DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2012
INTEGRASI
SELF ORGANIZING MAPS
DAN ALGORITME
K-MEANS UNTUK
CLUSTERING
DATA KETAHANAN PANGAN
KABUPATEN DI WILAYAH PROVINSI BALI, NUSA TENGGARA
BARAT, DAN NUSA TENGGARA TIMUR
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2012
INTEGRASI
SELF ORGANIZING MAPS
DAN ALGORITME
K-MEANS UNTUK
CLUSTERING
DATA KETAHANAN PANGAN
KABUPATEN DI WILAYAH PROVINSI BALI, NUSA TENGGARA
BARAT, DAN NUSA TENGGARA TIMUR
ULFA KHAIRA
Skripsi
sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
ABSTRACT
ULFA KHAIRA. Integration of Self Organizing Maps and K-means Algorithm for Food Security Cluster in Region Province of Bali, Nusa Tenggara Barat, and Nusa Tenggara Timur. Supervised by ANNISA.
The assessment of food security as a measure of development is very important. Food security in a region has multidimentional characteristics that need to be analyzed. The purpose of this research is to implement the S-K algorithm (combination of Self organizing maps -SOM- and K-means algorithm) for data clustering and to gain data characteristics as the result of data clustering. The used data is the indicator for the food security from 30 districts in the provinces of Bali, Nusa Tenggara Barat, and Nusa Tenggara Timur. These data are the input for S-K algorithm. SOM clustering result is validated using Davies-Bouldin Index (DBI). Centroid and the number of cluster from SOM are utilized as the input for K-means algorithm, which is used to refine the final cluster. In this research, these data are also clustered by K-means algorithm with randomly generated initial centroids. The value of DBI results of SOM, S-K, K-means clustering has been compared and it is found that S-K algorithm has the minimum value of DBI. Thus, it is proved that the S-K algorithm gives good clustering results. Based on the data analysis, the districts in the Province of Nusa Tenggara Timur are categorized as the areas with food insecurity. Meanwhile, the districts in the Province of Nusa Tenggara Barat are included in the relatively food insecurity areas. Food security in all districts in the Province of Bali are satisfactory.
Judul Skripsi : Integrasi Self Organizing Maps dan Algoritme K-means untuk Clustering Data Ketahanan Pangan Kabupaten di Wilayah Provinsi Bali, Nusa Tenggara Barat, dan Nusa Tenggara Timur
Nama : Ulfa Khaira
NIM : G64080064
Menyetujui: Pembimbing,
Annisa, S.Kom, M.Kom NIP 19790731 200501 2 002
Mengetahui:
Ketua Departemen Ilmu Komputer
Dr. Ir. Agus Buono, M.Si, M.Kom NIP. 19660702 199302 1 001
KATA PENGANTAR
Alhamdulillaahirabbil ‘aalamiin, rasa syukur penulis ucapkan kepada Allah Subhanahu wa
Ta’ala atas segala curahan rahmat dan karunia-Nya sehingga penulis dapat menyelesaikan tugas akhir yang berjudul Integrasi Self Organizing Maps dan Algoritme K-means untuk Clustering Data Ketahanan Pangan Kabupaten di Wilayah Provinsi Bali, Nusa Tenggara Barat, dan Nusa Tenggara Timur. Sholawat dan salam semoga senantiasa tercurah kepada Nabi Muhammad Shallallahu
a’laihi wasallam, keluarganya, para sahabat, serta para pengikutnya.
Terima kasih kepada kedua orang tua tercinta, Ayahanda Drs. H. M. Saman Sulaiman, M.A dan Ibunda Hj. Darniati yang sampai detik ini selalu memberikan dukungan, semangat, doa, dan curahan kasih sayang yang tiada terhingga, begitu juga dengan kedua adik penulis, Atar Satria Fikri dan Zahratirizka yang menjadi penyemangat bagi penulis untuk selalu melakukan yang terbaik. Serta keluarga besar penulis di Jambi terima kasih atas segala doa dan perhatiannya.
Penulis mengucapkan terima kasih kepada Ibu Annisa, S.Kom, M.Kom selaku pembimbing yang dengan sabar membimbing serta memberikan masukan kepada penulis. Terima kasih juga penulis sampaikan kepada Bapak Hari Agung Adrianto, S.Kom, M.Si dan Bapak Azis Kustiyo, S.Si, M.Kom selaku penguji yang telah banyak memberikan masukan dan perbaikan dalam menyempurnakan tugas akhir ini.
Penyelesaian penelitian ini tidak terlepas dari dukungan dan bantuan berbagai pihak, oleh karena itu penulis ingin mengucapkan terima kasih kepada:
1 Mrs.Coco Ushimaya, Bapak Dedi Junadi, dan seluruh staf United Nations World Food Programme (WFP) Indonesia yang telah membantu dalam penyediaan data ketahanan pangan.
2 Teman-teman satu bimbingan: Fahrul, Norma, Muti, Hutomo, Stefanus, Delki, dan Zico atas bantuan, dukungan, serta motivasi yang selalu diberikan.
3 Teman-teman yang selalu sabar ditanyai oleh penulis, senantiasa berbagi ilmu, membantu, dan mengajarkan penulis dalam proses menyelesaikan tugas akhir, yaitu: Isnan Mulia, Indra Lesmana, dan Wangi Saraswati.
4 Vininta Ayudiana, Kurnia Nuraeni, Mayanda Mega, serta teman-teman seperjuangan Ilmu Komputer angkatan 45 atas segala bantuan, dukungan, dan kenangan bagi penulis selama menjalani masa studi.
5 Teman-teman kostan SQ: Hana M, Fitra, Kak Dayu, Kak Mumpuni, Kak Septi, Nurul, Mita, Hana A, Orin, Anni, Fida, Lina, Nia, dan Lia atas segala dukungan untuk segera menyelesaikan tugas akhir ini.
6 Saudara seperantauan Himpunan Mahasiswa Jambi (HIMAJA) terima kasih atas segala bantuan, perhatian, dan semangat yang diberikan. Semoga kita bisa memajukan dan membangun Provinsi Jambi dengan ilmu yang kita dapatkan selama studi di IPB.
7 Suyitno, A.Md dan teman-teman Galaxy: Kak Agung, Uni Romi, Mba Dina, dan Mba Septy atas perhatian, nasihat, serta motivasi yang selalu diberikan. Semoga Allah
Subhanahu wa Ta’ala selalu menyambungkan tali silaturahim ini.
8 Seluruh staf dan karyawan Departemen Ilmu Komputer, serta pihak lain yang telah membantu dalam menyelesaikan penelitian ini.
Penulis menyadari bahwa penulisan tugas akhir ini masih jauh dari sempurna karena keterbatasan pengalaman dan pengetahuan yang dimiliki penulis. Segala kesempurnaan hanya milik Allah Subhanahu wa Ta’ala, semoga tulisan ini dapat bermanfaat, Aamin.
Bogor, Desember 2012
Ulfa Khaira
RIWAYAT HIDUP
Ulfa Khaira dilahirkan di Kota Jambi pada tanggal 29 Desember 1989 dari pasangan Bapak Drs. H. M.Saman Sulaiman, M.A dan Ibu Hj. Darniati. Penulis merupakan anak pertama dari tiga bersaudara. Pada tahun 2008, penulis lulus dari Sekolah Menengah Atas (SMA) Negeri 1 Kota Jambi dan diterima sebagai mahasiswa di Departemen Ilmu Komputer, Fakultas Matematika dan Pengetahuan Alam, Institut Pertanian Bogor melalui jalur Undangan Seleksi Masuk IPB (USMI).
