i
PENERAPAN ALGORITMA K-NEAREST NEIGHBOR UNTUK PREDIKSI HARGA CABAI RAWIT
DI YOGYAKARTA
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Informatika
oleh:
SEBASTIANUS RECZY S 155314102
PROGRAM STUDI INFORMATIKA JURUSAN INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii
IMPLEMENTATION OF K-NEAREST NEIGHBOR ALGORITHM TO PREDICT THE PRICE OF CAYENNE PEPPER
IN YOGYAKARTA
THESIS
Presented as Partial Fulfillment of the Requirements To Obtain the Sarjana Komputer Degree
In Informatics Study Program
By:
Sebastianus Reczy S
INFORMATICS STUDY PROGRAM DEPARTMENT OF INFORMATICS FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY YOGYAKARTA
iii
HALAMAN PERSETUJUAN
SKRIPSI
PENERAPAN ALGORITMA K-NEAREST NEIGHBOR UNTUK PREDIKSI HARGA CABAI RAWIT
DI YOGYAKARTA
Oleh:
Sebastianus Reczy S 155314102
Telah Disetujui Oleh:
Dosen Pemimbing
iv
HALAMAN PENGESAHAN
SKRIPSI
PENERAPAN ALGORITMA K-NEAREST NEIGHBOR UNTUK PREDIKSI HARGA CABAI RAWIT
DI YOGYAKARTA
Dipersiapkan dan disusun oleh: Sebastianus Reczy S
155314102
Telah dipertahankan di depan Panitia Penguji Pada tanggal ………...
Dan telah dinyatakan memenuhi syarat Susunan Panitian Penguji
Nama Lengkap Tanda Tangan Ketua : Drs. Haris Sriwindono, M.Kom., Ph.D. ……… Sekretaris : Eduardus Hardika Sandy Atmaja, S.Kom., M.Cs. ……… Anggota : Agnes Maria Polina, S.Kom., M.Sc. ………
Yogyakarta ………. Fakultas Sains dan Teknologi
Universitas Sanata Dharma Dekan
v
HALAMAN PERSEMBAHAN
Serahkanlah kuatirmu kepada Tuhan, maka ia akan memelihara engkau!
Tidak untuk selama-lamanya dibiarkan-Nya orang benar itu goyah.
(MAZMUR 55:23)
Karya ini kupersembahkan kepada Tuhan Yesus Kristus, Orang Tua, Keluarga, dan Sahabat.
vi
PERNYATAAN KEASLIAN KARYA
Saya menyatakan dengan sesungguhnya bahwa skripsi yang saya tulis ini tidak mengandung atau memuat hasil karya orang lain, kecuali yang telah disebutkan dalam daftar pustaka dan kutipan selayaknya karya ilmiah.
Yogyakarta, ……… Penulis,
vii ABSTRAK
Cabai merupakan tanaman yang banyak dibudidayakan oleh petani di Indonesia, karena tanaman cabai memiliki nilai jual yang tinggi. Akan tetapi harga jual cabai cenderung tidak stabil, hal ini terjadi karena faktor keterbatasan stok cabai dan faktor cuaca yang mengakibatkan petani gagal panen cabai. Dengan memprediksi harga cabai rawit dapat membantu petani sehingga petani tidak mengalami kerugian saat menjual cabai rawit. Dengan menggunakan data yang ada ada seperti luas penen, produksi panen dan curah hujan, maka bisa diperdiksi harga cabai kedepannya. Sehingga petani akan mengetahui ketika musim penghujan tiba petani tidak akan menanam cabai terlalu banyak sehingga hasil panen cabai tidak banyak yang rusak. Dan ketika hasil penen cabai rawit melimpah petani dapat mengendalikan stok dengan menjual sebagian hasil panen cabai. Dan sisa cabai dapat simpan atau diolah agar tidak rusak dan dapat dijual. Berdasarkan hasil percobaan prediksi menggunakan algoritma K-Nearest Neighbor dengan 3-fold cross validation diperoleh akurasi sebesar 72.222%, dengan keseluruhan dataset 36 record, dan nilai k (tetangga terdekat) yang menghasilkan akurasi tertinggi yaitu pada k=13.
viii ABSTRACT
Chili is a plant that is widely cultivated by farmers in Indonesia, because chili plants have a high selling value. However, the selling price of chili tends to be unstable, this happens because of the limitation of chili stock and weather factors that cause farmers to fail harvesting chili. By predicting the price of cayenne peppers can help farmers so that farmers do not experience losses when selling cayenne peppers. By using existing data such as harvest area, crop production and rainfall, it can be predicted the future price of chili. Therefore, farmer may identify when the rainy season arrives, farmers will not plant too many chilies so that not much of the chilli crops will be damaged. And when the yield of cayenne pepper is abundant, the farmer can control the stock by selling part of the chilli harvests. Also, the remaining chili can be stored or processed so that it may not be damaged and can be sold. Based on the results of prediction experiments using the K-Nearest Neighbor algorithm with 3-fold cross validation, it was obtained an accuracy of 72,222%, with a whole dataset of 36 records, and the value of k (nearest neighbor) which produced the highest accuracy at k = 13.
ix
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan di bawah ini, saya mahasiswa Universitas Sanata Dharma: Nama : Sebastianus Reczy S
NIM : 155314102
Demi pengembangan ilmu pengetahuan, saya memberikan kepada perpustakaan Universitas Sanata Dharma Yogyakarta karya ilmiah yang berjudul:
PENERAPAN ALGORITMA K-NEAREST NEIGHBOR UNTUK PREDIKSI HARGA CABAI RAWIT
DI YOGYAKARTA
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan kepada Perpustakaan Universitas Sanata Dharma Yogyakarta hak untuk menyimpan, mengalihkan dalam bentuk media lain, mengelola dalam bentuk pangkalan data, mendistribusikan secara terbatas, dan mempublikasikan di internet atau media lain untuk kepentingan akademis tanpa meminta izin dari saya maupun memberikan royalti kepada saya selama tetap mencantumkan nama saya sebagai penulis. Demikian pernyataan yang saya buat dengan sebenarnya.
Dibuat di Yogyakarta,
Pada tanggal ……… Yang menyatakan,
x
KATA PENGANTAR
Puji syukur kepada Tuhan Yang Maha Esa berkat karunianya penulis dapat menyelesaikan tugas akhir yang berjudul “PENERAPAN ALGORITMA K-NEAREST NEIGHBOR UNTUK PREDIKSI HARGA CABAI RAWIT DI YOGYAKARTA”. Tugas akhir ini ditulis sebagai salah satu syarat memperoleh gelar sarjana Komputer, Program Studi Informatka, Fakultas Sains dan Teknologi, Universitas Sanata Dharma.
Adapun penulis berterima kasih atas bantuan 1. Kepada Tuhan Yesus Kristus.
2. Keluarga besar di Kalimantan Barat yang mendukung dan mendoakan selama proses pengerjaan Tugas Akhir.
3. Bapak Sudi Mungkasi, S.Si, M.Math.Sc.,Ph.D. selaku Dekan Fakultas Sains dan Teknologi Universitas Sanata Dharma.
4. Bapak Robertus Adi Nugroho, ST., M.Eng. selaku ketua Program Studi Informatika Universitas Sanata Dharma.
5. Bapak JB. Budi Darmawan S.T., M.sc. selaku dosen pembimbing akademik 6. Ibu Agnes Maria Polina. S.kom., M.Sc. selaku dosen pembimbing tugas
akhir.
7. Yesy Mayang Sari yang selalu menemani saat mengerjakan skripsi, memberikan saran dan motivasi selama proses pengerjaan tugas akhir. 8. Seluruh staff program Studi Informatika Universitas Sanata Dharma. 9. Rekan – rekan mahasiswa Studi Informatika Universitas Sanata Dharma
angkatan 2015.
10. Teman – teman bootcamp yang telah membantu penulisan tugas akhir ini. Pada proses penulisan tugas akhir ini, penulis menyadari masih banyak kesalahan atau kekurangan. Oleh karena itu, penulis mengharapkan saran dan kritik untuk memperbaiki atau pun pengembangan di masa yang akan datang. Semoga tugas akhir ini bermanfaat untuk banyak pihak.
