METODE ENSEMBLE K-NEAREST NEIGHBOR UNTUK
PREDIKSI HARGA BERAS DI INDONESIA
DEWI SINTA
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa tesis berjudul Metode Ensemble k-Nearest Neighbor untuk Prediksi Harga Beras di Indonesia adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Januari 2015
Dewi Sinta
RINGKASAN
DEWI SINTA. Metode Ensemble k-Nearest Neighbor untuk Prediksi Harga Beras di Indonesia. Dibimbing oleh HARI WIJAYANTO dan BAGUS SARTONO.
Analisis deret waktu merupakan hal yang sangat penting dalam setiap bidang ilmu sains seperti prediksi keuangan, prediksi cuaca, penelitian dan ilmu medis (Chitra dan Uma 2010). Pada banyak kasus sangat jarang ditemukan data deret waktu yang memenuhi asumsi. Salah satu penyebabnya adalah adanya hubungan yang tidak linear antar peubahnya, sehingga sangat diperlukan suatu metode yang efisien. Banyak metode yang berkembang mengenai prediksi data deret waktu dengan ukuran data yang besar dan peubah penjelas yang banyak, seperti metode k-Nearest Neighbor (kNN). Metode kNN dapat digunakan untuk data yang tidak memenuhi asumsi klasik dan karakteristik data yang tidak linear.
Dalam metode kNN sangat penting untuk memilih nilai k-tetangga terdekat, karena hal ini dapat mempengaruhi hasil prediksi. Nilai k yang kecil dapat menghasilkan ragam yang besar pada hasil prediksi, sedangkan nilai k yang besar dapat mengakibatkan bias model yang besar. Metode alternatif yang biasanya digunakan untuk mengatasi masalah ini adalah optimasi parameter dengan menggunakan cross-validation, namun metode ini kurang efisien karena algoritma training harus diulang kembali untuk k selanjutnya. Teknik ensemble
merupakan suatu metode yang memiliki kemampuan keakuratan prediksi dan sangat efisien digunakan dalam metode kNN, sehingga tidak perlu dilakukan pencarian nilai k yang optimal.
Pada prinsipnya teknik ensemble adalah menggabungkan hasil pendugaan dari banyak model menjadi satu buah pendugaan akhir. Teknik ensemble dapat diaplikasikan dalam analisis deret waktuuntuk menghasilkan keakuratan prediksi. Sorjamaa et al. (2005) menggunakan mutual information untuk memilih input prediksi deret waktu dalam kNN. Yu et al. (2009) menggunakan Multiresponse Sparse Regression (MRSR) sebagai langkah ketiga untuk peringkat masing-masing k-tetangga terdekat dan terakhir melakukan pendugaan Leave-One-Out
sebagai langkah keempat dalam memilih tetangga terdekat. Sasu (2012) mengembangkan algoritma kNN untuk prediksi data deret waktu.
Penelitian tersebut menggunakan metode regresi kNN untuk memprediksi respon atau peubah output, namun dalam penelitian ini akan digunakan modifikasi prediksi untuk data deret waktu dengan konsep pembobot. Penelitian ini menerapkan metode kNN tunggal dan ensemble kNN pada data harga beras di Indonesia agar diperoleh keakuratan prediksi. Penelitian ini bertujuan untuk mengetahui kinerja metode kNN tunggal dan ensemble kNN, kemudian memprediksi harga beras di Indonesia menggunakan metode terbaik.
yang digunakan adalah X1 luas panen padi (ha), X2 produktivitas (ku/ha), X3 total produksi padi (ton) dan X4 jumlah penduduk (ribu).
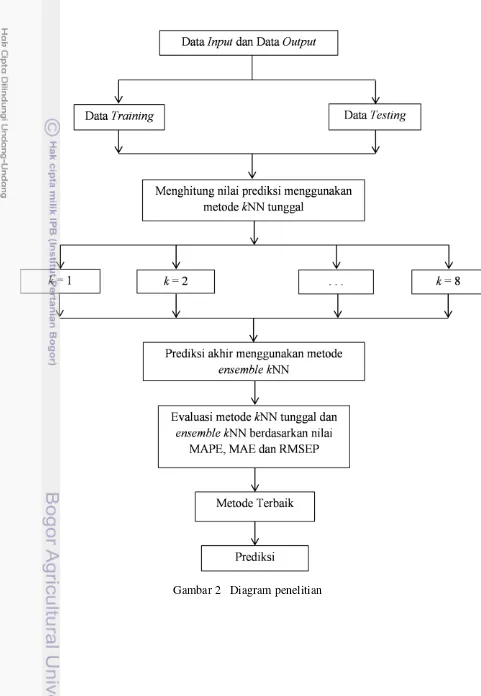
Langkah awal yang dilakukan dalam penelitian ini adalah menghitung prediksi harga beras dari Januari - Desember 2012 dengan metode kNN tunggal kemudian melakukan prediksi terhadap kedua metode menggunakan jumlah tetangga terdekat (k) yang berbeda. Langkah selanjutnya menghitung prediksi harga beras dengan metode ensemble kNN. Setelah diperoleh hasil prediksi masing-masing metode selanjutnya dilakukan evaluasi terhadap hasil prediksi akhir dengan harga beras pada data testing berdasarkan nilai MAPE (Mean Absolute Percentage Error), MAE (Mean Absolute Error) dan RMSEP (Root Mean Squared Error of Prediction). Prediksi harga beras di Indonesia menggunakan metode terbaik berdasarkan nilai MAPE, MAE dan RMSEP tersebut.
Nilai MAPE, MAE dan RMSEP hasil prediksi harga beras di Indonesia menunjukkan bahwa metode ensemble kNN memiliki kinerja yang lebih baik dibandingkan dengan metode kNN tunggal. Nilai-nilai tersebut semakin kecil jika nilai k yang dicobakan semakin besar, namun jika nilai k yang dicobakan sangat besar atau mendekati ukuran data training maka ketiga nilai tersebut memberikan hasil yang besar. Kisaran nilai prediksi harga beras hampir sama dengan harga beras sebenarnya. Selain itu, prediksi harga beras juga memiliki pola trend yang hampir sama dengan harga beras sebenarnya.
SUMMARY
DEWI SINTA. Ensemble k-Nearest Neighbor Method to Predict Rice Price in Indonesia. Supervised by HARI WIJAYANTO and BAGUS SARTONO.
Time series analysis is often used in any field of science such as financial forecasting, weather forecasting, and medical science (Chitra and Uma 2010). In many of the cases are, it is common that the assumptions are violated. One possible cause is the presence of non-linear relationship between the variables, so it need an efficient method. Many methods were developed on the prediction of time series data with large data sizes and large number of explanatory variables, such as k-Nearest Neighbor (kNN). Which can be used for data that does not meet the classical assumptions and non-linear characteristics of the data.
In kNN method is very important to choose the number of k-nearest neighbors because this can affect the predicted results. Small values of k can produce a great variety on the prediction results, whereas a large value of k can lead to a large bias of models. Alternative methods are usually used to overcome this problem is the optimization of parameters using cross-validation, but this method is less efficient because the training algorithm must be repeated again for the next k. Ensemble technique is a method that has ability of accuracy prediction and efficiently used in kNN method, so it is not necessary to search the optimal value of k.
