INDAH RATIH ANGGRIYANI
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
Dengan ini saya menyatakan bahwa tesis Kajian Analisis Gerombol Berbasis pada Data yang Menyebar Normal Ganda, adalah karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Bogor, Agustus 2011
Indah Ratih Anggriyani G151090021
Distribution Multivariate Data. Under direction of KUSMAN SADIK, and UTAMI DYAH SAFITRI
Cluster analysis is data method classify objects into groups based on similarity or dissimilarity. One of approach is model based clustering. The assumptions used is the data derived from a mixture of two or more distribution probability with certain proportions. The final cluster is determined by BIC. The object of each cluster were obtained by EM algorithm. This study aims to assess the effectiveness of the model based clustering on the data are from multivariate normal distribution. Effectiveness would include the percentage of classification errors produced at a several distance, comparing with the k-means, and their application. If the distance between the center of a large and diverse cluster each different variables, then averaging the resulting classification error rate small. generally model based to cluster is more effective than the method of k-means. The MAP was better than the MLE since it can overcome the singularity problem, the rest same as MLE.
Data yang Menyebar Normal Ganda. Dibimbing oleh KUSMAN SADIK dan UTAMI DYAH SAFITRI
Analisis gerombol merupakan suatu metode penggerombolan yang bertujuan untuk mengelompokkan objek ke dalam beberapa kelompok sedemikian hingga objek yang berada di dalam kelompok yang sama cenderung mempunyai karakteristik yang lebih homogen dari pada objek yang berada di kelompok yang berbeda. Hal ini dilakukan dengan suatu ukuran jarak seperti jarak euclidean. Pengukuran kemiripan antar objek dengan menggunakan jarak akan sangat sulit dilakukan jika ukuran data yang digunakan sangat besar dan kondisi objek yang ada saling tumpang tindih.
Dengan memperhatikan sebaran dari data yang digunakan untuk penggerombolan, Mclachlan dan Basford (1988) memberikan suatu pendekatan terbaru dalam analisis gerombol yaitu penggerombolan berbasis model campuran. Metode ini mengasumsikan bahwa sebaran data yang digunakan adalah sebaran campuran dengan setiap subpopulasi mewakili suatu gerombol yang berbeda. Tujuan dari metode ini adalah untuk mengoptimalkan kemiripan antar objek dengan menggunakan pendekatan model peluang. Tehnik perpindahan objek berdasarkan pada algoritma Expectation Maximization (EM) dan penentuan jumlah gerombol ditentukan berdasarkan nilai Bayes Information Criterion (BIC) terbesar. Penggunaan algoritma EM dalam pendugaan parameternya dikarenakan algoritma tersebut merupakan metode perhitungan iterasi yang sangat cocok untuk pendugaan parameter dari fungsi kemungkinan pada data tidak lengkap seperti yang terdapat pada sebaran campuran.
Sama halnya dengan metode penggerombolan lainnya, metode penggerombolan berbasis model dilakukan untuk mengetahui jumlah gerombol maupun anggota tiap gerombol. Dengan demikian, efektifitas dari metode ini dibandingkan dengan metode berdasarkan ukuran jarak adalah suatu hal yang sangat penting untuk diketahui. Tujuan dari penelitian ini yaitu mengkaji efektifitas analisis gerombol berbasis model yang meliputi efektifitas pada beberapa kondisi jarak antar pusat gerombol, perbandingan dengan metode klasik atau k-rataan serta efektifitas analisis penggerombolan berbasis model berdasarkan maximum likelihood (MLE) dan maximum posterior (MAP) pada beberapa contoh penerapan. Perbandingan dengan metode klasik atau k-rataan, keefektifannya dapat dikethaui dengan menghitung persentase rataan tingkat kesalahan klasifikasi yang dihasilkan, sedangkan efektifitas MLE dan MAP dapat diketahui berdasarkan persentase rataan tingkat kesalahan klasifikasi serta nilai BIC yang dihasilkan.
ragam setiap peubah untuk setiap gerombol sama dan berukuran besar, maka nilai korelasi berpengaruh terhadap hasil akhir penggerombolan. Nilai korelasi lebih dari 0,5 ( ) memberikan tingkat kesalahan klasifikasi yang kecil. Jika dilakukan perbandingan dengan metode k-rataan, kedua metode ini memberikan efektifitas yang sama pada kondisi ragam setiap peubah untuk setiap gerombol kecil. Pada kondisi ragam setiap peubah untuk setiap gerombol sama dan besar, k-rataan menghasilkan efektifitas terbaik pada kondisi nilai korelasi kecil. Kondisi ragam setiap peubah untuk setiap gerombol berbeda, penggerombolan berbasis model menghasilkan efektifitas yang lebih baik dibandingkan dengan metode k-rataan. Tingkat kesalahan klasifikasi yang dihasilkan berdasarkan metode kemungkinan maksimum dan metode Bayes tidak berbeda jauh. Munculnya singularitas untuk matriks peragam dapat diatasi dengan menggunakan metode Bayes.
© Hak Cipta milik IPB, tahun 2011 Hak Cipta dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan yang wajar IPB
INDAH RATIH ANGGRIYANI
Tesis
Sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada
Program Studi Statistika
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
NIM : G151090021
Disetujui
Komisi Pembimbing
Dr. Kusman Sadik, M.Si Utami Dyah Syafitri, S.Si, M.Si Ketua Anggota
Diketahui ,
Ketua Program Studi Statistika Dekan Sekolah Pascasarjana
Dr. Ir. Erfiani, M.Si Dr. Ir. Dahrul Syah, M.Sc. Agr
segala rahmat dan karunia-Nya, sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian ini adalah analisis gerombol, dengan judul
“Kajian Analisis Gerombol Berbasis Model pada Data yang Menyebar Normal Ganda ”.
Terima kasih penulis ucapkan kepada Bapak Dr. Kusman Sadik, M.Si selaku pembimbing I dan Ibu Utami Dyah Syafitri, S.Si, M.Si selaku pembimbing II, yang telah memberikan bimbingan, kesabaran dan waktunya sehingga penulis bisa menyelesaikan penelitian ini. Terima kasih juga penulis sampaikan kepada Ibu Dr. Ir. Erfiani, M.Si selaku penguji luar komisi pada ujian tesis, dan seluruh staf Program Studi Statistika.
Ucapan terimakasih juga penulis sampaikan kepada suami, orang tua dan seluruh keluarga atas do’a dukungan, dan kasih sayangnya yang tiada terputus. Terimakasih kepada Ula Susilawati, S.Si, teman-teman Statistika angkatan 2009 serta keluarga besar Statistika yang tidak dapat penulis sebutkan satu per satu atas diskusi dan motivasi yang diberikan kepada penulis.
Semoga Allah SWT membalas segala kebaikan yang telah diberikan kepada penulis, dan semoga karya ilmiah ini bermanfaat.
anak tunggal dari pasangan Bapak Indah Suat dan Ibu Haryani
DAFTAR TABEL ... xiii
DAFTAR GAMBAR ... xiv
DAFTAR LAMPIRAN ... xvi
PENDAHULUAN Latar Belakang ... 1
Tujuan ... 2
TINJAUAN PUSTAKA Gambaran Umum Analisis Gerombol ... 3
Penggerombolan Berbasis Model ... 4
Algoritma Expextation Maximization (EM) ... 5
Karakteristik Geometrik Model ... 9
Penentuan Jumlah Gerombol ... 11
DATA DAN METODE Sumber Data ... 14
Metode Penelitian ... 15
HASIL DAN PEMBAHASAN Kondisi Jarak Antar Pusat Gerombol Sama ... 21
Kondisi Jarak Antar Pusat Gerombol Dekat ... 25
Kondisi Jarak Antar Pusat Gerombol Sedang ... 29
Kondisi Jarak Antar Pusat Gerombol Jauh ... 33
Data Pohon ... 36
Data Diabetes ... 40
SIMPULAN DAN SARAN Simpulan ... 44
Saran ... 44
DAFTAR PUSTAKA ... 45
1 Matriks peragam untuk model campuran ganda dan interpretasi
geometrik ... 12
2 Parameter bebas tiap model ... 12
3 Kondisi setiap kasus simulasi ... 15
4 Statistika deskriptif peubah data pohon ... 33
5 Nilai BIC setiap model berdasarkan maksimum likelihood untuk data pohon ... 36
6 Nilai BIC setiap model berdasarkan maksimum posterior untuk data pohon ... 39
7 Statistika deskriptif peubah data diabetes ... 40
8 Nilai BIC setiap model berdasarkan maksimum likelihood untuk data diabetes ... 42
1 Diagram alur penelitian ... 18
2 Diagram alur metode penggerombolan berbasis model ... 19
3 Diagram alur pembangkitan data dengan R ... 20
4 Plot skor dua komponen utama hasil klasifikasi pada jarak antar pusat
gerombol sama ... 22
5 Persentase rataan tingkat kesalahan klasifikasi pada kondisi jarak
sama ... 23
6 Persentase rataan tingkat kesalahan klasifikasi pada kondisi jarak
sama berdasarkan MLE dan MAP ... 23
7 Persentase rataan tingkat kesalahan klasifikasi pada kondisi jarak
sama berdasarkan model based dan k-means ... 24
8 Plot skor dua komponen utama hasil klasifikasi pada jarak antar pusat
gerombol dekat ... 25
9 Persentase rataan tingkat kesalahan klasifikasi pada kondisi jarak
dekat ... 26
10 Persentase rataan tingkat kesalahan klasifikasi pada kondisi jarak
dekat berdasarkan MLE dan MAP ... 27
11 Persentase rataan tingkat kesalahan klasifikasi pada kondisi jarak
dekat berdasarkan model based dan k-means ... 28
12 Persentase rataan tingkat kesalahan klasifikasi pada kondisi jarak
dekat berdasarkan jumlah amatan ... 29
13 Plot skor dua komponen utama hasil klasifikasi pada jarak antar pusat
gerombol sedang ... 30
14 Persentase rataan tingkat kesalahan klasifikasi pada kondisi jarak
sedang ... 31
15 Persentase rataan tingkat kesalahan klasifikasi pada kondisi jarak
sedang berdasarkan MLE dan MAP ... 32
16 Persentase rataan tingkat kesalahan klasifikasi pada kondisi jarak
18 Persentase rataan tingkat kesalahan klasifikasi pada kondisi jarak
jauh ... 34
19 Persentase rataan tingkat kesalahan klasifikasi pada kondisi jarak sedang berdasarkan model based dan k-means ... 36
20 Plot dua komponen utama data pohon ... 37
21 Plot kuantil-kuantil data pohon ... 37
22 Plot nilai BIC setiap model berdasarkan maksimum likelihood untuk data pohon ... 38
23 Plot nilai BIC setiap model berdasarkan maksimum posterior untuk data pohon ... 39
24 Plot dua komponen utama data diabetes ... 41
25 Plot kuantil-kuantil data diabetes ... 41
1 Plot dua komponen utama pada salah satu ulangan dengan jumlah data
tiap gerombol 50 ... 46
2 Persentase rataan tingkat kesalahan klasifikasi ... 49
3 Data pohon ... 53
4 Data Diabetes ... 54
5 Sintaks membangkitkan data simulasi ... 56
PENDAHULUAN
Latar Belakang
Analisis gerombol merupakan suatu metode penggerombolan satuan objek pengamatan menjadi beberapa gerombol berdasarkan karakteristik yang dimiliki. Tujuan dari penggerombolan adalah untuk mengelompokkan objek ke dalam beberapa kelompok sedemikian hingga objek yang berada di dalam kelompok yang sama cenderung mempunyai karakteristik yang lebih homogen dibandingkan
objek yang berada pada kelompok yang berbeda. Hal ini dilakukan dengan suatu ukuran kemiripan atau ketidakmiripan. Semakin mirip dua objek maka semakin
tinggi peluang untuk dikelompokkan dalam suatu gerombol, sebaliknya semakin tidak mirip maka semakin rendah peluang untuk dikelompokkan dalam satu gerombol. Pengukuran kemiripan antar objek menggunakan informasi jarak. Pengukuran kemiripan antar objek dengan menggunakan jarak, akan sangat sulit dilakukan jika ukuran data yang digunakan sangat besar dan kondisi objek yang ada saling tumpang tindih.
