i
ANALISIS TEKS BERBAHASA INDONESIA
MENGGUNAKAN TEORI
KNOWLEDGE GRAPH
RUSIYAMTI
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
ii
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI
Dengan ini saya menyatakan bahwa tesis berjudul Analisis Teks Berbahasa Indonesia Menggunakan Teori Knowledge Graph ini adalah karya saya dengan arahan dan bimbingan dari komisi pembimbing serta belum pernah diajukan dalam bentuk apapun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan oleh pihak lain telah penulis sebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Bogor, Agustus 2008
Rusiyamti
iii
ABSTRACT
RUSIYAMTI. Indonesian Text Analysis Using Knowledge Graph Theory. Under direction of SRI NURDIATI and PRAPTO TRI SUPRIYO.
Knowledge graph theory is a new approach for natural language understanding. In Knowledge graph theory, there are 9 binary relationships and 4 frame relationships. A word is a basic unit in a natural language processing. In the theory of knowledge graph, word is represented by a word graph, and sentence is represented by a sentence graph. The objective of this thesis is to derive chunk indicators to analyze some Indonesian texts having ”Tsunami” theme. The indicators will be used as criteria to cut a sentence into several chunks. Every sentence will be analyzed using the resulted chunk indicators. The analysis of the Indonesian texts will produce a kind of sentence graph for the texts. The sentence graph describes semantics aspect of the sentence.
iv
RINGKASAN
RUSIYAMTI. Analisis Teks Berbahasa Indonesia Menggunakan Teori Knowledge Graph. Dibimbing oleh SRI NURDIATI, PRAPTO TRI SUPRIYO
Teori Knowledge Graph (KG) adalah suatu pendekatan baru yang dapat digunakan untuk memahami natural language (bahasa alami). Bahasa alami adalah bahasa yang paling populer digunakan untuk menyampaikan atau menerima informasi. Penelitian tentang teori KG dalam jangka panjang bertujuan untuk merancang suatu metode yang dapat digunakan untuk membaca sembarang dokumen berbahasa Indonesia sehingga dihasilkan informasi dalam bentuk teks graf. Teks graf tersebut merupakan intisari dari dokumen yang dipelajari. Penelitian ini merupakan tahap awal untuk mencapai tujuan tersebut. Selama ini struktur teori KG disusun dalam bahasa Inggris. Pada penelitian ini penulis menggunakan teori KG untuk menganalisis dokumen berbahasa Indonesia. Dokumen berbahasa Indonesia yang dimaksud dalam penelitian ini adalah dokumen yang bertema tsunami yang diambil dari beberapa sumber.
Penelitian ini bertujuan menentukan chunk indicators yang dapat digunakan sebagai kriteria pada bagian mana sebuah kalimat harus dipotong ketika kalimat tersebut dianalisis. Manfaat penelitian ini adalah memberikan salah satu alternatif dalam menganalisis teks berbahasa Indonesia.
Dalam teori KG, setiap kata akan berhubungan dengan sebuah word graph, dan menyatakan arti dari kata. Gabungan beberapa word graph akan membentuk sentence graph, dan gabungan beberapa sentence graph akan membentuk sebuah text graph.
v
kemungkinan dari sesuatu, sedangkan relasi NECPAR untuk menyatakan suatu kebutuhan.
Adapun tahapan-tahapan yang dilakukan dalam penelitian ini: Studi literatur dokumen berbahasa Indonesia. Pada tahap ini penulis mengumpulkan dokumen yang berkaitan dengan tsunami yang diambil dari beberapa sumber. Penulis memilih beberapa kalimat untuk dianalisis, yaitu kalimat yang dipandang dapat memberikan gambaran tentang kejadian tsunami serta merupakan intisari dari dokumen yang dipelajari. Tahap selanjutnya menentukan chunk indicators dokumen berbahasa Indonesia. Chunk indicator adalah kriteria yang digunakan untuk menentukan pada bagian mana sebuah kalimat harus dipotong ketika kalimat tersebut dianalisis. Dalam teori KG yang strukturnya bahasa Inggris ada 6 chunk indicators, pada tahap ini penulis mengidentifikasi apakah chunk indicators dalam bahasa Inggris tersebut sesuai apabila diterapkan pada dokumen yang berbahasa Indonesia atau mungkin perlu dilakukan beberapa perubahan disesuaikan dengan struktur bahasa Indonesia. Tahap selanjutnya, masing-masing kalimat hasil studi literatur dokumen berbahasa Indonesia yang bertema tsunami dan telah dipilih untuk dianalisis tersebut dipotong-potong menurut kriteria atau chunk indicators yang telah ditentukan pada tahap kedua. Langkah selanjutnya setiap potongan kalimat dibuat word graph atau chunk graph-nya. Chunk graph terdiri dari sebuah word graph, bisa juga terdiri dari gabungan beberapa word graph. Word graph dari setiap chunk dapat dilihat dalam kamus word graph, kemudian word graph atau chunk graph dari setiap potongan kalimat tersebut digabungkan menjadi sebuah sentence graph.
Dari hasil studi literatur dokumen berbahasa Indonesia, penulis memilih sepuluh kalimat untuk dianalisis. Adapun alasan pemilihan sepuluh kalimat tersebut dikarenakan kalimat-kalimat itu memberikan informasi penting tentang tsunami. Dalam penelitian ini kalimat-kalimat tersebut diperoleh secara manual. Untuk selanjutnya diharapkan kalimat seperti itu nantinya dapat diperoleh secara otomatis dengan bantuan komputer. Dengan kata lain, begitu dimasukkan dokumen berbahasa Indonesia sebagai input ke dalam komputer, maka komputer akan menghasilkan output berupa text graph yang menjadi intisari dari dokumen yang dipelajari. Dalam penelitian ini diberikan kamus word graph dari beberapa jenis kata seperti: kata benda, kata kerja, kata depan, serta kata sifat yang terdapat pada dokumen berbahasa Indonesia yang bertema tsunami.
Hasil penelitian ini berupa chunk indicators yang digunakan sebagai kriteria pada bagian mana sebuah kalimat harus dipotong. Chunk indicators yang digunakan untuk menganalisis teks berbahasa Indonesia dengan teori knowledge graph antara lain: Indikator 1: Koma atau titik, Indikator 2: Kata penunjuk dan kata penghubung, Indikator 3: Kata kerja bantu, Indikator 4: Kata depan (preposisi), Indikator 5: Lompatan (jump), dan Indikator 6: Kata-kata dalam logika (logic word). Selain itu hasil penelitian ini berupa sentence graph dari masing-masing kalimat. Struktur dari sentence graph tersebut menunjukkan arti (aspek semantik) dari kalimat yang dianalisis.
vi
@Hak cipta milik Institut Pertanian Bogor, tahun 2008
Hak cipta dilindungi Undang-undang
1. Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumber.
a. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik dan tinjauan suatu masalah.
b. Pengutipan tidak merugikan kepentingan yang wajar Institut Pertanian Bogor.
vii
ANALISIS TEKS BERBAHASA INDONESIA
MENGGUNAKAN TEORI
KNOWLEDGE GRAPH
RUSIYAMTI
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada
Departemen Matematika
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
BOGOR
viii
Karya tulis ini aku persembahkan kepada:
* Kedua orangtua yang selalu mendoakanku
* Suamiku tercinta yang selalu memberi dorongan dan semangat
* Muhammad Rosyid Aunillah anandaku tersayang
ix
PRAKATA
Puji dan syukur penulis panjatkan kehadirat Allah SWT yang telah melimpahkan rahmat serta hidayah-Nya sehingga penulis dapat menyelesaikan penulisan tesis ini. Shalawat dan salam semoga senantiasa tercurahkan kepada junjungan kita nabi besar Muhammad SAW beserta keluarga dan para sahabat, serta seluruh umat manusia yang mengikuti petunjuk dan ajaran beliau.
Penulis merasa bahagia telah dapat menyelesaikan penulisan tesis yang berjudul Analisis Teks Berbahasa Indonesia Menggunakan Teori Knowledge Graph. Tesis ini disusun sebagai salah satu syarat memperoleh gelar Magister Sains Program Studi Matematika Terapan pada Departemen Matematika Institut Pertanian Bogor.
Terima kasih penulis ucapkan kepada Departemen Agama RI yang telah memberikan beasiswa sehingga penulis dapat belajar dan menyelesaikan Program Magister Matematika Terapan di Sekolah Pascasarjana Institut Pertanian Bogor. Ucapan terima kasih juga penulis sampaikan kepada Dr. Ir. Sri Nurdiati, M.Sc dan Drs. Prapto Tri Supriyo, M.Kom selaku dosen pembimbing yang telah memberikan arahan dan bimbingan selama penulis menyusun tesis ini, serta Dr. Sugi Guritman selaku penguji yang telah banyak memberikan saran. Ucapan yang sama penulis sampaikan kepada Dra. Siti Nurdiyati, M.Pd.I selaku Kepala Madrasah Tsanawiyah Negeri Babadan Baru yang telah memberikan izin kepada penulis untuk menempuh pendidikan S2 ini.
Ucapan terima kasih penulis ucapkan kepada seluruh anggota keluarga yang selalu memberikan dukungan selama penulis menempuh pendidikan S2 di Institut Pertanian Bogor ini, juga kepada segenap dosen dan karyawan Departemen Matematika, rekan-rekan mahasiswa S2 baik BUD maupun reguler, serta semua pihak yang tidak dapat penulis sebutkan satu persatu.
