PENINGKATAN PEROLEHAN METADATA MELALUI SISTEM TERDISTRIBUSI
TESIS
Oleh
DANI GUNAWAN 087034027/MTE
FAKULTAS TEKNIK
UNIVERSITAS SUMATERA UTARA MEDAN
PENINGKATAN PEROLEHAN METADATA MELALUI SISTEM TERDISTRIBUSI
TESIS
Untuk Memperoleh Gelar Magister Teknik dalam Program Studi Magister Teknik Elektro pada Fakultas Teknik Universitas Sumatera Utara
Oleh:
DANI GUNAWAN 087034027/MTE
FAKULTAS TEKNIK
Telah Diuji pada
Tanggal: 19 Agustus 2011
PANITIA PENGUJI TESIS
Ketua : Prof. Dr. Ir. Usman Baafai
Anggota : 1. Dr. Benny B. Nasution, Dipl.Ing, M.Eng 2. Amer Sharif, S.Si, M.Kom
3. Prof. Dr. Tulus, M.Si 4. Ori Novanda, ST, MT
ABSTRAK
Peningkatan jumlah dokumen digital yang pesat telah menyebabkan para pengguna Internet harus tetap up-to-date dengan dokumen terbaru. Penyedia dokumen digital saat ini menyimpan informasi yang terkandung pada dokumen tersebut seperti judul, nama penulis, tahun penerbitan dan lain-lain menggunakan metadata. Berbagai jenis metadata dapat digunakan untuk menyimpan informasi tersebut. Penyeragaman penggunaan metadata dengan mengikuti kaidah OAI-PMH (Open Archives Initiative Protocol for Metadata Harvesting) dapat mempermudah proses pembacaan data digital oleh mesin sekaligus mengatasi masalah perbedaan penggunaan jenis metadata.
Hal utama yang ingin dicapai adalah menghasilkan pengumpul metadata OAI-PMH terdistribusi dan mengetahui peningkatan perolehan metadatanya terhadap pengumpul metadata tunggal. Pengumpul metadata terdistribusi terdiri dari satu buah komputer sebagai koordinator dan empat buah komputer sebagai pengumpul yang terhubung di dalam satu jaringan LAN (Local Area Network). Aplikasi ini dibuat menggunakan bahasa pemrograman java. Protokol komunikasi antara pengumpul dan koordinator menggunakan RMI (Remote Method Invocation). Metadata dikumpulkan dari 1460 repositori yang terdaftar di www.openarchives.org selama 10 jam.
Hasil rancangan pengumpul metadata terdistribusi telah memenuhi beberapa aspek untuk sebuah sistem agar dikatakan terdistribusi yaitu pengguna dan sumber daya, transparansi, keterbukaan dan skalabilitas. Perolehan metadata dapat ditingkatkan dengan melakukan penambahan proses paralel.
ABSTRACT
The rapid increase of the number of digital documents has caused the Internet users to be always up to date with the new documents. The providers of digital documents nowadays, who store information in the documents such as the titles, names of authors, years of publication, etc., use metadata. Various metadata can be used to store the information. The uniformity of using the metadata by following OAI-PMH (Open Archives Initiative Protocol for Metadata Harvesting) principle can simplify the process of reading the digital data by machine and automatically handle the problem of different way of using the type of metadata.
The main objective which was going to achieved was to produce the collection of distributed OAI-PMH metadata and to know the increase of acquisition of its metadata on the collection of single metadata. The collection of distributed metadata consisted of a computer as the coordinator and four computers as the collectors that were connected in a LAN (Local Area Network). This application was made by using java programming language. The communicating protocol between the collectors and the coordinators used RMI (Remote Method Invocation). Metadata were collected from 1460 repositories which were registered in www.openarchives.org within 10 hours.
The results of the design of distributed metadata collection have fulfilled some aspects for a system so that it can be said distributed; that is, the user and resources, transparency, openness, and scalability. The acquisition of metadata can be increased by doing the additional parallel process.
KATA PENGANTAR
Puji dan syukur kehadirat Allah SWT, karena berkat rahmat dan karunia-Nya
sehingga penulis dapat menyelesaikan tesis yang berjudul: “Peningkatan Perolehan
Metadata Melalui Sistem Terdistribusi”. Salawat beriring salam tak lupa penulis
persembahkan kepada junjungan umat Islam, Nabi Muhammad SAW.
Pada kesempatan ini penulis mengucapkan terima kasih kepada Bapak Prof. Dr. Ir. Usman Baafai, selaku ketua komisi pembimbing, Bapak Dr. Benny B. Nasution, Dipl.Ing, M.Eng dan Bapak Amer Sharif, S.Si, M.Kom selaku anggota komisi pembimbing yang dengan penuh sabar, arif dan bijaksana memberikan bimbingan, petunjuk dan arahan serta dorongan kepada penulis. Tak lupa penulis mengucapkan terima kasih kepada Bapak Prof. Dr. Tulus, M.Si, Bapak Prof. Dr. Opim Salim Sitompul, M.Si dan Bapak Ori Novanda, ST, MT selaku Pembanding utama yang telah memberikan kritik dan masukan terhadap tesis ini.
Penulis menyadari masih ada kekurangan dalam tulisan ini, namun penulis mengharapkan tulisan ini dapat memenuhi persyaratan yang diperlukan untuk suatu tesis dalam Program Studi Magister Teknik Elektro Fakultas Teknik Universitas Sumatera Utara. Akhir kata penulis mengucapkan banyak terima kasih dan semoga tesis ini dapat berguna bagi dunia pendidikan pada khususnya dan bagi masyarakat pada umumnya.
Medan, Agustus 2011 Hormat saya,
DAFTAR RIWAYAT HIDUP
Saya yang bertanda tangan di bawah ini,
Nama : Dani Gunawan
Tempat/Tanggal Lahir : Dumai, 15 September 1982 Jenis Kelamin : Laki-laki
Agama : Islam
Bangsa : Indonesia
Alamat : Jl. Karya Ujung Gg. Keluarga 30 Helvetia Timur, Medan 20124
Menerangkan dengan sesungguhnya, bahwa:
PENDIDIKAN
1. Tamatan Teknik Elektro USU Tahun 2006 2. Tamatan SMA Negeri 3 Medan Tahun 2000 3. Tamatan SMP Swasta YKPP Dumai Tahun 1997 4. Tamatan SD Swasta YKPP Dumai Tahun 1994
PEKERJAAN
Demikian riwayat hidup ini saya buat dengan sebenarnya untuk dapat dipergunakan sebagaimana mestinya.
Medan, 19 Agustus 2011 Tertanda,
DAFTAR ISI
Halaman
ABSTRAK ... i
ABSTRACT ... ii
KATA PENGANTAR ... iii
DAFTAR RIWAYAT HIDUP ... v
DAFTAR ISI ... vii
DAFTAR TABEL ... x
DAFTAR GAMBAR ... xi
BAB 1 PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan masalah ... 3
1.3 Tujuan Penelitian ... 4
1.4 Batasan Masalah ... 4
1.5 Metode Penelitian ... 4
1.6 Sistematika Pembahasan ... 5
BAB 2 TINJAUAN PUSTAKA ... 6
2.2 Format Metadata ... 9
2.3 OAI-PMH ... 10
2.4 Sistem Pengumpul Metadata Terdistribusi ... 16
2.5 Sinkronisasi Proses Paralel ... 24
BAB 3 METODE PENELITIAN... 26
3.1 Sistem Pengumpul Metadata Tunggal ... 27
3.2 Sistem Pengumpul Metadata Terdistribusi ... 30
3.3 Prinsip Kerja Pengumpulan Metadata ... 34
3.4 Daftar Antrean ... 39
3.5 Pengunduhan Metadata ... 42
3.6 Penyimpanan Metadata ... 46
3.7 Implementasi Perancangan Pengumpul Metadata Terdistribusi ... 48
3.8 Perhitungan Peningkatan Perolehan Metadata... 62
3.9 Sumber Data... 63
3.10 Instrumen Penelitian ... 63
BAB 4 HASIL DAN ANALISIS ... 64
4.7 Pengumpul Metadata Tunggal ... 64
4.8 Pengumpul Metadata Terdistribusi ... 66
4.9 Pengunduhan Metadata ... 69
BAB 5 KESIMPULAN DAN SARAN ... 75
5.1 Kesimpulan ... 75
5.2 Saran ... 75
DAFTAR TABEL
Nomor Judul Halaman
1.1 Penelitian tentang Pengumpul Metadata Dan Sistem Terdistribusi ... 3
2.1 Pemetaan Metadata Antara MARC dan Dublin Core unqualified ... 7
2.2 Penggunaan Kode 20X – 24X pada Metadata MARC ... 8
3.1 Kode Kesalahan Server ... 45
3.2 Spesifikasi Tabel Daftar Antrean ... 51
3.3 Status Pengunduhan Repositori ... 52
4.1 Perolehan Metadata Sistem Pengumpul Tunggal ... 65
4.2 Perolehan Metadata Pengumpul Terdistribusi ... 68
4.3 Rata-Rata Penggunaan Memori Pengumpul Terdistribusi ... 72
DAFTAR GAMBAR
Nomor Judul Halaman
2.1 Diagram Arsitektur Penyedia Data... 14
2.2 Ilustrasi Mekanisme resumptionToken ... 14
2.3 Permasalahan pada Implementasi resumptionToken ... 16
2.4 Diagram Sekuensial untuk Remote Procedure Call (RPC) ... 18
2.5 Stub dan Skeleton ... 20
2.6 Ilustrasi Implementasi RMI ... 21
2.7 Pemanggilan Referensi Server oleh Klien... 22
3.1 Hasil Rancangan Sistem Pengumpulan Metadata Terdistribusi ... 26
3.2 Blok Diagram Rancangan Pengumpul Metadata Tunggal ... 27
3.3 Diagram Arsitektur Pengumpul Metadata Tunggal ... 28
3.4 Diagram Use Case Pengumpul Metadata Tunggal ... 29
3.5 Blok Diagram Rancangan Pengumpul Metadata Terdistribusi ... 30
3.6 Diagram Arsitektur Pengumpul Metadata Terdistribusi ... 31
3.7 Diagram Use Case Sistem Pengumpul Metadata Terdistribusi ... 33
3.8 Diagram Aktivitas Sistem Pengumpulan Metadata Tunggal ... 35
3.9 Diagram Aktivitas Sistem Pengumpulan Metadata Terdistribusi ... 37
3.10 Antrean pada Sistem Pengumpul Metadata Tunggal ... 40
ABSTRAK
Peningkatan jumlah dokumen digital yang pesat telah menyebabkan para pengguna Internet harus tetap up-to-date dengan dokumen terbaru. Penyedia dokumen digital saat ini menyimpan informasi yang terkandung pada dokumen tersebut seperti judul, nama penulis, tahun penerbitan dan lain-lain menggunakan metadata. Berbagai jenis metadata dapat digunakan untuk menyimpan informasi tersebut. Penyeragaman penggunaan metadata dengan mengikuti kaidah OAI-PMH (Open Archives Initiative Protocol for Metadata Harvesting) dapat mempermudah proses pembacaan data digital oleh mesin sekaligus mengatasi masalah perbedaan penggunaan jenis metadata.