Dengan memperhatikan sebaran dari data yang digunakan untuk penggerombolan, Mclachlan dan Basford (1988) memberikan suatu pendekatan terbaru dalam analisis gerombol yaitu penggerombolan berbasis model campuran. Tujuan dari metode ini adalah mengoptimalkan kemiripan antar objek dengan menggunakan pendekatan model peluang. Model peluang yang dimaksud adalah menerapkan pengaturan karakteristik yang berbeda–beda pada data yang dimiliki. Asumsi yang digunakan adalah keseluruhan objek merupakan campuran dari sebaran peluang. Masing–masing sebaran mewakili suatu gerombol dengan parameter tertentu. Parameter tersebut dapat diduga melalui algoritma Expectation Maximization (EM), hal ini dikarenakan algoritma EM merupakan metode perhitungan iterasi yang sangat cocok untuk pendugaan parameter dari fungsi kemungkinan pada data tidak lengkap seperti yang terdapat pada sebaran campuran. Penentuan jumlah gerombol ditentukan dengan menggunakan Bayes Information Criterion (BIC).
penggerombolan berbasis model selain mengetahui jumlah gerombol dan anggota tiap gerombol dapat diketahui kepadatan yang mendasari tiap komponen. Hal ini membuat metode penggerombolan berbasis model cukup berkembang. Beberapa penelitian yang berhubungan dengan penggerombolan berbasis model campuran telah dilakukan. Banfield dan Raftery (1993) menerapkan sebaran normal dan bukan sebaran normal dalam penggerombolan. Kesimpulan yang diberikan dalam penelitian ini yaitu bahwa data outlier dapat diatasi dengan menambahkan proses poisson. Dempster, Laird dan Rubin (1997) membahas tentang metode kemungkinan maksimum untuk data tidak lengkap melalui algoritma EM. Penentuan jumlah gerombol dan anggota tiap gerombol dalam analisis gerombol berbasis model, dilakukan oleh Fraley (1998). Kombinasi antara penggerombolan berhirarki dengan algoritma EM dan faktor Bayes dalam pemilihan model,
dilakukan oleh Fraley (2002). Pardede (2002) membandingkan metode berbasis model dengan metode ward dan metode k-rataan dalam analisis gerombol. Pendugaan parameter dengan metode kemungkinan maksimum yang digunakan dalam penelitian itu menyimpulkan bahwa metode berbasis model merupakan metode yang lebih baik dibandingkan metode ward dan metode k-rataan, akan tetapi dalam keadaan bentuk gerombol tertentu terjadi kesalahan penggerombolan. Fraley (2007) melakukan pendekatan bayes dalam pendugaan parameternya guna mengatasi munculnya singularitas untuk beberapa model. Pada penelitian ini akan dilakukan pengkajian analisis gerombol berbasis model campuran pada data yang menyebar normal ganda.
Tujuan
Tujuan yang ingin dicapai dalam penelitian ini yaitu
1. Mengkaji efektifitas analisis gerombol berbasis model. Kajian yang dimaksud meliputi efektifitas analisis gerombol berbasis model pada beberapa kondisi jarak antar pusat gerombol,
TINJAUAN PUSTAKA
Gambaran Umum Analisis Gerombol
Analisis gerombol merupakan salah satu metode analisis peubah ganda yang bertujuan untuk mengelompokkan objek kedalam kelompok – kelompok tertentu yang relatif homogen berdasarkan kemiripan atau ketidakmiripan karakteristik– karakteristik yang dimiliki (Hair et al, 1998). Ukuran kemiripan yang digunakan adalah fungsi jarak antara dua objek. Bila antar peubah yang digunakan saling
bebas digunakan jarak euclidean -
sedangkan bila terdapat
korelasi antar peubah digunakan jarak mahalanobis - - -
dengan adalah matriks ragam peragam. Secara umum terdapat dua metode
penggerombolan yang menggunakan ukuran jarak, yaitu metode penggerombolan berhirarki dan metode penggerombolan tak berhirarki (Johnson, 1998).
a. Metode berhirarki
Metode penggerombolan berhirarki dimulai dengan mengelompokkan dua atau lebih objek yang memiliki kesamaan terdekat menjadi suatu gerombol baru sehingga jumlah gerombol berkurang satu pada setiap tahap, atau dengan menganggap seluruh objek berasal dari satu gerombol kemudian ketidakmiripan yang paling tinggi dipisah hingga tiap observasi menjadi gerombol sendiri– sendiri. Metode ini digunakan bila jumlah gerombol yang akan dibentuk belum diketahui sebelumnya.
b. Metode tak berhirarki
Metode penggerombolan tak berhirarki digunakan bila banyaknya gerombol yang akan dibentuk sudah diketahui sebelumnya. K-rataan merupakan metode tak berhirarki yang paling banyak digunakan. Penentuan objek kedalam gerombol tertentu pada metode ini berdasarkan rataan terdekat, yang terdiri dari tiga tahap. Tahap pertama mengambil k unit data pertama yang digunakan sebagai k pusat gerombol awal. Tahap kedua, menggabungkan setiap (n-k) data yang merupakan
kemudian dilakukan penggabungan kembali dari setiap unit data ke dalam titik pusat terdekat. Ketiga tahap ini dilakukan hingga diperoleh gerombol yang konvergen yaitu adanya titik pusat yang tetap dan tidak ada lagi perubahan anggota di setiap gerombol. Metode penggerombolan tak berhirarki lainnya adalah metode penggerombolan berbasis model campuran.
Penggerombolan Berbasis Model
Metode penggerombolan berbasis model campuran mengasumsikan bahwa sebaran data yang digunakan adalah sebaran campuran dengan setiap subpopulasi mewakili suatu gerombol yang berbeda, sehingga dalam mendefinisikan setiap gerombol yang terbentuk digunakan distribusi statistik (Fraley,1998). Tujuan dari metode ini adalah untuk mengoptimalkan kemiripan antar objek dengan
menggunakan pendekatan model peluang. Pendekatan tersebut dapat memodelkan data yang dimiliki dengan menerapkan pengaturan karakteristik yang
berbeda-beda dan menentukan jumlah gerombol yang sesuai dengan data seiring proses pemodelan karakteristik dari masing-masing gerombol tersebut. Berbeda dengan k-rataan yang perpindahan objek secara berulang dari satu gerombol ke gerombol lain mulai dari partisi awal berdasarkan jarak metrik, tehnik perpindahan objek pada analisis gerombol berbasis model didasarkan pada algoritma EM. Penentuan banyaknya gerombol dalam metode ini ditentukan dengan menggunakan BIC.
Sebaran campuran merupakan campuran dari beberapa sebaran statistik, dimana contoh berasal dari populasi yang tidak sama. Sebaran ini digunakan dalam dua keadaan yaitu struktur campuran dari populasi diketahui dan struktur campuran dari populasi tidak diketahui. Dengan demikian pada keadaan pertama dapat diduga sebaran masing – masing subpopulasi dan proporsinya, sedangkan pada keadaan kedua dapat dilakukan klasifikasi data ke dalam subpopulasi berdasarkan peluang akhir (Mclachlan dan Basford 1988). Misalkan
adalah proporsi subpopulasi ke- dan adalah fmp atau fkp subpopulasi.
Fungsi kepekatan campuran (fkp) dari subpopulasi tidak harus memiliki parameter dan sebaran yang sama, namun dalam penelitian ini digunakan fkp subpopulasi yang memiliki sebaran yang sama dan parameter yang berbeda. Dengan demikian fkp campuran untuk beberapa vektor parameter yang tidak diketahui yaitu:
(1)
Dengan asumsi contoh acak bebas stokastik dan identik, dengan fungsi
kepekatan objek dari gerombol ke-k yaitu , maka fungsi kepekatan
campuran pada persamaan (1) didefinisikan sebagai:
(2)
dimana merupakan peluang suatu pengamatan berada pada komponen ke-k
.