xi
Yogyakarta, ... Penulis,
xii DAFTAR ISI
JUDUL ... i
HALAMAN PERSETUJUAN ... iii
HALAMAN PENGESAHAN ... iv
HALAMAN PERSEMBAHAN ... v
PERNYATAAN KEASLIAN KARYA ... vi
ABSTRAK ... vii
ABSTRACT ... viii
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH .. ix
KATA PENGANTAR ... x
DAFTAR ISI ... xii
DAFTAR GAMBAR ... xv
DAFTAR TABEL ... xvi
BAB I PENDAHULUAN ... 1 1.1 Latar Belakang ... 1 1.2 Rumusan Masalah ... 2 1.3 Batasan Masalah ... 2 1.4 Tujuan Penelitian ... 2 1.5 Sistematika Penulisan ... 3
BAB II LANDASAN TEORI ... 4
2.1 Cabai ... 4
2.2 Tinjauan Pustaka ... 4
2.3 Penambangan Data ... 5
2.3.1 Pengelompokan Data Mining ... 5
2.3.2 Knowledge Discovery in Database... 7
2.4 K-Nearest Neighbor ... 8
2.4.1 Contoh Perhitungan Algoritma K-nearest Neighbor ... 9
2.5 Klasifikasi Data Mining ... 12
2.6 Evaluasi Kerja... 13
2.6.1 Cross Validation ... 13
xiii
BAB III METODOLOGI PENELITIAN ... 15
3.1 Bahan/Data Penelitian ... 15
3.2 Alat Penelitian ... 15
3.3 Tahap Penelitian ... 15
3.3.1 Pengumpulan Data ... 15
3.3.2 Studi Pustaka ... 15
3.3.3 Knowlegde Discovery in Database (KDD) ... 16
3.4 Pembangunan Sistem ... 17
3.5 Analisis dan Pembuatan Laporan ... 18
BAB IV PEMROSESAN AWAL DAN PERANCANGAN SISTEM ... 19
4.1. Pemrosesan Awal ... 19
4.1.1 Integrasi Data ... 19
4.1.2 Transformasi Data ... 19
4.2 Perancangan Sistem ... 20
4.2.1 Diagram Use Case ... 20
4.2.2 Narasi Use Case ... 21
4.2.3 Flowchart Algoritma K-Nerarest Neighbor ... 26
4.2.4 Desain Antarmuka ... 27
BAB IV IMPLEMENTASI DAN ANALISA HASIL ... 31
5.1 Implementasi Antarmuka ... 31
5.2 Pengujian Perangkat Lunak ... 34
5.2.1 Pengujian perhitungan akurasi secara manual menggunakan Microsoft Excel. ... 34
5.2.2 Pengujian perhitungan akurasi menggunakan perangkat lunak ... 46
5.2.3 Penggujian prediksi data tunggal secara manual menggunakan Microsoft Excel. ... 51
5.2.4 Pengujian prediksi data tunggal menggunakan perangkat lunak ... 54
xiv
BAB V KESIMPULAN DAN SARAN ... 58
6.1 Kesimpulan ... 58
6.2 Saran ... 58
xv
DAFTAR GAMBAR
Gambar 4.1 Gambar Use Case Perangakat Lunak ... 20
Gambar 4.2 Gambar Flowchart Algoritma K-Nearest Neighbor ... 26
Gambar 4.3 Gambar Desain Antarmuka Halaman Login ... 27
Gambar 4.4 Gambar Desain Antarmuka Halaman Home ... 28
Gambar 4.5 Gambar Desain Antarmuka Halaman Proses Data ... 29
Gambar 4.6 Gambar Desain Antarmuka Form Pengujian Data Tunggal ... 29
Gambar 4.7 Gambar Desain Antarmuka Halaman About ... 30
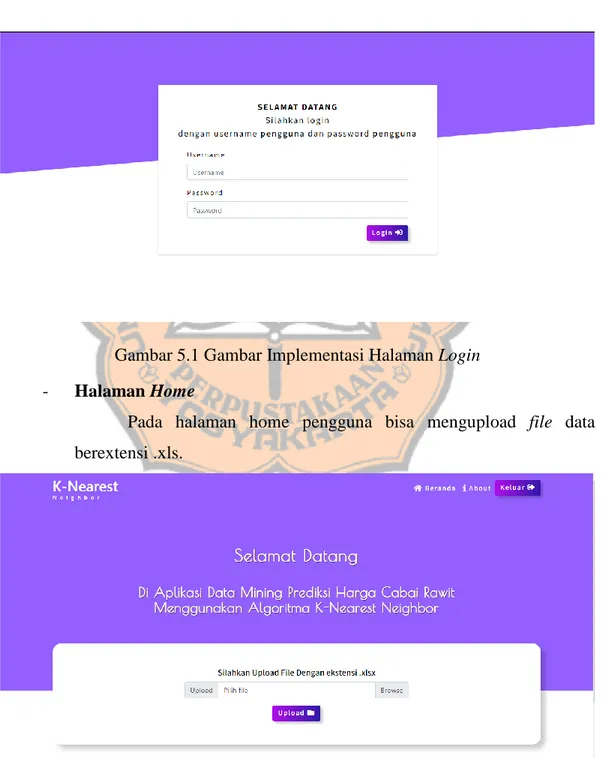
Gambar 5.1 Gambar Implementasi Halaman Login ... 31
Gambar 5.2 Gambar Implementasi Halaman Home ... 32
Gambar 5.3 Gambar Implementasi Halaman Proses Data ... 32
Gambar 5.4 Gambar Implementasi Halaman Form Pengujian Data Tunggal ... 33
Gambar 5.5 Gambar Implementasi Halaman About ... 33
Gambar 5.6 Gambar hasil akurasi prediksi harga cabai rawit ... 46
Gambar 5.7 Gambar listing program method 1-fold ... 47
Gambar 5.8 Gambar listing program method 2-fold ... 47
Gambar 5.9 Gambar listing program method 3-fold ... 48
Gambar 5.10 Gambar listing program membuat variabel nilai k ... 48
Gambar 5.11 Gambar listing program menghitung jarak ... 48
Gambar 5.12 Gambar listing program mencari k data jarak terdekat ... 49
Gambar 5.13 Gambar listing program mencari label mayoritas ... 50
Gambar 5.14 Gambar listing program menghitung akurasi ... 50
Gambar 5.15 Gambar listing program menghitung total akurasi ... 50
Gambar 5.16 Gambar form inputan pengujian data tunggal ... 54
Gambar 5.17 Gambar listing program membuat variabel nilai k ... 55
Gambar 5.18 Gambar listing program menghitung jarak ... 55
Gambar 5.19 Gambar listing program mencari nilai k jarak terkecil ... 55
Gambar 5.20 Gambar listing program mengurutkan jarak ... 56
Gambar 5.21 Gambar listing program mengecek label ... 56
xvi
DAFTAR TABEL
Tabel 2.1 Tabel Cross Validation 3-fold ... 13
Tabel 2.2 Tabel Confusion Matriks ... 14
Tabel 4.1 Tabel hasil transformasi data ... 20
Tabel 4.2 Tabel narasi Use Case login... 21
Tabel 4.3 Tabel narasi Use Case masukkan file ... 22
Tabel 4.4 Tabel narasi Use Case proses data ... 23
Tabel 4.5 Tabel narasi Use Case proses prediksi ... 24
Tabel 4.6 Tabel narasi Use Case logout... 25
Tabel 5.1 Tabel dataset cabai rawit ... 34
Tabel 5.2 Tabel data 1-fold ... 35
Tabel 5.3 Tabel data testing dan data training 1-fold ... 35
Tabel 5.4 Tabel hasil perhitungan jarak data testing dan data training 1-fold ... 37
Tabel 5.5 Tabel data jarak urut 1-fold ... 38
Tabel 5.6 Tabel Confusion matriks 1-fold ... 38
Tabel 5.7 Tabel data 2-fold ... 39
Tabel 5.8 Tabel data testing dan data training 2-fold ... 39
Tabel 5.9 Tabel hasil perhitungan jarak data testing dan data training 2-fold ... 41
Tabel 5.10 Tabel jarak urut 2-fold ... 41
Tabel 5.11 Tabel Confusion matriks 2-fold ... 42
Tabel 5.12 Tabel data 3-fold ... 42
Tabel 5.13 Tabel data testing dan data training 3-fold ... 42
Tabel 5.14 Tabel hasil perhitungan jarak data testing dan data training 3-fold .... 44
Tabel 5.15 Tabel jarak urut 3-fold ... 45
Tabel 5.16 Tabel Confusion matriks 3-fold ... 45
Tabel 5.17 Tabel data uji dan data training ... 51
Tabel 5.18 Tabel hasil perhitungan jarak ... 52
Tabel 5.19 Tabel jarak urut ... 53
Tabel 5.20 Tabel 3 jarak terkecil... 53
1 BAB I
PENDAHULUAN 1.1 Latar Belakang
Indonesia merupakan salah satu negara penghasil sayuran dan buah-buahan semusim. Tahun 2017, lima komoditas sayuran semusim dengan produksi terbesar secara berurutan adalah bawang merah, kubis, cabai besar, kentang, dan cabai rawit. Produksi bawang merah, cabai besar dan cabai rawit pada tahun 2017 mengalami peningkatan karena kenaikan luas panen (Badan Pusat Statistik). Cabai merupakan tanaman yang banyak dibudidayakan oleh petani di Indonesia, karena tanaman cabai memiliki nilai jual yang tinggi. Hasil tanaman cabai juga dapat diolah salah satunya dijadikan bumbu masakan.
Faktor yang mendasari terjadinya kenaikan harga pada cabai rawit adalah keterbatasan stok cabai. Dimana saat stok cabai sedikit maka harga cabai dapat naik, sebaliknya jika stok cabai rawit melimpah harga cabai dapat turun. Keterbatan stok cabai terjadi karena hasil panen pertanian cabai rawit yang sedikit. Hal ini dipicu oleh faktor cuaca yaitu saat musim penghujan. Musim penghujan dengan intensitas curah hujan yang tinggi mengakibatkan tanaman cabai dapat rusak dan mudah terserang hama dan penyakit sehingga hasil panen cabai rawit yang dihasilkan sedikit. Selain itu nilai jual yang tinggi dari agen pemasok cabai mengakibatkan pedagang cabai menjual dengan harga yang tinggi.
Dengan memprediksi harga cabai rawit dapat membantu petani sehingga petani tidak mengalami kerugian saat menjual cabai rawit. Dengan menggunakan data yang ada ada seperti luas penen, produksi panen dan curah hujan, maka bisa diperdiksi harga cabai kedepannya. Sehingga petani akan mengetahui ketika musim penghujan tiba petani tidak akan menanam cabai terlalu banyak sehingga hasil panen cabai tidak banyak yang rusak. Dan ketika hasil penen cabai rawit melimpah petani dapat mengendalikan stok dengan menjual sebagian hasil panen cabai. Dan sisa cabai dapat simpan atau diolah agar tidak rusak dan dapat dijual.
