KAJIAN OVERDISPERSI PADA REGRESI POISSON
BERDASARKAN MODEL
GENERALIZED
POISSON
MARTISAH
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi yang berjudul Kajian Overdispersi pada Regresi Poisson Berdasarkan Model Generalized Poisson adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
MARTISAH. Kajian Overdispersi pada Regresi Poisson Berdasarkan Model Generalized Poisson. Dibimbing oleh KUSMAN SADIK dan DIAN KUSUMANINGRUM.
Model Generalized Poisson (GP) merupakan salah satu model yang dapat digunakan untuk mengatasi masalah overdispersi pada data Poisson. Pendeteksian overdispersi pada data simulasi menggunakan statistik uji skor, uji SSR-LRT, dan uji Wald. Data simulasi yang digunakan dibangkitkan mengikuti sebaran GP. Kebaikan model GP dianalisis menggunakan metode Root Mean Square Error (RMSE) serta Akaike Information Criteria (AIC). Selain data simulasi, penelitian ini juga menggunakan data aplikasi berupa data kasus gizi buruk di Kabupaten Lombok Barat. Hasil penelitian menunjukkan bahwa data aplikasi yang digunakan mengalami overdispersi pada taraf nyata 5% dan didapatkan bahwa persentase keluarga yang tinggal di pemukiman kumuh berpengaruh nyata terhadap penyebaran kasus gizi buruk di Lombok Barat. Pada data simulasi didapatkan bahwa kuasa uji untuk uji skor cenderung lebih baik dibandingkan uji yang lain, sehingga penggunaan uji skor lebih disarankan di dalam mendeteksi masalah overdispersi.
Kata kunci : Generalized Poisson, kuasa uji, uji SSR-LRT, uji skor, uji Wald.
ABSTRACT
MARTISAH. Overdispersion Assessment in Poisson Regression Based on Generalized Poisson Model. Supervised by KUSMAN SADIK and DIAN Kusumaningrum.
Generalized Poisson (GP) model is one model that can be used to overcame overdispersion in Poisson data. Detection of overdispersion in simulation data used score test, SSR-LRT test, and Wald test. Simulation data was generated based on the GP distribution. Goodness of fit of GP models in this study were analyzed by using the Root Mean Square Error (RMSE) and Akaike Information Criteria (AIC). In addition to the simulation data , this study also used applied case study data which malnutrition data in West Lombok. The results showed that the applied case study used indicated overdispersion at 5% significance level and the percentage of families living in slum area have impact on the spread of malnutrition in West Lombok. The simulation data showed that power of test of score test is more better than the other test, so that score test is consider as the most appropriate test in detecting overdispersion.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Statistika
pada
Departemen Statistika
KAJIAN OVERDISPERSI PADA REGRESI POISSON
BERDASARKAN MODEL
GENERALIZED
POISSON
MARTISAH
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Judul Skripsi : Kajian Overdispersi pada Regresi Poisson Berdasarkan Model Generalized Poisson
Nama : Martisah NIM : G14090071
Disetujui oleh
Dr Kusman Sadik, MSi Pembimbing I
Dian Kusumaningrum, MSi Pembimbing II
Diketahui oleh
Dr Ir Hari Wijayanto, MSi Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kehadirat Allah SWT atas segala karunia-Nya sehingga penulis dapat menyelesaikan penelitian dan penulisan karya ilmiah yang berjudul Kajian Overdispersi pada Regresi Poisson Berbasis Model Generalized Poisson.
Terima kasih penulis ucapkan kepada Bapak Dr Kusman Sadik, MSi selaku pembimbing utama dan Ibu Dian Kusumaningrum, MSi selaku pembimbing anggota, atas bimbingan dan motivasi yang diberikan selama kegiatan penelitian dan penulisan karya ilmiah ini. Penulis mengucapkan terima kasih yang sebesar-besarnya kepada kedua orangtua yang selalu memberikan doa dan motivasi baik moril maupun material kepada penulis. Tidak lupa kepada adik dan kakak tercinta atas perhatian dan motivasinya.
Penulis banyak mengucapkan terima kasih kepada Program Beasiswa Santri Berprestasi (PBSB) Kementerian Agama RI atas bantuan beasiswa yang diberikan sehingga penulis bisa menyelesaikan studinya hingga selesai. Terima kasih saya ucapkan juga kepada Ustad Ece Hidayat, Ustad Abdurrahman, dan Ustad Dudi Supiandi beserta para keluarga yang telah memberikan nasihat-nasihat yang berharga dalam kehidupan. Tidak lupa saya ucapkan terima kasih kepada teman-teman Statistika 46, CSS MORA 46 serta rekan-rekan santri/at Al-Ihya Darmaga yang telah memberikan dukungan dalam penyelesaian skripsi ini. Semoga karya ilmiah ini bermanfaat.