Dalam penelitian ini digunakan sebaran normal ganda yang dinotasikan
dengan ( , sehingga jika merupakan fungsi kepekatan peubah
ganda campuran normal dengan parameter vektor rataan dan matriks peragam
dapat dinyatakan dalam bentuk
Algoritma EM
Dalam analisis gerombol berbasis model, algoritma EM dapat digunakan sebagai tehnik perpindahan objek sehingga dapat memutuskan hasil gerombol. Menurut Dempster (1977), algoritma ini merupakan metode perhitungan iterasi yang sangat cocok untuk pendugaan parameter dari fungsi kemungkinan maksimum pada data tidak lengkap seperti yang terdapat pada sebaran campuran. Pada sebaran campuran dinyatakan bahwa data terdiri dari n pengamatan peubah
ganda yang diperoleh dari , dengan merupakan peubah yang teramati
dan merupakan peubah yang tidak teramati. memetakan objek ke dalam
gerombol dimana yang didefinisikan dengan
diasumsikan saling bebas dan terdistribusi identik menurut sebaran multinomial
dari G kategori dengan peluang dan fkp dari dengan adalah
. Setiap iterasi pada algoritma EM terdiri atas dua tahap yaitu
expectation-step (tahap E) dan maximization-step (tahap M).
Diketahui bahwa contoh acak saling bebas dan yang
menentukan objek dari gerombol mana berasal, maka
dengan
Fungsi kemungkinan yang diperoleh yaitu
Jika digunakan fungsi kepekatan peubah ganda campuran normal, maka fungsi kemungkinannya adalah:
- - - -
Tahap E
Pada tahap E merupakan tahap untuk menghitung nilai harapan bersyarat dari loglikelihood. Dengan demikian, diperoleh:
- - - -
dengan
Tahap M
Pada tahap M merupakan tahap untuk memaksimalkan nilai harapan bersyarat
dari loglikelihood. Paramater yang diduga yaitu proporsi campuran ( ), rata-rata
( ), dan matrik kovarian ( ).
- - - -
-Terdapat dua metode pendugaan parameter yang bisa digunakan dalam tahap ini, yaitu metode kemungkinan maksimum dan metode Bayes.
a. Metode kemungkinan maksimum
Pendugaan parameter dengan menggunakan metode kemungkinan maksimum bertujuan untuk mencari nilai fungsi loglikelihood yang paling maksimum (Fraley, 2002). Fungsi kemungkinan maksimum untuk peubah ganda normal (n objek) yaitu
- - - - - - - - (4
Pada model campuran dengan G komponen, fungsi kemungkinan maksimum likelihood didefinisikan sebagai:
Jika fkp dari pengamatan yang diberikan oleh adalah , maka
loglikelihood data lengkap adalah:
(5)
Fraley & Raftery (2002) mengemukakan bahwa penduga parameter yang memaksimalkan dihitung menggunakan yang diperoleh pada
tahap E, dengan formula parameter sebagai berikut:
b. Metode Bayes
awal yang dimaksud untuk peubah ganda normal yaitu sebaran normal untuk kondisi rata-rata dengan syarat matriks peragam dan sebaran kebalikan wishart untuk kondisi matriks peragam. Dengan demikian fkp sebaran awal merupakan hasil kali dari sebaran normal dengan sebaran kebalikan wishart. Sebaran awal untuk rata-rata adalah sebaran normal (bersyarat pada matriks peragam), didefinisikan sebagai
- - (6)
dan sebaran awal matriks peragam yaitu sebaran kebalikan wishart, didefinisikan sebagai
.
(7)
dan diasumsikan sama untuk semua komponen, dengan rincian sebagai berikut:
: rata-rata dari data
: 0,01 (pemulusan bagian kurva BIC)
: p+2
(untuk model spherical dan diagonal)
: ( (untuk model ellipsoidal)
dan adalah matriks peragam.
Fraley (2007) mengemukakan bahwa formula parameter yang digunakan guna memaksimalkan posterior, yang dihitung menggunakan pada tahap E sebagai
berikut:
Algoritma EM membutuhkan inisialisasi nilai awal dalam algoritmanya. Tingkat konvergensi bisa sangat lama apabila tidak digunakan nilai inisialisasi awal yang wajar. Banfiled (1993) menggunakan metode analisis gerombol berhirarki sebagai inisialisasi nilai awal , kemudian secara iteratif dugaan nilai parameter akan
diperbaharui. Berdasarkan Fraley (2010), penentuan nilai awal berdasarkan penggabungan objek dilakukan berdasarkan jarak minimum.
Karakteristik Geometrik Model
Setiap gerombol yang terbentuk berpusat di dan matriks peragam
yang dihasilkan akan menentukan karakteristik geometrik yaitu bentuk, volume dan orientasi (Fraley dan Raftery 2002). Pencirian sebaran geometrik (orientasi, bentuk, volume) mungkin akan diperoleh dari berbagai macam bentuk gerombol atau terbatas pada gerombol yang sama. Bentuk komponen matriks peragam terdiri atas tiga macam yaitu spherical, diagonal dan ellipsoidal. Fraley (2007) mengemukakan formula berdasarkan metode pendugaan parameter yang digunakan, yaitu:
a. Metode kemungkinan maksimum
1. Bentuk spherical (sebanding dengan matriks identitas) - Spherical sama
- Spherical berbeda
2. Bentuk diagonal (sejajar sumbu) - Diagonal sama
- Diagonal berbeda
3. Bentuk ellipsoidal - Diagonal sama
- Diagonal berbeda
b. Metode bayes
1. Bentuk spherical (sebanding dengan matriks identitas) - Spherical sama
- Spherical berbeda
2. Bentuk diagonal (sejajar sumbu) - Diagonal sama
- Diagonal berbeda
3
3. Bentuk ellipsoidal - Diagonal sama
- Diagonal berbeda
Guna mendefinisikan kelas metode penggerombolan berhirarki berdasarkan geometri lintas gerombol, Branfield dan Raftery (1993) menyatakan matriks peragam melalui suku-suku dekomposisi akar ciri untuk komponen gerombol
model campuran peubah ganda dalam bentuk:
(9
dimana
adalah matriks vektor ciri
adalah akar ciri terbesar dari
adalah matriks diagonal dengan elemennya proporsional terhadap akar ciri
dari , yaitu dimana
Ketiga suku dekomposisi diatas mencirikan karakteristik geometrik dimana mencirikan orientasi dari k gerombol, mencirikan ukuran dan mencirikan
bentuk. Ukuran tersebut diartikan sebagai volume dari cluster dalam p peubah yang berisi objek.
Pencirian sebaran geometrik (orientasi, bentuk, volume) mungkin akan diperoleh dari berbagai macam bentuk gerombol atau terbatas pada gerombol yang sama. Matriks peragam untuk semua komponen bisa sama atau bervariasi, yang secara umum dapat dilihat pada Tabel 1.
Penentuan Jumlah Gerombol
Jumlah gerombol terbaik dapat ditentukan dengan memilih model terbaik melalui nilai BIC terbesar. Fraley (1998) menyatakan bahwa pemilihan model terbaik dilakukan dengan membandingkan model parameterisasi matriks peragam yang berbeda dan banyaknya gerombol yang berbeda. Secara umum formulasi yang digunakan adalah sebagai berikut:
(10)
dimana
= loglikelihood yang dimaksimalkan untuk model dan data = jumlah parameter bebas yang diduga dalam model
Tabel 1 Matriks peragam untuk model campuran normal ganda dan interpretasi geometrik
Simbol Mclust
Bentuk Prior Dipakai untuk
EII Spherical Inverse gamma
VII Spherical Inverse gamma
EEI Diagonal Inverse gamma Setiap anggota diagonal
VEI Diagonal
EVI Diagonal
VVI Diagonal Inverse gamma Setiap anggota diagonal EEE Ellipsoidal Inverse wishart
VEE Inverse gamma
Inverse wishart EVE Ellipsoidal
VVE Ellipsoidal Inverse gamma Setiap anggota diagonal EEV Ellipsoidal Inverse gamma Setiap anggota diagonal VEV Ellipsoidal
EVV Ellipsoidal Inverse gamma
Inverse wishart VVV Ellipsoidal Inverse wishart Sumber: (Fraley, 2007).
Jika pada algoritma EM ingin dihasilkan nilai maksimum posterior yang
konvergen, maka pada persamaan diatas diganti dengan nilai
posterior (Fraley,2007). Dalam perhitungan nilai BIC setiap model dibutuhkan informasi mengenai jumlah parameter bebas yang diduga, yang secara garis besar dapat dilihat pada Tabel 2.
Tabel 2 Parameter bebas tiap model
Model Parameter Bebas
(
(
(
( (
Fraley (2002) membuat strategi metode berbasis model dengan mengkombinasikan penggerombolan hirarki, algoritma EM dan faktor bayes, dengan langkah–langkah sebagai berikut:
1. Tentukan banyak gerombol maksimum ( ) dari himpunan model campuran
2. Lakukan penggerombolan secara hirarki penggabungan, untuk setiap model campuran normal ganda. Hasil gerombol ini ditransformasikan ke dalam peubah indikator, yang kemudian digunakan sebagai nilai awal untuk algoritma EM
3. Lakukan algoritma EM untuk setiap model dan setiap gerombol 3 ,
yang dimulai dengan klasifikasi dari gerombol berhirarki
DATA DAN METODE
Sumber Data
Data yang digunakan dalam penelitian ini adalah data hasil simulasi dan data dari paket Mclust ver 3.4.8. Data simulasi dibuat dalam dua jumlah amatan yaitu 50 dan 150. Tujuan dari data simulasi ini adalah untuk mengenalkan model karena data ini dihasilkan berdasarkan kondisi yang diinginkan. Penggunaan jumlah amatan yang berbeda, bertujuan untuk mengetahui efektifitas analisis gerombol berbasis model pada jumlah amatan kecil dan besar. Setiap kasus simulasi dilakukan sebanyak lima kali ulangan, hal ini dikarenakan setiap kasus yang digunakan pemilihannya dilakukan secara acak. Pemilihan jarak antar pusat gerombol dan ragam setiap peubah mengacu pada Pardede (2002). Guna melihat
pengaruh tingkat korelasi antara peubah terhadap hasil akhir penggerombolan, dicobakan empat tingkat korelasi yaitu tidak ada korelasi (0), korelasi rendah
(0,2), korelasi sedang (0,5) dan korelasi tinggi (0,8).