DAFTAR TABEL ... vi
DAFTAR GAMBAR ... vi
DAFTAR LAMPIRAN ... vi
PENDAHULUAN Latar Belakang ... 1
Tujuan Penelitian ... 1
Ruang Lingkup Penelitian ... 1
TINJAUAN PUSTAKA Clustering ... 1
Normalisasi z-score ... 2
Algoritme K-means ... 2
Self Organizing Maps (SOM)... 2
Algoritme Self Organizing Maps ... 3
Validitas Cluster ... 3
Indeks Davies-Bouldin ... 4
Ketahanan Pangan ... 4
METODE PENELITIAN Data Indikator Ketahanan Pangan ... 4
Praproses Data ... 4
Data Mining ... 4
Representasi Pengetahuan ... 5
Lingkungan Implementasi ... 5
HASIL DAN PEMBAHASAN Data Indikator Ketahanan Pangan ... 5
Praproses Data ... 6
Tiga Metode Clustering ... 6
Penerapan Algoritme SOM ... 6
Indeks Davies-Bouldin (DBI) ... 6
DBI Terbaik ... 6
Clustering dengan Algoritme S-K ... 6
Perbandingan Hasil Clustering ... 7
Deskripsi Hasil Cluster ... 8
SIMPULAN DAN SARAN Simpulan ... 9
Saran ... 9
DAFTAR PUSTAKA ... 9
DAFTAR TABEL
Halaman
1 Indeks Davies-Bouldin terbaik untuk tiap ukuran cluster ... 6
2 Banyak anggota masing-masing cluster dengan ukuran cluster 3... 7
3 Nama anggota pada masing-masing cluster hasil clustering dengan algoritme S-K ... 7
4 Nama anggota pada masing-masing cluster hasil clustering dengan algoritme SOM ... 7
5 Nama anggota pada masing-masing cluster hasil clustering dengan algoritme K-means ... 7
DAFTAR GAMBAR
Halaman 1 Ilustrasi lingkungan (Demuth dan Beale 2003)... 32 Diagram alur penelitian ... 5
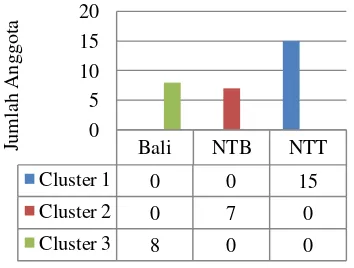
3 Gambar sebaran jumlah anggota berdasarkan provinsi ... 8
DAFTAR LAMPIRAN
Halaman 1 Langkah-langkah clustering dengan algoritme K-means ... 112 Langkah-langkah clustering dengan algoritme SOM ... 13
3 Langkah perhitungan Indeks Davies-Bouldin ... 20
4 Indikator ketahanan pangan ... 22
5 Data indikator ketahanan pangan sebelum dinormalisasi ... 23
6 Data indikator ketahanan pangan setelah dinormalisasi ... 26
7 Pengamatan terhadap DBI ... 29
8 Hasil clustering dari algoritme SOM, K-means, dan S-K ... 31
9 Bobot optimal dari SOM sebagai initialcentroid bagi K-means ... 32
10 Penilaian setiap indikator ... 33
PENDAHULUAN
Latar Belakang
Kebijakan peningkatan ketahanan pangan yang ditetapkan dalam kerangka pembangunan nasional berimplikasi bahwa pengkajian ketahanan pangan sebagai tolak ukur keberhasilan pembangunan menjadi penting. Ketahanan pangan di suatu wilayah mempunyai sifat multidimensional yang memerlukan analisis dari berbagai indikator, tidak hanya produksi dan ketersediaan pangan saja. Meskipun tidak ada cara spesifik untuk mengukur ketahanan pangan, kompleksitas ketahanan pangan dapat disederhanakan dengan menitikberatkan pada tiga dimensi yang berbeda namun saling berkaitan yaitu ketersediaan pangan, akses pangan oleh rumah tangga, dan pemanfaatan pangan oleh individu.
Pengelompokan daerah berdasarkan indikator ketahanan pangan sangat penting dilakukan untuk mengambil kebijakan dalam hal penentuan sasaran dan memberikan rekomendasi untuk intervensi kerawanan pangan di tingkat provinsi dan kabupaten. Teknik data mining diperlukan untuk ekstraksi informasi dari data. Clustering
merupakan salah satu metode dalam data mining untuk mengelompokkan himpunan objek ke dalam kelas-kelas. Pada data mining
baik algoritme k-means dan self organizing maps (SOM) merupakan proses unsupervised learning yang penting untuk mendapatkan pola pada kumpulan data yang tidak berlabel. SOM tidak dapat menyajikan hasil clustering
yang tepat dan kecepatan konvergensi yang lambat. Sedangkan K-means bergantung pada
initial centroid, jika terjadi kesalahan pada pengambilan initial centroid maka hasil
clustering yang terjadi akan berkumpul pada titik yang tidak optimal.
Penelitian ini menggunakan algoritme S-K (Wang et al. 2010) yang merupakan kombinasi dari SOM dan K-means untuk pengelompokan daerah berdasarkan indikator ketahanan pangan. Pada penelitian Wang (2010), algoritme S-K memberikan efisiensi yang baik dan cluster yang akurat. Self organizingmaps digunakan untuk mengetahui jumlah cluster dan initial centroid yang digunakan sebagai input untuk k-means, selanjutnya, akan dihasilkan clustering terbaik dari metode k-means (Kuo et al. 2001).
Tujuan Penelitian
Tujuan dari penelitian ini yaitu:
1 Menerapkan algoritme S-K untuk
clustering ketahanan pangan.
2 Memperoleh karakteristik data ketahanan pangan kabupaten di wilayah Provinsi Bali, Nusa Tenggara Barat, dan Nusa Tenggara Timur.
Ruang Lingkup Penelitian
Penelitian ini dibatasi pada penggunaan teknik clustering dengan metode self-organizing maps (SOM) dan k-means. Data yang digunakan adalah data indikator ketahanan pangan kabupaten di wilayah Provinsi Bali, Nusa Tenggara Barat, dan Nusa Tenggara Timur.
TINJAUAN PUSTAKA
Clustering
Clustering adalah pengelompokan dari
record, observasi-observasi atau kasus-kasus ke kelas yang memiliki kemiripan objek-objeknya. Cluster adalah koleksi dari record
yang mirip, dan tidak mirip dengan record
dari cluster lain. Clustering berbeda dengan klasifikasi, dalam hal tidak ada variabel target untuk clustering. Clustering tidak mengklasifikasikan, meramalkan, atau memprediksi nilai dari sebuah variabel target. Algoritme-algoritme clustering digunakan untuk menentukan segmen keseluruhan himpunan data menjadi subgroup yang relatif sama atau cluster, dengan kesamaan record
dalam cluster dimaksimumkan dan kesamaan
record di luar cluster diminimumkan (Larose 2004).
Secara umum metode utama clustering
dapat diklasifikasikan menjadi kategori-kategori berikut (Han dan Kamber 2006): Metode partisi. Misalkan ada sebuah
basis data berisi n objek. Metode partisi membangun k partisi pada basis data tersebut, dengan tiap partisi merepresentasikan cluster dan k ≤ n. Partisi yang terbentuk harus memenuhi syarat yaitu setiap cluster harus berisi minimal satu objek dan setiap objek harus termasuk tepat satu cluster.
o Agglomerative, dimulai dengan titik-titik sebagai cluster
individu. Pada setiap tahap dilakukan penggabungan setiap pasangan titik pada cluster
sampai hanya satu titik (atau
cluster) yang tertinggal.
o Divisive, dimulai dengan satu
cluster besar yang berisi semua titik data.Pada setiap langkah, dilakukan pemecahan sebuah cluster sampai setiap cluster berisi sebuah titik (atau terdapat k cluster).
Metode berdasarkan kepekatan, merupakan pendekatan yang berdasarkan pada konektivitas dan fungsi kepadatan.
Metode berdasarkan grid, merupakan pendekatan yang berdasarkan pada struktur multiple-level granularity. Metode berdasarkan model, yaitu:
sebuah model yang dihipotesis untuk tiap cluster dan ide dasarnya adalah untuk menemukan model yang cocok untuk tiap cluster.
Normalisasi z-score
Normalisasi merupakan bagian dari transformasi data, yaitu atribut diskalakan ke dalam rentang nilai tertentu yang lebih kecil seperti -1,0 – 1,0 atau 0,0 – 1,0. Salah satu teknik normalisasi yang dapat digunakan adalah z-score.
Normalisasi z-score (zero-mean normalization) merupakan normalisasi berdasarkan nilai rata-rata dan standar deviasi dari suatu atribut. Misalkan nilai v merupakan elemen dari A, Ᾱ adalah rata-rata, dan σA
adalah nilai standar deviasi dari atribut A, maka nilai v akan ditransformasikan menjadi
v’ dengan fungsi v' = v-A
σA ...(1) Normalisasi z-score berguna ketika nilai aktual dari maksimum dan minimum suatu atribut tidak diketahui atau ketika outlier
mendominasi pada normalisasi min-max. (Han dan Kamber 2006).
Algoritme K-means
K-Means merupakan algoritme
clustering yang bersifat partitional yaitu
cluster tetap) yang meminimalkan total square error. Misal, diberikan himpunan N objek
didefinisikan sebagai centroid dari cluster
(Kantardzic 2003)
Langkah-langkah dalam algoritme K-means adalah (Kantardzic 2003):
1. Ditentukan initial partion dengan k
cluster berisi sample yang dipilih secara acak, kemudian dihitung pusat cluster dari tiap-tiap cluster,
2. Dibangkitkan partisi baru dengan penugasan setiap sample terhadap pusat
cluster terdekat,
3. Hitung pusat-pusat cluster baru,
4. Ulangi langkah 2 dan 3 sampai nilai optimum dari fungsi kriteria dipenuhi (atau sampai cluster membership telah stabil).
Untuk lebih jelasnya langkah-langkah
clustering dengan algoritme K-means untuk jumlah cluster 3 dapat dilihat pada Lampiran 1. Hasil cluster dengan metoda K-means sangat bergantung pada nilai pusat cluster awal yang diberikan. Pemberian nilai awal yang berbeda bisa menghasilkan hasil cluster yang berbeda.