Teriring do’a ”Jazakumullaahu khoiron katsiira” semoga amal kebaikan mereka diterima di sisi Allah SWT, dan mendapat balasan yang setimpal. Amin. Penulis juga meyakini, bahwa tesis ini masih banyak kekurangan, maka dari itu segala kritik dan saran yang bersifat membangun dari para pembaca sangat penulis harapkan. Semoga tesis ini membawa berkah dan manfaat.
Bogor, Agustus 2008
x
RIWAYAT HIDUP
i
ANALISIS TEKS BERBAHASA INDONESIA
MENGGUNAKAN TEORI
KNOWLEDGE GRAPH
RUSIYAMTI
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
ii
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI
Dengan ini saya menyatakan bahwa tesis berjudul Analisis Teks Berbahasa Indonesia Menggunakan Teori Knowledge Graph ini adalah karya saya dengan arahan dan bimbingan dari komisi pembimbing serta belum pernah diajukan dalam bentuk apapun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan oleh pihak lain telah penulis sebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Bogor, Agustus 2008
Rusiyamti
iii
ABSTRACT
RUSIYAMTI. Indonesian Text Analysis Using Knowledge Graph Theory. Under direction of SRI NURDIATI and PRAPTO TRI SUPRIYO.
Knowledge graph theory is a new approach for natural language understanding. In Knowledge graph theory, there are 9 binary relationships and 4 frame relationships. A word is a basic unit in a natural language processing. In the theory of knowledge graph, word is represented by a word graph, and sentence is represented by a sentence graph. The objective of this thesis is to derive chunk indicators to analyze some Indonesian texts having ”Tsunami” theme. The indicators will be used as criteria to cut a sentence into several chunks. Every sentence will be analyzed using the resulted chunk indicators. The analysis of the Indonesian texts will produce a kind of sentence graph for the texts. The sentence graph describes semantics aspect of the sentence.
iv
RINGKASAN
RUSIYAMTI. Analisis Teks Berbahasa Indonesia Menggunakan Teori Knowledge Graph. Dibimbing oleh SRI NURDIATI, PRAPTO TRI SUPRIYO
Teori Knowledge Graph (KG) adalah suatu pendekatan baru yang dapat digunakan untuk memahami natural language (bahasa alami). Bahasa alami adalah bahasa yang paling populer digunakan untuk menyampaikan atau menerima informasi. Penelitian tentang teori KG dalam jangka panjang bertujuan untuk merancang suatu metode yang dapat digunakan untuk membaca sembarang dokumen berbahasa Indonesia sehingga dihasilkan informasi dalam bentuk teks graf. Teks graf tersebut merupakan intisari dari dokumen yang dipelajari. Penelitian ini merupakan tahap awal untuk mencapai tujuan tersebut. Selama ini struktur teori KG disusun dalam bahasa Inggris. Pada penelitian ini penulis menggunakan teori KG untuk menganalisis dokumen berbahasa Indonesia. Dokumen berbahasa Indonesia yang dimaksud dalam penelitian ini adalah dokumen yang bertema tsunami yang diambil dari beberapa sumber.
Penelitian ini bertujuan menentukan chunk indicators yang dapat digunakan sebagai kriteria pada bagian mana sebuah kalimat harus dipotong ketika kalimat tersebut dianalisis. Manfaat penelitian ini adalah memberikan salah satu alternatif dalam menganalisis teks berbahasa Indonesia.
Dalam teori KG, setiap kata akan berhubungan dengan sebuah word graph, dan menyatakan arti dari kata. Gabungan beberapa word graph akan membentuk sentence graph, dan gabungan beberapa sentence graph akan membentuk sebuah text graph.
v
kemungkinan dari sesuatu, sedangkan relasi NECPAR untuk menyatakan suatu kebutuhan.
Adapun tahapan-tahapan yang dilakukan dalam penelitian ini: Studi literatur dokumen berbahasa Indonesia. Pada tahap ini penulis mengumpulkan dokumen yang berkaitan dengan tsunami yang diambil dari beberapa sumber. Penulis memilih beberapa kalimat untuk dianalisis, yaitu kalimat yang dipandang dapat memberikan gambaran tentang kejadian tsunami serta merupakan intisari dari dokumen yang dipelajari. Tahap selanjutnya menentukan chunk indicators dokumen berbahasa Indonesia. Chunk indicator adalah kriteria yang digunakan untuk menentukan pada bagian mana sebuah kalimat harus dipotong ketika kalimat tersebut dianalisis. Dalam teori KG yang strukturnya bahasa Inggris ada 6 chunk indicators, pada tahap ini penulis mengidentifikasi apakah chunk indicators dalam bahasa Inggris tersebut sesuai apabila diterapkan pada dokumen yang berbahasa Indonesia atau mungkin perlu dilakukan beberapa perubahan disesuaikan dengan struktur bahasa Indonesia. Tahap selanjutnya, masing-masing kalimat hasil studi literatur dokumen berbahasa Indonesia yang bertema tsunami dan telah dipilih untuk dianalisis tersebut dipotong-potong menurut kriteria atau chunk indicators yang telah ditentukan pada tahap kedua. Langkah selanjutnya setiap potongan kalimat dibuat word graph atau chunk graph-nya. Chunk graph terdiri dari sebuah word graph, bisa juga terdiri dari gabungan beberapa word graph. Word graph dari setiap chunk dapat dilihat dalam kamus word graph, kemudian word graph atau chunk graph dari setiap potongan kalimat tersebut digabungkan menjadi sebuah sentence graph.
Dari hasil studi literatur dokumen berbahasa Indonesia, penulis memilih sepuluh kalimat untuk dianalisis. Adapun alasan pemilihan sepuluh kalimat tersebut dikarenakan kalimat-kalimat itu memberikan informasi penting tentang tsunami. Dalam penelitian ini kalimat-kalimat tersebut diperoleh secara manual. Untuk selanjutnya diharapkan kalimat seperti itu nantinya dapat diperoleh secara otomatis dengan bantuan komputer. Dengan kata lain, begitu dimasukkan dokumen berbahasa Indonesia sebagai input ke dalam komputer, maka komputer akan menghasilkan output berupa text graph yang menjadi intisari dari dokumen yang dipelajari. Dalam penelitian ini diberikan kamus word graph dari beberapa jenis kata seperti: kata benda, kata kerja, kata depan, serta kata sifat yang terdapat pada dokumen berbahasa Indonesia yang bertema tsunami.
Hasil penelitian ini berupa chunk indicators yang digunakan sebagai kriteria pada bagian mana sebuah kalimat harus dipotong. Chunk indicators yang digunakan untuk menganalisis teks berbahasa Indonesia dengan teori knowledge graph antara lain: Indikator 1: Koma atau titik, Indikator 2: Kata penunjuk dan kata penghubung, Indikator 3: Kata kerja bantu, Indikator 4: Kata depan (preposisi), Indikator 5: Lompatan (jump), dan Indikator 6: Kata-kata dalam logika (logic word). Selain itu hasil penelitian ini berupa sentence graph dari masing-masing kalimat. Struktur dari sentence graph tersebut menunjukkan arti (aspek semantik) dari kalimat yang dianalisis.
vi
@Hak cipta milik Institut Pertanian Bogor, tahun 2008
Hak cipta dilindungi Undang-undang
1. Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumber.
a. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik dan tinjauan suatu masalah.
b. Pengutipan tidak merugikan kepentingan yang wajar Institut Pertanian Bogor.
vii
ANALISIS TEKS BERBAHASA INDONESIA
MENGGUNAKAN TEORI
KNOWLEDGE GRAPH
RUSIYAMTI
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada
Departemen Matematika
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
BOGOR
viii
Karya tulis ini aku persembahkan kepada:
* Kedua orangtua yang selalu mendoakanku
* Suamiku tercinta yang selalu memberi dorongan dan semangat
* Muhammad Rosyid Aunillah anandaku tersayang
ix
PRAKATA
Puji dan syukur penulis panjatkan kehadirat Allah SWT yang telah melimpahkan rahmat serta hidayah-Nya sehingga penulis dapat menyelesaikan penulisan tesis ini. Shalawat dan salam semoga senantiasa tercurahkan kepada junjungan kita nabi besar Muhammad SAW beserta keluarga dan para sahabat, serta seluruh umat manusia yang mengikuti petunjuk dan ajaran beliau.
Penulis merasa bahagia telah dapat menyelesaikan penulisan tesis yang berjudul Analisis Teks Berbahasa Indonesia Menggunakan Teori Knowledge Graph. Tesis ini disusun sebagai salah satu syarat memperoleh gelar Magister Sains Program Studi Matematika Terapan pada Departemen Matematika Institut Pertanian Bogor.
Terima kasih penulis ucapkan kepada Departemen Agama RI yang telah memberikan beasiswa sehingga penulis dapat belajar dan menyelesaikan Program Magister Matematika Terapan di Sekolah Pascasarjana Institut Pertanian Bogor. Ucapan terima kasih juga penulis sampaikan kepada Dr. Ir. Sri Nurdiati, M.Sc dan Drs. Prapto Tri Supriyo, M.Kom selaku dosen pembimbing yang telah memberikan arahan dan bimbingan selama penulis menyusun tesis ini, serta Dr. Sugi Guritman selaku penguji yang telah banyak memberikan saran. Ucapan yang sama penulis sampaikan kepada Dra. Siti Nurdiyati, M.Pd.I selaku Kepala Madrasah Tsanawiyah Negeri Babadan Baru yang telah memberikan izin kepada penulis untuk menempuh pendidikan S2 ini.
