PADA IDENTIFIKASI PEMBICARA
JAYANTA
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
Dengan ini saya menyatakan bahwa Tesis Pengembangan Model Jaringan Syaraf Tiruan Probabilistik (PNN) pada Identifikasi Pembicara, adalah karya sendiri dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal dari atau dikutip dari karya yang diterbitkan
maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Bogor, Mei 2007
Jayanta
JAYANTA. Pengembangan Model Jaringan Syaraf Tiruan Probabilistik (PNN) pada Identifikasi Pembicara. Dibimbing oleh AGUS BUONO dan AZIZ KUSTIYO.
Sistem komputer dapat dimanfaatkan untuk mengidentifikasi pembicara dari suara yang diucapkan. Penelitian ini memperkenalkan pengembangan model jaringan syaraf tiruan probabilistik pada identifikasi pembicara dengan pendekatan metoda text-dependent. Kami menggunakan kombinasi metoda analisis komponen utama (PCA) dengan metoda Mel-Frequency Cepstral Coefficient (MFCC) pada proses ekstraksi ciri dengan beberapa parameter yaitu koefisien Mel, lebar frame, lebar overlap dan rasio nilai eigen untuk meningkatkan kinerja PNN. Untuk mengukur rata-rata keluaran yang dihasilkan oleh PNN digunakan metoda Leave-one out. Hasil penelitian menunjukkan bahwa penggunaan koefisien mel 20, ukuran frame 40 ms, ukuran overlap 50% pada metoda MFCC menghasilkan data yang mampu memberi nilai ketelitian identifikasi pembicara sebesar 96%. Implementasi metoda PCA dengan rasio nilai eigen 95% ke data yang dihasilkan metoda MFCC juga memberikan nilai ketelitian hingga 96% dengan waktu komputasi 90% lebih baik.
JAYANTA. Development of Model of Probabilistic Neural Networks on Speaker Identification. Under the direction of AGUS BUONO and AZIZ KUSTIYO.
Computer system can be exploited to identify speaker from voices that was uttered. This research introduce development model PNN at speaker identification with approach of method text-dependent. We use combination of method of PCA with method of MFCC at process of feature extraction with a few the parameters, which is coefficient Mel, size of frame, size of overlap and ratio of eigen value, to increase performance of PNN. To measuring average of output yielded by PNN is used method of Leave one out. Result of the research show that use mel 20, size of frame 40 ms, size of overlap 50% at method of MFCC yield data capable to give value of accuration of speaker identification of equal to 96%. Implementation of method of PCA with ratio of eigen value equal to 95% to data that was yielded method of MFCC also assign value accuration of equal to 96% with time of computing 90% better.
©
Hak cipta milik Institut Pertanian Bogor, tahun 2007
Hak cipta dilindungi
PADA IDENTIFIKASI PEMBICARA
JAYANTA
Tesis
Sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada
Departemen Ilmu Komputer
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
Nama : JAYANTA NIM : G.651030064
Disetujui
Komisi Pembimbing
( Ir. Agus Buono, M.Si, M.Kom ) ( Aziz Kustiyo, S.Si, M.Kom )
Ketua Anggota
Diketahui,
Ketua Program Studi Ilmu Komputer Dekan Sekolah Pascasarjana IPB
( Dr. Sugi Guritman, MSc.) ( Prof. Dr. Ir. Khairil Anwar Notodiputro, MS )
Syukur Alhamdulillah, penulis panjatkan kepada illahi robbi Allah SWT, atas rahmat dan hidayahnya sehingga akhirnya karya ilmiah ini dapat diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak Desember 2005 ini adalah sistem identifikasi pembicara, dengan judul Pengembangan Model Jaringan Syaraf Tiruan Probabilistik (PNN) pada Identifikasi Pembicara.
Pada kesempatan ini, penulis menyampaikan ucapan terima kasih dan penghargaan yang setinggi – tingginya kepada bapak Ir. Agus Buono, M.Si, M.Kom, dan bapak Aziz Kustiyo, S.Si, M.Kom, atas kesediaanya meluangkan waktu untuk membimbing sejak awal pemilihan tema penelitian hingga selesainya karya ilmiah ini. Penghargaan yang tulus penulis sampaikan pula, kepada para dosen Program Studi Ilmu Komputer, Sekolah Pascasarjana, Institut Pertanian Bogor, yang telah memberi wawasan pengetahuan bagi penulis.
Atas do’a, pengorbanan, kesabaran serta dukungan moril, penulis ucapkan terima kasih dan rasa hormat yang tulus pada ibu dan istri tercinta, serta seluruh keluarga.
Semoga, hasil karya ilmiah yang jauh dari sempurna ini dapat bermanfaat.
Bogor, Mei 2007
Penulis dilahirkan di Jakarta pada tanggal 30 September 1961 dari ayah Sirtoe Astrodiwiryo dan ibu Fatimah Haryana Prawira. Penulis adalah putra kedua dari tiga bersaudara.
Pada tahun 1981 penulis lulus dari SMA Negeri 1 Jakarta. Pendidikan sarjana ditempuh pada tahun 1989 di Sekolah Tinggi Manajemen Informatika dan Komputer Gunadarma, jurusan Manajemen Informatika, lulus pada tahun 1993. Pada tahun 2003 penulis mendapat kesempatan untuk melanjut pendidikan ke program magister pada program Studi Ilmu Komputer, Sekolah Pascasarjana IPB.
Penulis bekerja di Universitas Pembangunan Nasional ”Veteran” Jakarta, pada Fakultas Ilmu Komputer sejak tahun 1987 hingga sekarang. Pada tahun 1996 hingga tahun 1999 penulis dipercaya sebagai kepala laboratorium komputer Fakultas Ilmu Kompter UPN ”Veteran” Jakarta. Pada tahun 1999 hingga tahun
2000 penulis mendapat kesempatan menjadi staff pengajar yunior, di jurusan Teknologi Informatika, Fakultas Teknik pada Hoogeschool van Arnhem en Nijmegen, Belanda. Sejak tahun 2005 penulis dipercaya sebagai Ketua Jurusan Teknologi Informatika pada Fakultas Ilmu Komputer UPN ”Veteran” Jakarta.
DAFTAR ISI
Halaman
DAFTAR TABEL ... iii
DAFTAR GAMBAR ... iv
DAFTAR LAMIRAN ... vi
PENDAHULUAN Latar Belakang ... 1
Tujuan Penelitian ... 2
Ruang Lingkup ... 2
Manfaat Penelitian ... 3
TINJAUAN PUSTAKA Sinyal Suara ... 4
Prinsip Identifikasi Pembicara ... 4
Preemphasis ... 5
Frame ... 5
Window ... 6
Transformasi Fourier Diskret (DFT) ... 7
Mel-Frequency Cepstral Coefficients (MFCC) ………. 8
Peubah Acak Kontinyu ……….. 10
Analisis Komponen Utama (PCA) .……… 12
Normalisasi Data ………….………... 14
Kaidah Bayes ………. 15
Jaringan Syaraf Tiruan Probabilistik (PNN) ... 16
Validasi Hasil Pengukuran ... 18
Penelitian Terkait ... 19
DATA DAN METODE Keragka Pikir Penelitian ... 21
Struktur Data Penelitian ... 33
Bahan dan Alat ... 34
Waktu Penelitian ... 35
PADA IDENTIFIKASI PEMBICARA
JAYANTA
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
Dengan ini saya menyatakan bahwa Tesis Pengembangan Model Jaringan Syaraf Tiruan Probabilistik (PNN) pada Identifikasi Pembicara, adalah karya sendiri dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal dari atau dikutip dari karya yang diterbitkan
maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Bogor, Mei 2007
Jayanta
JAYANTA. Pengembangan Model Jaringan Syaraf Tiruan Probabilistik (PNN) pada Identifikasi Pembicara. Dibimbing oleh AGUS BUONO dan AZIZ KUSTIYO.
Sistem komputer dapat dimanfaatkan untuk mengidentifikasi pembicara dari suara yang diucapkan. Penelitian ini memperkenalkan pengembangan model jaringan syaraf tiruan probabilistik pada identifikasi pembicara dengan pendekatan metoda text-dependent. Kami menggunakan kombinasi metoda analisis komponen utama (PCA) dengan metoda Mel-Frequency Cepstral Coefficient (MFCC) pada proses ekstraksi ciri dengan beberapa parameter yaitu koefisien Mel, lebar frame, lebar overlap dan rasio nilai eigen untuk meningkatkan kinerja PNN. Untuk mengukur rata-rata keluaran yang dihasilkan oleh PNN digunakan metoda Leave-one out. Hasil penelitian menunjukkan bahwa penggunaan koefisien mel 20, ukuran frame 40 ms, ukuran overlap 50% pada metoda MFCC menghasilkan data yang mampu memberi nilai ketelitian identifikasi pembicara sebesar 96%. Implementasi metoda PCA dengan rasio nilai eigen 95% ke data yang dihasilkan metoda MFCC juga memberikan nilai ketelitian hingga 96% dengan waktu komputasi 90% lebih baik.
JAYANTA. Development of Model of Probabilistic Neural Networks on Speaker Identification. Under the direction of AGUS BUONO and AZIZ KUSTIYO.
Computer system can be exploited to identify speaker from voices that was uttered. This research introduce development model PNN at speaker identification with approach of method text-dependent. We use combination of method of PCA with method of MFCC at process of feature extraction with a few the parameters, which is coefficient Mel, size of frame, size of overlap and ratio of eigen value, to increase performance of PNN. To measuring average of output yielded by PNN is used method of Leave one out. Result of the research show that use mel 20, size of frame 40 ms, size of overlap 50% at method of MFCC yield data capable to give value of accuration of speaker identification of equal to 96%. Implementation of method of PCA with ratio of eigen value equal to 95% to data that was yielded method of MFCC also assign value accuration of equal to 96% with time of computing 90% better.