Hal utama yang ingin dicapai adalah menghasilkan pengumpul metadata OAI-PMH terdistribusi dan mengetahui peningkatan perolehan metadatanya terhadap pengumpul metadata tunggal. Pengumpul metadata terdistribusi terdiri dari satu buah komputer sebagai koordinator dan empat buah komputer sebagai pengumpul yang terhubung di dalam satu jaringan LAN (Local Area Network). Aplikasi ini dibuat menggunakan bahasa pemrograman java. Protokol komunikasi antara pengumpul dan koordinator menggunakan RMI (Remote Method Invocation). Metadata dikumpulkan dari 1460 repositori yang terdaftar di www.openarchives.org selama 10 jam.
Hasil rancangan pengumpul metadata terdistribusi telah memenuhi beberapa aspek untuk sebuah sistem agar dikatakan terdistribusi yaitu pengguna dan sumber daya, transparansi, keterbukaan dan skalabilitas. Perolehan metadata dapat ditingkatkan dengan melakukan penambahan proses paralel.
ABSTRACT
The rapid increase of the number of digital documents has caused the Internet users to be always up to date with the new documents. The providers of digital documents nowadays, who store information in the documents such as the titles, names of authors, years of publication, etc., use metadata. Various metadata can be used to store the information. The uniformity of using the metadata by following OAI-PMH (Open Archives Initiative Protocol for Metadata Harvesting) principle can simplify the process of reading the digital data by machine and automatically handle the problem of different way of using the type of metadata.
The main objective which was going to achieved was to produce the collection of distributed OAI-PMH metadata and to know the increase of acquisition of its metadata on the collection of single metadata. The collection of distributed metadata consisted of a computer as the coordinator and four computers as the collectors that were connected in a LAN (Local Area Network). This application was made by using java programming language. The communicating protocol between the collectors and the coordinators used RMI (Remote Method Invocation). Metadata were collected from 1460 repositories which were registered in www.openarchives.org within 10 hours.
The results of the design of distributed metadata collection have fulfilled some aspects for a system so that it can be said distributed; that is, the user and resources, transparency, openness, and scalability. The acquisition of metadata can be increased by doing the additional parallel process.
BAB 1 PENDAHULUAN
1.1 Latar Belakang
Peningkatan jumlah dokumen digital yang pesat telah menyebabkan para pengguna Internet harus tetap up-to-date dengan dokumen terbaru. Karena jumlah penyedia dokumen digital yang sangat banyak, maka tidak mungkin seorang pengguna mengingat alamat masing-masing penyedia dokumen digital. Salah satu solusinya adalah dengan membangun sebuah daftar indeks dokumen digital. Pada prinsipnya hampir mirip dengan pencari web (web search engine) yang mengindeks alamat URL (Uniform Resource Locator) [1].
Penyedia dokumen digital mempunyai sejumlah informasi baik hanya berupa informasi nama penulis, judul dan lain-lain yang berkaitan dengan dokumen tersebut. Masing-masing halaman mempunyai informasi dan ukuran yang berbeda. Seiring dengan berkembangnya jumlah web yang ada, maka informasi yang terkandung di dalamnya mempunyai jumlah yang sangat banyak [2]. Informasi tersebut tersimpan dalam berbagai macam bentuk salah satunya adalah metadata.
digital oleh mesin sekaligus mengatasi masalah perbedaan penggunaan jenis metadata
sesuai dengan rekomendasi Shuming Li pada penelitiannya yang berjudul “Research
of Metadata Based Digital Education Resource Sharing” [4]. OAI-PMH telah diterapkan pada institusi yang menggunakan perangkat lunak DSpace (www.dspace.org) dan ePrints (www.eprints.org). Kedua perangkat lunak ini digunakan sebagai repositori digital. Untuk menangani jumlah metadata yang sedemikian banyak tersebut, timbul suatu pemikiran bagaimana merancang sistem terdistribusi untuk menangani beban kerja yang tinggi sekaligus jumlah data yang besar.
Seperti yang tertera pada Tabel 1.1, telah dilakukan penelitian oleh Iqbal
Syamsu yang berjudul “Perancangan Penjelajah Web (Crawler) Terdistribusi”
dengan objek penelitiannya adalah dokumen web [5]. Pada penelitian tersebut dilakukan penelusuran web dan pengumpulan dokumen-dokumen di dalamnya dengan tujuan merancang suatu crawler terdistribusi untuk search engine. Merujuk
pada penelitian Michael L. Nelson yang berjudul “Efficient, Automatic Web Resource
Tabel 1.1 Penelitian tentang Pengumpul Metadata dan Sistem Terdistribusi
Penulis Judul Penelitian Pembahasan
Penelitian yang dilakukan Tahun Iqbal Syamsu Perancangan Penjelajah Web (Crawler) Terdistribusi Penjelajahan dokumen web Pengumpulan metadata 2008 Shuming Li, dkk Research of Metadata Based Digital Educational Resource Sharing Rekomendasi penggunaan metadata OAI-PMH Menggunakan metadata OAI-PMH 2008 Michael L. Nelson, dkk Efficient, Automatic Web Resource Harvesting Pengumpulan metadata menggunakan modul Apache Metadata OAI-PMH 2006
Pada penelitian Michael L. Nelson, dihasilkan sebuah pengumpul metadata OAI-PMH yang diintegrasikan dengan web server Apache dan merupakan sistem tunggal. Sedangkan aplikasi pengumpul pada penelitian ini merupakan sebuah aplikasi yang berdiri sendiri serta merupakan sistem terdistribusi.
1.2 Rumusan masalah
1.3 Tujuan Penelitian
Hal utama yang ingin dicapai pada penelitian ini adalah menghasilkan pengumpul metadata OAI-PMH terdistribusi dan mengetahui peningkatan perolehan metadatanya terhadap pengumpul metadata tunggal.
1.4 Batasan Masalah
Masalah yang dibahas pada tulisan ini dibatasi agar dapat fokus pada hal-hal yang meliputi:
a. Perancangan dasar sistem pengumpul metadata
b. Model komunikasi yang digunakan untuk menerapkan sistem terdistribusi adalah RMI
c. Analisis unjuk kerja sistem pengumpul metadata terdistribusi terhadap sistem pengumpul metadata tunggal
d. Kinerja sistem pengumpul metadata diukur dari perolehan metadata selama 10 jam
1.5 Metode Penelitian
Adapun metode penelitian yang dilakukan dalam penelitian ini meliputi: a. Studi literatur dari buku dan referensi, untuk menjadikan landasan dan acuan
bagi penelitian ini
c. Melakukan pengujian pengumpul metadata serta analisis dari data yang diperoleh untuk mendapatkan kesimpulan
1.6 Sistematika Pembahasan
Pada tulisan ini disusun sebanyak lima bab yang terdiri dari:
BAB 1 : PENDAHULUAN (berisi kerangka penelitian yaitu latar belakang, rumusan masalah, tujuan penelitian, batasan masalah, dan metode yang ditempuh).
BAB 2 : TINJAUAN PUSTAKA (memuat berbagai teori metadata yang dijadikan landasan dalam melakukan penulisan dan perancangan pengumpul metadata).
BAB 3 : METODE PENELITIAN (berisi rancangan dalam membangun pengumpul metadata yang terdistribusi).
BAB 4 : HASIL DAN ANALISIS (berisi analisis dari hasil pengujian yang dilakukan terhadap sistem pengumpul metadata terdistribusi yang dirancang).
BAB 2
TINJAUAN PUSTAKA
2.1 Metadata
Metadata adalah data dari objek yang mendeskripsikan sumber informasi atau data. Metadata berasal dari jenis media apa saja dan mempunyai bermacam-macam bentuk sesuai dengan tipe data dan konteks penggunaan [7]. Tujuannya yaitu mengenali dan mengevaluasi sumber daya, melacak perubahan pada proses sumber daya aplikasi, merealisasikan manajemen yang sederhana dan efisien pada jaringan data skala besar dan merealisasikan penemuan yang efisien, pencarian, integrasi dan manajemen sumber daya informasi [8].