Ucapan terima kasih penulis ucapkan kepada seluruh anggota keluarga yang selalu memberikan dukungan selama penulis menempuh pendidikan S2 di Institut Pertanian Bogor ini, juga kepada segenap dosen dan karyawan Departemen Matematika, rekan-rekan mahasiswa S2 baik BUD maupun reguler, serta semua pihak yang tidak dapat penulis sebutkan satu persatu.
Teriring do’a ”Jazakumullaahu khoiron katsiira” semoga amal kebaikan mereka diterima di sisi Allah SWT, dan mendapat balasan yang setimpal. Amin. Penulis juga meyakini, bahwa tesis ini masih banyak kekurangan, maka dari itu segala kritik dan saran yang bersifat membangun dari para pembaca sangat penulis harapkan. Semoga tesis ini membawa berkah dan manfaat.
Bogor, Agustus 2008
x
RIWAYAT HIDUP
xi
DAFTAR ISI
Halaman
DAFTAR TABEL ... xii
DAFTAR GAMBAR ... xiii
I PENDAHULUAN ... 1
1. Latar Belakang Masalah ... 1
2. Tujuan dan Manfaat Penelitian ... 2
II TINJAUAN PUSTAKA ... 3
1. Kelas Kata... 3
1.1 Kata Benda ... 3
1.2 Kata Kerja ... 4
1.3 Kata Sifat ... 4
1.4 Kata Tugas ... 5
2. Kalimat ...5
2.1 Pola Kalimat...6
2.2 Kalimat Pasif dan Kalimat Aktif...6
3. Definisi (Graf) ... 6
3.1 Definisi (Graf Berarah) atau (Digraph) ... 7
3.2 Definisi Subgraf ... 7
4. Knowledge Graph (KG) ...7
4.1 Definisi KG... 8
4.2 Konsep ... 9
4.3 Word Graph... 10
. 4.4 Aspek-Aspek Ontologi ... 10
4.5 Ekspresi Semantik dengan KG ... 14
5. Natural Language... 15
6. Grammar (Tata Bahasa) ... 16
7. Kalimat Pasif dan Representasinya dalam KG... 16
8. Chunking (Pembuatan Potongan Kalimat) ... 17
III METODE PENELITIAN ... 19
1. Studi Literatur Dokumen Berbahasa Indonesia... 19
2. Pembuatan Chunk Indicator... 19
3. Pembuatan Chunk Graph... 19
4. Menggabungkan Chunk Graph menjadi Sebuah Sentence Graph... 19
IV HASIL DAN PEMBAHASAN... 20
V KESIMPULAN DAN SARAN ... 52
xii
DAFTAR TABEL
Halaman
1. Kamus word graph dari kata benda pada kalimat 1 dan 2... 23 2. Kamus word graph dari frasa kata benda pada kalimat 1 dan 2 ... 24 3. Kamus word graph dari preposisi pada kalimat 2... 25 4. Kamus word graph dari frasa preposisi pada kalimat 2 ... 26 5. Kamus word graph dari kata sifat pada kalimat 3... 33 6. Kamus word graph dari kata sifat pada kalimat 4... 35 7. Kamus word graph dari kata-kata pada kalimat 7 ... 43 8. Kamus word graph dari kalimat 10... 47 9. Kata jadian yang telah ada representasi word graph-nya... 50
xiii
DAFTAR GAMBAR
Halaman
1 Contoh graf berarah... 7 2 Graf G dan sebuah subgraf dari G... 7 3 Knowledge graph dari G1...8
4 Contoh penggunaan relasi CAU... 11 5 Contoh penggunaan relasi EQU ... 11 6 Contoh penggunaan relasi SUB ... 12 7 Contoh penggunaan relasi ALI... 12 8 Contoh penggunaan relasi DIS... 12 9 Contoh penggunaan relasi ORD... 12 10 Contoh penggunaan relasi PAR ... 13 11 Contoh penggunaan relasi SKO ... 13 12 Contoh penggunaan ontologi F ... 13 13 Contoh penggunaan 4 frame relationships... 14 14 Ekspresi semantik ”pria lajang” dengan KG ... 15 15 Word graph dari kata kerja transitif ... 16 16 Word graph dari kata kerja intransitif ... 16 17 Word graph dari kata ”ialah, adalah” ... 17 18 Sentence graph dari ”Roy menendang bola” ... 17 19 Sentence graph dari ”Bola ditendang Roy” ... 17 20 Word graph dari frasa kata benda ... 23 21 Word graph dari kata ”yang” ... 26 22 Word graph dari kata kerja ”dipicu” ... 27 23 Word graph dari kata kerja ”menimpa” ... 27 24 Chunk graph dari ”gempa di lepas pantai” ... 28 25 Chunk graph dari ”letusan gunung di dekat permukaan laut”... 28 26 Chunk graph dari ”pergeseran lapisan di bawah laut” ... 29 27 Chunk graph dari ”hantaman meteor yang menimpa laut” ... 29 28 Ontologi proposisi p q dengan AND-frame... 30
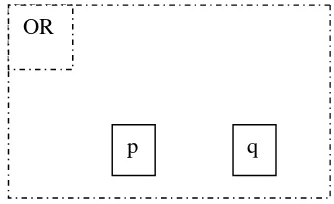
xiv
30 Ontologi proposisi p q dengan OR-frame... 30
31 Definisi konsep ”Tsunami” dengan AND-frame... 31 32 Definisi konsep ”Tsunami” dengan OR-frame... 32 33 Chunk graph dari ”panjang gelombang tsunami” ... 34 34 Chunk graph dari ”50-200 kilometer”... 34 35 Sentence graph dari ”Panjang gelombang tsunami 50-200 kilometer”... 35 36 Chunk graph dari ”tinggi gelombang tsunami”... 36 37 Chunk graph ”di pusat gempa”... 37 38 Chunk graph dari ”1,0-3,0 meter” ... 37 39 Sentence graph ”Tinggi gelombang tsunami di pusat gempa 1,0-3,0 meter” 38 40 Word graph dari kata ”melemah”... 39 41 Word graph dari kata ”mengecil”... 39 42 Word graph dari kata ”daerah”... 40 43 Chunk graph ”di daerah pantai” ... 40 44 Sentence graph ”Panjang gelombang tsunami mengecil di daerah pantai” ... 41 45 Word graph dari kata ”membesar” ... 42 46 Sentence graph ”Tinggi gelombang tsunami membesar di daerah pantai” .... 42 47 Sentence graph dari “Gelombang tsunami berbeda dengan gelombang yang dibangkitkan oleh angin” ... 43 48 Word graph dari kata kerja ”menggerakkan” ... 44 49 Word graph dari kata benda ”air”... 44 50 Chunk graph dari ”permukaan air laut”... 44 51 Sentence graph dari “Gelombang yang dibangkitkan oleh angin
1
BAB I
PENDAHULUAN
1. Latar Belakang Masalah
Memahami isi sebuah dokumen menjadi persoalan tersendiri bagi setiap, karena setiap orang mungkin akan memiliki pemahaman yang berbeda terhadap apa yang dibacanya. Untuk memahami sebuah dokumen berbahasa Indonesia dalam jumlah besar, misalnya dokumen yang terdiri dari beratus-ratus halaman mungkin menjadi masalah tersendiri. Hal ini dikarenakan untuk membaca dokumen tersebut dibutuhkan waktu yang lama, sampai akhirnya didapatkan suatu pengetahuan. Dalam hal ini teori Knowledge Graph (KG) dapat digunakan untuk mengatasi kesulitan memahami dokumen tersebut, namun penerapannya baru untuk dokumen berbahasa Inggris. Struktur bahasa Inggris tidak persis sama dengan bahasa Indonesia, untuk itu perlu dilakukan analisis terhadap struktur bahasa Indonesia sehingga teori KG dapat digunakan untuk menganalisis teks atau dokumen berbahasa Indonesia.
Upaya menerapkan teori KG untuk menganalisis dokumen berbahasa Indonesia telah dilakukan oleh beberapa peneliti sebelumnya, diantaranya: Hulliyah menganalisis teks dengan tema sistem pendidikan nasional (2007), Ikhwati menganalisis teks dengan tema kemiskinan (2007). Keduanya langsung mengadopsi begitu saja aturan-aturan KG dalam bahasa Inggris untuk menganalisis dokumen berbahasa Indonesia dan hasilnya berupa text graph. Berri (2008) mengubah kalimat sembarang menjadi kalimat efektif kemudian mengubahnya ke dalam bentuk text graph dan merancang algoritme pembentukan text graph, serta Wulandari (2008) melanjutkan penelitian Berri dengan
merancang algoritme pembentukan combined graph dan simplified graph untuk dokumen berbahasa Indonesia.
2
tujuan tersebut. Dalam penelitian ini, penerapan teori KG akan dibatasi untuk menganalisis teks berbahasa Indonesia dengan tema tsunami yang diambil atau dipilih dari beberapa sumber.
2. Tujuan dan Manfaat Penelitian
Tujuan
Penelitian ini bertujuan untuk menentukan chunk indicators yang digunakan sebagai petunjuk dalam menganalisis teks berbahasa Indonesia.
Manfaat
3
BAB II
TINJAUAN PUSTAKA
Pada bab ini diberikan beberapa penjelasan yang akan digunakan pada bab-bab selanjutnya.
1. Kelas Kata
Semantik (Yunani : semanein = berarti, bermaksud; semanticos = makna) adalah cabang ilmu bahasa yang meneliti makna dalam bahasa tertentu, mencari asal-usul dan perkembangan arti kata, mempelajari klasifikasi perubahan kata-kata atau bentuk bahasa sebagai faktor dalam perkembangan bahasa.