©
Hak cipta milik Institut Pertanian Bogor, tahun 2007
Hak cipta dilindungi
PADA IDENTIFIKASI PEMBICARA
JAYANTA
Tesis
Sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada
Departemen Ilmu Komputer
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
Nama : JAYANTA NIM : G.651030064
Disetujui
Komisi Pembimbing
( Ir. Agus Buono, M.Si, M.Kom ) ( Aziz Kustiyo, S.Si, M.Kom )
Ketua Anggota
Diketahui,
Ketua Program Studi Ilmu Komputer Dekan Sekolah Pascasarjana IPB
( Dr. Sugi Guritman, MSc.) ( Prof. Dr. Ir. Khairil Anwar Notodiputro, MS )
Syukur Alhamdulillah, penulis panjatkan kepada illahi robbi Allah SWT, atas rahmat dan hidayahnya sehingga akhirnya karya ilmiah ini dapat diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak Desember 2005 ini adalah sistem identifikasi pembicara, dengan judul Pengembangan Model Jaringan Syaraf Tiruan Probabilistik (PNN) pada Identifikasi Pembicara.
Pada kesempatan ini, penulis menyampaikan ucapan terima kasih dan penghargaan yang setinggi – tingginya kepada bapak Ir. Agus Buono, M.Si, M.Kom, dan bapak Aziz Kustiyo, S.Si, M.Kom, atas kesediaanya meluangkan waktu untuk membimbing sejak awal pemilihan tema penelitian hingga selesainya karya ilmiah ini. Penghargaan yang tulus penulis sampaikan pula, kepada para dosen Program Studi Ilmu Komputer, Sekolah Pascasarjana, Institut Pertanian Bogor, yang telah memberi wawasan pengetahuan bagi penulis.
Atas do’a, pengorbanan, kesabaran serta dukungan moril, penulis ucapkan terima kasih dan rasa hormat yang tulus pada ibu dan istri tercinta, serta seluruh keluarga.
Semoga, hasil karya ilmiah yang jauh dari sempurna ini dapat bermanfaat.
Bogor, Mei 2007
Penulis dilahirkan di Jakarta pada tanggal 30 September 1961 dari ayah Sirtoe Astrodiwiryo dan ibu Fatimah Haryana Prawira. Penulis adalah putra kedua dari tiga bersaudara.
Pada tahun 1981 penulis lulus dari SMA Negeri 1 Jakarta. Pendidikan sarjana ditempuh pada tahun 1989 di Sekolah Tinggi Manajemen Informatika dan Komputer Gunadarma, jurusan Manajemen Informatika, lulus pada tahun 1993. Pada tahun 2003 penulis mendapat kesempatan untuk melanjut pendidikan ke program magister pada program Studi Ilmu Komputer, Sekolah Pascasarjana IPB.
Penulis bekerja di Universitas Pembangunan Nasional ”Veteran” Jakarta, pada Fakultas Ilmu Komputer sejak tahun 1987 hingga sekarang. Pada tahun 1996 hingga tahun 1999 penulis dipercaya sebagai kepala laboratorium komputer Fakultas Ilmu Kompter UPN ”Veteran” Jakarta. Pada tahun 1999 hingga tahun
2000 penulis mendapat kesempatan menjadi staff pengajar yunior, di jurusan Teknologi Informatika, Fakultas Teknik pada Hoogeschool van Arnhem en Nijmegen, Belanda. Sejak tahun 2005 penulis dipercaya sebagai Ketua Jurusan Teknologi Informatika pada Fakultas Ilmu Komputer UPN ”Veteran” Jakarta.
DAFTAR ISI
Halaman
DAFTAR TABEL ... iii
DAFTAR GAMBAR ... iv
DAFTAR LAMIRAN ... vi
PENDAHULUAN Latar Belakang ... 1
Tujuan Penelitian ... 2
Ruang Lingkup ... 2
Manfaat Penelitian ... 3
TINJAUAN PUSTAKA Sinyal Suara ... 4
Prinsip Identifikasi Pembicara ... 4
Preemphasis ... 5
Frame ... 5
Window ... 6
Transformasi Fourier Diskret (DFT) ... 7
Mel-Frequency Cepstral Coefficients (MFCC) ………. 8
Peubah Acak Kontinyu ……….. 10
Analisis Komponen Utama (PCA) .……… 12
Normalisasi Data ………….………... 14
Kaidah Bayes ………. 15
Jaringan Syaraf Tiruan Probabilistik (PNN) ... 16
Validasi Hasil Pengukuran ... 18
Penelitian Terkait ... 19
DATA DAN METODE Keragka Pikir Penelitian ... 21
Struktur Data Penelitian ... 33
Bahan dan Alat ... 34
Waktu Penelitian ... 35
Halaman
HASIL DAN PEMBAHASAN
Hasil Pra-proses ... 36
Hasil Ekstraksi Ciri ... 36
Hasil Pengujian PNN70 ... 38
Hasil Pengujian PNN90 ... 40
Waktu Komputasi ... 42
Hasil Pengujian dengan Data Noise ... 45
Pengaruh Parameter Pembentuk Data Ciri ... 47
SIMPULAN DAN SARAN Simpulan ... 51
Saran ... 51
DAFTAR PUSTAKA ... 52
DAFTAR TABEL
Halaman
1 Komposisi dan jumlah vektor ciri untuk metode validasi holdout... 27
2 Komposisi dan jumlah vektor ciri untuk metode validasi leave-one out ... 27 3 Nilai parameter pembentuk data ciri ... 33
4 Jumlah frame suara untuk frekuensi suara 16000 Hz ... 36
5 Jumlah sampel data per satu frame ... 36
6 Nama kelompok data ... 37
7 Dimensi data penelitian hasil ekstraksi ciri suara untuk data asli ... 38
8 Dimensi data penelitian hasil ekstraksi ciri suara untuk data noise.. 38
9 Hasil pengujian model PNN70 ... 39
10 Hasil Pengujian model PNN90 ... 41
11 Waktu komputasi model PNN70 ... 43
12 Waktu komputasi model PNN90 ... 44
13 Hasil pengujian model PNN90 untuk data noise 20 desibel ... 45
14 Hasil pengujian model PNN90 untuk data noise 30 desibel ... 46
15 Hasil pengujian model PNN90 untuk data noise 40 desibel ... 46
DAFTAR GAMBAR
Halaman
1 Visualisasi satu frame suara ... 6
2 Bentuk kurva Hamming window ... 7
3 Hasil penerapan hamming window terhadap frame suara ………. 8
4 Skema transformasi fourier ………... 8
5 Blok diagram metode MFCC ………. 9
6 Mel filter-bank dengan triangular badpass ... 10
7 Arsitektur PNN ……….. 18
8 Blok kerangka pikir penelitian pengembangan model JST
probabilistik (PPN) pada identifikasi pembicara ………... 21 9 Blok diagram sistem identifikasi pembicara ... 22
10 Antar muka modul rekam suara ... 23
11 Cuplikan program rekam suara ... 23
12 Blok diagram alir proses pengumpulan suara ... 24
13 Antar muka proses penambahan noise ... 24
14 Cuplikan program tambah noise ... 25
15 Diagram alir proses kegiatan pra-proses ... 25
16 Diagram alir proses ekstraksi ciri dengan metode MFCC ... 26
17 Diagram alir proses model identifikasi pertama ... 28
18 Diagram alir proses model identifikasi kedua ... 29
19 Diagram pembentukan data pelatihan ... 30
20 Diagram pembentukan data pengujian ... 30
21 Rancang bangun pengembangan model jaringan syaraf tiruan
probabilistik pada identifikasi pembicara ... 32 22 Antar muka modul menu ... 33
23 Struktur pohon data penelitian ... 34
Halaman
24 Visualisasi grafis hasil pengujian model PNN70 ... 40
25 Visualisasi grafis hasil pengujian model PNN90 ... 42
26 Visualisasi waktu komputasi model PNN70 ... 43
27 Visualisasi waktu komputasi model PNN90 ... 44
28 Visualisasi hasil pengujian PNN90 untuk data noise ... 47
29 Perbandingan nilai akurasi kelompok data 1, 2, dan 3 ... 48
30 Perbandingan nilai akurasi kelompok data 4, 5, dan 6 ... 49
31 Perbandingan nilai akurasi kelompok data 10, 11, dan 12 ... 50
DAFTAR LAMPIRAN
Halaman
1 Bentuk sinyal suara ... 54
2 Visualisasi grafis hasil pengujian data asli ... 64
3 Visualisasi grafis hasil pengujian data noise ... 68
4 Perbandingan hasil pengujian data asli dan data noise ... 74
1.1 Latar Belakang
Suara sebagai salah satu sumber data biometrik mempunyai keunggulan sifat tidak dapat dihilangkan, dilupakan, atau dipindahkan dari satu orang ke orang lain. Suara dapat dijadikan data masukkan untuk mengidentifikasikan
seseorang. Melalui dukungan teknologi informasi yang semakin baik dan murah, di masa depan teknologi berbasis data biometrik akan mirip fenomena komputer, yang kemudian menjadi bagian dari sebuah kebutuhan hidup sehari-hari.
Suara adalah suatu gelombang yang merambat diudara, dan merupakan salah satu sumber data alamiah yang membawa informasi bagi sipendengar, terutama mengenai berita yang akan disampaikan melalui kata-kata. Beberapa informasi lain yang dapat diperoleh dari gelombang suara, adalah: bahasa yang di gunakan untuk berbicara; emosi; jenis kelamin; usia dan identitas pemilik suara (Reynolds 2002).
