PENGEMBANGAN MODEL PROBABILISTIC NEURAL NETWORK BERTINGKAT
MENGGUNAKAN FUZZYC-MEANS UNTUK IDENTIFIKASI PEMBICARA
Oleh :
VICKY ZILVAN G64103043
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PENGEMBANGAN MODEL PROBABILISTIC NEURAL NETWORK BERTINGKAT
MENGGUNAKAN FUZZYC-MEANS UNTUK IDENTIFIKASI PEMBICARA
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Oleh :
VICKY ZILVAN G64103043
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
ABSTRAK
VICKY ZILVAN. Pengembangan Model Probabilistic Neural Network Bertingkat Menggunakan
Fuzzy C-Means untuk Identifikasi Pembicara. Dibimbing oleh AGUS BUONO dan SRI NURDIATI.
Salah satu kajian dalam speech processing adalah identifikasi pembicara. Metode yang digunakan untuk identifikasi pembicara pada penelitian ini adalah Probabilistic Neural Network
dengan data latih yang di-cluster-kan menggunakan Fuzzy C-Means dan untuk ekstraksi ciri sinyal suara menggunakan MFCC. Jenis identifikasi pembicara pada penelitian ini bersifat tertutup dan bergantung pada teks, dan kata yang digunakan dalam pelatihan dan pengujian adalah “komputer”. Hasil dari penelitian ini adalah suatu model Probabilistic Neural Network dengan data latih yang di-cluster-kan menggunakan Fuzzy C-Means untuk identifikasi pembicara yang bersifat tertutup dan bergantung pada teks.
Tingkat akurasi tertinggi dari model yang menggunakan data asli diperoleh dengan data pelatihan sebanyak 40, dengan tingkat akurasi sebesar 96%. Di sisi lain, untuk model yang menggunakan data dengan SNR sebesar 30 dB, nilai akurasi tertinggi diperoleh dengan data pelatihan sebanyak 40, dengan tingkat akurasi sebesar 89%. Tingkat akurasi tertinggi dari model yang menggunakan data dengan SNR sebesar 20 dB diperoleh dengan data pelatihan sebanyak 30, dengan tingkat akurasi sebesar 60%. Untuk identifikasi dengan threshold, nilai akurasi dari model yang menggunakan data asli dengan 40 data pelatihan sebesar 91% untuk pembicara yang dikenal, sedangkan untuk pembicara yang tidak dikenal tingkat akurasi mencapai 80%.
Judul : Pengembangan Model
Probabilistic Neural Network
Bertingkat
Menggunakan Fuzzy C-Means untuk Identifikasi Pembicara
Nama : Vicky Zilvan
NRP : G64103043
Menyetujui:
Pembimbing I,
Pembimbing II
Ir. Agus Buono, M.Si., M.Kom.
Dr. Ir. Sri Nurdiati, M.Sc.
NIP 132045532
NIP 131578805
Mengetahui:
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Prof. Dr. Ir. Yonny Koesmaryono, MS
NIP 131473999
RIWAYAT HIDUP
Penulis dilahirkan di Cianjur pada tanggal 3 Oktober 1984 sebagai anak kesatu dari tiga bersaudara dari pasangan Agust Salfa dan Aziza M.B. Penulis menyelesaikan pendidikan menengah atas di SMU Negeri 1 Cianjur dan lulus pada tahun 2003.
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah SWT atas limpahan nikmat dan hidayah-Nya sehingga penulis dapat menyelesaikan karya ilmiah ini. Sholawat dan salam semoga senantiasa tercurah kepada nabi besar Muhammad SAW, keluarganya, para sahabat, serta para pengikutnya yang tetap istiqomah mengemban risalah-Nya.
Melalui lembar ini, penulis ingin menyampaikan penghargaan dan terima kasih kepada semua pihak atas bantuan, dorongan, saran, kritik, serta koreksi yang ditujukan selama penulisan karya ilmiah ini. Ucapan terima kasih penulis ucapkan kepada :
1. Kedua orang tuaku tercinta, Adik-adikku, kedua Nenekku, dan seluruh keluargaku atas doa, kasih sayang, dan pengorbanan yang telah diberikan selama ini.
2. Bapak Ir. Agus Buono, M.Si., M.Kom. selaku pembimbing I, Ibu Dr. Ir. Sri Nurdiati, M.Sc. selaku pembimbing II dan Bapak Aziz Kustiyo, S.Si., M.Kom. selaku dosen penguji.
3. Eno, Thessi, Yustin, Ghoffar, Pandi, Mulyadi, Nanik, Vita yang telah menyumbangkan suaranya untuk data dalam penelitian ini.
4. Seluruh staf pengajar yang telah memberikan bekal ilmu dan wawasan selama penulis menuntut ilmu di Departemen Ilmu Komputer.
5. Seluruh staf administrasi dan perpustakaan atas bantuannya.
6. Komang, Dani, Gemma, Cuning, Bastut, Iqbal, Inang, Dona, Mulyadi dan Nacha yang sudah memberikan banyak sekali kenangan selama tinggal bersama.
7. Jemi dan Yayan yang telah bersedia meminjamkan laptopnya. 8. Rekan-rekan Departemen Ilmu Komputer angkatan 40.
Sebagaimana manusia yang tidak luput dari kesalahan, penulis menyadari bahwa karya ilmiah ini jauh dari sempurna. Namun penulis berharap semoga karya ilmiah ini dapat bermanfaat bagi siapapun yang membacanya.
Bogor, Mei 2007
DAFTAR ISI
Halaman
DAFTAR TABEL ...vi
DAFTAR GAMBAR ...vi
DAFTAR LAMPIRAN...vi
PENDAHULUAN ...1
Latar Belakang ...1
Tujuan...1
Ruang Lingkup...1
Manfaat...1
TINJAUAN PUSTAKA ...2
Jenis Pengenalan Pembicara ...2
Dijitalisasi Gelombang Suara...2
Signal to Noise Ratio (SNR) ...2
Ekstraksi Ciri Sinyal Suara ...3
MFCC (Mel-Frequency Cepstrum Coefficients) ...3
Fuzzy C-Means (FCM) ...4
Jaringan Saraf Tiruan ...4
Probabilistic Neural Network...5
METODE PENELITIAN...5
Data Suara...6
Ekstraksi Ciri Sinyal Suara dengan MFCC...6
Probabilistic Neural Network Bertingkat Menggunakan Fuzzy C-Means (FCM)...7
Hasil Identifikasi ...7
Penggunaan Threshold...8
Lingkungan Pengembangan ...8
HASIL DAN PEMBAHASAN ...8
Data Suara...8
Praproses dengan MFCC ...8
Probabilistic Neural Network Bertingkat Menggunakan Fuzzy C-Means (FCM)...8
Pemilihan Nilai Smoothing Parameter...9
Hasil Identifikasi Menggunakan Nilai Smootihng Parameter yang Telah Dipilih ...9
Pengaruh Penggunaan Threshold...11
KESIMPULAN DAN SARAN ...12
Kesimpulan ...12
Saran...12
DAFTAR TABEL
Halaman
1 Kombinasi pembagian data pengujian dan data pelatihan setiap suara model
untuk jumlah data yang sama ...6
2 Kombinasi proporsi data pelatihan dengan jumlah data pengujian yang sama untuk setiap setiap suara model...6
3 Tingkat akurasi setiap model dengan jumlah data yang sama...9
4 Tingkat akurasi setiap model dengan data pengujian yang sama...10
5 Hasil identifikasi 40 data pelatihan untuk 10 data pengujian pada data asli dengan menggunakan threshold...11
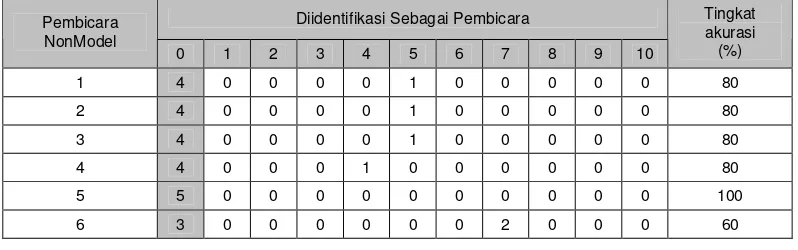
6 Hasil identifikasi 40 data pelatihan untuk 30 data pengujian non-model pada data asli dengan menggunakan threshold...12
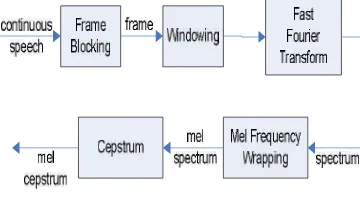
DAFTAR GAMBAR Halaman 1 Diagram blok dari proses MFCC (Do 1994) ...3
2 Struktur Probabilistic Neural Network (Ganchev 2005)...5
3 Blok diagram sistem identifikasi pembicara...5
4 Struktur Probabilistic Neural Network Bertingkat ...7
5 Perbandingan tingkat akurasi setiap pembicara pada model yang menggunakan data asli...10
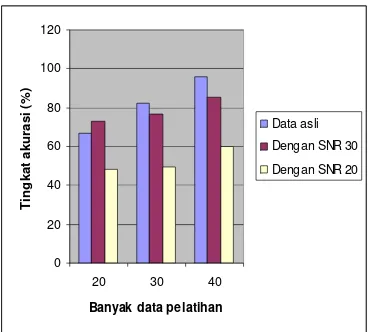
6 Perbandingan tingkat akurasi untuk setiap model dengan jumlah data yang sama ...10
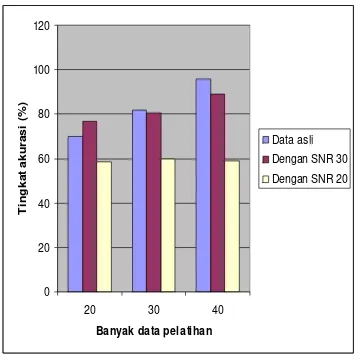
7 Perbandingan tingkat akurasi antara data yang ditambahkan SNR dengan data asli...11
8 Perbandingan tingkat akurasi model dengan menggunakan threshold dan dengan model yang tidak menggunakan threshold...11
DAFTAR LAMPIRAN Halaman 1 Hasil peng-cluster-an 20 data pelatihan ...15
2 Hasil peng-cluster-an 30 data pelatihan ...15
3 Hasil peng-cluster-an 20 data pelatihan dengan SNR 30dB...15
4 Hasil peng-cluster-an 30 data pelatihan SNR 30 dB...15
5 Hasil peng-cluster-an 20 data pelatihan dengan 20 dB ...15
6 Hasil peng-cluster-an 30 data pelatihan dengan 20 dB ...16
7 Tingkat akurasi model dengan nilai smoothingparameter yang berbeda pada data asli...16
8 Tingkat akurasi model dengan nilai smoothingparameter yang berbeda pada data dengan SNR 30 dB...19
9 Tingkat akurasi model dengan nilai smoothingparameter yang berbeda pada data dengan SNR 20 dB ...21
10 Hasil identifikasi 20 data pelatihan dengan 30 data pengujian untuk data asli ...24
11 Hasil identifikasi 30 data pelatihan untuk 20 data pengujian untuk data asli...25
12 Hasil identifikasi 40 data pelatihan untuk 10 data pengujian untuk data asli...25
13 Hasil identifikasi 20 data pelatihan untuk 30 data pengujian pada data dengan SNR 30 dB ....25
14 Hasil identifikasi 30 data pelatihan untuk 20 data pengujian pada data dengan SNR 30 dB ....26
15 Hasil identifikasi 40 data pelatihan untuk 10 data pengujian pada data dengan SNR 30 dB ....26
16 Hasil identifikasi 20 data pelatihan untuk 30 data pengujian pada data dengan SNR 20 dB ....26
17 Hasil identifikasi 30 data pelatihan untuk 20 data pengujian pada data dengan SNR 20 dB ....27
18 Hasil identifikasi 40 data pelatihan untuk 10 data pengujian pada data dengan SNR 20 dB ....27
PENDAHULUAN
Latar Belakang
Pengenalan pola masih menjadi kajian yang menarik bagi para peneliti. Hal ini dilakukan tidak hanya untuk keperluan penelitian maupun peningkatan produktifitas kerja saja, tetapi lebih mengarah pada kebutuhan di era high technology, di mana kemajuan di bidang elektronika dan teknologi informasi diharapkan secara sinergi memenuhi tuntutan kebutuhan manusia. Oleh karena itu, permasalahan pengenalan pola telah berkembang pesat dan digunakan dalam berbagai bidang.
