DAFTAR PUSTAKA
Agarwal, N., Rawat, M. & Maheshwari, V. 2014. Comperative analysis of jaccard coefficient and cosine similarity for web document similarity measure. International Journal for Advance Research in Engineering and Technology. 2: 18-21.
Azma, S. 2006. Pembuatan alat bantu dalam proses data cleaning pada intra-govermental access to shared information system (IGASIS). Skripsi. Universitas Telkom.
Chahal, M. 2016. Information retrieval using jaccard similarity coefficient. International Journal of Computer Trends and Technology(IJCTT). 36 (3): 140-142.
Han, J. & Kamber, M. 2006. Data Mining: Concept and techniques. Second Edition. Elsevier: The United States of America.
He, L., Zhang, Z., Tan, Y. & Liao, M. 2011. An Efficient Data Cleaning Algorithm Based on Attributes Selection. 6th International Conference on Computer Science and Convergence Information Technology (ICCIT), IEEE, pp. 375-379.
Hermawati, F.A. 2013. Data mining. Yogyakarta: Penerbit Andi.
Liliana., Budhi, G. S., Wibisono, A. & Tanojo, R. 2012. Pengecekan plagiarisme pada code dalam bahaca C++. Jurnal Informatika. Universitas Kristen Petra Surabaya. (Online) http://jurnalinformatika.petra.ac.id/index.php /inf/article/view/18649 (18 Mei 2016).
Prasetyo, E., 2014. Data mining: Mengolah data menjadi informasi menggunakan matlab. Yogyakarta: Penerbit Andi.
Primadani, Y. 2014. Simulasi algoritma leveinsthein distance untuk fitur autocomplete pada aplikasi katalog perpustakaan. Skripsi. Universitas Sumatera Utara.
Rahm, d & Do, H.H. 2000. Data Cleaning: Problem and current approaches. IEEE Bulletin of the Technical Committee on Data Engineering 23(4): 1-11.
Riezka, A. 2011. Analisis dan implementasi data cleaning menggunakan metode multi-pass neighborhod(MPN). Skripsi. Universitas Telkom
43
Tamilselvi, J.J. & Saravan, V., 2010. An Evaluation on Current Research Trends in Data Cleaning on Data Warehouseing. International Journal of Computational Intelligence Research 6(3): 405-430.
BAB 3
ANALISIS DAN PERANCANGAN
Bab ini membahas tentang analisis dan perancangan sistem. Analisis yang dilakukan berhubungan dengan penerapan metode leveinsthein distance dalam mengidentifikasi duplikasi pada data identitas perusahaan dan tahap-tahap yang akan dilakukan dalam perancangan sistem.
3.1. Data Yang Digunakan
18
3.2. Analisis Sistem
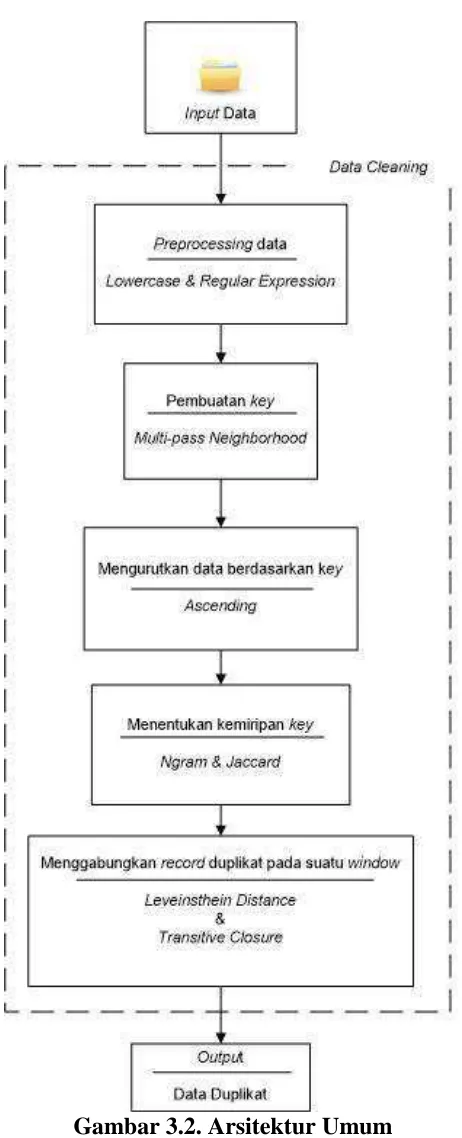
Sistem identifikasi duplikasi pada data duplikat costumer perusahaan menggunakan metode leveinsthein distance merupakan sistem yang berfungsi untuk mengidentifikasi data duplikat serta melakukan cleaning data pada data perusahaan.
Gambar 3.2. Arsitektur Umum 3.2.1 Input Data
20
3.2.2 Pre-Processing
Pada tahap pre-proccessing dilakukan beberapa tahapan persiapan data sehingga data dapat dengan mudah diproses untuk tahap selanjutnya. Tahapan pre-processing dari penelitian ini terdiri dari mengubah data menjadi lowercase dan regular expression. 1. Lowercase
Pada tahap ini data pada keseluruhan teks akan diubah menjadi huruf kecil (toLowerCase).
2. Regular Expression
Penerapan regular expression dilakukan dengan memeriksa kata yang digunakan (token) yang diterima sesuai dengan pattern yang akan digunakan. Pada data alamat akan menghilangkan kata jalan., jln., jl., dan lainnya. Pada kolom lainnya juga dilakukan dengan penentuan kata yang berbeda dan akan menghilangkan kata pada tahap pre-processing.
3.2.3 Pembentukan Key
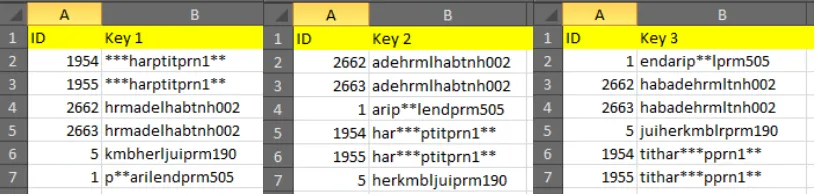
Setelah data mengalami proses pre-processing, kemudian data tersebut disimpan sebagai data awal yang akan digunakan untuk tahap pembuatan key menggunakan metode multipass neighborhood. Dalam penyimpanan data awal ini, data di berikan tanda pengenal berupa id record sebagai key pada data. Berikut ini adalah tahapan multipass neighborhood :
1. Pembuatan key
Menggabungkan record 3 huruf nama depan, nama belakang, dan nama ibu yang akan digunakan sebagai key. Pembuatan key pada tahap multi- pass akan dilakukan sebanyak 3 key yang bersal dari kombinasi nama depan, nama belakang, dan nama ibu.
Key 1 terdiri dari tiga huruf konsonan dari nama belakang, tiga huruf pertama dari nama depan, tiga huruf konsonan nama ibu. Pada key 1 akan diurutkan berdasarkan field nama belakang.
Key 3 terdiri dari, tiga huruf konsonan nama ibu, tiga huruf pertama dari nama depan, tiga huruf pertama dari nama belakang dan. Pada key 3 akan diurutkan berdasarkan nama ibu.