Self Organizing Maps (SOM)
Self Organizing Maps (SOM) diperkenalkan oleh Teuvo Kohonen seorang ilmuwan Finlandia pada tahun 1982, sehingga SOM dikenal juga dengan jaringan Kohonen. SOM merupakan salah satu jaringan syaraf tiruan yang dikonfigurasi untuk pengelompokan data. Jaringan SOM Kohonen menggunakan metode pembelajaran
kooperasi yaitu setiap simpul pemenang bekerjasama dengan lingkungannya, dan adaptasi yaitu perubahan simpul pemenang dan lingkungannya (Larose 2004).
Algoritme Self Organizing Maps
Misalkan himpunan dari m nilai-nilai field
untuk record ke-n menjadi sebuah vektor input xn = xn1, xn2, xn3,…, xnm, dan himpunan
dari m bobot untuk simpul output tertentu j
menjadi vektor bobot wj= w1j, w2j,…, wmj
(Larose 2004).
Langkah-langkah clustering dengan algoritme SOM dapat dilihat pada Lampiran 2. Secara garis besar langkah-langkah algoritme SOM (Larose 2004) seperti yang dijelaskan di bawah ini.
Untuk setiap vektor x, lakukan: pemenang j didefinisikan oleh lingkungan berukuran R. Untuk simpul-simpul ini, lakukan:
Adaptasi. Perbarui nilai bobot:
wij,new = wij,current+ ( xni– wij,current)
...(3)
Perbarui learning rate ( ) dan ukuran
lingkungan R seperlunya.
Hentikan perlakuan ketika kriteria pemberhentian dicapai.
Keterangan:
Inisialisasi nilai bobot biasanya menggunakan nilai tengah (middle point/midpoint) atau menggunakan nilai acak (Demuth dan Beale 2003).
Lingkungan berukuran R berisi indeks dari semua simpul-simpul yang berada dalam radius R dari simpul pemenang i*. Ni(d) =
{j,dij≤ R} (Demuth dan Beale 2003).
Gambar 1 Ilustrasi lingkungan (Demuth dan Beale 2003)
Gambar 1 mengilustrasikan konsep lingkungan. Gambar 1 kiri menunjukkan lingkungan dari radius R=1 sekeliling simpul 13. Gambar 1 kanan menunjukkan lingkungan dari radius R=2. Topologi lingkungan yang umum digunakan ada tiga yaitu topologi grid,
topologi hexagonal, dan topologi random
(Demuth dan Beale 2003, diacu dalam Edward 2006).
Fungsi jarak biasanya digunakan jarak Euclidean
D(wj, xn) = i wij-xni 2
... (4) (Demuth dan Beale 2003).
Perubahan tingkat pembelajaran ( LR/α/ ) 0 < <1 ,dengan rumus α(t+1) = α(t). Lambang adalah penurunan tingkat pembelajaran (PLR), menurun seiring perubahan waktu t (Laurence 1994). Kriteria pemberhentian bias berupa
pembatasan jumlah iterasi, atau ketika = 0 (Larose 2004).
Validitas Cluster
Validasi clustering adalah prosedur yang mengevaluasi hasil analisis cluster secara kuantitatif dan objektif (Jain dan Dubes 1988). Terdapat tiga pendekatan untuk mengeksplorasi validitas cluster:
1. kriteria eksternal, mengevaluasi hasil dari metode clustering berdasarkan pra-spesifikasi struktur yang diterima dari sebuah data yang mencerminkan intuisi pengguna tentang struktur clustering dari data,
2. kriteria internal, mengevaluasi hasil
clustering dalam konsep kuantitatif yang didapat dari data, dan
3. kriteria relatif, membandingkan sebuah struktur clustering dengan struktur
clustering yang lain yang didapatkan dari metode clustering yang sama tetapi nilai-nilai parameternya dimodifikasi (Salazar
et al. 2002).
Untuk memilih skema clustering optimal, ada dua kriteria (Salazar et al. 2002):
1. Compactness, yaitu anggota dari masing-masing cluster harus sedekat mungkin dengan yang lain, dan
2. Separation, yaitu cluster harus terpisah secara luas dari cluster lain. Indeks validitas digunakan sebagai metode validasi cluster untuk evaluasi kuantitatif dari hasil clustering (Salazar et al. 2002).
Indeks Davies-Bouldin
Pendekatan pengukuran ini untuk memaksimalkan jarak inter-cluster antara
cluster Ci dan Cjdan pada waktu yang sama
mencoba untuk meminimalkan jarak antar titik dalam sebuah cluster. Jarak intra-cluster sc (Qk) dalam cluster Qk ialah:
sc(Qk) = �||��−� ||
� ...(5) dengan Nk adalah banyak titik yang termasuk dalam cluster Qk dan Ck adalah centroid dari
Cluster Qk. Jarak Inter-cluster didefinisikan:
dkl= Ck-Cl ...(6)
clustering yang optimal menurut Indeks Davies-Bouldin ialah yang memiliki Indeks Davies-Bouldin minimal (Salazar et al. 2002). Langkah-langkah perhitungan Indeks Davies-Bouldin disajikan pada Lampiran 3.
Ketahanan Pangan
Dalam undang undang No.7 tahun 1996 tentang pangan, pengertian ketahanan pangan adalah kondisi terpenuhinya pangan bagi rumah tangga yang tercermin dari ketersediaan yang cukup, baik dalam jumlah maupun mutunya, aman, merata dan terjangkau. Dari pengertian tersebut, tersirat bahwa upaya mewujudkan ketahanan pangan nasional harus lebih dipahami sebagai pemenuhan kondisi-kondisi: (1) terpenuhinya pangan dengan kondisi ketersediaan yang cukup, dengan pengertian ketersediaan pangan dalam arti luas, mencakup pangan yang berasal dari tanaman, ternak dan ikan dan memenuhi kebutuhan atas karbohidrat, vitamin dan mineral serta turunan, yang bermanfaat bagi pertumbuhan dan kesehatan manusia, (2) terpenuhinya pangan dengan kondisi aman, diartikan bebas dari pencemaran biologis, kimia, dan benda lain yang lain dapat mengganggu, merugikan, dan membahayakan kesehatan manusia, serta aman untuk kaidah agama, (3) terpenuhinya pangan dengan kondisi yang merata, diartikan bahwa distribusi pangan harus mendukung tersedianya pangan pada setiap saat dan merata di seluruh tanah air, (4) terpenuhinya pangan dengan kondisi terjangkau, diartikan
bahwa pangan mudah diperoleh rumah tangga dengan harga yang terjangkau.
Ketahanan pangan pada tataran nasional merupakan kemampuan suatu bangsa untuk menjamin seluruh penduduknya memperoleh pangan dalam jumlah yang cukup, mutu yang layak, aman, dan juga halal, yang didasarkan pada optimalisasi pemanfaatan dan berbasis pada keragaman sumber daya domestik. Salah satu indikator untuk mengukur ketahanan pangan adalah ketergantungan ketersediaan pangan nasional terhadap impor (Saliem et al. 2007).
METODE PENELITIAN
Penelitian akan dilakukan dalam beberapa tahap. Gambar 2 menunjukan tahapan dari metode penelitian.
Data Indikator Ketahanan Pangan
Data indikator ketahanan pangan yang digunakan adalah data yang dikumpulkan oleh DKP dan WFP (2009). Pada penelitian ini difokuskan pada wilayah Provinsi Bali, Nusa Tenggara Barat, dan Nusa Tenggara Timur.
Praproses Data
Penelitian ini akan dilakukan menggunakan proses data mining. Tahapan yang termasuk dalam praproses yaitu pembersihan data, integrasi data, transformasi data, dan seleksi data. Tahap pembersihan dan integrasi data telah dilakukan sebelumnya oleh tim dari United Nations World Food Programme (WFP) dan Dewan Ketahanan Pangan (DKP). Selanjutnya pada tahap seleksi data akan dipilih data indikator ketahanan pangan di wilayah Provinsi Bali, Nusa Tenggara Barat, dan Nusa Tenggara Timur. Pada tahap transformasi dilakukan pengubahan data agar dapat digunakan dalam proses data mining, transformasi data yang dilakukan pada penelitian ini adalah melakukan normalisasi data dengan normalisasi z-score.
Data Mining
Data mining yang dilakukan pada penelitian ini adalah clustering data menggunakan algoritme SOM. Masukan ke algoritme SOM adalah data dari praproses dengan kombinasi dari parameter awal. Parameter awal dari algoritme SOM yang akan digunakan adalah:
3. Ukuran lingkungan (R): 1
4. Penurunan learning rate ( ): 0.1, 0.5, 0.9, dan 1.
Metode inisialisasi nilai vektor bobot menggunakan midpoint dengan topologi yang digunakan adalah topologi grid. Fungsi jarak yang digunakan adalah Euclidean, dan kriteria pemberhentian algoritme SOM adalah epoch, dengan banyak epoch: 100, 200, dan 300.
