengundang perhatian penelitian pada kategori pattern recognition dimana potensi kemampuan metode SVM dikembangkan baik dari sisi teoretisnya juga dari sisi aplikasinya. Pada saat ini pengaplikasian metode SVM sudah berhasil untuk penyelesaian masalah yang praktis.
Persoalan klasifikasi merupakan suatu kegiatan memisahkan antara dua kelompok data dengan membuat suatu garis. Untuk menemukan Hyperplane pemisah yang paling baik dilakukan pengukuran margin hyperplane serta menemukan titik yang maksimal. Margin yang dimaksud merupakan jarak antara pattern terdekat dengan hyperplane pada tiap kelas. Pattern terdekat yang ada
12
disebut dengan support vector. Hal ini menjadi inti pembelajaran SVM yaitu proses dalam menemukan lokasi hyperplane.
2.3 Pencarian Parameter Terbaik SVM Menggunakan PSO
Terkait metode klasifikasi SVM, Pemilihan fungsi kernel dan parameternya memainkan peran penting pada hasil. Radius Basis Function (RBF) adalah kernel yang umum digunakan (Xie et al., 2018). Seperti pada kernel RBF-SVM, dua parameter yaitu c dan γ, digunakan untuk mengontrol performa SVM. Parameter penalti c menentukan trade-off antara minimalisasi kesalahan pemasangan dan maksimalisasi margin antar kelas. Parameter γ menentukan bandwidth RBF.
Sehingga diperlukan teknik yang efektif untuk menemukan pasangan c dan γ yang mengoptimalkan hasil klasifikasi SVM.
PSO merupakan suatu metode stochastic optimization yang didasarkan pada populasi (burung, lebah, ikan, dll) diperkenalkan di tahun 1995 oleh James Kennedy dan Russell C. Eberhart yang diinspirasi oleh kecenderungan aktifitas sosial ikan atau burung dalam kegiatan pencarian makanan. Berbagai aplikasi dan bidang penelitian yang telah berhasil menerapkan PSO, diantaranya pengontrolan sistem fuzzy, permainan sudoku, optimasi fungsi, menyelesaikan persoalan rantai suplay (Habibi, 2017) dan masih banyak lagi penerapan lainnya. Apabila dibandingan dengan teknik yang lain, PSO mempunyai teknik penyelesaian masalah yang dapat bekerja dengan sederhana dan cepat serta menghasilkan luaran yang lebih baik. PSO bersimulasi dengan perilaku dari sekawanan burung dalam skenario berikut. Dalam suatu kelompok (misalnya) burung di suatu daerah mencari makanan secara acak, dimana di daerah yang dicari hanya terdapat satu potong sumber makanan. Setiap burung tidak mengetahui sejauh apa posisi makanan tersebut berada. Oleh karena itu, untuk menemukan makanan tersebut, diterapkan strategi yang terbaik dengan cara mengikuti burung-burung yang memiliki posisi paling dekat dari posisi sumber makanan. Skenario inilah yang diadopsi PSO untuk diterapkan untuk memecahkan persoalan optimasi “Burung”
yang dimaksud dalam PSO dianggap satu solusi pada ruang pencarian yang disebut individu atau partikel.
13
Individu-individu yang optimal akan diikuti oleh setiap partikel. Posisi setiap partikel direkam sebagai solusi terbaik yang telah diperoleh atau dalam GA disebut fitness. Dimana nilai fitness nya, disebut dengan pbest juga ikut direkam.
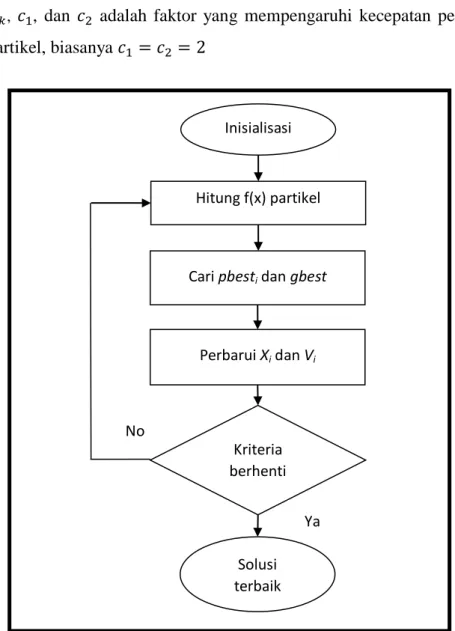
Turut pula disimpan lbest (local best) yaitu nilai terbaik yang diperoleh individu lain di sekitarnya dan nilai terbaik secara keseluruhan yang disebut gbest (global best). Kemudian, pada setiap individu terdapat akselerasi antara lokasi pbest dan gbest. Bilangan acak digunakan sebagai bobot akselerasi. Diagram alir dari PSO dapat dilihat pada Gambar 2.2.