In principle, the ensemble technique is to combine the results of the estimation of many models into one final prediction. Ensemble techniques can be applied in time series analysis to produce accurate predictions. Sorjamaa et al. (2005) using mutual information to select the input time series prediction in kNN. Yu et al. (2009) uses Multiresponse Sparse Regression (MRSR) as the third step in order to rank each k-nearest neighbor and finally perform estimation Leave-One-Out as the fourth step in choosing the number of nearest neighbors. Sasu (2012) developed the kNN algorithm for the prediction of time series data.
The study used kNN regression method to predict the response or output variable, but in this study will be used modify prediction to time series data with a weighted concept. This research applies the single ensemble kNN method on rice price data in Indonesia to obtain a prediction accuracy. This study aims to investigate the performance of single and ensemble kNN methods, and then predict the rice price in Indonesia using the best method.
The first step in this research is to calculate the predicted price of rice from January to December 2012 with a single kNN method then make a prediction of the model using the number of nearest neighbors (k) are different. The next step is to calculate the price of rice to the model prediction ensemble kNN. Once the model is obtained subsequent to evaluate the predicted results with the price of rice at the end of the testing data is based on the value of MAPE (Mean Absolute Percentage Error), MAE (Mean Absolute Error) and RMSEP (Root Mean Squared Error of Prediction). Prediction of rice prices in Indonesia using the best method based on the value of MAPE, MAE and the RMSEP.
Value of MAPE, MAE and RMSEP prediction results in rice prices in Indonesia showed that the ensemble kNN method has better performance than the single kNN method. The values are getting smaller if the tested values of k greater, however, if the value of k is tested very large or close to the size of the training data then these values gives great results. The range of the predicted value is almost equal to the price of rice in rice prices actually. Moreover, rice price forecast trend also has a pattern similar to the real price of rice.
© Hak Cipta Milik IPB, Tahun 2015
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains
pada
Program Studi Statistika
METODE ENSEMBLE K-NEAREST NEIGHBOR UNTUK
PREDIKSI HARGA BERAS DI INDONESIA
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2015
Judul Tesis : Metode Ensemble k-Nearest Neighbor untuk Prediksi Harga Beras di Indonesia
Nama : Dewi Sinta
NIM : G151110061
Disetujui oleh Komisi Pembimbing
Dr. Ir. Hari Wijayanto, M. Si Ketua
Dr. Bagus Sartono, S. Si, M. Si Anggota
Diketahui oleh
Ketua Program Studi Statistika
Dr. Ir. Anik Djuraidah, MS
Dekan Sekolah Pascasarjana
Dr. Ir. Dahrul Syah, M. Sc. Agr
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan November 2013 ini ialah data harga beras di Indonesia, dengan judul Metode Ensemble k-Neraest Neighbor
untuk Prediksi Harga Beras di Indonesia. Keberhasilan penulisan tesis ini tidak lepas dari bantuan, bimbingan, dan arahan dari berbagai pihak.
Terima kasih penulis ucapkan kepada Bapak Dr. Ir. Hari Wijayanto, M.Si. dan Bapak Dr. Bagus Sartono, M.Si selaku pembimbing yang telah meluangkan waktu untuk memberikan bimbingan, arahan, dan saran kepada penulis dalam menyelesaikan tesis ini. Terimakasih untuk Bapak Dr. Ir. Aji Hamim Wigena, M.Sc selaku penguji tesis dan Bapak Dr. Ir. I Made Sumertajaya, M.Si selaku Moderator dalam pengujian tesis. Di samping itu, penulis juga mengucapkan terimakasih kepada seluruh staf administrasi Rektorat dan staf Program Studi Statistika yang telah turut membantu kelancaran administrasi dalam penyelesaian tesis ini.
Ungkapan terimakasih terkhusus penulis sampaikan kepada ayahanda (Karnadi), Ibunda (Pepi Yetni) dan kakak (Lina Karnadi) serta seluruh keluarga atas do’a yang tulus, pengorbanan yang tak ternilai, dukungan dan kasih sayangnya. Terimakasih juga untuk teman-teman Statistika (S2 dan S3) dan Statistika Terapan (S2) atas bantuan, saran, dan ilmu yang positif.
Penulis menyadari sepenuhnya bahwa tesis ini masih banyak kekurangan dan jauh dari kesempurnaan. Oleh karena itu, penulis mengharapkan kritik dan saran yang bersifat membangun guna menyempurnakan tesis ini dan karya ilmiah secara utuh. Semoga tesis ini dapat menambah wawasan dan bermanfaat.
Bogor, Januari 2015
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
1 PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 2
2 TINJAUAN PUSTAKA 3
Data Deret Waktu 3
Teknik Ensemble 3
k-Nearest Neighbor (kNN) 4
3 METODE PENELITIAN 6
Data 6
Metode Analisis 6
4 HASIL DAN PEMBAHASAN 10
Eksplorasi Data 10
kNN Tunggal dan EnsemblekNN 14
5 SIMPULAN DAN SARAN 17
Simpulan 17
Saran 17
DAFTAR PUSTAKA 17
LAMPIRAN 19
DAFTAR TABEL
1. Nilai MAPE, MAE dan RMSEP hasil prediksi harga beras di Indonesia menggunakan data testing Januari – Desember 2012 15 2. Nilai MAPE, MAE dan RMSEP hasil prediksi harga beras di Indonesia
menggunakan data testing Januari 2011 – Desember 2012 15 3. Prediksi harga beras per kilogram di Indonesia Januari – Desember 2012 16
DAFTAR GAMBAR
1. Diagram pemilihan k-tetangga terdekat pada data testing 5
2. Diagram penelitian 9
3. Pergerakan harga beras di Indonesia Januari 1998 – Desember 201210 4. Grafik data : (a) Luas Panen (Ha), (b) Produktivitas (Ku/Ha), (c)
Produksi (Ton) dan (d) Jumlah Penduduk (Ribu) 11
5. Prediksi harga beras pada metode kNN tunggal dan ensemblekNN 14
DAFTAR LAMPIRAN
1. Data harga beras, luas panen, produktivitas, produksi dan jumlah penduduk di Indonesia dari Januari 1998 - Desember 2012 19 2. Syntax program R prediksi harga beras dengan metode kNN tunggal dan
ensemblekNN 20
3. Hasil prediksi harga beras di Indonesia dengan metode kNN tunggal dan
1
1. PENDAHULUAN
Latar Belakang
Data yang diperoleh pada suatu penelitian seringkali berupa fungsi atas waktu, dan antar pengamatannya terdapat suatu hubungan (autokorelasi), sehingga untuk menganalisis hubungan fungsional antara pengamatan dengan waktunya tidak dapat menggunakan analisis regresi sederhana. Data seperti ini dinamakan data deret waktu (times series) dan untuk menganalisisnya harus menggunakan metode analisis data deret waktu. Analisis deret waktu merupakan hal yang sangat penting dalam setiap bidang ilmu sains seperti prediksi keuangan, prediksi cuaca, penelitian, ilmu medis dan lain sebagainya (Chitra dan Uma 2010). Pada banyak kasus sangat jarang ditemukan data deret waktu yang memenuhi asumsi. Salah satu penyebabnya adalah adanya hubungan yang tidak linear antar peubahnya, sehingga sangat diperlukan suatu metode yang efisien. Banyak metode yang berkembang mengenai prediksi data deret waktu dengan ukuran data yang besar dan peubah penjelas yang banyak, seperti metode Artificial Neural Network
(ANN), Radial Basis Function Networks (RBF), k-Nearest Neighbor (kNN) dan
Self Organizing Map (SOM). Metode kNN dapat digunakan untuk data yang tidak memenuhi asumsi klasik dan karakteristik data yang tidak linear.