Data simulasi yang dibangkitkan merupakan data himpunan campuran normal ganda, yang dibangkitkan dengan menggunakan fungsi mvnorm pada perangkat lunak program R ver.2.12.1. Kondisi kasus simulasi yang digunakan terbagi dalam empat kondisi jarak antar pusat gerombol yaitu (1) pusat antar gerombol sama, (2) pusat antar gerombol berdekatan, (3) pusat antar gerombol memiliki jarak sedang dan (4) pusat antar gerombol saling terpisah.
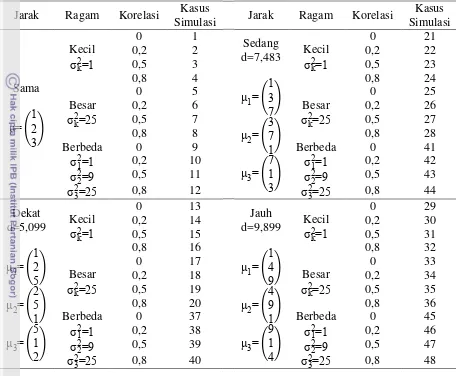
Tabel 3 Kondisi setiap kasus simulasi
Jarak Ragam Korelasi Kasus
Simulasi Jarak Ragam Korelasi
Kasus
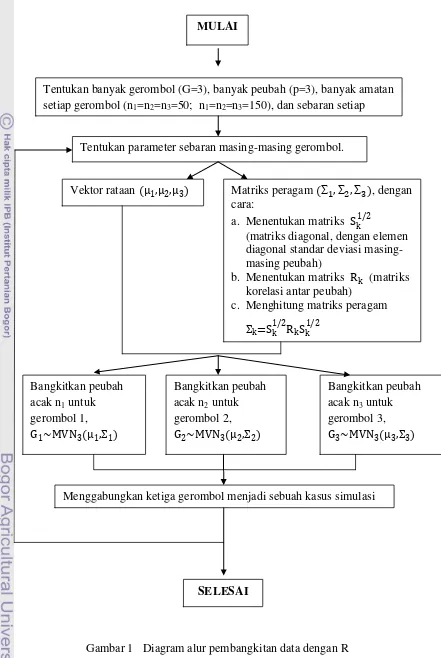
Pada data simulasi, prosedur yang digunakan terdiri atas tujuh tahap, yaitu: 1. Membangkitkan data simulasi dengan menggunakan paket R
Tahapan yang dilakukan dalam membangkitkan data simulasi dengan menggunakan paket R adalah sebagai berikut:
i. Menentukan banyak gerombol (G=3), banyak peubah (p=3) dan banyak amatan setiap gerombol (n1=n2=n3=50), dan sebaran setiap
gerombol (Gk Normal Ganda)
ii. Menentukan parameter sebaran masing-masing gerombol, yaitu vektor rataan , dan matriks peragam . Matriks peragam
a. Menentukan matriks yang merupakan matriks diagonal
dengan elemen diagonalnya adalah standar deviasi masing-masing peubah, berdimensi 3x3
b. Menentukan matriks yang merupakan matriks korelasi antar
peubah, k=1,2,3
c. Menghitung matriks peragam
iii. Membangkitkan peubah acak sebanyak untuk gerombol 1,
iv. Membangkitkan peubah acak sebanyak untuk gerombol 2,
v. Membangkitkan peubah acak sebanyak untuk gerombol 1,
vi. Menggabungkan ketiga gerombol tersebut menjadi sebuah kasus simulasi
vii. Ulangi tahap ii - vi untuk kondisi penggerombolan yang telah ditentukan
Secara garis besar alur pembangkitan data dapat dilihat pada Gambar 1. 2. Membuat plot dua komponen utama pada setiap kasus simulasi, guna
melihat pola data dan mengidentifikasi penggerombolan objek.
3. Menerapkan metode analisis gerombol berbasis model dengan menggunakan paket Mclust pada program R. Tahapan yang digunakan dalam penggerombolan berbasis model adalah sebagai berikut:
i. Melakukan penggerombolan berhirarki gabungan dengan
menggunakan model sehingga diperoleh nilai untuk
G=1,2,..M dimana M merupakan jumlah gerombol maksimum. ii. Melakukan algoritma EM
yang dimulai dengan iterasi saat m=0 Tahap E
Tahap M
- Metode kemungkinan maksimum - Metode Bayes
(
(
( (
( ( ( (
( (
(
tergantung model ( tergantung model Lakukan untuk iterasi (m+1) dan seterusnya, hingga diperoleh nilai maksimum loglikelihood atau masksimum posterior yang konvergen. iii. Menghitung nilai BIC
iv. Melakukan tahap i–iii untuk banyak gerombol yang berbeda,
v. Membandingkan nilai BIC untuk setiap solusi gerombol yang terbentuk dan nilai BIC terbesar yang terpilih.
4. Membandingkan dugaan parameter yang dihasilkan pada tahap 3 dengan parameter yang sebenarnya
5. Membandingkan hasil klasifikasi tiap amatan yang dihasilkan dengan hasil klasifikasi yang sebenarnya
6. Menghitung rataan persentase salah pengelompokkan setiap gerombol 7. Rataan persentase salah pengelompokkan yang terkecil menunjukkan bahwa
metode analisis gerombol berbasis model lebih baik.
8. Lakukan tahap 1-7 untuk jumlah amatan tiap gerombol 150.
Prosedur yang digunakan untuk contoh penerapan terdiri atas empat tahap yaitu: 1. Membuat plot dua komponen utama dari data yang digunakan untuk
melihat pola dan mengidentifikasi penggerombolan objek 2. Melakukan uji normal ganda
3. Menerapkan metode analisis gerombol berbasis model dengan menggunakan paket Mclust pada program R
4. Membandingkan nilai BIC yang dihasilkan oleh metode kemungkinan maksimum (MLE) dan metode Bayes (MAP)
Tentukan banyak gerombol (G=3), banyak peubah (p=3), banyak amatan setiap gerombol (n1=n2=n3=50; n1=n2=n3=150), dan sebaran setiap
Tentukan parameter sebaran masing-masing gerombol.
Vektor rataan
Matriks peragam , dengan cara:
a. Menentukan matriks
(matriks diagonal, dengan elemen diagonal standar deviasi masing-masing peubah)
b. Menentukan matriks (matriks korelasi antar peubah)
c. Menghitung matriks peragam
Bangkitkan peubah acak n1 untuk
gerombol 1,
Bangkitkan peubah acak n2 untuk
gerombol 2,
Bangkitkan peubah acak n3 untuk
gerombol 3,
Menggabungkan ketiga gerombol menjadi sebuah kasus simulasi
SELESAI
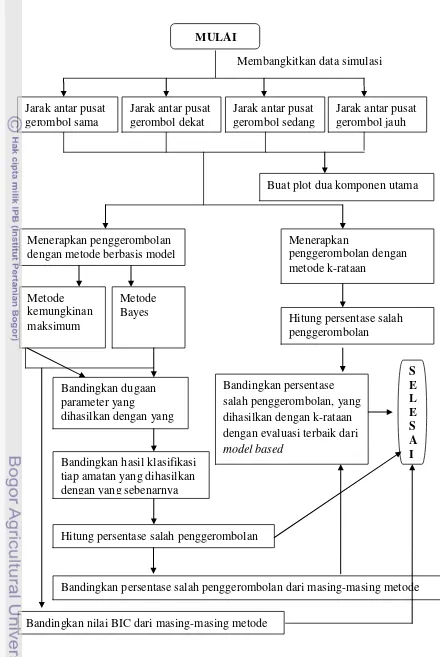
MULAI
Buat plot dua komponen utama
Menerapkan penggerombolan dengan metode berbasis model
Bandingkan dugaan
Gambar 2 Diagram alur penelitian Bandingkan hasil klasifikasi
tiap amatan yang dihasilkan dengan yang sebenarnya
Hitung persentase salah penggerombolan Metode
Bayes
Bandingkan persentase salah penggerombolan dari masing-masing metode Hitung persentase salah penggerombolan
Bandingkan persentase salah penggerombolan, yang dihasilkan dengan k-rataan dengan evaluasi terbaik dari model based
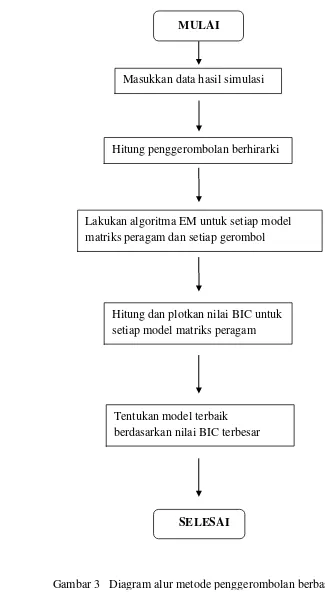
MULAI
Masukkan data hasil simulasi
Hitung penggerombolan berhirarki
Lakukan algoritma EM untuk setiap model matriks peragam dan setiap gerombol
Hitung dan plotkan nilai BIC untuk setiap model matriks peragam
Tentukan model terbaik
berdasarkan nilai BIC terbesar
SELESAI
HASIL DAN PEMBAHASAN
Data yang dibangkitkan terdiri dari 96 kasus data simulasi, dengan setiap kasus data simulasi terdiri dari tiga gerombol. Kasus data simulasi tersebut dibedakan atas jarak antar pusat gerombol, ragam setiap peubah pada setiap gerombol, nilai korelasi, dan banyak data.