Data mining atau penambangan data merupakan kegiatan yang meliputi pengumpulan, pengunaan data historis untuk menemukan keteraturan, pola dan hubungan dalam dataset yang berukuran besar. Dalam penelitian ini implementasi algoritma data mining menggunakan algoritma K-Nearest Neighbor, Algoritma ini dapat digunakan untuk membantu prediksi harga. Penelitian yang dilakukan oleh Wily Yustina (2012) dalam penelitiannya untuk memprediksi harga jual tanah dan menghasilkan akurasi sebesar 80%.
Berdasarkan permasalahan diatas, penulis tertarik membangun sistem menggunakan metode K-Nearest Neighbor untuk pemodelan prediksi harga cabai rawit dengan menggunakan data luas panen, produksi panen dan curah hujan.
1.2 Rumusan Masalah
1. Bagaimana menerapakan algoritma K-Nearest Neighbor untuk memprediksi harga cabai rawit?
2. Berapakah tingkat akurasi yang dihasilkan dari algoritma K-Nearest Neighbor untuk memprediksi harga cabai rawit?
3. Berapakah nilai k yang menghasilkan nilai akurasi paling tinggi untuk prediksi harga cabai rawit?
1.3 Batasan Masalah
1. Data yang digunakan adalah data cabai rawit di Yogyakarta dari tahun 2015-2017
2. Variabel yang digunakan yaitu luas panen (Ha), produksi panen (Ton), curah hujan (Mm) dan Harga rata-rata cabai rawit(Rp).
3. Sistem akan diimplementasikan berbasis web. 1.4 Tujuan Penelitian
1. Menerapkan algoritma K-Nearets Neighbor untuk memprediksi harga cabai rawit.
2. Mengetahui tingkat akurasi dari algoritma K-Nearest Neighbor pada prediksi harga cabai rawit.
3. Mengetahui nilai k yang menghasilkan nilai akurasi tertinggi untuk prediksi harga cabai rawit.
1.5 Sistematika Penulisan
1. BAB 1: PENDAHULUAN
Pada bab ini menjelaskan tentang latar belakang, rumusan masalah, batasan masalah, tujuan penelitian, dan sistematika penulisan untuk kasus yang akan dipecahkan.
2. BAB II: LANDASAN TEORI
Bab ini menjelaskan tentang teori-teori yang akan digunakan untuk penelitian prediksi harga cabai rawit.
3. BAB III: METODOLOGI PENELITIAN
Bab ini menjelaskan langkah-langkah metode penelitian untuk prediksi harga cabai rawit menggunakan algoritma K-Nearest Neighbor. 4. BAB IV: PEMROSESAN AWAL DAN PERANCANGAN SISTEM
Bab ini menjelaskan tentang pemrosesan awal data yang digunakan pada penelitian ini dan perancangan sistem.
5. BAB V: IMPLEMENTASI DAN ANALISIS HASIL
Bab ini menjelaskan bagaimana penerapan algoritma K-Nearest Neighbor dan menganalisis hasil algoritma K-Nearest Neighbor untuk prediksi harga cabai rawit.
6. BAB VI: KESIMPULAN DAN SARAN
Bab ini berisi kesimpulan hasil penelitian dan saran untuk penelitian selanjutnya.
4 BAB II
LANDASAN TEORI 2.1 Cabai
Cabai adalah tanaman perdu dari famili terong-terongan yang memiliki nama ilmiah capsicum sp. Tanaman cabai berasal dari benua Amerika, dan menyebar ke negara-negara benua Amerika, Eropa dan Asia termasuk Negara Indonesia. Diperkirakan terdapat 20 spesies yang sebagain besar hidup di Negara asalnnya. Masyarakat pada umumnya hanya mengenal beberapa jenis saja, yakni Cabai besar, cabai keriting, cabai rawit dan paprika.
Cabai meruapakan salah satu sayuran yang penting yang dibudidayakan secara komersial di negara-negara tropis. Tercatat berbagai spesies cabai yang telah didomestikan, namun hanya Capsicum annumm L. dan C. Frutescens L. yang memiliki potensi ekonomis (Sulandari, 2004). Cabai yang dibudidayakan secara luas di Indonesia juga termasuk kedua spesies ini. Cabai besar dan cabai keriting, misalnnya, termasuk spesies C. annum sedangakan cabai rawit termasuk C. frutescens.
2.2 Tinjauan Pustaka
Wiyli Yustanti (2012) dalam penelitian yang bertujuan memprediksi harga jual tanah menggunkana algoritma k-nearest neighbor. Dalam penelitian menggunakan data sekunder. Dan pengembangan perangkat lunak menggunakan Waterfall Model. Hasil akurasi prediksi sebesar 80%.
Nathania Palar, Paulus A. Pangemanan, Ellen G. Tangkere (2016) dalam jurnal ilmiahnya tentang faktor-faktor yang mempengaruhi harga cabai rawit di kota Manado.
2.3 Penambangan Data
Data mining atau penambangan data adalah suatu istilah yang digunakan untuk menguraikan pengetahuan (knowledge) dalam database. Data mining adalah proses yang mengunakan teknik statistik, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasikan informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database besar(Turban,et.al.2015).
2.3.1 Pengelompokan Data Mining
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat dilakukan, yaitu (larose, 2005):
a. Deskripsi
Deskripsi bertujuan untuk mengidentifikasi pola yang muncul secara berulang pada suatu data dan mengubah pola tersebut menjadi aturan dan kriteria yang dapat mudah dimengerti oleh para ahli pada domain aplikasinya. Aturan yang dihasilkan harus mudah dimengerti agar dapat dengan efektif meningkatkan tingkat pengetahuan (knowledge) pada sistem. Tugas deskriptif merupakan tugas data mining yang sering dibutuhkan pada teknik postprocessing untuk melakukan validasi dan menjelaskan hasil dari proses data mining.
b. Prediksi
Prediksi memiliki kemiripan seperti klasifiksi dan estimasi, akan tetapi dalam prediksi akan mencari suatu nilai baru di masa depan dengan mengamati data-data di masa lalu. Contoh dari penerapan prediksi yaitu prediksi harga saham dalam tiga bulan ke depan.
c. Estimasi
Estimasi memiliki kemiripan dengan klasifikasi akan tetapi target variable untuk estimasi dalam bentuk angka. Model yang disusun menggunakan record yang lengkap sehingga nilai variable target dapat sebagai nilai prediksi. Contoh dari tugas estimasi adalah memperkirakan nilai rata-rata (IPK) dari seorang mahasiswa pascasarjana.
d. Klasifikasi
Klasifikasi merupakan proses menemukan sebuah model atau fungsi yang mendeskripsikan dan membedakan data ke dalam kelas-kelas. Klasifikasi melibatkan proses pemeriksaan karakteristik dari objek dan memasukkan objek ke dalam salah satu kelas yang sudah didefinisikan sebelumnya.
e. Clustering
Clustering merupakan pengelompokan data tanpa berdasarkan kelas data tertentu ke dalam kelas objek yang sama. Sebuah kluster adalah kumpulan record yang memiliki kemiripan suatu dengan yang lainnya dan memiliki ketidakmiripan dengan record dalam kluster lain. Tujuannya adalah untuk menghasilkan pengelompokan objek yang mirip satu sama lain dalam kelompok - kelompok.
f. Asosiasi
Dalam data mining atau penambangan data asosiasi adalah proses menemukan pola dari atribut yang muncul. Pada umumnya asosias banyak digunakan untuk menganalisis pola keranjang belanja. Dan tugas dari asosiasi adalah menemukan hubungan antar dua atau lebih atribut.
2.3.2 Knowledge Discovery in Database
Berikut ini adalah proses Knowledge Discovery in Database secara garis besar dapat dijelaskan sebagai berikut (Fayyad, 1996): a. Data Selection (seleksi data)
Pemilihan data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang akan digunakan untuk proses data mining.
b. Pre-processing/Cleaning (pembersihan data)
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning pada data yang menjadi fokus KDD. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data.
c. Transformation (mengubah data)
Transformation adalah menggubah data kedalam bentuk yang sesuai untuk ditambang.
d. Data Mining (penambangan data)
Data mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu.
e. Interpretasi/Evaluasi
Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Seperti menggunakan visualisai atau tempilan yang dapat menjelaskan luaran sistem.
2.4 K-Nearest Neighbor
K-Nearest-Neighbor adalah algoritma yang bertujuan untuk mengklasifikasi objek data baru. Proses pengkasifikasikan objek data baru akan dilatih berdasarkan atribut dan data sample latih. Pemodelan klasifikasi objek baru hanya berdasarkan pada memori. Metode ini bekerja dengan mencari sejumlah k objek data (data latih) yang paling dekat dengan data uji yang diberikan, kemudian memilih kelas dengan jumlah voting terbanyak.
Langkah-langkah dari algoritma K-Nearest Neighbor sebagai berikut: 1. Menentukan parameter k (jumlah tetangga paling dekat).
2. Menghitung kuadrat jarak Eucliden objek terhadap data training yang diberikan
3. Selanjutnya mengurutkan hasil no 2 secara ascending (berurutan dari nilai tinggi ke rendah)
4. Mengumpulkan kategori Y (klasifikasi nearest neighbor berdasarkan nilai k)
5. Dengan menggunakan kategori nearest neighbor yang paling mayoritas maka dapat diprediksi objek yang baru.
k pada algoritma k-nearest neighbor adalah banyaknnya tetangga terdekat yang akan digunakan sebagai titik untuk melakukan klasfikasi pada data atau objek baru. Dalam menentukan jumlah nilai k, sebaiknya menggunakan angka ganjil. Untuk menghitung jarak antar objek data pada algoritma k-nearest neighbor dapat dilakukan dengan beberapa cara, salah satunya adalah dengan Ecludiean Distance. Berikut rumus dari Euclidean Distance:
dist(x1, x2) = √∑𝑛𝑖=1(𝑥1𝑖− 𝑥2𝑖)2 (2.1)
dist(x1, x2) = Jarak antar obyek 𝑥1𝑖 𝑑𝑎𝑛 𝑥2𝑖
𝑥1𝑖 = Data uji atau data testing 𝑥2𝑖 = Data training
2.4.1 Contoh Perhitungan Algoritma K-nearest Neighbor
Berikut ini adalah contoh perhitungan penerapan algoritma K-Nearest Neighbor dengan menggunakan data sampel pada tahun 2015.