Seluruh hasil clustering dari algoritme SOM akan divalidasi menggunakan validasi
cluster Indeks Davies-Bouldin (DBI). Dari berbagai kombinasi parameter awal, akan dipilih clustering yang menghasilkan DBI minimal sebagai clustering terbaik.
Jumlah cluster dan bobot dari hasil metode SOM merupakan input untuk metode K-means, bobot yang optimal dari hasil metode SOM dijadikan sebagai initial centroid bagi K-means. Dari hasil clustering tersebut akan dilakukan validasi dan perbandingan terhadap
clustering dengan menggunakan metode algoritme SOM saja dan K-means saja.
Apabila hasil valid dan memiliki nilai yang lebih kecil dari metode algoritma lain maka dilanjutkan dengan melakukan analisa hasil klaster, namun apabila masih belum maka akan kembali dilakukan pemilihan dan pembersihan data.
Representasi Pengetahuan
Representasi pengetahuan akan dilakukan terhadap cluster yang sudah divalidasi. Representasi tersebut akan memperlihatkan karakteristik masing-masing
cluster. Informasi penting yang terdapat dari hasil clutering diharapkan bermanfaat sehingga dapat diperoleh penanganan terhadap cluster yang bersangkutan.
Lingkungan Implementasi
Beberapa perangkat lunak dan perangkat keras yang digunakan untuk mengembangkan sistem adalah sebagai berikut:
Perangkat lunak:
Monitor dengan resolusi 1366×768 Mouse dan keyboard
Gambar 2 Diagram alur penelitian
HASIL DAN PEMBAHASAN
Data Indikator Ketahanan Pangan
Data sumber yang digunakan pada penelitian ini adalah data indikator ketahanan pangan kabupaten di wilayah Provinsi Bali, Nusa Tenggara Barat (NTB), dan Nusa Tenggara Timur (NTT) pada tahun 2009 dengan jumlah record sebanyak 30 baris dan 9
atribut. Indikator ketahanan pangan dan definisinya dapat dilihat pada Lampiran 4.
Praproses Data
Proses normalisasi terhadap data dilakukan terlebih dahulu sebelum masuk ke tahap proses data mining, karena data yang digunakan memiliki rentang nilai yang sangat besar. Rentang nilai yang sangat besar cukup mempengaruhi pada metode clustering yang berbasis jarak. Normalisasi pada umumnya digunakan untuk menyetarakan atribut agar atribut satu dengan lainnya memiliki ukuran yang sama, memiliki rataan dan standar deviasi nol. Normalisasi juga membuat rentang nilai menjadi jauh lebih kecil sehingga membantu perhitungan jarak menjadi lebih cepat dan efisien. Teknik normalisasi yang digunakan pada penelitian ini adalah z-score. Data indikator ketahanan pangan sebelum dan sesudah dinormalisasi disajikan pada Lampiran 5 dan Lampiran 6.
Tiga Metode Clustering
Pada penelitian ini akan dilakukan perbandingan terhadap tiga metode clustering
yaitu: a. SOM
Dengan menggunakan parameter awal yang dapat menghasilkan nilai DBI terbaik.
b. SOM+Kmeans (Algoritme S-K)
Dengan menggunakan ukuran cluster 3 dan initial centroid yang didapatkan dari metode SOM yang menghasilkan DBI terbaik, namun menggunakan algoritme k-means.
c. K-means
Menggunakan ukuran cluster 3 dan initial centroid yang dibangkitkan secara acak.
Penerapan Algoritme SOM
Data indikator ketahanan pangan yang telah dinormalisasi akan di-cluster
menggunakan algoritme Self Organizing Maps (SOM). Masukan ke algoritme SOM adalah data dari praproses dengan kombinasi dari parameter awal.
Kriteria pemberhentian clustering
dilakukan dengan pembatasan jumlah epoch. Algoritme SOM dijalankan dengan 100, 200, dan 300 epoch. Hasil pengamatan Indeks Davies-Bouldin disajikan pada Lampiran 7. Jumlah cluster dan bobot yang didapat dari
algoritme SOM akan menjadi input awal bagi algoritme clustering K-means.
Indeks Davies-Bouldin (DBI)
Pengamatan terhadap DBI dilakukan untuk mengukur validitas dari hasil clustering
algoritme SOM dengan kombinasi berbagai parameter. Skema clustering yang optimal menurut Indeks Davies-Bouldin adalah yang memiliki Indeks Davies-Bouldin minimal. Hasil pengamatan dengan kombinasi berbagai parameter disajikan pada Lampiran 7. DBI terbaik untuk tiap ukuran cluster dapat dilihat pada Tabel 1.
Tabel 1 Indeks Davies-Bouldin terbaik untuk tiap ukuran cluster
Ukuran
Dari hasil penelitian, Indeks Davies-Bouldin terbaik dihasilkan dengan parameter awal: ukuran cluster 3, learning rate 0.5, penurunan learning rate 1, iterasi 100 menghasilkan DBI 2.696 (Tabel 1). Bobot optimal dengan ukuran cluster 3 dapat dilihat pada Lampiran 8.
Clustering dengan Algoritme S-K
Ukuran cluster dan bobot dari SOM dengan Indeks Davies-Bouldin terbaik menjadi masukan bagi algoritme K-means untuk mendapatkan final cluster (Tabel 2).
Initial centroid sangat dibutuhkan pada algoritme K-means karena pada K-means nilai
initial centroid dipilih secara acak sehingga mempengaruhi hasil clustering. Begitu juga dengan ukuran cluster, algoritme K-means tidak dapat menentukan ukuran cluster yang baik. Bobot optimal yang dihasilkan SOM digunakan sebagai initial centroid bagi algoritme K-means.
Pada tahap ini akan dihasilkan cluster
Banyaknya anggota masing-masing cluster
dengan ukuran cluster 3 disajikan pada Tabel 2. Nama-nama anggota masing-masing cluster
dengan ukuran cluster 3 dapat dilihat pada Tabel 3 .
Tabel 2 Banyak anggota masing-masing
cluster dengan ukuran cluster 3
Cluster
Tabel 3 Nama anggota pada masing-masing
cluster hasil clustering dengan algoritme S-K
Cluster ke- Anggota
1 Sumba Barat, Sumba Timur, Timor Tengah Selatan, Kupang, Timor Tengah Utara,
Belu, Lembata, Sikka, Manggarai, Rote Ndao, Manggarai Barat, Alor, Ende,
Flores Timur, Ngada.
2 Lombok Barat, Lombok
Tengah, Lombok Timur, Sumbawa, Dompu, Bima,
Sumbawa Barat. 3 Jembrana, Tabanan, Badung,
Gianyar, Klungkung, Bangli, Buleleng, Karang Asem.
Perbandingan Hasil Clustering
Dalam penelitian ini akan dilakukan perbandingan terhadap hasil clustering
algoritme SOM, S-K, dan K-means.
Clustering menggunakan algoritme K-means dengan ukuran cluster 3 dan initial centroid
yang dibangkitkan secara acak menghasilkan
cluster dengan nilai DBI sebesar 1.635.
Final cluster dari penerapan algoritme S-K menghasilkan nilai DBI sebesar 1.011. Nilai DBI hasil clustering menggunakan algoritme S-K lebih kecil dibanding nilai DBI hasil
clustering SOM sebelumnya yang sebesar 2.696. Nama-nama anggota masing-masing
cluster dengan ukuran cluster 3 hasil
clustering SOM dan hasil clustering K-means disajikan pada Tabel 4 dan Tabel 5. Nomor
cluster tidak menunjukan tingkatan.
Tabel 4 Nama anggota pada masing-masing
cluster hasil clustering dengan algoritme SOM
Cluster ke- Anggota
1 Sumba Barat, Sumba Timur, Timor Tengah Selatan, Kupang, Timor Tengah Utara, Belu, Lembata, Sikka,
Manggarai, Rote Ndao, Manggarai Barat, Alor,
Ende.
2 Lombok Barat, Lombok Tengah, Lombok Timur, Sumbawa, Dompu, Bima,
Sumbawa Barat, Flores Timur, Ngada. 3 Jembrana, Tabanan, Badung,
Gianyar, Klungkung, Bangli, Buleleng, Karang Asem.
Tabel 5 Nama anggota pada masing-masing
cluster hasil clustering dengan algoritme K-means
Cluster ke- Anggota
1 Sumbawa, Bima, Sumbawa Barat, Kupang, Timor Tengah
Utara, Belu, Alor, Lembata, Flores Timur, Sikka, Ende,
Ngada, Manggarai, Rote Ndao, Manggarai Barat. 2 Lombok Barat, Lombok
Tengah, Lombok Timur, Dompu, Sumba Barat,
Sumba Timur, Timor Tengah Selatan. 3 Jembrana, Tabanan, Badung,
Gianyar, Klungkung, Bangli, Buleleng, Karang Asem.
