VISUALISASI KETERHUBUNGAN TANAMAN OBAT DENGAN
KHASIATNYA MENGGUNAKAN ALGORITME
FRUCHTERMAN-REINGOLD
NADYA ELSANOVIANY PUTRI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Visualisasi Keterhubungan Tanaman Obat dengan Khasiatnya Menggunakan Algoritme Fruchterman-Reingold ialah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
NADYA ELSANOVIANY PUTRI. Visualisasi Keterhubungan Tanaman Obat dengan Khasiatnya Menggunakan Algoritme Fruchterman-Reingold. Dibimbing oleh FIRMAN ARDIANSYAH.
Suatu tanaman obat dapat memiliki berbagai macam khasiat dan satu khasiat dapat dimiliki oleh lebih dari satu tanaman obat. Hal ini menunjukkan terdapat pola keterhubungan antara tanaman obat dengan khasiatnya. Data tanaman obat beserta khasiat merupakan data dalam bentuk teks, sehingga akan memakan waktu lebih banyak untuk memahami dan menganalisis keseluruhan makna dari teks tersebut. Oleh sebab itu, pendekatan visualisasi informasi digunakan untuk menyelidiki lebih lanjut mengenai keterhubungan tersebut. Penelitian ini menggunakan visualisasi dalam bentuk graf yang sering kali digunakan untuk mewakili data keterhubungan. Tanaman obat dan khasiat dari tanaman obat direpresentasikan dengan nodes yang dibedakan dengan warna dan keterhubungan antartanaman obat dengan khasiatnya direpresentasikan dengan edges. Algoritme yang diterapkan merupakan algoritme Fruchterman-Reingold. Algoritme tersebut menghasilkan graf yang dapat memodelkan keterhubungan antara tanaman obat dengan khasiatnya. Graf tersebut diimplementasikan dalam aplikasi berbasis web untuk membantu pengguna mengeksplorasi data yang terdapat pada graf keterhubungan tersebut dan menemukan pengetahuan.
Kata Kunci: graf keterhubungan, khasiat, tanaman obat, visualisasi.
ABSTRACT
NADYA ELSANOVIANY PUTRI. Visualization of Herb Plants-Efficacies Relationships using Fruchterman-Reingold Algorithm. Supervised by FIRMAN ARDIANSYAH.
Herb plants may have more than one efficacies and a certain efficacy may belong to more than one herb plants. It shows a relationship among herb plants and their efficacies. Data of herb plants and their efficacies are represented in the text form, so it will take a lot of time to understand and analyse the meaning of research applies Fruchertman-Reingold algorithm. This algorithm produced a graph which can visualize the relationship among herb plants and their efficacies. The graph was implemented in a web based application to help users exploring the data on the graph and to uncover patterns.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
VISUALISASI KETERHUBUNGAN TANAMAN OBAT DENGAN
KHASIATNYA MENGGUNAKAN ALGORITME
FRUCHTERMAN-REINGOLD
NADYA ELSANOVIANY PUTRI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Penguji :
Judul Skripsi : Visualisasi Keterhubungan Tanaman Obat dengan Khasiatnya Menggunakan Algoritme Fruchterman-Reingold
Nama : Nadya Elsanoviany Putri NIM : G64090009
Disetujui oleh
Firman Ardiansyah, SKom MSi Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Oktober 2012 ini ialah visualisasi informasi, dengan judul Visualisasi Keterhubungan Tanaman Obat dengan Khasiatnya Menggunakan Algoritme Fruchterman Reingolf.
Terima kasih penulis ucapkan kepada Bapak Firman Ardiansyah, SKom, MSi selaku pembimbing, serta Ibu Dr Yani Nurhadryani, SSi, MT dan Bapak Rudi Heryanto, SSi, MSc yang telah banyak memberi saran. Ungkapan terima kasih juga disampaikan kepada ayah dan ibu tersayang, Fadhila Meylinda Annisa, Syakhrul Ambosaka Patompo, Fahrul Abdullah Hudri, Faiza Libby Shabira atas doa dan dukungannya. Terima kasih juga disampaikan untuk rekan-rekan tersayang di Pondok Nuansa Sakinah, yaitu Gina, Inka, Wenny, Husnul, Anisaul, Ufiq, Nurifah, Lizza, Ambar dan Annisa. Selain itu, terima kasih juga penulis sampaikan untuk rekan-rekan PKM KC Visualisasi, rekan-rekan ilmu komputer angkatan 46 khususnya Bimo Setyawan dan Chusnul Arifin yang telah banyak membantu, serta rekan-rekan lainnya atas segala doa dan kasih sayangnya.
Semoga karya ilmiah ini bermanfaat.
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 1
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE 2
Tahapan Penelitian 2
Value 2
Data Transformation 3
Analytical Abstraction 7
Visualization Transformation 7
Visualization Abstraction 7
Visual Mapping Transformation 8
View 10
Lingkungan Pengembangan Sistem 11
HASIL DAN PEMBAHASAN 11
Value 11
Data Transformation 12
Analytical Abstraction 20
Visualization Transformation 21
Visualization Abstraction 23
Visual Mapping Transformation 24
View 28
SIMPULAN DAN SARAN 30
Simpulan 30
Saran 30
DAFTAR PUSTAKA 30
DAFTAR TABEL
1 Contoh data yang diperoleh 11
2 Contoh data hasil tokenisasi kalimat pada atribut effect 12 3 Contoh data hasil tokenisasi bagian tanaman pada atribut effect 13 4 Contoh data sebelum pencocokan field part_of_plant dengan
thesaurus dari field position 14
5 Contoh data setelah pencocokan field part_of_plant dengan
thesaurus dari field position 14
6 Contoh data sebelum tokenisasi frasa khasiat 15 7 Contoh data setelah tokenisasi frasa khasiat 15 8 Contoh data hasil pembuatan posting list frasa khasiat 15 9 Contoh data hasil tokenisasi kata di atribut effect 16 10 Contoh data hasil indexing khasiat per kata 16 11 Contoh data hasil perhitungan frekuensi kata 16
12 Contoh data sebelum penghapusan stopwords 17
13 Proses penghapusan stopwords 17
14 Contoh data hasil penghapusan records yang tidak lengkap 18 15 Contoh data sebelum penanganan kesalahan pengetikan 18 16 Contoh data hasil pengklusteran frasa khasiat dan perhitungan
frekuensi tanaman obat di setiap frasa khasiat 19 17 Contoh data hasil penerapan algoritme Levenshtein 19 18 Contoh data setelah penanganan kesalahan pengetikan 19
19 Contoh data sebelum indexing 20
20 Contoh data hasil indexing frasa khasiat 21
21 Contoh data hasil indexing frasa tanaman obat 21 22 Contoh data yang direpresentasikan sebagai nodes 23 23 Contoh data yang direpresentasikan sebagai edges 23
DAFTAR GAMBAR
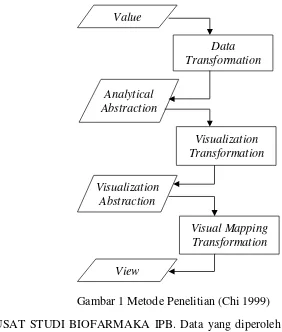
1 Metode Penelitian (Chi 1999) 3
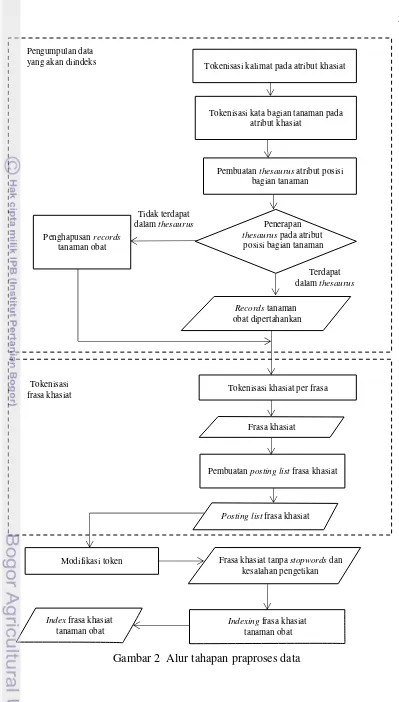
2 Alur tahapan praproses data 5
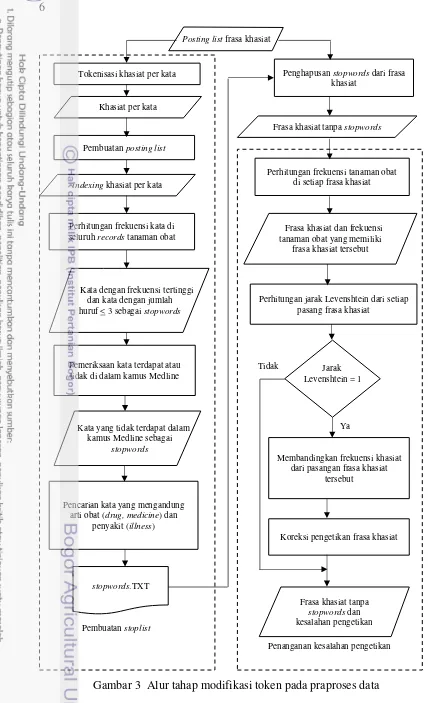
3 Alur tahap modifikasi token pada praproses data 6
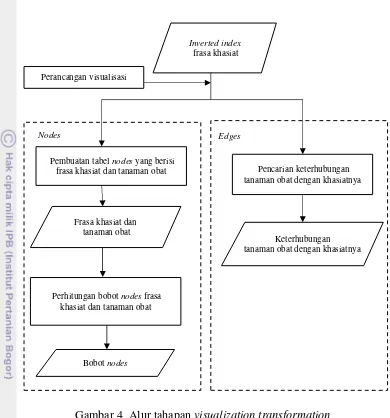
4 Alur tahapan visualization transformation 8
5 Alur tahapan pada visual mapping transformation 9
6 Bentuk visual dasar 22
7 Perbaikan bentuk visual dasar 22
8 Graf asal dengan random layout 24
9 Graf hasil algoritme Fruchterman-Reingold 25
10 Graf dengan penerapan kluster khasiat dan posisi tanaman 26
11 Graf dengan penerapan bobot nodes 26
12 Graf hasil penerapan algoritme Noverlap 27
13 Pemberian label pada nodes 27
DAFTAR LAMPIRAN
1 Thesaurus dari atribut position 32
2 Pseudocode algoritme layout Fruchterman Reingold 33 3 Komunitas yang terbentuk pada graf berdasarkan position 34 4 Tenik interaksi select pada graf visualisasi 35 5 Teknik interaksi explore pada graf visualisasi 36 6 Antarmuka teknik interaksi reconfigure pada graf visualisasi 37 7 Antarmuka teknik interaksi abstract pada graf visualisasi 38 8 Antarmuka teknik interaksi filter pada graf visualisasi 39
PENDAHULUAN
Latar Belakang
Jamu merupakan tanaman herbal Indonesia yang dibuat melalui penggabungan beberapa jenis tanaman. Oleh sebab itu, komposisi tanaman yang digunakan akan menentukan khasiat dari jamu tersebut (Afendi et al. 2010). Tanaman yang digunakan merupakan tanaman yang berfungsi sebagai obat bagi penyakit-penyakit tertentu sesuai dengan khasiat yang dikandungnya. Indonesia memiliki sekitar 9600 spesies tanaman obat, namun baru sekitar 200 spesies yang telah dimanfaatkan sebagai bahan baku pada industri obat tradisional dan dari jumlah tersebut baru sekitar 4% yang dibudidayakan (BBPP 2012).