Di perkotaan maupun industri, suara, sidik jari, pola geometri telapak tangan, maupun wajah digunakan sebagai mesin absensi. Di dunia perbankan, suara digunakan untuk berbagai kepentingan seperti, layanan bank melalui telepon. Di dunia kedokteran, iris mata digunakan untuk mengidentifikasi adanya faal pada organ tubuh, serta pupil mata untuk mengidentifikasi tingkat kelelahan pada seseorang.
Penelitian yang dilakukan dengan menggunakan data sinyal suara umumnya disebut dengan pemrosesan sinyal suara (speech processing). Speech processing sendiri memiliki beberapa cabang kajian. Salah satu kajian dalam speech processing adalah identifikasi pembicara. Identifikasi pembicara (speaker identification) adalah suatu proses mengenali seseorang berdasarkan suaranya (Campbell 1997).
Banyak sekali metode yang dikembangkan para peneliti untuk melakukan identifikasi, antara lain Dynamic Time Warping (DTW), Model Markov Tersembunyi, Vector Quantization (VQ), Bayesian classifiers, Principal Components Analysis (PCA), algoritma K-Means clustering, jaringan syaraf tiruan maupun logika Fuzzy. Di samping itu, gabungan dari beberapa metode tersebut pun sering digunakan.
Salah satu metode yang digunakan untuk identifikasi pembicara adalah Model Markov Tersembunyi yang telah dikembangkan oleh Purnamasari pada tahun 2006. Secara keseluruhan dari penelitian yang telah dilakukan, untuk pelatihan dengan 20 data menghasilkan tingkat akurasi 71,25%, untuk pelatihan dengan 30 data menghasilkan tingkat akurasi 77,92%, dan pelatihan dengan 40 data menghasilkan tingkat akurasi tertinggi yaitu sebesar 86,25%.
Untuk mencoba meningkatkan akurasi identifikasi pembicara, pada penelitian ini akan dilakukan penelitian untuk identifikasi pembicara dengan Probabilistic Neural Network (PNN) bertingkat menggunakan
Fuzzy C-Means (FCM). Metode Fuzzy C-Means (FCM) dipilih karena merupakan salah satu teknik peng-cluster-an yang sering diterapkan dalam langkah persiapan pada proses data mining dengan menghasilkan
cluster-cluster yang digunakan sebagai input untuk berbagai teknik, seperti jaringan syaraf tirun. Di sisi lain, metode Probabilistic Neural Network (PNN) dipilih karena merupakan salah satu jenis jaringan syaraf tiruan yang telah terbukti memiliki tingkat akurasi yang cukup tinggi dalam mengidentifikasi pembicara, yaitu sebesar 96% (Sarimollaoglu et al. 2004).
Tujuan
Penelitian ini bertujuan untuk mengembangkan model Probabilistic Neural Network bertingkat menggunakan Fuzzy C-Means (FCM) untuk identifikasi pembicara. Pada penelitian ini juga, akan dilakukan pembandingan tingkat akurasi model antara suara yang diberi noise dan yang tidak diberi
noise. Selain itu, dilakukan pembandingan tingkat akurasi model yang menggunakan
threshold dan tingkat akurasi model yang tidak menggunakan threshold.
Ruang Lingkup
Pada penelitian ini :
1.pembahasan difokuskan pada tahap pemodelan pembicara dengan
Probabilistic Neural Network bertingkat menggunakan Fuzzy C-Means (FCM), tidak pada pemrosesan sinyal analog sebagai praproses sistem.
2.parameter FCM yang akan dicobakan adalah :
- Banyaknya cluster = 3,
- Error terkecil yang diharapkan = 1×10-5, - Pangkat pembobot = 2,
- Maksimum iterasi = 100.
3.ekstraksi ciri sinyal suara menggunakan
Mel-Frequency Cepstrum Coefficients
(MFCC).
4.identifikasi bersifat tertutup dan bergantung pada teks.
Manfaat
Bertingkat menggunakan Fuzzy C-Means
(FCM) untuk Identifikasi Pembicara. Selain itu, model yang dihasilkan diharapkan dapat digunakan untuk mengembangkan sistem identifikasi yang bersifat tertutup dan bergantung pada teks.
TINJAUAN PUSTAKA
Jenis Pengenalan Pembicara
Menurut Campbell (1997), pengenalan pembicara berdasarkan jenis aplikasinya dibagi menjadi:
1. Identifikasi pembicara adalah proses mengenali seseorang berdasarkan suaranya. Identifikasi pembicara dibagi dua, yaitu:
• Identifikasi tertutup (closed-set identification) di mana suara masukan yang akan dikenali merupakan bagian dari sekumpulan suara pembicara yang telah terdaftar atau diketahui.
• Identifikasi terbuka (open-set identification) di mana suara masukan boleh tidak ada pada kumpulan suara pembicara yang telah terdaftar
2. Verifikasi pembicara adalah proses menerima atau menolak permintaan identitas dari seseorang berdasarkan suaranya.
Pengenalan pembicara berdasarkan aspek kebahasaan dibagi menjadi dua (Ganchev 2005), yaitu:
1. Pengenalan pembicara bergantung teks yang mengharuskan pembicara untuk mengucapkan kata atau kalimat yang sama baik pada pelatihan maupun pengujian. 2. Pengenalan pembicara bebas teks yang
tidak mengharuskan pembicara untuk mengucapkan kata atau kalimat yang sama baik pada pelatihan maupun pengujian.
Dijitalisasi Gelombang Suara
Suara adalah gelombang longitudinal yang merambat melalui medium. Medium atau zat perantara ini dapat berupa zat cair, padat, atau gas. Manusia mendengar bunyi saat gelombang bunyi, yaitu getaran di udara atau medium lain, sampai ke gendang telinga manusia.
Gelombang suara merupakan gelombang analog, sehingga agar dapat diolah dengan peralatan elektronik, gelombang suara harus direpresentasikan dalam bentuk dijital. Proses mengubah masukan suara dari gelombang analog menjadi representasi data dijital disebut digitalisasi suara.
Proses dijitalisasi suara terdiri dari dua tahap yaitu sampling dan kuantisasi (Jurafsky
& Martin 2000). Sampling adalah proses pengambilan nilai setiap jangka waktu tertentu. Nilai ini menyatakan amplitudo (besar/kecilnya) volume suara pada saat itu. Hasilnya adalah sebuah vektor yang menyatakan nilai-nilai hasil sampling. Panjang vektor data ini tergantung pada panjang atau lamanya suara yang didijitalisasikan serta sampling rate yang digunakan pada proses dijitalisasinya.
Sampling rate itu sendiri adalah banyaknya nilai yang diambil setiap detik. Sampling rate
yang biasa digunakan adalah 8000 Hz dan 16000 Hz (Jurafsky & Martin 2000). Hubungan antara panjang vektor data yang dihasilkan dengan sampling rate dan panjangnya data suara yang didijitalisasikan dapat dinyatakan secara sederhana sebagai berikut:
S = Fs * T, dengan
S = panjang vektor,
Fs = sampling rate yang digunakan
(Hertz),
T = panjang suara (detik).