DAFTAR ISI
DAFTAR TABEL ix DAFTAR GAMBAR ix
DAFTAR LAMPIRAN ix
PENDAHULUAN 1
Latar Belakang 1 Tujuan Penelitian 2
TINJAUAN PUSTAKA 2
Sebaran Poisson 2
Generalized Linear Model (GLM) 2 Model Poisson 2
Mendeteksi Overdispersi 3 Uji Skor 3
Uji Wald 3
Uji SSR-LRT 4
Model Generalized Poisson(GP) 4
METODE 4
Data 4
Data Simulasi 5 Data Aplikasi 5 Prosedur 5
HASIL DAN PEMBAHASAN 6
Data Simulasi 6
Eksplorasi Data Aplikasi 10
Identifikasi Overdispersi Data Aplikasi 11 Model Terbaik Data Aplikasi 11
Model Generalized Poisson(GP) Data Aplikasi 12 SIMPULAN 13
DAFTAR PUSTAKA 13 LAMPIRAN 15
DAFTAR TABEL
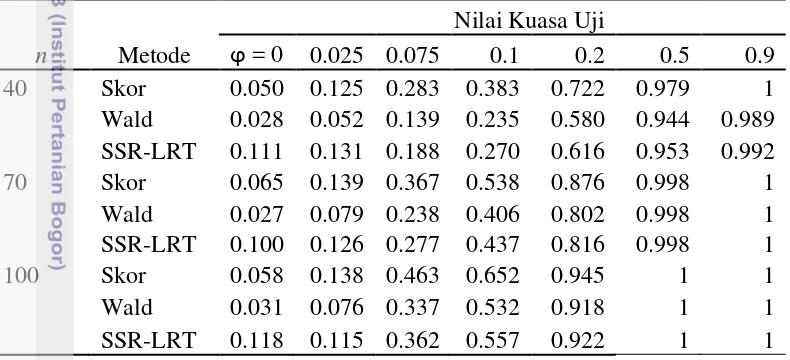
1 Nilai kuasa uji untuk uji skor, SSR-LRT, dan uji Wald pada berbagai kondisi n dan φ
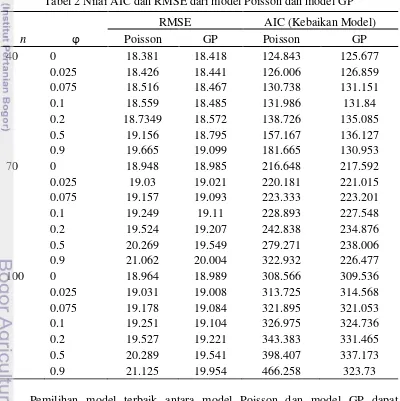
8 2 Nilai AIC dan RMSE dari model Poisson dan model GP 10
3 Hasil uji multikolinieritas 11
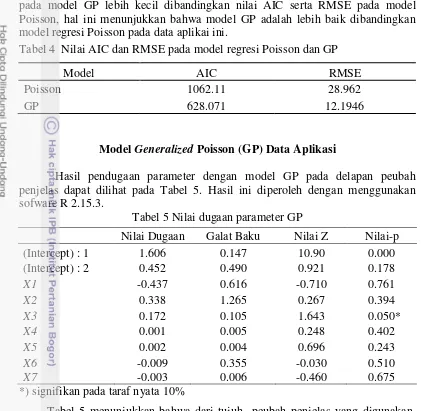
4 Nilai AIC dan RMSE dari model Poisson dan model GP 12
5 Nilai dugaan parameter GP 12
DAFTAR GAMBAR
1 Sebaran jumlah penderita gizi buruk pada 10 desa dengan jumlah
penderita gizi buruk tertinggi 9
DAFTAR LAMPIRAN
1 Grafik hasil simulasi pada berbagai data amatan 15
2 Hasil simulasi AIC pada berbagai n 16
PENDAHULUAN
Latar Belakang
Model Poisson merupakan salah satu model yang dapat digunakan untuk menganalisis data dengan peubah respon berupa data cacah yang diharapkan jarang terjadi. Misalnya data banyaknya penderita kanker serviks di suatu daerah, banyaknya kecelakaan mobil setiap bulan, dan banyaknya penderita gizi buruk di suatu desa. Penerapan model Poisson pada data cacah harus memenuhi beberapa asumsi, salah satunya adalah asumsi equidispersi. Asumsi ini mengharuskan ragam dan nilai tengah dari peubah responnya harus bernilai sama. Akan tetapi di dalam penerapannya, asumsi equidispersi ini sulit terpenuhi karena ragam peubah respon seringkali lebih besar atau lebih kecil dari nilai tengahnya. Kondisi data dengan ragam yang lebih besar dari nilai tengah peubah respon disebut overdispersi, sedangkan ragam peubah respon yang lebih kecil dari nilai tengah peubah respon disebut underdispersi (Ismail dan Jemain 2007). Menurut Molla dan Muniswamy (2012), data overdispersi yang dianalisis menggunakan model Poisson akan mengakibatkan galat baku bagi parameter dugaan regresi akan berbias ke bawah, sehingga menyebabkan kesalahan dalam penarikan kesimpulan regresi. Akibatnya model Poisson tidak tepat digunakan pada data overdispersi. Diperlukan suatu analisis alternatif untuk mengatasi masalah overdispersi tersebut. Salah satu model regresi yang dapat digunakan adalah model Generalized Poisson (GP). Model GP tidak hanya mampu menganalisis data cacah dengan kasus overdispersi saja, melainkan juga untuk kasus underdispersi. Namun penelitian ini hanya difokuskan pada masalah overdispersi berdasarkan penelitian Yang et al. (2009).