Data tanaman obat beserta khasiat merupakan data dalam bentuk teks. Hal ini membuat data menjadi sulit untuk dianalisis karena akan memakan waktu lebih banyak untuk memahami keseluruhan teks dalam data dan menganalisis makna dari teks tersebut (Uchida et al. 2009). Oleh sebab itu, penyajian informasi dalam bentuk tulisan dirasa kurang efektif dan dibutuhkan suatu cara agar seseorang bisa menyelidiki lebih lanjut mengenai keterhubungan antartanaman obat dengan khasiat yang dimilikinya.
Suatu tanaman obat dapat memiliki berbagai macam khasiat, sedangkan satu khasiat dapat dimiliki oleh lebih dari satu tanaman obat. Oleh sebab itu, terdapat keterhubungan antartanaman obat dengan khasiatnya. Visualisasi merupakan cara mendapatkan informasi yang memanfaatkan kemampuan persepsi manusia dari pemahaman visual. Umumnya seseorang tertarik pada struktur, fitur, pola, trends, anomali dan keterhubungan pada sekumpulan data. Visualisasi mendukung hal tersebut dengan merepresentasikan data dalam beberapa bentuk dengan interaksi yang berbeda (Grinstein dan Ward 2002).
Penelitian ini mencoba merepresentasikan data keterhubungan tanaman obat dengan khasiatnya dalam bentuk graf. Teknik visualisasi yang diterapkan dalam penelitian ini ialah algoritme Fruchterman-Reingold. Teknik tersebut mencoba menempatkan khasiat yang memiliki keterhubungan erat dalam letak yang berdekatan. Hal ini disebabkan oleh seseorang cenderung menganggap hal-hal yang ditempatkan secara berdekatan berada di dalam grup yang sama (Holloway 2010).
Perumusan Masalah
Setiap tanaman obat yang berada di Indonesia memiliki berbagai macam khasiat yang berbeda-beda. Begitu pula, satu khasiat dapat dimiliki oleh banyak tanaman obat. Oleh sebab itu, terdapat keterhubungan tanaman obat dengan khasiatnya, sehingga muncul pertanyaan sebagai berikut:
1 bagaimana model visualisasi keterhubungan tanaman obat dengan khasiatnya?
2
Tujuan Penelitian
Penelitian ini bertujuan mengembangkan aplikasi visualisasi informasi yang memodelkan keterhubungan antartanaman obat dengan khasiatnya guna membantu masyarakat dalam melakukan pencarian dan penelusuran terkait tanaman obat dan khasiatnya.
Manfaat Penelitian
Hasil dari penelitian ini diharapkan dapat digunakan oleh kalangan peneliti jamu sekaligus masyarakat untuk melihat keterhubungan tanaman obat dengan khasiatnya dan mendapatkan lebih banyak pengetahuan mengenai hal tersebut.
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini ialah :
1 data penelitian yang digunakan dalam penelitian ini ialah data tanaman obat yang telah digunakan pada industri jamu Indonesia, berasal dari PUSAT STUDI BIOFARMAKA IPB.
2 visualisasi diterapkan dengan mencari keterhubungan antartanaman obat Indonesia dengan khasiatnya.
3 pengguna dapat melakukan pencarian berdasarkan nama khasiat dalam bahasa Inggris dan nama tanaman dalam bahasa Inggris disertai dengan bagian tanamannya yang berkhasiat.
4 data yang digunakan dalam visualisasi ini masih bersifat statis, sehingga belum dapat menangani penambahan data tanaman obat ke dalam database. 5 pengguna dapat mencetak hasil pencarian yang diperoleh dalam fail dengan
format CSV.
METODE
Tahapan Penelitian
Metode yang digunakan dalam penelitian ini merupakan kerangka metode yang digunakan oleh Chi(1999). Metode ini dibagi ke dalam 4 tahap utama, yaitu Data, Analytical Abstraction, Visualization Abstraction, and View. Selain itu, terdapat 3 langkah pengolahan utama diantara 4 tahap tersebut, yaitu Data Transformation. Visualization Transformation, dan Visual Mapping Transformation (Chi 1999). Alur tahapan penelitian dapat dilihat pada Gambar 1.
Value
3
PUSAT STUDI BIOFARMAKA IPB. Data yang diperoleh sudah dalam bentuk database. Atribut data yang digunakan dalam penelitian ini, antara lain id dari tanaman obat, nama ilmiah tanaman obat, nama tanaman obat dalam bahasa Inggris, nama tanaman obat dalam bahasa Indonesia, posisi bagian tanaman yang berkhasiat, dan deskripsi khasiat dari posisi tanaman obat yang berkhasiat.
Data Transformation
Data transformation merupakan proses transformasi tahap data menjadi tahap analytical abstraction. Data transformation merupakan tahap pengolahan data dengan melakukan ekstraksi data (Chi 1999). Pada tahap ini, dilakukan proses pembersihan data dan praproses data agar diperoleh data yang sudah memiliki informasi untuk dipetakan menjadi inverted index dari frasa khasiat. Tahap pembersihan data meliputi penghapusan duplikasi data dan data yang tidak lengkap. Atribut khas yang dibutuhkan pada penelitian ini ialah atribut yang menyatakan nama tanaman obat dan khasiat dari tanaman obat tersebut, sehingga data yang tidak memiliki nilai pada salah satu atau kedua atribut tersebut dikatakan data yang tidak lengkap. Data yang digunakan dalam penelitian ini merupakan data dalam bentuk teks yang memberikan deskripsi mengenai tanaman obat dan khasiat yang dimiliki tanaman obat tersebut, sehingga harus dilakukan praproses data terlebih dahulu.
Praproses data untuk data dalam bentuk teks meliputi tahapan-tahapan dalam pembuatan inverted index. Menurut Manning et al. (2009), pembuatan inverted index meliputi empat tahap utama, yakni pengumpulan data yang akan
4
diindeks, tahap tokenisasi, tahap memodifikasi token serta pengindeksan kata. Alur tahapan praproses data yang dilakukan pada penelitian ini dapat dilihat pada Gambar 2. Di samping itu, alur tahapan ketiga pada praproses data, yaitu penghapusan stopwords dan koreksi kesalahan pengetikan pada atribut khasiat ditunjukkan pada Gambar 3. Data transformation dilakukan dengan menggunakan bahasa pemrograman PHP, Database Management System (DBMS) MySQL, perangkat lunak Notepad++ dan Microsoft Excel 2010.
Pengumpulan Data yang Akan Diindeks
Tahap pembuatan inverted index yang pertama ini meliputi tokenisasi kalimat pada atribut khasiat, tokenisasi kata bagian tanaman pada atribut khasiat, pembuatan thesaurus atribut posisi bagian tanaman, penerapan thesaurus pada atribut posisi bagian tanaman dan penghapusan records tanaman yang bagian tanamannya tidak terdapat dalam thesaurus.