Setelah melalui tahap sampling, proses dijitalisasi suara selanjutnya adalah kuantisasi yaitu menyimpan nilai amplitudo ini ke dalam representasi nilai 8 bit atau 16 bit (Jurafsky & Martin 2000).
Signal to Noise Ratio (SNR)
Signal-to-noise ratio (yang biasa disingkat menjadi SNR atau S/N) adalah suatu konsep yang mendefinisikan perbandingan antara kekuatan sinyal dengan kekuatan noise yang merusak sinyal. Secara sederhana, signal-to-noise ratio
membandingkan level dari sinyal yang diinginkan (seperti suara piano dalam suatu konser) dengan level dari sinyal yang tidak diinginkan (seperti suara orang yang bercakap-cakap dalam suatu konser). Semakin kecil nilai SNR, semakin tinggi pengaruh noise dalam merusak sinyal asli.
Secara umum, SNR didefinisikan sebagai berikut: , 2 = = noise signal noise signal A A P P SNR
dengan P adalah rata-rata dari daya (power) dan A adalah akar kuadrat rata-rata dari amplitudo. Pada umumnya, sinyal suara memiliki jangkauan dinamis yang sangat tinggi. Hal ini menyebabkan SNR akan lebih efisien jika diekspresikan dalam skala
perbandingan daya. Jika sinyal dan noise
dihitung dalam impedansi yang sama maka nilai SNR bisa didapatkan dengan menggunakan rumus berikut:
( )
= noise signal P P dBSNR 10log10
, log 20 10 = noise signal A A
sehingga semakin kecil nilai SNR dalam desibel, semakin tinggi pengaruhnya dalam merusak sinyal asli.
Ekstraksi Ciri Sinyal Suara
Sinyal suara merupakan sinyal bervariasi yang diwaktukan dengan lambat atau biasa disebut quasi-stationary (Do 1994). Ketika diamati dalam jangka waktu yang sangat pendek (5 - 100 ms), karakteristiknya hampir sama. Namun, dalam jangka waktu yang panjang (0,2 detik atau lebih) karakteristik sinyal berubah dan merefleksikan perbedaan sinyal suara yang diucapkan. Oleh karena itu, digunakan spektrum waktu pendek (short-time spectral analysis) untuk mengkarakterisasi sinyal suara.
Beberapa fitur yang biasa digunakan antara lain Linear Predictive Coding, Perceptual Linear Prediction, dan Mel-Frequency Cepstrum Coefficients.
MFCC (Mel-Frequency Cepstrum
Coefficients)
MFCC didasarkan pada variasi yang telah diketahui dari jangkauan kritis telinga manusia dengan frekuensi. Filter dipisahkan secara linear pada frekuensi rendah dan logaritmik pada frekuensi tinggi. Hal ini telah dilakukan untuk menangkap karakteristik penting dari sinyal suara.
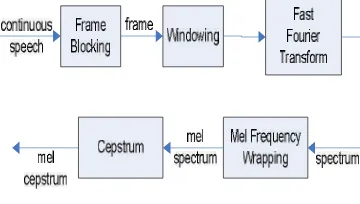
Tujuan utama MFCC adalah untuk meniru perilaku telinga manusia. Selain itu MFCC telah terbukti bisa menyebutkan variasi dari gelombang suara itu sendiri. Diagram blok dari proses MFCC dapat dilihat pada Gambar 1.
Gambar 1 Diagram blok dari proses MFCC (Do 1994)
Penjelasan tiap tahapan pada proses MFCC sebagai berikut (Do 1994):
1. Frame Blocking. Pada tahap ini sinyal suara (continous speech) dibagi ke dalam
frame-frame. Tiap frame terdiri dari N
sampel.
2. Windowing. Proses selanjutnya adalah melakukan windowing pada tiap frame
untuk meminimalkan diskontinuitas sinyal pada awal dan akhir tiap frame. Konsepnya adalah meminimisasi distorsi spektral dengan menggunakan window
untuk memperkecil sinyal hingga mendekati nol pada awal dan akhir tiap
frame. Jika window didefinisikan sebagai
w(n), 0 ≤ n ≤ N-1, dengan N adalah banyaknya sampel tiap frame, maka hasil dari windowing adalah sinyal dengan persamaan:
Yt(n)=x1(n)w(n), 0 ≤ n ≤ N-1.
Pada umumnya, window yang digunakan adalah hamming window, dengan persamaan:
w(n)=0.54-0.46cos(2πn/N-1), 0 ≤ n ≤ N-1.
3. Fast Fourier Transform (FFT). Tahap ini mengkonversi tiap frame dengan N sampel dari time domain menjadi
frequency domain. FFT adalah suatu algoritma untuk mengimplementasikan
Discrete Fourier Transform (DFT) yang didefinisikan pada himpunan N sampel
{xn} sebagai berikut:
∑−
= = −
− = 1
0 , 0,1,2,..., 1 /
2
N
k n N
N jkn e k x n
X π ,
j digunakan untuk menotasikan unit imajiner, yaitu j = −1. Secara umum
Xn adalah bilangan kompleks. Barisan
{Xn} yang dihasilkan diartikan sebagai
berikut: frekuensi nol berkorespondensi dengan n = 0, frekuensi positif 0 < f <
Fs/2berkorespondensi dengan nilai 1 ≤ n
≤ N/2-1, sedangkan frekuensi negatif –
Fs/2 < f < 0 berkorespondensi dengan N/2+1 < n < N-1. Dalam hal ini Fs adalah
sampling frequency. Hasil yang didapatkan dalam tahap ini biasa disebut dengan spektrum sinyal atau
periodogram.
setiap nada dengan frekuensi aktual f
(dalam Hertz), tinggi subjektifnya diukur dengan skala ‘mel’. Skala mel-frequency
adalah selang frekuensi di bawah 1000 Hz dan selang logaritmik untuk frekuensi di atas 1000 Hz, sehingga pendekatan berikut dapat digunakan untuk menghitung mel-frequency untuk frekuensi f dalam Hz:
Mel(f) = 2595*log10(1+f/700).
5. Cepstrum. Langkah terakhir, konversikan log mel spectrum ke domain waktu. Hasilnya disebut mel frequency cepstrum coefficients. Representasi cepstral spektrum suara merupakan representasi properti spektral lokal yang baik dari suatu sinyal untuk analisis frame. Mel spectrum coefficients (dan logaritmanya) berupa bilangan real, sehingga dapat dikonversikan ke domain waktu dengan menggunakan
Discrete Cosine Transform (DCT). Fuzzy C-Means (FCM)
Menurut Jang et al. (1997), Fuzzy C-Means
merupakan algoritma clustering data di mana setiap titik data masuk dalam sebuah cluster
dengan ditandai oleh derajat keanggotaan. FCM membagi sebuah koleksi dari n data vektor xj (j=1, 2, …, n) menjadi c cluster, dan
menemukan sebuah pusat cluster (center) untuk tiap kelompok dengan meminimalisasi ukuran dari fungsi objektif. Pada FCM hasil dari clustering adalah sebuah titik data dapat menjadi anggota untuk beberapa cluster yang ditandai oleh derajat keanggotaannya antara 0 dan 1.
Berikut tahapan clustering menggunakan algoritma FCM:
1. Inisialisasi keanggotaan matriks U yang berisi derajat keanggotan terhadap cluster
dengan nilai antara 0 dan 1, sehingga . ,..., 1 , 1 1 n u c i j ij= ∀ =
∑
=
2. Penghitungan c sebagai pusat cluster, ci , i = 1, …, c dengan menggunakan
∑
∑
= = = n j m ij n j j m ij i u x u c 1 1 ) ( ) ) (( .3. Penghitungan fungsi objektif (Ji):
∑ ∑
∑
= = = = c i n j ij m ij c i ic J u d
c c U J 1 2 1
1,..., ) ,
(
di mana:
• uij adalah elemen matriks U yang
bernilai antara 0 dan 1,
• dij = ||ci - xj|| adalah jarak antara
pusat cluster ke-i dan titik data ke-j,
• ci adalah pusat cluster ke-i,
• m
∈
[1,∞
] adalah parameterfuzzifikasi. Nomalnya, nilai m berada pada selang [1.25,2] (Cox 2005).
Kemudian kondisi berhenti dicek:
• Jika (|Jt –Jt-1| < nilai toleransi terkecil
yang diharapkan) atau (t > maksimal iterasi) maka proses berhenti.
• Jika tidak : t = t + 1.
4. Sebelum perhitungan diulangi kembali dari langkah 2, matriks U baru dihitung terlebih dahulu menggunakan formula berikut : ( ) . 1 1 1 2 ∑ = − = c k m ij d d u kj ij
Jaringan Saraf Tiruan
Jaringan saraf tiruan diinspirasi oleh cara kerja otak manusia dimana untuk berpikir, otak manusia mendapat rangsangan dari neuron-neuron yang terdapat pada indera manusia, kemudian hasil rangsangan tersebut diolah sehingga menghasilkan suatu informasi. Pada komputer, masukan yang diberikan diumpamakan sebagai neuron-neuron dimana masukan tersebut dikalikan dengan suatu nilai dan kemudian diolah dengan fungsi tertentu untuk menghasilkan suatu keluaran. Pada saat pelatihan, pemasukan tersebut dilakukan berulang-ulang hingga dicapai keluaran seperti yang diinginkan. Setelah proses pelatihan, diharapkan komputer dapat mengenali suatu masukan baru berdasarkan data yang telah diberikan pada saat pelatihan.
