Analisis perbandingan Klasifikasi penyakit jantung
dengan menggunakan naïve bayes
Muhammad Sulkifly Said
Program Studi Magister Teknologi Informasi, Universitas Gadjah Mada Jl. Grafika No.2 Kampus UGM, Yogyakarta 55281
Abstrak – salah satu fungsi data mining adalah melakukan klasifikasi berdasarkan inputan attribute-atribute yang ada, dalam paper ini akan dijelaskan metode pengklasifikasian guna melakukan identifikasi apakah seseorang terkena penyakit jantung atau tidak, tools yang digunakan dalam penelitian adalah WEKA, dalam paper ini akan dilakukan seleksi terhadap beberapa attribute dalam dataset jantung guna meningkatkan akurasi, kecepatan dan error dan kemudian akan dilakukan perbandingan apakah terdapat perbedaan yang signifikan diantara kedua metode yang diusulkan
abstrak: naïve bayes, weka, klasifikasi
1. Pendahuluan
Dataset yang digunakan bersumber dari data rekam medis penyakit jantung Cleveland yang didapatkan secara online di UCI repository. Dataset memiliki 14 atribut, atribut yang terakhir merupakan kelas, attribute terdiri dari age, sex, cp, trestbps, chol, fbs, restecg, thalach, exang, oldpeak, slope, ca, thal, num.
berdasarkan studi literature pada sebuah penelitian tentang wawancara dokter ahli jantung menjelaskan bahwa attribute yang digunakan untuk penyakit jantung khususnya penyankit jantung koroner. Attribute diatas dibagi menjadi 2 bagian yang disesuaikan dengan gejala penyakit jantung yaitu kronis dan akut. Gejala penyakit kronis memerlukan hamper semua attribute untuk diagnose gangguan pada jantung dimana attribute nomor 1,2,5 dan 6 merupakan attribute bebas (penunjang). Sementara untuk gejala akut, attribute nomor 3 sampai 7 dan 14 merupakan attribute
penunjang. Attribute nomor 8 sampai 13 berkaitan dengan latihan (treatmill) tidak diikutsertakan. Pada penelitian ini attribute pada data penelitian digunakan hanya untuk memprediksi penyakit jantung dengan gejala kronis.
Beberapa attribute diatas memiliki nilai continue. Pada penelitian ini dilakukan diskretisasi terhadap nilai kontinu menjadi nilai diskrit. Data diskrit biasanya memberikan hasil prediksi yang lebih baik dibandingkan data continue, beberapa attribute yang didiskretisasikan adalah age, trestbps, chol, thalach, oldpeak.
Data mining adalah suatu proses menemukan sebuah hubungan yang berarti, pola, dan kecenderungan dengan memeriksa dalam sekumpulan besar data yang tersimpan dalam penyimpanan dengan menggunakan teknik pengenalan pola seperti teknik statistic, matematika, kecerdasan buatan dan machine learning. Salah satu metode data mining adalah klasifikasi. Klasifikasi adalah proses untuk menemukan model atau fungsi yang menjelaskan atau membedakan konsep atau kelas data.
Dalam penelitian ini digunakan algoritma naïve bayes, naïve bayes merupakan salah metode probabilistic reasoning. Algoritma naïve bayes bertujuan untuk melakukan klasifikasi data pada kelas tertentu, kemudian pola tersebut dapat digunakan untuk memperkirakan indikasi sebuah penyakit jantung berdasarkan pengalaman pelatihan dimasa sebelumnya.
II LANDASAN TEORI 2.1 Penyakit Jantung
Penyakit jantung koroner adalah penyakit jantung yang terjadi karena rusaknya dinding pembuluh darah karena
beberapa factor resiko seperti radikal bebas yang terkandung dalam rokok dan polusi, kolesterol tinggi, hipertensi, diabetes, kebiasaan merokok dan sebagainya. Kolesterol yang menimbun di dinding bagian dalam pembuluh darah, dapat mengakibatkan pembuluh darah mengalami penyempitan dan aliran darahpun menjadi tersumbat. Akibatnya, fungsi jantung terganggu karena harus bekerja lebih keras untuk memompa alirah darah. Seiring perjalanan waktu, arteri-arteri koroner makin sempit dan mengeras. Inilah yang disebut aterosklerosis.