Berdasarkan plot skor dua komponen utama yang dihasilkan untuk setiap kasus simulasi, dapat diketahui kondisi yang terbentuk dari ketiga gerombol yang dibangkitkan. Terdapat tiga macam kondisi yang terbentuk dari ketiga gerombol yang dibangkitkan, yaitu saling berdekatan, saling berjauhan maupun saling tumpang tindih. Plot skor dua komponen utama untuk n=50 yang dibuat pada salah satu ulangan, secara lengkap dapat dilihat pada Lampiran 1.
Guna melihat efektifitas dari metode analisis gerombol berbasis model, maka metode tersebut diterapkan pada setiap kasus simulasi. Semakin kecil rataan tingkat kesalahan klasifikasi yang dihasilkan, maka metode ini semakin efektif dalam menggerombolkan kasus simulasi sesuai dengan gerombol awal. Rataan tingkat kesalahan klasifikasi yang dihasilkan, secara lengkap dapat dilihat pada Lampiran 2.
Kondisi Jarak Antar Pusat Gerombol Sama
Kondisi jarak antar pusat gerombol sama dapat diartikan bahwa setiap
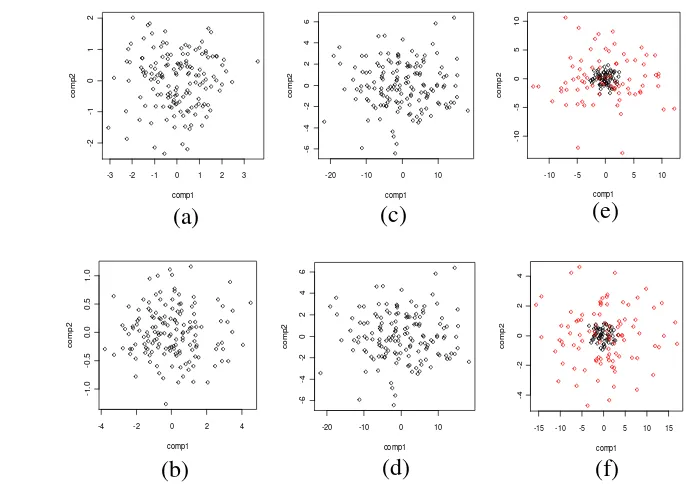
gerombol yang terbentuk memiliki titik pusat gerombol yang sama. Dengan menerapkan metode penggerombolan berbasis model pada kondisi jarak antar pusat gerombol sama, hasil gerombol yang diperoleh dapat diketahui berdasarkan warna yang berbeda pada plot dua komponen utama. Contoh plot dua komponen utama hasil klasifikasi pada tingkat korelasi rendah dan tinggi dengan jumlah amatan tiap gerombol 50, dapat dilihat pada Gambar 4.
Gambar 4 Plot skor dua komponen utama hasil klasifikasi pada jarak antar pusat gerombol sama (a) ragam kecil korelasi rendah, (b) ragam kecil korelasi tinggi, (c) ragam besar korelasi rendah, (d) ragam besar korelasi tinggi, (e) ragam berbeda korelasi rendah, (f) ragam berbeda korelasi tinggi.
Jika ragam setiap peubah berbeda dan titik pusat antar gerombol sama, walaupun kondisi gerombol yang terbentuk saling tumpang tindih akan menghasilkan dua gerombol. Hal ini dikarenakan titik pusat gerombol yang bertumpuk pada satu titik, walaupun ragam setiap peubah untuk setiap gerombol berbeda menyebabkan amatan setiap gerombol menyebar disekitar titik pusat.
Hasil klasifikasi gerombol yang telah diperoleh, didukung oleh persentase
tingkat kesalahan klasifikasi yang dihasilkan. Jika ragam setiap peubah untuk setiap gerombol sama maka tingkat kesalahan klasifikasi yang dihasilkan lebih dari 60%, sebaliknya jika ragam setiap peubah untuk setiap gerombol berbeda maka tingkat kesalahan klasifikasi yang dihasilkan kurang dari 43%. Persentase tingkat kesalahan klasifikasi yang dimaksud dapat dilihat pada Gambar 5.
Ditinjau dari tingkat korelasi antar peubah menunjukkan bahwa pada kondisi ragam setiap peubah sama tidak ada pengaruh tingkat korelasi antar peubah terhadap persentase salah penggerombolan, sedangkan pada kondisi ragam setiap peubah berbeda terjadi penurunan persentase salah penggerombolan pada
tingkat korelasi tinggi, walaupun penurunan tersebut hampir tidak ada perbedaan yang berarti.
Gambar 5 Persentase rataan tingkat kesalahan klasifikasi pada kondisi jarak sama. ragam kecil, ragam besar, ragam berbeda
Dengan menggunakan kedua metode pendugaan parameter yang ada pada penggerombolan berbasis model, hasil penggerombolan yang diperoleh berdasarkan metode kemungkinan maksimum dan metode Bayes menunjukkan tidak adanya perbedaan yang berarti. Hal ini dapat dilihat berdasarkan persentase tingkat kesalahan klasifikasi yang dihasilkan, yang secara lengkap dapat dilihat pada Gambar 6.
Gambar 6 Persentase rataan tingkat kesalahan klasifikasi pada kondisi jarak sama berdasarkan (a) MLE dan (b) MAP. ragam kecil, ragam besar, ragam berbeda
Dari kedua metode pendugaan parameter tersebut, akan dipilih metode pendugaan
yang menghasilkan penggerombolan terbaik. Hasil penggerombolan terbaik berdasarkan nilai BIC dan tingkat kesalahan klasifikasi yang dihasilkan. Nilai BIC secara lengkap dapat dilihat pada Lampiran 3. Model yang dihasilkan berbeda-beda yaitu (1) untuk tingkat korelasi 0 dan 0,2 di berbagai kondisi ragam adalah
VII, (2) untuk tingkat korelasi 0,5 dan 0,8 pada kondisi ragam identik adalah VVV serta (3) untuk tingkat korelasi 0,5 dan 0,8 pada kondisi ragam berbeda adalah VEV. Bentuk yang dihasilkan pada model VII adalah bulat sehingga komponen utama yang dihasilkan pararel dengan sumbu kooordinat serta ukuran setiap gerombol berbeda. Model VVV merupakan model terbaik dengan bentuk yang dihasilkan adalah ellipsoidal, serta memiliki karakteristik yang berbeda untuk setiap gerombol. pada model VEV, ukuran setiap gerombol sama dengan bentuk yang dihasilkan adalah ellipsoidal. Tingkat kesalahan klasifikasi terbaik akan dibandingkan dengan hasil klasifikasi yang diperoleh dengan menggunakan metode k-rataan guna melihat keefektifan dari kedua metode penggerombolan tersebut. Hasil perbandingan tingkat klasifikasi dapat dilihat pada Gambar 7.
Gambar 7 Persentase rataan tingkat kesalahan klasifikasi pada kondisi jarak sama berdasarkan (a) model based , (b) k-means. ragam kecil, ragam besar, ragam berbeda
Berdasarkan hasil perbandingan yang diperoleh, pada parameter yang identik yaitu rataan dan nilai peragam setiap gerombol sama, penggerombolan berbasis model maupun penggerombolan berdasarkan k-rataan tidak efektif memisahkan objek sesuai dengan kondisi gerombol awal. Jika kondisi ragam setiap peubah untuk setiap gerombol berbeda, persentase tingkat kesalahan klasifikasi yang dihasilkan berdasarkan penggerombolan berbasis model lebih kecil dibandingkan
dengan hasil yang diperoleh berdasarkan metode k-rataan. Dengan demikian, penggerombolan berbasis model lebih efektif dibandingkan dengan penggerombolan berbasis model atau metode k-rataan.
ini berarti bahwa ukuran amatan tiap gerombol yang dicobakan tidak terlalu berpengaruh terhadap hasil penggerombolan pada kondisi ini.
Kondisi Jarak Antar Pusat Gerombol Dekat
Kondisi jarak antar pusat gerombol dekat dapat diartikan bahwa setiap gerombol yang terbentuk mulai terpisah tetapi masih dalam jarak dekat. Sama halnya dengan kondisi jarak antar pusat gerombol sama, hasil gerombol yang diperoleh metode penggerombolan berbasis model dapat diketahui berdasarkan warna yang berbeda pada plot dua komponen utama. Berikut contoh plot dua komponen utama hasil klasifikasi pada tingkat korelasi rendah dan tinggi dengan jumlah amatan tiap gerombol 50.
Gambar 8 Plot skor dua komponen utama hasil klasifikasi pada jarak antar pusat gerombol sama (a) ragam kecil korelasi rendah, (b) ragam kecil korelasi tinggi, (c) ragam besar korelasi rendah, (d) ragam besar korelasi tinggi, (e) ragam berbeda korelasi rendah, (f) ragam berbeda korelasi tinggi.
Pada kondisi jarak antar setiap gerombol dekat, ragam setiap peubah kecil maupun besar akan menghasilkan tiga gerombol. Hal ini disebabkan karena titik
pusat gerombol yang berbeda dan ragam setiap peubah yang kecil, menyebabkan amatan menyebar disekitar titik pusat gerombol sehingga masing-masing
gerombol dapat terpisah dengan jelas. Ukuran korelasi antar peubah berpengaruh pada kondisi ini. Pada kondisi jarak antar setiap gerombol dekat dan ragam setiap peubah besar, menghasilkan satu gerombol. Hal ini disebabkan karena ragam setiap peubah besar membuat amatan akan menyebar jauh dari rataan, sehingga jika jarak antar pusat gerombol dekat maka ketiga gerombol akan tumpang tindih. Ukuran korelasi antar peubah tidak berpengaruh pada kondisi ini. Pada kondisi jarak antar setiap gerombol dekat dan ragam setiap peubah berbeda, ukuran korelasi antar peubah berpengaruh terhadap hasil akhir penggerombolan. Korelasi antar peubah rendah dan jarak antar pusat gerombol dekat menyebabkan amatan menyebar dekat dengan rataan dari ketiga gerombol sehingga menghasilkan dua gerombol, sebaliknya pada kondisi korelasi antar peubah tinggi dan jarak antar pusat gerombol dekat menyebabkan amatan menyebar sesuai dengan titik pusat
masing-masing gerombol sehingga menghasilkan tiga gerombol.