Probabilistic Neural Network
Probabilistic Neural Network
diperkenalkan oleh Donald F. Specht tahun 1990 dalam tulisannya berjudul “Probabilistic
Neural Network” yang merupakan
penyempurnaan ide-ide sebelumnya yang telah dilakuannya sejak tahun 1966. Probabilistic Neural Network dirancang berdasarkan ide dari teori probabilitas klasik yaitu Bayesian dan estimator pengklasifikasi Parzen untuk
Probability Density Function. Dengan menggunakan pengklasifikasi Bayesian dapat ditentukan bagaimana sebuah data masukan diklasifikasi sebagai anggota suatu kelas dari beberapa kelas yang ada, yaitu yang mempunyai nilai maksimum pada kelas tersebut.
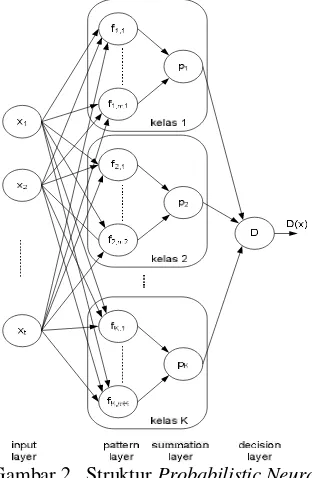
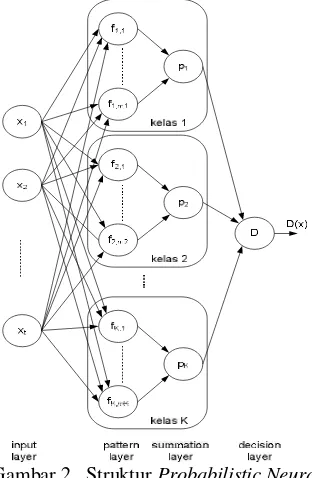
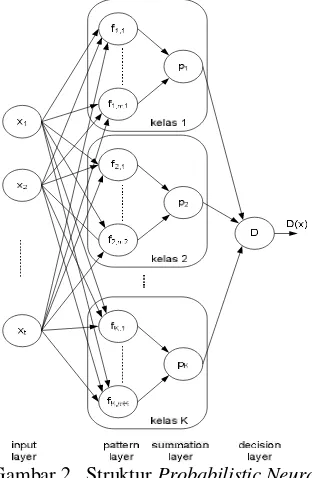
Adapun struktur dari PNN ini dapat dilihat pada Gambar 2, yang terdiri atas empat layer
yaitu input layer, pattern layer, summation layer, dan decision layer. Dengan menerima vektor tes x dari input layer, keluaran dari
pattern layer dapat dihitung melalui persamaan sebagai berikut :
( )
− =∏
= j ih j d j h x x k x f 1 , dengan :d = dimensi vektor,
k(z) = 0.5z2
e− × ,
xj = vektor input kolom ke-j,
xij = vektor bobot baris ke-i kolom ke-j, hj = smoothing parameter
(a×simpangan baku ke-j×n1/5 ). Di sisi lain, untuk summation layer dihitung dengan persamaan sebagai berikut :
( )
( )
∑
= =
−
Π
=
n i j ij nj d j d dh
x
x
k
n
h
h
h
x
p
1 1 2 1 2 /...
2
1
π
,dengan n adalah banyaknya observasi. Suatu vektor tes x diklasifikasikan pada
desicion layer sebagai kelas Y jika nilai DY(x)
paling besar untuk kelas Y.
Gambar 2 Struktur Probabilistic Neural Network (Ganchev 2005)
METODE PENELITIAN
Pada model yang akan dikembangkan ini, proses identifikasi terdiri atas dua fase, yaitu fase pelatihan dan fase pengujian. Pada fase pelatihan, contoh suara dari setiap pembicara dikumpulkan dan kemudian akan di-cluster -kan mengguna-kan FCM. Hasil peng-cluster -an ini lah y-ang ak-an digunak-an sebagai data pelatihan pada PNN. Di sisi lain, pada fase pengujian diberikan contoh data suara hasil perekaman untuk diketahui pemilik suara tersebut. Untuk lebih jelasnya, kedua fase tersebut dapat dilihat pada Gambar 3.
Data Suara
Data yang digunakan pada penelitian ini adalah gelombang suara yang telah didijitasi dan direkam dari 10 pembicara (yang selanjutnya disebut dengan data suara model), yaitu 5 pembicara laki-laki dan 5 pembicara perempuan dengan rentang usia 20-25 tahun. Masing-masing pembicara diambil suaranya dalam jangka waktu yang sama dan tanpa pengarahan (unguided). Yang dimaksud tanpa pengarahan adalah pembicara dapat menggunakan cara pengucapan, intonasi, dan logat apapun pada saat merekam data.
Jenis identifikasi pembicara yang dilakukan bersifat bergantung pada teks, maka kata yang diucapkan baik untuk pelatihan maupun pengujian telah ditentukan yaitu “komputer”. Kata tersebut diucapkan sebanyak 60 kali oleh setiap pembicara, sehingga terdapat 600 file data. Di samping itu, diperlukan juga data ber-noise dengan jumlah yang sama untuk mengetahui pengaruh noise
terhadap akurasi model yang dikembangkan. Selain itu, untuk menguji model yang dikembangkan terhadap identifikasi tertutup, maka dibutuhkan data tambahan yang berasal dari pembicara lainnya sebanyak 6 pembicara (yang selanjutnya disebut data suara non-model).
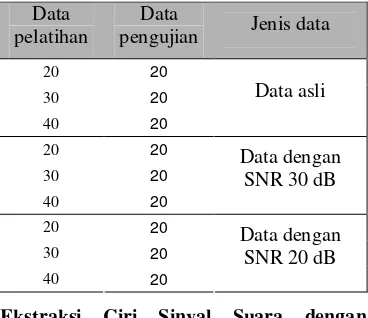
Pada penelitian ini untuk melihat proporsi terbaik dengan jumlah data yang sama akan dicobakan 3 kombinasi proporsi pembagian data pelatihan dan data pengujian. Kombinasi ini juga dipakai untuk data yang diberi tambahan noise. Kombinasi proporsi tersebut dapat dilihat pada Tabel 1.
Tabel 1 Kombinasi pembagian data pengujian dan data pelatihan setiap suara model untuk jumlah data yang sama
Data pelatihan
Data
pengujian Jenis data
20 30
30 20
40 10
Data asli
20 30
30 20
40 10
Data dengan SNR 30 dB
20 30
30 20
40 10
Data dengan SNR 20 dB
Selain itu, untuk melihat pengaruh banyaknya proporsi data pelatihan terhadap tingkat akurasi model yang dihasilkan akan
dicobakan 3 kombinasi proporsi pembagian data pelatihan. Kombinasi ini juga dipakai untuk data yang diberi tambahan noise. Kombinasi proporsi tersebut dapat dilihat pada Tabel 2.
Tabel 2 Kombinasi proporsi data pelatihan dengan jumlah data pengujian yang sama untuk setiap suara model
Data pelatihan
Data
pengujian Jenis data
20 20
30 20
40 20
Data asli
20 20
30 20
40 20
Data dengan SNR 30 dB
20 20
30 20
40 20
Data dengan SNR 20 dB
Ekstraksi Ciri Sinyal Suara dengan MFCC
Ekstraksi ciri sinyal suara pada penelitian ini menggunakan MFCC. Pada implementasi MFCC ini, kecuali tahap frame blocking, digunakan fungsi dari Auditory Toolbox yang dikembangkan oleh Slanley pada tahun 1998. Fungsi ini menggunakan lima parameter, yaitu:
1. Input yaitu masukan suara yang berasal dari tiap pembicara.
2. Sampling rate yaitu banyaknya nilai yang diambil dalam satu detik. Dalam penelitian ini digunakan sampling rate
sebesar 16000 Hz.
3. Time frame yaitu waktu yang diinginkan untuk satu frame (dalam milidetik).Time frame yang digunakan adalah 30 ms. 4. Lap yaitu overlaping yang diinginkan
(harus kurang dari satu). Lap yang digunakan sebesar 0.5.
5. Cepstral coefficient yaitu jumlah
cepstrum yang diinginkan sebagai output.
Cepstral coefficient yang digunakan sebanyak 13.
Setiap data suara dari setiap pembicarakan dibagi menjadi 66 frame
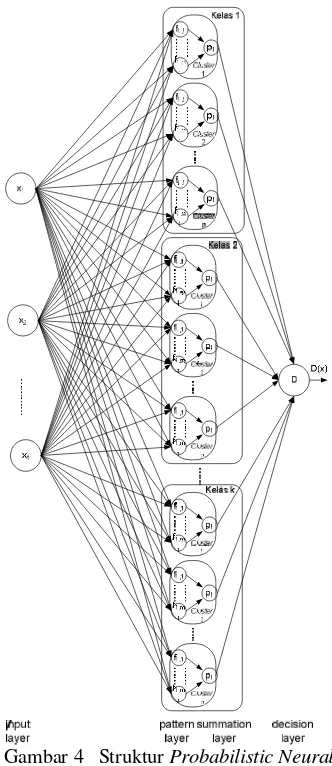
Probabilistic Neural Network Bertingkat Menggunakan Fuzzy C-Means (FCM)
Pada model yang akan dikembangkan ini, data untuk pelatihan dari masing-masing pembicara (data suara model) di-cluster-kan menggunakan Fuzzy C-Means (FCM), dengan parameter FCM yang akan dicobakan adalah:
- Banyaknya cluster = 3,
- Error terkecil yang diharapkan = 1×10-5, - Pangkat pembobot = 2,
- Maksimum iterasi = 100.
Kemudian, data setiap cluster yang terbentuk akan digunakan oleh PNN sebagai data setiap kelas.