Metadata dapat berfungsi sebagai identifikasi sumber daya yang diperlukan maupun menjadi katalog yang menjelaskan detail dan spesifikasi suatu data, serta sebagai arsip untuk disimpan dalam jangka waktu yang lama [4]. Berdasarkan pengalaman kerja, menggunakan metadata dapat membantu pembacaan dan pemrosesan data digital oleh mesin menjadi lebih mudah. Ada beberapa standar metadata yang dapat digunakan seperti DC (Dublin Core), MARC ( Machine-Readable Cataloging), IEEE LOM (Institute of Electrical and Electronics Engineering Learning Object Model) dan lain-lain [9] [10].
Dublin Core memiliki dua jenis tingkatan yaitu unqualified dan qualified. Dublin Core unqualified memiliki lima belas elemen sedangkan Dublin Core qualified termasuk tiga elemen tambahan yaitu Audience, Provenance, dan RightHolder yang disebut juga qualifier untuk menyempurnakan semantik elemen yang mungkin berguna pada penelusuran sumber daya. Semantik Dublin Core telah didirikan oleh sebuah grup lintas disiplin yang mencakup ilmu perpustakaan, ilmu komputer, komunitas museum dan bidang lainnya yang berhubungan [11].
Tabel 2.1 Pemetaan Metadata antara MARC dan Dublin Core Unqualified
MARC Dublin Core
100, 110, 111, 700, 710, 711 Contributor 720
651, 662 Coverage
751, 752
Creator
008/07-10 Date
260$c$g
500-599, except 506, 530, 540, 546 Description
340 Format
856$q
020$a, 022$a, 024$a Identifier 856$u
008/35-37 Language
041$a$b$d$e$f$g$h$j 546
260$a$b Publisher
530, 760-787$o$t Relation
506, 540 Rights
534$t Source
786$o$t
050, 060, 080, 082 Subject 600, 610, 611, 630, 650, 653
245, 246 Title
Beragam standar metadata yang dapat digunakan akan menjadi masalah pada saat integrasi akan dilakukan. Pada implementasinya, harus digunakan satu jenis metadata yang dapat menyatukan seluruh metadata yang akan digunakan sebagai format standar untuk pengumpulan data. Pemetaan metadata dapat digunakan untuk transformasi elemen yang terdapat pada satu jenis metadata ke jenis metadata lainnya. Contoh pemetaan metadata antara MARC dan Dublin Core unqualified dijabarkan pada Tabel 2.1.
Tabel 2.2 Penggunaan Kode 20X – 24X pada Metadata MARC [12]
Kode Keterangan
210 Abbreviation Title = singkatan judul
222 Key Title = judul unik tertentu yang digunakan untuk serial
240 Uniform Title = judul utama yang muncul untuk dokumen-dokumen yang memiliki judul ganda
242 Translation of Title by Cataloging Agency = terjemahan judul oleh agensi pengatalogan
243 Collective Uniform Title = judul umum yang digagas oleh pengatalog untuk mengumpulkan karya-karya pengarang yang produktif
245 Title Statement = judul utama sebuah dokumen
246 Varying Form of Title = bentuk alternatif dari judul muncul ketika sebuah bentuk yang pada dasarnya berbeda dari judul pada kode 245 dan jika berkontribusi untuk identifikasi lebih lanjut
247 Former Title = digunakan apabila satu dokumen katalog mewakili beberapa judul yang berhubungan dengan satu kesatuan
dengan bentuk 20X – 24X merupakan sekumpulan kode tertentu yang dapat digunakan untuk merepresentasikan judul dan segala sesuatu yang berhubungan dengan judul. Keterangan mengenai kode 20X – 24X dijabarkan pada Tabel 2.2.
Dari beberapa kode pada Tabel 2.2 yang berhubungan dengan judul, diambil sebanyak dua kode untuk dijadikan sebagai referensi pemetaan metadata yaitu 245 dan 246. Pemilihan dua kode tersebut didasari pada kedekatan pengertian kedua kode tersebut dengan Title pada Dublin Core unqualified.
Keakuratan dan ketepatan yang dipengaruhi oleh transformasi metadata tidak dapat diabaikan. Elemen kombinasi, definisi elemen semantik dan bidang aplikasi dari bentuk standar harus dapat diadopsi dan dikenali dengan baik oleh sebagian besar sistem [13].
2.2 Format Metadata
Perhatian yang cukup besar telah diberikan untuk meningkatkan efisiensi dan ruang lingkup web crawler. Web crawler komersial diperkirakan hanya mencakup sekitar 16% keseluruhan isi web [14]. Untuk meningkatkan efisiensi, sejumlah teknik telah diusulkan seperti memperkirakan pembuatan web dan pembaharuan yang lebih akurat, serta strategi crawling yang lebih efisien [15] [16].
pendekatan telah diusulkan untuk memperbaharui semantik pada server HTTP, mulai dari konvensi tentang bagaimana menyimpan indeks URL yang populer [18], hingga kombinasi indeks dan ekstensi HTTP [19]. WebDAV (Web-based Distributed Authoring and Versioning) [20] telah menyediakan beberapa pembaharuan semantik melalui ekstensi HTTP, akan tetapi tidak diterapkan secara luas. RSS (Really Simple Syndication) [21] merupakan format sindikasi yang telah diterapkan secara luas, tidak dapat digunakan untuk memilih data berdasarkan selang waktu tertentu. OAI-PMH memiliki kelengkapan semantik yang umum dan sangat baik yang merupakan standar de facto untuk pertukaran metadata dalam komunitas perpustakaan digital [17] [6]. Penerapan repositori OAI-PMH berdasarkan dokumen XML (eXtensible Markup Language) telah diuraikan [22], dibatasi oleh skenario tertentu, bukan konten web umum dan tidak terintegrasi langsung ke web server. Karena tidak terintegrasi oleh web server, beberapa peneliti berusaha untuk mengintegrasikan OAI-PMH dengan web server Apache menggunakan modul yang dinamakan mod_oai [17].
2.3 OAI-PMH
diakses via Internet, antarmuka pemrograman, indentifikasi arsip, identifikasi nilai unik untuk masing-masing dokumen, jenis metadata Dublin Core unqualified, penanggalan untuk metadata (tanggal dibuat/modifikasi terakhir) dan hirarki logika.
Di sisi lain, penyedia layanan mengumpulkan metadata melalui OAI-PMH sebagai dasar untuk membangun layanan tambahan. OAI-PMH menggunakan satu standar metadata yaitu Dublin Core unqualified [11]. Penyedia karya ilmiah yang masih menggunakan metadata selain Dublin Core dapat melakukan transformasi metadata menjadi Dublin Core unqualified tanpa perlu menghapus metadata yang sedang digunakan.
Akses terhadap metadata yang dimiliki harus diberikan secara bebas agar metadata tersebut dapat dimanfaatkan oleh pihak lain. Dalam hal ini, penyedia karya ilmiah berperan sebagai penyedia data. Penyedia karya ilmiah harus memiliki sebuah repositori, yaitu sebuah server yang dapat diakses melalui jaringan komputer, dan dapat memproses enam permintaan OAI-PMH yaitu Identify, ListMetadataFormats, ListSets, ListRecords, GetRecord dan ListIdentifiers [23]. Fungsi repositori ini adalah untuk mempublikasikan metadata kepada pengumpul metadata.
Berikut ini entitas OAI-PMH dicetak dengan huruf miring, sedangkan protokol permintaan dicetak dengan jenis huruf courier [17]:
b. Item adalah titik awal ke seluruh metadata yang berhubungan dengan sumber daya. Pada protokol, item diidentifikasikan sebagai identifier.
c. Sebuah item dapat memberikan akses ke satu atau lebih record. Record berisi metadata (dan informasi sekunder mengenai metadata). Sebuah record tertentu pada OAI-PMH diidentifikasikan sebagai kombinasi dari identifier (dari item), metadataPrefix untuk menentukan format metadata yang digunakan pada publikasi metadata dan datestamp. Datestamp adalah tanggal dan waktu pembuatan atau modifikasi metadata. Sebagai catatan bahwa datestamp adalah properti catatan metadata, bukan item sebagaimana yang digunakan pada OAI-PMH versi 1.x. Hal ini mencerminkan bahwa metadata dari berbagai macam format metadata kemungkinan tersedia dan dapat dimodifikasi sendiri sehingga mempunyai datestamp yang berbeda.
d. OAI-PMH juga mendefinisikan set sebagai konsep pilihan untuk pengelompokan item untuk tujuan pengumpulan data tertentu. Repositori dapat mengorganisir item menjadi set.
OAI-PMH mendukung tiga protokol permintaan yang ditujukan untuk membantu pengumpul agar mengerti repositori OAI-PMH yaitu:
a. Identify: digunakan untuk mengambil informasi mengenai sebuah
repositori seperti administrator dan lain-lain.
b. ListMetadataFormats: digunakan untuk mengambil format metadata
c. ListSets: digunakan untuk mengambil struktur set dari sebuah repositori. Informasi ini sangat berharga untuk pengumpulan jenis metadata tertentu. OAI-PMH mendefinisikan tiga buah protokol permintaan lainnya yang ditujukan untuk pengumpulan metadata secara aktual yaitu:
a. ListRecords: digunakan untuk mengumpulkan record dari sebuah
repositori. Argumen pilihan mengizinkan pengumpulan secara selektif terhadap records berdasarkan set dan/atau datestamp.
b. GetRecord: digunakan untuk mengambil sebuah record tertentu dari sebuah repositori. Dibutuhkan argumen yang menjelaskan bahwa identifier sebuah item berasal dari record yang diminta dan metadata format dari metadata harus disertakan pada record.
c. ListIdentifiers merupakan penyingkatan dari ListRecords yang
hanya mengambil informasi mengenai identifier, datestamp dan set.