Ketika individu (partikel) telah mendapatkan dua nilai terbaik diatas, maka pembaruan kecepatan dan posisinya dilakukan dengan menggunakan persamaan (Tuegeh et al., 2009):
( )
( ) (2.1)
(2.2)
dimana:
: kecepatan individu atau partikel
: posisi individu (partikel) pada suatu iterasi (solusi) : nilai terbaik milik individu di sekitarnya
: nilai terbaik secara keseluruhan : adalah nomor acak antara (0,1)
: bobot inertia : bobot kognitif : bobot social
14
, , dan adalah faktor yang mempengaruhi kecepatan perpindahan partikel, biasanya
Gambar 2.1 Diagram Alir PSO (Xiao et al., 2018)
Istilah-istilah umum yang terdapat pada PSO diantaranya yaitu (Tuegeh et al., 2009):
1. Swarm : kelompok atau populasi partikel.
2. Partikel: anggota (individu) bagian dari swarm.
Inisialisasi
Hitung f(x) partikel
Cari pbesti dan gbest
Perbarui Xi dan Vi
Kriteria berhenti
Solusi terbaik
Ya No
15
suatu solusi yang potensial direpresentasikan oleh suatu partikel dalam menyelesaikan masalah. Solusi yang ada merepresentasikan posisi dari suatu partikel saat ini.
3. Pbest : posisi Pbest suatu partikel yang menunjukkan posisi partikel yang disimpan atau direkam untuk dipertimbangkan sebagai solusi terbaik.
4. Gbest : posisi optimal suatu partikel dari semua kawanan.
5. Velocity (vektor) : vektor yang mempengaruhi pergerakan partikel pada proses optimisasi serta menentukan arah untuk memperbarui posisi yang lebih baik.
6. Inertia weight : bobot inertia disimbolkan w, merupakan parameter yang digunakan dalam mengontrol pergerakan suatu partikel sebagai dampak yang diakibatkan velocity.
Sebagaimana dijelaskan sebelumnya, dalam PSO, sekumpulan partikel bergerak mencari solusi secara bersamaan, di mana setiap partikel mewakili solusi kandidat. Partikel tersebut mencatat solusi terbaiknya (pbest) dan solusi terbaik yang ditemukan oleh segerombolan (gbest) sejauh ini. Dua posisi terbaik diharapkan memimpin gerombolan untuk menjelajahi wilayah pencarian yang menjanjikan. Posisi partikel diwakili oleh vektor yang merupakan representasi alami untuk pemilihan parameter. Secara khusus, setiap elemen vektor sesuai dengan nilai asli parameter.
2.4 Evaluasi Klasifikasi
Salah satu hal penting di dalam kegiatan klasifikasi adalah pengukuran atas kinerja metode klasifikasi yang digunakan. Pengukuran kinerja klasifikasi memberikan informasi sejauh mana sistem mengklasifikasikan data dengan baik.
Salah satu metode yang bisa dipakai dalam mengukur kinerja dari metide klasifikasi yang digunakan, adalah Confusion Matrix. Confusion matrix pada prinsipnya mengukur kinerja klasifikasi dengan melakukan perbandingan antara hasil klasifikasi yang seharusnya dengan hasil klasifikasi yang dihasilkan oleh sistem.
16
Pada penggunaan confusion matrix dalam pengukuran kinerja, ada 4 istilah yang merepresentasikan hasil klasifikasi, yaitu True Negative (TN), True Positive (TP), False Negative (FN) dan False Positive (FP). Nilai True Negative (TN) merepresentasikan jumlah kelas negatif yang dideteksi dengan benar, sedangkan True Positive (TP) merepresentasikan data positif yang dideteksi sebagai positif (benar). Sementara itu, False Positive (FP) merupakan data negatif yang dideteksi sebagai data positif (salah), sedangkan False Negative (FN) adalah data positif, namun dideteksi sebagai data negatif. Pada kasus klasifikasi binary yang hanya terdapat 2 label kelas, tampilan confussion matriks dapat dilihat pada Tabel 2.1.
Tabel 2.1 Confusion Matrix
Kelas Hasil Diagnosa Positif Hasil Diagnosa Negatif
Positif True Positive (TP) False Negative (FN)
Negatif False Positive (FP) True Negative (TN)
Dari tabel confusion matrix, selanjutnya dapat diperoleh nilai akurasi, recall, presisi dan juga nilai f1-score berdasarkan nilai dari setiap kolom TN, FP, FN dan TP. Untuk mendapatkan nilai akurasi, dapat digunakan Persamaan 2.3.
Nilai precision merepresentasikan banyak data yang berkategori positif dan terklasifikasi secara tepat kemudian dibagi dengan jumlah keseluruhan data yang terklasifikasi positif. Untuk mendapatkan precision, dapat dihitung menggunakan persamaan 2.4. Sedangkan recall merepresentasikan berapa persen data yang berkategori positif dan diklasifikasikan dengan tepat oleh model klasifikasi.