Pada bagian lain, input layer pada PNN merupakan matriks berukuran 13 x 66 yang berasal dari suara pembicara yang akan diidentifikasi yang telah mengalami proses analisis fitur suara. Pada pattern layer,
dilakukan perhitungan dengan persamaan sebagai berikut :
( )
− Π = = j ij j d j h x x k x f 1 , dengan :d = dimensi vektor,
k(z) = 0.5z2
e− × ,
xj = vektor input kolom ke-j,
xij = vektor bobot baris ke-i kolom ke-j, hij = smoothing parameter
(a×simpangan baku ke-j×n1/5 ). Setiap keluaran dari pattern layer akan dijumlahkan dengan keluaran dari pattern layer lainnya yang satu kelas, di mana banyaknya kelas dalam penelitian ini adalah banyaknya cluster yang terbentuk dari 10 orang pembicara (data suara model). Proses ini termasuk dalam summation layer yang dihitung melalui persamaan sebagai berikut :
( )
( )
∑
= =
−
Π
=
n i j ij nj d j d dh
x
x
k
n
h
h
h
x
p
1 1 2 1 2 /...
2
1
π
.Dari summation layer inilah akan diperoleh nilai terbesar untuk suatu kelas. Nilai terbesar ini mencerminkan bahwa suara yang diujikan diidentifikasi sebagai pembicara kelas tersebut. Untuk lebih jelasnya, struktur Probabilistic Neural Network bertingkat menggunakan
Fuzzy C-Means (FCM) dapat dilihat pada Gambar 4.
Gambar 4 Struktur Probabilistic Neural Network Bertingkat
Hasil Identifikasi
Hasil identifikasi merupakan bagian akhir dari identifikasi pembicara yang berupa identifikasi pemilik suara berdasarkan input suara yang diujikan. Identifikasi yang dimaksud adalah apakah suara yang diujikan diidentifikasi sebagai pembicara 1, 2, 3, 4, 5, 6, 7, 8, 9, atau 10.
Penggunaan Threshold
Nilai threshold ini digunakan untuk melakukan seleksi yang lebih akurat dari hasil identifikasi setiap suara. Nilai threshold dari tiap pembicara berfungsi sebagai ambang batas nilai keluaran yang diterima untuk dapat diidentifikasikan sebagai pembicara tersebut. Apabila suatu data uji memiliki nilai terbesar pada suatu kelas, maka data uji tersebut tidak langsung diidentifikasi sebagai pembicara yang memiliki kelas tersebut, tetapi akan dilakukan pembandingan, yaitu pembandingan antara nilai keluaran terbesar pada suatu kelas untuk suatu data uji dengan nilai threshold
suatu kelas di mana data uji tersebut memiliki nilai keluaran paling besar di kelas tersebut dibandingkan kelas lainnya. Jika nilainya lebih besar dari nilai threshold, maka suara yang diujikan diidentifikasi sebagai pembicara dari kelas tersebut. Sebaliknya jika lebih kecil, maka suara tersebut diidentifikasikan sebagai pembicara 0 (tidak terdaftar).
Lingkungan Pengembangan
Perangkat keras yang digunakan adalah
microphone jenis headset dan komputer personal dengan prosesor AMD Duron 800 MHz, RAM sebesar 256 MB, serta kapasitas
harddisk sebesar 40 GB.
Sistem operasi yang digunakan adalah Windows XP Profesional. Perangkat lunak yang digunakan adalah Matlab 7.0.1 dan untuk MFCC digunakan beberapa fungsi dari
Auditory Toolbox.
HASIL DAN PEMBAHASAN
Data Suara
Data suara yang digunakan berasal dari suara 10 orang pembicara (data suara model) yang direkam menggunakan fungsi wavrecord pada Matlab, dan disimpan menjadi file berekstensi WAV. Karena jenis pengenalan pembicara pada penelitian ini bersifat bergantung pada teks, maka setiap pembicara mengucapkan kata yang sama, yaitu “komputer” sebanyak 60 kali sehingga didapat 600 data suara. Setiap suara diambil tanpa pengarahan (unguided) dengan sampling rate
16000 Hz dan direkam selama 1 detik, yang kemudian masing-masing akan menghasilkan ukuran file 31,2 KB.
Untuk mendapatkan data yang diberi noise
secara manual, data hasil perekaman (sebanyak 600 file) disalin sebanyak dua kali, sehingga akan didapat 1200 file data hasil salinan. Kemudian, data suara hasil salinan tersebut,
yaitu salinan pertama dan salinan kedua, masing-masing akan ditambahkan noise
sesuai dengan besarnya SNR menggunakan fungsi awgn pada Matlab. Pada penelitian ini, besarnya SNR yang akan ditambahkan sebesar 20 dB dan 30 dB. Dengan demikian, total seluruh data suara yang didapat sebanyak 1800 file, yaitu 600 file data suara asli dan 600 file data suara yang dengan SNR sebesar 20 dB dan 600 file data suara yang dengan SNR sebesar 30 dB.
Selain itu, untuk menguji model yang dikembangkan terhadap identifikasi tertutup, maka dibutuhkan data tambahan yang berasal dari pembicara lainnya (data suara non-model) yang diperoleh dengan cara yang sama sebagaimana yang telah dijelaskan sebelumnya. Pada penelitian ini, data suara non-model diambil dari 6 pembicara, di mana suara masing-masing pembicara direkam sebanyak lima kali.
Praproses dengan MFCC
Implementasi MFCC ini, kecuali tahap
frame blocking, digunakan fungsi dari
Auditory Toolbox yang dikembangkan oleh Slanley pada tahun 1998. Setiap data suara akan dibagi menjadi frame berukuran masing-masing 30 ms dengan overlap 50%, dengan demikian akan dihasilkan 66 frame. Hasil dari analisis fitur suara MFCC ini adalah 13 koefisien mel cepstrum untuk masing-masing frame. Pemilihan nilai time frame, lap, dan cepstral coefficient berturut-turut sebesar 30 ms, 0.5, dan 13 didasarkan pada penelitian sebelumnya yang dilakukan Mandasari (2005) dan Purnamasari (2006).
Dari hasil praproses ini, maka setiap data berubah dari matriks yang berukuran 16000 x 1 menjadi matriks 13 x 66. Hasil ini merupakan masukan untuk PNN.
Probabilistic Neural Network Bertingkat Menggunakan Fuzzy C-Means (FCM)
Untuk meng-cluster-kan data yang telah diekstraksi dengan MFCC digunakan Fuzzy C-Means (FCM). Pada awalnya banyaknya
SNR 20 dB untuk 20 data pelatihan, 30 data pelatihan, dan 40 data pelatihan dapat dilihat pada Lampiran 1 s.d Lampiran 6.
Pada bagian lain, input bagi Probabilistic Neural Network merupakan data suara pelatihan dan data suara pengujian yang telah mengalami proses ekstraksi ciri sinyal suara dengan MFCC. Pada bagian pelatihan, data suara yang digunakan merupakan data dari setiap pembicara yang telah di-cluster-kan sebelumnya menggunakan Fuzzy C-Means.
Cluster- cluster yang terbentuk ini lah yang akan menjadi kelas pada PNN.
Pada penelitian ini, untuk menghitung nilai
smoothing parameter (h = a×simpangan baku ke-j×n1/5), akan dicobakan beberapa nilai a
untuk mendapatkan model yang paling optimal untuk setiap proporsi data pelatihan yang berbeda.
Pada bagian pattern layer akan dilakukan perhitungan antara data pelatihan dan data pengujian. Kemudian hasil dari pattern layer
ini akan dijumlahkan dengan hasil pattern layer lainnya yang satu kelas. Proses penjumlahan ini terjadi pada bagian
summation layer. Selanjutnya, dari summation layer ini lah diperoleh nilai terbesar untuk suatu kelas.
Pemilihan Nilai Smoothing Parameter Tingkat akurasi model yang dikembangkan dengan nilai smoothing parameter yang berbeda dapat dilihat pada Lampiran 7 s.d Lampiran 9.
Dari Lampiran 7 dapat dilihat untuk model yang menggunakan data asli dengan banyaknya data pelatihan sebesar 20 memiliki tingkat akurasi maksimum dengan memilih nilai a sebesar 8.3. Di sisi lain, model dengan banyaknya data pelatihan sebesar 30 memiliki tingkat akurasi maksimum dengan memilih nilai a yang berada pada selang [7.8,8.1] atau pada selang [10.5,11]. Model dengan banyaknya data pelatihan sebesar 40 memiliki tingkat akurasi maksimum dengan memilih nilai a yang berada pada selang [7.6,13.4].
Di sisi lain, untuk model yang menggunakan data dengan SNR sebesar 30 dB, tingkat akurasi maksimum untuk data pelatihan sebanyak 20 didapat dengan memilih nilai a yang berada pada selang [11.4,11.6]. Model dengan banyaknya data pelatihan sebesar 30 memiliki tingkat akurasi maksimum dengan memilih nilai a yang berada pada selang [2.1,4.5], dan model dengan banyaknya data pelatihan sebesar 40 memiliki tingkat akurasi maksimum dengan memilih nilai a
yang berada pada selang [2.1,5.2], sebagaimana yang terlihat pada Lampiran 8. Untuk model yang menggunakan data dengan SNR sebesar 20 dB, tingkat akurasi yang dihasilkan dengan nilai smoothing parameter yang berbeda dapat dilihat pada Lampiran 9. Dari lampiran tersebut dapat dilihat bahwa model dengan banyaknya data pelatihan sebesar 20 memiliki tingkat akurasi maksimum dengan memilih nilai a yang berada pada selang [12.7,12.9] atau pada selang [13.5,14.3]. Di sisi lain, model dengan banyaknya data pelatihan sebesar 30 memiliki tingkat akurasi maksimum dengan memilih nilai a sebesar 8.4, sedangkan banyaknya data pelatihan sebesar 40 memiliki tingkat akurasi maksimum dengan nilai a yang berada pada selang [6.1,6.9] atau pada selang [9.9,10.5].