Dengan menggunakan informasi spesifik yang terdapat dalam gelombang suara, sistem pengenalan pembicara secara otomatis akan mengenali identitas seseorang, teknik ini dapat diterapkan untuk mengidentifikasi dan memverifikasi identitas seseorang ketika mengakses suatu jasa layanan menggunakan suara melalui jaringan telepon (Furui 1997).
Secara ekonomi, aplikasi teknologi informasi berbasis pengenalan suara dapat memberikan nilai jual produk teknologi yang sangat besar. Penjualan produk teknologi berbasis sistem pengenalan suara pada tahun 1997, memberikan nilai sebesar 500 juta dolar Amerika, dan meningkat menjadi 38 milyar dolar Amerika pada tahun 2003 (Rabah 2004).
Penting untuk diperhatikan dalam mengembangkan sistem ceras berbasis suara, yaitu: sistem harus mampu mengurangi gangguan sinyal (noise), dan mampu mendapatkan informasi spesifik (feature) dari suara dalam berbagai
Selain suara harus minim noise, dimensi suara juga merupakan kendala tersendiri karena besarnya dimensi suara dapat mempengaruhi kinerja sistem. Salah satu cara mengatasi kendala dimensi suara adalah dengan menyederhanakan dimensi suara melalui proses ekstraksi ciri. Teknik yang dapat diterapkan pada proses ekstraksi ciri diantaranya adalah Mel-Frequency Cepstral Coefficients (MFCC), dan analisis komponen utama (PCA).
Klasifikasi pola suara merupakan dasar kerja sistem pengenalan pembicara, dengan demikian, untuk mengetahui apakah kinerja sistem dalam melakukan proses klasifikasi itu baik atau tidak, perlu ditetapkan alat yang dapat melakukan proses klasifikasi. Salah satu alat yang dapat digunakan untuk melakukan proses klasifikasi adalah jaringan syaraf tiruan (JST). Melalui proses pembelajaran, JST akan membentuk suatu model referensi berdasarkan data pelatihan (data acuan) yang ditetapkan, kemudian JST yang telah melakukan pembelajaran, dapat digunakan sebagai alat untuk melakukan pencocokan pola (Kusumadewi 2004). Keunggulan dari penggunaan jaringan syaraf tiruan (JST) adalah kemampuannya untuk melakukan klasifikasi data yang belum diberikan pada saat pembelajaran sebelumnya (Li Min Fu 1994).
Bolat dan Yildirim (Bolat et al. 2003) menerapkan kombinasi metode PCA untuk memperbaiki kinerja JST Probabilistik, sedangkan penelitian yang
memanfaatkan MFCC dan JST Probabilistik dilakukan oleh Low dan Togneri (1998) dan Ganchev et al. (2002b).
Berdasarkan hasil-hasil penelitian tersebut pada penelitian ini akan dikombinasikan MFCC dan PCA untuk mengatasi masalah dimensi data.
1.2 Tujuan Penelitian
Tujuan penelitian ini adalah mengamati pengaruh kombinasi metode PCA dengan MFCC pada pengembangan model jaringan syaraf tiruan probabilistik
(PNN) pada identifikasi pembicara.
1.3 Ruang Lingkup
Lingkup penelitian dibatasi, pada:
2 Penggunaan jaringan syaraf tiruan probabilistik (Probabilistic Neural
Networks) sebagai alat klasifikasi pola suara;
3 Penerapan kombinasi metode PCA dengan metode MFCC, sebagai alat
ekstraksi ciri;
4 Sampel data yang digunakan, berupa teks “Sembilan” yang diucapkan
dalam bahasa Indonesia, oleh 10 orang dewasa, terdiri atas: 5 pria dan 5 wanita.
5 Untuk mempermudah dan mempercepat proses ekstraksi ciri, data
penelitian dibentuk menggunakan:
a Lebar waktu frame (16 ms, 30 ms, dan 40 ms); b Lebar overlap (40% dan 50%);
c Koefisien mel atau filter bank (16 dan 20).
6 Penggunaan noise sebesar 20, 30 dan 40 desibel terhadap sinyal suara asli.
1.4 Manfaat Penelitian
2.1 Sinyal Suara
Sinyal adalah kumpulan tanda atau bunyi untuk menyampaikan pesan atau informasi. Suara adalah bentuk kompleks yang dapat disampaikan dengan cerdas melalui partikel udara dengan berbagai intensitas gelombang bunyi. Untuk setiap
gelombang bunyi yang dikirimkan mengandung karakteristik, ciri dan bentuk informasi tertentu yang akan disampaikan (Shiavi 1991).
Sinyal suara merupakan rangkaian bunyi yang merambat dan berubah secara lambat melalui partikel udara dalam kurun waktu tertentu. Analisis terhadap sinyal suara akan memberikan nilai karakteristik memadai dan stabil, apabila dilakukan pada inteval waktu cukup pendek (antara 5 ms hingga 100 ms). Bila interval waktu tersebut diperpanjang menjadi lebih dari, atau sama dengan 200 ms, akan memberikan perubahan nilai karakteristik (Rabiner et al. 1993).
Sinyal suara merupakan sumber data alamiah yang dapat memberikan bermacam informasi, antara lain: informasi mengenai rangkaian huruf pembentuk kata atau kalimat; bahasa yang di gunakan untuk berbicara; emosi; jenis kelamin; serta usia dan identitas pemilik suara (Reynolds 2002). Visualisasi sinyal suara dapat dilihat pada Lampiran 1.
2.2 Prinsip Identifikasi Pembicara
Identifikasi pembicara, merupakan proses mengklasifikasikan pembicara dari sejumlah alternatif pembicara yang diberikan, sebagai suatu keputusan terbaik. Jumlah alternatif pembicara adalah sama dengan jumlah populasi pembicara terregistrasi.
Meniru kemampuan manusia mengenal identitas seseorang melalui suara yang didengar, merupakan dasar kerja yang diadopsi oleh sistem identifikasi pembicara, sehingga sistem identifikasi pembicara dapat dimasukan kedalam kelompok sistem kecerdasan buatan (Kusumadewi 2003).
proses pencocokan nilai ciri suara yang diterima dengan nilai ciri suara acuan (basis data ciri suara) (Furui 1997).
Dari sudut pandang linguistik, terdapat dua metode yang dapat diterapkan untuk mengembangkan sistem identifikasi pembicara. Metode pertama disebut text-dependent, dan metode kedua disebut text-independent. Sistem identifikasi pembicara yang mengadopsi metode text-dependent, harus mengetahui dan menentukan terlebih dahulu teks yang akan diucapkan pembicara. Contoh penerapan metode text-dependent adalah pada pengucapan PIN (nomor identitas diri) yang digunakan sebagai kata kunci. Sistem identifikasi pembicara yang mengadopsi metode text-independent, tidak perlu menentukan teks apa yang harus diucapkan pembicara, sehingga pembicara bebas menentukan pilihan teks yang akan diucapkannya (Furui 1997).
2.3 Preemphasis
Preemphasis adalah teknik yang digunakan untuk menyaring sinyal suara, umumnya dilakukan menggunakan Finite Impulse Response (FIR). Persamaan yang digunakan pada proses preemphasis mempunyai bentuk sebagai berikut:
F(w) = 1 – a.Z -1 (0 < a <1) (1) dimana a adalah faktor preemphasis, nilai yang direkomendasikan untuk a adalah 0,95 (Rabiner et al. 1993). Jika Z adalah e jw, maka fungsi penyaringan preemphasis dapat dinyatakan dengan
F(w) = 1 – a.e -j.w (2)
Preemphasis diterapkan pada sinyal dijital untuk menstabilkan spektrum sinyal dan memperkecil dampak keterbatasan ketelitian perhitungan. Persamaan (2) diatas, dapat dituliskan kembali sebagai berikut (Rabiner et al. 1993).
F(w) = 1 – 0,95* e -j.w (3)
2.4 Frame
Untuk memudahkan dan mempercepat proses analisis suara, dilakukan pemecahan sinyal suara menjadi beberapa partisi, disebut juga frame. Pembentukan frame dilakukan menggunakan parameter lebar waktu tertentu (umumnya 10 ms hingga 50 ms) dan lebar overlap.
* , 1000 fs
fr
N = (4)
dimana fr adalah lebar waktu frame, fs adalah frekuensi suara, dan N adalah jumlah data per frame.
Metode Welch, adalah salah satu metode yang dapat digunakan untuk membentuk frame. Pembentukan frame, dilakukan dengan membagi sinyal suara dijital menjadi sejumlah K frame. Dengan N data per satu frame-nya, dan D titik awal terjadinya overlapping dalam frame, maka N dikurangi D atau (N - D), adalah jumlah data pada bagian overlap. Secara matematis persamaan untuk mendapatkan sejumlah frame dari satu sinyal suara, dapat dituliskan sebagai
berikut: K = ((L – N)/(N – D)) + 1, dimana L merupakan panjang sinyal suara (Shiavi 1991).
Overlap merupakan bagian dari frame, berfungsi menjaga keterkaitan antar frame yang berdampingan, dan memperkecil tingkat resiko kehilangan informasi dan nilai ciri yang terdapat pada setiap frame. Contoh visualisasi 1 frame disajikan pada Gambar 1.