Metode kNN merupakan salah satu algoritma Machine Learning (ML) yang dianggap sebagai suatu metode yang sederhana untuk diterapkan dalam analisis data dengan dimensi peubah yang banyak (Alkhatib et al. 2013). Walaupun metode ini sederhana namun metode ini memiliki kelebihan dibandingkan metode lain, yaitu dapat menggeneralisasi himpunan data training
yang relatif kecil (Rokach 2010). Pada awalnya kNN merupakan metode untuk analisis klasifikasi, namun beberapa dekade terakhir digunakan untuk prediksi. Dalam pendekatan klasifikasi, himpunan data dibagi menjadi himpunan data
training dan data testing. kNN menggunakan ukuran kemiripan untuk membandingkan data testing yang diberikan dengan data training.kNN memilih k
data dari data training yang dekat dengan data testing dalam memprediksi peubah
output. kNN juga dianggap sebagai lazy learning yang tidak membangun model atau fungsi, tetapi menghasilkan k-tetangga terdekat dari data training yang mempunyai kemiripan dengan data testing (Alkhatib et al. 2013). Dalam metode
kNN sangat penting untuk memilih nilai k-tetangga terdekat, karena hal ini dapat mempengaruhi hasil prediksi. Nilai k yang kecil dapat menghasilkan ragam yang besar pada hasil prediksi, sedangkan nilai k yang besar dapat mengakibatkan bias model yang besar. Metode alternatif yang biasanya digunakan untuk mengatasi masalah ini adalah optimasi parameter dengan menggunakan cross-validation, namun metode ini kurang efisien karena algoritma training harus diulang kembali untuk k selanjutnya. Teknik ensemble merupakan suatu metode yang memiliki kemampuan keakuratan prediksi dan sangat efisien digunakan dalam metode kNN, sehingga tidak perlu dilakukan pencarian nilai k yang optimal.
2
ensemble yang bisa dilakukan yaitu teknik hybrid dan non-hybrid (De Bock et al.
2010). Teknik hybrid bekerja dengan melibatkan berbagai algoritma pemodelan dan selanjutnya menggabungkan prediksi yang dihasilkan oleh masing-masing algoritma menjadi satu prediksi akhir. Sedangkan teknik non-hybrid bekerja dengan satu jenis algoritma namun menggunakannya berkali-kali untuk menghasilkan banyak model berbeda, dan selanjutnya hasil prediksi dari model berbeda digabungkan menjadi satu. Berbagai penelitian menunjukkan bahwa
ensemble mampu memberikan hasil yang lebih akurat. Zhu (2008) menyatakan bahwa teknik ensemble menjadi salah satu teknik penting dalam peningkatan kemampuan prediksi dari berbagai model standar. Friedman dan Popescu (2008) melakukan studi simulasi dan mendapatkan hasil bahwa teknik ensemble
mendeteksi dengan baik peubah yang berpengaruh dan saling berinteraksi. Liu et al. (2009) menggunakan teknik ensemble dalam membangun model prediksi ketika data bersifat ill-conditioned seperti pada kasus jumlah kelas yang tidak seimbang pada data. De Bock et al. (2010) dan Kocev et al. (2013) juga menyatakan pada pemodelan klasifikasi model pohon ensemble memberikan ketepatan dugaan yang umumnya lebih tinggi dibandingkan pohon tunggal.
Teknik ensemble dapat diaplikasikan dalam analisis deret waktu untuk menghasilkan keakuratan prediksi. Sorjamaa et al. (2005) menggunakan mutual information untuk memilih input prediksi deret waktu dalam kNN. Yu et al. (2009) menggunakan Multiresponse Sparse Regression (MRSR) sebagai langkah ketiga untuk peringkat masing-masing k-tetangga terdekat dan terakhir melakukan pendugaan Leave-One-Out sebagai langkah keempat dalam memilih jumlah tetangga terdekat. Sasu (2012) mengembangkan algoritma kNN untuk prediksi data deret waktu. Alkhatib et al. (2013) menggunakan algoritma kNN yang masih sederhana untuk prediksi stock price. Penelitian tersebut menggunakan metode regresi kNN untuk memprediksi respon atau peubah output, namun dalam penelitian ini akan digunakan modifikasi prediksi untuk data deret waktu dengan konsep pembobot. Penelitian ini menerapkan metode kNN tunggal dan ensemble kNN pada data harga beras di Indonesia agar diperoleh keakuratan prediksi. Akurasi prediksi diperlukan untuk membantu pemerintah dalam menetapkan kebijakan suplay dan demand beras di setiap wilayah sehingga gejolak harga beras dapat diminimalkan. Oleh karena itu penelitian ini bertujuan untuk mengetahui kinerja metode kNN tunggal dan ensemble kNN, kemudian memprediksi harga beras di Indonesia menggunakan metode terbaik.
Tujuan Penelitian
3
2. TINJAUAN PUSTAKA
Data Deret Waktu
Data deret waktu adalah data yang dikumpulkan dari waktu kewaktu untuk menggambarkan perkembangan suatu kegiatan (perkembangan produksi, harga, jumlah penduduk dan lain sebagainya). Periode waktu dapat berupa tahunan, mingguan, bulanan, semester, kuartal dan lain-lain. Analisis deret waktu adalah salah satu prosedur statistika pada data deret waktu yang diterapkan untuk memprediksi keadaan yang akan datang dalam rangka pengambilan keputusan. Data deret waktu biasanya dianalisis untuk menemukan pola-pola pertumbuhan atau perubahan masa lalu yang dapat digunakan untuk memprediksi pola-pola masa mendatang sejalan dengan kebutuhan operasi bisnis. Beberapa literatur menyebutkan, bahwa pola data cenderung akan berulang pada periode waktu mendatang. Identifikasi pola terhadap data deret waktu juga berfungsi untuk menentukan metode yang akan digunakan untuk menganalisis data tersebut.
