PERBANDINGAN PENGGUNAAN METODE ANALISIS REGRESI RIDGE DAN METODE ANALISIS REGRESI KOMPONEN UTAMA DALAM
MENYELESAIKAN MASALAH MULTIKOLINIERITAS
(Studi Kasus Data PDRB Propinsi Sumatera Utara)
SKRIPSI
MARIANTI ROSANNA PASARIBU
100823006
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
MEDAN
PERSETUJUAN
Judul : PERBANDINGAN PENGGUNAAN METODE
ANALISIS REGRESI RIDGE DAN METODE ANALISIS REGRESI KOMPONEN UTAMA DALAM MENYELESAIKAN MASALAH MULTIKOLINIERITAS
(Studi Kasus Data PDRB Propinsi Sumatera Utara)
Kategori : SKRIPSI
Nama : MARIANTI ROSANNA PASARIBU
Nomor Induk Mahasiswa : 100823006
Program Studi : SARJANA (S1) MATEMATIKA
Fakultas : MATEMATIKA DAN ILMU PERNGETAHUAN
ALAM (FMIPA) UNIVERSITAS SUMATERA UTARA
Diluluskan di Medan, Juli 2012
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Drs. Gim Tarigan, M.Si Drs. Henry Rani Sitepu, M.Si NIP 19550202 198601 1 001 NIP 19530303 198303 1 002
Diketahui / Disetujui Oleh
Departemen Matematika FMIPA USU Ketua,
Dr.Tulus, M.Si
PERNYATAAN
PERBANDINGAN PENGGUNAAN METODE ANALISIS REGRESI RIDGE DAN METODE ANALISIS REGRESI KOMPONEN UTAMA DALAM
MENYELESAIKAN MASALAH MULTIKOLINIERITAS (Studi Kasus Data PDRB Propinsi Sumatera Utara)
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil kerja saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya,
Medan, Juli 2012
MARIANTI ROSANNA PASARIBU
PENGHARGAAN
Puji syukur dan terima kasih penulis panjatkan kepada Tuhan Yang Maha Esa atas
kasih karunia dan pertolonganNya, sehingga penulis dapat menyelesaikan penulisan
skripsi ini.
Ucapan terima kasih juga penulis ucapkan kepada Bapak Drs. Henry Rani
Sitepu, M.Si sebagai Dosen Pembimbing I dan Bapak Drs. Gim Tarigan, M.Si selaku
Dosen Pembimbing II dalam penyelesaian skripsi ini, atas setiap bimbingan,
dukungan, dan waktu yang telah diberikan. Penulis juga mengucapkan terima kasih
kepada Bapak Drs. Pengarapen Bangun, M.Si dan Bapak Drs. Rachmad Sitepu, M.Si
sebagai Dosen Penguji, atas setiap saran dan masukannya selama pengerjaan skripsi
ini. Ucapan terima kasih juga penulis tujukan kepada Ketua dan Sekretaris
Departemen Prof. Dr. Tulus, M.Si dan Dra. Mardiningsih, M.Si dan kepada Bapak/Ibu
dosen pada Departemen Matematika FMIPA USU beserta semua Staf Administrasi di
FMIPA USU.
Terima kasih yang sebesar-besarnya juga penulis tujukan kepada kedua orang
tua penulis Bapak L.E. Pasaribu dan Ibu M.Br. Sinaga atas semua dukungan dalam
doa, motivasi, kasih sayang, serta semua dukungan materil maupun moril yang
membantu penulis dalam menyelesaikan skripsi ini. Ucapan terima kasih juga penulis
sampaikan kepada abang dan adek penulis (Johan dan Agnes), terima kasih atas doa
dan dukungan kalian. Terima kasih kepada bang Binara yang selalu memberi
semangat dan saran dalam membantu saya menyusun skripsi ini. Tak lupa juga
penulis mengucapkan terima kasih kepada teman-teman Ekstensi Matematika Statistik
Stambuk 2010, atas kebersamaannya selama ini, atas doa dari teman-teman juga
sangat membantu penulis dalam menyelesaikan skripsi ini. Terima kasih juga penulis
ucapkan kepada semua teman dan sahabat yang lain yang membantu penyelesaian
skripsi ini. Terima kasih atas semua doa dan dukungannya. Akhirnya biarlah kasih
karunia Tuhan Yang Maha Esa yang menyertai kita semua. Semoga tulisan ini
ABSTRAK
Multikolinieritas adalah kondisi dimana dalam sebuah regresi terdapat korelasi yang
sangat tinggi antara variabel bebasnya. Analisis Regresi Ridge dan Analisis Regresi
Komponen Utama adalah metode untuk menyelesaikan multikolinearitas yang terjadi
pada analisis regresi ganda. Metode Analisis Regresi Ridge adalah metode yang
memberikan tetapan bias yang relatif kecil dengan cara mengalikan tetapan bias θ
pada diagonal matriks identitas, sehingga parameter penduganya menjadi :
. Metode Analisis Regresi Komponen utama pada dasarnya
adalah bertujuan untuk menyederhanakan variabel yang diamati dengan cara
menyusutkan (mereduksi) dimensinya. Hal ini dilakukan dengan cara menghilangkan
korelasi diantara variabel bebas melalui transformasi variabel bebas asal ke variabel
baru yang tidak berkorelasi sama sekali atau yang biasa disebut dengan komponen
utama (principal component). Pengujian koefisien yang diperoleh dari kedua metode
akan menunjukkan bahwa multikolinieritas dalam suatu regresi linier berganda sudah
ABSTRACT
Multicollinearity is a condition where there is a regression in a very high correlation
between the independent variables. Ridge Regression Analysis and Principal
Component Regression analysis is a method to solve the multicollinearity that occurs
in multiple regression analysis. Ridge Regression Analysis is a method that gives a
relatively small constant bias by multiplying the constant bias on the diagonal identity
matrix θ, so the estimation parameter be:
. Principal Component Regression analysis is basically
aimed to simplify the variables observed by shrinking (reduced) the dimension. This is
done by removing the correlation between independent variables through the
transformation of the independent variables of origin to a new variable that does not
correlate at all, or so-called principal component (principal component). Testing
coefficients obtained from the two methods would indicate that multicollinearity in a
DAFTAR ISI
Halaman
Persetujuan ii
Pernyataan iii
Penghargaan iv
Abstrak v
Abstract vi
Daftar Isi vii
Daftar Tabel ix
BAB 1 PENDAHULUAN 1
1.1 Latar Belakang 1
1.2 Perumusan Masalah 3
1.3 Pembatasan Masalah 3
1.4 Tujuan Penelitian 3
1.5 Manfaat Penelitian 4
1.6 Tinjauan Pustaka 4
1.7 Metodologi Penelitian 5
BAB 2 LANDASAN TEORI 6
2.1 Aljabar Matriks 6
2.1.1 Definisi 6
2.1.2 Nilai Eigen dan Vektor Eigen 9
2.2 Analisis Regresi Linier Berganda 10
2.3 Penduga Parameter 12
2.4 Metode Centering and Rescaling dan Matriks Korelasi 13
2.4.1 Metode Centering and Rescaling 13
2.4.2 Matriks Korelasi 14
2.6 Pendeteksian Multikolinieritas 16
2.7Metode Regresi Ridge 17
2.8Uji Koefisien Korelasi Ganda 19
2.9 Metode Analisis Regresi Komponen Utama 20
2.9.1 Menentukan Komponen Utama 20
2.9.2 Komponen Utama Berdasarkan Matriks Korelasi 21
2.9.3 Kriteria Pemilihan Komponen Utama 22
BAB 3 PEMBAHASAN 23
3.1 PDRB (Produk Domestik Regional Bruto) 23
3.2 Analisis Dengan Regresi Linier Berganda 26
3.3 Pendeteksian Multikolinieritas 28
3.4 Metode Analisis Regresi Ridge 30
3.5 Uji Keberartian Regresi 39
3.6 Regresi Komponen Utama 40
3.7 Analisis Regresi Komponen Utama 42
3.7.1 Model Regresi Yang Cocok 46
3.7.2 Perbandingan Hasil Analisis Regresi Ridge dan Analisis Regresi
Komponen Utama 48
BAB 4 KESIMPULAN DAN SARAN 49
4.1 Kesimpulan 49
4.2 Saran 50
Daftar Pustaka 51
DAFTAR TABEL
Halaman
Tabel 3.1 Data PDRB Propinsi Sumatera Utara 26
Tabel 3.2 Estimator Parameter Regresi Kuadrat Terkecil 27
Tabel 3.3 ANOVAb 27
Tabel 3.4 Tabel VIF dan TOL 28
Tabel 3.5 Koefisien Korelasi Parsial 29
Tabel 3.6 Transformasi Ridge 31
Tabel 3.7 Nilai dengan berbagai harga 34
Tabel 3.8 Nilai VIF dengan Berbagai Nilai 37
Tabel 3.9 ANAVA Regresi Ridge 39
Tabel 3.10 Matriks Korelasi 43
Tabel 3.11 Nilai Eigen, Proporsi Total Variansi, dan Proporsi Variansi Kumulatif 43
Tabel 3.12 Koefisien Komponen Utama (Vektor Eigen) 45
Tabel 3.13 Skor Faktor Komponen Utama 45
Tabel 3.14 Uji Signifikansi Koefisien Regresi Komponen Utama 46
ABSTRAK
Multikolinieritas adalah kondisi dimana dalam sebuah regresi terdapat korelasi yang
sangat tinggi antara variabel bebasnya. Analisis Regresi Ridge dan Analisis Regresi
Komponen Utama adalah metode untuk menyelesaikan multikolinearitas yang terjadi
pada analisis regresi ganda. Metode Analisis Regresi Ridge adalah metode yang
memberikan tetapan bias yang relatif kecil dengan cara mengalikan tetapan bias θ
pada diagonal matriks identitas, sehingga parameter penduganya menjadi :
. Metode Analisis Regresi Komponen utama pada dasarnya
adalah bertujuan untuk menyederhanakan variabel yang diamati dengan cara
menyusutkan (mereduksi) dimensinya. Hal ini dilakukan dengan cara menghilangkan
korelasi diantara variabel bebas melalui transformasi variabel bebas asal ke variabel
baru yang tidak berkorelasi sama sekali atau yang biasa disebut dengan komponen
utama (principal component). Pengujian koefisien yang diperoleh dari kedua metode
akan menunjukkan bahwa multikolinieritas dalam suatu regresi linier berganda sudah
ABSTRACT
Multicollinearity is a condition where there is a regression in a very high correlation
between the independent variables. Ridge Regression Analysis and Principal
Component Regression analysis is a method to solve the multicollinearity that occurs
in multiple regression analysis. Ridge Regression Analysis is a method that gives a
relatively small constant bias by multiplying the constant bias on the diagonal identity
matrix θ, so the estimation parameter be:
. Principal Component Regression analysis is basically
aimed to simplify the variables observed by shrinking (reduced) the dimension. This is
done by removing the correlation between independent variables through the
transformation of the independent variables of origin to a new variable that does not
correlate at all, or so-called principal component (principal component). Testing
coefficients obtained from the two methods would indicate that multicollinearity in a
BAB 1
PENDAHULUAN
1.1Latar Belakang
Analisis regresi merupakan analisis yang mempelajari bagaimana membangun sebuah
model fungsional dari data untuk dapat menjelaskan ataupun meramalkan suatu
fenomena alami atas dasar fenomena yang lain. Dalam perkembangannya terdapat dua
jenis regresi yang sangat terkenal, yaitu regresi linier sederhana dan regresi linier
berganda. Regresi linier sederhana digunakan untuk menggambarkan hubungan antara
satu variabel bebas dengan satu variabel tak bebas . Sedangkan jika variabel
bebas yang digunakan lebih dari satu, maka persamaan regresinya adalah
persamaan regresi linier berganda.