Gambar 1 Visualisasi satu frame suara
2.5 Window
Window, adalah fungsi yang dapat digunakan untuk mengarahkan nilai data pada setiap frame sesuai dengan bentuk kurva window. Window yang umum digunakan pada proses analisis suara (ekstraksi ciri), adalah hamming window, dinyatakan dengan persamaan (Porat 1997),
, 1 2 cos 46 . 0 54 . 0 ) ( ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − = N n n
dimana N merupakan lebar window, umumnya memiliki nilai yang sama dengan lebar waktu frame. Visualisasi hamming window, disajikan pada Gambar 2. Jika window dinyatakan dengan simbol w(n), dan frame dinyatakan dengan xi(n), maka penerapan window terhadap setiap frame, akan menghasilkan sinyal baru
(lihat Gambar 3), dan dapat dinyatakan dengan persamaan berikut: (Rabiner
et al. 1993) )
( ~x n
~x(n)=xi(n).w(n), 0 ≤ n ≤ N – 1 (6)
[image:32.595.116.509.213.431.2]Gambar 2 Bentuk kurva hamming window
Gambar 3 Hasil penerapan hamming window terhadap frame suara
2.6 Transformasi Fourier Diskret (DFT)
Transformasi sinyal akan lebih stabil dan sinyal berbentuk periodik dengan periode N, bila dilakukan pada interval waktu yang cukup pendek atau dalam bentuk frame. Transformasi Fourier cepat (FFT), merupakan varian dari transformasi Fourier diskret (DFT), biasa digunakan pada proses analisis suara. FFT, merupakan metode transformasi hasil perbaikan dari DFT, dan memiliki pengulangan proses yang lebih sedikit dibanding DFT. Persamaan transformasi Fourier yang digunakan, adalah (Rabiner et al. 1993).
( )
nkN j N
n
k x n .e
X ⎟⎠
⎞ ⎜ ⎝ ⎛ − − =
∑
= π 2 1 0, dimana 0 ≤ k ≤ N – 1 (7)
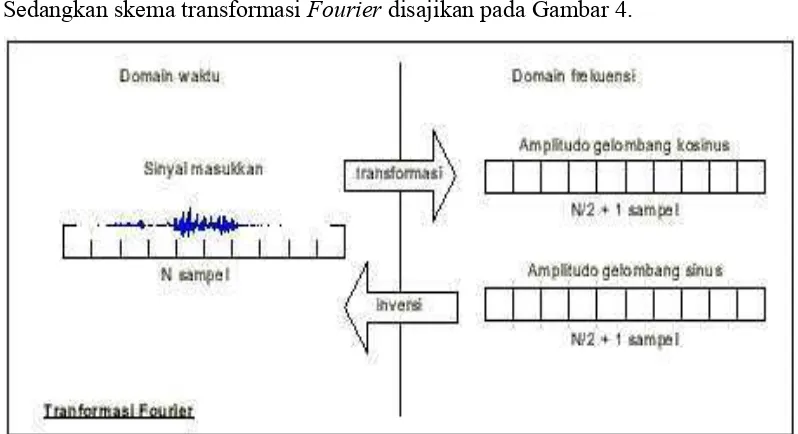
[image:33.595.112.511.279.496.2]Sedangkan skema transformasi Fourier disajikan pada Gambar 4.
Gambar 4 Skema transformasi Fourier (Karpov 2003)
2.7 Mel-Frequency Cepstral Coefficients
Untuk setiap nada frekuensi f, yang dinyatakan dalam Hertz (Hz), adalah suatu titi nada yang diukur menggunakan skala pengukuran, disebut skala “mel”. Sebagai titik acuan, suatu titi nada 1 kHz nada, 40 dB diatas batas kemampuan pendengaran manusia, dinyatakan sebagai 1000 mel. Hubungan lain dengan nilai titi nada, diperoleh dengan menyesuaikan frekuensi nada, menjadi setengah atau 2 kali frekuensi acuan, dan dinyatakan dengan 500 mel atau 2000 mel.
Skala Mel (Melodi) di bawah 1000 Hz, merupakan frekuensi linier, dan mel dengan skala di atas 1000 Hz, merupakan frekuensi logaritmik. Skala mel ekivalen dengan nilai frekuensi f , dapat dinyatakan dengan persamaan
dimana f menunjukan frekuensi sebenarnya, dan mel(f) adalah frekuensi yang dihasilkan dalam skala mel.
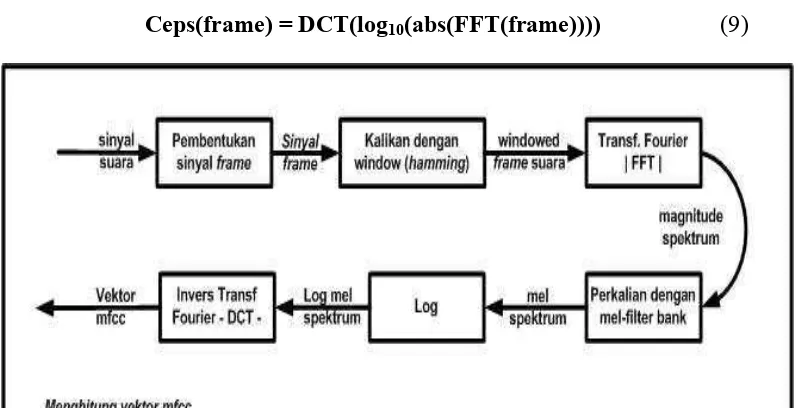
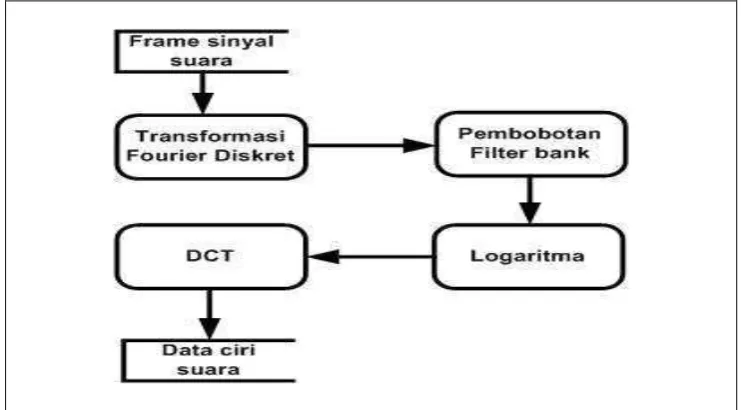
Mel-Frequency Cepstral Coefficients (MFCC), merupakan salah satu metode untuk mendapatkan informasi spesifik atau nilai ciri dari suara. Dengan menerapkankan koefisien mel pada penyaringan mel-triangular (lihat Gambar 6), setiap frame suara yang telah melalui proses transformasi fourier, disaring dengan mel-triangular filter bank, kemudian hasil penyaringan tersebut dikompresi menggunakan fungsi log, untuk selanjutnya ditransformasikan menjadi koefisien cesptral menggunakan Discrete Cosine Transformation (DCT). Tahapan proses MFCC dituangkan dalam suatu blok diagram proses, disajikan pada Gambar 5.
Hasil proses metode MFCC, adalah vector yang berisi data ciri atau Cepstrum, tahapan proses metode MFCC dapat dinyatakan menggunakan pseudocode berikut (Karpov 2003):
[image:34.595.113.512.355.559.2]Ceps(frame) = DCT(log10(abs(FFT(frame)))) (9)
Gambar 5 Blok diagram proses MFCC
Discrete Cosine Transformation (DCT), digunakan untuk mendapat nilai koefisien cepstral. DCT dinyatakan dengan persamaan:
N k N k n n x k k y N n , ... , 1 , 2 ) 1 ( ) 1 2 ( cos ) ( ) ( ) ( 1 = − − =
∑
= πω (10)
Gambar 6 mel filter-bank dengan triangular bandpass
2.8 Peubah Acak Kontinyu.1
Dalam kehidupan nyata, banyak dijumpai permasalahan dimana nilai-nilai pengamatan tidak dapat dihitung. Sebagai contoh, waktu tunggu suatu job hingga diproses sampai selesai, waktu hidup komponen perangkat keras komputer (CPU, RAM, Harddisk, dsb). Peubah – peubah acak dengan nilai seperti di atas disebut sebagai peubah acak kontinyu. Nilai peubah acak kontinyu adalah dalam domain real.
Pernyataan bahwa: fungsi distribusi kumulatif, untuk suatu peubah acak y
adalah sama dengan peluang F
( )
y0 = P(
y ≤ y0)
, dari pernyataan tersebut, makauntuk peubah acak diskret dan kontinyu dapat di tuliskan menjadi:
a Peubah acak diskret :
( )
∑
(
)
≤ ∀ = = 0 0 0 y y y y P yF (11)
b Peubah acak kontinyu :
( )
∫
( )
(12)∞ − = 0 0 y dy y f y F
Karena bentuk distribusi fungsi untuk peubah acak diskret dan kontinyu berbeda, untuk peubah acak diskret bentuknya seperti tangga, sedang untuk peubah acak kontinyu bentuknya berupa kurva mulus, dalam hal ini disebut
sebagai fungsi kepekatan peluang (probability density function --PDF--).
Beberapa pustaka menuliskan sebagai
) (y f
( )
yfy , yang artinya fungsi kepekatan
peluang peubah acak y. Perbedaan mendasar antara kedua jenis peubah tersebut adalah bahwa nilai peluang peubah acak diskret untuk suatu titik tertentu, dapat
1
saja tidak nol, sedangkan untuk peubah acak kontinyu, peluang untuk munculnya suatu titik, pasti nol. Hal ini karena nilai peluang diartikan sebagai luas daerah di bawah kurva fungsi kepekatan peluang.
Pernyataan bahwa: jika F
( )
y adalah fungsi distribusi kumulatif peubahacak y, maka fungsi kepekatan peluang dari peubah acak y tersebut adalah fy
( )
yyang dirumuskan sebagai:
( )
( )
dy y dF y
fy = (13)
Sifat dari fungsi kepekatan peluang adalah:
a. fy
( )
y ≥0, −∞≤ y ≤∞ (14)b.