Tokenisasi Frasa Khasiat
Tahap selanjutnya ialah tokenisasi frasa khasiat. Tahap ini meliputi tokenisasi khasiat per frasa dan pembuatan posting list frasa khasiat.
Modifikasi Token
Tahap berikutnya ialah modifikasi token, yaitu pembuatan stoplist, penghapusan stopwords pada frasa khasiat dan penanganan kesalahan pengetikan pada frasa khasiat. Pembuatan stoplist bertujuan mendaftarkan kata-kata pada frasa khasiat yang dianggap tidak akan mengubah arti jika kata-kata tersebut dihilangkan. Selain itu, pada data berupa teks sering kali terjadi kesalahan pengetikan yang dapat mengubah makna dari kata tersebut, sehingga perlu dilakukan penanganan kesalahan pengetikan pada frasa khasiat.
Pembuatan stoplist meliputi proses tokenisasi khasiat per kata, indexing khasiat per kata, perhitungan frekuensi kata khasiat di seluruh records, pemeriksaan kata khasiat terdapat atau tidak di dalam kamus kedokteran Medline dan pencarian kata yang mengandung arti obat dan penyakit. Hasil dari proses ini akan disimpan pada fail dengan format TXT.
Di samping itu, penanganan kesalahan pengetikan meliputi penghapusan stopwords dari frasa khasiat, perhitungan frekuensi tanaman obat di setiap frasa khasiat, pencarian frasa yang mengalami kesalahan pengetikan menggunakan algoritme jarak Levenshtein dan dilakukan koreksi terhadap frasa khasiat yang mengalami kesalahan pengetikan.
Indexing Frasa Khasiat dan Tanaman Obat
5
Gambar 2 Alur tahapan praproses data
Terdapat dalam thesaurus Pengumpulan data
yang akan diindeks
Tokenisasi frasa khasiat
Tokenisasi kalimat pada atribut khasiat
Tokenisasi kata bagian tanaman pada atribut khasiat
Pembuatan thesaurus atributposisi bagian tanaman
Penerapan thesaurus pada atribut posisi bagian tanaman
Records tanaman obat dipertahankan Penghapusan records
tanaman obat
Tidak terdapat dalam thesaurus
Tokenisasi khasiat per frasa
Pembuatan posting list frasa khasiat Frasa khasiat
Posting list frasa khasiat
Modifikasi token
Indexing frasakhasiat tanaman obat
Frasa khasiat tanpa stopwords dan kesalahan pengetikan
6
Gambar 3 Alur tahap modifikasi token pada praproses data
Posting list frasa khasiat
Tokenisasi khasiat per kata
Pembuatan posting list
Perhitungan frekuensi kata di seluruh records tanaman obat
Kata dengan frekuensi tertinggi dan kata dengan jumlah huruf < 3 sebagai stopwords
Pemeriksaan kata terdapat atau tidak di dalam kamus Medline
Kata yang tidak terdapat dalam kamus Medline sebagai
indexing khasiat per kata
Perhitungan frekuensi tanaman obat di setiap frasa khasiat
Frasa khasiat dan frekuensi tanaman obat yang memiliki
frasa khasiat tersebut
Perhitungan jarak Levenshtein dari setiap pasang frasa khasiat
Koreksi pengetikan frasa khasiat
Frasa khasiat tanpa stopwords dan kesalahan pengetikan
Ya Tidak
Penghapusan stopwords dari frasa khasiat
Frasa khasiat tanpa stopwords
Pembuatan stoplist
7 Analytical Abstraction
Analytical transformation merupakan hasil dari pengolahan data yang belum dipetakan namun sudah memiliki informasi yang diekstraksi dari data mentah (Chi 1999). Pada tahap ini, diperoleh data hasil pembersihan data dan praproses data dengan atribut yang sama dengan tahap value, namun memiliki atribut tambahan berupa id khasiat. Data pada tahap ini merupakan inverted index dari frasa khasiat yang terdapat di dalam database.
Visualization Transformation
Tahap ini merupakan tahap pengolahan visualisasi informasi yang mengambil nilai dari analytical abstraction dan mengambil beberapa hal utama yang nantinya akan menjadi bentuk visualization abstraction. Pada tahap ini dilakukan perancangan visualisasi dan pengolahan data yang siap dipetakan. Alur tahapan pada visualization transformation dapat dilihat pada Gambar 4. Visualization abstraction dilakukan dengan menggunakan bahasa pemrograman PHP, DBMS MySQL dan perangkat lunak Notepad++.
Perancangan Visualisasi
Perancangan visualisasi dilakukan untuk membuat visualisasi yang akan digunakan untuk merepresentasikan keterhubungan tanaman obat dengan khasiatnya. Visualisasi yang dibentuk harus dapat merepresentasikan keterhubungan tanaman obat dengan khasiatnya, posisi tanaman obat yang berkhasiat dan khasiat yang paling banyak dimiliki oleh tanaman obat Indonesia. Pengolahan Data yang Akan Dipetakan
Pada proses pengolahan data yang akan dipetakan ini, dilakukan pencarian keterhubungan tanaman obat dengan khasiatnya dan perhitungan bobot nodes untuk tanaman obat dan khasiatnya. Hal ini dilakukan agar diperoleh representasi visual seperti yang telah dirancang pada tahap perancangan visualisasi.
Visualization Abstraction
8
Visual Mapping Transformation
Tahap ini merupakan tahap pembuatan graf dengan menggunakan perangkat lunak Gephi versi 0.8.2, open source software untuk mengeksplorasi dan memanipulasi networks (Bastian et al. 2009). Visual mapping transformation merupakan tahap pengambilan seluruh informasi dan menampilkannya dalam bentuk tampilan grafis kepada pengguna (Chi 1999). Pada tahap ini diterapkan algoritme layout Fruchterman Reingold untuk menentukan koordinat dari setiap nodes di dalam graf agar dapat lebih mudah dipahami oleh pengguna. Kemudian, diterapkan pewarnaan nodes berdasarkan posisi tanaman dan khasiat, serta penempatan label pada graf visualisasi yang terbentuk. Alur tahapan visual mapping transformation dapat dilihat pada Gambar 5.
Gambar 4 Alur tahapan visualization transformation
Inverted index frasa khasiat
Perancangan visualisasi
Pencarian keterhubungan tanaman obat dengan khasiatnya
Keterhubungan tanaman obat dengan khasiatnya Edges
Nodes
Frasa khasiat dan tanaman obat
Pembuatan tabel nodes yang berisi frasa khasiat dan tanaman obat
Perhitungan bobot nodes frasa khasiat dan tanaman obat
9
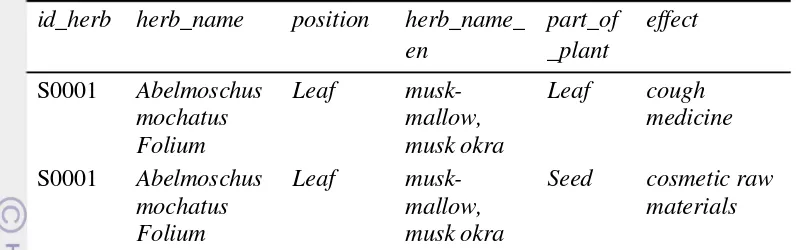
Gambar 5 Alur tahapan pada visual mapping transformation
Graf
Tahap ini merupakan tahap memetakan informasi yang telah diperoleh dari tahap sebelumnya ke dalam bentuk graf visualisasi. Graf yang terbentuk pada
Graf
Layout
Partition
Ranking
Visualisasi graf dengan random layout
Tabel nodes dan edges
Algoritme layout Fruchterman Reingold
Pembobotan nodes
Algoritme Noverlap untuk mengatasi nodes tumpang tindih
Pengaturan ukuran dan jenis font untuk label di nodes
Pewarnaan graf
Label
Graf akhir
Graf dengan layout yang renggang (tidak ada nodes
tumpang tindih) Graf dengan ukuran nodes yang bervariasi
Graf dengan warna bervariasi per kluster Graf dengan layout baru
10
tahap ini merupakan graf dengan posisi yang tidak beraturan atau random layout. Oleh sebab itu, graf yang terbentuk akan sulit dibaca oleh pengguna.
Layout
Tahap selanjutnya merupakan penerapan algoritme layout untuk menentukan posisi nodes dan edges. Algoritme layout yang diterapkan pada penelitian ini merupakan algoritme Fruchterman Reingold.
Partition
Selanjutnya ialah tahap pencarian struktur komunitas di dalam graf atau pengklusteran nodes di dalam graf. Pengklusteran nodes ditunjukkan dengan menggunakan pewarnaan nodes berdasarkan nodes yang menunjukkan posisi tanaman dan khasiat, sehingga pengguna dapat melihat dengan lebih jelas kluster yang terbentuk.
Ranking
Tahap berikutnya ialah pemberian ranking atau pembobotan pada graf. Pembobotan pada nodes dilakukan berdasarkan jumlah keterhubungan yang dimiliki oleh setiap nodes. Oleh sebab itu, pembobotan nodes yang menunjukkan posisi bagian tanaman didasarkan pada jumlah khasiat yang dimiliki oleh tanaman obat tersebut, sedangkan nodes yang menunjukkan khasiat didasarkan pada jumlah tanaman obat yang memiliki khasiat tersebut. Pembobotan ini akan menyebabkan terjadinya nodes yang tumpang tindih sehingga diterapkan algoritme Noverlap untuk merenggangkan nodes.