Berdasarkan struktur bentuk, morfologi dan kelompok kata (fraseologi), kata dibagi menjadi 4 kelas besar, yaitu :
1) Kelas kata benda yang memuat sub kelas kata ganti dan kata sandang 2) Kelas kata kerja
3) Kelas kata sifat yang memuat sub kelas kata bilangan
4) Kelas kata tugas yang memuat sub kelas kata depan, kata sambung, kata keterangan (Gorys Keraf, 1991).
1.1 Kata Benda
Kata benda adalah semua kata yang dapat diterangkan atau diperluas dengan yang + kata sifat. Contohnya: perumahan, kesadaran dan udara adalah kata benda karena dapat diperluas dengan ”yang + kata sifat” yaitu:
Perumahan yang baru, kesadaran yang tinggi, dan udara yang bersih.
Kata ganti dimasukkan dalam sub kelas kata benda karena kata-kata ini dipakai untuk mengganti kata benda atau yang dibendakan pada posisi tertentu. Menurut sifat dan fungsinya, kata ganti dibedakan menjadi: kata ganti orang, kata ganti milik, kata ganti penunjuk, kata ganti penghubung, kata ganti penanya, dan kata ganti tak tentu. Kata ganti milik adalah kata yang berfungsi menggantikan orang dalam kedudukan sebagai pemilik. Oleh karena itu dalam bahasa Indonesia sebenarnya tidak ada kata ganti milik.
4
tersebut. Contoh kata sandang adalah kata yang. Mula-mula kata yang berfungsi sebagai penentu. Fungsi yang lain sebagai alat nominalisasi yaitu kata yang bersama-sama kata lainnya menduduki posisi kata benda (Gorys Keraf, 1991).
1.2 Kata Kerja
Kata kerja adalah segala macam kata yang dapat diperluas dengan kelompok kata ”dengan + kata sifat”.
Berdasarkan relasinya dengan objek, kata kerja dibagi menjadi: 1) Kata kerja transitif yaitu kata kerja yang membutuhkan objek Contoh: memukul, menerima, melempar, menghancurkan, memberi 2) Kata kerja intransitif yaitu kata kerja yang tidak membutuhkan objek Contoh: mandi, datang, merupakan, berbicara, berasaskan Pancasila Berdasarkan fungsinya sebagai predikat, kata kerja dibedakan:
1) Kata kerja penuh yaitu kata kerja yang langsung berfungsi sebagai predikat. 2) Kata kerja bantu.
Ada tiga macam kata kerja bantu yang dapat dirangkai bersama untuk membatasi kata kerja utama, yaitu:
Keharusan: harus, mesti, perlu
Kemampuan: dapat, sanggup, mampu, boleh, dan bisa
Keinginan: ingin, hendak, mau, dan suka (Gorys Keraf, 1991).
1.3 Kata Sifat
Berdasarkan segi semantik, kata sifat dapat dibagi atas: 1) Deskripsi warna
Contoh: hitam, putih, ungu, coklat, biru, oranye, merah jambu, kuning. 2) Deskripsi ukuran
Contoh: luas, sempit, dalam, tipis, dingin, panas, singkat, cepat, muda, tua. 3) Deskripsi suasana hati
Contoh: sedih, gembira, perih, bahagia, susah, terharu, senang. 4) Deskripsi kualitas
5
1.4 Kata Tugas
Kata tugas adalah kelas kata yang hanya menduduki fungsi bawahan kalimat, serta dari sudut semantik hanya mengandung konsep-konsep relasional. Semua kata yang tidak termasuk dalam kelas kata benda, kelas kata kerja, dan kelas kata sifat termasuk dalam kelas kata tugas ini. Kata tugas memuat sub kelas kata depan, kata keterangan, dan kata sambung.
1) Kata depan
Contoh: di, ke, dari, pada, kepada, sampai, akan, dengan, serta, karena, sebab. Dalam bahasa Inggris here, there, beside, in, dan between merupakan kata depan, tetapi padanannya dalam bahasa Indonesia seperti di mana, di sini, di samping, ke dalam, ke depan, dan di antara, bukan kata depan. Konstruksi
semacam itu termasuk kategori frasa preposisional yang berfungsi sebagai keterangan lokasi.
2) Kata keterangan
Contoh: sangat, amat, agaknya, sungguh, mungkin, memang, terlalu, sekali. 3) Kata hubung
Contoh: adalah, merupakan, maupun, ketika, setelah, tetapi, melainkan, sebab, seperti, supaya, agar, jika, semakin, misalnya, padahal (Gorys Keraf, 1991).
2. Kalimat
6
2.1 Pola kalimat
Pola dasar sebuah kalimat berkaitan dengan kelas mana yang membentuk kalimat tersebut. Telah dijelaskan sebelumnya bahwa kata dibagi atas 4 kelas kata yaitu kata benda, kata kerja, kata sifat dan kata tugas. Oleh karena itu pola dasar kalimat terdiri atas :
Pola I : kata kerja – kata kerja atau disebut kalimat verbal Pola II : kata benda – kata sifat atau disebut kalimat atributif Pola III : kata benda – kata benda atau disebut kalimat nominal
pola IV: kata benda – kata keterangan atau disebut kalimat adverbial (Gorys Keraf, 1991).
2.2 Kalimat Aktif dan Kalimat Pasif
Kalimat verbal dibedakan menjadi kalimat verbal transitif dan intransitif. Kalimat verbal transitif adalah kalimat yang predikatnya kata kerja transitif yaitu kata kerja yang menghendaki objek. Kalimat verbal intransitif adalah kalimat yang predikatnya kata kerja intransitif yaitu kata kerja yang tidak menghendaki objek. Kalimat transitif selanjutnya dibedakan lagi atas kalimat aktif dan kalimat pasif, berdasarkan relasi antara subjek dan predikatnya. Suatu kalimat dikatakan sebagai kalimat aktif kalau subjek kalimat menjadi pelaku perbuatan yang menjadi predikat kalimat tersebut. Suatu kalimat dikatakan sebagai kalimat pasif kalau subjek kalimat dikenai perbuatan yang menjadi predikat kalimat tersebut (Gorys Keraf, 1991).
3. Definisi (Graf)
7
3.1 Definisi (Graf Berarah) atau (Digraph)
Digraph (graf berarah) D adalah pasangan terurut (V,A) dengan V adalah
himpunan tak kosong dari sejumlah berhingga elemen yang disebut simpul (node) dan A adalah himpunan berhingga (tidak perlu berbeda) dari pasangan terurut elemen-elemen dalam V yang disebut busur (arc) (Wilson RJ, 1979).
Gambar 1 Contoh graf berarah
3.2 Definisi (Subgraf)
Graf G' disebut subgraf dari G jika semua simpul dari G' dan semua sisi dari G' terletak di G, dan setiap sisi dari G' mempunyai simpul ujung yang sama dengan simpul ujung di G (Martono, 1990).
Gambar 2 Graf G dan sebuah subgraf dari G
4. Knowledge Graph (KG)
Teori KG adalah suatu pendekatan baru yang dapat digunakan untuk menyatakan bahasa manusia. Perbedaan yang mendasar antara teori KG dengan teori representasi lain adalah bahwa teori KG ini hanya menggunakan ontologi atau relasi yang jumlahnya sangat terbatas. Teori KG mampu melukiskan atau menggambarkan aspek semantik yang lebih mendasar, dengan menggunakan
1
2 3
4 5
6
1
2a 3
8
sejumlah relasi yang banyaknya terbatas. Teori ini memberikan cara baru melakukan penelitian untuk memahami bahasa manusia dengan bantuan komputer (Zhang, 2002).
KG merupakan salah satu teori yang dapat digunakan untuk merepresentasikan suatu informasi dalam bentuk graf berarah, sehingga diharapkan akan mudah untuk dipahami. Hasil dari KG ini merupakan suatu graf berarah yang terdiri dari node untuk merepresentasikan konsep sedangkan relasi antar konsep direpresentasikan dengan link, dan jenis relasi yang digunakan sangat terbatas (Lehmann (1992) dalam Kramer (1996)).
4.1 Definisi KG
Misalkan C suatu himpunan konsep-konsep, dan T suatu himpunan jenis-jenis relasi. Knowledge graph G adalah bagian dari himpunan G = (N,A) yang memuat fungsi n: N C, dan a: A T,
N : himpunan node dari G dan A NxN adalah himpunan arc dari G.
n: label khusus dari sebuah node (nama sebuah konsep) dan a: label
khusus dari sebuah arc (nama dari jenis relasi) (Van Den Berg, 1993).
Contoh berikut diambil dari Van Den Berg (1993):
Knowledge graph G1 = ({c , c , c1 2 3},{c c , c c1 2 3 2}) dengan a(c c )1 2 r1 dan
3 2 2
(c c ) r
a dimana c , c , c1 2 3 C dan r , r1 2 T . G1 dapat digambarkan sebagai
berikut :
Gambar 3 Knowledge graph dari G1
KG merupakan suatu pendekatan baru dari knowledge representation yang termasuk dalam kategori jaringan semantik. Teori KG pada prinsipnya terdiri atas concept, binary relationships dan multivariate relationships (Zhang, 2002).