Satu dari asumsi model regresi linier adalah bahwa tidak terdapat
multikolinearitas diantara variabel bebas yang termasuk dalam model.
Multikolinearitas terjadi apabila terdapat hubungan atau korelasi diantara beberapa
atau seluruh variabel bebas.
Seperti yang dapat dilihat sebagai studi kasus adalah pada kasus data PDRB
(Produk Domestik Regional Bruto) Propinsi Sumatera Utara (SUMUT), dimana pada
data PDRB ada berbagai faktor yang dapat mempengaruhi PDRB tersebut yaitu :
jumlah penduduk, konsumsi, investasi, dan ekspor-impor. Faktor yang mempengaruhi
PDRB adalah variabel bebas sedangkan data PDRB merupakan variabel tak bebas.
Ternyata data PDRB mengandung multikolinieritas karena adanya korelasi atau
multikolinieritas dalam data PDRB dapat menyebabkan adanya varian yang besar
sehingga model yang dihasilkan akan memberikan galat yang besar. Untuk itu, perlu
dilakukan penanggulangan masalah multikolinieritas pada data PDRB tersebut
sehingga nanti akan diperoleh model atau persamaan yang lebih baik dalam
penaksiran yang mempunyai nilai galat atau kesalahan yang kecil.
Ada beberapa cara yang dapat digunakan untuk mengatasi masalah
multikolinieritas, diantaranya ialah :
1. Metode Regresi Ridge, regresi ini merupakan modifikasi dari model kuadrat
terkecil dengan cara menambah tetapan bias c yang kecil pada diagonal
matriks .
Sehingga dugaan koefisien regresi menjadi :
dengan :
= estimator Ridge regression
θ = Ridge parameter (bilangan kecil positif terletak antara 0 dan 1) = matriks n x k yang merupakan hasil transformasi variabel regressor.
2. Analisis regresi komponen utama, pada analisis regresi komponen utama
semua peubah bebas masuk ke dalam model, tetapi sudah tidak terjadi
multikolinieritas karena sudah dihilangkan pada tahap analisis komponen
utama.
Pada persamaan regresi komponen utama, variabel diganti
dengan variabel baku .
Berdasarkan hal tersebut, penulis tertarik untuk menyelesaikan masalah
multikolinieritas yang ada dalam data PDRB propinsi Sumatera Utara, yaitu dengan
judul skripsi “Perbandingan Penggunaan Metode Analisis Regresi Ridge dan
Metode Analisis Regresi Komponen Utama dalam Menyelesaikan Masalah Multikolinieritas (Studi Kasus Data PDRB Propinsi Sumatera Utara)”
Sesuai dengan uraian di atas yang menjadi permasalahan adalah bagaimana cara
mengatasi masalah multikolinieritas pada studi kasus data PDRB Propinsi Sumatera
Utara dengan menggunakan metode analisis regresi Ridge dan metode analisis regresi
komponen utama sehingga akan diperoleh persamaan regresi linier berganda dari data
tersebut yang terbaik dan tidak memiiki masalah multikolinieritas.
1.3Pembatasan Masalah
Peneliti membatasi permasalahan yang akan dibahas adalah mengenai masalah
multikolinieritas pada studi kasus data PDRB Propinsi Sumatera Utara dan
penyelesaiannya dengan menggunakan metode analisis regresi Ridge dan metode
analisis regresi komponen utama, kemudian nanti akan dilihat metode yang paling
baik berdasarkan kriteria yang telah ditentukan yaitu berdasarkan nilai galat (MSE).
1.4Tujuan Penelitian
Tujuan dari penelitian ini adalah untuk mengatasi masalah multikolinieritas pada studi
kasus data PDRB Propinsi Sumatera Utara sehingga diperoleh model persamaan
regresi yang lebih baik berdasarkan kriteria yang telah ditentukan setelah
membandingkan kedua metode dalam penyelesaiannya.
Penelitian ini diharapkan dapat memberi manfaat bagi pembaca untuk lebih
mengetahui mengenai masalah multikolinieritas dan cara mengatasinya. Serta
memberi solusi untuk mengatasi masalah multikolinieritas bagi peneliti untuk
menganalisis penelitian pada berbagai bidang ilmu, seperti penelitian-penelitian di
bidang sosial, ekonomi, pertanian dan lain-lain.
1.6Tinjauan Pustaka
Gujarati (1978), Istilah Multikolinearitas pertama kali ditemukan oleh Ragnar Frisch
yang berarti adanya hubungan liniear yang “sempurna” atau pasti diantara beberapa
atau semua variabel bebas dari model regresi berganda.
Walpole dan Myers (1995), Koefisien determinasi adalah nilai yang
menunjukkan seberapa besar nilai variabel Y dijelaskan oleh variable X. Koefisien
determinasi merupakan salah satu patokan yang biasa digunakan untuk melihat apakah
suatu model regresi yang dicocokkan belum atau sudah memadai, yang dinotasikan
dengan . Koefisien determinasi ini hanya menunjukkan ukuran proporsi variansi
total dalam respon Y yang diterangkan oleh model yang dicocokkan.
Vincent Gasperst (1991), Analisis komponen utama bertujuan untuk
menyederhanakan variabel yang diamati dengan cara menyusutkan dimensinya. Hal
ini dilakukan dengan menghilangkan korelasi variabel melalui transformasi variabel
asal ke variabel baru yang tidak berkorelasi. Variabel baru ( ) disebut sebagai
komponen utama yang merupakan hasil transformasi dari variabel asal yang
modelnya dalam bentuk catatan matriks adalah:
Walpole dan Myers (1995), suatu cara dalam menghadapi multikolinieritas
penaksiran yang bias. Dengan cara ini, pada dasarnya kita bersedia menerima
sejumlah bias tertentu dalam taksiran agar variansi penaksir dapat diperkecil. Taksiran
bias yang diperoleh disini untuk koefisien regresi dalam model :
dinyatakan dengan dan disebut taksiran regresi Ridge.
1.7Metodologi Penelitian
Adapun metode penelitian dalam skripsi ini adalah :
1. Terlebih dahulu menjelaskan megenai operasi matriks yaitu determinan
matriks, invers matriks, nilai eigen dan vektor eigen, dan matriks korelasi,
analisis regresi linier berganda, multikolinieritas, metode analisis regresi Ridge
serta metode analisis regresi komponen utama
2. Mendeteksi keberadaan multikolinieritas.
3. Menguraikan penyelesaian masalah multikolinieritas dalam studi kasus PDRB
Propinsi Sumatera Utara dengan menggunakan metode analisis regresi Ridge.
4. Menguraikan penyelesaian masalah multikolinieritas menggunakan metode
analisis regresi komponen utama.