Nilai recall dapat dihitung dengan menggunakan persamaan 2.5. F1-Score adalah nilai rata-rata keseimbangan antara recall dan precision, yang dihitung dengan mengaplikasikan persamaan 2.6.
Akurasi = (TN + TP) / (TP + FP+TN + FN)) * 100% . ……… (2.3) Precision = (TP / (FP + TP)) * 100%. ……….. (2.4)
17
Recall = (TP / (TP + FN)) * 100%. ……… (2.5) F1 Score = 2 * (Precision * Recall) / (Precision + Recall) ...……… (2.6) dimana:
TP (True Positive), adalah banyak data positif yang diklasifikasikan dengan tepat oleh model.
TN (True Negative), adalah banyak data negatif yang diklasifikasikan dengan tepat oleh model.
FN (False Negative), adalah banyak data negatif yang diklasifikasikan dengan salah oleh model.
FP (False Positive), adalah banyak data positif yang diklasifikasikan dengan salah oleh model.
Disisi lain, dalam mengklasifikasi kasus set data yang memiliki multi-class (banyak kelas lebih dari dua), akurasi, recall dan presisi dihitung dengan cara menghitung rata-rata dari nilai akurasi, recall dan presisi pada setiap kelas. Secara umum, dalam membangun suatu model yang akan melakukan prediksi, dibentuk dengan kemampuan memprediksi semua data latih dengan benar, lalu saat model dihadapkan pada data tes, maka saat itulah kinerja suatu model yang diperoleh dari suatu algoritma klasifikasi diketahui.
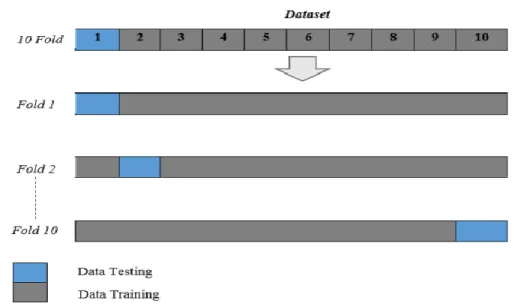
2.5 k-Fold Cross Validation (Metode Validasi Klasifikator)
Pada setiap algoritma machine learning, banyak data merupakan hal yang penting dan berpengaruh kuat. Jumlah instances data dalam jumlah yang besar memberi pengaruh positif pada hasil klasifikasi, akan tetapi untuk memperoleh data yang banyak bukanlah hal mudah. Dalam penelitian ini, validasi k-fold cross digunakan sebagai teknik validasi kinerja klasifikasi. Validasi k-fold cross secara umum digunakan sebagai teknik validasi pada suatu klasifikasi yang menggunakan data terbatas (banyak instance yang sedikit). Validasi k-fold cross adalah suatu teknik yang berfungsi untuk dapat mengetahui keberhasilan rata-rata yang dihasilkan sistem dengan memproses masukan
18
atribut secara acak dalam beberapa perulangan agar sistem yang digunakan teruji pada beberapa input yang acak.
Dalam prosesnya validasi k-fold cross dimulai dari mengelompokkan data menjadi n-fold (n buah partisi) yang dikehendaki dengan banyak data yang sama.
Kemudian kegiatan training dan testing diproses berulang n kali perulangan. Pada iterasi ke-i, yang menjadi data testing adalah partisi Di, kemudian sisanya disusun sebagai data latih (training). Dalam model dianjurkan penggunaan validasi 10 fold cross sebagai jumlah fold yang terbaik untuk pengujian validitas (Prasetyo, 2014).
Sebagai contoh, pada proses validasi 10-fold cross, pembagian dataset dapat dilihat pada Gambar 2.3.
Gambar 2.3 Validasi 10-fold Cross dalam Perulangan Iterasi (Prasetyo, 2014)
Langkah proses validasi k-fold cross yaitu (Prasetyo, 2014):
1. Jumlah semua instance dikelompokkan ke dalam N bagian.
2. Fold yang ke-1 dimaksud ketika kelompok ke-1 sebagai data testing dan sisanya menjadi data training.
19
Kemudian, akurasi dihitung menggunakan data dengan porsi tersebut.
Akurasi dihitung dengan melakukan perhitungan rumus 2.17 berikut ini (Prasetyo, 2014):
(2.7)
3. Fold yang ke-2
yaitu menggunakan data kelompok ke-2 menjadi data testing dan sisanya menjadi data training. Kemudian, akurasi dihitung menggunakan data dengan porsi tersebut. Demikian proses diulang sampai tercapai fold ke-k.
Selanjutnya, akurasi rata-rata dari sebanyak k buah akurasi pfold di atas di hitung. Akurasi final dihitung dari akurasi rata-rata tersebut.