9
4.2 Konsep
Menurut Zhang dan Hoede (2002), konsep merupakan komponen terpenting dalam pemikiran manusia. Konsep merupakan sesuatu yang penting dalam membentuk suatu pengertian dari khusus ke umum atau sebaliknya. Menurut Van Den Berg (1993), konsep dapat dibedakan menjadi tiga jenis, yaitu token, type dan name.
a. Token
Dalam teori KG, token merupakan konsep yang dipahami oleh seseorang menurut cara pandang masing-masing, sehingga token ini bersifat subjektif. Setiap persepsi selalu berhubungan dengan token. Sebuah konsep berhubungan dengan arti dari kata (Zhang, 2002). Contoh sebuah token, misal seseorang menemukan kata ”apel”, orang tersebut dapat menghubungkan hal ini dengan informasi bentuk, warna, rasa, demikian juga orang lain akan menghubungkan dengan hal yang berbeda. Sebuah token, dalam teori KG dinyatakan dengan simbol ” ”. Seseorang dalam mengamati sesuatu, pada kenyataannya akan dibandingkan dengan dunia nyata. Dengan demikian dalam teori KG segala sesuatu akan dihubungkan dengan token.
b. Type
Type adalah konsep yang berupa informasi umum dan bersifat objektif
karena merupakan kesepakatan yang dibuat sebelumnya. Contoh type misalnya buah, binatang dan sebagainya.
c. Name
Name adalah sesuatu yang bersifat individual, sebagai contoh : fuji adalah
sebuah name yaitu nama dari sebuah apel. Sesuatu dapat dikelompokkan ke dalam beberapa type yang berbeda. Demikian juga name, sesuatu dapat diberi name dengan banyak cara.
Type dan name dalam teori KG direpresentasikan dengan cara yang hampir
10
4.3 Word graph
Word graph merupakan graf dari kata. Dalam teori KG setiap kata
berhubungan dengan sebuah word graph, menyatakan arti dari kata dan disebut dengan semantic word graph. Gabungan beberapa word graph dari kata-kata dalam suatu kalimat menghasilkan sentence graph. Word graph dapat dinyatakan sebagai graf berarah yang diberi label. Beberapa sentence graph yang digabung dalam sebuah teks disebut text graph, dan memuat pengetahuan yang terkandung dalam suatu teks (Hoede dan Nurdiati, 2008).
4.4 Aspek-Aspek Ontologi
Ontologi merupakan gambaran dari beberapa konsep dan relasi antar konsep yang bertujuan untuk mendefinisikan ide-ide yang merepresentasikan konsep, relasi dan logikanya. Berdasarkan ontologi yang dimiliki inilah maka KG dapat membangun sebuah model yang dapat digunakan untuk memahami bahasa alami (natural language). Hal ini diperlukan agar arti dari suatu kalimat dapat diekspresikan. Arti dari kata terlebih dahulu harus diketahui untuk dapat mengartikan sebuah kalimat (Ikhwati, 2007).
Ontologi word graph sampai saat ini terdiri dari token yang dinyatakan dengan node, 9 binary relationships, dan 4 frame relationships. Sembilan binary relationships tersebut :
1. Causality : CAU
2. Equality : EQU
3. Subset : SUB
4. Alikeness : ALI 5. Disparateness : DIS
6. Ordering : ORD
7. Attribution : PAR 8. Informational dependency : SKO 9. Ontologi F (fokus dari suatu graf)
11
1. Relasi CAU (CAUSALITY)
Relasi causal antara 2 buah tokens digambarkan dengan anak panah berlabel CAU. Relasi CAU digunakan untuk menghubungkan dua tokens yang memiliki hubungan sebab akibat. Menurut Hoede dan Nurdiati (2008), relasi CAU dapat digunakan untuk menghubungkan dua konsep yang terdiri dari kata benda dan kata kerja, yaitu untuk menghubungkan subjek dengan predikat atau predikat dengan objek. Contoh : Kucing makan nasi. Kalimat tersebut dapat dinyatakan sebagai berikut:
Gambar 4 Contoh penggunaan relasi CAU
Gambar 4 di atas memberikan contoh penggunaan relasi CAU untuk menghubungkan kata benda ”kucing” (subjek kalimat tersebut) dengan kata kerja ”makan” (predikat kalimat tersebut) serta menghubungkan kata kerja ”makan” (predikat) dengan kata benda ”nasi” (objek kalimat tersebut).
2. Relasi EQU (EQUALITY)
Relasi EQU digunakan untuk menghubungkan sebuah name dengan token. Contoh: Fuji adalah name dari apel, word graph-nya seperti pada Gambar 5 (kiri). Relasi ini bisa juga untuk menyatakan kata hubung seperti ”adalah” dan ”merupakan”, word graph-nya dapat dilihat pada Gambar 5 (kanan).
Gambar 5 Contoh penggunaan relasi EQU 3. Relasi SUB (SUBSET)
Jika dua tokens menyatakan word graph, dan word graph yang satu merupakan bagian dari word graph yang lain, maka kedua tokens dihubungkan dengan relasi SUB. Tetapi untuk konsep yang dinyatakan dengan graf, dapat dikatakan bahwa graf A subgraf dari graf B, sehingga antara A dan B digunakan relasi FPAR. Contoh: ekor merupakan bagian dari kucing, maka dapat dinyatakan dengan word graph berikut:
CAU kucing ALI
makan
ALI
nasi
CAU ALI
12
Gambar 6 Contoh penggunaan relasi SUB 4. Relasi ALI (ALIKENESS)
Relasi ALI digunakan untuk menghubungkan sebuah type dengan token. Contoh: buah adalah type, maka dapat dinyatakan dengan word graph berikut:
Gambar 7 Contoh penggunaan relasi ALI 5. Relasi DIS (DISPARATENESS)
Dalam logika matematika, relasi DIS digunakan untuk menyatakan bahwa dua tokens tidak mempunyai satu elemen pun yang sama., sehingga dapat
diformulasikan sebagai berikut: A DIS B berarti bahwa A B = . Relasi ini juga dapat digunakan untuk menyatakan kata ”berbeda”, misalnya air berbeda dengan minyak yang dapat dinyatakan dengan graf berikut:
Gambar 8 Contoh penggunaan relasi DIS
Pada gambar di atas relasi DIS digambar tanpa menggunakan tanda panah, hal ini dikarenakan relasi DIS tersebut bersifat simetris yaitu A DIS B dapat juga dinyatakan dengan B DIS A.
6. Relasi ORD (ORDERING)
Relasi ORD menyatakan bahwa dua hal memiliki urutan tertentu, baik urutan waktu maupun urutan tempat. Contoh penggunaan relasi ORD, misalnya untuk menyatakan word graph ”dari permukaan sampai dasar”, yaitu:
Gambar 9 Contoh penggunaan relasi ORD 7. Relasi PAR (ATTRIBUTE)
Relasi PAR digunakan untuk menyatakan bahwa sesuatu mempunyai sifat sesuatu yang lain. Hal ini dapat dilihat pada contoh ”baju biru”. Kata
buah ALI
air ALI DIS ALI minyak
ALI dasar
permukaan ORD ALI
ALI kucing
13
biru merupakan warna dari baju, atau dengan kata lain biru adalah attribute dari baju. Frasa “baju biru” dapat dinyatakan dengan KG sebagai berikut:
Gambar 10 Contoh penggunaan relasi PAR 8. Relasi SKO (SKOLEM)
Dua buah tokens dalam teori KG dihubungkan dengan relasi SKO, jika token yang satu informasinya bergantung pada token yang lain. Menurut Van Den Berg (1993), relasi SKO dalam teori KG menyatakan informasi bergantung dan mampu menggambarkan kuantifikasi. Relasi ini digunakan dalam logika predikat yang memuat existential quantifiers maupun universal quantifiers. Perhatikan pernyataan x N y N x( 2 y) yang memuat universal quantifiers. Pada pernyataan tersebut pemilihan y bergantung pada x. Word
graph-nya dapat dinyatakan sebagai berikut:
Gambar 11 Contoh penggunaan relasi SKO 9. Ontologi F (FOCUS)
Ontologi F digunakan untuk menunjukkan fokus dari suatu graf. Penggunaan ontologi ini, misalnya untuk menyatakan word graph ”gempa merusak bangunan” yang dapat dinyatakan sebagai berikut :
Gambar 12 Contoh penggunaan ontologi F
Gambar di atas menunjukkan bahwa fokus dari ”gempa merusak bangunan” terletak pada token gempa.
Di sisi lain, empat frame relationships yang dimaksud adalah: 1) Focusing on a situation : FPAR
2) Negation of a situation : NEGPAR
biru ALI PAR ALI baju
SKO
x ALI ALI y
bangunan CAU
gempa ALI
merusak
ALI
CAU ALI
F
14
3) Possibility of a situation : POSPAR 4) Necessity of a situation : NECPAR
Jika suatu graf merepresentasikan suatu pernyataan, misal p: Hari ini hujan, yang dinyatakan dengan frame. Negasi dari p dinyatakan dengan graf yang sama dan diberi frame dengan relasi NEGPAR, sedangkan modal preposisi dinyatakan dengan graf yang sama dan diberi frame dengan relasi POSPAR atau NECPAR (Zhang, 2002). Untuk lebih jelasnya dapat digambar sebagai berikut :
Gambar 13 Contoh penggunaan 4 frame relationships
Gambar tersebut secara berurutan menunjukkan graf dari pernyataan bahwa hari ini hujan, tidak benar bahwa hari ini hujan, mungkin hari ini hujan, dan seharusnya hari ini hujan.