5. Menyimpulkan persamaan dan perbedaan kedua metode tersebut di atas
BAB 2
LANDASAN TEORI
2.1 Aljabar Matriks
2.1.1 Definisi
Matriks
Matriks adalah suatu kumpulan angka-angka yang juga sering disebut elemen-elemen
yang disusun secara teratur menurut baris dan kolom sehingga berbentuk persegi
panjang, dimana panjang dan lebarnya ditunjukkan oleh banyaknya kolom dan baris
serta dibatasi tanda “[ ]” atau “( )”. Sebuah matriks dinotasikan dengan simbol huruf besar seperti A, X, atau Z dan sebagainya. Sebuah matriks A yang berukuran m baris
dan n kolom dapat ditulis sebagai berikut :
Atau juga dapat ditulis :
Kombinasi Linier
Vektor w merupakan kombinasi linier dari vektor-vektor jika terdapat
skalar sehingga berlaku :
, (2.1)
Jika vektor w = 0 maka disebut persamaan homogen dan disebut vektor
yang bebas linier, yang mengakibatkan , tetapi jika ada
bilangan yang tidak semuanya sama dengan nol, maka
disebut bergantung linier.
Determinan Matriks
Misalkan = [ ] adalah matriks . Fungsi determinan dari ditulis dengan
atau . Secara matematiknya ditulis :
Dimana ∑ menunjukkan bahwa suku-suku tersebut harus dijumlahkan terhadap semua permutasi dan simbol (+) atau (-) dapat dipilih dalam masing-masing
suku sesuai dengan apakah permutasi itu genap atau ganjil. Anton (1995, hal : 64)
Teorema
Jika A = [ ] adalah matriks yang mengandung sebaris bilangan nol, maka
.
Teorema
Jika adalah matriks segitiga nxn, maka adalah hasil kali elemen – elemen
Teorema
Jika adalah sebarang matriks kuadrat, maka .
Invers Matriks
Misalkan A matriks nxn disebut non singular (invertible) jika terdapat matriks B maka
AB = BA = I
Matriks B disebut invers dari A jika tidak terdapat matriks B maka matriks A disebut
singular (non-invertible).
Secara umum invers matriks A adalah :
Adjoint matriks A adalah suatu matriks yang elemen-elemennya terdiri dari semua
elemen-elemen kofaktor matriks A, dengan adalah kofaktor elemen-elemen
Sehingga dapat ditulis dalam bentuk matriks sebagai berikut :
dengan :
= minor entri yaitu determinan suatu matriks yang diperoleh dengan
menghapus baris ke –i dan kolom ke-j dari matriks A.
a. Jika A adalah
matriks non singular, maka adalah non singular dan
b. Jika A dan B adalah
matriks non singular, maka AB adalah non singular dan
2.1.2 Nilai Eigen dan Vektor Eigen
Jika A adalah matriks nxn, maka vektor tak nol X di dalam dinamakan vektor
eigen(eigenvektor) dari A jika AX adalah kelipatan skalar dari X yakni :
AX = λX (2.2)
Untuk suatu skalar λ. Skalar λ dinamakan nilai eigen (eigen value) dari A dan X
dikatakan vektor eigen yang bersesuaian dengan λ.
Untuk mencari nilai eigen matriks yang berukuran nxn, dari persamaan
(2.2) dapat ditulis kembali sebagai suatu persamaan homogen :
Dengan I adalah matriks identitas yang berordo sama dengan matriks A, dalam
catatan matriks :
, ,
untuk memperoleh nilai
n buah akar
Jika nilai eigen disubstitusi pada persamaan , maka solusi
dari vektor eigen Xn adalah
(2.3)
Jadi apabila matriks mempunyai akar karakteristik dan ada
kemungkinan bahwa diantaranya mempunyai nilai yang sama, bersesuaian dengan
akar-akar karakteristik ini adalah himpunan vektor–vektor karakteristik yang
orthogonal (artinya masing-masing nilai akar karakteristik akan memberikan vektor
karakteristik) sedemikian sehingga :
i,j=1,2,…,n
Dalam perkembangannya terdapat dua jenis regresi yang sangat terkenal, yaitu regresi
linier sederhana dan regresi linier berganda. Regresi linier sederhana digunakan untuk
menggambarkan hubungan antara suatu variabel bebas (X) dengan satu variabel tak
bebas (Y) dalam bentuk persamaan linier sederhana.
i = 1,2,…, n (2.4)
Regresi linier berganda merupakan perluasan dari regresi linier sederhana.
Perluasannya terlihat dari banyaknya variabel bebas pada model regresi tersebut.
Bentuk umum regresi linier berganda dapat dinyatakan secara statistik sebagai berikut:
(2.5)
dengan :
= variabel tak bebas
= variabel bebas
= parameter regresi
= variabel gangguan
Dalam melakukan analisis regresi linier berganda, sering dijumpai masalah
multikolinieritas pada peubah – peubah bebasnya (X). Akibatnya adanya pelanggaran
terhadap salah satu asumsi yang disyaratkan pada penggunaan regresi linier tersebut
sehingga mempengaruhi sifat – sifat penduga atau penaksir koefisien regresi linier
bergandanya.
Adapun asumsi – asumsi yang mendasari analisis regresi berganda tersebut
antara lain :
1. Nilai rata-rata kesalahan pengganggu nol, yaitu untuk i = 1, 2, …, n
2. , adalah konstan untuk semua kesalahan pengganggu
(asumsi homokedastisitas).
3. Tidak ada otokorelasi antara kesalahan pengganggu , berarti kovarian
.
4. Variabel bebas konstan dalam sampling yang terulang dan bebas
terhadap kesalahan pengganggu .
6. , artinya kesalahan pengganggu menyebar mengikuti distribusi
normal dengan rata-rata 0 dan varian .
Dalam data PDRB propinsi Sumatera Utara, salah satu asumsi yaitu tidak ada
multikolinieritas diantara variabel bebasnya yaitu antara faktor – faktor yang
mempengaruhinya telah dilanggar sehingga mengakibatkan penduga koefisien regresi
linier ganda relatif tidak stabil atau kurang tepat (dalam hal ini dianggap asumsi
lainnya telah terpenuhi).
2.3 Penduga Parameter
Metode Kuadrat Terkecil
Metode kuadrat terkecil merupakan suatu metode yang paling banyak digunakan
untuk menduga parameter-parameter regresi. Pada model regresi linier berganda juga
digunakan metode kuadrat terkecil untuk menduga parameter. Biasanya penduga
kuadrat terkecil ini diperoleh dengan meminimumkan jumlah kuadrat galat. Misalkan
model yang akan diestimasi adalah parameter dari persamaan dengan n pengamatan,
maka diperoleh :
Persaman-persamaan diatas dapat ditulis dalam bentuk matriks :
(2.6)
Untuk mendapatkan penaksir-penaksir MKT (Metode Kuadrat Terkecil) bagi ,
maka dengan asumsi klasik ditentukan dua vektor ( dan e) sebagai:
Persamaan hasil estimasi dari persamaan (2.6) dapat ditulis sebagai :
Sedangkan untuk taksiran parameter pada analisis regresi linier berganda dapat dinyatakan sebagai berikut :
2.4 Met
ode Centering and Rescaling dan Matriks Korelasi
2.4.1 Metode Centering and Rescaling
Dalam persamaan regresi yang memiliki model :
Persamaan tersebut di atas dapat dibentuk menjadi :
menurut rumus untuk mendapatkan yaitu :
sehingga
jika
Prosedur untuk membentuk persamaan pertama menjadi persamaan terakhir
disebut dengan prosedur centering. Prosedur ini mengakibatkan hilangnya yang
membuat perhitungan untuk mencari model regresi menjadi lebih sederhana.
Bila dari persamaan di atas kita bentuk persamaan :
dengan
maka prosedur ini disebut dengan prosedur rescaling. Keseluruhan dari prosedur di
atas disebut prosedur centering and rescaling.
2.4.2 Matriks Korelasi
Persamaan yang didapat melalui prosedur Centering and Rescaling di atas bila
untuk,
Hal ini berlaku juga untuk
sedangkan untuk
Matriks yang diperoleh disebut matriks korelasi.
2.5 Mult
ikolinieritas
Istilah multikolinieritas mula – mula dikemukakan oleh Ragner Frisch pada tahun
1934. Pada mulanya multikolinieritas ini berarti adanya hubungan linier yang
“sempurna” atau pasti, diantara beberapa atau semua variabel yang menjelaskan dari model regresi, atau dapat diartikan sebagai hubungan linier antara variabel
eksplanatoris dari suatu model regresi adalah sempurna.
Maksud tidak ada hubungan linier (kolinieritas) antara regressor adalah
sebagai berikut :
Misalkan terdapat dua variabel bebas, dan jika dapat dinyatakan sebagai
fungsi linier dari atau sebaliknya, maka dinyatakan bahwa ada kolinieritas antara
dan . Contohnya, misalkan ada tiga variabel bebas yaitu dan . Jika nilai
merupakan penjumlahan dari dan maka akan terjadi perfect multikolinearity.
Adanya multikolinieritas di antara varabel bebas pada koefisien regresi penduga yang
diperoleh dengan metode kuadrat terkecil akan berpengaruh karena varian akan
semakin besar sehingga penduga kuadrat terkecil akan memiliki varian yang besar
juga.
Menurut Motgomery dan Peck, beberapa sumber penyebab multikolinieritas
adalah:
1. Metode pengumpulan data yang digunakan membatasi nilai dari regressor.
2. Kendala model pada populasi yang diamati.
3. Spesifikasi model
4. Penentuan jumlah variabel eksplanatoris yang lebih banyak dari jumlah
observasi atau overdetermined model.