2.6 Preprocessing Data
Kualitas dari keputusan-keputusan yang diambil dipengaruhi oleh kualitas data yang olah, itu sebabnya preprocessing data menjadi langkah yang penting ketika dilakukan proses penggalian informasi (Kumar & Chadha, 2012). Penggunaan preprocessing data biasanya diterapkan agar kesalahan data dan sistematis bias yang terdapat pada data mentah dapat dikurangi sebelum dilakukan analisis apapun (Tong et al., 2011). Preprocessing data merupakan tahapan yang sangat penting dalam proses data mining, dikarenakan input data yang berkualitas akan dapat memberikan output analisis yang berkualitas pula. Adapun tahapan data preprocessing terdiri dari: transformasi data kategorial, data cleaning, serta normalisasi data.
2.6.1 Transformasi Data Kategorial
Karakteristik data pada set data yang akan digunakan dapat berupa data yang berbentuk kategorial maupun numerik. Dalam klasifikasi SVM (metode klasifikasi yang digunakan pada penelitian ini), diperlukan perhitungan dari setiap data, sehingga data-
20
data yang bersifat kategorial perlu diubah ke dalam bentuk numerik.
Pengubahannya dapat diterapkan dengan mengubah data dengan bilangan tertentu tetapi harus bilangan yang konsisten (Written, 2011). Misalkan suatu atribut yaitu status akun giro yang dimiliki calon peminjam yang datanya berbentuk kategorial sebagai berikut:
A62: ... Rp 0
A64: 0 ... Rp 10 juta
A66: ... 10 Juta / penugasan gaji untuk setidaknya 1 tahun A68: tidak ada akun giro
Nilai-nilainya diubah sebagai berikut:
A62 = 1 A64 = 2 A66 = 3 A68 = 4
2.6.2 Pembersihan Data (Data Cleaning)
Sebelum data diproses dalam data mining, maka data tersebut merupakan data mentah yang membutuhkan persiapan terlebih dahulu. Pada data mentah, sering ditemukan redundant data (data ganda), missing value (nilai yang hilang/kosong) serta outlier data (pencilan). Data yang mengandung redundant data, missing value serta outlier merupakan data yang berkualitas rendah. Data dengan kualitas rendah akan menghasilkan kualitas penambangan yang buruk (Han dan Kamber, 2006). Oleh karena itu, perlu dilakukan data cleaning agar tidak mempengaruhi performa proses klasifikasi yang dilakukan pada penelitian ini. Proses data cleaning atau pembersihan dilakukan sebagai berikut:
(1) Penanganan redundant atau data ganda.
Redudansi data merupakan duplikasi atau pencatatan data yang memiliki nilai yang sama secara berulang dalam beberapa instance data, sehingga data yang sama dicatatkan pada lebih dari 1 instance, yang mengakibatkan data menjadi tidak konsisten. Penanganan redundant diawali dengan pendeteksian data redundant, untuk menemukan adanya data yang berulang (data ganda).
21
Setelah data redundant ditemukan, selanjutnya dilakukan penanganan terhadap data redundant yang telah terdeteksi. Salah satu cara penanganan data redundant yaitu dengan melakukan penghapusan data redundant dan menyisakan 1 data dari data redundant tersebut.
(2) Penanganan missing value
Missing value atau missing data merupakan kondisi dimana sebagai informasi atau data ada yang “hilang” atau kosong atau tidak tersedia pada variabel tertentu terkait subjek penelitian yang diakibatkan faktor error non sampling (Eric, et al., 2008). Salah satu cara penangan missing value yang biasa dilakukan adalah dengan menggunakan metode mean substitution.
Metode mean substitution yaitu penggatian missing value dengan menggunakan nilai rata-rata (mean) yang merupakan suatu teknik estimasi yang sangat sering digunakan dimana prosesnya nilai yang hilang digantikan dengan nilai rata-rata pada variabel tersebut (Eric, et al., 2008).
Kelebihan dari teknik ini (yang terkadang disebut juga dengan tunggal imputasi) yaitu nilai yang hilang diganti dengan nilai actual yang menghasilkan analisis yang dapat meningkatkan sampel menjadi nilai ukuran aslinya, dibandingkan menyelesaikan masalah "data hilang" yang ditangani dengan menerapkan teknik penghapusan.
Kelebihan yang kedua dari teknik ini adalah penggunaannya yang cenderung lebih mudah; karena tidak membutuhkan keahlian statistik maupun perangkat lunak komputasi khusus, dimana karena hanya memerlukan fungsi dasar statistik untuk menerapkan prosedur mean substitusi ini.
(3) Penanganan outlier data.
Menurut Han dan Kamber (2006), data outlier adalah kumpulan objek-objek yang dioandang sangat berbeda dibandingkan keseluruhan data. Jadi dapat
22
dikatakan, outlier adalah data yang berbeda/tidak sama atau tidak konsisten dengan keseluruhan set data. Penanganan outlier diawali dengan pendeteksian data outlier, untuk menemukan adanya data yang tidak normal (pencilan). Salah satu teknik mendeteksi outlier yaitu dengan cara membandingkan data dengan standar deviasi pada masing-masing atribut.