Tabel 1 Data Training
Luas Produksi Curah Hujan Harga 264 2864 389 Mahal 296 3123 182 Murah 321 3172 463 Murah 178 2069 158.2 Mahal
Tabel 2 Data Testing
Luas Produksi
Curah
Hujan Harga
205 3240 217 ?
1. Menentukkan nilai k (tetangga terdekat). Misalkan K = 3.
2. Menghitung jarak antara data uji dengan data training dengan Euclidean Distance.
Hitung jarak data uji dengan data training pertama
Jarak = √(205 − 264) 2 + (3240 − 2864) 2+ (217 − 389) 2)
= 418
Hitung jarak data uji dengan data training kedua
Jarak = √(205 − 296) 2+ (3240 − 3123) 2+ (217 − 182) 2)
Hitung jarak data uji data training ketiga
Jarak = √(205 − 312) 2+ (3240 − 3172) 2 + (217 − 463) 2)
= 280
Hitung jarak data uji dengan data training ke empat
Jarak =√(205 − 178) 2+ (3240 − 2069) 2+ (217 − 158) 2)
= 1173
Tabel 3 hasil perhitungan jarak
Luas Produksi Curah Hujan
Euclidean
Distance Rangking Harga
264 2864 389 418 3 Mahal
296 3123 182 152 1 Murah
321 3172 463 280 2 Murah
178 2069 158.2 1173 4 Mahal
3. Setelah menghitung jarak satu persatu data uji ke data training selanjutnya mencari jarak yang terkecil dengan mengurutkan hasil perhitungan jarak secara ascending (berurutan dari jarak terkecil ke jarak terbesar).
Tabel 4 jarak urut hasil perhitungan jarak
Luas Produksi Curah Hujan
Euclidean
Distance Rangking Harga
296 3123 182 152 1 Murah
321 3172 463 280 2 Murah
264 2864 389 418 3 Mahal
4. Selanjutnya mengumpulkan jarak terkecil yang telah diurutkan berdasarkan inputan nilai k (tetangga terdekat). Karena nilai k = 3, maka yang diambil 3 terkecil.
Tabel 5 Tetangga terdekat k= 3.
Luas Produksi Curah Hujan
Euclidean
Distance Rangking Harga
296 3123 182 152 1 Murah
321 3172 463 280 2 Murah
264 2864 389 418 3 Mahal
5. Berdasarkan tabel 5 diatas label yang banyak muncul adalah murah, maka hasil prediksi adalah murah.
2.5 Klasifikasi Data Mining
Klasifikasi pada data mining adalah teknik mempelajari sekumpulan data sehingga dihasilkan aturan yang bisa mengklasifikasikan atau mengenali data-data yang baru yang belum pernah dipelajari. Klasifikasi dapat didefiniskan sebagai kategori (kelas) yang telah didefinisikan sebelumnnya (Zaki et al. 2013).
Proses klasifikasi dapat dilakukan menjadi 2 proses. Proses pertama yaitu learning (fase training), dimana proses klasifikasi dibuat untuk menganalisi data training dan akan direpresentasikan ke dalam bentuk aturan klasifikasi. Proses kedua yaitu data testing atau data uji dilakukan evaluasi untuk mengetahui akurasi dari aturan klasifikasi (Han, 2006).
Terdapat empat komponen proses klasifikasi (Gorunescu, 2011): 1. Kelas
Pada komponen kelas varaibel dependen yang berupa kategorikal yang mempresentasikan label yang terdapat objek. Misalnya resiko oenyakit jantung, resiko kredit, kesetiaan pelanggan dan jenis gempa. 2. Predictor
Pada komponen predictor adalah variabel independen yang direpresentasikan oleh karakterisktik data. Misalnnya meroko, minum, alkohol, tekanan darah, tabungan. asset dan gaji.
3. Training dataset
Set data yang terdapat nilai label dan kelas yang akan digunakan dalam menentukan kelas atau label yang cocok berdasarkan predictor. 4. Testing dataset
Satu data baru yang akan diklasifikasikan dengan model yang sudah dibuat. Dan akan mengevaluasi hasil akurasi klasifikasi.
2.6 Evaluasi Kerja
2.6.1 Cross Validation
Cross validation merupakan metode yang digunakan untuk mengetahui hasil kinerja dari algoritma. Metode ini membagi dataset mejadi dua subset yaitu data proses pembelajaran dan data validasi / evaluasi. Pemodelan dari algoritma dilatih oleh subset pembelajaran dan divalidasi oleh subset. Selanjutnya pemilihan jenis validation dapat didasarkan dari ukuran dataset. Biasannya cross-validation digunakan karena dapat mengurangi waktu komputasi dengan tetap menjaga keakuratan estimasi. (Antoni Wibowo, 2017). Berikut ini adalah gambaran dari metode k-fold cross-validation 3-fold: Data Testing Data Training
Tabel 2.1 Tabel Cross Validation 3-fold 2.6.2 Confusion Matrix
Cunfusion matrix adalah suatu metode yang digunakan untuk mengukur perhitungan akurasi dari suatu algoritma. Pemodelan algoritma yang sudah dibuat akan dievaluasi untuk melihat seberapa baik kineja dari algoritma tersebut dan akan diukur dengan tingkat akurasi yang dihasilkan dari data testing yang telah di prediksi.
Tabel 2.2 Tabel Confusion Matriks
Aktual Hasil Klasifikasi
positif (true) negatif (false) positif True positif False negatif negatif False negatif True negatif
Berikut ini adalah rumus menghitug akurasi Accuracy =𝑇𝐹+𝑇𝑁
(𝑝+𝑛) (2.2)
di mana:
TF = adalah true positif, yaitu jumlah data positif yang terprediksi dengan benar oleh sistem
TN = adalah true negatif, yaitu jumlah data negatif yang terprediksi benar oleh sistem
N = adalah false negatif, yaitu jumlah data negatif terprediksi salah oleh sistem
P = adalah false positif, yaitu jumlah data postif terprediksi salah oleh sistem
15 BAB III
METODOLOGI PENELITIAN 3.1 Bahan/Data Penelitian
Pada penelitian ini, bahan data yang digunakan adalah data laporan sayuran dan buah-buahan semusim dari tahun 2015 sampai 2017 dari web bps.go.id. Dan data yang digunakan meliputi luas panen, produksi panen, curah hujan data data harga rata-rata cabai rawit. Keseluruhan data tersebut sebanyak 36 record (baris).
3.2 Alat Penelitian
a. Spesifikasi Software
1. Operating System : Microsoft Windows 8.1 2. Compiler : Netbeans 8.0.2
b. Spesifikasi Hardware
1. Procesor : Intel Core i5
2. Memory : RAM 4GB
3. Hardisk : 500 GB
3.3 Tahap Penelitian 3.3.1 Pengumpulan Data
Bahan data yang digunakan pada penelitian ini diambil dari situs web bps.go.id dan situs web Kementrian Pertanian Republik Indonesia. 3.3.2 Studi Pustaka
Setelah mengumpulkan data, tahap selanjutnya adalah penulis mencari referensi yang mendukung penelitian ini. Referensi yang digunakan adalah jurnal ilmiah dan buku mengenai algoritma yang digunakan pada penelitian ini.
3.3.3 Knowlegde Discovery in Database (KDD)
Pada tahap ini, sebelum data digunakan perlu dilakukan beberapa proses yaitu dengan Knowledge Discovery in Database. Berikut proses dari KDD:
a. Data Integration (integrasi data)
Proses data integration adalah data yang diperoleh dari sumber yang berbeda dapat digabungkan menjadi satu dataset. Pada penelitian ini data diperoleh dari sumber yang berbeda yaitu data harga cabai rawit digabungkan menjadi satu dataset.
b. Data Selection (seleksi data)
Proses data selection adalah pemilihan data atau atribut yang akan digunakan dan menghapus data yang tidak digunakan dari dataset. Pada tahap ini penulis melakukan selesksi data secara manual menggunakan Microsoft Excel. c. Data Transformation (mengubah data)
Proses data transformation adalah melakukan proses perubahan nilai pada data dan diubah ke dalam bentuk data yang akan ditambang. Pada penelitian ini penulis melakukan proses transformation data harga secara menual menggunakan Microsoft Excel.
d. Data mining (penambangan data)
Pada penelitian ini metode klasifikasi menggunakan K-Nearest Neighbor untuk pengalian informasi. Kaitan prediksi dan klasifikasi adalah model prediksi klasifikas yaitu membedakan data ke dalam kelas-kelas. Sedangkan model prediksi akan mencari nilai baru di masa depan. Kedua model prediksi sama-sama menggunakan data-data historis. Algoritma K-Nearest Neighbor menggunakan klasifikasi ketetanggan sebagai nilai prediksi dan uji data tunggal.
e. Interpretasi/Evaluasi (evaluasi pola)
Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Pada penelitian ini hasil visualisai dalam bentuk hasil akurasi.
3.4 Pembangunan Sistem
Pada penelitian ini, pembangunan sistem menggunakan metode waterfall. Secara garis besar metode waterfall mempunyai langkah-langkah yaitu analisa, desain, penulisan, pengujian dan penerapan serta pemeliharaan. (Kadir, 2003).