Teknik-teknik peramalan data deret waktu digunakan untuk menghitung perubahan sepanjang waktu dengan memeriksa pola-pola (konstan, musiman, siklus, dan trend) atau menggunakan informasi mengenai periode waktu sebelumnya untuk memperkirakan hasil periode mendatang. Jenis pola data sangat penting untuk diketahui karena akan berpengaruh terhadap hasil prediksi. Ada beberapa asumsi yang penting yang harus dipenuhi agar data deret waktu dapat digunakan dalam keperluan prediksi. Beberapa diantaranya adalah adanya ketergantungan antara kejadian masa mendatang terhadap masa sebelumnya atau lebih dikenal dengan istilah adanya autokorelasi antara Zt dan Zt-k, kestasioneran
data dan kehomogenan ragam. Akurasi yang dihasilkan dari prediksi deret waktu, sangat ditentukan oleh seberapa jauh asumsi-asumsi diatas dipenuhi.
Metode yang dilakukan untuk menganalisis data deret waktu seperti moving average, exsponential smoothing, dekomposisi, ARIMA (Autoregressive Integrated Moving Average), dan MARIMA (Multivariate Autoregressive Integrated Moving Average). Sebagian besar metode melibatkan model matematis terbaik untuk menyatakan perilaku dari sistem yang diamati. Terkadang dalam mengidentifikasi model memerlukan keahlian khusus karena karakteristik yang tidak linear pada model cukup sulit untuk diidentifikasi. Perbedaan prediksi mungkin terjadi pada model yang berbeda jika menggunakan himpunan pengamatan yang sama. Beberapa analisis dapat diterapkan pada deret waktu untuk menentukan unsur-unsur statistiknya sehingga dapat memberikan gambaran mengenai model yang mungkin cocok untuk data tersebut. Pada analisis data deret waktu yang terpenting adalah koefisien autokorelasi, yaitu hubungan data deret waktu dengan dirinya sendiri, dengan lag 0, 1, 2 atau lebih periode.
Teknik Ensemble
4
Teknik ensemble ditentukan dalam dua cara, tahap pertama memilih peubah
output dari anggota ensemble yang terbaik untuk memperoleh prediksi akhir. Tahap kedua menggabungkan peubah output dari anggota ensemble menggunakan beberapa algoritma kombinasi (Lim dan Goh 2007). Pada dasarnya teknik
ensemble merupakan teknik peramalan yang mengkombinasikan beberapa peubah
output dari metode peramalan.Teknik ensemble menjadi salah satu metode peramalan yang popular, khususnya pada prediksi iklim. Studi terakhir telah menunjukkan bahwa kombinasi beberapa model dapat memperbaiki kekekaran dan kehandalan, yaitu ensemble (Lusia dan Suhartono 2013).
Salah satu teknik ensemble yang digunakan untuk memprediksi adalah
Weighted Mean (rataan terboboti).
, (1)
dengan merupakan nilai prediksi dari model ke-i dan adalah pembobotnya.
k-Nearest Neighbor (kNN)
k-Nearest Neighbor (kNN) adalah suatu metode yang menggunakan algoritma supervised dimana data testing yang baru diklasifikasikan berdasarkan mayoritas kelas pada kNN. Tujuan dari algoritma ini adalah mengklasifikasi objek baru berdasarkan atribut dan data training. Pengklasifikasian tidak menggunakan model apapun untuk dicocokkan dan hanya berdasarkan pada memori. Prinsip dari
kNN adalah menemukan k objek dari data training yang paling dekat dengan data
testing. Algoritma kNN sangat sederhana, bekerja berdasarkan pada jarak terdekat dari data testing dengan data training untuk menentukan k-tetangga terdekat (kNN), kemudian diambil mayoritas dari kNN untuk dijadikan prediksi dari data
testing. Gambar 1 menunjukkan bagaimana memilih k-tetangga terdekat. Misalnya untuk k = 3, pada gambar ditunjukkan dalam lingkaran pertama, yaitu terdapat 3 data training yang memiliki jarak paling dekat dengan data testing. Sedangkan untuk k = 5, tetangga terdekat dari data testing pada lingkaran kedua, yaitu terdapat 5 data training yang memiliki jarak paling dekat dengan data testing.
5
kNN memiliki beberapa kelebihan yaitu kekar terhadap data training
yang noise dan efektif apabila data training kecil. Sedangkan kelemahan dari kNN adalah perlunya ketelitian dalam menentukan nilai dari parameter k (jumlah dari tetangga terdekat). Metode ini sangat sensitif terhadap peubah yang tidak relevan atau berlebihan karena semua peubah berkontribusi terhadap kesamaan dan klasifikasi (Chitra dan Uma 2010). kNN banyak diterapkan dalam analisis data yang memiliki banyak dimensi peubah, seperti data keuangan dan bisnis. Prediksi data yang pengamatannya merupakan dimensi waktu dapat menggunakan kombinasi pendekatan klasifikasi data (Alkhatib et al. 2013). kNN merupakan salah satu metode yang digunakan untuk memprediksi peubah output dari data tersebut menggunakan pendekatan klasifikasi. Dalam pendekatan klasifikasi, himpunan data dibagi menjadi himpunan data training dan data testing. kNN menggunakan ukuran kemiripan untuk membandingkan data testing yang diberikan dengan data training. Salah satu ukuran kemiripan yang digunakan adalah jarak euclid antara dua titik yaitu titik pada data training (xtrain) dan titik
pada data testing (xtest), yaitu
, (2)
kNN memilih k data dari data training yang dekat dengan data testing dalam memprediksi peubah output. Nilai output dari k data training yang terpilih sebagai tetangga terdekat digunakan untuk memprediksi nilai output dari data testing yang tidak diketahui. Regresi kNN menggunakan formula sebagai berikut untuk memprediksi nilai tersebut (Sorjamaa et al. 2005),
(3) dengan k merupakan banyaknya tetangga terdekat dari . Rumus ini kurang efisien jika digunakan pada data deret waktu, karena tidak mempertimbangkan korelasi antar pengamatan (waktu). Formulasi umum yang digunakan untuk memprediksi data testing adalah
, (4)
6
3. METODOLOGI PENELITIAN
Data
Jenis dan Sumber Data
Data yang digunakan dalam penelitian ini adalah data sekunder yang diperoleh dari Kementerian Pertanian (KEMENTAN) bagian distribusi dan cadangan pangan. Data merupakan hasil rekapitulasi penarikan contoh harga akhir dari beberapa pedagang di pasar-pasar tradisional dari Januari 1998 hingga Desember 2012. Dalam penelitian ini data yang digunakan untuk memprediksi harga beras di Indonesia adalah data harga beras Januari 2010 hingga Desember 2012. Data dibagi menjadi 2 kelompok, data dari Januari 2010 hingga Desember 2011 (t=1 hingga t=24) dijadikan sebagai data training dan sisanya dari Januari - Desember 2012 (t=25 hingga t=36) sebagai data testing.
Peubah Penelitian
Peubah output ( ) yang digunakan dalam penelitian ini adalah data harga beras per bulan dari Januari 2010 hingga Desember 2012. Peubah input dalam penelitian ini adalah X1 luas panen padi (ha), X2 produktivitas (ku/ha), X3 total produksi padi (ton) dan X4 jumlah penduduk (ribu). Peubah input ini merupakan data persubround (tiga bulanan) sehingga data terlebih dahulu diinterpolasi agar menjadi data bulanan. Hal ini perlu dilakukan karena peubah output yang digunakan merupakan data bulanan.