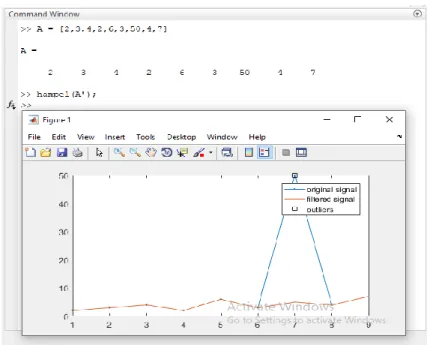
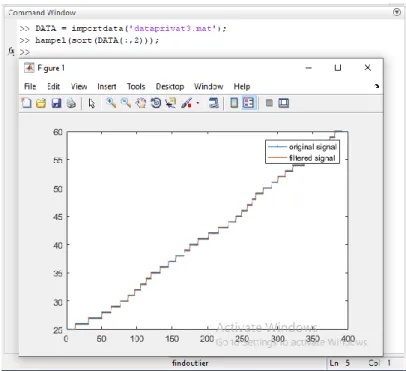
Setelah outlier ditemukan, selanjutnya dilakukan penanganan terhadap data outlier yang telah terdeteksi. Salah satu cara penanganan data outlier yaitu dengan menggunakan metode median substitution. Pada program matlab, pendeteksian dan penanganan outlier menggunakan perintah:
y = hampel (sort(DATA(:,x));
Penggunaan perintah di atas menerapkan filter Hampel ke vektor input, DATA, untuk mendeteksi dan menghilangkan pencilan data pada kolom x.
Untuk setiap sampel DATA, fungsi menghitung median jendela yang terdiri dari sampel dan enam sampel sekitarnya, tiga per sisi. Ini juga memperkirakan deviasi standar setiap sampel tentang median jendela menggunakan deviasi absolut median. Jika sampel berbeda dari median lebih dari tiga standar deviasi, itu diganti dengan median. Jika DATA adalah matriks dengan banyak kolom (atribut), maka hampel memperlakukan setiap kolom x sebagai saluran independen. Contoh tampilan pencilan (outlier) di program matlab dapat dilihat pada gambar berikut:
23
Gambar 2.4 Tampilan Outlier yang Terdeteksi pada Data
2.6.3 Normalisasi Data
Normalisasi merupakan metode pemetaan atau metode penskalaan (patro &
Kumar, 2015). Melalui normalisasi, rentang yang ada pada data akan disesuaikan menjadi rentang baru. Teknik normalisasi diterapkan apabila set data mengandung nilai yang tidak seimbang dimana terdapat data yang sangat kecil dan sekaligus terdapat data yang sangat besar (Haryati et al, 2016). Penggunaan normalisasi akan membantu menyeimbangkan batas nilai data yang terkecil dan terbesar dengan menerapkan standarisasi nilai menjadi bernilai dalam interval 0 sampai dengan 1 (Amalia, 2016).
Data atribut dengan nilai yang besar memiliki pengaruh yang lebih besar dalam melakukan prediksi klasifikasi daripada data dengan nilai yang kecil.
Untuk mengatasi masalah tersebut, digunakan teknik normalisasi sehingga semua data berada pada jangkauan yang sama dan tidak ada data yang memiliki pengaruh dominan terhadap data lainnya. Untuk menghitung normalisasi data digunakan rumus (Haryati et al, 2016):
24
(2.8)
Dimana,
X : Data atribut yang akan di normalisasi : Nilai terkecil atribut tersebut
: Nilai tertinggi atribut tersebut
2.7 Penelitian Terkait
Penelitian terkait klasifikasi risiko kredit telah banyak dilakukan sebelumnya dan berbagai metode atau algoritma klasifikasi telah dipelajari dan diterapkan.
Ivandari et al. (2017) mempelajari data publik berupa dataset persetujuan kredit yang diperoleh dari repositori UCI dan juga menggunakan privat data yang merupakan set data persetujuan kredit bersumber dari bank local. Masing-masing atribut pada penelitian mereka dihitung bobotnya dengan menggunakan algoritma perolehan informasi. Setiap atribut mempunyai bobot yang tidak sama berdasarkan perhitungan yang dilakukan. Algoritma K-NN yang digunakan untuk klasifikasi menghasilkan akurasi yang meningkat sebesar 3,26% untuk dataset lokal dan 7,53% untuk dataset UCI. Penelitian mereka menunjukkan bahwa keluaran yang dihasilkan dari model klasifikasi tidak dipengaruhi setiap atribut setelah dilakukan seleksi atribut di dua dataset tersebut.