Sebagai contoh sebuah repositori yang mendukung OAI-PMH pada URL http://repository.usu.ac.id/oai/, protokol permintaan berikut digunakan untuk memperoleh metadata seluruh item yang mengalami perubahan sejak 10 Oktober 2010 dalam bentuk Dublin Core:
http://repository.usu.ac.id/oai/request?verb=ListRecords&
Bahasa Pemrograman (cth. PHP, Java Servlets)
Skrip:
- Uraikan argumen - Buat pesan kesalahan - Buat query SQL - Buat keluaran XML
Web Server (cth. IIS, Apache)
Permintaan SQL Balasan DB Database Permintaan OAI (HTTP) Balasan OAI (XML) Penyedia Data OAI
Gambar 2.1 Diagram Arsitektur Penyedia Data [24]
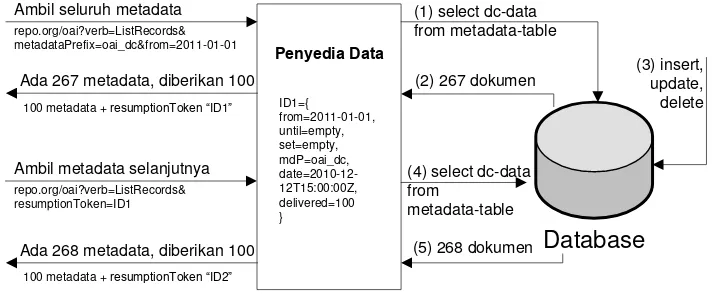
Pada OAI-PMH terdapat mekanisme untuk membatasi jumlah metadata yang dapat ditampilkan oleh penyedia data. Metadata yang tidak lengkap harus memiliki sebuah tag tambahan, yaitu resumptionToken pada akhir metadata. Tag ini berisi argumen yang membentuk satu alamat URL untuk menampilkan metadata berikutnya. Mekanisme penggunaan resumptionToken diilustrasikan pada Gambar 2.2.
Penyedia Layanan
Penyedia Data Ambil seluruh metadata
Memberikan 100 dari150 metadata
100 metadata + resumptionToken “ID1” repo.org/verb=ListRecords&metadataPrefix=oai_dc
Ambil metadata berikutnya
repo.org/verb=ListRecords&resumptionToken=ID1
Memberikan 50 metadata terakhir
[image:31.612.158.486.111.288.2]50 metadata
[image:31.612.181.493.512.665.2]Penggunaan resumptionToken ditujukan untuk memisahkan respon yang berpotensi memakan waktu yang lama menjadi beberapa respon waktu yang lebih pendek. Sebagai contoh jika sebuah repositori memberikan respon sebanyak satu juta record, belum ada repositori maupun pengumpul yang dapat menangani respon tersebut. Untuk mengatasinya repositori dapat memilih untuk memisahkan seluruh record yang terkumpul menjadi beberapa bagian yang masing-masing berjumlah 1000 record. Ukuran resumptionToken ditentukan oleh repositori, bukan pengumpul.
Karena masing-masing repositori memiliki ketenuan yang berbeda untuk menentukan nilai resumptionToken, mengakibatkan penyedia layanan kesulitan untuk memprediksi nilainya. Ada beberapa parameter pilihan yang dapat ditambahkan yaitu:
a. expirationDate, yaitu batas waktu yang disediakan penyedia data untuk
memastikan bahwa metadata yang dikirimkan adalah sah
b. completeListSize, yaitu jumlah daftar metadata selengkapnya
c. cursor, yaitu jumlah metadata yang telah dikirim
terkirim maka akan ada kemungkinan terjadinya ketidaksesuaian pada permintaan selanjutnya.
Ada dua buah solusi yang dapat diterapkan yaitu menduplikasi data pada tabel permintaan dan solusi lainnya adalah menyimpan tanggal permintaan awal dengan parameter lainnya dan menggunakannya seperti argumen until.
Database (1) select dc-data
from metadata-table
(2) 267 dokumen
(3) insert, update, delete
(4) select dc-data from
metadata-table
(5) 268 dokumen Ambil seluruh metadata
repo.org/oai?verb=ListRecords& metadataPrefix=oai_dc&from=2011-01-01
Ada 267 metadata, diberikan 100
100 metadata + resumptionToken “ID1”
Ambil metadata selanjutnya repo.org/oai?verb=ListRecords& resumptionToken=ID1
Ada 268 metadata, diberikan 100
100 metadata + resumptionToken “ID2”
[image:33.612.154.510.269.416.2]Penyedia Data ID1={ from=2011-01-01, until=empty, set=empty, mdP=oai_dc, date=2010-12-12T15:00:00Z, delivered=100 }
Gambar 2.3 Permasalahan pada Implementasi resumptionToken
2.4 Sistem Pengumpul Metadata Terdistribusi
Empat tujuan utama yang harus terpenuhi dalam membangun sebuah sistem terdistribusi yaitu [25]:
a. Menghubungkan pengguna dan sumber daya
Sistem terdistribusi yang dibangun ditujukan untuk mempermudah pengguna dalam mengakses sumber daya yang jauh dan membaginya dengan pengguna lain.
b. Transparansi
Distribusi proses dan sumber daya yang secara fisik terdiri dari beberapa komputer harus disembunyikan sehingga pengguna hanya merasa menggunakan komputer tunggal.
c. Keterbukaan
Sistem terdistribusi yang dibangun adalah sebuah sistem yang menawarkan layanan berdasarkan peraturan standar yang menjelaskan sintaks dan semantik layanan tersebut.
d. Skalabilitas
2.4.1 Komunikasi
[image:35.612.163.470.366.589.2]Komunikasi antar proses adalah jantung dari sistem terdistribusi. Pertukaran informasi antar mesin yang berbeda merupakan hal yang sangat penting. Empat model komunikasi yang sering digunakan adalah Remote Procedure Call (RPC) [27], Remote Method Invocation (RMI) [28], Message-Oriented Middleware (MOM) [29] dan stream [25]. Model komunikasi yang dipilih pada penelitian ini adalah RMI karena dapat diimplentasikan pada platform komputer yang berbeda. Ruang lingkup penelitian yang berupa jaringan komputer lokal juga menjadi pertimbangan pemilihan RMI.
Gambar 2.4 Diagram Sekuensial Untuk Remote Procedure Call (RPC) [30]
RMI merupakan pengembangan dari RPC yang mendukung polymorphism [31]. Pada level dasar, RMI mirip dengan mekanisme RPC seperti pada Gambar 2.4.
RMI mempunyai beberapa kelebihan dibandingkan dengan RPC karena merupakan bagian dari pendekatan berorientasi objek dalam bahasa pemrograman java. Konektivitas pada sistem menggunakan fungsi native, artinya RMI dapat menggunakan pendekatan yang alami (natural), langsung dan sangat mendukung teknologi komputasi terdistribusi sehingga dapat ditambahkan fungsi java pada sistem. Sedangkan RPC tidak dapat menyediakan fungsi yang tidak tersedia pada platform target. Untuk mengimplementasikan fitur cross-platform seperti pada java, RPC membutuhkan usaha yang lebih besar dibandingkan dengan RMI. RPC harus mengkonversi argumen antar arsitektur sehingga masing-masing komputer dapat menggunakan tipe data native. Keterbatasan RMI dikarenakan pemanggilan fungsi hanya dapat dilakukan dengan java. Untuk memanggil fungsi dalam bahasa lain RMI bergantung pada teknologi lain seperti JNI (Java Native Interface) [32], JDBC (Java DataBase Connectivity) [33], RMI-IIOP (Remote Method Invocation over Internet Inter-Orb Protocol) [34] dan lain-lain.
multiple-Sistem RMI dirancang untuk menyediakan pondasi bagi komputasi terdistribusi yang berorientasi objek. Arsitekturnya memungkinkan untuk penambahan server dan tipe referensi sehingga RMI dapat menambah fitur dengan terkoordinir [37].
Gambar 2.5 Stub dan Skeleton [37]
Ketika klien menerima referensi ke sebuah server, RMI mengunduh stub yang menerjemahkan panggilan terhadap referensi menjadi panggilan jarak jauh ke server. Seperti yang ditunjukkan pada Gambar 2.5, stub menggabungkan argumen ke prosedur menggunakan serialisasi objek dan mengirimkannya ke server. Di sisi server sistem RMI menerima panggilan tersebut dan terhubung ke skeleton, yang bertanggung jawab untuk memisahkan argumen dan mengimplementasikan prosedur yang dipanggil. Ketika implementasi di sisi server telah selesai, apakah hasilnya adalah nilai atau exception, skeleton akan menggabungkan hasil tersebut dan mengirimkannya ke stub. Stub akan memisahkan balasan sesuai dengan yang dikirimkan dari server. Stub dan skeleton biasanya dibuat menggunakan program
expServer.getPolicy();
Menggabung parameter Kirim permintaan
Memisahkan parameter Invoke implementation
return new TodayPolicy()
Menerima hasil (atau exception) Menggabung hasil (atau exception) Kirim balasan
Memisahkan balasan
Kembalikan nilai (atau exception)
Stub Skel
kompilasi yang disebut rmic. Stub menggunakan referensi untuk “berbicara” dengan skeleton.