Label
Tahap terakhir pada visual mapping transformation ialah pemberian label pada nodes. Pada tahap ini dilakukan pengaturan ukuran dan jenis font yang dipasang di setiap nodes agar pengguna dapat lebih mudah dalam memahami graf yang terbentuk dan melakukan penelusuran.
View
11 Lingkungan Pengembangan Sistem
Spesifikasi beberapa perangkat lunak dan perangkat keras yang digunakan dalam penelitian ini ialah sebagai berikut:
1 Perangkat lunak:
Sistem Operasi Microdoft Windows 8 Professional 32-bit,
Database Management System (DBMS) MySQL untuk penyimpanan database tanaman obat dan khasiatnya,
XAMPP untuk mengkonfigurasikan Apache, MySQL dan bahasa pemrograman PHP yang digunakan sampai dengan tahap visualization abstraction,
Gephi sebagai tool pada tahap visual mapping transformation,
Google Chrome Browser untuk menampilkan halaman web yang dihasilkan dalam penelitian ini,
Notepad++ digunakan sebagai Integrated Development Environment (IDE),
Microsoft Excel 2010 digunakan untuk melihat hasil praproses data. 2 Perangkat Keras:
Processor Intel Core 2 Duo,
Memory 4 GB RAM,
VGA ATI Radeon HD 4300 Series.
HASIL DAN PEMBAHASAN
Value
Data yang digunakan pada penelitian ini diperoleh dari PUSAT STUDI BIOFARMAKA IPB yang berisi 1133 records jenis tanaman obat yang dimanfaatkan oleh industri obat tradisional di Indonesia. Contoh data dapat dilihat pada Tabel 1. Data yang diperoleh menggunakan merupakan teks dalam bahasa
Tabel 1 Contoh data yang diperoleh id_herb herb_
12
Inggris, sehingga penelitian ini menggunakan bahasa Inggris dalam proses pengolahan data dan pengembangan sistem. Atribut dari data yang diperoleh ialah sebagai berikut :
Id tanaman obat dengan nama field id_herb
Nama ilmiah dari tanaman obat ditambah satu kata yang menyatakan nama ilmiah dari bagian tanaman yang berkhasiat dengan nama field herb_name
Nama tanaman obat dalam bahasa Indonesia dengan nama field herb_name_id
Nama tanaman obat dalam bahasa Inggris dengan nama field herb_name_en
Nama ilmiah tanaman obat dengan nama field science_name
Bagian tanaman obat yang memiliki khasiat dengan nama field position
Daftar khasiat yang dimiliki tanaman obat dengan nama field effect
Sumber informasi mengenai tanaman obat tersebut dengan nama field reference.
Terdapat kesalahan-kesalahan dari data yang diperoleh, antara lain terdapat tanaman obat yang tidak disebutkan khasiatnya atau atribut effect bernilai “-“, sehingga dilakukan pembersihan data berupa penghapusan records tanaman obat. Dari 1133 records tanaman obat terdapat 42 records (3.71%) yang tidak disebutkan khasiatnya. Pembersihan data menghasilkan data yang lengkap tanpa terdapat atribut effect yang bernilai “-“.
Selain itu, terdapat atribut effect yang masih berisi daftar khasiat dari setiap bagian tanaman yang mengandung khasiat, sedangkan id dari tanaman obat pada setiap record sudah berdasarkan pada atribut herb_name. Oleh sebab itu, perlu dilakukan proses penghapusan pada sebagian isi dari atribut effect yang dianggap tidak sesuai dengan nilai atribut position pada records tersebut. Proses tersebut dilakukan pada tahap data transformation.
Data Transformation
Pengumpulan Data yang Akan Diindeks
Pengumpulan data yang akan diindeks merupakan tahap yang dilakukan pada atribut effect dari 1091 records tanaman obat hasil pembersihan data. Tahap ini diawali dengan tokenisasi kalimat pada atribut effect. Nilai atribut effect yang terdapat dalam data mentah masih berupa daftar bagian tanaman dan khasiat yang dimiliki tanaman obat per bagian. Daftar antarbagian tanaman dan khasiatnya tersebut dipisahkan dengan tanda “.”, sehingga dilakukan tokenisasi kalimat pada atribut effect. Setiap kali bertemu dengan tanda “.”, maka akan terbentuk record
id_herb herb_name position herb_name_en effect
S0001 Abelmoschus
13
baru yang memisahkan kalimat pada atribut effect. Setelah dilakukan pemisahan kalimat pada atribut effect, data yang dihasilkan berjumlah 1356 records. Contoh data hasil proses tokenisasi kalimat pada atribut effect dapat dilihat pada Tabel 2.
Selanjutnya, dilakukan tokenisasi kata bagian tanaman pada atribut khasiat. Pemisahan bagian tanaman dengan khasiatnya dilakukan dengan menggunakan token berupa tanda “:”. Hal ini dilakukan sebab setiap records menunjukkan bahwa atribut effect terdiri atas bagian tanaman yang berkhasiat kemudian dilanjutkan tanda “:” sebagai pemisah dengan khasiat dari bagian tanaman obat tersebut. Kata-kata yang berada sebelum titik dua akan disimpan pada kolom terpisah dengan khasiat, yakni pada kolom part_of_plant, sedangkan kata-kata yang berada setelah tanda “:” akan tetap berada pada kolom effect. Contoh data hasil dari proses tokenisasi kata bagian tanaman pada atribut effect dapat dilihat pada Tabel 3.
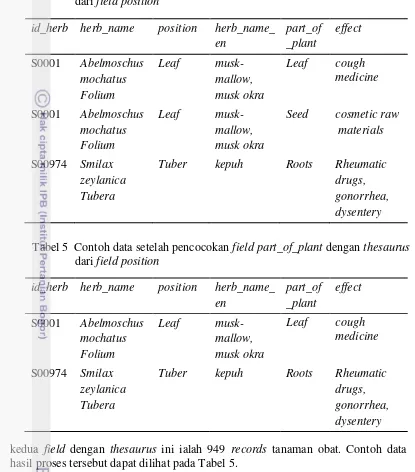
Kemudian, dilakukan tahap pencocokan field part_of_plant dengan position. Jika nilai kedua field tersebut sama, record tanaman obat tersebut dipertahankan. Di samping itu, jika nilai kedua field tersebut berbeda, record tanaman obat tersebut akan dihapus. Berdasarkan data hasil proses tersebut, atribut position terdiri atas 17 nilai yang berbeda, namun atribut part_of_plant terdiri atas 76 nilai yang berbeda. Oleh sebab itu, dilakukan pembuatan thesaurus untuk mencari nilai atribut part_of_plant yang memiliki makna sama dengan nilai atribut position pada record yang sama. Hal ini dilakukan sebab terdapat kemungkinan bahwa kata yang terdapat pada nilai atribut part_of_plant merupakan persamaan kata dari nilai position. Thesaurus yang dihasilkan pada proses tersebut ditunjukkan pada Lampiran 1.
Proses berikutnya ialah penerapan thesaurus pada pencocokan nilai atribut part_of_plant dengan atribut position. Jika kata pada atribut part_of_plant terdapat dalam thesaurus nilai atribut position tersebut, record tersebut akan dipertahankan. Namun, jika tidak terdapat dalam thesaurus, dilakukan penghapusan terhadap record tanaman obat tersebut. Contoh data sebelum proses pencocokan kedua field dengan thesaurus dapat dilihat pada Tabel 4.
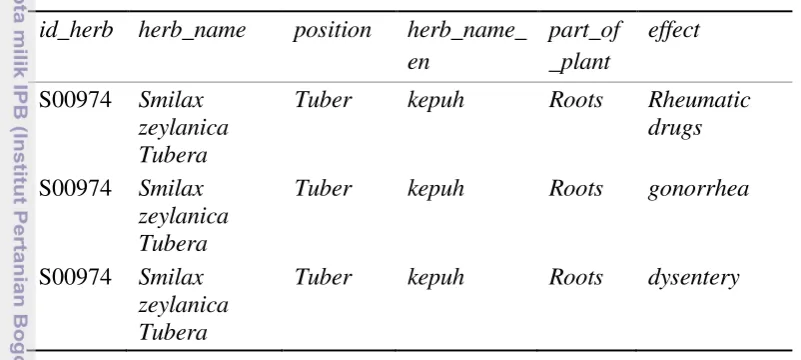
Pada Tabel 4, record pertama menunjukkan atribut position bernilai “Leaf”, sedangkan part_of_plant bernilai “Leaf” juga. Oleh sebab itu, record pertama dipertahankan. Di samping itu, record kedua menunjukkan atribut position bernilai “Leaf”, sedangkan atribut part_of_plant bernilai “Seed”. Kata “Seed” tidak terdapat dalam thesaurus kata “Leaf”, sehingga dilakukan penghapusan terhadap record tersebut. Jumlah data yang diperoleh dari proses pencocokan
14
kedua field dengan thesaurus ini ialah 949 records tanaman obat. Contoh data hasil proses tersebut dapat dilihat pada Tabel 5.