Metode Analisis
Langkah awal yang dilakukan dalam penelitian ini adalah analisis deskriptif pada setiap peubah yang digunakan dalam analisis. Tahapan analisis data dalam penelitian ini dibagi menjadi tiga tahap, yaitu:
Tahap I: Menghitung prediksi harga beras dari Januari - Desember 2012 dengan metode kNN tunggal. Pada tahap ini dilakukan prediksi terhadap metode menggunakan jumlah tetangga terdekat (k) yang berbeda. Langkah-langkah analisis sebagai berikut:
1. Menentukan nilai k, dengan k terdiri dari 3, 4, 6, 9, 10, 12, 15 dan 24.
2. Membakukan setiap peubah input. Hal ini bertujuan untuk menyamakan skala yang berbeda dari setiap peubah input.
3. Menghitung jarak Euclid antar pengamatan dari data training dan data testing berdasarkan peubah input menggunakan formula
dengan p merupakan banyaknya peubah input.
7
5. Menghitung nilai pembobot untuk setiap data training yang terpilih sebagai tetangga terdekat, oleh karena data yang dianalisis merupakan data deret waktu yang memperhatikan urutan data. Data training yang nomor urutnya jauh dari data testing akan diboboti kecil, sedangkan data training yang dekat dengan data testing akan diboboti besar, sehingga formula pembobot yang digunakan adalah dengan = pembobot kNN tunggal untuk tetangga ke- yang terpilih, = urutan waktu, dan = banyaknya amatan pada data
training. Nilai pembobot ini digunakan untuk memboboti peubah output yang terpilih menjadi tetangga terdekat.
6. Menghitung prediksi peubah output dengan metode kNN tunggal. Prediksi bukan hanya menggunakan rata-rata k-tetangga terdekat dari peubah output
seperti halnya regresi kNN. Agar nilai prediksi yang dihasilkan tetap mengikuti pola data yang memiliki trend, maka dalam penelitian ini prediksi menggunakan modifikasi metode regresi kNN yaitu dengan menambahkan faktor koreksi trend dan perubahan waktu, yaitu menggunakan formula
,
dengan = slope dari model regresi antara (waktu) terhadap (peubah
output) sedangkan = Rata-rata selisih antara nomor urut data testing dengan data training yang terpilih menjadi k tetangga terdekat. dalam hal ini merupakan faktor koreksi untuk memperhatikan kondisi trend data dan perubahan data terhadap waktu.
7. Nilai prediksi yang diperoleh pada langkah 1-6 dijadikan sebagai data
training untuk memprediksi peubah output data testing berikutnya. Banyaknya data training yang digunakan dalam analisis selalu sama yaitu sebanyak 24 data, sehingga untuk prediksi peubah output yang kedua, data dengan nomor urut pertama tidak diikutsertakan dalam analisis. Untuk memprediksi data yang ketiga, data dengan nomor urut pertama dan kedua tidak diikutsertakan. Hal ini dilakukan juga pada prediksi selanjutnya.
8
Tahap II: Menghitung prediksi harga beras dengan metode ensemble KNN. Langkah-langkah analisis sebagai berikut:
1. Menghitung prediksi menggunakan metode kNN tunggal dengan jumlah tetangga terdekat (k) berbeda-beda yaitu 3, 4, 6, 9, 10, 12, 15 dan 24. Nilai-nilai k ini digunakan untuk melihat bagaimana pengaruh nilai k terhadap hasil prediksi.
2. Menggabungkan kedelapan hasil prediksi tersebut menggunakan formula , dengan merupakan banyaknya metode kNN tunggal yang digunakan, pembobot ensemble merupakan korelasi antara data harga beras dengan prediksi metode kNN tunggal ke-h ( menggunakan formula . Korelasi menggambarkan besarnya hubungan antara data harga beras dengan prediksi metode kNN tunggal. Prediksi yang baik akan mengikuti pola data yang sebenarnya, jika prediksi mengikuti pola trend yang searah dengan pola data sebenarnya maka korelasi yang dihasilkan besar, sehingga pembobot wh juga besar.
3. Melakukan evaluasi terhadap hasil prediksi akhir dengan harga beras pada data testing berdasarkan nilai MAPE, MAE dan RMSEP.
9
10
4. HASIL DAN PEMBAHASAN
Bab ini membahas mengenai hasil prediksi harga beras di Indonesia dengan metode ensemble k-Nearest Neighbor (kNN). Harga beras akan diprediksi menggunakan metode kNN tunggal dan ensemble kNN. Kemudian ditentukan metode mana yang memiliki kinerja lebih baik untuk memprediksi harga beras di Indonesia. Kinerja metode tersebut diukur berdasarkan nilai kebaikan model yaitu MAPE, MAE dan RMSEP antara data prediksi dengan data aktual.
Eksplorasi Data
Ketersediaan beras sangat penting bagi penduduk Indonesia, karena beras merupakan makanan pokok penduduk Indonesia. Ada istilah yang berkembang “Belum makan kalau belum makan nasi (beras)”, hal ini membuktikan betapa pentingnya beras bagi penduduk Indonesia. Dengan semakin meningkatnya jumlah penduduk akan meningkatkan permintaan terhadap beras. Permasalahan timbul dengan terjadinya peningkatan jumlah penduduk Indonesia yang tidak diikuti dengan peningkatan produksi beras di Indonesia. Dalam komponen pengeluaran konsumsi masyarakat Indonesia, beras mempunyai bobot yang paling tinggi. Oleh karena itu inflasi nasional sangat dipengaruhi oleh perubahan harga beras. Kondisi harga beras di Indonesia terus berubah (tidak stabil). Hal ini dapat terlihat pada Gambar 3.
Gambar 3 memperlihatkan bahwa data harga beras di Indonesia pada Januari 1998 - Desember 2012 mengalami kenaikan secara signifikan dan membentuk pola trend positif. Hal ini menunjukkan adanya ketidakstasioneran data yang dipengaruhi oleh beberapa faktor, yaitu tahun 1998 pada bulan Januari hingga September harga beras cenderung meningkat dari harga kurang lebih Rp 1290 per kilogram mencapai harga Rp 3000 per kilogram. Kenaikan ini
11
merupakan akibat dari krisis ekonomi moneter yang terjadi di Indonesia mulai tahun 1997-1998 yang memberikan pengaruh yang sangat besar terhadap harga beras. Upaya pemerintah untuk menurunkan harga beras dapat terlihat dari turunnya harga beras pada penghujung tahun 2000 mencapai harga Rp 2349 per kilogram. Namun pada tahun 2001 hingga tahun 2004 harga beras terus meningkat tetapi masih dibawah angka Rp 3000 per kilogram. Selanjutnya perilaku harga beras mulai meningkat tajam, harga beras melambung tinggi mulai dari Rp 3335 per kilogram hingga Rp 8700 per kilogram. Adanya kenaikan harga beras yang cukup besar ini diduga terjadi karena adanya masalah pada pasokan distribusi (Kusumaningrum 2008).