Dari Tabel 3, Tabel 4, dan Tabel 5 terlihat bahwa hasil clustering dengan SOM, S-K, dan K-means untuk cluster 3 sama persis, perbandingan anggota hasil clustering
2.696, nilai DBI hasil clustering algoritme S-K sebesar 1.011, dan nilai DBI clustering K-means sebesar 1.635, skema clustering yang optimal menurut Indeks Davies-Bouldin (DBI) adalah yang memiliki DBI minimal. Sehingga dapat kita simpulkan bahwa algoritme S-K memberikan hasil clustering
yang terbaik.
Deskripsi Hasil Cluster
Untuk mengetahui karakteristik indikator ketahanan pangan perlu dilakukan analisis, untuk mendapatkan hasil analisis yang baik tentunya membutuhkan hasil clustering yang valid. Dari hasil pengamatan nilai DBI SOM sebesar 2.696, DBI algoritme S-K 1.011, dan DBI K-means 1.635, menunjukan bahwa algoritme S-K menghasilkan clustering yang valid.
Menurut instrumen situasi ketahanan pangan suatu wilayah, penilaian ketahanan pangan dikategorikan menjadi enam prioritas, di mana prioritas 1 merupakan wilayah sangat rawan pangan, prioritas 2 wilayah rawan pangan, prioritas 3 wilayah agak rawan pangan, prioritas 4 wilayah cukup tahan pangan, prioritas 5 wilayah tahan pangan, dan prioritas 6 wilayah sangat tahan pangan (DKP dan WFP 2009). Penilaian setiap indikator dan karakteristik cluster disajikan pada Lampiran 10 dan Lampiran 11.
Cluster 1 yang memiliki 50% dari data (Tabel 2), adalah cluster yang memiliki nilai buruk pada indikator akses listrik, berat badan bayi di bawah standar, dan kemiskinan (prioritas 1). Hal yang perlu menjadi perhatian serius dari pemerintah adalah perbaikan di bidang ekonomi untuk mengurangi angka kemiskinan, akses yang cukup terhadap listrik perlu ditingkatkan secara signifikan, merevitalisasi peran dan fungsi posyandu, PKK, dan bidan desa untuk menekan angka berat badan bayi di bawah standar, penyuluhan kesehatan dan gizi lebih digiatkan agar masyarakat dapat hidup sehat. Cluster 1 termasuk wilayah rawan pangan.
Cluster 2 (23.33% dari data) adalah cluster
yang memiliki nilai buruk pada indikator kemiskinan, berat badan bayi di bawah standar, dan angka harapan hidup berada prioritas 2, indikator perempuan buta huruf berada pada prioritas 3. Penduduk yang hidup di bawah garis kemiskinan perlu ditangani secara optimal dengan pembangunan ekonomi produktif, akses terhadap listrik perlu ditingkatkan, dan pemerintah daerah perlu
merevitalisasi peran dan fungsi posyandu, PKK, dan bidan desa, serta penyuluhan pola pengasuhan agar balita dapat berkembang dengan baik. Kondisi kerentanan terhadap kerawanan pangan pada cluster 2 ini adalah agak rawan pangan.
Cluster 3 (26.67% dari data) adalah cluster
yang memiliki indikator ketahanan terbaik. Namun cluster 3 berada di prioritas 3 pada indikator perempuan buta huruf. Program pendidikan, baik formal dan non-formal perlu diperhatikan dan dilaksanakan. Untuk indikator lainnya berada pada prioritas 5 dan prioritas 6. Ketahanan pangan di cluster 3 terjamin.
Dari Gambar 3 dapat dilihat bahwa kabupaten yang berada di Provinsi Bali termasuk dalam cluster yang memiliki kondisi ketahanan pangan yang terjamin (cluster 3). Bali harus melanjutkan usaha-usaha terbaiknya untuk memelihara tingkat komitmen saat ini. Seluruh kabupaten di Provinsi Nusa Tenggara Barat termasuk dalam
cluster 2 dengan kondisi agak rawan pangan. Seluruh kabupaten di Provinsi Nusa Tenggara Timur berada di cluster yang memiliki nilai indikator yang buruk (cluster 1) dengan kondisi rawan pangan.
SIMPULAN DAN SARAN
Simpulan
Pada penelitian ini telah diimplementasikan clustering menggunakan algoritme S-K untuk data ketahanan pangan di Provinsi Bali, Nusa Tenggara Barat, dan Nusa Tenggara Timur. Dari hasil percobaan menggunakan SOM ditemukan bahwa
clustering data ketahanan pangan yang memiliki Indeks Davies-Bouldin minimal adalah ukuran cluster 3, learning rate 0.5, penurunan learning rate 1, epoch 100 menghasilkan nilai Indeks Davies-Bouldin sebesar 2.696. Bobot optimal yang dihasilkan SOM kemudian digunakan sebagai initial centroid bagi algoritme K-means untuk mendapatkan final cluster. Hasil validasi final cluster didapatkan nilai DBI sebesar 1.011. Pada penelitian ini juga dilakukan clustering
dengan algoritme K-means yang initial centroid-nya dibangkitkan secara acak, hasil validasi dengan DBI sebesar 1.635. Jika dibandingkan nilai DBI hasil clustering
algoritme SOM, S-K, dan K-means, algoritme S-K memiliki nilai DBI yang minimal. Terbukti bahwa algoritme S-K memberikan hasil clustering yang baik. Akan tetapi, pada penelitian ini masih terdapat anomali pada nilai DBI yang dihasilkan dari clustering
SOM, secara teori seharusnya nilai DBI yang dihasilkan dari clustering SOM tidak terlalu jauh dari nilai DBI clustering S-K. Perlu penelitian lebih lanjut mengenai validasi
clustering.
Provinsi Nusa Tenggara Timur berada pada cluster yang memiliki status rawan pangan. Provinsi Nusa Tenggara Barat termasuk dalam cluster dengan kondisi agak rawan pangan. Provinsi Bali berada pada
cluster dengan kondisi ketahanan pangan terjamin.
Saran
Pada penelitian selanjutnya dapat menggunakan kombinasi dari algoritme
clustering lainnya seperti integrasi algoritme semut dan K-means. Selain itu, diharapkan adanya penelitian lebih lanjut untuk mengevaluasi hasil analisis cluster.
DAFTAR PUSTAKA
Demuth H, Beale M. 2003. Neural Network Toolbox For Use with MATLAB®. Massachusetts: The MathWorks.
[DKP dan WFP] Dewan Ketahanan Pangan dan World Food Programme. 2009. Peta Ketahanan dan Kerawanan Pangan Indonesia. Jakarta: Dewan Ketahanan Pangan, Departemen Pertanian RI.
Edward. 2006. Clustering menggunakan self organizing maps (studi kasus: data PPMB IPB) [skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Han J, Kamber M. 2006. Data Mining:
Concepts and Techniques. Ed ke-2. San Francisco: Morgan Kaufman.
Jain AK, Dubes RC. 1988. Algorithms for Clustering Data. New Jersey: Prentice Hall.
Kantardzic M. 2003. Data Mining: Concepts, Models, Methods, and Algorithm. New Jersey: John Wiley & Sons.
Kuo RJ, Ho LM, Hu CM. 2001. Integration of self organizing feature map and K-means algorithm for market segmentation.
Computers and Operations Research 29: 1475-1493.
Larose DT. 2004. Discovering Knowledge in Data: An Introduction to Data mining. New Jersey: Wiley.
Laurence F. 1994. Fundamentals of Neural Networks. New Jersey: Prentice Hall. Salazar GEJ, Veles AC, Parra MCM, Ortega
LO. 2002. A cluster validity index for comparing non-hierarchical clustering methods. [terhubung berkala]. http://citeseer.ist.psu.edu/rd/salazar02clust er.pdf [20 Jun 2012].
Saliem HP, Lokollo EM, Ariani M, Purwantini TB, Marisa Y. 2007. Wilayah Rawan Pangan dan Gizi Kronis di Papua, Kalimantan Barat Dan Jawa Timur. Laporan Penelitian Puslitbang Sosek Pertanian, Badan Litbang Pertanian. Departemen Pertanian RI.
Jumlah cluster 3
Initial centroid 1.230 0.718 -0.423 0.769 0.523 0.537 0.999 0.099 0.088
-0.082 -0.972 -0.333 -0.363 0.243 -0.306 0.468 -0.118 0.062
-1.021 -0.516 0.473 -1.118 -0.810 -0.766 -0.967 0.599 0.678
Bobot optimal dari SOM digunakan sebagai initial centroid bagi K-means
Data (x)
-1.113 -0.529 0.422 -1.273 -0.865 -0.875 -1.065 0.690 1.008 V1
-0.655 -0.660 -0.010 0.236 -0.260 -0.537 0.699 -0.933 -0.956 V2
1.418 0.813 -0.456 0.814 0.580 0.525 1.094 0.201 0.131 V3
0.210 -1.250 -0.560 -0.749 0.558 -0.224 0.371 0.328 0.632 V4
Iterasi 1 Menghitung jarak antara data vektor input dan centroid dengan rumus jarak euclidean, jarak minimal menentukan vektor input
masuk ke dalam cluster mana.