Data cacah yang akan dianalisis menggunakan model Poisson harus dipastikan tidak mengalami overdispersi terlebih dahulu agar model Poisson yang akan digunakan merupakan model yang tepat. Penentuan uji di dalam mendeteksi overdispersi perlu dilakukan untuk melihat uji yang paling baik di dalam mendeteksi overdispersi. Menurut Yang et al. (2009), overdispersi pada data amatan dapat dideteksi menggunakan uji skor, uji Signed Square-Root of Likelihood Ratio Test (SSR-LRT), dan uji Wald. Pada penelitian ini digunakan metode simulasi untuk membandingkan nilai kuasa uji dari ketiga statistik uji tersebut. Nilai kuasa uji merupakan peluang untuk menolak hipotesis nol yang salah dalam suatu pengujian. Menurut Engle (1984), statistik uji yang disarankan penggunaannya di dalam mendeteksi overdispersi adalah statistik uji yang memiliki nilai kuasa uji yang paling tinggi diantara yang lainnya. Penelitian dilanjutkan dengan analisis model terbaik antara model regresi Poisson dan model GP dari data amatan yang telah dibangkitkan. Model terbaik diidentifikasi menggunakan nilai Akaike Information Criteria (AIC) serta Root Mean Square Error (RMSE) terkecil dari kedua model tersebut.
2
Tujuan Penelitian
Tujuan dari penelitian ini adalah sebagai berikut:
1. Membandingkan nilai kuasa uji dari statistik uji skor, uji Wald, dan uji SSR-LRT untuk menguji overdispersi pada regresi Poisson berdasarkan model GP 2. Membandingkan nilai AIC serta RMSE dari data amatan untuk melihat model
terbaik antara model Poisson dan model GP dari data yang telah dibangkitkan .
TINJAUAN PUSTAKA
Sebaran Poisson
Peubah acak Y dikatakan menyebar Poisson dengan parameter µ jika nilainya merupakan bilangan cacah = 0, 1, 2,... dengan fungsi kepekatan peluang adalah sebagai berikut (Yang et al. 2009):
P(yi, µi) = e-µµy
y!
dengan µ adalah rata-rata banyaknya kejadian dalam suatu interval tertentu. Nilai tengah dan ragam dari sebaran Poisson adalah E Y =VarY =µ. Kesamaan nilai tengah dan ragam ini disebut equidispersi (Long 1997).
Generalized Linear Model (GLM)
Generalized Linear Model (GLM) merupakan perluasan dari model regresi linear klasik untuk mengatasi kendala peubah respon yang tidak menyebar normal. McCullagh dan Nelder (1989) menyatakan ada tiga komponen utama dalam GLM yaitu :
1. Komponen acak; yaitu komponen yang menyatakan sebaran dari peubah respon (Y) yang berasal dari keluarga sebaran eksponensial.
2. Komponen sistematik; yaitu komponen yang menyatakan fungsi linear dari peubah-peubah penjelas yang digunakan: η = β1x1i+ β2x2i + β3x3i+ … + βkxki 3. Fungsi penghubung g(.); menyatakan fungsi dari nilai harapan komponen acak
sama dengan komponen sistematik, sehingga η = g(µ).
Model Poisson
Regresi Poisson termasuk ke dalam GLM karena fungsi sebaran Poisson merupakan anggota dari keluarga eksponensial yang dapat dituliskan sebagai berikut:
f(yi , µi) = exp [yi log(µi) - µi - log(yi!)]
3 Fungsi penghubung untuk regresi Poisson adalah (Mc Cullagh dan Nelder 1989):
ηi = log(µi) = xiTβ
fungsi penghubung log menjamin bahwa nilai peubah responnya akan bernilai non-negatif. Model regresi Poisson dapat dituliskan (Long 1997):
ln(µi) = xiTβ
= β0+ β1xi1+ β2xi2+ ... +βkxik
Pendugaan parameter koefisien regresi Poisson diduga dengan menggunakan metode Maximum Likelihood Estimation (MLE). Fungsi kemungkinan dari regresi Poisson adalah (Myers 1989):
L(yi, µi) = ni=1P(yi,µi)
dengan logaritma natural bagi fungsi kemungkinannya adalah: log L(yi ,µi) = ni=1[yi log(µi) - µi - log(yi!)] dengan µi = exp (xiTβ), sehingga:
log L(yi ,xi, β) = ni=1[yi(xiTβ) - exp (xiTβ) - log(yi!)] (Cameron dan Trivedi 1999).
Mendeteksi Overdispersi
Yang et al. (2009) menyatakan bahwa overdispersi pada data amatan dapat dideteksi menggunakan uji skor, uji SSR-LRT, dan uji Wald. Pengujian ketiga statistik uji tersebut dapat menggunakan hipotesis: H0 : ϕ = 0 dan H1 : ϕ > 0 dengan taraf nyata yang digunakan adalah sebesar 5%.
Uji Skor
Penggunaan statistik uji skor di dalam mendeteksi masalah overdispersi menggunakan (Yang et al. 2009): baku dari dugaan ϕ (Famoye et al. 2004), yang dapat dituliskan sebagai berikut:
W
=
φSE (φ)
4 mengakibatkan model LRT tersebut mengikuti sebaran normal baku dan didefinisikan sebagai uji SSR-LRT (Signed-Square Root of Likelihood Ratio Test) dengan rumusan sebagai berikut:
LRT= -2[l µ - l µ, φ ]
Penelitian ini difokuskan pada uji SSR-LRT yang diasumsikan mengikuti sebaran normal baku. Aturan keputusan bagi uji SSR-LRT adalah tolak H0 jika SSR-LRT > α.
Model Generalized Poisson(GP)
Fungsi peluang untuk sebaran GP adalah (Famoye et al. 2004): f yi,µi,φ = µi
: vektor berdimensi k dari parameter regresi Model GP dapat dituliskan sebagai berikut:
log(µi) = xiTβ
= β0+ β1xi1+ β2xi2+ ... + βk xik.