5. Data time series, trend tercakup dalam nilai variabel eksplanatoris yang
ditunjukkan oleh penurunan atau peningkatan sejalan dengan waktu. Kadang
kala aplikasi data sekunder mengalami masalah penaksiran atau menolak
2.6 Pendeteksian Multikolinieritas
Ada beberapa cara untuk mengetahui ada tidaknya multikolinieritas dalam suatu
data,antara lain :
a. Faktor Variansi Inflasi (VIF) dan Tol(Tolarance)
Tolerance adalah indikator seberapa banyak variabilitas sebuah variabel bebas
tidak bisa dijelaskan oleh variabel bebas lainnya. Tolerance dihitung dengan
rumus untuk setiap variabel bebas. Jika nilai Tolerance sangat kecil (<
0,1), maka itu menandakan korelasi berganda satu variabel bebas sangat tinggi
dengan variabel bebas lainnya dan mengindikasikan multikolinieritas. Nilai
VIF merupakan invers dari nilai Tolerance ). Jika nilai VIF > 10,
maka itu mengindikasikan terjadinya multikolinieritas.
b. Koefisien Korelasi Partial
koefisien korelasi partial menunjukkan besar hubungan antara variabel bebas.
Jika koefisien korelasi sederhana mencapai atau melebihi 0,8 maka hal
tersebut menunjukkan terjadinya masalah multikolinearitas
dalam regresi.
c. Nilai Determinan
Nilai determinan terletak antara 0 dan 1. Bila nilai determinan satu, kolom
matriks X adalah orthogonal (seregresi) dan apabila nilai 0 disana ada sebuah
ketergantungan linier yang nyata antara kolom X. Nilai yang lebih kecil
2.7 Metode Regresi Ridge
Salah satu metode yang dapat digunakan untuk menaksir parameter regresi dari model
regresi linier berganda adalah Metode Kuadrat Terkecil. Dugaan parameter koefisien
regresi dengan Metode Kuadrat Terkecil yang dapat dibuat dalam bentuk matriks
adalah :
Dengan membentuk menjadi bentuk matriks korelasi, maka kesalahan
yang disebabkan pengaruh pembulatan menjadi lebih kecil (Draper & Smith,1992).
Terutama jika variabel regressornya lebih dari dua dan data yang ada besar. Jika
yang merupakan matriks korelasi adalah matriks identitas maka nilai dugaan variabel
regressand akan sama dengan nilai sebenarnya. Apabila tidak mendekati matriks
identitas melainkan menjauhinya, maka dapat dikatakan hampir singular (buruk).
Kondisi ini disebut sebagai ill conditioned (Draper & Smith ,1992). Kondisi ini terjadi
apabila terdapat korelasi antar variabel regressor yang cukup tinggi sehingga
menyebabkan determinan mendekati nol. Maka antara variabel regressor terjadi
multikolinieritas ganda tidak sempurna.
Apabila terjadi situasi tersebut, penaksiran parameter koefisien regresi masih
mungkin dilakukan dengan metode kuadrat terkecil, tetapi dengan konsekuensi
simpangan bakunya menjadi sangat sensitif sekalipun terjadi perubahan yang sangat
kecil dalam datanya. Simpangan baku ini cenderung membesar sejalan dengan
meningkatnya multikolinieritas.
Apabila terjadi multikolinieritas tidak sempurna pada variabel regressor pada
diagonal utama ditambah bilangan kecil positif yang bernilai antara 0 dan 1,
maka prosedur ini disebut Ridge Trace. Kemudian dengan mentransformasikan
matriks menjadi matriks korelasi sehingga dugaan koefisien regresi menjadi
:
= estimator Ridge regression
θ = Ridge parameter (bilangan kecil positif terletak antara 0 dan 1) = matriks n x k yang merupakan hasil transformasi variabel regressor.
Sehingga nilai dugaan untuk variabel regressand menjadi :
Proses tersebut di atas disebut dengan Ridge regression. Analisis regresi Ridge dapat
digunakan apabila tidak singular. Asumsi yang digunakan hanyalah ada
dan tidak sulit mendapatkannya.
Umumnya sifat dari penafsiran Ridge ini memiliki variansi yang minimum
sehingga diperoleh nilai VIF nya yang merupakan diagonal utama dari matriks :
Dari berbagai nilai yang ada, akan dipilih harga yang memberikan nilai
VIF relatif dekat dengan 1.
Hubungan parameter , dalam model baru dengan parameter
dalam model semula adalah :
2.8 Uji Koefisien Korelasi Ganda
Koefisien korelasi ganda dihutung dengan rumus :
(2.8)
Jadi statistik yang digunakan untuk menguji hipotesi nol adalah :
(2.9)
Tolak hipotesa nol bahwa koefisien korelasi berarti jika , dalam hal
ini hipotesa bahwa koefisien korelasi ganda berarti harus diterima.
2.9 Metode Analisis Regresi Komponen Utama
Analisis komponen utama pada dasarnya adalah bertujuan untuk menyederhanakan
variabel yang diamati dengan cara menyusutkan (mereduksi) dimensinya. Hal ini
dilakukan dengan cara menghilangkan korelasi diantara variabel bebas melalui
transformasi variabel bebas asal ke variabel baru yang tidak berkorelasi sama sekali
Variabel baru ( disebut sebagai komponen utama yang merupakan hasil
transformasi dari variabel asal ( yang modelnya dalam bentuk catatan matriks
adalah :
= A
dengan : A adalah matriks yang melakukan transformasi terhadap variabel asal
sehingga diperoleh vektor komponen .
Penjabarannya adalah sebagai berikut :
2.9.1 Menentukan Komponen Utama
Komponen utama dapat ditentukan melalui matriks ragam peragam (Σ) dan matriks
korelasi dari . Matriks kovarian Σ digunakan untuk membentuk
komponen utama apabila semua variabel yang diamati mempunyai satuan pengukuran
yang sama. Sedangkan, matriks korelasi digunakan apabila variabel yang diamati
tidak mempunyai satuan pengukuran yang sama. Variabel tersebut perlu dibakukan,
sehingga komponen utama berdasarkan matriks korelasi ditentukan dari variabel baku.
Data PDRB Propinsi Sumut dapat dilihat mempunyai satuan pengukuran yang
tidak sama antara variabelnya. Oleh karena itu, dalam skripsi ini, komponen utama
akan ditentukan melalui matrik korelasi.
Jika variabel yang diamati tidak mempunyai satuan pengukuran yang sama, maka
variabel tersebut perlu dibakukan sehingga komponen utama ditentukan dari variabel
baku. Variabel asal pun perlu ditransformasikan ke dalam variabel baku Z, dalam
catatan matriks adalah :
(2.10)
dengan :
= variabel baku
= variansi
= variabel pengamatan
= nilai rata-rata pengamatan
Setelah dipilih komponen-komponen utama yang akan digunakan (sebanyak k
buah) selanjutnya ditentukan persamaan regresi dari peubah tak bebas Y dengan
komponen utama tersebut. Untuk meregresikan komponen utama dengan variabel tak
bebas, maka perlu dihitung skor komponen dari setiap pengamatan. Untuk komponen
utama yang diturunkan dari matriks korelasi.
2.9.3 Kriteria Pemilihan Komponen Utama
Salah satu tujuan dari analisis komponen utama adalah mereduksi dimensi data asal
yang semula, terdapat p variable bebas menjadi k komponen utama .
1. Didasarkan pada akar ciri yang lebih besar dari satu, dengan kata lain hanya
komponen utama yang memiliki akar ciri lebih besar dari satu yang dilibatkan
dalam analisis regresi komponen utama.
2. Proporsi kumulatif keragaman data asal yang dijelaskan oleh k komponen utama
minimal 80%, dan proporsi total variansi populasi bernilai cukup besar.
BAB 3
1. Didasarkan pada akar ciri yang lebih besar dari satu, dengan kata lain hanya
komponen utama yang memiliki akar ciri lebih besar dari satu yang dilibatkan
dalam analisis regresi komponen utama.
2. Proporsi kumulatif keragaman data asal yang dijelaskan oleh k komponen utama
minimal 80%, dan proporsi total variansi populasi bernilai cukup besar.
BAB 3
3.1PDRB (Produk Domestik Regional Bruto)
PDRB merupakan catatan tentang jumlah nilai rupiah dari barang dan jasa akhir yang
dihasilkan oleh suatu perekonomian dalam suatu negara untuk waktu satu tahun
(Nurrochmat et al, 2007). Suatu negara dikatakan mengalami pertumbuhan ekonomi
apabila terjadi peningkatan PDRB riil di negara tersebut, dimana hal ini dapat
dijadikan sebagai indikasi keberhasilan pembangunan ekonomi (Wikipedia, 2010).
Selama ini perhitungan nilai PDRB yang dilakukan oleh Badan Pusat
Statistik (BPS) adalah PDRB dengan pendekatan produksi yang dibentuk dari
sembilan sektor atau lapangan usaha, yaitu : (1) Pertanian, (2) Pertambangan dan
Penggalian, (3) Industri Pengolahan, (4) Listrik, Gas dan Air Bersih, (5)
Konstruksi/Bangunan, (6) Perdagangan, Hotel dan Restoran, (7) Pengangkutan dan
Komunikasi, (8) Keuangan, Persewaan dan Jasa Perusahaan, dan (9) Jasa-Jasa.
Kesembilan sektor pembentuk PDRB tersebut merupakan faktor-faktor penting yang
mempengaruhi pertumbuhan ekonomi nasional maupun daerah. Perhitungan yang
tepat perlu dilakukan supaya dapat diketahui diantara kesembilan sektor tersebut mana
yang lebih berpotensi dalam meningkatkan perekonomian. Sehingga hasil perhitungan
tersebut dapat digunakan sebagai dasar penentuan strategi dan kebijaksanaan
pemerintah, agar sasaran pembangunan dapat dicapai dengan tepat.
