SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
MOCH NURHALIMI ZD 10111492
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS TEKNIK DAN ILMU KOMPUTER
iii
Assalamualaikum Wr. Wb.
Alhamdulillahi Rabbil ‘Alamiin, puji dan syukur penulis panjatkan kehadirat Allah SWT atas rahmat dan karunia-Nya sehingga penulis dapat menyelesaikan skripsi yang berjudul “IMPLEMENTASI ALGORITMA LESK UNTUK SYNONIM
RECOGNITION DAN RABIN KARP PADA PENDETEKSIAN PLAGIARISME”
untuk memenuhi salah satu syarat dalam menyelesaikan studi jenjang strata satu (S1) di Program Studi Teknik Informatika, Fakultas Teknik dan Ilmu Komputer, Universitas Komputer Indonesia.
Dikarenakan keterbatasan yang dimiliki Penulis, penyusunan skripsi ini tidak akan terwujud tanpa mendapat dukungan, bantuan dan masukan dari berbagai pihak. Untuk itu melalui kata pengantar ini, penulis ingin menyampaikan terimakasih yang sebesar-besarnya kepada:
1. Allah SWT atas segala nikmat yang telah diberikan sehingga Penulis dapat menyelesaikan skripsi ini.
2. Kedua orang tua berserta kakak yang telah memberikan kasih sayang, doa dan dukungan baik moril maupun materi sehingga Penulis dapat menyelesaikan skripsi ini tepat pada waktunya.
3. Ibu Ednawati Rainarli, S.Si., M.Si., selaku dosen pembimbing dan dosen wali Penulis di kelas IF-11/2011 penulis. Terimakasih karena telah banyak meluangkan waktu untuk memberikan bimbingan, saran dan nasehatnya selama proses penyusunan skripsi ini.
4. Bapak Irfan Maliki, S.T., M.T., selaku reviewer Penulis. Terimakasih karena telah banyak meluangkan waktu untuk memberikan bimbingan, saran, nasehat, serta masukan kepada Penulis selama proses penyusunan skripsi ini.
iv
6. Bapak dan Ibu dosen serta seluruh staf pegawai Program Studi Teknik Informatika Universitas Komputer Indonesia yang telah membantu penulis selama proses perkuliahan.
7. Teman-teman seperjuangan di kelas IF-11/2011 yang selalu memberi dukungan dan semangat kepada Penulis selama penyusunan skripsi ini.
8. Teman-teman sompreters yang selalu memberikan dukungan, motivasi, serta telah meluangkan waktunya untuk melakukan refreshing bersama seperti bermain poker dan lain lain.
9. Serta seluruh pihak yang tidak dapat Penulis sebutkan satu persatu, terimakasih atas segala bentuk dukungan untuk menyelesaikan skripsi ini.
Penulis menyadari bahwa penulisan skripsi ini masih jauh dari sempurna. Oleh karena itu, penulis mengharapkan saran dan masukan yang bersifat membangun untuk perbaikan dan pengembangan skripsi ini. Akhir kata, semoga penulisan skripsi ini dapat bermanfaat bagi penulis khususnya dan bagi pembaca umumnya.
Wassalamualaikum Wr. Wb.
Bandung, Februari 2016
v
ABSTRAK ... i
ABSTRACT ... ii
KATA PENGANTAR ... iii
DAFTAR ISI ... v
DAFTAR GAMBAR ... ix
DAFTAR TABEL ... xi
DAFTAR SIMBOL ... xiv
DAFTAR LAMPIRAN ... xvi
BAB 1 PENDAHULUAN ... 1
1.1 Latar Belakang Masalah ... 1
1.1 Identifikasi Masalah ... 2
1.2 Maksud Dan Tujuan ... 2
1.3 Batasan Masalah... 2
1.4 Metodologi Penelitian ... 3
1.4.1 Metoda Pengumpulan Data ... 3
1.5 Metode Pembangunan Perangkat Lunak ... 3
1.6 Sistematika Penulisan ... 4
BAB 2 TINJAUAN PUSTAKA ... 7
2.1 Metoda pendeteksian Plagiarisme ... 7
2.2 Pencocokan String (String Macthing) ... 8
2.3 Proses Prepsocessing ... 9
2.3.1 Pemisahan Kalimat... 9
2.3.2 Casefolding ... 9
2.3.3 Filtering ... 10
2.3.4 Tokenizing ... 10
2.3.5 Stopword Removal ... 10
2.3.6 Stemming ... 10
vi
2.4.1 Fungsi cURL ... 14
2.5 Synonim Recognition ... 14
2.6 Algoritma Lesk ... 14
2.7 Metoda K – Gram ... 15
2.8 Algoritma Rabin Karp ... 15
2.9 Peningkatan Performa Algoritma Rabin Karp ... 20
2.10 Hashing ... 21
2.11 Dice Similarity Coeficients ... 22
2.12 Analisis Terstruktur ... 22
2.12.1 Diagram Konteks ... 22
2.12.2 Data Flow Diagram ... 23
2.12.3 Spesifikasi Proses ... 23
2.12.4 Kamus Data ... 24
2.13 Perangkat Lunak Pendukung... 24
2.13.1 MySQL ... 24
2.13.2 Xampp ... 24
2.13.3 PHP ... 25
BAB III ANALISIS DAN PERANCANGAN SISTEM ... 27
3.1 Analisis Sistem ... 28
3.2 Analisis Data Masukan ... 29
3.3 Analisis Proses Preprocessing ... 30
3.3.1 Pemisahan Kalimat dan pemilihan kalimat ... 30
3.3.2 Casefolding ... 35
3.3.3 Filtering ... 36
3.3.4 Tokenizing ... 38
3.3.5 Stopword ... 40
3.3.6 Stemming ... 42
3.4 Analisi Proses Grabbing Makna Dan Sinonim ... 45
3.5 Analisis Proses Synonim Recognition dengan Algoritma Lesk ... 50
3.6 Analisis Parsing K-Gram ... 60
vii
3.8 Analisis Pencocokan String (Rabin Karp) ... 69
3.9 Analisis Perhitungan Similiarity ... 70
3.10 Spesifikasi Kebutuhan Perangkat Lunak ... 70
3.11 Analisis Kebutuhan Non Fungsional ... 71
3.11.1 Analisis Kebutuhan Perangkat Keras ... 71
3.11.2 Analisis Kebutuhan Perangkat Lunak ... 72
3.12 Analisis Basis Data ... 72
3.13 Analisis Kebutuhan Fungsional ... 73
3.13.1 Diagram Konteks ... 74
3.13.2 Data Flow Diagram ... 74
3.13.3 Spesifikasi Proses ... 75
3.13.4 Kamus data ... 81
3.14 Perancangan Sistem ... 84
3.14.1 Perancangan Basis Data ... 84
3.14.2 Perancangan Struktur Menu ... 89
3.15 Perancangan Antarmuka ... 90
3.15.1 Perancangan Form ... 90
3.15.2 Perancangan Pesan ... 95
3.15.3 Jaringan Semantik ... 95
BAB IV IMPLEMENTASI DAN PENGUJIAN SISTEM ... 97
4.1 Implementasi Sistem ... 97
2.1.1 Implementasi Perangkat Keras ... 97
4.2 Implementasi Perangkat Lunak ... 97
4.2.1 Implementasi Basis Data ... 98
4.3 Implementasi Antarmuka ... 100
4.4 Pengujian System ... 101
4.4.1 Rencana Pengujian ... 101
4.4.2 Skenario Pengujian Sistem ... 102
4.4.3 Hasil Pengujian System ... 103
4.4.4 Kesimpulan Pengujian Sistem ... 112
viii
117
6 DAFTAR PUSTAKA
[1] R. R. Hutami and Suyanto, "IMPLEMENTASI SISTEM PENDETEKSI PLAGIAT PADA DOKUMEN BAHASA," Teknik Informatika, Fakultas Teknik Informatika, Universitas Telkom, 2012.
[2] S. Dewanto, Indriati and I. Cholissodin, "DETEKSI PLAGIARISME DOKUMEN TEKS MENGGUNAKAN ALGORITMA RABIN-KARP DENGAN SYNONYM RECOGNITION," Program Studi Ilmu Komputer, Program Teknologi Informatika dan Ilmu Komputer , Universitas Brawijaya Malang.
[3] D. D. Purwanto, "Sinonim dan Word Sense Disambigution Untuk Melengkapi Detektor Plagiat Dokumen Tugas Akhir," Sistem Informasi Sekolah Tinggi Teknik Surabaya.
[4] H. B. FIrdaus, "Deteksi Plagiarisme Dokumen Menggunakan Algoritma Rabin Karp," Jurnal Ilmu Komputer Dan Teknologi Informasi , Vols. Vol 3 , No 2, 2003.
[5] A. M. Surahman, "PERANCANGAN SISTEM PENENTUAN SIMILARITY KODE PROGRAM PADA BAHASA C DAN PASCAL DENGAN MENGGUNAKAN ALGORITMA RABIN-KARP," Program Studi Teknik Informatika , Fakultas Teknik Universitas Tanjungpura.
[6] E. Nugroho, "Perancangan Sistem Deteksi Plagiarisme Dokumen Teks Dengan Menggunakan Algoriam Rabin Karp," Program Studi Ilmu Komputer , Universitas Brawijaya, 2011.