Model GP merupakan perluasan dari model regresi Poisson. Apabila nilai ϕ pada model GP di atas bernilai 0, maka fungsi peluang tersebut akan kembali menjadi model Poisson biasa. Terjadinya overdispersi pada data cacah berlaku apabila nilai ϕ pada fungsi peluang tersebut bernilai lebih besar dari nol (ϕ > 0) (Famoye et al. 2004).
METODE
Data
5
Data Simulasi
Secara umum prosedur simulasi ini mengikuti algoritma Yang et al. (2009). Data simulasi didasarkan pada model GP dengan model yang akan dibentuk adalah sebagai berikut:
ln(µi) = β0+ β1xi1
Parameter yang diperlukan untuk membentuk model tersebut yaitu β0, β1, dan peubah bebas x1, serta φ yang merupakan parameter dispersi dari sebaran GP.
Penentuan parameter ditentukan secara subjektif oleh peneliti, dalam hal ini parameter β0 dan β1 ditetapkan β0= 0.1, dan β1= 0.2, sedangkan peubah bebas x1 dibangkitkan mengikuti sebaran seragam sebanyak n data amatan, dengan n = 40, 70, dan 100. Adapun ϕ ditetapkan secara subjektif oleh peneliti dengan ϕ = 0, 0.025, 0.075, 0.2, 0.5, dan 0.9. Masing-masing � tersebut digunakan untuk membangkitkan sebaran GP pada masing-masing n (ukuran data amatan).
Data Aplikasi
Data aplikasi bersumber dari data Podes 2008 dengan fokus penelitian pada data kasus gizi buruk di Kabupaten Lombok Barat. Peubah penjelas yang digunakan pada penelitian ini merupakan faktor-faktor yang mempengaruhi terjadinya kasus gizi buruk berdasarkan penelitian Rohimah (2011). Satuan pengamatan yang digunakan adalah sebanyak 121 satuan pengamatan yang merupakan banyaknya desa dan kelurahan yang terdapat di Kabupaten Lombok Barat.
Peubah respon yang digunakan adalah banyaknya penderita gizi buruk pada tiap desa/kelurahan (�) di Kabupaten Lombok Barat, sedangkan peubah penjelas yang digunakan meliputi:
1. Persentase posyandu di setiap desa/kelurahan (X1)
2. Persentase sarana pendidikan SD dan SMP di setiap desa/kelurahan (X2) 3. Persentase keluarga yang bertempat tinggal di pemukiman kumuh di setiap
desa/ kelurahan (X3)
4. Persentase keluarga yang anggotanya menjadi buruh tani di setiap desa/kelurahan (X4)
5. Persentase keluarga yang menerima kartu ASKESKIN dalam satu tahun terakhir di setiap desa/ kelurahan (X5)
6. Persentase tenaga kesehatan yang tinggal di desa/kelurahan (X6)
7. Persentase penggunaan lahan tidak berpengairan di setap desa/kelurahan (X7).
Prosedur
Tahapan analisis yang digunakan untuk simulasi data adalah sebagai berikut:
1. Membangkitkan n buah peubah bebas x1yang menyebar seragam (1,2). 2. Menetapkan β0 dan β1, dengan β0 = 0.1dan β1 = 0.2.
3. Mengitung nilai µi pada masing-masing amatan dengan µi = exp (β0 + βixi1) sehingga didapatkan nilai µ sebanyak n.
6
dengan membangkitkan n buah peubah respon yang menyebar GP (y
i~ GP
(µi, φ))
5. Melakukan analisis regresi Poisson dan regresi GP pada peubah yang didapatkan terhadap peubah bebas x1.
6. Menghitung nilai uji skor, uji SSR-LRT dan uji Wald pada masing-masing n (data amatan) untuk melihat nilai kuasa uji dari ketiga uji tersebut. Hipotesis yang digunakan adalah H0: ϕ = 0 dan H1: ϕ > 0 dengan titik kritis sebesar =
0.05. Penolakan H0 terjadi jika nilai yang dihasilkan dari masing-masing statistik uji lebih besar dari nilai α.
7. Mengulang prosedur 1-5 sebanyak 1000 kali untuk mendapatkan hasil pendugaan yang mewakili populasi. Nilai peubah bebas x1 yang digunakan pada penelitian ini adalah sama pada setiap ulangan.
8. Meghitung nilai kuasa uji dari masing-masing uji dengan melihat banyaknya jumlah n yang signifikan pada setiap ulangan.
9. Mengulang prosedur 1-7 untuk masing-masing n yaitu � = 40, 70, dan 100. 10. Menghitung nilai AIC dan RMSE pada model Poisson dan model GP.
Nilai AIC dirumuskan dengan (Ismail dan Jemain 2007): AIC =-2l + 2p
dimana � adalah fungsi kemungkinan dengan semua peubah penjelas, sedangkan p adalah banyaknya parameter yang digunakan.
Adapun RMSE didapatkan dengan (Moses dan Devadas 2012): RMSE = 1
n( (yj-yj)
n j=1
2
11. Membandingkan AIC dan RMSE pada model Poisson dan model GP. Model dengan nilai AIC serta RMSE yang terkecil merupakan model yang lebih disarankan penggunaannya.
Tahapan untuk pemodelan studi kasus gizi buruk adalah sebagai berikut: 1. Melakukan eksplorasi data terhadap peubah penjelas dan peubah respon. 2. Memilih peubah penjelas untuk menghindari multikoliniearitas.