Radikal bebas adalah ion molekul tanpa pasangan yang mengikat molekul lain yang mengakibatkan molekul/zat tadi menjadi rusak dan berubah sifat. Misalnya sel-sel pembuluh darah menjadi cepat mati atau pembuluh darah menjadi sempit. Sel-sel yang berubah sifat contohnya adalah sel-sel kanker. Sumber radikal bebas antara lain:
Asap rokok
Polusi udara
Polusi kimiawi / lingkungan (semprotan nyamuk, inteksida, cat)
Polusi elektromagnetik (handphone, layar tv, layar monitor)
Polusi dari tubuh sendiri (penyakit kronis seperti diabetes)
Obesitas dapat menyebabkan penyakit jantung karena terlalu banyak mengkonsumsi makan. Jantung koroner bisa diturunkan dari keluarga, jika salah satu anggota keluarga mempunyai riwayat penyakit jantung koroner. Artinya ada kecenderungan dalam keluarga. Namun, penyebab dasar jantung koroner pada hakikatnya adalah kelainan metabolisme.
2.1 Data Mining
Data mining adalah penambangan atau penemuan informasi baru dengan mencari pola aturan tertentu dari sejumlah data yang sangat besar. Data mining juga disebut sebagai serangkaian proses untuk menggali nilai tambah berupa pengetahuan yang selama ini tidak diketahui secara manual dari suatu kumpulan data.
Tahapan dari proses knowledge discovery (KDD) adalah: 1. Selection 2. Pre-Processing / Cleaning 3. Transformation 4. Data mining 5. Interpretation / evaluation 2.1 Klasifikasi
Klasifikasi pertama kali diterapkan pada bidang tanahaman yang mengklasifikasikan suatu spesies tanaman tertentu, seperti yang dilakukan oleh carolus von linne (atau dikenal dengan nama carolus Linnaeus) yang pertama kali mengklasifikasikan spesies berdasarkan karakteristik fisik. Selanjutnya dia dikenal sebagai bapak klasifikasi.
Komponen utama dari proses klasifikasi antara lain adalah:
1. Kelas, merupakan variable tak bebas yang merupakan table dari hasil klasifikasi. Sebagai contoh adalah kelas loyalitas pelanggan, kelas badai atau gempa bumi dan lain-lain.
2. Predictor, merupakan variable bebas suatu model berdasarkan dari karakteristik attribute data yang diklasifikasi, misalnya merokok, minum-minum beralkohol, tekanan darah, status perkawinan, dan sebagainya.
3. Set data pelatihan, merupakan sekumpulan data lengkap yang berisi kelas dan predictor untuk dilatih agar model dapat mengelompokkan ke dalam kelas yang tepat. Contohnya adalah grup pasien yang telah di-test terhadap serangan jantung, grup pelanggan di suatu supermarket, dan sebagainya.
4. Set data uji, berisi data-data baru yang akan dikelompokkan oleh model guna mengetahui akurasi dari model yang telah dibuat.