Gambar 3.3. Gambar Data Setelah Pre-Processing Key 1
Tiga huruf konsonan “nama belakang” ( menjadi ***)
Tiga huruf pertama “nama depan” ( hartati menjadi har)
Satu huruf “jenis kelamin”(p menjadi p)
Tiga huruf pertama “nama ibu”(titin menjadi tit)
Tiga huruf konsonan dan tiga angka nomer rumah “alamat”(perintis 1 menjadi prn1**)
Key 2
Tiga huruf pertama “nama depan” (hartati menjadi har)
Tiga huruf konsonan “nama belakang” ( menjadi ***)
Satu huruf “jenis kelamin”( p menjadi p)
Tiga huruf pertama “nama ibu”( titin menjadi tit)
Tiga huruf konsonan dan tiga angka nomer rumah “alamat”( perintis 1 menjadi prn1**)
Key 3
Tiga huruf pertama “nama ibu”( titin menjadi tit)
Tiga huruf pertama “nama depan” (hartati menjadi har)
Tiga huruf konsonan “nama belakang” ( menjadi ***)
Satu huruf “jenis kelamin”( p menjadi p)
22
3.2.4 Pengurutan Data pada Key
Pada proses ini dilakukan pengurutan data pada setiap key secara ascending (A-Z). Pengurutan record dilakukan bertujuan untuk memudahkan penghitungan edit distance pada string hanya pada key yang berada pada satu window. Key yang berbeda akan diberikan label yang berbeda dan berada pada window yang berbeda.
Gambar 3.5. Gambar Data Hasil Ascending
3.2.5 Pemisahan String pada Key
Pemisahaan kata pada setiap key dilakukan menggunakan n-gram. N-gram merupakan algoritma string similarity (pencocokan string), dengan pergeseran window dengan panjang n sepanjang karakter string. N-gram memisahkan string menjadi potongan string dengan panjang n. Kesamaan string pada kolom key 1,2,3 dilakukan menggunakan n-gram.
3.2.6 Pengukuran Kesamaan pada Key
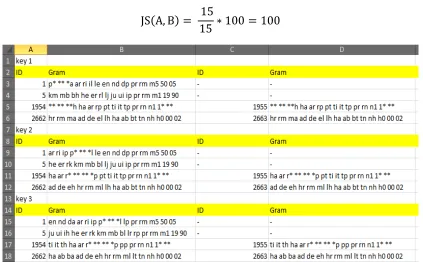
Pengukuran kesamaan data pada key dilakukan menggunakan metode jaccard. Jaccard merupakan algoritma untuk mengukur kesamaan antara dua string. Rentang nilai yang dihasilkan berupa 0 untuk menandakan tidak ada kesamaan dan 100 adalah sama persis. Tahap pada algoritma ini ada tiga yaitu, menghitung panjang string, menemukan jumlah karakter yang sama pada kedua string dan menemukan jumlah transposisi. Transposisi adalah karakter yang sama dan tertukar urutannya pada string. Perhitungan jaccard untuk mencari rentang nilai kemiripan pada data menggunakan persamaan (2.1).
(2.1)
Hasil dari n-gram :
har***ptitprn1*** ha ar r* ** ** *p pt ti it tp pr rn n1 ** ** har***ptitprn1*** ha ar r* ** ** *p pt ti it tp pr rn n1 ** **
24
3.2.7 Pengukuran Kesamaan Data Tiap Kolom pada Data
Pada penelitian ini, record yang telah diurutkan akan dilakukan penggabungan record yang teridentifikasi duplikat menjadi satu window dengan parameter edit-distance.
Algoritma leveinsthein distance dilakukan untuk edit distance pada proses untuk mengetahui jarak antara dua string pada nama depan, nama belakang, jenis kelamin dan nama ibu. Perbedaan string berupa penambahan (insert), penghapusan (delete) dan penggantian karakter (substitute). Perhitungan leveinsthein distance untuk mencari jarak terdekat pada masing-masing data menggunakan persamaan (2.2) dan (2.3).
…
∑
dimana : V untuk i = 1,2,…,l d( ) = 0 jika d( ) = 1 jika
Data nama = hartati & hartati ∑
= d( s1,t1 ) + d( s2,t2 ) + d( s3,t3 ) + d( s4,t4 ) + d( s5+t5 ) + d( s6,t6 ) + d( s7,t7 )
= d(h,h) + d(a,a) + d(r,r) + d(t,t) + d(a,a) + d(t,t) + d(i,i) = 0 + 0 + 0 + 0 + 0 + 0 + 0
= 0
3.2.8 Pembacaan Data Duplikat pada Suatu Window
Pembacaan data duplikat pada suatu window dilakukan menggunakan metode transitive closure. Transitive closure (R+) dari relasi R pada data merupakan relasi terkecil yang mengandung R sebagai subset dan bersifat transitive. Suatu graph dikatakan transitive. Suatu graph dikatakan transitive jika terdapat jalan dari titik A ke titik B dan sebuah jalan dari titik B ke titik C, sehingga ada jalan dari titik A ke titik C.
3.3. Perancangan Sistem
Pada tahap perancangan sistem, dilakukan perencanaan untuk menentukan bagaimana sistem ini dapat mengidentifikasi record dimana duplikat pada penelitian ini berupa data identitas yang memiliki duplikat record.
3.3.1 Analisis Pengguna
Sistem data cleaning duplikasi record pada data identitas menggunakan metode leveinsthein distance merupakan sistem yang berfungsi untuk mengidentifikasi duplikat record pada data identitas. Pengguna dapat menginstall sistem ini dalam komputer mereka untuk menggunakannya.
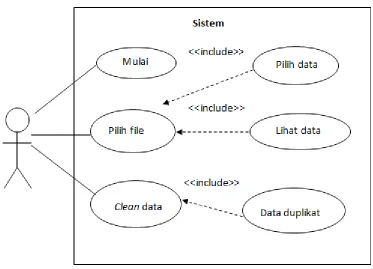
3.3.2 Use Case diagram
26
Gambar 3.9. Use case sistem
3.3.3 Deskripsi Use Case
Adapun penjelasan mengenai kegiatan- kegiatan di dalam diagram use case sistem data cleaning pada gambar 3.9 dapat dilihat pada Table 3.1.
Tabel 3.1. Deskripsi Use Case Sistem Data Cleaning
No. UseCase Deskripsi
1. Start Use case ini berfungsi untuk memulai sistem data cleaning.
2. Pilih File Use case ini berfungsi untuk menentukan data yang akan digunakan dan dapat melihat data yang dipilih.
3. Clean data Use case ini berfungsi sebagai proses untuk melakukan cleaning data sehingga dapat melihat data duplikat
3.3.4 Activity Diagram
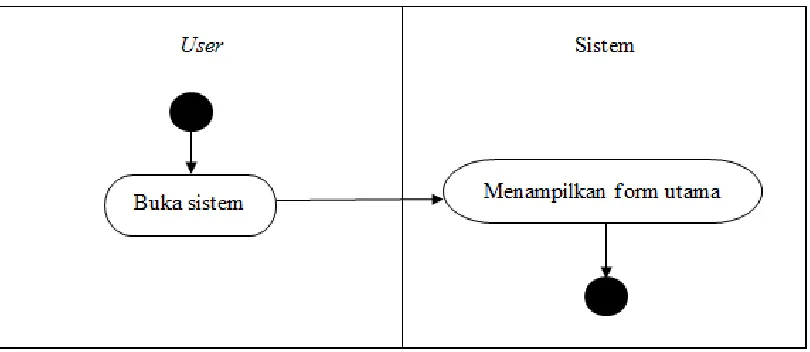
Gambar 3.10. Activity Diagram Melihat Form Utama
Pada Gambar 3.10. dapat dilihat ketika user ingin melihat tampilan utama, user dapat memilih tampilan utama pada sistem pada saat memulai sistem. Sistem akan menampilkan form utama yang ada pada sistem.