Khashei & Torbat (2019) mempelajari keunggulan kecerdasan komputasi serta metode komputasi lunak, yaitu pendekatan hybrid baru untuk meningkatkan manajemen risiko kredit. Dalam penelitiannya, mereka menerapkan metode pemodelan dalam kondisi ketidakpastian, dimana parameter jaringan saraf, termasuk bobot dan kesalahan, dipertimbangkan dalam bentuk bilangan fuzzy.
Dalam metode ini, sistem yang mendasari pertama-tama dimodelkan menggunakan ANN dan kemudian, menggunakan inferensi fuzzy, keputusan optimal akan ditentukan dengan tingkat keunggulan tertinggi. Hasil empiris
25
penggunaan metode yang diusulkan menunjukkan efisiensi dan akurasi yang tinggi dari metode ini dalam menganalisis masalah peringkat kredit.
Gafarova (2017) mempelajari klasifikasi antara nasabah baik dan nasabah buruk dengan dua puluh variabel dari kumpulan Dataset Credit German. Dua teknik non-statistik digunakan dalam penelitian mereka yaitu ANN dan SVM.
Karena terdapat berbagai kelebihan dan kekurangan dalam implementasi model, maka dapat dikatakan model dengan keberhasilan prediksi tertinggi, menurut kumpulan data yang digunakan adalah metode SVM. Maldonado et al. (2017) mempelajari pendekatan profit-driven untuk konstruksi pengklasifikasi dan pemilihan variabel simultan berdasarkan SVM linier. Tujuan utamanya adalah untuk memasukkan informasi terkait bisnis seperti biaya akuisisi variabel, biaya kesalahan Tipe I dan II, dan keuntungan yang dihasilkan oleh contoh yang diklasifikasikan dengan benar, ke dalam proses pemodelan. Kerangka yang diusulkan dipelajari dalam masalah penilaian kredit untuk bank Chili, dan menghasilkan kinerja yang unggul sehubungan dengan tujuan terkait bisnis.
Hartono et al. (2018) mempelajari bahwa ketidakseimbangan kelas terjadi ketika instance di kelas jauh lebih tinggi daripada di kelas lain. Masalah utama pembelajaran mesin ini dapat memengaruhi akurasi yang diprediksi. Penelitian mereka menunjukkan bahwa SVM adalah metode yang handal dan tepat dalam menangani masalah ketidakseimbangan kelas tetapi lemah dalam distribusi data bias. Yu et al. (2018) mempelajari paradigma pembelajaran berbasis resampling menggunakan SVM berbasis Deep Believe Network (DBN) untuk mengatasi masalah ketidakseimbangan data dalam klasifikasi kredit. Hasil eksperimen menunjukkan bahwa kinerja klasifikasi meningkat secara efektif ketika strategi ensemble berbasis DBN diintegrasikan dengan teknik resampling, terutama pada masalah imbalanced-data. Paradigma pembelajaran ensemble SVM resampling berbasis DBN yang diterapkankan dapat digunakan sebagai alat yang menjanjikan untuk klasifikasi risiko kredit dengan data yang tidak seimbang.
Han et al. (2018) mempelajari bahwa penggunaan SVM untuk klasifikasi risiko kredit menarik untuk dilakukan karena SVM dicirikan oleh keserbagunaan, ketahanan, dan kesederhanaan komputasi. Pada saat yang sama, bahkan dalam
26
kasus jumlah sampel yang terbatas, SVM dapat memperoleh hasil klasifikasi yang lebih baik. Xie et al. (2018) mempelajari terkait metode klasifikasi SVM, menyimpulkan bahwa pemilihan fungsi kernel dan parameternya memainkan peran penting pada hasil. Radius Basis Function (RBF) adalah kernel yang umum digunakan. Untuk RBF-SVM, dua parameter yaitu c dan γ, digunakan untuk mengontrol performa SVM. Parameter penalti c menentukan trade-off antara minimalisasi kesalahan pemasangan dan maksimalisasi margin antar kelas.
Parameter γ menentukan bandwidth RBF. Sehingga pada penelitian ini, diusulkan suatu teknik yang efektif untuk menemukan pasangan parameter c dan γ yang akan mengoptimalkan hasil klasifikasi SVM.
27
BAB 3
METODE PENELITIAN
3.1 Data yang Digunakan
Penelitian ini menggunakan dua set data kredit, yaitu: (1) set Data Credit German yang merupakan set data kredit benchmark yang diterbitkan UCI dataset, dan (2) set Data Kredit Privat yang merupakan set data kredit yang diterbitkan suatu Bank lokal yang ada di Sumatera Utara. Berikut ini dijelaskan informasi terkait masing-masing set data.