C1 C2 C3 Cluster
V1 4.616 2.847 0.421 3
V2 3.150 1.718 3.220 2
V3 0.269 2.852 4.540 1
Menghitung centroid baru
C1 1.2303 0.7176 -0.4234 0.7690 0.5233 0.5368 0.9986 0.0991 0.0881
C2 -0.2227 -0.9550 -0.2850 -0.2566 0.1487 -0.3805 0.5350 -0.3025 -0.1616
C3 -1.0212 -0.5161 0.4729 -1.1175 -0.8097 -0.7662 -0.9665 0.5994 0.6784
Iterasi 2 Menghitung jarak antara data vektor input dan centroid dengan rumus jarak euclidean, jarak minimal menentukan vektor input masuk ke dalam cluster mana. Lakukan hingga anggota cluster stabil.
c1 c2 c3 Cluster
v1 4.616 2.949 0.421 3
v2 3.150 1.356 3.220 2
v3 0.269 2.941 4.540 1
v4 2.926 1.356 2.699 2
Menghitung centroid baru
C1 1.230 0.718 -0.423 0.769 0.523 0.537 0.999 0.099 0.088
C2 -0.223 -0.955 -0.285 -0.257 0.149 -0.381 0.535 -0.302 -0.162
Lampiran 2 Langkah-langkah clustering dengan algoritme SOM
Clustering dengan algoritme SOM
Tentukan parameter awal
Learning rate 0.5
Penurunan learning
rate 0.9
Ukuran tetangga 0
Ukuran cluster 3
Bobot awal (w)
0.735 0.465 -0.337 0.651 0.373 0.569 0.747 -0.170 -0.025
0.049 -0.090 0.096 0.150 -0.113 0.035 0.254 -0.178 -0.120
-0.779 -0.483 0.607 -0.709 -0.663 -0.478 -0.707 0.361 -0.192
Data (x)
-1.113 -0.529 0.422 -1.273 -0.865 -0.875 -1.065 0.690 1.008
-0.655 -0.660 -0.010 0.236 -0.260 -0.537 0.699 -0.933 -0.956
1.418 0.813 -0.456 0.814 0.580 0.525 1.094 0.201 0.131
Lampiran 2 Lanjutan
Epoch 1
Untuk vektor (x1)
D(1) 4.170
D(2) 2.972
D(3) 1.531
D(3) minimum maka vektor bobot di baris 3 dimodifikasi.
w3 baru -0.946 -0.506 0.515 -0.991 -0.764 -0.677 -0.886 0.525 0.408
w baru 0.735 0.465 -0.337 0.651 0.373 0.569 0.747 -0.170 -0.025
0.049 -0.090 0.096 0.150 -0.113 0.035 0.254 -0.178 -0.120
-0.946 -0.506 0.515 -0.991 -0.764 -0.677 -0.886 0.525 0.408
Untuk Vektor (x2)
D(1) 2.561
D(2) 1.629
D(3) 2.943
D(2) minimum maka vektor bobot di baris 2 dimodifikasi.
w2 baru -0.30 -0.38 0.04 0.19 -0.19 -0.25 0.48 -0.56 -0.54
w baru 0.74 0.47 -0.34 0.65 0.37 0.57 0.75 -0.17 -0.02
-0.95 -0.51 0.51 -0.99 -0.76 -0.68 -0.89 0.53 0.41
Untuk vektor (x3)
D(1) 0.977
D(2) 2.757
D(3) 4.345
D(1) minimum maka vektor bobot di baris 1 dimodifikasi.
w1 baru 1.077 0.639 -0.397 0.732 0.477 0.547 0.921 0.016 0.053
w baru 1.077 0.639 -0.397 0.732 0.477 0.547 0.921 0.016 0.053
-0.303 -0.375 0.043 0.193 -0.187 -0.251 0.476 -0.555 -0.538
-0.946 -0.506 0.515 -0.991 -0.764 -0.677 -0.886 0.525 0.408
Untuk vektor (x4)
D(1) 2.807
D(2) 2.236
D(3) 2.593
D(2) minimum maka vektor bobot di baris 2 dimodifikasi.
w2 baru -0.047 -0.813 -0.259 -0.278 0.185 -0.237 0.424 -0.114 0.047
w baru 1.077 0.639 -0.397 0.732 0.477 0.547 0.921 0.016 0.053
-0.047 -0.813 -0.259 -0.278 0.185 -0.237 0.424 -0.114 0.047
-0.946 -0.506 0.515 -0.991 -0.764 -0.677 -0.886 0.525 0.408
Epoch 2
Learning rate baru = 0.45
Untuk vektor (x1)
D(1) 4.470
D(2) 2.823
D(3) 0.765
D(3) minimum maka vektor bobot di baris 3 dimodifikasi
w3 baru -1.021 -0.516 0.473 -1.118 -0.810 -0.766 -0.967 0.599 0.678
w baru 1.077 0.639 -0.397 0.732 0.477 0.547 0.921 0.016 0.053
-0.047 -0.813 -0.259 -0.278 0.185 -0.237 0.424 -0.114 0.047
-1.021 -0.516 0.473 -1.118 -0.810 -0.766 -0.967 0.599 0.678
Untuk vektor (x2)
D(1) 2.961
D(2) 1.662
D(3) 3.220
D(2) minimum maka vektor bobot di baris 2 dimodifikasi
w2 baru -0.321 -0.744 -0.147 -0.047 -0.015 -0.372 0.548 -0.482 -0.404
w baru 1.077 0.639 -0.397 0.732 0.477 0.547 0.921 0.016 0.053
-0.321 -0.744 -0.147 -0.047 -0.015 -0.372 0.548 -0.482 -0.404
-1.021 -0.516 0.473 -1.118 -0.810 -0.766 -0.967 0.599 0.678
Untuk vektor (x3)
D(1) 0.489
D(2) 2.915
D(3) 4.540
D(1) minimum maka vektor bobot di baris 1 dimodifikasi
w1 baru 1.230 0.718 -0.423 0.769 0.523 0.537 0.999 0.099 0.088
w baru 1.230 0.718 -0.423 0.769 0.523 0.537 0.999 0.099 0.088
-0.321 -0.744 -0.147 -0.047 -0.015 -0.372 0.548 -0.482 -0.404
-1.021 -0.516 0.473 -1.118 -0.810 -0.766 -0.967 0.599 0.678
Untuk vektor (x4)
D(1) 2.926
D(2) 1.821
D(3) 2.699
w2 baru -0.082 -0.972 -0.333 -0.363 0.243 -0.306 0.468 -0.118 0.062
w baru 1.230 0.718 -0.423 0.769 0.523 0.537 0.999 0.099 0.088
-0.082 -0.972 -0.333 -0.363 0.243 -0.306 0.468 -0.118 0.062
-1.021 -0.516 0.473 -1.118 -0.810 -0.766 -0.967 0.599 0.678
Misalkan maksimum epoch adalah 2, maka bobot akhir yang kita dapatkan adalah
w 1.230 0.718 -0.423 0.769 0.523 0.537 0.999 0.099 0.088
-0.082 -0.972 -0.333 -0.363 0.243 -0.306 0.468 -0.118 0.062
-1.021 -0.516 0.473 -1.118 -0.810 -0.766 -0.967 0.599 0.678
Pengelompokan vektor dilakukan dengan menghitung jarak vektor dengan bobot optimal
vektor(x1) vektor(x2) vektor(x3)
D(1) 4.616 D(1) 3.150 D(1) 0.269
D(2) 2.847 D(2) 1.718 D(2) 2.852
D(3) 0.421 D(3) 3.220 D(3) 4.540
vektor(x4)
D(1) 2.926
D(2) 1.001
D(3) 2.699
Vektor (x4) masuk ke cluster 2
Lampiran 3 Langkah perhitungan Indeks Davies-Bouldin
Indeks Davies-Bouldin(DBI)
Nk = 3
Centroid 1.230 0.718 -0.423 0.769 0.523 0.537 0.999 0.099 0.088
-0.223 -0.955 -0.285 -0.257 0.149 -0.381 0.535 -0.302 -0.162
-1.021 -0.516 0.473 -1.118 -0.810 -0.766 -0.967 0.599 0.678
Xi -1.113 -0.529 0.422 -1.273 -0.865 -0.875 -1.065 0.690 1.008
-0.655 -0.660 -0.010 0.236 -0.260 -0.537 0.699 -0.933 -0.956
1.418 0.813 -0.456 0.814 0.580 0.525 1.094 0.201 0.131
0.210 -1.250 -0.560 -0.749 0.558 -0.224 0.371 0.328 0.632
Mencari jarak intra cluster
sc(Qk) = i||Xi-Ck||
Nk
Xi = data , Ck= Centroid
Nk=Banyak anggota dalam cluster
Sc (c1) 0.421
Sc (c2) 1.356
Sc (c3) 0.269
Mencari jarak inter-cluster
dkl = � − � Ck= Centroid dari cluster Qk
d1,2 2.720
d1,3 4.346
d2,1 2.720
d2,3 2.643
d3,1 4.346
Lampiran 3 Lanjutan
Indeks Davies-Bouldin
DB(nc)= 1
nc max
sc Q
k+sc(Ql)
dkl(Qk,Ql)
nc
k=l
nc = number of cluster
(Sc1+Sc2)/d1,2 0.653 (Sc2+Sc1)/d2,1 0.653 (Sc3+Sc1)/d31 0.159 (Sc1+Sc3)/d1,3 0.159 (Sc2+Sc3)/d2,3 0.615 (Sc3+Sc2)/d3,2 0.615
max 0.653 max 0.653 max 0.615
DB (nc) = 1
3 0.653+0.653+0.615
Lampiran 4 Indikator ketahanan pangan
No Indikator Definisi
1 Rasio konsumsi normatif per kapita terhadap ketersediaan bersih ‘padi+jagung+ubi kayu+ubi jalar’
Ketersediaan bersih serealia per kapita per hari dihitung dengan membagi total ktersediaan serealia kabupaten dengan jumlah populasi. Konsumsi normatif serealia/hari/kapita adalah 300
gram/orang/hari.