[7] W. E. Widhaprasa Dan K. L. Masayu, "Update Summarization Untuk Kumpulan Dokumen Berbahasa Indonesia," Jurnal Cybermatika, vol. vol. 1, p. No 2, Desember 2013.
[9] A. Ledy, "Perbandingan Algoritma Stemming Porter Dengan Algoritma Nazief & Adriani Untuk Stemming Dokumen Teks Bahasa Indonesia,"
Konferensi Nasional Sistem dan Informatika, 2009.
[10] M. H Dan A. H. M. B. O. Daniel, "Porter Stemmer Information Retrieval,"
Mini Paper Project, 2012.
[11] Z. F. Tala, "A Study of Stemming Effects on Information Retrieval in Bahasa Indonesia," Language and Computation Universeit Van Amsterdam, 2003. [12] Rosihanari, 4 April 2010. [Online]. Available:
http://blog.rosihanari.net/teknik-grabbing-mengambil-teks-dari-situs-lain-dengan-curl/. [Accessed 10 1 2016].
[13] w. santoso, "Teknik Grabbing (Mengambil dari situs lain)," 2010. [Online]. Available: http://wahyusantoso.staff.umm.ac.id/ilmu-umum/master-program/buku-php-mysql/teknik-grabbing-text-dari-web-lain. [Accessed 10 1 2016].
[14] A. Suharsono, "Sistem Temu Kembali : Tutorial cURL," 2011. [Online]. Available: http://aswinsuharsono.lecture.ub.ac.id/2010/09/sistem-temu-kembali-informasi-tutorial-curl. [Accessed 10 1 2016].
[15] "cURL," 2012. [Online]. Available: http://curl.haxx.se. [Accessed 12 12 2016].
[16] A. M. Surahman, "PERANCANGAN SISTEM PENENTUAN SIMILARITY," Program Studi Teknik Informatika.
[17] R. S. Chiler. And. B. Kochar, "RB-Matcher. String Matching Technique,"
Rem (Text), Vols. 234567, no 11, p.3, 2008.
[18] Yakub, Pengantar Sistem Informasi, Yogyakarta: Graha Ilmu, 2012.
[19] A. Solichin, Mysql 5 dari Pemula Hingga Mahir, Jakarta: Universitas Budi Luhur, 2010.
[21] Sugiyono, Metode Penelitian Kombinasi (Mixed Methods), Bandung: Alfabeta, 2011.
[22] B. Liu, Sentiment Analysis and Opinion Mining, Morgan & Claypool Publisher, 2012.
[23] N. Hayatin, M. Mentari and A. Izzah, "Opinion Extraction of Public Figure Based on Sentiment Analysis in Twitter," IPTEK, Journal of Engineering,
vol. I, no. 1, pp. 9-14, 2014.
[24] A. Hamzah, "Deteksi Bahasa untuk Dokumen Teks Berbahasa Indonesia," in
Seminar Nasional Informatika (SemnasIF), Yogyakarta, 2010.
[25] Andri, S. Ariana and M. Andriani, "Aplikasi Korelasi Kesalahan Berbasis pada Tulisan Berbahasa Indonesia untuk Meningkatkan Kualitas Penulisan Karya Ilmiah," in Prosiding Seminar Nasional Aplikasi Sains & Teknologi (SNAST), Yogyakarta, 2014.
[26] R. S. S. M. O. A. L. S. M. Recky T. Djaelangkara, "Perancangan Sistem Informasi Akademik," e-jurnal Teknik Elektro dan Komputer, Vols. ISSN: 2301-8402 , 2015.
[27] Sumarsono and Ahmad Syihab Husin , "Sistem Terintegrasi Portal Web Perguruan TInggi Agama Islam Negeri Menggunakan Metoda Grabbing,"
Program Studi Teknik Informatika, Fakultas Sains dan Teknologi UIN Sunan Kalijaga , Vols. Vol. IX, No. 2, 2013 .
[28] Sandy Dewanto, Indriati, ST., M.Kom and Imam Cholissodin, S.Si., M.Kom, "Deteksi Plagiarisme Dokumen Teks Menggunakan Algoritma Rabin Karp Dengan Synonim Recognition," Program Studi Ilmu Komputer, Program Teknologi Informatika dan Ilmu Komputer.
[29] R. A.s and M. Shalahudin, Rekayasa Perangkat Lunak Terstruktur, Bandung : Informatika, 2013.
1
1 BAB 1
PENDAHULUAN
1.1 Latar Belakang Masalah
Penjiplakan atau plagiarisme berarti mencontoh atau meniru tulisan dan karya orang lain yang kemudian diakui sebagai karanganya sendiri dengan ataupun tanpa seizin penulisnya. Penjiplakan dokumen digital bukanlah hal yang susah, cukup dengan menggunakan teknik copy-paste-modify pada sebagian isi dokumen dan bahkan keseluruhan isi dokumen sudah bisa dikatakan bahwa dokumen tersebut merupakan hasil duplikasi dari dokumen lain [2]. Plagiarisme juga dapat dilakukan dengan dengan cara menambah atau menghilangkan kata [1]. Terkadang
plagiarisme juga dilakukan dengan mengganti kata-kata yang mengandung kata - kata sinonim, dengan maksud agar terlihat berbeda dari dokumen aslinya. Dimana hanya merubah kata – kata yang mengandung sinonim yang terdapat di dokumen asli dengan merubah nya sesuai dengan kata yang ada di Kamus bahasa indonesia , tanpa memperhatikan struktur kalimat dari dokumen aslinya[3]. Pendeteksian plagiarism dapat dilakukan dengan cara pencocokan string (string matching). Metode ini dapat digunakan untuk menghitung kemiripan teks antara satu dokumen dengan dokumen lainnya.
Beberapa penelitian mengenai deteksi plagiarisme telah dilakukan sebelumnya diantaranya oleh Sandi Dewanto [2] dimana penelitian ini menggunakan algoritma
Rabin-Karp menghasilkan efisiensi waktu yang baik dalam mendeteksi string yang memiliki lebih dari satu pola. Hal ini membuat algoritma Rabin-Karp dimanfaatkan dalam melakukan pendeteksian terhadap tindak plagiat dokumen.
Berdasarkan uraian di atas, pada penelitian ini akan mengombinasikan Algoritma Lesk dalam Pengenalan sinonim dengan memanfaatkan wordnet indonesia dan Rabin Karp untuk mendeteksi tingkat similiarity plagriarsme dokumen.
1.1 Identifikasi Masalah
Berdasarkan penjelasan dari latar belakang ditemukan permasalahan yang dirumuskan ke dalam suatu rumusan masalah adalah bagaimana mengkombinasikan Algoritma Lesk dalam Pengenalan sinonim dengan memanfaatkan wordnet indonesia dan Rabin Karp untuk mendeteksi tingkat similiarity plagriarsme dokumen.
1.2 Maksud Dan Tujuan
Maksud dari penelitian yang akan dilakukan adalah menerapkan algoritma
Lesk Dan Rabin Karp untuk mendeteksi plagiarisme dua dokumen.
Sedangkan tujuan yang ingin dicapai adalah mengetahui besarnya tingkat similiarity dari kombinasi Algoritma Lesk dalam Pengenalan sinonim dengan memanfaatkan wordnet indonesia dan Rabin Karp yang akan diterapkan untuk mendeteksi plagiarism dua dokumen.
1.3 Batasan Masalah
Agar penelitian yang dilakukan lebih terarah dan mencapai sasaran yang ditentukan, maka perlukan sebuah pembatasan masalah atau ruang lingkup kajian, yaitu sebagai berikut:
1. Data dokumen yang bisa di upload oleh user hanya berextensi doc dan .docx 2. Kasus uji yang digunakan adalah latar belakang skripsi informatika.
3. Menggunakan medota k-gram kata , dengan nilai k-gram secara dinamis yaitu bisa di inputkan oleh user.
5. Steming pada penelitian ini menggunakan algoritma porter stemmer.
6. Menggunakan Algoritma Rabin Karp varian Chillar-Kochar untuk mendeteksi plagiarism dokumen.
7. Mengunakan algoritma lesk untuk pengenalan dan pemilihan persamaan kata dengan teknik WSD (Word Disambiguition Sense) menggunakan kamus sinonim dari database.
8. Makna kata tiap kalimat diambil dari website kbbi.web.id 9. Sinonim kata tiap kalimat diambil dari website sinonimkata.com
10.Pendekatan pembangunan perangkat lunak yang digunakan pada penelitian ini adalah pendekatan terstruktur.
1.4 Metodologi Penelitian
Metodologi penelitian yang digunakan dalam penelitian ini adalah penelitian kuantitatif. Metode yang digunakan dalam penulisan laporan penelitian ini menggunakan dua metode, yaitu metode pengumpulan data dan metode pembangunan perangkat lunak.
1.4.1 Metoda Pengumpulan Data
Metode yang digunakan dalam pengumpulan data pada penelitian ini adalah sebagai berikut:
a. Studi Literatur
Pengumpulan data dengan cara mengumpulkan referensi seperti jurnal, paper, buku referensi dan bacaan-bacaan yang ada kaitannya dengan judul penelitian. b. Pengumpulan Dokumen
Pengumpulan dokumen disini yaitu pengumpulan dokumen – dokumen asli yang akan dijadikan objek untuk dideteksi dengan dokumen yang merupakan hasil modify.