3.1.1 Set Data Benchmark Credit German
Set data benchmark Credit German merupakan set data kredit diterbitkan oleh University of California Irivine (UCI) yang tersedia di UCI Machine Learning Repository. Set data terdiri dari 1000 instance dan sebanyak 21 atribut yang termasuk dalam kelas biner. Data kredit yang dimaksudkan merupakan pengajuan pinjaman yang dilakukan calon peminjam kepada Bank untuk tujuan tertentu. Informasi masing-masing atribut set data dapat dilihat pada Tabel 3.1, dan tampilan sebagian isi data ditunjukkan oleh Tabel 3.2. Set data dapat diakses di:
https://archive.ics.uci.edu/ml/datasets/Statlog+(German+Credit+Data Adapun Karakteristik dataset Credit German dijelaskan sebagai berikut:
Nama Dataset : Set Data Benchmark German Credit Karakteristik Data Set : Multivariate
Karakteristik Atribut : Categorial, Integer
Banyak Data : 1000
Banyak Atribut : 20
Nilai Yang Hilang : Tidak Ada
Sektor : Keuangan
28
28
Tabel 3.1 Informasi Atribut Set Data Kredit German
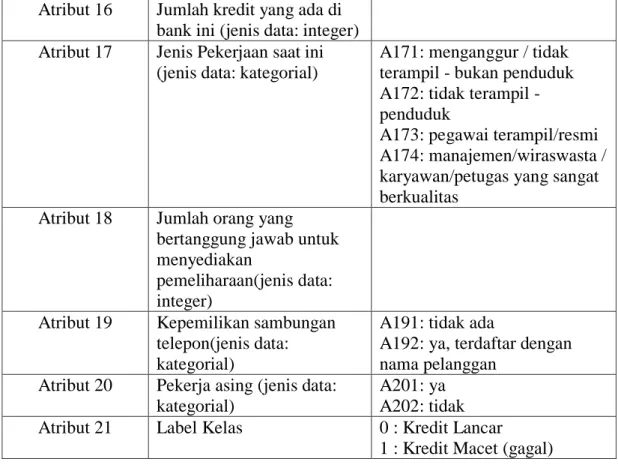
Nomor Atribut Atribut Keterangan
Atribut 1 Status akun giro yang ada(jenis data: kategorial)
A11: ... <0 DM A12: 0 ... <200 DM
A13: ... 200 DM / penugasan gaji untuk setidaknya 1 tahun A14: tidak ada akun giro Atribut 2 Durasi dalam sebulan (jenis
data: integer)
Atribut 3 Sejarah kredit (jenis data:
kategorial)
A30: tidak ada kredit yang diambil / semua kredit dibayar kembali sebagaimana mestinya A31: semua kredit di bank ini dibayar kembali dengan semestinya
A32: kredit yang ada dibayar kembali sepatutnya sampai sekarang
A33: keterlambatan dalam melunasi di masa lalu A34: akun kritis / kredit lain yang ada (tidak di bank ini) Atribut 4 Tujuan pengajuan kredit
(jenis data: kategorial)
A40: mobil (baru) A41: mobil (bekas) A42: perabot / peralatan A43: radio / televisi
A44: peralatan rumah tangga A45: perbaikan
A46: pendidikan
A47: (liburan - tidak ada?) A48: pelatihan ulang A49: bisnis
A410: lainnya Atribut 5 Jumlah (besaran) kredit
yang diajukan (jenis data:
integer)
Atribut 6 Rekening tabungan / obligasi yang dimiliki saat mengajukan kredit (jenis data: kategorial)
A61: ... <100 DM
A62: 100 ... 500 DM A63: 500 ... 1000 DM A64: ... 1000 DM A65: akun tabungan tidak
29
dikenal / tidak ada Atribut 7 Bekerja pada pekerjaan
sekarang sejak? (jenis data:
kategorial)
A71: menganggur A72: ... <1 tahun A73: 1 ... <4 tahun A74: 4 ... <7 tahun A75: ... 7 tahun Atribut 8 Tingkat angsuran dalam
persentase dari pendapatan yang bisa dipotong (jenis data: integer)
Atribut 9 Status pribadi dan jenis kelamin (jenis data:
kategorial)
A91: pria: bercerai / terpisah A92: perempuan: bercerai / berpisah / menikah
A93: pria: lajang
A94: pria: menikah / janda A95: perempuan: lajang Atribut 10 Debitur / penjamin lainnya
(jenis data: kategorial)
A101: tidak ada
A102: pendaftar bersama A103: penjamin
Atribut 11 Berdomisili di tempat tinggal sejak awal pindah sampai saat ini (jenis data:
integer)
Atribut 12 Kepemilikan pemohon kredit (jenis data:
kategorial)
A121: real estat
A122: jika tidak A121:
membangun perjanjian
tabungan masyarakat / asuransi jiwa
A123: jika tidak A121 / A122:
mobil atau lainnya, tidak dalam atribut 6
A124: tidak diketahui / tidak ada properti
Atribut 13 Usia pemohon kredit di tahun ini (jenis data:
integer)
Atribut 14 Paket angsuran lainnya (jenis data: kategorial)
A141: bank A142: toko A143: tidak ada Atribut 15 Status Kepemilikan
rumah/tempat tinggal (jenis data: kategorial)
A151: sewa A152: sendiri A153: gratis
30 Atribut 16 Jumlah kredit yang ada di