Data yang digunakan untuk memprediksi harga beras adalah data Januari 2010 hingga Desember 2011. Harga beras pada tahun tersebut kenaikannya mulai stabil dan tidak terlalu tajam, namun masih memiliki trend yaitu mulai dari harga Rp 6623 hingga Rp 8705 per kilogram. Hal ini berarti data training yang digunakan untuk memprediksi harga beras tahun 2012 hanya terdiri dari 24 data saja. Metode yang digunakan untuk memprediksi harga beras dengan menggunakan kondisi data training yang sedikit adalah metode kNN, karena salah satu kelebihan dari metode tersebut adalah memiliki kinerja yang sama dengan metode lain walaupun data training yang digunakan lebih sedikit (Rokach 2010).
(a) (b)
(c) (d)
12
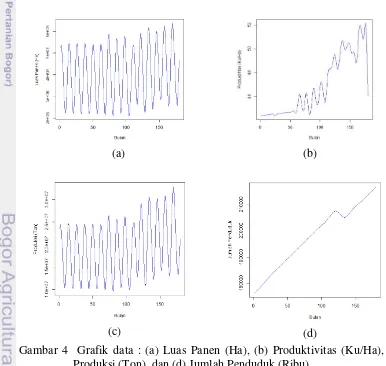
Grafik data pada gambar 4 terdiri dari grafik data luas panen, produktivitas, produksi dan jumlah penduduk. Ke empat peubah ini merupakan peubah input
yang dapat mempengaruhi harga beras di Indonesia, harga beras merupakan peubah output. Gambar 4(a) merupakan grafik data luas panen bulanan, data tersebut merupakan hasil interpolasi data per subround (tiga bulanan) dari tahun 2003 hingga tahun 2012. Pada gambar tersebut membentuk pola musiman.
Pada dasarnya beras tersedia dalam jumlah paling banyak pada satu bulan setelah periode panen raya yaitu terjadi pada bulan Februari hingga Juni, yang berarti puncak stok beras terjadi pada bulan Maret hingga Juli. Pada bulan Februari luas lahan meningkat dibandingkan pada bulan Januari dari sebesar 5.26 juta hektar menjadi 5.37 juta hektar. Begitu juga halnya dengan luas lahan pada periode-periode selanjutnya, pada bulan Februari tiap tahunnya mengalami kenaikan dari 5.26 juta hektar menjadi 6.37 juta hektar. Periode panen gadu yang terjadi berturut-turut pada bulan Juli, Agustus, September dan Oktober. Panen padi gadu pada umumnya menghasilkan beras bermutu bagus, tetapi jumlahnya tidak sebanyak beras pada penen raya. Pada periode ini harga beras secara rata-rata nasional merupakan harga yang sewajarnya, karena adanya keseimbangan antara pasokan dan permintaan pasar (sapuan 1999). Periode panen kecil adalah hasil penanaman musim kemarau, yang terdapat di wilayah beririgasi teknis dan biasanya hamparan panennya tidak luas karena di selang-seling oleh tanaman palawija atau hortikultura. Panen kecil terjadi pada bulan Nopember, Desember dan Januari. Pada periode panen ini stok beras sudah menipis, dan pada wilayah-wilayah lahan kering terjadi musim paceklik.
Pada gambar 4(b) merupakan grafik data produktivitas bulanan, data tersebut merupakan hasil interpolasi data per subround (tiga bulanan) dari tahun 2003 hingga tahun 2012. Pada gambar data produktivitas padi mengalami trend
dan tidak stasioner dalam rata-rata. Pada periode Februari-Maret 2003 mengalami kenaikan dari 45.11 kuintal/hektar hingga 46.00 kuintal/hektar. Masih pada tahun 2003 hingga Desember 2004 terjadi penurunan produktivitas dari 45.69 kuintal/hektar hingga 44.70 kuintal/hektar. Hal itu terjadi untuk tiap tiga bulan berikutnya, hingga pada Januari 2005 hingga Oktober 2012 produktivitas mengalami peningkatan dari 45.07 kuintal/hektar sampai 50.17 kuintal/hektar. Pada penghujung tahun 2012 mengalami penurunan menjadi 46.03 kuintal/hektar. Penyebab turun naiknya produktivitas dalam budidaya padi sawah adalah perubahan cuaca di Indonesia mengalami perubahan yang cukup dinamis. Salah satu kondisi yang dirasakan adalah semakin meningkatnya suhu udara dan tidak seimbangnya jumlah air di musim kemarau dan musim hujan. Masyarakat mengalami kekurangan air di musim kemarau dan kebanjiran di musim hujan. Sementara itu, petani tidak cukup mampu beradaptasi terhadap perubahan cuaca yang ditandai dengan tidak berubahnya pola penggunaan air pada padi sawah yang makin terbatas jumlahnya.
13
sebesar 12.65 juta ton dan perlahan naik hingga bulan Januari 1999 menjadi 23.55 juta ton begitu seterusnya turun dan naik pada bulan-bulan tertentu. Hal ini disebabkan oleh luas panen padi yang terjadi pada bulan-bulan tertentu, seperti pada panen raya terjadi pada bulan Februari hingga Juni, terbukti pada bulan Februari tiap tahunnya mengalami produksi padi yang besar dibandingkan dengan bulan lainnya yaitu rata-rata sebesar 23 juta ton bahkan Februari 2012 produksi padi meningkat menjadi 32.82 juta ton, kenaikan produksi diperkirakan terjadi karena peningkatan luas panen sebesar 6 juta hektar. Periode panen selanjutnya adalah panen gadu yang terjadi pada bulan Juli hingga Oktober. Pada Panen padi gadu pada umumnya menghasilkan beras bermutu bagus, tetapi jumlahnya tidak sebanyak beras pada penen raya.Terbukti pada periode ini hasil produksi padi hanya 10 juta hingga 12 juta ton, karena adanya keseimbangan antara pasokan dan permintaan pasar.
Gambar 4(d) merupakan grafik data jumlah penduduk bulanan, data tersebut merupakan hasil interpolasi data tahunan dari tahun 1998 hingga tahun 2012. Pada grafik jumlah penduduk mengalami kenaikan yang signifikan tiap tahun terbukti pada gambar membentuk pola trend linear. Ledakan pertumbuhan penduduk akan berdampak pada penyediaan bahan pangan. Terbukti dari tahun 1998 hingga tahun 2012 jumlah penduduk mengalami kenaikan yang signifikan. Meningkatnya jumlah penduduk harus disertai dengan jumlah bahan pangan yang tersedia khususnya ketersediaan akan bahan pokok seperti beras. Banyaknya penduduk akan mengurangi lahan yang akan digunakan untuk pertanian, perternakan, dan lahan-lahan untuk produksi pangan. Dengan berkurangnya lahan hijau di dunia karena banyaknya jumlah penduduk, maka kualitas alam dalam penyediaan kebutuhan manusia khususnya kebutuhan akan beras semakin menurun sebagai akibat pertumbuhan penduduk. Sikap pemerintah dan masyarakat yang peduli terhadap keseimbangan antara pertumbuhan jumlah penduduk dan ketersediaan bahan pangan sangat penting. Bentuk hubungan antara pertumbuhan penduduk dan pembangunan ekonomi adalah positif di negara maju, tetapi di negara yang sedang berkembang hubungan tersebut masih negatif. Dalam upaya menanggulangi kelaparan, kemiskinan dan peningkatan pendidikan, akan sangat diuntungkan jika angka pertumbuhan penduduk dapat diturunkan agar kuantitas dan kualitas sumber daya alam akan mengalami penurunan, seiring dengan tingginya angka pertumbuhan penduduk.