1.5 Metode Pembangunan Perangkat Lunak
Metode yang dilakukan dalam proses pembangunan aplikasi ini adalah model
1. Analisis dan definisi persyaratan.
Analisis dan definisi persyaratan meruapakan tahap pengumpulan kebutuhan secara lengkap kemudian dianalisis dan didefinisikan secara rinci yang selanjutnya akan berfungsi sebagai spesifikasi sistem.
2. Perancangan sistem dan perangkat lunak.
Tahap perancangan sistem dan perangkat lunak meruapakan tahap mendesain perangkat lunak yang akan dibangun.
3. Implementasi dan pengujian unit.
Implementasi dan pengujian unit meruapakan tahap perancangan perangkat lunak yang direalisasikan sebagai serangkaian program atau unit program dengan bahasa pemrograman yang sudah ditentukan. Pengujian dilakukan secara unit untuk memastikan setiap unit dari program sudah berfungsi.
4. Integrasi dan pengujian sistem.
Integrasi dan pengujian sistem merupakan tahap penyatuan unit-unit program menjadi sebuah program utuh. Dilakukan pengujian perangkat lunak secara keseluruhan, sehingga perangkat lunak siap untuk digunakan.
1.6 Sistematika Penulisan
Sistematika penulisan penelitian ini disusun untuk memberikan gambaran umum mengenai penelitian yang dikerjakan. Sistematika penulisan penelitian sebagai berikut:
BAB I PENDAHULUAN
Pada bab ini berisi penjelasan mengenai latar belakang permasalahan, identifikasi masalah, maksud dan tujuan, batasan masalah, metodologi penelitian, serta sistematika.
BAB II LANDASAN TEORI
Pada bab ini berisi teori-teori atau tinjauan dari literatur pendukung yang akan digunakan untuk penerapan algoritma untuk mendeteksi plagiarism dokumen. BAB III ANALISIS DAN PERANCANGAN
recognition. Selain itu juga dijelaskan analisis kebutuhan fungsional dan non-fungsional untuk membangun aplikasi yang akan digunakan sebagai untuk penerapan dan pengujian dari tahap-tahap yang dijelaskan di atas.
BAB IV IMPLEMENTASI DAN PENGUJIAN
Pada bab ini ditampilkan implementasi tahap-tahap hasil dari analisis dan perancangan yang sudah dilakukan sebelumnya menjadi sebuah aplikasi. Pada aplikasi yang sudah dibuat dilakukan pengujian alpa yaitu pengujian terhadap fungsionalnya. Lalu aplikasi digunakan untuk melakukan pengujian 2 dokumen dan menghitung jumlah nilai similiarity kesamaan dokumen tersebut.
BAB 5 KESIMPULAN DAN SARAN
7
2 BAB 2
TINJAUAN PUSTAKA
Plagiarisme berasal dari bahasa latin,”plagiarius” yang berarti pencuri. Plagiarisme didefinisikan sebagai tindakan mengambil, mengumpulkan atau menyampaikan pemikiran, tulisan atau hasil karya orang lain selayaknya itu adalah hasil karya diri sendiri tanpa persetujuan dari pemilik hasil karya tersebut. Dengan kata lain, melakukan plagiarisme bearti mencuri hasil karya atau kepemilikan intelektual orang lain. Ide atau materi apapun yang diambil dari sumber lain untuk penggunaan secara tertulis maupun lisan harus disetujui oleh pemilik hasil karya tersebut, terkecuali informasi tersebut merupakan pengetahuan umum.
Beberapa type plagiarisme yaitu :
1. Word-to-word plagiarism adalah menyalin setiap kata secara langsung tanpa diubah sedikit pun.
2. Plagiarism of authorship adalah mengakui hasil karya orang lain sebagai karya sendiri dengan cara mencantumkan nama sendiri menggantikan nama pengaran sebenarnya.
3. Plagiarism of ideas adalah mengakui hasil pemikiran atau ide orang lain. 4. Plagiarism of source, jika seseorang penulis menggunakan kutipan dari penulis
lainya tanpa mencantumkan sumbernya. [5]
2.1 Metoda pendeteksian Plagiarisme
Metode pendeteksi plagiarisme dibagi menjadi tiga bagian yaitu metode perbandingan teks lengkap, metode dokumen fingerprinting, dan metode kesamaan kata kunci. Metode pendeteksi plagiarisme dapat dilihat pada gambar 2.1 berikut :
Metoda Pendeteksian Plagiarisme
Perbandingan Teks Lengkap
Dokumen Fingerprinting
Kesamaan Kata Kunci
Berikut ini penjelasan dari masing-masing metode dan algoritma pendeteksi plagiarisme :
1. Perbandingan teks lengkap. Metode ini diterapkan dengan membandingkan semua isi dokumen. Dapat diterapkan untuk dokumen yang besar. Pendekatan ini membutuhkan waktu yang lama tetapi cukup efektif, karena kumpulan dokumen yang diperbandingkan adalah dokumen yang disimpan pada penyimpanan lokal. Metode perbandingan teks lengkap tidak dapat diterapkan untuk kumpulan dokumen yang tidak terdapat pada dokumen lokal. Algoritma yang digunakan pada metode ini adalah algoritma Brute-Force, algoritma edit distance, algoritma Boyer Moore dan algoritma lavenshtein distance.
2. Dokumen Fingerprinting. Dokumen fingerprinting merupakan metode yang digunakan untuk mendeteksi keakuratan salinan antar dokumen, baik semua teks yang terdapat di dalam dokumen atau hanya sebagian teks saja. Prinsip kerja dari metode dokumen fingerprinting ini adalah dengan menggunakan teknik hashing. Teknik hashing adalah sebuah fungsi yang mengkonversi setiap string menjadi bilangan. Misalnya Rabin-Karp, Winnowing dan Manber. 3. Kesamaan Kata Kunci. Prinsip dari metode ini adalah mengekstrak kata kunci
dari dokumen dan kemudian dibandingkan dengan kata kunci pada dokumen yang lain. Pendekatan yang digunakan pada metode ini adalah teknik dot. [6]
2.2 Pencocokan String (String Macthing)
Teks yang akan dilakukan proses teks mining, pada umumnya memiliki beberapa karakteristik diantaranya adalah memiliki dimensi yang tinggi, terdapat noise pada data, dan terdapat struktur teks yang tidak baik. Cara yang digunakan dalam mempelajari suatu data teks, adalah dengan terlebih dahulu menentukan fitur-fitur yang mewakili setiap kata untuk setiap fitur yang ada pada dokumen.
2.3 Proses Prepsocessing
Preprocessing adalah tahapan untuk mempersiapkan teks menjadi data yang akan diolah di tahapan berikutnya. Input-an awal pada proses ini adalah berupa dokumen asli dan dokumen yang akan di uji. Preprocessing pada penelitian ini terdiri dari beberapa tahapan, yaitu: proses pemisahan kalimat, proses case folding, proses filtering, proses tokenizing, proses stopword dan proses stemming. Berikut gambaran tahap preprocessing dapat dilihat pada gambar 2.2 berikut :
Pemisahan
Kalimat Filtering Tokenizing
Stopword Removal Case
Folding Stemming
Gambar 2. 2 Gambar tahap preprocessing
2.3.1 Pemisahan Kalimat
Pemisahan kalimat adalah proses memecah teks pada dokumen menjadi kumpulan kalimat-kalimat yang merupakan langkah awal tahapan text preprocessing. Teknik yang digunakan dalam pemisahan kalimat adalah memisahkan kalimat dengan tanda titik (.), tanda tanya (?), dan tanda seru (!) sebagai pemisah (delimiter). Menghilangkan delimeter tersebut dokumen akan terpotong menjadi kalimat [7].
Pada proses pemisahan kalimat ini juga akan ada proses pemilihan kalimat , kalimat yang terpadat sumber referensi akan di hapus dan tidak akan diproses ke tahap selanjutnya.
2.3.2 Casefolding
2.3.3 Filtering
Data teks dalam dokumen yang sebelumnya sudah diubah ke dalam huruf kecil semua. Selanjutnya dilakukan proses filtering teks. Filtering adalah tahapan pemrosesan teks dimana semua teks selain karakter “a” sampai “z” akan dihilangkan dan hanya menerima spasi [8].
2.3.4 Tokenizing
Proses Tokenizing adalah proses pemotongan string input berdasarkan tiap kata yang menyusunnya, memecahkan data kalimat dan memisahkannya menjadi setiap kata. Pemecahan kalimat menjadi kata-kata tunggal dilakukan dengan men-scan kalimat dan setiap kata terindentifikasi atau terpisahkan dengan kata yang lain oleh pemisah spasi [8].
2.3.5 Stopword Removal
Proses Stopword Removal merupakan proses penghilangan stopword.
Stopword adalah kata-kata yang tidak deskriptif yang dapat dibuang dalam pendekatan bag-of-words [6]. Untuk mendeteksi apakah suatu kata merupakan suatu stopword atau bukan adalah menggunakan kamus stopword yang sudah ditentukan sebelumnya.