Data hasil proses tersebut merupakan data yang akan diindeks pada proses pembuatan inverted index berikutnya. Khasiat yang terdapat dalam database merupakan gabungan kata yang mengandung arti atau biasa disebut frasa, sehingga tokenisasi akan dilakukan dalam bentuk frasa khasiat.
Tokenisasi Frasa Khasiat
Tahap pembuatan inverted index yang kedua ialah tokenisasi khasiat per frasa. Token yang digunakan pada tahap ini ialah “,;/\(){}[]<>”. Tokenisasi frasa khasiat ini menghasilkan 3923 records tanaman obat. Contoh data sebelum tokenisasi frasa khasiat ini dapat dilihat pada Tabel 6, sedangkan contoh data setelah tokenisasi frasa khasiat dilakukan dapat dilihat pada Tabel 7.
Tabel 4 Contoh data sebelum pencocokan field part_of_plant dengan thesaurus dari field position
id_herb herb_name position herb_name_ en
Tuber kepuh Roots Rheumatic
drugs, gonorrhea, dysentery
Tabel 5 Contoh data setelah pencocokan field part_of_plant dengan thesaurus dari field position
id_herb herb_name position herb_name_ en
Tuber kepuh Roots Rheumatic
15
Tahap tokenisasi frasa khasiat ini kemudian dilanjutkan dengan pembuatan posting list dari frasa khasiat. Pada tahap ini dilakukan penambahan atribut berupa id khasiat untuk membuat frasa khasiat menjadi atribut yang unik. Tahap ini menghasilkan data yang menunjukkan suatu frasa khasiat dan daftar tanaman obat yang memiliki frasa khasiat tersebut.
Data yang dihasilkan dari pembuatan posting list frasa khasiat masih berjumlah 3923 records tanaman obat, sebab tidak ada pengulangan frasa khasiat yang sama di dalam suatu record tanaman obat. Contoh posting list yang terbentuk dapat dilihat pada Tabel 8. Contoh data tersebut menunjukkan bahwa frasa khasiat “rheumatic drugs” dimiliki oleh tanaman obat dengan id S00974, S00010 dan S00028, sedangkan “dysentery” dimiliki oleh tanaman obat dengan id S00974 dan S00989.
Tabel 6 Contoh data sebelum tokenisasi frasa khasiat id_herb herb_name position herb_name_
en
Tuber kepuh Roots Rheumatic
drugs, gonorrhea, dysentery
Tabel 7 Contoh data setelah tokenisasi frasa khasiat id_herb herb_name position herb_name_
en
Tuber kepuh Roots Rheumatic
drugs
S00974 Smilax zeylanica Tubera
Tuber kepuh Roots gonorrhea
S00974 Smilax zeylanica Tubera
Tuber kepuh Roots dysentery
Tabel 8 Contoh data hasil pembuatan posting list frasa khasiat
id_effect effect id_herb
K0001 rheumatic drugs S00974
K0001 rheumatic drugs S00010
K0001 rheumatic drugs S00028
K0002 dysentery S00974
16
Modifikasi Token
Tahap modifikasi token terbagi ke dalam dua proses yaitu pembuatan stoplist dan penghapusan stopwords pada atribut effect, serta penanganan kesalahan pengetikan nilai pada atribut effect. Hal ini dilakukan untuk meminimalkan kesalahan dalam pencarian keterhubungan antarkhasiat akibat kesalahan pengetikan yang menimbulkan perbedaan makna khasiat.
1 Pembuatan stoplist
Pembuatan stoplist pada atribut effect dimulai dengan langkah tokenisasi kata pada atribut effect dengan token berupa spasi (“ “), koma (“,”), titik koma (“;”), titik dua (“:”), dan tanda kurung (“( )”). Tahap ini menghasilkan 9593 kata. Kemudian, seluruh kata diubah ke dalam lower case untuk mempermudah praproses data. Contoh data hasil tokenisasi kata di atribut effect ini dapat dilihat pada Tabel 9. Kemudian, dilakukan indexing kata pada atribut effect dan menghasilkan 1251 daftar kata berbeda yang berada di dalam atribut effect. Contoh data hasil indexing ini dapat dilihat pada Tabel 10.
Selanjutnya, dilakukan perhitungan frekuensi kata di seluruh records dalam database, sehingga dapat diketahui bahwa terdapat 5 kata dengan frekuensi tertinggi yang merupakan kata konjungsi, antara lain and, of, the, in, dan with. Kata-kata konjungsi tersebut merupakan kata yang dimasukkan ke dalam stoplist.
Tabel 9 Contoh data hasil tokenisasi kata di atribut effect
effect id_herb
Tabel 10 Contoh data hasil indexing khasiat per kata
effect id_herb
rheumatic S00974, S00010, S00028
drugs S00974, S00010, S00028
dysentery S00974, S00989
Tabel 11 Contoh data hasil perhitungan frekuensi kata
effect id_herb frekuensi
rheumatic S00974, S00010, S00028 3
drugs S00974, S00010, S00028 3
17 Kemudian, kata-kata yang memiliki jumlah huruf kurang dari 3 dimasukkan pula ke dalam stoplist. Contoh data hasil perhitungan frekuensi kata ini dapat dilihat pada Tabel 11.
Selain itu, dilakukan pemeriksaan hasil token kata dengan kamus kedokteran Medline. Hal ini dilakukan sebab tidak ditemukan pola struktur bahasa yang dapat menentukan hasil token tersebut benar merupakan istilah penyakit atau bukan. Kata-kata yang tidak terdapat pada kamus Medline dianggap sebagai stopwords dan dimasukan ke dalam stoplist.
Kemudian, kata yang berarti obat seperti medicine dan drug serta kata-kata yang berarti penyakit seperti illness dan disease juga dimasukkan ke dalam stoplist, sebab ada atau tidaknya kata-kata tersebut tidak mengurangi maksud dari khasiat tanaman obat tersebut.
Oleh sebab itu, kata-kata yang masuk ke dalam stoplist terdiri atas kata konjungsi (kata penghubung), kata dengan jumlah huruf maksimal tiga, kata yang berarti obat (medicine, drug), kata yang berarti penyakit (illness, disease), dan kata-kata yang tidak terdapat pada Medline dictionary (kamus kedokteran). Kemudian, dihasilkan 358 kata yang dijadikan sebagai stopwords dan dimasukkan ke dalam stoplist. Stoplist tersebut dibuat dalam fail dengan format TXT.
2 Penghapusan stopwords dalam frasa khasiat
Setelah tahap pembuatan stoplist selesai, dilakukan proses penghapusan stopwords dari 3923 records frasa khasiat yang dihasilkan dari tahap tokenisasi frasa khasiat. Contoh data sebelum proses penghapusan stopwords ditunjukkan pada Tabel 12, sedangkan contoh data setelah proses penghapusan stopwords ditunjukkan pada Tabel 13. Proses ini akan menghasilkan frasa khasiat tanpa terdapat stopwords di dalamnya, namun menimbulkan nilai NULL pada atribut effect atau data menjadi tidak lengkap. Oleh sebab itu, dilakukan penghapusan
Tabel 12 Contoh data sebelum penghapusan stopwords
id_effect effect id_herb
K0001 rheumatic drugs S00974
K0001 rheumatic drugs S00010
K0002 dysentery S00974
K0005 cough medicine S00001
K0007 impairment of yin S00898
K0010 AP S00888
Tabel 13 Proses penghapusan stopwords
id_effect effect id_herb
K0001 rheumatic S00974
K0001 rheumatic S00010
K0002 dysentery S00974
K0005 cough S00001
K0007 - S00898
18
records terhadap 452 records (11.52 %) yang memiliki nilai NULL pada atribut effect. Hasil dari tahap ini menghasilkan 3471 records dengan nilai atribut effect hanya berupa satu frasa khasiat. Contoh data hasil penghapusan records tanaman obat yang memiliki nilai NULL pada atribut effect dapat dilihat pada Tabel 14.
3 Penanganan kesalahan pengetikan
Kesalahan pengetikan pada pemasukan data dapat menyebabkan perbedaan makna dari kata yang dituliskan, misalnya coughs dan cough. Kedua kata tersebut dapat dianggap berbeda arti karena memiliki satu huruf yang berbeda pada pengejaannya. Oleh sebab itu, perlu dilakukan praproses data yang dapat menangani masalah kesalahan pengetikan tersebut menggunakan algoritme Levenshtein, sehingga coughs dan cough dapat tetap dianggap memiliki makna yang sama.
Data yang digunakan ialah posting list frasa khasiat tanpa stopwords berjumlah 3471 records. Kemudian dilakukan klusterisasi berdasarkan frasa khasiat. Proses klusterisasi ini menghasilkan 1185 records khasiat, kemudian dilakukan perhitungan jumlah tanaman obat yang memiliki khasiat tersebut. Perhitungan jumlah tanaman obat yang memiliki suatu khasiat dianggap sebagai frekuensi khasiat di dalam database. Contoh data sebelum penangan kesalahan pengetikan dan pengklusteran khasiat dapat dilihat pada Tabel 15, sedangkan contoh data hasil pengklusteran frasa khasiat dan perhitungan frekuensi tanaman obat di setiap frasa khasiat dapat dilihat pada Tabel 16.