2.2 Algoritma Naïve Bayes
Algoritma Naïve Bayes merupakan salah satu algoritma yang terdapat pada teknik klasifikasi. Naïve bayes merupakan pengklasifikasian dengan metode probabilitas dan statistic yang dikemukakan oleh ilmuwan inggris
Thomas bayes, yaitu memprediksi peluang di masa depan berdasarkan pengalaman dimasa sebelumnya sehingga dikenal sebagai teorema bayes, yaitu memprediksi peluang di masa depan berdasarkan pengalaman diasa sebelumnya sehingga dikenal sebagai teorema bayes. Teorema tersebut dikombinasikan dengan naïve dimana diasumsikan kondisi antar attribute saling bebas. Klasifikasi naïve bayes diasumsikan bahwa ada atau tidak cirri tertentu dari sebuah tidak ada hubungannya dengan cirri dari kelas lainnya. Persamamaan dari teorema bayes adalah:
P(H|X) =
P ( X
|
H ). P(H)
P( X )
Keterangan:X : Data dengan class yang diketahui
H : Hipotesis data X merupakan suatu class spesifik
P(H|X) : Probabilitas hipotesis H berdasar kondisi X
(posteriori probability)
P(H) : Probabilitas X berdasarkan kondisi pada sebuah hipotesis H
P(X) : Probabilitas X 2.3 Confusion Matrix
Confusion matrix adalah tools yang digunakan untuk melakukan evaluasi model klasifikasi untuk memperkirakan objek yang benar atau salah. Sebuah matrix dari prediksi yang akan dibandingkan dengan kelas yang asli dari inputan atau dengan kata lain berisi nilai actual dan prediksi pada proses klasifikasi
Evaluasi dan validasi hasil dapat dihitung menggunakan rumus akurasi, precision, recall dan f-measure berdasarkan confusion matrix
1. Akurasi
Perhitungan akurasi dilakukan dengan cara membagi jumlah data yang diklasifikasi secara benar dengan total sample data testing yang diuji.
Akurasi =
TP+TN
TP+TN +FP+FN
2. Precisionmenghitung nilai precision dengan cara membagi jumlah data benar yang bernilai positif (true positive)
dibagi dengan jumlah data benar yang bernilai positif (true positive) dan data salah yang bernilai negative (false negatife)
Precision =
TP
TP+FP
3. RecallSedangkan recall dihitung dengan cara membagi data benar yang bernilai positif (true positive) dengan hasil penjumlahan dari data benar yang bernilai positif (true positive) dan data salah bernilai negatif (false negative)
Recall =
TP
TP+FN
4. F-measureNilai F-measure didapat dari perhitungan pembagian hasil dari perkalian precision dan recall dengan hasil penjumlahan precision dan recall, kemudian dikalikan dua.
F – Measure = 2 *
Precision∗recall
Precision+recall
III. METODOLOGISeleksi attribute merupakan proses mengidentifikasi dan menghilangkan attribute dengan nilai yang tidak relevan atau berlebihan. Pada penelitian ini dilakukan seleksi attribute dengan menggunakan information gain yang diimplementasikan pada algoritma naïve bayes untuk tugas klasifikasi dalam memprediksi penyakit jantung. Information gain bertujuan melakukan pengurutan attribute berdasarkan peringkat (rank) dimana besar nilai information gain dari suatu attribute maka semakin signifikan attribute tersebut untuk tugas prediksi.
Metode pengujian yang digunakan dalam penelitian ini adalah metode holdout dimana data penelitian menjadi dua bagian, 2/3 dari jumlah data yang dijadikan sebagai data training dan 1/3 dari jumlah data digunakan sebagai data testing (Han and Kamber, 2006). Pengujian dilakukan dengan dua tahap dengan langkah-langkah sebagai berikut:
1. Pada tahap pertama data training diproses dengan menggunakan algoritma naïve bayes yang melibatkan keseluruhan attribute. Dari data training yang dilatih terbentuk aturan klasifikasi. Kemudian data testing diujikan sehingga diperoleh hasil prediksi dengan nilai akurasi, error dan kecepatan proses
2. Pada tahap kedua data training terlebih dahulu diproses dengan menggunakan algoritma informasi gain. Setiap attribute dihitung informasi gain-nya dan diurutkan dari nilai tertinggi sampai terendah. Attribute rendah direduksi (dibuang), dan sisanya dipilih untuk kemudian di training dengan menggunakan algoritma naïve bayes. Kemudian data testing diujikan sehingga diperoleh hasil prediksi dengan nilai akurasi, error dan kecepatan proses.