Untuk activity diagram tampilan form proses yang dapat ditampilkan dengan menggunakan tombol start oleh user pada form utama dapat dilihat pada Gambar 3.11.
28
Pada Gambar 3.11 dapat dilihat bahwa user dapat melakukan mengklik tombol start pada form utama. Sistem akan memproses yang dilakukan oleh user kemudian sistem akan menampilkan form proses kepada user.
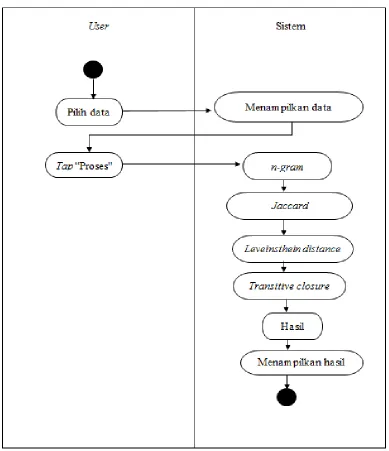
Untuk activity diagram pada form proses dapat dilihat pada Gambar 3.12.
Gambar 3.12. Activity Diagram Proses Data Cleaning
memilih data, menampilkan data, menampilkan proses sort key, menampilkan proses n-gram, jaccard, leveinsthein distance, dan menampilkan data duplikat sebagai hasil. 3.4. Perancangan Antarmuka Sistem
Perancangan antarmuka sistem merupakan gambaran secara umum dari tampilan sistem yang akan dibangun.
3.4.1 Rancangan Tampilan Halaman Utama
Gambar 3.14. Rancangan Tampilan Halaman Utama Keterangan :
1) Judul
Label ini digunakan untuk menampilkan judul dari sistem yang dibangun. 2) Logo
Tampilan logo ini dibuat untuk menampilkan logo. 3) Tombol start
30
3.4.2 Rancangan Tampilan Proses
Gambar 3.15. Rancangan Tampilan Proses Keterangan :
1) File Location
File location berguna untuk mengetahui lokasi data yang dipilih. 2) Tombol Browse
Tombol browse merupakan tombol yang digunakan untuk membuka data identitas yang akan diinput ke dalam sistem.
3) Tombol Proses
Tombol proses merupakan tombol yang digunakan untuk memulai proses pengcleaningan data.
4) Tombol Export
Tombol export merupakan tombol yang digunakan untuk mengeksport hasil proses pengcleaningan data.
5) Table Data Pelanggan
6) Table Data Preprocessing
Table data preprocessing merupakan tabel yang digunakan untuk menampilkan data yang dipilih.
7) Tabel Key
Table Key merupakan tabel yang digunakan untuk menampilkan hasil data setelah proses mengurutkan data berdasarkan key.
8) Tabel Jaccard
Table jaccard merupakan tabel yang digunakan untuk menampilkan hasil data setelah proses sortir data berdasarkan key.
9) Table Leveinsthein
Table Leveinsthein merupakan tabel yang digunakan untuk menampilkan hasil data setelah proses pengurutan data berdasarkan key.
10)Table Data Clean
BAB 4
IMPLEMENTASI DAN PENGUJIAN
Pada bab ini akan membahas implementasi dan pengujian aplikasi berdasarkan analisis dan perancangan sistem yang telah dibahas pada bab sebelumnya. Tahapan ini memiliki tujuan untuk menampilkan hasil perancangan sistem dan proses pengujiannya dalam melakukan identifikasi terhadap duplikat data pada data cleaning. 4.1. Kebutuhan Aplikasi
Dalam melakukan perancangan sistem data cleaning menggunakan leveinsthein distance memerlukan perangkat keras dan perangkat lunak sebagai pendukung, diantaranya yaitu:
4.1.1Perangkat keras
Spesifikasi perangkat keras yang digunakan pada aplikasi ini yaitu:
Processor : Intel(R) Core(TM) i5-2410M CPU @ 2.30GHz 2.30 GHz RAM : 3.42 GB
Harddisk : 300 GB 4.1.2Perangkat Lunak
Spesifikai perangkat lunak yang digunakan pada aplikasi ini yaitu: 1. Windows 7 Ultimate 32-bit
3. Microsoft excel
4.2. Implementasi Perancangan Antarmuka
Tampilan dari perancangan antarmuka yang telah diimplementasikan adalah sebagai berikut:
4.2.1Halaman Utama
Halaman utama merupakan halaman awal yang ditampilkan pada saat sistem dijalankan. Pada halaman utama ini terdapat tombol start yang akan membantu pengguna untuk berpindah ke tampilan halaman proses serta terdapat tombol keluar yang akan menutup sistem pada saat tombol tersebut dipilih. Tampilan halaman utama sistem dapat dilihat pada Gambar 4.1.
Gambar 4.1. Tampilan Halaman Utama
4.2.2Halaman Proses
34
Gambar 4.2. Tampila Halaman Proses
Pada halaman proses ini terdapat tombol pilih data dan tombol proses. Tombol pilih data berfungsi untuk memilih data yang akan diproses untuk diketahui duplikat data yang terdapat pada data tersebut. Sedangkan tombol proses digunakan untuk melakukan serangkaian proses dalam mengidentifikasi duplikat data dan dapat dilihat pada Gambar 4.3.
Gambar 4.3. Tampilan File Location
Pada saat tombol pilih data diklik, maka akan tampil pop-up yang akan menampilkan pilihan untuk memilih data, dapat dilihat pada Gambar 4.4.