Setiap kata akan diperiksa apakah masuk dalam daftar stopword, jika sebuah kata masuk di dalam daftar stopword maka kata tersebut tidak akan diproses lebih lanjut dan kata tersebut akan dihilangkan. Sebaliknya apabila sebuah kata tidak termasuk di dalam daftar stopword maka kata tersebut akan masuk keproses berikutnya. [8]. Kandidat umum stopword adalah article, preposisi, dan konjungsi.
2.3.6 Stemming
Proses Stemming merupakan proses pencarian akar kata (root word) dari tiap kata yaitu dengan mengembalikan suatu kata berimbuhan ke bentuk dasarnya (stem). Untuk pemrosesan pada bahasa Indonesia, proses stemming dilakukan dengan menghilangkan imbuhan yang mengawali dan mengakhiri kata sehingga diperoleh bentuk dasar dari kata tersebut [8]. Algoritma ini dikembangkan oleh Fadillah Z. Tala pada tahun 2003. Berupa algoritma stemmer untuk bahasa.
untuk dikembangkan sebagai algoritma stemmer untuk bahasa Indonesia, karena pemikiran dasar dari algoritma Porter Stemmer cocok dengan struktur morfologi kata-kata di dalam bahasa Indonesia[8]. Perbedaan algoritma ini dengan algoritma yang telah dikembangkan oleh Nazief & Adriani yaitu tidak adanya dictionary
sehingga algoritma ini dapat dikatakan murni berbasis rule[8]. Berdasarkan hasil penelitian [9] Perbedaan algoritma ini dengan algoritma yang telah dikembangkan oleh Nazief & Adriani yaitu tidak adanya dictionary sehingga algoritma ini dapat dikatakan murni berbasis rule [9]. Adapun gambar desain dari algoritma Porter Stemmer bahasa Indonesia dapat dilihat pada gambar 2.3 [10].
Kata
Menghapus Partikel
Menghapus Kata Ganti
Menghapus Awalan Pertama
Menghapus Awalan Kedua Menghapus Akhiran
Menghapus Akhiran Menghapus Awalan Kedua
Kata Dasar
ditemukan tidak ditemukan
ditemukan
tidak ditemukan
pada algoritma Porter Stemmer bahasa Indonesia terdapat 5 kelompok aturan yang dapat dilihat pada tabel 2.1 sampai tabel 2.5 berikut [11].
Tabel 2. 1 Kelompok Aturan Pertama : Pembentukan Partikel
Akhiran Pengganti Kondisi
Ukuran
Kondisi
Tambahan Contoh
-kah NULL 2 NULL bukukah → buku
Akhiran Pengganti Kondisi
Ukuran
Kondisi
Tambahan Contoh
-lah NULL 2 NULL pergilah → pergi
-pun NULL 2 NULL bukupun → buku
-tah NULL 2 NULL apatah → apa
Tabel 2. 2 Kelompok Aturan Kedua : Pembentukan Kata Ganti
Akhiran Pengganti Kondisi
Ukuran
Kondisi
Tambahan Contoh
-ku NULL 2 NULL bukuku → buku
-mu NULL 2 NULL bukumu → buku
-nya NULL 2 NULL bukunya → buku
Tabel 2. 3 Kelompok Aturan Ketiga : Pembentukan Awalan Pertama
Awalan
Pertama Pengganti
Kondisi
Ukuran
Kondisi
Tambahan Contoh
meng- NULL 2 NULL mengukur → ukur
meny- S 2 V… menyapu → sapu
men- NULL 2 NULL menduga → duga
men- T 2 V… menuduh → tuduh
mem- P 2 V… memilah → pilah
mem- NULL 2 NULL membaca → baca
me- NULL 2 NULL merusak → rusak
peng- NULL 2 NULL pengukur → ukur
peny- S 2 V… penyapu → sapu
pen- NULL 2 NULL penduga → duga
Awalan
Pertama Pengganti
Kondisi
Ukuran
Kondisi
Tambahan Contoh
pem- P 2 V… pemilah → pilah
pem- NULL 2 NULL pembaca → baca
di- NULL 2 NULL diukur → ukur
ter- NULL 2 NULL tersapu → sapu
Tabel 2. 4 Kelompok Aturan Keempat : Pembentukan Awalan Kedua
Awalan
Kedua Pengganti
Kondisi
Ukuran
Kondisi
Tambahan Contoh
ber- NULL 2 NULL berlari → lari
Awalan
Kedua Pengganti
Kondisi
Ukuran
Kondisi
Tambahan Contoh
bel- NULL 2 ajar belajar → ajar
be- NULL 2 kerja bekerja → kerja
per- NULL 2 NULL perjelas → jelas
pel- NULL 2 ajar pelajar → ajar
pe- NULL 2 NULL pekerja → kerja
Tabel 2. 5 Kelompok Aturan Kelima : Pembentukan Akhiran
Akhiran Pengganti Kondisi
Ukuran Kondisi Tambahan Contoh
-kan NULL 2 Awalan bukan anggota {ke, peng} tarikkan → tarik
-an NULL 2 Awalan bukan anggota {di, meng,
ter} perjanjian → janji
-i NULL 2 Awalan bukan anggota
{ber, ke, peng}
mendapati →
dapat
2.4 Teknik Grabbing
Teknik grabbing adalah teknik mengambil teks atau konten pada situs lain dengan cURL kemudian diletakan pada website lain. Konsep grabbing berbeda dari
web service, dimana informasi atau data yang di ambil tidak disajikan dalam bentuk tertentu sepetti XML atau JSON. Data yang diambil berada pada halaman website
Pada teknik grabbing, selain membaca file HTML dengan cURL diperlukan pula sebuah metoda untuk mengambil data atau informasi yang terselip pada file
HTML, yaitu dengan fungsi explode [13]. Konsep dari function explode adalah memotong suatu data dalam hal ini tag HTML, berdasar keyword tertentu dan menghasilkan data array.
Konsep dari teknik grabbing sendiri dalam penerapan menggunakan fungsi untuk membaca halaman website dan fungsi untuk memotong tag HTML, sehingga diperoleh konten atau teks yang dibutuhkan.
2.4.1 Fungsi cURL
cURL (Client URL), dikembangkan sebagai alat bantu untuk transfer data dan file dengan sintaks URL melalui bermacam – macam protokol. Fungsi – fungsi cURL tersimpan dalam libcurl yang tersedia untuk berbagai bahasa pemrograman termasuk PHP [14] .
cURL digunakan untuk mentransfer data dari server. Sebernarnya ada banyak perangkat transfer data layaknya cURL, namum cURL memiliki fitur yang lebih lengkap di antara perangkat – perangkat lainya seperti dukungan terhadap HTTP, FTP, SFTP, SOCKS, TFTP, IMAP, POP3, SMTP dan lain – lain [15] .
2.5 Synonim Recognition
Synonymrecognition atau pengenalan sinonim adalah salah satu pendekatan yang digunakan untuk membantu proses pendeteksian plagiarisme. Synonym recognition merupakan pendekatan semantik terhadap dokumen teks. Pendekatan ini memanfaatkan kesamaan makna dalam kata yang kemungkinan banyak terjadi. Dengan mendeteksi kata-kata yang sama (sinonim) antara dokumen teks satu dengan yang lain pendekatan ini menambah tingkat keakuratan proses deteksi plagiarism [2]. Algoritma yang digukanan untuk pengenalan dan pemilihan synonim adalah dengan algoritma lesk.
2.6 Algoritma Lesk
dengan definisI.definisi dari kata tetangganya berdasarkan definisi kamus. Algoritma lesk menggunakan wordnet sebagai kamus atau acuan makna [4].
2.7 Metoda K – Gram
K-Gram adalah rangkaian terms dengan panjang K. Kebanyakan yang digunakan sebagai terms adalah kata. K-Gram merupakan sebuah metode yang diaplikasikan untuk pembangkitan kata atau karakter. Metode K-Gram ini digunakan untuk mengambil potongan-potongan karakter huruf sejumlah k dari sebuah kata yang secara kontinuitas dibaca dari teks sumber hingga akhir dari dokumen [12]. Dalam Markov Model nilai K-Gram yang sering digunakan yaitu, 2-gram (bigram), 3-gram (trigram) dan seterusnya disebut K-Gram (4-gram, 5-gram dan seterusnya). Dalam natural language processing, penggunaan K-Gram (atau lebih dikenal dengan ngram), proses parsing token (tokenisasi) lebih sering menggunakan 3-gram dan 4-gram, sedangkan 2-gram digunakan dalam parsing sentence, misal dalam part of-speech (POS). Penggunaan 2-gram dalam tokenisasi akan menyebabkan tingkat perbandingan antar karakter akan semakin besar. Contohnya pada kata „makan‟ dan „mana‟ yang merupakan dua kata yang sama sekali berbeda. Dengan menggunakan metode bigram dalam mencari similarity, hasil dari bigram tersebut yaitu kata “makan” akan menghasilkan bigram ma, ak, ka, an serta kata “mana” akan menghasilkan bigram ma, an, na. Dengan demikian, akan terdapat kesamaan dalam pengecekannya similarity. Namun jika menggunakan 3-gram (“makan” = mak, aka, kan dan “mana” = man,ana) atau 4-gram (“makan” = maka, akan, dan “mana” = mana) akan mengecilkan kemungkinan terjadinya kesamaan pada kata yang strukturnya berbeda [16].