bank ini (jenis data: integer) Atribut 17 Jenis Pekerjaan saat ini
(jenis data: kategorial)
A171: menganggur / tidak terampil - bukan penduduk A172: tidak terampil - penduduk
A173: pegawai terampil/resmi A174: manajemen/wiraswasta / karyawan/petugas yang sangat berkualitas
Atribut 18 Jumlah orang yang bertanggung jawab untuk menyediakan
pemeliharaan(jenis data:
integer)
Atribut 19 Kepemilikan sambungan telepon(jenis data:
kategorial)
A191: tidak ada
A192: ya, terdaftar dengan nama pelanggan
Atribut 20 Pekerja asing (jenis data:
kategorial)
A201: ya A202: tidak Atribut 21 Label Kelas 0 : Kredit Lancar
1 : Kredit Macet (gagal)
Tabel 3.2 Tampilan sebagian Set Data Kredit German
31 3.1.2 Set Data Privat dari Bank Lokal
Pada model analisis risiko kredit, salah satu masalah yang perlu diperhatikan adalah tidak tersedianya data kredit yang nyata dari lembaga keuangan pemberi kredit, karena data kredit pelanggan bersifat rahasia di sebagian besar lembaga keuangan.
Saat ini, peneliti memperoleh data privat yang merupakan set data kredit yang diterbitkan suatu bank lokal yang ada di Sumatera Utara. Data terdiri dari 390 instance dengan 16 atribut. Set data yang diperoleh dari bank lokal ini merupakan set data pinjaman (Kredit) permodalan yang diberikan kepada calon peminjam untuk tujuan tertentu, diantaranya: modal kerja/usaha, investasi ataupun konsumtif .
Data yang direkam oleh bank, sebagian merupakan data yang berhubungan dengan calon peminjam serta data yang terkait dengan besar kredit yang diajukan.
Dari 390 peminjam kredit yang datanya telah direkam, ada sebanyak 162 peminjam yang masuk dalam kelompok kredit macet, yang dinotasikan dengan kelas 1, dan terdapat 228 peminjam yang masuk dalam kelompok kredit lancar, yang dinotasikan dengan kelas 0. Adapun karakteristik data dari setiap atribut yang ada pada dataset telah dijelaskan pada Tabel 3.3 yang menampilkan informasi terkait atribut set data, dan tampilan sebagian set data dapat dilihat pada Tabel 3.4. Untuk selanjutnya, set data kredit dari bank lokal ini disebut Data Kredit Privat. Adapun karakteristik set Data Kredit Privat dijelaskan sebagai berikut:
Nama Dataset : Set Data Kredit Privat
Karakteristik Atribut : Categorial, Numerik, Integer
Banyak Data : 390
Banyak Atribut : 16 (8 numerik, 7 kategorial, 1 label kelas) Nilai Yang Hilang : Tidak Ada
Sektor : Keuangan
32
Tabel 3.3 Informasi Atribut Set Data Kredit Privat
Nomor Atribut Atribut Keterangan
Atribut 1 Jenis Kelamin (jenis data:
kategorial)
1 : Pria 2 : Wanita Atribut 2 Usia dalam tahun (jenis
data: numerik)
- Atribut 3 Status Pernikahan (jenis
data: kategorial)
1 : Menikah 2 : Lajang 3 : Bercerai Atribut 4 Jumlah Tanggungan (jenis
data: integer)
Atribut 5 Jenis Pekerjaan (jenis data:
kategorial)
1000 : Pertanian 3000 : Perindustruan 6000 : Perdagangan 8000 : Jasa-jasa 9990 : Lain-lain Atribut 6 Lama Bekerja (jenis data:
kategorial)
1 : kurang dari 1 tahun 2 : antara 1 – 4 tahun 3 : antara 4 – 7 tahun 4 : lebih dari 7 tahun Atribut 7 Status Kepemilikan Tempat
Tinggal (jenis data : ketegorial)
1 : Milik Sendiri 2 : Sewa
Atribut 8 Jangka Waktu Kredit, dalam bulan (jenis data: numerik)
-
Atribut 9 Plafon Awal (jenis data:
numerik)
- Atribut 10 Outstanding (jenis data:
numerik)
- Atribut 11 Rate (jenis data: numerik) - Atribut 12 Angsuran Bunga (jenis data:
numerik)
- Atribut 13 Angsuran Pokok (jenis data:
numerik)
- Atribut 14 Tujuan pengajuan kredit
(jenis data: kategorial)
10 : Modal Kerja 20 : Investasi 39 : Konsumtif Atribut 15 Sifat (jenis data: kategorial) 0 : Gabungan