Penelitian ini menggunakan bahasa java karena RMI hanya dapat diimplementasikan dengan bahasa tersebut. Implementasi RMI membutuhkan tiga buah lapisan abstraksi yang diilustrasikan pada Gambar 2.6.
Gambar 2.6 Ilustrasi Implementasi RMI [38]
Fungsi ketiga lapisan abstraksi tersebut adalah:
a. Stub dan Skeleton yang menerima pemanggilan fungsi yang dibuat oleh klien ke variabel referensi di interface dan melewatkannya ke layanan RMI yang jauh.
b. Remote Reference digunakan untuk menginterpretasikan dan referensi manajemen yang dibuat dari klien ke layanan objek yang jauh.
c. Transport Layer, berdasarkan koneksi TCP/IP antara mesin-mesin di dalam jaringan komputer.
Stub dan Skeleton
Remote Reference Layer
Program Klien
Stub dan Skeleton
Remote Reference Layer
Program
Server
Transport Layer
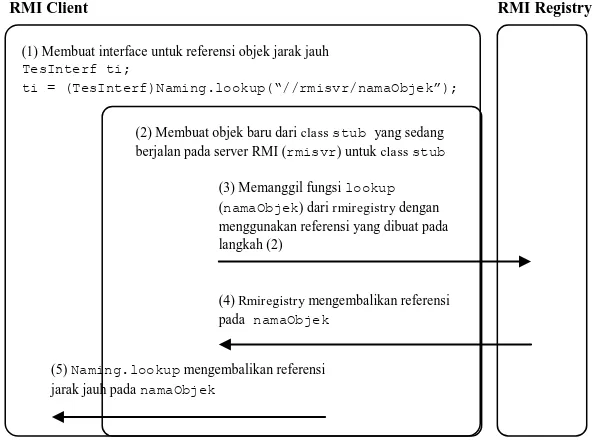
Klien yang akan menghubungi server RMI harus mempunyai referensi server RMI terlebih dahulu. Penggunaan fungsi Naming.lookup adalah mekanisme yang umum digunakan oleh klien untuk menginisialisasi referensi server RMI. Yang dilakukan oleh fungsi ini adalah menggunakan stub untuk membuat pemanggilan fungsi jarak jauh terhadap rmiregistry, yang kemudian mengembalikan referensi pada objek yang melakukan permintaan menggunakan fungsi lookup (Gambar 2.7).
[image:39.612.168.465.399.619.2]Setiap referensi jarak jauh berisi nama server dan nomor port agar klien dapat menentukan lokasi Virtual Machine yang melayani objek jarak jauh tertentu. Referensi nama server dan nomor port yang diperoleh klien akan digunakan untuk membuka koneksi soket ke server yang dituju.
Gambar 2.7 Pemanggilan Referensi Server oleh Klien (1) Membuat interface untuk referensi objek jarak jauh
TesInterf ti;
ti = (TesInterf)Naming.lookup(“//rmisvr/namaObjek”);
(3) Memanggil fungsi lookup
(namaObjek) dari rmiregistry dengan menggunakan referensi yang dibuat pada langkah (2)
(4) Rmiregistry mengembalikan referensi pada namaObjek
(5) Naming.lookup mengembalikan referensi jarak jauh pada namaObjek
RMI Client RMI Registry
Pemanggilan fungsi pada server dilakukan oleh klien dan akan diproses melalui stub dan skeleton. Secara umum, parameter yang dapat dilewatkan pada stub dan skeleton hanyalah variabel native seperti String dan Integer. Akan tetapi, pada umumnya parameter yang akan dikirimkan baik melalui server ataupun klien tidak hanya berupa variabel native. Pengiriman objek dari sebuah class tertentu, baik class yang didefinisikan oleh Java maupun yang dibuat oleh pengembang program memerlukan implementasi class Serialization. Dengan adanya implementasi serialisasi, objek tertentu dapat dilewatkan melalui stream baik dari klien menuju server maupun sebaliknya.
2.4.2 Kebutuhan Penggunaan Sistem Terdistribusi
Pertumbuhan metadata OAI-PMH yang dipublikasikan di Internet menyebabkan timbulnya kesulitan bila hanya dilakukan oleh satu pengumpul. Seperti halnya crawler, penggunaan beberapa pengumpul secara bersamaan dengan sistem terdistribusi akan sangat bermanfaat [39]. Dengan menggunakan metode ini diharapkan dapat meningkatkan kemampuan pengumpulan metadata secara maksimal. Beberapa manfaat dari sistem terdistribusi adalah:
b. Penyebaran dan pengurangan beban jaringan, jika pengumpul dijalankan pada lokasi yang secara geografis berjauhan dan masing-masing mengumpulkan metadata pada lokasi geografisnya masing-masing.
2.5 Sinkronisasi Proses Paralel
Sumber daya yang dimiliki oleh komputer tidak dapat dimanfaatkan secara maksimal apabila hanya menggunakan satu proses untuk melakukan pengumpulan metadata. Solusi yang dapat diterapkan untuk memanfaatkan sumber daya yang belum terpakai adalah dengan menggunakan proses paralel. Pada bahasa pemrograman java, proses paralel diterapkan menggunakan classThread.
Dengan menggunakan proses paralel pada bahasa java dapat menimbulkan sebuah masalah baru. Akses yang bersamaan terhadap satu objek tertentu memungkinkan untuk terjadinya kesalahan yaitu gangguan pada thread dan konsistensi memori. Untuk menghindari kesalahan-kesalahan ini diperlukan sinkronisasi pada objek agar dapat menerapkan satu akses khusus pada satu waktu (mutual exclusive access) pada bagian yang kritis diantara dua proses. Sinkronisasi diperlukan hanya untuk objek yang nilainya dapat berubah. Objek yang bersifat hanya dapat dibaca tidak perlu menerapkan sinkronisasi.
BAB 3
METODE PENELITIAN
Penelitian ini menggunakan eksperimen laboratorium yaitu mengumpulkan metadata yang diperoleh dari masing-masing penyedia karya ilmiah ke dalam berkas XML. Proses pengumpulan metadata dilakukan dengan dua cara yaitu menggunakan sistem pengumpul metadata tunggal dan sistem pengumpul metadata terdistribusi. Data yang direkam adalah jumlah metadata yang terkumpul dalam selang waktu 10 jam. Sesuai dengan tujuan penelitian, setelah data terkumpul akan dilakukan analisa mengenai peningkatan penggunaan pengumpul metadata terdistribusi terhadap pengumpul metadata tunggal.
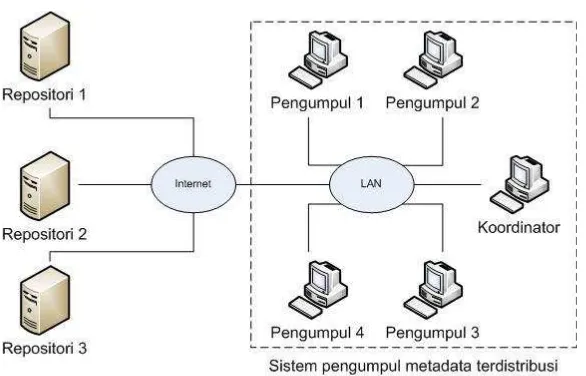
[image:43.612.194.487.489.677.2]Arsitektur pengumpul metadata terdistribusi yang telah dirancang diilustrasikan pada Gambar 3.1.
3.1 Sistem Pengumpul Metadata Tunggal
[image:44.612.174.476.373.455.2]Pada pengumpul metadata tunggal, pengumpul hanya dapat mengumpulkan metadata pada satu repositori tertentu dalam satu waktu (Gambar 3.2). Pengumpul akan memulai pengumpulan metadata pada repositori berikutnya setelah menyelesaikan pengumpulan metadata yang sedang berlangsung. Pengumpulan metadata yang berasal dari beberapa alamat repositori dalam waktu yang bersamaan dimungkinkan dengan penerapan pemrograman paralel. Dengan pemrograman paralel, satu proses terlihat seolah-olah seperti beberapa buah proses yang melakukan pekerjaan secara bersamaan.
Gambar 3.2 Blok Diagram Rancangan Pengumpul Metadata Tunggal
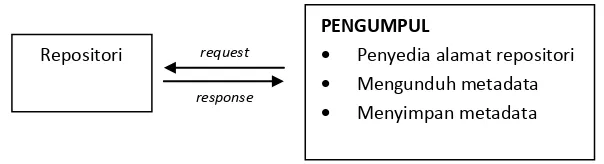
Desain keseluruhan dari rancangan sistem pengumpulan metadata tunggal dapat dilihat pada Gambar 3.3. Karena hanya terdiri dari satu komputer, pengumpul metadata tunggal mengerjakan seluruh proses yang berkaitan dengan pengumpulan metadata. Pengumpul metadata tunggal mengatur sendiri daftar antreannya untuk mendapatkan alamat repositori metadata yang akan dikumpulkan. Pengumpulan metadata hanya dapat dilakukan setelah pengumpulan metadata pada alamat repositori sebelumnya telah selesai.
request
response
PENGUMPUL
Penyedia alamat repositori
Mengunduh metadata
Menyimpan metadata
Begitu juga dengan proses penyimpanan metadata. Proses ini dilakukan setelah berhasil mengunduh metadata dari repositori. Pada keadaan ini sumber daya komputer yang tidak terpakai menjadi kurang bermanfaat. Artinya, sumber daya komputer tidak dapat dimanfaatkan secara maksimal.