2.8 Algoritma Rabin Karp
menambahkan nilai keterurutan setiap huruf dalam alfabet (a = 1, b = 2, dst.) dan melakukan modulo dengan 3. Didapatkan nilai hash dari “cab” adalah 0 dan tiga
karakter pertama pada teks yaitu “aab” adalah 1.
Gambar 2. 4 Fingerprint Awal
Hasil perbandingan ternyata tidak sama, maka substring pada teks akan begeser satu karakter ke kanan. Algoritma tidak menghitung kembali nilai hash
substring. Disinilah dilakukan apa yang disebut rolling hash yaitu mengurangi nilai karakter yang keluar dan menambahkan nilai karakter yang masuk sehingga didapatkan kompleksitas waktu yang relatif konstan pada setiap kali pergeseran.
Gambar 2. 5 Menggeser Fingerprint
Gambar 2. 6 Pembandingan Kedua
Hasil perbandingan juga tidak sama, maka dilakukan pergeseran. Begitu pula dengan perbandingan ketiga. Pada perbandingan keempat, didapatkan nilai
hash yang sama.
Gambar 2. 7 Perbandingan keempat (nilai hash sama)
Karena nilai hash sama, maka dilakukan perbandingan string karakter per karakter antara “bca” dan “cab”. Didapatkan hasil bahwa kedua string tidak sama. Kembali substring bergeser ke kanan.
Gambar 2. 8 Perbandingan kelima (string ditemukan)
dan n adalah jumlah looping yang dilakukan untuk menemukan solusi. Hasil ini jauh lebih mangkus daripada kompleksitas waktu yang didapat menggunakan algoritma brute-force yaitu O(mn). [6]
Untuk pola yang panjang dan teks yang besar, algoritma ini menggunakan operasi mod, setelah dikenai operasi mod q, nilainya akan menjadi lebih kecil dari q, missal :
BAN = 1 + 0 + 13 = 14 = 14 mod 13 = 1 = BAN → 1
CARD = 2 + 0 + 17 + 3 = 22 = 22 mod 13 = 9 = CARD → 9
Tetapi tidak semua nilai hash yang cocok berarti polanya cocok. Hal ini sering terjadi pada beberapa kasus, ini disebut spurious hits. Kemungkinan terjadinya diantaranya karena :
Operasi mod terinterfensi oleh keunikan nilai hash (nilai mod q biasanya dipilih bilangan prima sehingga 10q hanya cocok dengan 1 kata komputer).
14 mod 13 = 1 27 mod 13 = 1
Informasi hilang setelah penjumlahan. BAN → 1 + 0 + 13 = 14
CAM → 2 + 0 + 12 = 14
RABIN-KARP-MATCHER (T, P, d, q)
n = T.length
m = P.length
h = dm-1 mod q
p = 0
t0 = 0
for i = 1 to m // preprocessing
p = (dp + P[i]) mod q
t0 = (dt0 + T[i]) mod q
for s = 0 to n – m
if p == ts // matching
if P[1 .. m] == T[s + 1 .. s + m]
print Pattern occurs with shift s
if s < n – m
ts+1 = (d(ts - T[s + 1] h) + T[s + m + 1]) mod q
Gambar 2. 9 Pseudocode Algoritma RabinKarp Rumus matematis:
ts+1 ` = (d (ts – T [s + 1] h) + T [s + m + 1] mod q Dimana :
ts = Nilai desimal dengan panjang m dari substring T [s + 1 .. s + m], untuk s = 0, 1, ..., n – m.
ts+1 = Nilai desimal selanjutnya yang dihitung dari ts. d = Radix desimal (bilangan basis 10).
H = dm-1
n = Panjang teks
m = Panjang pola
q = Nilai modulo
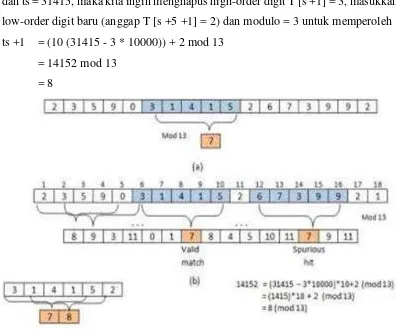
dan ts = 31415, maka kita ingin menghapus high-order digit T [s +1] = 3, masukkan low-order digit baru (anggap T [s +5 +1] = 2) dan modulo = 3 untuk memperoleh ts +1 = (10 (31415 - 3 * 10000)) + 2 mod 13
= 14152 mod 13 = 8
Gambar 2. 10 Gambaran Algoritma RabinKarp Dengan Nilai Mod 2.9 Peningkatan Performa Algoritma Rabin Karp
Telah kita pahami bahwa spurious hit adalah beban tambahan bagi algoritma yang akan meningkatkan waktu proses. Hal ini dikarenakan algoritma harus membandingkan pola terhadap teks yang hasil modulonya sama tetapi nilai hashnya berbeda. Untuk menghindari pencocokan yang tidak perlu, Singh dan Kochar (2008) memberikan solusi untuk tidak hanya membandingkan sisa hasil bagi, tetapi membandingkan hasil baginya juga [17].
REM (n1/q) = REM (n2/q) (2.3)
QUOTIENT (n1/q) = QUOTIENT (n2/q) (2.4)
melakukan pencocokan lagi. Hal ini berarti tidak ada pemborosan waktu untuk mengecek spurious hit.
RB_IMPROVED (T, P, d, q)
n = T.length m = P.length h = dm-1 mod q p = 0
t0 = 0
Q = 0
pq = 0
h = dm-1 mod q
for i = 1 to m // preprocessing
p = (dp + P[i]) mod q t0 = (dt0 + T[i]) mod q
for s = 0 to n – m
Q=T{s+1...s+ m] div q
If ( ts = p and Q = pq) // matching
print Pattern occurs with shift s
if s < n – m
ts+1 = (d(ts - T[s + 1] h) + T[s + m + 1]) mod q
Gambar 2. 11 PseoudecodeRabinKarp (2)
2.10 Hashing
Hashing adalah suatu cara untuk mentransformasi sebuah string menjadi suatu nilai yang unik dengan panjang tertentu (fixed-length) yang berfungsi sebagai penanda string tersebut. Hash function atau fungsi hash adalah suatu cara menciptakan fingerprint dari berbagai data masukan. Hash function akan mengganti atau mentranspose-kan data tersebut untuk menciptakan fingerprint, yang biasa disebut hash value.
sama. Masalah yang kedua belum tentu string yang mempunyai hash value yang sama cocok untuk mengatasinya maka untuk setiap string yang di-assign dilakukan pencocokan string secara brute-force.
Untuk melakukan pengubahan tersebut menggunakan persamaan sebagai berikut :
H = C1 * ak− + C2 * ak− + C3 * a k− … + Ck * a0 (2.5)
Reminder = H / Nilai Mod (2.6)
Keterangan: H = hash value
c = nilai ascii karakter a = basis
k = banyaknya karakter
2.11 Dice Similarity Coeficients
Untuk menghitung nilai similarity dari dokumen fingerprint yang didapat maka digunakan Dice Similarity Coeficients dengan cara menghitung nilai dari jumlah K-Gram yang digunakan pada kedua dokumen yang diuji, sedangkan dokumen fingerprint didapat dari jumlah nilai K-Gram yang sama. Nilai Similarity tersebut dapat dihitung dengan menggunakan :
S =
+ (2.7)
. Dimana S merupakan nilai similarity, dan C merupakan jumlah K-Gram yang sama dari dua buah teks yang di bandingkan, sedangkan A, B merupakan jumlah K-Gram dari masing-masing teks yang dibandingkan. [6]
2.12 Analisis Terstruktur
Model analisis yang digunakan dalam pembangunan aplikasi ini adalah analisis terstruktur. Adapun tools pemodelan dalam analisis terstruktur akan dijelaskan di bawah ini.
2.12.1 Diagram Konteks
dipresentasikan dengan lingkaran tunggal yang mewakili keseluruhan sistem. Dalam CD, sistem masih dianggap kesatuan yang utuh. Entitas luar bisa berupa pengguna, mesin ataupun database yang berada di luar sistem namun berhubungan dengan sistem. Garis masuk dari entitas luar ke dalam sistem menggambarkan input, sedangkan garis keluar dari sistem ke entitas luar menggambarkan output. [18]
2.12.2 Data Flow Diagram
DataFlowDiagram (DFD) adalah suatu model logika data atau proses yang dibuat untuk menggambarkan dari mana asal data dan kemana tujuan data yang keluar dari sistem, dimana data disimpan, proses apa yang menghasilkan data tersebut dan interaksi antara data yang tersimpan dan proses yang dikenakan pada data tersebut. DFD sering digunakan untuk menggambarkan suatu sistem yang telah ada atau sistem baru yang akan dikembangkan secara logika tanpa mempertimbangkan lingkungan fisik dimana data tersebut mengalir atau dimana data tersebut akan disimpan . [18]
DFD terdiri dari diagram rinci (DFD Levelled). DFD levelled menggambarkan sistem sebagai jaringan kerja antara fungsi yang berhubungan satu sama lain dengan aliran dan penyimpanan data, model ini hanya memodelkan sistem dari sudut pandang fungsi. Dalam DFD levelled akan terjadi penurunan level dimana dalam penurunan level yang lebih rendah harus mampu merepresentasikan proses tersebut ke dalam spesifikasi proses yang jelas. Jadi dalam DFD levelled bisa dimulai dari DFD level 0 kemudian turun ke DFD level 1 dan seterusnya. Setiap penurunan hanya dilakukan bila perlu. Aliran data yang masuk dan keluar pada suatu proses di level x harus berhubungan dengan aliran data yang masuk dan keluar pada level x+1 yang mendefinisikan proses pada level x tersebut.