Data yang akan dianalisis dalam skripsi ini adalah data PDRB propinsi
Sumatera Utara yaitu faktor – faktor yang mempengaruhi PDRB propinsi Sumatera
Adapun faktor-faktor yang mempengaruhi PDRB yang diambil dalam riset
adalah sebagai berikut :
1. Jumlah Penduduk
Standar hidup penduduk diukur dengan kenaikan pendapatan riil perkapita.
Pendapatan riil perkapita, adalah setara dengan Pendapatan Domestik Regional
Bruto (PDRB) selama satu tahun dibagi jumlah penduduk didaerah tersebut.
Jadi standar hidup tidak dapat dinaikkan kecuali jika PDRB-nya meningkat
dengan lebih cepat dibanding pertumbuhan penduduk.
2. Konsumsi
Dalam beberapa tahun terakhir, pembentukan nilai PDRB Sumatera Utara
masih didominasi oleh komponen konsumsi. Hal ini terlihat dari komposisinya
yang cenderung tinggi dan meningkat, walaupun terjadi fluktuasi setiap
tahunnya.
Makanan merupakan kebutuhan pokok manusia untuk tetap hidup, sehingga
sebesar apapun pendapatan seseorang, ia akan tetap berusaha untuk
mendapatkan makanan yang memadai. Seseorang atau suatu rumah tangga
akan terus menambah konsumsi makanannya sejalan dengan bertambahnya
pendapatan, namun sampai batas tertentu penambahan pendapatan tidak lagi
menyebabkan bertambahnya jumlah makanan yang dikonsumsi, karena
kebutuhan manusia akan makanan pada dasarnya mempunyai titik jenuh.
Bila secara kuantitas kebutuhan seseorang telah terpenuhi maka lazimnya ia
akan mementingkan kualitas atau beralih pada pemenuhan kebutuhan bukan
makanan. Hal ini tergambar dari porsi jenis pengeluaran konsumsi rumah
tangga, yaitu porsi pengeluaran makanan dan non makanan.
Selain konsumsi rumah tangga, terdapat juga konsumsi Konsumsi Lembaga
Swasta Yang Tidak Mencari untung dan Konsumsi Pemerintah yang
mempengaruhi PDRB.
Yang dimaksud dengan investasi dalam arti luas adalah semua bentuk
kekayaan yang dapat digunakan langsung maupun tidak langsung dalam
produksi untuk menambah output. Investasi selalu dikaitkan dengan kegiatan
menanamkan uang dalam proses produksi, dengan harapan mendapatkan
keuntungan atau peningkatan kualitas sistem pada masa yang akan datang.
Pengertian investasi dalam penghitungan PDRB menurut penggunaan, dibatasi
pada penambahan/pembentukan barang modal tetap bruto dan perubahan stok,
baik itu barang setengah jadi maupun barang jadi.
4. Ekspor – Impor
Salah satu komponen PDRB menurut penggunaan adalah ekspor dan impor
barang dan jasa. Komponen ini termasuk variabel penting dalam penciptaan
nilai tambah, dimana impor merupakan pengurangan bagi nilai ekspor untuk
mendapatkan ekspor netto. Dalam kontribusinya terutama perolehan
pendapatan negara, segala upaya dilakukan untuk meningkatkan ekspor
terutama ekspor non migas. Komoditi andalan ekspor luar negeri Sumatera
Utara adalah hasil industri olahan kelapa sawit berupa CPO (Crude Palm Oil)
dan minyak inti sawit, getah karet alam, aluminium dan olahan minyak lemak
nabati serta hewani. Sedangkan komoditi impor yang utama adalah biji
aluminium dan pekatannya, pupuk buatan pabrik, makanan ternak, hasil-hasil
minyak bumi dan beras.
Data PDRB merupakan data sekunder yang diperoleh dengan melakukan riset
di Badan Pusat Statistik Provinsi Sumatera Utara Jl. Kapten Muslim No. 67 dan 71
[image:38.595.108.529.677.767.2]Medan, pada tanggal 12, 15, dan 22 Maret 2012.
Tabel 3.1 Data PDRB Propinsi Sumatera Utara
Tahun
PDRB Konsumsi Investasi Ekspor-Impor Jumlah Penduduk
2001 79,33 46,27 12,12 13,52 117,23
2003 103,40 66,86 19,28 17,26 118,90
2004 118,10 73,84 23,62 20,64 121,23
2005 139,61 86,90 28,45 24,26 123,27
2006 160,38 102,89 27,76 29,73 126,43
2007 181,82 122,96 34,18 24,68 128,34
2008 213,93 141,42 44,64 27,87 130,42
2009 236,35 163,96 51,06 21,33 132,48
2010 275,70 196,95 58,15 20,60 129,82
Dengan :
= PDRB (dalam triliun rupiah)
= Konsumsi (dalam triliun rupiah)
= Investasi (dalam triliun rupiah)
= Ekspor-Impor (dalam triliun rupiah)
= Jumlah Penduduk (dalam ratusan ribu jiwa)
3.2Analisis Dengan Regresi Linier Berganda
Analisis regresi dengan metode kuadrat terkecil menghasilkan persamaan seperti pada
[image:39.595.105.525.693.761.2]persamaan (2.4) sebagai berikut (perhitungan menggunakan program SPSS) :
Tabel 3.2 Estimator Parameter Regresi Kuadrat Terkecil
Peubah Penduga Parameter Simpangan Baku
Konstan -87,140 96,092
0,356 0,621
0,250 0,383
[image:40.595.106.529.85.157.2]0,931 0,878
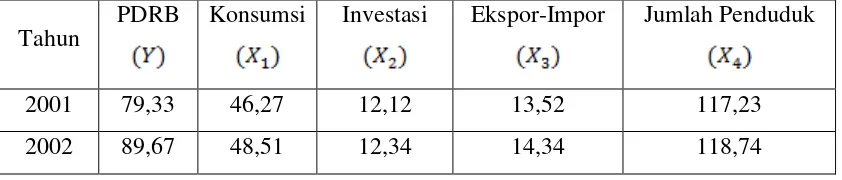
Tabel 3.3 ANOVA
Model Sum of Squares Df Mean Square F
1 Regression 39355,694 4 9838,924 670,158
Residual 73,407 5 14,681
Total 39429,102 9
Berdasarkan output SPSS tabel ANOVA di atas, diperoleh F hitung adalah
670,158. Dengan mengambil nilai dengan derajat bebas pembilang 4 dan
derajat bebas penyebut 5 maka kemudian melihat tabel distribusi F dapat diperoleh F
tabel = 5,19.
Variabel X secara simultan tidak berpengaruh terhadap nilai taksiran Y
Variabel X secara simultan berpengaruh terhadap nilai taksiran Y
dengan
Kriteria pengujian : Tolak bila ; dalam hal lain terima .
Berdasarkan kriteria pengujian ternyata menunjukkan , sehingga
disimpulkan bahwa pengaruh variabel bebas ( ) berpengaruh secara
signifikan terhadap variabel tak bebas Y.
3.3 Pendeteksian Multikolinieritas
[image:40.595.115.514.207.314.2]Dalam skripsi ini, memiliki empat buah variabel bebas: dan dan keempatnya akan diregresikan dengan sebuah variabel tak bebas Y. Nilai VIF dan Tol penulis hitung untuk masing-masing X adalah sebagai berikut :
Untuk , prosedurnya adalah :
1. Regresikan terhadap dan , atau modelnya = +
2. Hitung dari model tersebut 3. Tol untuk adalah
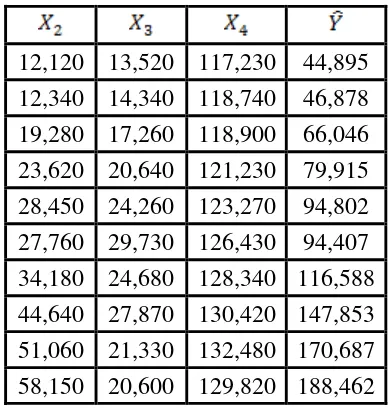
[image:41.595.234.429.331.538.2]4. VIF untuk adalah Diperoleh model untuk
Tabel 3.4 Hasil Estimasi
12,120 13,520 117,230 44,895
12,340 14,340 118,740 46,878
19,280 17,260 118,900 66,046
23,620 20,640 121,230 79,915
28,450 24,260 123,270 94,802
27,760 29,730 126,430 94,407
34,180 24,680 128,340 116,588
44,640 27,870 130,420 147,853
51,060 21,330 132,480 170,687
dianggap sebagai Y yaitu variabel tak bebasnya dan dan sebagai variabel
bebasnya.