∫
∞( )
( )
(15)∞
− fy y dy =F ∞ =1
Pernyataan bahwa: jika y adalah peubah acak kontinyu dengan fungsi
kepekatan peluang , maka nilai harapan dan ragam dari y dinyatakan
sebagai:
( )
y fy(16)
( )
∫
∞( )
∞ −
= y f y dy y
Ey y
(17)
( )
(
( )
)
∫
∞(
( )
) (
∞ − − = −= E y E y y E y f y dy
y
Var 2 2 y
)
Fungsi kepekatan untuk peubah acak Uniform menjelaskan nilai kejadian untuk cakupan terbatas, dinyatakan dengan
( )
⎪⎩ ⎪ ⎨ ⎧ ≤ ≤ − = lainnya y nilai untuk b y a a b y fx 0 , 1 (18)Fungsi kepekatan untuk peubah acak eksponensial, menjelaskan nilai kejadian untuk cakupan semi terbatas, dinyatakan dengan rumusan,
( )
( ) ⎪⎩ ⎪ ⎨ ⎧ ≤ ≤ ≤ ⋅ = − − a y b y a e b y f b a y x 0 , 1 / (19)Fungsi kepekatan peluang untuk peubah acak normal y, mempunyai persamaan sebagai berikut
( )
(
)
⎟⎟ −∞≤ ≤∞ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − −= y y
y f , 2 exp . 2 1 2 2 σ μ π
persamaan ini dapat digunakan untuk menjelaskan banyak bentuk, seperti noise atau gangguan sinyal.
2.9 Analisis Komponen Utama (PCA) 2
Metode statistik yang paling popler untuk mereduksi dimensi data adalah metode Karhunen-Loeve, disebut juga Principal Component Analysis (PCA). PCA merupakan salah satu teknik analisis peubah ganda yang sering digunakan untuk mereduksi dimensi data tanpa harus kehilangan nilai informasi berarti. Peubah, hasil transformasi pca merupakan kombinasi linier dari peubah asli, tidak berkorelasi antar sesama, tersusun berdasarkan informasi yang dikandungnya.
Andaikan peubah asli adalah suatu vektor X, berdimensi p: X = (x1, x2, …, xp)T,
maka peubah hasil transformasi adalah vektor Y, berdimensi q:
Y = (y1, y2, …, yq),
dengan q << p. Dalam hal ini yi dirumuskan sebagai:
y1 = a11.x1 + a12.x2 + …….. + a1p.xp = a1Tx
y2 = a21.x1 + a22.x2 + …….. + a2p.xp = a2Tx
……….
yq = aq1.x1 + aq2.x2 + …….. + aqp.xp = aqTx
Jika matriks koragam (covariance matrix) dari vektor X adalah Σ, maka
ragam (variance) yi dirumuskan sebagai:
ragam(yi) = σ2yi = ai
T
.Σ.ai, (21)
Dari penjabaran diatas diketahui bahwa permasalahan transformasi, adalah bagaimana memilih koefisien dari kombinasi linier tersebut, sehingga:
Informasi y1 > informasi y2 > …….> informasi yq
dengan kata lain
ragam(y1) > ragam(y2) > ……….. > ragam(yq)
Dari sudut pandang geometrik, unsur – unsur dalam vektor ai merupakan
komponen penyusun sumbu koordinat. Oleh karenanya dapat dipilih vektor ai
yang mempunyai panjang satu dan saling ortogonal. Dengan demikian ini menjadi
2
masalah optimasi dengan fungsi tujuan memaksimumkan ragam(yi), dengan
kendala aiTai = 1, dan cov(ai,aj) = 0, untuk i ≠ j.
Penentuana1
Masalah optimasi
Maksimumkan : ragam(y1) = a1TΣa1 Kendala : a1Ta1 = 1
Melalui pengganda Lagrange, fungsi yang dimaksimumkan adalah:
f(a1) = a1TΣa1 – λ (a1Ta1 – 1) (22) Optimasi dilakukan dengan cara menurunkan fungsi f, terhadap peubah – peubah yang dicari, dan diperoleh
(
a a)
00 a 2 a 2 a f 1 1 1 1 1 = − Σ ⇔ = − Σ = ∂ ∂ λ λ
Ini berarti a1 merupakan vektor eigen dari matriks Σ dengan nilai eigen λ. Berdasarkan hasil di atas, maka
(
Σ −λ)
= ⇔ Σ =λ ⇔ ΤΣ = Τλ = Τ λ = λ =λ 1 a a a a a a a a 0 aa1 1 1 1 1 1 1 1 1 1
Ini berarti ragam(y1), adalah λ yang merupakan nilai eigen matriks Σ.
Karena di inginkan peubah hasil transformasi tersusun berdasarkan ‘pentingnya’, maka vektor a1 adalah vektor eigen yang bersesuaian dengan nilai eigen terbesar
pertama.
Penentuan a2
Masalah optimasi
Maksimumkan : ragam(y2) = a2TΣa2
Kendala : a2Ta2 = 1 dan a1Ta2 = 0
Melalui pengganda larange, fungsi yang dimaksimumkan adalah
f(a2) = a2TΣa2 – λ2 (a2Ta2 – 1). δ(a1Ta2) (23)
Setelah dideferensialkan, diperoleh:
0 a a 2 a 2 a f 1 2 2 2 2 = − − Σ = ∂ ∂ λ δ
Dengan mengalikan a2T pada ruas kiri dan kanan diperoleh
2 2 2 1 2 2 2 2 2
2 a 2 a a a a 0 a a
a
Oleh karena itu Σ.a2 = λ2a2 yang berarti bahwa vektor a2 merupakan vektor eigen
dari Σ yang bersesuaian dengan nilai eigen terbesar ke dua, λ2.
Penentuan ai
Memperhatikan cara diatas, maka vektor ai merupakan vektor eigen dari
matriks Σ yang bersesuaian dengan nilai eigen terbesar ke i, yaitu λi, atau dengan
kata lain berlaku:
Λ=ΑΤΣΑ
dengan matriks Λ=diag
{ }
λi dan A = [a1,a2, ….., ap]T
Berapa banyak nilai komponen utama diperlukan sebagai data penelitian, atau seberapa efektif dimensi data dapat dijadikan data penelitian. Pertanyaan tersebut dapat dijawab dengan menerapkan perhitungan proporsi nilai eigen, yaitu membagi jumlah r nilai eigen dengan jumlah seluruh nilai eigen, kita akan mendapatkan hasil pengukuran untuk kualitas dari representasi yang didasarkan pada r komponen utama. Hasil penghitungan di ekspresikan sebagai persentasi.
Untuk jelasnya, kriteria nilai ciri yang representatif, didasarkan pada rasio dari jumlah r nilai eigen terbesar, untuk mencuplik nilai komponen utama dari dalam matriks. Jika nilai eigen diberi label λ1 ≥ λ2 ≥ …≥λq, maka penghitungan rasio dapat dituliskan sebagai berikut (Kantardzic 2003):
∑
∑
= = = q i i r i i Rasio 1 1 λλ . (24)
Menurut Johnson dan Wichern, persentasi rasio 80%, dan 90% dari total nilai eigen, akan memberikan sebanyak r kompenen utama untuk menggantikan data asli tanpa banyak kehilangan informasi (Johnson et. al 1998).
2.10 Normalisasi Data
kemudian, untuk nilai ciri ke i ditransformasikan menggunakan persamaan (Kantardzic 2003).
v’(i) = (v(i) – mean(v)) / sd(v) (25) Contoh: Jika nilai ciri v = {1, 2, 3}, maka mean(v) = 2, sd(v) = 1, maka nilai ciri hasil normalisasi adalah v* = {-1, 0, 1}.
2.11 Kaidah Bayes
Kaidah Bayes dapat digunakan untuk melakukan klasifikasi terhadap sejumlah kategori. Pengambilan keputusan didasarkan pada hasil perhitungan jarak antar fungsi kepekatan peluang dari vektor ciri.
Kaidah Bayes mengasumsikan bahwa kesalahan dalam pengambilan keputusan mempunyai nilai sama, nilai benar dalam pengambilan keputusan adalah 0 (nol), dan kaidah pengambilan keputusan Bayes dapat dinyatakan dengan d(x) = θi, anggaplah ada sejumlah i kelas θ1, θ2, θ3, .., θi, dimana vektor x
dinyatakan masuk dalam kelas θi, jika
P(θi). p(x |θi) ≥ P(θj). p(x | θj), ∀i,j = 1, 2, 3, .. N (26) Dimana:
P(θi) adalah peluang, dimana vektor masukkan berada dalam kelas θi.
Terjadinya peluang terdahulu dapat di nyatakan dengan hi, untuk
kelas θi, dimana i = 1, 2, 3, …., N.
p(x|θi) adalah fungsi kepekatan peluang kelas bersyarat dari x yang di
berikan, di mana x masuk dalam kelas θi. Fungsi kepekatan
peluang kelas bersyarat terdahulu dari x untuk setiap kelas θi, dapat
juga di nyatakan dengan fi(x).
gi(x) = P(θi). p(x|θi), gi(x) adalah fungsi pengambilan keputusan Bayes.
gi(x) > gk(x) untuk k ≠ i, adalah kaidah pengambilan keputusan Bayes.
Dalam kaidah pengambilan keputusan Bayes, d(x) = θi, hasil pengujian
vektor x, akan masuk dalam kelas θi jika hi.li.fi(x) > hk.lk.fk(x), untuk k ≠ i, dimana li adalah nilai peluang kesalahan dalam pengambilan keputusan pada kelas
θi, dalam banyak kasus, nilai peluang kesalahan pengambilan keputusan (li) dapat di anggap sama, sehingga dapat di abaikan, dan hi adalah nilai peluang dari kejadian fungsi peluang terdahulu (fi-1) dari vektor – vektor pada kelas θi, dan
Pengambilan keputusan, dilakukan berdasarkan nilai tertinggi yang mendekati nilai fungsi kepekatan peluang fi(x) dari vektor x untuk dapat masuk
dalam kelas tertentu (θi), (argmax{ hn.ln.fn(x)}, dimana n = 1, …,K,) (Specht 1992,
Zaknich 1995).