Hasil klasifikasi gerombol yang telah diperoleh, didukung oleh persentase tingkat kesalahan klasifikasi yang dihasilkan yang dapat dilihat pada Gambar 9.
Gambar 9 Persentase rataan tingkat kesalahan klasifikasi pada kondisi jarak dekat. ragam kecil, ragam besar, ragam berbeda
Jika ragam setiap peubah untuk setiap gerombol kecil maka tingkat kesalahan klasifikasi yang dihasilkan kurang dari 1,1%, sebaliknya jika ragam setiap peubah untuk setiap gerombol besar maka tingkat kesalahan klasifikasi yang dihasilkan lebih dari 60%. Pada kondisi ragam setiap peubah untuk setiap gerombol berbeda maka tingkat kesalahan klasifikasi yang dihasilkan kurang dari 36%.
Ditinjau dari tingkat korelasi antar peubah menunjukkan bahwa pada
kondisi ragam kecil semakin besar ukuran korelasi, masing-masing dapat terpisah dengan jelas. Pada kondisi ragam setiap peubah besar tidak ada pengaruh tingkat korelasi antar peubah terhadap persentase salah penggerombolan, hal ini
dikarenakan kondisi jarak antar pusat gerombol yang dekat. Jika korelasi ragam setiap peubah berbeda maka semakin tinggi ukuran korelasi antar peubah persentase tingkat kesalahan yang dihasilkan semakin kecil.
Dengan menggunakan kedua metode pendugaan parameter yang ada pada penggerombolan berbasis model, sama halnya dengan kondisi jarak sama, hasil penggerombolan yang diperoleh berdasarkan metode kemungkinan maksimum dan metode Bayes menunjukkan tidak adanya perbedaan yang berarti. Persentase tingkat kesalahan klasifikasi yang dihasilkan dari kedua metode pendugaan secara lengkap dapat dilihat pada Gambar 10.
Gambar 10 Persentase rataan tingkat kesalahan klasifikasi pada kondisi jarak dekat berdasarkan (a) MLE dan (b) MAP. ragam kecil, ragam besar, ragam berbeda
Dari kedua metode pendugaan parameter tersebut, akan dipilih metode pendugaan yang menghasilkan tingkat kesalahan klasifikasi terkecil. Hasil penggerombolan terbaik berdasarkan nilai BIC dan tingkat kesalahan klasifikasi yang dihasilkan. Nilai BIC secara lengkap dapat dilihat pada Lampiran 3. Model yang dihasilkan berbeda-beda untuk setiap kondisi ragam. Pada kondisi ragam kecil jika ukuran
korelasi yang digunakan 0 dan 0,2 maka model yang dihasilkan EII, sedangkan untuk korelasi 0,5 dan 0,8 model yang dihasilkan EEE. Pada kondisi ragam besar jika ukuran korelasi yang digunakan 0 dan 0,2 maka model yang dihasilkan VII, sedangkan untuk korelasi 0,5 yaitu EII dan untuk korelasi 0,8 adalah VVV. Pada kondisi ragam berbeda jika ukuran korelasi yang digunakan 0 dan 0,2 maka model yang dihasilkan VII, sedangkan untuk korelasi 0,5 dan 0,8 adalah VEV. Bentuk yang dihasilkan pada model VII adalah bulat sehingga komponen utama yang dihasilkan pararel dengan sumbu kooordinat serta ukuran setiap gerombol
berbeda. Bentuk yang dihasilkan pada model EII dan VII adalah bulat sehingga komponen utama yang dihasilkan pararel dengan sumbu kooordinat. Ukuran setiap gerombol pada model EII adalah sama sedangkan pada model VII berbeda. Hal ini dapat dapat dilihat berdasarkan akar ciri yang dihasilkan. Betuk yang dihasilkan pada model EEE, VEV dan VVV adalah ellipsoidal. Bentuk yang dihasilkan pada model EEE dan VEV adalah sama untuk setiap gerombol, sedangkan pada model VEV bentuk setiap gerombol berbeda. Tingkat kesalahan klasifikasi terbaik akan dibandingkan dengan hasil klasifikasi yang diperoleh dengan menggunakan metode k-rataan guna melihat keefektifan dari kedua metode penggerombolan tersebut. Hasil perbandingan tersebut dapat dilihat pada Gambar 11.
Gambar 11 Persentase rataan tingkat kesalahan klasifikasi pada kondisi jarak dekat berdasarkan (a) model based dan (b) k-means. ragam kecil, ragam besar, ragam berbeda.
Berdasarkan Gambar 11 dapat diketahui bahwa pada kondisi ragam kecil dan kondisi ragam besar, hasil yang diperoleh dari kedua metode ini adalah sama. Pada kondisi ragam setiap peubah untuk setiap gerombol berbeda, jika ukuran korelasi rendah maka kedua metode ini menghasilkan tingkat kesalahan klasifikasi yang sama, sebaliknya jika ukuran korelasi yang digunakan tinggi maka penggerombolan berbasis model lebih efektif dibandingkan dengan metode k-rataan.
tingkat kesalahan klasifikasi yang dihasilkan. Hal ini dikarenakan kondisi jarak antar pusat gerombol yang dekat.
Ragam setiap peubah kecil, jarak antar setiap peubah dekat dan jumlah amatan yang besar menyebabkan 50 objek pada kondisi ini tidak dapat diklasifikasikan sesuai dengan klasifikasi sebenarnya karena posisi amatan tiap gerombol yang saling berdekatan. Jika penggerombolan tersebut dilakukan berdasarkan metode pendugaan kemungkinan maksimum, maka kesalahan klasifikasi dapat terjadi. Akan tetapi hal ini dapat diatasi dengan menggunakan informasi sebaran awal tiap gerombol atau metode Bayes.
Gambar 12 Persentase rataan tingkat kesalahan klasifikasi pada kondisi jarak dekat berdasarkan (a) jumlah amatan tiap gerombol 50, (b) jumlah amatan tiap gerombol 150. ragam kecil, ragam
besar, ragam berbeda.
Persentase tingkat kesalahan klasifikasi yang dihasilkan pada kondisi ragam setiap peubah untuk setiap gerombol berbeda, jarak antar pusat gerombol dekat dan jumlah amatan yang besar, lebih kecil dari yang dihasilkan pada jumlah amatan kecil.
Kondisi Jarak Antar Pusat Gerombol Sedang
Gambar 13 Plot skor dua komponen utama hasil klasifikasi pada jarak antar pusat gerombol sedang (a) ragam kecil korelasi rendah, (b) ragam kecil korelasi tinggi, (c) ragam besar korelasi rendah, (d) ragam besar korelasi tinggi, (e) ragam berbeda korelasi rendah, (f) ragam berbeda korelasi tinggi.
Pada kondisi jarak antar setiap gerombol sedang, ragam setiap peubah kecil, besar maupun berbeda akan menghasilkan tiga gerombol. Ukuran korelasi yang digunakan sangat berpengaruh terhadap hasil akhir penggerombolan.
Hasil klasifikasi yang diperoleh didukung oleh persentase tingkat kesalahan klasifikasi yang dihasilkan. Persentase tingkat kesalahan klasifikasi yang dihasilkan dapat dilihat pada Gambar 14.
Gambar 14 Persentase rataan tingkat kesalahan klasifikasi pada kondisi jarak sedang. ragam kecil, ragam besar, ragam berbeda.
Berdasarkan Gambar 14 dapat diketahui bahwa (1) pada kondisi ragam setiap peubah besar, jika tingkat korelasi antar peubah lebih dari 0,5 maka persentase salah penggerombolan yang dihasilkan semakin kecil, (2) pada kondisi ragam setiap peubah kecil, semakin tinggi korelasi antar peubah tidak mempengaruhi
persentase kesalahan klasifikasi yang dihasilkan dan (3) pada kondisi ragam setiap peubah untuk setiap gerombol yang berbeda, persentase tingkat kesalahan klasifikasi yang dihasilkan akan meningkat jika korelasi tiap peubah sebesar 0,5.
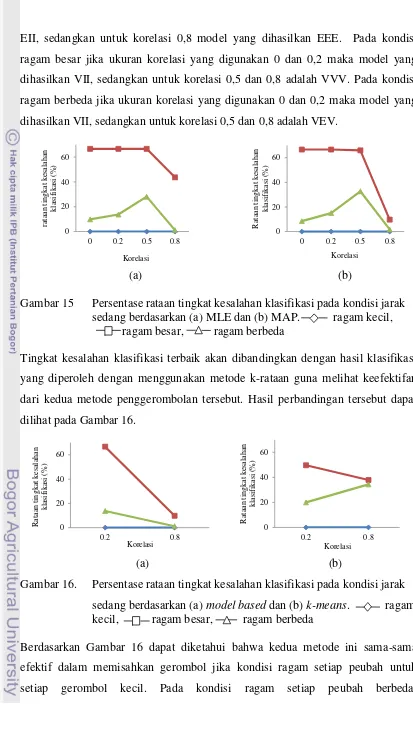
Dengan menggunakan kedua metode pendugaan parameter yang ada pada penggerombolan berbasis model, hasil penggerombolan yang diperoleh berdasarkan metode kemungkinan maksimum dan metode Bayes menunjukkan adanya perbedaan pada ukuran korelasi tinggi dengan ragam setiap peubah besar. Persentase tingkat kesalahan klasifikasi yang dihasilkan dengan menggunakan metode Bayes lebih kecil dibandingkan dengan hasil dari metode kemungkinan maksimum. Persentase tingkat kesalahan klasifikasi yang dihasilkan dari kedua metode pendugaan secara lengkap dapat dilihat pada Gambar 15.