1. Analisa Kebutuhan
Pada tahap ini, analisa terhadapa kebutuhan sistem dapat dilakukan dengan berbagai cara, salah satunnya bisa melalui wawancara maupun melalui studi literatur.
2. Desain Sistem
Setelah menganalisi kebutuhan sistem, tahap selajutnya adalah memikirkan dan merancang sistem yang akan dibangun, salah satunnya adalah pembuatan dokumen. Pembuatan dokumen ini akan membantu programmer untuk mengimplementasikan sistem yang akan dibangun. 3. Penulisan Kode Program
Pada tahap ini, sistem yang sudah di desain akan di implemtasikan dalam bentuk code.
4. Pengujian Program
Setelah pembuatan program selesai, tahap berikutnya adalah melakukan pengujian pada sistem. Tahap pengujian yaitu dengan membandingkan proses hasil perhitungan manual pada luaran sistem yang dihasilkan.
3.5 Analisis dan Pembuatan Laporan
Pada tahap ini, setelah sistem selesai di bangun maka sistem akan di analisa sesuai dengan rumusan masalah yang telah dipaparkan pada bab sebelumnya. Proses analisa akan melihat hasil sistem yang telah di bangun dengan perhitungan manual pada Microsoft Excel. Dan menganalisa hasil akurasi yang diperoleh dari pemodelan prediksi. Hasil dari analisa tersebut akan disusun dalam laporan tugas ahkir.
BAB IV
PEMROSESAN AWAL DAN PERANCANGAN SISTEM 4.1. Pemrosesan Awal
4.1.1 Integrasi Data
Pada tahap ini, data yang diperoleh dari database atau situs web yang berbeda akan digabungkan ke dalam satu tabel dataset. 4.1.2 Transformasi Data
Pada tahap ini, data atribut harga yang sebelumnya Integer akan diubah menjadi String untuk dijadikan sebagai label. Berikut ini langkah-langkah mengubah data harga menjadi String.
1. Mencari nilai maksimal dan minimal pada data harga. - Maksimal = 120158, Minimal = 9606
2. Mengurangi nilai maksimal dan minimal untuk mencari range data.
- 120158 – 9606 = 110552
3. Hasil range data dibagi 3 untuk membagi menjadi 3 kategori.
- 110552
3 = 36850
4. Hasil data minimal ditambah dengan hasil range dan hasilnya menjadi batas range untuk kategori 1 yaitu range harga murah Rp. 9606 – Rp. 46456
- 9606 + 36850 = 46456
5. Hasil range ditambah dengan hasil batas range kategori 1 dan hasilnya untuk kategori 2 yaitu range harga mahal Rp. 46456 – Rp.83307
- 36850 + 46456 = 83.307
6. Hasil range ditambah dengan hasil batas range kategori 2 dan hasilnya menjadi batas untuk kategroi 3 yaitu range harga sangat mahal Rp. 83.307 – Rp. 120.158.
Tabel 4.1 Tabel hasil transformasi data Harga Kategori >= Rp. 9606– Rp. <= 46.456 Murah >Rp. 46.454 – Rp. <= 83.307 Mahal >Rp. 83. 307 – Rp. <= 120.158 Sangat Mahal 4.2 Perancangan Sistem 4.2.1 Diagram Use Case
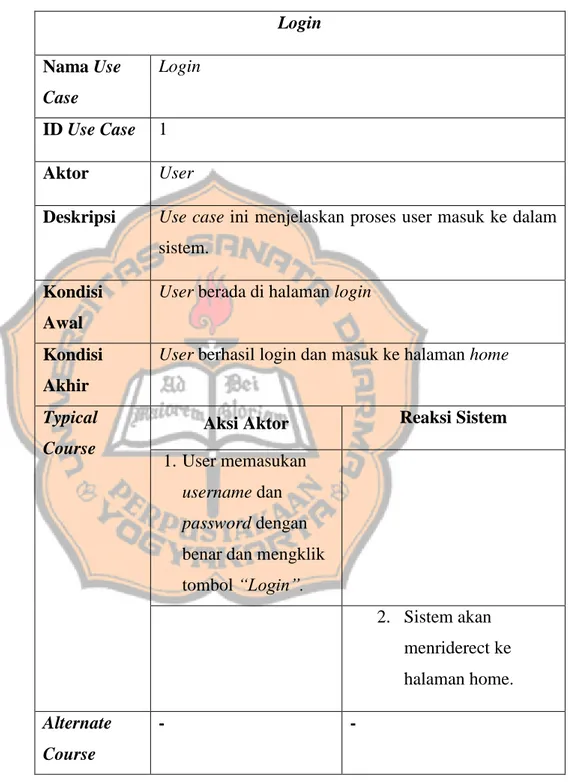
4.2.2 Narasi Use Case
Tabel 4.2 Tabel narasi Use Case login Login Nama Use Case Login ID Use Case 1 Aktor User
Deskripsi Use case ini menjelaskan proses user masuk ke dalam sistem.
Kondisi Awal
User berada di halaman login
Kondisi Akhir
User berhasil login dan masuk ke halaman home
Typical Course
Aksi Aktor Reaksi Sistem 1. User memasukan
username dan password dengan benar dan mengklik tombol “Login”. 2. Sistem akan menriderect ke halaman home. Alternate Course - -
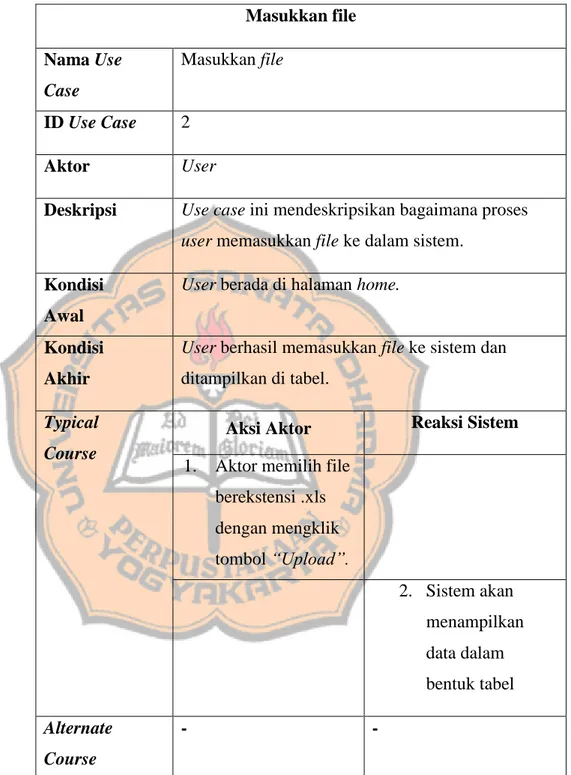
Tabel 4.3 Tabel narasi Use Case masukkan file Masukkan file Nama Use Case Masukkan file ID Use Case 2 Aktor User
Deskripsi Use case ini mendeskripsikan bagaimana proses user memasukkan file ke dalam sistem.
Kondisi Awal
User berada di halaman home.
Kondisi Akhir
User berhasil memasukkan file ke sistem dan ditampilkan di tabel.
Typical Course
Aksi Aktor Reaksi Sistem 1. Aktor memilih file
berekstensi .xls dengan mengklik tombol “Upload”. 2. Sistem akan menampilkan data dalam bentuk tabel Alternate Course - -
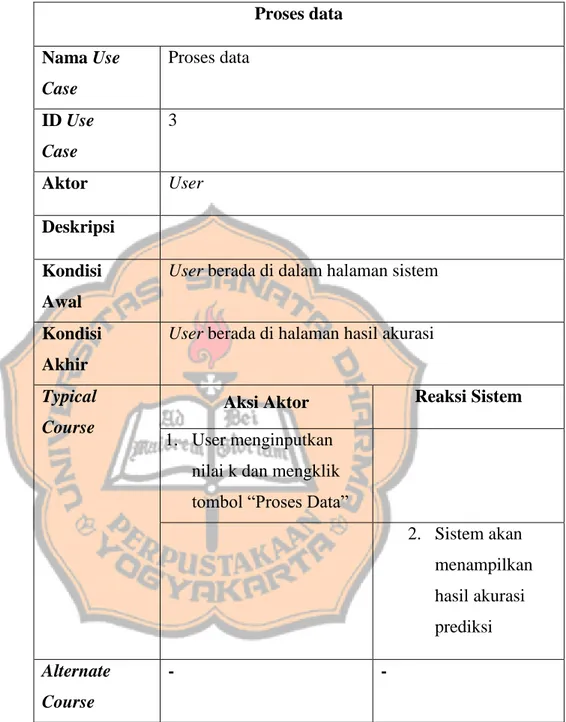
Tabel 4.4 Tabel narasi Use Case proses data Proses data Nama Use Case Proses data ID Use Case 3 Aktor User Deskripsi Kondisi Awal
User berada di dalam halaman sistem
Kondisi Akhir
User berada di halaman hasil akurasi
Typical Course
Aksi Aktor Reaksi Sistem 1. User menginputkan
nilai k dan mengklik tombol “Proses Data”
2. Sistem akan menampilkan hasil akurasi prediksi Alternate Course - -
Tabel 4.5 Tabel narasi Use Case proses prediksi Proses Prediksi Nama Use Case Proses Prediksi ID Use Case 4 Aktor User Deskripsi Kondisi Awal
User berada di halaman form prediksi harga
Kondisi Akhir
User berada di halaman hasil prediksi harga
Typical Course
Aksi Aktor Reaksi Sistem 1. User menginputkan
nilai k, luas panen, produksi panen, curah hujan dan mengklik tombol “Proses Prediksi”. 2. Sistem akan menampilkan hasil prediksi. Alternate Course - -
Tabel 4.6 Tabel narasi Use Case logout Logout Nama Use Case Logout ID Use Case 5 Aktor User Deskripsi Kondisi Awal
User berada di halaman sistem
Kondisi Akhir
User berada di halaman login
Typical Course
Aksi Aktor Reaksi Sistem 1. User mengklik tombol “Logout”. 2. Sistem akan menriderect ke halaman login. Alternate Course - -
4.2.3 Flowchart Algoritma K-Nerarest Neighbor
Berikut dibawah ini flowchar algoritma k-nearest neighbor dapat dilihat pada gambar 4.2 berikut.