Setelah data yang akan diidentifikasi duplikatnya dipilih dan lokasi file akan ditampilkan pada kolom file location, langkah selanjutnya dilakukan klik (pilih) tombol proses. Pada saat tombol proses diklik maka serangkaian proses yang dilakukan akan dimulai dari proses lowercase dan regular expression dimana data akan diubah menjadi data yang siap untuk diproses, selanjutnya akan dilanjutkan dengan proses multi-pass neighborhood sebagai proses pembentukkan key dari data yang mana data inilah yang akan digunakan untuk proses yang dilakukan untuk efisiensi pembersihan data. Tampilan halaman proses dapat dilihat pada Gambar 4.5
Gambar 4.5. Tampilan Setelah Tombol Proses Diklik
36
Gambar 4.6. Tampilan Proses Data Cleaning
Setelah keseluruhan proses selesai akan ditampilkan hasil dari identifikasi duplikat data. Hasil identifikasi ini akan ditampilkan ke tabel data clean yang berisi tampilan data duplikat yang telah ditemukan dan dapat dilihat pada Gambar 4.7
Gambar 4.7. Tampilan Hasil Output Data Duplikat
4.3. Pengujian Sistem
Tabel 4.1. Tabel Data
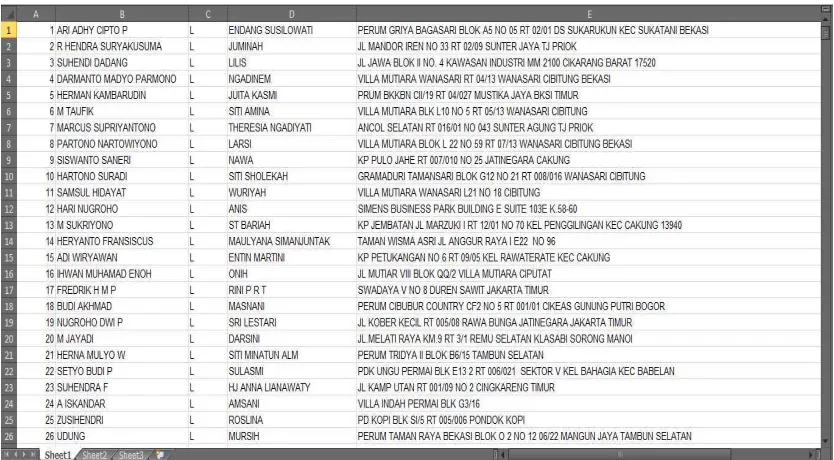
ID Nama Jk Nama ibu Alamat
1 ARI ADHY CIPTO
P
L ENDANG
SUSILOWATI
PERUM GRIYA
BAGASARI BLOK A5 NO 05 RT 02/01 DS
SUKARUKUN KEC SUKATANI BEKASI
2 R HENDRA
SURYAKUSUMA
L JUMINAH JL MANDOR IREN NO 33
RT 02/09 SUNTER JAYA TJ PRIOK
3 SUHENDI
DADANG
L LILIS JL JAWA BLOK II NO. 4
KAWASAN INDUSTRI MM 2100 CIKARANG BARAT 17520
4 DARMANTO
MADYO PARMONO
L NGADINEM VILLA MUTIARA
WANASARI RT 04/13 WANASARI CIBITUNG BEKASI
5 HERMAN
KAMBARUDIN
L JUITA KASMI PRUM BKKBN CII/19 RT
04/027 MUSTIKA JAYA BKSI TIMUR
6 ARI ADHY CIPTO
P
L ENDANG
SUSILOWATI
PERUM GRIYA
BAGASARI BLOK A5 NO 05 RT 02/01 DS
SUKARUKUN KEC SUKATANI BEKASI - - - - - - - - - -
3018 JORDY SUHARLY L NANI S JL. CIPINANG LONTAR
NO. 80 RT 14/06 CIPINANG MUARA, JATINEGARA, JAKARTA TIMUR
3019 OBED UBAIDI L ROSIH JL PINTU 2 MES SPBU NO
3 RT 13/17 PEGANGSAAN DUA KELAPA GADING
3020 DIAN FITRIANI P SUPIANAH JL RAJAWALI KEBON
NANAS RT 001 RW 001 CIKOKOL TANGERANG 3021 FITRI
DESTIAWANTI
P MULYANAH KP NEGLASARI RT 001
RW 002 KARYASARI LEUWILANG
3022 ABDUL AZIS L CHALIMAH CIBANGKONG RT 005
RW 003 PEKUNCEN Tabel 4.2. Tabel Hasil Data Duplikat
ID Nama Jk Nama ibu Alamat
38
- - - - -
1693 julius s l Zubaedah komp perkt pulomas bl ii no 14 p kemerdekaan 1694 julius s l Zubaedah komp perkt pulomas bl ii no 14 p kemerdekaan
Proses pengujian pada sistem ini menggunakan precision, recall dan akurasi. Precision merupakan tingkat kebenaran informasi pada sistem. Recall merupakan tingkat kebenaran sistem menemukan informasi. Sedangkan akurasi merupakan tingkat kedekatan antara nilai prediksi dengan nilai aktual. Berdasarkan hasil uji yang dilakukan pada sistem data cleaning pada data duplikat menggunakan leveinsthein distance tersebut, dapat diperoleh nilai akurasi dengan rata-rata %. Hasil ini didapat melalui persamaan 4.1, 4.2, 4.3
(4.1)
=
= 37%
(4.2)
=
= 93%
(4.3)
=
= 95%
Tabel 4.2. Tabel Pengujian
Nilai sebenarnya
True False
Nilai Prediksi
True TP (True Positive) Correct Result
FP (False Positive) Unexpected Result False FN (False Negative)
Missing Result
TN(True Negative) Correct absence of result
Tabel 4.3. Tabel Hasil Pengujian Nilai sebenarnya
True False
Nilai Prediksi
True 93 154
False 7 2769
(4.4)
=
= 37%
(4.5)
=
= 93%
(4.6)
=
BAB 5
KESIMPULAN DAN SARAN
Bab ini akan membahas kesimpulan dan saran yang diperoleh dalam merancang sistem data cleaning pada data duplikat dengan leveinsthein distance.
5.1 Kesimpulan
Kesimpulan yang dapat diambil dari pengujian sistem data cleaning pada identifikasi data duplikat menggunakan leveinsthein distance adalah sebagai berikut:
1. Metode leveinsthein distance dapat melakukan identifikasi data duplikat dengan baik, sehingga identifikasi duplikat data pada data dapat memperoleh tingkat akurasi yang cukup tinggi.
2. Tingkat akurasi yang diperoleh dalam melakukan identifikasi duplikat data mencapai 95%.
5.2 Saran
Adapun saran untuk penelitian selanjutnya yaitu:
1. Dapat membandingkan metode leveinsthein distance dengan metode lainnya dalam hal melakukan identifikasi duplikat data dengan adanya kesamaan string pada data identitas.
BAB 2
LANDASAN TEORI
2.1.Data Mining
Data mining adalah bagian dari knowledge discovery di database yang menganalisa database berukuran besar untuk menemukan pola yang berguna pada data (Silberschatz, et al. 2006). Data mining merupakan proses yang mempekerjakan teknik pembelajaran komputer (machine learning) untuk mengekstraksi pengetahuan (knowledge) secara otomatis (Hermawati, 2013).
7
Tahap pada knowledge discovery database (Han & Kamber, 2006), yaitu : 1. Data cleaning (untuk menghilangkan noise dan data yang tidak konsisten). 2. Data integration (mengkombinasikan beberapa sumber data).
3. Data selection (pengambilan data yang relevan dengan analisis database). 4. Data transformation (mengubah bentuk data kedalam bentuk yang sesuai).
5. Data mining (proses penting penggunaan metode yang diterapkan untuk mengekstrak pola data).
6. Pattern evaluation (mengidentifikasi pola-pola yang menarik yang mewakili pengetahuan didasarkan pada beberapa langkah yang menarik).
7. Knowledge presentation (visualisasi dan teknik representasi pengetahuan digunakan untuk menyajikan pengetahuan yang berguna untuk pengguna).
Adapun beberapa teknik data mining yang dapat digunakan (Hermawati, 2013), adalah sebagai berikut :
1. Klasifikasi
Klasifikasi adalah menentukan sebuah record data baru ke salah satu dari beberapa kategori yang telah didefinisikan sebelumnya, klasifikasi itu merupakan supervised learning.
2. Regresi
Memprediksi nilai dari suatu variabel yang berkelanjutan berdasarkan nilai dari variable yang lain, dengan mengasumsikan sebuah model ketergantungan linear atau nonlinear. Teknik ini banyak dipelajari dalam statistika, bidang jaringan syaraf tiruan (neural network).
3. Klasterisasi (clustering)
4. Kaidah Asosiasi (association rules)
Mendeteksi beberapa atribut yang muncul bersamaan dengan frekuensi yang sering, dan membentuk sejumlah kaidah dari atribut tersebut. Tujuannya adalah untuk menemukan pola yang menarik dengan cara yang efisien (Prasetyo, 2014).