2.12.3 Spesifikasi Proses
2.12.4 Kamus Data
Kamus Data (KD) adalah katalog fakta tentang data dan kebutuhan-kebutuhan informasi dari suatu sistem [18]. Kamus data merupakan bagian yang berisi dari data yang mengalir pada DFD. Penjelasan struktur data pada tiap data harus sama dengan yang sudah dimodelkan. Tipe data tiap struktur data harus digambarkan dengan sejelas mungkin agar input yang diberikan sesuai. [18]
2.13 Perangkat Lunak Pendukung
Perangkat lunak pendukung merupakan perangkat lunak yang digunakan dalam mendukung pembangunan perangkat lunak. Berikut penjelasan dari perangkat lunak pendukung :
2.13.1 MySQL
MySQL adalah sebuah perangkat lunak sistem manajemen basis data SQL atau DBMS yang multithread, multi-user, dengan sekitar 6 juta instalasi di seluruh dunia. MySQL AB membuat MySQL tersedia sebagai perangkat lunak gratis di bawah lisensi GNU General Public License (GPL), tetapi mereka juga menjual dibawah lisensi komersial untuk kasus-kasus dimana penggunaannya tidak cocok dengan penggunaan GPL. Tidak seperti PHP atau Apache yang merupakan
software yang dikembangkan oleh komunitas umum, dan hak cipta untuk kode sumber dimiliki oleh penulisnya masing-masing, MySQL dimiliki dan disponsori oleh sebuah perusahaan komersial Swedia yaitu MySQL AB. MySQL AB memegang penuh hak cipta hampir atas semua kode sumbernya. Kedua orang Swedia dan satu orang Finlandia yang mendirikan MySQL AB adalah: David Axmark, Allan Larsson, dan Michael "Monty" Widenius [19].
2.13.2 Xampp
dan MySQL secara manual. XAMPP akan menginstalasi dan mengkofigurasikannya secara otomatis.
2.13.3 PHP
Pembangunan aplikasi untuk menguji akurasi analisis sentimen menggunakan bahasa pemrograman PHP. PHP (singkatan rekrusif PHP : Hypertext Preprocessir) adalah bahasa scripting yang banyak digunakan umum secara open source yang cocok digunakan untuk pengembangan website dengan ditanamkan ke dalam HTML [20]. Kode PHP diawali dengan tanda lebih kecil (<) dan diakhiri dengan tanda lebih besar (>). Ada tiga cara untuk menuliskan script PHP ditampilkan pada gambar 2.14 berikut:
Gambar 2. 12 Cara Penulisan Script PHP
Untuk membuat atau menambahkan komentar, standar penulisannya ditampilkan pada gambar 2.15 berikut:
115
5 BAB V
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Berdasarkan hasil penelitian yang telah dilakukan, dapat disimpulkan bahwa dari hasil pengujian sejumlah nilai parameter K-Gram ( K = 2, k = 3, k = 4, k = 5) dapat disimpulkan bahwa kombinasi algoritma lesk untuk proses synonym recognition dan rabin rabin karp dalam penerapan pada kasus plagiarism (kesamaan) menghasilkan presentase rata – rata sebesar 85,78% dibandingkan dengan yang tidak menggunakan kombinasi algoritma lesk untun proses synonim recognition yang hanya menghasilkan presentase sebesar 77.45%. meskipun membutuhkan waktu proses yang lebih tinggi daripada yang tidak menggunakan
synonym recognition.
5.2 Saran
Berdasarkan hasil penelitian yang telah dilakukan, masih perlu dilakukan beberapa kajian lebih lanjut. Adapun saran untuk penelitian lebih lanjut yaitu :
1. Perlu adanya proses pendeteksian plagirisme untuk mengatasi perubahan kalimat aktif dan pasif.
2. Perlu adanya proses untuk mendeteksi plagiarism pada tingkat perubahan stuktur kalimat (pharafrase).
3. Perlu adanya proses untuk menangani, plagiarisme pada perubahan urutan kalimat.
Riwayat Pendidikan
1998 – 2004 SD Negeri 1 Bojongkoneng 2004 – 2007 SMP Negeri 1 Soreang
2007 – 2010 SMK Negeri 1 Katapang, Jurusan Teknik Kompter Dan jaringan 2011 – 2016 Universitas Komputer Indonesia, S1 Program Studi Teknik
Informatika
Demikian biodata ini saya buat dengan sebenar – benarnya.
Bandung, 27 Februari 2015
Moch Nurhalimi Z.D
BIODATA
Data Pribadi
Nama : Moch Nurhalimi Z.D
Nim : 10111492
Tempat/Tanggal Lahir : Bandung, 27 Juli 1993 Jenis Kelamin : Laki-laki
Agama : Islam
Alamat : KMP Bojongkoneng RT 001 RW 006 Desa
Cingcin Kecamatan Soreang Kabupaten Bandung
No. Telepon : 083817407608
PADA PENDETEKSIAN PLAGIARISME Moch Nurhalimi ZD1, Ednawati Rainarli2
1,2 Teknik Informatika – Universitas Komputer Indonesia
Jl. Dipatiukur 112-114 Bandung
E-mail : [email protected], [email protected]
ABSTRAK
Penjiplakan dokumen digital bukanlah hal yang susah, cukup dengan menggunakan teknik copy-paste-modify. Salah satu metoda yang digunakan untuk mendeteksi plagiarisme adalah string macthing. Salah satu algoritma string matching yang sering digunakan adalah rabin karp menurut salah satu jurnal algoritma rabin karp menghasilkan efesiensi waktu yang lebih baik dalam mendeteksi string yang memiliki pola banyak. Terkadang plagiarisme juga dilakukan dengan mengganti kata-kata yang mengandung kata-kata - kata-kata sinonim, dengan maksud agar terlihat berbeda dari dokumen aslinya. Sehingga setelah proses preprocessing dilakukan proses pengenalan sinonim dan pemilihan kata sinonim (synonim recognition). Diperlukan suatu proses untuk mendeteksi kesamaan dokumen yaitu proses preprocessing, synonym recognition, parsing k-gram, konversi hashing, pencocokan string, hitung similiarity.
Berdasarkan pengujian dapat disimpulkan bahwa kombinasi algoritma lesk untuk proses synonym recognition dan rabin rabin karp dalam penerapan pada kasus plagiarism (kesamaan) menghasilkan presentase kesamaan rata – rata yaitu sebesar 85,78%, dibandingkan yang tidak menggunakan proses synonim recognition yaitu menghasilkan rata – rata sebesar 77.45%, meskipun membutuhkan waktu proses yang lebih banyak daripada tidak menggunakan synonym recognition
Kata Kunci : string matching, Plagirisme, Synonim recognition , algoritma rabin karp.
1. PENDAHULUAN
Penjiplakan atau plagiarism berarti mencontoh atau meniru tulisan dan karya orang lain yang kemudian diakui sebagai karanganya sendiri dengan ataupun tanpa seizin penulisnya. Penjiplakan dokumen digital bukanlah hal yang susah, cukup dengan menggunakan teknik copy-paste-modify pada sebagian isi dokumen dan bahkan keseluruhan isi dokumen sudah bisa dikatakan bahwa dokumen tersebut merupakan hasil duplikasi dari dokumen lain
[1]. Terkadang plagiarisme juga dilakukan dengan mengganti kata-kata yang mengandung kata - kata sinonim, dengan maksud agar terlihat berbeda dari dokumen aslinya. Dimana hanya merubah kata – kata yang mengandung sinonim yang terdapat di dokumen asli dengan merubah nya sesuai dengan kata yang ada di Kamus bahasa indonesia , tanpa memperhatikan struktur kalimat dari dokumen aslinya[1].
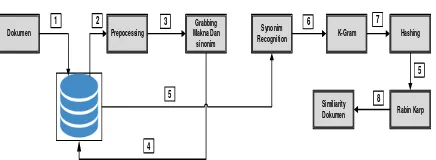
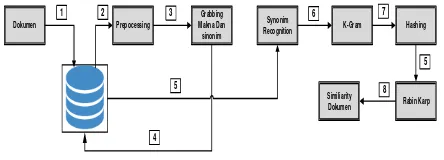
Pada penelitian ini terdapat beberapan tahapan dalam proses mendeteksi kesamaan dokumen dari 2 (dua) buah dokumen. Diantaranya proses tersebut adalah pertama tahap pertama adalah tahap pemilihan dokumen asli dan dokumen uji yang akan di hitung nilai kesamaanya, setelah itu melalui tahap prepcoessing dimana hasil dari tahap ini akan digunakan untuk proses pemilihan dan penentuan kata mana yang akan dipilih buat melengkapi tindak plagiarism pada perubahan kata sinonim menggunakan algoritma lesk. Kemudian dilakukan proses parsing k-gram dari kedua array kata (dokumen asli dan dokumen uji), dimana buat penentuan nilai K nya bersifat experimental, namun jika semakin kecil nilai K maka nilai similiairity akan semakin besar, dan semakin besar nilai K maka nilai similiairy akan semakin kecil [2]. Kemudian hasil dari parsing k-gram tersebut akan dikonversi kedalam nilai hashing dimana nilai tersebut yang nantinya akan di cocokan menggunakan algoritma rabin karp. Dan kemudian dilakukan proses perhitungan nilai similiairity dari kesamaan dokumen uji terhadap dokumen asli menggunakan metoda dice similiairity.