= 1- = 0,016
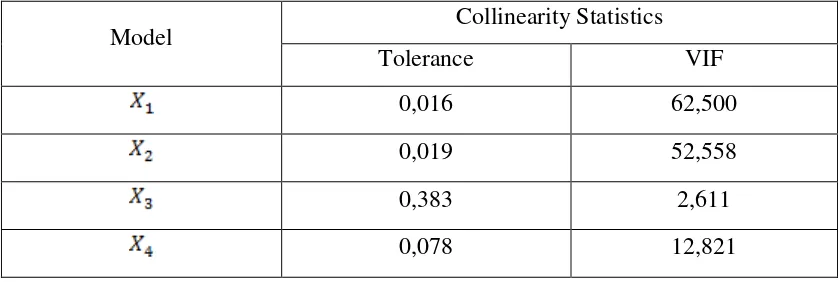
[image:42.595.107.526.474.615.2]Kemudian dengan cara yang sama diperoleh tabel nilai VIF dan Tol untuk masing-masing dan seperti di bawah ini :
Tabel 3.5 VIF dan TOL
Model Collinearity Statistics
Tolerance VIF
0,016 62,500
0,019 52,558
0,383 2,611
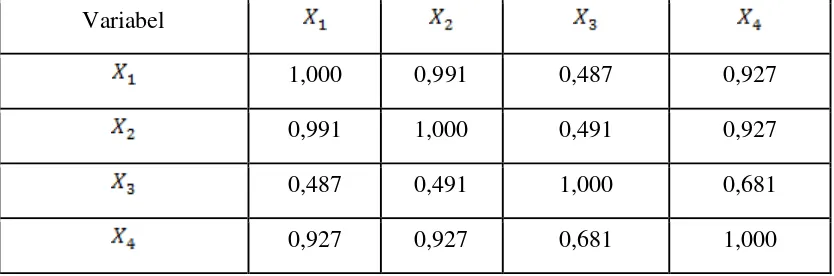
3.3.2 Menghitung Koefisien Korelasi Partial
Untuk mencari korelasi variabel dan :
Sehingga dengan menggunakan cara yang sama, maka akan diperoleh koefisien
[image:43.595.108.525.629.767.2]korelasi dari masing-masing variabel bebas seperti yang terlihat pada tabel berikut :
Tabel 3.6 Koefisien Korelasi Parsial
Variabel
1,000 0,991 0,487 0,927
0,991 1,000 0,491 0,927
0,487 0,491 1,000 0,681
Berdasarkan Tabel 3.5 dan Tabel 3.6 dapat dilihat bahwa :
1. dan memiliki nilai VIF>10 dan TOL<0,1
2. koefisien korelasi parsial memiliki nilai >0,8 yaitu :
dan dan , dan
3. Dari koefisien korelasi parsial, dapat diketahui nilai determinannya, yaitu :
= 0,00094776
Nilai determinan dari matriks korelasi mendekati 0. Ketiga hal di atas dapat
menunjukkan adanya multikolinieritas antara variabel bebasnya.
3.4 Metode Analisis Regresi Ridge
Regresi Ridge bertujuan untuk mengatasi multikolinieritas yang terdapat dalam
regresi linier berganda yang mengakibatkan matriks nya hampir singular yang
pada akhirnya menghasilkan nilai estimasi parameter yang tidak stabil.
Adapun tahapan penaksiran koefisien regresi Ridge yang akan dilakukan untuk
menyelesaikan masalah multikolinieritas dalam data PDRB propinsi Sumatera Utara
adalah sebagai berikut :
1. Lakukan transformasi tehadap matriks X dan vektor Y.
2. Hitung matriks = = matriks korelasi dari variable bebas, serta hitung
= korelasi dari variabel bebas terhadap variabel tak bebas y.
3. Hitung nilai penaksir parameter dengan berbagai kemungkinan tetapan
bias , .
4. Tentukan harga yang memenuhi dengan melihat nilai VIF.
Maka selanjutnya, perhitungan dengan cara yang sama akan dilakukan terhadap setiap
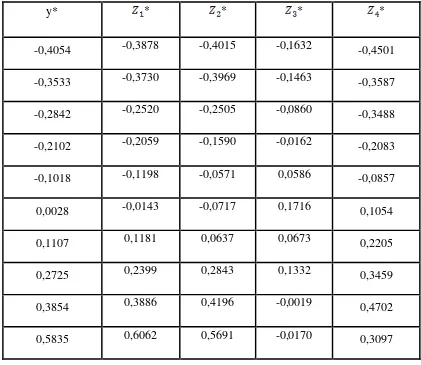
[image:48.595.104.525.314.679.2]data ke - i untuk transformasi Y dan Z seperti pada tabel berikut :
Tabel 3.7 Transformasi Ridge
y* * * * *
-0,4054 -0,3878 -0,4015 -0,1632 -0,4501
-0,3533 -0,3730 -0,3969 -0,1463 -0,3587
-0,2842 -0,2520 -0,2505 -0,0860 -0,3488
-0,2102 -0,2059 -0,1590 -0,0162 -0,2083
-0,1018 -0,1198 -0,0571 0,0586 -0,0857
0,0028 -0,0143 -0,0717 0,1716 0,1054
0,1107 0,1181 0,0637 0,0673 0,2205
0,2725 0,2399 0,2843 0,1332 0,3459
0,3854 0,3886 0,4196 -0,0019 0,4702
0,5835 0,6062 0,5691 -0,0170 0,3097
=
Korelasi dari variabel bebas terhadap variabel tak bebas y
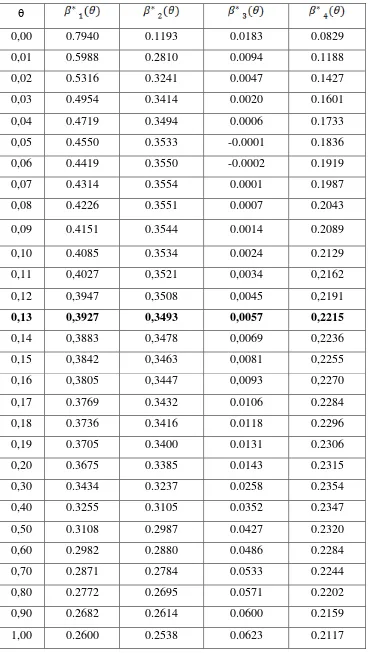
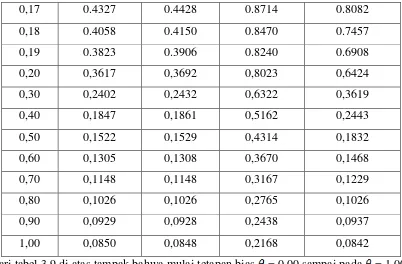
3.4.2 Menghitung Nilai dengan berbagai harga
Rumus untuk menghitung koefisien regresi Ridge adalah :
dengan θ adalah Ridge parameter (bilangan kecil positif terletak antara 0 dan 1).
Sehingga, dalam skripsi ini, akan dicoba untuk memasukkan tiap nilai θ tersebut,
dengan perhitungan :
untuk θ = 0,13
Dan selanjutnya untuk setiap θ akan dilakukan perhitungan dengan yang sama. Tetapi
dalam skripsi ini, untuk mempermudah perhitungan dibantu dengan software
Tabel 3.8 Nilai dengan berbagai harga
0,00 0.7940 0.1193 0.0183 0.0829
0,01 0.5988 0.2810 0.0094 0.1188
0,02 0.5316 0.3241 0.0047 0.1427
0,03 0.4954 0.3414 0.0020 0.1601
0,04 0.4719 0.3494 0.0006 0.1733
0,05 0.4550 0.3533 -0.0001 0.1836
0,06 0.4419 0.3550 -0.0002 0.1919
0,07 0.4314 0.3554 0.0001 0.1987
0,08 0.4226 0.3551 0.0007 0.2043
0,09 0.4151 0.3544 0.0014 0.2089
0,10 0.4085 0.3534 0.0024 0.2129
0,11 0,4027 0,3521 0,0034 0,2162
0,12 0,3947 0,3508 0,0045 0,2191
0,13 0,3927 0,3493 0,0057 0,2215
0,14 0,3883 0,3478 0,0069 0,2236
0,15 0,3842 0,3463 0,0081 0,2255
0,16 0,3805 0,3447 0,0093 0,2270
0,17 0.3769 0.3432 0.0106 0.2284
0,18 0.3736 0.3416 0.0118 0.2296
0,19 0.3705 0.3400 0.0131 0.2306
0,20 0.3675 0.3385 0.0143 0.2315
0,30 0.3434 0.3237 0.0258 0.2354
0,40 0.3255 0.3105 0.0352 0.2347
0,50 0.3108 0.2987 0.0427 0.2320
0,60 0.2982 0.2880 0.0486 0.2284
0,70 0.2871 0.2784 0.0533 0.2244
0,80 0.2772 0.2695 0.0571 0.2202
0,90 0.2682 0.2614 0.0600 0.2159
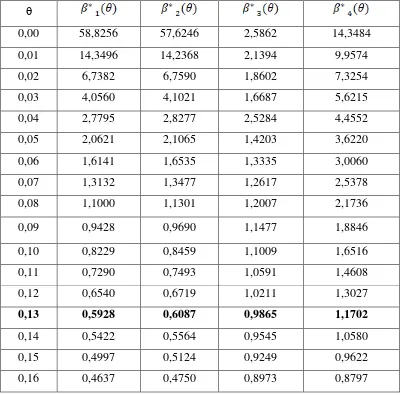
Tabel 3.9 Nilai VIF dengan Berbagai Nilai
0,00 58,8256 57,6246 2,5862 14,3484
0,01 14,3496 14,2368 2,1394 9,9574
0,02 6,7382 6,7590 1,8602 7,3254
0,03 4,0560 4,1021 1,6687 5,6215
0,04 2,7795 2,8277 2,5284 4,4552
0,05 2,0621 2,1065 1,4203 3,6220
0,06 1,6141 1,6535 1,3335 3,0060
0,07 1,3132 1,3477 1,2617 2,5378
0,08 1,1000 1,1301 1,2007 2,1736
0,09 0,9428 0,9690 1,1477 1,8846
0,10 0,8229 0,8459 1,1009 1,6516
0,11 0,7290 0,7493 1,0591 1,4608
0,12 0,6540 0,6719 1,0211 1,3027
0,13 0,5928 0,6087 0,9865 1,1702
0,14 0,5422 0,5564 0,9545 1,0580
0,15 0,4997 0,5124 0,9249 0,9622
0,17 0.4327 0.4428 0.8714 0.8082
0,18 0.4058 0.4150 0.8470 0.7457
0,19 0.3823 0.3906 0.8240 0.6908
0,20 0,3617 0,3692 0,8023 0,6424
0,30 0,2402 0,2432 0,6322 0,3619
0,40 0,1847 0,1861 0,5162 0,2443
0,50 0,1522 0,1529 0,4314 0,1832
0,60 0,1305 0,1308 0,3670 0,1468
0,70 0,1148 0,1148 0,3167 0,1229
0,80 0,1026 0,1026 0,2765 0,1026
0,90 0,0929 0,0928 0,2438 0,0937
1,00 0,0850 0,0848 0,2168 0,0842
dari tabel 3.9 di atas tampak bahwa mulai tetapan bias = 0,00 sampai pada = 1,00,
VIF koefisien estimator semakin lama semakin kecil. Nilai VIF yang diambil
adalah VIF yang relatif dekat dengan satu, sedangkan nilai koefisien estimator
[image:53.595.115.517.83.347.2]parameter dengan bebagai kemungkinan tetapan bias dapat dilihat pada
tabel 3.7.