Berikut ini adalah penjelasan dari flowchart algoritma K-Nearest Neighbor pada gambar 4.2
g. Masukkan nilai k tetangga terdekat untuk memberi titik uji untuk menemukan k objek (data training) data yang paling dekat dengan titik uji.
h. Hitung jarak antara data testing dan data training adalah untuk mencari jarak antar data testing dan training dan diambil jarak terkecil berdasarkan nilai inputan k (tetangga terdekat). i. Cari k data jarak terdekat, adalah untuk menemukan jarak
terdekat berdasarkan masukkan nilai k, ketika nilai k = 1, maka jarak yang diambil adalah jarak terkecil 1.
j. Cari label mayoritas adalah mencari label yang paling banyak muncul dan diambil sebagai nilai prediksi.
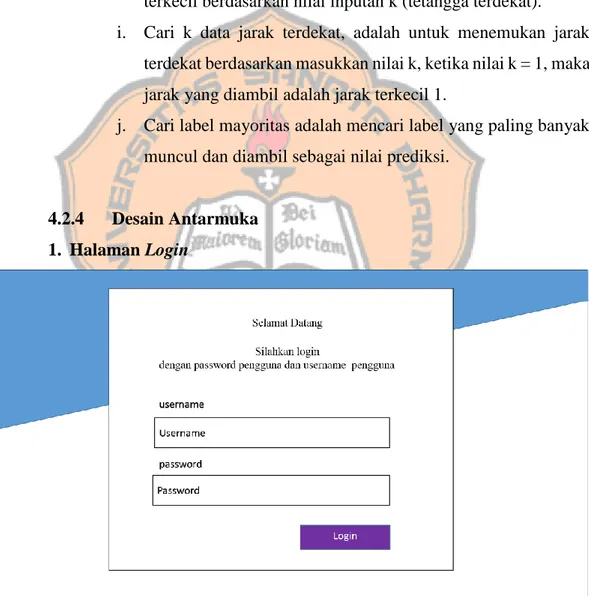
4.2.4 Desain Antarmuka 1. Halaman Login
Halaman login tampilan utama pada sistem ini, untuk masuk ke sistem user harus memasukkan username dan password terlebih dahulu.
2. Halaman Home
Setelah login user masuk ke halam home, pada halaman ini user dapat mengupload file .xls data yang akan digunakan untuk proses prediksi
Gambar 3.4 Gambar Desain Antarmuka Halaman Home 3. Halaman Perhitungan
Setelah data diupload, maka data akan ditampilkan pada halaman perhitungan. Pada halaman ini untuk melakukan proses data terlebih dahulu menginputkan nilai k, selanjutnya mengklik tombol “Proses data“maka sistem akan menampilkan luaran berupa hasil akurasi.
Gambar 4.5 Gambar Desain Antarmuka Halaman Proses Data 4. Halaman Form Uji Data Tunggal
Pada Halaman uji data tunggal untuk menguji data yang baru yang sebelumnya belum diketahui hasil prediksinya.
5. Halaman About
Pada halaman ini akan menjelaskan algoritma K-Nearest Neighbor Gambar 4.7 Gambar Desain Antarmuka Halaman About
BAB IV
IMPLEMENTASI DAN ANALISA HASIL 5.1 Implementasi Antarmuka
- Halaman Login
Tampilan awal sebelum masuk ke sistem, pengguna harus login terlebih dahulu dengan memasukkan username dan password.
Gambar 5.1 Gambar Implementasi Halaman Login - Halaman Home
Pada halaman home pengguna bisa mengupload file data berextensi .xls.
Gambar 5.2 Gambar Implementasi Halaman Home - Halaman Proses Data
Halaman ini akan menampilkan hasil data yang sudah diupload, kemudian untuk memproses data yang sudah upload penggua dapat melakukan proses prediksi dengan memasukkan nilai k pada field masukkan jumlah k. Setelah pengguna memasukkan nilai k, maka sistem akan memberi luaran berupa hasil akurasi.
- Halaman Form Uji Data Tunggal
Pada halaman ini user memasukkan data satu persatu pada field yang tersedia, fungsi form ini untuk melakukan penggujian data tunggal yang belum diketahui apa hasil prediksinya.
Gambar 5.4 Gambar Implementasi Halaman Form Pengujian Data Tunggal
- Halaman About
Pada halaman ini berisi penjelasan dari algoritma K-Nearest Neighbor.
-
5.2 Pengujian Perangkat Lunak
Pengujian sistem dilakukan untuk mengevaluasi kecocokkan hasil perhitungan manual menggunakan Microsoft Exel dan hasil perhitungan menggunakan perangkat lunak. Jika hasil perhitungan sistem sama dengan hasil pada perhitungan manual, maka sistem yang telah di implementasikan dengan benar.
5.2.1 Pengujian perhitungan akurasi secara manual menggunakan Microsoft Excel.
Pada penelitian ini, pengujian akurasi dilakukan secara manual menggunakan Microsoft Exel. Data yang digunakan sebanyak 9 data. Dari 9 data dibagi menjadi data training data data testing. 1/3 dari 9 data untuk data training dan 2/3 untuk data testing.
Berikut ini langkah - langkah perhitungan manual akurasi menggunakan Microsoft Exel.
Contoh dataset cabai rawit untuk pengujian akurasi dengan variabel luas panen (Ha), produksi (Ton), curah hujan (Mm), dan harga. Tabel 5.1 Tabel dataset cabai rawit
Luas Panen(Ha) Produksi(Ton) Curah Hujan(Mm) Harga Data training 264 2864 389 Mahal Data testing 296 3123 182 Murah 321 3172 463 Murah 287 3199 370 Murah 278 2889 53 Murah 238 2341 49 Murah 194 2154 158.2 Murah 178 2069 158.2 Mahal 195 2013 158.2 Murah
1. Menentukan jumlah data training dan data testing dengan k-fold. 2. Menentukan nilai k (tetangga terdekat). K = 1.
Tabel 5.2 Tabel data 1-fold Luas Panen (Ha) Produksi (Ton) Curah hujan (Mm) Harga 273 6344 149 SangatMahal 217 3420 141 SangatMahal 169 4629 101 Mahal 314 10710 31 Mahal 351 10260 27 Murah 280 7438 6 Murah 404 10605 0 Murah 302 9215 83 Murah 256 7670 54 Murah
Tabel 5.3 Tabel data testing dan data training 1-fold Luas Panen(Ha) Produksi(Ton) Curah Hujan(Mm) Harga Luas Panen (Ha) Produksi (Ton) Curah Hujan (Mm) Harga 273 6344 149 SangatMahal 314 10710 31 Mahal 217 3420 141 SangatMahal 351 10260 27 Murah 169 4629 101 Mahal 280 7438 6 Murah 404 10605 0 Murah 302 9215 83 Murah 256 7670 54 Murah
3. Menghitung jarak setiap data testing satu persatu ke data training menggunakan rumus Euclidean Distance.
Data testing pertama
Jarak = √(273 − 314) 2+ (6344 − 10710) 2+ (149 − 31) 2
= 4368
Jarak = √(273 − 351) 2+ (6344 − 10260) 2+ (149 − 27) 2
Jarak = √(273 − 280) 2+ (6344 − 7438) 2+ (149 − 6) 2 = 1103 Jarak = √(273 − 404) 2+ (6344 − 10605) 2+ (149 − 0) 2 = 4266 Jarak = √(273 − 302) 2+ (6344 − 9215) 2+ (149 − 83) 2 = 2872 Jarak = √(273 − 256) 2+ (6344 − 7670) 2+ (149 − 54) 2 =1330
Data testing kedua
Jarak = √(217 − 314) 2+ (3420 − 10710) 2+ (141 − 31) 2 = 7291 Jarak = √(217 − 351) 2+ (3420 − 10260) 2+ (141 − 27) 2 = 6842 Jarak = √(217 − 280) 2+ (3420 − 7438) 2+ (141 − 6) 2 = 4021 Jarak = √(217 − 404) 2+ (3420 − 10605) 2+ (141 − 0) 2 = 7189 Jarak = √(217 − 302) 2+ (3420 − 9215) 2+ (141 − 83) 2 = 5796 Jarak = √(217 − 256) 2+ (3420 − 7670) 2+ (141 − 54) 2 = 4251
Data testing ketiga Jarak = √(169 − 314) 2+ (4629 − 10710) 2+ (101 − 31) 2 = 6083 Jarak = √(169 − 351) 2+ (4629 − 10260) 2+ (101 − 27) 2 = 5634 Jarak = √(169 − 280) 2+ (4629 − 7438) 2+ (101 − 6) 2 = 2813 Jarak = √(169 − 404) 2+ (4629 − 10605) 2+ (101 − 0) 2 = 5981 Jarak = √(169 − 302) 2+ (4629 − 9215) 2+ (101 − 83) 2 = 4588 Jarak = √(169 − 256) 2+ (4629 − 7670) 2+ (101 − 54) 2 = 3043
Tabel 5.4 Tabel hasil perhitungan jarak data testing dan data training 1-fold
Jarak Harga Jarak Harga Jarak Harga
4368 Mahal 7291 Mahal 6083 Mahal
3919 Murah 6842 Murah 5634 Murah
1103 Murah 4021 Murah 2813 Murah
4266 Murah 7189 Murah 5981 Murah
2872 Murah 5796 Murah 4588 Murah
4. Selanjutnya mengurutkan jarak yang telah dihitung secara ascending dari jarak terkecil ke terbesar.
Tabel 5.5 Tabel data jarak urut 1-fold
5. Selanjutnya mengumpulkan jarak yang telah diurutkan, karena nilai k (tetangga terdekat) =1, maka ambil 1 jarak terkecil.