- Mengunduh dokumen XML - Parsing dokumen XML - Mencari resumptionToken
Menyimpan dokumen XML yang valid Balasan
OAI (XML)
Permintaan OAI (HTTP)
Pengumpul Tunggal
Memperoleh alamat repositori Menyimpan
resumptionToken
[image:45.612.147.519.239.363.2]Daftar Antrean
Gambar 3.3 Diagram Arsitektur Pengumpul Metadata Tunggal
3.1.1 Pemanfaatan Sumber Daya pada Pengumpul Tunggal
setiap kali ada pengambilan alamat repositori, pengumpulan metadata dan penyimpanan metadata ke dalam database.
Walaupun terdapat modifikasi terhadap mekanisme daftar antrean pada penerapan pemrograman paralel, proses pengunduhan dan penyimpanan metadata tidak memerlukan modifikasi tertentu. Perubahan yang dirasakan dengan penerapan pemrograman paralel adalah pengunduhan dan penyimpanan metadata antara satu proses dengan yang lainnya dapat dilakukan bersama-sama tanpa harus menunggu proses sebelumnya selesai.
3.1.2 Pemodelan Pengumpul Metadata Tunggal
[image:46.612.219.458.432.663.2]Secara umum pemodelan pengumpul metadata tunggal dapat diilustrasikan pada diagram use case seperti Gambar 3.4.
Gambar 3.4 Diagram Use Case Pengumpul Metadata Tunggal Pengumpul Tunggal
Mengelola daftar antrean
Mengunduh metadata
Menyimpan metadata
Pada pengumpulan metadata tunggal tidak diperlukan metode tertentu untuk mengatur pembagian alamat url karena hanya terdapat satu proses. Pengaturan tersebut diperlukan pada saat uji coba pengumpulan metadata tunggal yang dilakukan secara paralel. Pada sistem ini pengaturan daftar antrean, pengunduhan hingga penyimpanan metadata dilakukan pada satu komputer tunggal.
3.2 Sistem Pengumpul Metadata Terdistribusi
[image:47.612.131.526.496.606.2]Perancangan pengumpul metadata terdistribusi dilakukan dengan memperhatikan aspek skalabilitas. Untuk itu dengan menganggap bahwa satu buah proses sama dengan satu buah pengumpul, dan apabila jumlah ketersediaan komputer dan peralatan pendukung jaringan tidak menjadi masalah, maka sejumlah pengumpul dapat ditambah dengan cara diintegrasikan ke dalam sistem dengan mudah. Masing-masing pengumpul melakukan tugasnya secara terpisah tetapi bekerja berdasarkan informasi yang disediakan oleh koordinator (Gambar 3.5).
Gambar 3.5 Blok Diagram Rancangan Pengumpul Metadata Terdistribusi
Desain keseluruhan dari rancangan sistem pengumpulan metadata terdistribusi dapat dilihat pada Gambar 3.6. Secara keseluruhan proses yang dilakukan mirip
Pengumpul 1 Repositori 1
Pengumpul n Repositori n
request
response
request
response
KOORDINATOR
Penyedia alamat
repositori
Menyimpan metadata
dengan sistem pengumpul metadata tunggal. Hanya saja, terdapat pemisahan tempat pemrosesan beberapa prosedur yang dilakukan pada sistem pengumpul metadata terdistribusi. Pada sistem ini, koordinator berperan untuk mengatur beberapa pengumpul yang terpisah.
- Mengunduh dokumen XML - Parsing dokumen XML - Mencari tag resumptionToken
Menyimpan dokumen XML yang valid Balasan
OAI (XML)
Permintaan OAI (HTTP)
Pengumpul
dokumen XML
resumptionToken
Simpan dokumen XML Ambil daftar
antrean
Alamat repositori
Koordinator
Memperoleh alamat repositori Menyimpan
resumptionToken
[image:48.612.150.525.235.445.2]Daftar Antrean
Gambar 3.6 Diagram Arsitektur Pengumpul Metadata Terdistribusi
Proses pengunduhan dan penyimpanan metadata sementara dilakukan pada masing-masing pengumpul. Kedua proses ini dilakukan secara berurutan pada satu komputer yang sama. Seperti pada sistem pengumpul metadata tunggal, sumber daya komputer yang tidak terpakai menjadi kurang bermanfaat. Sumber daya komputer pada masing-masing pengumpul tidak dapat digunakan secara maksimal.
terdapat beberapa proses pengunduhan dan penyimpanan metadata yang berjalan secara bersamaan.
3.2.1 Komunikasi antara Koordinator dan Pengumpul
Di dalam koordinator terdapat daftar antrean repositori yang bersifat global, dalam artian data antreannya terbuka untuk seluruh anggota pengumpul. Koordinator berperan untuk mencegah duplikasi pengambilan alamat repositori yang terdapat di dalam daftar antrean dengan menggunakan metode yang sama dengan pengumpul metadata tunggal.
Daftar antrean disimpan pada sisi koordinator. Koordinator menyimpan daftar tersebut di dalam sebuah database. Untuk mengambil data antrean tersebut, pengumpul tidak melakukan koneksi langsung dengan server database, melainkan melalui koordinator. Komunikasi pengumpul dengan koordinator dilakukan menggunakan protokol RMI. Dengan penerapan RMI, pengambilan alamat repositori dari koordinator oleh pengumpul seolah-olah dilakukan pada komputer lokal.
Penyimpanan metadata yang telah diunduh oleh masing-masing pengumpul ke server juga dilakukan dengan memanfaatkan protokol RMI. Koordinator telah menyediakan metode yang dapat digunakan untuk menyimpan hasil unduhan metadata ke server. Metode inilah yang diakses oleh masing-masing pengumpul.
3.2.2 Pemodelan Pengumpul Metadata Terdistribusi
Gambar 3.7 Diagram Use Case Sistem Pengumpul Metadata Terdistribusi
Pengumpul metadata terdistribusi menggunakan pendekatan teknik dekomposisi, yaitu satu proses yang besar dibagi menjadi proses-proses lain yang lebih kecil. Konsekuensinya, harus ada satu metode yang mengatur pembagian alamat repositori agar proses dapat didistribusikan secara optimal. Pengumpulan metadata dilakukan oleh beberapa komputer yang masih berada pada satu jaringan yang sama. Selain itu dilakukan juga uji coba pengumpulan secara paralel pada sistem terdistribusi. Pada sistem ini dilakukan pemisahan yaitu antara pengumpul dan koordinator. Pengumpul bertugas untuk mengunduh dan menyimpan metadata
Pengumpul
Mengunduh metadata
Koordinator Mengelola daftar
antrean
Menyimpan metadata
Menyimpan resumptionToken
sementara, sedangkan koordinator bertugas untuk mengelola daftar antrean serta menyimpan nilai resumptionToken dan metadata ke koordinator.
3.3 Prinsip Kerja Pengumpulan Metadata
Pengumpul metadata tunggal mempunyai suatu daftar alamat repositori yang dinamakan daftar antrean. Dalam daftar antrean, alamat diperoleh dengan cara menyimpannya secara manual maupun secara otomatis dari program. Alamat yang dikumpulkan secara manual merupakan alamat masing-masing repositori yang diperoleh dari openarchive.org. Repositori menyediakan alamat metadata yang dapat diunduh pada tag resumptionToken. Tag inilah yang dimanfaatkan untuk mendapatkan alamat metadata yang dikumpulkan secara otomatis.
Gambar 3.8 menunjukkan diagram aktivitas pengumpulan metadata tunggal. Pada diagram tersebut, terdapat perulangan yang meliputi pengambilan alamat repositori yang berasal dari daftar antrean. Bila pengumpul tidak mendapat alamat repositori dengan alasan bahwa alamat repositori tidak tersedia, maka pengumpul akan mencoba mengambil alamat repositori lainnya. Proses tersebut dilakukan berulang-ulang hingga akhirnya program dihentikan secara manual.
maka pengumpul akan diam untuk beberapa saat dan kemudian kembali mengambil alamat repositoridi dalam daftar antrean.
Ambil URL dari Daftar Antrean
[URL tersedia]
Beri tanda "1" pada daftar antrean Mengunduh metadata
Menyimpan metadata ke berkas XML
Beri tanda "2" pada daftar antrean
[Ada
resumptionToken]
Simpan URL resumptionToken ke daftar
antrean
[Tidak ada resumptionToken]
[URL tidak tersedia]
Beri tanda "3" pada daftar antrean
[Gagal mengunduh metadata] [Berhasil mengunduh
[image:52.612.182.497.169.671.2]Bila tidak ada kendala, pengumpul mengunduh dokumen XML yang disediakan oleh repositori tersebut. Dokumen XML yang tidak sah akan ditolak dan pengumpul melanjutkan kembali proses pengumpulan metadata dari awal yaitu mengambil alamat repositoridari daftar antrean. Sedangkan dokumen XML yang sah akan disimpan.
Setelah berhasil menyimpan metadata, pengumpul memeriksa tag
resumptionToken. Apabila tag tersedia, maka pengumpul menambahkan alamat
yang terdapat pada resumptionToken ke dalam daftar antrean. Proses berikutnya, pengumpul kembali ke proses awal yaitu mengambil alamat repositori dari daftar antrean.
3.3.1 Pengumpul Metadata Terdistribusi
Pada diagram aktivitas yang diilustrasikan pada Gambar 3.9, terlihat kemiripan aktivitas antara pengumpul metadata tunggal dengan pengumpul metadata terdistribusi. Karena dalam sistem terdistribusi, pekerjaan yang dilakukan seolah-olah hanya melibatkan satu komputer saja.