Hasil Identifikasi Menggunakan Nilai
Smootihng Parameter yang Telah Dipilih
Hasil identifikasi terkait erat dengan
decision layer pada Probabilistic Neural Network. Dari decision layer akan diperoleh nilai maksimum untuk suatu kelas. Nilai terbesar ini mencerminkan bahwa suara yang diujikan diidentifikasi sebagai pembicara kelas tersebut.
Setelah melalui Probabilistic Neural Network dapat diketahui identitas pemilik suara yang diujikan. Identitas yang dimaksud adalah apakah sebagai pembicara 1, 2, 3, 4, 5, 6, 7, 8, 9, atau pembicara 10.
Hasil Identifikasi dengan nilai smoothing parameter yang telah dipilih untuk semua model dapat dilihat pada Lampiran 10 s.d Lampiran 18. Dari lampiran tersebut, dapat dihitung tingkat akurasi masing-masing model dengan cara yang telah dipaparkan sebelumnya. Pada Tabel 3 diberikan tingkat akurasi untuk setiap model dengan jumlah data yang sama, dan pada Tabel 4 diberikan tingkat akurasi untuk setiap model dengan data pengujian yang sama.
Tabel 3 Tingkat akurasi setiap model dengan jumlah data yang sama
Banyak Data Pelatihan Banyak Data Pengujian Tingkat Akurasi (%) Jenis Data
20 30 70
30 20 82
40 10 96
0 10 20 30 40 50 60 70 80 90 100 T in g kat a ku rasi (%)
1 2 3 4 5 6 7 8 9 10
Pe m bicar a
20 Pelatihan
30 Pelatihan 40 Pelatihan
Gambar 5 Perbandingan tingkat akurasi setiap pembicara pada model yang menggunakan data asli Tabel 3 Lanjutan
Banyak Data Pelatihan Banyak Data Pengujian Tingkat Akurasi (%) Jenis Data
20 30 76.67
30 20 80.5
40 10 89
Data dengan SNR 30
dB
20 30 58.33
30 20 60
40 10 59
Data dengan SNR 20
dB Tabel 4 Tingkat akurasi setiap model dengan data pengujian yang sama.
Banyak Data Pelatihan Banyak Data Pengujian Tingkat Akurasi (%) Jenis Data
20 20 67
30 20 82
40 20 96
Data asli
20 20 73
30 20 77
40 20 85.5
Data dengan SNR 30
dB
20 20 48.5
30 20 49.5
40 20 60
Data dengan SNR 20
dB Berdasarkan hasil identifikasi yang dapat dilihat pada Lampiran 10 s.d Lampiran 12, tingkat akurasi setiap pembicara untuk proporsi yang berbeda dengan menggunakan data asli dapat dilihat Gambar 5. Dari gambar tersebut dapat dilihat bahwa tingkat akurasi tiap pembicara mengalami perubahan pada jumlah pelatihan yang berbeda. Perubahan ini
disebabkan gaya berbicara yang tidak sama setiap pengambilan data.
Dilihat dari tingkat akurasi yang dihasilkan untuk jumlah data yang sama dengan menggunakan jenis data asli, model dengan banyaknya pelatihan sebesar 40 dan banyaknya pengujian sebesar 10 memiliki tingkat akurasi tertinggi apabila dibandingkan dengan proporsi lainnya pada jenis data asli. Untuk jenis data lainnya pun dapat dilihat proporsi terbaik berdasarkan tingkat akurasi yang dihasilkan, sebagaimana yang terlihat pada Gambar 6.
Selain itu untuk melihat pengaruh banyaknya data pelatihan, pada Gambar 7 diberikan hasil tingkat akurasi untuk masing-masing proporsi data pelatihan yang berbeda. Dari Gambar 7 terlihat bahwa semakin banyak data pelatihan maka tingkat akurasi juga akan semakin tinggi.
0 20 40 60 80 100 120
20 30 40
Banyak data pelatihan
Ti ngka t akura si (%) Data asli Dengan SNR 30 Dengan SNR 20
0 20 40 60 80 100 120
20 30 40
Banyak data pelatihan
Ti
ng
ka
t
ak
u
ras
i (
%
)
Data asli
Dengan SNR 30
Dengan SNR 20
Gambar 7 Perbandingan tingkat akurasi antara data yang ditambahkan SNR dengan data asli.
Pengaruh penambahan SNR dapat dilihat pada Gambar 6 dan Gambar 7. Dari kedua gambar tersebut terlihat bahwa semakin kecil nilai SNR yang diberikan mengakibatkan tingkat akurasi semakin mengecil. Hal ini terjadi karena dengan semakin mengecilnya nilai SNR, maka kekuatan noise dalam merusak sinyal semakin besar.
Pengaruh Penggunaan Threshold
Untuk melihat pengaruh threshold pada model yang telah dikembangkan, penggunaan
threshold hanya akan dicobakan pada model PNN yang optimal atau memiliki tingkat akurasi tertinggi, yaitu model yang menggunakan data asli dengan data pelatihan sebanyak 40.
Nilai threshold untuk tiap pembicara akan diambil dari 40 data pelatihan (data ke-1 s.d data ke-40 dari 60 data untuk setiap pembicara). Data keluaran yang diidentifikasi dari setiap kelas dari masing-masing
pembicara dikumpulkan, lalu disimpan dalam suatu matriks. Dari matriks tersebut kemudian diambil nilai minimum untuk setiap pembicara yang diwakili oleh beberapa kelas. Nilai keluaran minimum tersebut adalah nilai yang digunakan sebagai
threshold untuk setiap pembicara.
Pada Lampiran 19 diberikan nilai
threshold untuk masing-masing pembicara. Pada Tabel 5 dapat dilihat pengaruh
threshold pada hasil identifikasi 40 data pelatihan untuk 10 data pengujian pada data asli. Di sisi lain, dari Tabel 6 dapat dilihat pengaruh penggunaan threshold apabila data pengujian yang digunakan berasal dari pembicara non-model.
Perbandingan tingkat akurasi antara model yang menggunakan threshold dan dengan model yang tidak menggunakan
threshold untuk 40 data pelatihan pada data asli dapat dilihat pada Gambar 8.
88 89 90 91 92 93 94 95 96
40
Dengan threshold Tanpa threshold
Gambar 8 Perbandingan tingkat akurasi model dengan menggunakan threshold dan dengan model yang tidak menggunakan
threshold
Tabel 5 Hasil identifikasi 40 data pelatihan untuk 10 data pengujian pada data asli dengan menggunakan threshold
Diidentifikasi Sebagai Pembicara Pembicara
0 1 2 3 4 5 6 7 8 9 10
Tingkat akurasi (%)
1 1 9 0 0 0 0 0 0 0 0 0 90
2 1 0 9 0 0 0 0 0 0 0 0 90
3 0 0 0 8 1 0 1 0 0 0 0 80
4 0 2 0 0 8 0 0 0 0 0 0 80
5 0 0 0 0 0 10 0 0 0 0 0 100
6 1 0 0 0 0 0 9 0 0 0 0 90
7 1 1 0 0 0 0 0 8 0 0 0 80
8 0 0 0 0 0 0 0 0 10 0 0 100
9 0 0 0 0 0 0 0 0 0 10 0 100
Tabel 6 Hasil identifikasi 40 data pelatihan untuk 30 data pengujian non-model pada data asli dengan menggunakan threshold
Diidentifikasi Sebagai Pembicara Pembicara
NonModel
0 1 2 3 4 5 6 7 8 9 10
Tingkat akurasi (%)
1 4 0 0 0 0 1 0 0 0 0 0 80
2 4 0 0 0 0 1 0 0 0 0 0 80
3 4 0 0 0 0 1 0 0 0 0 0 80
4 4 0 0 0 1 0 0 0 0 0 0 80
5 5 0 0 0 0 0 0 0 0 0 0 100
6 3 0 0 0 0 0 0 2 0 0 0 60
KESIMPULAN DAN SARAN
Kesimpulan
Dari penelitian yang telah dilakukan, diperoleh suatu model Probabilistic Neural Network Bertingkat Menggunakan Fuzzy C-Means (FCM) untuk Identifikasi Pembicara.
Tingkat akurasi dengan jumlah data yang sama untuk model yang menggunakan data asli mencapai nilai tertinggi pada proporsi data dengan 40 data pelatihan dan 10 data pengujian, yaitu sebesar 96%. Di sisi lain, tingkat akurasi untuk model yang menggunakan data dengan tambahan SNR sebesar 30 dB mencapai nilai tertinggi pada proporsi data dengan 40 data pelatihan dan 10 data pengujian, yaitu sebesar 89%. Tingkat akurasi untuk model yang menggunakan data dengan tambahan SNR sebesar 20 dB mencapai nilai tertinggi pada proporsi data dengan 30 data pelatihan dan 20 data pengujian, yaitu sebesar 60%.
Di samping itu, tingkat akurasi antara model yang menggunakan threshold dan model yang tidak menggunakan threshold pun berbeda. Pada model yang menggunakan data asli dan tanpa threshold untuk 40 data pelatihan dan 20 data pengujian yang dikenal tingkat akurasi sebesar 96%, sedangkan untuk model yang menggunakan threshold tingkat akurasi sebesar 91%. Untuk pembicara yang tidak dikenal (30 data penngujian) tingkat akurasi tanpa threshold dengan 40 pelatihan sebesar 80%.
Saran
Pada penelitian ini, model yang dikembangkan belum cukup mampu menangani identifikasi pembicara dengan suara yang ber-noise cukup tinggi. Oleh karena itu, untuk penelitian selanjutnya disarankan untuk mencoba suatu metode ekstraksi ciri suara yang telah terbukti mampu
memisahkan antara suara asli dari seorang pembicara dan noise yang merusak suara tersebut.