Selanjutnya, dilakukan pembentukan pasangan dari seluruh khasiat yang ada dan diterapkan algoritme jarak Levenshtein untuk mendapatkan nilai kesalahan pengejaan khasiat. Algoritme jarak Levenshtein mencocokkan setiap pasangan khasiat yang terbentuk dan menghitung berapa banyak karakter yang berbeda dari pengetikan pasangan khasiat tersebut. Pada penelitian ini diberikan threshold
Tabel 14 Contoh data hasil penghapusan records yang tidak lengkap
id_effect effect id_herb
K0001 rheumatic S00974
K0001 rheumatic S00010
K0002 dysentery S00974
K0005 cough S00001
Tabel 15 Contoh data sebelum penanganan kesalahan pengetikan
id_effect effect id_herb
K0005 cough S00001
K0008 lactagoga S00198
K0008 lactagoga S00509
K0005 cough S00676
K0005 cough S00345
K0005 cough S00021
K0090 coughs S00852
19 jarak minimal untuk mengoreksi khasiat yang dianggap memiliki kesalahan pengetikan. Hal tersebut diperlukan untuk meminimalisir kesalahan pengetikan. Threshold yang digunakan pada penelitian ini ialah 1, sebab kesalahan pengetikan diasumsikan hanya terjadi pada satu karakter. Selain itu, penggunaan threshold lebih dari 1 ternyata menyebabkan perubahan makna dari khasiat, misalnya penggunaan threshold 2 mendeteksi fever sebagai kesalahan pengetikan dari liver. Oleh sebab itu, threshold lebih dari 1 tidak diterapkan dalam penelitian ini. Contoh data hasil penerapan algoritme Levenshtein dapat dilihat pada Tabel 17.
Selanjutnya, dilakukan proses membandingkan frekuensi khasiat dari setiap pasangan frasa khasiat untuk pasangan khasiat yang memiliki jarak Levenshtein bernilai 1 berjumlah 25 records. Proses ini dimaksudkan untuk melakukan koreksi pada kesalahan pengetikan yang terjadi. Frasa khasiat yang memiliki nilai frekuensi kecil diganti dengan frasa khasiat yang memiliki nilai frekuensi lebih tinggi. Hal ini dilakukan dengan asumsi bahwa frasa khasiat dengan frekuensi kecil dianggap sebagai khasiat yang mengalami kesalahan pengetikan, sedangkan frasa khasiat dengan frekuensi yang lebih besar dianggap sebagai frasa khasiat yang benar dalam pengetikannya. Hasil dari proses tersebut merupakan 3471 records frasa khasiat yang tidak mengalami kesalahan pengetikan. Contoh data hasil penanganan kesalahan pengetikan dapat dilihat pada Tabel 18.
Tabel 16 Contoh data hasil pengklusteran frasa khasiat dan perhitungan frekuensi tanaman obat di setiap frasa khasiat
id_effect effect id_herb frekuensi
K0005 cough S00001,
S00676,
S00345, S00021
4
K0008 lactagoga S00198, S00509 2
K0090 coughs S00852 1
K0045 laktagoga S00567 1
Tabel 17 Contoh data hasil penerapan algoritme Levenshtein id_effect
Tabel 18 Contoh data setelah penanganan kesalahan pengetikan
id_effect effect id_herb
K0005 cough S00001
K0008 lactagoga S00198
K0008 lactagoga S00509
K0005 cough S00676
K0005 cough S00345
K0005 cough S00021
K0006 cough S00852
20
Indexing Frasa Khasiat dan Indexing Tanaman Obat
Tahap pembuatan inverted index yang terakhir ialah indexing frasa khasiat dan tanaman obat. Indexing frasa khasiat dan tanaman obat dilakukan terhadap 3471 records hasil tahap modifikasi token. Pada tahap indexing frasa khasiat, id tanaman obat yang memiliki frasa khasiat yang sama akan ditempatkan di satu record. Hasil dari tahap indexing ini merupakan inverted index yang berisi frasa khasiat beserta daftar id tanaman obat yang memiliki frasa khasiat tersebut. Di samping itu, pada tahap indexing tanaman obat, id khasiat yang dimiliki oleh satu id tanaman obat yang sama akan ditempatkan di satu record berdasarkan id yang telah mengalami pembersihan dan praproses data. Data yang dihasilkan dari proses tersebut berupa inverted index dari frasa khasiat dengan asumsi tanpa stopwords dan kesalahan pengetikan.
Data yang dihasilkan dari proses tersebut merupakan inverted index dari frasa khasiat berjumlah 1160 records dan inverted index dari tanaman obat berjumlah 891 records. Contoh data sebelum pembuatan inverted index dapat dilihat pada Tabel 19. Di samping itu, contoh data hasil indexing frasa khasiat dapat dilihat pada Tabel 20 dan contoh data hasil indexing tanaman obat dapat dilihat pada Tabel 21. Contoh data pada Tabel 20 tersebut menyatakan bahwa frasa khasiat cough terdapat pada id tanaman obat S00001, S00676, S00345, S00021, S00567 dan S00852. Selain itu, frasa khasiat lactagoga terdapat pada id tanaman S00198, S00509 dan S00567. Contoh data pada Tabel 21 tersebut menyatakan bahwa id tanaman obat S00567 memiliki khasiat cough, lactagoga dan diarrhea.
Tabel 19 Contoh data sebelum indexing
id_effect effect id_herb
K0005 cough S00001
K0008 lactagoga S00198
K0008 lactagoga S00509
K0005 cough S00676
K0005 cough S00345
K0005 cough S00021
K0005 cough S00852
K0008 lactagoga S00567
K0005 cough S00567
21
Visualization Transformation
Pada tahap ini dilakukan proses perancangan visualisasi untuk menentukan hasil pengolahan data yang dibutuhkan untuk pembuatan aplikasi visualisasi. Selain itu, dilakukan pencarian keterhubungan antartanaman obat dengan khasiatnya.
Perancangan Visualisasi
Perancangan visualisasi dibagi menjadi dua tahap, yaitu pemilihan bentuk visual dasar dan perbaikan bentuk visual. Graf sering kali digunakan untuk mewakili data yang memiliki keterhubungan (Keim 2002). Oleh sebab itu, penelitian ini mencoba menampilkan keterhubungan tanaman obat dengan khasiatnya melalui representasi berupa graf. Sebuah graf terdiri atas sekumpulan objek, yang disebut nodes, dan keterhubungan antara objek-objeknya disebut edges (Keim 2002). Khasiat dan tanaman obat pada penelitian ini direpresentasikan dengan nodes dan keterhubungan antartanaman obat dengan khasiatnya direpresentasikan dengan edges (garis yang menghubungkan dua nodes). Bentuk visual dasar dari keterhubungan tanaman obat dengan khasiatnya ditunjukkan pada Gambar 6.
Tahap berikutnya pada perancangan visual merupakan perbaikan bentuk visual dasar (Gambar 7). Perbaikan bentuk pada bentuk visual dasar tersebut, yaitu:
1 ukuran node khasiat merepresentasikan bobot khasiat pada node tersebut. Semakin besar ukuran node dibanding nodes yang lain maka semakin besar bobot khasiat tersebut. Bobot khasiat ditentukan dengan banyaknya jumlah edges yang dimiliki oleh suatu node. Hal tersebut berarti semakin banyak keterhubungan node tersebut dengan nodes tanaman obat.
Tabel 20 Contoh data hasil indexing frasa khasiat
Id_effect effect Id_herb
K0005 cough S00001, S00676, S00345,
S00021, S00852
K0008 lactagoga S00198, S00509, S00567
K0020 diarrhea S00567
Tabel 21 Contoh data hasil indexing frasa tanaman obat
Id_herb Id_effect effect
S00001 K0005 cough
S00198 K0008 lactagoga
S00509 K0008 lactagoga
S00676 K0005 cough
S00345 K0005 cough
S00021 K0005 cough
S00852 K0005 cough
22
2 ukuran node tanaman obat merepresentasikan bobot tanaman obat pada node tersebut. Bobot tanaman obat merepresentasikan jumlah khasiat yang dimiliki oleh suatu tanaman obat. Semakin besar ukuran suatu node dibandingkan dengan nodes yang lain, maka semakin banyak khasiat yang dimiliki oleh tanaman obat tersebut.
3 pemilihan warna untuk nodes berdasarkan pengklusteran posisi tanaman yang berkhasiat dan node yang menunjukkan khasiat.
Pengolahan Data yang Akan Dipetakan
Pada tahap ini dilakukan pengolahan data untuk data yang akan dipetakan pada proses pembuatan visual mapping transformation. Data yang digunakan merupakan hasil indexing dari frasa khasiat dan hasil indexing dari tanaman obat. Pada pembuatan tabel nodes, frasa khasiat dan tanaman obat hasil indexing tersebut akan dimasukkan ke dalam tabel nodes untuk direpresentasikan sebagai nodes.
Gambar 6 Bentuk visual dasar
23 Nodes pada perancangan visualisasi merepresentasikan frasa khasiat dan tanaman obat yang terdapat di dalam database. Id dari frasa khasiat dan id dari tanaman obat akan menjadi id dari nodes serta frasa khasiat dan nama tanaman obat dalam bahasa Inggris digabung dengan posisi tanaman obat akan menjadi label dari nodes. Tabel nodes mengikutsertakan atribut position dari tanaman untuk pewarnaan graf berdasarkan kluster posisi tanaman. Selain itu, nodes khasiat akan diberikan warna yang berbeda dan menjadi kluster tersendiri pada graf, sehingga atribut position dari nodes khasiat akan bernilai NULL.