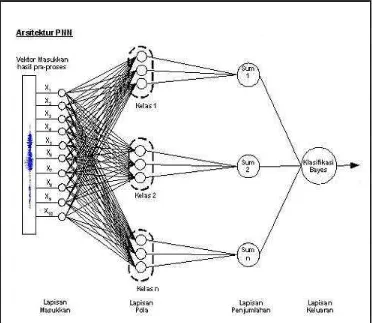
2.12 Jaringan Syaraf Tiruan Probabilistik
Jaringan syaraf tiruan probabilistik atau probabilistic neural networs (PNN), diperkenalkan oleh D.F Specht pada tahun 1988, sebagai jaringan syaraf tiruan dengan 3 lapisan tesembunyi setelah lapisan masukkan (input layer), yaitu: lapisan pola (pattern layer), lapisan penjumlahan (summation layer), lapisan keluaran (output layer), dan bersifat feed-forward, dieksekusi dengan satu kali proses (one pass) (Specht 1990).
Kelebihan algoritma PNN, adalah kemudahan yang diberikan untuk modifikasi jaringan, ketika dilakukan penambahan atau pengurang data pelatihan yang digunakan. Kelemahan algoritma PNN, adalah terjadinya peningkatan penggunaan ruang memori komputer, dan waktu komputasi, ketika penggunaan data pelatihan bertambah besar, karena semua data pelatihan harus dimasukkan ke dalam algoritma PNN (Bolat et al. 2003, Zaknich 1995).
Kerja PNN, didasarkan pada penghitungan nilai fungsi kepekatan peluang (fi(x)) untuk setiap data (vektor). Fungsi (fi(x)) merupakan fungsi pengambilan
keputusan Bayes (gi(x)), untuk data (vektor) x dan xij yang telah dinormalisasi.
Persamaan fungsi fi(x) atau gi(x), tuliskan sebagai berikut, (Specht 1992, Zaknich
1995).
(
) (
)
(
)
∑
= Τ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎣ ⎡ ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎝ ⎛ − ⋅ − − == Mi
j ij ij i i i . x x x x exp M ) ( ) x ( g ) x ( f 1 2 2 2 2 1 σ σ π ρ
ρ (27)
dengan i = 1, 2, …., K. dimana:
T Transpose
i Jumlah kelas j Jumlah pola
xij Vektor pelatihan ke j dari kelas i
x Vektor pengujian
Mi Jumlah vektor pelatihan dari kelas i
ρ Dimensi vektor x
Sampel data untuk data pelatihan tidak sama dengan sampel data untuk data pengujian PNN. Blok diagram arsitektur PNN, disajikan pada Gambar 7. Posisi
node – node yang dialokasikan dalam PNN setelah lapisan input, adalah:
1 Node lapisan Pola (Pattern Layer), digunakan 1 node pola untuk setiap data pelatihan yang digunakan. Setiap node pola, merupakan perkalian titik (dot product) dari vektor masukkan x yang akan diklasifikasikan, dengan vektor bobot xij, yaitu Zi = x . xij, kemudian di lakukan operasi non-linier terhadap Zi sebelum menjadi keluaran yang akan mengaktifkan lapisan penjumlahan, operasi
non-linier yang digunakan adalah exp[(Zi - 1)/ σ2], dan bila x dan xij, dinormalisasikan terhadap panjang vektor, maka persamaan yang digunakan pada lapisan pola, adalah: ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎣ ⎡ − − − Τ 2 2σ ) x x ( ) x x (
exp ij ij (28)
2 Node lapisan Penjumlahan (Summation Layer), menerima masukkan dari node lapisan pola yang terkait dengan kelas yang ada, persamaan yang digunakan pada lapisan ini, adalah:
⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎣ ⎡ − − − Τ =
∑
21 2σ
) x x ( ) x x (
exp ij ij
N
i
(29)
3 Node lapisan Keluaran (Output Layer), menghasilkan keluaran biner (0,1), dan hanya mempunyai variabel bobot tunggal Ck. Ck dihitung menggunakan
peramaan: jk ik ik ik jk jk k m m l h l h
C =− ⋅ ; (30)
Dimana:
mik = Jumlah pelatihan pola dari kelas θik;
Gambar 7 Arsitektur PNN
2.13 Validasi Hasil Pengukuran
Validasi terhadap hasil penelitian dilakukan untuk mengetahui tingkat akurasi yang dicapai. Terdapat beberapa metode validasi yang dapat digunakan, dua diantaranya adalah, metode holdout, dan metode leave-one out.
Metode holdout, metode ini menggunakan separuh data, atau dua per tiga data, sebagai data pelatihan dan sisanya sebagai data pengujian. Data pelatihan dan data pengujian adalah bebas, dan pengukuran hasil penelitian bersifat pesimistik. Perbedaan pembagian data akan memberikan hasil pengukuran yang berbeda. Pengulangan proses dilakukan dengan data pelatihan dan data pengujian yang dipilih secara acak, kemudian mengintegrasikan hasil pengukuran kedalam suatu standar parameter akan meningkatkan hasil pengukuran model (Kantardzic 2003).
Metode leave-one out, pada metode ini, data pelatihan dirancang menggunakan (n-1) data penelitian, dan dievaluasi menggunakan sisa data. Proses
Kerugian menggunakan pendekatan ini adalah penggunaan waktu komputasi yang dibutuhkan besar, bila jumlah data yang digunakan besar (Kantardzic 2003).
Akurasi pengukuran model adalah bagian dari pengujian data yang diklasifikasikan secara benar, dan dihitung menggunakan persamaan,
(
)
% 100 * S E SA= − (31)
dimana S adalah jumlah data, dan E kesalahan klasifikasi, A adalah nilai akurasi umumnya dinyatakan dalam prosen.
2.14 Penelitian terkait.
Beberapa peneliti, yang telah mengunakan PNN pada penelitian mereka,
antara lain:
1 Raymond Low dan Robeto Togneri, menggunakan PNN untuk mengubah
suara menjadi rangkaian teks dalam bahasa Inggris. Penelitian tersebut menggunakan suara yang direkam pada frekuensi 8000 Hz dan kuantisasi amplitudo 8 bit. Nilai ciri suara didapat melalui proses ekstraksi ciri menggunakan metode MFCC dengan lebar waktu frame 20 ms, overlap 50% dan koefisien mel 12. Penelitian tersebut memberikan nilai akurasi 94,1% untuk pengubahan suara menjadi teks angka, dan 88,6% untuk pengubahan suara menjadi teks alfabet (Low et. al. 1998).
2 Ganchev dan Fakotakis, menggunakan PNN pada pengenalan pembicara
melalui jaringan telepon tetap dengan basis data Polycost, 110 pembicara teregistrasi, dan 24 pembicara semu (tidak teregistrasi). Penggunakan metode MFCC pada proses ekstraksi ciri dengan lebar waktu frame 30 ms, overlap 50%, dan nilai koefisien mel 20 memberikan nilai EER (Equal Error Rate) 2,57% atau nilai akurasi sebesar 97,43%, merupakan nilai akurasi tertinggi untuk pengujian PNN (Ganchev et. al 2002a).
3.1 Kerangka Pikir Penelitian
Pengguna sistem identifikasi pembicara adalah orang yang memiliki hak akses terhadap suatu layanan tertentu, dimana suara oleh sistem digunakan sebagai parameter untuk mengijinkan seseorang dapat mengakses suatu layanan tersebut atau tidak. Untuk mewujudkan sistem tersebut, dilakukan penelitian pengembangan model jaringan syaraf tiruan probabilistik pada identifikasi pembicara. Tahap kegiatan penelitian dituangkan dalam suatu blok kerangka pikir penelitian, seperti disajikan pada Gambar 8.
3.1.1 Studi Pustaka
Studi pustaka, merupakan kegiatan untuk membuka wawasan dan mempelajari beberapa pustaka terkait dengan topik penelitian. Studi pustaka yang sedang dan telah dilakukan, meliputi: prinsip dasar sistem identifikasi pembicara (speaker recognition), pengelolaan sinyal dijital, jaringan syaraf tiruan probabilistik (PNN), ekstraksi ciri suara dengan Mel-Frequency Cepstral Coefficients (MFCC), penggunaan analisis komponen utama (PCA), fungsi kepekatan peluang (PDF), pemrograman dengan perangkat lunak Matlab V6.5, dan beberapa penelitian terdahulu dengan topik manipulasi suara.
Setelah mempelajari beberapa pustaka yang terkait dengan sistem pengenalan pembicara, dapat disimpulkan bahwa kerja sistem identifikaasi pembicara secara umum dapat digambarkan dengan blok diagaram seperti disajikan pada Gambar 9.
Gambar 9 Blok diagram sistem identifikasi pembicara
3.1.2 Pengembangan Modul Rekam Suara
Gambar 10 Antar muka modul rekam suara
Dur_Fs = Durasi * Frekuensi_sampel;
DtSuara = wavrecord(Dur_Fs, Frekuensi_sampel, 'double'); Nama_arsip = [get(handles.Folder,'String'),...
get(handles.NmPembicara,'String')... ,num2str(Ke_Sekian),'.wav'];
wavwrite(DtSuara, Fs, Nama_arsip);
Gambar 11 Cuplikan program rekam suara
3.1.3 Pengumpulan Suara
Suara dikumpulkan menggunakan alat bantu mikrofon standar PC dan komputer personal yang telah diprogram untuk dapat melakukan poses rekam suara. Suara direkam pada frekuensi 16000 Hz dan kuantisasi amplitudo 16 bit, sumber suara berasal dari 10 dewasa usia 21 tahun hingga 51 tahun, terdiri atas 5 orang wanita dan 5 orang laki-laki. Setiap orang diminta mengucapkan kata sandi “Sembilan” sebanyak 10 kali dengan durasi rekam suara 2 detik untuk setiap pengucapan kata sandi.