3. Hasil prediksi dan kecepatan proses dari tahap kedua dianalisis untuk melihat apakah ada perubahan nilai akurasi, error dan kecepatan proses dari tahap yang pertama
IV. HASIL DAN PEMBAHASAN Pada bab ini dijelaskan hasil pengujian yang dilakukan dalam melakukan pelatihan dan tugas klasifikasi dalam memprediksi penyakit jantung dengan menggunakan algoritma naïve bayes dan informasi gain sebagai parameter seleksi attribute. Pelatihan data dan tugas klasifikasi diuji dengan menggunakan aplikasi yang penulis bangun dengan menggunakan tools data mining WEKA. Berdasarkan pada hasil pengujian pelatihan dan tugas klasifikasi dari data rekam medis nantinya dapat ditarik kesimpulan, apakah algoritma naïve bayes dengan seleksi attribute dapat meningkatkan nilai akurasi prediksi penyakit jantung dan kecepatan proses dibandingkan dengan pelatihan dan tugas klasifikasi dengan algoritma naïve bayes secara umum. 4.1 hasil pengujian
hasil pengujian diukur dari seberapa besar nilai akurasi serta kecepatan dari proses training data. Pengukuran akurasi
dilakukan dengan menggunakan table klasifikasi yang disebut dengan confusion matrix dan kecepatan proses diukur dari lama waktu yang dibutuhkan dalam proses training dan testing data. Jumlah data training terdiri dari 195 baris data (2/3 dari jumlah baris data penelitian) dan jumlah testing terdiri dari 101 baris baris data (1/3 dari jumlah baris data penelitian)
4.1.1 hasil pengujian tahap pertama
pengujian pada tahap pertama menggunakan seluruh attribute data rekam medis penyakit jantung dalam pelatihan data dan tugas klasifikasi dalam memprediksi penyakit jantung. Dari data training yang diproses dengan algoritma naïve bayes diperoleh hasil pelatihan sebagai berikut: waktu proses pelatihan data dengan melibatkan seluruh attribute yang ditampilkan pada table diatas adalah 0,38135 detik.
Berdasarkan hasil dari training data dilakukan pengujian terhadap data testing dan diperoleh hasil prediksi yang ditampilkan dalam table confusion matrix berikut:
Table 4.2 hasil pengujian data testing dataset tahap pertama Prediksi
Sakit Tidak Sakit Aktual yang
sebenarnya
Sakit 38 10
Tidak sakit 7 46
Dari table diatas diperoleh nilai prediksi yang benar untuk yang sakit ada 38 orang dan untuk yang tidak sakit 46 orang. Sementara prediksi yang salah teridiri dari 10 orang diprediksi tidak sakit (sebenarnya sakit). Nilai akurasi dan error dapat diperoleh sebagai berikut:
Akurasi tahap pertama =
TP+TN
P+N
=38+46
101
=0,83168 = 83,17%
Error tahap pertama =
FP+FN
P+N
=10+7
101
=0,16831 = 16,83%
Waktu proses pengujian dari data testing yang melibatkan seluruh attribute dari table 4.1 adalah: 0.57582 detik. 4.1.2 Hasil pengujian tahap kedua
Pengujian pada tahap kedua menggunakan beberapa atribut data rekam medis penyakit jantung yang dipilih berdasarkan nilai informasi gain untuk pelatihan data dan tugas klasifikasi dalam memprediksi penyakit jantung. Attribute diurutkan berdasarkan nilai informasi gain yang paling tinggi ke yang paling rendah.
Pada tahap ini attribute dengan nilai terkecil (fbs) tidak diikut sertakan dalam proses training dan testing data. Kemudian dilihat nilai akurasi yang dihasilkan dari hasil pengujian tersebut.
Pada percobaan ini untuk hasil data training sama dengan table 4.1 namun tanpa atribut fbs. Untuk proses training data yang melibatkan 12 atribute adalah: 0,35456 detik.