4.5 Ekspresi Semantik dengan KG
Teori KG membangun struktur arti. Arti dari kata dinyatakan dengan word graph, dan arti dari kalimat dinyatakan dengan sentence graph. Sentence graph
dapat diperoleh dengan cara menggabungkan beberapa word graph yang mengekspresikan arti dari kata dalam kalimat tersebut
Dalam bahasa Inggris dan bahasa Indonesia arti yang sama dapat dinyatakan dengan kalimat yang bervariasi, sehingga kalimat yang terlihat berbeda sebenarnya mempunyai arti yang identik. Kalimat yang bervariasi namun mempunyai arti yang identik tersebut dengan teori KG akan dinyatakan dengan sentence graph yang sama. Arti kata didapat dengan menghubungkan konsep
yang satu dengan konsep lainnya. Perhatikan contoh berikut yaitu kata ”pria lajang”. Arti kata ”pria lajang” dapat ditentukan dengan menghubungkan konsep pria dengan konsep tidak menikah. Konsep pria ditunjukkan dengan frame sebelah kiri pada Gambar 14, sedangkan konsep tidak menikah ditunjukkan dengan frame sebelah kanan pada gambar yang sama. Jika kedua struktur tersebut dihubungkan, diperoleh struktur baru yang menyatakan arti dari kata ”pria lajang”.
p NEG
p POS
p NEC
15
Berikut ini diberikan ekspresi semantik dari kata ”pria lajang” dengan KG. Kedua kata tersebut dapat dihubungkan dengan dua konsep yaitu konsep ”pria” dan konsep ”tidak menikah”. Arti dari ”pria lajang” menurut Zhang (2002), jika diekspesikan dengan struktur dari KG adalah sebagai berikut:
Gambar 14 Ekspresi Semantik ”pria lajang” dengan KG
Dari gambar tersebut dapat dilihat bahwa konsep ”menikah” ditunjukkan dengan dua token yang dihubungkan, ini menunjukkan bahwa menikah merupakan sesuatu yang melibatkan dua orang. Misalnya, Roy menikah dengan Marry. Jadi token yang satu menyatakan Roy dan token yang lain menyatakan Marry. Selain
itu juga digunakan relasi PAR yang menyatakan bahwa kata ”tidak menikah” merupakan attribute dari kata ”pria”.
5. Natural Language
Natural Language adalah suatu sistem simbol spesial yang digunakan untuk
mengekspresikan ide-ide manusia dalam membentuk informasi menjadi suatu pengetahuan (Wulandari, 2008).
Natural Language (bahasa alami yang digunakan manusia) adalah bahasa
yang paling mudah dan populer digunakan dalam memberikan atau menerima informasi. Memahami sesuatu adalah mengubah suatu bentuk representasi ke bentuk yang lain. Sebuah kalimat dalam natural language dapat dianalisis dari dua sudut pandang yaitu sintaks dan semantik. Sintaks (grammar atau tata bahasa) memperhatikan bentuk kalimat, namun dalam penelitian ini analisis lebih ditekankan pada aspek semantik.
Perhatikan contoh kalimat berikut dalam bahasa Inggris: ”He saw any air plane”. Secara sintaks (tata kalimat), kalimat tersebut tidak benar, karena ”any”
menikah NEG
16
biasanya digunakan dalam kalimat negatif. Sebagai catatan bahwa sintaks tidak mengatakan sesuatu tentang arti dari kalimat. Di sisi lain, semantik memperhatikan arti dari suatu kalimat. Bagimanapun semantik lebih penting daripada sintaks, karena itu orang akan lebih tertarik pada arti dari kalimat itu sendiri. Perhatikan kalimat ”Ia melihat gadis cantik dengan teleskop”. Kalimat tersebut menimbulkan ambiguitas, karena dapat diartikan berbeda oleh orang yang berbeda. Kalimat itu dapat diartikan seseorang sebagai berikut: ”Ia melihat seorang gadis cantik yang membawa teleskop” atau dapat juga diartikan ”Ia menggunakan alat teleskop untuk melihat seorang gadis cantik”. Kalimat tersebut menjadi jelas atau tidak ambigu bila diberikan informasi semantik (Zhang, 2002).
6. Grammar (Tata Bahasa)
Tata bahasa mempelajari komponen kalimat dan aturan komposisinya. Fokusnya adalah menentukan komponen mana yang merupakan subjek dan komponen mana yang merupakan objek dan seterusnya. Dari sudut pandang tata bahasa, subjek suatu kalimat menyatakan topik yang dibahas dalam kalimat itu. Pertanyaannya sekarang adalah komponen mana yang merupakan agen atau aktor (yang melakukan aksi) dan komponen mana yang menerima aksi tersebut.
Menurut Liu X. dan Hoede C. (2002), dalam teori KG yang strukturnya bahasa Inggris, ada 3 representasi untuk menyatakan jenis kata kerja (KK) yang berbeda dari suatu kalimat, yaitu:
1. Kata Kerja Transitif dapat direpresentasikan sebagai berikut:
Gambar 15 Word graph dari kata kerja transitif
2. Kata Kerja Intransitif dapat direpresentasikan sebagai berikut:
Gambar 16 Word graph dari kata kerja intransitif
CAU CAU
ALI KK transitif
CAU
17
3. Kata kerja bantu ” is, am, are” atau biasa disebut to be, yang padanannya dalam bahasa Indonesia ”ialah atau adalah” dapat dinyatakan dengan word graph berikut:
Gambar 17 Word graph dari kata ”ialah, adalah”
Kata ”ialah atau adalah” dalam bahasa Indonesia bukan merupakan kata kerja bantu tapi termasuk dalam kelompok kata penghubung.
7. Kalimat Pasif dan Representasinya dalam KG
Kalimat pasif adalah kalimat yang subjeknya (dari sudut pandang sintaks) berkedudukan sebagai penerima aksi atau dikenai pekerjaan (dari sudut pandang semantik). Perhatikan kalimat-kalimat berikut: ”Bola ditendang Roy” dan ”Roy menendang bola”. Subjek dari kalimat 1 adalah ”bola” sedangkan subjek dari kalimat 2 adalah ”Roy”. Dengan mengacu pada paper Hoede dan Nurdiati (2008) kedua kalimat tersebut direpresentasikan sebagai berikut:
Gambar 18 Sentence graph dari ”Roy menendang bola”
Dari gambar di atas, fokusnya terletak pada token paling kiri (subjek kalimat tersebut) yaitu Roy. Pada kalimat pasif ”Bola ditendang Roy”, fokus terletak pada token yang paling kanan (objek kalimat tersebut) yaitu bola. Kalimat tersebut
dapat direpresentasikan sebagai berikut:
Gambar 19 Sentence graph dari ”Bola ditendang Roy” EQU
tendang ALI
ALI CAU
EQU CAU
Roy bola
menendang ALI F
PAR
EQU bola
Roy
tendang ALI
ALI
CAU CAU
ditendang ALI
18
8. Chunking (Pemotongan Kalimat)
Chunk merupakan potongan kalimat atau potongan ucapan pada waktu
seseorang berbicara. Untuk menganalisis teks langkah pertama yang dilakukan adalah menentukan ”chunk”. Langkah selanjutnya, dari setiap chunk akan dibuat chunk graph yang merupakan representasi graf dari masing-masing potongan
kalimat. Chunk graph terdiri dari sebuah word graph, atau bisa juga terdiri dari gabungan beberapa word graph. Menurut Abney (1994), dalam mengucapkan sebuah kalimat, seseorang akan mengucapkannya dalam beberapa bagian atau potongan yang disebut dengan chunk. Hal ini ditandai dengan selaan napas atau pemberhentian ketika mengucapkannya.
Menurut Zhang (2002), dalam KG yang strukturnya bahasa Inggris ada lima chunk indicators, yaitu :
1. Pairs of comma’s or period sign yaitu tanda koma atau titik yang menandakan bahwa suatu kalimat terbagi menjadi beberapa bagian.
2. Auxiliary verb atau kata kerja bantu, misalnya: can, will, must, be
3. Reference word misalnya ”the”, ”that”.
4. Jump atau lompatan yang terjadi bila dua kata berurutan tidak dapat dihubungkan. Contohnya dalam bahasa Inggris kata ”the” selalu diikuti oleh kata benda seperti ”the cat”. Jika ada kata ”cat the”, maka kata ”the” tersebut pasti bukan milik dari cat karena pasti ada kata benda lain yang mengikuti kata ”the” tersebut. Ini berarti bahwa cat dan the harus diletakkan dalam chunk yang berbeda.
5. Preposition, yang biasanya sebagai penghubung antar bagian dalam kalimat. Contoh preposition dalam bahasa Inggris adalah in, on, with, at.
Hoede dan Nurdiati (2008) menambahkan sebuah chunk indicator, yaitu : logic word atau kata-kata dalam logika seperti kata ”dan” serta ”atau”. Jadi dalam KG
19
BAB III
METODE PENELITIAN
Pada bab ini dibahas beberapa tahapan yang dilakukan dalam penelitian ini :
1. Studi Literatur Dokumen Berbahasa Indonesia
Studi literatur ini adalah kegiatan yang dilakukan untuk mengumpulkan semua bahan pustaka yang relevan dan sesuai dengan topik atau tema yang dibahas, dalam hal ini tentang tsunami. Pada tahap ini akan dipilih beberapa kalimat atau teks yang memberikan informasi tentang tsunami dan kalimat-kalimat inilah yang nantinya akan dianalisis.