Hubungan antar proses yang dilibatkan dalam proses pengumpulan suara dituangkan dalam diagram alir proses seperti disajikan pada Gambar 12.
[image:49.595.143.510.465.715.2]Untuk memudahkan pengguna sistem dalam melakukan pengumpulan sura, maka proses pengumpulan suara dilengkapi tampilan antar muka rekam suara (Gambar 10) dan tampilan antar muka penambahan noise (Gambar 13), sedangkan cuplikan program penambahan noise, disajikan pada Gambar 14.
Gambar 12 Blok diagram alir proses pengumpulan suara
NamaFile = ['D:\GUI_TESIS_V01\Suara\',NamaRelawan, ... num2str(n), '.wav'];
[DataWav, Fs, Bit] = wavread(NamaFile);
DataNoise = awgn(DataWav,V_Desibel,'measured');
Gambar 14 Cuplikan program tambah noise
3.1.4 Pra-proses
Pra-proses merupakan kegiatan yang terdiri atas proses pembentukan frame suara dan proses pembobotan window hamming. Kegiatan pra-proses diterapkan pada data suara asli (Sr_Asli) dan data suara noise (Sr_Noise). Hasil pra-proses berupa frame yang telah mendapatkan pembobotan window hamming, dan menjadi data masukkan bagi proses ekstraksi ciri.
Langkah pertama dari kegiatan pra-proses, adalah memecah sinyal suara menjadi beberapa frame suara menggunakan parameter lebar waktu frame dan lebar overlap. Pada penelitian ini digunakan besaran nilai lebar
waktu frame suara 16 ms, 30 ms, 40 ms, sedangkan untuk besaran nilai overlap digunakan 40% dan 50% dari nilai lebar waktu frame yang diunakan. Langkah kedua dari kegiatan pra-proses, adalah memboboti frame suara dengan window hamming. Diagram alir proses kegiatan pra-proses, disajikan pada Gambar 15.
Gambar 15 Diagram alir proses kegiatan pra-proses
3.1.5 Ekstraksi Ciri
Setiap orang memiliki karakteristik suaranya sendiri, meskipun suara tersebut tidak begitu jelas. Karakteristik suara yang terbaik, dapat digunakan
Hubungan spektral, tangga nada, intensitas suara, bentuk pengucapan, penggukuran sepstral, merupakan ciri yang digunakan pada pengolahan suara. Data ciri memberikan hasil baik pada satu situasi, tetapi dapat juga memberikan hasil buruk di situasi yang lain, sehingga, sekali ciri-ciri suara dipilih untuk digunakan dalam proses pengolahan suara, maka akan diekstraksi dari suara yang diucapkan, dan dapat digunakan untuk mengidentifikasi pembicara.
Dimensi data yang terlalu besar dapat menyebabkan hasil perhitungan fungsi kepekatan peluang menjadi tidak stabil, sehingga hasil klasifikasi tidak handal. Untuk mengatasi masalah tersebut sering digunakan teknik mereduksi dimensi data, salah satu teknik yang dapat diterapkan untuk mereduksi data adalah Mel-Frequency Cepstral Coefficients (MFCC). MFCC diketahui memiliki kinerja yang baik dalam mendukung sistem identifikasi pembicara, dan juga dapat mereduksi data suara dengan baik.
[image:51.595.140.511.416.621.2]Tahapan proses ekstraksi ciri dengan metode MFCC, digambarkan dalam suatu blok diagram alir data seperti disajikan pada Gambar 16.
Gambar 16 Diagram alir proses ekstraksi ciri dengan metode MFCC
3.1.6 Penyebaran Data Ciri
Penyebaran data ciri kedalam kelompok-kelompok tersebut, adalah untuk mengetahui data ciri (vektor ciri) mana saja yang akan dijadikan data pelatihan saat proses rekonstruksi model JST Probabilistik dilakukan, dan data ciri mana saja yang akan dijadikan data pengujian.
Bagaimana komposisi data ciri (vektor ciri) dan berapa jumlahnya yang akan dijadikan anggota kelompok data pelatihan dan kelompok data pengujian ditentukan berdasarkan aturan yang berlaku pada metode validasi yang dijadikan acuan pada penelitian ini. Komposisi dan jumlah data ciri pada kelompok data pelatihan dan kelompok data pengujian untuk model PNN yang akan divalidasi dengan metode holdout disajikan pada Tabel 1.
Tabel 1 komposisi dan jumlah vektor ciri untuk metode validasi holdout
Pengujian
ke. Kelompok Data Pelatihan
Kelompok Data Pengujian 1 Vc2, Vc4, Vc6, Vc8, Vc10, Vc7, Vc9 Vc1, Vc3, Vc5 2 Vc1, Vc3, Vc5, Vc7, Vc9, Vc8, Vc10 Vc2, Vc4, Vc6 3 Vc2, Vc4, Vc6, Vc8, Vc10, Vc1, Vc3 Vc5, Vc7, Vc9 4 Vc1, Vc3, Vc5, Vc7, Vc9, Vc2, Vc4 Vc6, Vc8, Vc10 5 Vc4, Vc5, Vc6, Vc7, Vc8, Vc9, Vc10 Vc1, Vc2, Vc3 6 Vc1, Vc2, Vc3, Vc4, Vc5, Vc6, Vc7 Vc8, Vc9, Vc10
Sedangkan komposisi dan jumlah data ciri pada kelompok data pelatihan dan kelompok data pengujian untuk model PNN yang akan divalidasi dengan metode leave-one out disajikan pada Tabel 2.
Tabel 2 komposisi dan jumlah vektor ciri untuk metode validasi leave-one out
Pengujian
ke. Kelompok Data Pelatihan
3.1.7 Identifikasi Suara
Penelitian ini menerapkan 2 model identifikasi. Pertama, adalah model identifikasi suara yang menggunakan data ciri (vektor ciri) hasil proses ekstraksi ciri dengan metode MFCC. Kedua, adalah model identifikasi suara yang menggunakan data ciri (vektor ciri) yang dihasilkan melalui proses ekstraksi ciri yang menerapkan kombinasi metode MFCC dan Metode PCA. Kedua model identifikasi akan divalidasi dengan metode holdout dan metode leave-one out. Dalam melakukan proses validasi digunakan data pelatihan dan data pengujian sesuai hasil proses penyebaran data ciri (lihat Tabel 1 dan Tabel 2).
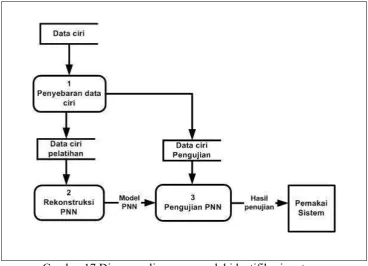
[image:53.595.142.511.394.660.2]Blok diagram model identifikasi yang pertama disajikan pada Gambar 17, pada model ini data ciri pelatihan langsung digunakan sebagai data pelatihan untuk merekonstruksi dan melatih model JST Probabilistik, sedangkan data ciri pengujian digunakan sebagai data untuk menguji model JST Probabilistik (PNN).
Gambar 17 Diagram alir proses model identifikasi pertama
Gambar 18 Diagram alir proses model identifikasi kedua
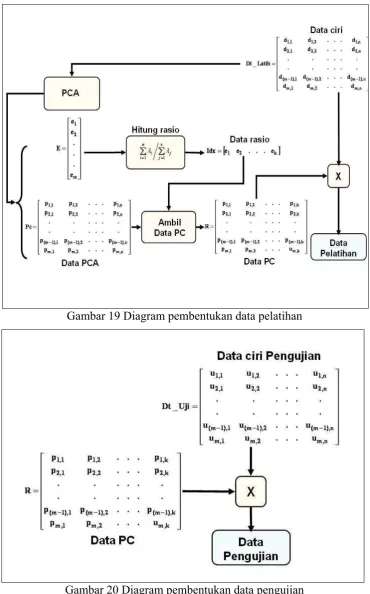
Data pelatihan untuk model kedua didapat dengan memasukan data ciri yang dihasilkan proses MFCC kedalam proses tranformasi PCA untuk mendapatkan nilai eigen dan nilai komponen utama (PC). Penerapan PCA terhadap data ciri pelatihan dengan ukuran (i x j) akan menghasilkan matriks komponen utama dengan ukuran (j x j) dan vektor eigen (λ).
Gambar 19 Diagram pembentukan data pelatihan
[image:55.595.141.512.81.676.2]
Gambar 20 Diagram pembentukan data pengujian
pelatihan yang tidak diambahkan noise, sedangkan pengujian model PNN dilakukan dengan data pengujian yang telah ditambahkan noise.
Dari hasil penerapan proses PCA, dilakukan penghitungan rasio nilai
eigen menggunakan persamaan
∑
∑
= = q i i r i i 1 1 λλ , dimana λ merupakan nilai
eigen dan r≠ q. Berdasarkan hasil perhitungan rasio nilai eigen, didapat m kolom matriks komponen utama yang akan membentuk matriks pengali dengan ukuran (j x m).
Pembentukan data pelatihan (Gambar 19) dilakukan dengan mengalikan matriks data ciri pelatihan berukuran (i x j) dengan matriks
pengali (j x m), hingga didapat matriks data pelatihan berukuran (i x m), sedangkan pembentukan data pengujian (Gambar 20) dilakukan dengan mengalikan matriks data ciri pengujian berukuran (u x j) dengan matriks pengali (j x m), hingga didapat matriks data pengujian berukuran (u x m).