3. Mengidentifikasi terjadinya kasus overdispersi pada data amatan dengan uji skor, uji SSR-LRT, dan uji Wald.
4. Membandingkan nilai AIC dan RMSE pada model Poisson dan model GP. Model dengan nilai AIC serta RMSE yang terkecil merupakan model yang lebih disarankan penggunaannya.
5. Memodelkan data amatan dengan model yang menghasilkan AIC serta RMSE terkecil.
HASIL DAN PEMBAHASAN
Data Simulasi
7 menggunakan pendekatan hipotesis alternatif dan mempertimbangkan pergerakan ke arah hipotesis nol, dan pada LRT (dalam hal ini SSR-LRT) kedua hipotesis (hipotesis nol dan hipotesis alternatif) dibandingkan secara langsung. Penentuan uji terbaik di dalam mendeteksi overdispersi perlu dilakukan untuk mendapatkan hasil analisis yang sesuai. Statistik uji yang disarankan penggunaannya di dalam mendeteksi overdispersi memiliki nilai kuasa uji yang paling tinggi diantara yang lainnya (Engle 1984). Penelitian ini menggunakan metode simulasi untuk membandingkan nilai kuasa uji dari ketiga statistik uji tersebut.
Kuasa uji merupakan peluang untuk menolak hipotesis nol yang salah dalam suatu pengujian (Park 2010). Hipotesis nol yang digunakan pada penelitian ini adalah tidak terjadinya overdispersi pada data amatan (H0: φ = 0), sehingga nilai kuasa uji didefinisikan sebagai peluang menolak hipotesis nol ketika φ yang digunakan tidak bernilai nol. Nilai kuasa uji didapatkan dengan menghitung banyaknya hipotesis nol yang ditolak untuk setiap ulangan yang digunakan pada masing-masing uji (uji skor, uji SSR-LRT, dan uji Wald).
Ulangan yang dilakukan pada penelitian ini adalah sebanyak 1000 kali ulangan, sehingga untuk mendapatkan nilai kuasa uji dilakukan perhitungan banyaknya data dengan hipotesis nol yang ditolak dengan taraf nyata 5% pada masing-masing ulangan. Apabila dari 1000 kali ulangan tersebut didapat 1000 data amatan yang hipotesis nolnya ditolak, maka dikatakan bahwa nilai kuasa uji yang dihasilkan dari uji yang digunakan bernilai 1. Pendeteksian overdispersi pada data hasil simulasi ditunjukkan pada Tabel 1.
Pada Lampiran 1 terdapat tiga buah gambar yang merupakan grafik simulasi pada setiap n. Gambar pertama merupakan grafik untuk n = 40, gambar kedua untuk n = 70, dan gambar ketiga untuk n = 100. Ketiga grafik tersebut menunjukkan bahwa semakin besar nilai φ yang digunakan, maka nilai kuasa uji yang dihasilkan akan semakin meningkat. Nilai kuasa uji dilambangkan dengan (1-β) yang merupakan komplemen dari peluang salah jenis II (β) yaitu peluang menerima hipotesis nol padahal kenyataanya salah (Mc.Clave 2010). Semakin kecil nilai β, maka nilai kuasa uji (1-β) yang dihasilkan akan semakin besar. Pada kenyataanya, nilai β merupakan daerah nonpenolakan (penerimaan) bagi hipotesis nol, dan nilai β tersebut akan semakin menurun ketika nilai φ yang sebenarnya semakin jauh dari nilai hipotesis nol (H0 : φ = 0). Karena nilai kuasa uji (1- β) merupakan komplemen dari β, maka menurunnya nilai β akan semakin meningkatkan nilai kuasa uji. Dengan kata lain, untuk setiap n dan nilai α (taraf nyata) yang tetap, semakin kecil nilai β maka nilai kuasa uji akan meningkat bila jarak antara nilai hipotesis nol (H0: φ = 0) dan hipotesis alternatif (H1: φ > 0) semakin besar (McClave 2010). Apabila nilai φ yang digunakan sangat kecil atau bahkan nol, nilai kuasa uji yang dihasilkan akan sangat kecil. Hal ini terjadi karena jarak antara nilai antara nilai hipotesis nol (H0: φ = 0) dan hipotesis alternatif (H1: φ > 0) sangat kecil.