Dari berbagai harga yang ada, nilai VIF mulai tampak ada penurunan, dan
harga yang memberikan nilai VIF yang relatif dekat dengan 1, yaitu pada .
Ini menunjukkan bahwa pada , koefisien lebih stabil. Dengan demikian,
regresi Ridge yang diperoleh jika yang diambil sebesar 0,13 yaitu :
3.5 Uji Koefisien Regresi Ridge
Untuk mengetahui apakah koefisien yang diperoleh berarti atau tidak dilakukan
koefisien korelasi berarti
koefisien korelasi tidak berarti
dengan
[image:54.595.61.574.407.644.2]Kriteria Pengujian : Terima bila ; dalam hal lain tolak .
Tabel 3.10 Nilai dari Persamaan Regresi Ridge
y* * * * *
-0,3888 -0,3878 -0,4015 -0,1632 -0,4501 -0,3932 -0,3932 0,1546 -0,3888 0,1512 -0,3388 -0,3730 -0,3969 -0,1463 -0,3587 -0,3654 -0,3654 0,1335 -0,3388 0,1148 -0,2725 -0,2520 -0,2505 -0,0860 -0,3488 -0,2642 -0,2642 0,0698 -0,2725 0,0743 -0,2015 -0,2059 -0,1590 -0,0162 -0,2083 -0,1826 -0,1826 0,0334 -0,2015 0,0406 -0,0976 -0,1198 -0,0571 0,0586 -0,0857 -0,0856 -0,0857 0,0073 -0,0976 0,0095 0,0027 -0,0143 -0,0717 0,1716 0,1054 -0,0063 -0,0064 0,0000 0,0027 0,0000 0,1062 0,1181 0,0637 0,0673 0,2205 0,1179 0,1178 0,0139 0,1062 0,0113 0,2613 0,2399 0,2843 0,1332 0,3459 0,2709 0,2709 0,0734 0,2613 0,0683 0,3696 0,3886 0,4196 -0,0019 0,4702 0,4033 0,4033 0,1626 0,3696 0,1366 0,5596 0,6062 0,5691 -0,0170 0,3097 0,5053 0,5053 0,2554 0,5596 0,3131
0,0002 0,9039 0,9197
Perhitungan Statistik :
Dengan menggunakan rumus persamaan (2.8) dan (2.9) maka jumlah kuadrat dapat
[image:55.595.107.531.570.656.2]diperoleh dan dapat dibentuk dalam tabel ANAVA sebagai berikut :
Tabel 3.11 ANAVA Regresi Ridge
Sumber Variasi JK Dk RJK
Regresi 0,9039 4 0,2457 71,8348 5,19
Sisa 0,0171 5 0,0034
Total 0,9197 9
Hasil : dengan taraf nyata maka , jadi ,
terima , sehingga dapat disimpulkan bahwa koefisien variabel bebas X secara
Maka dengan menggunakan persamaan (2.7), persamaan di atas dikembalikan
ke variabel-variabel asal dengan :
, , , , ,
, , , , sehingga
diperoleh persamaan regresinya :
3.6 Regresi Komponen Utama
Setelah dideteksi bahwa data PDRB Sumut mengalami masalah multikolinieritas pada
variabel bebasnya. Masalah multikolinieritasnya juga sudah diselesaikan dengan
menggunakan analisis regresi Ridge. Tetapi selain menggunakan analisis regresi
Ridge, masalah multikolinieritas juga dapat diselesaikan menggunakan analisis regresi
komponen utama. Disini peneliti ingin melihat persamaan dan perbedaan diantara
kedua metode sehingga akan dilihat metode yang lebih baik dalam menyelesaikan
masalah multikolinieritas pada data PDRB Sumut. Maka selanjutnya, data tersebut
akan dianalisis menggunakan analisis regresi komponen utama.
Regresi komponen utama adalah teknik yang digunakan untuk meregresikan
komponen utama dengan variabel tak bebas melalui metode kuadrat terkecil. Tahap
pertama pada prosedur regresi komponen utama yaitu menentukan komponen utama
variabel tak bebas diregresikan pada komponen utama dalam sebuah model regresi
linier.
Persamaan regresi komponen utama berdasarkan matriks kovarian pada
dasarnya hampir sama dengan persamaan regresi komponen utama berdasarkan
matriks korelasi yaitu variabel diganti dengan variabel baku
. Kedua persamaan tersebut digunakan sesuai dengan pengukuran
variabel-variabel yang diamati.
Apabila diberikan notasi sebagai banyaknya komponen utama
yang dilibatkan dalam analisis regresi komponen utama, di mana k lebih kecil
daripada banyaknya variabel penjelas asli X, yaitu sejumlah p (k<p)
Maka Bentuk umum persamaan regresi komponen utama adalah :
(3.1)
dengan :
= variabel tak bebas
= variabel komponen utama
= parameter model regresi komponen utama
Komponen utama merupakan kombinasi linier dari variabel Z :
(3.2)
dengan :
= koefisien komponen utama
= variabel baku
Komponen utama dalam persamaan (3.2) disubstitusikan ke dalam
persamaan regresi komponen utama (3.1), maka diperoleh :
(3.3)
dengan :
(3.4)
3.7 Analisis Regresi Komponen Utama
Karena skala pengukuran dari setiap variabel yang diamati tidak sama, maka variabel
tersebut ditransformasikan ke dalam variabel baku Z persamaan (2.10). Kemudian
akan dianalisis dengan analisis komponen utama yang ditentukan berdasarkan matriks
[image:58.595.107.525.550.696.2]korelasi.
Tabel 3.12 Matriks Korelasi
Korelasi
1,000
0,991 1,000
0,487 0,491 1,000
0,927 0,927 0,681 1,000
Untuk mengetahui variabel komponen utama berdasarkan matriks korelasi,
terlebih dahulu dihitung nilai eigen, maka diperoleh nilai eigen, serta proporsi total
sehingga diperoleh :
3,297
= 0,645
0,050
0,009
Mencari Proporsi Total Varansi :
dengan :
= akar ciri terbesar ke – j dari matriks korelasi
= jumlah semua akar cirri yang diperoleh dari matriks korelasi
Tabel 3.13 Nilai Eigen, Proporsi Total Variansi, dan Proporsi Variansi Kumulatif
Komponen Nilai Eigen Proporsi Total Variansi (%)
Proporsi Variansi
Kumulatif (%)
1 3,297 82,404 82,404
2 0,645 16,121 98,525
3 0,050 1,250 99,775
4 0,009 0,225 100
Berdasarkan kriteria pemilihan komponen utama maka komponen yang
terpilih adalah komponen utama keempat karena memiliki nilai eigen lebih besar dari
1 serta proporsi keragaman komponen utama tersebut telah mampu menjelaskan
82,404% keragaman dari variabel asal.
Setelah nilai eigen diketahui maka akan dihitung koefisien komponen utama.
Hasil perhitungan diperoleh seperti pada tabel berikut.
Tabel 3.14 Koefisien Komponen Utama (Vektor Eigen)
Variabel Komponen Utama
0,291
0,291
0,212
0,298
sumber : perhitungan dengan menggunakan SPSS
Berdasarkan persamaan (3.2), maka persamaan komponen utama adalah :
(3.5)
Untuk meregresikan komponen utama dengan variabel bebas, maka dihitung
[image:60.595.104.530.507.629.2]matriks korelasi, maka didapatkan skor komponen utama dari unit pengamatan ke –i
[image:61.595.221.412.161.402.2]seperti pada tabel berikut :
Tabel 3.15 Skor Faktor Komponen Utama
No Skor Faktor Y
1 -1.4032 79,33
2 -1.2725 89,67
3 -0.9151 103,40
4 -0.5359 118,10
5 -0.1189 139,61
6 0.3467 160,38
7 0.4843 181,82
8 1.0214 213,93
9 1.1225 236,35
10 1.2708 275,70
sumber : perhitungan dengan menggunakan SPSS
Skor-skor faktor yang dihasilkan dapat digunakan untuk menggantikan
skor-skor pada varibel bebas yang asli. Setelah komponen hasil metode regresi komponen
utama yang bebas multikolinearitas diperoleh maka komponen-komponen tersebut
diregresikan atau dianalisa pengaruhnya terhadap variabel tak bebas dengan
menggunakan analisis regresi linier.