14
kNN Tunggal dan EnsemblekNN
Prediksi harga beras dalam penelitian ini menggunakan metode kNN tunggal dan ensemble kNN. Metode yang memiliki kinerja yang baik dalam memprediksi selanjutnya digunakan untuk memprediksi harga beras di Indonesia. Kinerja kedua metode tersebut dilihat berdasarkan nilai MAPE, MAE dan RMSEP. Metode yang baik digunakan untuk memprediksi memiliki nilai MAPE, MAE dan RMSEP yang lebih kecil.
Metode kNN tunggal yang digunakan untuk memprediksi harga beras tahun 2012 dibedakan berdasarkan nilai k-tetangga terdekat yaitu k = 3, k = 4, k=6, k=9,
k=10, k=12, k=15 dan k=24. Metode kNN tunggal sangat sederhana dan efektif digunakan apabila ukuran data training kecil dan data yang mempunyai dimensi peubah yang banyak, kNN tunggal juga kekar terhadap data training yang noise. Metode kNN mempunyai prinsip bahwa objek-objek dalam ruang input yang sama juga sama dengan objek-objek dalam ruang outputnya, sehingga metode ini bekerja berdasarkan kemiripan peubah-peubah inputnya (Zhou 2012). Metode
kNN menggunakan ukuran kemiripan untuk membandingkan data testing yang diberikan dengan data training.
Gambar 5 memperlihatkan hasil prediksi metode kNN tunggal dan ensemble kNN. Hasil prediksi harga beras baik dengan menggunakan metode kNN tunggal maupun ensemble kNN mempunyai fluktuasi dan pola yang hampir sama seperti harga beras aktual tahun 2012. Hal ini membuktikan bahwa objek-objek dalam ruang input yang sama juga sama dalam ruang outputnya. Pada gambar tersebut terlihat bahwa harga beras memiliki pola yang sangat fluktuatif, yaitu bulan 1-3 masih stabil begitu juga dengan hasil prediksinya, sedangkan pada bulan ke-4 harga beras naik namun tidak terlalu signifikan. Harga beras juga memiliki pola
trend pada bulan 9-12 dan beberapa hasil prediksi masih mengikuti pola tersebut. Gambar 5 Prediksi Harga Beras berdasarkan Metode kNN Tunggal dan
15
Pemilihan model akhir yang diperoleh dari satu model yang terbaik biasanya penduga parameter yang dihasilkan bias dan ragam penduganya
underestimate, selain itu distribusi dari penduga parameter tersebut jauh dari distribusi normal (Claeskens dan Hjort 2008). Pada faktanya rata-rata merupakan penduga parameter yang tak bias dan memiliki ragam kecil. Ensemble kNN menggunakan konsep rata-rata terboboti dari penduga parameter beberapa hasil prediksi metode kNN tunggal. Metode ini diharapkan menghasilkan hasil prediksi yang lebih baik dibandingkan metode kNN tunggal.
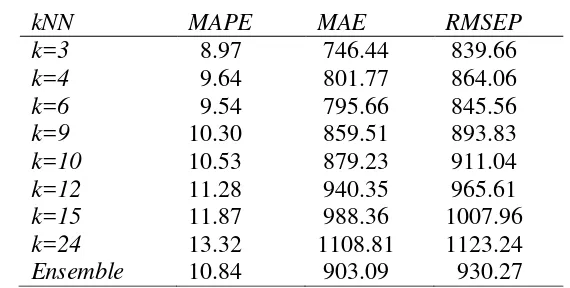
Tabel 1 Nilai MAPE, MAE dan RMSEP Hasil Prediksi Harga Beras di Indonesia menggunakan Data Testing Januari – Desember 2012
kNN MAPE MAE RMSEP
Tabel 1 memperlihatkan nilai MAPE, MAE, dan RMSEP dari hasil prediksi beberapa metode kNN tunggal dan metode ensemble kNN. Dalam metode kNN sangat penting untuk memilih nilai k-tetangga terdekat, karena hal ini dapat mempengaruhi hasil prediksi. Nilai k yang kecil dapat menghasilkan ragam yang besar pada hasil prediksi, sedangkan nilai k yang besar dapat mengakibatkan bias model yang besar. Hal ini terlihat pada Tabel 1 bahwa nilai MAPE, MAE, dan RMSEP hasil prediksi semakin kecil jika nilai k yang dicobakan semakin besar, namun jika nilai k yang dicobakan sangat besar atau mendekati ukuran data
training maka ketiga nilai tersebut memberikan hasil yang besar.
Tabel 2 Nilai MAPE, MAE dan RMSEP Hasil Prediksi Harga Beras di Indonesia menggunakan Data Testing Januari 2011 – Desember 2012
16
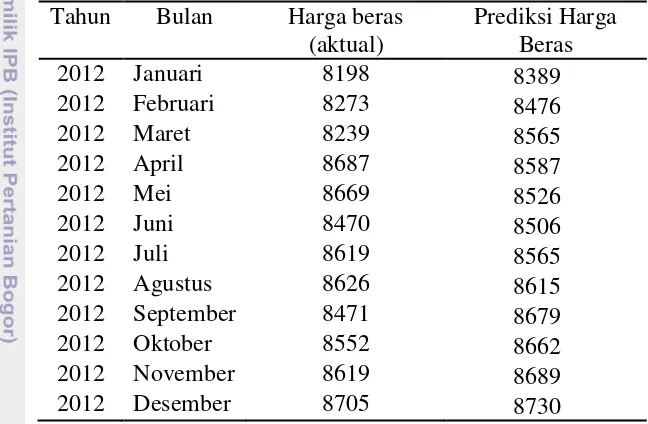
Tabel 1 juga memperlihatkan bahwa metode ensemble kNN menghasilkan nilai MAPE, MAE dan RMSEP yang lebih kecil dibandingkan kNN tunggal walaupun pada kasus k =15 nilai-nilai tersebut lebih kecil, namun hasil ini akan berbeda jika nilai k yang sama dan banyaknya data training yang digunakan berbeda. Hal ini dapat dibuktikan pada Tabel 2, dengan data training dari Januari 2007 hingga Desember 2010 dan data testing dari Januari 2011 – Desember 2012. Tabel tersebut memperlihatkan bahwa nilai k= 3 yang memberikan nilai lebih kecil dibandingkan dengan nilai k lainnya dan k=15 menghasilkan nilai yang cukup besar. Dari hasil tersebut terbukti bahwa metode kNN tunggal tidak memberikan hasil yang konsisten. Sedangkan, metode ensemble kNN menghasilkan prediksi yang lebih stabil dibandingkan metode kNN tunggal. Tabel 3 Prediksi Harga Beras per kilogram di Indonesia Januari – Desember 2012
Tahun Bulan Harga beras
17
5.