8
sedangkan untuk n = 100 menghasilkan nilai kuasa uji sebesar 0.058 (uji skor), 0.031 (uji Wald), dan 0.118 (uji SSR-LRT). Pada ϕ > 0, terlihat bahwa nilai kuasa uji dari masing-masing n mulai meningkat dibandingkan ketika ϕ = 0. Hasil simulasi pada uji skor misalkan, untuk n = 40 menunjukkan bahwa untuk φ = 0.025 nilai kuasa uji yang dihasilkan adalah sebesar 0.125, meningkat menjadi 0.283 ketika φ = 0.075, 0.383 ketika φ = 0.1, dan meningkat menjadi 0.721 ketika φ = 0.2. Untuk n = 70, nilai kuasa uji dari φ = 0.025 adalah 0.139, meningkat menjadi 0.367 pada ϕ = 0.075, dan terus meningkat seiring bertambah besarnya parameter dispersi yang digunakan. Untuk n = 100, nilai kuasa uji dari φ = 0.025 adalah 0.138, meningkat menjadi 0.463 untuk φ = 0.075, dan bertambah seiring besarnya nilai φ yang digunakan. Pola yang sama terlihat pada uji SSR-LRT maupun uji Wald pada masing-masing n data amatan. Nilai kuasa uji yang dihasilkan akan semakin meningkat seiring dengan bertambah besarnya φ yang digunakan. Lampiran 1 menunjukkan bahwa untuk ukuran data terbesar, n = 100, kuasa uji bertambah sangat cepat dan semakin mendekati 1 ketika ϕ ≥ 0.2, hal yang sama juga terlihat pada n = 70, kuasa uji semakin mendekati 1 ketika ϕ ≥ 0.5, dan untuk ukuran data terkecil, n = 40, kuasa uji yang dihasilkan bertambah sangat lambat dan mendekati 1 ketika ϕ≥ 0.9. Hasil simulasi juga menunjukkan bahwa perbedaan antara uji Wald dan uji SSR-LRT cenderung sama pada setiap ukuran data amatan (n), walaupun uji SSR-LRT lebih mendominasi dibandingkan uji Wald. Pada saat ϕ = 0, terlihat bahwa uji yang paling mendominasi adalah uji SSR-LRT, dalam hal ini uji skor belum terlalu sensitif di dalam mendeteksi masalah overdispersi karena ϕ yang digunakan masih sangat kecil. Ketika ϕ yang digunakan mulai membesar (ϕ > 0), kuasa uji dari statistik uji skor mulai menunjukkan kemampuannya di dalam mendeteksi overdispersi. Statistik uji skor semakin mendominasi diantara uji yang lain dan mulai mencapai kemampuan yang sama di dalam mendeteksi overdispersi dengan uji yang lain pada saat ϕ = 0.9 untuk n = 40, ϕ = 0.5 untuk n = 70, ϕ = 0.2 untuk n = 100.
9 dibandingkan uji Wald maupun uji SSR-LRT, sehingga penggunaan uji skor lebih disarankan di dalam mendeteksi overdispersi dibandingkan dua uji yang lain. Hal ini sesuai dengan pernyataan Molla dan Muniswamy (2012). Pada Lampiran 1 grafik pertama (n = 40), terlihat bahwa nilai kuasa uji untuk ϕ = 0.075 adalah sebesar 0.283, sedangkan nilai kuasa uji untuk uji Wald dan SSR-LRT yang dihasilkan secara berturut-turut adalah sebesar 0.139 dan 0.188. Untuk n = 70 (grafik kedua Lampiran 1) pada ϕ = 0.075, uji skor menghasilkan nilai kuasa uji sebesar 0.367, sedangkan nilai kuasa uji yang dihasilkan dari uji Wald dan uji SSR-LRT masing-masing sebesar 0.238 dan 0.277. Pada data amatan n = 100 nilai kuasa uji yang dihasilkan dari uji skor untuk ϕ = 0.075 adalah sebesar 0.463. Nilai ini lebih besar daripada nilai uji Wald maupun uji SSR-LRT yang dihasilkan dari nilai ϕ yang sama. Nilai kuasa uji yang dihasilkan dari uji Wald adalah sebesar 0.337, sedangkan untuk uji SSR-LRT diperoleh sebesar 0.362. Hal yang sama akan berlaku pada setiap ϕ (0.025, 0.1, 0.2, 0.5, dan 0.9), dimana nilai kuasa uji dari uji skor cenderung lebih tinggi dibandingkan uji Wald maupun uji SSR-LRT pada semua data amatan (n).
Tabel 2 Nilai AIC dan RMSE dari model Poisson dan model GP
10
nilai RMSE merupakan salah satu ukuran yang dapat digunakan untuk melihat seberapa besar galat yang dihasilkan dari suatu pendugaan (Soedjianto 2006), semakin kecil nilai RMSE yang dihasilkan maka model dikatakan semakin baik. Tabel 2 menunjukkan bahwa untuk data dengan ϕ = 0, nilai RMSE yang dihasilkan pada model Poisson dari setiap amatan akan selalu lebih kecil dibandingkan RMSE dari model GP, sehingga dapat dikatakan bahwa model Poisson pada data dengan kasus equidispersi (ϕ = 0) adalah lebih baik dibandingkan model GP pada penelitian ini. Berbeda halnya dengan kasus equidispersi, pada kasus overdispersi (ϕ > 0) penggunaan model GP lebih disarankan dibandingkan model Poisson, hal ini dapat dilihat dari tabel hasil simulasi yang menunjukkan bahwa nilai RMSE pada model GP selalu lebih kecil dibandingkan model Poisson, sehingga dapat dikatakan bahwa model GP lebih baik dibandingkan model Poisson pada data kasus overdispersi (ϕ > 0).
Nilai AIC menunjukkan bahwa untuk n = 40, perbedaan antara penggunaan model Poisson dan model GP belum terlalu jelas pengaruhnya ketika ϕ < 0.1. Ketika ϕ yang digunakan mulai membesar (ϕ ≥ 0.1), pengaruh overdispersi mulai terlihat dan AIC untuk model GP terlihat mulai lebih kecil dibandingkan AIC pada model Poisson. Hal yang sama juga terlihat pada saat n = 70 dan 100, perbedaan antara penggunaan model Poisson dan model GP belum terlalu jelas pengaruhnya ketika ϕ < 0.075. Ketika ϕ ≥ 0.075, pengaruh overdispersi mulai terlihat dan AIC untuk model GP terlihat mulai lebih kecil dibandingkan AIC pada model Poisson.