DAFTAR PUSTAKA
Campbell, Jr JP. 1997. Speaker Recognition: A Tutorial. Proceeding IEEE, Vol 85 No.9, hal 1437-1461, September 1997. Cox, E. 2005. Fuzzy Modelling and Genetic
Algorithms for Data Mining and Exploration. USA: Academic Press. Do MN. 1994. Digital Signal Processing
Mini-Project: An Automatic Speaker Recognition System. Audio Visual Communications Laboratory, Swiss Federal Institute of Technology,
Laussanne, Switzerland.
http://lcavwww.epfl.ch/~minhdo/asr_pro ject.pdf [12 Juli 2006].
Fausett L. 1994. Fundamentals of Neural Networks Architectures, Algorithm, and Applications. New Jersey: Prentice Hall. Ganchev, TD. 2005. Speaker
Recognition[Tesis]. Greece: Wire Communication Laboratory, Department of Computer and Electrical Engineering,
University of Patras.
http://wcl.ee.upatras.gr/ai/papers/Ganche v_PhDThesis.pdf [16 November 2006]. Jang JSR, Sun CT, Mizutani Eiji. 1997.
Neuro-Fuzzy and Soft Computing. London: Prentice-Hall International, Inc.
Jurafsky D, Martin JH. 2000. Speech and Language Processing An Introduction to
Natural Language Processing,
Computational Linguistic, and Speech Recognition. New Jersey: Prentice Hall. Mandasari Y. 2005. Pengembangan Model
Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor.
Purnamasari W. 2006. Pengembangan Model Markov Tersembunyi Untuk Identifikasi Pembicara. [Skripsi]. Bogor: Departemen Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor.
Sarimollaoglu M, Serhan D, Kamran I, Coskun B. 2004. A Text-independent Speaker Identification System Using
Probabilistic Neural Network.
Pembicara Cluster ke-1
Cluster
ke-2
Cluster
ke-3
1 11 6 3
2 8 8 4
3 6 6 8
4 7 6 7
5 9 2 9
6 5 9 6
7 8 5 7
8 6 8 6
9 6 8 6
10 8 6 6
Lampiran 2 Hasil peng-cluster-an 30 data pelatihan
Pembicara Cluster ke-1
Cluster
ke-2
Cluster
ke-3
1 13 10 7
2 10 10 10
3 13 11 6
4 9 14 7
5 15 15 -
6 12 9 9
7 9 9 12
8 11 10 9
9 11 13 6
10 10 8 12
Lampiran 3 Hasil peng-cluster-an 20 data pelatihan dengan SNR 30dB
Pembicara Cluster ke-1
Cluster
ke-2
Cluster
ke-3
1 3 17 -
2 12 8 -
3 2 8 10
4 9 11 -
5 9 11 -
6 9 11 -
7 11 9 -
8 9 11 -
9 10 10 -
10 12 8 -
Lampiran 4 Hasil peng-cluster-an 30 data pelatihan SNR 30 dB
Pembicara Cluster
ke-1
Cluster
ke-2
Cluster
ke-3
1 4 11 15
2 14 16 -
3 14 16 -
4 16 14 -
5 16 14 -
6 19 11 -
7 14 16 -
8 16 14 -
9 14 16 -
10 14 16 -
Lampiran 5 Hasil peng-cluster-an 20 data pelatihan dengan 20 dB
Pembicara Cluster
ke-1
Cluster
ke-2
Cluster
ke-3
1 5 6 9
2 7 5 8
3 10 10 -
4 8 4 8
5 11 9 -
6 9 11 -
7 10 10 -
8 8 5 7
9 10 10 -
Pembicara Cluster ke-1
Cluster
ke-2
Cluster
ke-3
1 19 7 4
2 3 14 13
3 7 8 15
4 11 7 12
5 11 19 -
6 9 10 11
7 14 16 -
8 2 13 15
9 4 14 12
10 15 15 -
Lampiran 7 Tingkat akurasi model dengan nilai smoothingparameter yang berbeda pada data asli
Tingkat Akurasi (%)
a
20 data pelatihan 30 data pelatihan 40 data pelatihan
2 69.6667 79 94
2.1 69.6667 79 94
2.2 69.6667 79.5 94
2.3 69.6667 79.5 95
2.4 69.6667 79.5 95
2.5 69.6667 79.5 95
2.6 69.6667 79.5 95
2.7 69.6667 79.5 95
2.8 69.6667 79.5 95
2.9 69.6667 79.5 95
3 69.6667 79.5 95
3.1 69.6667 79.5 95
3.2 69.6667 79.5 95
3.3 69.6667 79.5 95
3.4 69.6667 79.5 95
3.5 69.6667 79.5 95
3.6 69.6667 79.5 95
3.7 69.6667 79.5 95
3.8 69.6667 79.5 95
3.9 69.6667 79.5 95
4 69.6667 79.5 95
4.1 69.6667 79.5 95
4.2 69.6667 79.5 95
4.3 69.6667 79.5 95
4.4 69.6667 79.5 95
4.5 69.6667 79.5 95
4.6 69.6667 79.5 95
4.7 69.6667 79.5 95
4.8 69.6667 79.5 95
4.9 69.6667 80 95
5 69.6667 80 95
5.1 69.6667 80 95
5.2 69.6667 80 95
5.3 69.6667 80.5 95
5.4 69.6667 80.5 95
5.5 69.6667 80.5 95
5.6 69.6667 80.5 95
Tingkat Akurasi (%)
a
20 data pelatihan 30 data pelatihan 40 data pelatihan
5.8 69.6667 80.5 95
5.9 69.6667 80.5 95
6 69.6667 80.5 95
6.1 69.6667 80.5 95
6.2 69.6667 80.5 95
6.3 69.6667 81 95
6.4 69.6667 81 95
6.5 69.6667 81 95
6.6 69.6667 81 95
6.7 69.6667 81 95
6.8 69.6667 81 95
6.9 69.6667 81 95
7 69.6667 81 95
7.1 69.6667 81 95
7.2 69.6667 81 95
7.3 69.6667 81.5 95
7.4 69.6667 81.5 95
7.5 69.6667 81.5 96
7.6 69.6667 81.5 96
7.7 69.6667 81.5 96
7.8 69.6667 82 96
7.9 69.6667 82 96
8 69.6667 82 96
8.1 69.6667 82 96
8.2 69.6667 81.5 96
8.3 70 81.5 96
8.4 69.6667 81.5 96
8.5 69.6667 81.5 96
8.6 69.6667 81.5 96
8.7 69.6667 81.5 96
8.8 69.6667 81.5 96
8.9 69.6667 81.5 96
9 69.6667 81.5 96
9.1 69.6667 81.5 96
9.2 69.6667 81.5 96
9.3 69.6667 81.5 96
9.4 69.6667 81.5 96
9.5 69.6667 81.5 96
9.6 69.6667 81.5 96
9.7 69.3333 81.5 96
9.8 69.3333 81.5 96
9.9 69.6667 81.5 96
10 69.6667 81 96
10.1 69.6667 81 96
10.2 69.6667 81.5 96
10.3 69.6667 81.5 96
10.4 69.6667 81.5 96
Tingkat Akurasi (%)
a
20 data pelatihan 30 data pelatihan 40 data pelatihan
10.6 69.3333 82 96
10.7 69.3333 82 96
10.8 69.3333 82 96
10.9 69.3333 82 96
11 69 82 96
11.1 69 81.5 96
11.2 68.6667 81.5 96
11.3 68.6667 81.5 96
11.4 68.6667 81.5 96
11.5 68.6667 81.5 96
11.6 68.6667 81.5 96
11.7 68.6667 81.5 96
11.8 68.6667 81.5 96
11.9 68.6667 81.5 96
12 68.6667 81.5 96
12.1 68.6667 81.5 96
12.2 68.6667 81 96
12.3 68.6667 81 96
12.4 68.3333 80 96
12.5 68.3333 80 96
12.6 68.3333 80 96
12.7 68.3333 80 96
12.8 68.3333 80 96
12.9 68.3333 80 96
13 68 80 96
13.1 68 80 96
13.2 68 80 96
13.3 68 80 96
13.4 68 80 96
13.5 68 80 95
13.6 68 80 95
13.7 68 80 95
13.8 68 80 95
13.9 68 80 95
14 68 80 95
14.1 68.3333 80 95
14.2 68 80 95
14.3 68 80 95
14.4 68 80 95
14.5 68 80 95
14.6 68 79 95
14.7 68 79 95
14.8 68 79 95
14.9 67.6667 79 95
dengan SNR 30 dB
Tingkat Akurasi (%)
a
20 data pelatihan 30 data pelatihan 40 data pelatihan
2 75.6667 80 87
2.1 75.6667 80.5 89
2.2 75.6667 80.5 89
2.3 75.6667 80.5 89
2.4 75.6667 80.5 89
2.5 75.6667 80.5 89
2.6 75.6667 80.5 89
2.7 75.6667 80.5 89
2.8 75.6667 80.5 89
2.9 75.6667 80.5 89
3 75.6667 80.5 89
3.1 76 80.5 89
3.2 76 80.5 89
3.3 76 80.5 89
3.4 76 80.5 89
3.5 76 80.5 89
3.6 76 80.5 89
3.7 76 80.5 89
3.8 76 80.5 89
3.9 76 80.5 89
4 76 80.5 89