Kemudian dihitung rasio konsumsi normatif perkapita terhadap ketersediaan bersih serealia perkapita. Rasio lebih besar dari 1 menunjukan daerah defisit pangan dan daerah dengan rasio lebih kecil dari 1 adalah surplus untuk produksi serealia.
2 Persentase penduduk hidup di bawah garis kemiskinan
Nilai rupiah pengeluaran perkapita setiap bulan untuk memenuhi standar minimum kebutuhan-kebutuhan konsumsi pangan dan non pangan yang dibutuhkan oleh seorang individu untuk hidup secara layak. Garis
kemiskinan nasional menggunakan US$ 1,55 (Purchasing Power Parity) per orang per hari.
3 Persentase desa yang tidak memiliki akses penghubung yang memadai
Lalu lintas antar desa yang tidak bisa dilalui oleh kendaraaan roda empat.
4 Persentase rumah tangga tanpa akses listrik
Persentase rumah tangga yang tidak memiliki akses terhadap listrik dari PLN dan/atau non PLN, misalnya generator.
5 Angka harapan hidup pada saat lahir
Perkiraan lama hidup rata-rata bayi baru lahir dengan asumsi tidak ada perubahan pola mortalitas sepanjang hidupnya.
6 Berat badan balita di bawah standar (Underweight)
Anak di bawah lima tahun yang berat badannya kurang dari -2 Standar Deviasi (-2 SD) dari berat badan normal pada usia dan jenis kelamin tertentu (Standar WHO 2005). 7 Perempuan buta huruf Persentase perempuan di atas 15 tahun yang tidak dapat
membaca atau menulis. 8 Persentase rumah tangga
tanpa akses ke air bersih
Persentase rumah tangga yang tidak memiliki akses ke air minum yang berasal dari air leding/PAM, pompa air , sumur, atau mata air yang terlindungi.
9 Persentase rumah tangga yang tinggal lebih dari 5 km dari fasilitas kesehatan
Lampiran 5 Data indikator ketahanan pangan sebelum dinormalisasi
ID PROVINSI Kabupaten Listrik Air
Buta
Huruf Kemiskinan Jalan Kesehatan
BB bayi di bawah standar
Angka harapan hidup
Rasio konsumsi
1 Bali Jembrana 1.63 17.42 17.63 9.92 0 11.4 12.2 71.63 0.88
2 Bali Tabanan 0.77 8.57 19.41 7.46 0.78 2.7 7.1 74.32 0.32
3 Bali Badung 0.54 3.31 14.3 4.28 0 0 7.4 71.64 0.6
4 Bali Gianyar 0.65 2.9 26.28 5.98 0 0.2 6.8 71.99 0.45
5 Bali Klungkung 6.01 26.18 28.61 9.14 0 2 12.9 68.95 0.44
6 Bali Bangli 3.82 24.4 25.7 7.48 0 2.4 11.7 71.4 0.48
7 Bali Karang Asem 6.06 37.5 38.33 8.95 0 14.7 19.8 67.77 0.49
8 Bali Buleleng 2.45 15.7 23.43 8.68 0 1.7 14.9 68.65 0.79
9 Nusa Tenggara Barat Lombok Barat 11.18 16.49 34.46 28.97 0 11.8 27.6 59.54 0.68
10 Nusa Tenggara Barat Lombok Tengah 20.9 23.96 37.38 25.74 0.81 1.6 18.2 59.82 0.46
11 Nusa Tenggara Barat Lombok Timur 21.7 14.14 26.47 25.6 0 1.3 25.5 59.16 0.63
12 Nusa Tenggara Barat Sumbawa 5.62 5.64 14.16 28.78 8.48 0.2 27.8 60.4 0.23
13 Nusa Tenggara Barat Dompu 21.58 4.45 26.25 28.57 0 4.9 30 60.7 0.3
Lampiran 5 Lanjutan
ID PROVINSI Kabupaten Listrik Air
Buta
Huruf Kemiskinan Jalan Kesehatan
BB bayi di bawah standar
Angka harapan hidup
Rasio konsumsi
15 Nusa Tenggara Barat Sumbawa Barat 5.92 8.61 16.74 28.63 8.16 5.6 21.4 60.76 0.27
16 Nusa Tenggara Timur Sumba Barat 82.41 76.1 29.78 42.96 10.42 11.4 30.3 64.11 0.39
17 Nusa Tenggara Timur Sumba Timur 65.98 60.71 21.4 39.08 12.18 25 24.7 61.42 0.62
18 Nusa Tenggara Timur Kupang 59.87 54.62 13.4 31.32 9.17 11.1 37.9 64.77 0.63
19 Nusa Tenggara Timur
Timor Tengah
Selatan 79.63 61.26 21.33 37.43 8.75 34.7 40.2 66.4 0.3
20 Nusa Tenggara Timur
Timor Tengah
Utara 67.59 31.84 15.64 30.12 4.05 16.4 37.5 67.27 0.36
21 Nusa Tenggara Timur Belu 66.93 39.04 19.64 21.02 12.98 11.7 33.9 64.72 0.48
22 Nusa Tenggara Timur Alor 55 21.73 10.67 28.49 26.29 12.5 31.6 65.89 1.05
23 Nusa Tenggara Timur Lembata 60.2 24.86 10 34.45 9.3 10.5 31 66.17 0.52
24 Nusa Tenggara Timur Flores Timur 41.92 1.65 15.33 14.38 11.95 7.1 29.8 67.17 0.7
25 Nusa Tenggara Timur Sikka 51.61 36.63 11.98 19.15 15 16.5 36.7 68.06 0.76
26 Nusa Tenggara Timur Ende 35.51 20.67 13.75 20.33 21.13 10 33.6 64.16 1.32
Lampiran 5 Lanjutan
ID PROVINSI Kabupaten Listrik Air
Buta
Huruf Kemiskinan Jalan Kesehatan
BB bayi di bawah standar
Angka harapan hidup
Rasio konsumsi
28 Nusa Tenggara Timur Manggarai 77.96 41.85 16.19 31.41 12.14 13.3 37.3 66.65 0.58
29 Nusa Tenggara Timur Rote Ndao 66.37 27.46 13.76 28.26 0 1.7 40.8 66.78 0.5
Lampiran 6 Data indikator ketahanan pangan setelah dinormalisasi
No Provinsi Kabupaten Listrik Air
Buta
Huruf Kemiskinan Jalan Kesehatan
BB bayi di bawah standar
Angka harapan hidup
Rasio konsumsi
1 Bali Jembrana -1.141 -0.441 -0.281 -1.159 -0.865 0.295 -1.325 1.418 1.385
2 Bali Tabanan -1.170 -0.895 -0.065 -1.385 -0.772 -0.755 -1.817 2.076 -0.956
3 Bali Badung -1.177 -1.165 -0.685 -1.677 -0.865 -1.081 -1.788 1.421 0.215
4 Bali Gianyar -1.174 -1.186 0.768 -1.521 -0.865 -1.056 -1.846 1.506 -0.412
5 Bali Klungkung -0.994 0.009 1.050 -1.230 -0.865 -0.839 -1.258 0.763 -0.454
6 Bali Bangli -1.067 -0.082 0.697 -1.383 -0.865 -0.791 -1.374 1.362 -0.287
7 Bali Karang Asem -0.992 0.590 2.229 -1.248 -0.865 0.694 -0.593 0.475 -0.245
8 Bali Buleleng -1.113 -0.529 0.422 -1.273 -0.865 -0.875 -1.065 0.690 1.008
9 Nusa Tenggara Barat Lombok Barat -0.821 -0.488 1.760 0.590 -0.865 0.344 0.159 -1.537 0.549
10 Nusa Tenggara Barat Lombok Tengah -0.495 -0.105 2.114 0.293 -0.769 -0.887 -0.747 -1.468 -0.371