Pada proses model identifikasi kedua data pelatihan yang dihasilkan melalui proses pembentukan data pelatihan digunakan untuk merekonstruksi dan melatih model PNN, sedangkan data pengujian digunakan untuk menguji model PNN.
Hasil proses penghitungan data pelatihan dan data pengujian disebut
Pca80 untuk persentasi rasio nilai eigen 80, Pca90 untuk persentasi rasio nilai eigen 90, dan Pca95 untuk persentasi rasio nilai eigen 95. Sedangkan untuk data pelatihan dan data pengujian yang dihasilkan metode MFCC disebut vekt_mfcc.
Mengacu pada metode validasi yang digunakan, yaitu: metode holdout dan metode leave-one out, maka proses rekonstruksi akan menghasikan 2 model PNN, model pertama diberi nama PNN70, dan model kedua diberi nama PNN90.
3.1.8 Rancang Bangun Aplikasi
Pengembangan model jaringan syaraf tiruan probabilistik pada identifikasi pembicara merupakan aplikasi sistem identifikasi pembicara yang dikembangkan menggunakan beberapa modul yang saling terkait, dan tergabung dalam suatu modul pemanggil yang diberi nama ”modul_menu”, modul-modul tersebut antara lain, modul penyiapan suara, modul ekstraksi ciri, modul eksekusi PNN, dan modul generalisasi.
Rancang bangun aplikasi sistem identifikasi pembicara disajikan pada Gambar 21, dimana setiap modul dalam rancang bangun aplikasi merupakan program–program pendukung penelitian yang dikembangkan menggunakan perangkat lunak Matlab v6.5.
Gambar 21 Rancang Bangun pengembangan model jaringan syaraf tiruan Probabilistik pada identifikasi pembicara.
Pengembangan aplikasi sistem identifikasi pembicara, mengacu pada
model siklus hidup pengembangan sistem air terjun (water fall).
program pemanggil yang berfungsi sebagai modul utama aplikasi, visualisasi tampilan layar modul utama aplikasi, disajikan pada Gambar 22.
Gambar 22 Antar muka modul menu
3.1.9 Dokumentasi dan Penulisan Laporan
Dokumentasi dan penulisan laporan, merupakan kegiatan terakhir dari penelitian. Seluruh hasil penelitian di laporkan dalam bentuk penulisan tesis,
dan dokumentasi hasil penelitian merupakan bagian dari pelaporan (tesis).
3.2 Struktur Data Penelitian
Sinyal suara hasil pengucapan teks ”sembilan”, dianalisis menggunakan metode short-term. Beberapa parameter digunakan untuk mendapatkan informasi spesifik (ciri-ciri) suara, yaitu: sekala mel (mel), lebar waktu frame (fr), lebar overlap antar frame (over), besaran nilai ketiga parameter tersebut disajikan pada tabel 3. Berdasarkan nilai parameter pada tabel 3, dapat digambarkan pohon kelompok data ciri (data penelitian), seperti disajikan pada Gambar 23.
Tabel 3 Nilai parameter pembentuk data ciri.
No Parameter Nilai
1. Lebar waktu frame ( fr) (16 ms, 30 ms, dan 40 ms)
2. Lebar overlap (over) (40%, dan 50%)
3. Konstanta mel ( mel) (16 dan 20)
Selain parameter tersebut dalam tabel 3, digunakan juga parameter lebar window (wd), durasi perekaman suara (tr) sebesar 2 detik, frekuensi sampel suara (fs) sebesar 16 kHz, koefisien transformasi Fourier (Ft) sebesar 512.
[image:59.595.115.513.188.477.2]Nilai parameter diatas juga berlaku terhadap duplikat sinyal suara yang telah ditambahkan White Gaussian Noise (wgn) sebesar 30 desibel.
Gambar 23 Struktur pohon data penelitian
3.3 Bahan dan Alat
Bahan baku penelitian adalah suara, berasal dari 10 orang pengucap dewasa, yang terdiri atas: 5 orang pengucap pria dan 5 orang pengucap wanita, selanjutnya disebut sebagai Pengucap01 sampai Pengucap10.
“Sembilan”, merupakan teks yang diucapkan sebanyak 10 kali oleh setiap pengucap, dengan durasi 2 detik untuk satu kali pengucapan teks. Suara ucapan direkam dalam format dijital kedalam berkas audio ber-ekstensi wav (*.wav) pada frekuensi (sampling rate) 16 kHz, dan kuantisasi amplitudo 16 bit.
adalah, sistem operasi Microsoft Windows XP, bahasa pemrograman Matlab versi 6.5, Microsoft Office, microsoft Visio.
3.4 Waktu Penelitian
4.1 Hasil Pra-Proses
Hasil akhir kegiatan pra-proses, adalah 6 jenis frame suara asli yang telah diboboti window hamming, dan 6 jenis frame suara Noise yang telah diboboti window hamming. Penerapan kombinasi lebar waktu frame dengan lebar overlap dapat digunakan untuk membentuk blok frame suara. Jumlah frame suara dalam 1 blok, disajikan pada Tabel 4.
Tabel 4 Jumlah frame suara untuk frekuensi suara 16000 Hz
Parameter No Lebar waktu frame
(ms)
Lebar Overlap
(ms)
Jumlah frame
dalam 1 blok
1. 16 6,4 103
2. 30 12 55
3. 40 16 41
4. 16 8 124
5. 30 15 66
6. 40 20 49
Untuk mengetahui jumlah sampel data pada setiap frame suara, dilakukan dengan mengeksekusi persamaan fr/1000 * fs, dimana fr adalah lebar waktu frame, dan fs adalah frekuensi suara. Penerapan beberapa nilai parameter lebar waktu frame (16 ms, 30 ms dan 40 ms) dan frekuensi suara 16000 Hz, terhadap persamaan diatas, akan didapat jumlah sampel data untuk setiap frame suara seperti disajikan pada Tabel 5.
Tabel 5 Jumlah sampel data per satu frame
No Lebar waktu frame
(ms) Jumlah sampel data
1. 16 256
2. 30 480
3. 40 640
Frame suara yang terbentuk pada kegiatan pra-proses, merupakan frame suara yang telah diboboti dengan window hamming.
4.2 Hasil Ekstraksi Ciri
Hasil penerapan metode MFCC adalah vektor dengan sejumlah nilai ciri suara, disebut data ciri suara. Mengacu pada penggunaan parameter lebar waktu frame, lebar overlap, dan koefisien mel, maka penerapan metode MFCC akan menghasilkan 12 kelompok data. Setiap kelompok data memiliki 100 vektor ciri. Pemberian nama kelompok data menggunakan nilai parameter dengan susunan “mel.frame.overlap”, lihat Tabel 6.
Tabel 6 Nama kelompok data
Parameter pembentuk data ciri No
Mel Frame (ms) Overlap (%)
Nama kelompok data ciri
1 16 16.16.40
2 30 16.30.40
3 40 40
16.40.40
4 16 16.16.50
5 30 16.30.50
6
16
40
50
16.40.50
7 16 20.16.40
8 30 20.30.40
9 40 40
20.40.40
10 16 20.16.50
11 30 20.30.50
12
20
40
50
20.40.50
Penerapan metode MFCC pada proses ekstraksi ciri dapat mereduksi dimensi vektor suara hingga 84%, sedangkan penerapan kombinasi metode PCA dengan MFCC dapat mereduksi dimensi vektor suara hingga 99%. Rinci hasil proses ekstraksi ciri dapat dilihat pada Tabel 7 dan Tabel 8.
Penerapan metode PCA terhadap data pelatihan, akan menghasilkan matriks
berisi nilai komponen utama dan vektor yang berisi nilai eigen. Menurut Johnson, sebagian data hasil proses PCA dapat digunakan untuk menggantikan fungsi data
hasil proses PCA sebagai data penelitian. Pemilihan sampel data pengganti dilakukan melalui penghitungan rasio nilai eigen (R), yaitu: membagi hasil penjumlahan sejumlah nilai eigen, dengan hasil penjumlahan seluruh nilai eigen, secara matematis penghitungan rasio nilai eigen dituliskan dengan persamaan R =
∑
∑
= = n j j m i i 1 1 λλ , dimana λ adalah nilai eigen. Persentasi rasio 80, 90 dan 95 dari
Penerapan proses ekstraksi ciri suara juga berlaku untuk data noise. Dimensi setiap vektor hasil ekstraksi suara, disajikan pada tabel 7 (data asli) dan tabel 8 (data noise).
Tabel 7 Dimensi data penelitian hasil ekstraksi ciri suara untuk data asli
Ukuran vektor ciri hasil pencuplikan
No Kelompok
data
Ukuran Vekt_mfcc
Ukuran Vekt_Pca
Pca80 Pca90 Pca95
1 16.16.40 3120 99 8 19 36
2 16.30.40 1650 99 8 18 32
3 16.40.40 1230 99 8 17 31
4 16.16.50 3735 99 10 22 40
5 16.30.50 1980 99 9 20 36
6 16.40.50 1485 99 9 19 34
7 20.16.40 3952 99 9 21 39
8 20.30.40 2090 99 8 19 35
9 20.40.40 1558 99 8 18 33
10 20.16.50 4731 99 11 24 43
11 20.30.50 2508 99 10 22 39
12 20.40.50 1881 99 10 21 36
Tabel 8 Dimensi data penelitian hasil ekstraksi ciri suara untuk data noise
Ukuran vektor ciri hasil pencuplikan
No Kelompok
data
Ukuran Vekt_mfcc
Ukuran Vekt_Pca