6. Selanjutnya mengecek label hasil prediksi dengan label aktual, dengan menggunakan confusion matriks.
Tabel 5.6 Tabel Confusion matriks 1-fold
Aktual Hasil Prediksi
Murah Mahal Sangat Mahal
Murah 0 0 0 Mahal 0 0 0 Sangat Mahal 3 0 0 Akurasi 1-fold = 0+0 1+1+1= 0.00 %
Jarak Harga Jarak Harga Jarak Harga
1103 Murah 4021 Murah 2813 Murah
1330 Murah 4251 Murah 3043 Murah
2872 Murah 5796 Murah 4588 Murah
3919 Murah 6842 Murah 5634 Murah
4266 Murah 7189 Murah 5981 Murah
Tabel 5.7 Tabel data 2-fold Luas Panen (Ha) Produksi (Ton) Curah hujan (Mm) Harga 273 6344 149 SangatMahal 217 3420 141 SangatMahal 169 4629 101 Mahal 314 10710 31 Mahal 351 10260 27 Murah 280 7438 6 Murah 404 10605 0 Murah 302 9215 83 Murah 256 7670 54 Murah
Tabel 5.8 Tabel data testing dan data training 2-fold
1. Hitung jarak antara data testing dan training menggunakan rumus Euclidean Distance
Data testing pertama
Jarak = √(314 − 273) 2+ (10710 − 6344) 2+ (31 − 149) 2 = 4368 Jarak = √(314 − 217) 2+ (10710 − 3420) 2+ (31 − 141) 2 = 7291 Jarak = √(314 − 169) 2+ (10710 − 4629) 2+ (31 − 101) 2 = 6083 Jarak = √(314 − 404) 2+ (10710 − 10605) 2+ (31 − 0) 2 = 142 Luas Panen(Ha) Produksi(Ton) Curah Hujan(Mm) Harga Luas Panen(Ha) Produksi(Ton) Curah Hujan(Mm) Harga 314 10710 31 Mahal 273 6344 149 SangatMahal 351 10260 27 Murah 217 3420 141 SangatMahal 280 7438 6 Murah 169 4629 101 Mahal 404 10605 0 Murah 302 9215 83 Murah 256 7670 54 Murah
Jarak = √(314 − 302) 2+ (10710 − 9215) 2+ (31 − 83) 2
= 1496
Jarak = √(314 − 256) 2+ (10710 − 7670) 2+ (31 − 54) 2
= 3041
Data testing kedua
Jarak = √(351 − 272) 2+ (10260 − 6344) 2+ (27 − 149) 2 = 3919 Jarak = √(351 − 217) 2+ (10260 − 3420) 2+ (27 − 141) 2 = 6842 Jarak = √(351 − 169) 2+ (10260 − 4629) 2+ (27 − 101) 2 = 5634 Jarak = √(351 − 404) 2+ (10260 − 10605) 2+ (27 − 0) 2 = 350 Jarak = √(351 − 302) 2+ (10260 − 9215) 2+ (27 − 83) 2 = 1048 Jarak = √(278 − 256) 2+ (10260 − 7670) 2+ (27 − 54) 2 = 2592
Data testing ketiga
Jarak = √(280 − 272) 2+ (7438 − 6344) 2 + (6 − 149) 2 = 1103 Jarak = √(280 − 217) 2+ (7438 − 3420) 2 + (6 − 141) 2 = 4021 Jarak = √(280 − 169) 2+ (7438 − 4629) 2 + (6 − 101) 2 = 2813 Jarak = √(280 − 404) 2+ (7438 − 10605) 2+ (6 − 0) 2
= 3169
Jarak = √(280 − 302) 2+ (7438 − 9215) 2 + (6 − 83) 2
= 1779
Jarak = √(280 − 256) 2+ (7438 − 7670) 2 + (6 − 54) 2
= 238
Tabel 5.9 Tabel hasil perhitungan jarak data testing dan data training 2-fold
Jarak Harga Jarak Harga Jarak Harga
4368 SangatMahal 3919 SangatMahal 1103 SangatMahal 7291 SangatMahal 6842 SangatMahal 4021 SangatMahal
6083 Mahal 5634 Mahal 2813 Mahal
142 Murah 350 Murah 3169 Murah
1496 Murah 1048 Murah 1779 Murah
3041 Murah 2592 Murah 238 Murah
2. Selanjutnya mengurutkan jarak yang telah dihitung secara ascending dari jarak terkecil ke terbesar
Tabel 5.10 Tabel jarak urut 2-fold
3. Selanjutnya mengumpulkan jarak yang telah diurutkan, karena nilai k (tetangga terdekat) =1, maka ambil 1 jarak terkecil.
4. Selanjutnya mengecek label hasil prediksi dengan label aktual, dengan menggunakan confusion matriks.
Jarak Harga Jarak Harga Jarak Harga
142 Murah 350 Murah 238 Murah
1496 Murah 1048 Murah 1103 SangatMahal
3041 Murah 2592 Murah 1779 Murah
4368 SangatMahal 3919 SangatMahal 2813 Mahal
6083 Mahal 5634 Mahal 3169 Murah
Tabel 5.11 Tabel confusion matriks 2-fold Aktual Hasil Prediksi Murah Mahal Sangat Mahal Murah 2 0 0 Mahal 1 0 0 Sangat Mahal 0 0 0 Akurasi 2-fold = 1+1 1+1+1 = 66.67%
Tabel 5.12 Tabel data 3-fold
Tabel 5.13 Tabel data testing dan data training 3-fold Luas Panen(Ha) Produksi(Ton) Curah Hujan(Mm) Harga Luas Panen(Ha) Produksi(Ton) Curah Hujan(Mm) Harga 404 10605 0 Murah 273 6344 149 SangatMahal 302 9215 83 Murah 217 3420 141 SangatMahal 256 7670 54 Murah 169 4629 101 Mahal 314 10710 31 Mahal 351 10260 27 Murah 280 7438 6 Murah Luas Panen (Ha) Produksi (Ton) Curah hujan (Mm) Harga 273 6344 149 SangatMahal 217 3420 141 SangatMahal 169 4629 101 Mahal 314 10710 31 Mahal 351 10260 27 Murah 280 7438 6 Murah 404 10605 0 Murah 302 9215 83 Murah 256 7670 54 Murah
1. Hitung jarak antara data testing dan data training menggunakan rumus Euclidean Distance.
Data testing pertama
Jarak = √(404 − 273) 2+ (10605 − 6344) 2+ (0 − 149) 2 = 4266 Jarak = √(404 − 217) 2+ (10605 − 3420) 2+ (0 − 141) 2 = 7189 Jarak = √(404 − 169) 2+ (10605 − 4629) 2+ (0 − 101) 2 = 5981 Jarak = √(404 − 314) 2+ (10605 − 10710) 2 + (0 − 31) 2 = 142 Jarak = √(404 − 351) 2+ (10605 − 10260) 2 + (0 − 27) 2 = 350 Jarak = √(404 − 280) 2+ (10605 − 7438) 2+ (0 − 6) 2 = 3169
Data testing kedua
Jarak = √(302 − 273) 2+ (9215 − 6344) 2 + (83 − 149) 2 = 2872 Jarak = √(302 − 217) 2+ (9215 − 3420) 2 + (83 − 141) 2 = 5796 Jarak = √(302 − 169) 2+ (9215 − 4629) 2 + (83 − 101) 2 = 4588 Jarak = √(302 − 314) 2+ (9215 − 10710) 2+ (83 − 31) 2 = 1496 Jarak = √(302 − 351) 2+ (9215 − 10260) 2+ (83 − 27) 2
= 1048
Jarak = √(302 − 280) 2+ (9215 − 7438) 2 + (83 − 6) 2
= 1779
Data testing ketiga
Jarak = √(256 − 273) 2+ (7670 − 6344) 2 + (54 − 149) 2 = 1330 Jarak = √(256 − 217) 2+ (7670 − 3420) 2 + (54 − 141) 2 = 4251 Jarak = √(256 − 169) 2+ (7670 − 4629) 2 + (54 − 101) 2 = 3043 Jarak = √(256 − 314) 2+ (7670 − 10710) 2+ (54 − 31) 2 = 3041 Jarak = √(256 − 351) 2+ (7670 − 10260) 2+ (54 − 27) 2 = 2592 Jarak = √(256 − 280) 2+ (7670 − 7438) 2 + (54 − 6) 2 = 238
Tabel 5.14 Tabel hasil perhitungan jarak data testing dan data training 3-fold
2. Selanjutnya mengurutkan jarak yang telah dihitung secara ascending dari jarak terkecil ke terbesar
Jarak Harga Jarak Harga Jarak Harga
4266 SangatMahal 2872 SangatMahal 1330 SangatMahal 7189 SangatMahal 5796 SangatMahal 4251 SangatMahal
5981 Mahal 4588 Mahal 3043 Mahal
142 Mahal 1496 Mahal 3041 Mahal
350 Murah 1048 Murah 2592 Murah
Tabel 5.15 Tabel jarak urut 3-fold
3. Selanjutnya mengumpulkan jarak yang telah diurutkan, karena nilai k (tetangga terdekat) =1, maka ambil 1 jarak terkecil.