SIMPULAN DAN SARAN
Simpulan
Nilai MAPE, MAE dan RMSEP hasil prediksi harga beras di Indonesia menunjukkan bahwa metode ensemble kNN memiliki kinerja yang lebih baik dibandingkan dengan metode kNN tunggal. Nilai-nilai tersebut semakin kecil jika nilai k yang dicobakan semakin besar, namun jika nilai k yang dicobakan sangat besar atau mendekati ukuran data training maka ketiga nilai tersebut memberikan hasil yang besar. Kisaran nilai prediksi harga beras hampir sama dengan harga beras sebenarnya. Selain itu, prediksi harga beras juga memiliki pola trend yang hampir sama dengan harga beras sebenarnya.
Saran
Pada penelitian ini hanya melihat kinerja dari metode kNN tunggal dan
ensemblekNN menggunakan data harga beras dengan empat peubah input. Untuk penelitian selanjutnya bisa mengkaji kinerja dari metode kNN melalui rancangan simulasi. Selain itu bisa juga dilakukan dengan menambahkan peubah input yang mempengaruhi harga beras. Teknik ensemble yang dilakukan dalam penelitian ini menggunakan perhitungan rata-rata terboboti (Weighted Means), jadi penelitian selanjutnya bisa dilakukan dengan menggunakan teknik ensemble yang lain.
DAFTAR PUSTAKA
Alkhatib K, Najadat H, Hmeidi I, Shatnawi MKA. 2013. Stock Price Prediction Using k-Nearest Neighbor (kNN) Algorithm. International Journal of Business, Humanities and Technology. 3(3):32-44.
Chitra A, Uma S. 2010. An Ensemble Model of Multiple Classifiers for Time Series Prediction. International Journal of Computer Theory and Engineering. 2(3):454-458.
Claesken G, Hjort LN. 2008. Model Selection and Model Averaging. Cambridge: Cambridge University Press.
De Bock KW, Coussement K, Van Den PD. 2010. Ensemble Classification Based on Generalized Additive Models. Computational Statistics and Data Analysis. 54(6):1535-1546.
Friedman JH, Popescu BE. 2008. Predictive Learning via Rule Ensemble. The Annals of Applied Statistics. 2(3):916–954.
Kocev D, Vens C, Struyf J, Dzeroski S. 2013. Tree Ensembles for Predicting Structured Outputs. Pattern Recognition 46 (3):817-833.
18
Lim CP, Goh WY. 2007. The Application of an Ensemble of Boosted Elman Networks to Time Series Prediction: A Benchmark Study. International Journal of Information and Mathematical Sciences.3:2-9.
Liu XY, Wu J, Zhou ZH. 2009. Exploratory Undersampling for Class-Imbalance Learning. IEEE Transactions On Systems, Man and Cybernetics-Part B. 39(2):539-550.
Lusia DA, Suhartono. 2013. Ensemble Method Based on Two Level ARIMAXFFNN for Rainfall Forecasting in Indonesia. International Journal of Science and Research (IJSR). Indian online ISSN: 2(2):2319-7064.
Mendenhall W, Reinmuth JE, Beaver RJ. 1993. Statistics for Management and Economics. California: South-Western College Pub.
Rokach L. 2010. Pattern Classification Using Ensemble Methods. Singapore:
World Scientific Publishing.
Sapuan. 1999. Perkembangan Manajemen Pengendalian Harga Beras di Indonesia, 1969-1999. Agro Ekonomika. 29 (1):19-37.
Sasu A. 2012. K-Nearest Neighbor Algorithm for Univariate Time Series Prediction. Bulletin Transilvania University of Brasov. 5(54):147-152.
Sorjamaa A, Hao J, Lendasse A. 2005. Mutual Information and k-Nearest Neighbors Approximator for Time Series Prediction. Di dalam: Duch, Wlodzislaw, Oja, Erkki, Zadrozny, Slawomir, editor. Artificial Neural Networks : Formal Models and Their Applications. ICANN; 2005 Sept 11-15; Warsaw, Poland. Berlin(DE): Springer. p 553-558.
Yu Q, Sorjamaa A, Miche Y, Severin E. 2009. A Methodology for Time Series Prediction in Finance [tesis]. Bogor (ID): Aalto University.
Zhou HZ. 2012. Ensemble Methods Foundations and Alghoritms. Florida(US): CRC Pr.
19
Lampiran 1 Data Harga Beras, Luas Panen, Produktivitas, Produksi dan Jumlah Penduduk di Indonesia dari Januari 1998 - Desember 2012
Tahun Bulan
1998 September 3010 2269014 44.44 10318800 178249
1998 Oktober 2725 2821626 44.45 12654143 178523
1999 September 2570 2261379 44.52 10278300 181778
1999 Oktober 2529 2817934 44.48 12621818 182075
2012 September 8471 2589362 51.64 13371776 215844
2012 Oktober 8552 3076001 50.17 15086393 216090
20
#k<-3; #k<-6; #k<-9; #k<-12; #k<-13; #k<-18; #k<-21; #k<-24; #k<-10; #k<-30; #k<-23; #k<-36; #k<-39;#k<-42;#k<-45;#k<-48;#k<-51;#k<-54;#k<-57;#k<-60;
21
w<-(urutan.data/n.training); rata2sel<-mean(w*selisih.jarak); y.pred<-((sum(y.utk.pred*w))/sum(w))+(b1*rata2sel)
pred<-c(pred,y.pred)
#pred.rata2<-c(pred.rata2,y.pred.rata2) #n.test<-n.test-1
y[var.test]<-y.pred var.test<-var.test+1 }
22
Lampiran 3 Hasil Prediksi Harga Beras di Indonesia dengan Metode kNN Tunggal dan EnsemblekNN Januari – Desember 2012
Tahun
Bulan
Harga
Beras k=3 k=4 k=6 k=9 k=10 k=12 k=15 k=24 Ensemble
23
RIWAYAT HIDUP
Penulis dilahirkan di Andaleh pada tanggal 15 Juli 1988 dari pasangan Bapak Karnadi dan Ibu Pepi Yetni. Penulis merupakan putri kedua dari dua bersaudara. Penulis menyelesaikan pendidikan Sekolah Menengah Atas di SMAN 1 Kecamatan Lareh Sago Halaban Payakumbuh pada tahun 2006 Program IPA dan pada tahun yang sama penulis melanjutkan pendidikan di Universitas Islam Bandung (UNISBA) pada Program Studi Statistika Fakultas Matematika dan Ilmu Pengetahuan Alam dan menyelesaikannya pada tahun 2010. Pada tahun 2011 penulis melanjutkan kuliah ke Sekolah Pascasarjana Institut Pertanian Bogor (SPs IPB) pada Program Studi Statistika. Penulis juga menulis karya ilmiah yang
telah dipublikasikan dalam jurnal international yang berjudul “Ensemble