3.7.1 Model Regresi yang Cocok
Setelah kita mendapatkan variabel bebas baru ( ) yang bebas multikolinearitas
melalui metode regresi komponen utama, maka kita akan meregresikan variabel bebas
yang baru ( ) tersebut terhadap variabel tak bebas . Misalkan saja variabel bebas
hanya satu, maka pada model tersebut digunakan analisis regresi linier sederhana
dengan persamaan sebagai berikut :
(3.6)
dengan
Tabel 3.16 Uji Signifikansi Koefisien Regresi Komponen Utama
Komponen
Utama
Koefisien
Regresi S.E Koefisien T-Hitung VIF
Konstanta 159,829 5,389 29,657
64,209 5,681 11,303 1
sumber : perhitungan dengan menggunakan SPSS
Dengan taraf nyata maka
Koefisien komponen utama sudah signifikan serta nilai VIF adalah 1, ini
menunjukkan bahwa sudah tidak ada lagi masalah multikolinieritas.
Artinya,
1. Jika PDRB sama sekali tidak dipengaruhi oleh variabel , maka PDRB
propinsi Sumatera Utara akan bernilai 159,829 triliun rupiah.
2. Untuk setiap kenaikan variabel ( ) sebesar satu triliun rupiah, akan
mengakibatkan meningkatnya PDRB propinsi Sumatera Utara sebesar
64,209 triliun rupiah.
Dari tabel 3.15 pun dapat dilihat bahwa , maka dapat
disimpulkan bahwa variabel memiliki pengaruh yang signifikan terhadap variabel
PDRB propinsi Sumatera Utara. Jika kita ingin mengetahui seberapa kuat hubungan
yang terjadi antara variabel dengan variabel PDRB propinsi Sumatera Utara, maka
kita dapat melihatnya melalui koefisien korelasi Pearson.
Model R R Square
Adjusted R
Square
Std. Error of
the Estimate
1 0,970a 0,941 0,934 17,04230
sumber : perhitungan dengan menggunakan SPSS
Dari tabel 3.15 didapatkan nilai koefisien korelasi (r) sebesar 0,970. Artinya,
terdapat hubungan yang sangat kuat antara variabel dengan variabel PDRB
propinsi Sumatera Utara. Selain itu, kita dapat mengetahui seberapa besar pengaruh
yang dapat diberikan variabel dengan variabel PDRB propinsi Sumatera Utara
melalui koefisien determinasi, dengan rumus sebagai berikut :
x 100%
= x 100%
= 94,1%
Artinya, sebesar 94,1% variabel dengan variabel PDRB propinsi Sumatera
Utara. Sedangkan sisanya sebesar 5,9% menyatakan bahwa variabel PDRB propinsi
Sumatera Utara dapat dipengaruhi oleh variabel-variabel bebas lainnya yang tidak
diteliti.
Dengan mensubstitusikan persamaan (3.5) ke persamaan (3.6) maka didapat
model regresi linier berganda yang melibatkan variabel Z yang merupakan hasil
transformasi dari variabel sebagai variabel bebas. Hasil transformasi ditunjukkan
pada persamaan (3.7) berikut :
Kemudian dengan menggunakan persamaan (2.10), persamaan (3.7) akan
diubah ke bentuk semula. Persamaan yang terdapat variabel Z ditransformasikan
menjadi variabel X sebagai variabel bebasnya dengan .
3.7.2 Perbandingan Hasil Analisis Regresi Ridge dan Analisis Regresi Komponen Utama
Dengan menggunakan persamaan baru yang diperoleh dari analisis regresi Ridge dan
analisis regresi komponen utama untuk mengatasi masalah mulikolinieritas, maka
diperoleh nilai MSE (Mean Square Error).
Hasil MSE Analisis Regresi Ridge :
Hasil MSE Analisis Regresi Komponen Utama :
BAB 4
KESIMPULAN DAN SARAN
4.1 Kesimpulan
Berdasarkan pengolahan dan hasil perhitungan yang diperoleh pada studi kasus data
1. Dengan metode analisis regresi Ridge, diperoleh persamaan regresi yang tepat
untuk data PDRB propinsi SUMUT, yaitu :
2. Dengan metode analisis regresi komponen utama, diperoleh persamaan regresi
yang tepat untuk data PDRB propinsi SUMUT, yaitu :
3. MSE dari analisis regresi Ridge pada data PDRB propinsi SUMUT adalah
32,5883 sedangkan MSE dari Metode analisis regresi komponen utama adalah
3.366,1383.
4. Pada studi kasus data PDRB propinsi SUMUT, dapat dilihat bahwa metode
analisis regresi ridge lebih baik dalam menyelesaikan masalah multikolinieritas
dibandingkan dengan metode analisis regresi komponen utama berdasarkan nilai
MSE sebagai kriterianya. Karena nilai MSE dari metode analisis regresi Ridge
lebih kecil dibandingkan nilai MSE dari metode analisis regresi komponen
utama.
4.2 Saran
Melalui penulisan ini disarankan agar dalam pengambilan data yang mengandung
multikolinieritas, para peneliti lebih teliti lagi dalam menganalisa data yang akan
diolah atau diteliti. Dan lebih teliti lagi melihat persamaan yang dibentuk dari sebuah
data yang mengandung multikolinieritas, karena tidak semua persamaan yang
dibentuk dan yang mengandung multikolinieritas itu harus diselesaikan dengan salah
satu dari metode di atas mengingat nilai galat yang cukup besar apabila ke depannya
DAFTAR PUSTAKA
Algifari. 2000. Analisis Regresi, Teori, Kasus, dan Solusi. Edisi Kedua. Yogyakarta :
Badan Penerbit Fakultas Ekonomi UGM
Anton, Howard. 1995. Aljabar Linier Elementer. Edisi Kelima. Jakarta : Erlangga.
Drapper, N.R. dan Smith. 1992. Analisis Regresi Terapan. Edisi Kedua. Jakarta : PT Gramedia Pustaka Utama
Gasperz, Vincent. 1991. Ekonometrika Terapan. Jilid 2. Bandung : Tarsito
Gujarati, Damodar. 1995. Ekonometrika Dasar. Jakarta : Erlangga.
Soemartini. 2008. Penyelesaian Multikolinieritas Melalui Metode Ridge Regression. Jurnal Jurusan Statistika FMIPA UNPAD Jatinangor.
Soemartini. 2008. Principal Component Analysis (PCA) Sebagai Salah Satu Metode untuk Mengatasi Masalah Multikolinieritas. Jurnal Jurusan Statistika FMIPA UNPAD Jatinangor.
Sudarmanto, Gunawan R. 2005. Analisis Regresi Linear Ganda dengan SPSS. Edisi Pertama. Yogyakarta : Graha Ilmu
Suharjo, Bambang. 2008. Analisis Regresi Terapan dengan SPSS. Yogyakarta : Graha Ilmu.
Wahana Komputer. 2004. Model Penelitian dan Pengolahannya dengan SPSS 10.01. Yogyakarta : Andi.
Walpole, R.E. dan R.H. Myers. 1995. Ilmu Peluang dan Statistika untuk Insinyur dan Ilmuwan. Edisi Keempat. Bandung : ITB Bandung.
Widiharih, Tatik. 2004. Penanganan Multikolinieritas (Kekolinieran Ganda) Dengan Analisis Regresi Komponen Utama. Jurnal Matematika FMIPA UNDIP. Semarang.
http://www.bagusco.wordpress.com/2008/10/16/menghitung-vif/. Diakses tanggal 06
Juni 2012.
http://www.setabasri01.blogspot.com/2011/04/uji-regresi-berganda.html. Diakses
LAMPIRAN
MSE RIDGE
Y
79,33 46,27 12,12 13,52 117,23 81,4034 -2,0734 4,2990 89,67 48,51 12,34 14,34 118,74 86,9405 2,7295 7,4501
103,40 66,86 19,28 17,26 118,90 107,1596 -3,7596 14,1344 118,10 73,84 23,62 20,64 121,23 123,5156 -5,4156 29,3288 139,61 86,90 28,45 24,26 123,27 142,9635 -3,3535 11,2459
181,82 122,96 34,18 24,68 128,34 183,3725 -1,5525 2,4102 213,93 141,42 44,64 27,87 130,42 213,9085 0,0215 0,0005 236,35 163,96 51,06 21,33 132,48 239,8991 -3,5491 12,5963 275,70 196,95 58,15 20,60 129,82 260,1320 15,5680 242,3616
1.598,29 325,8832
159,83 MSE 32,5883
MSE KOMPONEN UTAMA
Y
79,33 46,27 12,12 13,52 117,23 83,1002 -3,7702 14,2147
89,67 48,51 12,34 14,34 118,74 90,1080 -0,4380 0,1918 103,40 66,86 19,28 17,26 118,90 108,1136 -4,7136 22,2177 118,10 73,84 23,62 20,64 121,23 126,7420 -18,5120 342,6953
139,61 86,90 28,45 24,26 123,27 147,3965 -36,5165 1,333,4527 160,38 102,89 27,76 29,73 126,43 168,0476 -46,7076 2,181,6024 181,82 122,96 34,18 24, 68 128,34 185,4114 -57,1114 3,261,7113
213,93 141,42 44,64 27,87 130,42 214,4932 -84,0432 7,063,2655 236,35 163,96 51,06 21,33 132,48 232,0331 -94,8231 8,991,4123
275,70 196,95 58,15 20,60 129,82 242,7883 -102,2283 10,450,6196
1.598,29 33.661,3833