5. Pencarian pola sekuensial (sequence mining)
Mencari sejumlah kejadian yang secara umum terjadi bersama-sama. 2.2.Data Cleaning
Data cleaning merupakan salah satu tahap pada data mining. Data cleaning biasa disebut dengan data cleansing atau scrubbing. Proses data cleaning dilakukan untuk menghilangkan kesalahan informasi pada data (Rahm & Do, 2000). Sehingga proses data cleaning digunakan untuk menentukan data yang tidak akurat, tidak lengkap atau tidak benar dan akan memperbaiki kualitas data melalui pendeteksian kesalahan pada data (Tamilselvi & Saravan, 2010). Data cleaning juga merupakan langkah yang dilakukan untuk mendeteksi serta mengkoreksi atau menghapus sejumlah record yang kurang atau tidak akurat yang disebabkan adanya kesalahan pada data (Riezka, 2010). Data cleaning dapat dilakukan dengan satu sumber atau beberapa sumber data, juga terdapat permasalahan pada level skema ataupun level instance. Permasalahan pada level skema dapat diselesaikan dengan perbaikan desain, translation dan integration skema. Sedangkan pada tingkat instance terdapat kesalahan dan tidak konsisten pada data yang merupakan fokus permasalahan yang dapat diselesaikan dengan data cleaning. (Rahm & Do, 2000).
9
Gambar 2.2. Gambar Duplikasi Data (Riezka, 2010)
Pada gambar 2.2 terdapat format data yang memiliki hubungan relational, tetapi terdapat juga beberapa permasalahan data pada kedua sumber tersebut. Pada bagian skema data, ada beberapa permasalahan pada penamaan (persamaan antara “Customer/Client”, “Cid/Cno”, “Sex/Gender”) dan pada bagian permasalahan struktural (perbedaan pada atribut “Name” dan “Address”). Permasalahan pada duplikat data dapat dieliminasi dengan Metode sort-neighborhood atau metode pegembangannya multi-pass neighborhood.
2.3. Data Duplikat
Permasalahan utama yang menyebabkan adanya data duplikat adalah terjadinya overlapping data atau data yang tumpang tindih (Riezka, 2010). Overlapping pada data umumnya terjadi pada data-data identitas seperti data mahasiswa, data pegawai dan data costumer.
2.4. Pre-Processing
1. Lowercase
Mengubah keseluruhan teks menjadi huruf kecil (toLowerCase). 2. Regular Expression
2.5. Multi-Pass Neighborhood
Multi-pass neighborhood merupakan metode pengembangan metode sorted neighbourhood yang dapat mengunakan key yang berbeda dan menggunakan window yang lebih kecil (Riezka, 2010). Selanjutnya dapat dilakukan tahap transitive closure untuk mengetahui relasi record (Tamilselvi & Saravan, 2010). Metode ini memiliki tiga tahapan dasar, yaitu :
1. Pembentukan key
[image:31.595.139.493.327.390.2]Membentuk key dilakukan pada setiap record dengan mengekstrak field atau menggunakan sebagian field yang relevan dari atribut yang dipilih
Gambar 2.3. Gambar Tabel Data Dan Key (Riezka, 2010)
2. Sorting data
Mengurutkan record pada list data menggunakan key yang telah dibentuk. Pada proses ini dilakukan pengurutan data berdasarkan key secara ascending (Z-A). Pengurutan record dilakukan bertujuan untuk memudahkan penghitungan edit distance pada string hanya pada key yang berada pada satu window.
3. Merge data
11
Gambar 2.4. Window Pada Tahap Merge (Riezka, 2010)
2.6. N-gram
N-gram merupakan algoritma string similarity (pencocokan string), dengan pergeseran window dengan panjang n sepanjang karakter string (Azma, 2006). N-gram memisahkan string menjadi potongan string dengan panjang n.
2.7. Jaccard
Jaccard similarity merupakan algoritma untuk mengukur kesamaan antara dua string (Agarwal et al, 2014). Metode ini membandingkan string dengan melihat posisi penulisan yang berbeda (Liliana et al, 2012). Rentang nilai yang dihasilkan berupa 0 untuk menandakan tidak ada kesamaan dan 100 adalah sama persis (Chahal, 2016). Nilai antara 0 dan 100 menunjukkan probabilitas kemiripan antara dua string. Perhitungan jaccard untuk mencari rentang nilai kemiripan pada data menggunakan persamaan (2.1).
(2.1)
2.8.Approximate String Matching
2.6.1. Leveinsthein Distance
Leveinsthein distance merupakan algoritma yang dapat membandingkan string dengan panjang yang berbeda. Leveinsthein distance melakukan perhitungan jumlah minimal operasi penambahan (insert), penghapusan (delete), dan penggantian karakter (substitute) yang dibutuhkan untuk menyamakan kedua string (Riezka, 2010). Untuk mengetahui leveinsthein distance tahap yang dilakukan adalah edit distance, untuk mengetahui nilai jumlah modifikasi yang dibutuhkan antara suatu bentuk string dengan string lain. (Ugon, et al. 2015). Persamaan Leveinsthin distance untuk menghitung edit distance antara string s dan string t (Primadani, 2014), dapat dilihat pada persamaan 2.2 dan 2.3 dibawah ini :
D = d( s1, t1 ) + d( s2, t2 ) + … + d( , ) (2.2)
l
D (s, t) = (2.3)
i=1
dimana : V untuk i = 1,2,…,l
d( ) = 0 jika
d( ) = 1 jika
D(s,t) merupakan banyaknya operasi minimum dari operasi penghapusan, penyisipan, dan penggantian untuk menyamakan string s dan t. Beberapa penggunaan operasi tersebut untuk menentukan jarak leveinsthein sebagai berikut ini.
1. Operasi penghapusan
Operasi penghapusan dilakukan dengan menghapus karakter pada indeks tertentu untuk menyamakan string sumber (s) dengan string target (t).
2. Operasi penyisipan
13
3. Operasi pengantian
Operasi penggantian dilakukan dengan mengganti karakter pada indeks tertentu untuk menyamakan string sumber (s) dengan string target (t).
2.9. Transitive closure
Transitive closure merupakan tahap untuk dapat mendeteksi apabila record a dan b serupa, record b dan c serupa sehingga tahap ini dapat menandai record a dan c serupa. Hal ini dilakukan apabila hubungan relasi tidak terdeteksi oleh equational theory. Penggunaan transitive closure pada setiap single pass di metode sorted-neighborhood dapat mengurangi ukuran scanning window (Tamilselvi, J.J. & Saravan, V., 2010).
2.10. Peneliti Terdahulu
Efisiensi pada data cleaning dapat dilakukan untuk mendapatkan kualitas data yang baik (Riezka, 2010). Pengimplementasian data cleaning pada penelitian ini dilakukan dengan menggunakan data mahasiswa menggunakan metode multi-pass neighborhood (MPN). Metode Multi-pass neighborhood dapat mendeteksi duplikasi record dengan lebih efisien pada data identitas mahasiswa dengan jumlah data 1987 record. Proses dilakukan dengan pembuatan key dari beberapa kolom pada record dan pengurutan key dilakukan berdasarkan last name, first name dan alamat. Ditetapkan tiga buah parameter untuk melihat kinerja metode tersebut, yaitu ukuran lebar window, pengaruh kombinasi rule yang digunakan, dan jumlah passes yang dipakai saat eksekusi. Penentuan ukuran lebar window dan proses pengambilan keputusan duplikat data pada penelitian ini menggunakan leveinsthein distance. Sedangkan untuk mengetahui hubungan record yang diidentifikasi duplikat dilakukan menggunakan transitive closure.
Proses cleaning pada data digunakan untuk mendapatkan kualitas data yang baik. Data cleaning pada penelitian ini dilakukan dengan algoritma n-gram pada data yang tidak konsisten dan skema lokasi atau wilayah pada data BKKBN, DEPTAN, dan BPS (Azma, S, 2006).