4. Selanjutnya mengecek label hasil prediksi dengan label aktual, dengan menggunakan confusion matriks.
Tabel 5.16 Tabel Confusion matriks 3-fold
Aktual Hasil Klasifikasi
Murah Mahal Sangat Mahal
Murah 2 0 0 Mahal 1 0 0 Sangat Mahal 0 0 0 Akurasi 3-fold = 1+1 1+1+1 = 66,67% Akurasi Final = 0.00%+66.67%+66,67% 3 = 44.444
Akurasi final didapatkan dari hasil rata-rata keseluruhan akurasi 1-fold, 2-fold dan 3-fold.
Jarak Harga Jarak Harga Jarak Harga
142 Mahal 1048 Murah 238 Murah
350 Murah 1496 Mahal 1330 SangatMahal
3169 Murah 1779 Murah 2592 Murah
4266 SangatMahal 2872 SangatMahal 3041 Mahal
5981 Mahal 4588 Mahal 3043 Mahal
5.2.2 Pengujian perhitungan akurasi menggunakan perangkat lunak Pada pengujian akurasi menggunakan perangkat lunak mencocokan hasil perhitungan manual dengan hasil perhitungan sistem. Data yang digunakana sebanyak 9 data. Dengan mengupload file .xls dalam perangkat lunak, kemudian memasukkan nilai k = 1. Sistem akan memberi luaran berupa hasil akurasi.
Berikut ini implemententasi proses data algoritma k-nearest neighbor 1. Menentukan jumlah data training dan data testing dengan k-fold. Berikut
ada code membagi data training data data testing
Gambar 5.7 Gambar listing program method 1-fold
Gambar 5.9 Gambar listing program method 3-fold
Code diatas membuat method k-fold 1, k-fold 2 dan k-fold 3, dimana pada method tersebut sudah dibagi setiap data training dan data testing.
2. Menentukan nilai k (tetangga terdekat)
Gambar 5.10 Gambar listing program membuat variabel nilai k
Membuat variabel dengan nama nilai_knn untuk memasukkan nilai k (tetangga terdekat) yang akan di inputkan.
3. Menghitung jarak antara data testing dan data training. Berikut ini adalah code menghitung jarak menggunakan rumus Euclidean Distance.
Gambar 5.11 Gambar listing program menghitung jarak
Code diatas untuk menghitung setiap jarak satu persatu variabel luas, produksi, curah hujan data testing ke setiap variabel luas, produksi, curah hujan data training.
4. Cari k data jarak terdekat
Gambar 5.12 Gambar listing program mencari k data jarak terdekat Pada code ditas, setelah data training dan data testing dihitung maka, setiap hasil perhitungan jarak di urutkan dari jarak yang terkecil ke terbesar. Setelah di urutkan mencari nilai k yang sudah di inputkan. Karena nilai k = 1, maka ambil 1 jarak terkecil.
Gambar 5.13 Gambar listing program mencari label mayoritas Pada code diatas, untuk mengecek label prediksi untuk diambil hasil prediksinya.
6. Method menghitung akurasi
Gambar 5.14 Gambar listing program menghitung akurasi 7. Method menghitung total akurasi
5.2.3 Penggujian prediksi data tunggal secara manual menggunakan Microsoft Excel.
Pada penelitian ini, pengujian data tunggal untuk menguji data baru yang belum diketahui hasil prediksinya. Pengujian dilakukan secara manual menggunakan Microsoft Excel. Data yang digunakan sebanyak 9 data. Data tersebut sebagai data training dan data pengujian menggunakan data tahun 2017. Dengan menginputkan luas panen, produksi panen dan curah hujan, dan jumlah nilai k adalah 3.
Tabel 5.17 Tabel data uji dan data training Luas Penen (Ha) Produksi (Ton) Curah Hujan (Mm) Harga Luas Panen (Ha) Produksi (Ton) Curah hujan (Mm) Harga 141 4434 159 ? 273 6344 149 SangatMahal 217 3420 141 SangatMahal 169 4629 101 Mahal 314 10710 31 Mahal 351 10260 27 Murah 280 7438 6 Murah 404 10605 0 Murah 302 9215 83 Murah 256 7670 54 Murah
1. Menentukan nilai k (tetangga terdekat). Misal k = 3
2. Menghitung jarak antara data testing dan data training menggunakan Euclidean Distance.
Jarak = √(141 − 273) 2+ (4434 − 6344) 2 + (159 − 149) 2
= 1915
Jarak = √(141 − 217) 2+ (4434 − 3420) 2 + (159 − 141) 2
Jarak = √(141 − 169) 2+ (4434 − 4629) 2 + (159 − 101) 2 = 205 Jarak = √(141 − 314) 2+ (4434 − 10710) 2+ (159 − 31) 2 = 6280 Jarak = √(141 − 351) 2+ (4434 − 10260) 2+ (159 − 27) 2 = 5831 Jarak = √(141 −) 2+ (4434 − 7438) 2+ (159 − 6) 2 = 3011 Jarak = √(141 −) 2+ (4434 − 10605) 2+ (159 − 0) 2 = 6179 Jarak = √(141 −) 2+ (4434 − 9215) 2+ (159 − 83) 2 = 4784 Jarak = √(141 −) 2+ (4434 − 7670) 2+ (159 − 54) 2 = 3240
Tabel 5.18 Tabel hasil perhitungan jarak
Jarak Harga 1915 SangatMahal 1017 SangatMahal 205 Mahal 6280 Mahal 5831 Murah 3011 Murah 6179 Murah 4784 Murah 3240 Murah
3. Setelah menghitung jarak satu persatu data uji ke data training selanjutnya mencari jarak yang terkecil dengan mengurutkan hasil perhitungan jarak secara ascending (berurutan dari jarak terkecil ke jarak terbesar).
Tabel 5.19 Tabel jarak urut
Jarak Harga 205 Mahal 1017 SangatMahal 1915 SangatMahal 3011 Murah 3240 Murah 4784 Murah 5831 Murah 6179 Murah 6280 Mahal
4. Selanjutnya mengumpulkan jarak terkecil yang telah diurutkan berdasarkan inputan nilai k (tetangga terdekat). Karena nilai k = 3, maka yang diambil 3 terkecil.
Tabel 5.20 Tabel 3 jarak terkecil
Jarak Harga
205 Mahal
1017 SangatMahal
1915 SangatMahal
5. Cari label mayoritas, berdasarkan tabel jarak k = 3, label yang banyak muncul adalah sangat mahal, maka hasil prediksi adalah sangat mahal.
5.2.4 Pengujian prediksi data tunggal menggunakan perangkat lunak Pada pengujian menggunakan perangkat lunak, data yang digunakan sama dengan data yang digunakan pada perhitungan manual. Pengujian dengan menginputkan data luas panen, produksi panen, curah hujan, dan nilai k (tetangga terdekat) = 3. Kemudian sistem akan menampilkam luaran hasil prediksi harga cabai rawit.
Berikut ini implementasi algoritma k-nearest neighbor untuk uji data tunggal.
1. Menentukan nilai k (tetangga terdekat)
Membuat variabel nilai_knn untuk mengirim parameter nilai k yang diinputkan.
Gambar 5.17 Gambar listing program membuat variabel nilai k 2. Menghitung jarak antara data uji dan data training satu persatu
menggunakan rumus Euclidean Distance.
Gambar 5.18 Gambar listing program menghitung jarak 3. Mencari k jarak terkecil.
Gambar 5.19 Gambar listing program mencari nilai k jarak terkecil
4. Mengurutkan jarak menggunakan Collections.sort di java, dengan membandingkan jarak terlebih dahulu kemudian simpan jarak ke dalam arraylist.
Gambar 5.20 Gambar listing program mengurutkan jarak 5. Mengecek label yang akan diambil sebagai nilai prediksi.
5.3 Analisa Hasil
Pada penelitian ini, setelah melakukan pengujian menggunakan dataset sebanyak 36 data dengan menggunakan 3-fold cross validation dihasilkan akurasi tertinggi sebesar 72.222%. Hasil akurasi ini diperoleh dari setiap percobaan nilai k (tetangga terdekat) mulai dari 1, 3 ,5, 7, 9, 11, 13. Dan nilai k yang menghasilkan akurasi tertinggi yaitu k = 13. Hasil akurasi dan jumlah tetangga terdekat dapat dilihat pada tabel di bawah ini.
Tabel 5.21 Tabel akurasi prediksi algoritma K-Nearest Neighbor Jumlah Tetangga Hasil Akurasi
1 44.444% 3 50% 5 52.778% 7 58.333% 9 63.889% 11 66.667% 13 72.222%
Gambar 5.22 Gambar grafik akurasi prediksi cabai rawit 0.000% 10.000% 20.000% 30.000% 40.000% 50.000% 60.000% 70.000% 80.000% 1 3 5 7 9 11 13 Aku ra si Jumlah Tetangga
58 BAB V
KESIMPULAN DAN SARAN 6.1 Kesimpulan
Pada penelitian penerapan algoritma K-Nearest Neighbor untuk prediksi harga cabai rawit dapat diambil keseimpulan sebagai berikut:
1. Algoritma K-Nearest Neighbor telah berhasil di implementasikan dengan baik.
2. Hasil akurasi Algoritma K-Nearest Neighbor untuk prediksi harga cabai rawit diperoleh sebesar 72.222%.
3. Nilai k (tetangga terdekat) yang menghasilkan akurasi tertinggi yaitu k =13.
6.2 Saran
Pada pengembangan penelitian selanjutnya, peneliti memberikan saran untuk pengembangan selanjutnya:
1. Mencari data atau variabel-variabel lain yang mempengaruhi harga cabai rawit.