2. Pembuatan ChunkIndicator
Chunk indicator adalah petunjuk pada bagian mana suatu kalimat harus dipotong sehingga memudahkan proses pembentukan sentence graph. Dalam teori KG yang strukturnya bahasa Inggris ada 6 chunk indicators. Pada tahap ini penulis mengidentifikasi dari 6 chunk indicators tersebut mana yang sesuai untuk struktur bahasa Indonesia. Chunk indicators dalam bahasa Inggris yang sesuai untuk struktur bahasa Indonesia akan digunakan sebagai chunk indicators untuk dokumen berbahasa Indonesia.
3. Pembuatan Chunk Graph
Pada tahap ini akan dilakukan analisis setiap teks yang telah dipilih untuk dianalisis. Setiap kalimat tersebut akan dipotong-potong menjadi beberapa potongan kalimat (chunk). Setiap chunk akan ditunjukkan grafnya yang disebut dengan chunk graph. Chunk graph bisa berupa word graph bisa juga berupa gabungan beberapa word graph.
4. Menggabungkan Chunk Graph menjadi Sebuah Sentence Graph.
20
BAB IV
HASIL DAN PEMBAHASAN
Dari hasil studi literatur dokumen berbahasa Indonesia dengan tema tsunami, diperoleh sepuluh kalimat yang dipilih untuk dianalisis dalam penelitian ini. Alasan pemilihan kalimat tersebut karena sepuluh kalimat itu dipandang mampu memberikan gambaran tentang kejadian tsunami. Dalam penelitian ini kalimat-kalimat tersebut diperoleh secara manual. Untuk selanjutnya diharapkan kalimat seperti itu nantinya dapat diperoleh secara otomatis dengan bantuan komputer. Dengan kata lain, begitu dimasukkan dokumen berbahasa Indonesia sebagai input ke dalam komputer, maka komputer akan menghasilkan output berupa text graph yang menjadi intisari dokumen yang dipelajari. Sepuluh kalimat yang dipilih untuk dianalisis tersebut antara lain :
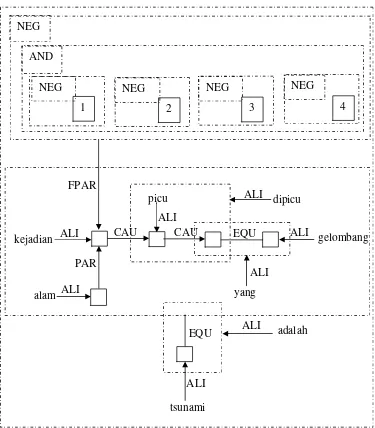
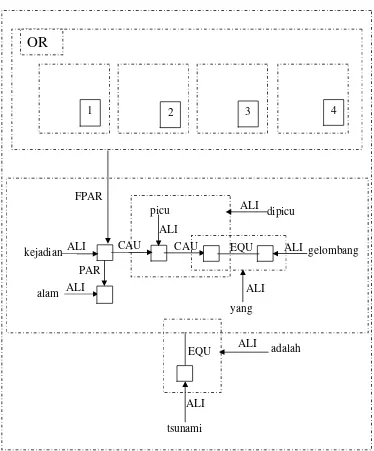
1. Tsunami adalah gelombang yang dipicu oleh kejadian alam.
2. Kejadian alam tersebut gempa di lepas pantai, letusan gunung di dekat permukaan laut, pergeseran lapisan di bawah laut atau hantaman meteor yang menimpa laut.
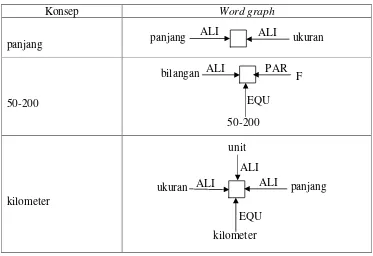
3. Panjang gelombang tsunami 50 – 200 kilometer.
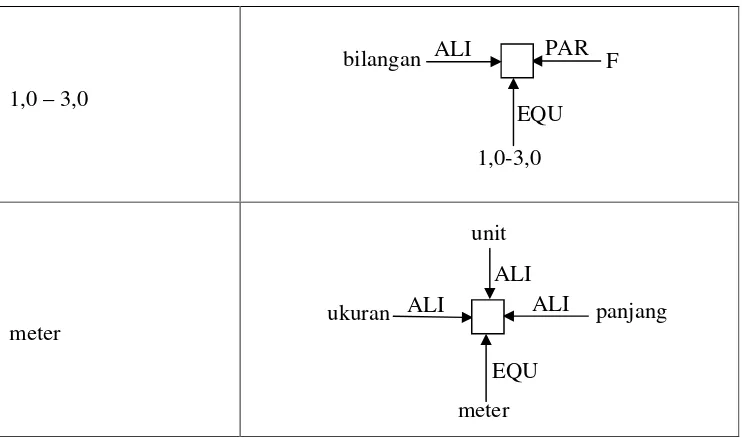
4. Tinggi gelombang tsunami di pusat gempa 1,0 - 3,0 meter. 5. Panjang gelombang tsunami mengecil di daerah pantai. 6. Tinggi gelombang tsunami membesar di daerah pantai.
7. Gelombang tsunami berbeda dengan gelombang yang dibangkitkan oleh angin. 8. Gelombang yang dibangkitkan angin menggerakkan permukaan air laut. 9. Gelombang tsunami menggerakkan permukaan air laut sampai dasar. 10. Kapal yang lewat di atas pusat gempa tidak merasakan guncangan.
Chunk Indicators
Chunk indicators adalah kriteria yang digunakan untuk menentukan pada
21
menyatakannya dalam bentuk word graph. Chunk indicators yang digunakan untuk menganalisis teks berbahasa Indonesia dengan teori KG antara lain:
Indikator 1: koma atau titik
Koma atau titik menandakan bahwa suatu kalimat terbagi menjadi beberapa bagian yang disebut chunk. Misalnya pada kalimat ”Tsunami, Nangroe Aceh Darussalam, terjadi pada 26 Desember 2004, menewaskan ratusan ribu jiwa”. Kalimat di atas terdiri dari empat chunks yaitu [Tsunami], [Nangroe Aceh Darussalam], [terjadi pada 26 Desember 2004], dan [menewaskan ratusan ribu jiwa].
Indikator 2: Kata penunjuk atau kata penghubung
Kata penunjuk atau kata penghubung seperti ”yang, tersebut, adalah” dapat digunakan sebagai chunk indicator.
Indikator 3: Kata kerja bantu
Kata kerja bantu dalam hal ini, misalnya kata dapat, harus, boleh, bisa, sanggup dan sebagainya. Kata kerja bantu tersebut menandakan sebuah chunk indicator.
Indikator 4: Kata depan (preposisi)
Kata depan sering digunakan dalam natural language (bahasa alami), namun seringkali dihubungkan dengan kata yang lain. Kata depan tersebut misalnya : di, ke, dari, oleh, lepas, bawah, pada dan seterusnya. Kata depan juga mengisyaratkan sebuah chunk.
Indikator 5: Lompatan (jump)
Jump atau lompatan terjadi jika dua buah kata berurutan tidak dapat diletakkan
dalam satu chunk. Contoh pada kalimat ”Adik makan setelah pulang sekolah”, kata makan dan setelah tidak mungkin diletakkan dalam satu chunk, atau terjadi lompatan pada kedua kata tersebut, sehingga harus diletakkan pada chunk yang berbeda.
Indikator 6: Kata-kata logika (logic word)
22
Sebelum dilakukan analisis terhadap kalimat-kalimat yang telah dipilih, terlebih dahulu akan diberikan prosedur pemotongan (chunking), yang merupakan urutan proses pemotongan kalimat. Pemotongan kalimat tersebut merupakan suatu proses iterasi. Prosedur yang dimaksud adalah :
1. Pertama akan dilihat apakah kalimat yang dianalisis memuat chunk indicator 1 yaitu koma atau titik. Chunk indicator 1 menduduki urutan pertama untuk diidentifikasi pada proses analisis setiap kalimat.
2. Langkah selanjutnya diidentifikasi apakah kalimat tersebut memuat kata-kata logika seperti ”dan”, ”atau”. Chunk indicator 6 menduduki urutan kedua untuk diidentifikasi.
3. Urutan selanjutnya akan diidentifikasi apakah kalimat tersebut memuat kata penunjuk atau penghubung. Chunk indicator 2 menduduki urutan ketiga untuk diidentifikasi pada proses analisis tersebut.
4. Langkah berikutnya diidentifikasi apakah kalimat tersebut memuat kata depan atau preposisi. Chunk indicator 4 menduduki urutan keempat untuk diidentifikasi pada proses analisis setiap kalimat.
5. Selanjutnya diidentifikasi apakah kalimat tersebut memuat kata kerja bantu seperti: dapat, harus, bisa, sanggup, akan, dan seterusnya. Chunk indicator 3 menduduki urutan kelima untuk diidentifikasi pada proses analisis setiap kalimat.
6. Urutan terakhir akan diidentifikasi apakah pada kalimat tersebut terjadi lompatan atau jump, yaitu apabila terdapat dua kata berurutan yang tidak dapat diletakkan dalam satu chunk.