Selanjutnya, dilakukan perhitungan bobot pada nodes frasa khasiat dan tanaman obat. Pada nodes tanaman obat, bobot nodes merupakan jumlah khasiat yang dimiliki oleh tanaman obat. Di samping itu, pada nodes frasa khasiat, bobot nodes merupakan jumlah tanaman obat yang memiliki khasiat tersebut. Bobot dari setiap nodes disimpan dalam atribut Weight.
Edges merupakan garis yang menghubungkan antardua nodes, sehingga tabel edges harus memiliki node asal (Source) dan node tujuan (Target). Data edges yang akan dipetakan merupakan posting list dari tanaman obat. Id tanaman obat akan menjadi node asal dan id dari khasiat akan menjadi node tujuan.
Visualization Abstraction
Proses Visualization Transformation menghasilkan tabel nodes dan edges yang siap dipetakan pada proses berikutnya. Tabel nodes yang dihasilkan berjumlah 1160 records frasa khasiat ditambah dengan 891 records tanaman obat, sehingga tabel nodes berjumlah 2051 records. Contoh data yang direpresentasikan sebagai nodes ditunjukkan pada Tabel 22. Data tersebut menunjukkan id node K0001 merupakan khasiat karena field position bernilai NULL dan bobotnya 40 menunjukkan bahwa terdapat 40 tanaman obat yang memiliki khasiat tersebut. Id node S0001 menunjukkan node tersebut merupakan tanaman obat dengan kluster posisi “seed” serta memiliki bobot sebesar 18 yang menunjukkan bahwa tanaman dengan id S0001 memiliki 18 khasiat. Di samping itu, tabel edges yang dihasilkan berjumlah 3471 records. Contoh data yang direpresentasikan sebagai edges ditunjukkan pada Tabel 23.
Tabel 22 Contoh data yang direpresentasikan sebagai nodes
Id Label position Weight
K0001 cough 40
K0003 sore throat 5
S0001 fennel’s seed seed 18
S0010 akasia’s root root 5
Tabel 23 Contoh data yang direpresentasikan sebagai edges
Source Target
S0001 K0002
S0001 K0003
24
Visual Mapping Transformation
Berdasarkan data yang diperoleh, dapat dibentuk visualisasi dalam bentuk graf yang dapat memodelkan keterhubungan tanaman obat dengan khasiatnya. Visualisasi informasi memiliki 2 komponen utama: representasi dan interaksi (Yi et al. 2007). Data pada visualization abstraction mengandung informasi yang siap dipetakan dan divisualisasikan di layar menggunakan minimal satu teknik visualisasi. Visual mapping transformation merupakan tahap yang melakukan eksplorasi pada salah satu komponen utama visualisasi, yakni representasi. Proses ini dilakukan dengan menggunakan Gephi untuk membantu memanipulasi visualisai network.
Graf
Data yang digunakan pada proses ini ialah data pada tahap visualization abstraction. Tabel edges dan nodes diimpor dari DBMS MySQL ke dalam software Gephi. Tipe graf yang digunakan ialah undirected graph, sebab jika suatu khasiat A terhubung dengan khasiat B, dapat dipastikan bahwa khasiat B juga terhubung dengan khasiat A. Jumlah node diperoleh sebanyak 2051 nodes dan jumlah edges diperoleh sebanyak 3471 edges. Hasil pengiriman data dari DBMS MySQL ke dalam Gephi merupakan sebuah graf dengan posisi yang tidak beraturan atau disebut dengan random layout. Pada kondisi graf tersebut, sulit untuk dipahami keterhubungan yang terbentuk antara suatu node dengan nodes lainnya, sebab letak nodes yang memiliki keterhubungan cenderung tidak berdekatan dan dihalangi oleh nodes lainnya. Hasil graf dengan random layout tersebut dapat dilihat di Gambar 8.
Layout
Untuk mendapatkan graf yang dapat lebih terbaca, pada graf asal yang terbentuk diterapkan algoritme layout. Algoritme layout digunakan untuk mendapatkan letak koordinat dari setiap nodes di dalam graf dengan menggunakan prinsip dari algoritme Fruchterman-Reingold (Lampiran 2). Prinsip algoritme tersebut meletakkan nodes yang terhubung oleh sebuah edge secara
25 berdekatan satu dengan yang lainnya namun nodes tersebut diusahakan tidak digambar terlalu berdekatan satu dengan yang lainnya (Fruchterman dan Reingold 1991). Algoritme ini menghasilkan graf yang ditunjukkan oleh Gambar 9 di mana terbentuk kelompok dari nodes tersebut dan menjadi dapat lebih terlihat, nodes yang berhubungan diletakkan secara berdekatan.
Partition
Klusterisasi nodes dalam graf digunakan untuk mendapatkan informasi yang lebih luas mengenai struktur dari graf (Blondel et al. 2008). Kluster, biasa disebut komunitas atau modul, ialah sekumpulan nodes yang biasanya memiliki atribut yang sama dan atau memiliki peran yang sama di dalam sebuah graf (Furtanto 2010). Pendekatan yang digunakan mendeteksi komunitas pada graf ialah dengan dengan menggunakan pengklusteran berdasarkan posisi tanaman dan khasiat tanaman obat.
Keberadaan komunitas dapat ditunjukkan dengan teknik pewarnaan graf berdasarkan partition. Partition ialah sebuah bagian dari graf yang terdapat di dalam satu kluster, sehingga dapat terlihat nodes mana saja yang masuk ke dalam satu kluster (Furtanto 2010). Penelitian ini menggunakan hasil komunitas yang terbentuk dari pengklusteran posisi tanaman untuk pewarnaan partition dari graf. Selain itu, untuk membedakan nodes khasiat dan nodes tanaman obat juga digunakan pewarnaan yang berbeda. Nodes khasiat diberikan satu warna sama yang dapat menyatakan bahwa nodes tersebut merupakan khasiat. Di samping itu, nodes tanaman obat dibedakan berdasarkan posisi tanaman yang berkhasiat, sehingga pewarnaan nodes dilakukan dengan menggunakan kluster posisi tanaman obat. Gambar 10 menunjukkan hasil pewarnaan graf berdasarkan kluster posisi yang terbentuk. Pemilihan warna didasarkan pada pengkodean warna Kuno (2004). Keterangan mengenai komunitas yang terbentuk dari teknik tersebut dapat dilihat di Lampiran 3.
26
Ranking
Penggalian informasi dari graf dapat juga dilakukan melalui representasi ranking. Ranking pada penelitian ini berupaya memberikan informasi terkait dengan urutan jenis khasiat yang banyak dimiliki oleh tanaman obat di Indonesia dan tanaman obat yang paling banyak memiliki khasiat di Indonesia. Graf dengan penerapan ranking ditunjukkan pada Gambar 11. Jenis khasiat yang banyak dimiliki oleh tanaman obat di Indonesia ditentukan menggunakan jumlah edges yang dimiliki oleh nodes tersebut, disebut dengan bobot. Semakin besar nilai bobot dari sebuah node, maka semakin banyak tanaman obat yang memiliki khasiat tersebut dan menjadikan semakin besar pula ukutan node khasiat tersebut. Selain itu, untuk nodes tanaman obat digunakan penerapan ranking dalam menyatakan jumlah khasiat yang dimiliki oleh setiap tanaman. Semakin besar ukuran node, maka semakin banyak khasiat yang dimiliki oleh tanaman obat tersebut. Bobot tersebut divisualisasikan dalam piksel dengan ukuran minimum node sebesar 10 piksel dan ukuran maksimum node sebesar 572 piksel. Ukuran
Gambar 10 Graf dengan penerapan kluster khasiat dan posisi tanaman
27 nodes akan disesuaikan dengan range bobot dari nodes, sebesar 1 sampai dengan 18 khasiat.
Representasi dengan ranking yang dilakukan pada langkah tersebut menyebabkan terjadinya nodes yang tumpang tindih yang menyulitkan penggalian informasi dari graf. Oleh sebab itu, penelitian ini menerapkan penggunaan algoritme Noverlap layout. Algoritme ini menghindari nodes dari keadaan tumpang tindih namun tetap menjaga bentuk asli dari graf dan cocok untuk graf dalam jumlah nodes yang besar (Bastian et al. 2009). Algoritme ini digunakan agar terdapat jarak antar nodes di dalam graf sehingga tidak menyembunyikan informasi yang terdapat pada graf tersebut. Algoritme ini lebih memilih kecepatan dibandingkan precision, rasio dibandingkan dengan jarak antara nodes yang besar, dan margin yang menyatakan nilai ruang kosong yang konstan di sekeliling node, serta dapat digunakan setelah penerapan algoritme layout yang lain sebelumnya (Bastian et al. 2009). Graf hasil penerapan algoritme ini ditunjukkan pada Gambar 12.
Gambar 12 Graf hasil penerapan algoritme Noverlap
28 Label
Representasi selanjutnya ialah pemberian label pada graf hasil visualisasi. Pemberian label dapat dilakukan pada nodes maupun edges. Namun penelitian ini hanya menerapkan pemberian label pada nodes. Label pada nodes yang digunakan ialah frasa khasiat dalam bahasa Inggris. Hasil pemberian label pada nodes graf ditunjukkan oleh Gambar 13.