Jurnal Ilmiah Komputer dan Informatika (KOMPUTA)
Gambar 1. Tahap Pendeteksian Plagiarisme
1.1 Preprocessing
Dokumen yang akan diproses, terlebih dahulu dilakukan tahap pertama yaitu proses preprocessing. Tahap preprocessing Adapun tahap-tahap dari proses
preprocessing yang akan dilakukan diantaranya
pemisahan kalimat [3], case folding [3], filtering [3], tokenizing [4], stopword removal [5] dan stemming [6]. Proses stemming dilakukan dengan menggunakan algoritma porter stemmer bahasa Indonesia [6]. Hasil dari tahapan proses preprocessing ini akan digunakan untuk melakuka proses ini akan digunakan untuk melakukann proses synonym recognition dengan menggunakan algoritma lesk.
1.2 Synonim Recognition
Synonym recognition atau pengenalan sinonim
adalah salah satu pendekatan yang digunakan untuk membantu proses pendeteksian plagiarisme. Synonym recognition merupakan pendekatan semantik terhadap dokumen teks. Pendekatan ini memanfaatkan kesamaan makna dalam kata yang kemungkinan banyak terjadi [1]. Algoritma yang digunakan pada proses synonym recognition adalah algoritma lesk.
Algoritma lesk adalah algoritma yang digunakan untuk menghilangkan ambiguitas makna kata. Algoritma lesk merupakan salah satu algoritma untuk menyelesaikan masalah word sense disambiguation dengan berbasis kamus. Algoritma ini bekerja dengan membandingkan definisi dari kata yang berambigu dengan definisI.definisi dari kata tetangganya berdasarkan definisi kamus. Algoritma lesk menggunakan wordnet sebagai kamus atau acuan
1.3 Parsing K-Gram
K-Gram adalah rangkaian terms dengan
panjang K. Kebanyakan yang digunakan sebagai terms adalah kata. K-Gram merupakan sebuah metode yang diaplikasikan untuk pembangkitan kata atau karakter. Metode K-Gram ini digunakan untuk mengambil potongan-potongan karakter huruf sejumlah k dari sebuah kata yang secara kontinuitas dibaca dari teks sumber hingga akhir dari dokumen [2].
1.4 Hashing
Hashing adalah suatu cara untuk
mentransformasi sebuah string menjadi suatu nilai yang unik dengan panjang tertentu (fixed-length)
yang berfungsi sebagai penanda string tersebut. Hash function atau fungsi hash adalah suatu cara menciptakan fingerprint dari berbagai data masukan. Hash function akan mengganti atau mentranspose-kan data tersebut untuk menciptamentranspose-kan fingerprint, yang biasa disebut hash value [7]. Untuk melakukan pengubahan tersebut menggunakan persamaan (1) berikut :
hash = C1 * ��− + C2 * ��− + C3 * ��− + Ck * a0 Dan persamaan (2) Berikut
rem = hash / Nilai mod.
Dimana ci adalah nilai ascii karakter , k adalah nilai paramaterter k-gram yang digunakan dan a adalah nilai basis.
1.5 Pencocokan String Dengan Rabin Karp Pada dasarnya, algoritma Rabin-Karp akan membandingkan nilai hash dari string masukan dan substring pada teks. Apabila sama, maka akan dilakukan perbandingan sekali lagi terhadap karakter-karakternya. Apabila tidak sama, maka substring akan bergeser ke kanan. Kunci utama performa algoritma ini adala perhitungan yang efisien terhadapa nilai hash substring pada saat penggeseran dilakukan.
Dikarenakan algoritma harus membandingkan pola terhadap teks yang hasil modulonya sama tetapi nilai hashnya berbeda. Untuk menghindari pencocokan yang tidak perlu, Singh dan Kochar (2008) memberikan solusi untuk tidak hanya membandingkan sisa hasil bagi, tetapi membandingkan hasil baginya juga [8].
REM (n1/q) = REM (n2/q) (3)
QUOTIENT (n1/q) = QUOTIENT (n2/q) (4)
Jadi, successful hit harus memenuhi dua syarat, yaitu nilai sisa hasil bagi dan nilai hasil baginya harus sama. Selebihnya adalah unsuccessful hit tanpa perlu melakukan pencocokan lagi. Hal ini berarti tidak ada pemborosan waktu untuk mengecek spurious hit.
1.6 Dice’s Similiairity Coeficients
Untuk menghitung nilai similarity dari dokumen fingerprint yang didapat maka digunakan Dice Similarity Coeficients dengan cara menghitung nilai dari jumlah K-Gram yang digunakan pada kedua dokumen yang diuji, sedangkan dokumen fingerprint didapat dari jumlah nilai K-Gram yang sama. Nilai Similarity tersebut dapat dihitung dengan menggunakan persamaan berikut :
S =
jumlah K-Gram dari masing-masing teks yang dibandingkan [5].
2. ISI PENELITIAN 2.1 Data Masukan
Analisis data masukan adalah terdiri dari dua dokumen , yaitu dokumen yang asli dan dokumen uji (dokumen yang telah di manipulasi) dengan format file berektensi .doc dan docx, dokumen di ambil dari latar belakang skripsi jurusan teknik informatika. Pada dokumen uji data hasil manipulasi nya yaitu merubah kata – kata yang merupakan kata sinonim agar dokumen uji tidak sama dengan dokumen asli.
Tabel 1. Data Masukan
Dokumen Asli Dokumen Uji
Plagiarisme merupakan salah satu tindakan yang dilarang, karena tindakan tersebut termasuk pelanggaran terhadap hasil karya seseorang yaitu dengan menjiplak atau mengakui hasil karya orang lain sebagai hasil karya sendiri tanpa adanya ijin. Selain itu, plagiat dapat menurunkan kreativitas
Plagiarisme ialah salah satu perbuatan yang diharamkan, karena perbuatan merupakan pelanggaran terhadap hasil ciptaan seseorang yaitu dengan mengakui hasil karya orang lain sebagai hasil karya sendiri tanpa adanya persetujuan. Selain itu, plagiat dapat menurunkan
seseorang dalam menciptakan hasil karya. Plagiarisme sering terjadi di berbagai kalangan. Pendeteksian plagiarism dapat dilakukan dengan cara pencocokan string (string matching). Metode ini dapat digunakan untuk menghitung kemiripan teks antara satu dokumen dengan dokumen lainnya.
kreativitas seseorang dalam menciptakan hasil ciptaan. Plagiarisme sering terjadi di berbagai kalangan[1]. Pendeteksian
penjiplakan bisa
dilakukan dengan menggunakan teknik pencocokan string (string matching).
2.2 Tahap Preprocessing
Tahap preprocessing yang akan dilakukan yaitu pemisahan kalimat, case folding, filtering, tokenizing, stopword removal dan stemming. Adapun pengertian, contoh serta gambaran sederhana dari tahap preprocessing dapat dilihat pada Tabel 2 sampai dengan Tabel 7.
Plagiarisme ialah salah satu perbuatan
yang diharamkan, hasil karya orang lain sebagai hasil karya sendiri tanpa adanya
persetujuan. Selain itu, plagiat dapat
Plagiarisme ialah salah satu perbuatan yang
diharamkan, karena
perbuatan merupakan pelanggaran terhadap hasil ciptaan seseorang yaitu dengan mengakui hasil karya orang lain sebagai hasil karya sendiri tanpa adanya
persetujuan. sering terjadi di berbagai kalangan[1].
Gambar 2. Pemisahan Kalimat
2. Case Folding
Tabel 3 . Casefolding
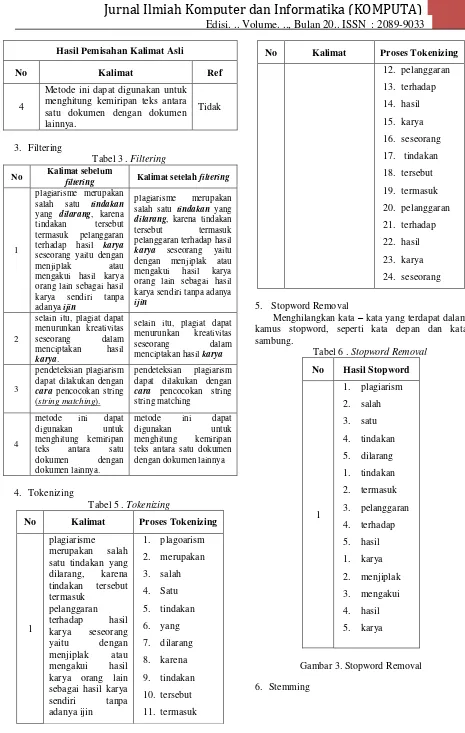
Hasil Pemisahan Kalimat Asli
No Kalimat Ref
1
Plagiarisme merupakan salah satu
tindakan yang dilarang, karena tindakan tersebut termasuk pelanggaran terhadap hasil karya
seseorang yaitu dengan menjiplak atau mengakui hasil karya orang menurunkan kreativitas seseorang dalam menciptakan hasil karya.