Sekarang akan dimulai untuk menganalisis teks yang terdiri dari kalimat 1 dan kalimat 2. Kedua kalimat ini menjelaskan tentang definisi konsep ”Tsunami”. Mula-mula kalimat-kalimat tersebut akan dibagi dalam beberapa chunk (potongan kalimat). Berdasarkan prosedur yang telah ditentukan, chunk yang diperoleh dari kedua kalimat tersebut adalah :
1) |Tsunami5| adalah2 | gelombang5 | yang2 | dipicu5 | oleh 4| kejadian alam1 |. 2) |Kejadian alam5 |tersebut2 |gempa di lepas pantai1 | letusan gunung di dekat
23
Kemudian dari kalimat kedua, chunk yang diperoleh berdasarkan indicator 1 yaitu koma dan titik, akan dibagi lagi menjadi beberapa subchunk dengan melihat chunk indicator yang telah ditentukan. Hasil pemotongan kalimat kedua diberikan
[image:47.612.137.505.287.597.2]sebagai berikut:
|Kejadian alam5 | tersebut2 | gempa5 | di4 | lepas4 | pantai5 | letusan gunung5 | di4 | dekat4 | permukaan laut5 | pergeseran lapisan5 | di4 | bawah4 | laut5 | hantaman meteor5 | yang2 | menimpa laut1 |.
Kalimat 1 dan kalimat 2 memuat konsep yang berupa kata benda yang dapat dilihat dalam kamus berikut, dan masing-masing konsep akan dibuat word graph-nya yang megraph-nyatakan inner structure sebuah token ” ”.
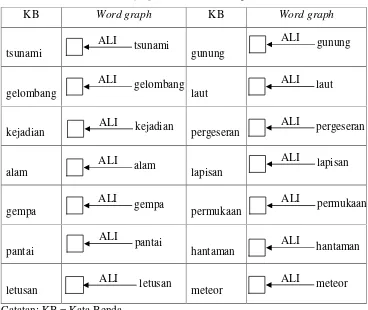
Tabel 1 Kamus word graph dari kata benda pada kalimat 1 dan 2
KB Word graph KB Word graph
tsunami gunung
gelombang
laut
kejadian pergeseran
alam lapisan
gempa permukaan
pantai hantaman
letusan meteor
Catatan: KB = Kata Benda
Gabungan dua kata benda N1 dan N2 dapat direpresentasikan dengan word graph
sebagai berikut:
Gambar 20 Word graph dari frasa kata benda ALI tsunami
gelombang ALI
ALI pergeseran ALI laut ALI gunung
ALI gempa kejadian ALI
ALI alam
ALI hantaman ALI permukaan ALI lapisan
ALI pantai
ALI letusan
PAR ALI
ALI
N1 N2
24
Pada kalimat 2 terdapat gabungan dua kata benda, namun sebelum ditunjukkan word graph dari gabungan kata benda, akan diperkenalkan terlebih dahulu
[image:48.612.136.504.187.609.2]ontologi ”F” untuk menyatakan fokus dari word graph tersebut. Gabungan dua kata benda atau frasa kata benda serta word graph-nya, yang terdapat pada kalimat 2 dapat dilihat pada kamus berikut :
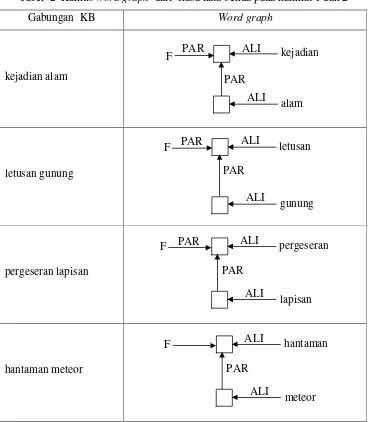
Tabel 2 Kamus word graph dari frasa kata benda pada kalimat 1 dan 2
Gabungan KB Word graph
kejadian alam
letusan gunung
pergeseran lapisan
hantaman meteor
Dari empat frasa kata benda tersebut terlihat bahwa fokusnya terletak pada token yang menyatakan kejadian, letusan, pergeseran, dan hantaman, sedangkan
kata alam, gunung, lapisan, dan meteor berfungsi untuk menjelaskan kata yang menjadi fokus tersebut sehingga digunakan relasi PAR.
PAR
ALI kejadian
alam ALI
F PAR
PAR ALI
gunung letusan
ALI F PAR
pergeseran
lapisan PAR
ALI
ALI F PAR
hantaman
meteor PAR
ALI
25
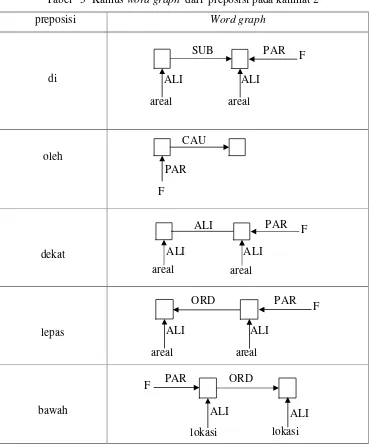
[image:49.612.137.508.185.631.2]Selain kata benda, kalimat 1 dan 2 juga memuat preposisi (kata depan) yang berfungsi untuk melekatkan suatu konsep. Preposisi yang terdapat dalam bahasa Indonesia misalnya: di, ke, dari, oleh, untuk, lepas dan seterusnya. Preposisi (kata depan) yang terdapat pada kalimat 2 beserta word graph-nya dapat dilihat pada kamus word graph berikut ini :
Tabel 3 Kamus word graph dari preposisi pada kalimat 2
preposisi Word graph
di
oleh
dekat
lepas
bawah
Dari tabel di atas, dapat dilihat bahwa word graph untuk kata ”lepas” dan ”bawah” keduanya menggunakan relasi ORD. Perbedaannya terletak pada fokus masing-masing. Kata ”lepas” fokusnya terletak pada token paling kanan sehingga
F
CAU
PAR
PAR F
areal areal SUB
ALI ALI
ALI ALI
PAR F
areal areal ALI
ALI ALI
PAR F
areal areal
ORD
lokasi
ORD
ALI
lokasi ALI PAR
26
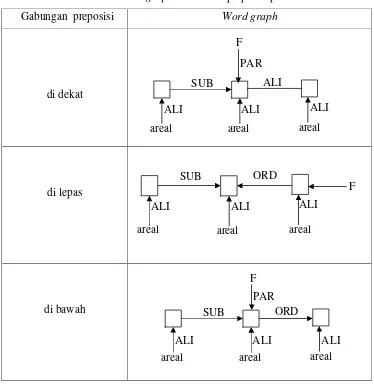
[image:50.612.131.505.227.611.2]arah panahnya ke kiri, sedangkan kata ”bawah” fokusnya terletak pada token paling kiri dan arah panahnya ke kanan. Untuk kalimat kedua juga terdapat gabungan dua preposisi. Dalam bahasa Indonesia, dua preposisi atau kata depan yang digabungkan tidak lagi membentuk preposisi, tetapi membentuk frasa preposisi. Frasa preposisi ini dapat berfungsi sebagai keterangan tempat atau keterangan waktu. Gabungan preposisi atau frasa preposisi tersebut, beserta word graph-nya dapat dilihat pada kamus berikut :
Tabel 4 Kamus word graph dari frasa preposisi pada kalimat 2
Gabungan preposisi Word graph
di dekat
di lepas
di bawah
Kalimat 2 memuat kata penunjuk ”yang”, dan word graph-nya dapat dinyatakan:
Gambar 21 Word graph untuk kata ”yang” EQU
ALI ALI ALI
ORD
areal areal SUB
areal
F PAR
ALI ALI
ALI
areal areal SUB
areal ALI F
ALI ALI ALI
ORD
areal areal SUB
areal F
27
Kalimat pertama memuat kata kerja ”dipicu” dan kalimat kedua memuat kata kerja ”menimpa”. Kedua kata kerja tersebut dapat dinyatakan dengan word graph berikut:
Gambar 22 Word graph untuk kata kerja ”dipicu”
Gambar di atas menunjukkan bahwa fokus terletak pada token paling kanan yaitu objek atau yang dikenai pekerjaan.
Gambar 23 Word graph untuk kata kerja ”menimpa”
Gambar di atas menunjukkan bahwa fokus untuk kata kerja ”menimpa” terletak pada token yang paling kiri yaitu subjek atau yang melakukan pekerjaan. Langkah selanjutnya, word graph dari masing-masing konsep dihubungkan dengan word graph dari konsep yang lain. Dalam kalimat kedua ada 4 kejadian, yaitu gempa di lepas pantai, letusan gunung di dekat permukaan laut, pergeseran lapisan di bawah laut dan hantaman meteor yang menimpa laut. Masing-masing kejadian dapat dinyatakan dengan chunk graph berikut:
1. Gempa di lepas pantai
Gempa di lepas pantai dapat dinyatakan dengan graf berikut: picu
ALI
CAU CAU
dipicu ALI
F PAR
menimpa ALI
CAU CAU
ALI timpa F
PAR
28
Gambar 24 Chunk graph dari ”gempa di lepas pantai”
Gambar 24 menunjukkan bahwa fokus terletak pada token gempa, sedangkan di lepas pantai merupakan attribute dari gempa maka digunakan relasi PAR.
2. Letusan gunung di dekat permukaan laut
[image:52.612.131.505.385.594.2]Letusan gunung di dekat permukaan laut dapat dinyatakan berikut ini:
Gambar 25 Chunk graph dari ”letusan gunung di dekat permukaan laut”
Gambar di atas menunjukkan bahwa fokus terletak pada token ”letusan”, di dekat permukaan laut dan gunung merupakan attribute dari letusan maka digunakan relasi PAR.
ALI
ALI letusan
gunung
SUB ALI
areal
ALI ALI
ALI
permukaan laut PAR PAR
ALI ALI
areal areal
di dekat
ALI ALI
PAR
PAR F
PAR
areal areal areal
SUB ORD ALI
PAR A