Representasi label pada nodes menyebabkan terjadinya tumpang tindih tulisan label tersebut pada graf, sehingga diterapkan algoritme Label Adjust, salah satu cara yang disediakan oleh Gephi dalam mengatasi hal tersebut (Bastian et al. 2009). Algoritme ini bekerja dengan pengaturan ukuran teks sehingga membuat keseluruhan teks dapat terbaca. Graf hasil penerapan algoritme ini dan merupakan graf akhir dari tahap visual mapping transformation ini ditunjukkan pada Gambar 14. Selanjutnya graf akan disimpan ke dalam fail graf dengan format GEXF. GEXF merupakan fail graf yang dihasilkan oleh perangkat lunak Gephi berisi posisi koordinat dan atribut yang dimiliki oleh nodes serta atribut yang dimiliki oleh edges.
View
View merupakan tahap akhir dari visual mapping yang menitikberatkan pada komponen kedua dari visualisasi informasi yakni interaksi. Interaksi berusaha membuat dialog antara pengguna dan sistem sehingga pengguna dapat melakukan eksplorasi terhadap visualisasi yang terbentuk. Tanpa interaksi, sistem visualisasi informasi hanya akan menjadi sebuah gambar biasa (Yi et al. 2007).
Penelitian ini menerapkan beberapa interaksi dalam implementasinya di sistem berbasis web sehingga memungkinkan pengguna untuk melakukan eksplorasi lebih dalam terkait graf yang dihasilkan. Teknik interaksi dalam
29 visualisasi informasi terdiri atas 7 kategori yakni select, explore, reconfigure, encode, abstract, filter, dan connect (Yi et al. 2007). Penelitian ini menyediakan pengguna 6 teknik interaksi dari yang disebutkan tersebut, antara lain select, explore, reconfigure, abstract, filter dan connect.
Select merupakan salah satu interaksi yang memberikan pengguna kesempatan untuk memilih informasi yang menarik atau ingin diketahuinya. Sistem dalam penelitian ini memberikan pengguna kebebasan untuk melakukan pencarian berdasarkan frasa khasiat daan tanaman obat serta melakukan penelusuran mengenai keterhubungan tanaman obat dengan khasiatnya. Antarmuka sebelum dan setelah dilakukannya teknik interaksi select ditunjukkan oleh Lampiran 4.
Explore merupakan salah interaksi yang memungkinkan pengguna mendapatkan informasi lain selain kueri yang diberikan olehnya. Interaksi explore yang digunakan pada penelitian ini ialah panning. Panning merupakan perpindahan kamera lintas layar atau perpindahan layar ketika kamera tetap fokus terhadap objek yang sama (Yi et al. 2007). Antarmuka sebelum dan setelah dilakukannya teknik interaksi explore ditunjukkan oleh Lampiran 5.
Reconfigure merupakan interaksi yang memberikan kesempatan pengguna untuk melakukan pengaturan terhadap visualisasi yang ditampilkan untuk memperoleh perspektif yang berbeda. Node maupun label node pada graf dapat menimbulkan overlapping sehingga dapat menimbulkan pemahaman yang berbeda dari pengguna. Pada penelian ini, node dan label node yang mengalami overlapping telah diatasi pada tahap visual mapping transformation, namun untuk membantu pengguna lebih mudah memahami dan menggali informasi dari node keterhubungan dengan density yang tinggi, pada penelitian ini diterapkan lens mode, yakni kaca pembesar untuk membantu pengguna memahami graf dengan density yang tinggi. Antarmuka sebelum dan setelah dilakukannya teknik interaksi reconfigure ditunjukkan oleh Lampiran 6.
Abstract merupakan interaksi yang menyediakan informasi yang lebih detail dari graf yang disajikan. Penelitian ini menerapkan salah satu teknik abstact, yaitu zooming. Pengguna dengan mudah mengubah skala representasi sehingga mereka dapat melihat graf dengan jumlah node yang lebih banyak dalam satu layar (menggunakan zoom-out) atau mengurangi jumlah node yang ditampilkan pada layar (menggunakan zoom-in). Antarmuka sebelum dan setelah dilakukannya teknik interaksi Abstract ditunjukkan oleh Lampiran 7.
Filter merupakan interaksi yang memungkinkan pengguna memilih graf yang ditampilkan di layar dengan kondisi tertentu. Pada teknik interaksi ini, pengguna dapat menspesifikasikan kondisi yang diinginkan untuk memudahkan pemahaman dan penggalian informasi, sehingga hanya data dengan kriteria tertentu yang ditampilkan. Penelitian ini menerapkan teknik filter dengan memberikan pilihan kepada pengguna untuk menampilkan atau tidak nodes dan edges yang tidak berhubungan dengan nodes yang menjadi fokus pengguna, sehingga pengguna dapat memilih untuk hanya menampilkan nodes dan edges yang memiliki keterhubungan dengan node fokus pengguna saja. Antarmuka sebelum dan setelah dilakukannya teknik interaksi Filter ditunjukkan oleh Lampiran 8.
30
node yang menjadi fokus pengguna. Selain itu, sistem pada penelitian ini juga membantu pengguna melakukan penelusuran terhadap nodes lainnya yang terhubung langsung dengan node yang menjadi fokus pengguna. Dengan menggeser mouse dan menyoroti nodes tetangga dari node fokus pengguna, akan ditampilkan nodes lainnya yang terhubung dengan node tetangga tersebut. Antarmuka sebelum dan setelah dilakukannya teknik interaksi Explore ditunjukkan oleh Lampiran 9.
SIMPULAN DAN SARAN
Simpulan
Penelitian ini menghasilkan aplikasi visualisasi informasi yang dapat memodelkan keterhubungan tanaman obat dengan khasiatnya. Penelitian ini menerapkan komponen representasi terhadap pengurutan khasiat yang banyak dimiliki oleh tanaman obat di Indonesia, jumlah tanaman obat sama yang dimiliki oleh setiap pasang khasiat, dan keeratan hubungan antarkhasiat. Penelitian ini juga menerapkan komponen interaksi untuk membantu pengguna mengeksplorasi informasi dari visualisasi graf yang dihasilkan.
Saran
Penelitian selanjutnya juga dapat menerapkan interaksi encode yang dapat menyesuaikan dengan kondisi pengguna, misalnya pengkodean ulang untuk mengubah representasi warna menjadi tekstur untuk pengguna yang menderita buta warna. Selain itu, penelitian selanjutnya dapat mengembangkan sistem visualisasi untuk data yang dinamis.
DAFTAR PUSTAKA
Afendi FM, Sulistiyani, Hirai A, Amin MA, Tahahashi H, Nakamura K, Kanaya S. 2010. Modelling ingredient of jamu to predict Its efficacy. Forum Statistika dan Komputasi [Internet]. [diunduh 2013 Mei 25]; 15(2):1-9. http://journal.ipb.ac.id/index.php/statistika/article/viewFile/4898/3330.
Bastian M, Heyman S, Jacomy M. 2009. Gephi : an open source software for exploring and manipulatif Networks. International AAAI Conference on Weblogs and Social Media[Internet]; 2009 Mar. [tempat pertemuan tidak diketahui]. North America(OA):Third International AAAI Conference on Weblogs and Social Media.
31 Blondel VD, Guillaume JL, Lambiotte R, Lefebvre E. 2008. Fast unfolding of communities in large networks. J Stat Mech. 2008(10):P10008.doi: 10.1088/1742-5468/2008/10/P10008.
Chi EH. 1999. A framework for information visualization spreadsheets [disertasi]. Minneapolis (US): University of Minnesota.
Fortunato S. 2010. Community detection in graphs. Physics Report. 486(3): 75-174.doi: 10.1016/j.physrep.2009.11.002.
Fruchterman TMJ, Reingold EM. 1991. Graph drawing by force-directed placement Softw Pract Exper. 21(11):1129-1164.
Grinstein GG, Ward MO. 2002. Introduction to data visualization. Di dalam: Fayyad U, Grinstein GG, Wierse A, editor. Information Visualization in Data Mining and Knowledge Discovery. San Francisco (US): Morgan Kaufmann Publishers. hlm 1-17.
Holloway T. 2010. The big picture : search and discovery. Di dalam: Steele J, Iliinsky N, editor. Beautiful Visualization Looking at Data through the Eyes of Experts. Sebastopol (CA): O'Reilly Media. hlm 143-156.
Keim DA. 2002. Information visualization and visual data mining. IEEE Trans Vis Comput Graph. 7(1):100-107.doi: 10.1109/2945.981847.
Kuno N. 2004. Tasteful Color Combinations. Singapura (SG): PageOne.
Manning CD, Raghavan P, Schütze H. 2009. An Introduction to Information Retrieval. Cambridge(UK): Cambridge University Press.
Uchida Y, Yoshikawa T, Furuhashi T, Hirao E, Iguchi H. 2009. Extraction of important keywords in free text of questionnaire data and visualization of relationship among sentences. Di dalam: FUZZ-IEEE International Conference 2009 Agus 20-24; Jeju,Korea Selatan. Jeju (KP): IEEE. hlm 1604-1608.