Metode Leveinsthein distance juga pernah digunakan untuk penelitian lain yaitu penelitian yang dilakukan oleh (Primadani, 2014). Leveinsthein distance digunakan untuk pencarian judul buku pada katalog perpustakaan. Algoritma ini digunakan untuk menghasilkan layanan autocomplete dalam memprediksi judul buku yang diberikan oleh pengguna.
[image:35.595.93.541.516.704.2]Pada penelitian ini, penulis menggunakan leveinsthein distance untuk menyelesaikan pengambilan keputusan duplikasi data pada data identitas costumer. Kelebihan dari metode leveinsthein distance ini adalah dapat mengetahui kemiripan string pada data dengan edit distance berupa jarak antara dua string (Ugon et al, 2015). Beda penelitian ini dari yang lain adalah metode n-gram dan jaccard pada penentuan ukuran window dan data yang dapat diinputkan dalam excell. Sedangkan untuk pre-processing data pada penelitian ini digunakan regular expression, mengubah data menjadi lowercase dan memisahkan atribut nama menjadi last name dan first name (Riezka, 2010). Dan proses penandaan duplikat data pada penelitian ini dilakukan menggunakan metode transitive closure.
Tabel 2.1 Penelitian Terdahulu
No
. Peneliti / Tahun Teknik yang digunakan Keterangan
1. Riezka, A (2010)
Metode multi-pass neighbohood (MPN)dan transitive closure
Metode multi-pass neighbohood (MPN) dan transitive closure
mampu melakukan
pengidentifikasian record yang duplikat menggunakan data mahasiswa.
2. He et al (2011) Metode n-gram dan smith-waterman
15
Tabel 2.1 Penelitian Terdahulu (Lanjutan)
No. Peneliti / Tahun Teknik yang digunakan Keterangan
3. Azma, S (2006) Metode n-gram
Mampu melakukan proses cleaning data yang tidak konsisten pada data wilayah pada data BKKBN, DEPTAN, dan BPS.
4. Primadani,Y (2014)
Metode leveinsthein distance
Mampu melakukan simulasi fitur autocomplete pada aplikasi katalog perpustakaan menggunakan Leveinsthein distance.
Adapun perbedaan penelitian yang dimiliki oleh penulis dengan penelitian terdahulu adalah :
1. Riezka, A (2010)
Sistem ini tidak dapat menggunakan data selain yang ada pada database dan menerapkan metode multipass neighborhood, leveinsthein distance dan transitive closure untuk proses cleaning data mahasiswa yang duplikat. Sedangkan pada penelitian ini dapat membaca data dari file excel menggunakan metode multipass neighborhood, n-gram, jaccard, leveinsthein distance dan transitive closure untuk proses cleaning data identitas pelanggan perusahaan yang duplikat.
2. He et al (2011)
Sistem ini menggunakan metode multipass neighborhood, smith waterman, n-gram dan transitive closure proses cleaning data. Sedangkan pada penelitian ini menggunakan metode multipass neighborhood, n-gram, jaccard, leveinsthein distance dan transitive closure untuk proses cleaning data.
3. Azma, S (2006)
4. Primadani,Y (2014)
BAB 1 PENDAHULUAN
1.1. Latar Belakang
Data cleaning merupakan salah satu tahap pada data mining. Data cleaning biasa disebut dengan data cleansing atau scrubbing. Proses data cleaning dilakukan untuk menghilangkan kesalahan informasi pada data (Rahm & Do, 2000). Sehingga proses data cleaning dapat digunakan untuk menentukan data yang tidak akurat, tidak lengkap atau tidak benar dan untuk memperbaiki kualitas data melalui pendeteksian kesalahan pada data (Tamilselvi & Saravan, 2010). Data cleaning dapat dilakukan dengan satu sumber atau beberapa sumber data. Pada satu atau beberapa sumber data juga terdapat permasalahan pada level skema ataupun level instance. Permasalahan pada level skema dapat diselesaikan dengan perbaikan desain, translation dan schema integration. Sedangkan pada tingkat instance terdapat kesalahan dan inkonsistensi pada data yang menjadi fokus permasalahan yang dapat diselesaikan dengan data cleaning (Rahm & Do, 2000). Salah satu permasalahan kesalahan pada data dari satu atau beberapa sumber data adalah data duplikat. Contoh permasalahan duplikat pada data yaitu terdapat beberapa data seseorang yang berisi nilai yang sama sehingga terjadi data duplikat. Oleh karena itu, dibutuhkan sebuah pendekatan untuk dapat mengoptimalkan proses data cleaning.
Penelitian yang dilakukan oleh (He et al, 2011) yaitu penggunaan multi-pass sorted-neighborhood (MPN) untuk melakukan efisiensi cleaning data duplikat yang dapat dilakukan dengan baik.
Metode leveinsthein distance juga pernah digunakan untuk penelitian lain yaitu penelitian yang dilakukan oleh (Primadani, 2014). Leveinsthein distance digunakan untuk pencarian judul buku pada katalog perpustakaan. Algoritma ini digunakan untuk menghasilkan layanan autocomplete dalam memprediksi judul buku yang diberikan oleh pengguna.
Pada penelitian ini, metode leveinsthein distance digunakan untuk menyelesaikan pengambilan keputusan duplikat data pada data identitas costumer. Kelebihan dari metode leveinsthein distance ini adalah dapat mengetahui kemiripan string pada data dengan edit distance berupa jarak antara dua string (Ugon et al, 2015). Perbedaan penelitian ini dengan yang lain adalah metode n-gram dan jaccard pada penentuan ukuran window dan data yang dapat diinputkan dalam excel. Sedangkan untuk pre-processing data pada penelitian ini menggunakan regular expression yang mengubah data menjadi lowercase dan memisahkan atribut nama menjadi last name dan first name (Riezka, 2010). Selanjutnya proses menghubungkan duplikat data pada penelitian ini akan menggunakan metode transitive closure.
Sebuah alternatif informasi tentang data cleaning pada duplikat record dapat dilakukan pada data identitas costumer. Untuk itu penulis mengusulkan sebuah pendekatan untuk mengidentifikasi data yang didalamnya terdapat duplikat record pada data identitas. Hasil penelitian ini diharapkan dapat memberikan manfaat dalam mengidentifikasi duplikat pada data. Sehingga dapat mempermudah dalam melakukan proses cleaning data duplikat.
1.2. Rumusan Masalah
3
dan menghabiskan banyak waktu karena jumlah data yang besar. Untuk itu dibutuhkan sebuah pendekatan untuk dapat mengoptimalkan proses data cleaning. 1.3. Batasan Masalah
Dalam melakukan penelitian ini, peneliti membatasi ruang masalah yang akan diteliti. Batasan-batasan masalah tersebut diantaranya yaitu :
1. Proses cleaning data yang akan dilakukan hanya pada data duplikat. 2. Tidak melakukan cleaning data inconsistence dan incorrect.
3. Hanya memproses data nama dengan maksimal dua kata yaitu first name dan last name.
4. Tidak melakukan proses penggabungan data.
5. Output yang dihasilkan adalah identifikasi duplikat record pada data.
1.4. Tujuan Penelitian
Adapun tujuan dari penelitian ini yaitu untuk mengidentifikasi duplikat data dalam proses cleaning data duplikat pada data identitas menggunakan leveinsthein distance.
1.5. Manfaat Penelitian
Manfaat dari penelitian ini yaitu :
1. Dapat mengoptimalkan proses cleaning data yang memiliki duplikat record. 2. Menambah pengetahuan penulis dalam penggunaan algoritma leveinsthein
distance.