Gambar 3.9 Diagram Aktivitas Sistem Pengumpulan Metadata Terdistribusi
Pengumpul Koordinator
Meminta URL dari daftar antrean
Mengirimkan URL
Beri tanda "1" pada daftar antrean [URL tidak tersedia] Mengunduh metadata [ada resumptionToken] [Gagal mengunduh metadata] [URL tersedia] [Berhasil mengunduh metadata] [Tidak ada resumptionToken] Memproses permintaan URL dari client
Menyimpan metadata sementara
Beri tanda "3" pada daftar antrean
Mengirim metadata ke serv er
Menyimpan metadata di serv er
Memproses perubahan tanda pada daftar antrean
Menyimpan resumptionToken
Perulangan yang meliputi pengambilan alamat repositori berasal dari daftar antrean yang berada di koordinator. Bila koordinator mengirimkan pesan bahwa alamat repositoriyang akan diambil tidak tersedia, maka pengumpul akan diam untuk beberapa saat dan kemudian mencoba melakukan koneksi dengan koordinator untuk mengambil alamat repositori lainnya. Proses tersebut dilakukan berulang-ulang hingga akhirnya program dihentikan secara manual.
Alamat repositori yang berhasil diambil akan digunakan sebagai rujukan alamat repositori penyedia metadata. Bagian ini menggunakan sumber daya pada komputer pengumpul. Beberapa kemungkinan gagalnya pengambilan metadata sama dengan penyebab gagalnya pengumpulan metadata pada pengumpul metadata tunggal.
Bila tidak ada kendala, pengumpul mengunduh dokumen XML yang disediakan oleh repositori tersebut. Selanjutnya pengumpul akan menyimpan metadata tersebut sementara. Proses ini masih dilakukan pada komputer pengumpul. Dokumen XML yang tidak valid akan ditolak dan pengumpul melanjutkan kembali proses pengumpulan metadata dari awal yaitu mengambil alamat repositoridari daftar antrean yang terletak di koordinator. Apabila dokumen XML valid, pengumpul akan melakukan koneksi dengan koordinator untuk menyimpan metadata hasil unduhan tersebut.
daftar antrean. Proses berikutnya, pengumpul kembali ke proses awal yaitu mengambil alamat repositoridari daftar antrean yang terletak di koordinator.
3.3.2 Perbedaan antara Pengumpul Tunggal dan Terdistribusi
Dari kedua diagram aktivitas pada Gambar 3.8 dan Gambar 3.9, perbedaan hanya terletak pada lokasi proses pengambilan alamat repositori dari daftar antrean maupun saat penyimpanan metadata. Pada pengumpul metadata tunggal kedua proses tersebut dilakukan pada komputer yang sama dengan komputer yang mengumpulkan metadata, sedangkan pada pengumpul metadata terdistribusi dilakukan pada komputer koordinator. Sumber daya komputer pengumpul hanya digunakan untuk mengumpulkan metadata. Pengumpul mendapat masukan (input) berupa url dan menghasilkan keluaran (output) berupa alamat url (bila ada) dan hasil uraian metadata.
3.4 Daftar Antrean
Alamat repositori yang akan dikumpulkan terbagi menjadi dua jenis. Yang pertama yaitu daftar repositori yang dikumpulkan dari openarchives.org, merupakan daftar repositori awal untuk pengumpulan metadata. Kedua, alamat repositori yang didapat dari metadata yang telah dikumpulkan. Alamat ini berisi nilai yang digunakan untuk pengambilan metadata berikutnya dan terletak di dalam tag
1 2 3 4 ... n
Daftar Antrean (tabel daftar_antrean)
Pengumpul
Ambil URL Simpan URL
[image:57.612.207.473.116.218.2]dari resumptionToken (bila ada)
Gambar 3.10 Antrean pada Sistem Pengumpul Metadata Tunggal
1 2 3 4 ... n
Daftar Antrean (tabel daftar_antrean)
Pengumpul y
Ambil URL Simpan URL
dari resumptionToken (bila ada)
Pengumpul x
Gambar 3.11 Antrean pada Sistem Pengumpul Metadata Terdistribusi
Sistem pengumpul metadata tunggal maupun terdistribusi mengambil alamat repositori dari daftar antrean. Tidak ada perbedaan mekanisme terhadap tata cara pengambilan alamat repositori tersebut meskipun lokasi daftar antrean antara pengumpul metadata tunggal dan terdistribusi berbeda. Pengumpul secara terus menerus akan mengecek ketersediaan alamat repositori di dalam daftar antrean.
3.4.1 Mekanisme untuk Mencegah Duplikasi
[image:57.612.198.476.262.396.2]yaitu kemungkinan terjadinya duplikasi. Oleh karena itu perlu dikembangkan mekanisme untuk mencegah terjadinya duplikasi pada pengumpulan metadata.
Mekanisme pencegah duplikasi yang digunakan pada penelitian ini adalah menyiapkan sebuah kolom baru pada tabel daftar antrean yaitu status. Status mempunyai nilai dari 0 – 3. Nilai 0 berarti bahwa alamat tersebut belum diambil sama sekali. Nilai awal alamat url dari openarchive.org maupun yang ditambahkan dari
resumptionToken adalah 0. Nilai 1 berarti bahwa alamat sedang diambil. Nilai 1 diberikan setelah pengumpul berhasil mengambil alamat repositori dari daftar antrean. Nilai 2 berarti bahwa alamat tersebut telah diambil dan metadata berhasil disimpan. Nilai ini diberikan setelah pengumpul melakukan penguraian dan menyimpan metadata ke dalam database. Terakhir, nilai 3 yang berarti bahwa alamat terebut telah diambil tetapi metadata tidak berhasil disimpan dikarenakan kegagalan pada server repositori, alamat url tidak valid, dokumen XML tidak valid maupun jaringan yang terputus.
Selain itu masih terdapat masalah apabila proses yang mengakses tabel daftar antrean tidak berasal dari satu komputer yang sama. Apabila proses yang berasal dari komputer yang berbeda secara bersamaan mengakses tabel daftar_antrean, maka penggunaan sinkronisasi tidak akan membantu. Untuk mengatasi masalah ini, sebuah fitur dari MySQL dapat membantu yaitu menggunakan fitur penguncian tabel (table locking). Apabila tabel daftar_antrean yang sedang digunakan dalam keadaan terkunci, maka proses lain harus menunggu proses tersebut selesai untuk dapat mengubah nilai pada tabel tersebut. Dengan metode ini, satu perubahan pada tabel daftar_antrean (Gambar 3.10 dan 3.11) hanya dapat dilakukan oleh satu proses dalam satu waktu.
3.5 Pengunduhan Metadata
Pada OAI-PMH, data dapat ditampilkan per subjek maupun secara keseluruhan. Pada penelitian ini, data diambil dari alamat yang menyajikan seluruh data pada repositori. Banyaknya data yang ditampilkan tergantung dari repositori tersebut. Ada kemungkinan bahwa data ditampilkan per seratus, dua ratus atau per seribu record, dan seterusnya.
ListRecords dan metadataPrefix yang bernilai oai_dc pada url. Contoh alamat repositori yang menyajikan keseluruhan data adalah sebagai berikut:
http://oai.iiep.unesco.org/oai2.php?verb=ListRecords&meta
dataPrefix=oai_dc
ListRecords berarti menunjukkan bahwa repositori akan menampilkan seluruh data yang ada. Sedangkan oai_dc berarti metadata yang akan ditampilkan mengikuti aturan Dublin Core.
Sebuah repositori yang memiliki puluhan ribu data tidak mungkin menampilkan seluruh data yang dimilikinya sekaligus. Hal ini tidak efisien baik dari segi penyedia data (repositori) maupun penyedia layanan (pihak yang memanfaatkan data). Dari sisi penyedia data hal tersebut akan memberatkan pekerjaan server karena harus mengambil banyak data dari database dan mengubahnya ke bentuk XML. Dari sisi penyedia layanan hal tersebut juga memberatkan karena harus mengunduh data yang sangat besar dan menyebabkan proses berjalan lambat.
nilai yang akan dijadikan alamat untuk menampilkan metadata berikutnya. Contoh tag resumptionToken yang berasal dari USU Repository yang beralamat di http://repository.usu.ac.id adalah sebagai berikut:
<resumptionToken
expirationDate="2011-05-06T01:09:44Z">0001-01-01T00:00:00Z/9999-12-31T23:59:59Z //oai_dc/100</resumptionToken>
Sesuai dengan ketentuan OAI-PMH, nilai di dalam tagresumptionToken
yang diperoleh dijadikan nilai query string resumptionToken menggantikan query string metadata_prefix. Query string verb tidak diubah karena mode pengambilan metadata masih tetap sama yaitu menampilkan seluruh record yang ada di dalam repositori. Berdasarkan ketentuan tersebut maka dapat diketahui bahwa URLuntuk mengambil metadata berikutnya adalah sebagai berikut:
http://repository.usu.ac.id/oai/request?verb=ListRecords&resum
ptionToken=0001-01-01T00:00:00Z/9999-12-31T23:59:59Z//oai_dc/100
Tag resumptionToken dapat ditemukan pada akhir metadata. Apabila
tidak terdapat tagresumptionToken maka alamat tersebut merupakan akhir dari seluruh metadata yang ditampilkan oleh repositori.
3.5.1 Penanganan Kesalahan
kesalahan server dengan kode 500, 501, 502, 503 dan 504 [40], alamat server tidak ditemukan, format dokumen XML tidak sesuai dengan ketentuan OAI-PMH dan kesalahan pengkodean dokumen. Seluruh kesalahan yang terjadi pada aplikasi ditangkap dengan menggunakan error handling dan kemudian dicatat.