EII, sedangkan untuk korelasi 0,8 model yang dihasilkan EEE. Pada kondisi ragam besar jika ukuran korelasi yang digunakan 0 dan 0,2 maka model yang dihasilkan VII, sedangkan untuk korelasi 0,5 dan 0,8 adalah VVV. Pada kondisi ragam berbeda jika ukuran korelasi yang digunakan 0 dan 0,2 maka model yang dihasilkan VII, sedangkan untuk korelasi 0,5 dan 0,8 adalah VEV.
Gambar 15 Persentase rataan tingkat kesalahan klasifikasi pada kondisi jarak sedang berdasarkan (a) MLE dan (b) MAP. ragam kecil, ragam besar, ragam berbeda
Tingkat kesalahan klasifikasi terbaik akan dibandingkan dengan hasil klasifikasi yang diperoleh dengan menggunakan metode k-rataan guna melihat keefektifan dari kedua metode penggerombolan tersebut. Hasil perbandingan tersebut dapat dilihat pada Gambar 16.
Gambar 16. Persentase rataan tingkat kesalahan klasifikasi pada kondisi jarak sedang berdasarkan (a) model based dan (b) k-means. ragam kecil, ragam besar, ragam berbeda
Berdasarkan Gambar 16 dapat diketahui bahwa kedua metode ini sama-sama efektif dalam memisahkan gerombol jika kondisi ragam setiap peubah untuk setiap gerombol kecil. Pada kondisi ragam setiap peubah berbeda,
penggerombolan berbasis model lebih efektif dibandingkan dengan k-rataan. Kondisi ragam setiap peubah besar dan tingkat korelasi antar peubah rendah menyebabkan k-rataan menghasilkan tingkat kesalahan klasifikasi yang kecil dibandingkan dengan penggerombolan berbasis model, sebaliknya pada tingkat korelasi tinggi persentase tingkat kesalahan klasifikasi yang dihasilkan oleh metode penggerombolan berbasis model lebih kecil dibandingkan dengan k-rataan. Jumlah amatan pada kondisi ini tidak berpengaruh terhadap persentase tingkat kesalahan klasifikasi yang dihasilkan.
Kondisi Jarak Antar Pusat Gerombol Jauh
Kondisi jarak antar pusat gerombol jauh dapat diartikan bahwa setiap gerombol yang terbentuk terpisah dengan jarak antar pusat gerombol jauh. Hasil
gerombol yang diperoleh metode penggerombolan berbasis model pada kondisi ini dapat diketahui berdasarkan warna yang berbeda pada plot dua komponen
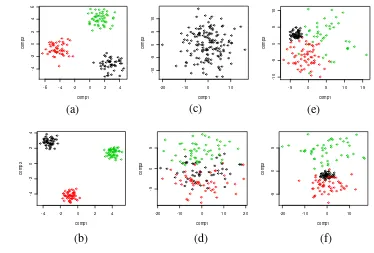
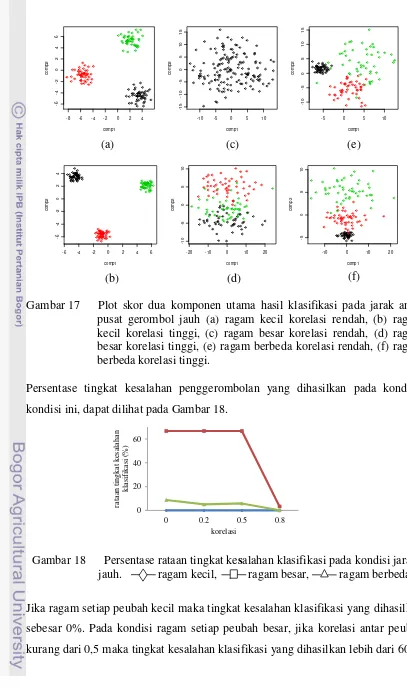
utama. Contoh plot dua komponen utama hasil klasifikasi pada tingkat korelasi rendah dan tinggi dengan jumlah amatan tiap gerombol 50, dapat dilihat pada Gambar 17.
Gambar 17 Plot skor dua komponen utama hasil klasifikasi pada jarak antar pusat gerombol jauh (a) ragam kecil korelasi rendah, (b) ragam kecil korelasi tinggi, (c) ragam besar korelasi rendah, (d) ragam besar korelasi tinggi, (e) ragam berbeda korelasi rendah, (f) ragam berbeda korelasi tinggi.
Persentase tingkat kesalahan penggerombolan yang dihasilkan pada kondisi-kondisi ini, dapat dilihat pada Gambar 18.
Gambar 18 Persentase rataan tingkat kesalahan klasifikasi pada kondisi jarak jauh. ragam kecil, ragam besar, ragam berbeda
Jika ragam setiap peubah kecil maka tingkat kesalahan klasifikasi yang dihasilkan sebesar 0%. Pada kondisi ragam setiap peubah besar, jika korelasi antar peubah
kurang dari 0,5 maka tingkat kesalahan klasifikasi yang dihasilkan lebih dari 60%,
sebaliknya jika korelasi antar peubah lebih dari 0,5 maka tingkat kesalahan klasifikasi yang dihasilkan kurang dari 11%. Jika kondisi ragam setiap peubah berbeda maka tingkat kesalahan klasifikasi yang dihasilkan kurang dari 9%. Semakin besar ukuran korelasi antar peubah maka tingkat kesalahan klasifikasi yang semakin kecil.
Sama halnya dengan kondisi-kondisi jarak antar pusat gerombol yang lain, sebelum dilakukan perbandingan antara metode penggerombolan berbasis model dengan metode k-rataan, terlebih dahulu akan dibandingkan hasil yang diperoleh dari kedua metode pendugaan parameter yang ada pada penggerombolan berbasis model.
Dari kedua metode pendugaan parameter tersebut, akan dipilih metode pendugaan yang menghasilkan tingkat kesalahan klasifikasi terkecil. Hasil
penggerombolan terbaik berdasarkan nilai BIC dan tingkat kesalahan klasifikasi yang dihasilkan. Nilai BIC secara lengkap dapat dilihat pada Lampiran 3. Model yang dihasilkan berbeda-beda untuk setiap kondisi ragam. Pada kondisi ragam kecil jika ukuran korelasi yang digunakan 0 dan 0,2 model yang dihasilkan EII, sedangkan untuk korelasi 0,5 dan 0,8 model yang dihasilkan EEE. Pada kondisi ragam besar jika ukuran korelasi yang digunakan 0; 0,2 dan 0,5 maka model yang dihasilkan VII, sedangkan untuk korelasi 0,8 adalah EEE. Pada kondisi ragam berbeda jika ukuran korelasi yang digunakan 0 dan 0,2 maka model yang dihasilkan VII, sedangkan untuk korelasi 0,5 dan 0,8 adalah VEV.
Tingkat kesalahan klasifikasi terbaik akan dibandingkan dengan hasil klasifikasi yang diperoleh dengan menggunakan metode k-rataan guna melihat keefektifan dari kedua metode penggerombolan tersebut. Hasil penggerombolan yang diperoleh dari kedua metode ini, yang dapat dilihat pada Gambar 19.
Pada kondisi ragam setiap peubah untuk setiap gerombol kecil dan berbeda, maka persentase tingkat kesalahan klasifikasi yang diperoleh berdasarkan penggerombolan berbasis model lebih kecil dibandingkan dengan metode k-rataan. Sama halnya dengan jarak antar pusat gerombol sedang, pada kondisi ragam setiap peubah besar dan tingkat korelasi antar peubah rendah menyebabkan k-rataan menghasilkan tingkat kesalahan klasifikasi yang kecil dibandingkan
(a). berdasarkan berbasis model (b). berdasarkan k-rataan
Gambar 19 Persentase rataan tingkat kesalahan klasifikasi pada kondisi jarak jauh berdasarkan (a) berbasis model dan (b) k-rataan.
ragam kecil, ragam besar, ragam berbeda
Pada tingkat korelasi tinggi, persentase tingkat kesalahan klasifikasi yang dihasilkan oleh metode penggerombolan berbasis model lebih kecil dibandingkan dengan k-rataan. Jumlah amatan pada kondisi ini tidak berpengaruh terhadap persentase tingkat kesalahan klasifikasi yang dihasilkan.
Data Pohon
Data pohon merupakan dari paket Mclust yang sering digunakan untuk
mengilustrasikan masalah pengklasifikasian. Tujuan digunakannya data ini adalah untuk melihat efektifitas analisis gerombol berbasis model pada data berukuran kecil. Data ini terdiri dari tiga jenis ukuran peubah yaitu keliling (girth), tinggi (height) dan volume. Masing-masing peubah terdiri dari 31 pengamatan. Data dari masing-masing peubah secara lengkap dapat dilihat pada Lampiran 4. Sebelum menerapkan metode analisis gerombol berbasis model terlebih dahulu diberikan gambaran umum berupa deskriptif dari ketiga peubah yang diamati.
Tabel 4 Statistik deskriptif peubah data pohon
Peubah Rata-rata Simpangan Baku Keliling 13,248 3,138
Tinggi 76,000 6.372 Volume 30,171 16.438
Guna mengetahui jumlah gerombol yang terbentuk terlebih dahulu dibuat plot dua komponen utama, yang dapat dilihat pada Gambar 20. Dapat diketahui bahwa pola yang dibentuk tidak jelas penggerombolannya.
Gambar 20 Plot dua komponen utama data pohon
Sebelum dilakukan penggerombolan berbasis model, terlebih dahulu dilakukan uji normal ganda yang dilakukan dengan plot kuantil. Jika plot kuantil yang dihasilkan membentuk garis lurus, maka data yang digunakan menyebar normal
ganda.