1.6. Metodologi Penelitian
Tahapan-tahapan yang akan dilakukan dalam pelaksanaan penelitian ini adalah sebagai berikut :
1. Studi Literatur
Tahap studi literatur ini dilaksanakan untuk mengumpulkan bahan-bahan referensi yang berkaitan dengan penelitian tentang duplikasi record, data mining, data cleaning, text processing, metode multi-pass neighborhood, transitive closure, n-gram dan leveinsthein distance.
2. Analisis Permasalahan
Pada tahap ini dilakukan analisis terhadap bahan referensi yang telah diperoleh yang terkait dengan penelitian agar didapatkan metode yang tepat untuk menyelesaikan masalah dalam penelitian ini.
3. Perancangan Sistem
Pada tahap ini dilakukan perancangan sistem untuk menyelesaikan permasalahan yang terdapat di dalam tahap analisis. Kemudian dilanjutkan dengan mengimplementasikan hasil analisis dan perancangan ke dalam sistem. 4. Implementasi
Pada tahap ini akan dilakukan proses implementasi program menggunakan metode yang telah ditentukan dan dari data yang telah dikumpulkan.
5. Pengujian Sistem
Pada tahap ini dilakukan proses pengujian terhadap sistem untuk memastikan sistem yang dibuat dapat berjalan seperti yang diharapkan.
6. Penyusunan Laporan
Pada tahap ini dilakukan dokumentasi dan penyusunan laporan terhadap analisis dan implementasi leveinsthein distance untuk mengidentifikasi duplikat record pada data identitas.
1.7. Sistematika Penulisan
5
BAB I : Pendahuluan
Bab ini berisikan latar belakang, rumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian, metodologi penelitian, dan sistematika penulisan.
BAB II : Landasan Teori
Bab ini berisikan teori-teori yang digunakan untuk memahami permasalahan yang dibahas pada penelitian ini. Pada bab ini dijelaskan tentang penerapan metode yang digunakan pada penelitian.
BAB III : Analisis dan Perancangan
Bab ini berisikan analisis terhadap permasalahan dan perancangan sistem yang akan dibangun berdasarkan metode yang akan diterapkan dalam sistem.
BAB IV : Implementasi dan Pengujian
Bab ini berisikan pembahasan tentang implementasi dari analisis dan perancangan yang disusun pada Bab III. Selain itu akan dijabarkan hasil implemetasi yang didapatkan.
BAB V : Kesimpulan dan Saran
ABSTRAK
Data cleaning merupakan salah satu tahap pada data mining. Data cleaning biasa disebut dengan data cleansing atau scrubbing. Proses data cleaning dilakukan untuk menghilangkan kesalahan informasi pada data. Data cleaning dapat dilakukan dengan satu sumber atau beberapa sumber data. Salah satu permasalahan kesalahan pada data dari satu sumber data adalah data duplikat. Data cleaning dapat dilakukan pada data duplikat untuk mendapatkan data yang berkualitas baik. Kualitas data yang baik dapat diketahui dengan adanya informasi yang benar pada data tanpa adanya data duplikat. Namun pembersihan data yang dilakukan secara manual membutuhkan ketelitian dan menghabiskan banyak waktu karena jumlah data yang besar. Penelitian ini mengidentifikasi data duplikat dalam proses cleaning data duplikat pada data identitas. Proses identifikasi data duplikat menggunakan metode leveinsthein distance untuk mengidentifikasi kemiripan jarak antara dua string pada data. Dalam penelitian ini menggunakan 3023 data dengan tingkat akurasi yang diperoleh mencapai 95%.
vii
DATA CLEANING ON DUPLICATE DATA WITH LEVEINSTHEIN DISTANCE METHOD
ABSTRACT
Data cleaning is one of the phases in data mining. Data cleaning is often called as data cleansing or data scrubbing. The process of data cleaning is aimed at removing the false information in the data. Data cleaning can be performed by one or several data resources. One of the common problems in data is duplicate data. Data cleaning can be used to remove duplicate data in order to get good quality of data. Quality of data can be seen from the availability of the right information without the existence of duplicate data. Unfortunately, data cleaning which is often performed manually needs thoroughness and spends a lot of time due to the size of the data. This research is to identify duplicate data existed in data cleaning from identity data. The identification process of duplicate data using leveinsthein distance has the purpose to identify the
similarity of both string’s distance in data. This research was using 3023 data with
95% of accuracy rate.
SKRIPSI
MARSHA AYUDIA 111402104
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
iv
PERSETUJUAN
Judul : DATA CLEANING PADA DATA DUPLIKAT
MENGGUNAKAN LEVEINSTHEIN DISTANCE
Kategori : SKRIPSI
Nama : MARSHA AYUDIA
Nomor Induk Mahasiswa : 111402104
Program Studi : SARJANA (S1) TEKNOLOGI INFORMASI
Departemen : TEKNOLOGI INFORMASI
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI
INFORMASI Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Romi Fadillah Rahmat, B.Comp.Sc., M.Sc Dr. Erna Budhiarti Nababan, M.Sc, IT NIP. 19860303 201012 1004 NIP. –
Diketahui/disetujui oleh
Program Studi S1 Teknologi Informasi Ketua,
PERNYATAAN
DATA CLEANING PADA DATA DUPLIKAT MENGGUNAKAN LEVEINSTHEIN DISTANCE
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, Oktober 2016
iv
UCAPAN TERIMA KASIH
Puji dan syukur kehadirat Allah SWT, karena rahmat dan izin-Nya penulis dapat menyelesaikan penyusunan skripsi ini, sebagai syarat untuk memperoleh gelar Sarjana Komputer, pada Program Studi S1 Teknologi Informasi Fakultas Ilmu Komputer dan Teknologi Informasi Universitas Sumatera Utara.
Ucapan terima kasih penulis sampaikan kepada:
1. Bapak Prof. Dr. Runtung Sitepu, SH, M.Hum selaku Rektor Universitas Sumatera Utara
2. Bapak Prof. Dr. Opim Salim Sitompul, M.Sc selaku Dekan Fasilkom-TI USU 3. Bapak Muhammad Anggia Muchtar, ST., MM.IT selaku Ketua Program Studi
S1 Teknologi Informasi Universitas Sumatera Utara.
4. Ibu Dr. Erna Budhiarti Nababan, M.IT selaku Dosen Pembimbing I yang telah memberikan bimbingan dan saran kepada penulis.
5. Bapak Romi Fadhillah Rahmat, ST., M.Sc selaku Dosen Pembimbing II yang telah memberikan bimbingan dan saran kepada penulis.
6. Bapak Dani Gunawan ST., M.T selaku Dosen Pembanding I yang telah memberikan kritik dan saran dalam penyempurnaan skripsi ini.
7. Ibu Amalia ST., M.T selaku Dosen Pembanding II yang telah memberikan kritik dan saran dalam penyempurnaan skripsi ini.
8. Seluruh Dosen dan Pegawai Program Studi S1 Teknologi Informasi Universitas Sumatera Utara
9. Ayahanda Ir.Dasmen Nazar M.M dan Ibunda drg.Nelmi Jamali yang selalu memberikan doa, kasih sayang dan dukungan kepada penulis.