Eksplorasi Data Aplikasi
Kabupaten Lombok Barat merupakan salah satu kabupaten yang terletak di Provinsi NTB. Kabupaten ini terdiri dari 121 desa/kelurahan yang tersebar di 15 kecamatan. Amatan yang digunakan pada penelitian ini adalah sebanyak 121 amatan yang merupakan banyaknya desa/kelurahan di Kabupaten Lombok Barat pada tahun 2008. Dari 121 desa terdapat 28 desa yang tidak terjangkit gizi buruk sama sekali. Sepuluh desa dengan penderita gizi buruk tertinggi disajikan dalam Gambar 1.
Gambar 1 Sebaran jumlah penderita gizi buruk pada 10 desa dengan jumlah penderita gizi buruk tertinggi.
11 sebesar 28 orang. Penderita gizi buruk tertinggi ketiga tersebar di desa Medana di Kecamatan Tanjung dengan penderita gizi buruk sebesar 26 orang.
Penelitian ini menggunakan tujuh faktor sebagai peubah penjelas yang mempengaruhi jumlah penderita gizi buruk sebagai peubah respon. Menurut D El-Dereny dan Rashwan (2011), Variance Inflation Factors (VIF) merupakan salah satu metode yang dapat digunakan untuk menguji apakah terdapat multikolinearitas antar peubah bebas pada suatu model regresi berganda. Nilai VIF > 10 menunjukkan terjadi multikolinieritas yang tinggi antar peubah bebas. Hasil pengujian multikolinieritas pada Tabel 3 menunjukkan bahwa seluruh peubah bebas memiliki nilai VIF < 10. Hal ini menunjukkan bahwa pada peubah-peubah bebas yang akan digunakan tidak terjadi kasus multikolinieritas, sehingga tujuh peubah bebas tersebut diikutsertakan d dalam analisis yang lebih lanjut.
Tabel 3 Hasil uji multikolinieritas
Indikasi besarnya underdispersi atau overdispersi dapat dapat diperoleh dengan membandingkan nilai tengah dan ragam dari peubah respon (Cameron dan Trivedi 1998). Nilai tengah dari peubah respon didapatkan sebesar 2.138, sedangkan ragam yang didapatkan sebesar 7.334. Karena ragam yang dihasilkan lebih besar dari nilai tengahnya, maka diduga terjadi overdispersi pada data amatan. Dugaan terjadinya overidispersi juga diperkuat dengan hasil parameter dispersi duga yang dihasilkan dari data, ϕ yang dihasilkan dari data aplikasi ini adalah sebesar 1.606 yang lebih besar dari 0, dimana menurut teori Famoye et al. (2004), ϕ > 0 menunjukkan terjadinya overdispersi pada data amatan.
Nilai statistik uji skor, uji SSR-LRT, dan uji Wald yang didapatkan pada penelitian ini secara berurutan adalah sebesar 54.766, 20.882, dan 10.897. Ketiga nilai statistik uji ini menunjukkan bahwa data gizi buruk yang digunakan mengalami overdispersi pada taraf nyata 5%, karena nilai ketiga statistik uji tersebut lebih besar dari zα.
Model Terbaik Data Aplikasi
12
pada model GP lebih kecil dibandingkan nilai AIC serta RMSE pada model Poisson, hal ini menunjukkan bahwa model GP adalah lebih baik dibandingkan model regresi Poisson pada data aplikai ini.
Tabel 4 Nilai AIC dan RMSE pada model regresi Poisson dan GP
Model AIC RMSE
Poisson 1062.11 28.962
GP 628.071 12.1946
Model Generalized Poisson(GP) Data Aplikasi
Hasil pendugaan parameter dengan model GP pada delapan peubah penjelas dapat dilihat pada Tabel 5. Hasil ini diperoleh dengan menggunakan sofware R 2.15.3.
Tabel 5 Nilai dugaan parameter GP
Nilai Dugaan Galat Baku Nilai Z Nilai-p
*) signifikan pada taraf nyata 10%
Tabel 5 menunjukkan bahwa dari tujuh peubah penjelas yang digunakan, terdapat satu peubah yang berpengaruh nyata terhadap respon yang diamati pada taraf nyata 10%. Peubah tersebut yaitu persentase keluarga yang bertempat tinggal di pemukiman kumuh di setiap desa/ kelurahan (X3). Kesimpulan ini diperoleh dengan melihat nilai-p dari peubah-peubah tersebut yang memiliki nilai yang lebih kecil dari 10%.
Persamaan model GP untuk semua peubah penjelas dapat dituliskan sebagai ln (µi) = β0+ β1X1+ β2X2 + β3X3+ β4X4+ β5X5+ β6X6 + β7X7
µi= exp (β0+ β1X1+ β2X2 + β3X3+ β4X4+ β5X5+ β6X6 + β7X7)
µi = exp (0.452 – 0.437X1 +0.338X2 + 0.172X3 + 0.001X4 +
0.002X5– 0.009X6 – 0.003X7)
13 terhadap daya beli makanan pada rumah tangga tersebut. Rendahnya kualitas dan kuantitas makanan merupakan penyebab langsung terjadinya gizi buruk pada balita (Novitasari 2012). Selain itu, tempat tinggal bagi penduduk yang tinggal di pemukiman kumuh memiliki sanitasi yang kurang baik, sehingga menyebabkan kesehatan penghuni rumah terutama anak-anak yang masih bayi dan balita menjadi terganggu, sehingga bayi dan balita di rumah pemukiman tersebut akan lebih mudah mengalami gizi buruk (Rohimah 2011).