4.1 76 80.5 89
4.2 76 80.5 89
4.3 76 80.5 89
4.4 76 80.5 89
4.5 76 80.5 89
4.6 76 80 89
4.7 76 80 89
4.8 76 80 89
4.9 76 80 89
5 76 80 89
5.1 76 80 89
5.2 76 80 89
5.3 76 80 88
5.4 76 80 88
5.5 76 80 88
5.6 76 80 88
5.7 76 80 88
5.8 76 80 88
5.9 76 80 88
6 76 80 88
6.1 76 80 88
6.2 76.3333 80 88
6.3 76.3333 80 88
6.4 76.3333 80 88
6.5 76.3333 80 88
Tingkat Akurasi (%)
a
20 data pelatihan 30 data pelatihan 40 data pelatihan
6.7 76.3333 80 88
6.8 76.3333 80 88
6.9 76.3333 80 88
7 76.3333 80 88
7.1 76.3333 80 88
7.2 76.3333 80 88
7.3 76.3333 80 88
7.4 76.3333 80 88
7.5 76.3333 80 88
7.6 76.3333 80 88
7.7 76.3333 80 88
7.8 76.3333 80 88
7.9 76.3333 80 88
8 76.3333 80 88
8.1 76.3333 80 88
8.2 76.3333 79.5 88
8.3 76.3333 79.5 88
8.4 76.3333 79.5 88
8.5 76.3333 79.5 88
8.6 76.3333 79.5 88
8.7 76.3333 79.5 88
8.8 76 79.5 88
8.9 76 79.5 88
9 76 79.5 88
9.1 76 79.5 88
9.2 75.6667 79.5 88
9.3 75.6667 79.5 88
9.4 75.6667 79.5 88
9.5 75.6667 79.5 88
9.6 75.6667 79.5 88
9.7 76 79.5 88
9.8 76.3333 79.5 88
9.9 76.3333 79.5 88
10 76.3333 79.5 88
10.1 76.3333 79.5 88
10.2 76.3333 79.5 88
10.3 76.3333 79.5 87
10.4 76.3333 79.5 87
10.5 76.3333 79.5 86
10.6 76.3333 79 86
10.7 76.3333 79 86
10.8 76.3333 79 86
10.9 76.3333 79 86
11 76.3333 79 86
11.1 76.3333 79 86
11.2 76.3333 79 86
11.3 76.3333 79 86
Tingkat Akurasi (%)
a
20 data pelatihan 30 data pelatihan 40 data pelatihan
11.5 76.6667 79 86
11.6 76.6667 78.5 86
11.7 76.3333 78.5 86
11.8 76 78.5 86
11.9 76 78.5 86
12 76 78 86
12.1 76 78 86
12.2 76 78 86
12.3 76 78 86
12.4 76 78 86
12.5 75.3333 78 85
12.6 75.3333 78 85
12.7 75.3333 78 85
12.8 75.3333 78 85
12.9 75.3333 78 85
13 75 78 84
13.1 74.6667 77.5 84
13.2 74.6667 77.5 84
13.3 74.6667 77.5 84
13.4 74.3333 77.5 84
13.5 74.3333 77.5 84
13.6 74.3333 77.5 84
13.7 74.3333 77.5 84
13.8 74.3333 77.5 84
13.9 74.6667 77.5 84
14 74.6667 77.5 83
14.1 74.6667 77.5 83
14.2 74.6667 77.5 83
14.3 74.6667 77.5 82
14.4 74.6667 77.5 82
14.5 74.6667 77.5 82
14.6 74.3333 77.5 82
14.7 74.3333 77.5 82
14.8 74.3333 77 82
14.9 74 77 82
15 74 77 82
Lampiran 9 Tingkat akurasi model dengan nilai smoothing parameter yang berbeda pada data dengan SNR 20 dB
Tingkat Akurasi (%)
a
20 data pelatihan 30 data pelatihan 40 data pelatihan
2 50 57.5 52
2.1 50 57.5 57
2.2 50 57.5 57
2.3 49.6667 57.5 57
2.4 49.6667 57.5 57
2.5 49.6667 57.5 57
Tingkat Akurasi (%)
a
20 data pelatihan 30 data pelatihan 40 data pelatihan
2.7 49.6667 58 57
2.8 49.6667 58 57
2.9 49.6667 58 57
3 49.6667 58 57
3.1 49.6667 57.5 57
3.2 49.6667 57 57
3.3 49.6667 57 57
3.4 49.6667 57 57
3.5 49.6667 57 57
3.6 49.6667 57 57
3.7 49.6667 57 57
3.8 49.6667 57 57
3.9 49.6667 57 57
4 49.6667 57 57
4.1 49.6667 57.5 57
4.2 49.3333 57.5 57
4.3 49.3333 57.5 57
4.4 49.3333 57 57
4.5 49.3333 57 57
4.6 49.3333 56.5 57
4.7 49.3333 56.5 57
4.8 49 56.5 58
4.9 49 56.5 58
5 49 56.5 58
5.1 49 56.5 58
5.2 49.6667 56.5 58
5.3 49.6667 56.5 58
5.4 49.6667 57 58
5.5 50 57 58
5.6 50.6667 57 58
5.7 50.6667 57 58
5.8 51 57 58
5.9 51 57 58
6 51 57 58
6.1 50.6667 57.5 59
6.2 50.6667 57.5 59
6.3 50.6667 57.5 59
6.4 50.6667 57.5 59
6.5 51 57.5 59
6.6 51 57.5 59
6.7 51 57 59
6.8 51 57.5 59
6.9 51 57.5 59
7 51.3333 57.5 58
7.1 51.3333 57.5 58
7.2 51.3333 57.5 58
7.3 51.3333 57.5 58
Tingkat Akurasi (%)
a
20 data pelatihan 30 data pelatihan 40 data pelatihan
7.5 51.3333 58 58
7.6 51 58 58
7.7 51.6667 58 58
7.8 51.6667 58.5 58
7.9 51.6667 58.5 58
8 52.3333 59 58
8.1 53 59 58
8.2 53.6667 59.5 58
8.3 54 59.5 58
8.4 54.3333 60 58
8.5 54.6667 59.5 58
8.6 55 59 58
8.7 55 59 58
8.8 55.6667 59 58
8.9 56 59 58
9 56.3333 59 58
9.1 56.3333 59 58
9.2 56.3333 59 58
9.3 56.6667 59 58
9.4 57 59 58
9.5 57.3333 59 58
9.6 57.3333 59 58
9.7 58 59 58
9.8 58 59 58
9.9 57.6667 59 59
10 57 59 59
10.1 57 59 59
10.2 56.6667 59 59
10.3 56.6667 58.5 59
10.4 56.6667 59 59
10.5 56.3333 59 59
10.6 56.3333 59 58
10.7 56.3333 58.5 58
10.8 56.6667 59 58
10.9 56.6667 58.5 58
11 56.6667 58.5 58
11.1 56.6667 58.5 58
11.2 56.6667 58 58
11.3 56.6667 58 57
11.4 56.3333 58 57
11.6 57 58 57
11.7 57 58 56
11.8 57.3333 58 56
11.9 57 58.5 56
12 57.3333 58 56
12.1 57.3333 58.5 56
12.2 57.3333 58.5 56
Tingkat Akurasi (%)
a
20 data pelatihan 30 data pelatihan 40 data pelatihan
12.4 57.6667 58 56
12.5 58 58 56
12.6 58 58 56
12.7 58.3333 58 55
12.8 58.3333 58 55
12.9 58.3333 57 55
13 58 57 55
13.1 58 57.5 55
13.2 58 56.5 55
13.3 58 56 55
13.4 58 56 54
13.5 58.3333 56 54
13.6 58.3333 56 54
13.7 58.3333 56 54
13.8 58.3333 56 54
13.9 58.3333 56 54
14 58.3333 56 54
14.1 58.3333 56 54
14.2 58.3333 55.5 54
14.3 58.3333 56 54
14.4 58 56.5 54
14.5 57.3333 56.5 54
14.6 57.3333 56 54
14.7 56.6667 56 55
14.8 56.6667 56 55
14.9 56.6667 56 55
15 57 56 55
Lampiran 10 Hasil identifikasi 20 data pelatihan dengan 30 data pengujian untuk data asli
Diidentifikasi Sebagai Pembicara Pembicara
1 2 3 4 5 6 7 8 9 10
1 28 0 0 2 0 0 0 0 0 0
2 0 27 0 0 0 0 0 0 3 0
3 0 0 22 0 0 7 0 0 0 0
4 1 0 0 29 0 0 0 0 0 0
5 0 0 0 0 26 0 0 4 0 0
6 1 0 0 5 0 24 0 0 0 0
7 4 0 0 2 0 0 24 0 0 0
8 0 0 0 0 0 0 0 30 0 0
9 0 0 0 0 30 0 0 0 0 0
Diidentifikasi Sebagai Pembicara
Pembicara
1 2 3 4 5 6 7 8 9 10
1 20 0 0 0 0 0 0 0 0 0
2 0 14 0 0 1 0 0 0 1 4
3 1 0 16 0 0 3 0 0 0 0
4 4 0 0 16 0 0 0 0 0 0
5 0 0 0 0 20 0 0 0 0 0
6 0 0 0 0 0 20 0 0 0 0
7 1 0 0 2 0 0 17 0 0 0
8 0 0 0 0 0 0 0 19 0 1
9 0 0 0 0 1 0 0 0 5 14
10 0 0 0 1 1 0 0 0 1 17
Lampiran 12 Hasil identifikasi 40 data pelatihan untuk 10 data pengujian untuk data asli
Diidentifikasi Sebagai Pembicara
Pembicara
1 2 3 4 5 6 7 8 9 10
1 10 0 0 0 0 0 0 0 0 0
2 0 10 0 0 0 0 0 0 1 0
3 0 0 9 1 0 0 0 0 0 0
4 2 0 0 8 0 0 0 0 0 0
5 0 0 0 0 10 0 0 0 0 0
6 0 0 0 0 0 10 0 0 0 0
7 1 0 0 0 0 0 9 0 0 0
8 0 0 0 0 0 0 0 10 0 0
9 0 0 0 0 0 0 0 0 10 0
10 0 0 0 0 0 0 0 0 0 10
Lampiran 13 Hasil identifikasi 20 data pelatihan untuk 30 data pengujian pada data dengan SNR 30