Tidak
3
Pendeteksian plagiarism dapat dilakukan dengan cara pencocokan string (string matching).
Jurnal Ilmiah Komputer dan Informatika (KOMPUTA)
Edisi. .. Volume. .., Bulan 20.. ISSN : 2089-9033
Hasil Pemisahan Kalimat Asli
No Kalimat Ref
4
Metode ini dapat digunakan untuk menghitung kemiripan teks antara satu dokumen dengan dokumen lainnya.
Tidak
3. Filtering
Tabel 3 . Filtering
No Kalimat sebelum
filtering Kalimat setelah filtering
1
plagiarisme merupakan salah satu tindakan yang dilarang, karena tindakan tersebut termasuk pelanggaran terhadap hasil karya seseorang yaitu dengan menjiplak atau mengakui hasil karya orang lain sebagai hasil karya sendiri tanpa adanya ijin
plagiarisme merupakan salah satu tindakan yang dilarang, karena tindakan tersebut termasuk pelanggaran terhadap hasil karya seseorang yaitu dengan menjiplak atau mengakui hasil karya orang lain sebagai hasil karya sendiri tanpa adanya ijin dapat dilakukan dengan cara pencocokan string (string matching).
pendeteksian plagiarism dapat dilakukan dengan cara pencocokan string
Tabel 5 . Tokenizing
No Kalimat Proses Tokenizing
1
No Kalimat Proses Tokenizing
12. pelanggaran
5. Stopword Removal
Menghilangkan kata – kata yang terdapat dalam kamus stopword, seperti kata depan dan kata sambung.
Tabel 6 . Stopword Removal
No Hasil Stopword
1
Gambar 3. Stopword Removal
No Array Kata Hasil
2.3 Tahap Synonim Recognition
Pada tahap ini merupakan tahap pengenalan sinonim dan pemilihan kata sinonim untuk menganti kata pada array kata dokumen asli dan array kata pada dokumen uji agar bisa mendeteksi plagiarisme tingkat subtitusi kata adapaun flowchart tahap synonym
recognition menggunakan algoritma lesk dapat
dilihat pada gambar 2 berikut
Array kata
Gambar 2 Flowchart Synonim recognition
Jurnal Ilmiah Komputer dan Informatika (KOMPUTA)
Edisi. .. Volume. .., Bulan 20.. ISSN : 2089-9033
Gambar 3 Proses Perhitungan Kesamaan Makna kata
Pada tahap ini dilakukan perhitungan bobot dari makna kata sinonim dan kata makna kata pembanding nya yang akan digukana untuk menentukan kata mana yang akan di pilih untuk menggantikan kata sinonim berdasarkan bobot yang tertinggi.
Tabel 8 . Perhitungan Bobot Kata
Sinonim
Kata
Pembanding Nilai Bobot
Buat
2.4 Tahap Parsing K-gram
Setelah melakukan tahap pengenalan sinonim dan penentuan pemilihan kata sinonim untuk menangani masalah subtitusi kata dengan mengunakan kamuss kata sinonim, langkah selanjutnya adalah parsing
kgram, yaitu memecah kata menjadi
potongan-potongan dimana setiap potongan-potongan mengandung karakter sebanyak k.
Tabel 9 . Parsing K-Gram Array Kata Hasil Parsing
K-Gram
Array Kata Hasil Parsing K-Gram
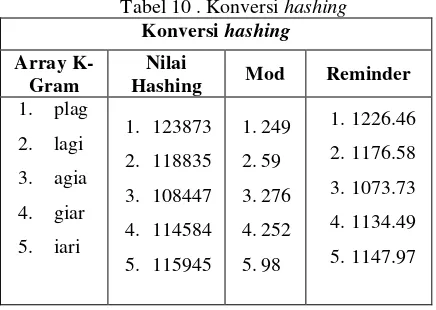
Setelah kumpulan – kumpulan gram terbentuk maka tahap selanjutnya adalah merubah kumpulan – kumpulan gram tersebut ke bentuk hash, melaluli nilai hash dapat dilihat pada tabel 10 berikut :
Tabel 10 . Konversi hashing Konversi hashing
Array K-Gram
Nilai
dalam bentuk hash , maka tahap selanjutnya adalah melakukan proses pencocokan nilai hash yang sama dari kumpulan nilai hash teks uji dan kumpulan nilai hash teks asli dengan menggunakan algoritma rabin - karp, Apabila nilai hash dari kedua dokumen yang diuji sama maka,makan akan dilakukan pengecekan terhadap nilai reminder nya,.Yang nanti nya akan di hitung berapa nilai similiaty kedua kumpulan nilai
hash tersebut. Adapun flowchart dari proses
Gambar 4 Proses Pencocokan String
Gambar 5 Hasil Proses Pencocokan String
Dimana hasil dari pencocokan string tersebut menghasilkan string yang sama adalah sejumlah 39 buah dari jumlah hash asli 54 buah dan hash uji sejumlah 49 buah.
maka dilakukan tahap penghitungan nilai similarity. Untuk menghitung nilai similarity dari dokumen fingerprint yang didapat maka digunakan Dice Similarity Coeficients dengan cara menghitung nilai dari jumlah K-Gram yang digunakan pada kedua dokumen yang diuji, sedangkan dokumen fingerprint didapat dari jumlah nilai K-Gram yang sama.
S =
+ = = 0.7878
Atau 78.78 %
3. PENUTUP
3.1 Kesimpulan
Berdasarkan hasil penelitian yang telah dilakukan, dapat disimpulkan bahwa dari hasil pengujian sejumlah nilai parameter K-Gram ( K = 2, k = 3, k = 4, k = 5) dapat disimpulkan bahwa kombinasi algoritma lesk untuk proses synonym recognition dan rabin rabin karp dalam penerapan pada kasus plagiarism (kesamaan) menghasilkan presentase rata – rata sebesar 85,78% dibandingkan dengan yang tidak menggunakan kombinasi algoritma lesk untun proses synonim recognition yang hanya menghasilkan presentase sebesar 77.45%. meskipun membutuhkan waktu proses yang lebih tinggi daripada yang tidak menggunakan synonym recognition.
3.2 Saran
Berdasarkan hasil penelitian yang telah dilakukan, masih perlu dilakukan beberapa kajian lebih lanjut. Adapun saran untuk penelitian lebih lanjut yaitu :
1. Perlu adanya proses pendeteksian plagirisme untuk mengatasi perubahan kalimat aktif dan pasif.
2. Perlu adanya proses untuk mendeteksi plagiarism pada tingkat perubahan stuktur kalimat (pharafrase).
3. Perlu adanya proses untuk menangani, plagiarisme pada perubahan urutan kalimat. 4. Perlu adanya proses untuk menangani, kata yang
Jurnal Ilmiah Komputer dan Informatika (KOMPUTA)
Edisi. .. Volume. .., Bulan 20.. ISSN : 2089-9033
DAFTAR PUSTAKA
[1] I. a. I. C. S. Dewanto, “DETEKSI
PLAGIARISME DOKUMEN TEKS
MENGGUNAKAN ALGORITMA
RABIN-KARP DENGAN SYNONYM
RECOGNITION,” Program Studi Ilmu Komputer, Program Teknologi Informatika dan Ilmu Komputer , Universitas Brawijaya Malang..
[2] A. M. Surahman, “PERANCANGAN SISTEM
PENENTUAN SIMILARITY,” Program Studi Teknik Informatika.
[3] W. E. W. d. K. L. Masayu, “Update Summarization Untuk Kumpulan Dokumen
Berbahasa Indonesia,” Jurnal Cybermatika, vol. vol. 1, p. No 2, Desember 2013.
[4] “F. Henry Dan Z. Ery,” Klastering Dokumen Berita dari Web menggunakan Algoritma Single Pass Clustering, vol. 18, pp. pp. 80-90, 2013.
[5] E. Nugroho, “Perancangan Sistem Deteksi Plagiarisme Dokumen Teks Dengan
Menggunakan Algoriam Rabin Karp,” Universitas Brawijaya, 2011.
[6] A. Ledy, “Perbandingan Algoritma Stemming Porter Dengan Algoritma Nazief & Adriani Untuk Stemming Dokumen Teks Bahasa
Indonesia,” Konferensi Nasional Sistem dan Informatika, 2009.
[7] H. B. Firdaus, “Deteksi Plagiarisme Dokumen Menggunakan Algoritma Rabin-Karp,” Program Studi Teknik Informatika Sekolah Teknik Elektro dan Informatika, Institut Teknologi Bandung.
[8] R. S. C. A. B. Kochar, “RB-Matcher. String
Matching Technique,” Rem (Text), vol. 234567, pp. no 11, p.3, 2008.
[9] P. Pitria, Analisis Sentimen Pengguna Twitter pada Akun Resmi Samsung Indonesia dengan menggunakan Naive Bayes, Perpustakaan Unikom, 2014.
[10] R. S. C. a. B. Kochar, “RB-Matcher. String