11. Kerabat dekat Bapak Fajar, Ibu Liliana Sari, Ibu dr. Zarni Jamali, Ibu Cici Siska Yani, Ibu Yunizam, drg.Vanazia Rizka Anggarini, Ayu Wahyuni dan Bapak Sony yang selalu memberikan doa, dan dukungan kepada penulis
12. Teman – teman wacana skripsi, Ade Oktariani, Fahrunissa Khairani, Mewati Panjaitan, Karina Ginting, Chairunnisaq, Rauva Chairani, Nabila Pindya dan Abbas Munandar yang telah memberikan dukungan dan bantuan kepada penulis. 13. Teman seangkatan Wulandari Taringan, Anwar Pasaribu, Nurul Fatihah, Ruri Dwi Pari, Tiffany Zatalini, Vanesa Felicia, Para senior Teknologi Informasi Indra Aulia, Rini Jannati, Silvi Ou, Handra Akira Saito, dan Andean Arippa yang telah memberikan nasehat dan pengetahuan kepada penulis.
14. Devina Monica, Jessica Putri, Nur Endah Safitri, Farah Nurul Huda yang selalu memberikan semangat dan motivasi kepada penulis.
15. Semua pihak yang terlibat langsung ataupun tidak langsung yang tidak dapat penulis ucapkan satu per satu yang telah membantu penyelesaian skripsi ini.
Semoga Allah SWT melimpahkan berkah kepada semua pihak yang telah memberikan bantuan, perhatian, serta dukungan kepada penulis dalam menyelesaikan skripsi ini.
Medan, Oktober 2016
vi
ABSTRAK
Data cleaning merupakan salah satu tahap pada data mining. Data cleaning biasa disebut dengan data cleansing atau scrubbing. Proses data cleaning dilakukan untuk menghilangkan kesalahan informasi pada data. Data cleaning dapat dilakukan dengan satu sumber atau beberapa sumber data. Salah satu permasalahan kesalahan pada data dari satu sumber data adalah data duplikat. Data cleaning dapat dilakukan pada data duplikat untuk mendapatkan data yang berkualitas baik. Kualitas data yang baik dapat diketahui dengan adanya informasi yang benar pada data tanpa adanya data duplikat. Namun pembersihan data yang dilakukan secara manual membutuhkan ketelitian dan menghabiskan banyak waktu karena jumlah data yang besar. Penelitian ini mengidentifikasi data duplikat dalam proses cleaning data duplikat pada data identitas. Proses identifikasi data duplikat menggunakan metode leveinsthein distance untuk mengidentifikasi kemiripan jarak antara dua string pada data. Dalam penelitian ini menggunakan 3023 data dengan tingkat akurasi yang diperoleh mencapai 95%.
DATA CLEANING ON DUPLICATE DATA WITH LEVEINSTHEIN DISTANCE METHOD
ABSTRACT
Data cleaning is one of the phases in data mining. Data cleaning is often called as data cleansing or data scrubbing. The process of data cleaning is aimed at removing the false information in the data. Data cleaning can be performed by one or several data resources. One of the common problems in data is duplicate data. Data cleaning can be used to remove duplicate data in order to get good quality of data. Quality of data can be seen from the availability of the right information without the existence of duplicate data. Unfortunately, data cleaning which is often performed manually needs thoroughness and spends a lot of time due to the size of the data. This research is to identify duplicate data existed in data cleaning from identity data. The identification process of duplicate data using leveinsthein distance has the purpose to identify the
similarity of both string’s distance in data. This research was using 3023 data with
95% of accuracy rate.
viii
DAFTAR ISI
Hal.
PERSETUJUAN ii
PERNYATAAN iii
UCAPAN TERIMA KASIH iv
ABSTRAK vi
ABSTRACT vii
DAFTAR ISI viii
DAFTAR GAMBAR xi
DAFTAR TABEL xii
BAB 1 PENDAHULUAN
1.1 Latar Belakang 1
1.2 Rumusan Masalah 2
1.3 Batasan Masalah 3
1.4 Tujuan Penelitian 3
1.5 Manfaat Penelitian 3
1.6 Metodologi Penelitian 4
1.7 Sistematika Penulisan 5
BAB 2 LANDASAN TEORI
2.1 Data Mining 6
2.2 Data Cleaning 8
2.3 Data Duplikat 9
2.4 Pre-Processing 9
2.5 Multi-pass Neighborhood 10
2.7 Jaccard 11
2.8 Approximate String Matching 11
2.8. 1 Leveisthein Distance 12
2.9 Transitive Closure 13
2.10 Penelitian Terdahulu 13
BAB 3 ANALISI DAN PERANCANGAN
3.1 Data Yang Digunakan 17
3.2 Analisis Sistem 18
3.2.1 Input Data 19
3.2.2 Pre-Processing 20
3.2.3 Prmbentukan Key 20
3.2.4 Pengurutan Data pada Key 22
3.2.5 Pemisahan string pada Key 22
3.2.7 Pengukuran Kesamaan pada Key 23
3.2.8 Pengukuran Kesamaan Data Tiap Kolom pada Data 24 3.2.9 Pembacaan Data Duplikat pada Suatu Window 25
3.3 Perancangan Sistem 25
3.3.1 Analisis Pengguna 25
3.3.2 Diagram Use Case 25
3.3.3 Deskripsi Use Case 26
3.3.4 Activity Diagram 26
3.4 Perancangan Antarmuka 29
3.4.1 Rancangan Tampilan Halaman Utama 29
3.4.2 Rancangan Tampilan Halaman Proses 29
BAB 4 IMPLEMENTASI DAN PENGUJIAN
4.1 Kebutuhan Aplikasi 32
4.1.1 Perangkat Keras 32
4.1.2 Perangkat Lunak 32
4.2 Implementasi Perancangan Antarmuka 33
33
4.2.2 Halaman Proses 33
4.3 Pengujian Sistem 37
BAB 5 KESIMPULAN DAN SARAN
5.1 Kesimpulan 41
5.2 Saran 42
DAFTAR GAMBAR
Hal. Gambar 2.1. Tahap pada Knowledge Discovery Database 6 Gambar 2.2. Gambar Tabel Data Yang Terdapat Duplikat 9
Gambar 2.3. Gambar Tabel Data Dan Key 10
[image:55.595.105.518.161.713.2]Gambar 2.4. Window Pada Tahap Merge 11
Gambar 3.1. Penggunaan Data 17
Gambar 3.2. Arsitektur Umum 19
Gambar 3.3. Gambar Data Setelah Preprocessing 21
Gambar 3.4. Gambar Data Hasil Pembentukan Key 1, Key 2, Key 3 21
Gambar 3.5. Gambar Data Hasil Ascending 22
Gambar 3.6. Gambar Data Hasil N-Gram 22
Gambar 3.7. Gambar Data Hasil Jaccard 23
Gambar 3.8. Gambar Data Hasil Leveinsthein Distance 24
Gambar 3.9. Use Case sistem 26
Gambar 3.10. Activity Diagram Melihat Form Utama 27
Gambar 3.11. Activity Diagram Halaman Data Cleaning 27 Gambar 3.12. Activity Diagram Proses Data Cleaning 28
Gambar 3.14. Rancangan Tampilan Halaman Utama 29
Gambar 3.15. Rancangan Tampilan Proses 30
Gambar 4.1. Tampilan Halaman Utama 33
Gambar 4.2. Tampilan Halaman Proses 34
Gambar 4.3. Tampilan File Location 34
Gambar 4.4. Tampilan Pop-up pada saat tombol browse di klik 35
Gambar 4.5. Tampilan Setelah Tombol Proses Diklik 35
Gambar 4.6. Tampilan Proses Data Cleaning 36
DAFTAR TABEL
Hal.
Tabel 2.1. Peneliti Terdahulu 14
Tabel 3.1. Deskripsi Use Case Data Cleaning 26
Tabel 4.1. Tabel Data 37
Tabel 4.2. Tabel Hasil Data duplikat 38
Tabel 4.3. Tabel Pengujian 39