Tabel 3.1 Kode Kesalahan Server
Kode
Kesalahan Keterangan
500
Server menemukan kondisi yang
mencegahnya untuk memenuhi permintaan klien
501 Server tidak dapat mengenali metode permintaan yang digunakan
502
Server menerima respon yang tidak valid dalam percobaan memenuhi permintaan klien
503
Server tidak dapat menangani permintaan karena kelebihan beban atau pemeliharaan server sementara
504
Server tidak menerima respon dari server upstream yang dispesifikasikan pada URI secara tepat waktu
layanan repositori hanya tidak dapat digunakan sementara. Dengan meletakkan alamat repositori yang gagal di akhir daftar antrean, maka akan diperlukan waktu untuk mengambilnya kembali. Batas maksimum pengumpul melakukan percobaan pengambilan metadata yang gagal ditetapkan sebanyak 10 kali. Jenis kesalahan akan dicatat apabila batas maksimum percobaan telah dilewati.
3.6 Penyimpanan Metadata
Metadata yang dikumpulkan dari berbagai repositori berbentuk dokumen XML dengan standar UTF-8. Berikut ini adalah contoh metadata yang diunduh dari repositori:
<metadata>
<oai_dc:dc
xsi:schemaLocation="http://www.openarchives.org/OAI/2.0/oai_dc
/ http://www.openarchives.org/OAI/2.0/oai_dc.xsd">
<dc:title>Respon Pertumbuhan Dan Produksi Mentimun (Cucumis
Sativus L.) Dengan Mutagen Kolkhisin</dc:title>
<dc:creator>Sofia, Diana</dc:creator>
<dc:description>Mentimun adalah salah satu sayuran buah
yang banyak dikonsumsi masyarakat Indonesia dalam bentuk
segar. Nilai gizi mentimun cukup baik karena sayuran buah ini
merupakan sumber mineral dan vitamin</dc:description>
<dc:date>2010-03-19T08:16:44Z</dc:date>
<dc:type>Lecture Papers</dc:type>
<dc:identifier>http://repository.usu.ac.id/handle/123456789
/786</dc:identifier>
<dc:language>id</dc:language>
</oai_dc:dc>
Di dalam tag metadata, terdapat tagoai_dc yang berarti bahwa seluruh tag di dalamnya merupakan jenis metadata Dublin Core, yaitu metadata yang digunakan pada OAI-PMH.
Pada pengumpul metadata tunggal, hasil unduhan metadata langsung disimpan di sebuah direktori yang telah ditentukan. Pengumpul memperoleh jumlah metadata yang terkumpul dan nilai resumptionToken setelah metadata disimpan menjadi berkas XML. Proses ini lebih efisien dan cepat dibandingkan dengan mencari jumlah metadata dan nilai resumptionToken terlebih dahulu sebelum menyimpannya. Jumlah metadata dan nilai resumptionToken tidak dapat diperoleh bersamaan dengan menyimpan metadata karena menggunakan satu stream koneksi yang sama. Menggunakan stream koneksi yang sama akan membuat kesalahan pada saat pembacaan maupun penyimpanan metadata. Kemungkinan yang dapat terjadi adalah pembacaan akan gagal atau berkas yang tersimpan tidak sempurna. Hal ini ditemukan pada saat mengembangkan pengumpul metadata tunggal.
metadata dari repositori dan satu stream koneksi lainnya berasal dari berkas XML yang telah disimpan di komputer lokal.
3.6.1 Penyimpanan Metadata pada Sistem Terdistribusi
Pada pengumpul metadata terdistribusi, masing-masing pengumpul tidak langsung mengirimkan metadata yang diperoleh ke server melainkan menyimpan metadata terlebih dahulu di komputer lokal. Pengumpul tidak dapat secara langsung mengirimkan metadata hasil unduhan ke server, karena untuk mendapatkan isi dokumen XML digunakan kelas InputStream yang tidak dapat dilewatkan pada protokol RMI. Hal ini disebabkan karena kelas InputStream tidak dapat diserialisasi [41]. Sehingga, sebelum metadata dikirimkan ke server, terlebih dahulu dikonversi menjadi byte dan disimpan di dalam sebuah berkas XML. Pengiriman metadata ke server dilakukan dalam byte dan akan dikonversi kembali oleh server menjadi berkas XML. Penyimpanan metadata di masing-masing pengumpul juga diperlukan untuk memperoleh jumlah metadata dan nilai resumptionToken.
3.7 Implementasi Perancangan Pengumpul Metadata Terdistribusi
3.7.1 Koordinator
Koordinator berfungsi untuk mengelola daftar antrean dan menerima berkas XML yang dikirimkan oleh masing-masing pengumpul. Koordinator tidak melakukan pengunduhan metadata secara langsung dari repositori. Di dalam sistem pengumpul metadata terdistribusi, koordinator hanya berhubungan dengan masing-masing pengumpul.
Pada program utama koordinator menjalankan perintah untuk mendeklarasikan alamat yang berisi fungsi untuk digunakan oleh pengumpul agar dapat mengenali fungsi-fungsi yang dapat gunakan seperti mengambil daftar antrean dan mengirim berkas XML. Perintah tersebut adalah:
RequestURLBufferInterf urlBuffer = new RequestURLBufferImpl();
Naming.rebind("rmi://localhost:1099/URLBufferServer",
urlBuffer);
ServerInterf server = new ServerImpl();
Naming.rebind("rmi://localhost:1099/FileServer", server);
Untuk melakukan komunikasi menggunakan RMI, dibutuhkan satu port tertentu yang tidak digunakan oleh aplikasi lainnya. Secara umum port yang digunakan adalah 1099. Nama URLBufferServer dan FileServer akan digunakan oleh pengumpul untuk mengenali koordinator.
3.7.2 Pengumpul
dahulu menginisialisasi alamat yang telah dideklarasikan oleh koordinator. Inisialisasinya adalah sebagai berikut:
buffer = (RequestURLBufferInterf)Naming.lookup
("rmi://alamat_server:1099/URLBufferServer");
server = (ServerInterf)Naming.lookup
("rmi://alamat_server:1099/FileServer");
Untuk mulai berkomunikasi dengan koordinator, pengumpul harus menginisialisasi sebuah objek yang menjadi penghubung antara pengumpul dan koordinator. Kata kunci alamat_server merupakan alamat yang dituju oleh pengumpul untuk mengirimkan berkas XML.
3.7.3 Daftar Antrean
Daftar antrean digunakan untuk menyimpan seluruh alamat repositori. Untuk mengimplementasikan daftar antrean, dibutuhkan satu buah tabel khusus dengan spesifikasi yang tertera pada Tabel 3.2. Tabel dibuat dengan menggunakan database MySQL.
Tabel terdiri dari beberapa kolom yaitu id, request_url, status,
user, start, finish, amount, log, attempt dan ordering. Kolom
request_url digunakan untuk menyimpan alamat repositori. Alamat
Tabel 3.2 Spesifikasi Tabel Daftar Antrean
Nama Kolom Tipe Data Keterangan
id Integer Primary key
request_url Varchar(255) Alamat
repositori
status Tinyint(3) Status
pengunduhan alamat repositori
user Char(5) Nama
pengumpul
start Datetime Waktu mulai
pengunduhan
finish Datetime Waktu selesai
pengunduhan
amount Integer Jumlah metadata
yang diunduh
log Text Catatan
kesalahan pada saat
pengunduhan
attempt Tinyint(3) Jumlah
percobaan
ordering Integer Urutan
pengunduhan yang dilakukan
Sebuah repositori memiliki beberapa keadaan yang ditampilkan pada kolom
akan dicatat di dalam kolom log. Sebaliknya, pencatatan tidak dilakukan apabila tidak terdapat masalah pada pengunduhan metadata.
Tabel 3.3 Status Pengunduhan Repositori
Status Keterangan
0 Repositori menunggu untuk diunduh
1 Repositori sedang diunduh oleh salah satu pengumpul 2 Repositori berhasil diunduh
3 Repositori gagal diunduh
Pada saat pengumpulan metadata diperlukan informasi mengenai nama pengumpul yang mengunduh metadata dari masing-masing alamat repositori. Nama pengumpul tersebut disimpan di kolom user.
Catatan waktu pengumpul memulai dan mengakhiri pengunduhan metadata disimpan di kolom start dan stop. Repositori yang telah selesai diunduh akan dihitung jumlah metadatanya dan kemudian dimasukkan ke dalam kolom a


![Tabel 2.2 Penggunaan Kode 20X – 24X pada Metadata MARC [12]](https://thumb-ap.123doks.com/thumbv2/123dok/392885.37876/25.612.155.493.353.632/tabel-penggunaan-kode-x-x-pada-metadata-marc.webp)
![Gambar 2.1 Diagram Arsitektur Penyedia Data [24]](https://thumb-ap.123doks.com/thumbv2/123dok/392885.37876/31.612.181.493.512.665/gambar-diagram-arsitektur-penyedia-data.webp)
![Gambar 2.4 Diagram Sekuensial Untuk Remote Procedure Call (RPC) [30]](https://thumb-ap.123doks.com/thumbv2/123dok/392885.37876/35.612.163.470.366.589/gambar-diagram-sekuensial-untuk-remote-procedure-rpc.webp)
![Gambar 2.5 Stub dan Skeleton [37]](https://thumb-ap.123doks.com/thumbv2/123dok/392885.37876/37.612.215.429.242.378/gambar-stub-dan-skeleton.webp)