11 Nusa Tenggara Barat Lombok Timur -0.468 -0.609 0.791 0.280 -0.865 -0.924 -0.043 -1.630 0.340
12 Nusa Tenggara Barat Sumbawa -1.007 -1.045 -0.702 0.572 0.145 -1.056 0.178 -1.327 -1.332
13 Nusa Tenggara Barat Dompu -0.472 -1.106 0.764 0.553 -0.865 -0.489 0.390 -1.253 -1.039
Lampiran 6 Lanjutan
ID PROVINSI Kabupaten Listrik Air
Buta
Huruf Kemiskinan Jalan Kesehatan
BB bayi di bawah standar
Angka harapan hidup
Rasio konsumsi 15 Nusa Tenggara Barat Sumbawa Barat -0.997 -0.893 -0.389 0.559 0.106 -0.405 -0.439 -1.239 -1.164
16 Nusa Tenggara Timur Sumba Barat 1.567 2.571 1.192 1.874 0.376 0.295 0.419 -0.420 -0.663
17 Nusa Tenggara Timur Sumba Timur 1.016 1.781 0.176 1.518 0.585 1.937 -0.121 -1.077 0.298
18 Nusa Tenggara Timur Kupang 0.812 1.469 -0.794 0.805 0.227 0.259 1.152 -0.259 0.340
19 Nusa Tenggara Timur
Timor Tengah
Selatan 1.474 1.809 0.167 1.366 0.177 3.107 1.374 0.140 -1.039
20 Nusa Tenggara Timur
Timor Tengah
Utara 1.070 0.300 -0.523 0.695 -0.383 0.899 1.113 0.353 -0.788
21 Nusa Tenggara Timur Belu 1.048 0.669 -0.038 -0.140 0.680 0.331 0.766 -0.271 -0.287
22 Nusa Tenggara Timur Alor 0.648 -0.219 -1.126 0.546 2.266 0.428 0.545 0.015 2.095
23 Nusa Tenggara Timur Lembata 0.823 -0.059 -1.207 1.093 0.242 0.187 0.487 0.084 -0.120
24 Nusa Tenggara Timur Flores Timur 0.210 -1.250 -0.560 -0.749 0.558 -0.224 0.371 0.328 0.632
25 Nusa Tenggara Timur Sikka 0.535 0.545 -0.967 -0.312 0.921 0.911 1.036 0.546 0.883
26 Nusa Tenggara Timur Ende -0.005 -0.274 -0.752 -0.203 1.651 0.126 0.737 -0.408 3.223
Lampiran 6 Lanjutan
ID PROVINSI Kabupaten Listrik Air
Buta
Huruf Kemiskinan Jalan Kesehatan
BB bayi di bawah standar
Angka harapan hidup
Rasio konsumsi
28 Nusa Tenggara Timur Manggarai 1.418 0.813 -0.456 0.814 0.580 0.525 1.094 0.201 0.131
29 Nusa Tenggara Timur Rote Ndao 1.030 0.075 -0.751 0.525 -0.865 -0.875 1.431 0.233 -0.203
Lampiran 7 Pengamatan terhadap DBI
No LR PLR Iterasi
Indeks Davies-Bouldin
3 Cluster 4 Cluster 5 Cluster 6 Cluster
1 0.1
1
100
3.003 3.119 3.034 2.747
2 0.5 2.696 3.326 2.924 2.991
3 0.9 2.763 3.233 3.134 2.947
4 0.1
200
3.086 3.003 3.161 3.024
5 0.5 2.982 3.166 3.374 2.746
6 0.9 2.738 3.363 3.133 2.989
7 0.1
300
2.884 3.003 3.057 2.805
8 0.5 2.798 3.371 2.883 2.918
9 0.9 2.753 2.996 2.746 3.233
10 0.1
0.9
100
3.094 3.124 2.799 2.872
11 0.5 2.765 3.213 2.909 2.979
12 0.9 2.770 3.200 2.929 2.707
13 0.1
200
2.731 3.129 3.176 2.880
14 0.5 2.943 3.111 2.782 2.911
15 0.9 2.834 3.106 2.810 3.034
16 0.1
300
2.830 3.224 2.920 3.087
17 0.5 2.743 3.106 2.875 2.891
18 0.9 2.832 3.075 2.929 2.872
19 0.1
0.5
100
2.781 3.041 2.912 2.925
20 0.5 2.902 3.174 2.854 2.918
21 0.9 2.831 3.237 3.013 2.928
22 0.1
200
2.860 3.217 2.992 3.078
23 0.5 2.827 3.042 2.838 2.764
24 0.9 2.839 3.343 2.907 2.880
25 0.1
300
2.714 3.167 3.205 2.888
26 0.5 2.755 3.103 3.061 2.912
No LR PLR Iterasi
Indeks Davies-Bouldin
3 Cluster 4 Cluster 5 Cluster 6 Cluster
28 0.1
0.1
100
2.716 3.175 2.918 2.803
29 0.5 2.907 3.210 2.860 2.967
30 0.9 2.888 3.009 3.110 2.894
31 0.1
200
2.789 3.219 2.861 2.959
32 0.5 2.792 3.199 3.126 2.947
33 0.9 2.791 3.233 2.986 3.100
34 0.1
300
2.862 3.116 2.930 2.995
35 0.5 2.801 3.250 3.590 2.956
36 0.9 2.895 3.267 2.949 2.896
Lampiran 8 Hasil clustering dari algoritme SOM, K-means, dan S-K
No SOM S-K K-means
1 Sumba Barat, Sumba Timur, Timor Tengah Selatan, Kupang, Timor
Tengah Utara, Belu, Lembata, Sikka, Manggarai, Rote Ndao, Manggarai Barat, Alor,
Ende.
Sumba Barat, Sumba Timur, Timor Tengah Selatan, Kupang, Timor
Tengah Utara, Belu, Lembata, Sikka, Manggarai, Rote Ndao, Manggarai Barat, Alor, Ende, Flores Timur, Ngada.
Sumbawa, Bima, Sumbawa Barat, Kupang,Timor
Tengah Utara, Belu, Alor,Lembata, FloresTimur,
Sikka, Ende, Ngada, Manggarai, Rote Ndao,
Manggarai Barat.
2 Lombok Barat, Lombok Tengah, Lombok Timur, Sumbawa, Dompu, Bima,
Sumbawa Barat, Flores Timur, Ngada.
Lombok Barat, Lombok Tengah, Lombok Timur, Sumbawa, Dompu, Bima,
Sumawa Barat.
Lombok Barat, Lombok Tengah, Lombok Timur, Dompu, Sumba Barat, Sumba Timur, Timor Tengah
Selatan.
3 Jembrana, Tabanan, Badung, Gianyar, Klungkung, Bangli, Buleleng, Karang Asem.
Jembrana, Tabanan, Badung, Gianyar, Klungkung, Bangli, Buleleng, Karang Asem.
Jembrana, Tabanan, Badung, Gianyar, Klungkung, Bangli,
Lampiran 9 Bobot optimal dari SOM sebagai initialcentroid bagi K-means
Cluster Listrik Air
Buta
Huruf Kemiskinan Jalan Kesehatan
BB bayi di bawah
standar Angka harapan hidup
Rasio konsumsi
1 0.9822 0.8199 -0.4938 0.6983 0.7253 0.7399 0.8027 -0.0679 0.2467
2 -0.4380 -0.7734 0.2538 0.1996 -0.2888 -0.5790 0.0702 -0.9809 -0.3844
Lampiran 10 Penilaian setiap indikator
Prioritas ke-
Nilai Indikator
Listrik Air Buta
Huruf
Kemiskinan Jalan Kesehatan Berat Bayi
Kurang
Harapan Hidup
Konsumsi Normatif
1 >50 >70 >40 >35 >30 >60 >30 <58 >.15
2 40-50 60-70 30-40 25-35 25-30 50-60 20-30 58-61 1.25-1.5
3 30-40 50-60 20-30 20-25 20-25 40-50 61-64 1.0-1.25
4 20-30 40-50 10-20 15-20 15-20 30-40 64-67 0.7-1.0
5 10-20 30-40 5-10 10-15 10-15 20-30 10-20 67-70 0.5-0.7
Lampiran 11 Karakteristik cluster
Cluster ke-
Prioritas ke-
Listrik Air Buta
Huruf
Kemiskinan Jalan Kesehatan Berat Bayi
Kurang
Harapan Hidup
Konsumsi Normatif
1 1 5 4 1 4 6 1 4 5
2 5 6 3 2 6 6 2 2 6