Gambar 21 Plot kuantil-kuantil data pohon
Plot kuantil yang dihasilkan membentuk garis lurus, dengan demikian data pohon yang digunakan menyebar normal ganda. Hasil penggerombolan yang diperoleh berdasarkan metode kemungkinan maksimum maupun metode Bayes akan dibahas satu persatu.
Berdasarkan metode kemungkinan maksimum, proporsi dari
masing-masing gerombol secara berturut-turut yaitu 69 dan 73. Vektor rataan yang dihasilkan untuk masing-masing gerombol adalah
7 347 79 7 5 35 dan 739 74 63 46 . Penentuan jumlah gerombol dapat diperoleh berdasarkan nilai BIC terbesar untuk setiap
-50 -40 -30 -20 -10 0 10 20
-1
0
-5
0
5
10
comp1
co
m
p
2
0 2 4 6 8 10 12
0 2 4 6 8 10 12
k
h
i^
2
model, dapat dilihat pada Tabel 5. Nilai BIC terbesar yaitu -535,7, berada pada model VVV dengan jumlah gerombol yang diberikan sebanyak dua gerombol.
Tabel 5 Nilai BIC setiap model berdasarkan metode kemungkinan maksimum, untuk data pohon
Gambar 22 Plot nilai BIC setiap model untuk data pohon, berdasarkan metode kemungkinan maksimum
Model terbaik yang dihasilkan adalah VVV dengan karaketrikstik dari matrik
peragamnya yaitu . Model tersebut memiliki matriks diagonal dan akar ciri setiap gerombol yang berbeda, sehingga bentuk dan volume setiap gerombol akan berbeda. Bentuk yang dihasilkan untuk setiap gerombol adalah ellipsoidal.
Tabel 6 Nilai BIC setiap model berdasarkan metode Bayes, untuk
Gambar 23 Plot nilai BIC setiap model untuk data pohon, berdasarkan
Metode Bayes
model. Model terbaik yang dihasilkan adalah EEV dengan nilai BIC -547,127.
Karakteristik matriks peragam berdasarkan model EEV yaitu . Model tersebut memiliki matriks diagonal dan akar ciri setiap gerombol yang sama,
sehingga bentuk dan volume setiap gerombol adalah sama. Bentuk yang dihasilkan untuk setiap gerombol adalah ellipsoidal.
Data Diabetes
Data diabetes merupakan contoh data dari paket mclust yang sering digunakan dalam buku teks statistic analisis peubah ganda untuk masalah pengklasifikasian. Data ini terdiri dari tiga jenis ukuran peubah yaitu glucoce, insulin dan sspg, yang masing-masing peubah terdiri dari 145 pengamatan. Setiap peubah secara klinikal diklasifikasikan atas tiga jenis yaitu normal (NO), chemical diabetes (CD) dan overt diabetes (OD). Data dari masing-masing peubah secara lengkap dapat dilihat pada Lampiran 5. Sebelum menerapkan metode analisis gerombol berbasis model, terlebih dahulu diberikan gambaran umum berupa deskriptif dari ketiga peubah yang diamati terangkum pada Tabel 7.
Tabel 7 Statistik deskriptif peubah-peubah data diabetes
Jenis Peubah Rata-rata Simpangan Baku normal glucoce 91.184 8.228
insulin 349.974 36.871 sspg 172.645 68.854 chemical glucoce 99.306 9.489
insulin 482.556 93.018 sspg 288,000 157.832 overt glucoce 217.667 76.563
insulin 1043.758 309.395 sspg 106,000 93.425
Gambar 24 Plot dua komponen utama data diabetes
Uji normal ganda yang dilakukan dengan plot kuantil pada data diabetes, dapat dilihat pada Gambar 25. Plot kuantil yang dihasilkan membentuk garis lurus, dengan demikian data diabetes yang digunakan menyebar normal ganda.
Gambar 25 Plot kuantil data diabetes
Berdasarkan metode kemungkinan maksimum, jumlah gerombol yang dihasilkan sebanyak tiga gerombol. Proporsi dan vector rataan masing-masing gerombol secara berturut-turut yaitu 56 ; 3 dan 3 5serta
9 4 358 8 8 66 56 ; 5 98 5 7 4 3 789 dan
9 4 4 4 369 98 335 . Jika dibandingkan dengan hasil klasifikasi sebenarnya, maka tingkat kesalahan klasifikasi yang diperoleh sebesar 9,6% dengan 14 objek terjadi kesalahan penggerombolan. Nilai BIC yang diperoleh untuk setiap model dapat dilihat pada Tabel 8.
-1000 -500 0 500
-1
0
0
0
100
300
500
comp1
co
m
p
2
0 5 10 15 20 25 30
0 5 10 15 20 25 30
k
h
i^
2
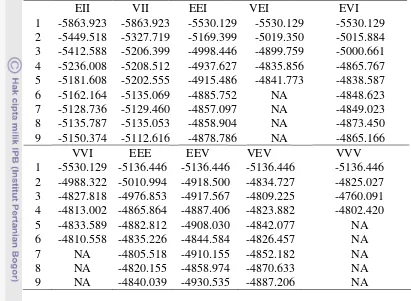
Tabel 8 Nilai BIC setiap model berdasarkan metode kemungkinan maksimum, untuk data diabetes
EII VII EEI VEI EVI
1 -5863.923 -5863.923 -5530.129 -5530.129 -5530.129 2 -5449.518 -5327.719 -5169.399 -5019.350 -5015.884 3 -5412.588 -5206.399 -4998.446 -4899.759 -5000.661 4 -5236.008 -5208.512 -4937.627 -4835.856 -4865.767 5 -5181.608 -5202.555 -4915.486 -4841.773 -4838.587 6 -5162.164 -5135.069 -4885.752 NA -4848.623 7 -5128.736 -5129.460 -4857.097 NA -4849.023 8 -5135.787 -5135.053 -4858.904 NA -4873.450 9 -5150.374 -5112.616 -4878.786 NA -4865.166
VVI EEE EEV VEV VVV
1 -5530.129 -5136.446 -5136.446 -5136.446 -5136.446 2 -4988.322 -5010.994 -4918.500 -4834.727 -4825.027 3 -4827.818 -4976.853 -4917.567 -4809.225 -4760.091 4 -4813.002 -4865.864 -4887.406 -4823.882 -4802.420 5 -4833.589 -4882.812 -4908.030 -4842.077 NA 6 -4810.558 -4835.226 -4844.584 -4826.457 NA 7 NA -4805.518 -4910.155 -4852.182 NA 8 NA -4820.155 -4858.974 -4870.633 NA 9 NA -4840.039 -4930.535 -4887.206 NA
Model terbaik yang dihasilkan adalah VVV dengan karaketrikstik dari matrik
peragamnya yaitu . Model tersebut memiliki matriks diagonal dan
akar ciri setiap gerombol yang berbeda, sehingga bentuk dan volume setiap gerombol akan berbeda. Bentuk yang dihasilkan untuk setiap gerombol adalah ellipsoidal. Nilai BIC yang dihasilkan sebesar -4760.091.
Gambar 26 Plot nilai BIC setiap model untuk data diabetes, berdasarkan (a) Metode kemungkinan maksimum dan (b) metode Bayes
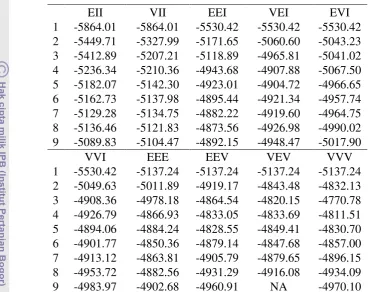
Tabel 9 Nilai BIC setiap model berdasarkan metode Bayes, untuk data diabetes
EII VII EEI VEI EVI
1 -5864.01 -5864.01 -5530.42 -5530.42 -5530.42 2 -5449.71 -5327.99 -5171.65 -5060.60 -5043.23 3 -5412.89 -5207.21 -5118.89 -4965.81 -5041.02 4 -5236.34 -5210.36 -4943.68 -4907.88 -5067.50 5 -5182.07 -5142.30 -4923.01 -4904.72 -4966.65 6 -5162.73 -5137.98 -4895.44 -4921.34 -4957.74 7 -5129.28 -5134.75 -4882.22 -4919.60 -4964.75 8 -5136.46 -5121.83 -4873.56 -4926.98 -4990.02 9 -5089.83 -5104.47 -4892.15 -4948.47 -5017.90
VVI EEE EEV VEV VVV
1 -5530.42 -5137.24 -5137.24 -5137.24 -5137.24 2 -5049.63 -5011.89 -4919.17 -4843.48 -4832.13 3 -4908.36 -4978.18 -4864.54 -4820.15 -4770.78 4 -4926.79 -4866.93 -4833.05 -4833.69 -4811.51 5 -4894.06 -4884.24 -4828.55 -4849.41 -4830.70 6 -4901.77 -4850.36 -4879.14 -4847.68 -4857.00 7 -4913.12 -4863.81 -4905.79 -4879.65 -4896.15 8 -4953.72 -4882.56 -4931.29 -4916.08 -4934.09 9 -4983.97 -4902.68 -4960.91 NA -4970.10
Jumlah gerombol yang dihasilkan yaitu tiga gerombol. Jika dibandingkan dengan klasifikasi sebenarnya, tingkat kesalahan klasifikasi yang dihasilkan sebesar 10,34% dengan 15 objek terjadi kesalahan penggerombolan. Nilai BIC yang
diperoleh untuk setiap model dapat dilihat pada Tabel 9. Proporsi dan vektor rataan masing-masing gerombol secara berturut-turut yaitu 574; 5
dan 3 serta 9 7 36 65 66 ;
5 366 5 78 3 7 877 dan 33 5 9 95 8 3 . Model terbaik yang dihasilkan adalah VVV dengan karaketrikstik dari matrik
peragamnya yaitu . Model tersebut memiliki matriks diagonal dan akar