Berasarkan hasil dari training data tanpa menggunakan attribute fbs dilakukan pengujian terhadap data testing dan diperoleh hasil prediksi yang ditampilkan dalam table confusion matrix berikut:
Table 4.4 hasil pengujian data testing dataset tahap kedua Prediksi
Sakit Tidak Sakit Aktual yang
sebenarnya
sakit 38 10
Tidak sakit 6 47
Dari table di atas diperoleh nilai prediksi yang benar untuk yang sakit ada 38 orang dan untuk yang tidak sakit ada 47 orang. Sementara prediksi yang salah terdiri dari 10 orang diprediksi tidak sakit (sebenarnya sakit) dan 6 orang diprediksi sakit (sebenarnya tidak sakit). Nilai akurasi dan error dapat diperoleh sebagai berikut:
Akurasi tahap pertama =
TP+TN
P+N
=38+47
101
=0,84158 = 84,16%
Error tahap pertama =
FP+FN
P+N
=10+6
101
=0,15481 = 15,84%
Waktu proses pengujian data testing yang melibatkan 12 atribute dari table 4.1 adalah: 0.65077 detik.
V. PEMBAHASAN
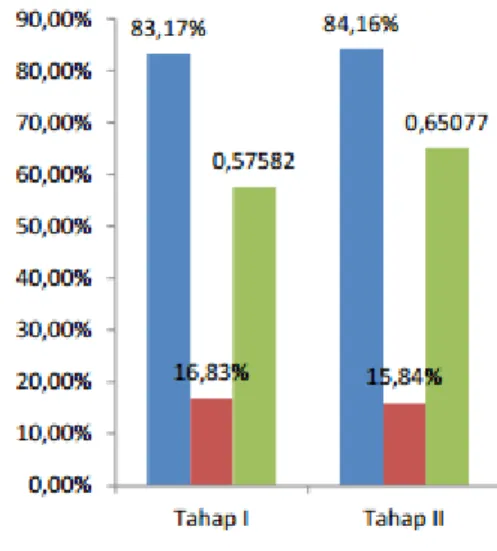
Dari hasil pengujian di atas dapat dilihat perbandingan akurasi, error dan waktu proses pada tahap pertama dan kedua, hasil akan ditampilkan dalam bentuk tabulasi Table 4.7 hasil pengujian percobaan tahap pertama dan kedua
Pengujian I Pengujian II
Atribute yang direduksi - Fbs
Jumlah attribute 13 12
Akurasi 83,17% 84,16%
Error 16,83% 15,84%
Waktu testing (detik) 0,57582 0,65077 Waktu training (detik) 0,38135 0,35456 Table 4.7 hasil pengujian percobaan tahap pertama dan kedua
Dari grafik diatas dapat dilihat bahwa hasil pengujian pada tahap kedua dimana atribut fbs tidak diikutsertakan memiliki nilai akurasi lebih baik yaitu 84,16% dibandingkan hasil pengujian tahap pertama yang mengikut sertakan keseluruhan attribute yaitu 83,47%
Dari hasil penelitian didapatkan bahwa, seleksi attribute dapat meningkatkan nilai akurasi dan mengurangi nilai error dari tugas klasifikasi. Hal ini dapat dilihat pada tahap kedua dimana attribute dengan nilai gain terendah (fbs) tidak diikutsertakan, menghasilkan nilai akurasi 84,16% dan nilai error 15,84%. Sementara jika menggunakan semua attribute (pengujian tahap pertama) akurasi diperoleh 83,17% dan error sebesar 16,83%.
[1] Dumitru, D. Prediction of recurrent events in breast cancer using the naïve Bayesian classification. 2009. Annals of university of Craiova, mathematics and computer series.
[2] Gorunescu, F. 2011. Data mining: concepts and techniques, second edition. Morgan Kauffman publishers.
[3] Kantardzic, M., 2003. Data mining: concepts, models, methods and algorithms. The institute of electrical engineering, Inc.
[4] Sansosa, B. 2007. Data mining teknik pemanfaatan data untuk keperluan bisnis. Yogyakarta. Graham ilmu.
[5] R. Nicole, “Title of paper with only first word capitalized,” J. Name