SIMPULAN
Hasil simulasi menunjukkan bahwa penggunaan uji skor lebih disarankan dibandingkan uji Wald maupun uji SSR-LRT karena nilai kuasa uji dari uji skor lebih tinggi dibandingkan uji yang lain. Pada data cacah dengan φ = 0 (equidispersi) nilai RMSE pada regresi Poisson lebih kecil dari nilai RMSE pada model GP, sedangkan pada data cacah dengan φ > 0 (overdispersi), didapatkan bahwa nilai RMSE pada model GP lebih kecil dari nilai pada model Poisson, sehingga dapat disimpulkan bahwa untuk data equidispersi, model yang lebih baik digunakan adalah model Poisson, sedangkan untuk data kasus overdispersi, model yang lebih baik digunakan adalah model GP. Pada nilai AIC, pengaruh overdispersi untuk n = 40 terlihat pada saat ϕ ≥ 0.1, dan untuk n = 70 dan 100, pengaruh overdispersi mulai terlihat pada saat ϕ ≥ 0.075. Pada data aplikasi didapatkan bahwa data yang digunakan overdispersi pada tingkat signifikansi 5%. Nilai AIC serta RMSE dari model GP lebih kecil dari model regresi Poisson sehingga dapat disimpulkan bahwa model GP lebih baik daripada model Poisson dalam penelitian ini.
DAFTAR PUSTAKA
Cameron AC, Trivedi PK. 1998. Regression Analysis of Count Data. New York (US): Cambridge University Pr.
El Dereni M, Rashwan NI. 2011. Solving Multicollinearity Problem Using Ridge Regression Models. J Contemp. Math. Sciences. 6(12): 585 – 600.
Engle RF. 1984. Wald, Likelihood Ratio, and Lagrange Multiplier Tests in Econometrics. California (USA): Universty of California.
Famoye F, Wulu JT, Singh KP. 2004. On The Generalized Model with an Application to Accident Data. JDS, (2):287-295.
Ismail N, Jemain AA. 2007. Handling overdispersion with Negative Binomial and Generalized Poisson Regression Models. Virginia (US): Casualty Actuarial Society Forum.
14
McClave JT, Bendon PG, Sincich T. 2010. Statistics for Business and Econometrics 11th Ed. Sabran B, penerjemah. Jakarta (ID): Erlangga. Molla DT, Muniswamy B. 2012. Power of Tests for Overdispersion Parameter in
Negative Binomial Regression Model. J of Mathematics. 4(1):2278-5728. Moses KP, Devadas MD. 2012. An Approach to Reduce Root Mean Square Error
in Toposheets. J of Scientific Research. 91(2):268 – 274.
Novitasari D. 2012. Faktor – Faktor Risiko Kejadian Gizi Buruk pada Balita yang Dirawat di RSUP Dr. Kariadi Semarang [Skripsi]. Semarang (ID): Universitas Diponegoro.
Park. 2010. Hypothesis Testing and Statistical Power of a Test. Bloomington (US): Indiana University Pr.
Rodrigue G. 2007. Poisson Models for Count Data. [internet]. [diunduh tanggal 20 April 2013]. Terdapat pada: http://data.pri-centon.edu/wws509/notes/c4.pdf.
Rohimah RS. 2011. Model Spasial Otoregresif Poisson Untuk Mendeteksi Faktor-Faktor Yang Berpengaruh Terhadap Jumlah Penderita Gizi Buruk Di Provinsi Jawa Timur [Tesis]. Bogor (ID): Institut Pertanian Bogor.
Soedjianto F, Oktavia T, Anggawinata JA. 2006. Perancangan dan Pembuatan Sistem Perencanaan Produksi (Studi Kasus Pada PT. Vonita Garment). Seminar Nasional Aplikasi Teknologi Informasi 2006 (SNATI 2006). Yogyakarta.
15
LAMPIRAN
Lampiran 1 Grafik hasil simulasi pada berbagai data amatan
16
Lampiran 2 Grafik hasil simulasi AIC pada berbagai n
17 Lampiran 3 Grafik hasil simulasi RMSE pada berbagai n
Untuk �= �
Untuk �= �
Untuk �=
17.5 18 18.5 19 19.5 20
ϕ = 0 0.025 0.075 0.1 0.2 0.5 0.9
Poisson
GP
17.5 18 18.5 19 19.5 20 20.5 21 21.5
ϕ = 0 0.025 0.075 0.1 0.2 0.5 0.9
Poisson
GP
17.5 18 18.5 19 19.5 20 20.5 21 21.5
ϕ = 0 0.025 0.075 0.1 0.2 0.5 0.9
Poisson
18
RIWAYAT HIDUP
Penulis dilahirkan pada tanggal 14 November 1990 di Lombok Barat, NTB. Penulis adalah anak ketiga dari pasangan Bapak Akmal dan Ibu Masnah. Riwayat pendidikan penulis adalah sebagai berikut : SD Negeri 2 Bagik Polak (1997-2003), MTs. Putri Al-Ishlahuddiny (2003-2006), MA Putri Al-Ishlahuddiny (2006-2009). Penulis diterima sebagai mahasiswa di Institut Pertanian Bogor pada bulan Juni 2009 melalui jalur Program Beasiswa Santri Berprestasi (PBSB) Kementerian Agama Republik Indonesia sebagai mahasiswa Statistika, FMIPA IPB.